


















 database
databaseSimilar presentations:
")
")
")




")


Реляционная модель данных. Структурная составляющая реляционной модели. Лекция 4
1.
Лекция 4. Реляционная модель данных. Структурная составляющаяреляционной модели
4.1 Введение в реляционную модель
Согласно Дейту, реляционная модель состоит из трех частей:
- структурной части;
- целостной части;
- манипуляционной части.
Структурная часть постулирует, что единственной структурой данных,
используемой в реляционной модели, является нормализованное n-арное отношение.
Целостная часть описывает ограничения специального вида, которые должны
выполняться для любых отношений в любых реляционных базах данных. Это
целостность сущностей и целостность внешних ключей (по ссылкам).
Манипуляционная
часть
описывает
два
эквивалентных
способа
манипулирования реляционными данными - реляционную алгебру и реляционное
исчисление.
2.
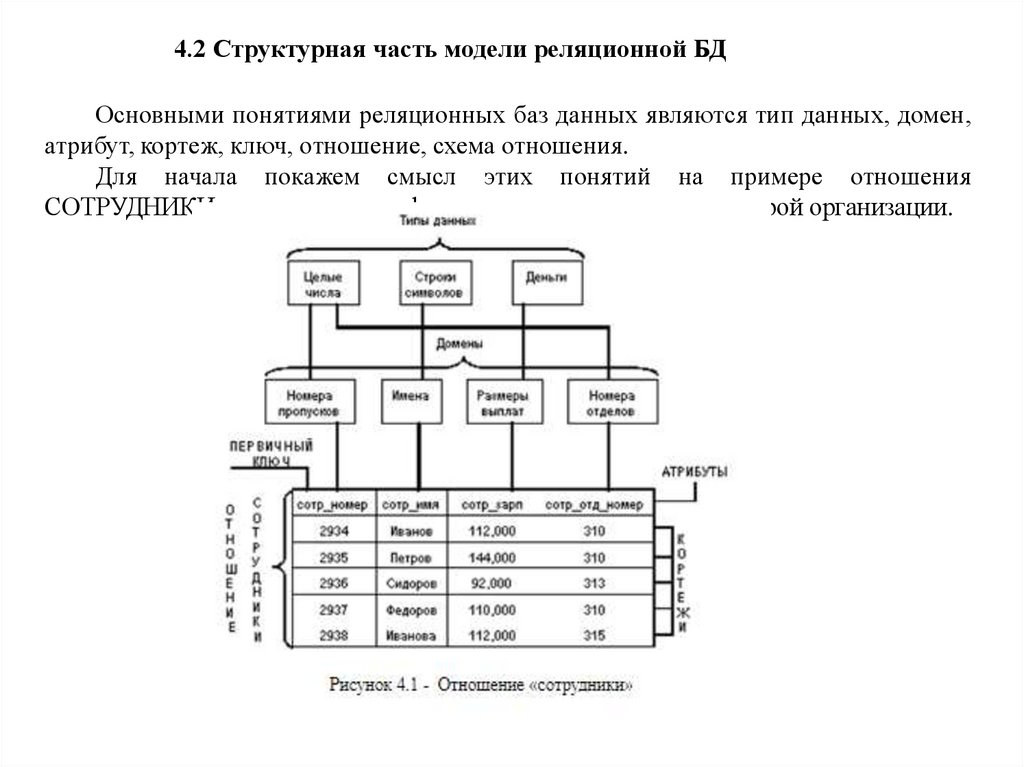
4.2 Структурная часть модели реляционной БДОсновными понятиями реляционных баз данных являются тип данных, домен,
атрибут, кортеж, ключ, отношение, схема отношения.
Для начала покажем смысл этих понятий на примере отношения
СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации.
3.
4.2.1 Тип данныхПонятие тип данных в реляционной модели данных полностью адекватно
понятию типа данных в языках программирования.
Тип данных (встречается также термин вид данных) — фундаментальное понятие
теории программирования. Тип данных определяет:
1) множество значений;
2) набор операций, которые можно применять к таким значениям;
3) способ реализации хранения значений и выполнения операций.
Реляционная модель требует, чтобы типы используемых данных были простыми.
