










































")
")
")


































")
")
")








")
")
")
")

 или дата-центр (data center) – это специализированное здание для размещения серверного и сетевого")




")





























")













































































































 криптовалют. Пример")










































































 electronics
electronicsSimilar presentations:










Вычислительные системы, сети и телекоммуникации
1.
2. Эволюция вычислительных систем
Вычислительные машины за свою историю прошли стремительный ивпечатляющий путь, отмеченный частыми сменами поколений ЭВМ. В этом
процессе развития можно выявить целый ряд закономерностей:
1. весь период развития средств электронной вычислительной техники
(ЭВТ) отмечен доминирующей ролью классической структуры ЭВМ
(структуры фон Неймана), основанной на методах последовательных
вычислений;
2. основным направлением совершенствования ЭВМ является неуклонный
рост производительности (быстродействия) и интеллектуальности
вычислительных средств;
3. совершенствование ЭВМ осуществлялось в комплексе (элементноконструкторская база, структурно-аппаратурные решения, системнопрограммный и пользовательский, алгоритмический уровни);
4. в настоящее время наметился кризис классической структуры ЭВМ,
связанный с исчерпанием всех основных идей последовательного счета.
Возможности микроэлектроники также не безграничны, существует
технолоческий предел.
3.
Дальнейшее развитие ВТ напрямую связано с переходом кпараллельным вычислениям, с идеями построения многопроцессорных
систем и сетей, объединяющих большое количество отдельных
процессоров и (или) ЭВМ. Здесь появляются огромные возможности
совершенствования средств вычислительной техники. Но следует
отметить, что при несомненных практических достижениях в области
параллельных вычислений до настоящего времени отсутствует их
единая теоретическая база.
Термин вычислительная система появился в начале - середине 60-х
гг. при появлении ЭВМ III поколения. Это время знаменовалось
переходом на новую элементную базу - интегральные микро-схемы.
Следствием этого явилось появление новых технических решений:
разделение процессов обработки информации и ее ввода-вывода,
множественный доступ и коллективное использование вычислительных
ресурсов в пространстве и во времени. Появились сложные режимы
работы ЭВМ - многопользовательская и многопрограммная обработка.
4.
Под вычислительной системой (ВС) будем пониматьсовокупность взаимосвязанных и взаимодействующих
процессоров или ЭВМ, периферийного оборудования и
программного обеспечения, предназначенную для
подготовки и решения задач пользователей. Отличительной
особенностью ВС по отношению к ЭВМ является наличие в
них нескольких вычислителей, реализующих параллельную
обработку.
Создание ВС преследует следующие основные цели:
- повышение производительности системы за счет ускорения
процессов обработки данных;
-повышение надежности и достоверности вычислений;
-предоставление пользователям дополнительных сервисных
услуг и т.д.
5.
Самыми важными предпосылками появления и развитиявычислительных систем служат экономические факторы. Анализ
характеристик ЭВМ различных поколений показал, что в пределах
интервала времени, характеризующегося относительной
стабильностью элементной базы, связь стоимости и
производительности ЭВМ выражается квадратичной зависимостью “законом Гроша”.
Сэвм=К1.П 2эвм
Построение же вычислительных систем позволяет существенно
сократить затраты, так как для них существует линейная формула:
Свс=К2.SПi
где Сэвм, Cвс - соответственно стоимость ЭВМ и ВС; К1 и К2 коэффициенты пропорциональности, зависящие от технического
уровня развития вычислительной техники; Пэвм , Пi производительность ЭВМ и i из n комплектующих вычислителей (ЭВМ
или процессоров). S-сумма Пi.
6. График зависимости стоимости от производительности ЭВМ и ВС
7.
Для каждого поколения ЭВМ и ВС существует критический порог сложностирешаемых задач Пкр, после которого применение автономных ЭВМ становится
экономически невыгодным, неэффективным.
Кроме выигрыша в стоимости технических средств, следует учитывать и
дополнительные преимущества. Наличие нескольких вычислителей в системе
позволяет совершенно по-новому решать проблемы надежности,
достоверности результатов обработки, резервирования, централизации
хранения и обработки данных, децентрализации управления и т.д.
Основные принципы построения, закладываемые при создании ВС:
-возможность работы в разных режимах;
-модульность структуры технических и программных средств, что позволяет
совершенствовать и модернизировать ВС без коренных их переделок;
-унификация и стандартизация технических и программных решений;
-иерархия в организации управления процессами;
-способность систем к адаптации, самонастройке и самоорганизации;
-обеспечение необходимым сервисом пользователей при выполнении
вычислений.
8.
В настоящее время накоплен большой практический опыт вразработке и использовании ВС самого разнообразного
применения. Эти системы очень сильно отличаются друг от
друга своими возможностями и характеристиками.
Различия наблюдаются уже на уровне структуры.
Структура ВС - это совокупность комплексируемых
элементов и их связей.
В качестве элементов ВС выступают отдельные ЭВМ и
процессоры. В ВС, относящихся к классу больших систем,
можно рассматривать структуры технических, программных
средств, структуры управления и т.д.
9.
ЭВМ- это комплекс технических ипрограммных средств предназначенных для
автоматизации подготовки и решения задач
пользователей.
10.
это взаимосвязанная совокупностьаппаратных средств вычислительной техники и
программного обеспечения, предназначенная для
обработки информации.
11.
Это совокупность элементов и их связей.Различают структуры технических, программных и
аппаратно-программных средств.
12.
Технические и эксплуатационные характеристикиЭВМ
- быстродействие
- надёжность
- габаритные размеры
- ёмкость оперативной памяти
- точность и т.д.
13.
- характеристики и состав функциональных модулейв базовой конфигурации ЭВМ
- возможности расширения состава технических и
программных средств
- возможности изменений структуры
14.
Состав программного обеспечения и сервисных услуг- операционная система
- средства автоматизации
- пакеты прикладных программ
15.
Это концептуальная структура вычислительноймашины, определяющая проведение обработки
информации и включающая методы
преобразования информации в данные и принципы
взаимодействия технических средств и
программного обеспечения.
16.
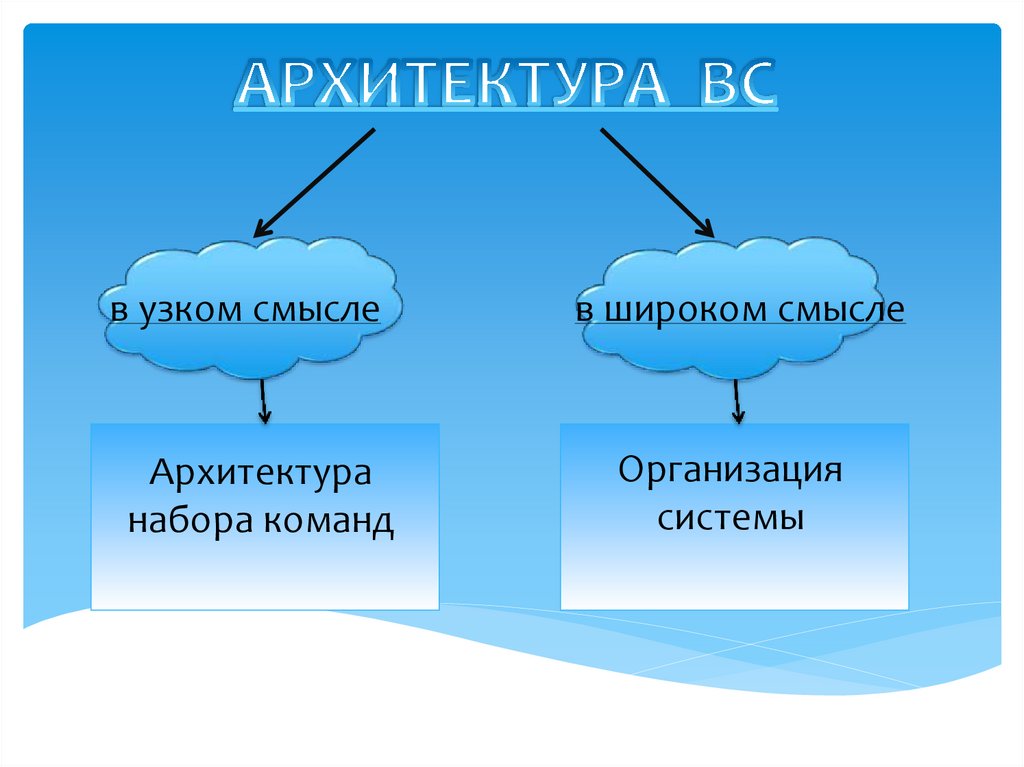
в узком смыслев широком смысле
Архитектура
набора команд
Организация
системы
17. ?
Для построения вычислительных систем необходимо,чтобы элементы или модули, комплексируемые в систему,
были совместимы. Понятие совместимости имеет три
аспекта: аппаратурный, или технический, программный и
информационный. Уровень прямого управления служит для
передачи коротких однобайтовых приказов-сообщений.
Последовательность взаимодействия процессоров
сводится к следующему. С момента появления первых
систем было опробовано большое количество
разнообразных структур систем, отличающихся друг от
друга различными техническими решениями. Но самым
главным было понятие параллелизма выполнения
программ.
18. Чарльз Бэббидж: первое упоминание о параллелизме
В 1840 году Ч.Бэббидж разработалсвою аналитическую машину,
прообраз современных ЭВМ.
" В случае выполнения серии
идентичных вычислений, подобных
операции умножения и необходимых
для формирования цифровых таблиц,
машина может быть введена в
действие с целью выдачи нескольких
результатов одновременно, что очень
существенно сократит весь объем
процессов"
19. Аналитическая машина Чарльза Бэббиджа в лондонском Музее науки
20. Определение параллелизма
А.С. ГоловкинПараллельная вычислительная система вычислительная система, у которой имеется по
меньшей мере более одного устройства
управления или более одного центрального
обрабатывающего устройства, которые
работают одновременно.
21. Определение параллелизма
П.М. КоугиПараллелизм - воспроизведение в нескольких
копиях некоторой аппаратной структуры, что
позволяет достигнуть повышения
производительности за счет одновременной
работы всех элементов структуры,
осуществляющих решение различных частей
этой задачи.
22. Области применения параллельных вычислительных систем
предсказания погоды, климата иглобальных изменений в атмосфере;
науки о материалах;
построение полупроводниковых приборов;
сверхпроводимость;
структурная биология;
разработка фармацевтических препаратов;
генетика;
23. Области применения параллельных вычислительных систем
квантовая хромодинамика;астрономия;
транспортные задачи;
гидро- и газодинамика;
управляемый термоядерный синтез;
эффективность систем сгорания топлива;
геоинформационные системы;
24. Области применения параллельных вычислительных систем
разведка недр;наука о мировом океане;
распознавание и синтез речи;
распознавание изображений;
военные разработки;
банковские и биржевые системы;
системы Искусственного интеллекта (ИИ);
облачные технологии.
Ряд областей применения находится на стыках
соответствующих наук.
25. Оценка производительности параллельных вычислительных систем
Пиковая производительность - величина, равнаяпроизведению пиковой производительности
одного процессора на число таких процессоров в
данной машине.
26.
Производительность ЭВМ определяется FLOPSами ( Floating PointOperations Per second)- число операций с плавающей точкой в секунду. В
системе СИ производительность от FLOPS имеет следующие обозначения:
Megaflops =10^6 Flops
Gigaflops =10^9 Flops
Teraflops =10^12 Flops
Petaflops =10^15 Flops
Exaflops =10^18 Flops
Данная величина (flops) определяется путем запуска на испытуемой ЭВМ
тестовой программы, которая решает задачу с известным количеством
операций и подсчитывает время, за которое она была решена. Самой
популярной тестовой программой является LINPACK – библиотека,
написанная на языке Фортран, которая содержит набор подпрограмм для
решения систем линейных алгебраических уравнений. Эта программа
используется для составления рейтинга суперкомпьютеров «TOP500» для
всего мира, и «TOP50» для СНГ.
27. ВС в современном мире
Суперкомпьютеры традиционно использовались в военных и научных целях, но в последниегоды в их применении произошли революционные изменения, связанные с тем, что их
мощность «доросла» до моделирования реальных процессов и предметов при доступной для
бизнеса стоимости. В авиапромышленности выпуск нового реактивного двигателя по
традиционной технологии — дорогостоящее удовольствие, например создание АЛ-31 для СУ-27
заняло 15 лет, потребовало создать и разрушить 50 опытных экземпляров и стоило 3,5 млрд.
долларов.
Сегодня в развитых европейских странах:
47,3% высокотехнологической продукции производится с использованием имитационного
моделирования фрагментов проектируемых сложных систем или изделий;
32,3% продукции производится с использованием имитационного моделирования
мелкомасштабных аналогов проектируемых систем и изделий;
15% продукции производится с использованием полномасштабного имитационного
моделирования проектируемых систем и изделий;
5,4% проектируемых сложных систем и изделий производится без имитационного
моделирования.
Суперкомпьютерные технологии в современном мире стали стратегической областью,
без которой невозможно дальнейшее развитие. Мощность национальных
суперкомпьютеров сейчас так же важна, как мощность электростанций или количество
боеголовок.
28. Гонка за экзафлопом
Дело в том, что в наши дни наблюдался 11 летний цикл прироста мощности. Гигафлоп,терафлоп, петафлоп… Петафлопный рубеж был преодолен в 2008 году, тогда же оборонщики
США поставили себе задачу — достигнуть в 2019 году уровня 1 экзафлоп. Ввиду важности
задачи в гонку включись все ведущие страны, так сейчас первое место занимает китайский
суперкомпьютер.
Суперкомпьютерные вычисления оказались на переднем крае гонки экономик по двум
причинам — во первых они востребованы как никогда раньше, а во-вторых исчерпан лимит
экстенсивного развития путем повышения частот процессоров при снижении их потребляемой
мощности.
Нерешенные пока проблемы:
1. Энергопотребление. Существующие суперкомпьютеры потребляют мегаватты энергии.
Экзафлопные по той же технологии будут потреблять гигаватты, что уже сравнимо с
энергопотреблением города.
2. Надежность. Чем больше узлов, тем меньше надежность, экзафлопные компьютеры будут
ломаться непрерывно и при их эксплуатации это должно непрерывно учитываться,
технологии программирования принципиально ненадежных систем находятся в зачаточном
состоянии.
3. Эффективность. С ростом количества ядер эффективность их совместной работы
непрерывно снижается. Как программировать экзафлопные системы с миллионами
параллельных ядер никто даже приблизительно не знает, понадобятся новые языки и смена
парадигм программирования.
29. ВС России в современном мире
В 2021 году «Яндекс» и Сбербанк вывели Россию в десятку стран почислу мощнейших суперкомпьютеров
15 ноября 2021 года был опубликован список топ-500 мощнейших
суперкомпьютеров мира, обновляемый два раза в год. В него вошли
7 российских суперкомпьютеров
Суперкомпьютер «Яндекса» «Червоненкис» занял 19-ю строчку
рейтинга суперкомпьютеров топ-500, став самой производительной
системой не только в России, но и во всей Восточной Европе. Его
реальная производительность составляет 21,53 Пфлопс
(квадриллионов операций с плавающей точкой в секунду). Кроме
«Червоненкиса», в топ-500 вошли ещё две ВС «Яндекса» —
«Галушкин» и «Ляпунов». Они заняли в рейтинге 36-е в и 40-е места
соответственно. Заявленная в списке реальная производительность
этих машин составляет 16,02 и 12,81 Пфлопс.
Новые ВС «Яндекса» названы в честь советских и российских учёных,
которые внесли вклад в теорию машинного обучения и
компьютерные науки.
30. ВС России в современном мире
Системы построены на базе процессоров AMD EPYC и графическихускорителей Nvidia A100 и используются для обучения
нейросетевых моделей с миллиардами параметров.
В топ-500 появился и новый суперкомпьютер Сбербанка, о запуске
которого компания сообщала незадолго до этого в ноябре.
«Кристофари нео» с реальной мощностью в 11,95 Пфлопс.
Даже после улучшения позиций в мировом рейтинге Россия сильно
отстает от стран-лидеров списка – Китая и США – и по общему числу
суперкомпьютеров, и по производительности самого мощного из них.
Китай представлен в списке со 173 системами, США – со 149
суперкомпьютерами.
Вместе с тем, Россия стала 8-й страной в списке по общей реальной
производительности представленных в нем суперкомпьютеров и 9-й по
общему количеству суперкомпьютеров. У России в рейтинге столько же
систем, как у Южной Кореи.
Лидером списка остаётся обновлённый японский суперкомпьютер
Fugaku, 7,6 млн ядер которой выдают 442 Пфлопс. И она всё ещё втрое
быстрее своего ближайшего конкурента Summit.
31. ВС России в современном мире
Суперкомпьютеры «Яндекса» — суперкомьютеры «Червоненкис»,«Галушкин» и «Ляпунов», созданные компанией «Яндекс» в 2020—
2021 годах. Названы в честь выдающихся учёных: Алексея
Яковлевича Червоненкиса, Александра Ивановича Галушкина и
Алексея Андреевича Ляпунова.
Занимают по состоянию на ноябрь 2021 года в рейтинге самых
мощных суперкомпьютеров мира ТОП500:
«Червоненкис» — 19 место (г.Саров Рязанская область);
«Галушкин» — 36 место (г.Владимир);
«Ляпунов» — 40 место (г.Саров Рязанская область);
«Кристофари нео» Сбер 43 место (Сколково).
Назван в честь Николая Кристофари — первого клиента Сбербанка,
открывшего в нём сберегательную книжку.
32. ВС России в современном мире
«Кристофари» — суперкомпьютер, созданный Сбербанком России наоснове оборудования корпорации Nvidia. Основное
предназначение — обучение нейросетей, также применяется для
научно-исследовательских и коммерческих расчётов[1]. По
состоянию на ноябрь 2020 года по данным суперкомпьютерного
рейтинга ТОП500 производительность суперкомпьютера составляет
6,669 петафлопса, а пиковая — 8,790 петафлопса.
Используется Сбербанком для внутренних задач (для работы коллцентра — распознавания речи и генерации голоса), для сервиса по
распознаванию снимков компьютерной томографии лёгких, также
предоставляется в аренду другим организациям (в составе
продуктовой линейки SberCloud AI Cloud; стоимость аренды — 5750
рублей в минуту).
33. Russia - Lomonosov 2 - T-Platforms
Суперкомпьютер «Ломоносов-2» — суперкомпьютер,построенный компанией «Т-Платформы» для МГУ им.
М.В. Ломоносова. Установлен в НИВЦ МГУ. Занимает
241 место в ТОР 500.
34. ТОП- 241 на ноябрь 2021 г.
В суперкомпьютере МГУ 5 вычислительных стоек с 1280-ю узлами на базе14-ядерных процессоров Intel® Xeon® E5-2697 v3 и ускорителей
NVIDIA® Tesla™ K40, с общим объёмом оперативной памяти более 80 ТБ.
В системе две независимые управляющие сети стандарта Ethernet и две
сети FDR InfiniBand. Одна из них используется для MPI-трафика и имеет
современную топологию Flattened Butterfly, которая не только лучше
масштабируется на системах большого размера, но и позволяет снизить
количество используемых сетевых коммутаторов, сокращая стоимость
сетевой инфраструктуры до 40% по сравнению с традиционными
топологиями. Вторая сеть InfiniBand используется для доступа к данным
и имеет стандартную топологию Fat Tree. Двухуровневая система
хранения включает хранилище расчетных данных объемом 344 ТБ на базе
параллельной файловой системы Lustre, а также одну полку Panasas
ActiveStor 16 для более размещения домашних файловых систем
пользователей.
35. Общая схема архитектуры суперкомпьютера Ломоносов
Вычислительные узлыx86_64
Архивно
е
хранили
ще
Основн
ое
хранили
ще
Узлы доступа и
компиляции
Интернет
Вычислительны
е узлы x86_64 +
GPU
Узлы
распределенной
файловой
системы Lustre
Дисковые
накопители
Infinibandфабрика
Общая схема архитектуры
суперкомпьютера Ломоносов
Служеб
ные
узлы
InfiniBand
Ethernet
36.
37.
38. TOP 500 ноябрь 2022
60-й рейтинг TOP500 был опубликован в ноябре 2022года. С июня 2022 года американский суперкомпьютер
Frontier является самым мощным суперкомпьютером в
TOP500, достигая 1102 петаФлопс (1,102 эксафлопс) в
бенчмарках LINPACK.[2] На Соединенные Штаты
приходится, безусловно, самая высокая доля общей
вычислительной мощности в списке (почти 50%),[3] в то
время как Китай в настоящее время лидирует в списке
по количеству систем с 173 суперкомпьютерами.
39. TOP 500 ноябрь 2022
На втором месте находится система Fugaku с производительностью в 442,01 петафлопс. Один PFLOPS –это 1015 FLOPS.
За время, прошедшее с момента публикации предыдущего рейтинга в ноябре 2022 года, два
суперкомпьютера из первой десятки сумели улучшить свои результаты. Однако этого оказалось
недостаточно для того, чтобы приблизиться к двум лидерам. Эти двое – LUMI и Leonardo – заняли третье
и четвертое места.
Десятка самых быстрых суперкомпьютеров в мире представлена теми же моделями, что и в прошлый раз,
расположившимися с том же порядке.
Измерение скорости производилось при выполнении эталонного теста High Performance Linpack (HPL),
оценивающего, насколько хорошо система решает систему линейных уравнений с плотной матрицей.
Половина из десяти самых быстрых суперкомпьютеров развернута в США, два находятся в Китае и по
одному в Финляндии, Италии и Японии.
Помимо лидерства в скорости Frontier занял первое место и в части пригодности с выполнению функций
искусственного интеллекта по классификации HPL-MxP.
Frontier и LUMI попали также в первую десятку по критерию эффективности энергопотребления,
измеряемой в гигафлопсах в пересчете на ватт. Frontier занял шестое место с результатом 52,592
GFLOPS/Вт, а LUMI – седьмое (51,382 GFLOPS/Вт).
Наибольшую эффективность энергопотребления продемонстрировала система Henri, развернутая в
Flatiron Institute в Нью-Йорке (65,396 GFLOPS/Вт).
40. Рейтинг ВС в современном мире за 2021г.
1. SUPERCOMPUTER FUGAKUСамый топовый компьютер в мире — это Fugaku. Его максимальная
производительность составляет 442 PFLOPS (потенциальный пик — 537), что
на 26 PFLOPS больше, чем в июне 2020 года, и в три раза быстрее, чем у
системы Summit. Такого результата удалось достичь благодаря увеличению
количества ядер до 7630848 (процессоры Arm A64FX) Компьютер построен
компанией Fujitsu и находится в Центре вычислительных наук RIKEN в Кобе,
Япония.
Директор Центра RIKEN Сатоши Мацуока заявил, что это достижение
покорилось им благодаря тому, что они «наконец-то смогли использовать всю
машину по максимуму, а не только её значительную часть». В то же время
Мацуока добавил: «Я не думаю, что мы способны ещё что-то улучшить в ней».
Fugaku лидирует во всех известных на сегодняшний день бенчмарках: Top500,
HPL-AI, HPCG, Graph500. В сумме мощность Фугаку превышает мощность 4
вместе взятых суперкомпьютеров, расположенных ниже в рейтинге. В
эксплуатацию введён в 2021 году.
41. ВС в современном мире Top500
2. SUMMIT IBM POWER SYSTEMS AC92Второй самый мощный компьютер в мире по характеристикам
производительности в 2022-м году — это модель Summit, которая
базируется в Национальной лаборатории Ок-Ридж (ORNL), штат
Теннесси. Лаборатория ведёт исследования в области нейтронной
физики, материаловедения и энергетики.
Является самой быстрой системой из всех представленных в США.
Запущенная в 2018 году, модель IBM Power Systems AC922 имеет
производительность 148,8 петафлопс, обладает 4356 узлами.
Основные процессоры — Power9 (2 414 592 ядра) + шесть
графических чипов NVIDIA Tesla V100.
Две команды, работающие над созданием Summit, получили
престижную премию Гордона Белла за выдающееся достижение в
области высокопроизводительных вычислений, которую обычно
называют «Нобелевской премией по суперкомпьютерам».
42. ВС в современном мире Top500
3. SIERRA IBM POWER SYSTEMS S922LCТройку самых мощных компьютеров 2022 года открывает Sierra.
Данная модель суперкомпьютера принадлежит Ливерморской
национальной лаборатории им. Лоуренса (LLNL) (Калифорния),
которая отвечает за надёжность и безопасность ядерного оружия
Соединённых Штатов Америки. Также в этой лаборатории
расположен Национальный комплекс лазерных термоядерных
реакций.
Суперкомпьютер Сьерра обладает производительностью в 94,6
петафлопс, 4320 узлами, 1,572,480 ядрами, двумя процессорами
Power9 и четырьмя графическими процессорами NVIDIA Tesla V100.
Его архитектура подобна архитектуре суперкомпьютера из позиции
№2 (Summit).
Sierra также заняла 15-е место в списке самых энергоэффективных
суперкомпьютеров в мире по версии Green500.
43. ВС в современном мире Top500
4. SUNWAY TAIHULIGHT SUNWAY MPPSunway TaihuLight построен Национальным
исследовательским центром параллельной
вычислительной техники и технологий Китая и
установлен в Национальном суперкомпьютерном центре
Уси. Ранее в официальном рейтинге Top500 занимал 1-е
место в течение двух лет (2016–2017). Однако с тех пор
его позиции несколько пошатнулись.
