












 education
educationSimilar presentations:


")



")



Advanced Analytics. Введение в текстовую аналитику
1.
Advanced AnalyticsВведение в текстовую
аналитику
Спикер: Амелия Полей-Добронравова
22.07.2024
2.
Кураторы стажерской программыАмелия Полей-Добронравова
Бизнес-аналитик практики
Продвинутой аналитики GlowByte
Дмитрий Киржанов
Руководитель направления
аналитики для производства и
операционной деятельности
Продвинутой аналитики GlowByte
Кирилл Блохнин
Бизнес-аналитик практики
Продвинутой аналитики GlowByte
3.
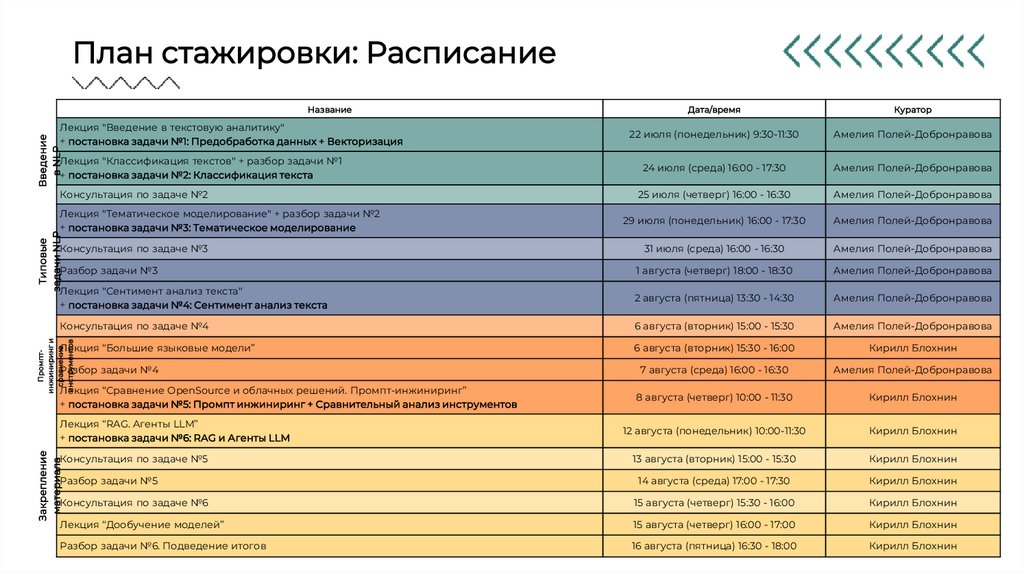
План стажировки: РасписаниеНазвание
Дата/время
Куратор
22 июля (понедельник) 9:30-11:30
Амелия Полей-Добронравова
Лекция "Классификация текстов" + разбор задачи №1
+ постановка задачи №2: Классификация текста
24 июля (среда) 16:00 - 17:30
Амелия Полей-Добронравова
Консультация по задаче №2
25 июля (четверг) 16:00 - 16:30
Амелия Полей-Добронравова
29 июля (понедельник) 16:00 - 17:30
Амелия Полей-Добронравова
31 июля (среда) 16:00 - 16:30
Амелия Полей-Добронравова
Разбор задачи №3
1 августа (четверг) 18:00 - 18:30
Амелия Полей-Добронравова
Лекция "Сентимент анализ текста"
+ постановка задачи №4: Сентимент анализ текста
2 августа (пятница) 13:30 - 14:30
Амелия Полей-Добронравова
Введение
в NLP
Лекция "Введение в текстовую аналитику"
+ постановка задачи №1: Предобработка данных + Векторизация
Типовые
задачи NLP
Лекция "Тематическое моделирование" + разбор задачи №2
+ постановка задачи №3: Тематическое моделирование
Консультация по задаче №3
6 августа (вторник) 15:00 - 15:30
Амелия Полей-Добронравова
Лекция “Большие языковые модели”
6 августа (вторник) 15:30 - 16:00
Кирилл Блохнин
Разбор задачи №4
7 августа (среда) 16:00 - 16:30
Амелия Полей-Добронравова
Лекция “Сравнение OpenSource и облачных решений. Промпт-инжиниринг”
+ постановка задачи №5: Промпт инжиниринг + Сравнительный анализ инструментов
8 августа (четверг) 10:00 - 11:30
Кирилл Блохнин
12 августа (понедельник) 10:00-11:30
Кирилл Блохнин
13 августа (вторник) 15:00 - 15:30
