




















































































































































































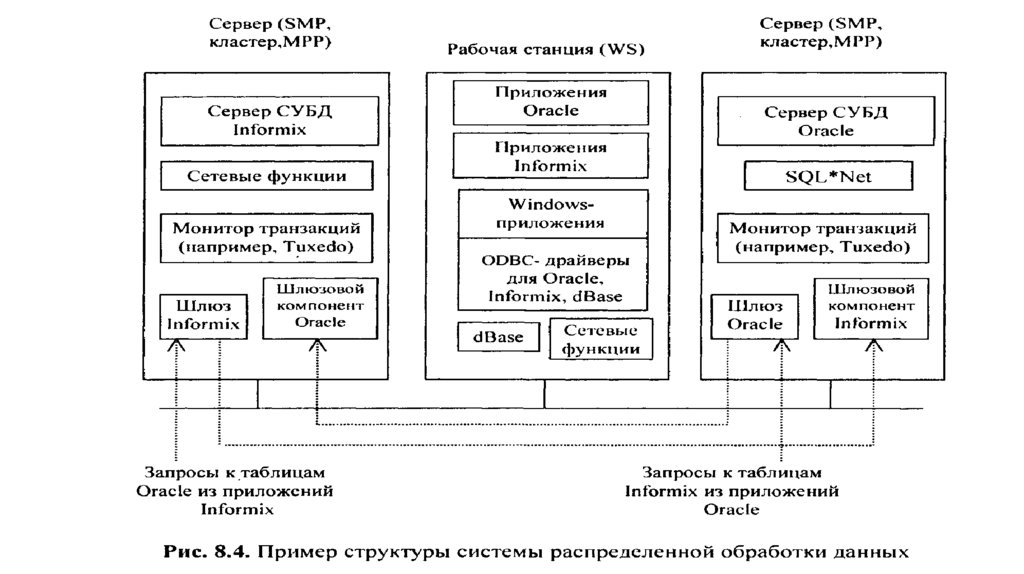


































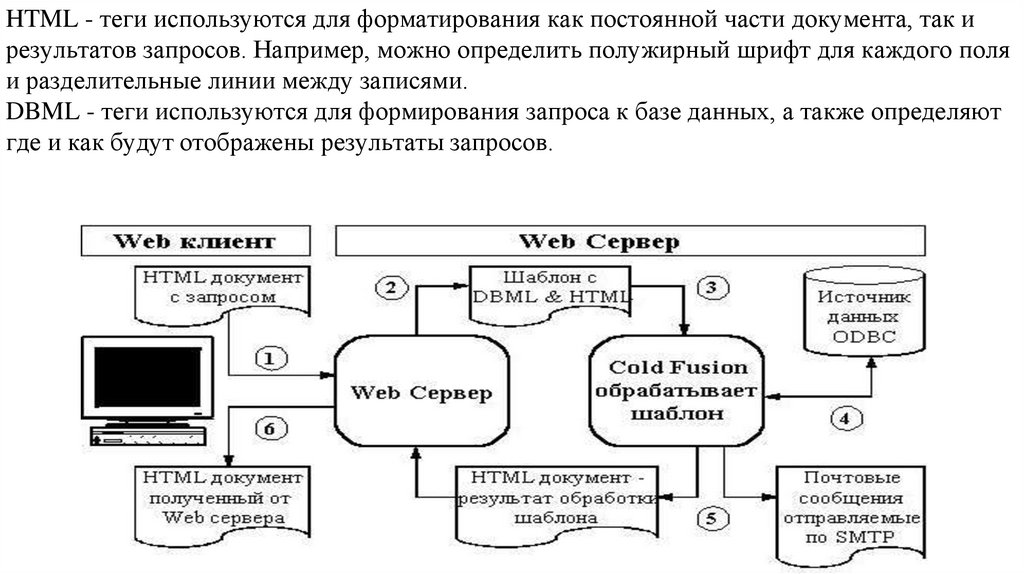

























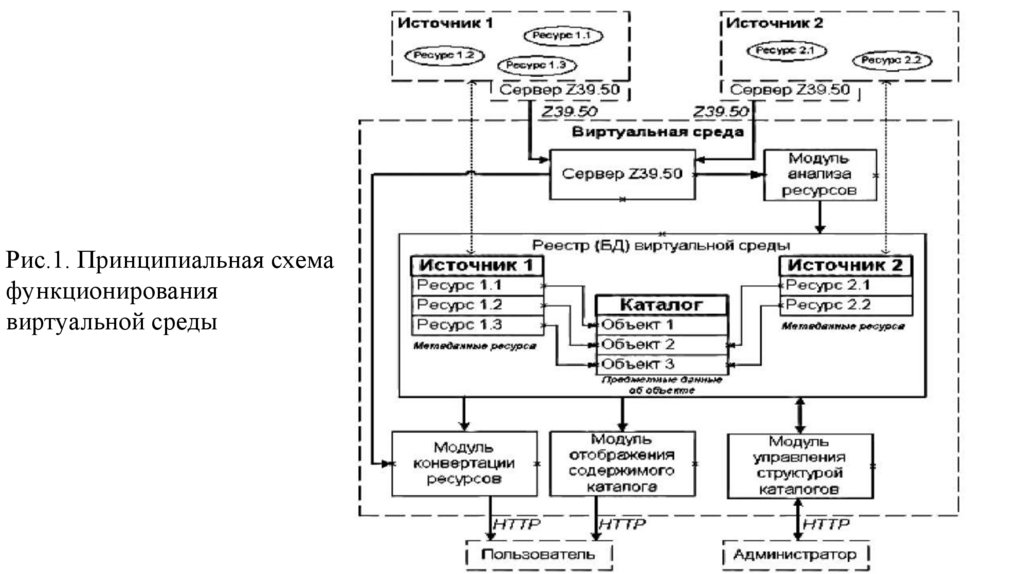
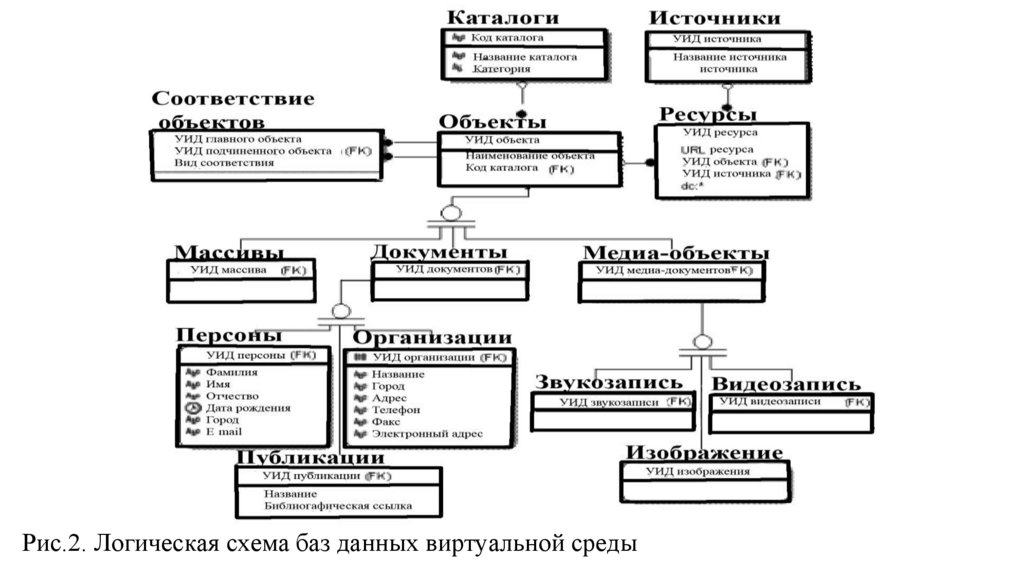














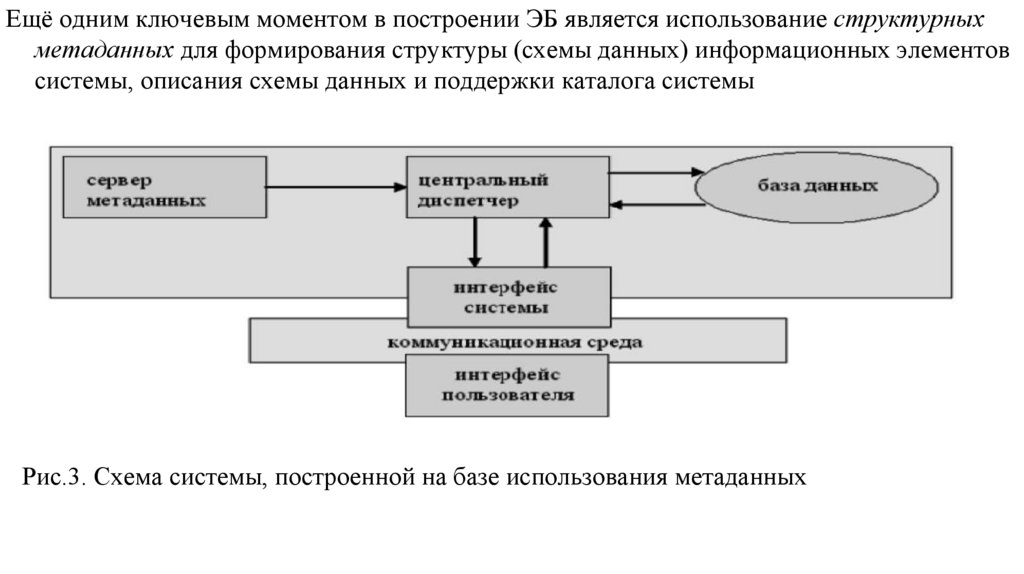

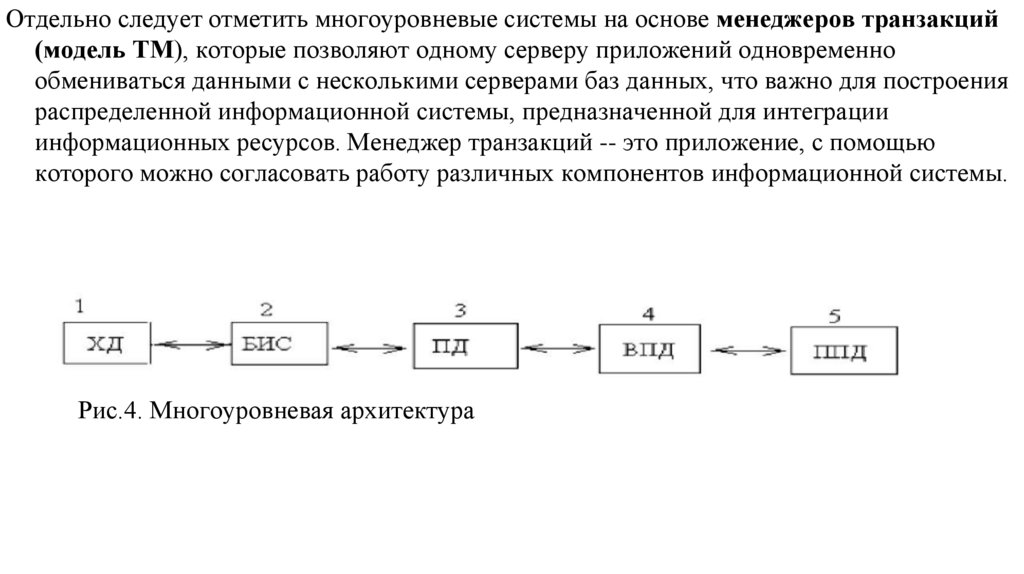


















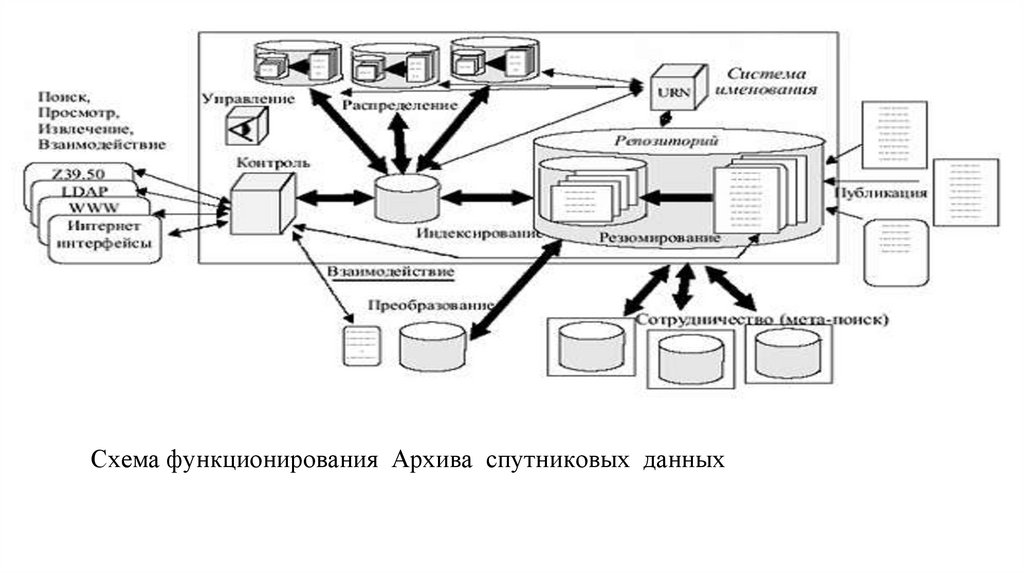
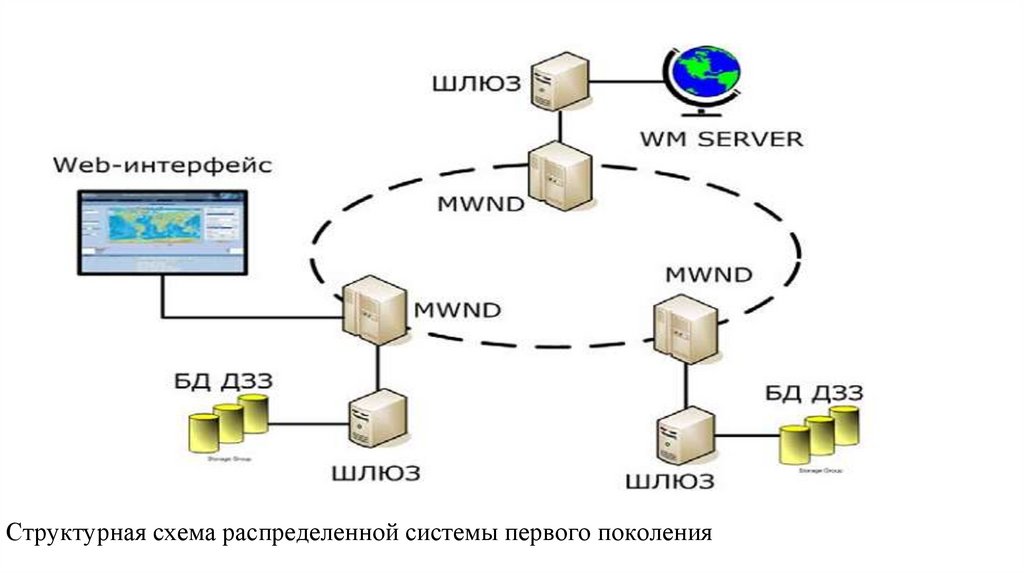








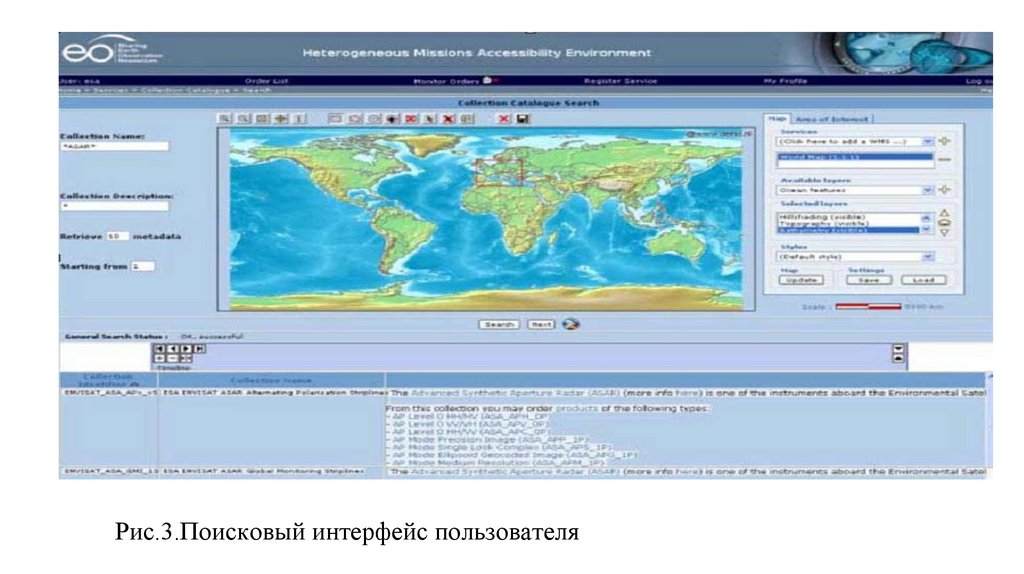





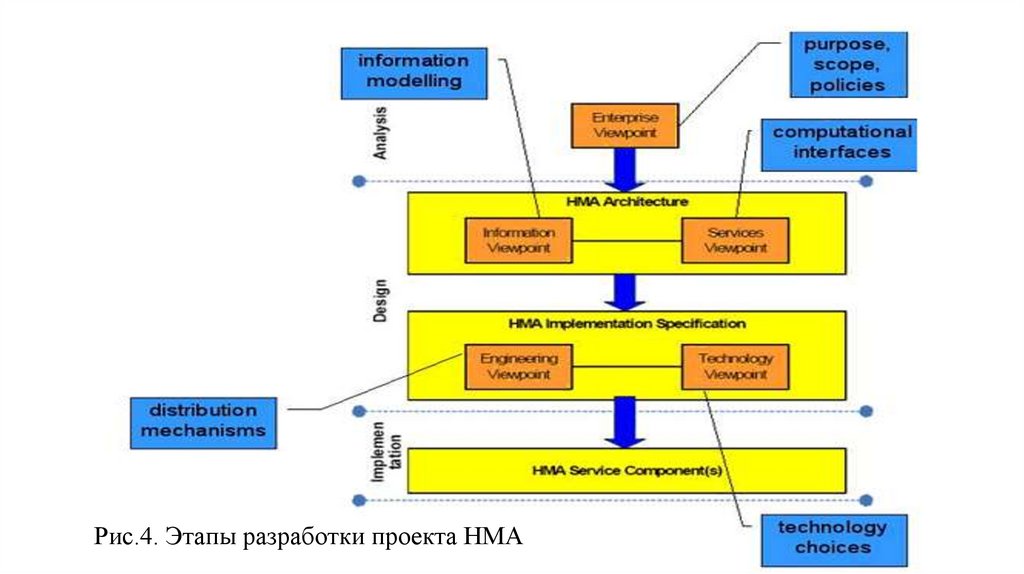
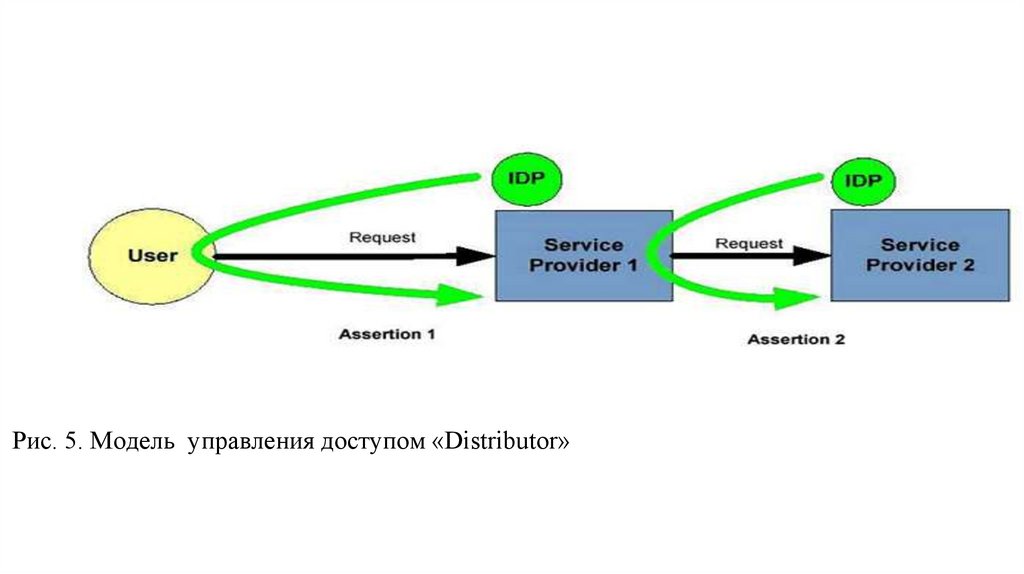







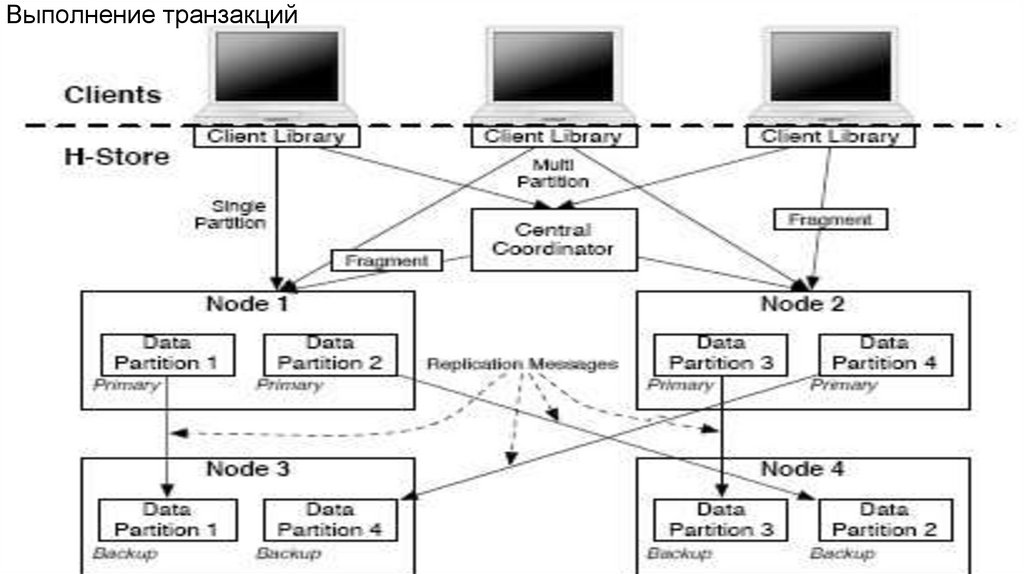

















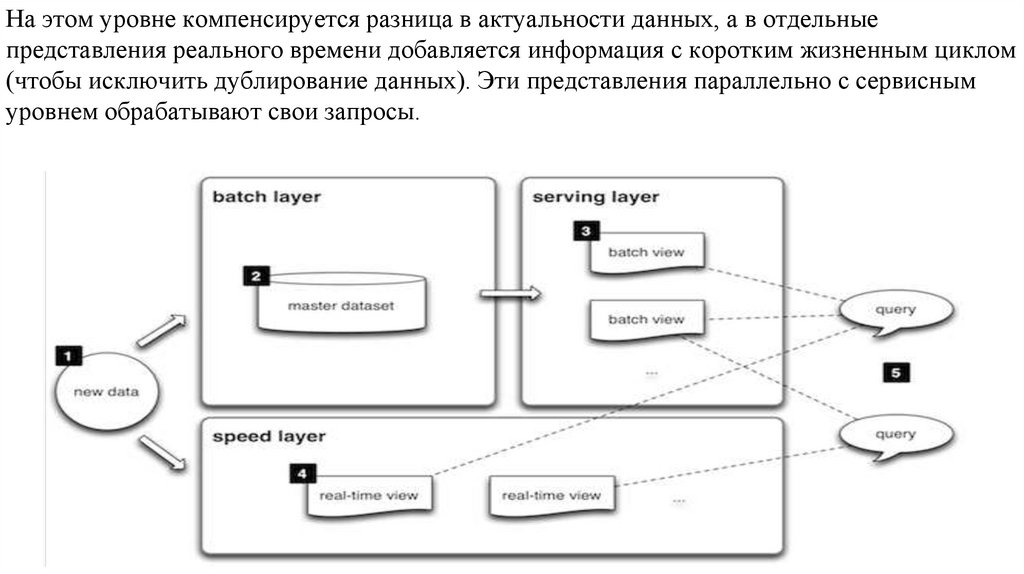

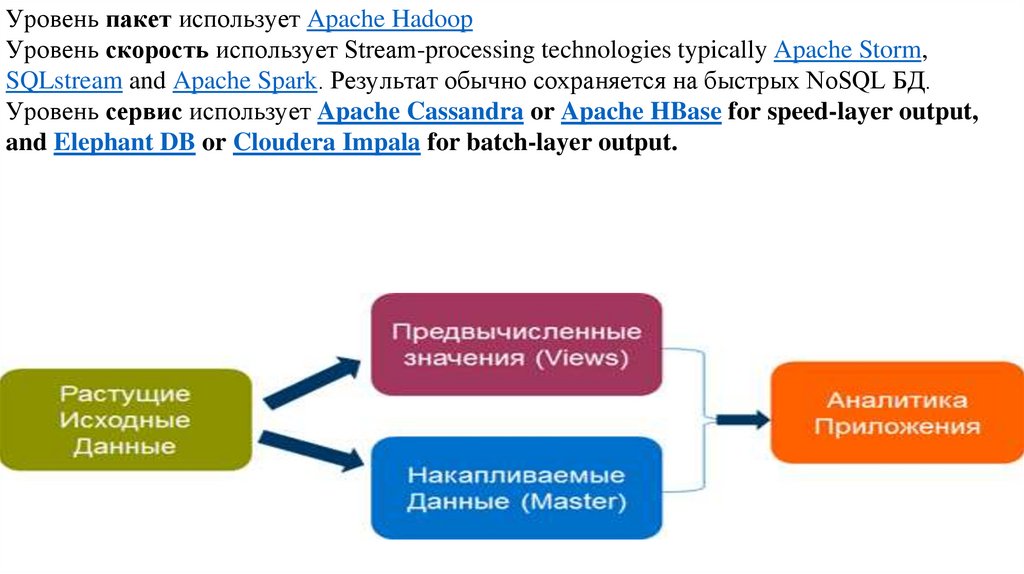


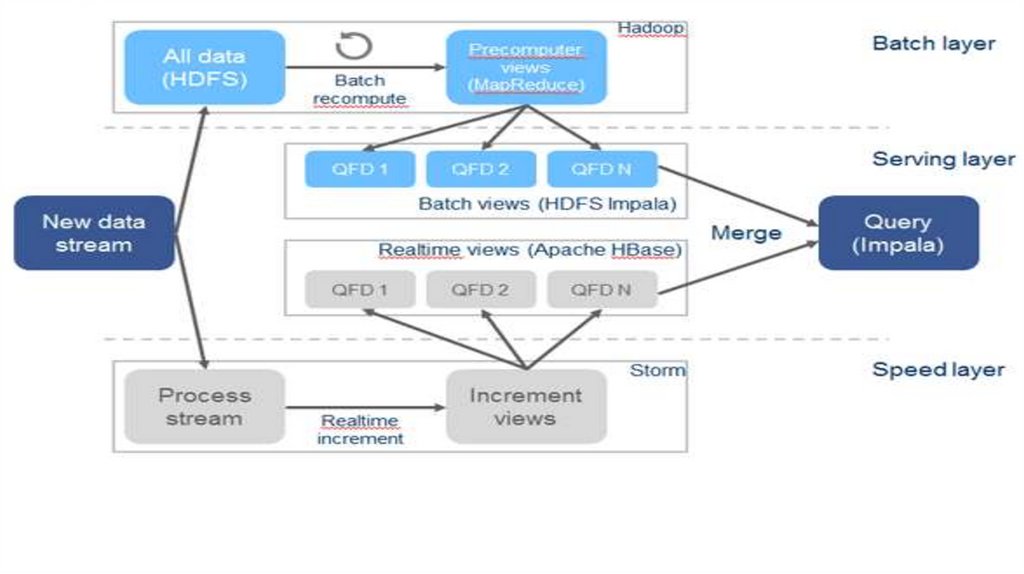
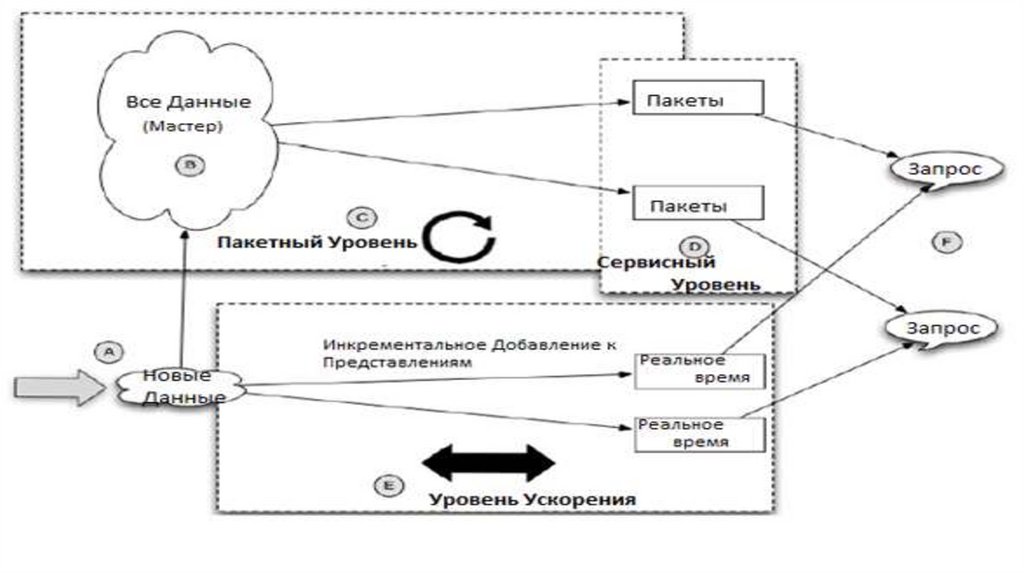

























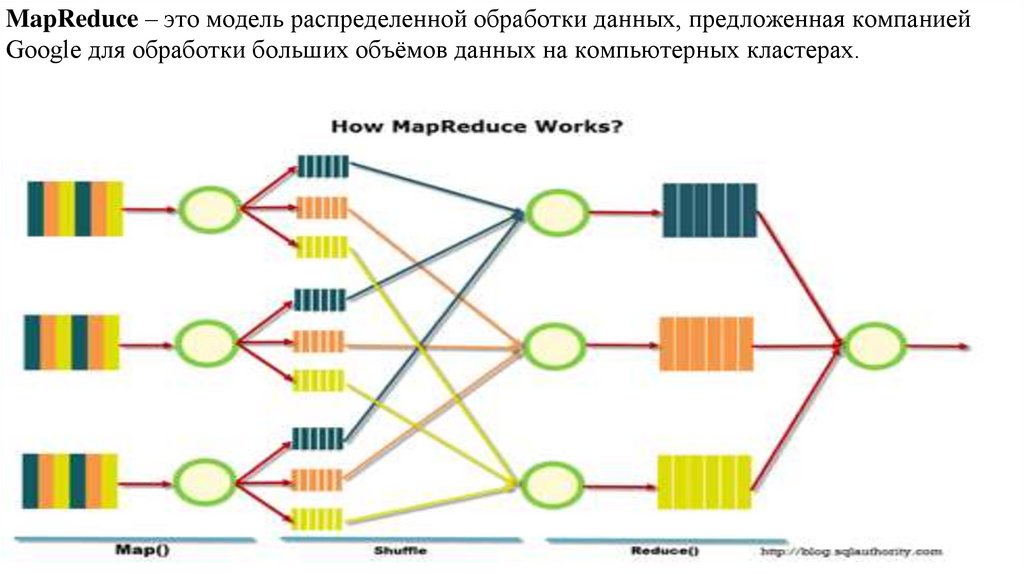







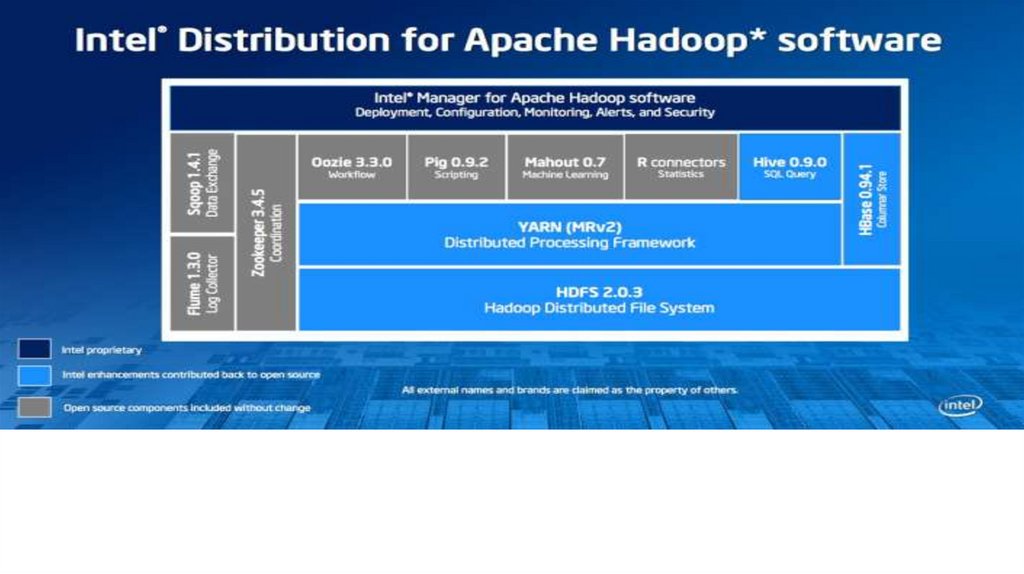






















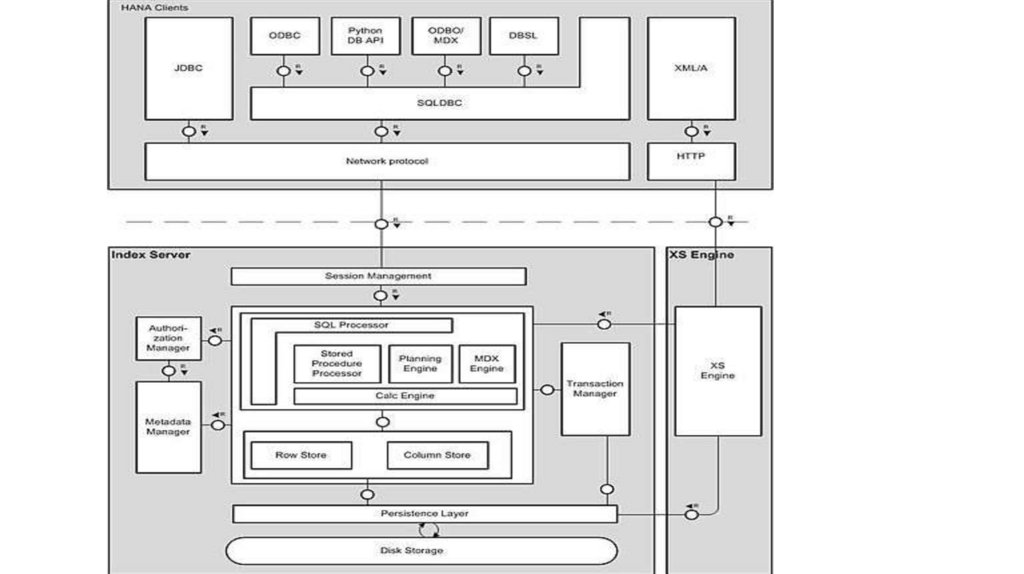

 database
databaseSimilar presentations:










