

























































 programming
programmingSimilar presentations:
")



")




")
Знакомство с OpenMP
1.
Знакомство с OpenMP2.
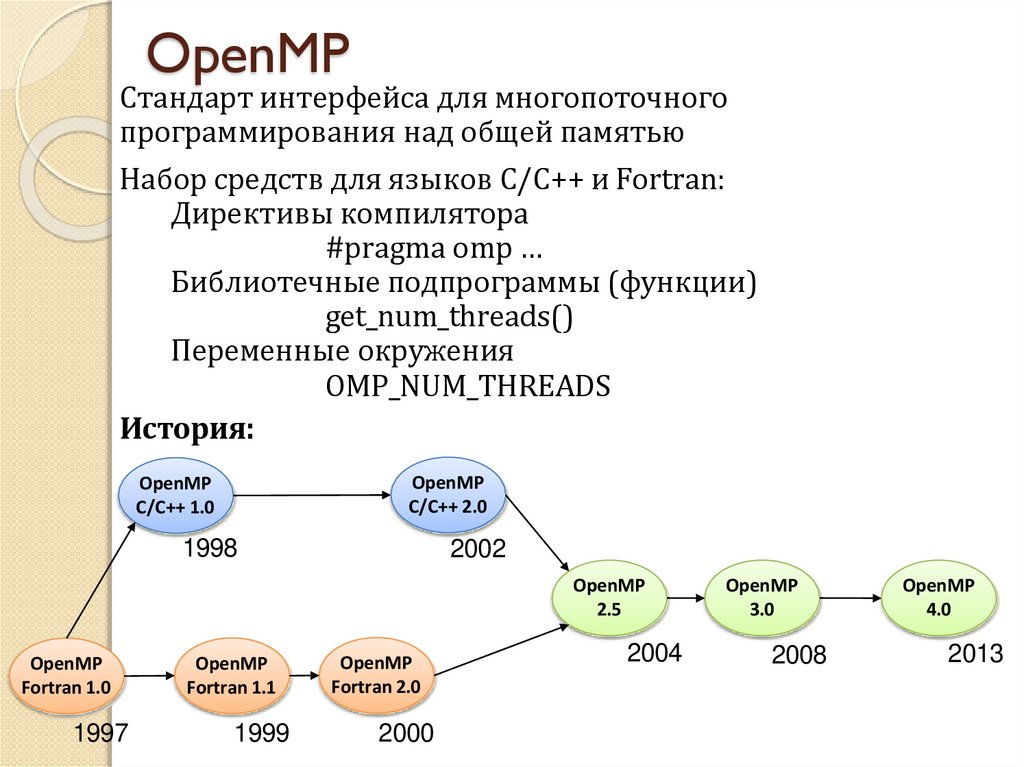
OpenMPСтандарт интерфейса для многопоточного
программирования над общей памятью
Набор средств для языков C/C++ и Fortran:
Директивы компилятора
#pragma omp …
Библиотечные подпрограммы (функции)
get_num_threads()
Переменные окружения
OMP_NUM_THREADS
История:
OpenMP
C/C++ 2.0
OpenMP
C/C++ 1.0
1998
2002
OpenMP
2.5
OpenMP
Fortran 1.0
1997
OpenMP
Fortran 1.1
OpenMP
Fortran 2.0
1999
2000
2004
OpenMP
3.0
2008
OpenMP
4.0
2013
3.
Основные понятия OpenMPСуперкомпьютерный консорциум университетов
России
OpenMP
–
технология
параллельного
программирования
для компьютеров с общей
памятью. Стандарт 3.0 принят в мае 2008 года.
Один вариант программы для
последовательного выполнения.
параллельного
и
Любой процесс состоит из нескольких нитей
управления,
которые имеют общее адресное
пространство, но разные потоки команд и раздельные
стеки.
4.
Понятие параллельной программыПод параллельной программой в
рамках OpenMP понимается программа, для которой в
специально указываемых при помощи директив
местах - параллельных фрагментах - исполняемый
программный код может быть разделен на несколько
раздельных командных потоков ( threads ). В общем
виде программа представляется в виде набора
последовательных ( однопотоковых ) и параллельных
( многопотоковых ) участков программного кода.
Разделение вычислений между потоками
осуществляется под управлением соответствующих
директив OpenMP.
5.
Потоки могут выполняться на разных процессорах(процессорных ядрах) либо могут группироваться для
исполнения на одном вычислительном элементе (в
этом случае их исполнение осуществляется в режиме
разделения времени). В предельном случае для
выполнения параллельной программы может
использоваться один процессор - как правило, такой
способ применяется для начальной проверки
правильности параллельной программы.
Количество потоков определяется в начале
выполнения параллельных фрагментов программы и
обычно совпадает с количеством
имеющихся вычислительных элементов в системе;
изменение количества создаваемых потоков может
быть выполнено при помощи целого ряда
средств OpenMP.
6.
Все потоки в параллельных фрагментах программыпоследовательно перенумерованы от 0 до np-1,
где np есть общее количество потоков. Номер
потока также может быть получен при помощи
функции OpenMP.
Использование в технологии OpenMP потоков для
организации параллелизма позволяет учесть
преимущества многопроцессорных
вычислительных систем с общей памятью. Прежде
всего, потоки одной и той же параллельной
программы выполняются в общем адресном
пространстве, что обеспечивает возможность
использования общих данных для параллельно
выполняемых потоков без каких-либо
трудоемких межпроцессорных передач сообщений
(в отличие от процессов в технологии MPI для
систем с распределенной памятью).
7.
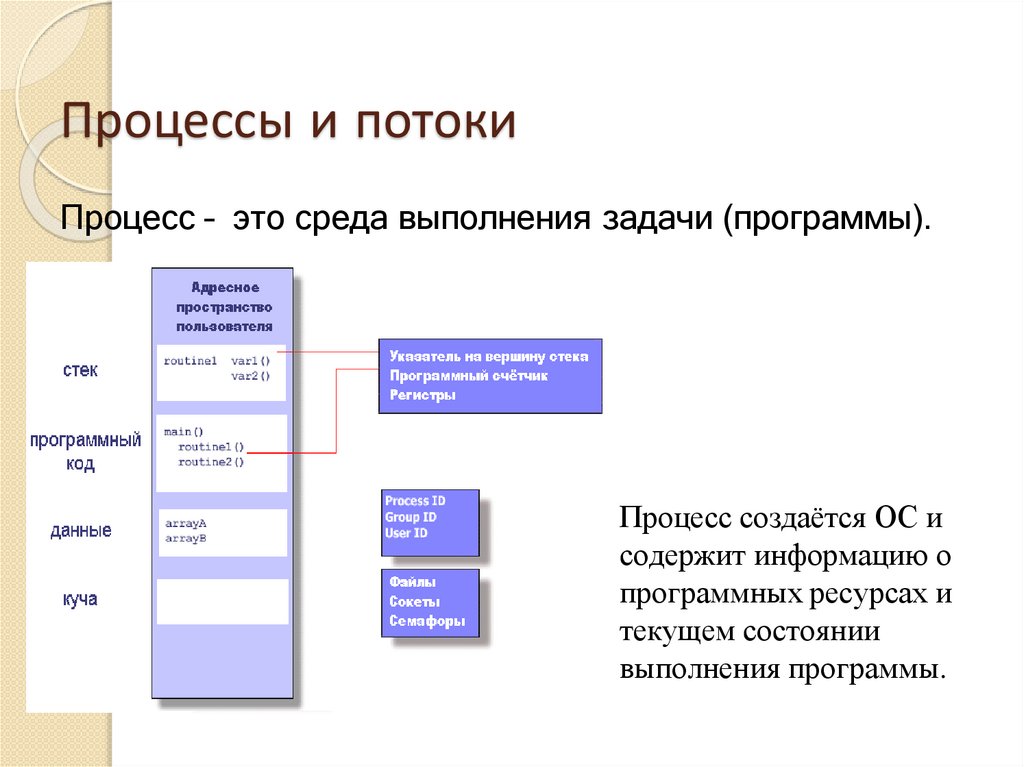
Процессы и потокиПроцесс – это среда выполнения задачи (программы).
