



















 programming
programmingSimilar presentations:





")




Динамические структуры данных. Связные списки: классификация
1.
Динамическиеструктуры данных
Связные списки:
классификация
2.
Динамические структуры данных3.
Динамические структурыструктуры данных
Динамические
данных
Динамические
данных
• Динамические
структуры данных —структуры
это структуры данных,
осуществляющие
организацию работы с данными, память под которые выделяется и освобождается
динамически по мере необходимости, так как до начала работы с данными
невозможно определить сколько памяти потребуется для их хранения.
• В контексте динамических структур данных подразумевается динамическое
выделение памяти отдельными блоками. Каждый элемент данных хранится в
отдельном блоке.
• Отдельный блок (node, узел) — тип данных, состоящий из полей для хранения
непосредственно самих данных и полей-связей с другими узлами через указатели.
• Для организации работы с узлами, связанными между собой по определенным
правилам, описывается тип данных соответствующей динамической структуры.
4.
Списки5.
СпискиДинамические
структуры данных
Динамические
структуры
данных
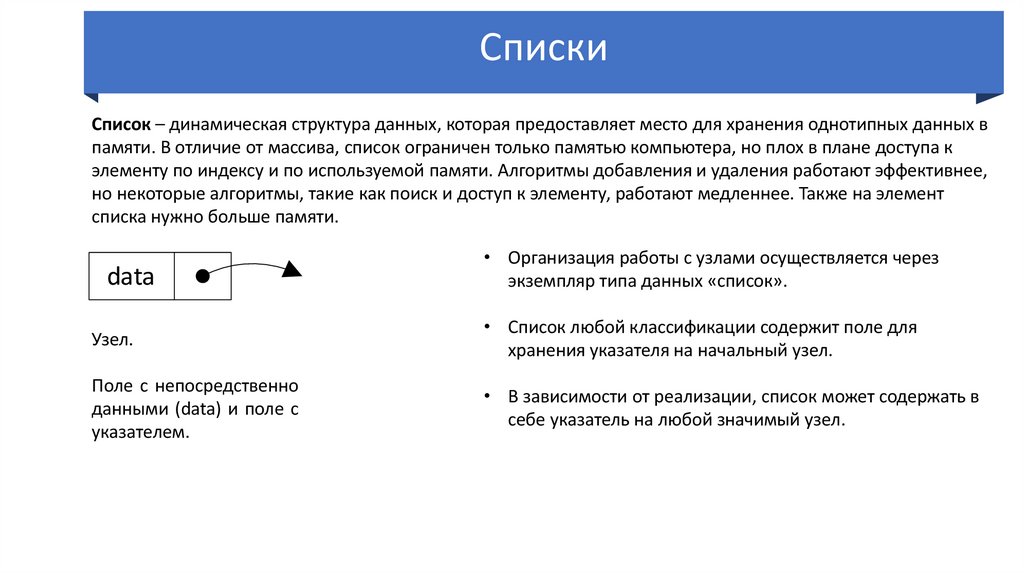
Список – динамическая
структура данных, которая
предоставляет место для
хранения однотипных данных в
памяти. В отличие от массива, список ограничен только памятью компьютера, но плох в плане доступа к
элементу по индексу и по используемой памяти. Алгоритмы добавления и удаления работают эффективнее,
но некоторые алгоритмы, такие как поиск и доступ к элементу, работают медленнее. Также на элемент
списка нужно больше памяти.
data
• Организация работы с узлами осуществляется через
экземпляр типа данных «список».
Узел.
• Список любой классификации содержит поле для
хранения указателя на начальный узел.
Поле с непосредственно
данными (data) и поле с
указателем.
• В зависимости от реализации, список может содержать в
себе указатель на любой значимый узел.
6.
Односвязные списки7.
Односвязные списки• Самый «базовый» список — односвязный
(однонаправленный).
• Каждый узел однонаправленного списка
содержит поле для хранения указателя на
следующий узел.