Производительность суперкомпьютера достигает 93
петафлопс в тесте HPL. Работает на процессорах Sunway
SW26010 с 10 649 600 ядрами. Теоретическая
производительность китайского суперкомпьютера
составляет 125,4 петафлопс.
44. ВС в современном мире Top500
5. SELENE NVIDIAЭтот один из самых мощных суперкомпьютеров в мире по состоянию на
2022 год используется компанией NVIDIA Corp, известной производством
видеокарт для персональных компьютеров в разных ценовых категориях.
Общая капитализация компании составляет $251,31 млрд. В рамках
последних тестирований Selene достигла мощности в 63,4 петафлопс на
бенчмарке HPL, что позволило ей практически удвоить свой предыдущий
результат (предыдущий показатель — 27,6 петафлопс).
NVIDIA представила свой суперкомпьютер Selene с искусственным
интеллектом в июне 2020 года, построив и запустив его менее чем за месяц.
Основные сферы применения включают разработку и тестирование
различных систем, внутренние разработки искусственного интеллекта и
микросхем.
Selene работает на чипах Nvidia DGX A100 SuperPOD и на базе процессоров
AMD EPYC с новыми графическими процессорами. Общее количество ядер
— 555 520.
45.
1. БыстродействиеЧисло команд выполняемых ЭВМ за одну секунду измеряются в MIPS или
MFLOPS. Быстродействие часто измеряется в единицах, которые
называются ФЛОПС – количество арифметических операций в секунду.
Первые ЭВМ имели быстродействие в несколько сотен ФЛОПС,
современные суперЭВМ достигают скорости в несколько десятков
ТераФЛОПС.
Единицы кратности:
МФЛОПС (МегаФЛОПС) - 1 миллион арифметических операций в секунду;
ГФЛОПС (ГигаФЛОПС) - 1 миллиард арифметических операций в секунду;
ТФЛОПС (ТераФЛОПС) - 1 триллион арифметических операций в секунду
46.
2. ПроизводительностьОбъём работы, осуществляемых ЭВМ в
единицы времени. Производительность зависит от
большего числа факторов:
- скорость выполнения элементарных операций
- скорость обмена информацией по каналам
- структура памяти
- характеристики периферийных устройств …
47. Производительность (MIPS)
Одной из альтернативных единиц измеренияпроизводительности процессора (по отношению к времени
выполнения) является MIPS - (миллион команд в секунду). В
общем случае MIPS есть скорость операций в единицу
времени, т.е. для любой данной программы MIPS есть просто
отношение количества команд в программе к времени ее
выполнения.
Таким образом, производительность может быть определена
как обратная к времени выполнения величина, причем более
быстрые машины при этом будут иметь более высокий
рейтинг MIPS.
48. Производительность (MFLOPS)
Для научно-технических задач производительностьпроцессора оценивается в MFLOPS (миллионах чиселрезультатов вычислений с плавающей точкой в секунду,
или миллионах элементарных арифметических операций
над числами с плавающей точкой, выполненных в секунду).
Как единица измерения, MFLOPS, предназначена для
оценки производительности только операций с плавающей
точкой, и поэтому не применима вне этой ограниченной
области.
49. Производительность ВС с коммуникацией (TPC-A, TPC-B, TPC-C)
Тест TPC-A определяет пропускную способностьсистемы, измеряемую количеством транзакций в секунду
(tps A), которые система может выполнить при работе с
множеством терминалов.
TPC-B измеряет пропускную способность системы в
транзакциях в секунду (tpsB).
В TPC-C обычно публикуются два результата. Один из
них, tpm-C, представляет пиковую скорость выполнения
транзакций (выражается в количестве транзакций в минуту).
Второй результат, $/tpm-C, представляет собой
нормализованную стоимость системы.
50.
3. Ёмкость запоминающих устройствЁмкость памяти измеряется количеством
структурных единиц информации, которая может
одновременно находится в памяти. Этот
показатель определяет какой набор программ и
данных может быть одновременно размещён в
памяти.
Ёмкость оперативной памяти(ОЗУ) и ёмкость
внешней памяти(ВЗУ) характеризуется отдельно
51.
4. НадёжностьСпособность ЭВМ при определённых условиях
выполнять требуемые функции в течении
заданного периода времени. Высокая надёжность
ЭВМ закладывается в процессе её проектирования
и производства.
52. Надёжность
Основными причинами, определяющимиповышенное внимание к вопросам надёжности встроенных
ВС (которые, как правило, распределённые), являются:
Рост сложности аппаратуры;
Более медленный рост уровня надёжности комплектующих
по сравнению с ростом числа элементов в аппаратуре;
Увеличение важности выполняемых аппаратурой функций
(системы жизненного риска, встроенные бортовые
комплексы);
Усложнение условий эксплуатации ВС.
53.
5. ТочностьЭто возможность различать почти равные
значения. Точность получения результатов
обработки в основном определяется разрядностью
ЭВМ, а также используемыми структурными
единицами представления информации
54.
6. ДостоверностьСвойство информации быть правильно
воспринятой. Достоверность характеризуется
вероятностью получения безошибочных
результатов. Заданный уровень достоверности
обеспечивается аппаратно-программными
средствами контроля самой ЭВМ.
55. 7.Стоимость
Тут всё просто – цена должна соответствоватькачеству. Чем лучше состояние и характеристика ВС,
тем она дороже.
Стоимость – понятие относительное. С ростом
характеристик ВС возрастает и её стоимость, но с
появлением более новых технологий, стоимость
предшествующих снижается.
56. Классификация вычислительных систем по Флинну
Самая ранняя и наиболее известная классификация архитектурвычислительных систем. Предложена в 1966 году М.Флинном.
Классификация базируется на понятии потока, под которым
понимается последовательность элементов, команд или данных,
обрабатываемых процессором. На основе числа потоков команд
и данных Флинн выделяет четыре класса архитектур.
Классы архитектур
SISD Single Instruction Stream – Single Data Stream ОКОД
SIMD Single Instruction Stream – Multiple Data Stream ОКМД
MISD Multiple Instruction Stream – Single Data Stream МКОД
MIMD Multiple Instruction Stream – Multiple Data Stream
МКМД
57. SISD-системы
К этому классу относятся, прежде всего,классические последовательные машины, или иначе,
машины фон-неймановского типа. В таких машинах есть
только один поток команд, все команды обрабатываются
последовательно друг за другом и каждая команда
инициирует одну операцию с одним потоком данных. Для
увеличения скорости работы команд и скорости выполнения
арифметических операций
может применять конвейерная.
58. SIMD-системы
В архитектурах подобного рода сохраняется одинпоток команд, включающий, в отличие от предыдущего
класса, векторные команды. Это позволяет выполнять одну
арифметическую операцию сразу над многими данными –
элементами вектора. Способ выполнения векторных
операций не оговаривается, поэтому обработка элементов
вектора может производиться либо процессорной
матрицей, как в ILLIAC IV, либо с помощью конвейера, как,
например, в машине CRAY-1.
59.
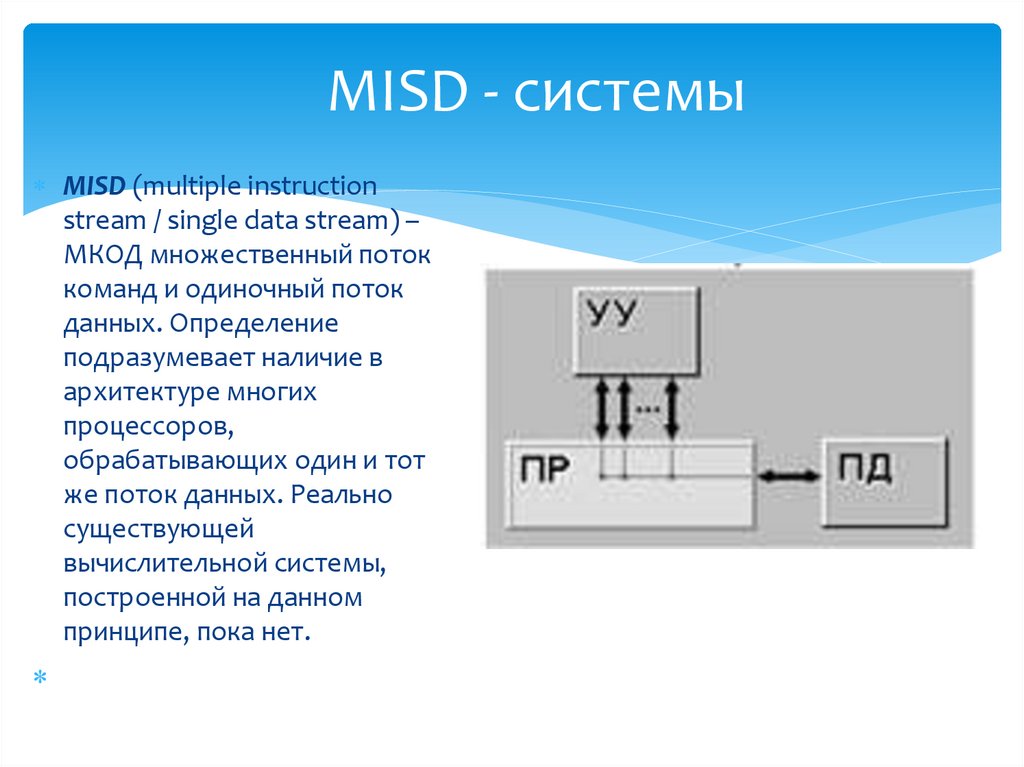
MISD - системыMISD (multiple instruction
stream / single data stream) –
МКОД множественный поток
команд и одиночный поток
данных. Определение
подразумевает наличие в
архитектуре многих
процессоров,
обрабатывающих один и тот
же поток данных. Реально
существующей
вычислительной системы,
построенной на данном
принципе, пока нет.
60. MIMD-системы
Этот класс предполагает, что в вычислительнойсистеме есть несколько устройств обработки команд,
объединенных в единый комплекс и работающих каждое со
своим потоком команд и данных. Данный класс очень велик,
поскольку включает в себя всевозможные
мультипроцессорные и
мультикомпьютерные
системы.
61. Классификация Флинна
• Предложенная классификация ЭВМ до настоящеговремени является самой применяемой при начальной
характеристике того или иного компьютера. Если говорят,
что ЭВМ принадлежит классу SIMD или MIMD, то сразу
становится понятным базовый принцип его работы, и в
некоторых случаях этого бывает достаточно.
• Наличие пустого класса MISD нельзя считать недостатком
классификации; это класс, по мнению специалистов, может
стать чрезвычайно полезным при разработке принципиально
новых концепций теории и практики построения ЭВМ.
• Кроме классификации Флинна, существует более 10 – ти
типов различных классификаций ЭВМ.
Устройство
памяти
Кэш L1
f (Мгц)
f ядра CPU
Кэш L2
½:f CPU
Кэш L3
½ - ¼ f CPU
ОЗУ
f
системной
шины
от 3-15 с
HDD
Объем (Кб, Мб)
8-32Кб
64-512 Кб – домашний
ПК
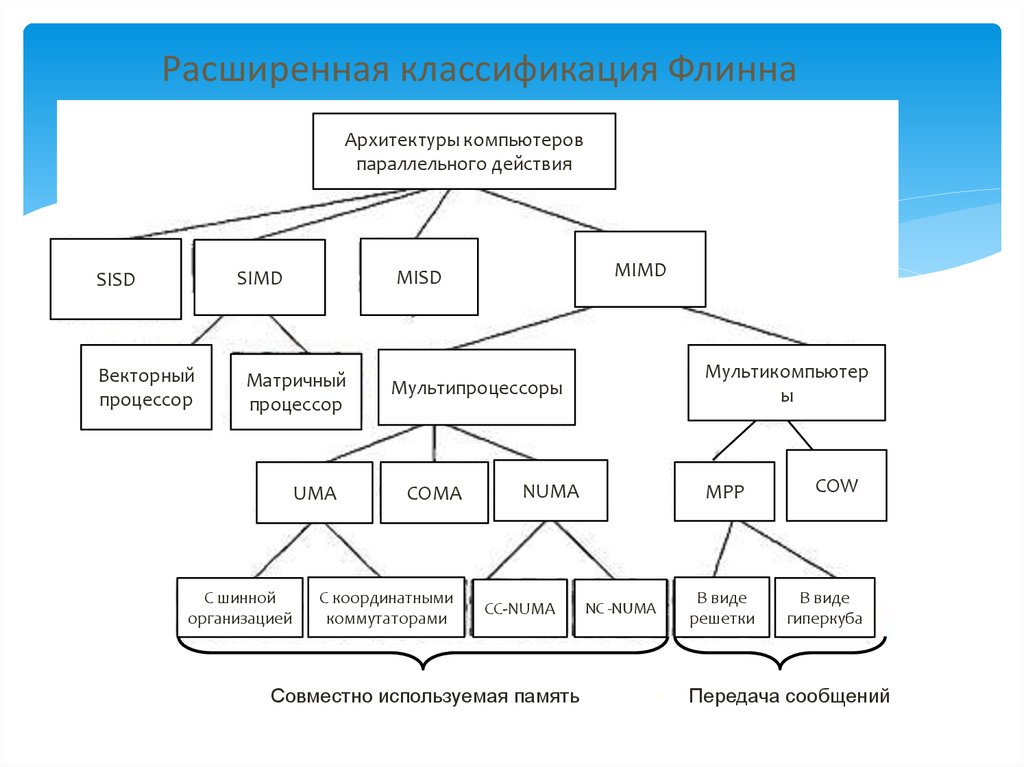
1-4 Мб - сервер
4 - Мб
2 - Мб
62. Расширенная классификация Флинна
Дальнейшее развитие ВС привело к расширениюпервоначальной классификации Флинна и разбиению
основных классов на подгруппы. .
SIMD-машины у нас распались на две подгруппы. В первую
подгруппу попадают многочисленные суперкомпьютеры и
другие машины, которые оперируют векторами, выполняя
одну и ту же операцию над каждым элементом вектора.
Во вторую подгруппу попадают машины типа ILLIAC IV, в
которых главный блок управления посылает команды
нескольким независимым АЛУ.
MIMD машины разделились на мультипроцессоры (С общей
памятью) и мультикомпьютеры (с передачей сообщений).
Мультикопьютеры разделились на MPP (Massively Parallel
Processor — процессор с массовым параллелизмом) и COW
(Cluster Of Workstattions кластеры рабочих станций).
63.
Расширенная классификация ФлиннаАрхитектуры компьютеров
параллельного действия
MIMD
SISD
SIMD
MISD
Векторный
процессор
Матричный
процессор
Мультипроцессоры
UMA
С шинной
организацией
COMA
С координатными
коммутаторами
Мультикомпьютер
ы
NUMA
СС-NUMA
Совместно используемая память
NC -NUMA
MPP
COW
В виде
решетки
В виде
гиперкуба
Передача сообщений
64. Расширенная классификация Флинна
В нашей классификации категория MIMD распалась намультипроцессоры (машины с общей памятью) и
мультикомпьютеры (машины с обменом сообщениями).
Существует три типа мультипроцессоров. Они
отличаются друг от друга механизмом доступа к общей
памяти и называются:
UMA (Uniform Memory Access — однородный доступ
к памяти);
NUMA (NonUniform Memory Access —
неоднородный доступ к памяти) ;
СОМА (Cache Only Memory Access — доступ только к
кэш-памяти).
Такое разбиение на подкатегории имеет смысл,
поскольку в больших мультипроцессорах память обычно
делится на несколько модулей.
65.
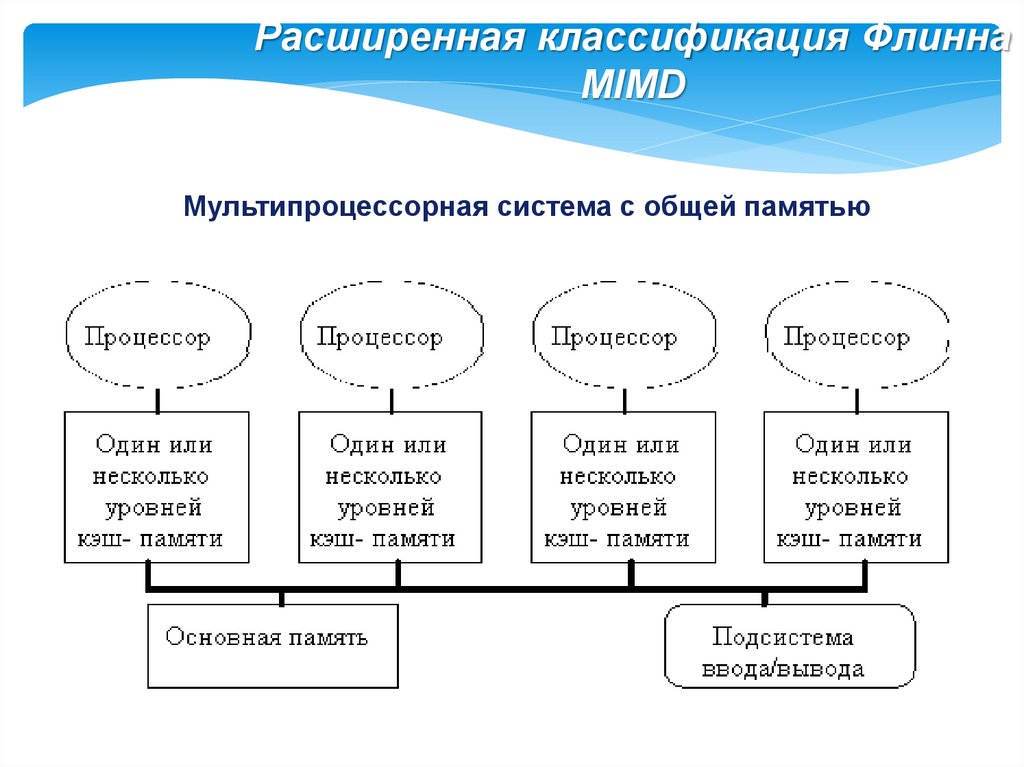
Расширенная классификация ФлиннаMIMD
Мультипроцессорная система с общей памятью
66.
Расширенная классификация ФлиннаВ UMA-машинах каждый процессор имеет одно и
то же время доступа к любому модулю памяти. Иными
словами, каждое слово может быть считано из памяти с
той же скоростью, что и любое другое слово.
Если это технически невозможно, самые
быстрые обращения замедляются, чтобы
соответствовать самым медленным, поэтому
программист не заметит никакой разницы.
Это и значит «однородный» доступ. Такая
однородность делает производительность
предсказуемой, а этот фактор очень важен для
создания эффективных программ.
67.
Расширенная классификация ФлиннаNUMA-машина, напротив, не обладает свойством
однородности. Обычно у каждого процессора есть один из
модулей памяти, который располагается к нему ближе, чем
другие, поэтому доступ к этому модулю памяти происходит
гораздо быстрее, чем к другим.
В этом случае с точки зрения производительности
очень важно, где окажутся программа и данные.
68.
Расширенная классификация ФлиннаВо вторую основную категорию MIMD-машин
попадают мультикомпьютеры, которые в отличие от
мультипроцессоров не имеют общей памяти на
архитектурном уровне.
Другими словами, операционная система процессора,
входящего в состав мультикомпьютера, не сможет получить
доступ к памяти другого процессора, просто выполнив
команду LOAD.
Процессору придется отправить сообщение и ждать
ответа. Именно способность операционной системы считать
слово из удаленного модуля памяти с помощью команды
LOAD отличает мультипроцессоры от мультикомпьютеров.
69. Расширенная классификация Флинна
Так как мультикомпьютеры не имеют непосредственногодоступа к удаленным модулям памяти, их иногда относят к
категории NORMA (NO Remote Memory Access — отсутствие
удаленного доступа к памяти).
Мультикомпьютеры тоже можно разделить на две
дополнительные категории.
К категории МРР (Massively Parallel Processor — процессор с
массовым параллелизмом) относятся дорогостоящие
суперкомпьютеры, которые состоят из
большого количества процессоров, связанных высокоскоростной
внутренней коммуникационной сетью.
В качестве хорошо известного коммерческого примера можно
назвать суперкомпьютеры CRAY T3E США) и МВС 1000 (СССР) .
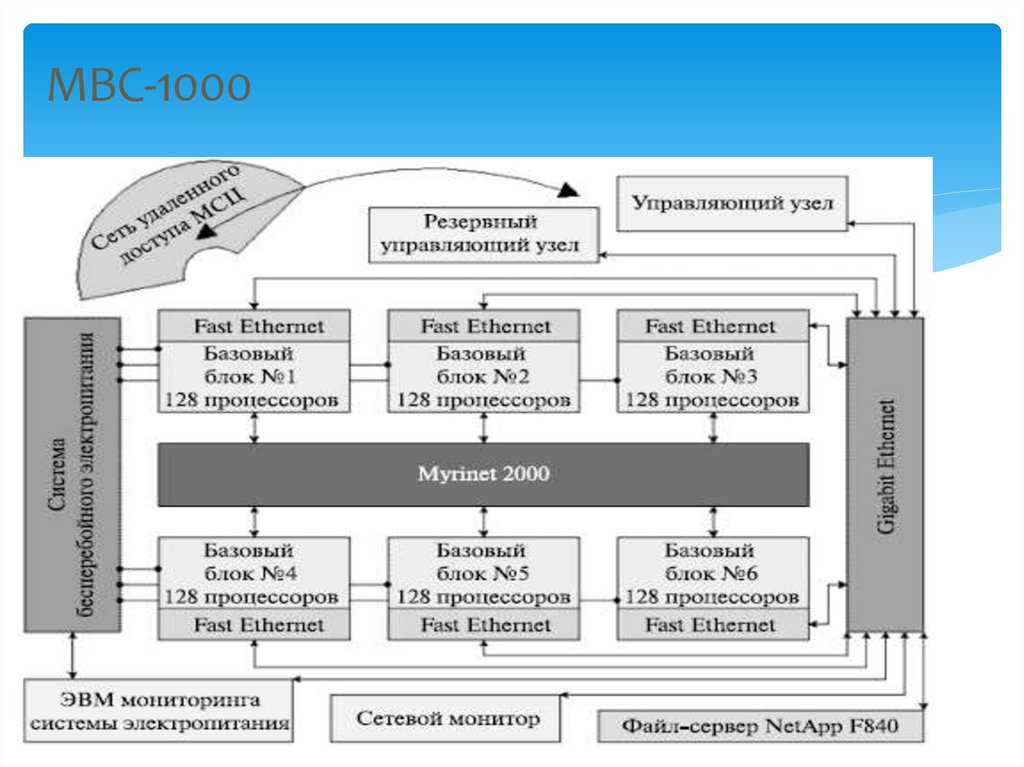
70.
МВС-100071.
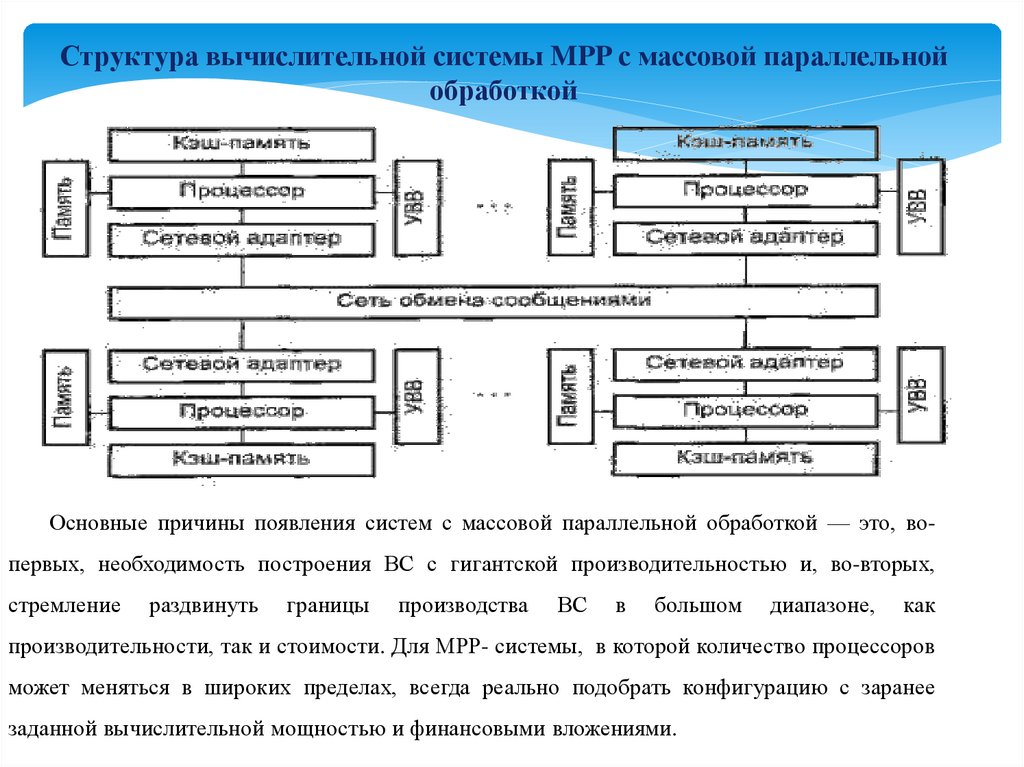
Структура вычислительной системы MPP с массовой параллельнойобработкой
Основные причины появления систем с массовой параллельной обработкой — это, вопервых, необходимость построения ВС с гигантской производительностью и, во-вторых,
стремление
раздвинуть
границы
производства
ВС
в
большом
диапазоне,
как
производительности, так и стоимости. Для МРР- системы, в которой количество процессоров
может меняться в широких пределах, всегда реально подобрать конфигурацию с заранее
заданной вычислительной мощностью и финансовыми вложениями.
72.
