






















 finance
finance informatics
informaticsSimilar presentations:










Применение алгоритмов машинного обучения к задаче выявления мошенничества при пользовании банковскими услугами
1. МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ОБРАЗОВАНИЯ«КАЛМЫЦКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИМЕНИ Б.Б. ГОРОДОВИКОВА»
КАФЕДРА ИНФОРМАТИКИ, ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ И ЦИФРОВОЙ
ЭКОНОМИКИ
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
• (бакалаврская работа)
ПРИМЕНЕНИЕ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ К ЗАДАЧЕ ВЫЯВЛЕНИЯ
МОШЕННИЧЕСТВА ПРИ ПОЛЬЗОВАНИИ БАНКОВСКИМИ УСЛУГАМИ
Научный руководитель:
к.п.н., доцент
Мантусов Анатолий
Бадьмаевич
Выполнил:
Обучающийся 4 курса очной
формы обучения, направления
10.03.01 «Информационная
безопасность», профиль
«Организация и технология
защиты информации»
Даванов Давид Сергеевич
2.
Цель работы: Целью работы является исследованиевозможностей, разработка и сравнительный анализ
эффективности применения различных алгоритмов
машинного обучения для решения задачи выявления
мошеннических
операций
при
пользовании
банковскими услугами.
Под этим подразумевается создание программных
решений
для
решения
задачи
выявления
мошеннических
операций
при
пользовании
банковскими услугами с учетом требований
выдвигаемых в системам данного типа
3.
Для достижения поставленной цели необходимо решить следующие задачи:Провести анализ современных видов банковского мошенничества, специфики данных,
используемых для его обнаружения.
Систематизировать и описать этапы построения ML-решения для фрод-детекшна,
специфичного для банковской сферы.
Исследовать и реализовать методы борьбы с дисбалансом классов (взвешивание,
SMOTE, ADASYN, комбинированные методы) и оценить их влияние на качество
моделей.
Провести сравнительный анализ эффективности классических и современных
алгоритмов машинного обучения.
Определить и обосновать ключевые метрики оценки качества моделей (Precision,
Recall, F1-Score, AUC-ROC, AUC-PR), адекватные задачам фрод-детекшна с учетом
приоритета минимизации пропущенных мошенничеств.
4.
• Объектомпроцессы
исследования
выявления
являются
мошеннических
операций при пользовании банковскими
услугами.
• Предметом
исследования
выступают
алгоритмы машинного обучения, методы
предобработки
данных
и
оценки
их
эффективности применительно к задаче
банковского фрод-детекшна.
5.
Выпускная квалификационная работа состоит из введения, двух глав, заключения и
списка
использованной
литературы.
Первая
глава
работы
посвящена
изучению
теоретических основ и анализу подходов к решению задачи выявления мошенничества при
пользовании
банковскими
услугами,
которые
будут
использованы
для
решения
поставленных задач.
Во второй главе моей работы рассматриваются методология построения системы
детекции мошенничества на основе машинного обучения, данная глава включает в себя
описание следующих этапов работы:
предобработка данных
выбор и оптимизация алгоритмов машинного обучения.
интеграция ml-модели в систему безопасности банка и аспекты иб.
В приложении содержатся скриншоты экранных форм, коды программных модулей системы
защиты.
6.
В первой главе ВКР рассмотрены теоретическиеосновы и анализ подходов к решению задачи
выявления мошенничества при пользовании
банковскими услугами Задача выявления
мошенничества при пользовании банковскими
услугами остаётся актуальной. По данным,
представленным в Отчёте Банка России в январе
— марте 2025 года преступники совершили
296,6 тыс. мошеннических банковских операций
и похитили 6,9 млрд рублей. В работе
рассмотрены методы выявления мошенничества
при пользовании банковскими услугами,
основанные
на
машинном
обучении,
представлен обзор этих методов.
7.
• Традиционные системы основанные на правилах исигнатурные методы детекции, основанные на заранее
известных шаблонах, все чаще демонстрируют свою
неэффективность перед лицом быстро
эволюционирующих, адаптивных и
высокотехнологичных мошеннических схем. В этих
условиях применение алгоритмов машинного обучения
(МО) для выявления аномальных и мошеннических
операций в режиме реального времени становится не
просто актуальным, а критически необходимым
инструментом обеспечения финансовой безопасности.
Разработка и внедрение эффективных ML-решений для
выявления мошенничества при пользовании
банковскими услугами являются ключевым фактором
минимизации финансовых потерь банков, защиты
активов клиентов и поддержания стабильности
финансовой системы в целом
8.
• рассматриваемое в ВКР банковское мошенничествопредставляет собой актуальную и разнородную угрозу.
