


















Similar presentations:



")


")
")


П6. Данные. Типы данных. Алгоритмы (2)
1.
Данные. Типы данных2.
Что такое данные?Данные (от лат. datum - «факт») - это зарегистрированная информация,
представленная в формализованном виде, удобном для хранения,
обработки и передачи. Проще говоря, это факты, идеи или сведения,
которые можно зафиксировать. Например, ваше имя, возраст, температура
на улице, текст этой статьи - всё это данные.
3.
ИнформацияСами по себе данные могут не нести явного смысла. Например, число
«36.6». Но если мы добавим контекст (температура тела человека в градусах
Цельсия), оно превращается в полезную информацию.
4.
Виды данныхДанные можно классифицировать по разным признакам, но чаще всего их
делят по формату представления
1. Числовые данные
2. Текстовые данные (символьные)
3. Графические данные
4. Звуковые данные
5. Видеоданные
5.
Что такое тип данных?6.
Представьте, что у вас есть две коробки. На одной написано «Только дляяблок», а на другой - «Только для книг».
Тип данных работает так же: он сообщаееет, что можно «положить» в
переменную (например, только целые числа или только текст) и что с этим
содержимым можно делать (например, числа можно складывать).
7.
1. Целочисленные типы (Integer)Представляют целые числа без дробной части. Могут быть положительными,
отрицательными или нулем. В зависимости от языка, они могут различаться
по диапазону хранимых значений (например, short, int, long).
Примеры: -5, 0, 120.
8.
2. Числа с плавающей точкойИспользуются для представления вещественных чисел. Они могут хранить
числа с десятичной точкой. Основные типы - float и double, которые
различаются по точности и диапазону значений.
Примеры: 3.14, -0.001, 15.5
9.
3. Логический типЭто самый простой тип, который может принимать только два значения:
истина (true) или ложь (false).
Примеры: true, false.
10.
4. Символьный типПредназначен для хранения одного символа: буквы, цифры, знака
препинания или специального символа.
Примеры: 'A', 'g', '5', '?'.
11.
5. Строковый типПредставляет собой последовательность символов. Строки используются
для хранения текста.
Примеры: "Привет, мир!"
12.
nullСпециальное значение, которое представляет "отсутствие значения" или
"пустую ссылку". Это означает, что переменная ни на что не указывает.
13.
Составные типы данных14.
1. Массивы (Arrays)Массив - это упорядоченная коллекция элементов одного типа, доступ к
которым осуществляется по индексу (номеру элемента). Индексация обычно
начинается с 0. Размер массива, как правило, фиксирован.
15.
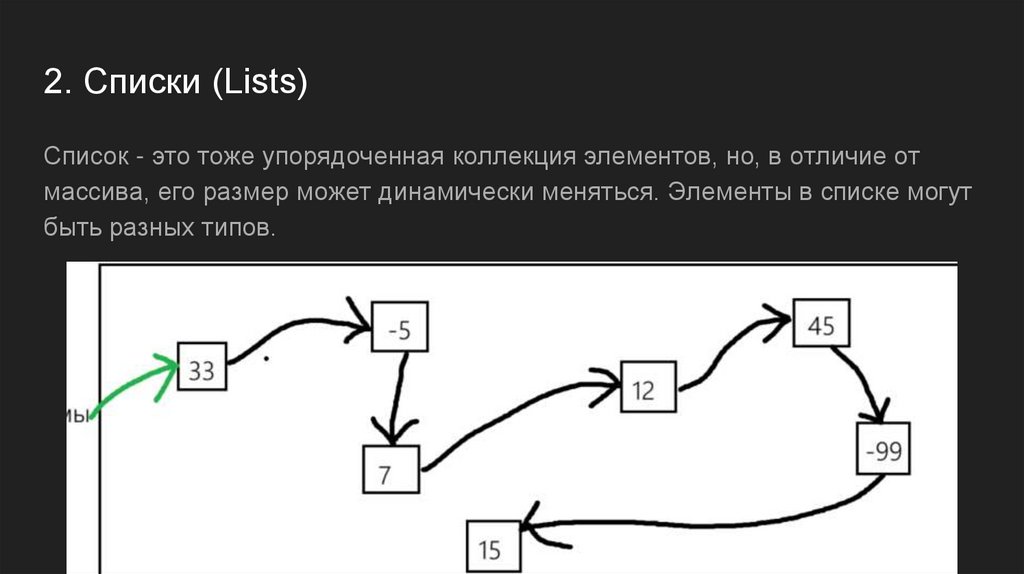
2. Списки (Lists)Список - это тоже упорядоченная коллекция элементов, но, в отличие от
массива, его размер может динамически меняться. Элементы в списке могут
быть разных типов.