Системы с массовой параллельной обработкой (МРР)Основным признаком, по которому вычислительную систему относят к
архитектуре к массовой параллельной обработкой (МРР, Massively Parallel
Processing), служит количество процессоров n. Строгой границы не существует, но
обычно при n>128 считается, что это уже МРР, а при n<32 — еще нет.
Главные особенности, по которым вычислительную систему причисляют к
классу МРР можно сформулировать следующим образом:
стандартные микропроцессоры;
физически распределенная память;
хорошая масштабируемость (до тысяч процессоров);
асинхронная MIMD-система пересылкой сообщений;
программа представляет собой множество процессов, имеющих отдельные
адресные пространства.
73.
Расширенная классификация ФлиннаMIMD
МРР (Massively Parallel Processors)- процессоры с массовым параллелизмом
Система состоит из однородных вычислительных узлов, включающих:
один или несколько центральных процессоров (обычно RISC),
локальную память (прямой доступ к памяти других узлов невозможен),
коммуникационный процессор или сетевой адаптер
иногда - жесткие диски и/или другие устройства В/В
К системе могут быть добавлены специальные узлы ввода-вывода и
управляющие узлы. Узлы связаны через некоторую коммуникационную среду
(высокоскоростная сеть, коммутатор и т.п.)
Используются два варианта работы операционной системы (ОС) на машинах
MPP-архитектуры:
полноценная операционная система (ОС) работает только на управляющей
машине, на каждом отдельном модуле функционирует сильно урезанный
вариант ОС, обеспечивающий работу только расположенной в нем ветви
параллельного приложения.
на каждом модуле работает полноценная UNIX-подобная ОС,
устанавливаемая отдельно.
74.
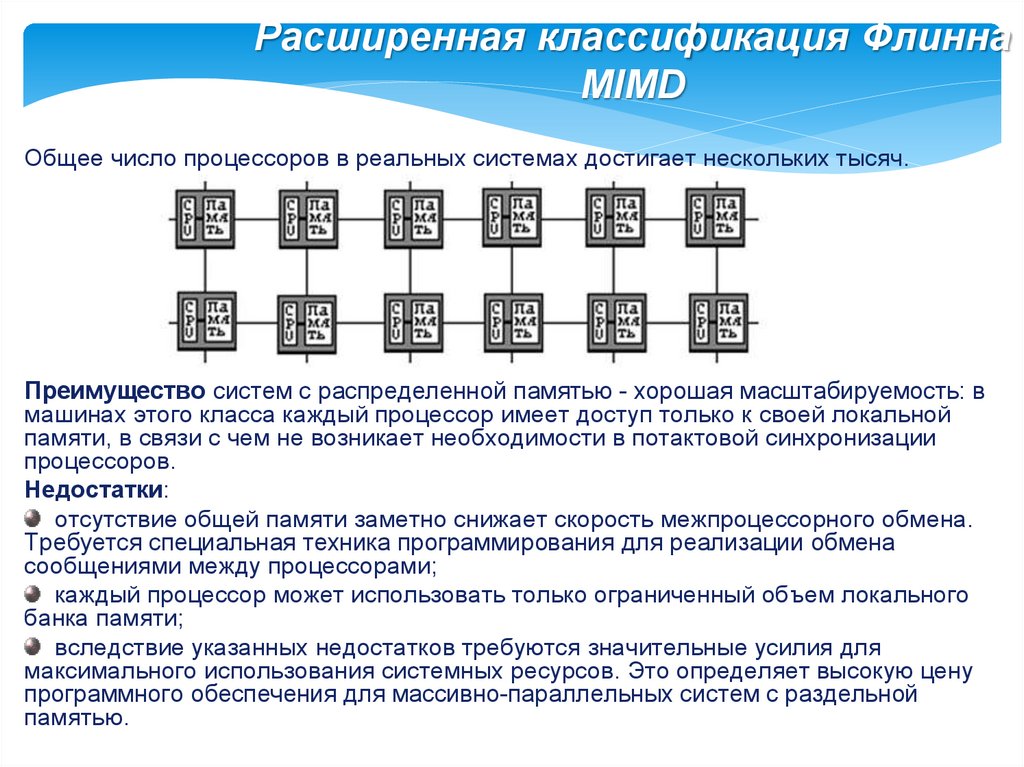
Расширенная классификация ФлиннаMIMD
Общее число процессоров в реальных системах достигает нескольких тысяч.
Преимущество систем с распределенной памятью - хорошая масштабируемость: в
машинах этого класса каждый процессор имеет доступ только к своей локальной
памяти, в связи с чем не возникает необходимости в потактовой синхронизации
процессоров.
Недостатки:
отсутствие общей памяти заметно снижает скорость межпроцессорного обмена.
Требуется специальная техника программирования для реализации обмена
сообщениями между процессорами;
каждый процессор может использовать только ограниченный объем локального
банка памяти;
вследствие указанных недостатков требуются значительные усилия для
максимального использования системных ресурсов. Это определяет высокую цену
программного обеспечения для массивно-параллельных систем с раздельной
памятью.
75.
Расширенная классификация ФлиннаMIMD
Сегодня не так много приложений могут эффективно
выполняться на MPP-компьютере, кроме этого имеется еще
проблема переносимости программ между MPP-системами,
имеющими различную архитектуру. Предпринятая в последние годы
попытка стандартизации моделей обмена сообщениями еще не
снимает всех проблем. Эффективность распараллеливания во
многих случаях сильно зависит от деталей архитектуры MPPсистемы, например топологии соединения процессорных узлов.
Самой эффективной была бы топология, в которой любой узел
мог бы напрямую связаться с любым другим узлом. Однако в MPPсистемах это технически трудно реализуемо. Обычно процессорные
узлы в современных MPP-компьютерах образуют или двумерную
решетку (например, в SNI/Pyramid RM1000) или гиперкуб (как в
суперкомпьютерах nCube ).
76.
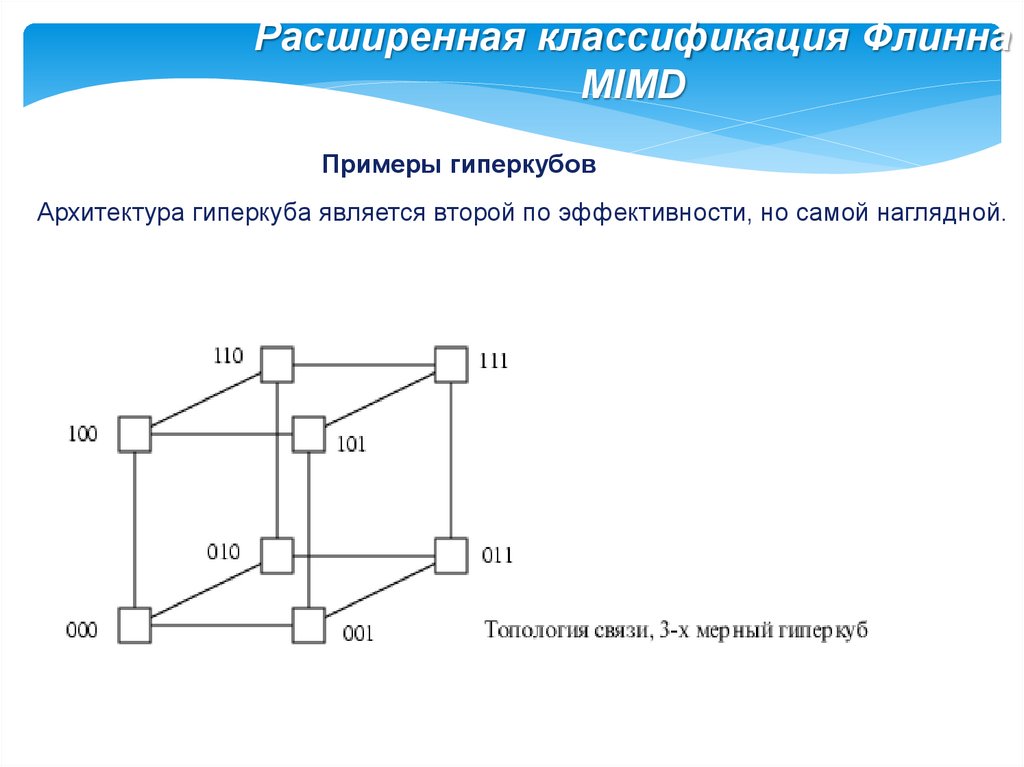
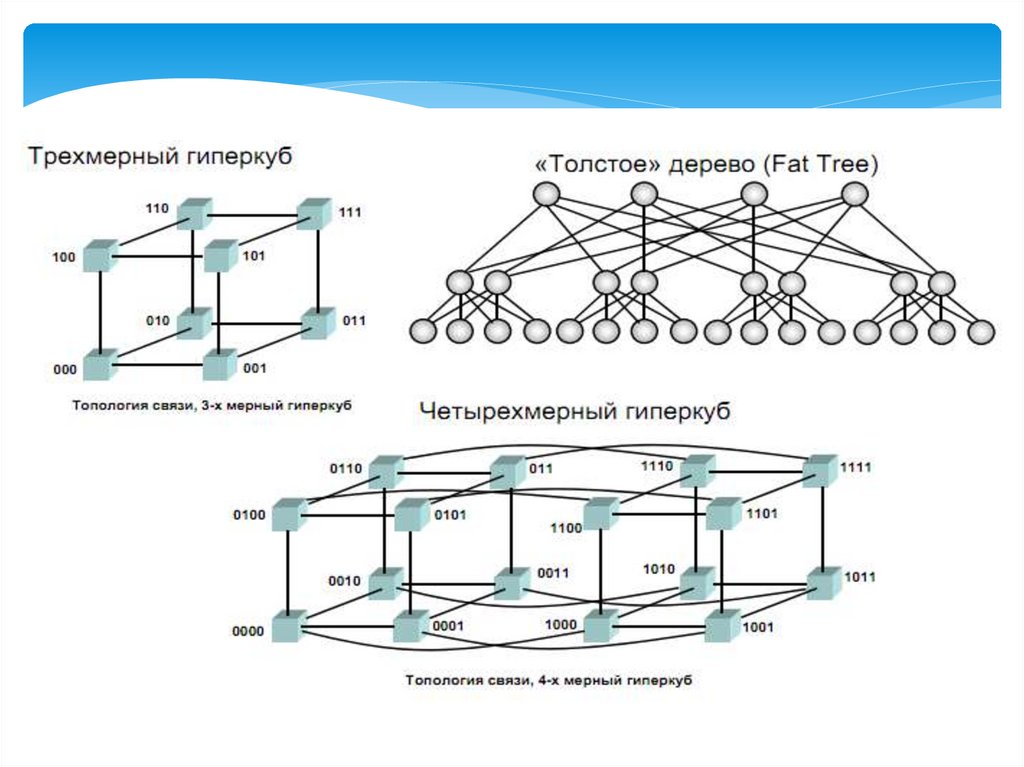
Расширенная классификация ФлиннаMIMD
Примеры гиперкубов
Архитектура гиперкуба является второй по эффективности, но самой наглядной.
77.
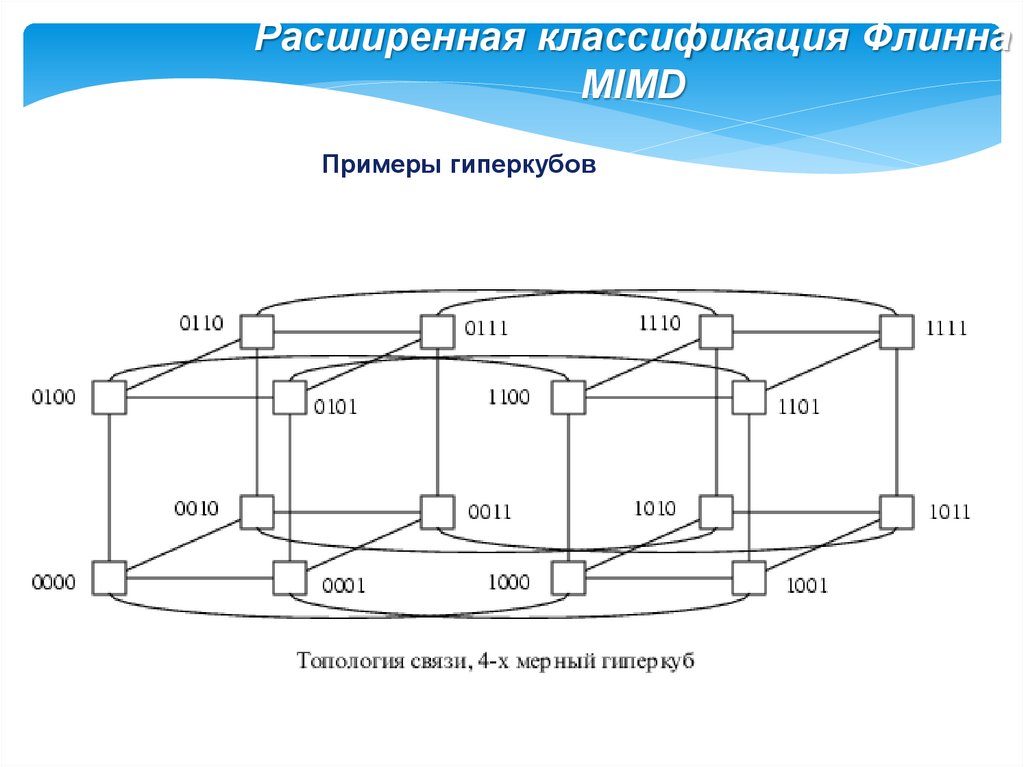
Расширенная классификация ФлиннаMIMD
Примеры гиперкубов
78.
79.
Расширенная классификация ФлиннаMIMD
При таком типе соединения, максимальное расстояние между
процессорами окажется равным 6 (количество связей между процессорами,
отделяющих самый ближний процессор от самого дальнего).
Теория же показывает, что если в системе максимальное расстояние
между процессорами больше 4, то такая система не может работать
эффективно. Поэтому, при соединении 16 процессоров друг с другом
плоская схема является не эффективной. Для получения более компактной
конфигурации необходимо решить задачу о нахождении фигуры, имеющей
максимальный объем при минимальной площади поверхности.
В трехмерном пространстве таким свойством обладает шар. Но,
поскольку, нам необходимо построить узловую систему, то вместо шара
приходится использовать куб (если число процессоров равно 8) или
гиперкуб, если число процессоров больше 8.
Размерность гиперкуба будет определяться в зависимости от числа
процессоров, которые необходимо соединить. Так, для соединения 16
процессоров потребуется 4-х мерный гиперкуб. Для его построения следует
взять обычный 3-х мерный куб, сдвинуть в еще одном направлении и,
соединив вершины, получить гиперкуб размером 4.
80. Расширенная классификация Флинна
Вторая категория мультикомпьютеров включает обычныеперсональные компьютеры или рабочие станции (иногда
смонтированные в стойки), которые связываются в соответствии с
той или иной коммерческой коммуникационной технологией.
С точки зрения логики принципиальной разницы здесь нет,
но мощный суперкомпьютер стоимостью в миллионы долларов
безусловно используется иначе, чем собранная конечными
пользователями компьютерная сеть, которая обходится во много
раз дешевле любой МРР-машины.
Эти «доморощенные» системы иногда называют сетями
рабочих станций (Network Of Work-stations, NOW), кластерами
рабочих станций (Cluster Of Workstattions, COW), или просто
кластерами (cluster).
81.
Расширенная классификация ФлиннаMIMD
COW — Clusters of Workstations
(кластеры рабочих станций)
Второй тип мультикомпьютеров — это системы COW (Cluster of
Workstations — кластер рабочих станций) или NOW (Network of
Workstations — сеть рабочих станций). Обычно он состоит из
нескольких сотен персональных компьютеров или рабочих станций,
соединенных посредством сетевых плат.
Различие между МРР и COW аналогично разнице между
большой вычислительной машиной и персональным компьютером.
У обоих есть процессор, ОЗУ, диски, операционная система
и т. д. Но в большой вычислительной машине все это работает
гораздо быстрее (за исключением, может быть, операционной
системы). Однако они применяютcя и управляются по-разному. Это
же различие справедливо для МРР и COW.
82.
Расширенная классификация ФлиннаMIMD
Преимущество системы COW над МРР в том, что
COW полностью состоит из доступных компонентов,
которые можно купить. Эти части выпускаются большими
партиями. Эти части, кроме того, существуют на рынке с
жесткой конкуренцией, из-за которой производительность
растет, а цены падают.
Вероятно, системы COW постепенно вытеснят МРР,
подобно тому как персональные компьютеры вытеснили
большие
вычислительные
машины,
которые
применяются теперь только в специализированных
областях.
83.
Расширенная классификация ФлиннаMIMD
Существует множество различных видов COW, но доминируют
два из них: централизованные и децентрализованные
Централизованные системы COW представляют собой
кластер рабочих станций или персональных компьютеров,
смонтированных в большой блок в одной комнате. Иногда они
компонуются более компактно, чем обычно, чтобы сократить
физические размеры и длину кабеля. Как правило, эти машины
гомогенны и не имеют никаких периферических устройств, кроме
сетевых карт и, возможно, дисков.
Децентрализованная система COW состоит из рабочих
станций или персональных компьютеров, которые раскиданы по
зданию или по территории учреждения.
Большинство из них простаивают много часов в день, особенно
ночью. Обычно они связаны через локальную сеть. Они гетерогенны
и имеют полный набор периферийных устройств. Самое важное, что
многие компьютеры имеют своих владельцев.
84. Типы кластеров
Условное деление на классы предложено Язеком Радаевским и ДугласомЭдлайном:
Класс I. Класс машин строится целиком из стандартных деталей, которые продают многие
продавцы компьютерных компонент (низкие цены, простое обслуживание, аппаратные
компоненты доступны из различных источников).
Класс II. Система имеет эксклюзивные или не широко распространенные детали. Этим
можно достичь очень хорошей производительности, но при более высокой стоимости.
Как уже указывалось выше, кластеры могут существовать в различных конфигурациях.
Наиболее употребляемыми типами кластеров являются:
отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой
доступности)
кластеры с балансировкой нагрузки (Load balancing clusters)
вычислительные кластеры (Computing clusters)
grid-системы
Отметим, что границы между этими типами кластеров до некоторой степени размыты, и
часто существующий кластер может иметь такие свойства или функции, которые выходят
за рамки перечисленных типов. Более того, при конфигурировании большого кластера,
используемого как система общего назначения, приходится выделять блоки,
выполняющие все перечисленные функции.
85. История развития кластерной архитектуры
1983 – DEC анонсировала концепцию кластернойсистемы, определив ее как «группу
объединенных между собой вычислительных
машин, представляющих собой единый узел
обработки информации».
86. История развития кластерной архитектуры
1994 – NASA (Goddard Space Flight Center) началасьработа над кластером Beowulf, для проекта Earth
and Space Sciences.
Был собран 16-процессорный кластер на
процессорах Intel 486DX4/100 МГц. На каждом
узле было установлено по 16 Мбайт оперативной
памяти и по 3 сетевых Ethernet-адаптера. Для
работы в такой конфигурации были разработаны
специальные драйверы, распределяющие трафик
между доступными сетевыми картами.
87. История развития кластерной архитектуры
1998 – суперкомпьютер Avalon (Лос-Аламосская национальнаялаборатория, астрофизик Майкл Уоррен). Linux-кластер на базе
процессоров Alpha 21164A с тактовой частотой 533 МГц.
Изначально Avalon состоял из 68 процессоров, затем
расширен до 140.
В каждом узле установлено по 256 Мбайт оперативной
памяти, жесткий диск на 3 Гбайт и сетевой адаптер Fast
Ethernet. Общая стоимость проекта составила 313 тыс.
долл., а показанная им производительность на тесте
LINPACK – 47,7 GFLOPS, позволила ему занять 114 место в
12-й редакции списка Top500 рядом с 152-процессорной
системой IBM RS/6000 SP.
88. Кластеры высокой доступности
Вычислительные кластерыСпециально выделяют высокопроизводительные
кластеры (HPC Cluster — High-performance computing
cluster).
Используются в вычислительных целях, в частности в
научных исследованиях. Для вычислительных
кластеров существенными показателями являются
высокая производительность процессора в
операциях над числами с плавающей точкой и
низкая латентность объединяющей сети, и менее
существенными — скорость операций ввода-вывода.
89. Кластеры распределения нагрузки
Вычислительные кластерыВычислительные кластеры позволяют уменьшить время
расчетов, по сравнению с одиночным компьютером,
разбивая задание на параллельно выполняющиеся ветки,
которые обмениваются данными по связывающей сети. Одна
из типичных конфигураций — набор компьютеров,
собранных из общедоступных компонентов, с установленной
на них операционной системой Linux, и связанных сетью
Ethernet, Myrinet, InfiniBand или другими относительно
недорогими сетями. Такую систему принято называть
кластером Beowulf.
90. Вычислительные кластеры
Схема Beowulf кластераГруппа идентичных РС (Client node) под управлением ОС Lunix (Server
node), объединенных в небольшую TCP/IP LAN
91. Вычислительные кластеры
Системы распределенныхвычислений (grid - системы)
Специальный агент, расположенный на компьютере
пользователя, определяет факт простоя этого
компьютера, соединяется с управляющим узлом
мета-компьютера и получает от него очередную
порцию работы (область в пространстве перебора).
По окончании счета по данной порции
вычислительный узел передает обратно отчет о
фактически проделанном переборе или сигнал о
достижении цели поиска.
92. Схема Beowulf кластера
Системы распределенных вычислений(grid - системы)
Технология GRID подразумевает слаженное
взаимодействие множества ресурсов, гетерогенных
по своей природе и расположенных в
многочисленных, возможно, географически
удаленных административных доменах.
93. Системы распределенных вычислений (grid)
Пример Grid - системы94. Системы распределенных вычислений (grid - системы)
GRID – предпосылки возникновенияНеобходимость в концентрации огромного
количества данных, хранящихся в разных
организациях
Необходимость выполнения очень большого
количества вычислений в рамках решения одной
задачи.
Необходимость в совместном использовании
больших массивов данных территориально
разрозненной рабочей группой
95. Системы распределенных вычислений (grid - системы)
Грид - системаДобровольные гриды
Научные гриды
гриды на основе
использования
добровольно
предоставляемого
свободного ресурса
персональных
компьютеров
хорошо
распараллеливаемые
приложения
программируются
специальным образом
(например, с
использованием Globus
Toolkit)
Гриды на основе выделения
вычислительных ресурсов
по требованию
обычные коммерческие
приложения работают на
виртуальном компьютере,
который, в свою очередь,
состоит из нескольких
физических компьютеров,
объединённых с помощью
грид-технологий
96. Пример Grid - системы
Идея грид-компьютинга возникла вместе сраспространением персональных
компьютеров, развитием интернета и
технологий пакетной передачи данных на
основе оптического волокна
(SONET, SDH и ATM), а также
технологий локальных сетей (Gigabit
Ethernet). Полоса пропускания
коммуникационных средств стала
достаточной, чтобы при необходимости
привлечь ресурсы другого компьютера.
Грид с точки зрения сетевой
Учитывая, что множество подключенных к организации представляет собой
глобальной сети компьютеров большую согласованную, открытую и
часть рабочего времени простаивает и
стандартизованную среду, которая
располагает ресурсами, большими, чем обеспечивает гибкое, безопасное,
необходимо для решения их
скоординированное
повседневных задач, возникает
разделение вычислительных ресурсов и
возможность применить их
ресурсов хранения[1] информации,
неиспользуемые ресурсы в другом месте которые являются частью этой среды, в
рамках одной виртуальной организации
97. GRID – предпосылки возникновения
Грид-cистема ЦЕРНа, предназначенная дляобработки данных, получаемых с Большого
адронного коллайдера, имеет иерархическую
структуру. Самая верхняя точка иерархии,
нулевой уровень — CERN (получение
информации с детекторов, сбор «сырых»
научных данных, которые будут храниться до
конца работы эксперимента).
Первый уровень, Tier1 — хранение
второй копии этих данных в других
Tier2 — следующие в иерархии,
уголках мира (11 центров:
в Италии, Франции, Великобритании, С многочисленные центры второго уровня.
Наличие крупных ресурсов для
ША, наТайване, а один центр первого
хранения данных не обязательно;
уровня — CMS Tier1 — в ЦЕРНе).
обладают хорошими вычислительными
Центры обладают значительными
ресурсами.
ресурсами для хранения данных.
Российские центры: в Дубне (ОИЯИ), три центра в Москве (НИИЯФ МГУ, ФИАН, ИТЭФ),
Троицке (ИЯИ), Протвино (ИФВЭ), Санкт-Петербурге (СПбГУ)[5] и Гатчине (ПИЯФ).
Кроме того, в единую сеть с этими центрами связаны и центры других стран-участниц
ОИЯИ — в Харькове, Минске, Ереване, Софии, Баку и Тбилиси.
98.
Grid-система – группа слабосвязанных компьютеров,объединенных с помощью локальной вычислительной
сети и способных выполнять вычисления одной задачи,
передавая результаты центральному (командному) узлу.
Отличительные признаки Grid-системы:
1. Клиент-серверная технология взаимодействия между
вычислительным и командным узлом.
2. Различность вычислительных узлов.
3. Стандартное системное программное обеспечение.
4. Наличие клиентской программы на вычислительном
узле.
99.
Grid-системыДостоинства:
1. Широкая масштабируемость.
2. Работоспособность клиентской части на различном оборудовании и под
управлением различных операционных систем.
3. Географическая удалённость узлов сети.
Недостатки:
1. Сложность обновления клиентской части программного обеспечения.
2. Непредсказуемость окончания расчетов.
100.
Области применения GRIDмассовая обработка потоков данных большого
объема;
многопараметрический анализ данных;
моделирование на удаленных суперкомпьютерах;
реалистичная визуализация больших наборов
данных;
сложные бизнес-приложения с большими объемами
вычислений.
101.
Проекты (grid - системы)Существующие географически-разделенные гридсистемы представлены рядом интереснейших проектов,
в которых участвуют добровольцы со всего мира. Одной
из платформ для таких проектов является BOINC (англ.