Простые, или атомарные, типы данных не обладают внутренней структурой. Конечно,
понятие атомарности относительно. Так, строковый тип данных можно рассматривать
как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь
то, что при переходе на такой низкий уровень теряется семантика (смысл) данных.
Если строку, выражающую, например, фамилию сотрудника, разложить в массив
символов, то при этом теряется смысл такой строки как единого целого. Требование,
чтобы тип данных был простым, нужно понимать так, что в реляционных операциях
не должна учитываться внутренняя структура данных. И должны быть описаны
действия, которые можно производить с данными как с единым целым. Более того, в
некоторых реляционных СУБД можно создать свой, сколь угодно сложный тип
данных, описать возможные действия с этим типом данных, и, если в операциях не
требуется знание внутренней структуры данных, то такой тип данных также будет
простым с точки зрения реляционной теории.
4.
В современных реляционных БД допускается хранение символьных, числовыхданных, битовых строк, специализированных числовых данных (таких как
"деньги"), а также специальных "темпоральных" данных (дата, время, временной
интервал). В нашем примере мы имеем дело с данными трех типов: строки
символов, целые числа и "деньги".
4.2.2 Домен
Домен - это семантическое понятие, которое можно рассматривать как
подмножество значений некоторого базового типа данных, имеющих определенный
смысл. Домен определяется заданием некоторого базового типа данных и
произвольного логического выражения, применяемого к элементу типа данных. Если
вычисление этого логического выражения дает результат "истина", то элемент данных
является элементом домена.
Домен характеризуется следующими свойствами:
- домен имеет уникальное имя (в пределах базы данных);
- домен определен на некотором простом типе данных или на другом домене;
- домен может иметь некоторое логическое условие, позволяющее описать
подмножество данных, допустимых для данного домена;
- домен несет определенную смысловую нагрузку.
Например, домен D, имеющий смысл "возраст сотрудника" можно описать как
следующее подмножество множества натуральных чисел:
5.
Отличие домена от понятия подмножества состоит именно в том, что доменотражает семантику, определенную предметной областью. Может быть несколько
доменов, совпадающих как подмножества, но несущие различный смысл. Например,
домены "Вес детали" и "Имеющееся количество" можно одинаково описать как
множество неотрицательных целых чисел, но смысл этих доменов будет различным, и
это будут различные домены.
Основное значение доменов состоит в том, что домены ограничивают сравнения.
Некорректно, с логической точки зрения, сравнивать значения из различных доменов,
даже если они имеют одинаковый тип.
Замечание. Не всегда очевидно, как задать для домена логическое условие,
ограничивающее возможные значения домена. Нельзя привести условие на
строковый тип данных, задающий домен "Фамилия сотрудника". Ясно, что строки,
являющиеся фамилиями не должны начинаться с цифр, служебных символов, с
мягкого знака и т.д. Но вот является ли допустимой фамилия "Ггггггыыыыы"?
Трудности такого рода возникают потому, что смысл реальных явлений далеко не
всегда можно формально описать.
6.
В основе реляционной модели данных лежит понятие отношения, которое задаетсясписком своих элементов и перечислением их значений. Рассмотрим пример,
представленный на рисунке
отношение «Сотрудники». Налицо определенная
структура. Каждый сотрудник имеет свой номер, характеризуется фамилией, размером
зарплаты и отделов, в котором работает. Эти сведения легко представляются в виде
таблицы. Заголовки колонок таблицы носят название атрибутов. Список их имен носит
названия схемы отношения. Каждый атрибут определяет тип представляемых им
данных, который вместе с областью его значений называется доменом. Вся таблица
целиком называется отношением, а каждая строка таблицы носит название кортежа
отношения. Таким образом, отношение можно представить в виде двумерной таблицы.
Подходы к определению понятия отношения могут быть различными.
Математически отношение может быть определено как множество кортежей,
являющейся подмножеством декартова произведения фиксированного числа областей
(доменов).
В результате получаем, что в каждом кортеже должно быть одинаковое число
компонент (атрибутов) и значение каждого из них выбирается из некоторого
определенного домена.
7.
Отношение содержит две части: заголовок и тело.Заголовок отношения содержит фиксированное количество атрибутов
отношения:
Имена атрибутов должны быть уникальны в пределах отношения. Часто имена
атрибутов отношения совпадают с именами соответствующих доменов.