Реляционная модель
1.
2.
Реляционная модель предоставляет средства описания данных на основе только ихестественной структуры, т.е. без потребности введения какой-либо дополнительной
структуры для целей машинного представления. Соответственно, эта модель обеспечивает
основу языка данных высокого уровня, который поддерживает максимальную
независимость программ, с одной стороны, и машинного представления и организации
данных с другой.
Преимуществом реляционного представления является также то, что оно образует
надежную основу для решения проблем порождаемости, избыточности и согласованности
отношений
С другой стороны, сетевая модель привела к возникновению ряда недоразумений, не
последним из которых является ошибочное образование связей при образовании
отношений
3.
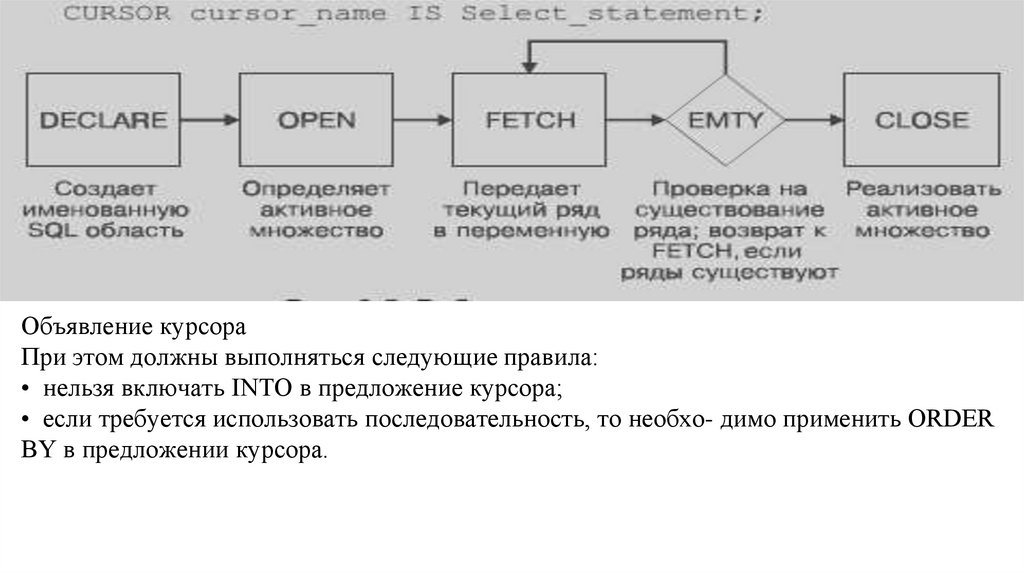
Зависимости данных в существующих системахОбеспечение таблиц описания данных в разрабатываемых сегодня системах является
существенным продвижением на пути к независимости данных . Наличие таких таблиц
облегчает изменения некоторых характеристик представления данных, хранимых в банках
данных. Однако набор характеристик представления данных, которые могут быть
изменены без нанесения логического ущерба некоторым прикладным программам,
продолжает оставаться ограниченным.
Модель данных, с которыми работают пользователи,
загромождается характеристиками представления;
в особенности это касается представлений коллекций данных (а не одиночных элементов
данных).
Тремя основными видами зависимости данных, которые все еще требуется устранить,
являются зависимость порядка, зависимость индексации и зависимость путей доступа.
В некоторых системах эти зависимости четко не отделены одна от другой.
4.
Зависимость порядка. Элементы данных в банке данных могут храниться разнымиспособами, некоторые из которых не предполагают наличия какого-либо порядка,
некоторые допускают участие каждого элемента только в одном порядке, а некоторые – в
нескольких порядках. Обратим внимание на те существующие системы, в которых
требуется или хотя бы допускается хранение элементов данных, по крайней мере, в одном
полном порядке, тесно связанном с зависимым от аппаратуры порядком адресов.
Например, записи в файле, описывающем детали, могут храниться в порядке убывания
серийных номеров. В таких системах обычно допускается, чтобы прикладные программы
основывались на предположении о том, что порядок представления записей идентичен
порядку их хранения (или является его частью). Эти прикладные программы,
использующие свойства упорядоченности файла, скорее всего не смогут правильно
работать, если по какой-то причине потребуется изменить этот порядок.
5.
Зависимость индексации. В контексте форматированных данных индекс обычнополагается компонентом представления данных, ориентированным исключительно на
увеличение эффективности. Наличие индексов ускоряет выполнение запросов и операций
обновления, но в то же время замедляет выполнение операций вставки и удаления.
С точки зрения информативности индекс является избыточным компонентом
представления данных. Если в системе используются индексы, и она должна хорошо
справляться с изменениями активности среды по отношению к банку данных, то, вероятно,
потребуется возможность время от времени создавать и уничтожать индексы.
Возникает вопрос: могут ли при этом остаться неизменными прикладные программы и
интерактивная деятельность?
В современных системах форматированных данных применяются разнообразные подходы
к индексации.
6.
В TDMS обеспечивается обязательная индексация по всем атрибутам.В текущей версии IMS пользователю предоставляется выбор для каждого файла: между
полным отсутствием индексации (иерархическая последовательная организация) и
индексацией только по первичному ключу (иерархическая индексно-последовательная
организация). Ни в одном из этих случаев логика пользовательского представления не
зависит от обязательно поддерживаемых индексов.
Однако в IDS проектировщикам файлов предоставляется возможность выбора индексных
атрибутов и добавления индексов в структуру файла с использованием средств
дополнительных цепочек.
Прикладные программы, в которых для повышения эффективности используются эти
индексные цепочки, должны ссылаться на них по именам. Такие программы не смогут
работать правильно, если эти цепочки будут впоследствии удалены
7.
Зависимость путей доступа. Многие существующие системы форматированных данныхпредоставляют пользователю файлы с древовидной организацией или немного более
общие сетевые модели данных. На прикладные программы, предназначенные для работы с
этими системами, логически влияют изменения структуры деревьев и сетей. Пример.
Предположим, что банк данных содержит информацию о деталях и проектах. Для каждой
детали хранится номер детали, название детали, описание детали, количество
используемых деталей этого типа и количество заказанных деталей. Для каждого проекта
хранится номер проекта, название проекта и описание проекта. Если в проекте
используется некоторый тип детали, регистрируется и количество деталей этого типа,
предназначенных для данного проекта. Предположим, что система требует, чтобы
пользователь или проектировщик файлов объявлял или определял данные в терминах
древовидных структур. Тогда для представления упомянутой выше информации годится
любая из представленных ниже иерархических структур
8.
Структура 1. Проекты подчинены ДеталямФайл
F
Сегмент
ДЕТАЛЬ
ПРОЕКТ
Поля
номер детали
наименование детали
описание детали
имеющееся количество
заказанное количество
номер проекта
наименование проекта
описание проекта
подтвержденное
количество
9.
Структура 2. Детали подчинены ПроектамФайл
F
Сегмент
ПРОЕКТ
ДЕТАЛЬ
Поля
номер проекта
наименование проекта
описание проекта
номер детали
наименование детали
описание детали
имеющееся количество
заказанное количество
подтвержденное
количество
10.
Структура 3. Детали и Проекты наравне, Связь, назначения деталей проектам,подчинена Проектам
Файл
F
Сегмент
ДЕТАЛЬ
G
ПРОЕКТ
ДЕТАЛЬ
Поля
номер детали
наименование детали
описание детали
имеющееся количество
заказанное количество
номер проекта
наименование проекта
описание проекта
номер детали
подтвержденное
количество
11.
Структура 4. Детали и Проекты наравне, Связь назначения деталей проектам подчиненаДеталям
Файл
F
Сегмент
ДЕТАЛЬ
ПРОЕКТ
G
ПРОЕКТ
Поля
номер детали
наименование детали
описание детали
имеющееся количество
заказанное количество
номер проекта
подтвержденное
количество
номер проекта
наименование проекта
12.
Структура 5. Детали, Проекты и Связь назначения деталей проектам наравнеФайл
F
G
H
Сегмент
ДЕТАЛЬ
Поля
номер детали
наименование детали
описание детали
имеющееся количество
заказанное количество
ПРОЕКТ
номер проекта
наименование проекта
описание проекта
ПОДТВЕРЖДЕНИЕ номер детали
номер проекта
подтвержденное количество
13.
Теперь рассмотрим задачу выборки номера детали, названия детали и количества деталейэтого типа для каждой детали, используемой в проекте с названием "альфа".
Если для этого разрабатывается программа P, ориентированная на использование одной из
приведенных выше структур (т.е. P не определяет, какова реальная структура
представления данных), то при любом выборе P не сможет работать, по меньшей мере, с
тремя потенциально возможными структурами Поскольку в общем случае непрактично
создавать прикладные программы, которые проверяют все древовидные структуризации,
допускаемые системой, эти программы перестают работать после выполнения
необходимых изменений структуры.
Системы, которые предоставляют пользователям сетевую модель данных, порождают
аналогичные трудности. И в случае деревьев, и в случае сетей пользователь (или его
программа) должен обеспечить набор путей доступа к данным. Неважно, находятся ли эти
пути в точном соответствии с определяемыми ссылками путями в хранимом представлении
(в IDS это соответствие является предельно простым, в TDMS – совсем наоборот).
14.
В результате, независимо от конкретного вида хранимого представления, интерактивнаядеятельность и программы становятся зависимыми от существования пользовательских
путей доступа.
Одно из решений состоит в следовании той политике, что определенный пользователем
путь доступа нельзя вывести из употребления до тех пор, пока существуют программы,
использующие этот путь доступа. Такая политика непрактична, поскольку число путей
доступа в модели, общей для сообщества пользователей банка данных, в конце концов
станет чрезмерно велико
Ко всем данным, находящимся в банке данных, можно относиться как к коллекции
изменяющихся во времени отношений. Эти отношения обладают разными степенями. Во
время существования каждого n-арного отношения в него могут вставляться
дополнительные кортежи степени n, удаляться существующие кортежи и изменяться
компоненты существующих в нем кортежей.
15.
Однако во многих коммерческих, правительственных и научных банках данных степенинекоторых отношений бывают достаточно велики (степень 30 не является редкостью).
Обычно не следует помнить порядок доменов в любом отношении (например, порядок
поставщик-деталь-количество в отношении поставка). Поэтому мы предлагаем, чтобы
пользователи имели дело не с отношениями с упорядоченными доменами, а со связями,
которые являются двойниками отношений с неупорядоченными доменами. Для
достижения этого домены должны быть однозначно идентифици-руемы, в пределах
любого данного отношения, без использования их позиции. Таким образом, там, где
существует два или более одинаковых домена, нужно, чтобы в каждом случае имена
доменов были уточнены отдельным именем роли, служащим для указания роли, которую
этот домен играет в данном отношении. Например, в отношении компонент, приведенном
на рис. 2, первый домен деталь может быть обозначен именем роли суб и второй - именем
супер, чтобы пользователи могли работать со связью компонент и ее доменами –
суб.деталь, супер.деталь, количество, не основываясь на каком-либо порядке этих
доменов
16.
Предлагается, чтобы пользователи взаимодействовали с реляционной моделью данных,состоящей из изменяющихся во времени связей (а не с отношениями). Каждый
пользователь не должен знать ничего больше про связь, кроме ее имени и имен ее доменов
(с указанными в случае необходимости именами ролей) и эта информация могла бы
предоставляться системой в меню-ориентированном стиле (с соблюдением ограничений
безопасности и конфиденциальности) по запросу пользователя. Существует много
альтернативных способов применения реляционной модели в банках данных
Общее требование для элементов отношения – обеспечение взаимосвязи с другими
элементами данного отношения или с элементами другого отношения. Ключи
обеспечивают средства пользовательского уровня (но не только эти средства), для
выражения таких взаимосвязей.
17.
Ранее существовала строгая тенденция трактовать данные в банке данных как состоящие издвух частей – одна часть состоит из описаний сущностей (например, описания
поставщиков), а другая часть состоит из отношений между различными сущностями или
типами сущностей (например, отношение поставка). Такое различие трудно сохранять,
если отношение может содержать внешние ключи для какого-либо другого отношения. В
пользовательской реляционной модели отсутствуют преимущества от проведения такого
разделения (тем не менее, такие преимущества могут существовать при применении
реляционных концепций к машинному представлению пользовательского набора связей).
18.
Сеть распределенных вычислений: решения OracleНедорогие - blade-серверы и ОС Linux гарантируют максимальную экономическую
эффективность сети распределенных вычислений.
Oracle 10g содержит оригинальные базовые технологии для создания GRID – Oracle Real
Application Clusters, Oracle Streams и Oracle Transportable Tablespaces и отвечает
эксплуатационным требованиям сети распределенных вычислений, таким как
универсальность, RAS (надежность, готовность, удобство обслуживания), защищенность,
масштабируемость и управляемость.
Комплект инструментов Oracle Globus Development Kit (OGDK) позволяет применять
технологию Oracle со стандартными инструментами Globus. Корпорация Oracle для
поддержки всех новых стандартов сети распределенных вычислений сотрудничает с
организацией Global Grid Forum (GGF).
19.
Oracle Real Application ClustersУправление кластерами БД как сетью распределенных вычислений предприятия
осуществляется за счет использования интегрированного кластерного программного
обеспечения (integrated clusterware). Это программное обеспечение представляет собой
набор общих сервисов по обслуживанию кластеров, встроенных в Oracle Database 10g с
целью облегчить создание кластеров базы данных и управление ими. Решение Oracle Real
Application Clusters 10g также включает новое программное обеспечение для управления
рабочей нагрузкой кластеров, предназначенное для перераспределения вычислительных
возможностей компонентов кластерной базы данных, как только это потребуется для
решения бизнес-задач.
20.
Включены усовершенствованные возможности автоматизированного управления и новаяконсоль Database Control с web-интерфейсом.
Database Control представляет собой диагностический монитор, отображающий в
графическом виде текущее состояние функционирующей базы данных.
Администраторы могут проводить профилактический мониторинг баз данных и
быстро получать предупреждения и рекомендации с целью обеспечения оптимальной
производительности и надежности работы систем.
Консоль Database Control может даже выявить неудачно написанный фрагмент кода
приложения, предложить лучший вариант и автоматически настроить базу данных для
обеспечения оптимальной производительности.
Можно проводить диагностику производительности, настройку приложений и
управление распределением памяти.
21.
Oracle Database 10g включает также модуль автоматическогоуправления хранилищем данных (Automatic Storage Management, ASM) – ПО,
предназначенное для упрощения конфигурирования системы хранения данных и
управления базами данных.
Модуль ASM автоматически реализует взаимодействие базы данных с файлами данных и
подсистемами хранения данных, распределяет нагрузку на систему хранения данных,
исключает необходимость постоянного мониторинга систем хранения данных для
поиска «точек повышенной загрузки» и «узких мест», которые снижают скорость
обработки данных; упрощает структуру информационного центра и снижает расходы на
управление системой. Oracle сотрудничает с компаниями-разработчиками
промышленных систем хранения данных, такими, как EMC, Hitachi, HP, Network
Appliance и Xiotech, для обеспечения совместной работы модуля ASM с сетевыми
устройствами хранения данных и сетями хранилищ данных, предлагаемыми этими
компаниями.
22.
СУБД Oracle 10g для Linux-кластеров обладает высокой масштабируемостью, что былодоказано на вычислительных комплексах с 32 и более узлами. Как выяснилось, не
существует принципиальных технологических барьеров для увеличения числа узлов в
кластерах. RAC обеспечивает высокую степень утилизации ресурсов, причем на
недорогих blade-фермах.
Технология Oracle RAC основана на архитектуре с разделяемым диском (shared disk
architecture), что отличает ее от СУБД других производителей, которые строятся на
принципиальной иной архитектуре (shared nothing architecture). Данные в такой
архитектуре искусственно разнесены по сегментам базы данных. При добавлении новых
blade-серверов все данные нужно заново сегментировать, чтобы перенести часть из них
на новые серверы. Аналогично, когда нужно изъять из системы blade-серверы, данные
тоже приходится предварительно сегментировать.
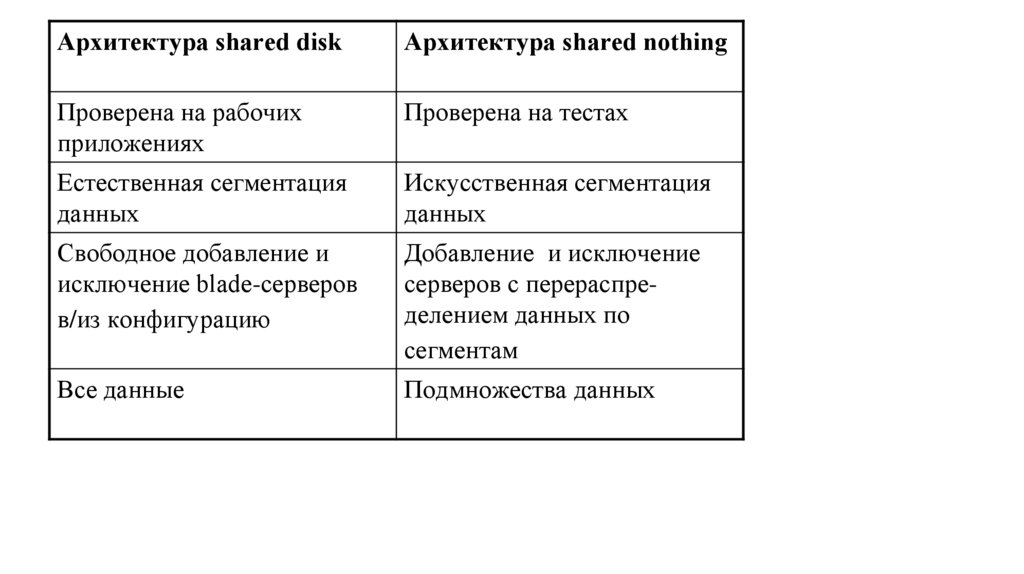
23.
Архитектура shared diskАрхитектура shared nothing
Проверена на рабочих
приложениях
Проверена на тестах
Естественная сегментация
данных
Искусственная сегментация
данных
Свободное добавление и
исключение blade-серверов
в/из конфигурацию
Добавление и исключение
серверов с перераспределением данных по
сегментам
Все данные
Подмножества данных
24.
Модуль Oracle Transportable Tablespaces обеспечивает пользователей сетираспределенных вычислений чрезвычайно быстрым механизмом перемещения
подмножества данных из одной базы данных Oracle в другую, позволяет
выделять фрагменты баз данных Oracle, переносить или копировать их в
другое место, а затем присоединять к другой базе данных. Перемещение
фрагментов данных заключается лишь в считывании или записи небольшого
количества метаданных. Кроме того, Transportable Tablespaces может
одновременно составлять таблицы «только для чтения» из двух или более баз
данных.
25.
Модуль Oracle Streams позволяет распространять данные среди баз данных, узлов илиферм blade-серверов сети распределенных вычислений. Он создает унифицирован-ную
структуру для распространения данных, формирования очередей сообщений,
репликации, управления событиями, загрузки данных в хранилище, оповещений и
публикации/ подписки в рамках единой технологии. Oracle Streams может
синхронизировать одновременно две или более копии баз данных по мере их
обновления. Модуль автоматически регистрирует изменения в базе данных,
распространяет эти изменения в узлы, которые подписаны на получение этих
изменений, реализует их; а также обнаруживает и разрешает возможные конфликты по
данным. Модуль может использоваться приложениями и непосредственно для
организации очередей сообщений, обеспечивающих связь между приложениями в
пределах сети распределенных вычислений.
26.
Модули Distributed SQL и Distributed TransactionsС помощью модуля Oracle Distributed SQL пользователи сети распределенных
вычислений могут эффективно получать и объединять данные, хранящиеся в различных
базах данных Oracle и базах данных других производителей. Прозрачный удаленный
доступ к данным посредством Distributed SQL позволяет приложениям работать с любой
другой базой данных без внесения каких-либо изменений в код программ. В процессе
интеграции данных из нескольких источников СУБД Oracle оптимизирует планы
исполнения запросов. Кроме того, СУБД Oracle автоматически выполняет транзакции с
данными из нескольких источников. Функция Oracle XA позволяет пользователям сети
распределенных вычислений координировать выполнение транзакций, затрагивающих
несколько баз данных.
Гетерогенный доступ посредством механизмов Transparent Gateways
27.
В данную группу включены следующие продукты:Oracle Open System Gateways – подгруппа продуктов (шлюзов), обеспечивающих доступ
(посредством SQL) к данным, хранящимся в отличных от Oracle базах данных на всех
платформах открытых систем. В настоящий момент поддерживается доступ к
следующим базам данных: MS SQL Server, Sybase, Rdb, Ingres, Informix, Teradata, RMS
Mainframe Integration Gateways – подгруппа продуктов (шлюзов), обеспечивающих
доступ к СУБД DB2 на мэйнфреймах.
Replication Services (сервисы репликации), обеспечивающие репликацию данных из БД
Oracle в «чужие» базы данных (равно как и из «чужих» баз данных в БД Oracle). Для
репликации используются прозрачные шлюзы.
Enterprise Integration Gateways – включает шлюзы к СУБД DB2 для платформы AS/400
(DB2/400) и шлюз к системам IBM DRDA, а также Procedural Gateways (процедурные
шлюзы),
28.
Procedural Gateways (процедурные шлюзы), обеспечиваю-щие обработку вызововудаленных процедур, причем удаленные процедуры определены и выполняются в
отличной от Oracle программной системе. В эту подгруппу включен и Access
Manager (менеджер доступа), основным назначением которого является поддержка
доступа «чужих» приложений посредством языка запросов SQL к базам данных
Oracle.
Пользователи СРВ могут применять функции планирования работ в СУБД
Oracle. Функции управления очередями заданий (jobs) обеспечивает гибкий
механизм планирова-ния задач СУБД. Задания можно выполнять в
определен-ное время и с определенными временными интервалами. Имеется
возможность указать максимальное число про-цессов, которое будет
использоваться для выполнения заданий. При использовании OracleReal
Application Cluster 10g можно направить задание на любой из доступных узлов
для исполнения соответствующим экземпляром Oracle Database.
29.
Oracle Resource Manager позволяет администраторам ресурсов ограничивать ресурсыСУБД Oracle, выделяемые пользователям сети. Функция управления ресурсами
гарантирует, что каждый пользователь сети получит долю имеющихся вычислительных
ресурсов в соответствии с их (пользователей) приоритетами
Стандартная среда сети распределенных вычислений
Комплект инструментов Oracle Globus содержит набор компонентов, которые можно
использовать для создания приложений СРВ, а также инструменты программирования.
Комплект Globus стал де-факто стандартом среды разработки СРВ.
Oracle Globus Development Kit (OGDK) содержит сценарии для эффективного
использования технологии Oracle с комплектом инструментов Globus.
30.
Доступ через СРВ к Oracle10g UtilitiesМодуль Globus Resource Allocation Manager (GRAM) обеспечивает выделение ресурсов,
создание и мониторинг процессов, а также управление ими. GRAM преобразуют
запросы на языке Resource Specification Language (RSL) в команды, понятные
локальным планировщикам. Применяя эту функцию, пользователи СРВ могут удаленно
задействовать такие утилиты Oracle, как export, import и sqlplus, для выполнения
необходимых действий в Oracle Database 10g. Этот механизм можно использовать для
настройки удаленных баз данных в сети распределенных вычислений. Доступ через
СРВ к Oracle10g Database
OGDK использует модуль Globus GRAM для исполнения программ PL/SQL или команд
SQL, описанных в Globus RSL. Он может применяться и для передачи заданий
планиров-щику Oracle через API PL/SQL планировщика, вследствие чего пользователи
сети могут выполнять задачи на удален-ных базах данных, планировать и
контролировать их испол-нение.
31.
Служба информации о ресурсах сети (GRIS) для Oracle DatabaseСлужба информации о ресурсах сети распределенных вычислений (GRIS),
входящая в комплекс инструментов Globus, предоставляет информацию для
контроля за ресурсами сети распределенных вычислений и их обнаружения.
Эта функция позволяет пользователям сети распределенных вычислений
обнаруживать базы данных Oracle и проверять их. GRIS для Oracle Database
отображает атрибуты и свойства базы данных, которые могут потребоваться
пользователям сети распределенных вычислений.
32.
Универсальность Oracle по отношению к операционным системам и оборудованиюозначает, что все продукты семейства Oracle 10g способны поддерживать неоднородные
СРВ, которые, как известно, позволяют использовать любое имеющееся оборудование, а
не только оборудование одного производителя.
Oracle 10g может работать как в конфигурациях СРВ, так и вне их, так что можно,
например, взять приложение, разработанное для SMP-систем, и перенести его в
инфраструктуру СРВ.
Oracle 10g работает на всех популярных операционных системах, причем обеспечивает
одни и те же функции и возможности, так как базовый код остается тем же.
Универсальность Oracle означает, что, в каком бы направлении ни развивалась сеть
распределенных вычислений, какая бы операционная система в ней ни доминировала,
Oracle 10g все равно будет работать в этой сети.
33.
Утилизация простаивающих ресурсов – один из примеров применения СРВ. Идеяутилизации неиспользуемых ресур-сов тысяч персональных компьютеров,
простаивающих каждую ночь, чрезвычайно привлекательна. У такого решения
огромный потенциал. Особенно популярно оно среди ученых: при значительной
нехватке средств им приходится решать параллельные задачи. Типичным примером СРВ
является центральный сервер, распределяющий работу между большим числом
небольших компьютеров. Этот же сервер собирает и систематизирует результаты
расчетов. И все же у такой модели СРВ много ограничений. Главная проблема в том, что
ресурсы – простаивающие персональные компьютеры – часто выходят из-под
административного контроля тех, кто ими пользуется. Степень готовности и надежности
распределенных ресурсов ограничена, что чрезвычайно затрудняет планирование
вычислений.
34.
Кроме того, слабость или отсутствие модели доверия (trust model) в таких СРВпрепятствуют их использованию для обработки какой бы то ни было конфиденциальной
или частной информации. Наконец, класс приложений, допускающих
распараллеливание, весьма ограничен, что минимизирует преимущества таких сетей
распределенных вычислений для многих организаций.
Тем не менее утилизация ресурсов посредством сети распределенных вычислений успешно
применяется для решения сложных проблем. Примером такой реализации сети
распределенных вычислений можно считать проект SETI@home, в котором свободные
компьютеры, подключенные к интернету, обрабатывают данные радиотелескопа с
целью поиска признаков существования внеземных цивилизаций.
35.
Разделение ресурсов – еще один способ реализации сети распределенных вычислений.Внедрив сеть распределенных вычислений с разделением ресурсов, организации
смогут задействовать недоиспользуемые ресурсы в пределах одного или нескольких
предприятий. Участники такой сети распределенных вычислений получают
возможность легко обмениваться вычислительными ресурсами и данными, перемещая
приложения и информацию по сети распределенных вычислений с тем, чтобы
задействовать свободные ресурсы.
В результате создается умеренное число средних и крупных узлов, которые могут
относиться к одному административному домену или охватывать несколько
административных доменов. Планировщики сети распределенных вычислений следят
за наличием свободных ресурсов и должным образом распределяют их.
36.
Для внедрения сети распределенных вычислений такого типа многие заказчики применяюттехнологию Oracle. CERN выбрал технологических партнеров для реализации проекта
сети распределенных вычислений LHC (Большой Адронный Коллайдер), которая
позволит тысячам физиков во всем мире анализировать петабайты распределенных
данных об элементарных частицах. Одним из участников проекта является компания
Oracle с программными продуктами Oracle Database 10g и Oracle Application Server 10g,
отвечающие требованиям сети распределенных вычислений LHC. Oracle Database 10g
гарантирует масштабируемость, разделение информации и функции поддержки
сверхбольших баз данных (VLDB), необходимые тысячам пользователей для обмена
данными в рамках сети распределенных вычислений LHC. Oracle Transportable
Tablespaces обеспечит CERN быстродействующим механизмом распределения больших
объемов данных между множеством узлов.
37.
Значительное количество администрируемых доменов, организационные барьеры,проблемы доверия и интенсивное перемещение данных между узлами сети ставят под
вопрос для многих организаций эффективность подхода разделения ресурсов
Сеть распределенных вычислений с выделением ресурсов решает эти проблемы за счет
создания централизованных пулов вычислительных ресурсов, которые могут
предоставляться всем приложениям-участникам.
38.
Испытания для определения предельных ограничений на передачу данных враспределенной среде
39.
Сотрудники Центра ядерных исследований CERN совершили масштабные испытанияраспределенной компьютерной сети Солидного адронного коллайдера (БАК),
наибольшего ускорителя элементарных частиц. Основной задачей нынешних испытаний
было узнать предельные ограничения на передачу данных в распределенной среде. На
протяжении опыта Scale Testing for the Experiment Programme ’09 объемные массивы
данных передавались между вычислительными узлами, расположенными в разных
государствах. В Европе сейчас насчитывается 11 вычислительных узлов, соединенных
выделенными волоконно-оптическими каналами. Эти узлы передают информацию на
обработку еще в 140 центров 33 государств. Ян Берд, начальник компьютерного
подразделения CERN, сказал, что тестирование прошло удачно, и мощностей
телекоммуникационной инфраструктуры хватит с запасом. Скорость передачи данных
по сетевым каналам на момент запуска БАК составит 1,3 Гбайт/с. Во время испытаний
удалось достичь скорости в 4 Гбайт/с.
40.
Грид-вычисления ( grid — решётка, сеть) — это форма распределенных вычислений, вкоторой «виртуальный суперкомпьютер» представлен в виде кластеров, соединённых с
помощью сети, слабосвязанных гетерогенных компьютеров, работающих вместе для
выполнения огромного количества заданий (операций, работ). Эта технология применяется
для решения научных, математических задач, требующих значительных вычислительных
ресурсов. Грид-вычисления используются также в коммерческой инфраструктуре для
решения таких трудоёмких задач, как экономическое прогнозирование, сейсмоанализ,
разработка и изучение свойств новых лекарств.
Грид с точки зрения сетевой организации представляет собой согласованную, открытую и
стандартизованную среду, которая обеспечивает гибкое, безопасное, скоординированное
разделение вычислительных ресурсов и ресурсов хранения информации, которые являются
частью этой среды, в рамках одной виртуальной организации
41.
Технология GRID используется для реализации географически распределеннойвычислительной и информационной среды, которая объединяет в единую
инфраструктуру ресурсы различных типов и обеспечивает коллективный доступ к этим
ресурсам В классической реализации GRID фокусируется на обеспечении
распределенных вычислений в фиксированной среде с заданной конфигурацией.
Основное решение – объедине-ние ресурсов в межпрограммном слое. Необходимо
создавать специальную инфраструктуру GRID вследствие сложности установки,
поддержки, управления, масштабирования GRID-сети, функциональных ограничений
программного обеспечения.
Одна из современных задач развития GRID это общедоступность и расширение области ее
использования, что требует значительного уменьшения сложности ее установки и
поддержки
42.
В настоящее время выделяют три основных типа грид-систем:Добровольные гриды — гриды на основе использования добровольно предоставляемого
свободного ресурса персональных компьютеров;
Научные гриды — хорошо распараллеливаемые приложения программируются
специальным образом (например, с использованием Globus Toolkit);
Гриды на основе выделения вычислительных ресурсов по требованию (коммерческий
грид, enterprise grid) — обычные коммерческие приложения работают на виртуальном
компьютере, который, в свою очередь, состоит из нескольких физических компьютеров,
объединённых с помощью грид-технологий.
43.
Общедоступная GRID должна обеспечивать предоставление по требованиюинфраструктуры и приложений, ориентированных на использование высоких
технологий во всех сферах деятельности человеческого сообщества - медицина,
электронные медиа, инженерная сфера, обеспечение коммуникаций для электронного
бизнеса и тому подобное для широкого слоя пользователей в хорошо защищенной,
общедоступной, расширяемой и стандартизированной компьютерной среде через
Промежуточное программное обеспечение GRID, поддерживающее массовое
распространение, должно обладать многими свойствами инфраструктуры «по
требованию». Оно должно быть разделяемым между разными пользователями,
предоставлять стандартизиро-ванные службы и протоколы связи, а также быть гибким и
расширяемым. Вычислительная парадигма современной GRID строится вокруг
основной цели: предоставлять ресурсы столь же легко, как электричество через сеть.
44.
Предъявляемые требования к интеграции и интероперабель-ности большого количестваприложений, обусловили развитие технологии GRID в направлении открытой
архитектуры OGSA (Open Grid Services Architecture).
Объединение GRID и соответствующих стандартов WEB-служб - большой шаг в
направлении уменьшения сложности использования, управления и поддержки GRID.
Использование стандарта WSRF, который является низкоуровневым описанием
инфраструктуры, реализации модели OGSA, предлагает возможность предоставлять
низкоуровневую виртуализацию доступных ресурсов, что значительно повышает
универсальность GRID.
Основной идеей сегодняшней GRID становиться формирование динамической среды,
состоящей из взаимодействующих неоднородных вычислительных узлов, без
определенной фиксированной инфраструктуры и с минимальными административными
требованиями.
45.
Мобильные GRIDНаиболее актуальные современные исследования в области GRID посвящены
необходимости решения проблемы совместимости GRID и мобильных сетей.
Использование беспроводных устройств, которые имеют достаточно ограниченные
ресурсы вычислительной мощности, энергии, адресного пространства, накладывают
существенные ограничения при решении вычислительных заданий повышенной
ресурсоемкости и хранения больших объемов данных, однако за счет привлечения
дополнительных ресурсов, доступных при сочетании с GRID, такое использование
вполне возможно. Более того использование мобильных GRID позволило бы обеспечить
применение приложений GRID в тех местах где это можно лишь представить, а в
будущем технология GRID могла бы
войти в набор обычных услуг для мобильных пользователей
46.
Мобильные GRID характеризуется динамической структурой и допускают перемещениекак пользователей GRID, так и запрашиваемых ресурсов. Узлы мобильных GRID не
является кластерами или супер-компьютерами, это произвольный диапазон мобильных
устройств с гетерогенными свойствами: вычислительный ресурс процессора, объем
памяти, пропускная способность каналов связи, задержка. Кроме того, мобильная сеть
подвержена проблемам разрыва связей и выхода узлов из строя или перемещения за
пределы досягаемости. Мобильные узлы имеют гетерогенное время выполнения
подзадачи, и могут останавливать вычисление произвольно в случае непредвиденного
перемещения. В связи с этим совместное выполнение задания временно откладывается,
и возникают проблемы реконфигурации, репликации, резервирования данных, и тому
подобное.
47.
Такие нестабильные ситуации называются автономными отказами, они приводятк задержке и блокировке выполнения подзадач и как следствие к частичной
или полной потере результатов выполнения задания. Отмеченные проблемы
осложняют планирование и управление выполняемыми подзадачами.
Таким образом, характеристики и особенности мобильных GRID обуславливают
необходимость разработки стратегий управления и механизмов планирования
которые бы адаптировались к динамической вычислительной среде.
48.
Тенденции·тенденции в области компьютерных платформ:
Каждый производитель компьютерной платформы либо анонсировал, либо уже поставляет
так называемые blade-серверы (blade servers). Они обеспечивают самую дешевую
вычислительную мощность – иногда на 80% дешевле той, что дают системы на основе
симметричной многопроцессорной обработки (SMP). Blade-серверы легко составляются
в blade-фермы (blade farms), которые представляют собой самую эффективную и
масштабируемую разновидность недорогой вычислительной системы. Теперь bladeфермы оснащаются каналами межкомпьютерного взаимодействия (interconnects), что
превращает их в кластеры – самую экономически эффективную форму недорогих
вычислительных комплексов. Эти кластеры, скорее всего, станут архитектурой
вычислительной техники будущего.
49.
· тенденции в области операционных систем:В сфере программного обеспечения Linux опережает по темпам роста популярности другие
операционные системы. Linux пока нельзя масштабировать до крупной SMPсистемы. Но на blade-серверах, оснащенных несколькими недорогими процессорами,
Linux работает отлично. Экономические преимущества blade-серверов перед SMPсистемами обеспечивают первым доминирование, а так как Linux уже сейчас является
ключевой операционной системой для blade-серверов, это еще сильнее ускоряет
распространение Linux. Наконец, у Linux есть ценовое преимущество, которое
приобретает все большее значение по мере роста числа blade-серверов, что опять-таки
способствует распространению этой ОС. И вполне естественно, что недорогие кластеры
хорошо сочетаются с недорогой операционной системой Linux.
50.
· виртуализация:Виртуализация – один из самых модных сегодня терминов как в индустрии
программного обеспечения, так и в индустрии аппаратуры. Нет ничего более
виртуального, чем коммунальные услуги. Множество поставщиков стараются
доказать, что их новая стратегия состоит в виртуализации или коммунальных
вычислениях, – а это именно то, что характерно для сети распределенных
вычислений. С большой долей вероятности можно утверждать, что скоро все
они возьмут на вооружение сети распределенных вычислений.
51.
· рост популярности концепции Grid:Grid – концепция сети распределенных вычислений – становится все популярнее
в индустрии информационных технологий. Некоторые крупные
производители, в том числе Oracle, уже предлагают технологию,
поддерживающую сеть распределенных вычислений. Другие, например IBM,
планируют предложить такую технологию. Создана организация по
стандартизации сети распределенных вычислений – Global Grid Forum (GGF),
которую поддержали все крупные производители.
52.
Рассмотрим службу каталогов OSI Х.500. Несмотря на то что службы каталогов доступны уже болеедесятилетия, они стали особенно популярными лишь недавно в виде упрощенных версий, реализованных как
службы Интернета.
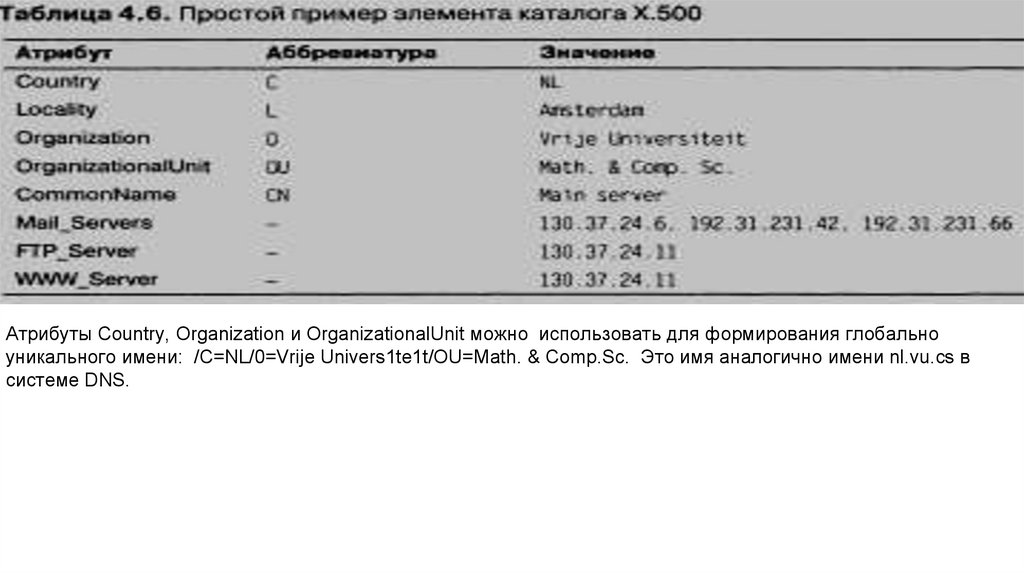
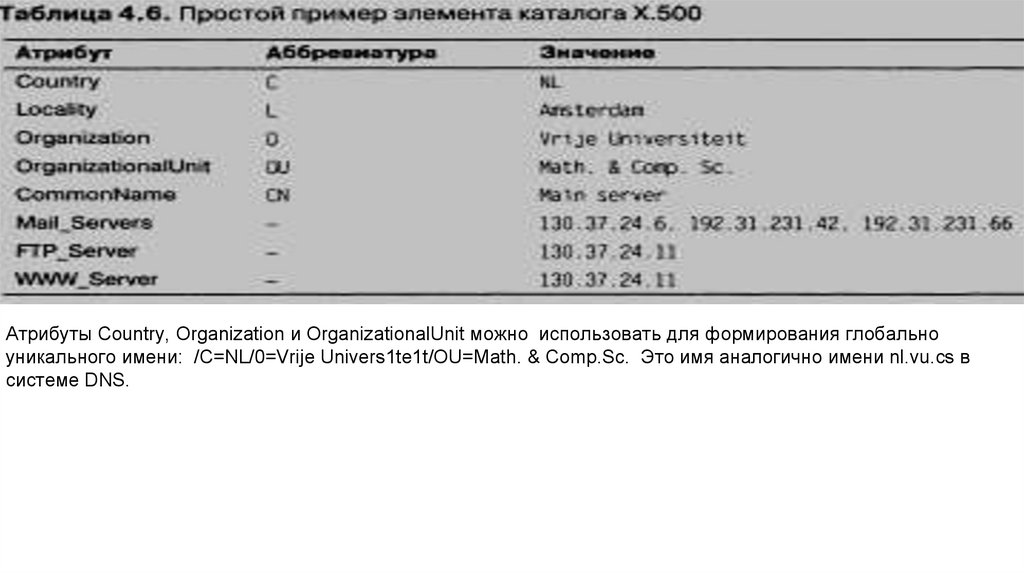
Концептуально служба каталогов Х.500 состоит из множества записей, которые обычно называются
элементами каталога. Элемент каталога в Х.500 похож на запись о ресурсах системы DNS. Каждая запись
состоит из набора пар (атрибут, значение), причем каждый атрибут имеет ассоциированный с ним тип.
Различаются атрибуты с одним значением (однозначные) и атрибу-ты с несколькими значениями
(многозначные), которые представ-ляют собой массивы или списки. Набор всех элементов каталога службы
каталогов Х.500 называется информационной базой ката-лога {Directory Information Base, DIB), каждая запись в
DIB имеет уникальное имя, чтобы ее можно было найти. Глобально уникаль-ное имя получается из
последовательности атрибутов именования каждой записи. Каждый атрибут именования называется относительно различимым именем {Relative Distinguished Name, RDN)
53.
Атрибуты Country, Organization и OrganizationalUnit можно использовать для формирования глобальноуникального имени: /C=NL/0=Vrije Univers1te1t/OU=Math. & Comp.Sc. Это имя аналогично имени nl.vu.cs в
системе DNS.
54.
Использование глобально уникальных имен, образуемых последо-вательным перечислением имен RDN,приведет нас к иерархии наборов элементов каталога, которую мы будем называть информационным деревом
каталогов {Directory Information Tree, DIT). DIT, в сущности, образует граф именования службы каталогов
Х.500, в котором каждый узел представляет собой элемент каталога. Кроме того, узел может также работать
каталогом в традиционном смысле, у него может быть несколько дочерних узлов, для которых он будет
родителем. Узел в графе именования Х.500 может, таким образом, быть представлен и в виде каталога в
традиционном смысле, и в виде записи Х.500. Это разница поддерживается двумя различными операциями
поиска. Операция read, предназначенная для чтения одиночной записи, дает ее путь в дереве DIT. С другой
стороны, операция list используется для построения списка имен всех ребер, исходящих из данного узла
дерева DIT. Каждое имя соответствует узлу, дочернему для данного. Отметим, что операция 11st не
возвращает записей, она возвращает только имена.
55.
При операциях с большим каталогом дерево DIT обычно разбивается и разносится по нескольким серверам,которые в терминологии Х.500 называются агентами службы каталогов {Directory Service Agents, DSA).
Каждая часть разбитого дерева DIT соответствует зоне в DNS. Точно так же каждый агент DSA ведет себя
очень похоже на обычный сервер имен, за исключением того, что он реализует несколько стандартных для
службы каталогов служб, таких как расширенные операции поиска.
Клиенты представлены тем, что называется агенты пользователей каталога {Directory User Agents, DUA).
Агент DUA подобен процедуре разрешения имен из традиционной службы именования. DUA обмениваются
информацией с DSA в соответствии со стандартным протоколом доступа. Что делает реализацию Х.500
отличной от реализации DNS — так это механизмы поиска в базе DIE. В частности, имеются механизмы для
поиска элемента каталога по заданному набору критериев, в который могут входить атрибуты искомых
элементов.
56.
На практике это еще означает, что следует перебрать также и множество агентов DSA. В противоположностьэтому, службы имен часто могут быть реализованы при помощи операции поиска, нуждающейся в доступе
только к одному листовому узлу. Система Х.500 находится в одном ряду с множеством других протоколов
OSI. Доступ к каталогу Х.500 в соответствии с официальными правилами — дело не простое. Чтобы
приспособить службу каталогов Х.500 к Интернету, был создан более простой протокол, известный как
упрощенный протокол доступа к каталогам (Lightweight Directory Access Protocol, LDAP). LDAP — это протокол
прикладного уровня, реализованный непосредственно поверх TCP. Кроме того, параметры операций поиска и
обновления могут быть переданы просто в виде строк.
57.
Для эффективной реализации полномасштабного пространства имен, такого как в DNS, удобно разбитьпространство имен на три уровня. Глобальный и административный уровни характеризуются тем, что
содержимое узлов этих частей пространства имен относительно постоянно. Вследствие этого репликация и
кэширование способны повысить эффективность реализации. Содержимое узлов управленческого уровня
часто изменяется. Поэтому производительность операций поиска и обновления на этом уровне можно
удовлетворить путем реализации узлов на локальных высокопроизводительных серверах имен.
58.
Z39.50 — клиент-серверный протокол для поиска и получения ин-формации с удаленных компьютерных базданных. Он описывается ANSI/NISO стандартом Z39.50, а также ISO-стандартом 23950. Основное агентство,
которое обслуживает стандарт — библиотека Конгресса. Широко применим в библиотечных кругах и часто
вклю-чен в автоматизированные библиотечные информационные системы и персональные системы
управления библиографической информа-цией. Межбиблиотечные поисковые каталоги для межбиблиотечного абонемента часто реализованы через запросы Z39.50. Протокол Z39.50 используется с 1970-х годов,
обновлённые версии выходили в 1988, 1992, 1995 и 2003 годах. На семантике протокола Z39.50 основан
универсальный язык запросов Contextual Query Language (CQL, ранее — Common Query Language).
Z39.50 наиболее часто используется для запросов к библиографи-ческим базам данных, представленным в
формате MARC, поэтому эти два стандарта обычно связывают между собой. Но, на самом деле, Z39.50 может
использоваться для доступа к данным, представ-ленным и в других форматах.
59.
Протокол Z39.50 поддерживает ряд функций, в том числе поиск, выборку, сортировку и просмотр. Поисковыезапросы формулируются с помощью атрибутов, как правило, из набора BIB-1, включающего в себя шесть
атрибутов, использующихся при поиске информации на сервере: использование, отношение, положение,
структура, усечение, полнота. Синтаксис протокола Z39.50 позволяет формулировать очень сложные запросы.
интаксис Z39.50 не привязан к структуре конкретной базы данных. Это позволяет формулировать без
необходимости знать что-либо о целевой базе данных; но это также означает, что результаты одного и того же
запроса могут варьироваться в широких пределах между различными серверами. Один сервер может
обратиться к индексу автора; другой, например, к индексу личных имен, вне зависимости от того, являются ли
они авторами; третий может не иметь индекса названия и перейти к поиску по индексу ключевых слов; а
четвёр-тый может вообще возвращать ошибку.
60.
Постольку, поскольку Z39.50 был разработан очень давно, он не очень хорошо сочетается с современнойинфраструктурой веб.
Библиотекой Конгресса США была разработана пара протоколов SRU/SRW (Search/Retrieve via URL и
Search/Retrieve Web service), которые позволяют выполнять запросы на Contextual Query Language, но