Процесс создаётся ОС и
содержит информацию о
программных ресурсах и
текущем состоянии
выполнения программы.
8.
Процессы и потокиПоток – это «облегченный процесс».
• Создается в рамках
процесса,
• Имеет свой поток
управления,
• Разделяет ресурсы
процесса-родителя с
другими потоками,
• Погибает, если
погибает
родительский
процесс.
9.
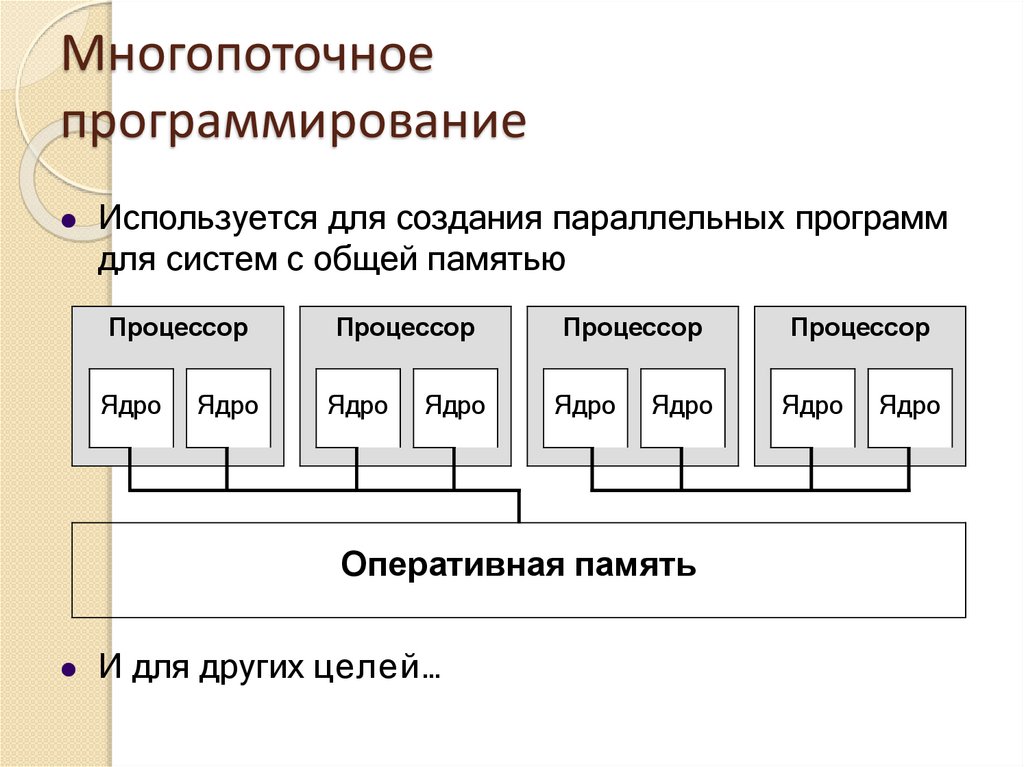
Многопоточноепрограммирование
Используется для создания параллельных программ
для систем с общей памятью
Процессор
Процессор
Процессор
Процессор
Ядро
Ядро
Ядро
Ядро
Ядро
Ядро
Ядро
Оперативная память
И для других целей…
Ядро
10.
OpenMP – это…Стандарт интерфейса для многопоточного
программирования над общей памятью
Набор средств для языков C/C++ и Fortran:
Директивы компилятора
#pragma omp …
Библиотечные подпрограммы
get_num_threads()
Переменные окружения
OMP_NUM_THREADS
11.
Порядок созданияпараллельных программ
1.
2.
3.
4.
5.
Написать и отладить последовательную
программу
Дополнить программу директивами
OpenMP
Скомпилировать программу
компилятором с поддержкой OpenMP
Задать переменные окружения
Запустить программу
12.
Вводный пример:последовательная программа
#include <math.h>
#define N 10000
float x[N];
int main()
{ int i;
float k = 2*3.14159265/N;
for (i=0;i<N;i++) x[i]=sin(k*i);
return 0;
}
13.
Вводный пример:параллельная программа
#include <math.h>
#define N 10000
float x[N];
int main()
{ int i;
float k = 2*3.14159265/N;
#pragma omp parallel for
for (i=0;i<N;i++) x[i]=sin(k*i);
return 0;
}
14.
Структура OpenMPКонструктивно в составе технологии OpenMP можно
выделить:
• Директивы,
• Библиотеку функций,
• Набор переменных окружения.
15.
