































 database
databaseSimilar presentations:








")

Лекция №2. Логическая и физическая независимость данных
1.
Логическая и физическая независимость данных2.
Глава 1Введение: проблема зависимости данных
3.
Почему независимость данных так важна?В ранних системах управления данными:
Проблемы:
Приложения напрямую работали с физической организацией
Сложность поддержки и масштабирования систем
данных
Дублирование данных
Любые изменения в структуре хранения требовали изменений в
Несогласованность информации
Высокие затраты на адаптацию при любых изменениях
Невозможность независимой оптимизации
коде приложений
Каждое приложение имело свое представление о данных
Отсутствовала единая схема данных
Эти проблемы привели к необходимости разработки новой архитектуры, которая бы обеспечивала независимость данных от их физической
реализации.
4.
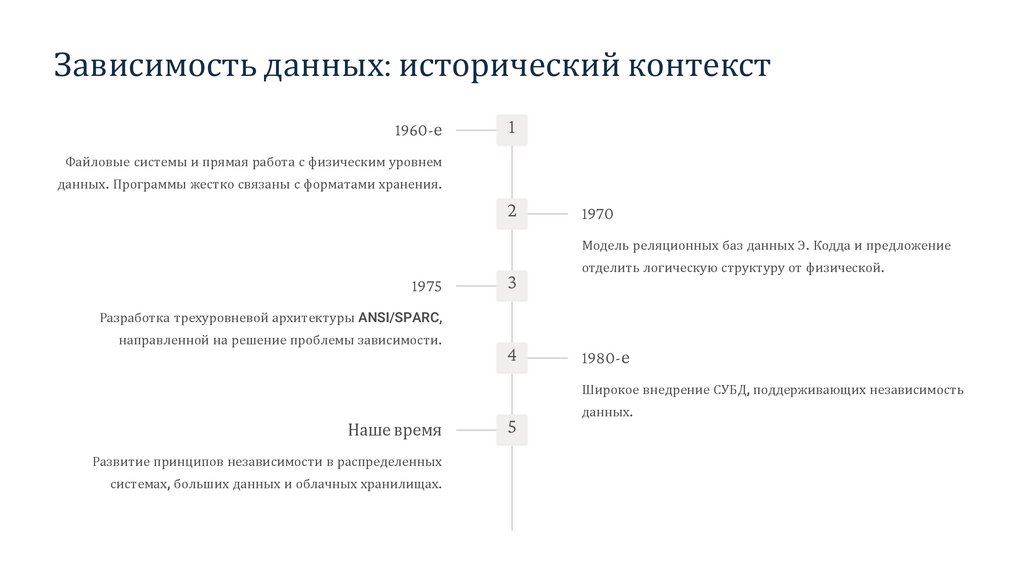
Зависимость данных: исторический контекст1960-е
1
Файловые системы и прямая работа с физическим уровнем
данных. Программы жестко связаны с форматами хранения.
2
1970
Модель реляционных баз данных Э. Кодда и предложение
1975
3
отделить логическую структуру от физической.
Разработка трехуровневой архитектуры ANSI/SPARC,
направленной на решение проблемы зависимости.
4
1980-е
Широкое внедрение СУБД, поддерживающих независимость
Наше время
Развитие принципов независимости в распределенных
системах, больших данных и облачных хранилищах.
5
данных.
5.
Глава 2Трехуровневая архитектура ANSI/SPARC
6.
Трехуровневая архитектура ANSI/SPARCАрхитектура ANSI/SPARC (American National Standards Institute / Standards Planning And Requirements Committee) – это концептуальная
модель, разработанная в 1975 году для обеспечения независимости данных в системах баз данных.
Внешний уровень (External Level)
Концептуальный уровень
(Conceptual Level)
Внутренний уровень (Internal
Level)
Физическое хранение данных. Структуры
Общая логическая структура всей базы
хранения, индексы, методы доступа к
Представления пользователей о данных.
данных. Интегрированное представление
данным.
То, что видят и с чем работают конечные
всех данных, независимое от приложений
пользователи и приложения.
и физической реализации.
7.