использовать HTTP в качестве транспорта. Они призваны заменить собой Z39.50, но, в настоящее время,
сосуществуют с ним. SRU — это REST-протокол, SRW использует технологию SOAP. Оба протокола работают
со структурами данных в формате XML и являются функционально идентичными.
61.
Основные службы протокола Z39.50В самом протоколе объявлены 11 сервисов, которые и выполняют весь спектр действий предусмотренных в
протоколе:
• служба Init: инициализирует Z-ассоциацию, и позволяет клиенту и серверу обменяться информацией о
поддерживаемых службах.
• служба Search: создает результирующее множество в соответствии с заданными клиентом критериями
поиска.
В качестве средства для отбора записей предусмотрено три типа запросов: 0, 1, 101.
• 0 – это запрос с произвольным синтаксисом.
• 1 – это запрос, записываемый в обратной польской записи (RPN) с операторами AND, OR, ANDNOT (язык,
равносильный STAIRS).
• 101 – запрос аналогичный 1, но с дополнительным оператором PROXY, описывающим синтагматическую
близость связываемых этим оператором терминов в тексте искомой записи.
62.
В качестве терминов используется текст, сопряженный с произволь-ным набором атрибутов, несущих какслужебную, так и поисковую информацию. В качестве результата служба возвращает идентифи-катор
результирующего множества и его мощность.
• служба Present: отвечает за передачу записей между клиентом и сервером. Передача предусматривает
выбор синтаксиса (если это необходимо), также возможна сегментация результирующего множества и/или
отдельных документов.
• служба Scan: осуществляет сканирование базы данных с целью извлечения терминов для поиска и
предоставления их списка клиенту. В качестве параметров принимает термин-шаблон, размер шага,
количество возвращаемых терминов.
• служба Explain: позволяет клиенту получать с сервера необходи-мую для поиска и настройки
вспомогательную информацию. В протоколе существуют специализированные форматы, призванные
описывать синтаксисы поддерживаемых форматов, подключенные к серверу базы данных, поддерживаемые
наборы атрибутов и т.д.
63.
служба Sort: осуществляет сортировку результирующего множества.• служба delResSet: позволяет клиенту удалять созданные им результирующие множества.
Остальные службы протокола имеют вспомогательный характер и не относятся непосредственно к процедуре
поиска. Особняком стоит слежба ExtendedService, которая позволяет присоединять к основным службам
протокола произвольные службы, создаваемые владельцами сервера. Z39.50 – это попытка
стандартизировать про-цедуру поиска. За счет этого можно строить различные поисковые системы, с самой
различной архитектурой. На сегодняшний момент протокол широко используется в области поиска
библиографичес-кой информации [LOC] , для обслуживания программы GILS (Government Information Locator
Service[GILS1] в США; Global Information Locator Service [GILS2] и в других странах), в медицин-ских базах
данных и в экологических[GELOS] и геодезических про-граммах типа FGDC [FGDC] ,
64.
а также в распределенных географических информационных системах ArcView[ESRI] и многочисленныхдругих[NSDI] ). Перечень URL со ссылками на географические ИПС можно найти, например, на сервере "GIS
Online В настоящее время протокол развит настолько, что позволяет обрабатывать различные данные —
финансовую, химическую, техническую информацию, тексты и изображения.
Технология сетевого доступа к базам данных по протоколу Z39.50 существенно отличается от других
технологий. Различие обусловлено самой сутью протокола: его ориентацией на работу с базами данных,
абстрагированных от конкретных систем.
65.
Минимальная конфигурация системы на основе Z39.50 –это програ-мма-сервер + программа-клиент, вбольшинстве случаев связанные между собою по сети TCP/IP – через Интернет (Z39.50 входит в число
"известных служб", и имеет порт 210). Также в эту конфигу-рацию могут добавляться программы-шлюзы,
тезаурусы, PROXY-серверы и др. средства.
Существующие реализации протокола, необходимо подразделить эти реализации на четыре категории:
• серверные части
• клиентские части
• программы-шлюзы
• вспомогательное программное обеспечение
Серверные части протокола Z39.50 представлены в двух категориях: коммерческие и бесплатные. Среди
коммерческих серверных программ (всего их насчитывается более 20) наиболее выделяется сервер Z39.
66.
MetaStar компании BlueAngel Technologies, который обладает большим набором возможностей и во всейполноте реализует протокол. Среди бесплатных серверов существуют лишь два: Isite, разрабатываемый
организацией CNIDR и Zebra server, разрабатыва-емый датской компаний еndexdata. Каждая серверная
реализация протокола обладает собственной, зачастую нигде более не встречаемой спецификой. К примеру,
Isite не поддерживает именование результатов и оператор PROXY, но корректно поддерживает индексацию
кириллицы на платформе Windows NT, а Zebra server Наоборот
Все реализации также существенно различаются по типам хранимых данных (тех, для которых могут быть
построены индексы, хранящие значения точек входа): например MetaStar ориентирован на формат XML, Isite
поддерживает SGML, HTML, и др., а Zebra – GRS-1, Text, MARC. Т.е. то, что в стандарте объявлено
универсальным, на практике создает проблему совместимости.
67.
Среди клиентских программ можно выделить две категории: специализированные клиенты, предназначенныедля работы со строго определенными серверами или данными (прежде всего, библиотечные клиенты) и
универсальные, способные конфигури-роваться под каждую конкретную задачу (Znavigator, Willow).
68.
Состав протокола Z39.50. В основе Z39.50 лежит модель абстрактной базы данных. Каждый элемент этоймодели имеет описание с однозначным толкованием и стандартизуется с присвоением уникального
идентификатора — OID.
Термин база данных в спецификации Z39.50 означает набор файлов каждый из которых имеет свое уникальное
имя. Единицей хранения информации, которая может быть найдена при обращении к базе данных, является
запись файла. Все записи одного файла должны иметь одинаковую структуру (т. е. состоять из одного и того же
набора элементов и точек доступа). Точка доступа — это уникальный или неуникальный ключ, который может
быть указан самостоятельно или в совокупности с другими ключами в поисковом критерии. Ключ может быть
элементом данных, состоять из нескольких элементов или быть частью элемента. Работа с каждой конкретной
СУБД согласно Z39.50 должна быть организована только через эту абстрактную модель путем обмена пакетами
данных (PDU), содержащими последовательности объектов, идентифицируемых по меткам. В стандарте описаны
следующие классы объектов:
69.
• контекст приложения (context);• протокольные блоки данных — protocol data unit (pdu);
• атрибуты (attributeset);
• диагностика (diagnostic);
• структура записей (recordsyntax);
• синтаксис преобразований (transfersyntax);
• отчет по ресурсам (resourcereport);
• контроль доступа (accesscontrol);
• расширенный сервис (extendedservice);
• пользовательская информация (userinfoformat);
• элементы (elementspec);
• варианты (variantset);
• схема данных (schema);
• схема меток (tagset).
70.
71.
Рассмотрим службу каталогов OSI Х.500. Несмотря на то что службы каталогов доступны уже болеедесятилетия, они стали особенно популярными лишь недавно в виде упрощенных версий, реализованных как
службы Интернета.
Концептуально служба каталогов Х.500 состоит из множества записей, которые обычно называются
элементами каталога. Элемент каталога в Х.500 похож на запись о ресурсах системы DNS. Каждая запись
состоит из набора пар (атрибут, значение), причем каждый атрибут имеет ассоциированный с ним тип.
Различаются атрибуты с одним значением (однозначные) и атрибу-ты с несколькими значениями
(многозначные), которые представ-ляют собой массивы или списки. Набор всех элементов каталога службы
каталогов Х.500 называется информационной базой ката-лога {Directory Information Base, DIB), каждая запись в
DIB имеет уникальное имя, чтобы ее можно было найти. Глобально уникаль-ное имя получается из
последовательности атрибутов именования каждой записи. Каждый атрибут именования называется относительно различимым именем {Relative Distinguished Name, RDN)
72.
Атрибуты Country, Organization и OrganizationalUnit можно использовать для формирования глобальноуникального имени: /C=NL/0=Vrije Univers1te1t/OU=Math. & Comp.Sc. Это имя аналогично имени nl.vu.cs в
системе DNS.
73.
Использование глобально уникальных имен, образуемых последо-вательным перечислением имен RDN,приведет нас к иерархии наборов элементов каталога, которую мы будем называть информационным деревом
каталогов {Directory Information Tree, DIT). DIT, в сущности, образует граф именования службы каталогов
Х.500, в котором каждый узел представляет собой элемент каталога. Кроме того, узел может также работать
каталогом в традиционном смысле, у него может быть несколько дочерних узлов, для которых он будет
родителем. Узел в графе именования Х.500 может, таким образом, быть представлен и в виде каталога в
традиционном смысле, и в виде записи Х.500. Это разница поддерживается двумя различными операциями
поиска. Операция read, предназначенная для чтения одиночной записи, дает ее путь в дереве DIT. С другой
стороны, операция list используется для построения списка имен всех ребер, исходящих из данного узла
дерева DIT. Каждое имя соответствует узлу, дочернему для данного. Отметим, что операция 11st не
возвращает записей, она возвращает только имена.
74.
При операциях с большим каталогом дерево DIT обычно разбивается и разносится по нескольким серверам,которые в терминологии Х.500 называются агентами службы каталогов {Directory Service Agents, DSA).
Каждая часть разбитого дерева DIT соответствует зоне в DNS. Точно так же каждый агент DSA ведет себя
очень похоже на обычный сервер имен, за исключением того, что он реализует несколько стандартных для
службы каталогов служб, таких как расширенные операции поиска.
Клиенты представлены тем, что называется агенты пользователей каталога {Directory User Agents, DUA).
Агент DUA подобен процедуре разрешения имен из традиционной службы именования. DUA обмениваются
информацией с DSA в соответствии со стандартным протоколом доступа. Что делает реализацию Х.500
отличной от реализации DNS — так это механизмы поиска в базе DIE. В частности, имеются механизмы для
поиска элемента каталога по заданному набору критериев, в который могут входить атрибуты искомых
элементов.
75.
На практике это еще означает, что следует перебрать также и множество агентов DSA. В противоположностьэтому, службы имен часто могут быть реализованы при помощи операции поиска, нуждающейся в доступе
только к одному листовому узлу. Система Х.500 находится в одном ряду с множеством других протоколов
OSI. Доступ к каталогу Х.500 в соответствии с официальными правилами — дело не простое. Чтобы
приспособить службу каталогов Х.500 к Интернету, был создан более простой протокол, известный как
упрощенный протокол доступа к каталогам (Lightweight Directory Access Protocol, LDAP). LDAP — это протокол
прикладного уровня, реализованный непосредственно поверх TCP. Кроме того, параметры операций поиска и
обновления могут быть переданы просто в виде строк.
76.
Для эффективной реализации полномасштабного пространства имен, такого как в DNS, удобно разбитьпространство имен на три уровня. Глобальный и административный уровни характеризуются тем, что
содержимое узлов этих частей пространства имен относительно постоянно. Вследствие этого репликация и
кэширование способны повысить эффективность реализации. Содержимое узлов управленческого уровня
часто изменяется. Поэтому производительность операций поиска и обновления на этом уровне можно
удовлетворить путем реализации узлов на локальных высокопроизводительных серверах имен.
77.
Z39.50 — клиент-серверный протокол для поиска и получения ин-формации с удаленных компьютерных базданных. Он описывается ANSI/NISO стандартом Z39.50, а также ISO-стандартом 23950. Основное агентство,
которое обслуживает стандарт — библиотека Конгресса. Широко применим в библиотечных кругах и часто
вклю-чен в автоматизированные библиотечные информационные системы и персональные системы
управления библиографической информа-цией. Межбиблиотечные поисковые каталоги для межбиблиотечного абонемента часто реализованы через запросы Z39.50. Протокол Z39.50 используется с 1970-х годов,
обновлённые версии выходили в 1988, 1992, 1995 и 2003 годах. На семантике протокола Z39.50 основан
универсальный язык запросов Contextual Query Language (CQL, ранее — Common Query Language).
Z39.50 наиболее часто используется для запросов к библиографи-ческим базам данных, представленным в
формате MARC, поэтому эти два стандарта обычно связывают между собой. Но, на самом деле, Z39.50 может
использоваться для доступа к данным, представ-ленным и в других форматах.
78.
Протокол Z39.50 поддерживает ряд функций, в том числе поиск, выборку, сортировку и просмотр. Поисковыезапросы формулируются с помощью атрибутов, как правило, из набора BIB-1, включающего в себя шесть
атрибутов, использующихся при поиске информации на сервере: использование, отношение, положение,
структура, усечение, полнота. Синтаксис протокола Z39.50 позволяет формулировать очень сложные запросы.
интаксис Z39.50 не привязан к структуре конкретной базы данных. Это позволяет формулировать без
необходимости знать что-либо о целевой базе данных; но это также означает, что результаты одного и того же
запроса могут варьироваться в широких пределах между различными серверами. Один сервер может
обратиться к индексу автора; другой, например, к индексу личных имен, вне зависимости от того, являются ли
они авторами; третий может не иметь индекса названия и перейти к поиску по индексу ключевых слов; а
четвёр-тый может вообще возвращать ошибку.
79.
Постольку, поскольку Z39.50 был разработан очень давно, он не очень хорошо сочетается с современнойинфраструктурой веб.
Библиотекой Конгресса США была разработана пара протоколов SRU/SRW (Search/Retrieve via URL и
Search/Retrieve Web service), которые позволяют выполнять запросы на Contextual Query Language, но
использовать HTTP в качестве транспорта. Они призваны заменить собой Z39.50, но, в настоящее время,
сосуществуют с ним. SRU — это REST-протокол, SRW использует технологию SOAP. Оба протокола работают
со структурами данных в формате XML и являются функционально идентичными.
80.
Основные службы протокола Z39.50В самом протоколе объявлены 11 сервисов, которые и выполняют весь спектр действий предусмотренных в
протоколе:
• служба Init: инициализирует Z-ассоциацию, и позволяет клиенту и серверу обменяться информацией о
поддерживаемых службах.
• служба Search: создает результирующее множество в соответствии с заданными клиентом критериями
поиска.
В качестве средства для отбора записей предусмотрено три типа запросов: 0, 1, 101.
• 0 – это запрос с произвольным синтаксисом.
• 1 – это запрос, записываемый в обратной польской записи (RPN) с операторами AND, OR, ANDNOT (язык,
равносильный STAIRS).
• 101 – запрос аналогичный 1, но с дополнительным оператором PROXY, описывающим синтагматическую
близость связываемых этим оператором терминов в тексте искомой записи.
81.
В качестве терминов используется текст, сопряженный с произволь-ным набором атрибутов, несущих какслужебную, так и поисковую информацию. В качестве результата служба возвращает идентифи-катор
результирующего множества и его мощность.
• служба Present: отвечает за передачу записей между клиентом и сервером. Передача предусматривает
выбор синтаксиса (если это необходимо), также возможна сегментация результирующего множества и/или
отдельных документов.
• служба Scan: осуществляет сканирование базы данных с целью извлечения терминов для поиска и
предоставления их списка клиенту. В качестве параметров принимает термин-шаблон, размер шага,
количество возвращаемых терминов.
• служба Explain: позволяет клиенту получать с сервера необходи-мую для поиска и настройки
вспомогательную информацию. В протоколе существуют специализированные форматы, призванные
описывать синтаксисы поддерживаемых форматов, подключенные к серверу базы данных, поддерживаемые
наборы атрибутов и т.д.
82.
служба Sort: осуществляет сортировку результирующего множества.• служба delResSet: позволяет клиенту удалять созданные им результирующие множества.
Остальные службы протокола имеют вспомогательный характер и не относятся непосредственно к процедуре
поиска. Особняком стоит слежба ExtendedService, которая позволяет присоединять к основным службам
протокола произвольные службы, создаваемые владельцами сервера. Z39.50 – это попытка
стандартизировать про-цедуру поиска. За счет этого можно строить различные поисковые системы, с самой
различной архитектурой. На сегодняшний момент протокол широко используется в области поиска
библиографичес-кой информации [LOC] , для обслуживания программы GILS (Government Information Locator
Service[GILS1] в США; Global Information Locator Service [GILS2] и в других странах), в медицин-ских базах
данных и в экологических[GELOS] и геодезических про-граммах типа FGDC [FGDC] ,
83.
а также в распределенных географических информационных системах ArcView[ESRI] и многочисленныхдругих[NSDI] ). Перечень URL со ссылками на географические ИПС можно найти, например, на сервере "GIS
Online В настоящее время протокол развит настолько, что позволяет обрабатывать различные данные —
финансовую, химическую, техническую информацию, тексты и изображения.
Технология сетевого доступа к базам данных по протоколу Z39.50 существенно отличается от других
технологий. Различие обусловлено самой сутью протокола: его ориентацией на работу с базами данных,
абстрагированных от конкретных систем.
84.
Минимальная конфигурация системы на основе Z39.50 –это програ-мма-сервер + программа-клиент, вбольшинстве случаев связанные между собою по сети TCP/IP – через Интернет (Z39.50 входит в число
"известных служб", и имеет порт 210). Также в эту конфигу-рацию могут добавляться программы-шлюзы,
тезаурусы, PROXY-серверы и др. средства.
Существующие реализации протокола, необходимо подразделить эти реализации на четыре категории:
• серверные части
• клиентские части
• программы-шлюзы
• вспомогательное программное обеспечение
Серверные части протокола Z39.50 представлены в двух категориях: коммерческие и бесплатные. Среди
коммерческих серверных программ (всего их насчитывается более 20) наиболее выделяется сервер Z39.
85.
MetaStar компании BlueAngel Technologies, который обладает большим набором возможностей и во всейполноте реализует протокол. Среди бесплатных серверов существуют лишь два: Isite, разрабатываемый
организацией CNIDR и Zebra server, разрабатыва-емый датской компаний еndexdata. Каждая серверная
реализация протокола обладает собственной, зачастую нигде более не встречаемой спецификой. К примеру,
Isite не поддерживает именование результатов и оператор PROXY, но корректно поддерживает индексацию
кириллицы на платформе Windows NT, а Zebra server Наоборот
Все реализации также существенно различаются по типам хранимых данных (тех, для которых могут быть
построены индексы, хранящие значения точек входа): например MetaStar ориентирован на формат XML, Isite
поддерживает SGML, HTML, и др., а Zebra – GRS-1, Text, MARC. Т.е. то, что в стандарте объявлено
универсальным, на практике создает проблему совместимости.
86.
Среди клиентских программ можно выделить две категории: специализированные клиенты, предназначенныедля работы со строго определенными серверами или данными (прежде всего, библиотечные клиенты) и
универсальные, способные конфигури-роваться под каждую конкретную задачу (Znavigator, Willow).
87.
Состав протокола Z39.50. В основе Z39.50 лежит модель абстрактной базы данных. Каждый элемент этоймодели имеет описание с однозначным толкованием и стандартизуется с присвоением уникального
идентификатора — OID.
Термин база данных в спецификации Z39.50 означает набор файлов каждый из которых имеет свое уникальное
имя. Единицей хранения информации, которая может быть найдена при обращении к базе данных, является
запись файла. Все записи одного файла должны иметь одинаковую структуру (т. е. состоять из одного и того же
набора элементов и точек доступа). Точка доступа — это уникальный или неуникальный ключ, который может
быть указан самостоятельно или в совокупности с другими ключами в поисковом критерии. Ключ может быть
элементом данных, состоять из нескольких элементов или быть частью элемента. Работа с каждой конкретной
СУБД согласно Z39.50 должна быть организована только через эту абстрактную модель путем обмена пакетами
данных (PDU), содержащими последовательности объектов, идентифицируемых по меткам. В стандарте описаны
следующие классы объектов:
88.
• контекст приложения (context);• протокольные блоки данных — protocol data unit (pdu);
• атрибуты (attributeset);
• диагностика (diagnostic);
• структура записей (recordsyntax);
• синтаксис преобразований (transfersyntax);
• отчет по ресурсам (resourcereport);
• контроль доступа (accesscontrol);
• расширенный сервис (extendedservice);
• пользовательская информация (userinfoformat);
• элементы (elementspec);
• варианты (variantset);
• схема данных (schema);
• схема меток (tagset).
89.
90.
Хранилища многомерных данных(Data Warehouse)Определение, сформулированное "отцом-основателем" хранилищ данных Биллом
Инмоном: "Хранилище данных - это предметно-ориентированное, привязанное ко времени
и неизменяемое собрание данных для поддержки процесса принятия управляющих
решений". Данные в хранилище попадают из оперативных систем (OLTP-систем), которые
предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может
пополняться за счет внешних источников, например статистических отчетов.
Под хранилищем можно понимать не обязательно гигантское скопление данных - главное,
чтобы оно было удобно для анализа. Для маленьких хранилищ предназначается отдельный
термин - Data Marts (киоски данных).
91.
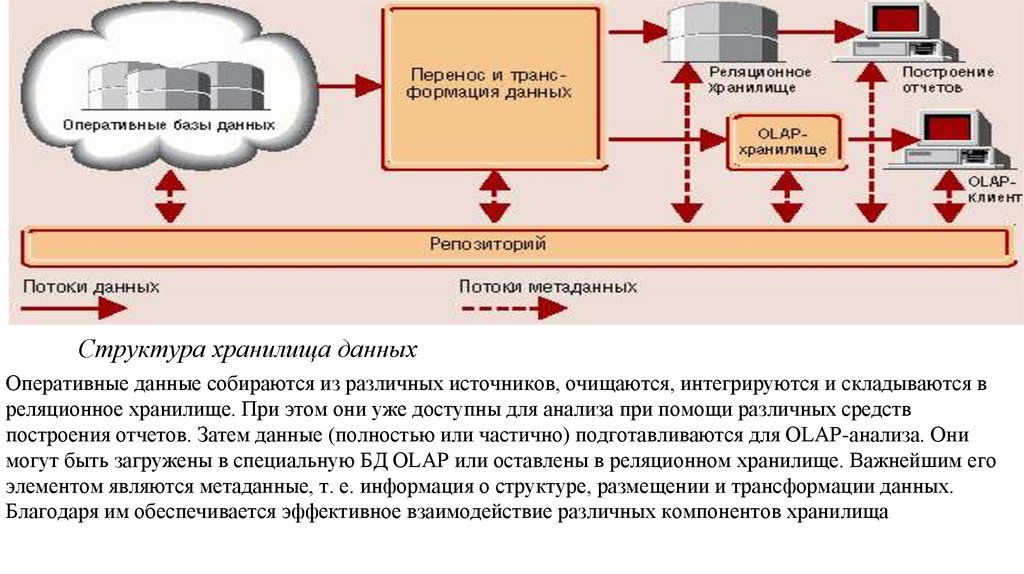
Структура хранилища данныхОперативные данные собираются из различных источников, очищаются, интегрируются и складываются в
реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств
построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они
могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его
элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных.
Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища
92.
Можно определить OLAP как совокупность средств многомерного анализа данных,накопленных в хранилище. Теоретически средства OLAP можно применять и
непосредственно к оперативным данным или их точным копиям (чтобы не мешать
оперативным пользователям).
OLAP - это Online Analytical Processing, т. е. оперативный анализ данных. 12
определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд - "изобретатель"
реляционных БД. Позже его определение было переработано в так называемый тест
FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого
анализа разделяемой многомерной информации .
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа
деловой информации. Пользователь получает естественную, интуитивно понятную модель
данных, организуя их в виде многомерных кубов (Cubes).
Осями многомерной системы координат служат основные атрибуты анализируемого
бизнес-процесса.
93.
Тест FASMIFast (Быстрый) - анализ должен производиться одинаково быстро по всем аспектам
информации. Приемлемое время отклика - 5 с или менее.
Analysis (Анализ) - должна быть возможность осуществлять основные типы числового и
статистического анализа, предопределенного разработчиком приложения или произвольно
определяемого пользователем.
Shared (Разделяемой) - множество пользователей должно иметь доступ к данным, при этом
необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) - это основная, наиболее существенная характеристика
OLAP.
Information (Информации) - приложение должно иметь возможность обращаться к любой
нужной информации, независимо от ее объема и места хранения.
94.
Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного изизмерений используется время. На пересечениях осей - измерений (Dimensions) - находятся
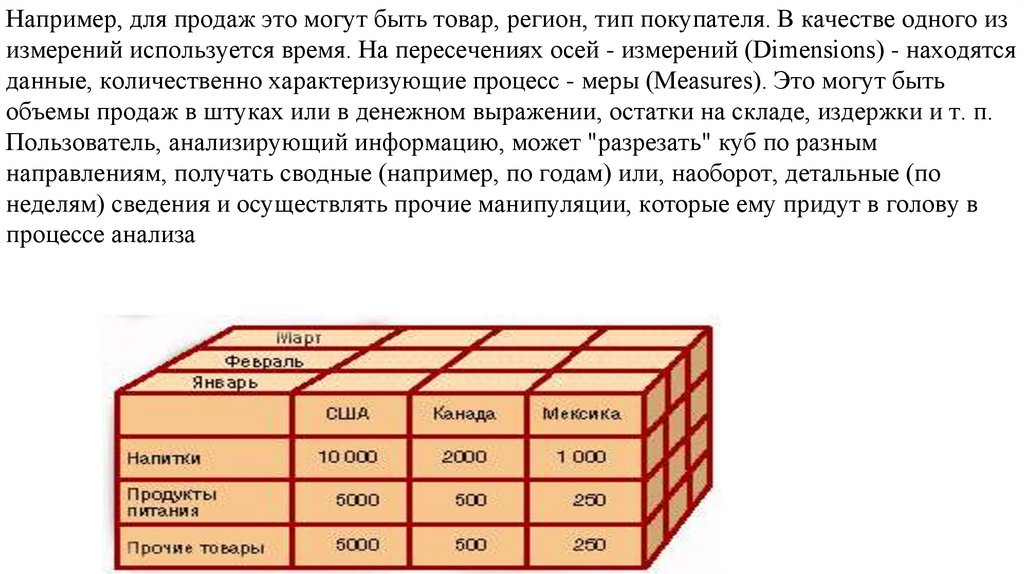
данные, количественно характеризующие процесс - меры (Measures). Это могут быть
объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п.
Пользователь, анализирующий информацию, может "разрезать" куб по разным
направлениям, получать сводные (например, по годам) или, наоборот, детальные (по
неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в
процессе анализа
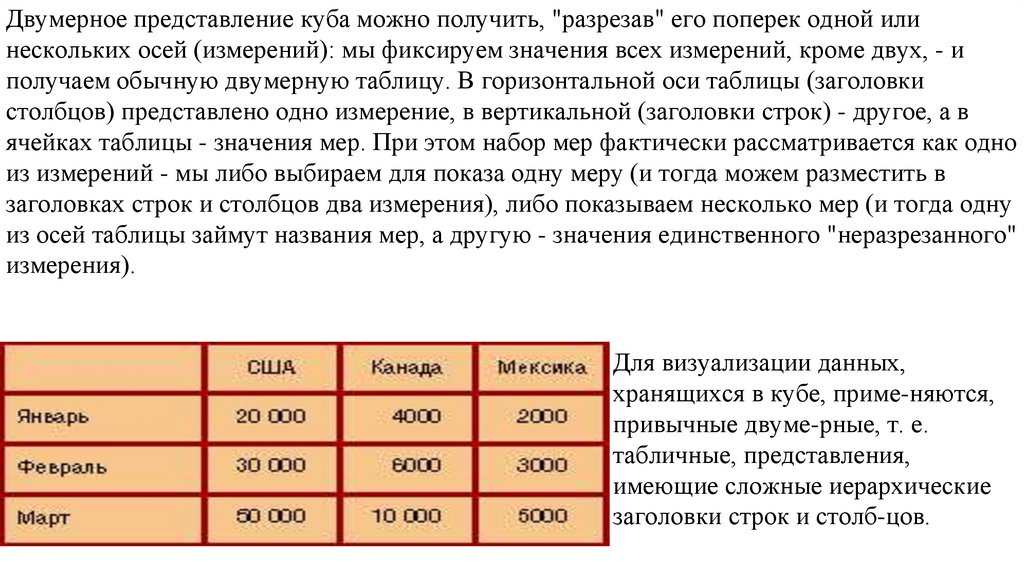
95.
Двумерное представление куба можно получить, "разрезав" его поперек одной илинескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, - и
получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки
столбцов) представлено одно измерение, в вертикальной (заголовки строк) - другое, а в
ячейках таблицы - значения мер. При этом набор мер фактически рассматривается как одно
из измерений - мы либо выбираем для показа одну меру (и тогда можем разместить в
заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну
из осей таблицы займут названия мер, а другую - значения единственного "неразрезанного"
измерения).
Для визуализации данных,
хранящихся в кубе, приме-няются,
привычные двуме-рные, т. е.
табличные, представления,
имеющие сложные иерархические
заголовки строк и столб-цов.
96.
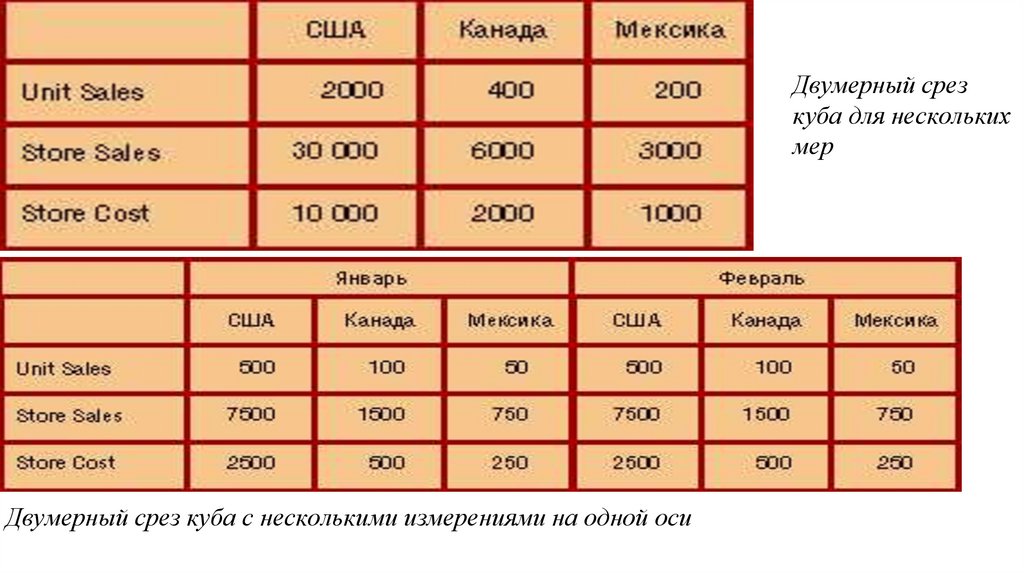
Двумерный срезкуба для нескольких
мер
Двумерный срез куба с несколькими измерениями на одной оси
97.
МеткиЗначения, "откладываемые" вдоль измерений, называются членами или метками (members).
Метки используются как для "разрезания" куба, так и для ограничения (фильтрации)
выбираемых данных - когда в измерении, остающемся "неразрезанным", нас интересуют не
все значения, а их подмножество, например три города из нескольких десятков. Значения
меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней
(levels). Например, метки измерения "Магазин" (Store) естественно объединяются в
иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
98.
Многомерность в OLAP-приложениях может быть разделена на три уровня:* Многомерное представление данных - средства конечного пользователя,
обеспечивающие многомерную визуализацию и манипулирование данными; слой
многомерного представления абстрагирован от физической структуры данных и
воспринимает данные как многомерные.
* Многомерная обработка - средство (язык) формулирования многомерных запросов
(традиционный реляционный язык SQL здесь оказывается непригодным) и процессор,
умеющий обработать и выполнить такой запрос.
* Многомерное хранение - средства физической организации данных, обеспечивающие
эффективное выполнение многомерных запросов.
99.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третийуровень, хотя и является широко распространенным, не обязателен, так как данные для
многомерного представления могут извлекаться и из обычных реляционных структур;
процессор многомерных запросов в этом случае транслирует многомерные запросы в SQLзапросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство
многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000
фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД,
OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAPсервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table
Service фирмы Microsoft.
100.
Средства OLAP-анализа могут извлекать данные и непосредственно из реляционныхсистем.
Такой подход был более привлекательным в те времена, когда OLAP-серверы
отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и
Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры,
которые не любят разводить в своих сетях "зоопарк" из ПО разных производителей, могут
купить (точнее, обратиться с соответствую-щей просьбой к руководству компании) OLAPсервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные
по-разному
В любом хранилище данных - и в обычном, и в многомерном - наряду с детальными
данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели
(агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по
категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью ускорить выполнение запросов.
101.
Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются всесуммарные показатели или их часть
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным
данным приходится платить увеличением объемов данных и времени на их загрузку.
Причем увеличение объема может стать буквально катастрофическим - в одном из
опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных
данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень "разбухания" данных
при вычислении агрегатов зависит от количества измерений куба и структуры этих
измерений, т. е. соотношения количества "отцов" и "детей" на разных уровнях измерения.
Для решения проблемы хранения агрегатов применяются подчас сложные схемы,
позволяющие при вычислении далеко не всех возможных агрегатов достигать
значительного повышения производительности выполнения запросов.
102.
Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо вмногомерных структурах.
Многомерное хранение позволяет обращаться с данными как с многомерным массивом,
благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и
различные многомерные преобразования по любому из измерений.
Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо
многомерное хранение.
Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также
третий вид - смешанный. Применяются следующие термины:
* MOLAP (Multidimensional OLAP)
* ROLAP (Relational OLAP)
* HOLAP (Hybrid OLAP)
103.
* MOLAP (Multidimensional OLAP) - и детальные данные, и агрегаты хранятся вмногомерной БД. В этом случае получается наибольшая избыточность, так как
многомерные данные полностью содержат реляционные.
* ROLAP (Relational OLAP) - детальные данные остаются там, где они "жили"
изначально - в реляционной БД; агрегаты хранятся в той же БД в специально созданных
служебных таблицах.
* HOLAP (Hybrid OLAP) - детальные данные остаются на месте (в реляционной БД), а
агрегаты хранятся в многомерной БД. Каждый из этих способов имеет свои преимущества
и недостатки и должен применяться в зависимости от условий - объема данных, мощности
реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема
"разбухания" за счет хранения пустых значений. Современные OLAP-продукты умеют
справляться с этой проблемой.
104.
Классическая многомерная модель сочетает в себе первичную структуру храненияинформации и механизм поиска.
В качестве первичных структур хранения информации используют-ся ячейки
многомерного пространства (при едином базисе измере-ний) или гиперкубы – области
ячеек многомерного пространства (при множественном базисе измерений). Второй
(поликубический) вариант получил наибольшее распространение в силу удобства
оперирования отдельными подмножествами многомерной базы данных, в том числе, при
обращении к энергонезависимому носителю информации.
Механизм поиска основан на перемещении вдоль оси каждого измерения на заранее
рассчитанное (с помощью формата записи) расстояние вплоть до координаты измерения,
соответствующей атрибуту элемента данных. В оперативной памяти компьютера для
каждого базиса измерений достаточно поддерживать представление осей измерений в виде
таблиц уникальных значений атрибутов, упорядоченных по возрастанию или убыванию.
105.
На пересечении осей измерений находится ячейка многомерного пространства,содержащая элемент данных или указатель на элемент данных, расположенный на
энергонезависимом носителе информации.
Единственный недостаток классической многомерной модели данных – "взрывной" рост
ячеек многомерного пространства при увеличении числа измерений и количества
координат в составе измерений. Объем многомерного пространства при этом возрастает по
экспоненте. Количество ячеек, заполненных NULL-значениями, на порядки превышает
количество ячеек, заполненных реальными данными. С целью сжатия многомерного
пространства используется прием, реализованный в навигационной модели данных –
адресные указатели, связывающие в том или ином порядке ячейки со значимыми данными.
Сжатое многомерное пространство, в свою очередь, требует замены механизма поиска,
основанного на однократных перемещениях вдоль осей измерений, на механизм поиска,
основанный на иерархических структурах.
106.
В этом виде многомерная модель может быть отнесена к группе навигационных моделейданных. Так же как иерархическую и сетевую, многомерную модель целесообразно
дополнить механизмом ссылок в виде внешних ключей, связывающих данные,
расположенные в разных гиперкубах. Полученную модель данных можно определить как
интегрированную модель, вобравшую лучшие качества иерархической (механизм
поиска), сетевой (произвольный доступ) и реляционной (логическое разделение первичных
структур хранения информации) моделей данных. Использование интегрированной модели
позволит отказаться от двойного представления информации, реализованного в гибридных
многомерно-реляционных базах данных, предлагаемых ведущими производителями
данного класса программного обеспечения. Это дополнительно увеличит скорость доступа
к данным.
107.
Интегрированная модель данных имеет широкие перспективы развития в направлениимноговерсионной архитектуры, замены процедуры, опережающей записи в журнал
транзакций, на специальные алгоритмы контроля полноты и достоверности контроля без
обращения к энергонезависимому носителю информации, управления отдельными
экземплярами атрибутов данных и т.д.
В заключение необходимо подчеркнуть важность сохранения преемственности в
использовании всего комплекса знаний и практического опыта, накопленных в области
управления базами данных, в первую очередь достижений в контроле транзакций,
поддержке версий данных, развитого языка программирования, совершенных механизмах
репликации и масштабирования. Интегрированная модель, безусловно, должна быть
оснащена всеми современными средствами управления базами данных.
108.
Типы сетей Fibre Channel, iSCSI, iSER, SRP, FCoE, FCIP и iFCP, HyperSCSI, FICON, ATAover Ethernet
•Сеть хранения данных, или Storage Area Network — это система, состоящая из
собственно устройств хранения данных — дисковых, или RAID — массивов, ленточных
библиотек и прочего, среды передачи данных и подключенных к ней серверов. Обычно
используется достаточно крупными компаниями, имеющими развитую IT инфраструктуру,
для надежного хранения данных и скоростного доступа к ним.
Упрощенно, СХД — это система, позволяющая раздавать серверам надежные быстрые
диски изменяемой емкости с разных устройств хранения данных. SAN характеризуются
предоставлением так называемых сетевых блочных устройств (обычно посредством
протоколов Fibre Channel, iSCSI или AoE), в то время как сетевые хранилища данных
(англ. Network Attached Storage, NAS) нацелены на предоставление доступа к хранящимся
на их файловой системе данным при помощи сетевой файловой системы (такой как NFS,
SMB/CIFS, или Apple Filing Protocol).
109.
Движущей силой для развития сетей хранения данных стал взрывной рост объема деловойинформации, требующей высокоскоростного доступа к дисковым устройствам на блочном
уровне. Ранее на предприятии возникали «острова» высокопроиз-водительных дисковых
массивов SCSI. Каждый такой массив был выделен для конкретного приложения и виден
ему как некоторое количество «виртуальных жестких дисков» (LUN'ов).
Сеть хранения данных позволяет объединить эти «острова» средствами высокоскоростной
сети. Также без использования технологий SCSI транспорта невозможно организовать
отказоус-тойчивые кластеры, в которых один сервер подключается к двум и более
дисковым массивам, находящимся на большом расстоянии друг от друга на случай
стихийных бедствий. Сети хранения помогают повысить эффективность использования
ресурсов систем хранения, поскольку дают возможность выделить любой ресурс любому
узлу сети. Устройства резервного копирования также подключаются к СХД (SAN). В
данный момент существуют как промышленные ленточные библиотеки (на несколько
тысяч лент) от ведущих брендов, так и low-end решения для малого бизнеса.
110.
Сети хранения данных позволяют подключить к одному хосту несколько приводов такихбиблиотек, обеспечив таким образом хранилище данных для резервного копирования от
сотен терабайт до нескольких петабайт.
1.Однокоммутаторная структура (англ. single-switch fabric) состоит из одного
коммутатора Fibre Channel, сервера и системы хранения данных. Обычно эта топология
является базовой для всех стандартных решений — другие топологии создаются
объединением однокоммутаторных ячеек
2.Каскадная структура (англ. cascaded fabric) — набор ячеек, коммутаторы которых
соединены в дерево с помощью межкоммутаторных соединений (англ. Inter-Switch link,
ISL). Во время инициализации сети коммутаторы выбирают «верхушку дерева»
(англ. principal switch, главный коммутатор) и присваивают ISL’ам статус «upstream»
(вверх) или «downstream» (вниз) в зависимости от того, ведет этот линк в сторону главного
свитча или на периферию.
111.
112.
3.Решетка (англ. meshed fabric) — набор ячеек, коммутатор каждой из которых соединен совсеми другими. При отказе одного (а в ряде сочетаний — и более) ISL соединения
связность сети не нарушается. Недостаток — большая избыточность соединений. 4.Кольцо
(англ. ring fabric) — практически повторяет схему топологии решётка. Среди
преимуществ — использование меньшего количества ISL соединений.
113.
Интерфейс Fibre Channel – это технология межсистемного взаимодействия, котораяобъединяет в себе возможности высокоскоростного ввода-вывода и сетевого обмена
данными, т.е.
– каналов передачи данных и сетей..
К каналам передачи данных между компьютерной системой и периферийным устройством
относятся интерфейсы SCSI (Small Computer System Interface) и HIPPI (High- Performance
Parallel Interface), которые реализуются средствами аппаратного обеспечения.
В отличие от каналов, сети в основном реализуются средствами программного уровня.
Один из подходов в объединении систем хранения данных и сетей заключается в том, что
сеть становится ключевым элементом, к которому добавляются новые возможности с
одновременной компенсацией недостатков подобного подхода. Речь идет о технологии
хранения данных на базе протокола IP
114.
Другой подход состоит в использовании центрального хранилища данных (канальнаясистема) и расширения существующих технологических функций. На базе этого метода
создавалась технология Fibre Channel. Одно из основных преимуществ Fibre Channel по
сравнению с IP Storage заключается в разработке продуктов Fibre Channel уже в течение 10
лет, в то время как решения для IP Storage появились сравнительно недавно.
Так как Fibre Channel основана на структуре каналов, стоит рассмотреть недостатки другой
известной технологии – SCSI.
Максимальная скорость передачи данных – до 320 Мбайт/с, чего явно недостаточно для
хранилищ данных большого объема.
Адаптер поддерживает только 16 устройств.
Преимущество, которое одновременно является и недостатком, – обратная совместимость.
Стандарт SCSI развивался много лет, и производители устройств смогли обеспечить
обратную совместимость для нескольких поколений устройств.
115.
Но администратор должен следить, чтобы к шине не подключались устройствапредыдущих поколений, поскольку шина автоматически перейдет в режим,
поддерживающий работу самого старого устройства.
Поддерживается длина кабелей, составляющая несколько десятков метров. Этого
недостаточно для создания обычных, а тем более географически распределенных
кластеров.
Существуют и другие альтернативы SCSI, например SSA (Serial Storage Architecture),
которые еще находятся в рамках архитектуры Intel или вообще представляют собой
открытый стандарт.
116.
Облачные хранилищаКомпания Seagate сотрудничает с партнерами по программе Cloud Alliance для создания
индивидуальных, гибких и масштабируемых серверных решений и решений в сфере
хранения данных для облачных систем. Сообщества Open Compute Project и OpenStack
прокладывают путь для высокомасштабируемых облачных ЦОД. Набирающие
популярность аппаратные и программные платформы с открытым исходным кодом
предоставляют компаниям целый ряд новых возможностей. Оптимизируя работу центров
обработки данных, многие поставщики облачных услуг предпочитают разрабатывать и
создавать собственные решения и программы для серверов и систем хранения или хотя бы
самостоятельно определять их параметры. И в то время как объемы информации растут в
геометрической прогрессии, руководители компаний хотят добиться большей гибкости в
обращении с данными, которая позволила бы им работать продуктивнее, быстрее и с
большей экономией средств.
117.
Индекс цифровой информации Symantec 2012. немного контекста для пояснения: 46 % всехкоммерческих данных в мире хранятся вне средств межсетевой защиты, и хотя какая-то
часть из этого объема приходится на мобильные устройства, все-таки большинство
корпоративных данных хранится в облаке. Взрыв данных: определяющие факторы
Исследование компании Symantec выявило одну доминирующую тенденцию:
коммерческие данные выходят за физические границы компаний и переходят в решения
для облачного хранения. Согласно отчету, 20 % всех корпоративных данных в Северной
Америке хранятся в облаке, а в некоторых странах этот показатель уже преодолел отметку
в 30 %. Разработчикам ЦОД приходится справляться с непрестанно растущим объемом
данных, и индустрия развлечений является прекрасным примером того, как объемы
цифровых ресурсов могут увеличиваться в геометрической прогрессии. Например, по
прогнозам отчета компании Coughlin Associates за 2012 год, спрос на хранение цифровых
данных в сфере развлечений вырастет в 5,6 раза в течение следующих шести месяцев, в
результате чего общий объем хранимых данных увеличится до 84 экзабайт к 2017 году.
118.
Хотя аналитики и не дают точных прогнозов относительно того, какая доля данныхмигрирует в облако, они подчеркивают, что решения для облачного хранения стали
неотъемлемой частью работы специалистов индустрии развлечения. Об усилении роли
облачных служб также свидетельствует успех таких служб потокового видео, как Netflix и
UltraViolet.
Запросы поставщиков видеосодержимого могут казаться уникальными, однако по мере
совершенствования технологий повышается качество видео, что приводит к росту
емкостей хранения, необходимых для того, чтобы вместить все это содержимое. Это
значит, что требования к решениям для основных хранилищ данных, резервного
копирования, архивирования и аварийного восстановления значительно возрастают.
119.
Последствия для систем храненияОдно из главных преимуществ облачных технологий состоит в том, что они могут
понизить совокупную стоимость владения благодаря оптимальному использованию
аппаратных средств. Согласно отчету компании Symantec, задействовано лишь 31 % общих
емкостей внутри системы межсетевой защиты. Облачные вычисления решают эту
проблему путем консолидации аппаратных средств.
Системы хранения не являются изолированным элементом в ЦОД. Поэтому факторы,
влияющие на оборудование хранилищ, приводят к значительным изменениям в совокупной
стоимости владения всей остальной системы.
120.
Использование CGI при создании интерактивных интерфейсов121.
CGI определяет 4 информационных потока.Переменные окружения
Стандартный входной поток
Стандартный выходной поток
Командная строка
CGI-интерфейс
122.
Переменные окружения условно делятся на два типа:общие для всех типов запросов (устанавливаются для всех типов)
зависящие от метода запроса
К переменным первого типа относятся следующие переменные:
SERVER_SOFTWARE содержит информацию о WWW сервере (название/версия)
SERVER_NAME содержит информацию об имени машины, на которой запущен WWW