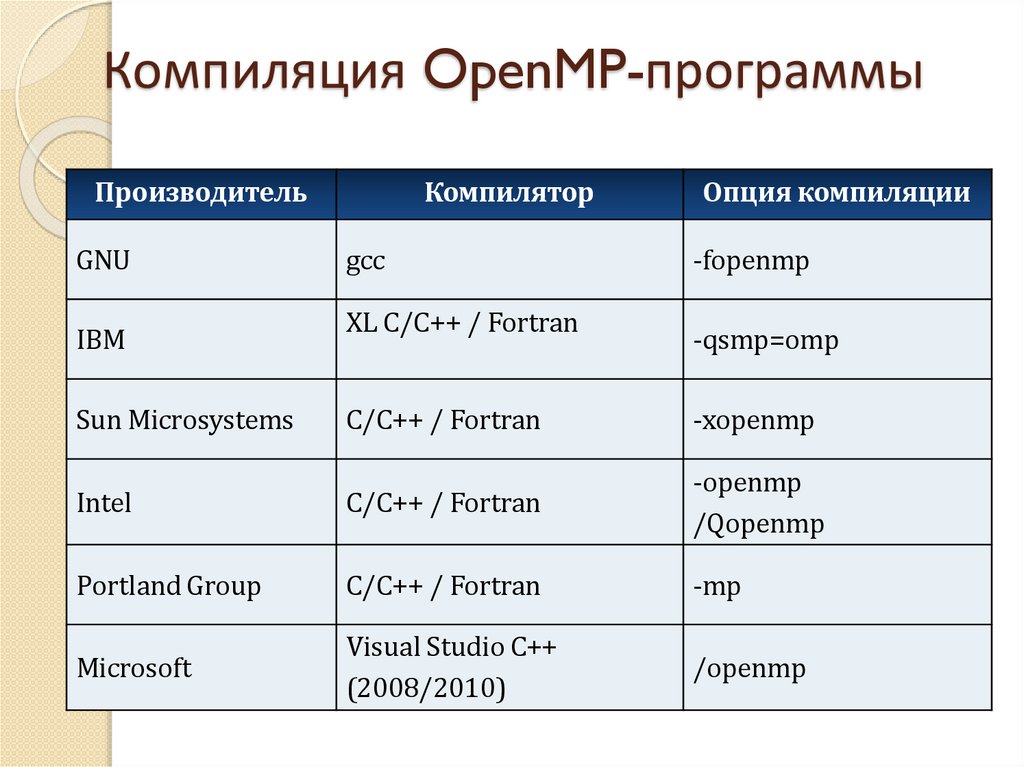
Компиляция OpenMP-программыПроизводитель
GNU
IBM
Компилятор
gcc
XL C/C++ / Fortran
Опция компиляции
-fopenmp
-qsmp=omp
Sun Microsystems
C/C++ / Fortran
-xopenmp
Intel
C/C++ / Fortran
-openmp
/Qopenmp
Portland Group
C/C++ / Fortran
-mp
Microsoft
Visual Studio C++
(2008/2010)
/openmp
16.
Формат директив, переменныеокружения
C/С++: регистр имеет значение, синтаксис:
#pragma omp название-директивы[ опция [ [,] опция ]...]
{
структурный блок
}
Продление: использовать «\» в прагме
Переменные окружения
Название
OMP_NUM_THREADS n
OMP_SCHEDULE “schedule,[chunk]”
OMP_DYNAMIC { TRUE | FALSE }
OMP_NESTED { TRUE | FALSE }
Описание
Устанавливает количество используемых потоков в
параллельной области программы
Устанавливает способ планирования и размер порции
при выполнении циклов.
Разрешает или запрещает динамическое регулирование
числом потоков
Устанавливает или отменяет вложенный режим
параллельной обработки.
17.
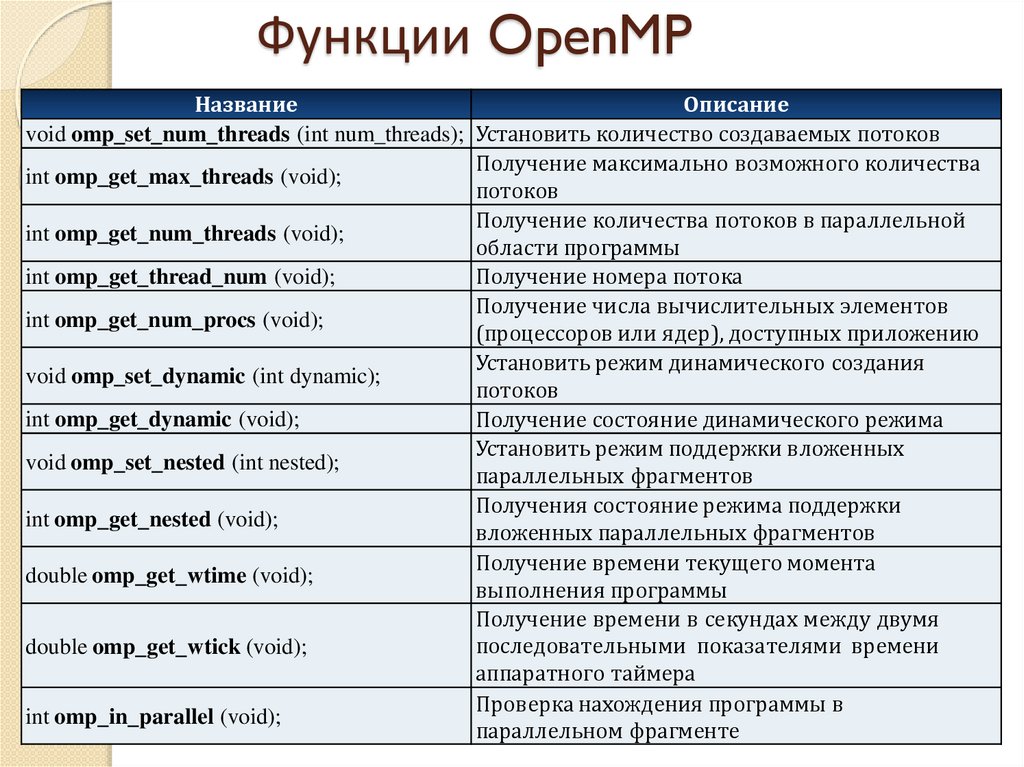
Функции OpenMPНазвание
Описание
void omp_set_num_threads (int num_threads); Установить количество создаваемых потоков
Получение максимально возможного количества
int omp_get_max_threads (void);
потоков
Получение количества потоков в параллельной
int omp_get_num_threads (void);
области программы
int omp_get_thread_num (void);
Получение номера потока
Получение числа вычислительных элементов
int omp_get_num_procs (void);
(процессоров или ядер), доступных приложению
Установить режим динамического создания
void omp_set_dynamic (int dynamic);
потоков
int omp_get_dynamic (void);
Получение состояние динамического режима
Установить режим поддержки вложенных
void omp_set_nested (int nested);
параллельных фрагментов
Получения состояние режима поддержки
int omp_get_nested (void);
вложенных параллельных фрагментов
Получение времени текущего момента
double omp_get_wtime (void);
выполнения программы
Получение времени в секундах между двумя
последовательными показателями времени
double omp_get_wtick (void);
аппаратного таймера
Проверка нахождения программы в
int omp_in_parallel (void);
параллельном фрагменте
18.
