






Similar presentations:

")








Презентация диплом Останин
1. Реализация веб-приложения для выделения целевого голоса с использованием нейросетевых технологий
Выполнил:Останин Александр Александрович
Научный руководитель:
Шаповалова Инна Анатольевна
2.
2Цель работы:
Создать веб-приложение, способное выделять целевой
голос диктора из аудиосмеси с использованием
нейросетевых методов.
Цель
и
задачи
ВКР
Задачи:
1.Разработать алгоритм выделения голоса диктора на
основе нейросетевых моделей.
2.Реализовать обработку аудио на сервере с нормализацией
и разделением смеси.
3.Интегрировать предобученные модели ConvTasNet и
ECAPA-TDNN в веб-приложение.
4.Реализовать интерфейс для загрузки файлов и просмотра
результата.
5.Провести оценку работы: SI-SDR, SD-SDR, PESQ, STOI,
ES-TOI, ECAPA.
3.
Постановка задачиРешается задача выделения нужного голоса из
аудиозаписи, где одновременно присутствуют несколько
дикторов и посторонние шумы.
Пользователь загружает смесь и небольшой
фрагмент голоса человека, которого нужно выделить.
Система
автоматически
обрабатывает
аудио,
разделяет дорожки и определяет, какая из них
принадлежит целевому диктору.
На выходе получается отдельная очищенная запись
его речи, а также метрики качества.
3
4.
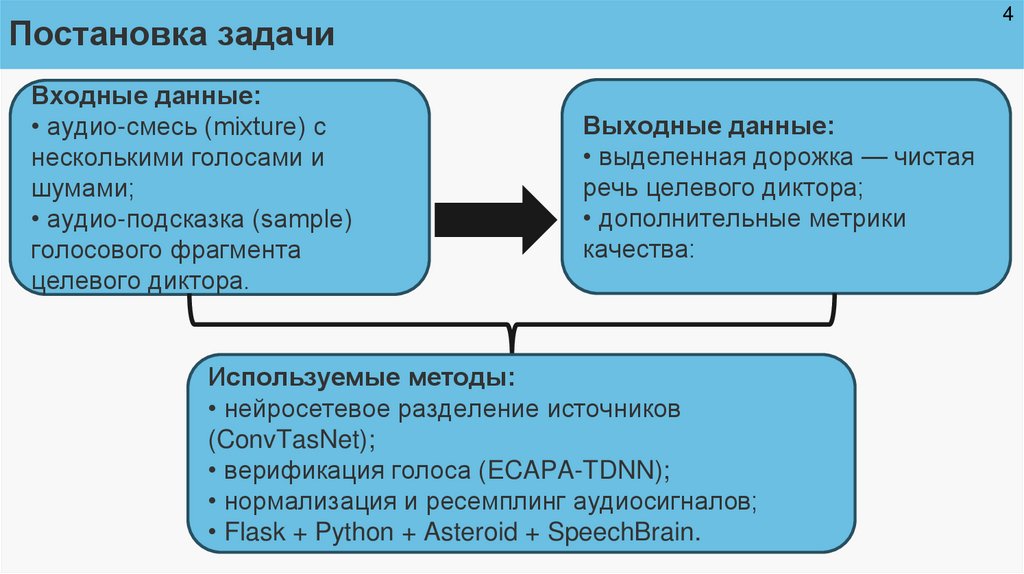
4Постановка задачи
Входные данные:
• аудио-смесь (mixture) с
несколькими голосами и
шумами;
• аудио-подсказка (sample)
голосового фрагмента
целевого диктора.
Выходные данные:
• выделенная дорожка — чистая
речь целевого диктора;
• дополнительные метрики
качества:
Используемые методы:
• нейросетевое разделение источников
(ConvTasNet);
• верификация голоса (ECAPA-TDNN);
• нормализация и ресемплинг аудиосигналов;
• Flask + Python + Asteroid + SpeechBrain.
5. Архитектура веб-приложения
5Архитектура веб-приложения
Входные данные
аудио-смесь
аудио-подсказка
аудио-подсказка
Нейросеть ConvTasNet
Нормализация
• конвертацию в
WAV
• перевод в моно
• установку частоты
дискретизации 8 или
16 кГц
• выравнивание
уровня сигнала
аудио-смесь
2 выделенных канала
Нейросеть ECAPA-TDNN
Сравнивает каждый
выделенный канал с
аудио-подсказкой
Вычисляет степень
похожести
Говорит, какой канал
принадлежит целевому
диктору
Выходные данные
Готовый
аудио-файл
Принимает
аудио-смесь,
Разделяет её на
несколько
источников
Выдаёт
отдельные
дорожки(каналы)
Примечание.
Используемые нейромодели были обучены на
стандартных речевых наборах данных:
LibriSpeech — чистая речь, используется для
модели верификации диктора (ECAPA-TDNN).
LibriMix — смеси голосов, применяется для
модели разделения источников (ConvTasNet).
LibriCSS — реальные многодикторные записи,
повышающие устойчивость моделей к шумам и
реверберации.