сервер, символическое имя или IP адрес соответствующие URL.
GATEWAY_INERFACE содержит информацию о версии CGI(CGI/версия)
Следующие переменные являются специфичными для разных типов запросов и значения
этим переменным присваиваются перед вызовом cgi-модуля.
CONTENT_LENGTH значение этой переменной соответствует длине стандартного
входного потока в символах.
CONTENT_TYPE эта переменная специфицирована для запросов содержащих
дополнительную информацию, таких как HTTP POST и PUT, и содержит тип данных этой
информации.
123.
SERVER_PROTOCOL эта переменная содержит информацию об имени и версииинформационного протокола (протокол/версия).
SERVER_PORT значение переменной содержит номер порта, на который был послан
запрос.
REQUEST_METHOD метод запроса, который был использован "POST","GET","HEAD" и
т.д.
PATH_INFO значение переменной содержит полученный от клиента виртуальный путь до
cgi-модуля
PATH_TRANSLATED значение переменной содержит физический путь до cgi-модуля,
преобразованный из значения PATH_INFO.
SCRIPT_NAME виртуальный путь к исполняемому модулю, используемый для получения
URL.
QUERY_STRING значение этой переменной соответствует строке символов следующей за
знаком "?" в URL соответствующему данному запросу. Эта информация не декодируется
сервером.
124.
REMOTE_HOST содержит символическое имя удаленной машины, с которой былпроизведен запрос. В случае отсутствия данной информации сервер присваивает пустое
значение и устанавливает переменную REMOTE_ADDRESS.
REMOTE_ADDRESS содержит IP адрес клиента
AUTH_TYPE если WWW-сервер поддерживает аутентификацию (подтверждение
подлинности) пользователей и cgi-модуль является защищенным от постороннего доступа
то, значение переменной специфицирует метод аутентификации.
REMOTE_USER содержит имя пользователя в случае аутентификации.
REMOTE_IDENT содержит имя пользователя, полученное от сер-вера (если сервер
поддерживает аутентификацию согласно RFC 931)
HTTP_ACCEPT список типов MIME известных клиенту. Каждый тип в списке должен
быть отделен запятой согласно спецификации HTTP (тип/подтип, тип/подтип и т.д.)
HTTP_USER_AGENT название программы просмотра которую использует клиент при
посылке запроса.
125.
Стандартный выводСGI - модуль выводит информацию в стандартный выходной поток. Этот вывод может
представлять собой или документ, сгенерированный cgi-модулем, или инструкцию
серверу, где получить необходимый документ. Обычно cgi-модуль производит свой вывод.
Преимущество такого подхода в том, что cgi-модуль не должен формировать полный
HTTP заголовок на каждый запрос.
Заголовок выходного потока
В некоторых случаях необходимо избегать обработки сервером вывода cgi-модуля, и
посылать клиенту данные без изменений. Для отличия таких cgi-модулей, CGI требует,
чтобы их имена начинались на nph-. В этом случае формирование синтаксически
правильного ответа клиенту cgi-модуль берет на себя.
Заголовки с синтаксическим разбором
Вывод cgi-модуля должен начинаться с заголовка содержащего определенные строки и
завершаться двумя символами CR(0x10).
126.
CGI спецификация определяет три директивы сервера:Content-type
MIME или тип возвращаемого документа
Например: Content-type: text/html <CR><CR> сообщает серверу, что следующие за этим
сообщением данные - есть документ в формате HTML
Location указывает серверу, что возвращается не сам документ, а ссылка на него
Если аргументом является URL, то сервер передаст указание клиенту на перенаправление
запроса. Если аргумент представляет собой виртуальный путь, сервер вернет клиенту
заданный этим путем документ, как если бы клиент запрашивал этот документ
непосредственно.
Например: Location: http://host/file.txt приведет к тому, что WWW сервер выдаст file.txt,
как если бы он был затребован клиентом. Если cgi-модуль возвращает ссылки на gopher
сервер, например на gopher://gopher.ncsa.uiuc.edu/. Вывод будет следующий:
Location: gopher://gopher.ncsa.uiuc.edu/
127.
*Status задает серверу HTTP/1.0 строку-статус, которая будет послана клиенту в формате:nnn xxxxx
где: nnn - 3-х цифровой код статуса
ххххх - строка причины
Например: HTTP/1.0 200 OK
Стандартный входной поток
В случае метода запроса POST данные передаются как содержимое HTTP запроса и
посылаются в стандартный входной поток.
Данные передаются cgi-модулю в следующей форме:
name=value&name1=value1&...&nameN=valueN
где name - имя переменной,
value - значение переменной,
N - количество переменных
На файловый дескриптор стандартного потока ввода посылается CONTENT_LENGTH
байт.
Так же сервер передает cgi-модулю CONTENT_TYPE (тип данных). Сервер не посылает
символ конца файла после передачи CONTENT_LENGTH байт данных или после того, как
cgi-модуль их прочитает.
128.
Переменные окружения CONTENT_LENGTH и CONTENT_TYPE устанавливаются в тотмомент, когда сервер выполняет cgi-модуль. Таким образом, если в результате исполнения
формы с аргументом тега FORM - METHOD="POST" сформирована строка данных
firm=МММ&price=100021, то сервер установит значение CONTENT_LENGTH равным 21 и
CONTENT_TYPE
в application/x-www-form-urlencoded, а в стандартный поток ввода посылается блок данных.
В случае метода GET, строка данных передается как часть URL.
Т.е. например
http://host/cgi-bin/script?name1=value1&name2=value2
В этом случае переменная окружения QUERY_STRING принимает значение
name1=value1&name2=value2
129.
Аргументы командной строкиСGI-модуль в командной строке от сервера получает:
остаток URL после имени cgi-модуля в качестве первого параметра (первый параметр
будет пуст, если присутствовало только имя cgi-модуля), и список ключевых слов в
качестве остатка командной строки для скрипта поиска, или чередующиеся имена полей
формы с добавленным знаком равенства и соответствующих значений переменных.
Ключевые слова, имена и значения полей формы передаются декодированными (из HTTP
URL формата кодирования) и перекодированными в соответствии с правилами
кодирования Bourne shell так, что cgi-модуль в командной строке получит информацию без
необходимости осуществлять дополнительные преобразования.
130.
Последовательность действий для обработки входных данных cgi-модуля для разныхметодов запроса GET и POST
Последовательность действий для обработки входных данных cgi-модуля для разных типов
запросов.
Для метода GET
1.Получить значение переменной QUERY_STRING
2.Декодировать имена и их значения (учитывая, что все пробелы при декодировании
сервером были заменены символом "+" и все символы с десятичным кодом больше 128
преобразованы в символ "%" и следующим за ним шестнадцатеричным кодом символа.)
3.Сформировать структуру соответствия "имя - значение" для дальнейшего использования
в cgi-модуле
Для метода POST
1.Получить из стандартного входного потока CONTENT_LENGTH символов
2.Декодировать имена и их значения (учитывая, что все пробелы при декодировании
сервером были заменены символом "+" и все символы с десятичным кодом больше 128
преобразованы в символ "%" и следующим за ним шестнадцатеричным кодом символа.)
3.Сформировать структуру соответствия "имя - значение" для дальнейшего
использования в cgi-модуле
131.
Возможно создание единого модуля для методов POST и GET. Необходимо толькодобавить в начало проверку значения переменной REQUEST_METHOD для определения
метода запроса. После формирования структуры "имя-значение" можно приступить к
решению задач, ради которых, собственно, создавался cgi-модуль. Следующим важным
моментом является динамическое формирование cgi-модулем HTML-документа
(оформление результата работы модуля).
Например, таблицы выборки из базы данных.
Для этого cgi-модуль должен выдать в стандартный выходной поток заголовок состоящий
из строки:
Content-type: text/html и пустой строки (двух символов CR)
После этого заголовка можно давать любой текст в формате HTML Примеры cgi-модулей
Для тестирования работы форм поставляются программы :
post-query - для тестирования работы форм с методом запроса POST
query - для тестирования работы форм с методом запроса GET
util.c - описание функций для обработки входного потока (используется query и post-query).
132.
<HTML><HEAD>
<TITLE>Пример использования CGI</TITLE>
</HEAD>
<BODY>
<FORM ACTION="http://iceman.cnit.nsu.ru/cgi-bin/post-query" METHOD="POST">
<B>Введите свое имя<I>(Фамилию Имя Отчество)</I>:</B>
<INPUT name=RealName type=text size=40 maxlength=60 value="Петров Иван
Сидорович"><P>
Пол: <INPUT name=Sex type=Radio value="Мужской" CHECKED>- мужской <INPUT
name=Sex type=Radio value="Женский">-женский<P>
<INPUT name=Submit type=submit value="Послать запрос"><BR>
<INPUT name=Reset type=reset value="Сброс">
</FORM>
</BODY>
</HTML>
133.
После инициации формы путем нажатия кнопки "Послать запрос" WWW серверобрабатывает поток данных от формы (заменяет все пробелы в именах и значениях на
символ "+", заменяет все символы с десятичным кодом большим 128 на символ "%" и
следующим за ним шестнадцатеричным кодом символа (например "И" в %С8)).
Выходной поток примет следующий вид:
RealName=%CF%E5%F2%F0%EE%E2+%C8%E2%E0%ED+%D1%E8%E4%EE%F0
%EE%E2%E8%F7&Sex=%CC%F3%E6%F1%EA%EE%E9&Submit=%CF%EE%F1
%EB%E0%F2%FC+%E7%E0%EF%F0%EE%F1
В момент передачи управления модулю post-query сервер присваивает значения
переменным окружения и аргументам командной строки:
134.
argc = 0. argv =SERVER_SOFTWARE = NCSA/1.5.1
SERVER_NAME = iceman.cnit.nsu.ru
GATEWAY_INTERFACE = CGI/1.1
SERVER_PROTOCOL = HTTP/1.0
SERVER_PORT = 80
REQUEST_METHOD = POST
HTTP_ACCEPT = image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,*/*
PATH_INFO =
PATH_TRANSLATED =
SCRIPT_NAME = /cgi-bin/test-cgi
QUERY_STRING =
REMOTE_HOST = fwa.cnit.nsu.ru
REMOTE_ADDR = 193.124.209.74
REMOTE_USER =
AUTH_TYPE =
CONTENT_TYPE = application/x-www-form-urlencoded
CONTENT_LENGTH = 142
135.
Результат работы post-query:<H1>Query Results</H1>You submitted the following name/value pairs:<p>
<ul>
<li> <code>RealName = Петров Иван Сидорович</code>
<li> <code>Sex = Мужской</code>
<li> <code>Submit = Послать запрос </code>
</ul>
И на экране браузера
Query Results
You submitted the following name/value pairs:
RealName = Петров Иван Сидорович
Sex = Мужской
Submit = Послать запрос
Для демонстрации реализации формы с методом запроса GET воспользуемся той же самой
формой, что и для метода POST и программой query.
136.
Для этого изменим значение атрибутов ACTION и METHOD в теге FORM. <FORMaction="http://iceman.cnit.nsu.ru/cgi-bin/query" METHOD=GET>
После инициации формы сервер установит следующие значения для переменных
окружения и аргументов командной строки:
argc = 0. argv is =
SERVER_SOFTWARE = NCSA/1.5.1
SERVER_NAME = iceman.cnit.nsu.ru
GATEWAY_INTERFACE = CGI/1.1
SERVER_PROTOCOL = HTTP/1.0
SERVER_PORT = 80
REQUEST_METHOD = GET
HTTP_ACCEPT = image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
137.
PATH_INFO =PATH_TRANSLATED =
SCRIPT_NAME = /cgi-bin/test-cgi
QUERY_STRING = RealName=%CF%E5%F2%F0%EE%E2+%C8%E2%E0%ED+%D1%E8
%E4%EE%F0%EE%E2%E8%F7&Sex=%CC%F3%E6%F1%EA%EE%E9&Submit=%CF%EE
%F1%EB%E0%F2%FC+%E7%E0%EF%F0%EE%F1
REMOTE_HOST = fwa.cnit.nsu.ru
REMOTE_ADDR = 193.124.209.74
REMOTE_USER =
AUTH_TYPE =
CONTENT_TYPE =
CONTENT_LENGTH =
138.
<FORM атрибуты>...</FORM>использование: предназначен для получения информации от клиента и определяет начало и
конец формы.
атрибуты:
Обязательные
ACTION - определяет URI (Universal Resource Identifier-адрес или место расположения
документа) CGI-скрипта
METHOD - определяет метод передачи информации скрипту. Возможные значения GET
или POST.
Необязательные
[ENCTYPE] - определяет тип MIME декодирования информации (значение этого атрибута
по умолчанию - "application/x-www-form-urlencoded").
[SCRIPT] - используется для передачи URI скрипта. Язык скрипта и интерфейс
пользователя при этом не являются частью спецификации HTML 3.0
Важно: Формы не могут быть вложенными!
139.
<INPUT> предназначен для создания различных по своей функциональности полей ввода.атрибуты: Обязательные:
TYPE - определяет тип поля формы.
Допустимые значения:
TEXT - позволяет символьный ввод.
PASSWORD - предназначено для "скрытого" ввода символов (вводимые символы не
отображаются).
CHECKBOX - поле, позволяющее два состояния ("есть", "нет"). Должен применяться с
атрибутами NAME и VALUE
RADIO - поле, позволяющее выбор "один из всех"
SUBMIT - кнопка инициирующая передачу информации из формы обрабатывающему
скрипту, определенному в ACTION в соответствии с методом, определенным
атрибутом METHOD.
RESET - кнопка, сбрасывающая все введенные ранее значения.
IMAGE - поле позволяющее воспроизвести событие SUBMIT при помощи вашего
изображения, при этом возвращается два значения: name.x = координата Х и name.y =
координата Y, где Х и Y коорди-наты положения курсора мыши на изображении в
момент щелчка.
140.
HIDDEN - поле создающее неотображаемое значение.RANGE - определяет поле позволяющее ввести цифровое значение с определенными
допустимыми верхним и нижним пределами.
Используется вместе с атрибутами MAX и MIN определяющими область допустимых
значений (например: TYPE=RANGE MIN=1 MAX=10).
NAME - значение этого атрибута определяет идентификатор поля.
VALUE - значение этого атрибута определяет что будет передано в качестве значения по
умолчанию для данного поля при инициации формы.
SRC - определяет URI файла изображения. Используется только с типом поля IMAGE.
[CHECKED] - позволяет установить начальное значение поля типа CHECKBOX.
SIZE - определяет размер поля.
[MAXLENGTH] - определяет максимальное количество символов, допустимое для ввода в
поле.
[ALIGN] - позволяет позиционирование
141.
Допустимые значения:по вертикали
TOP - выравнивание по верху.
MIDDLE - выравнивание по середине.
BOTTOM выравнивание по низу.
Эти значения используются только с TYPE=IMAGE.
по горизонтали
[LEFT] - выравнивание слева
[RIGHT] - выравнивание справа
[DISABLED] - определяет поле как "read only" - только для чтения. Значение в поле не
может быть изменено пользователем.
[ERROR] - определяет сообщение об ошибке, объясняющее, почему введенное значение в
поле не верно.
142.
<TEXTAREA атрибуты>...</TEXTAREA>использование: предназначен для определения области ввода текста. Размер поля
определяется атрибутами.
атрибуты:
NAME - значение этого атрибута определяет идентификатор поля. Возвращается при
инициации формы.
ROWS - определяет количество строк в текстовой области.
COLS - определяет количество столбцов в текстовой области.
[VALUE] - задает значение по умолчанию.
[DISABLED] - определяет поле как "read only" - только для чтения. Значение в поле не
может быть изменено пользователем.
[ERROR] - определяет сообщение об ошибке, объясняющее, почему введенное значение в
поле не верно.
143.
<SELECT атрибуты><OPTION > значение1
<OPTION > значениеN
</SELECT>
Атрибуты:
NAME - значение этого атрибута определяет идентификатор поля. Возвращается при
инициации формы.
[SIZE] - определяет количество видимых возможных значений.
[MULTIPLE] - определяет возможность множественного выбора.
[DISABLED] - определяет меню как "read only" - только для чтения. Значения в меню не
может быть выбрано пользователем и показывается серым цветом.
<OPTION атрибуты> значение
использование: используется только с <SELECT> для определения пунктов меню.
атрибуты:
SELECTED - определяет значение по умолчанию
VALUE - определяет возвращаемое значение
144.
Структура экземпляров Oracle.145.
Каждая база данных (БД) Oracle имеет связанный с ней экземпляр. Организацияэкземпляра позволяет СУБД обслуживать множество типов транзакций, обеспечивать
высокую производительность, целостность данных и безопасность. Термин процесс
означает лю- бую задачу, выполняемую без вмешательства пользователя. Открытие БД
Oracle включает три стадии. 1. Формирование экземпляра Oracle (предустановочная
стадия). 2. Установка базы данных экземпляром (установочная стадия). 3. Открытие БД
(стадия открытия).
Экземпляр, в котором нет базы данных, называется незанятым (idle), но он занимает
память и не выполняет никакой работы.
Экземпляр может подсоединиться только к одной БД, если не будет использован Parallel
Server, БД может быть подключена только к одному экземпляру Oracle. В экземпляре
выполняются все операции, в то время как в БД хранятся все данные. Большинство
настроек экземпляра связано с компонентами в глобальной системной области. Но
кроме них существуют и некоторые опции настройки, касающиеся фоновых процессов.
146.
В SGA (System Global Area) хранятся структуры памяти, необхо- димые дляманипулирования данными, анализа предложений SQL и кэширования транзакций.
К этой области одновременно имеет доступ множество процессов, которые могут
считывать данные из нее или модифицировать их. Все операции с БД используют
информацию, находящуюся в SGA. SGA выделяется сразу же после создания экземпляра
еще на предустановочной стадии. Освобождается эта область только после полного
выключения экземпляра.
SGA состоит из следующих компонентов:
• разделяемый пул (SHARED POOL);
• кэш-буфер данных (DATABASE BUFFER CACHE);
• буфер журнала транзакций (REDO LOG BUFFER);
• структуры сервера многозадачной среды (MULTI- THREADED SERVER — MTS).
Разделяемый пул содержит кэш библиотеки, кэш словаря и управляющие структуры
сервера (такие, как набор символов БД). Кэш библиотеки хранит план выполнения
предложений SQL.
147.
Здесь содержатся заголовки пакетов PL/SQL и процедур, выполнявшихся ранее.Кэш словаря хранит строки словаря данных, которые были использованы для
лексического анализа предложений SQL.
Сервер Oracle использует кэш библиотеки для повышения скорости выполнения
операторов SQL. Размер разделяемого пула задается параметром SHARED POOL SIZE
в файле INIT.ORA. Размерность значения параметра — байты. Объем пула необходимо
заказывать. Кэш-буфер данных состоит из блоков памяти того же размера, что и блоки
ORACLE. Все данные загружаются в кэш-буфер. В этих же блоках памяти выполняется
и любое обновление данных. СУБД переносит данные на диск — в соответствии с
порядком их размещения в списке LRU (LEAST RECENTLY USED). Этот список
отслеживает обращение к блокам данных и учитывает частоту обращений. Если
выполняется обращение к блоку данных, хранящемуся в кэш-буфере, то оно
помещается в тот конец списка, который носит название MRU (MOST RECENTLY
USED).
148.
Если серверу требуется место в кэш-буфере для загрузки нового блока, то он решает этотмомент с помощью списка LRU — какой из блоков перенести на диск, чтобы
освободить место для нового. Модифицированные блоки называются грязными (dirty) и
помещаются в соответствующий dirty-список.
Данные о транзакциях хранятся в этом буфере до тех пор, пока не будут переписаны в
файл оперативного журнала транзакций. После заполнения буфера его содержимое
переносится в файл журнала транзакций. Размер буфера журнала транзакций задается
параметром LOG_BUFFER. Значение параметра указывает размер буфера в байтах. В
процессе работы СУБД ORACLE просматривает тысячи записей в таблицах данных,
отвечает на сотни запросов пользователей одновременно. Вся работа распределяется
между множеством программ, которые работают независимо одна от другой.. В
совокупности эти программы называются фоновыми процессами ORACLE.
149.
Множество фоновых процессов Oracle включает: • SMON и PMON (System Monitor иProcess Monitor выполняют автоматическую “уборку” после внезапно прекратившихся
или завершившихся аварийно процессов. Эта “уборка” включает удаление сеанса,
блокировок, которые были им установлены, непринятых транзакций, освобождение
ресурсов глобальной системной области, выделенных этому процессу.
Запускаются при запуске системы),
• DBWR(DataBase Writer) — отвечает за перенос обновленных блоков, занесенных в dirtycписок из кэш-буфера данных в файлы данных. Вместо того, чтобы записывать каждый
блок на диск сразу, DBWR ждет, пока не будет выполнено одно из условий, а за- тем
просматривает dirty-cписок и все отмеченные в нем блоки переписывает на диск.
• LGWR (Log Writer последний фоновый процесс, запуск которого обязателен для
работы СУБД ORACLE. Этот процесс отвечает за перезапись информации из буфера
журнала транзакций, который находится в глобальной системной области, в файлы
оперативного журнала.
150.
ORACLE не считает транзакцию выполненной до тех пор, пока процесс LGWR неперезапишет данные о ней из буфера журнала транзакций в файл. ),
• Dnnn Фоновые процессы-диспетчера Dnnn. Все процессы сервера могут закрепляться за
определенными пользовательскими процессами, либо быть “разделяемые” (shared)
процессами или серверами. Для работы с применением разделяемого сервера необходима
установка Multi Threaded Server (MTS). При использовании разделяемых процессов, в
системе должен существовать как минимум один процесс диспетчер, который передает запросы
пользователей в очередь SGA и возвращает ответы сервера соответствующему процессу пользователя,
• ARCH (Archiver) отвечает за копирование полностью заполнен-ного оперативного
журнала транзакций в архивные файлы журналов транзакций. Во время перезаписи в
архив никакой другой процесс не может получить доступ к журналу. Во время
копирования в архив система должна находиться в состоянии ожидания,
151.
• СКРТ (Check Point) — это дополнительный фоновый процесс, который отвечает заобработку контрольных точек. Необходимость в нем возникает, когда надо снизить
нагрузку на LGWR.
• RECO (Recovery) отвечает за восстановление неза- вершенных транзакций в
распределенной системе БД. Когда возни- кает подозрительная транзакция, RECO
выполняет свои функции автоматически без вмешательства администратора БД.
• SNPn(Snapshot) выполняет автоматические обновления снимков БД и запускает
процедуры в соответствии с расписанием, зафиксированным в пакете DBMS_JOB. В файле
init.ora задается количество запускаемых процессов SNPn и длительность интер-вала, в
течение которого процесс “засыпает” прежде чем выпол- нить задание.
• LCKn(Parallel Server Lock) — в среде, производящей параллельное обслуживание
нескольких экземпляров БД, на LCKn возлагается ответственность за координацию
блокировок устанав- ливаемых разными экземплярами БД,
• Pnnn (Parallel Query) Сервер Oracle запускает и останавливает процессы Pnnn в
зависимости от активности работы с БД и на- строй-ки опций параллельных запросов.
152.
Количество запускаемых процессов определяется двумя параметрами:PARALLEL_MIN SERVERS и PARALLEL_MAX SERVERS, определяющими,
соответственно, минимальное и максимальное количество запускаемых процессов.
Процессы пользователя и сервера
Приложения и утилиты связываются с СУБД посредством процес- сов пользователя.
Каждый процесс пользователя подключается к про цессу сервера. Процесс сервера
анализирует и выполняет переданные ему операторы SQL и возвращает результат процессу
пользователя. Кроме того, процесс сервера считывает блоки данных из файлов данных и
размещает их в кэш-буфере данных. Приложения и клиентские части связываются с
сервером Oracle посредством “процессов пользователя”. Процесс сервера, анализирует и
выполняет переданные ему операторы SQL и возвращает результат процессу
пользователя, считывает блоки данных из файла данных и размещает их в кэш-буфере
данных. Каждому процессу пользователя выделяется область памяти, ко- торая
называется “глобальной областью процесса” — PGA (Process Global Area). Содержимое
PGA зависит от режима подключения процесса пользователя к процессу сервера.
153.
Если же процесс пользователя связан с разделяемым процессом сервера, то информация отекущем сеансе и текущем состоянии курсора хранится в SGA.
Основные объекты СУБД ORACLE.
Таблица (TABLE) является базовой структурой реляционной модели. Представление
(VIEW) — это поименованная, динамически поддерживаемая сервером выборка из
одной или нескольких таблиц.
Пользователь (USER) — объект, обладающий возможностью создавать и использовать
другие объекты ORACLE, а также запра- шивать выполнение функций сервера. Для
упрощения решения задач идентификации и именования в базе данных ORACLE
поддерживает объекты: последовательность и синоним. Последовательность
(SEQUENCE) — это объект, обеспечиваю-щий генерацию уникальных номеров в
условиях многопользова-тельского асинхронного доступа. Обычно элементы последовательности используются для вставки уникальных идентификацион- ных номеров для
элементов таблиц базы данных.
154.
Синоним (SYNONYM) — это альтернативное имя-псевдоним объекта ORACLE, которыйпозволяет пользователям базы данных иметь доступ к данному объекту. Синоним может
быть частным и общим. Общий (public) синоним позволяет всем пользователям базы
данных обращаться к соответствующему объекту по альтернативному имени. Для
управления эффективностью доступа к данным Oracle поддерживает объекты: индекс,
табличная область и кластер.
Индекс (INDEX) — создается для столбцов таблицы или для пред-ставления в
пространстве базы данных и обеспечивает более быстрый доступ к данным базы данных за
счет хранения прямых ссылок на место расположения строк, содержащих требуемые
данные. Табличная область (TABLESPACE) — именованная часть базы данных,
используемая для распределения памяти для таблиц и индексов.
Кластер (CLUSTER) — объект, задающий способ совместного хранения данных
нескольких таблиц, содержавших информацию, обычно обрабатываемую совместно..
155.
Кластеризация столбцов таблиц позволяет уменьшить время выполнения выборки. Строкитаблиц, имеющие одинаковое значение в кластеризованных столбцах, хранятся в базе
данных специальным образом
Для эффективного управления разграничением доступа к данным Oracle поддерживает
объект роль.
Роль (ROLE) — именованная совокупность привилегий, которые могут быть
предоставлены пользователям или другим ролям. Специфичными для распределенных
систем являются объекты ORACLE: снимок и связь базы данных.
Снимок (SNAPSHOT) — локальная копия таблицы удаленной базы данных, которая
используется либо для тиражирования (копирования) всей или части таблицы, либо для
тиражирования результата запроса данных из нескольких таблиц. Снимки могут быть
модифицируемыми или предназначенными только для чтения.
156.
Связь базы данных (DATABASE LINK) — это объект базы данных, который позволяетобратиться к объектам удаленной базы данных. Имя связи базы данных можно
рассматривать как ссылку на параметры механизма доступа к удаленной базе данных (имя
узла, протокол и т.п.). Использование одного имени упрощает работу с объектами
удаленной базы данных.
Для программирования алгоритмов обработки данных, реализа- ции механизмов
поддержки целостности базы данных Oracle ис- пользует объекты: процедура, функция,
пакет и триггер.
Процедура (PROCEDURE) — это поименованный, структури- рованный набор переменных
и операторов SQL и PL/SQL, предна- значенный для решения конкретной задачи. Функция
(FUNCTION) — это поименованный, структуриро- ванный набор переменных и
операторов SQL и PL/SQL, предна- значенный для решения конкретной задачи и
возвращающий зна- чение переменной. Пакет (PACKAGE) — это поименованный,
структурированный набор переменных, процедур и функций, связанных единым функциональным замыслом.
157.
ORACLE поставляет пакет DBMS_OUTPUT, в котором собраны процедуры и функции,предназначенные для организации ввода-вывода.
Триггер (TRIGGER) — это хранимая процедура, которая запуска- ется (автоматически
выполняется) тогда, когда происходит связанное с триггером событие. Обычно события
связаны с выполнением опера- торов INSERT, UPDATE или DELETE в некоторой таблице.
Типы данных ORACLE. Существует следующие типы данных в PL/SQL: • скалярный
(простой) тип;
• составной тип — запись;
• ссылочный — указатель на объект программы;
• LOB (LOCATORS) — графические образы.
Типы CHARACTER, VARCHAR, VARCHAR2[(длина)] , LONG, INTEGER, NUMBER,
DECIMAL и NUMERIC, RAW, LONG RAW, DATE, При определении даты без уточнения
времени по умолчанию принимается время полуночи. Функция SYSDATE присваивает переменной текущее значение даты и времени.
158.
Метод %TYPE. Предопределенный метод %TYPE позволяет определить типпеременной, совпадающий с типом атрибута некоторой таблицы, например:
V_ENAME EM.ENAME%TYPE;
V_MIN_BALANCE EM.BALANCE%TYPE := 10
К составным типам относятся: • PL/SQL записи;
• PL/SQL таблицы;
• таблица записей.
--Создание типа type_name
TYPE type_name is record (field_declaration[, field_declaration]...);
--Создание переменной типа type_name identifier type_name;
где field_declaration есть: field_name {field_type|variable%type
|table.column%type|table%rowtype} [[not null] {:=default}|expr]
где field_name — имя поля, field_type — его тип, expr — начальное значение field_name.
159.
Метод %ROWTYPE может применяться как ко всей таблице, так и к ее отдельнымполям ( атрибутам). При использовании этого метода с таблицей или представлением
объявляется запись той же структуры, что и таблица или представление, при этом
поля записи имеют имена и типы полей таблицы или представления. Использование
%ROWTYPE имеет ряд пре- имуществ:
• число и тип колонок базы данных может быть неизвестен;
• число типов колонок базы данных может меняться;
• этот атрибут полезен, когда колонка определяется с помощью SELECT утверждения.
Если метод %ROWTYPE применяется к отдельными полям (атрибутам), происходит
объявление переменной того же типа, что и столбец в таблице, например, dept_record
dept%rowtype
160.
Таблица является базовой структурой реляционной модели. Полное имя таблицы в базеданных состоит из имени схемы, как правило, совпадающем с именем пользователя, и имени
таблицы. Оператор определения таблиц имеет следующий синтаксис:
CREATE TABLE[имя_схемы.]имя таблицы
({ограничение_целостности_таблицы|имя_столбца тип_данных_столбца [DEFAULT
выражение] [ограничение_целостности_столбца...]},...)
[{CLUSTER имя_кластера(имя_столбца[,...])| {PCTFREE целое|PCTUSED целое| INITRANS
целое|MAXTRANS целое| TABLESPACE имя_табличной_области| STORAGE размер
памяти| {RECOVERABLE|UNRECOVERABLE}}...]
[PARALLEL возможность_параллельной_обработки]
[{ENABLE проверяемые_ограничения_целостности | DISABLE
игнорируемые_ограничения_целостности}...]
161.
Ключевое слово DEFAULT указывает на то, что при вводе данных соответствующемустолбцу будет присвоено значение, определенное переменной выражение, если в операторе
INSERT не указано явно другое значение столбца. Тип данных выражение должен
соответствовать типу данных столбца и выражение не должно содержать ссылок на
другие выражения.
Ключевые слова PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE,
STORAGE, RECOVERABLE, UNRECOVERABLE характеризуют пространство,
распределяют его при работе с таблицей.
Ключевое слово PCTFREE определяет процент пространства блока, который резервируетс
для модификации таблицы. Допустимые значения от 0 до 99. Значение по умолчанию 10,
то есть при запол- нении каждого блока 10% пространства остается не использован- ным. Эт
пространство используется для записи в него данных при выполнении в дальнейшем
модификации строк таблицы.
162.
Ключевое слово PCTUSED определяет минимальный процент ис- пользованияпространства блока, при котором в него вводятся дан- ные, по умолчанию 40, то есть
если в блоке занято менее 40% про- странства, в него вводятся данные при выполнении
операции вставки. Сумма значений параметров PCTFREE и PCTUSED не должна
превышать 100.
Ключевое слово INITRANS определяет начальное число параллельных транзакций,
которые могут выполняться для модификации данных блока. Значение по умолчанию 1.
Ключевое слово MAXTRANS определяет максимальное число параллельных
транзакций, которые могут выполняться для модификации данных блока. В
большинстве случаев явное задание этих параметров не требуется.
Ключевое слово TABLESPACE определяет имя табличной области, в которой будет
размещена таблица. Если значение параметра не определено, то таблица размещается в
табличной области, заданной по умолчанию для пользователя, который является
владельцем схемы, содержащей таблицу.
163.
Ключевое слово STORAGE определяет объем внешней памяти, вы- деляемый под таблицу.Для больших таблиц целесообразно явно выделять требуемую память, чтобы уменьшить
число запросов на динамическое выделение пространства.
Ключевые слова RECOVERABLE и UNRECOVERABLE. Для управления записью в
журнальный файл контрольной информации используются ключевые слова
RECOVERABLE, UNRECOVERABLE. Значение UNRECOVERABLE может быть
использовано только с ключевым словом AS подзапрос, при этом операция создания
таблицы выполняется быстрее за счет исключения записи управляющей информации в
журнал. Но при этом автоматическое восстановление операции создания таблицы в случае
сбоя становится невозможным.
Ключевое слово CLUSTER указывает привязку столбцов таблицы к кластеру. Обычно
столбцы кластера образуют из элементов первичного ключа.
164.
Ключевое слово ENABLE указывает на включение ограничений целостности дляданной таблицы. Соответствующее ограничение целостности должно быть определено в
данном предложении соз- дания таблицы. По умолчанию все ограничения целостности, определенные в предложении, включаются.
Ключевое слово DISABLE указывает на выключение ограничений целостности для данной
таблицы. Соответствующее ограничение целостности должно быть определено в данном
предложении соз- дания таблицы.
Ключевое слово AS запрос включает в создаваемую таблицу строки, являющиеся
результатом выполнения запроса. Необходима определенная осторожность при
использовании вставки строк через подзапрос и определение ограничений целостности в
том же предло жении. Если результат запроса не соответствует ограничениям целостности,
то Oracle не создает таблицу и возвращает сообщение об ошибке.
165.
Ключевое слово CACHE указывает на то, что блоки, выбираемые из таблицы,помечаются в системном кеше, как наиболее используе мые. Оно рекомендуется для
маленьких таблиц, используемых для преобразования кодов в значения. По
умолчанию используется NOCACHE, для которого выбранные блоки помещаются в
конец таблицы частот обращений к кешу.
Оператором DECLARE можно создать PL/SQL таблицу следую-щим образом:
TYPE type_name IS TABLE OF {column_type|variable%TYPE |table.column%TYPE}[not
null] [index by binary_integer]; identifier type_name;
Структура таблицы
PRIMARY KEY
COLUMN
1
Jones
2
Smith
BINARY_INTEGER SCALAR
166.
Следующие функции облегчают работу с таблицами:• EXISTS (N) — возвращает TRUE, если n-ый элемент в таблице существует;
• COUNT — возвращает количество элементов в данный момент в PL/SQL таблице;
• FIRST and LAST — возвращает первый и последний (самый маленький или самый
большой) индексы в PL/SQL таблице;
• PRIOR(N) — возвращает значение индекса, предшествующего индексу N в PL/SQL
таблице;
• NEXT — возвращает значение индекса, следующего за индексом N в PL/SQL таблице;
• EXTEND(n,i) — увеличивает размер таблицы, присоединяет n копий i–го элемента
PL/SQL таблицы;
• TRIM(N) — удаляет N элементов из конца PL/SQL таблицы;
• DELETE(N) — удаляет N элементов из PL/SQL таблицы.
Всякая программа на PL/SQL состоит из трех блоков: описаний, исполнительного и блока
обработки исключительных ситуаций. Исполнительный блок может быть структурирован с
использованием опера- торных скобок BEGIN и END.
167.
Структура программы на PL/SQLТипы блоков в PL/SQL
168.
Управление выполнением программы.Применяется одна из следующих форм оператора ветвления: IF — THEN — END IF
IF — THEN — ELSE — END IF
IF — THEN — ELSIF — END IF
Oracle использует следующий синтаксис конструкции ветвления в PL/SQL:
IF условие_1
THEN операторы_1; — ветвь 1 ELSIF условие_2
THEN операторы2; — ветвь2
ELSE оператор_n — операторы альтернативы
END IF;
В PL/SQL есть три типа оператора цикла:
• LOOP; • FOR LOOP; • WHILE LOOP.
Цикл LOOP имеет следующий синтаксис:
LOOP
Операторы
...
EXIT [WHEN УСЛОВИЕ]; END LOOP;
169.
Последовательность операторов между LOOP и END LOOP многократно повторяется дотех пор, пока условие не примет зна- чение TRUE.
Условие может принимать одно из трех значений: TRUE, FALSE, NULL.
Этот оператор выполняется, по крайней мере, хотя бы один раз, если будет отсутствовать
EXIT, то последовательность операторов будет выполняться бесконечно. Если условие
принимает значение TRUE, то будет выполняться следующий за LOOP оператор.
Цикл FOR LOOP
Вторая форма оператора цикла — это цикл с параметром, она имеет вид:
FOR counter IN [ REVERSE] lower_bound..upper_bound loop Оператор1; Оператор2; ...
END LOOP;
REVERSE означает изменение параметра ЦИКЛА от верхней границы до нижней
границы, при этом нижняя граница в операторе цикла опять стоит первой. Объявлять
параметр цикла counter в опе-раторе DECLARE нет необходимости, он по умолчанию
объявляет-ся как целый, lower_bound — нижняя граница изменения параметра цикла,
upper_bound — верхняя граница изменения параметра цикла.
170.
Оператор GOTO осуществляет переход по метке, присутствующей в теле программы. Спомощью уникального идентификатора, заключенного в двойные угловые скобки, можно
пометить любую часть программы PL/SQL для организации безусловного перехода по
метке.
Ключевым понятием языка PL/SQL является курсор.
Каждое SQL утверждение, выполняемое сервером ORACLE, имеет индивидуальный
курсор, связанный с:
• неявным курсором, объявленным для всех DML-утверждений;
• явным курсором, объявленным и поименованным программи- стом. Явный курсор –
это поименованный запрос, содержащий некоторое фиксированное число строк в выборке.
Чаще всего курсор содержит данные одной строки выбираемой таблицы. По существу,
курсор является окном, через которое пользователь получает доступ к информации базы
данных. Курсоры, в частности, могут использоваться для присваивания конкретных
значений переменным программы.
171.
Объявление курсораПри этом должны выполняться следующие правила:
• нельзя включать INTO в предложение курсора;
• если требуется использовать последовательность, то необхо- димо применить ORDER
BY в предложении курсора.
172.
Курсор может содержать параметр, синтаксис такого курсора имеет следующий вид:CURSOR cursor_name [(parametr_name datatype,...)] is select_statement;
• параметр добавляется при открытии курсора;
• каждый раз рекомендуется открывать курсор, когда меняется ак- тивное множество
элементов.
Оператор определения курсора может содержать параметричес-кий запрос. Значения
параметра задаются при открытии курсора.
После выбора всех строк из таблицы курсор должен быть закрыт, синтаксис команды:
CLOSE cursor_name; Если возникнет необходимость, курсор может быть повторно
открыт, однако, после закрытия курсора нельзя пользоваться командой FETCH.
Курсоры применяются совместно с командой LOOP. Большинство развитых языков
программирования обладает встроенными механизмами обработки исключительных
ситуаций.
173.
174.
Для обработки исключительных ситуаций, не входящих в перечень стандартных, можноиспользовать специальный обработчик PL/SQL OTHERS или описать пользовательскую
исключительную ситуацию и запрограммировать ее обработку.
Ключевое слово OTHERS блока EXCEPTION определяет механизм универсальной
обработки исключительных ситуаций, не вошедших в список си- туаций, обрабатываемых
явно в блоке EXCEPTION.
Создание пользовательских процедур и функций. Подпрограммы (процедуры и
функции) в PL/SQL бывают хранимые и локальные. Хранимые подпрограммы во многом
отличаются от локальных. Если подпрограмма должна будет вызываться из многих
блоков, то ее делают хранимой, она хранится в базе данных. Короткие процедуры и
функции рекомендуется объявлять локально в блоке, если они вызываются только из
одного конкретного фрагмента программы. Хранимые подпрограммы (процедуры и функ
ции) хранятся в базе данных в откомпилированном виде и могут вызываться из любого
блока.
175.
Хранимые процедуры и функции – это объекты базы данных и, следовательно, онисоздаются командой CREATE и уничтожаются командой DROP. При создании процедуры
и функции должны быть определены: имя объекта, перечень и тип параметров и логика работы процедуры или функции, описанные на языке PL/SQL Чтобы создать процедуру или
функцию, необходимо иметь системные привилегии CREATE PROCEDURE.
Для создания процедуры, функции или пакета в схеме, отличной от текущей схемы
пользователя, требуются системные привилегии CREATE ANY PROCEDURE. После
определения имени новой процедуры или функции необходимо задать ее имена,
типы и виды параметров. Для каждого параметра должен быть указан один из видов
параметра — IN, OUT или IN OUT. Вид параметра IN предполагает, что значение
параметра должно быть определено при обращении к процедуре и не изменяется
процедурой. Вид параметра OUT предполагает изменение значения параметра в процессе
работы процедуры, то есть параметр вида ОUТ — это возвращаемый параметр.
176.
Ключевое слово OR REPLACE указывает на безусловное замеще- ние старого текстапроцедуры. Если ключевое слово OR REPLACE не указано, и процедура определена, то
замещения старого значе- ния кода процедуры не происходит, и возвращается сообщение
об ошибке. В описании переменных процедуры не используется ключевое слово
DECLARE. Блок определения данных начинается сразу после ключевого слова AS (или
IS, по выбору пользователя).
Чтобы уточнить выявленные в процессе синтаксического анализа ошибки, можно
воспользоваться командой PL/SQL SHOW ERRORS. Эта команда показывает ошибки,
обнаруженные в про- цессе выполнения CREATE PROCEDURE, CREATE FUNCTION,
CREATE PACKAGE, CREATE PACKAGE BODY И CREATE TRIGGER. Если команда
SHOW ERRORS используется без пара- метров, то возвращаются ошибки последней
компилированной процедуры, функции, пакета, тела пакета или триггера.
177.
Модуль — это конструкция PL/SQL, которая позволяет хранить связанные объекты водном месте. Модули бывают только хранимыми и никогда локальными. Модуль — это
именованный раздел объявлений. Все, что может входит в раздел объявлений блока, может
входить и в модуль: типы, переменные, процедуры, функции, курсоры. Размещение их в
модуле полезно, так как это позволит ссылаться на них из других блоков PL/SQL, в
модулях можно описывать и глобальные переменные для PL/SQL.
Процедуры, функции и глобальные переменные, объединенные общим функциональным
замыслом, часто оформляют в виде еди- ного объекта базы данных — пакета.
Особенностью пакетов PL/SQL является раздельная компиляция и хранение
интерфейсной и исполнительной частей пакета. Пакет как объект состоит из двух частей:
спецификации пакета и тела пакета. В специ фикации пакета хранится описание процедур,
функций, глобальных переменных, констант и курсоров, которые доступны для
внешних приложений.
178.
В теле пакета определяются все процедуры, функции и перемен-ные, включая те, которыене были определены в спецификации пакета. Процедуры, функции и переменные,
определенные в теле пакета, но не описанные в его спецификации, являются локальными.
Внешние по отношению к пакету приложения не имеют права на использование локальных
объектов пакета. Локальные объекты предназначены исключительно для использования
только процедурами и функциями самого пакета.
Особенностью пакетов PL/SQL является поддержка перегружа-емых функций и
процедур. Процедуры или функции могут иметь одинаковое имя, но различный по типу
или количеству на- бор аргументов. В момент обращения к конкретной процедуре или
функции по числу и типу передаваемых аргументов автоматически определяется
требуемая процедура или функция, которая и испол- няется. Напомним, что для создания
пакета пользователь должен иметь привилегию CREATE PROCEDURE. Создание пакета в
схеме другого пользователя требует наличия привилегии CREATE ANY PROCEDURE.
179.
Оператор определения интерфейсной части ( спецификации) пакета ORACLE используетследующий синтаксис:
CREATE [OR REPLACE] PACKAGE [имя_схемы.]имя_пакета {IS | AS}
спецификация_пакета_на_PL/SQL
Оператор определения исполнительной части (тела) пакета ORACLE использует
следующий
CREATE [OR REPLACE] PACKAGE BODY [имя_схемы.]имя_пакета {IS | AS}
cneцификация_naкema_нa_PL/SQL