16.
3. Множества (Sets)Множество - это неупорядоченная коллекция уникальных элементов. Оно не
позволяет хранить дубликаты.
17.
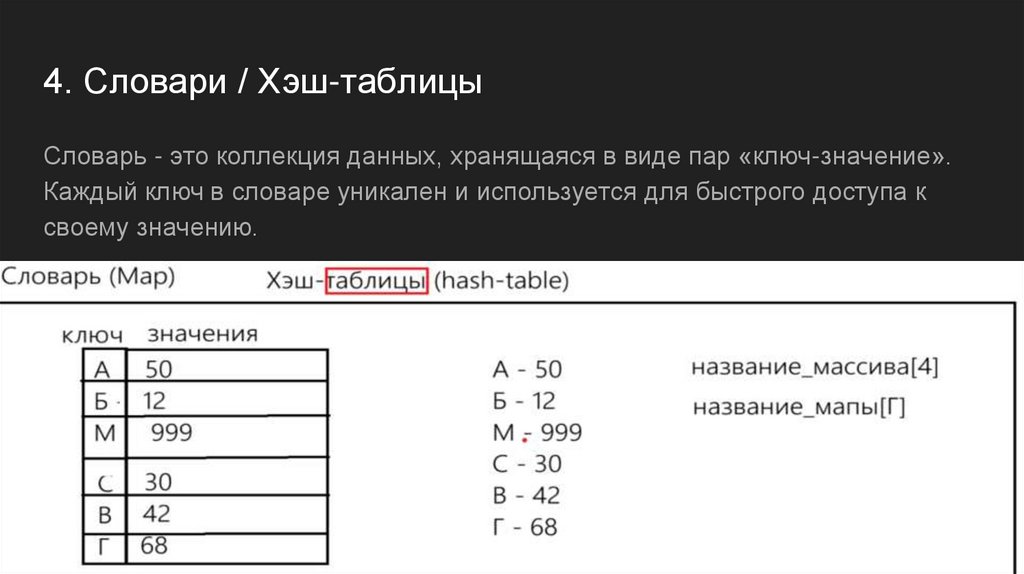
4. Словари / Хэш-таблицыСловарь - это коллекция данных, хранящаяся в виде пар «ключ-значение».
Каждый ключ в словаре уникален и используется для быстрого доступа к
своему значению.
18.
5. ДеревьяДерево - это иерархическая структура данных, состоящая из узлов,
связанных между собой. У каждого дерева есть корневой узел, а у каждого
узла могут быть дочерние узлы.
19.
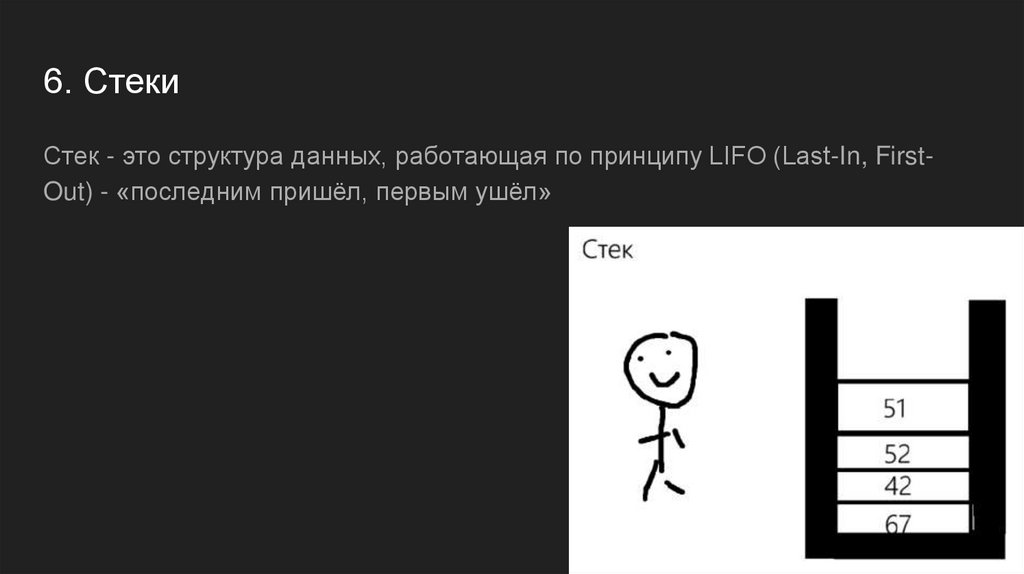
6. СтекиСтек - это структура данных, работающая по принципу LIFO (Last-In, FirstOut) - «последним пришёл, первым ушёл»
20.