Berkeley Open Infrastructure for Network Computing –
открытая программная платформа (университета) Беркли
для GRID вычислений). BOINC – это некоммерческий
программный комплекс для организации распределенных
вычислений, первоначально разработанный для проекта
SETI@home (от англ. Search for Extra-Terrestrial
Intelligence at Home – поиск внеземного разума на дому).
Впоследствии платформа стала доступной для
сторонних проектов.
102.
Проекты (grid - системы)Для создания грид-систем используется специализированный
программный инструментарий. Из всех средств развертывания гридсетей стандартом считается Globus Toolkit. Globus Toolkit
представляет собой набор инструментов и стандартов, главным из
которых является стандарт OGSA (Open Grid Services Architecture).
OGSA определяет единообразную семантику представления служб,
стандартные механизмы для создания, именования обнаружения
экземпляров Grid-служб, обеспечивает прозрачность
местонахождения и связывания различных протоколов и
поддерживает интеграцию с базовыми механизмами нижележащих
платформ. Разработка технической спецификации OGSA ведется в
рамках форума Grid Global Forum, разрабатывающего стандарты
для Grid-сообщества.
103. Области применения GRID
Проекты (grid - системы)Периодически составляется топ популярнейших проектов BOINC. Ниже
представлены топ-10 проектов BOINC на данный момент [:
SETI@Home – анализ сигналов с радиотелескопа Аресибо, а также ряда
других радиотелескопов, с целью поиска внеземного разума.
Einstein@Home – проверка гипотезы Эйнштейна о гравитационных
волнах, а также поиск радио- и гамма-пульсаров.
World Community Grid – поддерживает большое количество других
проектов, созданных для исследований в области поиска лекарств от
рака, СПИД, малярии, для разработки экологически чистых источников
энергии.
Rosetta@Home – помощь в исследованиях и разработках лекарств.
MilkyWay@Home – создание высокоточной трёхмерной модели
звёздных потоков нашей галактики.
104. Проекты (grid - системы)
PrimeGrid – поиск больших простых чисел. Climate Prediction – изучениеизменений климата. SIMAP – создание базы данных белков.
Cosmology@Home – поиск модели, которая наилучшим образом
описывала бы нашу вселенную в рамках доступных астрономических и
физических данных.
POEM@Home – изучение белковых структур.
В проектах BOINC участвуют команды волонтёров со всего света, в том
числе и из России, однако в Казахстане и России развитие собственных
грид-систем находится на невысоком уровне.
Россия активно использует суперкомпьютеры, Казахстан начинает их
использование (Казахский национальный технический университет и
Казахстанско-Британский технический университет пользуются
суперкомпьютерами невысокой производительности ), однако гридсистемы пока не получили большого распространения в Казахстане.
105. Проекты (grid - системы)
Data-центры,их структура и особенности
106. Проекты (grid - системы)
Центр обработки данных (ЦОД) или датацентр (data center) – это специализированноездание для размещения серверного и сетевого
оборудования и подключения абонентов к сети
интернет.
107. Проекты (grid - системы)
Центры обработки данных необходимы дляэффективной автоматизации бизнес — и
производственных процессов. Они
централизованы, охватывают всю структуру,
повышают надежность и эффективность
работы. Современные компании, которые
идут в ногу с постоянно меняющимися
потребностями рынка и остаются
высококонкурентоспособными, понимают,
что эти центры должны быть
профессионально организованными и
скоростными. Ведь зачастую от
своевременности принятия управленческих
решений зависит успех бизнеса в целом.
При динамичном развитии предприятия
постоянно растет объем обрабатываемой
информации, количество сотрудников, а,
значит, и число рабочих мест. И управлять
всеми процессами гораздо удобнее,
эффективнее и быстрее при наличии
единого центра.
108. Data-центры, их структура и особенности
109. Центр обработки данных (ЦОД) или дата-центр (data center) – это специализированное здание для размещения серверного и сетевого
Структура ЦОДВ основе ЦОД лежат:
Информационная инфраструктура,
включающая в себя серверное
оборудования и обеспечивающая
основные функции ЦОД –
обработку и хранение
информации;
Телекоммуникационная
инфраструктура, обеспечивающая
взаимосвязь элементов ЦОД, а
также передачу данных между
ЦОД и пользователями;
Инженерная инфраструктура,
обеспечивающая нормальное
функционирование основных
систем ЦОД.
110. Центры обработки данных необходимы для эффективной автоматизации бизнес — и производственных процессов. Они централизованы,
Инженерная инфраструктура включает в себя: кондиционирование дляподдержания температуры и уровня влажности; бесперебойное
электроснабжение для автономной работы ЦОД; охранно-пожарную
сигнализацию и систему газового пожаротушения; системы удаленного IP
контроля, управления питанием и контроля доступа.
Есть два основных документа, которые чаще всего упоминаются при
обсуждении стандартов центров обработки данных: это стандарт TIA 942
и классификация по уровням от Uptime Institute:
TIA 942 – стандарт разработанный ассоциацией телекоммуникационной
промышленности США, и в первую очередь касается вопросов
организации структурированных кабельных систем в ЦОД, и в меньшей
степени вопросов отказоустойчивости и других инженерных подсистем.
Носит рекомендательный характер
Uptime Institute – документ, а не стандарт, разработанный специально для
нормирования отказоустойчивости ЦОД. К примеру,
телекоммуникационная инфраструктура практически не рассматривается.
Носит обязательный характер. ЦОД получает сертификат, в котором
указано его соответствие уровню надёжности.
111.
Классификация ЦОД (Data Center)По размеру:
Крупные ЦОД. Имеют своё здание,
специально сконструированное для
обеспечения наилучших условий
размещения. Обычно имеют свои
каналы связи, к которым подключаются
серверы.
Средние ЦОД. Обычно арендуют
площадку определённого размера и
каналы связи.
Малые ЦОД. Размещаются в
малоприспособленных помещениях,
предоставляется самый минимум услуг.
Контейнерные ЦОД. Стойки с
оборудования размещаются в
стандартных ISO контейнерах размером
20 и 40 футов.
112. Структура ЦОД
По надёжности:Tier 1 – без резервирования.
Доступность 99.671%
Tier 2 – резервирование критических
узлов. Доступность 99.741%
Tier 3 – резервирование критических
узлов, источников электроэнергии и
трасс охлаждения. Есть возможность
вывода любого узла из эксплуатации
для обслуживания с сохранением
полной функциональности объекта в
целом. Доступность 99.982%
Tier 4 – самый отказоустойчивый
уровень, инженерные системы
двукратно зарезервированы. Имеется
возможность проведения любых работ
без остановки работы объекта.
113. Инженерная инфраструктура включает в себя: кондиционирование для поддержания температуры и уровня влажности; бесперебойное
Облачные центры обработки данныхБлагодаря активному развитию облачных
технологий и виртуализации, в России уже
появились провайдеры, предоставляющие
услугу «Облачный ЦОД», которая
позволяет полностью перевести ITинфраструктуру на аутсорсинг, сохранив
при этом высокий уровень
масштабируемости и надёжности. Стоит
такая услуга недёшево, но, при
взвешенном подходе, даёт возможность
более рационально использовать ресурсы
компании.
При выборе облачного ЦОД, как услуги,
можно отказаться от капитальных затрат
связанных с проектированием физического
ЦОД. Расходы провайдера будут заложены
в тариф на услугу, но в случае выбора
облака затраты будут не одномоментными,
а растянутся на несколько лет.
114. Классификация ЦОД (Data Center)
Облачный ЦОД позволяет:самостоятельно создавать виртуальные машины требуемой
конфигурации;
управлять конфигурацией сети, объединять виртуальные
машины в требуемые сетевые топологии с помощью
виртуальных коммутаторов и маршрутизаторов;
удалять виртуальные машины, включать и выключать их,
устанавливать практические любые операционные системы и
приложения;
менять конфигурацию уже существующих виртуальных машин
за несколько минут, причем часть операций для некоторых
операционных систем производится даже без остановки или
перезагрузки;
делать резервные копии и сохранять состояния работающих
машин в несколько кликов мыши.
115. По надёжности: Tier 1 – без резервирования. Доступность 99.671% Tier 2 – резервирование критических узлов. Доступность 99.741%
Управлять Облачным ЦОД намного проще и удобнее, чем обычным.Управление осуществляется при помощи web-портала а также с помощью
программного интерфейса (API).
Кроме управления ресурсами, портал также позволяет управлять
пользователями, назначая им полномочия по созданию, использованию,
управлению определенными виртуальными машинами в вашем Облачном
дата-центре. Облачный ЦОД может быть связан корпоративной
инфраструктурой, в т. ч. интегрирован с корпоративным Active Directory,
что еще более упростит управление им.
Использование виртуализации систем хранения данных позволяет
объединять большое количество физических систем хранения данных в
единый логический пул.
Другими словами, все доступные в дата-центре СХД (система хранения
данных) можно объединить в единое целое, видимое снаружи, например,
как 800 ТБ дисковой емкости. В этом случае фрагменты диска одного
виртуального сервера запросто смогут находиться на разных СХД
провайдера.
116. Облачные центры обработки данных
Таким образом, облачный ЦОД хорошоподойдёт для больших компаний, доход
которых напрямую не связан с разработкой
собственного программного обеспечения.
Также использование этого решения
позволяет существенно уменьшить
капитальные затраты, минимизировать
риски, связанные со стоимостью ITинфраструктуры и её обслуживания.
Ещё один бонус – это оперативная помощь
сотрудников провайдера при миграции в
облако, а также поддержка “гибридного
режима работы”. В этом режиме появляется
возможность работать одновременно с
облаком и физическое IT-инфраструктурой,
объединив их в одну сеть.
117. Облачный ЦОД позволяет: самостоятельно создавать виртуальные машины требуемой конфигурации; управлять конфигурацией сети,
Расширенная классификация ФлиннаSIMD
118. Управлять Облачным ЦОД намного проще и удобнее, чем обычным. Управление осуществляется при помощи web-портала а также с помощью
Лекция №Поколения ЭВМ
119. Таким образом, облачный ЦОД хорошо подойдёт для больших компаний, доход которых напрямую не связан с разработкой собственного
История развития ВТ.Докомпьютерная эпоха
Абаком называется дощечка,
покрытая слоем песка; острой
палочкой проводились линии или
клались какие-либо предметы (5-6
век н.э.) calculi или abakuli.
Прародитель канцелярских счёт.
1623 – машина Шиккарда –
востоковед и математик, описал
устройство «часов для счета» –
счетная машина с устройством
установки чисел и валиками
(сложение и вычитание)
1642 – «Паскалина» – арифмометр
Паскаля. Первая в мире
механическая счетная машина.
(сложение и вычитание)
Паскалина
Машина Шиккарда
120.
История развития ВТ.Докомпьютерная эпоха
Англичанин Роберт Бисакар, а
также в 1657 году независимо от
него, С. Патридж разработали
прямоугольную логарифмическую
линейку.
1672 – арифмометр Лейбница –
счетная машина для 12-ти
разрядных десятичных чисел (+,-,
*,/)
1820 – механический калькулятор
Томас (Чарльз Ксавьер Томас)
1890 – появление полезных функций
– запоминание промежуточных
результатов с использованием их в
последующих операциях, печать
результатов.
Логарифмическая линейка
Арифмометр Лейбница
Механический калькулятор Томас
121. Лекция №
Жаккардов ткацкий станокВ 1801 – 08 гг.
французский
изобретатель
Жозефом Мари
Жаккар создал
машину для
выработки
крупноузорчатых
тканей. Для
нанесения рисунка,
в ней применялись
специальные карты
с отверстиями
перфокарты.
122. История развития ВТ. Докомпьютерная эпоха
Арифмометр Однера (1874 –начало, а в 1890 – массовый
выпуск) – зубчатые колеса.
1836-1848 – аналитическая
машина Беббиджа. Первый
механический прототип ЭВМ.
Ввод и управление с помощью
перфокарт.
Особенности:
-Автоматическое выполнение
операций (АЛУ);
-Для хранения данных
использовалось память (ОЗУ);
-Построена в 1960 по чертежам
Беббиджа.
Арифмометр Однера
Аналитическая машина Беббиджа
123. История развития ВТ. Докомпьютерная эпоха
1836-1848 –аналитическая
машина
Бэббиджа
12 лет Чарльз Бэббидж разрабатывал механический
прототип первых ЭВМ. Его вычислительная машина
должна была выполнять вычисления по программе,
задаваемой
с
помощью
перфокарт.
Результаты
вычислений планировалось выдавать на печать или на
перфокарты. К сожалению, технологии того времени не
позволили Бэббиджу полностью воплотить идею
создания аналитической машины.
124.
Особенности машиныАвтоматическое выполнение
операций (АЛУ)
Для хранения данных
используется память
(ОЗУ)
Построена в 1960-х годах по
чертежам Ч. Бэббиджа.
125. История развития ВТ. Докомпьютерная эпоха
Язык программирования АДА1815-1852 Ада Лавлейс – первая женщина
программист.
Убедила Беббиджа использовать
двоичную систему счисления, разработала
основные принципы для создания языков
программирования.
Современный язык программирования –
АДА назван в её честь.
Была самой образованной женщиной того
времени. Не каждый мужчина мог
выдержать с ней логический спор более 15
минут. Дочь исвестного английского поэта
Байрона.
Ада Лавлейс
126. 1836-1848 – аналитическая машина Бэббиджа
Табулятор Холлерита 1887 гУстройство для обработки
данных, нанесенных на
перфокарты. Табуляторами
обрабатывались данные
национальных переписей
населения в США (1890г.) и
России (1897 г.). Один из
прародителей IBM –
американец Г. Холлерит
создал табулятор, опираясь
на идеи Жаккарда.
127.
128. Язык программирования АДА
129.
Они были аналоговыми и работали на основе новойтехники начала века - электромеханических реле.
Эти машины проводили непрерывные измерения
каких-либо величин, например, напряжения
электрического тока, и с помощью определенных
математических формул выдавали результат обычно
в виде разных графиков и диаграмм.
130.
Позже появились цифровые ЭВМ. Сейчас почтивсе компьютеры в мире являются цифровыми.
Принцип их действия основан на счете чисел и
использует для счета только два состояния
электрического тока: включено и выключено,
которые соответствуют цифрам 0 и 1, с которыми
и работает непосредственно “мозг” компьютера.
«Аналоговые» часы
«Цифровые» часы
131.
Начало XX века1939 – Энигма – шифровальная
машина (Германия)
Немецкий ученый Конрад Цузе
(1910-1995) создал первый
программируемый цифровой
компьютер Z3, работающий на
основе электрических реле,
выполняющий 3-4 операции
сложения в секунду
1943 – Колосс:
Спроектирована членом
Британского королевского
общества профессором
Максом Ньюманом (1897-1985).
Использовалась для
расшифровки кодов «Энигмы»
Энигма
Колосс
132.
Первое поколение ЭВМ1945-1954
Деление по поколениям ЭВМ основано на использование
элементной базы.
Особенности:
Применение электронно-вакуумных ламп;
Использование систем памяти на ртутных линиях задержки,
машинных барабанах, электронно-лучевых трубках;
Для ввода/вывода данных использовались перфоленты,
перфокарты, машинные ленты и печатающие устройства;
Была реализована концепция хранимой программы.
Быстродействие:
10-20 тыс. операций в секунду.
ПО:
Машинные языки.
133.
Первое поколение ЭВМ1942 – Джон Моукли и Джон
Эккерт в США разработали ENIAC
– электронный числовой
интегратор и калькулятор.
1943 – М.Ньюман и Т.Ф.Флауэрс
(Лондон) построена машина
Колосс.
1944 – Mark I – Говард Айкен (1900
– 1973) первый автоматический
компьютер в США
Длина 1м, вес 5 тонн;
Сложение – 3 сек, деление – 12 сек.
ENIAC
MARK I
134. Начало XX века
Первое поколение ЭВМMark II – первая многозадачная
машина
В 1946 году Джон фон Нейман
предложил ряд новых идей
организации ЭВМ (идею хранимой
программы и т.д.)
БЭСМ
В 1948в СССР Сергей
Александрович Лебедев (18901974) и Б.И.Рамеев - первый проект
отечественной цифровой ЭВМ.
МЭСМ – малая электронная
счетная машина (1951г Киев).
БЭСМ – быстродействующая
электронная счетная машина
(1952г Москва)
МЭСМ
135. Первое поколение ЭВМ 1945-1954
Первое поколение ЭВМВ 1951 году была закончена работа по созданию UNIVAC.
Грейс Хоппер создала первую транслирующую программу, которую
она назвала компилятором.
Джей Форрестер запатентовал память на магнитных сердечниках,
впервые она была применена на машине Вихрь I.
В СССР 1952-1953 гг. А.А.Ляпунов разработал операционный метод
программирования, а в 1953-1954
Л.В. Канторович – концепцию крупноблочного программирования.
Морис Уилисс представил доклад «Наилучший метод конструирования
автоматической машины», который стал работой по основам
микропрограммирования.
В 1951 году:
Выпущена первая серийная отечественная ВМ «Стрела».
В США был разработан первый компьютер на транзисторах.
Появился первый накопитель на магнитных лентах.
136. Первое поколение ЭВМ
Второе поколение1955 - 1964
Особенности:
Замена электронных ламп на транзисторы;
Компьютеры стали более надежными;
Потребление энергии уменьшилось;
С появлением памяти на магнитных сердечниках цикл ее работы
уменьшился до десятков микросекунд;
Главный принцип структуры – централизация;
Появилось устройство памяти на магнитных дисках.
Быстродействие: 100-500 тысяч операций в секунду.
ПО: Алгоритмические языки, диспетчерские языки, пакетный режим.
137. Первое поколение ЭВМ
Второе поколение ЭВМ«Традис» первый транзисторный компьютер.
1956 впервые появилась память на дисках
диаметром 61 мм.
1957 Джек Килби из Texas Instruments и Роберт
Нойс независимо друг от друга изобретают
интегральную схему.
Дж. Маккартни и К. Стрейчи предложили
концепцию разделения времени работы
компьютера.
1959 выпущена отечественная ВМ «Сетунь»,
работающая в троичной системе.
1964 IBM объявила о создании моделей
семейства IBM system360, ставшую первыми
компьютерами третьего поколения
138. Первое поколение ЭВМ
Третье поколение ЭВМ1965 - 1974
Особенности:
Компьютеры проектировались на основе интегральных схем малой
степени интеграции (МИС – 10- транзисторов на кристалле) и средней
степени интеграции ( СИС – 10-100 транзисторов на кристалле);
Появилась идея проектирования семейства компьютеров с одной и
той же архитектурой, в основу которой было положено ПО;
В конце шестидесятых годов прошлого века появился
миникомпьютер;
В 1971 появился первый микропроцессор.
Быстродействие: 1 миллион операций в секунду.
ПО: ОС ( управление памятью, устройствами ввода-вывода и другими
ресурсами) , режим разделения времени.
139. Второе поколение 1955 - 1964
Третье поколение ЭВМ1968г. в США фирма «Барроуз» выпустила быстродействующую ЭВМ на
БИСах (больших интегральный схемах – до 1000 транзисторов на
кристалл).
1967г. Под руководством Лебедева и Мельникова создана
быстродействующая ВМ БЭСМ – 6.
1969г. Фирма IBM начала продавать ПО отдельно от железа.
1971г. Intel создала первый микропроцессор Intel 4004 ( Эдвард Кофф).
1971г. Syntronics первый матричный принтер, карманный калькулятор
Pocketronic
1972г. С. Крей организовал фирму, которая за 4 года выпустила самый
мощный в мире компьютер CRAY – 1.
140. Второе поколение ЭВМ
Третье поколение ЭВМ1973г. Фирмой IBM была впервые разработана память на жестких
дисках типа «Винчестер».
1974г. Э. Робертс построил первый персональный компьютер Altair
8800, на базе чипа Intel-8080;
Первая разработка LISP компьютера в MIT, в системе команд которого
реализованы операции работы со списками и основные функции языка
LISP .
Altair 8800
141. Третье поколение ЭВМ 1965 - 1974
Четвертое поколение ЭВМ(1975 - …)
Особенности:
Использование при создании компьютеров больших интегральных
схем (БИС – 1000-10000 транзисторов на кристалле) и сверхбольших
интегральных схем (СБИС – 10,000-1,000,000 транзисторов на
кристалле)
Фирма Amdahl Corp. в 1975 выпустила 6 компьютеров AMDAHL 470 V/6,
в которых были применены БИС в качестве элементов базы.
Стали использоваться быстродействующие системы памяти в
интегральных схемах – МОП ЗУПВ емкостью в несколько мегабайт.
В середине 70-х появились первые персональные компьютеры
Быстродействие: десятки и сотни млн. операций в секунду.
ПО: базы и банки данных.
142. Третье поколение ЭВМ
Четвертое поколение ЭВМ1975 – студенты Пол Аллен и Билл
Гейтс впервые использовали язык
Basic для ПО ПК «Альтаир», основали
фирму Microsoft
1976 – Стив Джобс и Стив Возняк
организовали предприятие по
изготовление ПК «Apple»
Персональный компьютер PET ,
фирмы Commodore принадлежал к
немногочисленным компьютерам,
объединявшем в одном модуле
системный блок, монитор, накопители
и клавиатуру.
1977 – разработан мини-компьютер
VAX-11780 – первый 32-разрядный
представитель нового семейства
фирмы DEC
1978 – Intel 8086
PET
Intel 8086
143. Третье поколение ЭВМ
Четвертое поколение ЭВМ1979 – широкое распространение
флоппи-дисков
1982 – IBM приступила к изготовлению
профессиональных ПК IBM
1983 – Microsoft выпустила свою
первую мышь Bus Mouse для IMB PC
Ч. Зейтцем и его коллегами построен 64разрядный компьютер «Cosmic Cube»
1984 – Apple выпустили ПК Macintosh.
Sony и Philips разрабатывают стандарт
CD-ROM
1986 – Даниэль Хиллис построил
суперкомпьютер Connection Machine
1992 – DEC представили первый 64х
битный процессор RISC ALPHA
Флоппи-Диск
Мышь Bus Mouse
Процессор RISC ALPHA
144. Четвертое поколение ЭВМ (1975 - …)
Суперкомпьютеры№
Название
Страна
Год
Кол-во операций
в секунду
1
«ILLIAC - IV»
США
1972
20 млн.
2
«CRAY - 1»
США
1976
166 млн.
3
«Эльбрус - 1»
СССР
1980
15 млн.
4
«Эльбрус - 2»
СССР
1985
125 млн.
5
«CRAY - 2»
США
1985
2 млрд.
6
«CRAY - 3»
США
1989
5 млрд.
7
«GRAPE - 4»
Япония
1995
1,08 трлн.
8
«Earth Simulator»
Япония
2002
36 трлн.
9
«Blue Gene/L»
США
2005
100 трлн.
145. Четвертое поколение ЭВМ
Лекция №Классификация ЭВМ
146. Четвертое поколение ЭВМ
Основные понятия об ЭВМДать определение ЭВМ представляется сложным понятием, т.к. слово
«электронная» подразумевает электронные лампы в качестве
элементной базы, хотя современные ЭВМ состоят из микросхем.
Слово «вычислительная» подразумевает, что устройство предназначено
для проведения вычислительных операций.
Анализ работы современных ЭВМ показывает, что вычислительная
работа от общей производительности составляет 10-15%
Основное время затрачивается на выполнение операций пересылки
данных, сравнения, ввода-вывода и т.д.
147. Суперкомпьютеры
Основные понятия об ЭВМК понятию ЭВМ можно подойти с нескольких точек зрения:
Целесообразнее описать набор устройств, которые входят в
состав ЭВМ, и тем самым определить состав минимальной ЭВМ,
а также сформулировать принципы работы отдельных блоков
ЭВМ и принципы организации ЭВМ, как системы, состоящей из
взаимосвязанных функциональных блоков.
Также можно рассматривать ЭВМ с точки зрения некоторой
информационной вычислительной системы в виде
информационной модели ЭВМ, состоящей из совокупности
блоков переработки информации и множества информационных
потоков между этими блоками.
148. Лекция №
Организация ЭВМОрганизация ЭВМ отвечает на вопросы «Как устроено и как
функционирует?»
Конфигурация ЭВМ определяет внутренние составляющие с указанием их
конкретных характеристик.
Академик В.М.Глушков указывал на 3 глобальных
сферы деятельности человека, которые требуют
использования качественно различных типов ЭВМ:
Применение ЭВМ для автоматизации вычислений;
Направление, связанное с решением задач
искусственного интеллекта;
Использование ЭВМ в системах управления.
Академик В.М.Глушков
Она родилась в 1960-е годы, когда ЭВМ стали внедряться в контуры
управления автоматических и автоматизированных линий. Новое
применение ЭВМ требовало видоизменения их структуры и организации, т.е.
автоматизировать сбор данных и распределение результатов обработки.
149. Основные понятия об ЭВМ
Классификация ЭВМпо принципу действия
Критерием деления ВМ на 3 класса является форма
представления информации, с которой они работают.
Аналоговые ВМ – это ВМ непрерывного действия,
работают с информацией, представленной в
непрерывной (аналоговой форме), т.е. в виде
непрерывного ряда значений какой-либо физической
величины (чаще всего напряжения).
Цифровые ВМ – это ВМ дискретного действия,
работают с информацией, представленной в
дискретной, а точнее в цифровой форме.
Гибридные ВМ – это ВМ комбинированного действия,
работают с информацией, представленной и в
цифровой и в аналоговой форме; они совмещают в
себе достоинства АВМ и ЦВМ. ГВМ целесообразно
использовать для решения задач управления
сложными быстродействующими техническими
комплексами
Гибридные
ВМ
Вычислительные
машины
Аналоговые
ВМ
Цифровые
ВМ
150. Основные понятия об ЭВМ
Цифровые и аналоговыевычислительные машины
151. Организация ЭВМ
Классификация ЭВМ по назначениюУниверсальные – предназначены для решения
самых различных технических задач:
экономических, математических и т.д. Они
широко используются в вычислительных
центрах коллективного использования.