Определение тела пакета начинается с описания констант и переменных. Константы и
переменные, описанные в спецификации пакета, являются глобальными и в теле пакета
повторно не описыва ются. При описании констант и переменных пакета ключевое слово
DECLARE не используется. Константа или переменная, описанная в спецификации пакета, может быть доступна из пользовательской программы (конеч- но, если процедуре или
функции такой доступ разрешен). Чтобы обратиться к глобальной переменной или
константе пакета, нуж- но указать в качестве префикса имя пакета
180.
Триггер базы данных – это процедура PL/SQL, которая автомати- чески запускается привозникновении определенных событий, связанных с выполнением операций вставки,
удаления или модификации данных таблицы. Событие, управляющее запуском триггера,
описывается в виде логических условий. Когда возникает событие, соответствующее
условиям триггера, сервер ORACLE автоматически запускает триггер, то есть
интерпретирует код программы триггера, записанный на языке PL/SQL. Обычно триггеры
используют для выполнения сложных проверок ограничений целостности, многоаспектных
проверок выполнения правил разграничения доступа и т.п. Триггер запускается при
выполнении одной из трех операций изменения содержимого таблицы: INSERT, DELETE
или UPDATE. Триггер может запускаться и несколькими операторами, но хотя бы один
оператор из тройки должен быть обязательно указан в условии запуска триггера. Если
перечень операторов включает оператор UPDATE, то для условий срабатывания могут
быть указаны конкретные изменяемые столбцы. Код триггера может выполняться либо до,
либо после тех операторов, которые инициировали запуск триггера.
181.
Например, если триггер запускается для проверки полномочий пользователя на правовыполнения операции, то, конечно, нужно использовать триггер с запуском до
выполнения операции (с ключевым словом BEFORE). Если триггер применяется для
формирования данных для аудиторской записи, то разумно использовать триггер с
запуском после выполнения операции (с ключевым словом AFTER).
Код триггера может быть ассоциирован либо с операцией над таблицей в целом, либо с
каждой строкой, над которой выполняет- ся операция. В зависимости от этого триггеры
подразделяют на операторные триггеры и строчные триггеры.
Операторные триггеры обычно используют для проверки правил разграничения доступа,
оперирующих таблицей в целом, а строчные триггеры часто используют для проверки
ограничений целостности при вставке строк. Условие запуска строчного триггера может
быть уточнено дополнительным логическим условием.
182.
Чтобы создать триггер, необходимо иметь системные привиле- гии CREATE TRIGGER.Для создания триггера в схеме, отличной от текущей схемы пользователя, требуются
системные привилегии CREATE ANY TRIGGER. Оператор определения триггера
ORACLE использует следующий синтаксис:
CREATE[OR REPLACE] TRIGGER[имя схемы.]имя_триггера {BEFORE | AFTER}
{INSERT | DELETE | UPDATE[OF имя_столбца[,имя_столбца...]]} [OR {INSERT |
DELETE | UPDATE[OF имя_столбца[,имя_столбца...]]}...]
ON [имя_схемы.]{имя_таблицы | имя_представления} [FOR EACH ROW] [WHEN
условие] cneцификации_naкema_нa_PL/SQL
Ключевые слова BEFORE или AFTER указывают на выполнение кода триггера либо до,
либо, соответственно, после операторов ма- нипулирования данными, инициировавших
запуск триггера. Ключевые слова INSERT, DELETE или UPDATE определяют
конкретный оператор, запускающий триггер. Для оператора UPDATE могут быть
указаны столбцы, изменение которых запускает триггер.
183.
Если конкретные столбцы не указаны, то триггер запускает изменение любого столбца.Необязательное ключевое слово OR присоединяет дополнительный оператор,
запускающий триггер. Ключевое слово ON задает имя таблицы или представления, ассоциированного с триггером.
Необязательное ключевое слово FOR EACH ROW определяет триггер как строчный.
Необязательное ключевое слово WHEN задает дополнительное логическое условие,
сужающее область действия триггера.
В отличие от процедур, функций и пакетов сервер ORACLE не хранит код триггера в виде
скомпилированного блока PL/SQL. При первом запуске триггера его код считывается из
словаря данных, компилируется, и скомпилированная версия сохраняется в области SGA.
Поэтому для часто используемых триггеров целесообразно код, отвечающий за
процедурную часть триггера, включать в хра- нимую процедуру, а в теле триггера
оставлять только запись усло- вий запуска и вызовы соответствующих процедур и
функций.
184.
На предложения языка SQL, включенные в код триггера ORACLE, наложеныследующие ограничения.
Тело триггеpa не может включать в себя явное использование управляющих операторов
COMMIT, ROLLBACK и SAVEPOINT, операторов языка определения данных CREATE,
ALTER и DROP, операторов, управляющих разграничением доступа GRANT и REVOKE,
а также неявное выполнение перечисленных операторов через вызовы процедур и
функций.
О гр ан и ч ен и я и сп о ль з ов ан и я п ре д ло ж е ни й я зы к а Строчный триггер
срабатывает один раз для каждой строки. Внутри триггера можно обращаться к
строке, обрабатываемой в данный момент. Для этого служат две псевдозаписи —
:OLD и :NEW, синтаксически они рассматриваются как записи, хотя запи- сями не
являются, поэтому их называют псевдозаписями. Тип обеих псевдозаписей определяется
как Активирующая_таблица%ROWTYPE;
Псевдозапись :OLD не определена для операторов INSERT, а псевдозапись :NEW — для
оператора DELETE, при этом генери- роваться ошибка не будет, но значения полей обеих
записей будут NULL значениями. Двоеточие перед :NEW и :OLD обязательно
185.
Для создания связи пользователю в локальной базе данных не- обходимо иметь некоторуюточку входа в удаленной базе данных. Данная точка входа может совпадать с именем
пользователя, кото- рый создает связь, а может иметь и другое имя. Для создания общей
(PUBLIC) связи необходимо пользователю обладать привилегией CREATE PUBLIC
DATABASE LINK. Оператор создания связи с удаленной базой данных имеет следующий
синтаксис:
CREATE [PUBLIC] database link имя_связиБД [CONNECT to имя_пользователя
IDENTIFIED BY пароль_пользователя] USING 'строка_связи'
Если параметр PUBLIC отсутствует, то создается связь, доступная только создавшему ее
пользователю. При наличии этого парамет-ра создается связь, доступная всем
пользователям. Параметр ИМЯ_СВЯЗИБД задает имя создаваемой связи. Параметры
ИМЯ_ПОЛЬЗОВАТЕЛЯ, ПАРОЛЬ_ПОЛЬЗОВАТЕЛЯ за дают имя пользователя и его
пароль в удаленной базе данных. Строка 'СТРОКА_СВЯЗИ' определяет имя раздела
параметров SQL*NET, задающего спецификации связи с удаленной базой данных.
186.
Если фраза, содержащая имя пользователя и пароль, отсутствует, будем пользоватьсятекущим именем пользователя и его паролем. Создав связь с удаленной базой данных,
можно обращаться к таблицам в удаленной базе данных в запросах, при этом необходи- мо
после имени таблицы в удаленной базе данных добавить @ИМЯ_СВЯЗИ во фразе
FROM оператора SELECT.
Для удаления определенной связи с удаленной базой данных ис- пользуется команда DROP
PUBLIC LINK. Для выполнения этой команды необходимо быть владельцем связи с
удаленной базой данных либо иметь привилегию DROP ANY DATABASE LINK. Для
отмены общей связи необходимо иметь привилегию DROP PUBLIC DATABASE LINK.
Оператор уничтожения связи с уда- ленной базой данных имеет следующий синтаксис:
DROP [public] database link имя_связи;
187.
Снимок — это поименованная, динамически поддерживаемая сер- вером выборка изодной или нескольких таблиц или представлений, обычно размещенных на удаленной базе
данных. При помощи сним ков администратор безопасности обеспечивает доступ
пользова-телям к тем частям базы данных, которые необходимы им для работы. Чтобы
механизм снимков работал на локальной и удаленной базе данных, должен быть
установлен пакет DBMS_SNAPSHOT, в котором размещены процедуры обновления
снимков. Оператор определения снимков имеет следующий вид: CREATE SNAPSHOT
[имя_схемы.]имя_снимка [{PCTFREE целое | PCTUSED целое | INITRANS целое |
MAXTRANS целое | TABLESPACE имя_табличной_области | STORAGE размер
памяти}] | [CLUSTER имя_кластера (имя_столбца [,…])] [USING INDEX] [{PCTFREE
целое | PCTUSED целое | INITRANS целое | MAXTRANS целое | TABLESPACE
имя_табличной_области | STORAGE размер памяти}] | [REFRESH [{FAST | COMPLETE
| FORCE }] [START WITH дата_1] [NEXT дата_2]] [FOR UPDATE] AS запрос;
188.
Ключевые слова PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE,STORAGE характеризуют пространство, распреде- ляемое при работе со снимком.
Ключевое слово PCTFREE определяет размер блоков, резервируемых для дальнейшей
работы со снимком, допустимые значения от 0 до 99, значение по умолчанию 10, то есть
если этот параметр не указан, то 10% пространства остается не использованным для
записи в него данных для дальнейшей модификации строк снимка.
Ключевое слово PCTUSED определяет минимальный процент ис- пользования
пространства блока, при котором в него вводятся дан- ные, допустимые значения от 1 до
99. Значение по умолчанию 40, то есть если этот параметр не указан, то в блоке занято
менее 40% пространства, в него вводятся данные при выполнении операции вставки.
Ключевое слово INITRANS определяет начальное число параллельных транзакций,
которые могут выполняться для модификации данных блока. Значение по умолчанию 1.
параметров PCTFREE и PCTUSED не должна превышать 100.
189.
Параметр MAXTRANS определяет максимальное число параллельных транзакций,которые могут выполняться для модификации данных блока.
Ключевое слово TABLESPACE определяет имя табличной области, если оно не указано,
то снимок располагается в табличной области пользователя, который является владельцем
снимка.
Ключевое слово STORAGE определяет объем внешней памяти, вы- деляемой под снимок.
Ключевое слово CLUSTER указывает привязку столбцов снимка к кластеру.
Ключевое слово USING INDEX определяет создание индекса для уменьшения времени
доступа к данным снимка.
PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE, STORAGE
характеризуют пространство, отводимое для индекса снимка.
Ключевое слово REFRESH определяет технологию обновления снимка. Параметр
COMPLETE означает, что при обновлении данных снимка заново выполняется запрос,
формирующий снимок.
190.
При задании параметра FAST при обновлении данных снимка используется информацияоб измененных данных в мастер-таблице, хранящаяся в журнальном файле снимка. При
используемом по умолчанию параметре FORCE решение о технологии обновления
снимка принимается системой (обычно это быстрое обновление).
Ключевое слово START WITH определяет с помощью параметра дата_1 дату первого
обновления снимка. Ключевое слово NEXT опре- деляет с помощью параметра дата_2
интервал между автоматиче- скими обновлениями снимка. Если параметр REFRESH
отсутству- ет, то автоматического обновления данных снимка не происходит, так же не
происходит автоматического обновления данных снимка при отсутствии обоих ключевых
слов START WITH и NEXT. Ключевое слово FOR UPDATE указывает на возможность
измене- ния данных снимка. Ключевое слово AS запрос включает в создаваемый снимок
строки, являющиеся результатом выполнения запроса.
191.
Последовательность – это объект базы данных, генерирующий неповторяющиесяцелые числа. Числа, создаваемые последовательностью, могут либо возрастать
постоянно, либо до определенного предела, либо при достижении определенного предела,
начинать возрастать заново с начального значения. Последовательность может создавать
цепочки как увеличива-ющихся чисел, так и уменьшающихся, можно задавать и приращение значений последовательности. Для создания последова- тельности требуется
привилегия CREATE SEQUENCE. Для созда- ния последовательности в схеме другого
пользователя необходимо иметь привилегию CREATE ANY SEQUENCE. Оператор
определения последовательности имеет следующий синтаксис: CREATE SEQUENCE
[имя_схемы.]имя_последовательности [INCREMENT BY приращение] [START WITH
начальное_значение] [MAXVALUE наибольшее_значение | NOMAXVALUE]
[MINVALUE наименьшее_значение | NOMINVALUE] [CYCLE | NOCYCLE] [CACHE
число_элементов | NOCACHE] [ORDER | NOORDER]
192.
Ключевое слово INCREMENT BY определяет интервал между по- следовательныминомерами. Если этот параметр имеет отрицатель- ное значение, то последовательность
убывающая, если положи- тельное — то последовательность возрастающая. Значением
по умолчанию является 1, параметр приращения может быть любым целым числом не
равным нулю. Ключевое слово START WITH параметром начальное_значение задает
первый генерируемый номер. Если этот параметр отсутствует, то для возрастающих
последовательностей первый генерируемый номер равен значению параметра MINVALUE,
а для убывающей последовательности MAXVALUE.
Ключевое слово MAXVALUE параметром наибольшее_значение задает максимальное
значение, которое будет генерироваться последовательностью. Это число должно быть
больше, чем начальное_значение и наименьшее_значение. Это число может быть любым
числом с количеством знаков, не превышающим 28.
193.
Отсутствие верхней границы указывается ключевым словом NOMAXVALUE, котороеопределяет для убывающих последова-тельностей значение –1, а для возрастающих
последовательностей 1027. Ключевое слово MINVALUE параметром
наименьшее_значение задает минимальное число, которое будет генерироваться
последовательностью.
Это число должно быть меньше чем начальное_значение и наибольшее_значение. Это
число может быть любым числом с количеством знаков, не превышающем 28. Отсутствие
нижней границы указывается ключевым словом NOMINVALUE, которое определяет для
убывающих последовательностей значение –1026, а для возрастающих
последовательностей 1. Ключевое слово NOCYCLE является значением, используемым по
умолчанию, и означает завершение генерирования последовательности по достижении
конца последовательности. Если при определении последовательности указан параметр
CYCLE, то после достиже-ния очередным членом последовательности значения наиболшее
_значение (для возрастающих последовательностей) выдается зна- чение параметра
наименьшее_значение.
194.
Если параметры наименьшее_значение и наибольшее_значение не указаны, тоиспользуются их значения по умолчанию. Ключевое слово CACHE указывает на
использование техники ке- ширования, что обеспечивает более быструю генерацию
элементов последовательности. Ключевое слово число_элементов определя-ет
количество элементов области кеша, это число не должно превы- шать разницы между
MAXVALUE и MINVALUE. Ключевое слово ORDER обеспечивает генерацию
последовательных элементов точно в порядке поступления запросов. Одна
последовательность может использоваться для генерации первичных ключей для
нескольких таблиц. Если два пользователя обращаются к одной последовательности, то
каждый из них не видит последовательные номера, сгенерированные для другого
пользователя. Псевдостолбец NEXTVAL используется для генерирования оче- редного
номера из указанной последовательности. Обращение имеет следующий вид:
Имя_последовательности.NEXTVAL;
195.
Псевдостолбец CURVAL используется для ссылки на текущее значениепоследовательного номера, до ссылки на CURVAL в те- кущем сеансе NEXTVAL должен
быть использован хотя бы один раз. Обращение к CURVAL имеет следующий синтаксис:
Имя_последовательности.CURVAL;
Псевдостолбец NEXTVAL обычно используется для итерации значений первичных
ключей. Для получения текущего значения используется псевдостолбец CURVAL.
Для удаления последовательности используется команда DROP SEQUENCE. Для
выполнения данной операции необходимо быть владельцем последовательности либо
иметь привилегию DROP ANY SEQUENCE. Оператор удаления последовательности
имеет следующий син- таксис:
DROP SEQUENCE [имя_схемы.]имя_последовательноси Пример уничтожения
последовательности: DROP SEQUENCE SEQ1;
196.
197.
198.
199.
Свободно распространяемый инструментарий Globus Toolkit стал фактическим стандартомконструирования Grid-систем. На его основе созданы самые разные проекты: от систем
обеспечения работы научных групп, которым требуется удаленный доступ к
специализированными экспериментальным лабораториям, например, Network for
Earthquake Engineering Simulation (NEESgrid, www.neesgrid.org), до систем
распределенной аналитической обработки больших объемов информации, таких как
Grid Physics Network, EU DataGrid Project (www.griphyn.org) и Particle Physics Data Grid
(www.ppdg.net). Эволюция технологии Grid привела к возникновению архитектуры Open
Grid Services Architecture. В ней Grid-система предоставляет обширный набор служб,
которые виртуальные организации могут объединять различными способами.
200.
Архитектура OGSA, созданная на концепциях и технологиях,разработанных специалистами в области Grid и Web-служб,
определяет единообразную семантику предоставления служб,
стандартные механизмы для создания, именования и обнаружения
экземпляров Grid-служб, обеспечивает прозрачность
местонахождения и связывание различных протоколов и
поддерживает интеграцию с базовыми механизмами
нижележащих платформ.
201.
Каждую Grid-службу определяет набор интерфейсов, сконфигурированныйкак WSDL portType (рис. 11).
Служба должна поддерживать интерфейс GridService; кроме того, OGSA
определяет множество других интерфейсов для уведомления и
создания экземпляров. Конечно, пользователи также определяют
произвольные, ориентированные на конкретное приложение
интерфейсы. serviceType (элемент расширения WSDL) определяют
множество типов port-Type, которое поддерживает службы Grid вместе с
некоторой дополнительной информацией, касающейся отслеживания
версий.
202.
Grid-служба OCSA203.
Примерслужбы
добычи
данных
204.
Передаваемые гипертекстовые документы оформляются в стандарте HTML - языкеописания гипертекстовых документов. Эти документы могут либо храниться в статическом
виде (совокупность файлов на диске), либо динамически компоноваться в зависимости от
параметров запроса специальным программным обеспечением. Для динамической
компоновки HTML-документов, WWW-сервер использует специальным образом
оформленные программы- CGI-программы (Common Gateway Interface ). Эти программы,
обрабатывая запрос, просматривают содержимое БД и создают выходные HTML-документ,
возвращаемые клиенту (см.рис.1).
205.
HTML является простым подмножеством универсального языка разметки документовSGML (Standard Generalized Markup Language, Стандартный язык разметки документов),
являющегося стандартом для обмена документами между различными платформами.
Точнее, весь синтаксис HTML полностью описывается с помощью SGML DTD (Document
Type Definition). По этой причине почти все программы, совместимые с SGML, могут быть
использованы при подготовке HTML-документов.
Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется
промежуточная БД высокой производительности (см.рис.). Информационное наполнение
промежуточной БД осуществляется специализированным программным обеспечением
206.
Этап 1 - перегрузка данных207.
Этап 2 - обработка запросовПосле установления синхронизации данных информационного хранилища с основными БД
возможен перенос пользовательских интерфейсов на информационное хранилище, что
существенно повысит надежность и производительность, позволит организовать
распределенные рабочие места. Для загрузки содержимого основной БД в информационное
хранилище могут использоваться языки программирования, интегрированные средства, а
также специализированные средства перегрузки, поставляемые с SQL-сервером и
продукты поддержки информационных хранилищ.
208.
Стандартом де-факто для Unix-систем стало программное обеспече-ние (ПО) WWWсервера Национального Центра по Суперкомпь-ютерным Приложениям (NCSA)Иллинойского Университета. Все вновь создаваемые продукты поддерживают полную
совместимость с ПО NCSA по режимам работы и форматом данных. Cервер NCSA
является постоянно совершенствуемым продуктом, отражающим последние веяния WWWтехнологии. Созданная относительно недавно "Apache Group" разрабатывает свое
программное обеспечение WWW - сервера на базе продукта NCSA HTTPD.
Одной из основных технологий создания CGI-модулей для реализации функций
"преобразователя" и "обработчика" сценариев является язык C.
Язык Perl был создан для повышения эффективности обработки текстовых документов. Он
ориентирован на обработку строк. В настоящее время язык получил большое
распространение как инструмент создания исполняемых модулей WWW-сервера.
209.
. Две части интерактивного интерфейсаКлиентская часть -HTML-документ, в котором реализован интерфейс с пользователем
посредством форм
Серверная часть -исполняемые модули, решающие основные задачи обработки данных
поступающих от клиентской части, формирования ответа в формате HTML, и т.д. - cgiмодуль.
210.
Пакет WOW (Web - Oracle – Web) является свободно-распростра-няемым программнымсредством, предназначенным для создания интерактивных WWW-интерфейсов с СУБД
Oracle. Пакет WOW был первым и наиболее простым средством, выпущенным фирмой
Oracle. В настоящее время существует набор продуктов, развивающих функциональность
WOW'а - Oracle Web Server версий 1, 2, Oracle Web Arcitecture. Пакет WOW был
переработан в Новосибирском областном центре НИТ с целью поддержки нескольких
русскоязычных кодировок для обработкизапросов от WWW-сервера к SQL-серверу Oracle
в среде Unix.
Пакет Cold Fusion фирмы Allaire Corp предназначен для использования под ОС Windows
и позволяет обращаться к различным базам данных, поддерживающим интерфейс ODBC
через WWW-интерфейсы. Пакет имеет коммерческий статус, его "evaluation copy" является
свободно-распространяемой. Для доступа к базам данных используются конструкции
языка DBML - расширения языка HTML, дополненного средствами доступа к БД через
ODBC.
211.
Национальный Центр по Суперкомпьютерным Приложениям (NCSA) Иллинойскогоуниверситета стал второй организацией после ЦЕРН, интенсивно взявшейся за развитие
WWW - технологии. Сервер NCSA поставляется как в виде исходных текстов, так и в виде
исполняемых модулей для различных операционных систем. Распакованный дистрибутив
размещается в каталоге httpd_<номер версии>-<модификация> где <номер версии> версия программного обеспечения WWW сервера, <модификация> - модификация текущей
версии.
Например: httpd_1.5.1-export
В этом каталоге содержатся следующие файлы и подкаталоги:
README - текстовый файл для первоначального ознакомления. Содержит список всех
значимых файлов и каталогов с объяснением их назначения.
COPYRIGHT - текстовый файл с описанием лицензионного соглашения на использование
ПО WWW - сервера NCSA.
CHANGES - текстовый файл со списком изменений между различными версиями ПО
сервера.
212.
Makefile - файл верхнего уровня для утилиты make.Содержит список команд, которые необходимо выполнить для сборки и установки ПО
WWW - сервера.
src - каталог с исходными текстами ПО сервера.
conf - каталог, содержащий примеры конфигурационных файлов ПО сервера.
icons - каталог, содержащий иконки, необходимые для работы сервера.
cgi-bin - каталог, содержащий примеры CGI - программ.
cgi-src - каталог, содержащий исходные тексты примеров CGI - программ.
support - каталог с программным обеспечением, не являющимся часью ПО сервера, но
полезным при работе с ним.
Для запуска процедуры сборки и установки сервера необходимо в корневом каталоге
сервера, запустить утилиту make. Для сборки сервера необходимо указать команде make
аббревиатуру операционной системы: aix3, aix4, sunos, sgi4, sgi5, hp-cc, hp-gcc, solaris,
netbsd, svr4, linux, next, ultrix, osf1, aux, bsdi.
213.
После сборки сервера необходимо разместить его компоненты в файловой системе.Исполняемый модуль сервера httpd размещается в каталоге серверных программ /usr/local/sbin или /usr/sbin. Файлы конфигурации, журналы и стандартные cgi-программы
размещаются в подкаталогах каталога, определяемого параметром ServerRoot. Обычно это
/usr/local/etc/httpd, однако его можно изменить либо изменив параметр HTTPD_ROOT
файла src/config.h, либо указав ключ -d при запуске сервера.
Например: usr/local/sbin/httpd -d /var/httpd /
В каталоге, определяемом параметром ServerRoot, размещаются три подкаталога:
conf/ - содержащий файлы конфигурации сервера
logs/ - содержащий журналы работы сервера
cgi-bin/ - содержащий стандартные cgi-программы, поставляемые с сервером.
214.
Главный файл конфигурации (ГКФ) сервера содержит все параметры, необходимыесерверу для начала работы, а также пути других конфигурационных файлов. По
умолчанию, главный файл конфигурации сервера находится в подкаталоге conf/
каталога и имеет имя httpd.conf. При запуске серверу можно указать другой путь,
используя ключ -f.
Например: /usr/local/sbin/httpd -f /etc/httpd.config
Параметры запуска серверных процессов
1. ServerType
Определяет способ запуска сервера:
ServerType inetd серверный процесс запускается в ответ на каждое обращение клиента
через механизм inetd. После обработки запроса, сервер прекращает свою работу.
ServerType standalone серверный процесс запускается один раз и находится в состоянии
ожидания запросов клиентов. После обработки запроса, сервер остается запущенным.
215.
2. Port Port определяет порт tcp, по которому сервер принимает запросы клиентов. Этотпараметр используется только для сервера типа standalone. При механизме старта inetd
порт определяется конфигурационным файлом сервера inetd - inetd.conf. Стандартный
порт для WWW - сервера - 80. Port 80
3. StartServers и MaxServers
Для режима standalone определяют количество процессов сервера при многопоточной
обработке. StartServers - указывает число процессов сервера, создаваемых при запуске
httpd. MaxServers определяет максимальное число одновременно работающих процессов
сервера.
Пример: StartServers 3
MaxServers 5
4. TimeOut определяет время (в секундах), которое серверный процесс, запущенный в
режиме standalone, будет ожидать повторного обращения клиента. По умолчанию
используется 1200 секунд.
Пример: TimeOut 3600
216.
5. User и Group определяют имя пользователя и группу, права которого получает серверпри запуске в режиме standalone. Изменение прав сервера производится с целью
предотвращения доступа WWW - клиентов к файлам операционной системы, не
являющимися общедоступными. Например:
User nobody
Group nobody
Информационные параметры для WWW - клиентов
1. ServerName определяет имя сервера, которое пересылается клиенту вместе с другими
параметрами запроса. Используется в случае, если сервер имеет несколько имен
(синонимов).
Например: ServerName Indy.cnit.nsu.ru
2. ServerAdmin определяет адрес электронной почты администратора сервера. При
возникновении каких - либо ошибок в работе сервера, он выдает клиенту сообщение с
просьбой проинформировать о них администратора сервера по указанному Email.
Например: ServerAdmin fancy@nsu.ru
217.
Расположение необходимых файлов и каталогов-ServerRoot определяет местоположение каталога ServerRoot. По умолчанию, это
/usr/local/etc/httpd или измененное значение параметра HTTPD_ROOT файла
src/config.h.
Например: ServerRoot /var/httpd
-ErrorLog определяет местоположение файла - журнала ошибок , в который заносятся все
сообщения об ошибках, возникающих в процессе работы сервера. Если значение не
начинается со slash (/), подразумевается путь относительно ServerRoot.
Например: ErrorLog logs/errlog
Журналом ошибок является файл /var/httpd/logs/errlog
-TransferLog
Определяет местоположение файла - журнала доступа, в который заносятся данные обо
всех передачах данных между WWW - клиентом и WWW - сервером. Если значение не
начинается со slash (/), подразумевается путь относительно ServerRoot.
Например: TransferLog logs/translog
Журналом доступа является файл /var/httpd/logs/translog
218.
-AgentLogОпределяет местоположение файла - журнала клиентов, в который заносятся данные о
программном обеспечении, используемом WWW клиентами при доступе к данному
серверу. Если значение не начинается со slash (/), подразумевается путь относительно
ServerRoot.
Например: TransferLog logs/agentlog
Журналом клиентского программного обеспечения является файл /var/httpd/logs/agentlog
-RefererLog -определяет местоположение файла, в который записываются все факты
обращений к данным сервера в виде ссылок от клиентов к данным. Если значение не
начинается со slash (/), подразумевается путь относительно ServerRoot.
Например: RefererLog logs/reflog
Журналом ссылок является файл /var/httpd/logs/reflog
219.
-PidFile определяет местоположение файла, хранящего номер процесса запущенногоWWW - сервера. Используется для остановки работы сервера путем посылки сигнала
командой kill. Если значение не начинается со slash (/), подразумевается путь
относительно ServerRoot.
Например: PidFile logs/httpd.pid
Номер процесса - сервера записывается при старте в файл /var/httpd/logs/httpd.pid
-AccessConfig определяет местоположение файла управления доступом. Если значение не
начинается со slash (/), подразумевается путь относительно ServerRoot.
Например: AccessConfig conf/access.conf
-TypesConfig определяет местоположение файла, содержащего список соответствий
расширений файлов ОС типам MIME. По умолчанию используется файл
conf/mime.types в каталоге, определяемом ServerRoot. Если не начинается с backslash (/),
подразумевается путь относительно ServerRoot.
Например: TypesConfig /etc/mime.types
220.
-CoreDirectory определяет местоположение каталога, в который записывается файл дампапамяти при возникновении сбоя.
Например: CoreDirectory /tmp
Параметры протоколирования
- LogOptions определяет, будут ли несколько протоколов записываться в один файл
(Combined) или каждый будет записан в свой файл (Separate).
Например: LogOptions Separate
- RefererIgnore
Определяет имена серверов, обращения от которых не будут протоколироваться.
Например: RefererIgnore Indy.cnit.nsu.ru
Другие режимы работы
- DNSMode определяет интенсивность обращений WWW сервера к серверу имен Интернет.
Minimum означает, что сервер будет обращаться к DNS только при необходимости
проверить ограничения доступа по домену.
221.
Standard означает, что сервер будет обращаться к серверу имен каждый раз при обработкезапроса клиента. Maximum означает, что сервер будет дважды обращаться к серверу
имен при каждой обработке запроса.
Например: DNSMode Standard
Процедура определения конфигурации сервера
После запуска основного серверного процесса сервер пытается открыть главный
конфигурационный файл. Этот файл ищется по умолчанию в каталоге
/usr/local/etc/http/conf с именем httpd.conf. Умолчание можно изменить при сборке
системы редактированием файла src/config.h. За каталог отвечает параметр
HTTPD_ROOT, за имя файла - параметр SERVER_CONFIG_FILE. Изменить значения по
умолчанию можно при запуске сервера, указав ключи -h и-f
Конфигурация ресурсов
Расположение файлов данных, их интерпретация сервером и поведение сервера при
обращении к разным типам файлов определяются параметрами файла конфигурации
ресурсов. Ниже приведен список основных параметров с пояснениями.
222.
- DocumentRootОпределяет каталог локальной файловой системы, от которого начинается отсчет
виртуального пути URL.
Например: DocumentRoot /apply/www - UserDir Определяет название публичного
подкаталога пользователей.
ПО WWW - сервера позволяет обеспечить внешний доступ к гипертекстовым документам
пользователей базовой операционной системы. Для этого пользователям необходимо
создать в своем домашнем каталоге подкаталог с именем, определяемым параметром
UserDir. После этого все обращения по URL:
http://<имя_сервера>/~<имя_пользователя_ОС>
будут транслироваться в реальный путь до подкаталога, определенного параметром
UserDir в домашнем каталоге пользователя <имя_пользователя_ОС>.
Например: UserDir public_html
при этом при обращении по URL ttp://www.nsu.ru/~fancy/index.html
сервер будет искать файл Index.html в подкаталоге public_html/ домашнего каталога
пользователя fancy.
223.
- Redirect переадресует запрос к одной иерархии в запрос к другой иерархии, возможнорасположенной на другом сервере.
Например: Redirect /HTTPd/ http://hoohoo.ncsa.uiuc.edu/
- Alias
Определяет синоним для документа или каталога на локальном сервере.
Пример: Alias /icons /var/opt/images
- ScriptAlias
Определяет синоним для каталогов, содержащих CGI - программы.
Пример: ScriptAlias /hrv-cgi /var/opt/cgi
- DirectoryIndex определяет имена файлов, трактующихся сервером как индексные. Их
содержимое выдается сервером при обращении к данному каталогу.
Пример: DirectoryIndex index.html index.htm index.cgi
- AccessFileName определяет имя файла, трактующегося сервером как файл управления
доступом
Пример: AccessFileName .htaccess
224.
Выполнение основных операций администрирования1 Контроль работоспособности сервера
Проверка работоспособности сервера может осуществляться различными способами. На
Unix - платформе, в режиме standalone, можно посмотреть список процессов, выделив
среди них процессы с именем httpd:
# ps -aef | grep httpd
root 28816 1 0 Nov 14 ? 7:42 /usr/local/sbin/httpd
nobody 28817 28816 0 Nov 14 ? 5:50 /usr/local/sbin/httpd
nobody 28818 28816 0 Nov 14 ? 5:32 /usr/local/sbin/httpd
nobody 28819 28816 0 Nov 14 ? 4:49 /usr/local/sbin/httpd
nobody 28820 28816 0 Nov 14 ? 5:24 /usr/local/sbin/httpd
nobody 28821 28816 0 Nov 14 ? 5:42 /usr/local/sbin/httpd
root 19150 19145 0 14:57:58 pts/4 0:00 grep httpd
#
225.
Указано несколько процессов, у одного из которых собственником является root, а удругих - пользователь, определенный параметром User главного конфигурационного файла
(ГКФ).
Процесс с собственником root запускается первым.
Он контролирует работу остальных процессов - серверов.
По использованному процессорному времени (колонка 8 примера) можно судить о
загруженности серверов.
Если сервер работает в режиме inetd или необходимо проверить работоспособность
сервера извне, нужно выполнить команду telnet, указав ей имя машины - сервера и номер
порта. После установления соединения наберите команду GET /.
Сервер должен выдать содержимое корневого каталога документов или индексного файла,
находящегося в этом каталоге.
Номер порта обычно равен 80.
В режиме standalone он определяется параметром Port ГКФ. Для режима inetd он
определяется парой файлов - services и inetd.conf, определяющих соответствие между
входными tcp - портами и сервисами Unix.
226.
2 Обработка журналовВремя от времени возникает необходимость уменьшить размер файлов статистики путем
их удаления или переноса в другое место. Если сервер находится в режиме inetd, можно
свободно удалять и переносить файлы статистики. Они снова создадутся по указанным в
ГКФ путям. Если же сервер работает в режиме standalone, эти файлы постоянно открыты
процессами - серверами. Удаление или перенос их не освободят место на диске и не
приведут к созданию новых файлов. Для корректной работы с журналами в этом случае,
необходима остановка работы сервера. Необходимо "убить" процессы - серверы, перенести
файлы журналов и перезапустить сервер. "Убить" процессы - серверы можно послав
команду kill процессу с номером, указанном в файле PidFile (см. параметры ГКФ). Пример
последовательности команд для выполнения такой операции:
ill `cat /usr/local/etc/httpd/logs/httpd.pid`
mv /usr/local/etc/httpd/logs/*.log /otherdir
/usr/local/sbin/httpd
227.
3 Управление доступом. Сервер NCSA содержит гибкие средства управления доступом. Сих помощью можно централизованно или децентрализованно управлять доступом,
основываясь на структуре адреса WWW - клиента, создавать пары имя/пароль для
документов или целых подразделов, создавать несколько пар имя/пароль.
Управление доступом с использованием пар имя/пароль
Для введения ограничений на доступ ко всем документам определенного каталога
необходимо создать в этом каталоге файл управления доступом, который имеет
фиксированное имя, определяемое параметром AccessFileName файла конфигурации
доступа. По умолчанию, это файл .htaccess.
Пример содержимого файла .htaccess
AuthUserFile /otherdir/.htpasswd
AuthGroupFile /dev/null
AuthName ByPassword
AuthType Basic
<Limit GET>
require user pumpkin
</Limit>
228.
AuthUserFile указывает путь файла паролей, который должен находиться вне данногокаталога.
Limit GET ограничивает доступ по методу GET, предоставляя его только пользователю
pumpkin. Для ограничения других методов доступа (например, в каталогах CGI)
используется перечисление всех методов:
<Limit GET POST PUT>
require user pumpkin
</Limit>
Для создания файла паролей необходимо воспользоваться утилитой htpasswd, входящей в
состав дистрибутива сервера:
htpasswd -c /otherdir/.htpasswd pumpkin
После запуска она дважды запросит пароль для пользователя pumpkin и создаст файл
паролей /otherdir/.htpasswd.
229.
Использование нескольких пар имя/парольИспользование нескольких пар имя/пароль достигается путем описания группы, в которую
входят несколько пользователей, и указания имени группы в операторе Limit.
Необходимо создать несколько записей в файле паролей. Этого можно достичь, не
указывая ключа -c (create) для htpasswd:
htpasswd /otherdir/.htpasswd peanuts
htpasswd /otherdir/.htpasswd almonds
htpasswd /otherdir/.htpasswd walnuts
Создать файл описания группы, назвав его, например, /otherdir/.htgroup со следующим
содержимым:
my-users: pumpkin peanuts almonds walnuts
где my-users - имя группы,
pumpkin, peanuts, almonds, walnuts - список пользователей, входящих в группу.
230.
Изменить файл .htaccess следующим образом:AuthUserFile /otherdir/.htpasswd
AuthGroupFile /otherdir/.htgroup
AuthName ByPassword
AuthType Basic
<Limit GET>
require group my-users
</Limit>
Все документы данного каталога будут доступны всем членам группы my-users после
проведения процедуры аутентификации (ввода пароля). Ограничение доступа по
сетевому имени
В этом случае управление доступом осуществляется на основе сравнения сетевого имени
машины - клиента с заранее заданным образцом. Если выявится совпадение, начинают
действовать специальные правила доступа.
Пример ограничения доступа на чтение. Чтение разрешено всем пользователям машин
домена cnit.nsu.ru:
231.
Содержимое файла .htaccess:AuthUserFile /dev/null
AuthGroupFile /dev/null
AuthName ExampleAllowFromCNIT
AuthType Basic
<Limit GET>
order deny, allow
deny from all
allow from .cnit.nsu.ru
</Limit>
Оператор order указывает порядок определения требований к доступу:
сначала ограничения, затем разрешения.
deny from all - сначала запрещает доступ для всех,
allow from .cnit.nsu.ru - затем разрешает доступ для машин домена cnit.nsu.ru.
Оператор AuthName задает имя данного ограничения доступа - произвольную комбинацию
букв и цифр.
232.
Пример запрета на доступ для всех машин домена nstu.nsk.su:Содержимое файла .htaccess:
AuthUserFile /dev/null
AuthGroupFile /dev/null
AuthName ExampleAllowFromCNIT
AuthType Basic
<Limit GET>
order allow, deny
deny from .nstu.nsk.su
allow from all
</Limit>
6 Поддержка русскоязычных кодировок
Исторически сложилось, что в России распространены несколько русскоязычных
кодировок, в основном ориентированных на разные платформы. Наиболее известные из
них:
КОИ - 8 (8 - битовая кодировка по ГОСТ)
Microsoft Code Page 866 ("Альтернативная") - кодировка, используемая в MS-DOS
233.
ISO-8859-5 - кодировка, утвержденная международной организаци-ей по стандартизацииMicrosoft Code Page 1251 ("Windows") - кодировка, используемая в Microsoft Windows.
Всего в России имеют хождение 11 кодировок русского алфавита. Для поддержки
нескольких кодовых страниц применяется множе-ство методов, которые можно разбить на
две группы: использование файлов - копий одного документа в разных кодировках и
динами-ческое преобразование документов из кодировки, в которой они лежат на сервере,
в кодировку, поддерживаемую WWW - клиентом.
В первом случае, на сервере физически присутствуют все файлы во всех поддерживаемых
кодировках. Документы в различных кодировках отличаются между собой по правилам
образования путей и имен.
Например: indexw.html, indexa.html - добавление суффиксов, определяющих кодировку.
Или.../koi8/index.html, .../win/index.html - различные базовые каталоги для разных
кодировок.
234.
При этом выделяется одна мастер - кодировка, в которой новые документы располагаютсяна сервере, а все остальные варианты документов получаются после работы специальной
программы - перекодировщика. Программа - перекодировщик может запускаться вручную
- администратором WWW сервера или автоматически, с использованием команд cron, at.
Во втором случае, доступ к документам осуществляется через дополнительную программу
- перекодировщик, динамически перекодирующую документы сервера в кодировку WWW
- клиента. Эта программа может быть CGI - программой, через которую всегда
осуществляется доступ к русскоязычной части сервера. На вход такой программе
передается реальный путь документа и кодировка WWW - клиента, в которую нужно
перекодировать указанный документ
235.
Программа - перекодировщик может также располагаться между WWW - клиентом исервером (см.рис.12.2). В таком варианте она называется PROXY.
236.
Однако здесь возникает проблема с перекодировкой всех данных, включая графику, видео,аудио и других нетекстовых материалов. Для ее решения PROXY придается
дополнительный интеллект - определять тип передаваемых данных по заголовку MIME и
решать, перекодировать документ или нет, на основе его типа.
Программы - перекодировщики с различными кодировками обрабатывают обращения к
разным портам tcp сервера.
Клиенту работа с PROXY видна в URL.
Например:
http://www.nsu.ru:80/index.html - для кодировки КОИ-8,
http://www.nsu.ru:8000/index.html - для кодировки ISO-8859-5 и т.д.
237.
Клиентская часть применяет методы запроса POST и GET.Метод POST используется для запроса серверу, чтобы тот принял информацию,
включенную в запрос, как относящуюся к ресурсу, указанному идентификатором ресурса.
Метод GET используется для получения любой информации, идентифицированной
идентификатором ресурса в HTTP запросе.
Для WWW-сервера стандарта NCSA прикладные программы или CGI-модули,
обрабатывающие поток данных от клиента или (и) формирующие обратный поток данных
могут быть написаны на таких языках программирования как:
C/C++;
Любой UNIX shell;
Fortran;
Perl;
Visual Basic;
TCL;
AppleScript;
238.
Использование пакета Cold Fusion для MS Windows при построении WWW интерфейсов к базам данных.Пакет Cold Fusion фирмы Allaire - это средство для быстрой разработки интерактивных,
динамических документов для Web основанное на обработке информации из баз данных, в
основе которого лежит следующий набор технологий:
HTML (Hyper-Text Markup Language)
CGI (Common Gateway Interface)
SQL (Structured Query Language)
ODBC (Open Database Connectivity)
Cold Fusion запускается как CGI приложение на различных Web-серверах под Windows
Cold Fusion тестировался на совместимость со следующими серверами:
O'Reilly WebSite Microsoft Internet Server EMWAC HTTPS
Process Software Purveyor
Netscape Communications/Commerce Server
Internet Factory Communications/Commerce Builder
Spry Safety Web Server
CSM Alibaba
239.
Взаимодействие Cold Fusion с базами данныхCold Fusion позволяет динамически генерировать HTML документы основанные на
запросах пользователя,которые передаются в Cold Fusion CGI - скрипт (DBML.EXE),
который пересылает данные в Cold Fusion Engine обрабатывающий эти данные в
соответствии с заданным шаблоном, выполняя необходимые запросы и генерируя HTML
документ, который отправляется пользователю.
Основой динамического создания документов являются специальные теги, входящие в
язык разметки DBML, ориентированные на работу с базами данных. Почти все основные
возможности Cold Fusion сосредоточены в четырех тегах:
DBQUERY - выполнение SQL - запроса к базе данных;
DBINSERT & DBUPDATE - создание и модификация записей в базе данных;
DBOUTPUT - отображение результата запроса, допускающее его произвольное
размещение среди HTML - тегов.
Шаблон, на основе которого генерируется HTML - документ, представляет собой
комбинацию тегов HTML и DBML:
240.
HTML - теги используются для форматирования как постоянной части документа, так ирезультатов запросов. Например, можно определить полужирный шрифт для каждого поля
и разделительные линии между записями.
DBML - теги используются для формирования запроса к базе данных, а также определяют
где и как будут отображены результаты запросов.
241.
1.Когда пользователь нажимает кнопку типа "Submit" в форме или выбираетгипертекстную ссылку в документе, Web - браузер отправляет запрос на Web - сервер.
2.Web - сервер, если в запросе указан DBML - шаблон, запускает процесс Cold Fusion,
отправляя ему данные полученные от клиента.
3.Cold Fusion принимает данные полученные от клиента обрабатывает теги DBML в
шаблоне, включая подготовку запроса к базе данных и форматирование, которое будет
использоваться в результирующем документе.
4.Cold Fusion взаимодействует с базой данных используя ODBC.
5.Cold Fusion динамически генерирует HTML - документ содержащий результат
выполнения запросов к базе данных и возвращает его Web - серверу. Cold Fusion может
также динамически генерировать почтовое сообщение и отправлять его через почтовый
SMTP - сервер.
6.Web - сервер возвращает сгенерированный HTML - документ Web - клиенту.
242.
Передача параметров в DBML-шаблонСуществует несколько способов передачи параметров между шаблонами:
непосредственно в URL, использовать форму либо cookie.
Если параметры передаются через URL, то они добавляются к адресу вызываемого
шаблона через символ "&" (амперсант) в виде параметр = значение. Например,
гипертекстовая ссылка, приведенная ниже, отправляет параметр с именем 'user_id' и
значением 5 в шаблон 'example.dbm':
<A HREF="cgi-shl/dbml.exe?Template=example.dbm&user_id=5">
При передаче параметров через форму используются поля формы, которые должны иметь
имена, совпадающие с именами параметров, которые требуется передать. Ниже приведен
пример передачи параметра, из предыдущего примера используя форму:
<FORM ACTION="cgi-shl/dbml.exe?Template=example.dbm">
<INPUT TYPE="HIDDEN" NAME="user_id" VALUE="5">
<INPUT TYPE="SUBMIT" VALUE="Enter">
</FORM>
243.
При обращении к CGI - программе DBML.EXE должен быть определен стандартныйпараметр Template, указывающий на конкретный шаблон. Переменные, занесенные в
cookie браузера и переменные окружения CGI доступны в любом шаблоне.
При занесении и модификации данных с использованием тегов DBINSERT и
DBUPDATE для занесения или модификации данных, параметры должны быть переданы в
шаблон обязательно из формы, используя метод POST.
При использовании этих тегов необходимо определить атрибуты DATASOURCE и
TABLENAME. DATASOURCE это название источника данных ODBC, содержащего
редактируемую таблицу, а TABLENAME - имя этой таблицы.
Теги DBINSERT и DBUPDATE могут иметь также еще два необязательных атрибута:
TABLEOWNER - для тех источников данных которые поддерживают права собственности
на таблицы (например, SQL Server, Oracle и др.), этот атрибут можно использовать, чтобы
указать собственника таблицы.
244.
TABLEQUALIFIER - для различных источников данных этот атрибут может иметь разныйсмысл. Так, для SQL Server и Oracle - это имя базы данных, в которой содержится таблица,
а для Intersolv dBase - это директория в которой расположены DBF файлы.
Для выполнения запросов к базе данных используется тег DBQUERY. Этот тег имеет
следующий синтаксис:
<DBQUERY NAME="имя запроса"
DATASOURCE="имя источника данных odbc"
SQL="sql выражение" TIMEOUT=n MAXROWS=n DEBUG>
Атрибут NAME определяет имя запроса, которое должно начинаться с буквы и может
содержать буквы и цифры (пробелов быть не должно).
Атрибут DATASOURCE задает имя источника данных ODBC, который должен быть
создан с помощью интерфейса администратора Cold Fusion.
Ключевым атрибутом тега DBQUERY, является атрибут SQL, который собственно и
определяет запрос к базе данных на языке SQL
245.
Атрибут MAXROWS является необязательным и определяет максимальное количествозаписей, которые могут быть возвращены в результате выполнения запроса.
Атрибут TIMEOUT также является необязательным и определяет максимальное
количество миллисекунд для выполнения запроса, до выдачи сообщения об ошибке.
Заметим, что этот атрибут поддерживается только некоторыми ODBC - драйверами
(например, драйвером для MS SQL Server 6.0).
Атрибут DEBUG используется для отладки запросов. При наличии этого атрибута
пользователю отправляется дополнительная информация о выполнении этого запроса,
такая как текст выполненного SQL - запроса, число возвращенных записей и др.
Приведем пример запроса с именем 'AllPersons', который возвращает все записи таблицы
'Persons' из базы данных, с которой связан источник данных ODBC с именем 'Person DB':
<DBQUERY NAME="AllPersons" DATASOURCE="Person DB"
SQL="select * from Persons">
246.
Использование результатов запроса для динамического создания HTML - документаДля вывода данных возвращаемых в результате выполнения запроса определенного в
DBQUERY применяется тег DBOUTPUT. Внутри этого тега, связанного с конкретным
запросом, может находиться обычный текст, теги HTML, ссылки на поля определенные в
запросе. При обработке шаблона, содержимое тега DBOUTPUT отправляется клиенту для
каждой записи, возвращаемой в результате выполнения запроса, с подстановкой
соответствующих значений параметров и полей.
Тег DBOUTPUT имеет следующий синтаксис:
<DBOUTPUT QUERY="имя запроса" MAXROWS=n>
Текст, теги HTML,
ссылки на поля и параметры (т.е. #Name#)
</DBOUTPUT>
Теги DBTABLE и DBCOL всегда употребляются вместе для отображения результата
выполнения запроса в виде таблицы.
Атрибуты тега DBTABLE:
247.
· QUERY - имя DBQUERY, для которого нужно отобразить данные;· MAXROWS максимальное количество записей, которое может быть отображено в таблице;·COLSPACING - количество пробелов, которые будут вставлены между колонками (по
умолчанию 2);· HEADERLINES - количество строк, которые будут отведены для заголовка
(по умолчанию 2);· HTMLTABLE - при наличие этого тега результат запроса будет
отображен в виде HTML - таблицы, в противном случае будет использован тег HTML
<PRE>.· BORDER - используетя только вместе с атрибутом HTMLTABLE для
отображения рамки в таблице.Атрибуты тега DBTABLE:
· HEADER - текст, который будет выводиться как заголовок колонки;· WIDTH - ширина
колонки в символах (по умолчанию 20);· ALIGN -выравнивание содержимого колонки
(LEFT, RIGHT и CENTER);· TEXT -заключенный в кавычки текст, определяющий
содержимое колонки, в котором могут находиться те же теги, ссылки на параметры и др.,
что и в теге DBOUTPUT.
248.
Приведем пример использования тегов DBTABLE и DBCOL:<DBTABLE QUERY "AllPersons" MAXROWS=20>
<DBCOL HEADER="Фамилия Имя Отчество" WIDTH="30" TEXT="#FullName#">
<DBCOL HEADER="Телефон" WIDTH="10" TEXT="#Phone#">
<DBCOL HEADER="Дата рождения" WIDTH="9" TEXT="# DateFormat(Birthday)#">
</DBTABLE>
Каждый сеанс связи вызывающий CGI - программу имеет конкретные переменные
окружения. Доступ к ним из шаблона осуществляется, также как и к другим параметрам,
только используется префикс 'CGI.', например #CGI.REMOTE_ADDR#.
Cookies - это механизм, позволяющий приложениям о стороны сервера сохранять и
использовать параметры на стороне клиента. Для сохранения параметров в Cookies
используется тег DBCOOKIE, имеющий следующий синтаксис:
<DBCOOKIE NAME="Имя_параметра" VALUE="Значение параметра" EXPIRES="Срок
действия" SECURE>
249.
После выполнения запроса, результат его выполнения может быть использован в качествединамического параметра для спецификации другого запроса.
Каждый запрос, описанный тегом DBQUERY, после выполнения имеет два специальных
атрибута, RecordCount и CurrentRow, содержащих информацию о количестве
возвращенных в результате выполнения запроса записей и о текущей записи,
обрабатываемой тегом DBOUTPUT, соответственно. Используются эти атрибуты так же
как и поля запроса (#FindUser.RecordCount#).
250.
Perl - интерпретируемый язык, приспособленный для обработки произвольных текстовыхфайлов, извлечения из них необходимой информации и выдачи сообщений. Perl также
удобен для написания различных системных программ.
Cинтаксис выражений Perl-а близок к синтаксису C. В отличие от большинства утилит ОС
UNIX Perl не ставит ограничений на объем обрабатываемых данных и если хватает
ресурсов, то весь файл обрабатывается как одна строка. Рекурсия может быть
произвольной глубины. Хотя Perl приспособлен для обработки текстовых файлов, он
может обрабатывать так же двоичные данные и создавать .dbm файлы, подобные
ассоциативным массивам. Perl позволяет использовать регулярные выражения, создавать
объекты, вставлять в программу на С или C++ куски кода на Perl-е, а также позволяет
осуществлять доступ к базам данных, в том числе Oracle.
Этот язык часто используется для написания CGI-модулей, которые, в свою очередь, могут
обращаться к базам данных. Таким образом может осуществляться доступ к базам данных
через WWW.
251.
Для взаимодействия с Oracle в Perl есть специальный модуль Oraperl.pm. Основнымифункциями для доступа к базе данных являются:
&ora_login
$lda = &ora_login($system_id,$username,$password)
Для того, чтобы получить доступ к информации, хранимой в Oracle необходимо сначала
войти в систему с помощью вызова функции &ora_login(). Эта функция имеет три
параметра: системный идентификатор базы данных, имя пользователя в базе и пароль
пользователя.
Возвращается идентификатор регистрации в системе (Oracle Login Data Area).
Несколько доступов могут осуществляться одновременно. Эта функция эквивалентна
функции OCI(Oracle Call Interface) olon или orlon.
&ora_open
$csr = &ora_open($lda, $statement [,$cache])
252.
Для определения SQL-запроса в базу данных программа должна вызывать функцию&ora_open.
Эта функция имеет как минимум два параметра: идентификатор регистрации и SQL
выражение. Необязательный третий параметр описывает размер буфера строк для SELECT
оператора. Возвращается курсор Oracle.
Язык Perl очень широко используется при написании исполняемых модулей CGI (Common
Gateway Interface) для Web. Это обусловлено прежде всего тем, что Perl предоставляет
разработчикам простые и удобные средства обработки текста и взаимодействия с базами
данных.
253.
#!/usr/local/bin/perlsub Print {$len = 100;$buf = "";read(STDIN, $buf,$len);
# считываем из стандартного потока ввода# в переменную $buf количество символов#
$len@ar = split(/[&=]/,$buf);
# разбиваем строку в массив строк,# разделителями служат & и =.$output = "Content-type:
text/html\n\n
# посылает тип MIME передаваемого документа
<HTML><HEAD><TITLE>Result</TITLE></HEAD><BODY
BGCOLOR=\"#FFAAAA\"><H1>Hi there</H1><HR><BR>";$i = 0;while ($i <= $#ar) {$ar[$i]
=~ s/\+/ /g;
# заменяем в элементах массива + на пробел$output .= "$ar[$i]\n";
# конкатенация переменной $output с
# элементом массива$i++; }
$output .="<HR></BODY></HTML>";
# завершаем HTML страницуprint $output;}eval &Print;
# выполняем подпрограмму осуществляющую
# считывание, обработку и вывод информации
254.
Обработка файлов формата DBFДля взаимодействия с файлами этого формата существует специальный модуль - Xbase.pm
Этот модуль подключается стандартным образом: use Xbase;
Новый Xbase объект создается следующим образом:
$database = new Xbase;
Будет создан объект $database, который в дальнейшем будет использоваться для
взаимодействия со всевозможными методами, которые поддерживает модуль.
Доступ к базе данных осуществляется следующим образом:
$database->open_dbf($dbf_name,$idx_name);
255.
Пример программы, которая распечатывает статус базы данных и индексного файла, атакже дату последнего обновления и количество записей в базе данных.
#!/usr/bin/perluse Xbase;
# подключение модуля$database = new Xbase;
# создание объекта$d = "/home/smit/employee.dbf";
# имя файла с базой$i = "/home/smit/employee.cdx";
# имя индексного файла$database->open_dbf($d,$i);
# открываем базу данных$database->dbf_stat;
# печатаем статус и структуру# базы данных$database->idx_stat;
# печатаем статус и структуру# индексов@fields = $database->get_record;print @fields,"\n";
# печатаем содержимое текущей записиprint $database->last_update, "\n";
# печатаем дату последнего обновления$end = $database->lastrec;print $end;
#печатаем номер последней записи
256.
Пример - проект «Электронная библиотека Сибирского отделения РАН», разработанный вИВТ СО РАН. Единство системы достига-ется за счет унифицированного интерфейса и
централизованного администрирования. Построение библиотеки опирается на выбран-ный
способ организации информации, который конкретизируется в схеме атрибутов,
описывающих информацию в конкретных мета-данных. При этом общие для всей научной
области определения конкретных атрибутов представляют собой семантический уровень.
Основные задачи проекта следующие:
•обеспечение интероперабельности в глобальной программно-аппаратной инфраструктуре;
•диспетчеризация, включая идентификацию доступных ресурсов, статистику
использования и загрузки ресурсов и пр.;
•построение системы безопасности и контроля доступа, в т.ч. гибкое регулирование объема
прав и привилегий пользователей;
•обращение к наборам данных в удаленных архивах (включая протоколы, которые
необходимо использовать для работы с гетерогенными источниками данных, библиотеки
программных комплексов) и др.
257.
Ожидаемые прикладные результаты по проекту:· разработка динамической системы формирования электронных коллекций для
потребностей пользователей;
· разработка технологии обработки, анализа и интерпретации больших объемов
многомерных данных, включая данные, полученные методами дистанционного
зондирования, на основе непараметрической статистики и визуального представления
информации;
· разработка эффективных методов построения сетевых конфигураций и вычислительных
архитектур на основе оптимального проектирования сеточных пространств;
· разработка технологии поддержки распределенных каталогов информационновычислительных ресурсов СО РАН;
· разработка механизма авторизации пользователей и разграничения доступа к ресурсам
на основе криптографических методов;
· разработка прототипа распределенной виртуальной среды для наукоемких ресурсов и
создание информационной системы.
258.
Основа проекта - DataGrid, обеспечивающий:· интеграцию информационных и вычислительных ресурсов и создание распределенной
системы доступа к ним;
· разработку уникальной системы доступа к международным банкам данных, моделей и
программ анализа данных.
Основные этапы реализации проекта
1.Разработка прототипа виртуальной среды для обмена наукоемкими ресурсами,
основанного на едином каталоге ресурсов и предоставляющего пользователям
унифицированный интерфейс к разнородным информационно-вычислительным ресурсам.
2. Создание формальных моделей распределенных систем
3. Построение в рамках распределенной информационной системы интеллектуальной
системы обработки запросов
4. Разработка системы обеспечения безопасности использования ресурсов и разграничения
доступа
259.
1 этап включает разработку и интеграцию ряда компонент:- модуль анализа ресурсов, позволяющий извлекать описания ресурсов, имеющихся в сети,
и включать их в единый реестр;
- модуль конвертации ресурсов между форматами хранения специфическими для каждого
ресурса и форматом представления, выбранным пользователем;
- модуль доступа к данным и вычислительным ресурсам, включающий систему управления
распределенными вычислительными ресурсами, которая для каждой задачи будет
автоматически выполнять поиск в сети ресурсов, наиболее подходящих для её решения
и выполнять балансировку загрузки.
260.
2 этап включает разработку стандартов метаданных для описания информационных ивычислительных ресурсов, пригодных для решения задач интеграции разнородных
источников данных, создания интеллектуальных агентов и распределенного
моделирования. Создание прототипа системы распределенного мониторинга на примере
задачи мониторинга состояния окружающей среды.
3 этап состоит из реализации функций управления моделями данных и метаданных на
основе программного модуля-диспетчера. Разработка алгоритмов поиска и усвоения
информации, с использованием метаданных. Создание прототипа системы
интеллектуального поиска документов математического содержания.
4 этап включает анализ существующих криптографических протоколов с целью
определения их соответствия задачам обеспечения требуемой конфиденциальности при
работе с распределенными системами накопления, хранения и обработки данных.
261.
Проблемы в распределенных системах:- отсутствие стандартных механизмов классификации, каталогизации и систематизации
ресурсов не позволяет осуществлять поиск достаточно эффективно;
-формат содержимого ресурса не совпадает с форматом потребителей, требуется
трансформер;
- автоматизация функции получения данных из внешних источников
Использовался Microsoft SharePoint, который предоставляет средства обмена документами
и ориентирован на корпоративный электронный документооборот.
В качестве ресурсов приняты следующие базовые объекты данных:
Табличные данные - ресурсы, описывающие многомерные массивы однородных элементов.
Бинарные данные - ресурсы, содержание которых представляет собой двоичный код
Слабоструктурированные данные - ресурсы, содержание которых представляет собой
упорядоченную последовательность элементов с априори заданной семантикой
(форматом).
262.
Аналитическая обработка ресурсов должна включать автоматизированные функциианнотирования, функцию определения смежных ресурсов, функции определения
релевантных объектов. Автоматизированная функция аннотирования осуществляет
выборку метаданных ресурса и записывает их в соответствующий каталог виртуальной
среды. Функция определения смежных ресурсов согласно определенным критериям
осуществляет поиск среди ресурсов тех, которые соответствуют идентичным объектам.
Функция определения релевантных объектов осуществляет поиск объектов, которые
логически связаны друг с другом, например, персона является автором публикации или
сотрудником организации.
Доступ к опубликованным ресурсам должен включать в себя функции отображения
каталогов объектов и связанных с ними ресурсов, поиск объектов и ресурсов по каталогу.
Особый интерес представляет функция конвертации ресурсов, которая используется при
запросе пользователем ресурса в указанном формате.
263.
Основные характеристики виртуальной среды:•Распределенность ресурсов. Ресурсы пользователей могут располагаться на
географически удаленных серверах.
•Программная разнородность ресурсов. Ресурсы пользователей имеют различную
программную природу, т.е. они могут храниться в различных СУБД и формироваться с
помощью разных алгоритмов и их реализаций на различных язык программирования.
•Несогласованные схемы данных и форматы ресурсов. Ресурсы разных пользователей
могут иметь различные форматы и описывать данные в несогласованных между собой
схемах.
•Расширяемая модель данных среды. Необходимо обеспечить возможность
периодического внесения новых поддерживаемых схем данных, описывающих наукоемкие
ресурсы.
•Интероперабельность среды и открытость используемых стандартов. Основной
функцией среды является взаимодействие с внешними системами.
•Адаптируемость к требованиям пользователей. Возможность пре-доставить
пользователю ресурсы в соответствии с требованиями.
264.
Технологические решения, которые позволяют совместить разнородные модели данных ивзаимодействовать с источниками по единой унифицированной схеме это протоколы
Z39.50, LDAP (X.500) и CORBA. Был выбран протокол Z39.50, т.к. в рамках
существующих реализаций протокола Z39.50 (например, программное обеспечение
ZooPARK) предусмотрены механизмы преобразования данных из предметных схем в
абстрактную схему протокола Z39.50, что позволяет организовать стандартизованный
доступ к разнородным распределенным базам данных.
Каждый модуль виртуальной среды соответствует одному из указанных выше требований,
и реализуют следующие функции:
Модули управления структурой каталогов ресурсов
Создание нового каталога
Модификация структуры каталога
265.
Модули аналитической обработки ресурсов:Занесение информации о способе доступа к ресурсам каталога
Загрузка метаданных ресурса в каталог из источника
Обновление метаданных ресурса в каталоге из источника
Поиск соответствия между ресурсами каталога из различных источников
Модули отображения содержимого каталогов:
Просмотр метаданных ресурса
Загрузка ресурса из источника
Модули конвертации ресурсов
Модули диспетчеризации:
– Мониторинг ресурсов
– Актуализация сведений о ресурсах
– Оповещение пользователей
– Автоматизированная отправка конвертированных ресурсов
266.
Рис.1. Принципиальная схемафункционирования
виртуальной среды
267.
Рис.2. Логическая схема баз данных виртуальной среды268.
Для каждой коллекции необходимо описание ее абстрактной схемы данных. Дляопределения смежных ресурсов следует производить сравнение сведений о ресурсах в
абстрактной схеме данных. Критерием смежности является полное совпадение всех
сведений или частичное совпадения для специально указанных полей.
Механизм определения релевантных объектов является более сложным, чем нахождение
смежных ресурсов, т.к. ресурс может описывать сведения не об одном, но о нескольких
объектах. Наиболее сложной задачей является разработка моделей и средств конвертации
ресурсов в формат данных, запрошенный пользователем. В общей постановке задача не
может быть решена, но можно предложить набор частных решений для наиболее
востребованных случаев, посредством языка XSLT данные из базового XML-формата
могут быть преобразованы в любой другой формат XML-семейства, любому документу
должно соответствовать одно или несколько его представлений (образов), каждое из
которых согласовано с некоторым форматом.
269.
В конце 1980-х годов Международный консультативный комитет по телефонии ителеграфии CCITT (ныне ITU-T) предпринял попытку создания универсальной
справочной системы в основу которой были положены рекомендации (стандарт) X.500.
Однако эта система была реализована далеко не в полном объеме, так как предложенный
проект был излишне универсален, что привело к чрезмерной ``тяжеловесности''
системы.
В середине 1990-х годов возникло осознание необходимости интеграции разнородных
научных ресурсов сети Интернет в единые научные информационные системы (НИС),
которые позволили бы установить связи между разнородными документами,
организовывать единые каталоги документов, а также создавать специализированные
системы поиска.
Почтовые клиенты MS Outlook Express и Netscape Communicator, ориентированы на схему
данных X.500.
270.
Наиболее простой способ организации пользовательского доступа к подобной информации- создание и поддержка в актуальном состоянии специального WEB-сайта,
аккумулирующего информацию об информационной системе в целом. Однако при
реализации такого подхода возникает ряд проблем, которые растут вместе с ростом
количества серверов в распределенной системе:
Аккумуляция информации о каждом сервере в распределенной информационной системе в
одном месте требует значительных административных усилий.
При любых административных усилиях актуальность централизо-ванной информации о
распределенной системе всегда сомнительна, т.к. любое изменение периферийных
серверов происходит быстрее, чем регистрация этих изменений в центре.
Информация о распределенной системе, доступная через WEB-сайт, бесполезна для
смежных информационных систем, т.к. в WEB не определенны правила обмена подобной
информацией между субъектами сетевого взаимодействия. Ответственность за
достоверность информации на WEB-сайте лежит на администраторе этого сайта, а не на
тех, кто эту информацию порождает, т.е. не на администраторах периферийных серверов.
271.
В иерархическую структуру НИС должны входить биографический словарь, адреснотелефонная книга и библиографический каталог плюс вспомогательные подсистемы .Для формирования корпоративного каталога выполняется:
-создание скелета корпоративного каталога на основе фиксирован-ных схем данных, в том
числе и собственной разработки;
-наполнение каталога информацией до уровня организаций;
-создание WEB-шлюзов для доступа пользователей к корпоративному каталогу как к
справочной системе;
-создание и утверждение нормативной документации (регламента) по ведению
корпоративного каталога и разграничению полномочий администраторов;
-предоставление прав удаленного редактирования информации в глобальном каталоге на
центральном сервере представителям научных центров;
-запрещение доступа к корпоративным информационным ресурсам пользователям, не
прошедшим авторизация в корпоративном каталоге;
-установка периферийных серверов в научных центрах и организация системы репликаций
данных от периферии к центру.
272.
Методика проектирования информационных порталов может быть основана на канальнойинтеграции компонентов. При этом информационный портал здесь рассматривается как
единая интегрированная точка входа в распределенную совокупность информационновычислительных гетерогенных ресурсов, расположенных в корпоративной сети.
Разработка портала сводится к сборке и настройке готовых интерфейсных компонентов,
взаимодействующих через общую интеграционную среду. Канальная интеграция является
альтернативой широко применяемому контейнерному подходу. В канальном подходе
каждому рабочему сценарию сопоставляется определенная конфигурация
интеллектуальных информационных каналов, соединяющих задействованные компоненты.
Информационный портал - это магистраль обмена рабочими данными. Реализацию
каналов и компонентов можно выполнять на базе широко распространённых технологий
разработки распределённых систем J2EE или .NET. Среда канальной интеграции строится
на основе серверов приложений (application servers), которые хорошо приспособлены к
функционированию в режиме промежуточного слоя между web-клиентами и источниками
корпоративных данных
273.
Для моделирования и верификации архитектуры порталов реализован прототип CASEинструментаДля описания архитектуры используется язык, основанный на нотации XML
Распределенные вычислительные приложения организованы на основе технологий GRID с
использованием архитектуры Open Grid Services Architecture (OGSA). Эта архитектура
определяет поведение и механизмы для создания, именования и обнаружения служб
распределенных систем на постоянной основе.
Функции каналов разделяются на отдельные аспекты - самостоятельные сквозные потоки
функциональности, синхронизированные в заранее определенных точках. Создается
автоматический диспетчер аспектов, способный управлять эффективностью GRID приложения. Одновременно порождается портал.
274.
Основные требования, предъявляемые к системе защиты в GRID, включающие следующеебазовые элементы защиты:
Аутентификация - проверка подлинности идентификационных данных, или
удостоверений, участника взаимодействия.
Авторизация - определяют, допускает ли система реализацию затребованной операции, на
основе всех правил, установленных для каждого ресурса.
Конфиденциальность и целостность данных. Передаваемые или хранимые данные
должны быть защищены с помощью адекватных механизмов, препятствующих
нелегитимному доступу.
Биллинг и аудит - механизмы, способные контролировать и подсчитывать объем
использованных ресурсов и обеспечиваемых ими служб. Расчетные механизмы также
гарантируют, что все стороны соблюдают соглашения об использовании ресурсов.
Аудиторская информация о выполненных операциях дает возмож-ность восстановить
источник опасности или нарушения защиты.
Строгое выполнение обязательств подразумевает возможность определить, что данный
участник выполнил определенную задачу или согласился на ее выполнение, даже если сам
он это отрицает.
275.
Множества значений вместе с правилами выполнения операций образуют абстрактныетипы данных (АТД). Крупномасштабные распределенные вычислительные системы с
динамическим развертыванием задач известны под общим названием Grid. На
математическом языке динамика функционирования многокомпонентных систем
описывается с привлечением аппарата мутирующих (эволюционных) алгебр, известных
также как машины абстрактных состояний (МАС). В рамках этого аппарата подходящая
алгебра сопоставляется каждому состоянию каждого компонента, и вводится специальный
метаязык для описания правил перехода между состояниями .
Многие технологии разработки программного обеспечения специально ориентированы на
реализацию отдельных аспектов, поэтому аспектная декомпозиция облегчает организацию
деятельности коллектива разработчиков, являющихся узкими специалистами
276.
Интерфейсные аспекты служат поставщиками и получателями информации для аспектовхранения и анализа основных данных предметной области и реализуются на базе
современных технологий анализа данных класса OLAP (Online Analytical Processing).
Для придания модели обмена данными между аспектами универсального характера ее
структура должна соответствовать имеющимся международным стандартам, таким как
Common Information Model (CIM). Аспект ее ведения естественным образом реализуется на
базе реляционной СУБД.
Для поиска и анализа информации разработана теория использования мультиагентных
систем (МАС). Для успешного функционирования в такой среде агенты должны быть
способны решить две основные задачи: находить друг друга и взаимодействовать между
собой
277.
Построенные агенты обладают набором из следующих свойств:-способность к обучению: агент настраивается на тренировочных этапах;
-автономность: агент работает как самостоятельная программа, ставя себе цели и выполняя
действия для достижения этих целей;
-коллаборативность: агент может взаимодействовать с другими агентами несколькими
способами, например, играя роль поставщика/потребителя информации или одновременно
обе эти роли;
-способность к рассуждениям: агенты могут обладать механизмами вывода, например, как
приводить данные из различных источников к одному виду. Агенты могут
специализироваться на конкретной предметной области.
-коммуникативность: агенты могут общаться с другими агентами;
мобильность: способность к передаче кода агента с одного специализированного сервера
на другой.
В основу организации МАС положен принцип ассоциативного подхода, который удобен
для символьного представления знаний, сосредоточенных в словарях-тезаурусах.
278.
Для принятия решений и фильтрации информации от агента требуется значительныйинтеллект.
Адаптационные алгоритмы наделяют мобильных агентов способностью подстраиваться
под окружающую обстановку, что необходимо для распределенных приложений : 1.
перемещаясь к месту расположения электронного ресурса, агент может получить доступ к
нему локально и исключить дорогостоящую передачу данных по перегруженным сетям; 2.
агент не нуждается в постоянном соединении с основной машиной; 3. способности
сетевого опознавания дают возможность агентам самостоятельно находить основной
компьютер, даже если он изменил свое географическое местоположение. И, наконец,
агенты имеют независимость в принятии решений: используя возможность возврата, они
могут самостоятельно менять план работы или неправильно поставленные запросы.
С целью организации систем защиты и разграничения доступа к информационным
ресурсам проводилось исследование алгоритмов шифрования.
279.
Способы организации традиционных типов информации (данных) уже хорошо изучены иорганизованы, однако из-за возрастающего объема данных становится всё более сложно
организовывать эффективный поиск, систематизацию, обработку традиционных типов
данных - книг, статей, журналов, дневников, рукописных материалов. На сегодняшний
день наиболее эффективный способ решения таких проблем является организация
информации в информационные системы, электронные публикации и коллекции,
обличенные в форму электронных библиотек.
Электронные библиотеки - это распределённые каталогизированные информационные
системы, позволяющие хранить, обрабатывать, распространять, анализировать, а также
организовывать поиск в разнообразных коллекциях электронных документов через
глобальные сети передачи данных. Электронные публикации научных коллекций
представляют собой новую форму хранения и обмена информацией. Для нее характерны,
прежде всего, динамичность (возможность обновления) и глобальный доступ (через
компьютерные сети).
280.
В ходе создания ЭБ возникает целый ряд проблем, которые до сих пор в полной мере нерешены. Можно выделить следующие группы проблем:
технические:
-разработка технологии функционирования системы;
-создание эффективной системы описаний информационных объектов;
экономические:
-стоимость создания качественной ЭБ очень высока;
-высокая стоимость обслуживания
юридические:
-юридический статус ЭБ до сих пор четко не определён;
-проблемы защиты авторских прав;
-проблемы достоверности информации.
281.
В России приняты и реализуются несколько государственных программ, за рубежоморганизована федерация электронных библиотек - Digital Library Federation (DLF). Большая
часть работ по развитию ЭБ ведется в учебных и научных центрах - ВУЗах, научноисследовательских институтах, научных центрах крупных корпораций.
Электронная коллекция - это набор документов, объединённых по смысловому признаку и
имеющих одинаковую структуру. В этом случае каждый документ в коллекции имеет
одинаковую структуру, и они объединены по смыслу хранимой информации.
Объектный подход - это подход, при котором каждый информационный элемент системы
представляется в виде объекта в терминах объектно-ориентированного программирования
(ООП). Вкратце объект в терминах ООП можно охарактеризовать так:
-объект имеет уникальный идентификатор;
-у объекта имеется набор атрибутов (т.н. свойств);
-взаимодействие с объектом (например, работа с атрибутами) происходит через набор
методов объекта и только через них.
282.
Ещё одним ключевым моментом в построении ЭБ является использование структурныхметаданных для формирования структуры (схемы данных) информационных элементов
системы, описания схемы данных и поддержки каталога системы
Рис.3. Схема системы, построенной на базе использования метаданных
283.
В основу работы Базы Данных(БД) в системе заложен принцип многоуровневойархитектуры, который заключается в реализации двух основных принципов:
-минимизация функциональности клиентских компонентов, оставляющая за клиентом
только функции пользовательского интерфейса; -максимальное упрощение и унификация
клиентского программного обеспечения;
-освобождение сервера БД от несвойственных ему функций.
На практике эти принципы реализуются введением в систему сервера приложений. Такие
архитектуры более разумно распреде-ляют модули обработки данных, которые в этом
случае выполня-ются на одном или нескольких отдельных серверах. Различные серверы
приложений могут взаимодействовать между собой для более точного разделения системы
на функциональные блоки.
Многоуровневые архитектуры - применяется для характеристики любых архитектур,
расширяющих схему клиент-серверного взаимодействия путем введения дополнительных
промежуточных компонентов.
284.
Отдельно следует отметить многоуровневые системы на основе менеджеров транзакций(модель ТМ), которые позволяют одному серверу приложений одновременно
обмениваться данными с несколькими серверами баз данных, что важно для построения
распределенной информационной системы, предназначенной для интеграции
информационных ресурсов. Менеджер транзакций -- это приложение, с помощью
которого можно согласовать работу различных компонентов информационной системы.
Рис.4. Многоуровневая архитектура
285.
1- хранилище данных (ХД) - набор зарегистрированных баз данных, структура которыхзадана в системе регистрации данных;
2 - базовые информационные структуры (БИС), объединение которых составляет
содержание коллекций;
3 - провайдер данных (ПД) -- приложение, обеспечивающее обработку унифицированных
именованных запросов к коллекция и формирование ``внутреннего представления
документа'' (ВПД);
4 - обработчик ВПД - формирует унифицированные именованные запросы к коллекции и
отбор информации в ВПД;
5 - формирование ``презентационного представления документа'' (ППД) в соответствии с
выбранным стилем - приложение, которое осуществляет визуализацию документа в
удобном для пользователя виде, а также пользовательский интерфейс, с которого
вводятся параметры запроса.
286.
Указанный подход использован для сбора данных со станций приема космическойинформации с помощью низкоорбитальных спутников серии NOAA и Метеор в рамках
совместных исследований СО РАН и ИКИ РАН (г. Москва), представляющих
спутниковые снимки различных участков Земли. Полученная информация используется
в атласе для расчета характеристики отражения света от земной поверхности -- альбедо.
В этом случае измерительными компонентами являются сами спутники,
предоставляющие первичные данные измерений. Модуль расчета альбедо по данным
снимков, расположенный на сервере атласа, является вычислительным компонентом.
Таким образом, получается измерительный канал, измеряющий физическую величину
альбедо.
Результат -Атлас ``Атмосферные аэрозоли Сибири''
Другой пример - Атлас ``Биоразнообразие животного и растительного мира Сибири''
287.
Сетецентрическое управление распределённой обработкой информационнымиресурсами в составе открытой информационно-образовательной среды
Характерной чертой современного состояния комплексной информатизации сферы
образования является переход от использования разрозненных средств ИКТ к реализации
таких средств как элементов открытой интегрированной информационно-образовательной
среды (ИОС), охватывающей множество взаимосвязанных процессов, единообразно
реализуемых в границах масштаба от уровня организации (образовательного учреждения),
группы организаций, определенного сегмента сферы образовательных услуг, вплоть до
масштаба национальной системы образования, и далее, с учётом развивающихся процессов
глобализации
Реализация сетецентрической концепции управления распределённой обработкой
информационными ресурсами для сферы образования предполагает выполнение
требований следующих базовых положений:
288.
1. В рамках информационной инфраструктуры ИОС, – все её структурные элементы,представляют узлы преобразования информации и являются равноправными относительно
организации процесса распределённой обработки информационных ресурсов, причём
каждый элемент может стать как ведомым узлом преобразования, так и ведущим узлом,
инициирующим запрос-требование на преобразование.
2. Любая ИОС разрабатывается в рамках единой методологии, которая предполагает
построение концептуальной модели предметной области образовательных ИКТ,
представляющей состав, характер и взаимосвязи унифицируемых технических решений и
служащей фундаментом для разработки профилей стандартов и спецификаций ИОС.
Методология ориентирована на интеграцию функциональных сегментов ИОС,
участвующих в организации и реализации процесса распределённой обработки
информационных ресурсов, но традиционно развивавшихся обособленно друг от друга.
289.
Такие сегменты представляют:• технологии электронного обучения;
• средства ИТ-поддержки и автоматизации образовательных бизнес-процессов (БП) и
системы управления;
• разнородные информационные хранилища, включая библиотечные системы (для
традиционных и электронных библиотек).
Методология инварианта относительно конкретных архитектур ИОС и учитывает
современные технологические направления: распределенный характер реализации ИОС,
сервисно-ориентиро-ванную архитектуру, платформу XML, формирование модульных ИР
на базе многократно используемых единиц контента, объектно-ориентированную
парадигму и др.
3. Методологическим базисом эффективного управления организацией процесса
распределённой обработкой информации является систематизация информационных
ресурсов, позволившая сформировать формальную онтологию системы ИР для сферы
образования.
290.
Управление охватывает процессы, составляющие технологии преобразования информации,процессы учета ИР, публикации ИР и их метаданных, поиска, выбора, агрегации,
адаптации и распространения ИР, оценивания качества ИР, формирования заказов на
разработку ИР и др
4. Технологическим базисом реализации процесса распределённой обработки ИР в составе
ИОС является инфраструктура метаданных, представляющая как стандартизированную
форму представления ИР, так и метаданные для процессов обработки ИР. Технологически
метаданные интегрированы в уровень приложений, реализующих процессы обработки ИР
в узлах преобразования.
5. Наличие развитой сетевой инфраструктуры, формирующей в ИОС единое
информационно-функциональное пространство для открытого взаимодействия всех
участников организации процесса обработки информации, в части создания,
распространения и применения ИР: авторов, разработчиков и издателей ИР,
дистрибьюторов и провайдеров контента, учащихся и преподавателей, менеджеров
образовательных заведений и др.
291.
Предлагаемая инфраструктура представляет собой основанную на принципах открытостисреду для взаимодействия и конкуренции в области разработки, распространения и
применения ИР, а также реализации с их помощью образовательных услуг
292.
Инфраструктура распределенных хранилищ спутниковых данных:интегрированная распределенная среда неоднородных информационных
ресурсов исследования Земли из Космоса
Реализации информационных систем трех поколений –
от проекта первого поколения INTAS IRIS, до инициативы GMES HMA, которая сейчас
находится на стадии разработки и тестирования
1.От виртуальных центров научных данных к информационной инфраструктуре
Spatial Data Infrastructure (SDI, NSDI, GSDI) .
Концепция «Виртуального управления информацией» привела к идее построения
«Виртуального Научного Центра данных» В связи с бурным ростом количества
наблюдательных данных в астрономии интенсивно разрабатываются концептуальные
основы «Виртуальной Обсерватории» как интегрированной системы распределенных
гигантских астрономических архивов и баз данных.
293.
В США с 2000 года разрабатывается проект National Virtual Observatory, немногопозднее начался подобный проект в Европе. В июне 2002 года создан международный
консорциум IVOA (The International Virtual Observatory Alliance). Астрономические
каталоги становятся взаимосвязанными: создается сеть интегрированных,
интероперабельных баз данных в объемах, из
меряемых в петабайтах. Общий уровень финансирования проекта «Виртуальная
обсерватория» за последние 3-5 лет приблизился к 20 миллионам долларов США.
Тенденцию лавинообразного увеличения данных можно отметить в области наук о Земле, в
геофизике и в метеорологии.
Наряду с «Виртуальной обсерваторией» развивается программа «Виртуальный Научный
Центр данных геофизики плазмы и солнечно-земной физики». Международный
консорциум SPASE – Space Physics Archive Search and Extract создан научным
сообществом Европы и США. Проект в настоящее время получил поддержку National
Science Foundation USA и начал реализовы-ваться; уровень финансирования достигает
нескольких миллионов долларов США
294.
Объединение распределенных по всему миру гигантских цифровых архивов и базданных, фундаментально изменят характер исследований космической плазмы, позволит
решить проблему доступа к данным и обмена информацией в Солнечно-Земной физике.
«Виртуальный Научный Центр» в области изучения планет создается NASA (National
Aeronautics and Space Administration) – проект PDS (The Planetary Data System). Образован
международный консорциум и сформирована система on-line архивов, состоящая из
нескольких географически распределенных центров, связанных Сетью Интернет
Развитие геоинформационной инфраструктуры распределенных спутниковых данных
выполняется в проекте Института космических исследований РАН, который известен как
Распределенная среда интегрированных информационных ресурсов в области
космического мониторинга природной среды (Виртуальный Научный Центр
спутниковых данных)
295.
В США стратегия и концепция National Spatial Data Infrastructure (NSDI) началаразрабатываться с 1994 г.