Тело отношения содержит множество кортежей отношения.
Кортеж, соответствующий данной схеме отношения, - это множество пар {имя
атрибута, значение атрибута}, которое содержит одно вхождение каждого имени
атрибута, принадлежащего схеме отношения. "Значение" является допустимым
значением домена данного атрибута (или типа данных, если понятие домена не
поддерживается).
(<A1:Val1>, <A2:Val2>,... <An:Valn>)
таких что значение Vali атрибута Ai принадлежит домену Di
Отношение обычно записывается в виде:
R(<A1:D1>, <A2:D2>,... <An:Dn>),
или короче R(A1, A2, . . ., An), или просто R.
Число атрибутов в отношении называют степенью (или - арностью) отношения.
Число кортежей отношения называют мощностью отношения.
Схема отношения - это именованное множество пар {имя атрибута, имя домена
(или типа, если понятие домена не поддерживается)}.
Схема реляционной БД (в структурном смысле) - это набор именованных схем
отношений.
8.
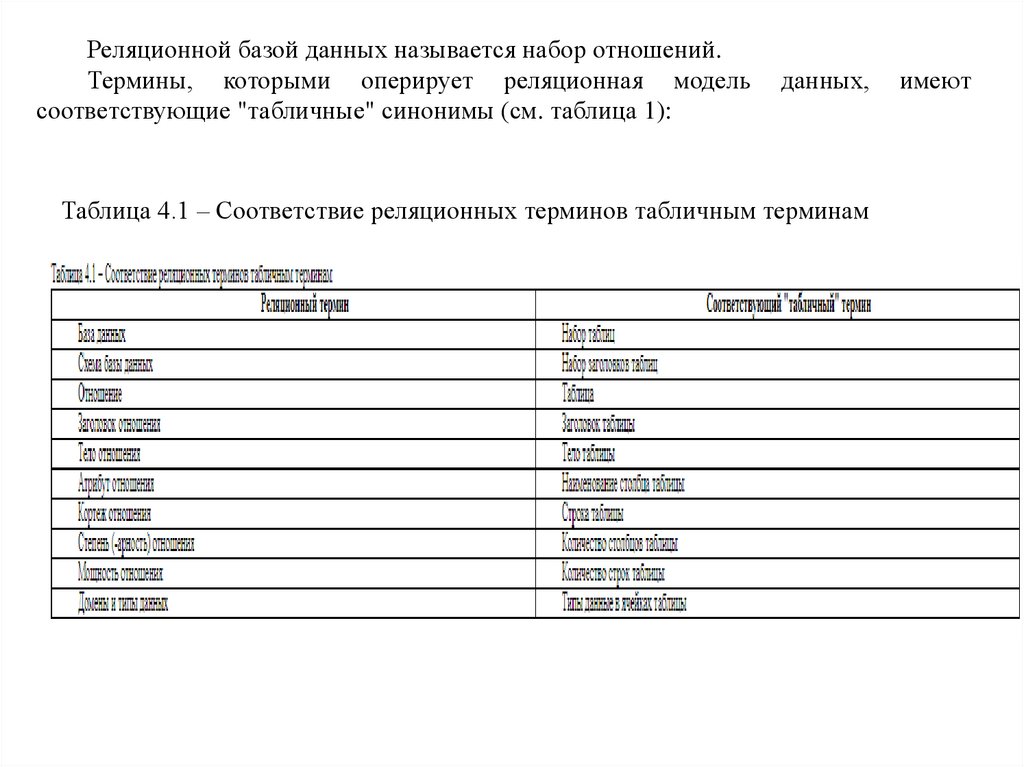
Реляционной базой данных называется набор отношений.Термины, которыми оперирует реляционная модель
соответствующие "табличные" синонимы (см. таблица 1):
данных,
Таблица 4.1 – Соответствие реляционных терминов табличным терминам
имеют
9.
4.3 Фундаментальные свойства отношенийСвойства отношений непосредственно следуют из приведенного выше определения
отношения. В этих свойствах в основном и состоят различия между отношениями и
таблицами.