Основные компоненты архитектурыВнешний уровень
Концептуальный уровень
Внутренний уровень
Множество пользовательских
Единая общая схема данных
Структуры файлов
представлений
Логические связи между сущностями
Индексы и методы доступа
Оптимизация хранения
Физическое распределение данных
Различные формы отображения для
разных пользователей
Правила целостности и ограничения
Не зависит от физического хранения
Настроенные под конкретные задачи
интерфейсы
Скрывает ненужные данные
Каждый уровень имеет собственное описание данных, а переходы между уровнями осуществляются с помощью специальных отображений
(mappings).
8.
Отображения между уровнямиВнешний уровень
Пользовательские представления (views)
Внешне-концептуальное отображение
Трансформирует запросы пользователей в термины концептуальной схемы
Концептуальный уровень
Общая логическая схема всей базы данных
Концептуально-внутреннее отображение
Преобразует операции над логической схемой в операции над физическими структурами
Внутренний уровень
Физическое хранение данных
Именно эти отображения позволяют реализовать логическую и физическую независимость данных.
9.
Пример трехуровневой архитектурыВнешний уровень
Представление менеджера:
Сотрудник: ID, ФИО, Должность, Отдел_ID,
ФИО_сотрудника, Должность, Отдел,
Зарплата, Адрес, Телефон, Паспорт_ID,
Зарплата
Дата_приема
Представление HR: ФИО, Должность,
Отдел, Адрес, Телефон, Паспорт
Концептуальный уровень
Представление бухгалтерии:
Табельный_номер, ФИО, Зарплата,
Налоги
Отдел: ID, Название, Руководитель_ID,
Бюджет
Документы: Паспорт_ID, Серия, Номер,
Внутренний уровень
Таблица "Сотрудники" с индексами по ID
и ФИО
B-дерево для быстрого доступа к
записям
Распределение по дисковым блокам
Методы сжатия данных
Дата_выдачи
На этом примере видно, что одни и те же данные представляются по-разному для разных пользователей, хотя физически хранятся единожды и
структурированы согласно общей концептуальной схеме.
10.
Глава 3Логическая независимость данных
11.
Что такое логическая независимость данных?Логическая независимость данных — это способность изменять концептуальную схему базы данных без необходимости изменения
пользовательских представлений (внешних схем) и прикладных программ.
Другими словами, логическая независимость позволяет изменять логическую структуру базы данных без влияния на работу уже
существующих приложений.
Ключевые аспекты:
Защищает внешний уровень от изменений в концептуальной схеме
Позволяет расширять или изменять структуру БД без переписывания приложений
Обеспечивается через механизм отображений между внешним и концептуальным уровнями
Реализуется через представления (views) и метаданные
12.
Как работает логическая независимость?Концептуальная схема
Определяет логическую структуру всей БД
Представления
Определяют, какие данные видны
конкретным приложениям
Отображения
Преобразуют запросы к представлениям в
запросы к концептуальной схеме
Абстракция
Скрывает сложности реальной структуры
от пользователей
Внешне-концептуальное отображение трансформирует запросы пользователей в термины концептуальной схемы. При изменении
концептуальной схемы меняются только правила отображения, а интерфейсы приложений остаются неизменными.
13.