7. ОчередиОчередь - это структура данных, работающая по принципу FIFO (First-In,
First-Out) - «первым пришёл, первым ушёл».
21.
Big O22.
Что это?«O» большое — математические обозначения для сравнения
асимптотического поведения (асимптотики) функций. Используются в
различных разделах математики, но активнее всего — в математическом
анализе, теории чисел и комбинаторике, а также в информатике и теории
алгоритмов
23.
А если просто?Big O — это способ измерить, насколько "медленным" становится алгоритм
(код), когда данных становится ОЧЕНЬ много.
Это не про точное время в секундах, а про то, как быстро растет время
выполнения с увеличением объема входных данных.
24.
На примереУ нас есть бумажная телефонная книга (это наши данные, n — количество
записей в ней) и нам нужно найти номер "Ивана Петрова".
25.
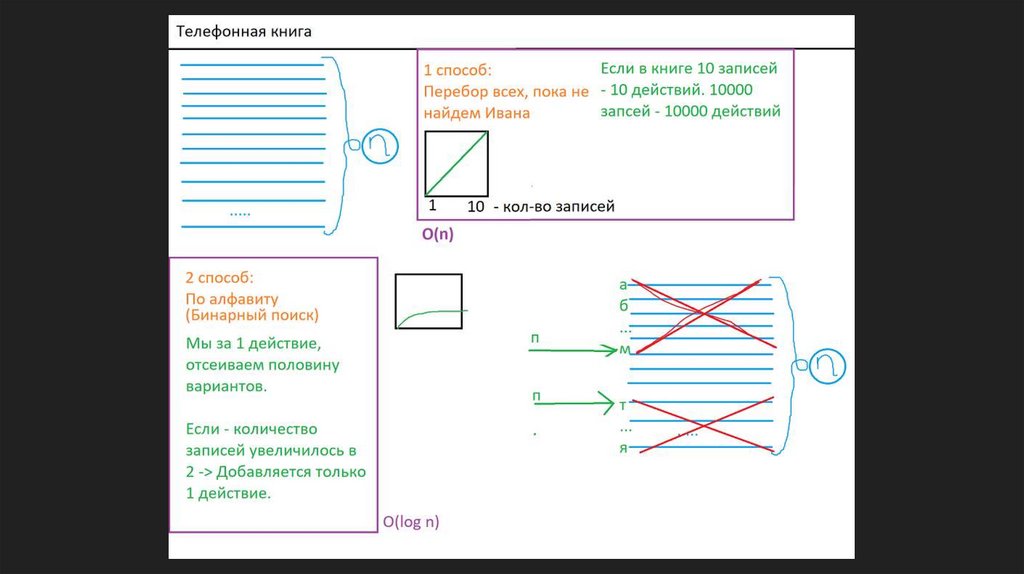
Плохой способ: O(n) — Линейный поискНачинаем с первой страницы и просматриваем каждую запись по порядку,
пока не найдем "Ивана Петрова"
В худшем случае (если Иван Петров последний в книге), придется
просмотреть все n записей. Если книга вырастет в 2 раза, время поиска тоже
вырастет в 2 раза.
Время растет линейно (прямо пропорционально) количеству данных.
26.
Хороший способ: O(log n) — Бинарный поискЗнаем, что книга отсортирована по алфавиту и открываем ее посередине.
Видим фамилию на "М", понимаем, что "П" идет после "М", поэтому
отбрасываем всю первую половину книги.
Берем оставшуюся вторую половину и снова открываем ее посередине.