Проблемно-ориентированные – служат для
решения более узкого круга задач, связанных,
как правило, с управлением технологическими
объектами, регистрацией, накоплением и
обработкой относительно небольших
объемов информации.
Вычислительные
машины
Универсальные
Проблемноориентированны
е
Специализированные
Обладают ограниченными по сравнению с универсальными ЭВМ аппаратными и
программными ресурсами. Можно отнести всевозможные управляющие
вычислительные комплексы.
Специализированные – используются для решения узкого круга задач или реализации
строго определенной группы функций. Такая узкая ориентация ЭВМ позволяет четко
специализировать их структуру, существенно снизить их сложность и стоимость при
сохранении высокой производительности. Можно отнести, например,
программируемые микропроцессоры спец.назначения.
152. Классификация ЭВМ по принципу действия
Классификация ЭВМ по размерам ифункциональным возможностям
По функциональным возможностям и размерам ЭВМ можно разделить
на супер-ЭВМ, большие, малые и микро-ЭВМ.
153. Цифровые и аналоговые вычислительные машины
Сравнительные параметры классовсовременных ЭВМ
Параметры
ЭВМ
Супер
ЭВМ
Большие
ЭВМ
Малые
ЭВМ
Микро
ЭВМ
Производительность
1000-100,000
10-1000
1-100
1-100
Емкость ОП(Мбайт)
2000-10,000
64-10,000
4-512
4-256
Емкость ВЗУ (Гбайт)
500-5000
50-1000
2-100
0,5-10
Разрядность (бит)
64-128
32-64
16-64
16-64
154. Классификация ЭВМ по назначению
Большие ЭВМИсторически первыми появились большие ЭВМ, которые за рубежом
часто называют мейнфреймами. Это компьютеры с высоким
быстродействием и большими вычислительными ресурсами, которые
могут обрабатывать большое количество данных и выполнять
обработку запросов несколько тысяч пользователей одновременно.
Физически мейнфреймы имеют один корпус – системный блок
размеров со шкаф, к которому может подключаться терминал,
состоящий из монитора и клавиатуры.
Мейнфреймы используются для хранения и обработки больших баз
данных, а также крупных web-узлов с большим количеством
одновременных обращений.
В 1995г в США было установлено 40.000 мейнфреймов. В России
используются около 5.000 мейнфреймов собственного производства
и примерно 5.000 фирменных от IBM и других.
155. Классификация ЭВМ по размерам и функциональным возможностям
Супер ЭВМЭто большие компьютеры, которые создаются для задач, требующих
больших вычислений , таких как определение координат далекой
звезды или галактики, моделирование климата.
Супер ЭВМ – это штучный продукт, которые создается для решения
конкретных задач заказчика; составляющие элементы супер ЭВМ
являются серийными.
Супер ЭВМ состоят из 100 и более процессов, имеющих большую ОП,
высокое быстродействие и занимают площадь 2-3 баскетбольных
площадок.
Супер ЭВМ создаются по кластерной технологии, т.е. она состоит из
нескольких десятков серверов, которые работают как единая система
156. Сравнительные параметры классов современных ЭВМ
Малые ЭВМЭто надежные, недорогие и удобные в эксплуатации компьютеры,
обладающие более низкими возможностями по сравнению с
мейнфреймами.
Они имеют следующие характеристики:
• Число поддерживаемых пользователей: 16-512 человек;
• Все малые ЭВМ разрабатывались на основе микропроцессорных
наборов интегральных микросхем для 16, 32, 64-х разрядных
микропроцессоров;
• Малые ЭВМ ориентированы на использование в качестве
управляющих вычислительных комплексов, т.е. для управления
технологическими процессами в системах автоматизированного
проектирования.
В СССР выпускались отечественные малые ЭВМ.
157. Большие ЭВМ
Микро ЭВМПерсональные компьютеры (ПК)
Стационарные
Лэптопы
Карманные ПК
Эл. записные
книжки
Блокнотного
типа
Эл. словари
Ноутбуки/
планшеты
158. Супер ЭВМ
Микро ЭВМНастольный ПК – это компьютеры, которые могут использоваться
одним человеком автономно, независимо от других сфер. Имеют
«дружественный» интерфейс и ПО, ориентированное на пользователя
без профессиональной подготовки, высокая надежность. Имеет малую
стоимость, открытую архитектуру, которая обеспечивает адаптивность
к разнообразным потребностям пользователя.
Переносной ПК – быстродействующий подкласс ПК. На сегодняшний
день занимает большую часть рынка. Современные ПК имеют
способность работать без питания до 8 часов.
159. Малые ЭВМ
ЛекцияЭВМ по фон Нейману.
Гарвардская архитектура ЭВМ.
160. Микро ЭВМ
Архитектура фон НейманаАрхитектура фон Неймана – широко известный принцип совместного
хранения программ и данных в памяти компьютера. ЭВМ такого рода
часто обозначают термином “машина фон Неймана”. SISD – ЭВМ
такого рода обозначают архитектуру фон Неймана.
Концепция хранимой в памяти программы впервые была изложена в
1945 году в статье фон Неймана. Сущность этой концепции можно
свести к принципам:
Программное
управление работы
ЭВМ
Принцип условного
перехода
Принцип использования
двоичной системы счисления
для представления информации
Принцип хранимой
программы
Принцип иерархичности ЗУ
161. Микро ЭВМ
Программное управлениеработы программы
Программы состоят из отдельных шагов – команд.
Команда осуществляет единичный акт преобразования информации.
Последовательность команд, необходимая для реализации алгоритма,
является программой.
Все разновидности команд, использующиеся в конкретной ЭВМ, в
совокупности являются языком машины или системой команд ЭВМ.
162. Лекция
Принцип условного переходаОн даёт возможность перехода в процессе вычислений на тот
или иной участок программы в зависимости от промежуточных,
получаемых в ходе вычислений результатов.
Благодаря этому принципу число команд в программе
получается во много раз меньше, чем число выполненных
машиной команд при выполнении данной программы за счёт
многократного вхождения в работу участков программы.
163. Архитектура фон Неймана
Принцип хранимой памятиЭто один из самых важных принципов, заключается в том, что
команды представляются в числовой форме и хранятся в том же
ОЗУ, что и исходные данные, но только команды для исполнения
выбираются из ОЗУ→УУ, а числа (операнды) из ОЗУ→АЛУ.
Но для машины и команда и число являются машинным словом и
если команду направить в АЛУ в качестве операнда, то над ней
можно произвести арифметические операции, изменив её.
Это открывает возможности преобразования программ в ходе их
выполнения; кроме того принцип хранимой в ОЗУ программы
обеспечивает одинаковое время выборки команд и операндов из
ОЗУ для выполнения, позволяет быстро менять программы или
части их, вводить непрямые системы адресации, видоизменять
программы по определенным правилам.
164. Программное управление работы программы
Принцип использованиядвоичной системы
Информация (командная и данные, числовая, текстовая, графическая и
т.д.) кодируется двоичными числами ноль и единица. Каждый тип
информации имеет форматы – структурные единицы информации,
закодированные двоичными цифрами – ноль и единица.
Обычно все форматы данных, используемых в ЭВМ, кратны байту и
состоят из целого числа байтов. Последовательность битов в формате,
имеющая определенный смысл, называется полем.
Например в каждой команде программы, различают поле кода
операции, поле адресов операндов. Применительно к числовой
информации выделяют знаковые разряды, старшие и младшие
разряды. Этот принцип существенно расширил номенклатуру
физических приборов и явлений, которые можно использовать в АЛУ и
ЗУ ЭВМ.
Двоичная система – единственно возможная система представления
информации в ЭВМ на сегодняшний день.
165. Принцип условного перехода
Принцип иерархичности ЗУС самого начала развития ЭВМ существовало несоответствие между
быстродействием АЛУ и ОЗУ; выполняя ОЗУ на тех же элементах, что и
логические устройства процессора, удавалось частично разрешить это
несоответствие, но такое ОЗУ получалось слишком дорогим и значительно
увеличивало количество радиоламп в первых ЭВМ, снижая в целом её
надёжность;
иерархическое
построение
ЗУ
позволяет
иметь
быстродействующее ОЗУ сравнительно небольшой ёмкости только для
операндов и команд, участвующих в счёте в данный момент и в ближайшее
время.
Следующий более низкий уровень – это внешнее ВЗУ, которое имеет объём
на несколько порядков больше ОЗУ. Иерархичность ЗУ в ЭВМ является
важным компромиссом между емкостью и быстрым доступом к данным,
обеспечивающим требования быстродействия, относительной дешевизны
и надёжности. Эта архитектура ЭВМ (Фон Неймана) самая
распространённая в мире, но не единственная.
166. Принцип хранимой памяти
Схема ЭВМ по фон НеймануВторичная память
Периферия ввода
Периферия вывода
Основная память
ЭВМ
Порты ввода
АЛУ
Порты вывода
УУ
167. Принцип использования двоичной системы
ЭВМ по фон НеймануЭВМ должна состоять из следующих основных устройств:
Устройство управления (УУ) руководит порядком выполнения
операций, координирует работу машины в целом и её
взаимосвязь с дополнительными устройствами. УУ формирует
команды управления и отправляет их в определенные моменты
времени, а также формирует адреса ячеек памяти и передает
эти адреса другим устройствам ЭВМ.
Арифметико-логическое устройство (АЛУ) предназначено для
выполнения всех арифметических и логических операций над
числовой и символьной информацией.
УУ и АЛУ объединены в одно устройство – процессор.
168. Принцип иерархичности ЗУ
ЭВМ по фон НеймануОперативное запоминающее устройство (ОЗУ) –
устройство, непосредственно связанное с процессором и
предназначенное для хранения данных, участвующих в его
операции.
Внешнее запоминающее устройство (ВЗУ) – устройство,
предназначенное для длительного хранения больших
массивов информации (дискета, жёсткий диск, компакт-диск
и т.д.)
Устройство ввода-вывода (УВВ) – устройство,
предназначенное для ввода/вывода информации.
169. Схема ЭВМ по фон Нейману
Компьютеры на архитектурефон Неймана
Первыми пятью компьютерами, в которых были реализованы основные
особенности фон Неймана, были:
MARK I – Манчестерский университет, Великобритания, 21 июня 1948
года;
EDSAK – Кембриджский университет, Великобритания, 6 мая 1949
года;
BINAC – США, апрель или август 1949 года;
SCIR MK1 – Австралия, ноябрь 1949 года;
SEAC – США, 9 мая 1950 года.
170. ЭВМ по фон Нейману
Фотография компьютера MARKI
171. ЭВМ по фон Нейману
Гарвардская архитектура ЭВМЕдинственное отличие Гарвардской архитектуры от фон Неймановской
состоит в том, что память программ и память данных разделены и они
используют физически разделённые линии (шины). Это позволяет
пересылать команды и данные одновременно.
Следовательно такая архитектура может значительно увеличить
производительность ЭВМ. Эта архитектура также имеет своё АЛУ, УУ и
устройство ввода/вывода. Основным недостатком являлась высокая цена
ЭВМ.
Эта архитектура была разработана в конце 1930-ых годов в Гарвардском
университете Говардом Айхеном. Была реализована ЭВМ Марк (1944-ый
год).
Гарвардская архитектура наиболее подходит для специализированных
ЭВМ, предназначенных для решения задач в реальном времени.
172. Компьютеры на архитектуре фон Неймана
Отличие архитектуры Гарвардаот фон Неймана
В чистой архитектуре фон Неймана процессор одномоментно может
либо читать инструкцию, либо читать/записывать единицу данных из/в
памяти. То и другое не может происходить одновременно, поскольку
инструкции и данные используют одну и ту же системную шину.
А в компьютере с использованием гарвардской архитектуры
процессор может читать инструкции и выполнять доступ к памяти
данных в то же самое время, даже без кэш-памяти.
Таким образом, компьютер с гарвардской архитектурой может быть
быстрее (при определенной сложности схемы), поскольку доставка
инструкций и доступ к данным не претендуют на один и тот же канал
памяти.
173. Фотография компьютера MARK I
Отличие архитектуры Гарвардаот фон Неймана
Также машина гарвардской архитектуры имеет различные адресные
пространства для команд и данных. Так, нулевой адрес инструкций —
это не то же самое, что и нулевой адрес данных.
Нулевой адрес инструкций может определятся 24-битным значением, в
то время как нулевой адрес данных может выглядеть как 8-битный
байт, который не являются частью этого 24-битного значения.
174. Гарвардская архитектура ЭВМ
Лекция №Классификация ПК по поколениям процессоров.
175. Отличие архитектуры Гарварда от фон Неймана
ПроцессорыПроцессор является основой ПК и это главное вычислительное
устройство, состоящее из миллионов транзисторов. ЦП, CPU,
микропроцессор - одно и то же название.
Процессор:
- выполняет арифметические и логические операции;
- управляет вычислительным процессом;
- координирует работу всех устройств компьютера.
Все микропроцессоры по системе команд и архитектуре различают на
2 вида процессоров:
CISC (Complete Instruction Set Computer) – Компьютеры
(процессоры) с полным набором команд (инструкций);
RISC (Reduced (Restricted) Instruction Set Computer) – Процессоры с
сокращённой системой команд или инструкций.
176. Отличие архитектуры Гарварда от фон Неймана
CISC-процессорыCISC-процессоры начали производить в
1971 году компанией Intel (Intagrated
Technology – интегрированная
электроника), основанной 18 июля 1968
года. Компания быстро росла и
расширялась и её продукция стала
пользоваться большим спросом на
мировом рынке. В 1978 году компания
выпустила модель Intel 8086, что
положило начало производства
семейства X86. Все модели этого
семейства нельзя отнести к CISCпроцессорам, т.к. процессор Intel 486DX
имел комбинированную архитектуру –
CISC-процессор и RISC-ядро процессора.
Intel 8086
Intel 486DX
177. Лекция №
CISC-процессорыОсобенности CISC-процессора:
это нефиксированное значение длины команды;
арифметические действия кодируются в одной
инструкции;
имеет небольшое число регистров, каждый из
которых выполняет строго определённую
функцию.
CISC имел набор команд из 120-250 штук.
Pentium MMX
Примеры CISC-процессоров:
Pentium (наиболее известный – Pentium MMX),
Celeron, Pentium II-IV, фирмы AMD: AMD-K6-II,
AMD-K6-III, ..., AMD-Athlon, AMD-Duron, Cyrix
6x86MX, Cyrix Media GX, IDT WinChip2 и другие
Cyrix 6x86MX
178. Процессоры
RISC-процессорыRISC-процессоры имеют:
минимальное количество команд (до 100 штук);
система команд отличается относительной простотой;
команды одинаковой длины и формата;
также отказались от некоторых сложных методов адресации.
В частности, для данных - обращение микропроцессора к ОЗУ
производится только двумя специальными командами: чтением и
записью; количество регистров общего назначения больше 32-х, что
позволяет оптимизировать выполнение команд и ускорить работу
микропроцессора.
RISC-процессоры выпускают фирмы:
Motorola, SPARC, Analog Devices, Texas Instruments. Чаще всего RISCпроцессоры используются в мобильных телефонах.
179. CISC-процессоры
MISC и VLIW-процессорыMISC (Minimal Instruction Set Computer) – дальнейшее развитие
архитектуры RISС, основанное на еще большем упрощении инструкций
и уменьшении их количества. Так, в среднем, в MISC-процессорах
используется 20-30 простых инструкций. Такой подход позволил еще
больше упростить устройство процессора, снизить энергопотребление
и максимально использовать возможности параллельной обработки
данных.
VLIW (Very long instruction word) – архитектура процессоров,
использующая инструкции большой длины, содержащие сразу
несколько операций, объединенных компилятором для параллельной
обработки. В некоторых реализациях процессоров длина инструкций
может достигать 128 или даже 256 бит.
Архитектура VLIW является дальнейшим усовершенствованием
архитектуры RISC и MISC с углубленным параллелизмом.
180. CISC-процессоры
VLIW-процессорыВ VLIW-процессорах задача оптимизации
параллельной работы возлагалась на компилятор,
который не был ограничен ни во времени, ни в
ресурсах и мог проанализировать всю программу для
составления оптимального для работы процессора
кода.
В результате, процессор VLIW выигрывал не только от
упразднения накладных расходов на организацию
параллельной обработки данных, но и получал прирост
производительности, из-за более оптимальной
организации параллельного выполнения инструкций.
Intel Itanium 2
181. RISC-процессоры
VLIW-процессорыКроме этого упрощалась конструкция процессора, так
как упрощались или вовсе упразднялись некоторые
блоки, отвечающие за анализ зависимостей и
организацию распараллеливания обработки
инструкций, а это, в свою очередь, вело к снижению
энергопотребления и себестоимости процессоров.
Transmeta Crusoe
TriMedia TM-1300
182. MISC и VLIW-процессоры
VLIW-процессорыПервые VLIW-процессоры появились в конце
1980-х годов и были разработаны компанией
Cydrome. Так же к процессорам с этой
архитектурой относятся процессоры TriMedia
фирмы Philips, семейство DSP C6000 фирмы
Texas Instruments, Эльбрус 2000 (также
Эльбрус S) – процессор российского
производства, разработанный компанией
МЦСТ при участии студентов МФТИ и др.
Поддержка длинных инструкций с явным
параллелизмом есть и в процессорах
семейства Itanium.
Эльбрус-S
183. VLIW-процессоры
Первое поколение процессоровПервое поколение:
Intel 4004 (4-х разрядный процессор);
Intel 8086;
Intel 8087 (сопроцессор);
Intel 8088.
Тактовая частота 4,7 МГц.
Родоначальником этого семейства является 16-ти
разрядный процессор Intel 8086, выпущенный в
1978 году. Он имел 16 регистров, 16-ти разрядную
шину данных (ШД); 23-разрядную шину адреса
(ША), а также сегментную систему адресации
оперативной памяти в пределах одного
мегабайта. В нём применялась малая
конвейеризация, т.е. пока одни узлы выполняли
текущую команду, блок предварительной
выборки выбирал из памяти следующую.
Intel 4004
Intel 8086
Intel 8087
184. VLIW-процессоры
Второе поколение процессоровВторое поколение:
Intel 80286;
Intel 80287 (сопроцессор).
Тактовая частота до 20 МГц.
Этот процессор имел 16 регистров, 16-разрядную
шину данных, 24-разрядную шину адреса. В этих МП
появился защищённый режим, позволяющий
использовать виртуальную память размером до 1 Гб
для каждой задачи, пользуясь адресуемой
физической памятью в пределах 16 Мб. Защищённый
режим является основой для построения
многозадачных ОС, в которых система привилегий
жёстко регламентируется взаимоотношением задач с
памятью, ОС и друг с другом. Производительность
МП возросла не только с ростом тактовой частоты, но
и за счёт усовершенствования конвейера.
Использовалась ОС MS DOS.
Intel 80286
185. VLIW-процессоры
Третье поколение процессоровТретье поколение:
Intel 80386;
В период с 1985 по 1989 гг. выпускались процессоры Intel
80386 DX, Intel 80386 LX, Intel 80386 SX и сопроцессор Intel
80387.
Модификация Intel 80386 DX имела 32 регистра, 32-х
разрядную шину данных и шину адреса. Работал на частоте
33-40 МГц. Модификация SX (дешёвая версия) имел 16
регистров, 16-ти разрядную шину данных и 24-х разрядную
шину адреса. Оперативная память у обоих модификаций до
16 МБ. На процессорах Intel 80386 DX была построена
система управления космического аппарата "Аполлон" для
полётов на Луну. Модификация LX использовалась в
ноутбуках, т.к. имела низкое энергопотребление.
Третье поколение процессоров ознаменовалось переходом
к 32-х разрядной архитектуре. На процессорах этого
поколения широко использовалась ОС Windows 3.11 (под
себя брал около 4 МБ).
Intel 80386 DX
186. Первое поколение процессоров
Четвёртое поколение процессоровЧетвёртое поколение:
Представлено серией Intel 80486 – процессоры Intel 80486
DX, Intel 80486 SX, Intel 80486 LX.
Данная линейка процессоров имела 32 регистра, 32-х
разрядную шину данных и шину адреса. Данное поколение
не внесло существенных изменений в архитектуру, но был
значительно улучшен исполняющий конвейер. В данном
поколении отказались от внешнего сопроцессора, его стали
размещать на одном кристалле с центральным процессором
(80486 DX - буквы DX говорят о наличии сопроцессора;
сопроцессор позволял считать с использованием чисел с
плавающей точкой), или его не было вовсе (Intel 80486 SX).
Особенностью четвёртого поколения было наличие кэша
первого уровня – 8 КБ.
Intel 80486 DX
187. Второе поколение процессоров
Пятое поколение процессоровПятое поколение:
Intel 80586 (серия процессоров – Pentium 1);
AMD K5.
Частота самого первого процессора этого поколения
(1993г.) – 66 МГц.
Эти процессоры имели 32 регистра общего назначения, 64-х
разрядную шину данных, 32-х разрядную шину адреса, кэш
первого уровня 16 КБ (8 для данных и 8 для адреса).
Напряжение питания - 3,5 Вольта (до этого - 5 Вольт).
Данное поколение дало суперскалярную архитектуру для
быстрого снабжения командами и данными из памяти.
Шина данных сделана 64-х разрядной, поэтому процессоры
этого поколения изначально называли 64-х разрядными.
188. Третье поколение процессоров
Пятое поколение процессоровМодификацией данного процессора было
расширение Pentium MMX (Miltimedia
Extension). Оно имело на 57 команд
больше для обработки видео и звукового
сопровождения. Команды MMX
оперируют сразу 64-мя разрядами.
Регистры MMX могут использоваться для
одновременного сложения 32-разрядных
слов и четырёх 16-разрядных слов. Такой
принцип получил название SIMD (SingleInstruction, Multiple-Data – с одним
потоком команд и многими потоками
данных, одна инструкция – много
данных).
Intel 80586
AMD-K5 PR200
189. Четвёртое поколение процессоров
Шестое поколение процессоровШестое поколение:
Intel Pentium PRO – Intel Pentium III, Celeron;
AMD K6-II, AMD-K6-III.
Pentium PRO имел 32 регистра, 64-х разрядную шину
данных, 36-разрядную шину адреса, поддерживал
AMD-K6-III
адресацию в оперативной памяти до 64-х ГБ.
Celeron отличался от Pentium'а тем, что работал только на
частоте 66 МГц, имел кэш не более 128 КБ, и не
поддерживал режим контроля чётности. Использовался
для домашних и офисных ПК (дешёвая версия).
Ключевым в этих процессорах является динамическое
исполнение, под которым понимается исполнение команд
не в том порядке, как это предполагается программным
кодом, а в том, как удобно процессору. В этом поколении
использовалась дополнительная мультимедийное
Intel Pentium III
расширение команд у Intel - SSE, а у AMD - 3DNOW!
190. Пятое поколение процессоров
Седьмое поколение процессоровСедьмое поколение:
Intel Pentium IV;
AMD Duron, AMD Athlon.
Причисление их к новому поколению обусловлено
развитием суперскалярности и суперконвейерности.
Конвейерная обработка предполагает разбивку
выполнения каждой команды на несколько этапов, причём
каждый этап выполняется на своей ступени конвейера
процессора. При выполнении команда продвигается по
процессору по мере освобождения следующих ступеней.
191. Пятое поколение процессоров
Седьмое поколение процессоровТаким образом на конвейере одновременно может
обрабатываться несколько команд. Конвейер
классического процессора Pentium имеет 5 ступеней.
Конвейеры процессоров суперконвейерной архитектуры
(Pentium IV) имеют большое количество ступеней (в
районе 20), что позволяет упростить каждую из них и,
следовательно, сократить время, пребывания в них
команд.
AMD Duron
AMD Athlon
Intel Pentium IV
192. Шестое поколение процессоров
Дальнейшее развитиеСкалярным называется процессор с одним конвейером - это процессоры до
Intel 486 включительно.
Суперскалярный процессор имеет более одного конвейера. Развитие
современных процессоров сильно связано с технологией их производства,
которое начиналось с одного микрона у Intel 80386 и пришло сегодня к 18-32
нанометров у Intel i7, i5, в последних разработках, до 4-8 нанометров.
Эта современная технология позволяет: двукратно увеличить плотность
размещения транзисторов, уменьшить размеры микропроцессора и
увеличить их количество на кристалле; увеличить скорость переключения
транзисторов на 20% и снизить токи утечки в 5 раз; на 30% уменьшить
энергопотребление; также это позволяет встраивать в один кристалл ЦПУ
контроллер памяти и графический контроллер; устанавливать в одном
корпусе 4 и более ядер, что позволяет распараллеливать приложения и
увеличивать общую производительность системы.
193. Седьмое поколение процессоров
Сравнительные хар-ки процессоров IntelЛоготип
Технологические
особенности
Количество
ядер
Количество
потоков
Тактовая
частота
Системная
шина
Кэш
память
Nenalem
Intel® Hyper-Treading
Intel® Turbo Boost
Intel® HD Boost
45нм техпроцесс
High-k диэлектрик
Intel® Smart Cache
Intel® Power Capability
Execute Disable Bit
Intel® HD Boost
45нм техпроцесс*
High-k диэлектрик*
Smart Cache
Intel® Power Capability
Execute Disable Bit
4 ядра
4 ядра
4 ядра
4 ядра
8 потоков
8 потоков
4 потока
4 потока
до 3,33 ГГц
до 3,06 ГГц
до 3,20 ГГц
до 3,00 ГГц
6,4 ГТ/с
4,8 ГТ/с
до 1600 МГц
до 1333 МГц
8 МБ L3
8 МБ L3
до 12 МБ L2
до 12 МБ L2
Рекомендации
Непревзойденная
производительность в
самых современных
экстремальных играх
Рекордная
производительность в
самых требовательных
приложениях и играх
Высочайшая
производительность,
широкие возможности
«разгона» (overclocking)
Погружение в мир
удовольствия от игр и
мультимедиа в формате
High-Definition (HD)
Мощный инструмент для
повседневной работы
2 ядра
45нм*, High-k*
Smart Cache
®
Intel Power Capability
Execute Disable Bit
2 потока
до 3,33 ГГц
до 1333 МГц
до 6 МБ L2
Обработка нескольких
приложений начального
уровня одновременно
2 ядра
2 потока
до 2,80 ГГц
до 1066 МГц
до 2 MБ L2
Доступное и надежное
решение
Smart Cache
Intel® Power Capability
Execute Disable Bit
1 или 2
1 или 2
* Действительно только для современных моделей процессоров
до 2,40 ГГц
до 800 МГц
512 KБ L2
194. Седьмое поколение процессоров
Встроенный контроллер памяти (IMC)Процессоры семейства Intel® Core™ i7 имеют встроенный 3-канальный контроллер
памяти (IMC = Integrated Memory Controller) встроенный в кристалл процессора, что
обеспечивает высокоскоростные параллельные каналы передачи данных напрямую
между процессором и распределенной общей памятью, а также графическое ядро.