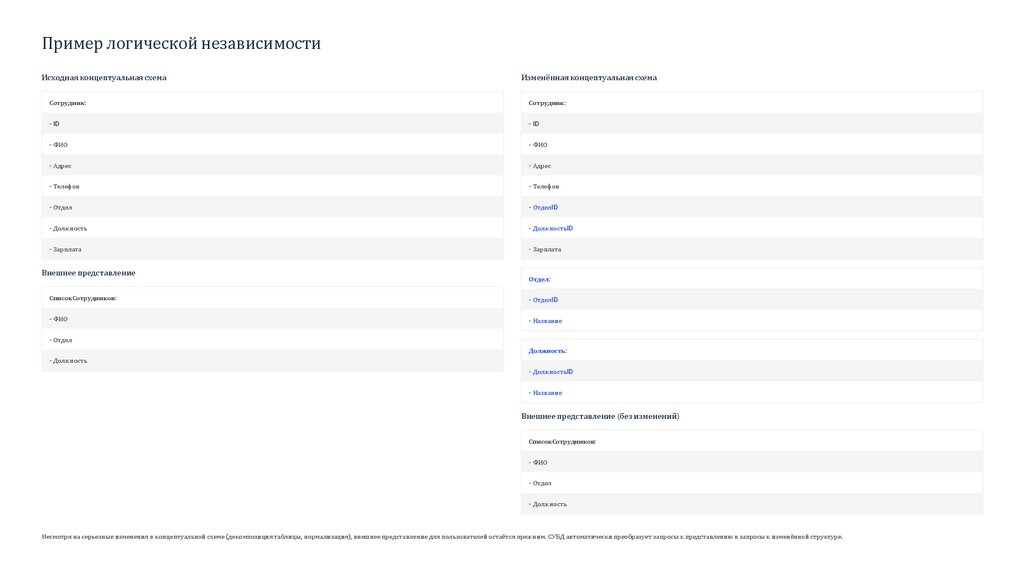
Пример логической независимостиИсходная концептуальная схема
Изменённая концептуальная схема
Сотрудник:
Сотрудник:
- ID
- ID
- ФИО
- ФИО
- Адрес
- Адрес
- Телефон
- Телефон
- Отдел
- ОтделID
- Должность
- ДолжностьID
- Зарплата
- Зарплата
Внешнее представление
Отдел:
СписокСотрудников:
- ОтделID
- ФИО
- Название
- Отдел
Должность:
- Должность
- ДолжностьID
- Название
Внешнее представление (без изменений)
СписокСотрудников:
- ФИО
- Отдел
- Должность
Несмотря на серьезные изменения в концептуальной схеме (декомпозиция таблицы, нормализация), внешнее представление для пользователей остаётся прежним. СУБД автоматически преобразует запросы к представлению в запросы к изменённой структуре.
14.
Примеры изменений на концептуальном уровнеБлагодаря логической независимости, следующие изменения концептуальной схемы не влияют на внешние представления и работу приложений:
1
2
3
Добавление новых таблиц
Например, добавление таблицы "Проекты" и связей с существующими таблицами.
Добавление новых атрибутов
Расширение существующих таблиц новыми полями (дата рождения сотрудника, семейное положение и т.д.).
Нормализация структуры
Разбиение большой таблицы на несколько связанных для устранения избыточности и аномалий.
4
Изменение ограничений целостности
Добавление новых правил проверки данных, уникальных ключей, внешних ключей.
5
Реструктуризация данных
Объединение или разделение таблиц, изменение иерархии данных.
15.
Механизмы обеспечения логической независимостиПредставления (Views)
Абстрактные интерфейсы
Метаданные
Виртуальные таблицы, которые
API и объектно-ориентированные
Описания схем и отображений,
динамически формируются на основе
интерфейсы, скрывающие детали
хранящиеся в системном каталоге СУБД и
запроса к базовым таблицам.
реализации концептуальной схемы.
используемые для трансляции запросов.
Пользователи работают с
представлениями, не зная о реальной
структуре.
Современные СУБД автоматически поддерживают эти механизмы, позволяя администраторам баз данных изменять концептуальную схему с
минимальным влиянием на пользовательские приложения.
16.
Глава 4Физическая независимость данных
17.
Что такое физическая независимость данных?Физическая независимость данных — это способность изменять внутреннюю схему базы данных (физическое представление) без
необходимости изменения концептуальной схемы и, соответственно, пользовательских представлений.
Проще говоря, физическая независимость позволяет изменять способ хранения данных и методы доступа к ним без влияния на логическую
структуру БД и работу приложений.
Ключевые аспекты:
Защищает концептуальный и внешний уровни от изменений в физической организации данных
Позволяет оптимизировать производительность БД без переписывания логики приложений
Обеспечивается через отображение концептуальной схемы на внутреннюю
Реализуется через системный каталог, буферный пул и методы доступа
18.