Кирилл Блохнин
Разбор задачи №5
14 августа (среда) 17:00 - 17:30
Кирилл Блохнин
Консультация по задаче №6
15 августа (четверг) 15:30 - 16:00
Кирилл Блохнин
Лекция “Дообучение моделей”
15 августа (четверг) 16:00 - 17:00
Кирилл Блохнин
Разбор задачи №6. Подведение итогов
16 августа (пятница) 16:30 - 18:00
Кирилл Блохнин
Промптинжиниринг и
сравнение
инструментов
Консультация по задаче №4
Закрепление
материала
Лекция “RAG. Агенты LLM”
+ постановка задачи №6: RAG и Агенты LLM
Консультация по задаче №5
4.
NLP - Natural Language ProcessingОбработка естественного языка
Задачи как понимания текста, так и генерации текста на естественном языке
04
Машинный
перевод
01
Классификация
07
Суммаризация
02
Анализ
настроения
Генерация текста
08
NER (поиск
именованных
сущностей)
05
03
Тематическое
моделирование
06 ответные системы
Вопросно-
09 Мультимодальность
5.
Предобработка текста индивидуальнаУдаление нерелевантных символов и слов (HTML-теги)
Замена символов (смайлики на слова)
Совмещение синонимов (Glowbyte, гб, гбк, глоубайт)
Стемминг/Лемматизация (приведение к одной форме слова)
Перевод чисел в письменный вид
Удаление стоп-слов (частые бесполезные артикли, библиотека nltk)
Удаление знаков препинания
6.
Числовое представление текста1
Токенизация
Разделение текста на компоненты, сопоставляем
компонентам номера в словаре
2 Векторизация
Конвертация в
числовые вектора
без учета
семантики
3 Эмбединги
Конвертация в
числовые вектора с
учетом семантики и
контекста
7.
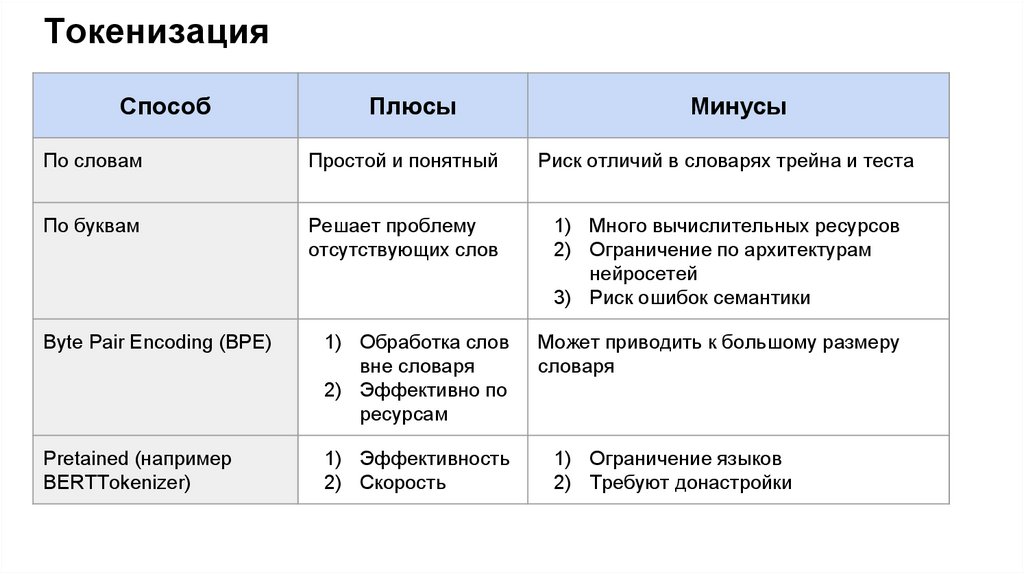
ТокенизацияСпособ
Плюсы
Минусы
По словам
Простой и понятный
Риск отличий в словарях трейна и теста
По буквам
Решает проблему
отсутствующих слов
1) Много вычислительных ресурсов
2) Ограничение по архитектурам
нейросетей
3) Риск ошибок семантики
Byte Pair Encoding (BPE)
1) Обработка слов
вне словаря
2) Эффективно по
ресурсам
Может приводить к большому размеру
словаря
Pretained (например
BERTTokenizer)
1) Эффективность
2) Скорость
1) Ограничение языков
2) Требуют донастройки
8.