Отсутствие кортежей-дубликатов. В отношении нет одинаковых кортежей. Это
свойство следует из определения отношения как множества кортежей и, как всякое
множество, не может содержать неразличимые элементы. Из этого свойства вытекает
наличие у каждого отношения так называемого первичного ключа - набора
атрибутов, значения которых однозначно определяют кортеж отношения. Таблицы в
отличие от отношений могут содержать одинаковые строки.
Отсутствие упорядоченности кортежей. Кортежи не упорядочены (сверху вниз). Это
свойство является следствием определения отношения как множества кортежей, а
множество не упорядочено. Отсутствие требования к поддержанию порядка на
множестве кортежей отношения дает дополнительную гибкость СУБД при хранении
баз данных во внешней памяти и при выполнении запросов к базе данных. Это не
противоречит тому, что при формулировании запроса к БД, например, на языке SQL
можно потребовать сортировки результирующей таблицы в соответствии со
значениями некоторых столбцов. Одно и то же отношение может быть представлено
разными таблицами, в которых строки идут в различном порядке.
10.
Отсутствие упорядоченности атрибутов. Атрибуты отношений не упорядочены(слева направо), поскольку каждый атрибут имеет уникальное имя в пределах
отношения, то порядок атрибутов не имеет значения. Для ссылки на значение
атрибута в кортеже отношения всегда используется имя атрибута. Это свойство
теоретически позволяет, например, модифицировать схемы существующих
отношений не только путем добавления новых атрибутов, но и путем удаления
существующих атрибутов. Однако в большинстве существующих систем такая
возможность не допускается.
Атомарность значений атрибутов. Все значения атрибутов атомарны. Это следует
из определения домена как потенциального множества значений простого типа
данных, т.е. среди значений домена не могут содержаться множества значений. Это
четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что
угодно - массивы, структуры и даже другие таблицы.
Замечание. Из свойств отношения следует, что не каждая таблица может задавать
отношение. Для того, чтобы некоторая таблица задавала отношение, необходимо:
- чтобы таблица имела простую структуру (содержала бы только строки и
столбцы, причем, в каждой строке было бы одинаковое количество полей);
- в таблице не должно быть одинаковых строк;
- любой столбец таблицы должен содержать данные только одного типа;
- все используемые типы данных должны быть простыми.
11.
Достоинство модели заключается в простоте, понятности и удобствефизической реализации на ЭВМ.
Недостаткам
модели
является
отсутствие
стандартных
средств
идентификации отдельных записей и сложность описания иерархических и
сетевых связей.
Примеры реляционных СУБД: IBM DB2 Universal Database, Oracle Database,
Microsoft SQL Server, IBM Informix Dynamic Server, Sybase Adaptive Server, Borland
InterBase, PostgreSQL, MySQL
12.
4.4 Внутренняя организация реляционных СУБДРеляционные СУБД обладают рядом особенностей, влияющих на их организацию.
К наиболее важным особенностям можно отнести следующие:
Для корректного управления данными во внешней памяти ПК необходимо
поддерживать служебную информацию в виде отношений-каталогов. Набор структур
служебной информации зависит от общей организации системы, но обычно требуется
поддержание следующих служебных данных:
Внутренние каталоги, описывающие физические свойства объектов базы данных,
например, число атрибутов отношения, их размер и, возможно, типы данных; описание
индексов (например, структура ключа индекса), определенных для данного отношения и
т.д.
Описатели свободной и занятой памяти в страницах отношения. Такая информация
требуется для нахождения свободного места при занесении кортежа.
Для выполнения требования надежного хранения баз данных необходимо
поддерживать избыточность хранения данных, что обычно реализуется в виде журнала
изменений базы данных.
13.
Соответственно возникают следующие разновидности объектов во внешнейпамяти базы данных:
- строки отношений – основная часть базы данных, большей частью
непосредственно видимая пользователям;
- управляющие структуры – индексы, создаваемые по инициативе пользователя
(администратора) или верхнего уровня системы из соображений повышения
эффективности выполнения запросов и обычно автоматически поддерживаемые
нижним уровнем системы;
- журнальная информация, поддерживаемая для удовлетворения потребности в
надежном хранении данных;
- служебная информация, поддерживаемая для удовлетворения внутренних
потребностей нижнего уровня системы (например, информация о свободной
памяти).
14.