• В последнем узле в поле для хранения
указателя на следующий узел хранится
нулевой указатель.
экземпляр списка
указатель на
головной узел
головной узел
узел
узел
последний
узел хранит
нулевой
указатель
• В зависимости от реализации,
однонаправленный список может
содержать указатель не только на
начальный (головной) узел, но и на
конечный (хвостовой) узел.
8.
Функция добавления элемента в конец списка9.
Функция добавления элемента в начало списка10.
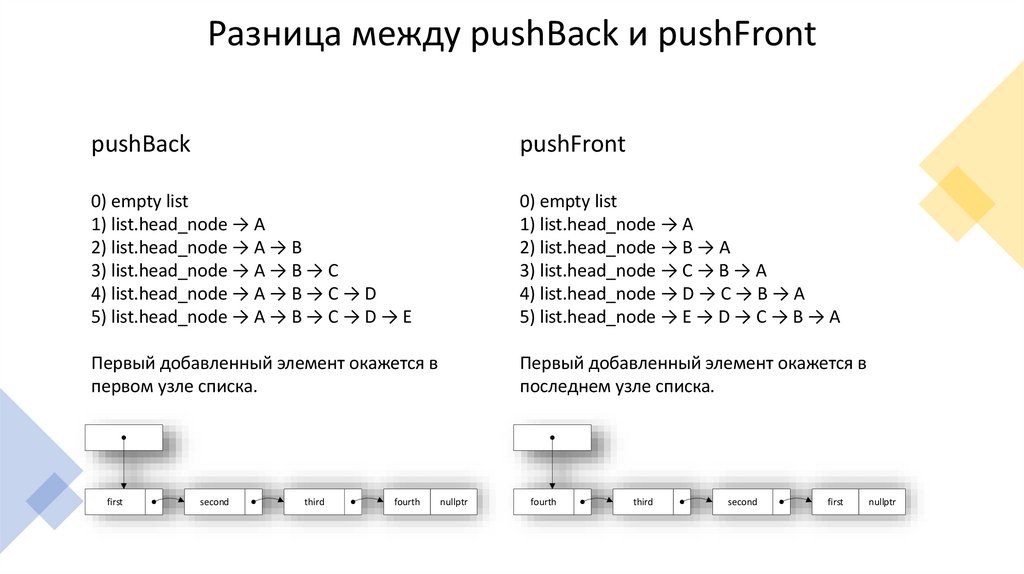
Разница между pushBack и pushFrontpushBack
pushFront
0) empty list
1) list.head_node → A
2) list.head_node → A → B
3) list.head_node → A → B → C
4) list.head_node → A → B → C → D
5) list.head_node → A → B → C → D → E
0) empty list
1) list.head_node → A
2) list.head_node → B → A
3) list.head_node → C → B → A
4) list.head_node → D → C → B → A
5) list.head_node → E → D → C → B → A
Первый добавленный элемент окажется в
первом узле списка.
Первый добавленный элемент окажется в
последнем узле списка.
first
second
third
fourth
nullptr
fourth
third
second
first
nullptr
11.
Пример добавления и вывода элементов списка12.
Функция удаления узла из начала списка13.
Возвращение адреса элемента по индексу (getAt)14.
Функция добавления после элемента с заданным индексом(insert)
15.
Функция удаления по индексу (erase)16.
Пример использования insert и erase17.
Двусвязные списки18.