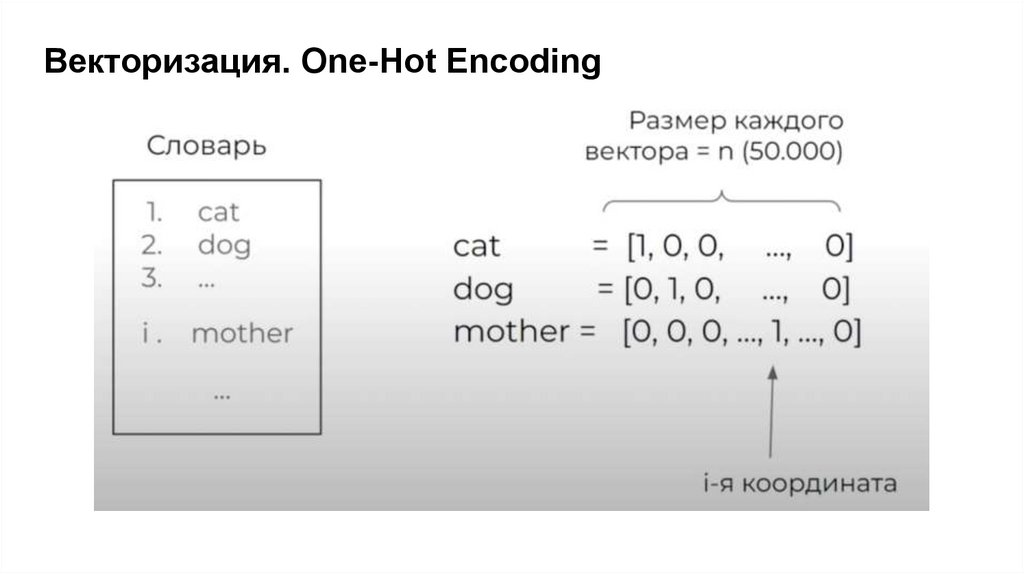
Векторизация. One-Hot Encoding9.
One-Hot Encoding. Недостатки● Векторы не отображают смысл слова.
Нельзя измерить похожесть слов
● Векторы сильно разрежены и требуют много памяти
● Размер словаря ограничен
● Слова, не попавшие в словарь, не могут быть обработаны
10.
Векторизация. Bag Of WordsСохраняются все предыдущие недостатки
11.
Векторизация. Tf-IDFСлова, повторяющиеся слишком часто, не зашумляют
другие, менее частотные, но важные слова
Tf-IDF = Tf * IDF
Tf - нормализованный показатель частоты
Tf = частотность токена / общее число токенов в документе
IDF - обратная частота документа
IDF = число документов с токеном / число документов
12.
Эмбеддинги. Word2VecЭмбеддинги учитывают контекст
Word2Vec работает со словами
king – man + woman = queen
Skip-Gram
CBOW
13.