6. В качестве входных сигналов выступают аудио-смесь, содержащая несколько голосов или шумовых компонентов, а также
Описание данныхВ качестве входных сигналов выступают аудио-смесь,
содержащая несколько голосов или шумовых компонентов, а
также аудио-подсказка, представляющая собой короткий
фрагмент речи целевого диктора.
Допустимые форматы файлов: WAV, MP3, AAC и FLAC.
Частота дискретизации входных данных – произвольная.
В результате обработка все аудиофайлы приводятся к
единому формату: формат WAV, монофонноый канал, частота
дискретизации 16 или 8 кГц, при необходимости выполняется
выравнивание уровня громкости.
6
7.
Интерфейс веб-приложения7
8.
8Анализ результатов
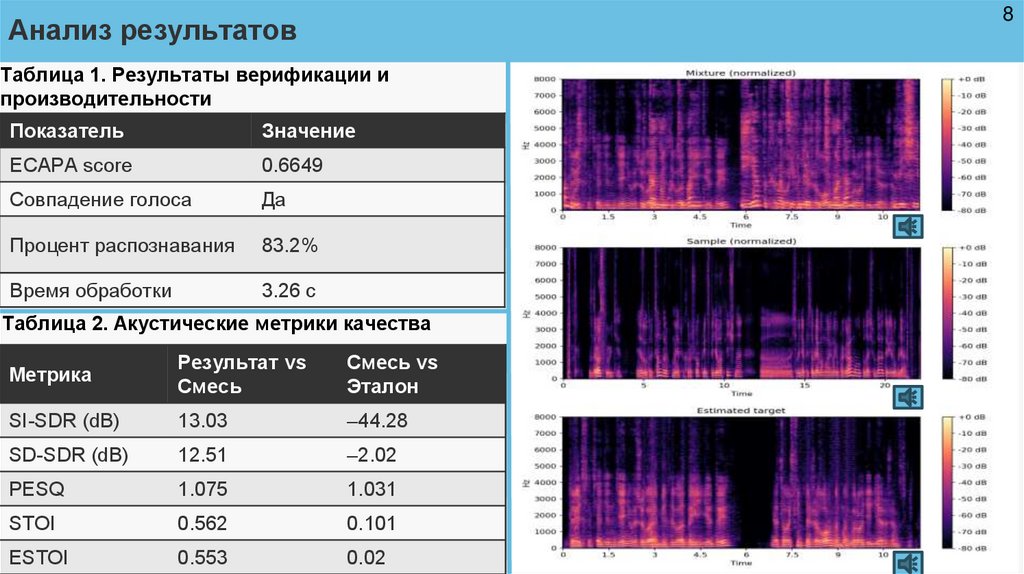
Таблица 1. Результаты верификации и
производительности
Показатель
Значение
ECAPA score
0.6649
Совпадение голоса
Да
Процент распознавания
83.2%
Время обработки
3.26 с
Таблица 2. Акустические метрики качества
Метрика
Результат vs
Смесь
Смесь vs
Эталон
SI-SDR (dB)
13.03
–44.28
SD-SDR (dB)
12.51
–2.02
PESQ
1.075
1.031
STOI
0.562
0.101
ESTOI
0.553
0.02
9.
Возможные проблемы и пути улучшения системыВозможные проблемы
Возможные улучшения
Похожие тембры голосов усложняют
разделение источников
Использование более современных моделей
TSE (SepFormer, TF-GridNet, MTSE)
Наличие шумов, эхо и реверберации
снижает качество выделения речи
Интеграция шумоподавления и
реверберационных моделей
Короткая или малоинформативная
аудиоподсказка ухудшает верификацию
диктора
Применение более длинных и
выразительных голосовых образцов
Артефакты после разделения смеси
влияют на разборчивость речи
Использование методов постобработки и
сглаживания артефактов
Ограниченная устойчивость моделей к
реальным пользовательским данным
Адаптация и дообучение моделей под
реальные сценарии
Сложности при пересекающихся репликах Переход на архитектуры, учитывающие
дикторов
длительные временные зависимости
9
10.
Заключение10
В ходе работы над ВКР:
изучены методы цифровой обработки речи, подходы к построению архитектур
для выделения и верификации голоса, а также практические аспекты создания
производительных веб-сервисов для работы с аудиоданными;
• разработан полнофункциональный веб-сервис, выполняющий автоматическое
выделение целевого диктора из аудио-смеси с использованием нейромоделей
обработки речи;
• реализован полный конвейер подготовки и обработки аудиоданных,
включающий
нормализацию
сигналов,
выбор
оптимальной
частоты
дискретизации, разделение смеси на отдельные каналы и определение
дорожки, соответствующей целевому голосу;
• создана серверная часть, обеспечивающая стабильное выполнение обработки,
а также веб-интерфейс, позволяющий пользователю удобно загружать файлы и
получать итоговый результат.