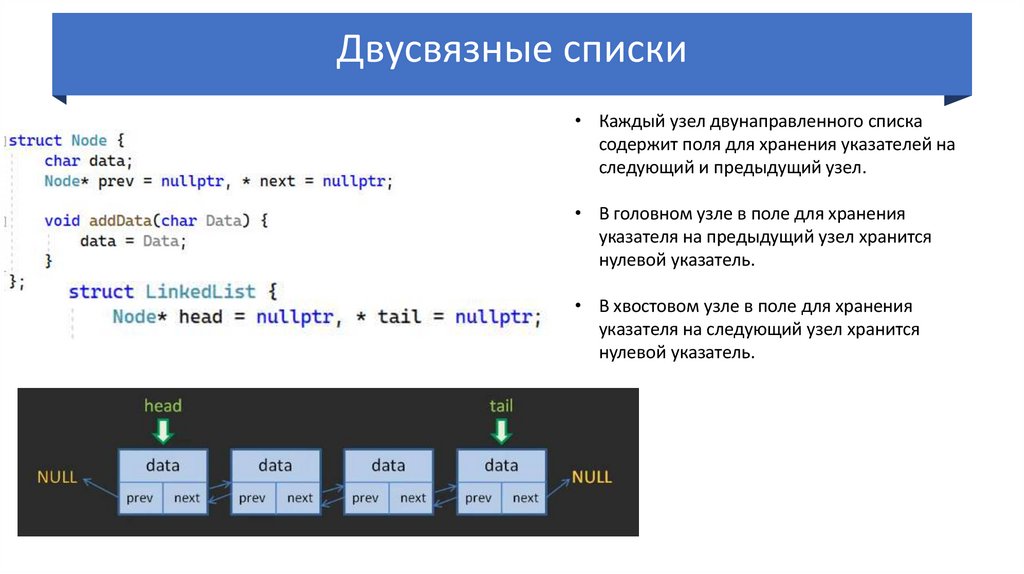
Двусвязные списки• Каждый
узел двунаправленного списка
Классификация списков:
двусвязный
содержит поля для хранения указателей на
следующий и предыдущий узел.
• В головном узле в поле для хранения
указателя на предыдущий узел хранится
нулевой указатель.
• В хвостовом узле в поле для хранения
указателя на следующий узел хранится
нулевой указатель.
19.
Функция добавления элемента в конец20.
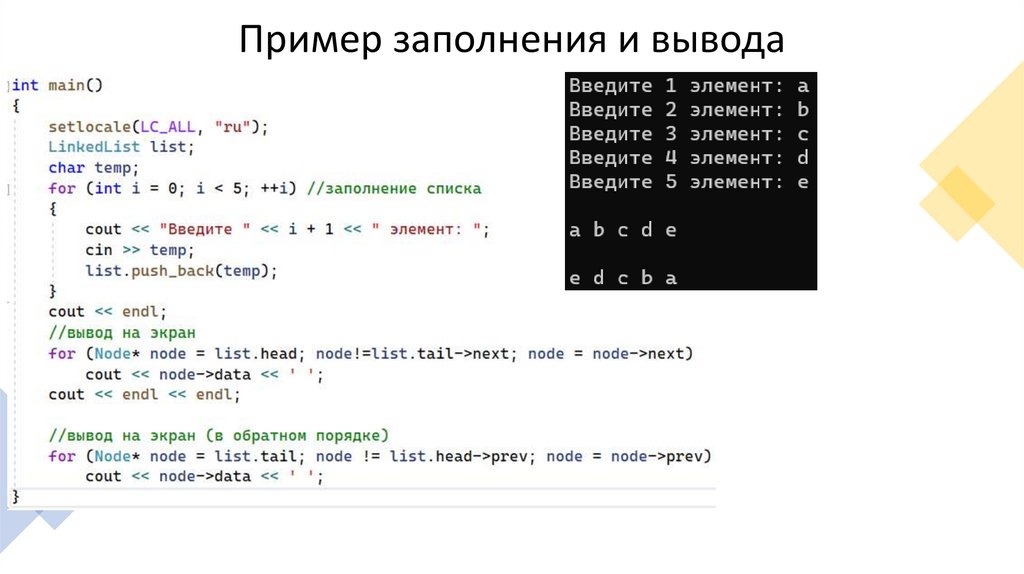
Пример заполнения и вывода21.
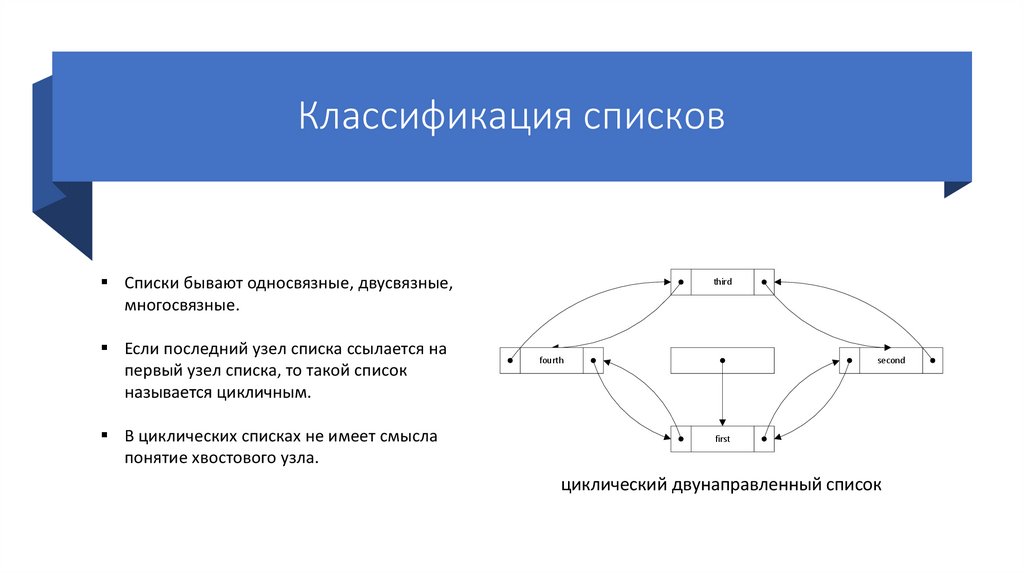
Классификация списковСписки бывают односвязные, двусвязные,
многосвязные.
Если последний узел списка ссылается на
первый узел списка, то такой список
называется цикличным.
В циклических списках не имеет смысла
понятие хвостового узла.
third
fourth
second
first
циклический двунаправленный список
22.
Сравнение массивов и списковДоступ к данным в массиве осуществляется
«напрямую» за константное время.
В списке необходимо переходить от одного
элемента к другому за линейное время.
Для изменения количества элементов в массиве
необходимо выделить новый участок памяти
требуемого размера, перенести элементы в
новый массив, удалить предыдущий массив.
Для изменения количества узлов в списке
достаточно выделить/высвободить память для
конкретного узла и переуказать указатели.
Любое изменение размера массива
«затратное» по памяти и производительности.
В циклическом списке можно менять головной
узел.
23.
Библиотека STL: listИнициализация:
Размер списка:
Возврат первого элемента:
Возврат последнего элемента:
Обмен значениями двух списков:
Добавление элемента в начало списка:
Добавление элемента в конец списка:
Удаление последнего элемента:
Удаление первого элемента:
Удаление всех элементов:
24.
Библиотека STL: iteratorИтератор — это объект, который способен перебирать
элементы контейнерного класса без необходимости
пользователю знать реализацию определенного
контейнерного класса.
Об итераторе можно думать, как об указателе на элемент
контейнерного класса с дополнительным набором
перегруженных операторов:
Оператор * возвращает элемент, на который в данный момент
указывает итератор.
Оператор ++ перемещает итератор к следующему элементу
контейнера. Большинство итераторов также предоставляют
оператор −− для перехода к предыдущему элементу.
Операторы == и != используются для определения того,
указывают ли оба итератора на один и тот же элемент или нет.
Для сравнения значений перед сравнением нужно
разыменовать итераторы.
Оператор = присваивает итератору новую позицию. Чтобы
присвоить значение сначала нужно разыменовать итератор.
Метод begin() возвращает итератор, представляющий
начальный элемент контейнера.
Метод end() возвращает итератор, представляющий
элемент, который находится после последнего
элемента в контейнере.
Метод cbegin() возвращает константный (только для
чтения) итератор, представляющий начальный
элемент контейнера.
Метод cend() возвращает константный (только для
чтения) итератор, представляющий элемент, который
находится после последнего элемента в контейнере.