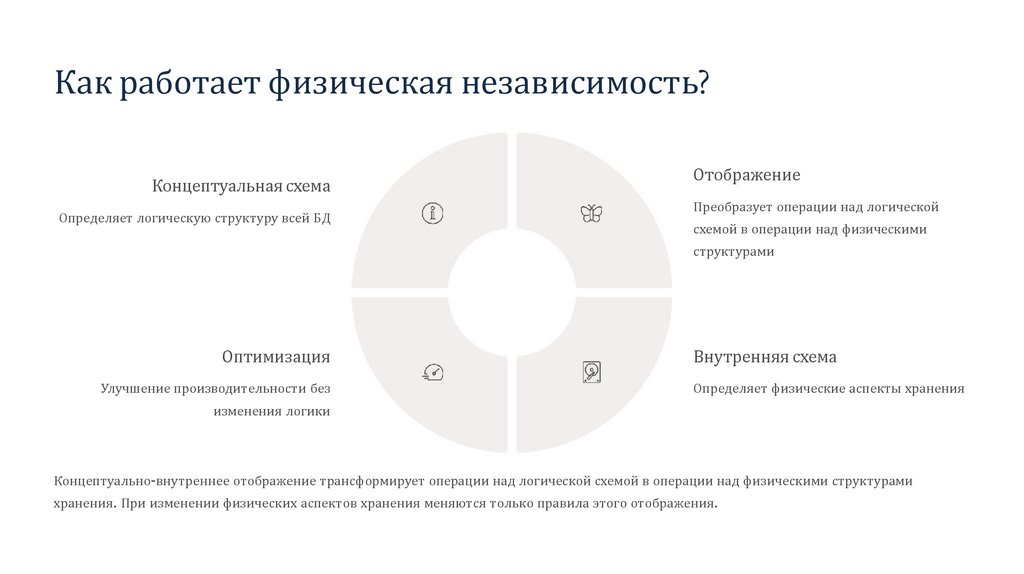
Как работает физическая независимость?Концептуальная схема
Определяет логическую структуру всей БД
Отображение
Преобразует операции над логической
схемой в операции над физическими
структурами
Оптимизация
Улучшение производительности без
Внутренняя схема
Определяет физические аспекты хранения
изменения логики
Концептуально-внутреннее отображение трансформирует операции над логической схемой в операции над физическими структурами
хранения. При изменении физических аспектов хранения меняются только правила этого отображения.
19.
Пример физической независимостиКонцептуальная схема
Исходная внутренняя схема
Таблица Клиенты:
Физическое хранение:
ID (первичный ключ)
Последовательный файл
ФИО
Хранение в порядке добавления
Полное сканирование при запросах
Телефон
Измененная внутренняя схема
Адрес
Дата_регистрации
Физическое хранение:
Индекс B-дерева по полю ID
Индекс по полю Дата_регистрации
SELECT ФИО, Email FROM Клиенты WHERE Дата_регистрации >
Кластеризация по Дата_регистрации
'2023-01-01'
Партиционирование по годам
Запрос:
После изменения внутренней схемы тот же самый запрос будет выполняться гораздо быстрее благодаря индексу и кластеризации, но его синтаксис остается
неизменным. Ни концептуальная схема, ни приложения не требуют модификации.
20.
Примеры изменений на физическом уровнеБлагодаря физической независимости, следующие изменения внутренней схемы не влияют на концептуальную схему и работу приложений:
1
2
Создание или удаление индексов
Добавление B-деревьев, хеш-индексов, индексов по нескольким полям для ускорения поиска.
Изменение структуры хранения
Переход от последовательной организации к индексной, хеш-организации или кластеризованной.
3
Изменение методов доступа
Переключение между различными алгоритмами поиска, сортировки и обработки данных.
4
Партиционирование данных
Горизонтальное или вертикальное разделение таблиц для распределения нагрузки и повышения производительности.
5
Настройка буферизации
Изменение размеров буфера, стратегии вытеснения страниц, предварительной загрузки данных.
21.
Механизмы обеспечения физической независимостиМенеджер хранения
Индексы и структуры доступа
Буферный менеджер
Компонент СУБД, отвечающий за
Механизмы быстрого поиска данных на
Система кэширования данных в
трансляцию логических операций в
физическом уровне, невидимые на
оперативной памяти для ускорения
физические операции доступа к данным.
логическом уровне.
доступа, прозрачная для приложений.
Все эти механизмы работают "под капотом" СУБД и не требуют изменений в логических структурах данных или приложениях при их
модификации.