Видим фамилию на "Т", понимаем, что "П" идет до "Т", и отбрасываем
вторую половину этого куска.
Даже если книга вырастет в два раза, понадобится всего одно
дополнительное действие (одно деление пополам).
27.
28.
Если в книге 1 000 000 записей, O(n) в худшемслучае потребует 1 000 000 шагов, а O(log n) —
всего около 20.
29.
Самые частые виды Big O30.
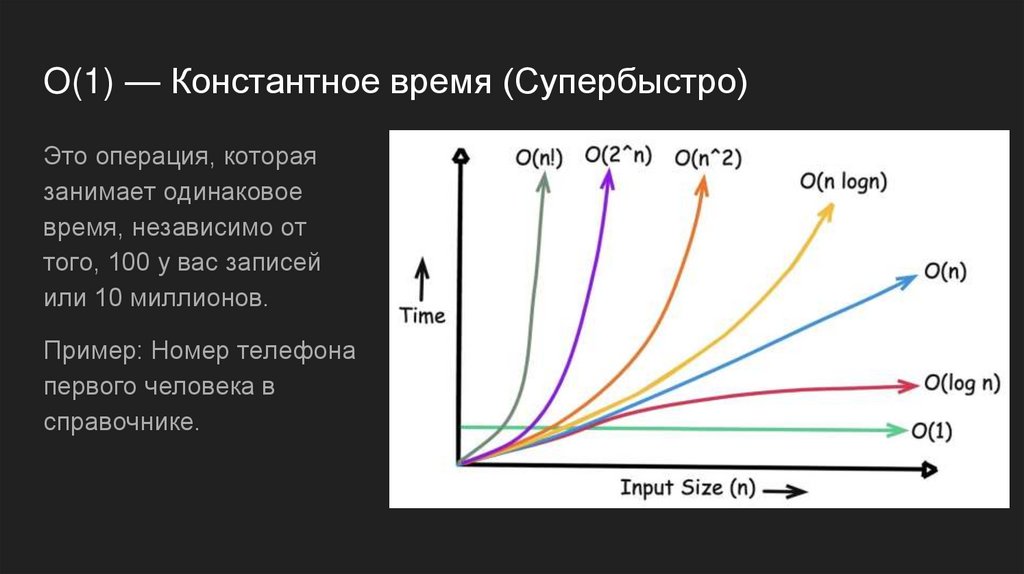
O(1) — Константное время (Супербыстро)Это операция, которая
занимает одинаковое
время, независимо от
того, 100 у вас записей
или 10 миллионов.
Пример: Номер телефона
первого человека в
справочнике.
31.
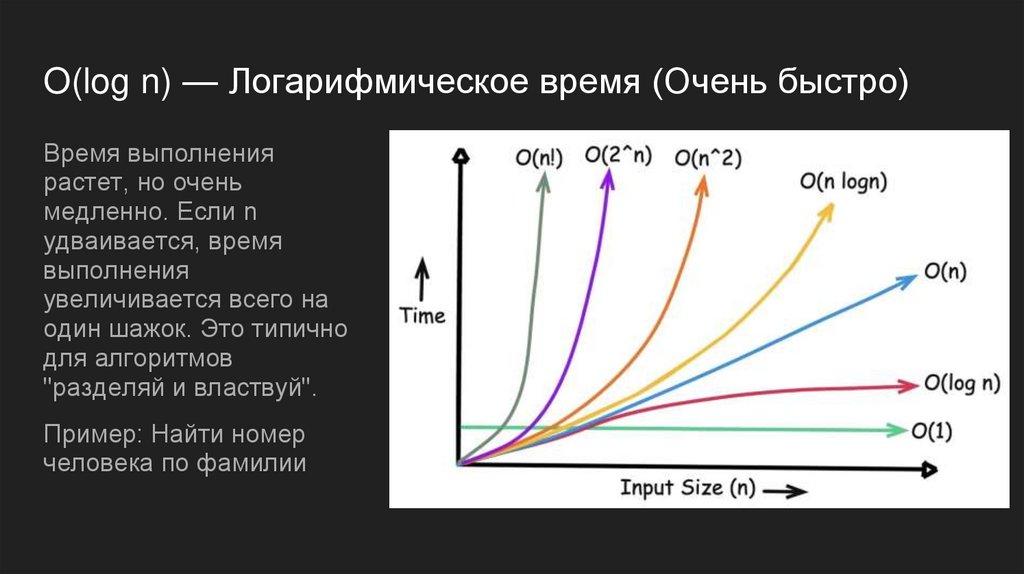
O(log n) — Логарифмическое время (Очень быстро)Время выполнения
растет, но очень
медленно. Если n
удваивается, время
выполнения
увеличивается всего на
один шажок. Это типично
для алгоритмов
"разделяй и властвуй".