• Только DDR3 память,
• 800/1066/1333 МГц,
• 1ГБ, 2ГБ, 4ГБ,
• x8 или x16 DRAM,
• 1 или 2 ранга на DIMM,
• 3 канала памяти c
поддержкой XMP*,
• Возможны любые
конфигурации плат по
количеству модулей
памяти на один канал
Система с внешним
контроллером памяти
Система со встроенным
контроллером памяти
Процессор
Процессор
Контроллер
памяти
Ключевые особенности
встроенного контроллера:
FSB
QPI
Контроллер
памяти
Оперативная
память
Контроллер
Ввода-вывода
* XMP (Extreme Memory Profiles)
представляет собой набор настроек для оперативной памяти, облегчающий ее «разгон».
Контроллер
Ввода-вывода
Оперативная
память
195. Дальнейшее развитие
ПРОЦЕССОРЫ РОССИЙСКОГОПРОИЗВОДСТВА
196.
ВведениеРоссийская IT-индустрия активно развивается. В
числе самых технологичных ее сегментов — это
разработка микропроцессоров, предназначенных
для использования в составе ПК, и серверов,
которые принято относить к IBM-архитектуре.
Сейчас на этом рынке властвуют два мировых
бренда — Intel и AMD. Конкурентных им
разработок в мире очень немного. Но таковые
могут быть предложены российскими инженерами.
197.
В числе перспективных микросхем из РФ, которые могутстать конкурентами Intel и AMD, принято считать
процессор «Байкал». Предполагается, что данный чип
будет устанавливаться на компьютеры, заказываемые
госструктурами. Самый, вероятно, известный
микропроцессорный вендор, создавший работающие и
готовящиеся к серийному выпуску образцы микросхем,
— это компания МЦСТ. Он выпускает чипы под брендом
«Эльбрус» в широком спектре модификаций
198. ПРОЦЕССОРЫ РОССИЙСКОГО ПРОИЗВОДСТВА
История зарожденияПервый компьютер, с которого начинается история
бренда, был создан советскими учеными в 70-х годах.
Им стал вычислительный комплекс «Эльбрус-1». Он был
основан на микросхемах типа TTL и содержал в своей
структуре 10 процессоров общей производительностью
порядка 15 мегафлопс. В некоторой степени это была
уникальная машина: в частности, в ней был реализован
принцип параллельного выполнения команд. По
некоторым данным, в мире подобных ЭВМ еще
разработано тогда не было. Объем ОЗУ в «Эльбрус-1»
составлял 64 МБ — более чем прилично
199. Введение
Образец защищённого военного ноутбука набазе процессора Эльбрус 2
200.
ПроизводителиПроизводство Российских процессов находится в Азии
однако есть уже образцы собираемые полностью в
России
201. История зарождения
Процессоры Эльбрус«Эльбрус-S» Первый серийный чип от МЦСТ - это процессор
«Эльбрус-S», который появился в 2010 году. Он выпускался по
стандарту 90 нм. Данная микросхема могла работать при
частоте в 500 МГц и обеспечивать производительность
порядка 8 гигафлопс.
202.
«Эльбрус-2С+» В 2011-м появилась следующая модификацияпроцессора — чип «Эльбрус-2С+». Он был изготовлен также в
соответствии с архитектурой 90 нм, но его производительность была
намного выше — 28 гигафлопс. Можно отметить, что аналогичных
показателей могли достигать такие чипы, как Intel Core 2 Duo, а также
Intel Core i3. Есть сведения, что подобного прогресса разработчикам
удалось достичь благодаря тому, что сопровождают процессор 4
ядра дополнительной микросхемы. Данный компонент осуществляет
цифровую обработку сигнала. Однако встроенный процессор
соответствующего типа, как посчитали инженеры МЦСТ,
характеризовался слишком высокой ресурсоемкостью в процессе
выпуска. Поэтому в следующих моделях «Эльбрус» он был заменен
альтернативными решениями.
203. Производители
«Эльбрус-4С» В 2014 году началсясерийный выпуск очередного
микропроцессорного шедевра - «Эльбрус4С». Данный чип изготовлен по технологии
65 нм. Его ядра (всего их, соответственно,
4) функционируют на частоте 800 МГц.
Каждое из них оснащено 2 МБ кэш-памяти.
Это позволило добиться
производительности процессора в 50
гигафлопс. Это почти столько же, как,
например, у чипа Intel Core i7-975 — 53
гигафлопса. При этом мощность
российского чипа — 45 Вт. В данном
аспекте питание процессора «Эльбрус-4С»,
как считают многие эксперты,
экономичнее, чем у американской
разработки. Чип с 4 ядрами от МЦСТ —
один из самых универсальных. Типы
компьютеров, в которые может быть
установлен данный процессор, — ПК,
ноутбуки, сервера, моноблоки.
Собственно, в линейке вычислительных
комплексов, которые также выпускает
компания МЦСТ, присутствуют машины во
всех отмеченных конфигурациях
204. Процессоры Эльбрус
«Эльбрус-8С» Новейший процессор от МЦСТ - обладающий 8 ядрами «Эльбрус-8С». Чипработает на базе стандарта 28 нм, что вплотную приближает его к ведущим мировым
образцам микропроцессоров. Кэш-память второго уровня на ядрах микросхемы «Эльбрус8С» — 4 МБ, третьего — 16 МБ. Процессор может работать с распространенным стандартом
ОЗУ типа DDR3 1600. Производительность чипа, измеряемая на вычислениях с одинарной
точностью, — 250 гигафлопс. В процессоре есть 4 контроллера памяти. Показатель
пропускной способности для каналов межпроцессорного обмена данными — 16 ГБ/сек.
Отмеченная производительность чипа — 250 гигафлопс. Как она соотносится с показателями
мировых аналогов российского процессора? Можно отметить, что чип Intel Core i7 4930K
выдает порядка 130-140 гигафлопс. Специально для новейших процессоров «Эльбрус»
создаются новые материнские платы, а также отдельная версия ОС. Также, возможно, будут
разработаны многопроцессорные компьютеры на базе чипа. Есть сведения, что к 2018 году
компания МЦСТ выпустит процессоры типа «Эльбрус-16С». Их расчетная производительность
— 1 терафлопс. Ожидается также, что технологический процесс чипов будет базироваться
на стандартах менее 28 нм.
205.
Эльбрус 8С206.
Рабочий Эльбрус 8с207.
Сервер Эльбурс208. Эльбрус 8С
ПерспективыКак оценивают эксперты выпускаемые российским брендом
процессоры? Отзывы очень многих IT-специалистов, можно сказать,
восторженные Причин тому несколько. Например, многие разработчики
гордятся уже тем, что процессор был создан именно в России, причем в
условиях, когда долгое время экономическая ситуация не
способствовала активному развитию IT-индустрии в столь
высокотехнологичном и наукоемком сегменте. В плане
производительности процессоров оценки также в целом
положительные. Есть некоторые замечания у специалистов, которые
касаются маркетинговых перспектив чипов. Чтобы сделать их
рентабельными, нужны большие рынки сбыта, которые заняты
мировыми лидерами. Соревноваться с ними, полагают эксперты, будет
непросто. Вместе с тем, как считают некоторые аналитики, процессоры
«Эльбрус» вполне могут стать достойной альтернативой решениям от
Intel и AMD внутри РФ, особенно в части военных поставок, при которых
к разработчикам выдвигаются самые жесткие требования в аспекте
надежности электронных компонентов и безопасности их
использования. Компания МЦСТ, полагают эксперты, вполне способна
обеспечить соответствие выпускаемых ею процессоров данным
требованиям.
209. Рабочий Эльбрус 8с
Процессоры БайкалРоссийские процессоры Байкал-Т1 и
Байкал-М
Если процессоры Эльбрус предназначены
сугубо для компьютеров и готовы
конкурировать с другими фирмамиизготовителями процессоров для ПК, то
процессоры Байкал предназначены
больше для промышленного сегмента и не
столкнутся с такой жесткой конкуренцией.
Однако уже разрабатываются и
процессоры Байкал-М, которые можно
будет использовать для настольных ПК
210. Сервер Эльбурс
ПрименениеПо данным Байкал Электроникс, процессоры Байкал-Т1 можно использовать
для маршрутизаторов, роутеров и другого телекоммуникационного
оборудования, для тонких клиентов и офисной техники, для мультимедийных
центров, систем ЧПУ. А вот процессоры Байкал-М смогут стать сердцем для
рабочих ПК, для промышленной автоматизации и для управления зданиями.
Уже интереснее! Но подробной информации о технических характеристиках
пока нет. Знаем только, что он будет работать на 8 ядрах ARMv8-A и будет
иметь на борту до восьми графических ядер ARM Mali-T628 и, что тоже
немаловажно, производители обещают сделать его очень энергоэкономным.
Посмотрим, что из этого выйдет.
Области применения Байкал-М
моноблок, автоматизированное рабочее место, графическая рабочая станция;
домашний (офисный) медиа-центр;
сервер и терминал видеоконференций;
микросервер;
NAS уровня небольшого предприятия;
маршрутизатор / брандмауэр.
211. Перспективы
Основные характеристики8 ядер ARM Cortex-A57 (разрядность 64 бит).
Рабочая частота до 2 ГГц.
Аппаратная поддержка виртуализации и технологии Trust Zone на уровне всей
СнК.
Интерфейс с оперативной памятью – два 64-битных канала DDR3/DDR4-2133 с
поддержкой ECC
Кэш-память – 4 МБ (L2) + 8 МБ (L3).
Восьмиядерный графический сопроцессор Mali-T628.
Видеотракт, обеспечивающий поддержку HDMI, LVDS
Аппаратное декодирование видео
Встроенный контроллер PCI Express поддерживает 16 линий PCIe Gen. 3.
Два контроллера 10-гигабитной сети Ethernet, два контроллера гигабитной
сети Ethernet. Контроллеры поддерживают виртуальные сети VLAN и
приоритезацию трафика.
Два контроллера SATA 6G, обеспечивающих скорость обмена данными до
6 Гбит/с каждый.
2 канала USB v.3.0 и 4 канала USB v.2.0.
Поддержка режима доверенной загрузки.
Аппаратные ускорители, поддерживающие ГОСТ 28147-89, ГОСТ Р 34.11-2012.
Энергопотребление – не более 30 Вт.
212. Процессоры Байкал
НИИСИСильные места НИИСИ: радиационная устойчивость и
неафишируемый проект высокопроизводительной микроархитектуры.
НИИСИ разрабатывает две линии процессоров, — обе по
архитектуре MIPS. Кроме того, НИИСИ также подготовила часть
кадров для процессорной команды Байкал Электроникс, которая тоже
использует MIPS.
Процессор КОМДИВ-32 сделан довольно давно, возможно, на
основе лицензированного у MIPS (тогда Silicon Graphics) ядра.
Основная гордость создателей КОМДИВ-32 — устойчивость к
радиации, по которой они меряются силами с BAE Systems, Gaisler
Aeroflex и Honeywell. Устойчивость к радиации необходима для систем,
предназначенных для использования в космосе.
213. Применение
Комдив-32 и Комдив-64214. Основные характеристики
Миландр«Миландр» выпускает микроконтроллеры для суровых
условий эксплуатации.
Микроконтроллеры имеют множество применений —
от медицинских приборов до дворников на автомашине и
управления двигателями. «Миландр» лицензировал
процессорные ядра микроконтроллерного класса у британской
компании ARM и сделал на них микроконтроллеры для суровых
условий со своими периферийными устройствами.
«Миландр» — одна из немногих компаний, которая
активно старается продвигать свои разработки не только на
специальные применения, но и в гражданский сектор.
215. НИИСИ
МультиклетПроцессоры
с
универсальной
мультиклеточной
архитектурой и микроархитектурой российского происхождения.
Предыстория создания отмечена, как «Лучший продукт года» в
2003 г. на конференции IEEE в Далласе (США), а также рядом
других зарубежных и отечественных наград. На 2015 г. созданы
два процессора СнК MultiClet P1 и MultiClet R1, которые
позиционируются, как производительные, низкопотребляющие
DSP процессоры (последний обладает более развитой
периферией и динамической реконфигурацией, позволяющей в
максимальной степени использовать возможности четырех клеток
процессора).
216. Комдив-32 и Комдив-64
МодульПотенциальные сферы применения:
цифровое телевидение, авиация и космос.
Как и «Миландр», «Модуль» является
лицензиатом ARM, причём плата с их
процессором на основе ARM стала широко
доступной для разработчиков.
217. Миландр
КМ211Ниши: смарткарты и чисто
российский микроконтроллер.
KM211
спроектировала
встроенный микропроцессор КВАРК,
который может использовать Линукс и
микроконтроллер
«Кролик».
Обе
разработки используют как российскую
архитектуру,
так
и
российскую
микроархитектуру, что делает KM211
уникальным проектом типа «Эльбруса»,
но на рынке «малых» процессоров.
218. Мультиклет
Лекция №Функционирование ЭВМ с шинной организацией.
Обобщённый алгоритм функционирования
классического процессора
219. Модуль
Функционирование ЭВМс шинной организацией
Шинная организация ЭВМ является простейшей формой организации ЭВМ.
В соответствие с принципами фон-Неймана подобная ЭВМ имеет
следующую упрощенную схему.
220. КМ211
Функционирование ЭВМс шинной организацией
CPU (central processing unit) – основная функциональная часть ЭВМ,
выполняющая основные операции по обработке данных и управлению
работой других блоков. Это наиболее сложный компонент ЭВМ, как с
точки зрения электроники, так и с точки зрения функциональных
возможностей.
CPU состоит из следующих основных взаимосвязанных элементов:
АЛУ (арифметико-логическое устройство);
УУ (устройство управления);
Регистров.
221. Лекция №
АЛУАЛУ выполняет основную работу по переработке информации, хранимой
в оперативной памяти. В нем выполняется арифметические и логические
операции. Кроме того, АЛУ вырабатывает управляющие сигналы,
позволяющие ЭВМ автоматически выбирать путь вычислительного
процесса в зависимости от получаемых результатов.
АЛУ формирует по двум входным переменным одну выходную, выполняя
заданную функцию (сложение, вычитание и т.д.). Выполняемая функция
определяется микрокомандой, получаемой от УУ.
222. Функционирование ЭВМ с шинной организацией
АЛУВ своем составе АЛУ содержит устройство, которое хранит
характеристику результата выполнения операции над данными и
называемое флаговым регистром (регистр признаков, регистр
состояний).
Отдельные разряды этого регистра указывают на равенство результата
операции “0”, на знак результата операции и на правильность
выполнения операции (наличие переноса за пределы разрядной сетки
или переполнение).
Программный анализ флагов позволяет производить операции
ветвления программы в зависимости от конкретных значений и данных.
Кроме того, в АЛУ имеется набор программно-доступных
быстродействующих ячеек памяти, которые называются регистрами
процессора.
223. Функционирование ЭВМ с шинной организацией
РегистрыРегистры составляют основу архитектуры процессора.
Среди обязательного набора регистров отметим следующие:
регистр данных (служит для временного хранения промежуточных
результатов при выполнении операций);
регистр-аккумулятор (служит для временного хранения результата
выполнения команды);
регистр-указатель стека (используется при операциях со стеком, т.е.
такой структурой данных, которая работает по принципу LIFO –
последний вошел, первый вышел; стек используется для организации
подпрограмм);
224. АЛУ
Регистрыиндексные (указательные);
базовые регистры (служат для хранения и вычисления адресов
операндов памяти);
регистры-счетчики (используются для организации циклических
участков в программах);
регистры общего назначения (используются для любых целей и их
назначение определяет программист при написании программы).
Количество регистров и связи между ними оказывают существенное
влияние на сложность и стоимость CPU. С другой стороны наличие
большого количества регистров с богатым набором возможностей
упрощает программирование и повышает гибкость ПО.
225. АЛУ
УУУУ – это часть CPU, которая вырабатывает распределенную во времени
и пространстве последовательность внутренних и внешних
управляющих сигналов, обеспечивающих выборку и выполнение
команд.
На этапе цикла выборки команды УУ интерпретирует команду,
выбранную из программной памяти. На этапе выполнения команды в
соответствие с типом реализуемой операции УУ формирует требуемый
набор команд низкого уровня для АЛУ и других устройств.
Эти команды задают последовательность простейших низкоуровневых
операций (микрокоманды) таких, как пересылка данных, сдвиг данных,
установка и анализ признаков, запоминание результатов и т.д.
226. Регистры
УУВ простейшем случае УУ имеет в своем составе 3 устройства:
регистр команд, который содержит код команды во время ее
выполнения;
программный счетчик, в котором содержится адрес очередной,
подлежащей выполнению команды;
регистр адреса, в котором вычисляются адреса операндов,
находящихся в памяти.
Для связи пользователя с ЭВМ предусмотрен пульт управления,
который позволяет выполнять действия: сброс ЭВМ с начальное
состояние, просмотр регистров или ячеек памяти, запись адреса в
программный счетчик, пошаговое выполнение программы при ее
отладке.
227. Регистры
ПамятьПамять – это устройство, предназначенное для запоминания, хранения
и выборки программ и данных. Память состоит из конечно числа ячеек,
каждая из которых имеет свой уникальный номер или адрес. Доступ к
ячейке осуществляется указанием ее адреса.
Память способна выполнять 2 вида операций над данными:
Чтение с сохранением содержимого;
Запись нового значения со стиранием предыдущего.
В большинстве современных ЭВМ, минимально адресуемым элементом
памяти, является байт (поле из 8 бит). Совокупность битов, которые
АЛУ может одновременно поместить в регистр или обработать, обычно
называют машинным «словом». Чем больше объём памяти, тем
медленнее к ней доступ, т.к. время доступа определяется временем,
необходимым для выборки из памяти или записи в неё информации.
Поэтому в ЭВМ существует несколько видов (уровней) запоминающих
устройств, различающихся объёмом и быстродействием.
228. УУ
Операции над памятьюОперация «считывания из ячейки памяти» производится следующим
образом:
Процессор переводит шину в состояние “занято” и на ША помещает
адрес, требуемой ячейки памяти;
Устанавливает на ШУ сигнал чтения, выдает синхросигнал задатчика;
Память принимает адрес, дешифрирует его, находит нужную ячейку
и помещает ее содержимое на ШД;
Далее память выдает синхросигнал исполнителя; получив ответ от
памяти, CPU считывает данные с шины, снимает свои управляющие
сигналы и освобождает шину.
229. УУ
Операции над памятьюОперация “запись в память” производится следующим образом:
Шина переводится в состоянии “занято”;
Адрес, требуемой ячейки памяти помещается на ША;
Данные, которые необходимо записать в память, помещаются на ШД;
На ШУ устанавливается сигнал “запись” и выдается сигнал
синхронизации задатчика;
Память принимает адрес, дешифрирует его, помещает в
соответствующую ячейку данные шины и выдает сигнал синхронизации
исполнителя;
Получив ответ от памяти, процессор снимает управляющие сигналы и
освобождает шину.
Такой способ обмена данными называется асинхронным ответом, а сама
операция запроса подтверждения носит название квитирование или
“рукопожатие”, которая широко применяется в различных видах ЭВМ.
230. Память
Оперативная память – это функциональный блок, хранящий информацию дляУУ (команды) и для АЛУ (данные).
Память должна вмещать достаточно большое количество информации, т.е.
иметь большую емкость.
По величине емкости можно судить об использовании той или иной ОС
(Windows 95 – 4-8 Мб, Windows 98 – 32-64 Мб, Windows XP – 64-256 Мб).
Память должна обладать достаточным быстродействием, соответствующим
быстродействию других устройств ЭВМ.
Устройства памяти
Частота F (МГц)
Объём (Кб, Мб, Гб)
Кэш L1 (1-уровень)
F ядра CPU
8-32 Кб
Кэш L2 (2-уровень)
½ F ядра CPU
64-512 Кб. 1-4Мб сервер
Кэш L3 (3-уровень)
½- ¼ F ядра CPU
4-8 Мб
ОЗУ
F системной шины
1-8 Гб
HDD (ПЗУ)
От 3до 15 сек
100 Гб и до …….
DVD
От 5 до 40 сек
4.7 Гб до 20 Гб
231. Операции над памятью
Функционирование ЭВМ с шиннойорганизацией
Периферийные устройства – устройства внешней памяти,
предназначенные для хранения данных большого объема и
коммуникационные устройства, предназначенные для связи ЭВМ с
внешним миром. Обмен данными с внешними устройствами
осуществляется через порты вводы/вывода.
Порт – это абстрактное понятие на самом деле не существующее. По
аналогии с ячейками памяти порты можно рассматривать как ячейки,
через которые можно записать в периферийное устройство или
прочитать из него. Также как и ячейки памяти, порты имеют
уникальные номера, т.е. адреса портов ввода/вывода.
232. Операции над памятью
Функционирование ЭВМ с шиннойорганизацией
Система шин.
Объединение функциональных блоков ЭВМ осуществляется
посредством следующей системы шин:
ШД (шина данных), по которой осуществляется обмен информацией
между блоками ЭВМ;
ША (шина адреса) используется для передачи адресов ячеек памяти
или портов, к которым производится обращение;
ШУ (шина управления) служит для передачи управляющих сигналов.
Совокупность этих 3 шин называют системной шиной, системной
магистралью или системным интерфейсом.
Принципиально общие моменты в организации шин: шина состоит из
отдельных проводников (линий), сигналы по линиям шины могут
передаваться либо импульсами, либо уровнем напряжения.
233. Память
Общая организация ЭВМ напримере ПК
Шириной шины называется количество линий (проводников),
входящих в состав шины. Ширина ША определяет размер адресного
пространства ЭВМ.
Если количество линий адреса, используемых для адресации памяти,
равно 20, то общее количество адресуемых ячеек памяти составит
2^20, т.е. примерно 1 млн. ячеек (1048576 ячеек).
Обычно на шине в любой момент можно выделить 2 активных
устройства. Одно из них называется задатчиком и инициирует
операцию обмена данными (формирует адреса и управляющие
сигналы). Другое называется исполнителем и выполняет операцию
дешифрации адресов и управляющих сигналов, а также принимает или
передает данные. В большинстве случаев задатчиком является CPU, а
память всегда выступает в качестве исполнителя.
234. Функционирование ЭВМ с шинной организацией
Линии в управляющей шинеИз управляющей шины выделим следующие линии:
Линии занятости (если они в состоянии “свободно” – то любой
задатчик, включая CPU, может начинать операцию обмена данными
на шине, иначе задатчику придется ждать пока шина освободится);
Линии, указывающие какая именно операция будет выполняться
(чтение или запись);
Линии синхронизации (задатчик в процессе операции обмена
выставляет на шине сигнал синхронизации, получив сигнал от
задатчика; исполнитель выполняет операцию обмена и выставляет
на шине ответный сигнал синхронизации; получив ответ от
исполнителя задатчик освобождает шину).
235. Функционирование ЭВМ с шинной организацией
Обобщенный алгоритм функционированияклассического процессора
1. Инициализация:
После включения ЭВМ или операции сброса в
регистры CPU заносятся некоторые начальные
значения. Обычно в процессе инициализации в
память ЭВМ помещается программа,
называемая первичным загрузчиком.
Основное назначение первичного загрузчика
загрузить в память с устройства внешней
памяти ОС. Это программа может быть
размещена в энергонезависимом устройстве
памяти или автоматически считываться с
некоторого устройства внешней памяти.
Программному счетчику присваивается
начальное значение, равное адресу первой
команды программы.
236. Общая организация ЭВМ на примере ПК
Обобщенный алгоритм функционированияклассического процессора
2. Выборка команды:
CPU производит операцию считывания
команды из памяти, в качестве адреса ячейки
памяти используется содержимое
программного счетчика.
3. Увеличение программного счетчика:
Содержимое считанной ячейки памяти
интерпретируется процессором, как команда
и помещается в регистр команды.
УУ приступает к интерпретации прочитанной
команды. По полю кода операции их первого
слова команды УУ определяет ее длину и, если
это необходимо, организует дополнительные
операции считывания, пока вся команда
полностью не будет прочитана процессором.
Вычисленная длина команды прибавляется к
исходному содержимому командного
счетчика и, когда команда полностью
прочитана, программный счетчик будет
хранить адрес следующей команды.
237. Линии в управляющей шине
Обобщенный алгоритм функционированияклассического процессора
4. По адресным полям команды УУ определяет имеет ли команда операнды в памяти. Если это так,
то на основе указанных в адресных полях режимах
адресации вычисляются адреса операндов и
производится операции чтения памяти для
считывания операндов.
5. УУ и АЛУ выполняют операцию, указанную в поле
операции команды. Во флаговом регистре CPU
запоминаются признаки результата операции (знак
результата, равно 0 или нет и т.д.).
6. Если это необходимо, УУ выполняет операцию
записи для того, чтобы поместить результат
выполнения команды в память.
7. Если последняя команда не была командой
“остановить CPU”, то описанная последовательность
действий повторяется с шага 1 (пункт 2). Описанная
последовательность действий CPU с пункта 2 до
пункта 6, называется циклом CPU.