Основными целями программы National Spatial Data Infrastructure являются:
Организация и проведение национальных дискуссионных форумов.
• Совершенствование механизма доступа к данным путем организации центров
информационного обмена и создания баз метаданных.
• Создание баз пространственных данных (БПД).
• Создание тематических данных, критически важных для государства.
• Подготовка образовательных программ для обучения персонала.
• Развитие всестороннего партнерства и координация сбора и использования
пространственных данных. В 2003 г. Европейская Комиссия приняла решение о
создании INSPIRE (Infrastructure for Spatial Information in Europe) – Глобальной
геоинформационной инфраструктуры данных в Европе. Аналогичный проект создается в
Канаде – Canadian Geospatial Data Infrastructure (CGDI).
296.
Основные задачи программы развития геоинформационной инфраструктуры Spatial DataInfrastructure (SDI) можно сформулировать следующим образом:
• Построение глобальной инфраструктуры ИТ и геоданных.
• Гармонизация спутниковой информации; использование согласованного набора
стандартов, «понятных» всем участникам данной системы.
• Интероперабельность между независимо созданными приложениями и базами данных;
Совместить между собой их интерфейсы, протоколы и форматы данных.
• Поддержка единой политики данных: а) доступ к данным и б) создание и поддержка
спутниковой информации – для задач экологии, но открытой и для
сельскохозяйственных и транспортных проблем.
Проблемы и особенности, с которыми сталкиваются национальные научные сообщества
исследователей Земли из космоса при поиске оптимального доступа к спутниковых
данным были выполнены в проекте INTAS IRIS Project:
297.
Integration of Russian Satellite Data Information Resources with the Global Network of EarthObservation Information Systems. Проблема интеграции спутниковых архивов является
примером актуальности инфраструктурных решений при организации удаленного доступа
и распределенной информационной среды.
В проекте исследуются новые задачи аэрокосмического дистанционного зондирования,
связанные с проблемой виртуального управления информацией в географически
удаленных спутниковых цифровых архивах.
Основное внимание при решении задач поиска ресурсов, взаимодействия с ресурсами,
извлечения ресурсов, совместного использования ресурсов необходимо уделять
проблемам разработки масштабной информационной инфраструктуры интеграции
ресурсов, удаленного доступа и управления гетерогенными ресурсами спутниковых
архивов.
Проект IRIS поддерживает объединение данных регионального спутникового
экологического мониторинга.
298.
Обеспечивается доступ российских пользователей к европейской информационнойсистеме INFEO (метаданные / on-line каталоги).
При запросе в единой точке системы поиск данных осуществляется одновременно в
ресурсах распределенных мировых каталогов. Запрос на метаданные оформляется единым
образом для всех спутниковых центров, и информация ищется сразу по всем центрам,
доступным из глобальных поисковых систем (в первую очередь, это система EOSDIS/
USA и система INFEO). Запрос на получение собственно спутниковых данных также
выполняется автоматически и единым образом, а данные приходят в удобном формате для
обработки в рамках GIS-систем. Формирование геоинформационной инфраструктуры
спутниковых данных определяется решением следующих задач: использование GIS и
Web технологий для разработки новых средств поиска и обна-ружения данных
аэрокосмического зондирования; включение российских спутниковых каталогов в
международную систему INFEO; создание описания российских спутниковых
коллекций и регистрации их в IDN (International Directory Network).
299.
Основной задачей проекта является интеграция географически удаленных российскихспутниковых архивов. Требуется обеспечить работу пользователей с данными, которые
получаются из различных источников и имеют разную структуру хранения. Создается
единая информационная система, основанная на концепции интероперабельных
распределенных архивов. Необходимо обеспечить требования действующих
международных стандартов: ISO/TC 211, FGDC USA (Federal Geographic Data Committee),
CEOS (Committee on Earth Observation Satellites).
2. Информационная система первого поколения: проект INTAS IRIS Международная
Информационная система INFEO (Information about Earth Observation) – инициатива
Европейского Космического Агентства (ESA), призванная решить проблему доступа к
распределенным данным дистанционного зондирова-ния Земли (ДЗЗ).
Основополагающим принципом системы является обеспечение интероперабельности –
возможности взаимодействия гетерогенных сервисов и каталогов данных в рамках
единой информационной системы.
300.
В проекте IRIS были исследованы информационные задачи в области аэрокосмическогодистанционного зондирования Земли, связанные с проблемой распределенного доступа
и управлением информации в географически удаленных спутниковых цифро-вых
архивах. Разработка методов и программных средств сбора, тематической обработки,
систематизации больших потоков аэрокосмической информации и хранения
экстремальных объемов изображений особенно актуальна для космического
мониторинга земной поверхности, водной среды, атмосферы, источников
антропогенных воздействий на них, опасных природных процессов и объектов
техносферы.
Основные задачи Активного Архива данных спутниковых исследо-ваний, следуя работе,
представим в такой последовательности: публикация, резюмирование, индексирование,
извлечение, распределение, преобразование, сотрудничество, контроль, управление.
301.
Публикация – процесс представления ресурса одним пользователем системы, врезультате которого другие пользователи могут найти этот ресурс и обратиться к нему.
Резюмирование – процесс извлечения представительного множест-ва характеристических
сведений (метаданных) из ресурса или его окружения.
Индексирование – процесс перевода информации, полученной после резюмирования, в
форму, обеспечивающую эффективный распределённый поиск.
Поиск – процесс обработки «индекса», имеющий целью сформи-ровать ответ на
запрос пользователя по распределённым метаданным.
Просмотр – контролируемая пользователем деятельность, направленная на обследование
распределённого информационного пространства, формируемого системой на основе
ресурсов и их связей.
Извлечение – деятельность пользователей, вызванная желанием получить (извлечь из
распределённого информационного пространства) обнаруженную информацию.
302.
Взаимодействие – процесс, ведомый пользователем и находящийся в рамках, ведомыхресурсом, в течение которого ресурс предоставляет пользователю информационный
или функциональный сервис.
Распределение – деятельность системы, имеющая целью обеспечение работы с
данными, расположенными на разных физических серверах, различных аппаратнопрограммных платформах. Преобразование – деятельность системы, направлен-ная на
перевод метаданных других систем, хранящихся в различных внутренних форматах,
во внутренний формат системы для обеспечения интеграции информации и эффективного
поиска. Сотрудничество – деятельность системы, ориентированная на совместную
деятельность с другими информационными системами по обслуживанию поисковых
запросов пользователей, в основном заключающихся в преобразовании поисковых
запросов для этих систем и интеграции результатов их ответов. информации в
распределённом информационном пространстве.
303.
Контроль – деятельность системы по представлению различных уровней привилегийдоступа к информации, её защите. Управление – деятельность по сопровождению
системы, её ресурсов, соблюдению актуальности, целостности и сохранности
Основная функция такой системы – создание единой информационной среды,
предоставление единой точки доступа для поиска и получения информации по всем
архивам и каталогам, зарегистрированным в системе, независимо от их географического
расположения и внутреннего формата данных. (рис.1).
Распределенная информационная система первого поколения представляет собой сеть
узлов, так называемых Middleware Nodes (MWNDs) (рис.2).
304.
Схема функционирования Архива спутниковых данных305.
Структурная схема распределенной системы первого поколения306.
Каждый из узлов содержит метаданные коллекций, описывающие данные, доступ ккоторым предоставляется через Шлюзы (Gateways). Пользователь для поиска
информации обращается к системе через WWW-сервер на одном из узлов MWND, где
формируется распределенный запрос, рассылаемый релевантным шлюзам. Результаты
выполнения запроса объединяются и возвращаются пользователю.
Шлюз представляет собой промежуточное звено между узлом MWND и каталогом или
архивом поставщика данных. Шлюз обменивается сообщениями по протоколу CIP
(Catalogue Interoperability Protocol) с узлом MWND, получая от него поисковые
запросы и возвращая ему результаты поиска. Запросы передаются транслятору RDBMS,
который преобразует их в запросы для непосредственного поиска в базе данных, либо
формирует запрос дл обращения к предоставляемому сервису (Web Map Server и т.п.).
В основе распределенной информационной сис-темы лежит протокол CIP,
регламентирующий правила взаимодействия пользователей и каталогов данных ДЗЗ.
307.
Для поддержки одновременного дос-тупа пользователя к множеству каталоговиспользуется трехуровневый принцип распределения запросов. Пользователь через
web-интерфейс задает поисковый запрос и посылает его к узлу MWND, который, в
свою очередь, перенаправляет запрос множеству серверов каталогов данных. Сервера,
имеющие данные, удовлетворяющие критериям поиска, возвращают ответы на узел
MWND, через который пользователь получает объединенный ре-зультат поиска.
3 Технология интеграции ресурсов и сервисов второго поколения: среда SSE
Система INFEO, являясь активным многоцелевым архивом космических данных,
предоставляет пользователям специализированные интерфейсы доступа к данным,
обеспечивает долговременное хранение данных и позволяет производить поиск
спутниковых снимков и коллекций данных.
308.
Развитие технологий интеграции второго поколения направлено на миграцию от подхода,основанного на технологии Z39.50/Gateways, к использованию веб-сервисов (XML над
SOAP/HTTP) для связи внешних каталогов с каталогами INFEO. Технологии интеграции
второго поколения, получившие название EOLI-XML, разрабатываются ESA в
сотрудничестве с национальными космическими Агентствами: Франции (Centre National
d’Etudes Spatiales – CNES), Италии (Italian Space Agency – ASI), Германии (German Space
Agency – DLR), European Union Satellite Centre (EUCS), Joint Research Centre (JRC) при
участии ряда партнеров в промышленности: SPOT Image, Siemens, Spacebel и др. EOLIXML представляет собой внешний интерфейс для обмена сообщениями между сервером и
клиентом на основе протокола SOAP. Технология EOLI-XML лежит в основе системы SSE
(Service Support Environment), разрабатываемой для решения указанных задач с
помощью создания открытой, сервис-ориентированной, распределенной среды.
309.
Система SSE является инфраструктурой, единой средой для потребителей и провайдеровданных и сервисов. SSE объединяет своих пользователей на основе стандарта XML с
исполь-зованием протоколов обмена сообщениями SOAP и языка описания веб-сервисов
WSDL (Web Service Definition Language)
Таким образом, любой сервис, интегрируемый в среду SSE, должен предоставить
SOAP-интерфейс, в соответствии с SSE ICD (Interface Control Document).Основные цели
создания инфраструктуры SSE:
• Предоставить среду, максимально упрощающую взаимодействие типа «сервиспровайдер – пользователь» и «сервис-провайдер – сервис-провайдер».
• Упростить интеграцию уже существующих сервисов, предоставляя универсальный
интерфейс на основе XML, позволяющий не изменять их структуры.
• Предоставить пользователям единую точку входа – Интернет-портал системы.
310.
Система SSE состоит из двух основных компонент: SSE Portal Server и AOI Server,образующих вместе Интернет-портал, с которым взаимодействует конечный пользователь.
SSE Portal Server предоставляет web-интерфейс для доступа пользователей к порталу.
Сервер построен с использованием промышленной технологии J2EE, которая
удовлетворяет требованиям SSE: хорошая масштабируемость, интеграция с
существующими информационными системами, гибкая политика безопасности,
поддержка стандартных протоколов и языков, переносимость компонент без
необходимости перекомпиляции
В качестве сервера приложений выбран сервер JBoss с открытым исходным кодом.
AOI Server работает в связке с SSE Portal Server и служит для предоставления для
сервис-провайдеров функций визуального выделения области на карте (area of interest,
AOI) при задании критериев поиска, а также визуализации результатов поиска.
311.
Так как большинство сервисов в качестве одного из входных параметров требуют указаниегеографической области, SSE Portal предоставляет специальную поддержку этой
возможности.
При обращении к сервису пользователь должен указать географиче-скую область и сделать
это он может разными способами: выбрать из списка, указать область на карте, загрузить
файл, описывающий AOI, задать AOI с помощью указания координат.
При обращении пользователя к сервису, SSE Portal использует апплет, загружаемый с
сервера AOI для визуального отображения выделенной об-ласти на карте. SSE
позволяет использовать для визуализации как локально хранимую информацию, так и
подключаться к OGC WMS серверам для за-грузки дополнительных слоев карты [22].
Выделенная на карте область затем преобразуется в описание в формате GML
(Geography Markup Language) [23] описание вместе с запросом отправляется сервиспровайдеру в виде SOAP сообщения.
312.
Типичный сценарий работы выглядит следующим образом. Пользователь черезинтерфейс SSE портала формирует запрос к нужному сервису, выделив на карте область
AOI и указав характеристики искомой информации. После этого сформирован-ный в
формате SOAP-сообщения запрос пересылается на URL сервиса, указанный
провайдером при регистрации. Здесь сообщение поступает на вход сервера вебприложений, где в зависимости от поступившего запроса запускается
соответствующий сервлет, который занимается дальнейшей обработкой запроса и
передачей его на внутренний интерфейс сервиса. Для выполнения сервлетов сервиспровайдеру вместе с Toolbox необходимо установить web-сервер с поддержкой
сервлетов (рекомендуется к установке веб-сервер Tomcat).
Обработка входного запроса и формирование ответа на запрос выполняется на основе
WSDL-документа в соответствии с XML-схемой сервиса. При установке Toolbox уже
имеется предопреде-ленная схема, но некоторые сервисы могут иметь специфические
параметры входных и выходных сообщений, отредактировав соответствующие файлы
XML-схем.
313.
Для поиска необходимой информации пользователь может воспользоваться поисковыминтерфей-сом по адресу http://catalogues.eoportal.org/eoli.html.
Интерфейс выполнен в виде Java-апплета (рис. 3). Существует возможность ограничивать
поиск либо по поставщикам данных (панель Find Products), либо по коллекциям
данных (Find Collections). В раздел Find Products входят крупные поставщики, имеющие
несколько собственных обширных коллекций.
После выбора типа данных, по которым будет ограничен поиск, следует выбрать
площадь земной поверхности. Для более точного поиска информации можно
воспользоваться режимом расширенного поиска Advanced Query Mode. Этот режим
позволяет дополнительно задавать ключевые слова для поиска, а также выбирать спутник
и сенсор, с помощью которого были получены данные. Ключевые слова служат для
отбора данных, поле описания которых содержит строку, заданную в поле Free Text.
314.
Рис.3.Поисковый интерфейс пользователя315.
4 Интеграция неоднородных распределенных информационных ресурсовспутниковых данных: инициатива GMES и проект HMA
Основным предназначением инициативы Global Monitoring for Environment Security
(GMES) является поддержка задач Европейского Союза, касающихся устойчивого
развития и глобального управления с помощью обеспечения доступа к
высококачественным данным дистанционного зондирования Земли в режиме реального
времени. Информация, получаемая с помощью проекта GMES, используется в трех
основных направлениях деятельности: экология и защита окружающей сре-ды,
поддержка развития инфраструктуры ЕС, обеспечение безопасности граждан, как в
повседневной жизни, так и в режиме чрезвычайных ситуаций. В настоящий момент
доступ к данным дистан зондирования Земли каждого спутникового оператора
осуществляется через отдельную точку доступа («портал») этого поставщика данных.
Пользователь вынужден выполнять поиск нужных ему данных отдельно в каждой точке
доступа.
316.
Особенно актуальной проблема своевременного получения данных становится вусловиях режима чрезвычайных ситуаций, когда счет идет на часы и минуты. Проект
Heterogeneous Missions Accessibility (HMA) обеспечит гармонизацию сервисов и данных
наземных сегментов поставщиков данных, с помощью сервис-ориентированной
архитектуры, предоставляя единообразный доступ к данным и сервисам каждого из
участников проекта. В данный момент проект находится на стадии активного внедрения и
тестовой эксплуатации. Основные этапы разработки проекта HMA показаны на рис. 4.
Большая часть архитектурных решений проекта находятся в свободном доступе, то
есть принадлежат области всеобщего достояния (public domain), что значительно
увеличивает возможности распространения технологий и программных продуктов
проекта.
Широко используются стандарты и протоколы ISO (International Organization for
Standardization) и OGC (Open Geospatial Consortium).
317.
Основополагающим стандартом системы является международный стандарт дляпостроения открытых распределенных систем (RM-ODP ISO/IEC 10746-1:1998).
Модель построения распределенных систем RM-ODP была выбрана в качестве базовой для
проекта HMA GMES для решения задач :
• Поддержка распределенной обработки.
• Поддержка интероперабельности между гетерогенными системами.
• Сокрытие механизмов распределенного взаимодействия от конечных пользователей и
системных разработчиков.
Определены пять основных направлений развития проекта, определяющих
минимальный набор требований и объектную модель, гарантирующую целостность и
логическую связность системы: • Организационное направление: определяет цели,
область применения, ограничения и правила использования и развития системы.
• Информационное направление: определяет семантику информационных процессов.
318.
• Вычислительное направление: декомпозиция всей системы на отдельные объекты,взаимодействующие между собой и с внешними интерфейсами с целью оптимизации
вычислительных затрат.
• Направление инжиниринга: разработка механизмов и функций, необходимых для
поддержки распределенного взаимодействия между отдельными объектами системы.
• Технологическое направление: определяет выбор конкретных технологических
решений, необходимых для выполнения поставленных задач.
Предложенная архитектура является сервис-ориентированной (Service Oriented
Architecture, SOA), в которой поставщики данных получат возможность предоставлять
доступ к своим сервисам через стандартизованные интерфейсы системы.
Ключевым компонентом системы HMA является интеграционный слой доступа к
данным (Data Access and Interoperability Layer – DAIL), предоставляющий единый
интерфейс доступа к каталогам и сервисам всех участников проекта GMES
319.
В структуре DAIL можно выделить основные компоненты:• Среда выполнения сервисов – среда для выполнения основных компонентов DAIL,
предоставляет средства выполнения сервисов и управления их взаимодействием с
другими компонентами DAIL.
• База данных – служит для хранения данных, необходимых для функционирования
служебных сервисов HMA.
• Рабочий процесс – основное приложение ядра архитектуры DAIL, служит для запуска
и управления сервисами DAIL.
• Репозитарий профилей пользователей – база данных для хранения профилей
пользователей системы и информации, необходимой для аутентификации пользователей в
системе.
• Сервер коллекций – служит для хранения списка доступных в системе коллекций и
отслеживания их статуса.
• Сервер сервисов – аналогично серверу коллекций, служит для хранения списка
доступных в системе сервисов и отслеживания их статуса.
• Виртуальный FTP сервер – компонента для поддержки обмена данными между
поставщиками и пользователями через систему HMA.
320.
Рис.4. Этапы разработки проекта HMA321.
Рис. 5. Модель управления доступом «Distributor»322.
Российский сегмент распределенной информационной системы спутниковых архивовбыл реализован при сотрудничестве ИКИ РАН и ИАПУ ДВО РАН. В качестве поставщика
данных дистанционного зондирования Земли выступает Лаборатория спутникового
мониторинга ИАПУ Дальневосточного Отделения РАН (http://satellite.dvo.ru).
Программное обеспечение и серверное оборудование для функционирования шлюза
сегмента установлено в Москве, в Институте Космических Исследований РАН
(http://iris.iki.rssi.ru)
Этот проект является одним из пунктов Программы фундаментальных исследований
Президиума РАН «Разработка фундаментальных основ создания научной распределенной
информационно-вычислительной среды на основе технологий GRID». Проект имеет
своей целью создание на основе технологий IT-инфраструктуры сетевой распределенной
информационно-аналитической системы по наукам о Земле, обеспечивающей
единообразный доступ к объединяемым в рамках проекта информационно-аналитическим
и другим ресурсам.
323.
. Создаваемая инфраструктура будет предоставлять возможность использования этихресурсов для решения фундаментальных и прикладных задач, компьютерого
моделирования и параллельных вычислений.
Участниками проекта являются свыше двадцати институтов РАН, как геофизической,
химической, картографической направленности, так и решающих задачи в сфере
распределенных вычислений и телекоммуникаций
324.
Управление параллелизмом с низкими накладными расходами для разделенныхбаз данных в основной памяти
Распределенная среда систем и приложений баз данных стала реальностью.
Этому способствуют как широкая распространен-ность корпоративных кластерных
технологий, так и развитие подхода "облачных" вычислений (cloud computing),
обеспечива-ющего возможность аренды "кластера" произвольного масштаба в
облачной инфрастуктуре.
Практически общепринятой точкой зрения на организацию распределенных систем
баз данных стала ориентация на архитектуры без совместно используемых
ресурсов (sharing nothing). В распределенных аналитических системах подобные
архитектуры обеспечивают линейное масштабирование, и основной текущей
проблемой технологии является обеспечение способов распараллеливания по
данным серверных приложений баз данных. По этому поводу в последнюю пару
лет выполнено много исследовательских проектов и написано много статей
325.
Естественный интерес вызывают и возможности применения распределенныхсистем баз данных в приложениях, которые традиционно назывались
транзакционными (on-line analytical processing, OLTP). Использование
распределенных систем баз данных в таких приложениях, вообще говоря,
позволяет повысить производительность этих приложений, а также способствует
увеличению уровней их надежности и доступности. Общим приемом для
повышения производительности, надежности и доступности является разделение
(partitioning) базы данных по нескольким узлам кластера, а также репликация
(replication) отдельных частей базы данных в нескольких узлах. Однако узким
местом в таких системах становится управление распределенными транзакциями,
в особенности фиксация (comiting) таких транзакций на основе традиционных двухи трехфазных протоколов, вызывающих недопустимо большое число сетевых
передач сообщений и приводящих к снижению уровня доступности приложений.
326.
Во многих приложениях OLTP имеются некоторые транзакции, которые производятдоступ к данным из нескольких разделов. Это приводит к сетевым задержкам из-за
потребности в координации транзакций, что ограничивает производительность
системы баз данных и не допускает параллельного выполнения транзакций.
.Возможны две схемы управления параллелизмом с низкими накладными
расходами. В первой схеме используются легковесные блокировки, а вторая схема
обеспечивает разновидность спекулятивного управления параллелизмом, при
котором избегаются накладные расходы отслеживания операций чтения и записи,
но иногда выполняется работа, которую рано или поздно приходится откатить.
327.
Схемы управления параллелизмом разработаны для систем разделенных данных восновной памяти типа H-Store.
В H-Store поддерживается только выполнение транзакций, которые заранее
объявляются в виде хранимых процедур. Вызов каждой хранимой процедуры
является одной транзакцией, которая должна быть либо аварийно завершена, либо
зафиксирована до возврата результатов клиенту. Устранение непредвиденных
транзакций приводит к отсутствию задержек из-за ожидания реакции пользователей,
что сокращает потребность в параллелизме.
При отсутствии задержек из-за ожидания реакции пользователей или обменов с
дисками в H-Store транзакции выполняются с начала до конца в одном потоке
управления. Для получения преимуществ от наличия нескольких физических машин
и нескольких процессоров данные должны быть разбиты на разъединенные
разделы. В каждом разделе транзакции выполняются независимо. Возникает
проблема нахождения способа разделения данных, при котором каждая транзакция
обращается к данным только одного раздела
328.
В последнее время в связи с этой проблемой часто упоминается теорема CAPЭрика Брювера (Eric Brewer), в которой утверждается , что в разделенной системе
баз данных, в которой допускается потеря связности узлов, невозможно
одновременно обеспечить доступность и согласованность данных. Однако
существует альтернативная точка зрения на проблему транзакционных
разделенных систем баз данных и теорему CAP- случаи потери связности узлов в
распределенных разделенных системах баз данных чрезвычайно редки, и
стремление к обеспечению высокого уровня доступности данных в ущерб их
согласованности не является оправданным.
Было установлено, что при выполнении части тестового набора TPC-C на
поддержку блокировок, защелок (latch) и буфера откатов, которая требуется при
наличии многопотокового управления параллелизмом, уходит 42% команд
процессора. Это говорит о том, что устранение управления параллелизмом может
привести к значительному повышению производительности.
329.
Выполнение транзакций330.
Компоненты системыСистема состоит из трех типов процессов, показанных на рис. 1.
1. данные сохраняются в разделах, для каждого из которых один процесс отвечает
за хранение данных в основной памяти и выполнение хранимых процедур с
использованием одного потока выполнения. В действительности для каждого
раздела имеются один основной (primary) процесс и k - 1 резервных (backup)
процессов, что обеспечивает устойчивость данных к k - 1 отказу.
2. Имеется один процесс, называемый центральным координатором и
используемый для координации всех распределенных транзакций. Это
обеспечивает глобальную упорядоченность распределенных транзакций. 3.
Клиентские процессы являются приложениями конечных пользователей,
запускающими в системе транзакции в форме вызовов хранимых процедур. Когда
клиентская библиотека подключается к базе данных, она загружает часть
системного каталога, в которой описываются доступные хранимые процедуры,
сетевые адреса разделов и способ распределения данных. Это позволяет
клиентской библиотеке направлять транзакции в соответствующие процессы.
331.
Транзакции оформляются в виде хранимых процедур, состоящих издетерминированного кода, который перемежается операциями над базой данных.
Клиент инициирует транзакцию путем посылки в систему сообщения с
требованием вызова некоторой хранимой процедуры. Система распределяет
работу между разделами.
Каждая транзакция разбивается на фрагменты. Фрагмент – это часть работы,
которую выполнить в точно одном разделе. В нем может выполняться некоторая
смесь пользовательского кода и операций над базой данных. Если клиент
определяет, что запрос является одноузловой транзакцией, он направляет его в
основной раздел, отвечающий за требуемые данные. Для обеспечения
долговечности хранения в соответствующем процессе основного раздела
используется протокол репликации между основным и резервными разделами. При
отсутствии сбоев процесс основного раздела получает запрос из сети и посылает
его копию процессам резервных разделов. Во время ожидания их подтверждения в
процессе основного раздела выполняется транзакция. Поскольку эта транзакция
является однораздельной, этот процесс не блокируется.
332.
После получения подтверждения от всех процессов резервных разделов результаттранзакции посылается клиенту. Этот протокол гарантирует долговечность
транзакции, если хотя бы одна сохраняется работоспособность хотя бы одной
реплики.
Для выполнения одноузловых транзакций не требуется никакого управления
параллелизмом. В большинстве случаев система выполняет такие транзакции без
сохранения информации, требуемой для откатов, что приводит к очень низким
накладным расходам. Это возможно благодаря тому, что транзакции
сопровождаются аннотациями, в которых указывается, может ли произойти
аварийное завершение транзакции по инициативе пользователя. Для транзакций,
для которых отсутствует возможность аварийного завершения по инициативе
пользователя, при использовании схем управления параллелизмом,
гарантирующих отсутствие синхронизационных тупиков, журнал отката не
поддерживается. В других случаях система поддерживает в основной памяти
буфер отката, который освобождается при фиксации транзакции.
333.
Чтобы обеспечить сериализуемый порядок выполнения многораздельныхтранзакций без возможности возникновения синхронизационных тупиков, они
направляются в систему через центральный координатор, который определяет им
глобальный порядок. Достоинством этого подхода является его простота, но
понятно, что наличие центрального координатора ограничивает число
одновременно выполняемых многораздельных транзакций. Чтобы обеспечить
возможность одновременного выполнения большего числа транзакций,
необходимо использовать несколько координаторов. Центральный координатор
разбивает транзакцию на фрагменты и посылает их в разделы. После получения
ответов координатор выполняет код приложения, чтобы определить, как следует
продолжать выполнение транзакции, для чего может потребоваться посылка
дополнительных фрагментов. В каждом разделе фрагменты данной транзакции
выполняются последовательно.
334.
Многораздельные транзакции выполняются с использованием буфера отката, адля принятия решения об успешности завершения транзакций применяется
двухфазный протокол фиксации (two-phase commit, 2PC). Координатор
присоединяет сообщение "подготовиться" ("prepare") протокола 2PC к последнему
фрагменту транзакции.
Когда процесс основного раздела получает заключительный фрагмент, он
отсылает все фрагменты транзакции процессам резервных разделов и ожидает их
подтверждения до отправки окончательных результатов координатору.
Это эквивалентно принуждению участника 2PC к выталкиванию на диск своего
решения о фиксации транзакции.
Когда у координатора имеются все решения участников, он завершает транзакцию,
посылая сообщение "фиксация" ("commit") процессам разделов и возвращая
окончательный результат приложению.
335.
При выполнении многораздельных транзакций при ожидании данных от процессовдругих разделов в процессе основного раздела могут возникнуть сетевые
задержки. Этот простой может стать фактором, ограничивающим
производительность, даже если многораздельные транзакции составляют лишь
малую долю рабочей нагрузки.
Простейшая схема управления многораздельными транзакциями состоит в том,
что до завершения активных транзакций прием на обработку других транзакций
блокируется. Когда процесс некоторого раздела получает первый фрагмент
некоторой многораздельной транзакции, он выполняет его и возвращает
результаты. Все другие транзакции ставятся в очередь. При получении
последующих фрагментов активной транзакции процесс обрабатывает их по
порядку. После того как данная транзакция фиксируется или откатывается,
обрабатываются транзакции, ранее поставленные в очередь.
336.
Спекулятивная обработка однораздельных транзакций. Для каждого разделаподдерживается очередь невыполненных транзакций и очередь
незафиксированных транзакций. В начале очереди незафиксированных
транзакций всегда находится некоторая не спекулятивная транзакция. После того,
как в разделе выполняется последний фрагмент некоторой многораздельной
транзакции, в нем спекулятивным образом выполняются дополни-тельные
транзакции, взятые из очереди невыполненных транзакций. Для каждой такой
транзакции поддерживается буфер отката. Если не спекулятивная транзакция
откатывается, выбирается каждая транзакция из оставшейся части очереди
незафиксированных транзакций, откатывается, а затем добавляется в начало
очереди невыполненных транзакций для повторного исполнения. Если не
спекулятивная транзакция фиксируется, то выбираются транзакции из очереди
незафиксированных транзакций, и результаты их выполнения посылаются в
приложение. Когда очередь незафиксированных транзакций опустошается,
система возобновляет выполнение транзакций в не спекулятивном режиме
337.
Это схема чисто локального спекулятивного выполнения, когда спекулятивныерезультаты буферизуются внутри раздела и не демонстрируются за его пределами
до тех пор, пока не станет известно, что они корректны. При такой схеме можно
спекулятивно выполнить только первый фрагмент многораздельной транзакции,
поскольку результаты, к которым м.б. применен откат, нельзя делать доступными
вне локального раздела. Однако можно допустить спекулятивное выполнение
многих многораздельных транзакций, если о спекулятивном выполнении знает
координатор. Спекулятивная обработка многораздельных транзакций.
Когда многораздельные транзакции зафиксируются, и очередь незафиксированных
транзакций станет пустой, процессы разделов смогут возобновить не
спекулятивное выполнение транзакций. Эта схема позволяет без блокирования
выполнять последовательность многораздельных транзакций, в каждой из которых
имеется по одному фрагменту для каждого раздела, если все эти транзакции
фиксируются. Мы называем такие транзакции простыми многораз-дельными
транзакциями. Транзакции этого вида довольно распространены.
338.
Например, если имеется некоторая таблицы, над которой в основном выполняютсяоперации чтения, то может оказаться полезно реплицировать ее по всем
разделам. Тогда операции чтения могут выполняться локально, в составе какойлибо однораздельной тразакции. Случайные операции модификации этой таблицы
выполняются в виде простой многораздельной транзакции над всеми разделами.
Другой пример представляет таблица, разделенная по столбцу x, доступ к записям
которой основывается на значении столбца y. Такой доступ может быть обеспечен
за счет обращения ко всем разделам этой таблицы, что также является простой
многораздельной транзакцией.
339.
У спекулятивной схемы выполнения транзакций имеется несколько ограничений.Во-первых, поскольку спекулятивное выполнение может применяться только после
выполнения последнего фрагмента транзакции, этот подход менее эффективен
при наличии транзакций с несколькими фрагментами над одним разделом.
Во-вторых, многораздельное спекулятивное выполнение транзакций можно
применять только в тех случаях, когда многораздельные транзакции поступают от
одного и того же координатора. Это требуется для того, чтобы координатор знал о
виде завершения более ранних транзакций и мог при необходи-мости каскадно
откатить несколько транзакций. Однако единственный координатор может стать
узким местом системы. Чтобы система могла получить пользу от этой оптимизации
при применении нескольких координаторов, каждый координатор должен
распределять транзакции по пакетам. Это может приводить к задержке
выполнения транзакций и требует настройки числа координаторов в соответствии с
особенностями рабочей нагрузки.
340.
Преимуществом спекулятивной схемы является то, что в этом случае не требуютсясинхронизационные блокировки и отслеживание наборов чтения/записи. Кроме
того, возникающие накладные расходы ниже, чем у традиционных схем
управления параллелизмом. Недостатком является предположение, что все
транзакции конфликтуют, из-за чего временами происходят ненужные откаты.
Синхронизационные блокировки.
В схеме с синхронизационными блокировками транзакции при своем выполнении
запрашивают синхронизационные блокировки элементов данных по чтению и
записи, и выполнение транзакции, запросившей конфликтующую
синхронизационную блокировку, приостанавливается. Транзакции должны
сохранять информацию, требуемую для отката, чтобы иметь возможность
откататься при возникновении синхронизационного тупика. Применение
синхронизационных блокировок позволяет в одном разделе выполнять и
фиксировать неконфликтующие транзакции во время сетевых задержек для
многораздельных транзакций.
341.
Механизм синхронизационных блокировок гарантирует, что результаты будутэквивалентны результатам выполнения транзакций в некотором последовательном
порядке. Недостатком является то, что транзакции выполняются с
дополнительными накладными расходами, связанными с запросами блокировок и
обнаружением тупиковых ситуаций. Блокировки запрашиваются только тогда, когда
имеются активные многораздельные транзакции.
В схеме синхронизационных блокировок следуют строгому двухфазному протоколу.
Поскольку это гарантирует получение сериализуемого плана выполнения
транзакций, клиенты посылают многораздельные транзакции прямо процессам
разделов, не используя центральный координатор. Этот подход более эффективен
при отсутствии конфликтующих синхронизационных блокировок, но при этом
появляется возможность распределенного синхронизационного тупика.
Для распознавания локальных тупиков используется выявление наличия циклов, а
наличие распределенных тупиков устанавливается с использованием механизма
тайм-аутов.
342.
При обнаружении цикла для его разрушения в жертву приносятся однораздельныетранзакции, потому что их повторное выполнение обходится более дешево.
Эффективность схемы с синхронизационными блокировками зависит от наличия
или отсутствия конфликтов между транзакциями. При отсутствии конфликтов
транзакции выполняются параллельно. Однако при их наличии возникают
дополнительные накладные расходы на приостановку и возобновление
выполнения. Синхронизационные тупики в этой рабочей нагрузке невозможны, что
позволило избежать влияния на производительность зависящих от реализации
политик разрешения такие ситуаций. Производительность системы с
использованием схемы синхронизационных блокировок при повышении частоты
конфликтов падает. Система с синхронизационными блокировками превосходит по
производительности систему с блокировочной схе-мой при наличии большого
числа многораздельных транзакций, потому что в данной рабочей нагрузке каждая
транзакция конфлик-тует только в одном разделе, так что некоторую часть работы
удается выполнять параллельно.
343.
Аварийное завершение транзакцийСпекулятивная схема основана не предположении, что транзакции будут
фиксироваться. Если транзакция завершается аварийно, то спекулятивно
выполненные транзакции должны откатываться и выполняться заново, что
приводит к лишним тратам времени процессора. Несмотря на наличие
ограничений центрального координатора, производительность системы со
спекулятивной схемой все еще превосходит производительность системы с
синхронизационными блокировками, пока доля аварийно завершаемых транзакций
не достигает 5%. Когда доля аварийно завершающихся транзакций достигает 10%,
система со спекулятивной схемой становится близка по производительности к
системе с блокировочной схемой, поскольку некоторые транзакции приходится
повторно выполнять много раз.
344.
Результаты анализа показывают, что выбор наилучшего механизма управленияпараллелизмом зависит от свойств рабочей нагрузки. Спекулятивная схема
работает значительно лучше, чем блокировочная схема и схема с
синхронизационными блокировками, при наличии многораздельных транзакций с
одним циклом коммуникаций и небольшой доли аварийно завершающихся
транзакций. Метод синхронизационных блокировок с низкими накладными
расходами оказывается предпочтительным, когда имеется много транзакций с
несколькими циклами коммуникаций.
Спекулятивная схема является предпочтительной, когда имеется немного
транзакций с несколькими циклами коммуникаций (транзакций общего вида) и
аварийных завершений транзакций.
345.
Родственные работы. В большинстве распределенных систем баз данных дляобработки параллельных запросов используется некоторая разновидность
двухфазных синхронизационных блокировок, которые лучше всего подходят при
наличии рабочих загрузок с малым числом конфликтов. Другие схемы, такие как
упорядочение по временным меткам, позволяют избежать синхронизационных
тупиков, допуская при этом параллельное выполнение транзакций. Для поддержки
таких схем требуется поддержка наборов чтения/записи, защелок и откатов.
Родственные работы. В большинстве распределенных систем баз данных
(например, для обработки параллельных запросов) используется некоторая
разновидность двухфазных синхронизаци-онных блокировок, которые в
соответствии с нашими результатами лучше всего подходят при наличии рабочих
загрузок с малым числом конфликтов. Другие схемы, такие как упорядочение по
временным меткам, позволяют избежать синхронизационных тупиков, допуская
при этом параллельное выполнение транзакций. Для поддержки таких схем
требуется поддержка наборов чтения/ записи, защелок и откатов.
346.
Для доступа к «большим и быстрым» данным была разработана лямбда-архитектура,которая представляет собой общий подход, направленный на применение произвольной
функции к произвольному набору данных, при этом обеспечивая минимальный период
ожидания возвращения функцией искомого значения. Она состоит из трех уровней:
пакетного (batch layer), сервисного (serving layer), уровня ускорения (speed layer).
Пакетный уровень – архив сырых исторических данных. Чаще всего, это «озеро данных» на
базе Hadoop, хотя встречается и в форме OLAP-хранилища данных, старые данные остаются
неизменными – происходит добавление новых.
Сервисный уровень индексирует пакеты и обрабатывает результаты вычислений,
происходящих на пакетном уровне.
Уровень ускорения отвечает за обработку данных, поступающих в систему в реальном
времени. Представляет собой совокупность складов данных, в которых те находятся в
режиме очереди, в потоковом или в рабочем режиме.
347.
На этом уровне компенсируется разница в актуальности данных, а в отдельныепредставления реального времени добавляется информация с коротким жизненным циклом
(чтобы исключить дублирование данных). Эти представления параллельно с сервисным
уровнем обрабатывают свои запросы.
348.
В основе Лямбда-архитектуры лежит несколько принципов:система не восприимчива к единичной потере данных и/или повреждению данных (faulttolerance);
неизменность данных – хранение данных в исходном неизменяемом виде;
перевычисление – есть возможность всегда провести вычисления на исходных данных.
Вся информация поступает в единое хранилище данных (мастер), в котором может быть и
другая статичная информация, и одновременно дублируется на уровне агрегации
краткосрочного периода. любой запрос имеет доступ к мастеру для получения полного
ответа на основе полных данных, и коррекции с учетом самой последней информации,
агрегированной за краткосрочный период, поскольку мастер, очевидно, имеет
определенную инерцию из-за скорости обработки большого объема информации.
349.
Уровень пакет использует Apache HadoopУровень скорость использует Stream-processing technologies typically Apache Storm,