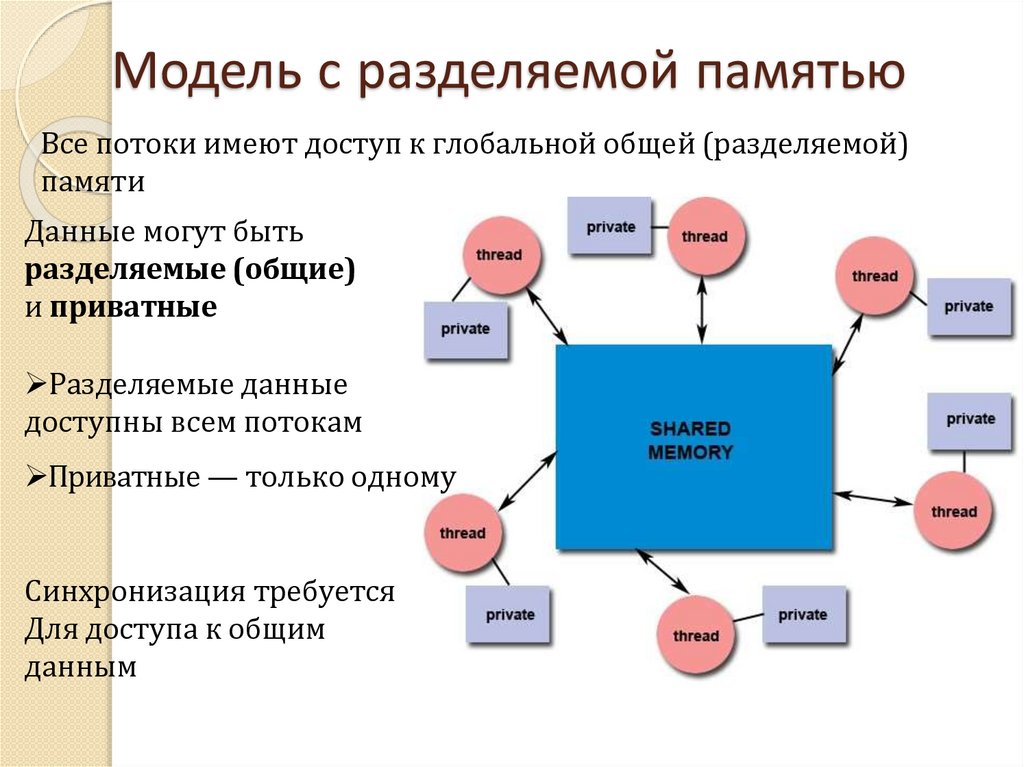
Модель с разделяемой памятьюВсе потоки имеют доступ к глобальной общей (разделяемой)
памяти
Данные могут быть
разделяемые (общие)
и приватные
Разделяемые данные
доступны всем потокам
Приватные — только одному
Синхронизация требуется
Для доступа к общим
данным
19.
Компиляция с OpenMPGNU C/C++ Compiler
gcc –fopemp –o prog prog.c
g++ –fopemp –o prog prog.cpp
Intel C/C++ Compiler
icc –openmp –o prog prog.c
icpc –openmp –o prog prog.cpp
20.
К задаче 121.
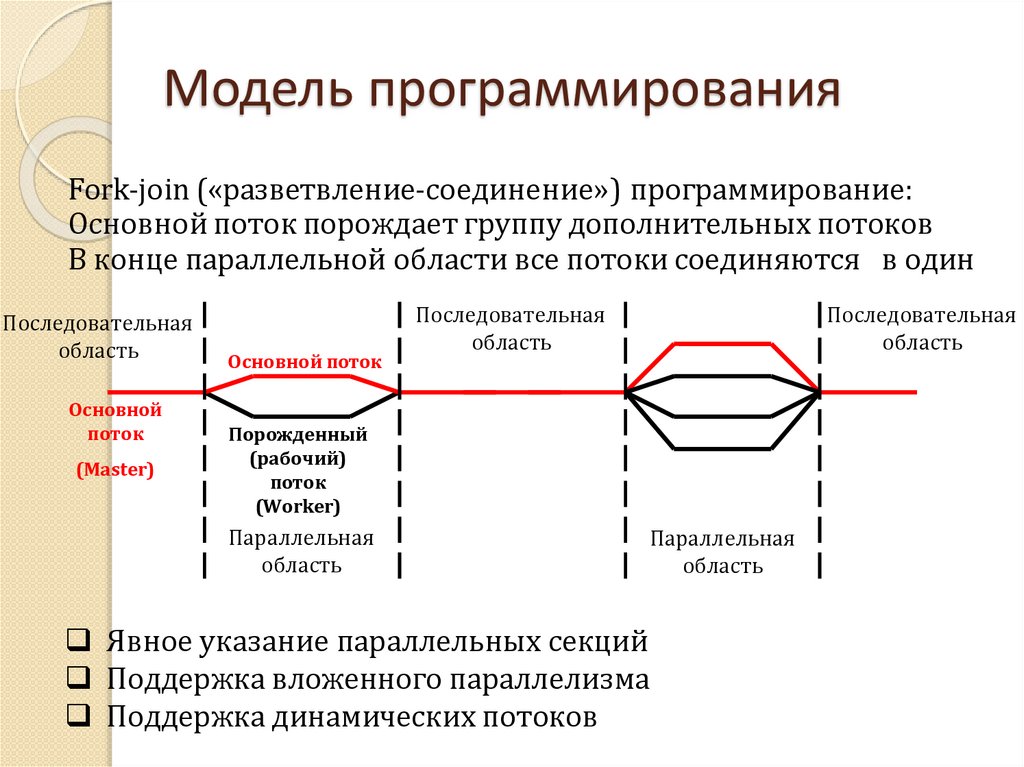
Модель программированияFork-join («разветвление-соединение») программирование:
Основной поток порождает группу дополнительных потоков
В конце параллельной области все потоки соединяются в один
Последовательная
область
Основной
поток
(Master)
Основной поток
Последовательная
область
Последовательная
область
Порожденный
(рабочий)
поток
(Worker)
Параллельная
область
Параллельная
область
Явное указание параллельных секций
Поддержка вложенного параллелизма
Поддержка динамических потоков
22.
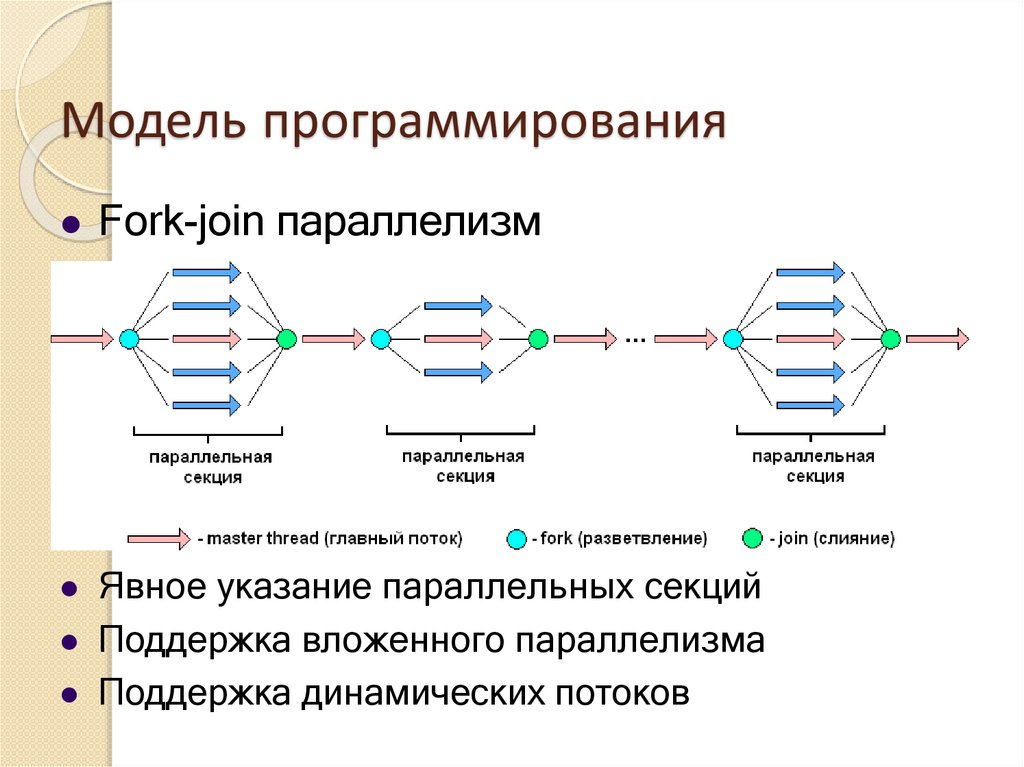
Модель программированияFork-join параллелизм
Явное указание параллельных секций
Поддержка вложенного параллелизма
Поддержка динамических потоков
23.