4.5 Способы хранение отношенийСуществуют два принципиальных подхода к физическому хранению отношений.
Наиболее распространенным является покортежное хранение отношений (единицей
физического хранения является кортеж). Это обеспечивает быстрый доступ к целому
кортежу, но при этом во внешней памяти дублируются общие значения разных кортежей
одного отношения и могут потребоваться лишние обмены с внешней памятью, если
нужна только часть информации часть кортежа.
К основным характеристикам этой организации можно отнести следующие:
Каждый кортеж обладает уникальным идентификатором (tid), не изменяемым во все
время существования кортежа.
Обычно каждый кортеж хранится целиком в одной странице. Из этого следует, что
максимальная длина кортежа любого отношения ограничена размерами страницы памяти.
Возникает вопрос: как быть с "длинными" данными, которые в принципе не помещаются
в одной странице? Применяются несколько методов. Наиболее простым решением
является хранение таких данных в отдельных (вне базы данных) файлах с заменой
"длинного" данного в кортеже на имя соответствующего файла. В некоторых системах
такие данные хранились в отдельном наборе страниц внешней памяти, связанном
физическими ссылками. Оба эти решения сильно ограничивают возможность работы с
длинными данными (как, например, удалить несколько байтов из середины 2-мегабайтной
строки?). В настоящее время все чаще используется метод, когда "длинные" данные
организуются в виде B-деревьев последовательностей байтов.
15.
Как правило, в одной странице данных хранятся кортежи только одногоотношения. Существуют, однако, варианты с возможностью хранения в одной
странице кортежей нескольких отношений. Это вызывает некоторые дополнительные
расходы по части служебной информации (при каждом кортеже нужно хранить
информацию о соответствующем отношении), но зато иногда позволяет резко
сократить число обменов с внешней памятью при выполнении соединений.
Изменение схемы хранимого отношения с добавлением нового столбца не
вызывает потребности в физической реорганизации отношения. Достаточно лишь
изменить информацию в описателе отношения и расширять кортежи только при
занесении информации в новый столбец.
Альтернативным и менее распространенным подходом является хранение
отношения по столбцам, т.е. единицей хранения является столбец отношения с
исключенными дубликатами. При такой организации суммарно в среднем тратится
меньше внешней памяти, поскольку дубликаты значений не хранятся; за один обмен
с внешней памятью в общем случае считывается больше полезной информации.
Дополнительным преимуществом является возможность использования значений
столбца отношения для оптимизации выполнения операций соединения. Но при этом
требуются существенные дополнительные действия для сборки целого кортежа (или
его части).
16.
4.6 ИндексыИндексы - это специальные структуры в базах данных, которые позволяют
ускорить поиск отдельных записей и их сортировку по определенному полю или
набору полей в таблице, а также используются для обеспечения уникальности данных.
Проще всего индексы сравнить с указателями в книгах. Если нет указателя, то нам
придется просмотреть всю книгу, чтобы найти нужное место, а с указателем то же
действие можно выполнить намного быстрее.
Основное назначение индексов состоит в обеспечении прямого доступа к кортежу
отношения по ключу. Обычно индекс определяется только для одного отношения.
Общей идеей организации индексов является хранение упорядоченного списка
значений
ключа
с
привязкой
к
каждому
значению
ключа
списка
идентификаторов кортежей отношения. Индекс базы данных упорядочен, и каждый
элемент индекса содержит название искомого объекта, а также один или несколько
указателей (идентификаторов записей) на место его расположения.
17.
18.
Наиболее популярным подходом при организации индексов в базах данныхявляется использование техники В-деревьев. Альтернативным подходом к
организации индексов является использование техники хэширования. Один
способ организации индексов отличается от другого, главным образом, в способе
поиска ключа с заданным значением.
Поскольку при выполнении многих операций языкового уровня требуется
сортировка отношений в соответствии со значениями некоторых атрибутов, то
полезным свойством индекса является обеспечение последовательного
просмотра кортежей отношения в диапазоне значений ключа в порядке
возрастания или убывания ключей.
Индексы поддерживаются динамически, т.е. после обновления БД –
добавлении или удалении записей, а также при модификации полей записи,
входящих в ключ, – индекс приводится в соответствие с обновленной версией
БД. Обновление индекса, естественно, занимает некоторое время (иногда, очень
большое), поэтому существование многих индексов может замедлить работу БД.