22.
Глава 5Примеры применения
23.
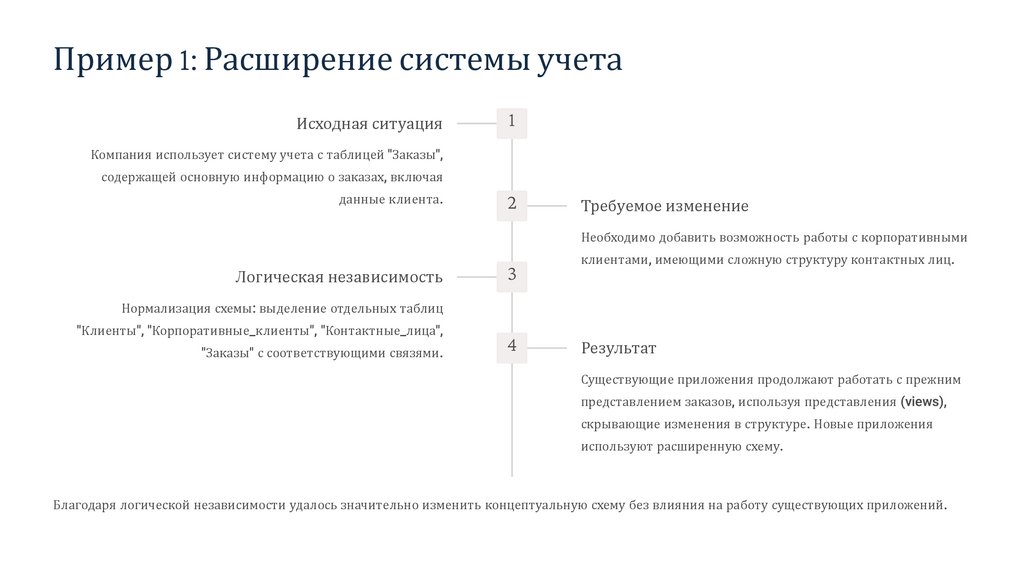
Пример 1: Расширение системы учетаИсходная ситуация
1
Компания использует систему учета с таблицей "Заказы",
содержащей основную информацию о заказах, включая
данные клиента.
2
Требуемое изменение
Необходимо добавить возможность работы с корпоративными
Логическая независимость
3
клиентами, имеющими сложную структуру контактных лиц.
Нормализация схемы: выделение отдельных таблиц
"Клиенты", "Корпоративные_клиенты", "Контактные_лица",
"Заказы" с соответствующими связями.
4
Результат
Существующие приложения продолжают работать с прежним
представлением заказов, используя представления (views),
скрывающие изменения в структуре. Новые приложения
используют расширенную схему.
Благодаря логической независимости удалось значительно изменить концептуальную схему без влияния на работу существующих приложений.
24.
Пример 2: Оптимизация производительностиИсходная ситуация
1
Растущая система интернет-магазина с миллионами
заказов. Поиск и фильтрация заказов стали работать
медленно.
2
Требуемое изменение
Необходимо ускорить выполнение типичных запросов без
Физическая независимость
3
изменения логики приложения.
Создание индексов по часто используемым полям поиска,
партиционирование таблицы заказов по датам, изменение
стратегии кэширования.
4
Результат
Скорость выполнения запросов увеличилась в 15-20 раз.
Приложение и его код остались полностью без изменений.
Пользователи просто заметили, что система стала работать
быстрее.
Физическая независимость позволила значительно оптимизировать производительность без необходимости переписывать логику
приложения или менять его интерфейс.
25.
Пример 3: Миграция на новую СУБДТребуемое изменение
Исходная ситуация
Компания использует устаревшую СУБД, которая больше не
Миграция на современную СУБД с совершенно другой
архитектурой хранения данных и оптимизации запросов.
поддерживается разработчиком и не справляется с растущими
нагрузками.
Результат
Реализация
Приложения продолжают работать с той же логической моделью
Благодаря физической независимости, концептуальная схема
данных. Запросы и операции выполняются гораздо быстрее за
переносится в новую СУБД без изменений. Внутренняя схема
счет более эффективных алгоритмов новой СУБД.