Пример: Найти номер
человека по фамилии
32.
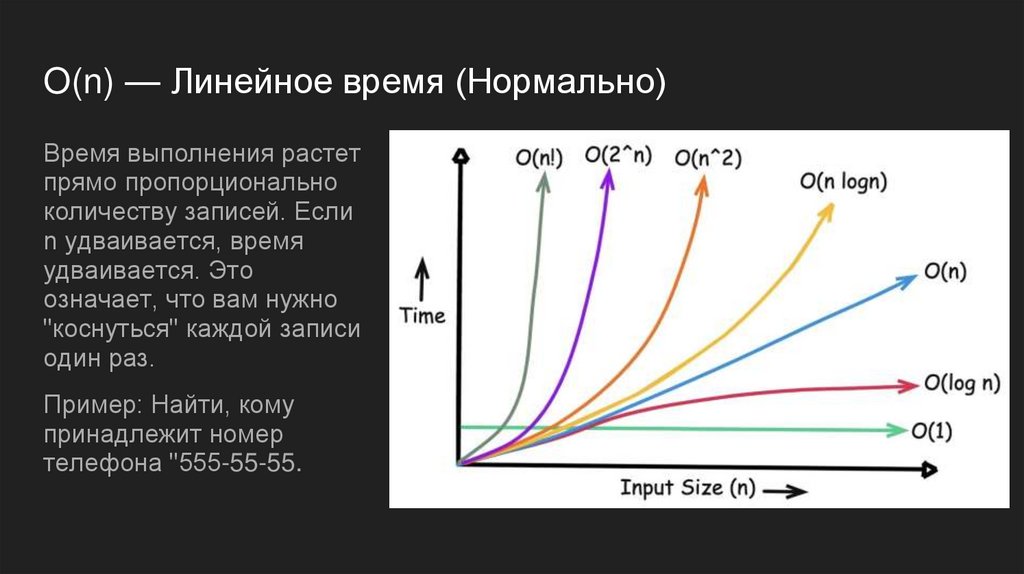
O(n) — Линейное время (Нормально)Время выполнения растет
прямо пропорционально
количеству записей. Если
n удваивается, время
удваивается. Это
означает, что вам нужно
"коснуться" каждой записи
один раз.
Пример: Найти, кому
принадлежит номер
телефона "555-55-55.
33.
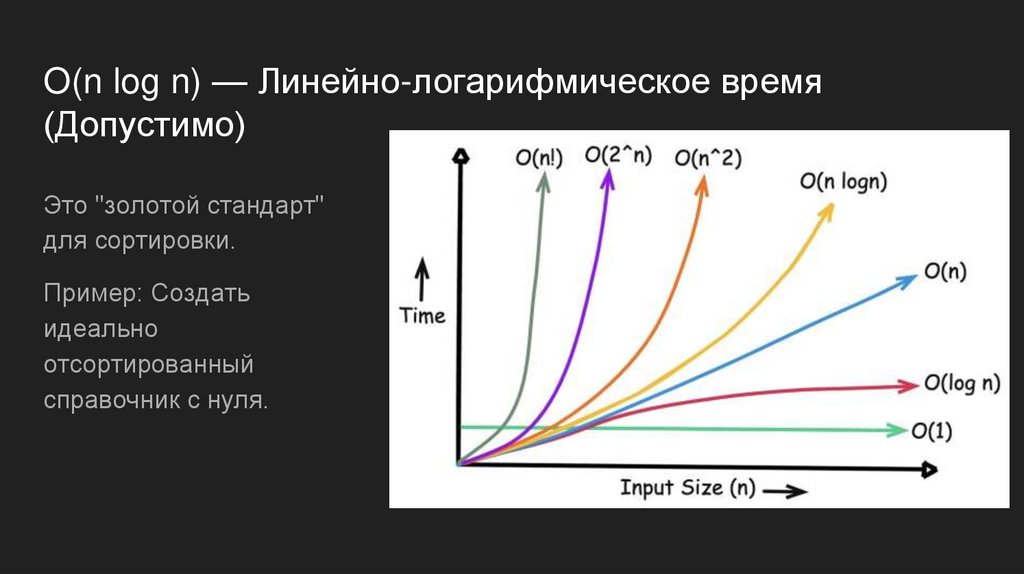
O(n log n) — Линейно-логарифмическое время(Допустимо)
Это "золотой стандарт"
для сортировки.