Объявление параллельной секцииКоманда parallel – основная директива OpenMP. Синтаксис:
#pragma omp parallel [ опция [ [,] опция ]...]
{
структурный блок
}
По-умолчанию, создается ровно столько потоков, сколько доступно
ядер/процессоров. Потоки пронумерованы от 0 до N, где 0 – основной
24.
Объявление параллельной секции#include <omp.h>
int main()
{
// последовательный код
#pragma omp parallel
{
// параллельный код
}
// последовательный код
return 0;
}
25.
Структурный блокДействие директив распространяется на структурный блок:
#pragma omp название-директивы[ опция [ [,] опция ]...]
{
структурный блок
}
Структурный блок — блок кода с одной точкой входа и одной
точкой выхода.
#pragma omp parallel
{
…
mainloop: res[id] = f (id);
if (res[id] != 0)
goto mainloop;
…
exit (0);
}
Структурный блок
#pragma omp parallel
{
…
mainloop: res[id] = f (id);
…
}
if (res[id] != 0) goto
mainloop;
Неструктурный блок
26.
Получение числа потоковФункция omp_get_num_threads()
#pragma omp parallel
{ …
int n = omp_get_num_threads();
…
}
27.
Пример:Hello, World!
#include <stdio.h>
#include <omp.h>
int main()
{ printf(“Hello, World!\n”);
#pragma omp parallel
{ int i,n;
i = omp_get_thread_num();
n = omp_get_num_threads();
printf(“I’m thread %d of %d\n”,i,n);
}
return 0;
}
28.
Пример:Hello, World!
#include <stdio.h>
#include <omp.h>
int main()
{ printf(“Hello, World!\n”);
#pragma omp parallel
{ int i,n;
i = omp_get_thread_num();
n = omp_get_num_threads();
printf(“I’m thread %d of %d\n”,i,n);
}
• Компиляция:
return 0;
> gcc –fopenmp –o hello hello.c
}
Запуск:
> OMP_NUM_THREADS=4 ./hello
Hello, World!
I’m thread 1 of 4
I’m thread 0 of 4
I’m thread 3 of 4
I’m thread 2 of 4
29.
К задаче 230.
Пример заполнения массива числами:последовательная программа
#include <math.h>
#define N 10000
float x[N];
int main()
{ int i;
float k = 2*3.14159265/N;
for (i=0;i<N;i++) x[i]=sinf(k*i);
return 0;
}
31.
Пример заполнения массива числами: параллельная программа
#include <math.h>
#define N 10000
float x[N];
int main()
{ int i;
float k = 2*3.14159265/N;
#pragma omp parallel for
for (i=0;i<N;i++) x[i]=sinf(k*i);
return 0;
}
32.
Изменение количества используемыхпотоков
1. Опция num_threads команды parallel
#pragma omp parallel num_threads (целое_значение)
#pragma omp parallel num_threads (4)
{ . . .
}
2. Функция omp_set_num_threads
(требуется подключение заголовочного файла openmp.h)
void omp_set_num_threads (int Количество_потоков);
omp_set_num_threads(4);
#pragma omp parallel
{ . . .
}
3. Переменная окружения OMP_NUM_THREADS
set OMP_NUM_THREADS = целое_значение
33.
Время выполнения программыДля оценки времени выполнения команды
(модуля) можно использовать функцию – clock().
Результат – указание времени в наносекундах.
34.
Время выполнения программы#include <iostream>
#include <time.h>
#include <math.h>
#include "omp.h"
using namespace std;
void test_fn(int epochs, int num_thread) {
omp_set_num_threads(num_thread);
double c = 0;
clock_t start = clock();
#pragma omp parallel for
for (int i = 0; i < epochs; i++) {
// Сделаем простой расчет
c += exp(1) * exp(1) * log(2);
}
clock_t end = clock();
cout << "count of potoks - " << num_thread << " Time - " << end - start << ends << " Repeats - " << epochs << endl;
}
int main()
{
test_fn(100000000, 1);
test_fn(100000000, 2);
test_fn(100000000, 4);
test_fn(100000000, 8);
test_fn(100000000, 12);
return 0;
}
35.
Время выполнения программы#include <iostream>
#include <time.h>
#include <math.h>
#include "omp.h"
using namespace std;
void test_fn(int epochs, int num_thread) {
omp_set_num_threads(num_thread);
double c = 0;
clock_t start = clock();
#pragma omp parallel for
for (int i = 0; i < epochs; i++) {
// Сделаем простой расчет
c += exp(1) * exp(1) * log(2);
}
clock_t end = clock();
cout << "count of potoks - " << num_thread << " Time - " << end - start << ends << " Repeats - " << epochs << endl;
}
int main()
{
test_fn(100000000, 1);
test_fn(100000000, 2);
test_fn(100000000, 4);
test_fn(100000000, 8);
test_fn(100000000, 12);
return 0;
}
36.
Время выполнения программыДля измерения времени библиотека OPEN МР
содержит функцию omp_get_wtime (), которая
возвращает время в секундах, прошедшее с
определенного момента времени, но в отличие от
time, возвращает не целое число секунд, а данное
типа double.
Для определения длительности одного такта (в
секундах) используется функция omp_get_wtick().
Заголовки функций:
double omp_get_wtime(void);
double omp_get_wtick(void);
Для использования функций библиотеки OPEN МР
необходимо подключить заголовочный файл omp.h.
37.
Время выполнения программы#include <iostream>
#include <time.h>
#include <math.h>
#include "omp.h"
using namespace std;
void test_fn(int epochs, int num_thread) {
omp_set_num_threads(num_thread);
double c = 0;
double start_time = omp_get_wtime();
#pragma omp parallel
for (int i = 0; i < epochs; i++) {
// Сделаем простой расчет
c += exp(1) * exp(1) * log(2);
}
double stop = omp_get_wtime() - start_time;
cout << "count of potoks - " << num_thread << " Time - " << stop << ends << " Repeats - " << epochs << endl;
}
int main()
{
test_fn(100000000, 1);
test_fn(100000000, 2);
test_fn(100000000, 4);
test_fn(100000000, 8);
test_fn(100000000, 12);
return 0;
}
38.
Время выполнения программы#include <iostream>
#include <time.h>
#include <math.h>
#include "omp.h"
using namespace std;
void test_fn(int epochs, int num_thread) {
omp_set_num_threads(num_thread);
double c = 0;
double start_time = omp_get_wtime();
#pragma omp parallel
for (int i = 0; i < epochs; i++) {
// Сделаем простой расчет
c += exp(1) * exp(1) * log(2);
}
double stop = omp_get_wtime() - start_time;
cout << "count of potoks - " << num_thread << " Time - " << stop << ends << " Repeats - " << epochs << endl;
}
int main()
{
test_fn(100000000, 1);
test_fn(100000000, 2);
test_fn(100000000, 4);
test_fn(100000000, 8);
test_fn(100000000, 12);
return 0;
}
39.