SQLstream and Apache Spark. Результат обычно сохраняется на быстрых NoSQL БД.
Уровень сервис использует Apache Cassandra or Apache HBase for speed-layer output,
and Elephant DB or Cloudera Impala for batch-layer output.
350.
Новые данные поступают на оба уровня: Пакетный и Ускорения (A). Мастер (B)представляет собой хранилище неизменяемой сырой информация, где исходные данные
только добавляются. Пакетный уровень (C) постоянно перевычисляет функции заново в
Пакеты. Сервисный Уровень (D) индексирует Пакеты, и здесь результаты обычно отстают
по времени из-за скорости прохождения мастера и индексирования. Уровень Ускорения (E)
компенсирует разницу в актуальности данных, и постоянно добавляет данные в
представления реального-времени с коротким жизненным циклом (ведь нам не нужно
дублирование в хранении данных, т.к. они накапливаются на Мастере). И, наконец,
запросы обрабатывают пакеты и представления реального времени (F).
351.
На данный момент существуют различные вариации технологических компонент дляЛямбда-архитектуры.
Например, проект Lambdoop, который объединяет компоненты эко-системы Hadoop для
всех трех слоев Лямбда-архитектуры: кластер Hadoop используется для пакетного уровня –
HDFS для мастера и MapReduce для быстрого перевычисления запроса на исходных
данных; для сервисного уровня используются Cloudera Impala для пакетов и Apache HBase
для создания представлений реального времени; и технология Storm для уровня ускорения.
Также Cloudera Impala решает вопрос агрегации результатов из уровней для ответа на
запрос.
Проект развивается с 2013 г.
352.
353.
354.
H-Store представляет собой инфраструктуру для системы, использующейразделение данных и однопотоковое выполнение для упрощения управления
параллелизмом.
Результаты особенно важны для систем, в которых разделение данных
используется для достижения параллелизма, поскольку рабочую нагрузку, не
разделенную должным образом, можно выполнять без накладных расходов,
свойственных управлению параллелизмом на основе синхронизационных
блокировок.
355.
Разработки Google356.
Google File System• Google File System (GFS) — распределенная файловая система,
созданная компанией Google в 2000 году для своих внутренних
потребностей.
• Используемая реализация является коммерческой тайной
компании Google, однако общие принципы построения системы
были опубликованы в 2003 году.
• Обновленная GFS второй версии (2009 год) имеет кодовое
название Colossus
357.
Особенности ГФС• Несовместима с POSIX, тесно интегрирована с MapReduce.
• POSIX — (англ. Portable Operating System Interface for Unix —
Переносимый интерфейс операционных систем Unix) — набор
стандартов, описывающих интерфейсы между операционной
системой и прикладной программой.
• MapReduce — модель распределённых вычислений,
представленная компанией Google, используемая для параллельных
вычислений над очень большими, несколько петабайт наборами
данных в компьютерных кластерах.
358.
Устройство GFS• GFS — кластерная система, оптимизированная для
центрального хранилища данных Google и нужд
поискового механизма, обладающая повышенной
защитой от сбоев. Система предназначена для
взаимодействия между вычислительными системами,
а не между пользователем и вычислительной
системой.
359.
Устройство GFS• В GFS файлы делятся на блоки данных (англ. chunk — кусок)
по 64 МБ (в первой версии, ориентированной на
обслуживание поисковых индексов) или по 1 МБ (в более
универсальной GFS 2.0). При разработке ФС предполагалось,
что файлы очень редко переписываются или уменьшаются в
размере хранимых данных, а лишь читаются или
увеличиваются в размере, посредством добавления в конец
новых данных.
360.
Безопасность ГФС• Вся информация копируется и хранится в трёх (или
более) местах одновременно, при этом система
способна очень быстро находить реплицированные
копии, если какая-то машина вышла из строя. Задачи
автоматического восстановления после сбоя
решаются с помощью программ, созданных по модели
MapReduce.
361.
Google App Engine• Google App Engine — сервис хостинга сайтов и webприложений на серверах Google с бесплатным именем
<имя_сайта>.appspot.com, либо с собственным именем,
задействованным с помощью служб Google
• Платформа Google конкурирует с аналогичными сервисами
от Amazon, которые предоставляют возможности размещать
файлы и веб-приложения, используя свою инфраструктуру.
362.
Особенности• App Engine представлена в апреле 2008, доступны как
бесплатные аккаунты (до 1 Гб дискового
пространства, 10 Гб входящего трафика в день, 10 Гб
исходящего трафика в день, 200 миллионов
гигациклов CPU в день и 2000 операций отправления
электронной почты в день),так и возможность
приобретения дополнительных ресурсов.
363.
• Приложения, разворачиваемые на базе App Engine, должныбыть написаны на Python, Java, Go либо PHP.
• Предоставлена возможность использовать планировщик
задач cron как для приложений реализованных на Python,
так и на Java. Разрешено планирование не более 20-ти
заданий
364.
• Использование службы аккаунтов Google позволяетбыстро начать работу с приложением, нет необходимости
проводить отдельную регистрацию учётных данных на
каждом сайте. Это также позволяет разработчику не
заботиться о реализации ещё одной системы регистрации
пользователей специально для своего приложения.
365.
Google Fusion Tables• BigTable — высокопроизводительная база данных,
построенная на основе Google File System (GFS),
Chubby Lock Service и некоторых других продуктах
Google. В настоящий момент не распространяется и
не используется за пределами Google, хотя Google
предлагает использовать её как часть Google App
Engine.
366.
• Google Fusion Tables была выпущена 9 июня 2009 года какэкспериментальная система для управления данными в
облаке.
• Fusion Tables это не столько таблицы, сколько база данных
заточенная под отображение геоинфомации, причем
координаты могут быть заданы как в формате
широта\долгота, так и адресом- минимум страной
367.
Apache Cassandra — распределённая система управления базами данных, относящаяся кклассу noSQL-систем и рассчитанная на создание высоко масштабируемых и надёжных
хранилищ огромных массивов данных, представленных в виде хэша.
Изначально проект был разработан в недрах Facebook и в 2009 году передан под крыло
фонда Apache Software Foundation, эта организация продолжает развитие проекта.
Промышленные решения на базе Cassandra развёрнуты для обеспечения сервисов таких
компаний, как Cisco, IBM, Cloudkick, Reddit, Digg, Rackspace и Twitter. К 2011 году
крупнейший кластер серверов, обслуживающий единую БД Cassandra, насчитывает более
400 машин и содержит данные размером более 300 Тб.
368.
СУБД Cassandra написана на языке Java и включает в себя полностью распределённуюhash-систему Dynamo, что обеспечивает практически линейную масштабируемость при
увеличении объёма данных. Cassandra использует модель хранения данных на базе
семейства столбцов (ColumnFamily), что отличается от систем, подобных memcachedb,
которые хранят данные только в связке ключ/значение, возможностью организовать
хранение хэшей с несколькими уровнями вложенности. Cassandra относится к категории
хранилищ, повышенно устойчивых к сбоям: помещённые в БД данные автоматически
реплицируются на несколько узлов распредёленной сети или даже равномерно
распределяются в нескольких дата-центрах. При сбое узла, его функции на лету
подхватываются другими узлами. Добавление новых узлов в кластер и обновление версии
Cassandra производится на лету, без дополнительного ручного вмешательства и
переконфигурации других узлов.
369.
Для упрощения взаимодействия с БД поддерживается язык формированияструктурированных запросов CQL (Cassandra Query Language), который на первый взгляд
напоминает SQL, но существенно урезанный в функциональности. Например, можно
выполнять только простейшие запросы SELECT с выборкой по определённому условию,
но без поддержки сортировки и группировки. Добавление и обновление осуществляется
через единое выражение UPDATE, операция INSERT отсутствует (если записи нет, при
выполнении UPDATE она создаётся). Из возможностей можно отметить поддержку
пространств имён и семейств столбцов, создание индексов через выражение "CREATE
INDEX". Драйверы с поддержкой CQL подготовлены для языков Python, Java
(JDBC/DBAPI2) и JavaScript (Node.js).
BigTable — проприетарная высокопроизводительная база данных, построенная на основе
Google File System (GFS), Chubby Lock Service и некоторых других продуктах Google. В
настоящий момент не распространяется и не используется за пределами Google, хотя
Google предлагает использовать её как часть Google App Engine
370.
Работа над BigTable была начата в 2004 году и сейчас СУБД используется в различногорода приложениях Google, таких как MapReduce, которое часто используется для создания
и модификации данных хранящихся в BigTable[2], Google Maps, Google Book Search,
Search_History, Google Earth, Blogger.com, Google Code hosting, Orkut и YouTube. Причины,
побудившие Google к созданию собственной базы данных — масштабируемость и
больший контроль над производительностью
Открытое ПО
HBase — система написана на Java, добавляет функциональность, аналогичную BigTable, в
ядро Hadoop.
Hypertable — система предназначена для управления хранением данных и обработки
информации в больших кластерах серверов.[8][7]
Cloudata — написанная на Java СУБД, разработанная корейским программистом Yk Kwon.
Apache Accumulo — клон Bigtable созданный в Агентстве национальной безопасности
США.
371.
Apache Cassandra — основанная на модели данных BigTable распределённая системахранения данных Facebook.
Project Voldemort — распределённая система хранения данных используемая LinkedIn.
Neptune (сайт больше не поддерживается) — система написана на Java, использует
компоненты Hadoop: ZooKeeper и HDFS.
KDI — клон BigTable созданный в Kosmix.
Google Fusion Tables
Google Fusion Tables была выпущена 9 июня 2009 года как экспериментальная система для
управления данными в облаке.[9][10]
372.
HBase — нереляционная распределённая база данных с открытым исходным кодом;написана на Java; является аналогом Google BigTable. Разрабатывается в рамках проекта
Hadoop фонда Apache Software Foundation. Работает поверх распределенной файловой
системы HDFS и обеспечивает отказоустойчивый способ хранения больших объёмов
разреженных данных.
Проект HBase запустили Чед Уолтерс и Джим Келлерман из компании Powerset, которой
было необходимо обрабатывать большие объёмы данных для создания поисковой системы
на естественном языке.
HBase не является прямой заменой классических SQL баз данных, хотя в последнее время в
этой сфере она стала работать существенно лучше и в настоящее время используется для
управления данными на нескольких веб-сайтах, в том числе Facebook использует её для
своей платформы сообщений.
Приложения хранят данные в таблицах, состоящих из строк и столбцов. Для ячеек таблицы
действует контроль версии. По умолчанию в качестве версии используется временная
метка, автоматически назначаемая HBase на момент вставки.
373.
Содержимое ячейки представляет собой неинтерпретируемый массив байтов.Ключи строктаблицы тоже являются байтовыми массивами, поэтому теоретически ключом строки
может быть что угодно — от строк до двоичных представлений. Строки таблицы
сортируются по ключу строк. Сортировка осуществляется в порядке следования байтов.
Все обращения к таблице выполняются по первичному ключу. Столбцы объединяются в
семейства столбцов. Все члены семейства столбцов имеют общий префикс. Физически все
члены семейств хранятся вместе в файловой системе. Таким образом HBase как столбцовоориентированное хранилище информации.
Hypertable - база данных предназначена для обслуживания задач по индексации
веба,хорошо масштабируемая и ориентированная на большое число подключений.В ней
отсутствуют транзакции, но она рассчитана на интенсивный трафик. Она может работать
не только с такими интенсивными сервисами, как Google и Amazon, но и с простыми
поисковыми системами, в которых заложена возможность увеличения числа запросов.
374.
В силу того, что Bigtable работает на основе Google File System, базовой файловойсистемой для Hypertable является GFS. Doug Judd, один из разработчиков, сказал, что при
выборе инструмента было решено отказаться от java в пользу С++ в силу того, что в
Hypertable вопрос реализации менеджеров памяти оказался критическим.
Принцип работы Hypertable:
-Hypertable хранит данные в табличном формате, сортируя записи по основному ключу с
указанием времени, когда они были созданы;
-для хранимых данных не используются какие-либо типы данных, любая ячейка
интерпретируется как байтовая строка;
-масштабируемость достигается путем разбиения таблиц на смежные интервалы строк и
хранения их на разных физических машинах;
-в системе используется два типа серверов:
375.
Master Server– мастер-сервер выполняет обязанности скорее административного характера: он
управляет работой Range серверов, работает с метаданными (которые хранятся просто в
отдельной таблице, наравне с остальными).
Range Server
– их задача стоит в собственно в хранении диапазонов строк из различных таблиц.
Каждый сервер может хранить несколько несмежных диапазонов строк, если диапазон
превышает по объему определенный лимит (по-умолчанию — 200 MB), то он разбивается
на пополам и одна половина обычно перемещяется на другой сервер. Если же на одном из
серверов подходит к концу дисковое пространство, то под руководством мастер-сервера
часть диапазонов с него перераспределяется на менее загруженные Range серверы.
-Еще одним компонентом системы является Hyperspace, этот сервер предоставляет
указатель на основную таблицу с метаданными, а также пространство имен. Помимо этого
этот сервис выступает в роли lock-механизма для клиентов системы.
376.
HBase и Hypertable выполняют достаточно похожие функции и преследуют практическиодни и те же цели, но HBase написана на Java, в то время как разработчики Hypertable
предпочли C++. Это повлекло за собой массу различий в реализации различных
операций.Для доступа к данным каждая из систем использует язык HQL, только в одном
случае аббревиатура расшифровывается как HBase Query Language, а в другом —
Hypertable Query Language.
377.
Gринципы работы с большими данными и парадигма MapReduce.Были определения Big Data
– это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
– это такие данные, которые невозможно обрабатывать в Excel
– это такие данные, которые невозможно обработать на одном компьютере
wikipedia — серия подходов, инструментов и методов обработки структурированных
и неструктурированных данных огромных объёмов и значительного многообразияия
для получения воспринимаемых человеком результатов, эффективных в условиях
непрерывного прироста, распределения по многочисленным узлам ВС, сформировавшихся
в конце 2000 годов, альтернативных традиционным СУБД и решениям класса Business
Intelligence, т.е. это методы обработки данных, которые позволяют распредёленно
обрабатывать информацию
378.
Основные принципы работы с Big Data:1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно
много – любая система, которая подразумевает обработку больших данных, должна быть
расширяемой.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что
машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000
машин.
3. Локальность данных. В больших распределённых системах данные распределены по
большому количеству машин. Если данные физически находятся на одном сервере, а
обрабатываются на другом – расходы на передачу данных могут превысить расходы на
саму обработку. Поэтому одним из важнейших принципов проектирования BigDataрешений является принцип локальности данных – по возможности обрабатываем данные
на той же машине, на которой их храним.
379.
MapReduce – это модель распределенной обработки данных, предложенная компаниейGoogle для обработки больших объёмов данных на компьютерных кластерах.
380.
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработкаданных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(),
которую определяет пользователь. Работа этой стадии заключается в предобработке и
фильтрации данных. Функция map() примененная к одной входной записи и выдаёт
множество пар ключ-значение. Множество – т.е. может выдать только одну запись,
может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет
находится в ключе и в значении – решать пользова-телю, но ключ – очень важная вещь, так
как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции
map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода
стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформи-рованная на стадии shuffle,
попадает на вход функции reduce().
381.
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины».Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduceзадачи.
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных
машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных
машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных
машинах кластера. 1-3 реализуют принцип горизонтальной масштабируемости.
4) Функция map применяется на той же машине, на которой хранятся данные – это позволяет снизить
передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет,т.е. MapReduce плохо
применим, когда ответ требуется очень быстро.
382.
Hadoop – одна из самых известных технологий для работы с большими данными,прозволяющая запускать MapReduce-задачи на Hadoop.
Основными (core) компонентами Hadoop являются:
Hadoop Distributed File System (HDFS) – распределённая файловая система, позволяющая
хранить информацию практически неограниченного объёма
Hadoop YARN – фреймворк для управления ресурсами кластера и менеджмента задач, в
том числе включает фреймворк MapReduce
Hadoop common
Не входящие в Hadoop core:
Hive – инструмент для SQL-like запросов над большими данными (превращает SQLзапросы в серию MapReduce–задач)
Pig – язык программирования для анализа данных на высоком уровне. Одна строчка кода
на этом языке может превратиться в последовательность MapReduce-зада
383.
Hbase – колоночная база данных, реализующая парадигму BigTable;Cassandra – высокопроизводительная распределенная key-value база данных;
ZooKeeper – сервис для распределённого хранения конфигурации и синхронизации
изменений этой конфигурации;
Mahout – библиотека и движок машинного обучения на больших данных.
Hbase — это распределенная, колоночно-ориентированная, мультиверсионная база типа
«ключ-значение».
Данные организованы в таблицы, проиндексированные первичным ключом, который в
Hbase называется RowKey.
Для каждого RowKey ключа может храниться неограниченны набор атрибутов (или
колонок). Колонки организованны в группы колонок, называемые Column Family. Для
каждого аттрибута может храниться несколько различных версий. Разные версии имеют
разный timestamp.
384.
Записи физически хранятся в отсортированном по RowKey порядке. При этом данныесоответствующие разным Column Family хранятся отдельно, что позволяет при
необходимости читать данные только из нужного семейства колонок.
При удалении определённого атрибута физически он сразу не удаляется, а лишь
маркируется специальным флажком tombstone. Физическое удаление данных произойдет
позже, при выполнении операции Major Compaction. Атрибуты, принадлежащие одной
группе колонок и соответствующие одному ключу, физически хранятся как
отсортированный список. Любой атрибут может отсутствовать или присутствовать для
каждого ключа, при этом если атрибут отсутствует — это не вызывает накладных
расходов на хранение пустых значений.
Список и названия групп колонок фиксирован и имеет четкую схему. На уровне группы
колонок задаются такие параметры как time to live (TTL) и максимальное количество
хранимых версий.
385.
Если разница между timestamp для определенно версии и текущим временем больше TTL— запись помечается к удалению. Если количество версий для определённого атрибута
превысило максимальное количество версий — запись также помечается к Удалению.В
hbase поддерживают-ся 4 основные операции:— Put: добавить новую запись в hbase.
Timestamp этой записи может быть задан руками, в противном случае он будет установлен
автоматически как текущее время.— Get: получить данные по определенному RowKey.
Можно указать Column Family, из которой будем брать данные и количество версий
которые хотим прочитать. — Scan: читать записи по очереди. Можно указать запись с
которой начинаем читать, запись до которой читать, количество записей которые
необходимо считать, Column Family из которой будет производиться чтение и
максимальное количество версий для каждой записи. — Delete: пометить определенную
версию к удалению. Физического удаления при этом не произойдет, оно будет отложено до
следующего Major Compaction.
386.
Hadoop — проект фонда Apache Software Foundation, свободно распространяемый наборутилит, библиотек ипрограммный каркас для разработки и выполнения распределённых
программ, работаю-щих на кластерах из сотен и тысяч узлов. Используется для реализации
поисковых и контекстных механизмов многих высоконагруженных веб-сайтов: для Yahoo!
и Facebook. Разработан на Java в рамках вычислительной парадигмы MapReduce (приложение разделяется на большое количество одинаковых элементарных заданий, выполнимых
на узлах кластера и естественным образом сводимых в конечный результат). По состоянию
на 2014 год проект состоит из четырёх модулей — Hadoop Common (связующее
программное обеспечение — набор инфраструктурных програм-мных библиотек и утилит,
используемых для других модулей и родственных проектов),
HDFS (распределенная файловая система),
YARN (система для планирования заданий и управления кластером) и
Hadoop MapReduce (платформа программирования и выполнения распределённых
MapReduce-вычислений)
387.
388.
Считается одной из основополагающих технологий «больших данных». Вокруг Hadoopобразовалась целая экосистема из связан-ных проектов и технологий, многие из которых
развивались cначала в рамках проекта, а впоследствии стали самостоятельными.
Со второй половины 2000-х годов идёт процесс активной коммерциализации технологии,
несколько компаний строят бизнес целиком на создании коммерческих дистрибутивов
Hadoop и услуг по технической поддержке экосистемы, а практически все крупные
поставщики информационных технологий для организаций в том или ином виде включают
Hadoop в продуктовые стратегии и линейки решений. Разработка была инициирована в
начале 2005 года Дугом Каттингом ( Doug Cutting) с целью построения программной
инфраструктуры распределённых вычислений для проекта Nutch — свободной
программной поисковой машины на Java, её идейной основой стала публикация
сотрудников Google Джеффри Дина и Санжая Гемавата о вычислительной концепции
MapReduce, проект был назван в честь игрушечного слонёнка ребёнка основателя проекта
389.
В январе 2006 корпорация Yahoo выделила Hadoop в отдельный проект для разработкиинфраструктуры распределённых вычислений. В феврале 2008 Yahoo запустила
кластерную поисковую машину на 10 тыс. процессорных ядер, управляемую средствами
Hadoop.
В апреле 2010 корпорация Google предоставила Apache Software Foundation права на
использование технологии MapReduce, через три месяца после её защиты в патентном
бюро США.
Начиная с 2010 года Hadoop неоднократно характеризуется как ключевая технология
«больших данных», прогнозируется его широкое распространение для массовопараллельной обработки данных, и, наряду с Cloudera, появилась серия технологических
стартапов, целиком ориентированных на коммерциализацию Hadoop. В течение 2010 года
несколько подпроектов Hadoop — Avro, HBase, Hive, Pig, Zookeeper — последовательно
стали проектами верхнего уровня фонда Apache, что послужило началом формирования
экосистемы вокруг Hadoop.
390.
В Hadoop Common входят библиотеки управления файловыми системами,поддерживаемыми Hadoop и сценарии создания необходимой инфраструктуры и
управления распределённой обработкой, для удобства выполнения которых создан
специализи-рованный упрощённый интерпретатор командной строки (FS shell, filesystem
shell), запускаемый из оболочки операционной системы командой вида: hdfs dfs -command
URI, где command — команда интерпретатора, а URI — список ресурсов с префиксами,
указывающими тип поддерживаемой файловой системы, например hdfs://example.com/file1
или file:///tmp/local/file2. Бо́льшая часть команд интерпретатора реализована по аналогии с
соответствую-щими командами Unix (таковы, например, cat, chmod, chown, chgrp, cp, du, ls,
mkdir, mv, rm, tail, притом, поддержаны некоторые ключи аналогичных Unix-команд,
например ключ рекурсивности -R для chmod, chown, chgrp), есть команды специфические
для Hadoop (например, count подсчитывает количество каталогов, файлов и байтов по
заданному пути, expunge очищает корзину, а setrep модифицирует коэффициент
репликации для заданного ресурса).
391.
HDFS (Hadoop Distributed File System) — файловая система, предназначенная для храненияфайлов больших размеров, поблочно распределённых между узлами вычислительного
кластера.
Все блоки в HDFS (кроме последнего блока файла) имеют одинаковый размер, и каждый
блок может быть размещён на нескольких узлах, размер блока и коэффициент репликации
(количество узлов, на которых должен быть размещён каждый блок) определяются в
настройках на уровне файла.
Благодаря репликации обеспечивается устойчивость распределённой системы к отказам
отдельных узлов. Файлы в HDFS могут быть записаны лишь однажды (модификация не
поддерживается), а запись в файл в одно время может вести только один процесс.
Организация файлов в пространстве имён — традиционная иерархическая: есть корневой
каталог, поддерживается вложение каталогов, в одном каталоге могут располагаться и
файлы, и другие каталоги.
392.
Развёртывание экземпляра HDFS предусматривает наличие центрального узла имён ( namenode), хранящего метаданные файловой системы и метаинформацию о распределении
блоков, и серии узлов данных ( data node), непосредственно хранящих блоки файлов. Узел
имён отвечает за обработку операций уровня файлов и каталогов — открытие и закрытие
файлов, манипуляция с каталогами, узлы данных непосредственно отрабатывают операции
по записи и чтению данных. Узел имён и узлы данных снабжаются веб-серверами,
отображающими текущий статус узлов и позволяющими просматривать содержимое
файловой системы. Административные функции доступны из интерфейса командной
строки.
Hadoop поддерживает работу и с другими распределёнными файловыми системами без
использования HDFS, поддержка Amazon S3 и CloudStore реализована в основном
дистрибутиве. С другой стороны, HDFS может использоваться не только для запуска
MapReduce-заданий, но и как распределённая файловая система общего назначения, в
частности, поверх неё реализована распределённая NoSQL-СУБД HBase, в её среде
работает масштабируемая система машинного обучения Apache Mahout
393.
YARN ( Yet Another Resource Negotiator — «ещё один ресурсный посредник») — модуль,появившийся с версией 2.0 (2013), отвечающий за управление ресурсами кластеров и
планирование заданий.
Если в предыдущих выпусках эта функция была интегрирована в модуль MapReduce, где
была реализована единым компонентом (JobTracker), то в YARN функционирует
логически самостоятельный демон — планировщик ресурсов (ResourceManager),
абстрагирующий все вычислительные ресурсы кластера и управляющий их
предоставлением приложениям распределённой обработки.
Работать под управлением YARN могут как MapReduce-программы, так и любые другие
распределённые приложения, поддерживающие соответствующие программные
интерфейсы; YARN обеспечивает возможность параллельного выполнения нескольких
различных задач в рамках кластера и их изоляцию (по принципам мульбтиарендности).
394.
Разработчику распределённого приложения необходимо реализовать специальный классуправления приложением (ApplicationMaster), который отвечает за координацию заданий в
рамках тех ресурсов, которые предоставит планировщик ресурсов; планировщик ресурсов
же отвечает за создание экземпляров класса управления приложением и взаимодействия с
ним через соответствующий сетевой протокол.
YARN может быть рассмотрен как кластерная операционная система в том смысле, что
ведает интерфейсом между аппаратными ресурсами кластера и широким классом
приложений, использующих его мощности для выполнения вычислительной обработки.
395.
Hadoop MapReduce — программный каркас для программирования распределённыхвычислений в рамках парадигмы MapReduce. Разработчику приложения необходимо
реализовать базовый обработчик, который на каждом вычислительном узле кластера
обеспечит преобразование исходных пар «ключ-значение» в промежуточный набор пар
«ключ — значение», и обработчик, сво-дящий промежуточный набор пар в окончательный,
сокращённый набор (свёртку, класс, реализующий интерфейс Reducer). Каркас передаёт на
вход свёртки отсортированные выводы от базовых обработчиков, сведе́ние состоит из трёх
фаз — shuffle (тасовка, выделение нужной секции вывода), sort (сортировка, группировка
по ключам выводов от распределителей — досортировка, требую-щаяся, когда разные
атомарные обработчики возвращают наборы с одинаковыми ключами, при этом, правила
сортировки на этой фазе могут быть заданы программно и использовать какие-либо
особен-ности внутренней структуры ключей) и собственно reduce (усече-ние) — получения
результирующего набора. Если свёртка не требу-ется, каркас возвращает набор
отсортированных пар, полученных базовыми обработчиками.
396.
Hadoop MapReduce позволяет создавать задания как с базовыми обработчиками, так и сосвёртками, написанными без использования Java: утилиты Hadoop streaming позволяют
использовать в качестве базовых обработчиков и свёрток любой исполняемый файл,
работающий со стандартным вводом-выводом операционной системы (например, утилиты
командной оболочки UNIX), есть также SWIG-совместимый прикладной интерфейс
программирования Hadoop pipes на С++.
В состав дистрибутивов Hadoop входят реализации различных конкретных базовых
обработчиков и свёрток, наиболее типично используемых в распределённой обработке. В
первых версиях Hadoop MapReduce включал планировщик заданий (JobTracker), начиная с
версии 2.0 эта функция перенесена в YARN, и начиная с этой версии модуль Hadoop
MapReduce реализован поверх YARN. Программные интерфейсы по большей части
сохранены, однако полной обратной совместимости нет (то есть для запуска программ,
написанных для предыдущих версий API, для работы в YARN в общем случае требуется их
модификация или рефакторинг, и лишь при некоторых ограничениях возможны варианты
обратной двоичной совместимости
397.
Одной из основных целей Hadoop изначально было обеспечение горизонтальноймасштабируемости кластера посредством добавления недорогих узлов (оборудования
массового класса, commodity hardware), без прибегания к мощным серверам и дорогим
сетям хранения данных. Функционирующие кластеры размером в тысячи узлов
подтверждают осуществимость и экономическую эффективность таких систем, так, по
состоянию на 2011 год известно о крупных кластерах Hadoop в Yahoo (более 4 тыс. узлов с
суммарной ёмкостью хранения 15 Пбайт каждый), Facebook (около 2 тыс. узлов на 21
Пбайт) и Ebay (700 узлов на 16 Пбайт). Тем не менее, считается, что горизонтальная
масштабиру-емость в Hadoop-системах ограничена, для Hadoop до версии 2.0 максимально
возможно оценивалась в 4 тыс. узлов при использова-нии 10 MapReduce-заданий на узел.
Этому ограничению способст-вовала концентрация в модуле MapReduce функций
контроля за жизненным циклом заданий, с выносом её в модуль YARN в Hadoop 2.0 и
децентрализацией — распределением части функций по мониторингу на узлы обработки
— горизонтальная масштабиру-емость повысилась.
398.
Ещё одним ограничением Hadoop-систем является размер оперативной памяти на узлеимён (NameNode), хранящем всё пространство имён кластера для распределения
обработки, притом общее количество файлов, которое способен обрабатывать узел имён —
100 млн. Для преодоления этого ограничения ведутся работы по распределению узла имён,
единого в текущей архитектуре на весь кластер, на несколько независимых узлов. Другим
вариантом преодоления этого ограничения является использование распределённых СУБД
поверх HDFS, таких как HBase, роль файлов и каталогов в которых с точки зрения
приложения играют записи в одной большой таблице базы данных. По состоянию на 2011
год типичный кластер строился из однопроцессорных многоядерных х86-64-узлов под
управлением Linux с 3—12 дисковыми устройствами хранения, связанных сетью с
пропускной способностью 1 Гбит/с.
399.
Существуют тенденции как к снижению вычислительной мощности узлов ииспользованию процессоров с низким энергопотреблением (ARM, Intel Atom), так и
применения высокопроизводительных вычислительных узлов одновременно с сетевыми
решениями с высокой пропускной способностью (InfiniBand в Oracle Big Data
Appliance[en], высокопроизводительная сеть хранения данных на Fibre Channel и Ethernet
пропускной способностью 10 Гбит/с в шаблонных конфигурациях FlexPod для «больших
данных»).
Масштабируемость Hadoop-систем в значительной степени зависит от характеристик
обрабатываемых данных, прежде всего, их внутренней структуры и особенностей по
извлечению из них необходимой информации, и сложности задачи по обработке, которые,
в свою очередь, диктуют организацию циклов обработки, вычислительную интенсивность
атомарных операций, и, в конечном счёте, уровень параллелизма и загруженность
кластера.
400.
В руководстве Hadoop (первых версий, ранее 2.0) указывалось, что приемлемым уровнемпараллелизма является использование 10—100 экземпляров базовых обработчиков на узел
кластера, а для задач, не требующих значительных затрат процессорного времени — до
300; для свёрток считалось оптимальным использование их по количеству узлов,
умноженному на коэффициент из диапазона от 0,95 до 1,75 и константу
mapred.tasktracker.reduce.tasks.maximum.
С бо́льшим значением коэффициента наиболее быстрые узлы, закончив первый раунд
сведения, раньше получат вторую порцию промежуточных пар для обработки, таким
образом, увеличение коэффициента избыточно загружает кластер, но при этом
обеспечивает более эффективную балансировку нагрузки. В YARN вместо этого
используются конфигурационные константы, определяющие значения доступной
оперативной памяти и виртуальных процессорных ядер, доступных для планировщика
ресурсов, на основании которых и определяется уровень параллелизма.
401.
На фоне популяризации Hadoop в 2008 году и сообщениях о построении Hadoop-кластеровв Yahoo и Facebook, в октябре 2008 года был создана компания Cloudera во главе с
Майклом Ольсоном, бывшим генеральным директором Sleepycat (фирмы-создателя
Berkeley DB), целиком нацеленная на коммерциализацию Hadoop-технологий. В сентябре
2009 в Cloudera из Yahoo перешёл основной разработчик Hadoop Дуг Каттинг, и благодаря
такому переходу комментаторы охарактеризовали Cloudera как «нового знаменосца
Hadoop», несмотря на то, что основная часть проекта была создана всё-таки сотрудниками
Facebook и Yahoo. В 2009 году основана компания MapR[en], поставившая целью создать
высокопроизводительный вариант дистрибутива Hadoop, и поставлять его как
собственническое программное обеспечение.
В апреле 2009 года Amazon запустил облачный сервис Elastic MapReduce,
предоставляющий подписчикам возможность создавать кластеры Hadoop и выполнять на
них задания с повременной оплатой. Позднее, в качестве альтернативы, подписчики
Amazon Elastic MapReduce получили выбор между классическим дистрибутивом от Apache
и дистрибутивами от MapR
402.
В 2011 году Yahoo выделила подразделение, занимавшееся разработкой и использованиемHadoop, в самостоятельную компанию — Hortonworks[en], вскоре новой компании удалось
заключить соглашение с Microsoft о совместной разработке дистрибутива Hadoop для
Windows Azure и Windows Server. В том же году все крупные производители
технологического программного обеспечения для организаций в том или ином виде
включили Hadoop-технологии в стратегии и продуктовые линейки. Так, Oracle выпустила
аппаратно-программный комплекс Big Data appliance (заранее собранный в
телекоммуникационном шкафе и предконфигурированный Hadoop-кластер с
дистрибутивом от Cloudera), IBM на основе дистрибутива Apache создала продукт
BigInsights, EMC лицензировала у MapR их высокопроизводи-тельный Hadoop для
интеграции в продукты незадолго до этого поглощённой Greenplum (позднее это бизнесподразделение было выделено в самостоятельную компанию Pivotal, и она перешла на
полностью самостоятельный дистрибутив Hadoop на базе кода Apache), Teradata заключила
соглашение с Hortonworks по интеграции Hadoop в аппаратно-программный комплекс
массово-параллельной обработки Aster MapReduce appliance. В 2013 году собственный
дистрибутив Hadoop создала Intel
403.
SAP HANA (High-Performance Analytic Appliance) — это высокопроизводительнаяNewSQL платформа для хранения и обработки данных, в основе которой лежит технология
вычислений in-memory с использованием принципа поколоночного хранения данных,
платформы, разработанной и выведенной на рынок компанией SAP SE
Кроме самой СУБД, в составе HANA предусмотрены встроенный веб-сервер и
репозиторий управления версиями, необходимые для разработки приложений. Приложения
HANA могут создаваться с использованием кода JavaScript на стороне сервера и HTMLкода.
Выпуск SAP HANA начался в конце ноября 2010 года. В сентябре 2011 года было
объявлено о выпуске SAP NetWeaver Business Warehouse на основе технологии SAP
HANA. Первые поставки этого решения начались в ноябре того же года.
В 2012 году SAP выпустила решение для облачных вычислений.
404.
В январе 2013 года было объявлено о выпуске SAP Enterprise Resource Planning,входившего в пакет Business Suite компании SAP, на базе SAP HANA, а поставки начались
в мае
Так же в мае 2013 года было объявлено о разработке решения «программное обеспечение
как сервис»: решение получило официальное название HANA Enterprise Cloud (HEC).
Вместо выпуска очередных версий в SAP HANA используется практика пакетов
обновлений. По состоянию на август 2015 свежим пакетом обновлений является SPS10.
SAP SE — немецкая компания, производитель программного обеспечения для
организаций. Штаб-квартира расположена в Вальдорфе. Компания SAP была создана
пятью бывшими сотрудниками IBM (Claus Wellenreuther, Hans-Werner Hector, Klaus
Tschira, Dietmar Hopp и Hasso Plattner) под наименованием нем. Systemanalyse und
Programmentwicklung (англ System Analysis and Program Development, рус. Системный
анализ и разработка программ). Первый офис фирмы находился в Мангейме в 1976.
405.
В октябре 2007 года корпорация за $6,8 млрд купила французскую фирму Business Object(fr) — разработчика программного обеспечения для анализа данных.
В июне 2008 года была приобретена американская компания Visiprise, базирующаяся в
городе Альфаретта, штат Джорджия, занимающаяся разработкой программного
обеспечения, позволяющего автоматизировать процессы производства и контроля качества
промышленным предприятиям. В мае 2010 года за $5,8 млрд была поглощена компания
Sybase - американский производитель программного обеспечения для обработки данных.
В декабре 2011 года за $3,4 млрд была приобретена компания SuccessFactors,
предоставляющая приложения по управлению человеческим капиталом по модели SaaS.
Среди поглощений 2012—2013 годов — компании Ariba (англ) ($4,3 млрд, глобальная сеть
поставщиков) и Kxen (англ) (разработчик программного обеспечения для предсказательной
аналитики на базе теории Вапника-Червоненкиса). Пакет российской локализации
разрабатыва-ется и поддерживается силами компании SAP CIS.
406.
ERP — R/3, где R из R/3 - «Realtime» - означает немедленную проводку и актуализациюданных, которые в рамках интеграции немедленно доступны всем заинтересованным
отделам предприятия. Цифра 3 означает, что в системе реализована трехзвенная модель
архитектуры клиент/сервер приложений/система управления базами данных.
Система SAP ERP содержит определённый набор элементов функциональности в
различных модулях, выполняющих функцию российской локализации (для обеспечения
исполнения требований российского законодательства). Это - в первую очередь
интерактивные отчёты (оборотно-сальдовая ведомость в материальном учёте), печатные
формы (счет-фактура, накладная ТОРГ-12, пакет стандартных форм материального учёта
(формы М-4 «Приходный ордер», М-8 «Лимитно-заборная карта», М-15 «Накладная на
отпуск материалов на сторону» и т. д.)), а также элементы функциональности диалоговых
транзакций 8 декабря 2011 года SAP анонсировал открытие своего дочернего
подразделения SAP Labs в инновационном центре»Сколково»
407.
Основной процесс называется «индексным сервером»Индексный сервер обеспечивает управление сеансами, авторизацию, управление
транзакциями и обработку команд. Следует помнить, что HANA поддерживает как
строчное, так и поколоночное хранение данных. Пользователи могут создавать таблицы с
использованием любого из типов хранения, но наибольшими возможностями обладает
формат хранения данных по столбцам. Кроме этого, индексный сервер обеспечивает
соответствие между файлами в постоянной памяти и оперативной памятью, содержащей
кэшированные образы объектов БД и файлов журналов.
Диспетчер авторизации обеспечивает работу служб аутентификации и авторизации.
Диспетчер авторизации обеспечивает защиту с использованием протоколов
аутентификации SAML, OAuth или Kerberos.
408.
Подсистема Extended Services (XS) представляет собой веб-сервер с привилегированнымдоступом к базе данных.
Для развертывания приложений в XS могут использоваться сервлеты Java Servlets или
приложения JavaScript на стороне сервера. Такими приложениями могут быть вебприложения HTML или конечные точки веб-службы REST. В состав JavaScript стороны
сервера входят расширения на основе jQuery для доступа к БД и для доступа к запросным и
ответным сообщениям HTTP. Движок JavaScript реализован на основе проекта Mozilla
SpiderMonkey.
Клиентские приложения получают доступ к базе данных HANA непосредственно с
использованием JDBC, либо через подсистему Extended Services с использованием HTTP.
Поддержку файлов журналов и долговременное хранение данных на диске обеспечивают
процессы фонового режима. Процессор запросов служит для обработки данных с
поддержкой массового параллелизма. Хранение данных по столбцах сокращает объем
требуемых операций считывания и устраняет необходимость индексирования данных.
409.
Приложения могут действовать в обход процессора SQL, получая непосредственныйдоступ к подсистеме вычислений с помощью запросов на основе XML. Существует три
типа non-SQL объектов: Attribute Views, Calculation Views and Analytic Views. Во многих
случаях использование этих объектов вместо запросов SQL позволяет улучшить
характеристики производительности приложений.
Для разработки приложений используется подключаемый программный модуль HANA
Studio для среды разработки Eclipse. Эта среда обеспечивает разработку приложений и
управление базами данных. Подключаемый программный модуль Eclipse служит для
создания, развертывания и отладки объектов БД (таблиц, представлений, хранимых
процедур и др.) Платформа HANA требует достаточно мощных аппаратных ресурсов.
Например, экземпляр, рекомендованный для Amazon, имеет в 8 раз больший объем и
требует наличия 32 ЦП, 60 ГБ памяти и 640 ГБ дискового пространства
410.
411.
MDX (Multidimensional Expressions) — SQL-подобный язык запросов, ориентированный на доступ кмногомерным структурам данных. В отличие от SQL, работающего с данными скалярных типов в кортежах и
ориентированного на работу с реляционными моделями, в MDX на синтаксическом уровне встроены такие
понятия, как измерения, иерархии и их уровни, меры — характерные для многомерных моделей.
DBSL - the Database Shared Library