создается заново с учетом особенностей новой СУБД.
Этот пример демонстрирует, как физическая независимость данных позволяет полностью изменить способ хранения и обработки данных без
влияния на бизнес-логику приложений.
26.
Пример 4: Развитие информационной системы университетаЛогическая независимость
Физическая независимость
Начальная схема:
Оптимизация производительности:
Студенты (ID, ФИО, Группа, ...)
Партиционирование таблицы "Оценки" по годам обучения
Преподаватели (ID, ФИО, ...)
Создание составного индекса (Студент_ID, Предмет_ID)
Предметы (ID, Название, ...)
Создание материализованных представлений для часто
Оценки (Студент_ID, Предмет_ID, Оценка, ...)
Расширение схемы:
Добавление таблицы "Факультеты"
Добавление таблицы "Специальности"
Разделение таблицы "Студенты" на "Базовая_информация" и
запрашиваемых отчетов
Переход на колоночное хранение для аналитических запросов
Реализация автоматического архивирования старых данных
"Учебная_информация"
Добавление системы электронного портфолио
Все эти изменения происходили постепенно в течение нескольких лет развития системы, и благодаря логической и физической независимости не
требовали переписывания существующих приложений.
27.
Глава 6Значение для современных
информационных систем
28.
Почему независимость данных критически важнасегодня?
Длительный жизненный цикл
систем
Растущая сложность
Современные информационные системы
сложные взаимосвязи и обслуживают
Требуется постоянное
развиваются десятилетиями, требуя
множество приложений с разными
совершенствование физических аспектов
постоянных изменений в структуре и
потребностями.
хранения и обработки, не нарушая работу
Системы включают тысячи таблиц,
методах хранения данных.
Экспоненциальный рост объема
данных
приложений.
В современном мире бизнес-требования и технологии меняются быстрее, чем когда-либо. Независимость данных позволяет системам
адаптироваться к этим изменениям без необходимости переписывать все приложения.
29.
Независимость данных в распределенных системахОблачные хранилища
Абстрагируют физическое размещение
Микросервисная архитектура
Каждый сервис имеет собственное
данных, позволяя прозрачно
представление данных, работая с общим
масштабировать хранилища
концептуальным уровнем
Репликация и шардинг
API как внешний уровень
Физическое распределение данных
прозрачно для приложений благодаря
физической независимости
Предоставляют стабильный интерфейс
взаимодействия с данными, скрывая
изменения в их организации
Современные распределенные системы развивают концепции независимости данных, добавляя новые уровни абстракции для работы с
географически распределенными и гетерогенными хранилищами.
30.
Развитие трехуровневой архитектуры в современныхсистемах
Дополнительные уровни
Новые технологии
Новые вызовы
Уровень кэширования (Redis,
Memcached)
Уровень федерации данных
Уровень виртуализации данных
Уровень семантического доступа
ORM-системы как мост между
концептуальным и внешним уровнями
Согласованность данных в
распределенных системах
Эволюция схемы в NoSQL базах данных
Версионирование API и данных
Интеграция гетерогенных источников
GraphQL для гибкого доступа к данным
NoSQL базы данных с гибкой схемой
Полиглот-персистентность
данных
(использование разных БД для разных
задач)
Несмотря на все изменения в технологиях и подходах, базовые принципы логической и физической независимости данных остаются
фундаментальными для обеспечения гибкости и масштабируемости современных систем.
31.
Независимость данных в контексте DataOpsDataOps — это набор практик, направленных на улучшение качества и скорости предоставления аналитических данных. Независимость данных
играет ключевую роль в этом подходе:
Источники данных
Процессы ETL/ELT
Разнообразные источники с собственными форматами и схемами
Извлечение, преобразование и загрузка данных в единую модель
Хранилище данных
Аналитические приложения
Логически организованное хранилище с оптимизированной
Работа с семантическим слоем, независимым от физического
физической структурой
хранилища
Логическая и физическая независимость позволяют изменять источники данных, оптимизировать процессы обработки и структуру хранения без
необходимости переделывать аналитические дашборды и отчеты.
32.
Вызовы в обеспечении независимости данныхПроизводительность
Сложность управления
Дополнительные уровни абстракции могут создавать
Поддержание нескольких уровней отображений и
накладные расходы. Важно находить баланс между уровнями
представлений требует дополнительных инструментов и
независимости и эффективностью.
компетенций администраторов БД.
Эволюция схемы данных
Специфика NoSQL-систем
Некоторые изменения в концептуальной схеме все равно могут
В системах без жесткой схемы (MongoDB, Cassandra) понятие
требовать адаптации внешнего уровня, особенно при удалении
независимости данных приобретает новое значение и требует
или существенном изменении сущностей.
других механизмов реализации.
33.
Независимость данных и Agile-разработкаСовременные методологии разработки требуют быстрой адаптации к изменениям, что невозможно без высокой степени независимости
данных.
Итерационная разработка
1
Схема данных эволюционирует с каждым спринтом.
Физическая и логическая независимость позволяют
модифицировать структуру БД, не нарушая работу
существующего функционала.
2
Микросервисы
Каждый сервис имеет собственное представление данных.
CI/CD и автоматизация
3
в структуре БД.
что обеспечивается через механизмы независимости
данных.
Непрерывная интеграция и доставка требуют стабильных
интерфейсов доступа к данным при постоянных изменениях
Изменения в одном сервисе не должны влиять на другие,
4
Эволюционная архитектура
Системы развиваются постепенно. Независимость данных
обеспечивает возможность инкрементальных изменений
без необходимости "большого взрыва".
34.
Реализация независимости данных в современных СУБДРеляционные СУБД
NoSQL и NewSQL
Oracle: материализованные представления, партиционирование,
MongoDB: проекции, индексы, шардинг, репликация
хранимые контексты
Cassandra: виртуальные таблицы, материализованные
PostgreSQL: гибкая система представлений, наследование
таблиц, декларативное партиционирование
Neo4j: виртуальные графы, проекции
SQL Server: индексированные представления, схемы,
Google Spanner: интерливинг, глобальное распределение,
динамическое управление памятью
представления
TrueTime
MySQL/MariaDB: представления, партиционирование, хранимые
процедуры
Современные СУБД предлагают множество специализированных механизмов для обеспечения логической и физической независимости
данных, адаптированных под конкретные модели данных и сценарии использования.
35.
Ключевые выводыОснова гибкости
Двойная независимость
Эволюция концепции
Трехуровневая архитектура ANSI/SPARC
Логическая независимость защищает
Современные системы расширяют
обеспечивает фундамент для создания
приложения от изменений логической
классическую модель, добавляя новые
гибких, адаптивных информационных
структуры, а физическая — от изменений
уровни абстракции для работы с
систем.
в способах хранения и доступа.
распределенными, гетерогенными
данными.
"Независимость данных — это не просто теоретическая концепция, а практический инструмент, обеспечивающий долгосрочную
жизнеспособность информационных систем в постоянно меняющемся технологическом и бизнес-ландшафте."
36.
Практические рекомендации1
Проектируйте с учетом будущих изменений
Изначально закладывайте в архитектуру возможность изменения как логической, так и физической структуры данных.
2
Используйте представления и API
Создавайте стабильные интерфейсы доступа к данным, независимые от базовой реализации.
3
4
Внедряйте абстрактные слои доступа к данным
Используйте паттерны Data Access Object (DAO), Repository, ORM для изоляции приложения от деталей хранения данных.
Постепенно оптимизируйте
Используйте физическую независимость для инкрементального улучшения производительности без переписывания бизнес-логики.
5
Документируйте все уровни
Поддерживайте актуальную документацию как логической модели данных, так и деталей физической реализации.
37.
Контрольные вопросыОсновные понятия
Механизмы реализации
Практическое применение
Дайте определение логической и
физической независимости данных
Перечислите три уровня
Какие механизмы используются для
Приведите пример ситуации, когда
обеспечения логической
логическая независимость
независимости?
критически важна
Какие механизмы используются для
Опишите сценарий оптимизации
архитектуры ANSI/SPARC и их
обеспечения физической
производительности БД с
назначение
независимости?
использованием физической
Как отображения помогают
независимости
Объясните разницу между внешней
и концептуальной схемами
реализовать независимость
данных?
Как независимость данных связана с
эволюцией информационных
систем?