Пример: Директива omp for...
#include <omp.h>
int main()
{
int i;
#pragma omp parallel
{
#pragma omp for
for (i=0;i<1000;i++)
printf("%d ",i);
}
return 0;
}
...
#include <omp.h>
int main()
{
int i;
#pragma omp parallel for
for (i=0;i<1000;i++)
printf("%d ",i);
return 0;
}
© к.т.н., доцент каф. ИВТ СибГУ им. М.Ф. Решетнева, Зотин Александр Геннадьевич 2017
40.
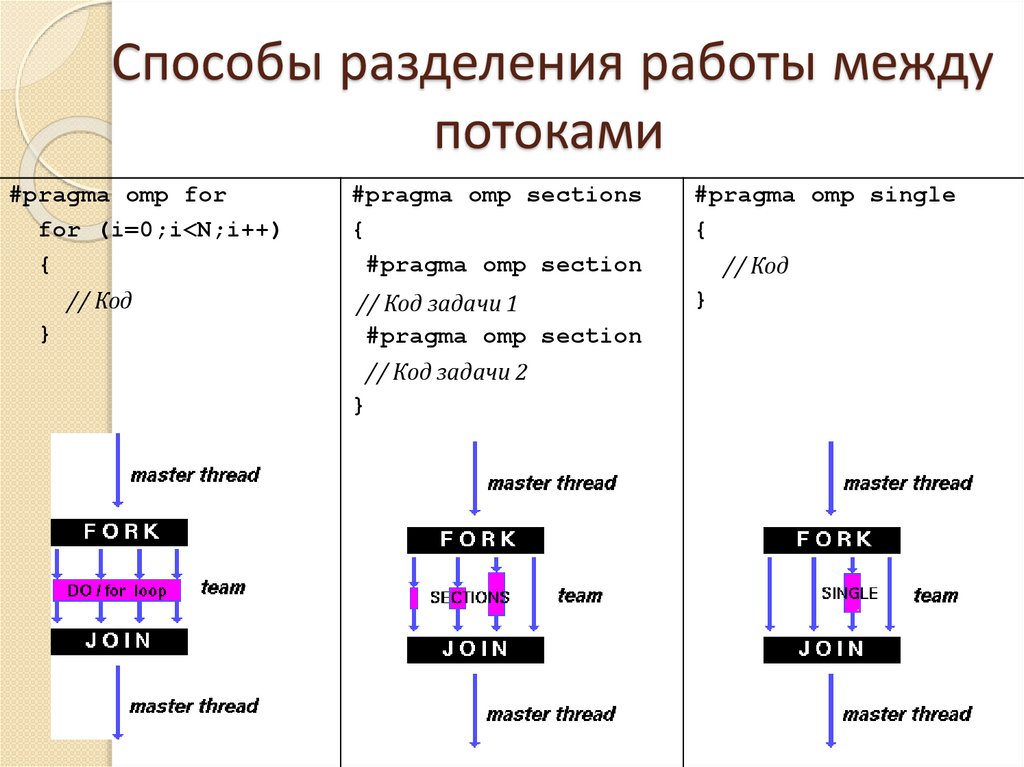
Способы разделения работы междупотоками
#pragma omp for
for (i=0;i<N;i++)
{
// Код
}
#pragma omp sections
{
#pragma omp section
#pragma omp single
{
// Код задачи 1
#pragma omp section
}
// Код задачи 2
}
// Код
41.
Пример: Директива omp sections...
Сложение чисел от 0 до 100
#include <omp.h>
в двух секциях
int main()
{
int i;
#pragma omp parallel sections private(i)
{
#pragma omp section {
printf("1st half\n");
for (i=0;i<500;i++) printf("%d ");
}
#pragma omp section {
printf("2nd half\n");
for (i=501;i<1000;i++) printf("%d ");
}
}
return 0;
}
42.
Пример: Директива omp sections…
int* a_parallelSection(int* A, int* B, int size)
{
Сложение двух массивов
int* array = new int[size];
чисел в двух секциях
int num_thread = 2;
int p0 = 0,
p1 = size / num_thread,
p2 = size;
omp_set_num_threads(num_thread);
#pragma omp parallel sections
{
#pragma omp section
{
for (int i = p0; i < p1; i++)
array[i] = A[i] + B[i];
}
#pragma omp section
{
for (int i = p1; i < p2; i++)
array[i] = A[i] + B[i];
}
}
return array;
}
43.
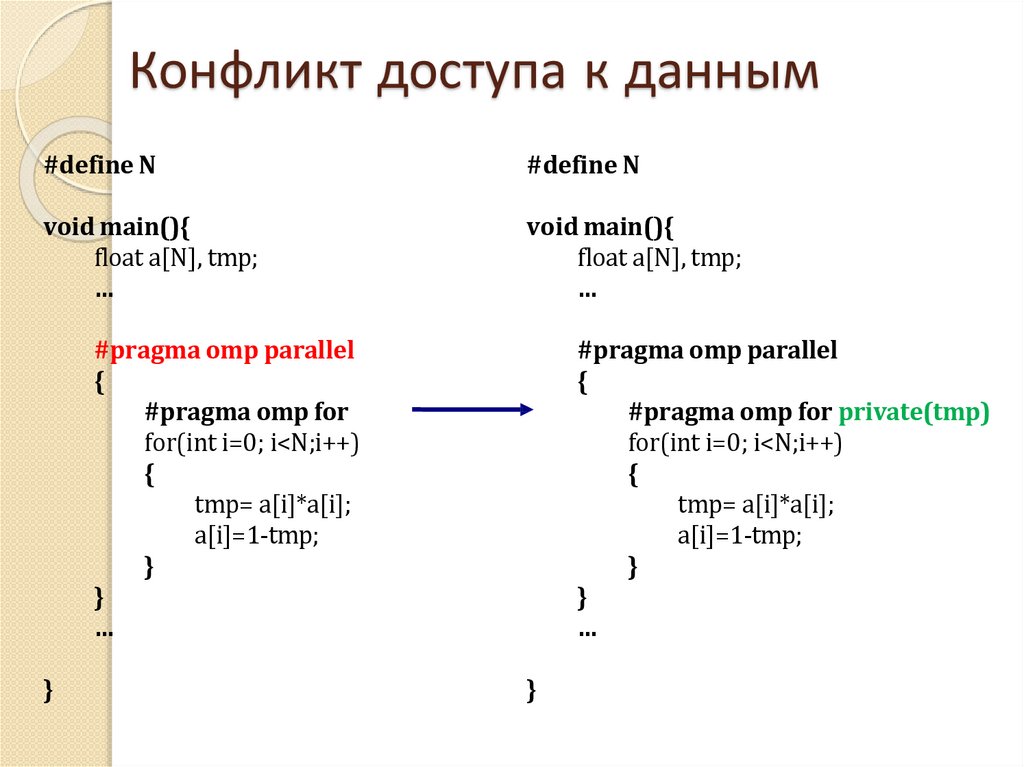
Конфликт доступа к данным#define N
void main(){
float a[N], tmp;
…
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<N;i++)
{
tmp= a[i]*a[i];
a[i]=1-tmp;
}
}
…
}
Ошибка возникает при одновременном
выполнении следующих условий:
Два или более потока обращаются к
одной и той же ячейке памяти.