238. Обобщенный алгоритм функционирования классического процессора
Пример чипсета МВЧипсет — набор микросхем,
спроектированных
для
совместной работы с целью
выполнения набора каких-либо
функций. Так, в компьютерах
чипсет,
размещаемый
на
материнской плате, выполняет
роль связующего компонента,
обеспечивающего совместное
функционирование
подсистем
памяти,
центрального
процессора (ЦП), ввода-вывода
и других. Чипсеты встречаются и
в других устройствах, например,
в сотовых телефонах и сетевых
медиаплеерах.
239. Обобщенный алгоритм функционирования классического процессора
Северный мостСеверный мост, предназначен для
осуществления
взаимодействия
между процессором, оперативной
памятью, видеокартой и южным
мостом, а точнее, устройств,
которые подключены к южному
мосту. Ещё северный мост могут
называть
системным
контроллером. В состав северного
моста входят такие важные
компоненты:
-Контроллер оперативной памяти;
-Контроллеры шин для управления
потоками информации между
процессором и остальными
устройствами;
-Встроенный графический
контроллер, выполняющий
функции видеокарты, такое
решение применяется в
компьютерах эконом‐класса;
240. Обобщенный алгоритм функционирования классического процессора
Южный мостПроцессор, оперативная память,
видеокарта
являются
в
компьютере самыми быстрыми
устройствами,
поэтому
они
подключены к северному мосту.
Южный мост, его ещё называют
мостом
ввода‐вывода,
объединяет более медленные
устройства, такие, как:
-Винчестер;
-Приводы компакт‐дисков;
-различные устройства PCI‐шины;
-контроллер прерываний;
-контроллер прямого доступа к
оперативной памяти;
-BIOS;
-часы реального времени (Real
Time Clock);
-сетевые карты;
-звук;
-клавиатуру, мышь, джойстики;
241. Пример чипсета МВ
ЧипсетВ свою очередь, северный и
южный мосты соединяются своей
шиной обмена, по которой
передаются
данные,
сигналы
управления и контроля в обоих
направлениях.
Сложившаяся структура чипсета
была не всегда такой. Раньше, во
времена
PC‐совместимых
компьютеров, собранных на базе
процессоров Intel 8086 и до
80486, понятие чипсета, в том
виде, как он оформился сейчас,
было
размыто.
На
плате
находились все эти контроллеры,
но как отдельные микросхемы.
Даже центральный процессор,
хотя в этой статье речь не о нём,
до линейки Pentium, состоял из
собственно
процессора
и
сопроцессора, который выполнял
вычисления
в
операциях
с
плавающей точкой.
242. Северный мост
КОНТРОЛЛЕР ПРЕРЫВАНИЙПредставляет собой электронное устройство, иногда выполненное как часть
самого процессора или же сложных микросхем его обрамления, входы которого
присоединены электрически к соответствующим выходам различных устройств.
Номер входа контроллера прерываний обозначается «IRQ». Следует отличать
этот номер от приоритета прерывания, а также от номера входа в таблицу
векторов прерываний (INT). Так, например, в IBM PC в реальном режиме
работы (в этом режиме работает MS-DOS) процессора прерывание от
стандартной клавиатуры использует IRQ 1 и INT 9.
В первоначальной платформе IBM PC
используется очень простая схема прерываний.
Контроллер прерываний представляет собой
простой счётчик, который либо
последовательно перебирает сигналы разных
устройств, либо сбрасывается на начало при
нахождении нового прерывания. В первом
случае устройства имеют равный приоритет, во
втором устройства с меньшим (или большим
при обратном счёте) порядковым номером
обладают большим приоритетом.
243. Южный мост
КОНТРОЛЛЕР ПРЯМОГО ДОСТУПА К ПАМЯТИDMA - Direct Memory Access, механизм, использующийся для
непосредственного обмена данными между устройством и оперативной
памятью компьютера, минуя центральный процессор.
Контроллер DMA - Используется для уменьшения нагрузки на
центральный процессор в случае длительного обмена большим
потоком данных с устройствами. К таким устройствам могут быть
причислены:
•Жёсткие диски (IDE, ATA, SCSI).
•Приводы для гибких магнитных накопителей (FDD).
•Оптические приводы (CD, DVD).
•Звуковые карты (DSP, MIDI).
•Различные мультимедиа-устройства.
PCI DMA - любое PCI устройство может обращаться к памяти
компьютера, минуя ЦП. Программирование зависит от конкретного
железа.
ISA DMA - старый контроллер DMA, который описан ниже.
В современные ПК устанавливаются два контроллера DMA:
•8-битный (каналы 0, 1, 2, 3).
•16-битный (каналы 4, 5, 6, 7).
244. Чипсет
Контроллеры245.
НовшестваСеверный и южный мосты (North-/South-Bridge). Раньше чипсет состоял из двух блоков.
Северный мост управлял потоком данных видеоплаты, а также, используя контроллер
памяти, потоком данных процессора и оперативной памяти. Южный мост отвечал за обмен
данными между дисками и устройствами ввода. Ныне и Intel и AMD переместили
большинство компонентов северного моста в процессор, а остальные компоненты
объединили в одной микросхеме чипсета. Тем самым удалось значительно ускорить
процесс обмена данными между ЦП и ОЗУ.
Графический чип. Несколько лет назад такие производители, как MSI и ASUS, оснащали
некоторые материнские платы дискретным графическим чипом. Он обеспечивал вывод
изображения без необходимости установки дополнительной видеоплаты. Теперь это в
прошлом, так как почти во всех современных процессорах Llano и Sandy Bridge имеется
встроенный графический процессор. Раньше процессор был соединен с северным и
южным мостами посредством шины Front Side Bus. Шина задавала также тактовую частоту,
с которой происходил обмен данными между отдельными компонентами ПК, например
процессором и оперативной памятью. В настоящее время весь северный мост (AMD) или
содержащийся в нем контроллер памяти (Intel) перекочевали в процессор. Таким образом,
сейчас производители материнских плат обеспечивают прямую связь соответствующего
процессориого ядра с чипсетом: вместо фронтальной шины используются более
современные технологии, например Quick Path Interconnect и Hyper Transport,
обеспечивающие более высокую скорость работы.
(U)EFI. Основной программой управления материнской платой долгое время была BIOS.
Она загружается при запуске ПК и позволяет изменять базовые параметры. С появлением
современных процессоров многие производители материнских плат перешли на
использование EFI- преемника BIOS. Преимущества: программа имеет свою собственную
графическую оболочку с поддержкой управления мышью, а ее базовые возможности могут
быть значительно расширены за счет множества специальных функций.
246.
Набор микросхем Intel® X58 ExpressРекомендован для пользователей настольных ПК с процессорами
Intel® Core™ i7 или Intel® Core™ i7 Extreme Edition
Ключевые особенности
• Маштабируемость сочетания дискретной графики
PCI Express 2.0 (2x16 или 4x8)
• Поддержка мультимедиа в формате HD
• Поддержка 3-канальной памяти DDR3
• Intel® QuickPath Interconnect
• Поддержка 6-ти портов интерфейса SATA2 с
пропускной способностью до 3-х Гбит/c
• Поддержка 12-ти портов интерфейса USB 2.0 с
двумя независимыми EHCI-контроллерами
3-канала памяти
DDR3
QPI
или
Дискретная
графика
247.
Новая платформаCore
Thread
Thread
Core
Thread
Thread
Thread
Thread
Core
Thread
Thread
Core
8 “процессоров” Intel
Hyper-Threading
Новый сокет LGA 1366
8M shared L3
CH A
CH B
CH C
DDR3
IMC
QPI
Частоты ядер 2.66 (920),
2.93 (940), 3.2 (965 XE).
Turbo Boost (1/1/1/2)
130W TDP
4 ядра
45нм техпроцесс
X58
IOH
ICH9
ICH
ICH1
/
10/R
0
Общий, разделяемый
8MB L3
Шина Intel QuickPath
до 25GB/s
3 канала памяти DDR3
HEDT X58&ICH10
совместимый
Дискретная графика 2 X16
или 4 X8 PCIe 2.0
248. Новшества
Встроенный контроллер памятиТолько память DDR3 (Unbuffered
/Registered-Xeon 5500)
800/1066 (1333 через обновление BIOS в
Q1)
1Gb, 2Gb, 4Gb; x8 или x16 DRAM
1 или 2 ранга на DIMM
3 канала памяти c поддержкой XMP
Возможны любые конфигурации плат по
количеству модулей на канал
Минимальное к-во модулей – 1
Первым устанавливается “дальний от
сокета” модуль в канале
249.
GA-P55AUD4Чипсет
- Intel P55
Поддержка процессоров
- Intel Core i7/Core i5 Processors with LGA 1156
Поддержка памяти
- DDR3 2200+/1333/1066
- 2 Channel, 4 DIMMs
Графические интерфейсы
- 2 PCIE2.0 x16 slots (@x16 or @x8, x8)
Звук
- 8ch HD audio via ALC889(108dB) with Dolby
Сеть
- Gb LAN (Realtek 8111D)
Дополнительно
- USB3.0, SATA6Gb, 3x USB Power Boost
- 12 phase power
- UD3, DES2, Smart 6
- SLI / CrossFireX support
- eSATA in rear
- SATA RAID 0,1, 5, 10
- 1394a x3
- 3*PCIE x1+2 PCI
- ATX (305x244mm)
By : ProductDivision
250. Новая платформа
GA-MA78LM-S2HCPU
SocketAM2+(HT3.0);AM2/AM2+/AM3
CPU
Chipset
AMD 760G+SB710
Memory
Dual-Ch 2DIMM,DDR2 1200+MHz
Int.graphics
ATI Radeon HD 3000(DX10)
GraphicSlot
1*PCI-E 2.0x16
PCI Slot
2
PCI-Ex1Slot
1
Storage
4SATA 3.0Gb/s +1PATA
RAID
0, 1, 0+1,JOBD
LAN
1*GbELAN
1394
N/A
USB2.0
12ports[8onrearpanel,4by cable]
Audio
6/8-Ch ALC888B HDaudio
BIOS
DualBIOS™
Display
HDMI, DVI,D-sub
FormFactor
mATX(244x220)
By : ProductDivision
251. Встроенный контроллер памяти
Расширенная классификация ФлиннаSIMD
252. GA-P55A-UD4
Описание и схемы ВС для«наработки»(майнинга)
криптовалют. Пример
253. GA-MA78LM-S2H
Что такое майнинг и как этоработает?
Чтобы вносить в блокчейн информацию о транзакциях
(помним, что они происходят каждую секунду, и сведений
- вагон и маленькая тележка), нужно создавать новые
блоки. Блоки - это “структурная единица” блокчейна,
то, из чего он состоит, его мельчайшие части.
Собственно, процесс формирования таких блоков и
называется майнингом. Пользователи со всего мира
проводят
сложные
математические
операции
(естественно, не сами - для этого есть процессоры и
видеокарты) и получают криптовалюту.
254.
Распространенные ВС длямайнинга:
В настоящее время существует 2 основных типа ВС для добычи криптовалют:
1.Asic-майнеры- это специализированное оборудование, которое создается
исключительно под этот процесс. Эти устройства достаточно дорогие, а на
сегодняшний день еще и труднодоступные, поскольку очередь на покупку
таких устройств расписана больше, чем на 3 месяца.
Но такие устройства славятся своей высокой производительностью. Самым
популярным производителем асиков, является китайская компания Bitmain.
Она выпускает довольно таки обширный список устройств, которые в
основном отличаются предназначением (криптовалютой, которую майнят).
Так как Bitcoin, Litecoin, Dash и некоторые другие монеты более разумно
майнить именно на таких специальных аппаратах чем, например, на GPU
фермах.
2.Майнинг на видеокартах- это сборное оборудование, которое состоит, как
правило, из нескольких видеокарт.
Самые распространенные видеокарты для майнинга: GTX 1080Ti, GTX 1080,
RX 580, RX 570
255. Описание и схемы ВС для «наработки»(майнинга) криптовалют. Пример
Плюсы и минусы Asic-майнеров.Плюсы:
Более высокая производительность в сравнении с видеокартами
Работает «из коробки»: достал, включил, вбил кошелёк, начал майнить.
Окупается быстрее ферм.
Минусы:
Цена
Большой спрос, приходится ждать по несколько месяцев
Заточен под определенную криптовалюту, при желании добывать
другую, асик будет бесполезен
Аппарат выделяет большое количество тепла, поэтом к арендной плате
нужно прибавить и разовую установку хорошей вентиляции.
256. Что такое майнинг и как это работает?
Состав системыСпециальные ASIC-платы, которые размещаются в блоке устройства. Как правило, они расположены
параллельно и обдуваются потоком воздуха для отвода тепла.
Чипы (микропроцессоры) — главный исполнительный орган устройства, который выполняет
математические действия и обеспечивает быструю добычу блоков интересующей криптовалютной сети.
Блок памяти — элемент аппарата, гарантирующий его работоспособность и выполнение возложенных
задач.
Блок питания. Назначение блока заключается в преобразовании бытового напряжения 220 Вольт в
постоянный ток, которым питаются внутренние элементы схемы асик-майнера. При выборе блока
питания важно ориентироваться на его мощность.
Кулеры. Не секрет, что в процессе работы комплектующие для асика (в первую очередь
микропроцессоры) перегреваются. Чтобы исключить риск поломки дорогостоящего устройства,
устанавливаются вентиляторы. Их количество различается в зависимости от комплектации устройства
— от одного до четырёх. Кроме того, на микропроцессорах устанавливаются алюминиевые радиаторы,
которые принимают на себя тепло и увеличивают тем самым площадь обдува.
Разъёмы. Не секрет, что готовый ASIC-майнер (купленный или собранный своими руками) требуется
подключить к локальной сети и блоку питания. Для этих целей как раз и применяются разъёмы. При
самостоятельной сборке (так и в готовых устройствах) для подключения к Сети применяются Ethernetпорты.
Кожух. При личном изготовлении асика корпус может быть любым. Главные требования — возможность
отвода постороннего тепла и стойкость к механическим воздействиям. Что касается готовых асиков,
производители делают коробки из алюминия, обеспечивающего отличный теплообмен и отличающийся
стойкостью к ударам.
257. Распространенные ВС для майнинга:
Плюсы и минусы майнинга навидеокартах.
Плюсы:
Видеокарты всегда есть в продаже. Ну, или почти всегда. Зашёл, купил, поставил — вперёд!
В ближайшие два-три года они будут востребованы, поэтому их можно продать геймерам.
На эти же год-три даётся гарантия, позволяющая легко заменить горелую карточку на новую или
починить в сервисе.
ферму можно поставить дома — шумит не сильно, греется нормально.
Можно майнить разные криптовалюты — видеокарты поддерживают множество разных
алгоритмов.
Минусы:
Для сборки нужен какой-никакой опыт и прямые руки. Сжечь материнскую плату, процессор или
пару карт — раз плюнуть.
Ставить ОС и программное обеспечение тоже нужно уметь. Да, это может показаться забавным, но
в наши дни тоже далеко не все умеют устанавливать на компьютер ПО.
Фермы получаются довольно громоздкими.
Обычно они окупаются дольше ASIC.
258. Плюсы и минусы Asic-майнеров.
Пример сборки майнинг-фермы:Собирать будем ферму на 8 карт, не важно NVIDIA или AMD. 8 карт —
оптимальное количество, Windows без проблем работает с 8 картами, а
материнские платы под 8 карт стоят относительно дешево. Можно
приобрести материнские платы под 13 карт, но тогда вам придется
ставить Linux, да и цена таких материнских плат выше. Наш выбор — 8
карт.
Карты нужно выбирать по соотношению цена-качество. Нет времени
думать и искать? NVIDIA GTX 1060/1070 — неплохой вариант для старта,
карты с этими чипами производит большое количество производителей,
карты универсальны (подходят под Ethash и Equihash
алгоритмы). Настоятельно не рекомендуется перемешивать в одном
риге(пачке видеокарт) карты AMD и NVIDIA. Если выбрали AMD —
покупайте все 8 карт AMD, если NVIDIA — все 8 NVIDIA.
259. Состав системы
1.Каркас.на 8 карт: 1 500 руб.Не стоит тратить свое время на изготовление
каркаса самостоятельно, это сэкономит кучу времени и денег.
260. Плюсы и минусы майнинга на видеокартах.
2.Материнская плата.ASUS PRIME Z270P от 7 300
руб. Z270P поддерживает
установку 6 видеокарт,
плюс имеет два разъема M2,
в которые при помощи
переходника M2 на PCI-e
можно установить еще 2
видеокарты. Итого 8 штук.
261. Пример сборки майнинг-фермы:
3.Процессор.2 530 руб. Берем
самый дешевый
процессор на 1151
сокете, на майнинг
это не влияет.
Желательно сразу
брать вариант
комплектации BOX
(с кулером), чтобы
не тратить время на
его выбор, более
того у BOX
процессоров
гарантия дольше!
262. 1.Каркас.
4.Жесткий диск.3 800 руб. Только SSD.
Быстрая установка системы,
высокая скорость работы,
оно того стоит. Не экономьте!
Мы берем 80 ГБ с запасом,
однако можно уместиться и в
60 ГБ.
263. 2.Материнская плата.
5.Оперативная память.3 600 руб. DDR4.
Традиционно берем
Kingston. Одной плашки
4Gb будет достаточно, на
майнинг не влияет.
264. 3.Процессор.
6.Блоки питания.22 632 руб. Мы берем
хорошие Corsair CX750M с
запасом — 3 шт. на ферму.
Да, многие берут всякое
noname «китайское чудо»
на 1600 Вт. Говорят, даже
работает. У нас по три
блока на 8 карт,
подключаете без проблем
любые 8 карт (проводами
из комплекта Corsair) и
еще остается запас
мощности.
265. 4.Жесткий диск.
7.Райзеры.3200 руб. 8ш. на ферму
по 400 руб. Модель
007S — 100% рабочие,
проверенные
временем.
266. 5.Оперативная память.
8. Переходники M2-PCI.700 руб. Нужно 2шт на
ферму по 350 руб. Правда,
с ними часто бывают
проблемы, т.к.
производство Китай,
качество оставляет
желать лучшего.
267. 6.Блоки питания.
9.Синхронизатор Б\П.600 руб на ферму 2шт. по
300 руб. Мы берем
проводные. Можно
бесплатно вставить
скрепку или если у вас
китайский мощный БП
(один на все карты), вам
они вообще не нужны.
268. 7.Райзеры.
10. Watchdog1080 руб. WatchDog Pro 2.
Гениальное устройство —
сторожевой таймер, который
перезагружает вашу ферму, если
она зависла или пропал
интернет.
269. 8. Переходники M2-PCI.
Итого:47 242 руб + карты.Осталось только все подключить и запустить!
Останется только проверять свой кошелек и
считать заработанные средства!????
270. 9.Синхронизатор Б\П.
Сети ЭВМДля создания компьютерных сетей необходимо:
- специальное аппаратное обеспечение (сетевое
оборудование)
специальное программное обеспечение (сетевые
программные средства).
Простейшее соединение двух компьютеров для
обмена данными называется прямым соединением.
271. 10. Watchdog
Основные понятия сетиИнформационная сеть (вычислительная, компьютерная, коммуникационная сеть,
network) – это система распределенных на территории аппаратных,
программных и информационных ресурсов, связанных между собой каналами
передачи
данных.
Пакет
(кадр,
блок) – «порция» информации, передаваемая в сети.
Пакет (Packet)
Заголовок (Header) Данные (Data)
Абонент (узел, хост, станция) — это устройство, подключенное к сети и
активно участвующее в информационном обмене.
Абонент
Клиент
(Рабочая
станция)
Сервер
Выделенный
сервер
274
Невыделенный
сервер
272. Итого:47 242 руб + карты.
Классификации компьютерныхсетей
В зависимости от того, какие абоненты
входят в сеть:
– одноранговые сети
– сети с выделенным сервером.
По составу вычислительных средств:
– однородные – объединяют однородные вычислительные средства (компьютеры);
– неоднородные – объединяют различные вычислительные средства (например:
ПК, торговые терминалы, веб-камеры и сетевое хранилище данных).
По способу связи:
– проводные;
– беспроводные.
По масштабности выделяют:
– локальные (ЛВС, LAN, Local Area Network) сети;
– региональные (MAN, Metropolitan Area Network) сети;
– глобальные (WAN, Wide Area Network или GAN, Global Area Network) сети.
Корпоративные сети, как и региональные, могут иметь черты как локальных, так и
глобальных сетей.
275
273. Сети ЭВМ
274. Основные понятия сети
Сети ЭВМВ соответствии с используемыми протоколами
компьютерные сети принято разделять:
локальные (LAN – Local Area Network) и глобальные
(WAN – Wide Area Network).
275. Классификации компьютерных сетей
Типы локальных сетейКомпьютер,
подключенный
к
вычислительной сети, называется рабочей
станцией или сервером.
Различают сети:
- с одним или несколькими выделенными
серверами
- сети без выделенных серверов, называемые
одноранговыми сетями.
276. Сети ЭВМ
ЛВС с выделенным серверомПри выборе компьютера на роль файлового сервера
необходимо учитывать следующие факторы:
быстродействие процессора;
скорость доступа к файлам, размещенным на жестком диске;
емкость жесткого диска;
объем оперативной памяти;
уровень надежности сервера;
степень защищенности данных.
277. Сети ЭВМ
Одноранговые ЛВСВ одноранговых сетях любой компьютер
может быть и файловым сервером, и рабочей
станцией одновременно.
278. Типы локальных сетей
Основные характеристики информационных сетейСамое общее требование, которое можно высказать в отношении работы сети –
это выполнение сетью того набора услуг, для оказания которых она предназначена.
Основные требования, предъявляемые к информационным сетям:
– Производительность
– Надежность
– Расширяемость и масштабируемость
– Прозрачность
– Управляемость
– Совместимость
Основные характеристики производительности сети:
– время реакции;
– скорость передачи трафика;
– пропускная способность;
– задержка передачи.
Для оценки надежности сложных систем применяется набор характеристик:
–готовность;
–сохранность данных;
–согласованность (непротиворечивость) данных;
–вероятность доставки данных;
–безопасность;
281
–отказоустойчивость.
279. ЛВС с выделенным сервером
Основные характеристики информационных сетейРасширяемость (extensibility) – возможность сравнительно легкого добавления
отдельных элементов сети (пользователей, компьютеров, приложений, служб),
наращивания длины сегментов сети и замены существующей аппаратуры более
мощной.
Масштабируемость (scalability) означает, что сеть позволяет наращивать
количество узлов и протяженность связей в очень широких пределах, при этом
производительность сети не ухудшается.
Прозрачность — свойство сети скрывать от пользователя детали своего
внутреннего устройства, что упрощает работу в сети.
Управляемость сети подразумевает возможность централизованно
контролировать состояние основных элементов сети, выявлять и решать
проблемы, возникающие при работе сети, выполнять анализ производительности
и планировать развитие сети.
Совместимость (интегрируемость) означает, что сеть может включать в себя
разнообразное программное и аппаратное обеспечение, то есть в ней могут
сосуществовать различные операционные системы, поддерживающие разные
стеки коммуникационных протоколов, и работать аппаратные средства и
приложения от разных производителей.
282
280. Одноранговые ЛВС
Основные стандарты сетейСтандарты сетей определяют принятую в сети среду передачи, топологию,
метод доступа, кодирование информации, формат пакета (кадра).
Исходя из этого определяется предельный размер сети, скорость передачи,
предельное число абонентов и т.д.
Большинство стандартов физических сетей разработано или одобрено
комитетом 802 IEEE (Институт инженеров по электротехнике и
электронике, Institute of Electrical and Electronics Engineers).
Физические сети
Проводные:
• Ethernet, Fast Ethernet, Gigabit
Ethernet...
• Arcnet
• Token-Ring
• 100VG-AnyLAN
• FDDI
Виртуальные сети (VPN)
Беспроводные:
• Bluetooth
• Wi-Fi
• WiMAX
• GPRS
283
281. Основные характеристики информационных сетей
Сети ЭВМСогласно модели ISO/OSI архитектуру
компьютерных
сетей
следует
рассматривать на разных уровнях (общее
число уровней – до семи).
Самый верхний уровень – прикладной.
Самый нижний уровень – физический.
282. Основные характеристики информационных сетей
Эталонная модель взаимодействия открытыхсистем
(ЭМВОС, OSI – Open Systems Interconnection Basic Reference Model)
Уровни взаимодействия:
7. Прикладной
6. Представления
Программное обеспечение
5. Сеансовый
4. Транспортный
- промежуточный уровень
3. Сетевой
2. Канальный
Аппаратное обеспечение
1. Физический
285
283. Основные стандарты сетей
Основные сетевые устройства– кабели для передачи информации;
– разъемы для присоединения кабелей;
– терминаторы;
– сетевые адаптеры;
– репитеры;
– трансиверы;
– концентраторы (хабы);
– коммутаторы (свичи);
– маршрутизаторы (роутеры);
– мосты;
– шлюзы.
Средой передачи информации называются те линии связи, по которым
производится обмен информацией между абонентами.
•сетевой кабель:
–коаксиальный кабель;
–витая пара;
–оптоволоконный кабель;
•беспроводная связь.
Среда передачи характеризуется максимальной скоростью и расстоянием
передачи,
полосой
пропускания,
помехоустойчивостью
и
286
взломозащищенностью.
284. Сети ЭВМ
Витая параВ настоящее время наиболее распространенный
тип кабеля для локальных сетей.
Может быть экранированной и
неэкранированной.
Полоса пропускания 250-1000МГц, расстояние
передачи до 100м, скорость от 10Мбит/с до
40ГБит/С.
Категории кабеля от CAT1 (телефон) до CAT7a
(40GbEthernet). Самый распространенный CAT5.
Для присоединения витой пары используются
разъемы (коннекторы) типа 8P8C (RJ-45).
Чаще всего витые пары используются в
топологиях типа звезда или кольцо.