Основные виды банковского мошенничества составляют
действия следующих типов:
• карточное,
• ATO,
• мошенничество с переводами,
• кредитное,
• инсайдерское.
Каждый описанный тип имеет свои специфические методы
реализации.
Традиционные системы обнаружения мошеннических действий на
основе правил критически устарели. Их ключевые недостатки
достточно серьёзны и включают в себя неспособность выявлять
новые схемы, высокий уровень ложных срабатываний, медленную
адаптацию, отсутствие возможности анализировать сложные
взаимосвязи в данных.
9.
Машинное обучение занимается разработкой моделей,способных извлекать знания из данных и решать
практические задачи. Существует несколько видов задач,
различающихся по типу входных данных и целевой функции.
Выделяют следующие три базовых класса задач мащинного
обучения ML:
1.
Обучение с учителем (Supervised Learning)
2.
Обучение без учителя (Unsupervised Learning)
3. Обучение с подкреплением (Reinforcement Learning)
10.
• Успех обучения и применения ML-моделидля детекции мошеннических действий
напрямую зависит от данных. Банковские
данные имеют уникальные черты, которые
сильно влияют на подготовку, обучение и
работу модели.
• Чтобы точно оценить риск мошенничества,
необходимо чтобы в датасете был
представлен не только номер транзакции и
сумма но и множество других параметров.
11.
В главе 2 рассмотрена методология построениясистемы детекции мошенничества на основе
машинного обучения. Так же во 2 главе были
рассмотрены
такие этапы как предварительная
обработка данных и генерация признаков. Этап
предобработки
и
очень
для
важен
конструирования
успеха
применении
системы
мошенничества
поскольку
в
признаков
построении
и
обнаружения
качество
данных
напрямую определяет эффективность ML-модели
12.
После прохождения этапаподготовки данных
переходим к этапу выбора
алгоритма ML для
системы фрод-детекшна. Выбор требует понимания
сильных сторон алгоритмов, свойственным им
ограничений и соответствия выбираемого алгоритма
специфике задачи.
Выбор алгоритмов для проведения обучения модели
основан на сравнении разноплановых подходов. Для
фрод-детекшина стандартный набор включает
алгоритм логистической регрессии (Logistic Regression)
поскольку базовый бенчмарк (baseline) состоит в том,
что этот алгоритм
простой, быстрый и
высокоинтерпретируемый
и
найденные
веса
признаков показывают направление влияния. Данный
алгоритм
позволяет
оценить
минимально
достижимый уровень качества на подготовленных
данных.
13.
• Для построения практического примераотправной точкой послужил выбор
качественного открытыго датасета по
банковскому мошенничеству.
• Были рассмотрены варианты, включающие в
себя:
• IEEE-CIS Fraud Detection Dataset (Kaggle)
• PaySim Synthetic Financial Dataset
• Credit Card Fraud Detection Dataset
• Synthetic Financial Datasets For Fraud Detection
• The ULB Machine Learning Group - Fraud
datasets
14.
• реализация логистической регрессии дляобнаружения мошенничества с
использованием Credit Card Fraud Detection
Dataset включает в себя этапы:
• Подготовка данных
• Предобработка данных
• Обучение модели
• Оценка модели
• Интерпретация результатов
15.
• Для построения модели использовался язынпрограммирования Python и следующие
библиотеки
• import pandas as pd
• import numpy as np
• from sklearn.model_selection import train_test_split
• from sklearn.preprocessing import StandardScaler
• from sklearn.linear_model import LogisticRegression
• from sklearn.metrics import classification_report,
confusion_matrix, roc_auc_score
• import matplotlib.pyplot as plt
• import seaborn as sns
16. Результаты обучения модели логистической регрессии
17.
Результаты обучения модель логистической регрессии для обнаружениямошеннических транзакций. показывают:
1. **ROC-AUC = 0.9714** - отличный показатель, модель хорошо разделяет
классы.
2. **Recall для класса 1 (мошенничество) = 0.92** - модель обнаруживает 92%
мошеннических операций, что очень важно в данной задаче.
3. **Precision для класса 1 = 0.06** - много ложных срабатываний (только 6%
предсказанных как мошенничество операций действительно являются
мошенническими). Это типично для сильно дисбалансированных данных.
**Топ-10 важных признаков:**
- `Amount_scaled` - самый важный признак (чем больше сумма, тем выше
риск).
- Признаки V14, V20, V10, V12, V16, V17, V28, V4, V1 также значимы.
18. Результаты обучения модели RandomForest
19.
Анализ результатов логистической регрессии:
ROC-AUC 0.9714 - отличный показатель:
Модель прекрасно разделяет два класса
Значение >0.9 считается превосходным для бинарной классификации
PR-AUC 0.7183 - хороший результат для дисбалансированных данных:
Precision-Recall AUC более информативен при сильном дисбалансе
классов
Показывает, что модель хорошо сохраняет баланс между точностью и
полнотой
Recall 0.92 - главная сильная сторона модели:
Обнаруживает 92% всех мошеннических операций
Критически важный показатель в системах фрод-детекции
Precision 0.06 - область для улучшения:
Только 6% операций, помеченных как мошеннические, действительно
являются мошенничеством
Значит, много ложных срабатываний (ложных блокировок)
20. Обучение нейронной сети с использованием Google Colab
21.
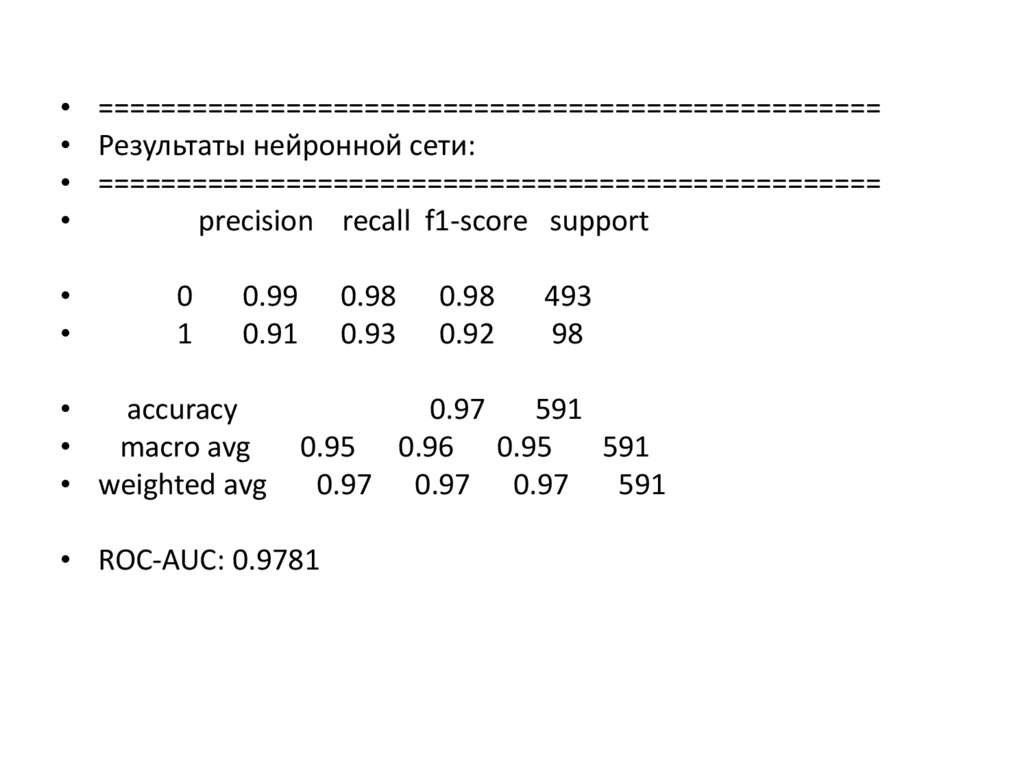
• ==================================================• Результаты нейронной сети:
• ==================================================
precision recall f1-score support
0
1
0.99
0.91
accuracy
macro avg
• weighted avg
0.98
0.93
0.98
0.92
493
98
0.97
591
0.95 0.96 0.95
591
0.97 0.97 0.97
591
• ROC-AUC: 0.9781
22.
Детальный анализ результатов:
• Общая точность (accuracy): 97% , то есть одель правильно
классифицирует 97% всех транзакций
• Метрики для класса 0 (легальные операции): Precision: 0.99 - из всех
операций, предсказанных как легальные, 99% действительно легальные
Recall: 0.98 - модель правильно идентифицирует 98%
всех
легальных операций
F1-score: 0.98 - высокий баланс между точностью и полнотой
• Метрики для класса 1 (мошеннические операции):
Precision: 0.91 - из всех операций, предсказанных как
мошеннические, 91% действительно мошеннические
Recall: 0.93 - модель обнаруживает 93% всех мошеннических
операций
F1-score: 0.92 - высокий показатель, демонстрирующий хороший
баланс
• ROC-AUC: 0.9781 Высокий показатель (максимум 1.0), означает отличную
способность модели разделять два класса
• Поддержка (support): Класс 0: 493 примера
Класс 1: 98 примеров
Сохраняется дисбаланс (примерно 5:1), но модель
справилась
хорошо
23.
В данной выпускной квалификационной работе былирассмотрены теоретические основы теоретических
основ и анализу подходов к решению задачи
выявления
мошенничества
при
пользовании
банковскими услугами, и их практическую реализация
в контексте машинного обучения.
В рамках исследования были предложены три
технологические решения которые основываются на
таких методах машинного обучения как логистическая
регрессия, случайный лес и нейроннная сеть.