По крайней мере, один из этих
доступов к памяти является записью.
Потоки не синхронизируют свой
доступ к данной ячейки памяти.
При одновременном выполнении всех
трех условий порядок доступа
становится неопределенным.
44.
Конфликт доступа к данным#define N
#define N
void main(){
float a[N], tmp;
…
void main(){
float a[N], tmp;
…
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<N;i++)
{
tmp= a[i]*a[i];
a[i]=1-tmp;
}
}
…
}
#pragma omp parallel
{
#pragma omp for private(tmp)
for(int i=0; i<N;i++)
{
tmp= a[i]*a[i];
a[i]=1-tmp;
}
}
…
}
45.
Области видимости переменныхПеременные, объявленные внутри
блока, являются локальными для потока:
параллельного
#pragma omp parallel
{
int num;
num = omp_get_thread_num()
printf("Поток %d\n", num);
}
Переменные, объявленные вне параллельного
определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copying
блока,
46.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
private
– firstprivate
Своя локальная переменная в каждом
потоке
– lastprivate
– shared
– default
– reduction
– threadprivate
– copying
int num;
#pragma omp parallel private(num)
{
num=omp_get_thread_num()
printf("%d\n",num);
}
47.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
firstprivate
Локальная переменная с инициализацией
– lastprivate
– shared
– default
– reduction
– threadprivate
– copying
int num=5;
#pragma omp parallel \
firstprivate(num)
{
printf("%d\n",num);
}
48.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
lastprivate
– shared
– default
– reduction
– threadprivate
– copying
Локальная переменная с сохранением
последнего значения
(в последовательном исполнении)
int i,j;
#pragma omp parallel for \
lastprivate(j)
for (i=0;i<100;i++) j=i;
printf("Последний j = %d\n",j);
49.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
– lastprivate
shared
– default
– reduction
Разделяемая (общая) переменная
int i,j;
#pragma omp parallel for \
shared(j)
for (i=0;i<100;i++) j=i;
– threadprivate printf("j = %d\n",j);
– copying
50.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
Задание области видимости не указанных
явно переменных
– lastprivate
– shared
default
– reduction
– threadprivate
– copying
int i,k,n=2;
#pragma omp parallel shared(n)\
default(private)
{ i=omp_get_thread_num() / n;
k=omp_get_thread_num() % n;
printf("%d %d %d\n",i,k,n);
}
51.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
Переменная для выполнения
редукционной операции
– lastprivate
– shared
– default
reduction
– threadprivate
– copying
int i,s=0;
#pragma omp parallel for \
reduction(+:s)
for (i=0;i<100;i++)
s += i;
printf("Sum: %d\n",s);
В качестве редукционной операции могут выступать:
арифметические или логических операции (+ , -, *, &, |, ^ , && || ) функции (max, min);
52.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
Объявление глобальных переменных
локальными для потоков
– lastprivate
– shared
– default
int x;
#pragma omp threadprivate(x)
int main()
{
threadprivate
. . .
}
– copying
– reduction
53.
Области видимости переменныхПеременные, объявленные вне параллельного блока,
определяются параметрами директив OpenMP:
– private
– firstprivate
– lastprivate
– shared
– default
– reduction
– threadprivate
copying
Объявление глобальных переменных
локальными для потоков c
инициализацией
int x;
#pragma omp copying(x)
int main()
{
. . .
}
54.
Условное объявлениепараллельной секции
Условие использования параллельной обработки
Используется опция if
#pragma omp название-директивы if (скалярное
выражение)
–Исполнить параллельно, если выражение истино
–В противном случае – последовательно
55.
Условное объявлениепараллельной секции
#include <omp.h> int
main()
{
// последовательный код
parallel if (expr)
{
// параллельный код
}
// последовательный код
return 0;
}
#pragma omp
56.
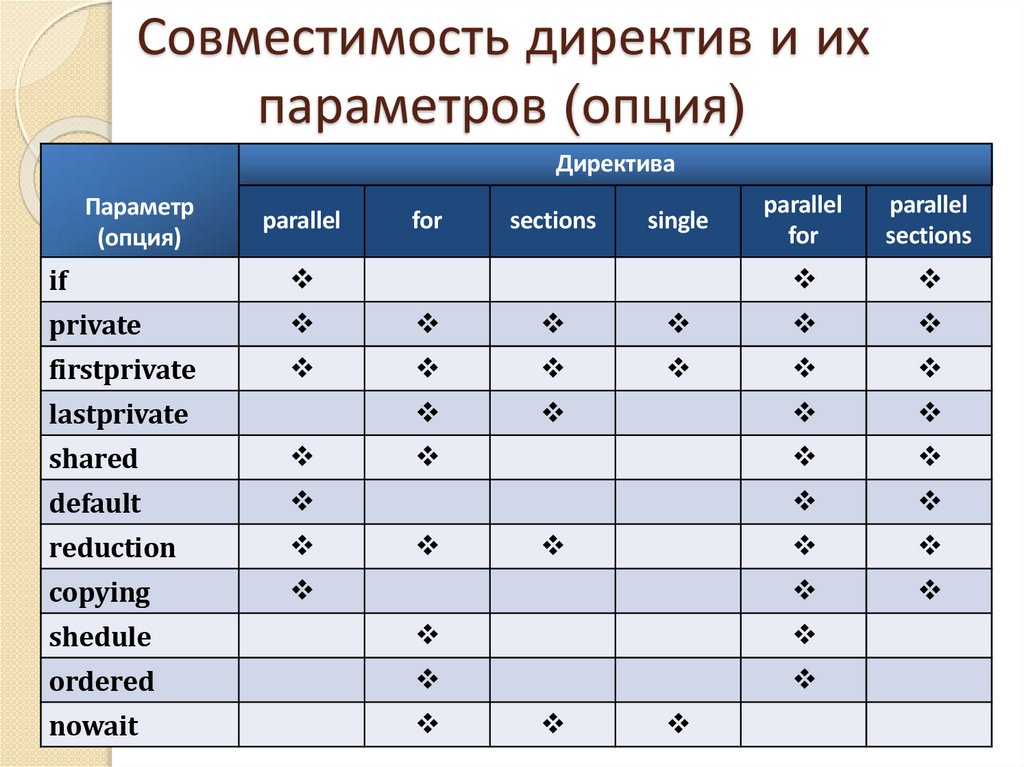
Совместимость директив и ихпараметров (опция)
Директива
Параметр
(опция)
parallel
for
sections
single
parallel
for
parallel
sections
if
private
firstprivate
lastprivate
shared
default
reduction
copying
shedule
ordered
nowait
57.