Пример: Создать
идеально
отсортированный
справочник с нуля.
34.
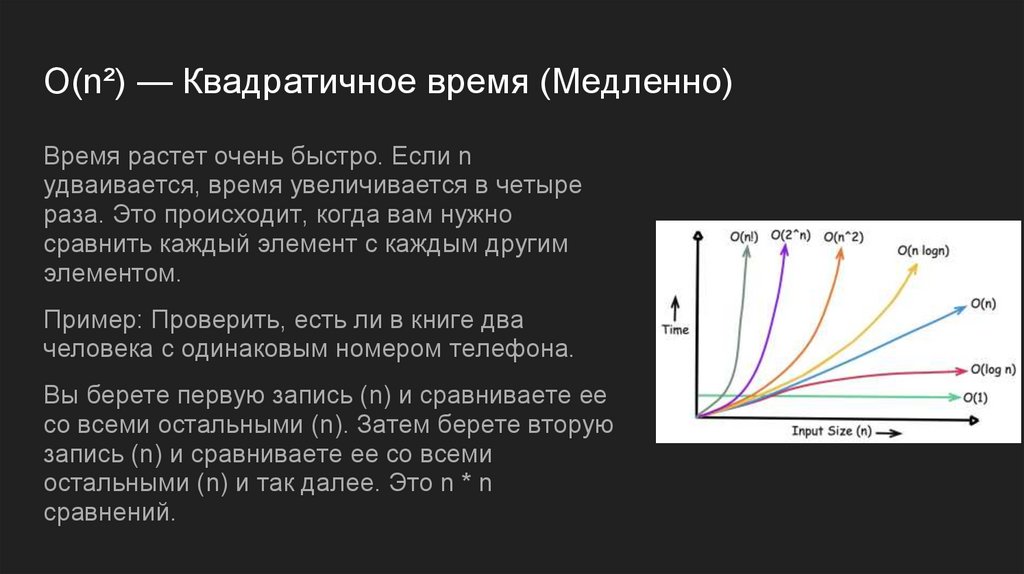
O(n²) — Квадратичное время (Медленно)Время растет очень быстро. Если n
удваивается, время увеличивается в четыре
раза. Это происходит, когда вам нужно
сравнить каждый элемент с каждым другим
элементом.
Пример: Проверить, есть ли в книге два
человека с одинаковым номером телефона.
Вы берете первую запись (n) и сравниваете ее
со всеми остальными (n). Затем берете вторую
запись (n) и сравниваете ее со всеми
остальными (n) и так далее. Это n * n
сравнений.
35.
O(2ⁿ) — Экспоненциальное время (Ужасно медленно)Время выполнения удваивается с каждой новой
записью. Такие задачи практически невыполнимы
для больших n.
Пример: Найти все возможные группы
(подмножества) людей из справочника.
Если в книге 1 человек, есть 2 варианта (он в
группе или нет). Если 2 человека - 4 варианта
(никто, только А, только Б, А+Б). Если 3 человека 8 вариантов. Если 30 человек, вариантов будет
больше миллиарда.
36.
O(n!) — Факториальное время (Абсолютнаякатастрофа)
Время растет еще быстрее. Используется для
поиска всех перестановок (порядков).
Пример: Найти все возможные маршруты, чтобы
обзвонить каждого человека в книге ровно по
одному разу.
Если у вас 10 человек, это 3.6 миллиона
вариантов. Если 20 человек - число вариантов
становится абсурдным.
37.
А другие нотацииЕсли Big O (O) - это «худший случай» (верхняя граница), то есть и нотации
для лучшего и среднего случаев.
Big Omega (Ω) - Лучший случай или нижняя граница.
Big Theta (