287
285. Эталонная модель взаимодействия открытых систем
Коаксиальныйкабель
Был сильно распространен до недавнего
времени. В настоящее время считается
устаревшим.
Чаще всего используется в сетях с
топологией шина, реже – звезда.
Высокая
защищенность
благодаря
экранированию.
Широкая
полоса
пропускания до 1ГГц.
Монтаж кабеля значительно труднее и
дороже (в 1,5-2 раза, чем витой пары).
Скорости до 10МБ/сек, расстояние
передачи – 100-500м.
288
286. Основные сетевые устройства
Оптоволоконныйкабель
Передается не электрический сигнал, а
световой импульс.
Сильная
помехозащищенность
взломоустойчивость.
и
Широкая
полоса
пропускания
(до
1000ГГц), высокая скорость (до терабит в
сек.) и расстояние передачи (тысячи км).
Виды: одномодовый, многомодовый.
Высокая
стоимость
и
трудность
прокладки.
Требуются
специальное
оборудование
для
преобразования
электрического сигнала в световой и
обратно.
Малейшие ошибки в его
установке или повреждение кабеля
сильно
искажают
или
полностью
нарушают передачу.
289
287. Витая пара
Беспроводная связьРадиоканал – наиболее распространенный канал беспроводной связи.
Особенность радиоканала состоит в том, что сигнал свободно излучается в
эфир, он не замкнут в кабель, поэтому возникают проблемы совместимости с
другими источниками радиоволн (радио- и телевещательными станциями,
радарами, радиолюбительскими и профессиональными передатчиками и т.д.).
Главными недостатками радиоканала является его плохая защита от
прослушивания и слабая помехозащищенность.
Радиоканал широко применяется в глобальных сетях как для наземной,
так и для спутниковой связи. В этом применении у радиоканала нет
конкурентов, так как радиоволны могут дойти до любой точки земного шара.
Иногда используют инфракрасный канал. Главное его преимущество по
сравнению с радиоканалом – нечувствительность к электромагнитным
помехам.
Все беспроводные каналы связи подходят для топологии типа шина, в
которой информация передается одновременно всем абонентам. Но при
использовании узконаправленной передачи и/или частотного разделения по
каналам можно реализовать любые топологии.
290
288. Коаксиальный кабель
Беспроводная связьСуществует два основных направления применения беспроводных
компьютерных сетей:
• Работа в замкнутом объеме (в пределах помещения);
• Соединение удаленных локальных сетей (или удаленных сегментов
локальной сети).
По дальности действия:
• Беспроводные персональные сети (WPAN — Wireless Personal Area
Networks). Bluetooth.
• Беспроводные локальные сети (WLAN — Wireless Local Area Networks). WiFi.
• Беспроводные сети масштаба города (WMAN — Wireless Metropolitan
Area Networks). WiMAX.
• Беспроводные глобальные сети (WWAN — Wireless Wide Area Network).
CSD, GPRS, EDGE, EV-DO, HSPA.
Поскольку радиоканал не обеспечивает высокой степени защиты от
прослушивания, необходимо использовать специальные механизмы защиты
информации: аутентификация для противодействия несанкционированному
доступу к сети и шифрование для предотвращения
перехвата информации.
291
289. Оптоволоконный кабель
Сравнение беспроводных технологийТехнологи
Стандарт
я
802.11a
802.11b
802.11g
Wi-Fi
Сеть
Локальная
802.11n
WiMax
Bluetooth
802.16d
802.16e
802.15.1
802.15.3
Региональная
802.11
Инфракрасная
линия
связи
Персональная
IrDa
Пропускная
способность
до 54 Мбит/с
до 11 Мбит/с
до 54 Мбит/с
Радиус
действия
300 м
300 м
300 м
до 450 Мбит/с
300 м
до 75 Мбит/с
до 40 Мбит/с
до 1 Мбит/с
до 2,1 Мбит/с
от 3 Мбит/с до 24
Мбит/с
25-80 км
1-5 км
10 м
100 м
5,0 ГГц
2,4 ГГц
2,4 ГГц
2,4 — 2,5 или
5,0 ГГц
1,5-11 ГГц
2,3-13,6 ГГц
2,4 ГГц
2,4 ГГц
100 м
2,4 ГГц
до 16 Мбит/с
292
Частоты
5-50см,
одноИнфракрасное
сторонняя – излучение
10 м
290. Беспроводная связь
Wi-Fi (Wireless Fidelity)— торговая марка Wi-Fi Alliance для беспроводных сетей набазе стандарта IEEE 802.11. Это целое семейство беспроводных сетей и
стандартов.
802.11 - первоначальный стандарт WLAN (1-2 Мбит/с).
802.11a -54 Мбит/c, частота 5 ГГц
802.11b - 5,5 и 11 Мбит/с, частота 2,4 ГГц
802.11g - 54 Мбит/c, частота 2,4 ГГц (обратная совместимость с b)
Другие спецификации устанавливают требования к качеству, порядок связи для
равноправных абонентов, решают проблемы безопасности, особенности для
стран и регионов и др.
Метод доступа к сети – CSMA/CA (Carrier Sense Multiple Access/Collision
Avoidance). Сеть строится по сотовому принципу.
Оборудование включает
• точки беспроводного доступа (Access Point, = мост + концентратор)
• беспроводные адаптеры для каждого абонента.
Каждая точка доступа может обслуживать несколько абонентов, но чем
больше абонентов, тем меньше скорость передачи для каждого из них. Также
293
возможно подключение двух клиентов в режиме точка-точка (Ad-hoc).
291. Беспроводная связь
WiMAXWireless MAN разработан с целью предоставления универсальной
беспроводной связи на больших расстояниях для широкого спектра устройств
(от рабочих станций и портативных компьютеров до мобильных телефонов).
Стандарт IEEE 802.16.
WiMAX следует считать жаргонным названием, так как это не технология, а
название форума, на котором Wireless MAN и был согласован.
WiMAX позволяет осуществлять доступ в Интернет на высоких скоростях, с
гораздо большим покрытием, чем у Wi-Fi-сетей. Подходит для решения задач:
• Соединения точек доступа Wi-Fi друг с другом и другими сегментами
Интернета.
• Обеспечения беспроводного широкополосного доступа как альтернативы
выделенным линиям.
• Предоставления высокоскоростных сервисов передачи данных и
телекоммуникационных услуг.
• Создания точек доступа, не привязанных к географическому положению.
294
292. Сравнение беспроводных технологий
Беспроводная связь между устройствами на расстоянии до 100 метров.Спецификация IEEE 802.15.1 Версии 1.0-4.0 с различными скоростями
передачи (1-24Мбит/с).
Применяется метод расширения спектра со скачкообразной перестройкой
частоты (FHSS): несущая частота сигнала скачкообразно меняется 1600 раз в
секунду.
Последовательность переключения между частотами для каждого
соединения является псевдослучайной и известна только передатчику и
приёмнику, которые каждые 625 мкс (один временной слот) синхронно
перестраиваются с одной несущей частоты на другую. Таким образом, если
рядом работают несколько пар приёмник-передатчик, то они не мешают друг
другу.
Этот алгоритм является также составной частью системы защиты
конфиденциальности передаваемой информации: переход происходит по
псевдослучайному алгоритму и определяется отдельно для каждого
соединения.
295
293.
Сетевой адаптерНазначение сетевого адаптера (сетевой карты) – сопряжение компьютера (или
другого абонента) с сетью, т.е. обеспечение обмена информацией между
абонентом и каналом связи в соответствии с принятыми правилами обмена
(протоколом).
ЦПУ
Магистральные
функции
Память
...
Компьютер
Шина
(магистраль
)
Сетевые
функции
Сетевой
адаптер
Буфе
р
296
Сеть
294. WiMAX
Промежуточные сетевыеустройства
Репитеры или повторители (repeater) только восстанавливают ослабленные
сигналы (их амплитуду и форму), приводя их к исходному виду. Цель –
увеличение длины сети.
Трансиверы или приемопередатчики (от английского
TRANsmitter + reCEIVER) служат для передачи информации
между адаптером и кабелем сети или между двумя
сегментами
сети.
Трансиверы
усиливают
сигналы,
преобразуют их уровни или преобразуют сигналы в другую
форму (например, из электрической в световую и обратно, из
проводного сигнала в беспроводной).
Репитеры так же как трансиверы не производят никакой информационной
обработки проходящих через них сигналов.
297
295.
Промежуточные сетевыеустройства
Концентратор (хаб, hub) служит для объединения в общую сеть нескольких
сегментов. Любой пришедший пакет передается всем подключенным к
концентратору устройствам.
Концентраторы представляют собой несколько собранных воедино
репитеров и выполняют те же функции.
298
296. Сетевой адаптер
Промежуточные сетевыеустройства
Коммутатор (свич, коммутирующий концентратор, switch), как и
концентраторы, служат для соединения сегментов в сеть, но выполняют
более сложные функции, производя сортировку поступающих на них пакетов.
Выполняет фильтрацию пакетов, и отправляет только в нужном
направлении. Определяет направление передачи на основе таблицы
коммутации MAC-адресов.
299
297. Промежуточные сетевые устройства
Мосты, маршрутизаторыи шлюзы служат для объединения в одну сеть
нескольких разнородных сетей.
Мосты (bridge) – наиболее простые устройства, служащие для
объединения сетей с разными стандартами обмена. Если подключить к мосту
одинаковые сети, то работает как и коммутатор.
В отличие от коммутаторов мосты принимают поступающие пакеты
целиком и в случае необходимости производят их простейшую обработку.
300
298. Промежуточные сетевые устройства
Маршрутизатор (router)осуществляют выбор оптимального маршрута
для каждого пакета для снижения нагрузки на сеть и обхода поврежденных
участков.
Применяются в сложных разветвленных сетях, имеющих несколько
маршрутов между отдельными абонентами. Решение о выборе маршрута
выполняется на основе таблицы маршрутизации (IP-адресов).
Существуют
также
гибридные
маршрутизаторы
(brouter),
представляющие собой гибрид моста и маршрутизатора. Они выделяют
пакеты, которым нужна маршрутизация и обрабатывают их как
маршрутизатор, а для остальных пакетов служат обычным мостом.
301
299. Промежуточные сетевые устройства
Шлюз (gateway) – это устройство для соединения сетей с сильноотличающимися протоколами, например, для соединения локальных сетей с
большими компьютерами или с глобальными сетями.
Это самые дорогие и редко применяемые сетевые устройства. Шлюзы
реализуют связь между абонентами на верхних уровнях модели OSI (с
четвертого по седьмой).
Сетевой шлюз — это точка сети, которая служит выходом в другую сеть.
Сетевые шлюзы могут быть аппаратным решением, программным
обеспечением или тем и другим вместе, но обычно это программное
обеспечение, установленное на роутер или компьютер. Сетевой шлюз часто
объединен с роутером, который управляет распределением и конвертацией
пакетов в сети.
302
300. Промежуточные сетевые устройства
Сети ЭВМПротоколы:
- аппаратного взаимодействия компонентов сети
(аппаратные протоколы). Физически эти функции
исполняют аппаратные устройства (интерфейсы).
- взаимодействие программ и данных (программные
протоколы). Физически эти функции исполняют
программные
средства
(программы
поддержки
протоколов).
301. Промежуточные сетевые устройства
Топология сетиТопология сети:
- Шинная.
- Звездообразная.
- Кольцевая.
302. Промежуточные сетевые устройства
Шинная структураВ случае реализации
шинной структуры все
компьютеры связываются
в цепочку.
303. Сети ЭВМ
Звездообразная архитектураПри
звездообразной
архитектуре в центре сети
необходимо
поместить
концентратор (hub).
304. Топология сети
Кольцевая структураКольцевая структура
используется в сетях Token
Ring и мало чем отличается
от шинной.
305. Шинная структура
Глобальные сетиДля работы в Интернете необходимо:
физически подключить компьютер к одному из узлов
Всемирной сети;
получить IP-адрес на постоянной или временной основе;
установить и настроить программное обеспечение.
306. Звездообразная архитектура
Основные протоколыПротоколы можно разделить на:
Прикладной.
Транспортный.
Сетевой.
307. Кольцевая структура
ИнтернетДень
рождения
Интернета
Дата
стандартизации протокола связи TCP/IP (1983 год).
TCP/IP – это два протокола, лежащих на
разных уровнях:
Протокол TCP – протокол транспортного уровня.
Протокол IP – адресный. Он принадлежит сетевому
уровню и определяет, куда происходит передача.
308. Глобальные сети
ИнтернетСлужбы Интернета:
Терминальный режим – Telnet.
Электронная почта (E-Mail).
Службы рассылок (Mail List).
Специальный прикладной протокол (FTP).
Служба телеконференций (Usenet).
WWW. World Wide Web («Всемирная паутина»).
309. Основные протоколы
Адреса ИнтернетАдрес URL состоит из трех частей:
Имя прикладного протокола, обеспечивающего доступ к ресурсам Интернет.
Например, для WWW прикладным протоколом является протокол HTTP (Hyper Text Transfer
Protocol):
http://…
доменное имя компьютера (сервера), на котором хранится данный ресурс:
http://www.ksu.ru
имя службы Интернет
суффикс принадлежности сервера
( домен 3-го уровня)
имя доменного сервера(домен второго уровня)
полный путь доступа к файлу на данном компьютере.
Таким образом, адрес файла в сети интернет будет записан в виде:
http://www.ksu.ru/ files/physfac/astro.htm
имена каталогов
имя файла web-страницы
310. Интернет
Стекпротоколов
TCP/IP
OSI
TCP/IP
Протоколы
7. Прикладной
6. Представления
5. Прикладной
DNS, HTTP (WWW), FTP, SMTP,
TFTP, NFS,...
5. Сеансовый
4. Транспортный
4.
Транспортный
TCP
ARP,
RARP
3. Сетевой
3. Сетевой
2. Канальный
2. Звена данных
1. Физический
1. Физический
UDP
ICM
IGMP
P
RIP, OFSP,
BPG
IP
313
Протоколы определяются
стандартом сети
311. Интернет
Сетевой уровеньСетевой уровень (Network Layer — NL) служит для образования сквозной
транспортной системы между оконечными устройствами пользователя через
все промежуточные сети связи – "из конца в конец".
Сетевые протоколы управляют адресацией, маршрутизацией, проверкой
ошибок и запросами на повторную передачу.
Логическая адресация. Необходима универсальная система адресации, в
которой каждый хост может быть идентифицирован уникально, независимо
от основной физической сети.
Маршрутизация. Чтобы передать пакет, средства сетевого уровня
собирают информацию о топологии сетевых соединений и используют ее для
выбора наилучшего пути.
Модель OSI допускает два основных метода взаимодействия абонентов в
сети:
– метод взаимодействия без логического соединения (метод
дейтаграмм);
– метод взаимодействия с логическим соединением.
314
312. Адреса Интернет
Протоколы сетевого уровняIP – протокол адресации
ARP
протоколы прямого и обратного отображения адресов
RARP
ICMP – протокол служебных сообщений
IGMP – протокол управления группами
RIP
OFSP
протоколы маршрутизации
BGP
315
313. Стек протоколов TCP/IP
Протокол IPПротокол включает описание адресации и структуры пакета.
IP – ненадежная служба доставки пакета без установления соединения, но
с "максимальными усилиями" (best-effort).
Пакет IP – дейтаграмма.
Каждая дейтаграмма транспортируется отдельно, может меняться их
порядок, они могут теряться и дублироваться. Маршрут не сохраняется.
Версии протокола IP:
– 4 версия (IPv4);
• классовая система адресации;
• бесклассовая система;
– 5 версия (не реализована);
– 6 версия (IPv6).
316
314. Сетевой уровень
IP-адресацияЗадача - обеспечить глобальную связь между всеми устройствами.
К IP-адресу предъявляются следующие требования:
– универсальность (два устройства в Интернете никогда не могут иметь
одного того же адреса);
– иерархичность;
– универсальность (для всех узлов);
– удобство.
317
315. Протоколы сетевого уровня
IP-адресация версии 4Стандарт протокола RFC 791.
Адресное пространство:
IP-адрес версии 4 состоит из 4 байт (32 бита). Максимальное число адресов
составляет 232 = 4 млрд. В реальности это число меньше, из-за наличия
зарезервированных диапазонов.
Способ представления:
двоичный
10010001 11011101 01010101 10010100
десятичный с точками
145.219.85.148
шестнадцатеричный
0x91dd5594
Примеры
10000001 00001011 00001011 11101111
11000001 10000011 00011011 11111111
111.56.45.78
75.45.34.78
0x810B0BEF
0xC1831BFF
Неверные IP-адреса:
111.56.045.78, 221.34.7.8.20, 75.45.301.14
318
316. Протокол IP
Классовая система адресацииIP-адрес разделен на сетевой (Netid) и локальный (Hostid) адреса. При
адресации по классам каждый класс разделен на фиксированное число
блоков, и каждый блок имеет фиксированный размер.
Макс.
Первые Наименьши
Макс.
число
Наибольший
Класс
биты IPй номер
число
узлов в
номер сети
адреса
сети
сетей
каждой
сети
A Большие
0
0.0.0.0
127.0.0.0
27 – 2
224 – 2
сети
B Средние сети 10
128.0.0.0
191.255.0.0
214 – 2
216 – 2
C Малые сети 110
192.0.0.0
223.255.255.0
221 – 2
28 – 2
D Групповые
1110
224.0.0.0
239.255.255.255 15 x 224
–
адреса
E Резерв
11110
240.0.0.0
255.255.255.255 7 x 224
–
1
бит
1
1
2
бит
1
3
бит
0
0
0
Класс A
Класс B
319
Класс
C
4
бит
0
Класс D
1
Класс E
317. IP-адресация
Бесклассовая система адресацииМаска определяет биты, относящиеся к Netid.
192.0.2.32/27
Октеты IP-адреса
192
0
2
32
Биты IP-адреса
11000000
00000000
00000010
00100000
Биты маски подсети
11111111
11111111
11111111
11100000
Октеты маски подсети
255
255
255
224
Количество адресов подсети не равно количеству возможных узлов.
Нулевой адрес IP резервируется для идентификации подсети, последний — в
качестве широковещательного адреса, таким образом в реально
действующих сетях возможно количество узлов на два меньшее количества
адресов.
Каждому классу соответствует маска подсети по умолчанию.
320
318. IP-адресация версии 4
Специальные адресаСпециальный адрес
Netid
Hostid
Назначение
Пример
Сетевой адрес
Заданный Все нули
Нет
75.10.0.0/16
Прямой
широковещательный
адрес
Заданный Все
единицы
Получатель
75.10.255.255/16
Ограниченный
широковещательный
адрес
Все
единицы
Все
единицы
Получатель
255.255.255.255
"Этот хост на этой сети"
Все нули
Все нули
Источник
0.0.0.0/8
"Заданный хост на этой
сети"
Все нули
Заданный
Получатель
0.0.121.5/8
Локальный адрес
(loopback)
127
Любой
Получатель
127.0.0.1/8
Групповые рассылки
224.0.0
Любой
Получатель
224.0.0.1/24
Конференц-связь
224.0.1
Любой
Получатель
224.0.1.16/24
Диапазоны, выделенные для локальных сетей в IPv4:
10.x.x.x
172.16.x.x-172.31.x.x
321
192.168.x.x
319. Классовая система адресации
Типы IP-адресовСтатический IP-адрес назначается пользователем в настройках устройства,
либо единоразово назначается автоматически при подключении устройства к
сети и не может быть присвоен другому устройству.
Динамический IP-адрес назначается автоматически при подключении
устройства к сети и используется в течение ограниченного промежутка
времени, указанного в сервисе назначавшего IP-адрес.
Для получения IP-адреса чаще всего используют протокол DHCP.
Частный IP-адрес (внутрисетевой, «серый») используется внутри локальной
сети. Назначение таких адресов никто не контролирует, в глобальном
масштабе они могут быть неуникальны.
Для выхода в глобальную сеть хосты с частными IP-адресами могут
использовать:
• прокси-сервер;
• маршрутизатор, поддерживающий NAT (Network Address Translation).
322
320. Бесклассовая система адресации
Структура пакета IPv4Бит №
0
0-3
4-7
Размер
Версия заголовк
а
32
64
8-13
14-15
DSCP
ECN
Идентификатор
TTL
16-18
19-31
Размер пакета
Флаги
Протокол
Смещение
фрагмента
Контрольная сумма заголовка
96
128
160
Адрес источника
Адрес приемника
Опции (если размер заголовка > 5)
...
Данные
Размер заголовка в 4-байтных словах – от 5 до 15.
Размер заголовка в байтах, включая заголовок – от 20 до 65,5 тыс.
TTL (Time to Live) Время жизни пакета
В флагах указывается, есть ли другие фрагменты
этого пакета
323
321. Специальные адреса
IP-адресация версии 6Стандарт протокола RFC 2460.
Адресное пространство:
IP-адрес версии 6 состоит из 16 байт (128 бит). Максимальное число
адресов составляет 2128 = 3,4*1038 или около 5*1028 на каждого жителя Земли.
Из-за иерархичности IPv6-адреса, не все возможные адреса будут
использованы.
Способ представления:
Предпочтительная форма (шестнадцатеричная система счисления с
двоеточием)
FEDC:BA98:7654:3210:FEDC:BA98:7654:3210.
Сжатая форма – запись длительной последовательности "0" путем
введения двойного двоеточия. Двойное двоеточие допускается
использовать только в одном месте адреса.
1080:0000:0000:0000:0008:0800:200C:417A => 1080::8:800:200C:417A
1::F56::8:801:20D => ?
Смешанная форма – шесть старших чисел (96 бит) записываются в сжатой
форме, а младшие числа (32 бита) представляются в виде, принятом в IPv4.
0:0:0:0:0:0:D:1:44:3 => ::D:1:0.68.0.3
324
322. Типы IP-адресов
IP-адресация версии 6Стандарт протокола RFC 2460.
Адресное пространство:
IP-адрес версии 6 состоит из 16 байт (128 бит). Максимальное число
адресов составляет 2128 = 3,4*1038 или около 5*1028 на каждого жителя Земли.
Из-за иерархичности IPv6-адреса, не все возможные адреса будут
использованы.
Способ представления:
Предпочтительная форма (шестнадцатеричная система счисления с
двоеточием)
FEDC:BA98:7654:3210:FEDC:BA98:7654:3210.
Сжатая форма – запись длительной последовательности "0" путем
введения двойного двоеточия. Двойное двоеточие допускается
использовать только в одном месте адреса.
1080:0000:0000:0000:0008:0800:200C:417A => 1080::8:800:200C:417A
1::F56::8:801:20D => ?
Смешанная форма – шесть старших чисел (96 бит) записываются в сжатой
форме, а младшие числа (32 бита) представляются в виде, принятом в IPv4.
0:0:0:0:0:0:D:1:44:3 => ::D:1:0.68.0.3
325
323. Структура пакета IPv4
Типы IPv6-адресовПрефикс – начало адреса, определяющее тип пакета. Длина префикса
записывается после адреса через / (как маска в IPv4).
Индивидуальный адрес
(Unicast) с префиксом
единственный интерфейс. Имеет иерархическую структуру.
110
определяет
110
регистраци поставщик абонент
подсеть
узел
я
Групповой адрес (Anycast) – доставка любому (ближайшему) узлу из
группы. Используется только маршрутизаторами. Префикс 1111111010.
Многоадресный адрес (Multicast) – аналог широковещательных адресов
IPv4, префикс 11111111.
::/128
«этот хост этой сети», аналог 0.0.0.0
::1/128
loopback, аналог 127.0.0.1
::ffff:xx.xx.xx.xx/96
адрес IPv4, отображенный на IPv6
fe80:: - febf::/10
link-local (Адрес местной линии)
fec0:: - feff::/10
site-local (Местный адрес сайта, устарел)
fc00::/7
Unique Local Unicast (вместо site-local)
326
324. IP-адресация версии 6
Структура пакета IPv6Байт
0
4
820
2436
37...
...
0
1
2
3
16-23
24-31
Метка потока
След. заголовок
Hop Limit
Бит
0-3
4-11
12-15
0
Версия Класс трафика
32
Длина полезной нагрузки
64IP-адрес отправителя
160
192IP-адрес получателя
288
320Расширенные заголовки
...
....
Данные
IPv6 предполагает возможность отправки больших пакетов (джамбограмм) до
4Гбит, но старые протоколы транспортного уровня (TCP, UDP) не
поддерживают такой размер пакетов.
327
325. IP-адресация версии 6
326. Типы IPv6-адресов
327. Структура пакета IPv6
328.
329.
Расширенная классификация ФлиннаSIMD
330.
TOP 500 ноябрь 2021На втором месте находится система Fugaku с производительностью в 442,01 петафлопс. Один PFLOPS –
это 1015 FLOPS.
За время, прошедшее с момента публикации предыдущего рейтинга в ноябре 2022 года, два
суперкомпьютера из первой десятки сумели улучшить свои результаты. Однако этого оказалось
недостаточно для того, чтобы приблизиться к двум лидерам. Эти двое – LUMI и Leonardo – заняли третье
и четвертое места.
Десятка самых быстрых суперкомпьютеров в мире представлена теми же моделями, что и в прошлый раз,
расположившимися с том же порядке.
Измерение скорости производилось при выполнении эталонного теста High Performance Linpack (HPL),
оценивающего, насколько хорошо система решает систему линейных уравнений с плотной матрицей.
Половина из десяти самых быстрых суперкомпьютеров развернута в США, два находятся в Китае и по
одному в Финляндии, Италии и Японии.
Помимо лидерства в скорости Frontier занял первое место и в части пригодности с выполнению функций
искусственного интеллекта по классификации HPL-MxP.
Frontier и LUMI попали также в первую десятку по критерию эффективности энергопотребления,
измеряемой в гигафлопсах в пересчете на ватт. Frontier занял шестое место с результатом 52,592
GFLOPS/Вт, а LUMI – седьмое (51,382 GFLOPS/Вт).
Наибольшую эффективность энергопотребления продемонстрировала система Henri, развернутая в
Flatiron Institute в Нью-Йорке (65,396 GFLOPS/Вт).