Пример: выполнениередукционной операции
Сложение массива чисел
int s_parallelReduction(int* mass, int size, int num_thread)
{
int result = 0;
omp_set_num_threads(num_thread);
#pragma omp parallel for reduction(+:result)
for (int i = 0; i < size; i++)
result += mass[i];
return result;
}
58.
Способ синхронизации данныхСинхронизация типа critical
Синхронизация типа critical используется для описания
структурных блоков, выполняющихся только в одном потоке
из всего набора параллельных потоков.
В программах, написанных на языке C/C++, используется
прагма (где name - имя критической секции):
#pragma omp critical [ name ]
{<структурный блок программы>}
Разные критические секции независимы, если они имеют
разные имена. Не поименованные критические секции
относятся к одной и той же секции.
Полезны для избавления от ошибок соревнования, чтения
записи данных (неопределенный порядок)
Может привести к тому, что параллельная программа станет
последовательной
59.
Способ синхронизации данныхСинхронизация типа critical (пример)
Моделирование очереди, в которой задание выбирается из очереди и
обрабатывается. Для защиты от многократной выборки потоками из
очереди одного и того же задания операция выборки должна выполняться
в критической секции. Т.к. две очереди в этом примере идентичны, то они
защищены критическими секциями с разными именами: xaxis и yaxis.
. . .
#pragma omp parallel shared(x, y) private(x_next, y_next)
{
#pragma omp critical ( xaxis )
x_next = dequeue(x);
work(x_next);
#pragma omp critical ( yaxis )
y_next = dequeue(y);
work(y_next);
}
. . .
60.
Пример: Синхронизация типаcritical
В этом примере определены две критических
секции name1 и name2, каждая из которых выполняется
только в одном из параллельных потоков.
…
#pragma omp parallel private(i) shared(cnt1,cnt2)
{
#pragma omp for for (i=0;i<n;i++)
{
… do work …
if (condition1)
#pragma omp critical (name1) cnt1 = cnt1 + 1;
else
#pragma omp critical (name1) cnt1 = cnt1 – 1;
if (condition2)
#pragma omp critical (name2)
cnt2 = cnt2+1;
}
}
61.
Пример: Синхронизация типаcritical
В этом примере определена одна критическая секция для
сложения элементов массива чисел.
long long totalSum = 0; // используем long long (64-битное число)
чтобы при суммировании int - не переполнился результат
#pragma omp parallel for
for (int i = 0; i < xs.size(); ++i)
{
#pragma omp critical // omp = OpenMP, critical = это критическая
секция кода, в нее потоки заходят по одному
{
totalSum += xs[i];
}
}
62.
Пример: Синхронизация типаcritical (1)
// Пример 2, Демонстрация защиты глобальных переменных в критических секциях
(имитация продажи билетов).
// Потоки 1 и 2 продают билеты одновременно, номера билетов 1–30.
int g_iTicket = 30; // Определяем глобальные переменные (общее количество голосов)
CRITICAL_SECTION g_cs; // Определяем дескриптор критической секции
// Функция потока 1
unsigned long __stdcall ThreadFunc1(void* lparm)
{
while (g_iTicket > 0)
{
/// 1. Определите, есть ли поток, занимающий общий ресурс, если нет, код ниже прямой,
в противном случае он блокируется и ждет, пока другие потоки освободят общий ресурс
EnterCriticalSection(&g_cs);
/// 2. Поток 1 начинает продажу билетов
cout << "Номер проданного билета thread1:" << g_iTicket << endl;
g_iTicket--;
_sleep(100);
/// 3. После выполнения кода освободите общие ресурсы и позвольте другим потокам
выполнить
LeaveCriticalSection(&g_cs);
}
return 0;
}
63.
Пример: Синхронизация типаcritical (2)
// Функция потока 2
unsigned long __stdcall ThreadFunc2(void* lparm)
{
while (g_iTicket > 0)
{
// 1. Определите, есть ли потоки, занимающие общие ресурсы, в противном случае
приведенный ниже код является прямым, в противном случае он блокируется и ожидает,
пока другие потоки освободят общие ресурсы
EnterCriticalSection(&g_cs);
// 2. Поток 2 начинает продажу билетов
cout << "Номер проданного билета thread2:" << g_iTicket << endl;
g_iTicket--;
_sleep(100);
// 3. После выполнения кода освободите общие ресурсы и позвольте другим потокам
выполнить
LeaveCriticalSection(&g_cs);
}
return 0;
}
64.
Пример: Синхронизация типаcritical (3)
int _tmain(int argc, _TCHAR* argv[])
{
// 1. Инициализируем объект критической секции
InitializeCriticalSection(&g_cs);
/// 2. Создайте поток 1 и поток 2, чтобы начать продажу билетов (общее количество билетов
g_iTicket = 30)
CreateThread(NULL, 0, ThreadFunc1, NULL, 0, NULL);
CreateThread(NULL, 0, ThreadFunc2, NULL, 0, NULL);
int i = 0;
cin >> i;
/// 3. Удалить объекты критического сечения
DeleteCriticalSection(&g_cs);
return 0;
}
65.
К заданию 1.366.
Работа программы на сборке Release67.
Показатели эффективностипараллельного алгоритма
T1(n) – время работы с n элементами массива при однопоточной работе,
Tp(n) – время работы с n элементами массива при использовании р
потоков.
Ускорение (speedup) получаемое при использовании параллельного алгоритма для p процессоров, по сравнению с последовательным
вариантом выполнения вычислений, определяется величиной
Sp(n)=T1(n)/Tp(n)
Эффективность (efficiency) использования параллельным алгоритмом процессоров при решении задачи определяется соотношением:
Ep(n)=T1(n)/(p∙Tp(n))=Sp(n)/p
Стоимость (cost) вычислений
Cp(n)=p∙Tp
68.
Медианное значение (медиана)Медианное значение (М) рассчитывается из числа
или пары чисел, которые больше одной половины
показателей и меньше другой. Чтобы найти
медиану, надо упорядочить набор чисел и просто
найти в нём середину.
Например, для ряда «1, 2, 1, 1, 3, 8, 10, 1, 587»
медиана будет равна 2, т.к. «1, 1, 1, 1, 2, 3, 8, 10, 587».
Если в ряде чётное количество показателей, как
например в «1, 1, 1, 1, 2, 3, 8, 10», надо взять два
средних числа. Это 1 и 2. Их нужно сложить, а сумму
разделить пополам:
(1+2)/2=1,5
69.
Среднеквадратическое отклонениеСреднее квадратическое отклонение ( ) равно квадратному корню из
среднего квадрата отклонений отдельных значений признака от средней
арифметической.
Пример: Опыт работы у пяти претендентов на предшествующей работе
составляет: 2,3,4,7 и 9 лет.
В нашем примере:
лет
В общем смысле среднеквадратическое отклонение можно считать
мерой неопределённости.
70.
При выполнении задания необходимо 20раз запускать вычисления при разном
количестве используемых потоков. Время
работы программы при каждом запуске
фиксировать.
В таблицу 1.2 необходимо внести данные
расчета медианы (М) и среднего
квадратического отклонения ( ),
т.е. в виде М .
Например, 1,23428 0,01206 с.