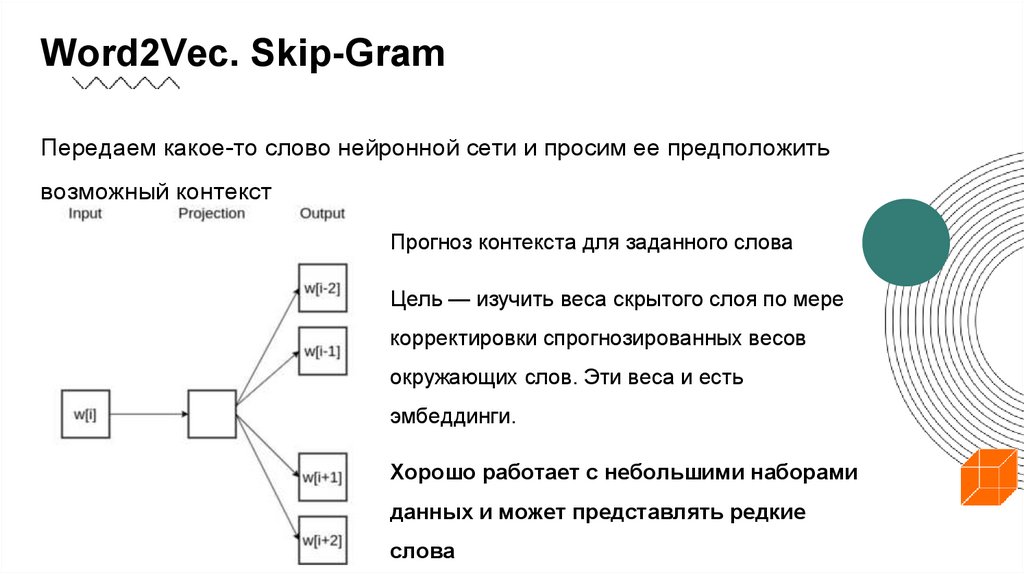
Word2Vec. Skip-GramПередаем какое-то слово нейронной сети и просим ее предположить
возможный контекст
Прогноз контекста для заданного слова
Цель — изучить веса скрытого слоя по мере
корректировки спрогнозированных весов
окружающих слов. Эти веса и есть
эмбеддинги.
Хорошо работает с небольшими наборами
данных и может представлять редкие
слова
14.
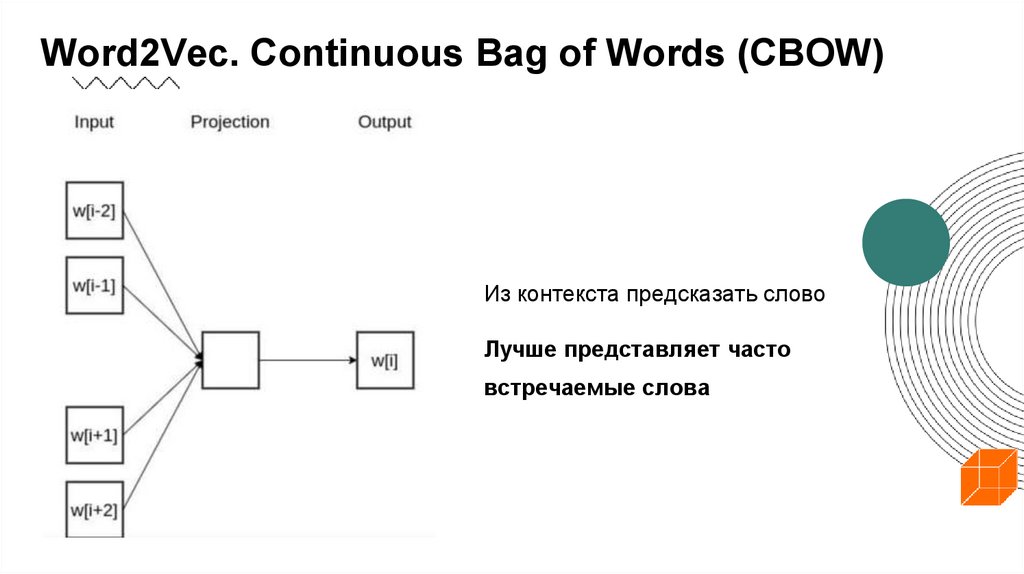
Word2Vec. Continuous Bag of Words (CBOW)Из контекста предсказать слово
Лучше представляет часто
встречаемые слова
15.
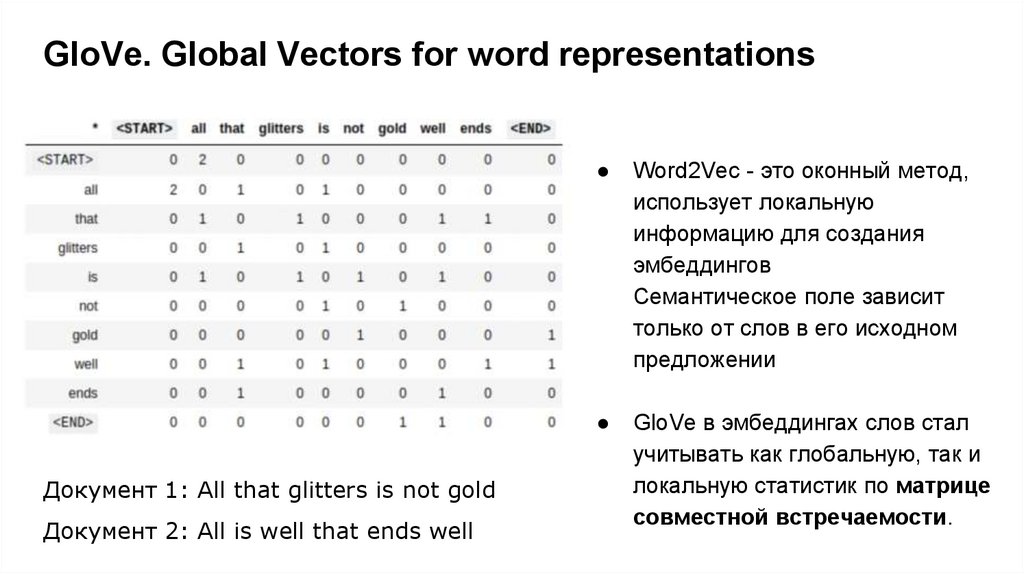
GloVe. Global Vectors for word representationsДокумент 1: All that glitters is not gold
Документ 2: All is well that ends well
Word2Vec - это оконный метод,
использует локальную
информацию для создания
эмбеддингов
Семантическое поле зависит
только от слов в его исходном
предложении
GloVe в эмбеддингах слов стал
учитывать как глобальную, так и
локальную статистик по матрице
совместной встречаемости.
16.
GloVeПрактика показала, что GloVe превосходит другие модели в задачах
выявления схожих слов, распознавания именованных сущностей
(Entity Recognition)
Поскольку GloVe учитывает глобальную статистику, он также может
улавливать семантику редких слов и эффективен даже на
небольшом корпусе текстов
17.
FastTextУмеет делать обобщения для неизвестных слов благодаря работе с
уровнем символов
Подходы как в Word2Vec
Итоговый эмбеддинг по
усреднению n-gram
эмбедингов
18.
Предобученные эмбеддинги19.
Дообучение моделей эмбедингаFine-tuning - термин
Доменная адаптация
Плюсы: повышает качество
Минусы: трудозатраты
20.
Задание 1Каждая строчка датасета - пост из твиттера, два класса: катастрофа и нет
1) Необходимо очистить данные от лишних символов и стоп-слов.
2) Построить информативные графики, демонстрирующие специфику
датасета.
3) Применить 3 способа токенизации (по словам, bpe, berttokenizer)
4) Сделать одну векторизацию и 2 варианта эмбеддингов. Один из
алгоритмов эмбеддингов предобученная модель (huggingface).
5) Визуализировать близость получившихся эмбеддингов, цветами
окрасить разные классы. Можно применить PCA перед отрисовкой
6) Для каждой используемой технологии в комментариях около ячейки с
кодом написать своими словами принцип (идею) алгоритма.
Описания похожие на текст от GPT приниматься не будут.
7) Выложить на github