Обращение к записи через индексы осуществляется в два этапа: сначала в
индексной структуре находится требуемое значение атрибута и соответствующий
адрес записи, затем по этому адресу происходит обращение к внешнему
запоминающему устройству (ВЗУ). Индекс загружается в оперативную память
целиком (или хранится в ней постоянно во время работы с БД).
19.
Файл, содержащий логические записи, называется файлом данных, а файл,содержащий индексные записи, - индексным файлом.
Типы индексов:
- первичный индекс. Файл данных последовательно упорядочивается по полю
ключа упорядочения, а на основе поля ключа упорядочения создается поле
индексации, которое гарантированно имеет уникальное значение в каждой записи;
- вторичный индекс. Файл данных последовательно упорядочивается по
неключевому полю и на основе этого неключевого поля формируется поле
индексации, поэтому в файле может быть несколько записей, соответствующих
значению этого поля индексации. Если в файле индексации содержится только одна
запись, соответствующих каждому значению индексируемого поля, то такой индекс
называют уникальным.
Для каждой таблицы БД можно одновременно поддерживать один первичный и
несколько вторичных индексов, что также относится к достоинствам индексирования.
Различают также одиночные индексы и составные. Составной индекс включает
два или более столбца одной таблицы.
Обычно чем больше индексов, тем больше производительность запросов к базе
данных. Однако при излишнем увеличении количества индексов падает
производительность операций изменения данных (вставка/изменение/удаление),
увеличивается размер БД, поэтому к добавлению индексов следует относиться
осторожно.
Некоторые общие принципы, связанные с созданием индексов:
20.
- индексы необходимо создавать для столбцов по которым часто производитсяпоиск и операции сортировки. При этом необходимо учесть, что индексы всегда
автоматически создаются для столбцов, на которые накладывается ограничение
primary key. Чаще всего они создаются и для столбцов с foreign key;
- индекс обязательно в автоматическом режиме создается для столбцов, на
которые наложено ограничение уникальности;
- лучше всего индексы создавать для тех полей, в которых - минимальное число
повторяющихся значений и данные распределены равномерно;
- если поиск постоянно производится по определенному набору столбцов
(одновременно), то в этом случае, возможно, есть смысл создать композитный
(составной) индекс (только в SQL Server) - один индекс для группы столбцов;
- при внесении изменений в таблицы автоматически изменяются и индексы,
наложенные на эту таблицу. В результате индекс может быть сильно фрагментирован,
что сказывается на производительности. Периодически следует проверять степень
фрагментации индексов и дефрагментировать их. При загрузке большого количества
данных иногда есть смысл вначале удалить все индексы, а после завершения
операции создать их заново;
- индексы можно создавать не только для таблиц, но и для представлений (только
в SQL Server). Преимущества - возможность вычислять поля не в момент запроса, а в
момент появления новых значений в таблицах.
В SQL Server предусмотрено два типа индексов: кластерные и некластерные.
21.
Кластерный индекс в таблице может быть только один. Каждый элемент индексасодержит название искомого объекта, и само значение этого объекта.
Проще всего сравнить таблицу, на которую наложен такой индекс, с телефонным
справочником: все записи в данной таблице упорядочены по кластерному индексу.
Относиться к выбору поля для кластерного индекса следует очень осторожно например, если в эту таблицу часто производится вставка данных, а кластерный индекс
наложен не на поле с автоприращением, то вполне может получиться так, что нам часто
придется вставлять новые записи в середину таблицы. Результат - большое количество
операций page split, фрагментация таблицы и, как следствие, серьезное падение
производительности (за счет фрагментации и за счет того, что само по себе page split достаточно ресурсоемкая операция. По умолчанию кластерный индекс создается для
поля первичного ключа, и, учитывая это, лучше делать первичный ключ числовым
полем с автоприращением.
Некластерный индекс. Каждый элемент индекса содержит название искомого
объекта, а также один или несколько указателей (идентификаторов записей) на место
его расположения.
Он больше всего похож на указатель в конце книги. Для таблицы можно создавать
таких индексов очень много (можно даже по нескольку для каждого столбца, но
большой пользы это не приносит).