






















 programming
programmingSimilar presentations:


")







Структура данных. Очередь
1.
СТРУКТУРА ДАННЫХОЧЕРЕДЬ
2.
Основные положенияОчередь — это структура данных, в которой элементы добавляются и
удаляются в порядке «первым пришел, первым ушел». Из-за такого поведения
стеки иногда называют списками FIFO, или просто FIFO.
Данная модель (как и любая другая структура данных) является
математической абстракцией над повседневной жизнью. Собственно, аналогии из
нашего быта — это всё ещё самый лучший способ понять и объяснить основные
структуры данных. Очередь за хлебом или в поликлинику (как социальное явление)
— это и есть та самая структура данных очередь. Собственно, и названа поэтому.
Смысл прост — кто первым пришёл, тот первым и будет обслужен. Данный
принцип скрывается за аббревиатурой FIFO (First In — First Out или ПППО порусски).
3.
Основные положенияFIFO — важная составляющая не только в информатике, но и в
логистике и многих других сферах жизни. Очередь используется сплошь и
рядом: любой конвейер, пулемётная лента, однополосная дорога с
односторонним движением, проходная на заводе и т.д.. Основной
характеристикой очереди является начало (голова) и конец (хвост).
Новые элементы добавляются только в конец, а «считывание»
происходит исключительно с головы. Если вы приходите первым на почту
— вас обслужат первым; если же перед вами до этого стояли люди — вам
необходимо дождаться когда будут обслужены все N-впереди стоящие.
Один за одним, итерационно. Это называется доступом к элементам
очереди.
4.
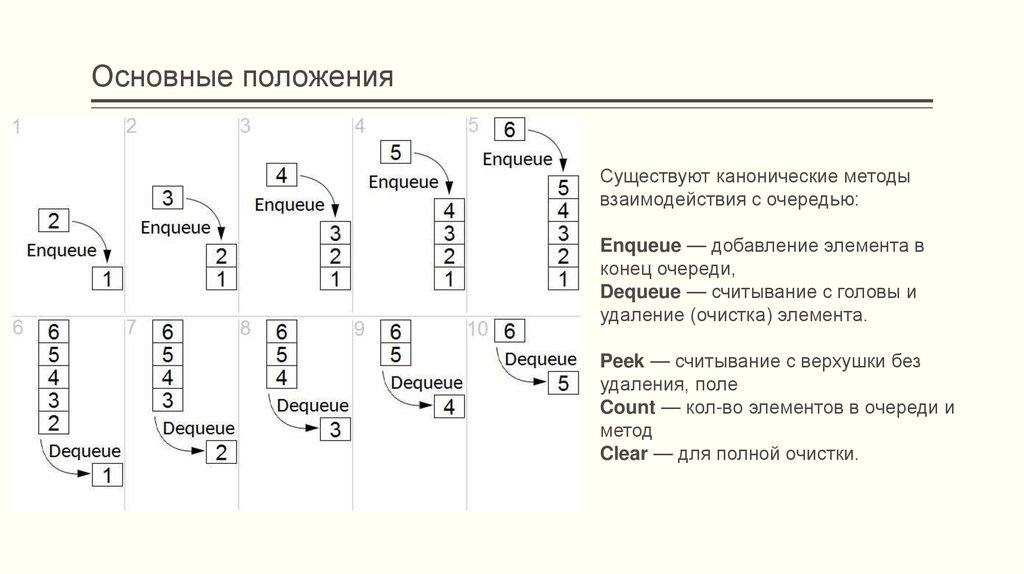
Основные положенияСуществуют канонические методы
взаимодействия с очередью:
Enqueue — добавление элемента в
конец очереди,
Dequeue — считывание с головы и
удаление (очистка) элемента.
Peek — считывание с верхушки без
удаления, поле
Count — кол-во элементов в очереди и
метод
Clear — для полной очистки.
5.
Основные положенияВ последнее время часто происходят споры с какой именно стороны
необходимо добавлять новые элементы — в хвост или голову (по
аналогии, что еда поступает змее в голову, а не хвост). Отсюда иногда
встречаются и такие картинки (с перевернутым направлением, что,
практически, сути не меняет):
6.
Описание алгоритма реализации очередиСуществует множество способов реализации структуры данных
очередь при помощи практически любых языков программирования.
Первый и самый простой способ — при помощи одного массива
фиксированного размера и нескольких локальных целочисленных
переменных front (head) и rear (tail), где первая указывает на голову
очереди, а последняя — на хвост. Алгоритм добавления и считывания в
очередь можно описать следующими шагами:
7.
Описание алгоритма реализации очередиШаг №1 — объявление переменных:
Объявим целочисленную переменную size, в которой будет хранится
размер очереди;
Объявляем локальный массив queue типа T с необходимой нам
размерностью (size);
Объявим две целочисленных локальных переменных front и rear, обе
равные -1;
8.
Описание алгоритма реализации очередиШаг №2 — функция\метод добавления элемента в очередь (enqueue):
Проверяем не заполнена ли очередь (условие, когда rear == size - 1);
Если очередь заполнена — выбрасываем ошибку;
Если ещё есть место — инкрементим rear++ и вставляем элемент в
массив queue [rear] = value;
9.
Описание алгоритма реализации очередиШаг №3 — функция\метод удаления элемента из очереди (dequeue):
Проверяем не пустая ли очередь (условие, когда front == rear);
Если очередь пустая — выбрасываем ошибку;
Если есть элементы — инкрементим front++ и показываем элемент из
массива queue [front] = value;
Проверить, если front == rear, то сбрасываем обе переменные к
значению -1;
10.
Описание алгоритма реализации очередиШаг №4 — функция\метод удаления элемента из очереди:
Проверяем не пустая ли очередь (условие, когда front == rear);
Если очередь пустая — выбрасываем ошибку;
Если есть элементы — показываем элемент из массива
queue [front+1] = value;
11.
Нативная реализация на C#Заметим, что собственная реализация подобных базовых структур,
как правило, избыточна. Всё уже давно реализовано, наверное, для всех
платформ и на всех языках программирования. Конечно, .NET C# не
исключение.
В пространстве имён System.Collections.Generic
Queue<T>, который отвечает за данный функционал.
есть
класс
Но цель этого - показать как раз таки нативную реализацию
алгоритма. Такой подход к организации очереди — самая простая и
служит скорее для демонстрации, чем для использования в реальных
проектах. Это базис, служащий исключительно для понимания основных
принципов очереди.
12.
Нативная реализация на C#Создадим класс и назовём его Queue.
Объявим внутри локальные целочисленные
переменные:
_Size — размер массива,
_Front — позиция головы (инициализируем
со значением по-умолчанию -1),
_Rear — позиция хвоста (также -1),
_Count — кол-во элементов.
Также локальный массив типа T.
13.
Нативная реализация на C#Создадим конструктор, в котором определим размер очереди и
создадим массив нужной длины:
14.
Нативная реализация на C#Согласно алгоритму, описанному в предыдущей статье, нам для
работы понадобится два метода: IsFull, проверяющий заполнена
ли очередь (условие, когда значение _Rear подобралось к размеру
всего массива) и IsEmpty, возвращающий true если очередь пуста:
15.
Нативная реализация на C#Непосредственно переходим к методу добавления элементов в
очередь: Enqueue. Мы проверяем заполнен ли полностью массив и
если да — выбрасываем ошибку. В случае, когда есть ещё место —
мы устанавливаем наш новый элемент в позицию _Rear + 1 и
инкрементим на единицу переменную _Rear:
16.
Нативная реализация на C#Следующий метод Dequeue — проверяет не пустая ли очередь и если нет,
то считывает элемент: возвращает его нам и удаляет из очереди. В случае,
когда _Rear и _Front равны — это означает, что из очереди были вычитаны
все элементы и мы заново присваиваем этим двум переменным значение -1.
17.
Нативная реализация на C#Следующий метод Dequeue — проверяет не пустая ли очередь и если нет,
то считывает элемент: возвращает его нам и удаляет из очереди. В случае,
когда _Rear и _Front равны — это означает, что из очереди были вычитаны
все элементы и мы заново присваиваем этим двум переменным значение -1.
18.
Нативная реализация на C#В целом, описанное выше уже полностью удовлетворяет алгоритму:
можно добавлять элементы, можно считывать. Всё, что пойдёт далее — это
больше удобства и расширение базового функционала. К примеру, мы можем
инкапсулировать некоторые локальные переменные в открытые public
свойства:
19.
Нативная реализация на C#Метод Peek служит для считывания верхнего элемента, но без его
удаления. В целом, он очень похож на Dequeue с небольшими изменениями:
20.
Нативная реализация на C#И, конечно, было бы неплохо добавить GetEnumerator для того, чтобы
иметь возможность получать данные при помощи foreach. Для этого
необходимо нашему классу реализовать интерфейс IEnumerable<T> и
добавить следующий код:
Оператор
yield
return
используется для возврата каждого
элемента
по
одному.
Последовательность,
которая
возвращается
после
выполнения
метода
итератора,
можно
использовать с помощью оператора
foreach
21.
Нативная реализация на C#Теперь можно написать несколько
примеров использования. Допустим
вы приоритизировали свои
утренние дела следующим образом:
«Встать с кровати«, «Почистить
зубы«, «Позавтракать» и «Пойти на
учебу»
Мы добавляем в очередь наши
задачи в том порядке, в каком они
должны быть выполнены. Две из
них «исполняем» сразу, т.е.
вычитываем и в очереди остаётся
последние 2 задачи.
22.
Нативная реализация на C#В конце работы консольного приложения выводим счётчик оставшихся задач и ждём
реакцию пользователя: