






 marketing
marketingSimilar presentations:







 и выведение продукта на рынок (Customer Development)")


Разработка рекомендательной системы предложения сопутствующих товаров
1.
ФГБОУ ВО КУБАНСКИЙ ГОСУДАРСТВЕННЫЙТЕХНОЛОГИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра ИВТ
Институт КСИБ
РАЗРАБОТКА РЕКОМЕНДАТЕЛЬНОЙ СИСТЕМЫ
ПРЕДЛОЖЕНИЯ СОПУТСТВУЮЩИХ ТОВАРОВ
ВЫПОЛНИЛ: СТУДЕНТ 4 КУРСА
ГРУППЫ 20-КБ-ИВ1
КОЗЫРЕВ О.И.
ДИПЛОМНЫЙ РУКОВОДИТЕЛЬ:
К.Т.Н. ДОЦ. ВАСИЛЕНКО Н.В..
2.
Цели и задачиЦелью дипломного проектирования является исследование методов построения
рекомендательных систем и разработка рекомендательной системы предложения
сопутствующих товаров.
Для реализации поставленной цели были выполненных следующие задачи:
– проведен анализ предметной области,
– проведено предпроектное исследование,
– разработана архитектура системы,
– реализованы модули аналитики данных.
2
3.
Понятие рекомендательных системРекомендательные системы представляют собой комплекс сервисов и программ, который
анализирует предпочтения пользователей и пытается предсказать, что может из
заинтересовать.
Рекомендательные системы имеют широкую область применения и назначение.
Основная задача подобных систем – познакомить клиента с продуктами, похожими на те,
что он уже покупал и/или интересовался.
Основа работы рекомендательной системы – набор данных о клиентах и их поведении. Эта
информация анализируется с помощью алгоритмов и выдает рекомендации покупателям.
3
4.
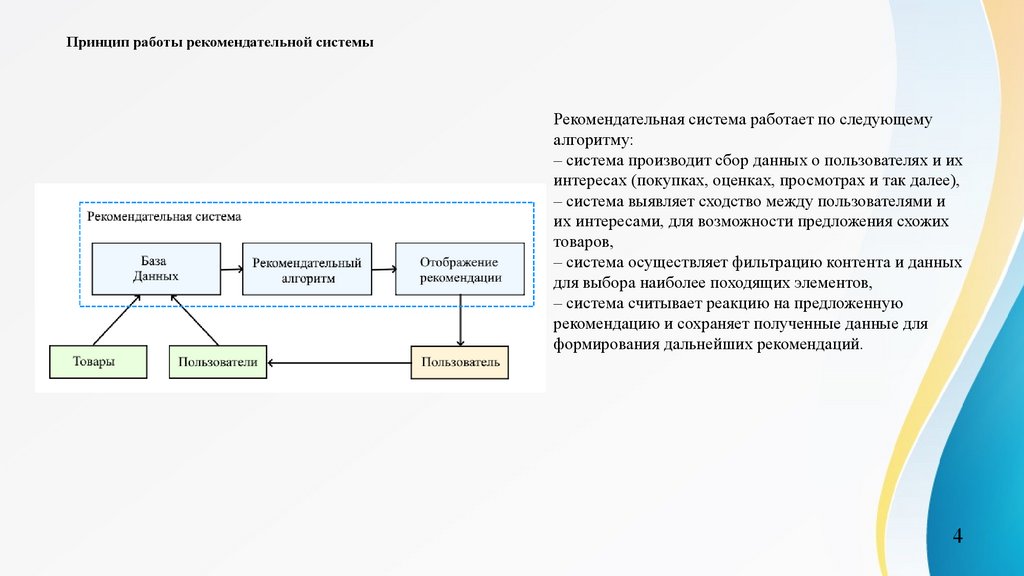
Принцип работы рекомендательной системыРекомендательная система работает по следующему
алгоритму:
– система производит сбор данных о пользователях и их
интересах (покупках, оценках, просмотрах и так далее),
– система выявляет сходство между пользователями и
их интересами, для возможности предложения схожих
товаров,
– система осуществляет фильтрацию контента и данных
для выбора наиболее походящих элементов,
– система считывает реакцию на предложенную
рекомендацию и сохраняет полученные данные для
формирования дальнейших рекомендаций.
4
5.
Описание процессов системыОсновной задачей разрабатываемой системы
является автоматизация процесса анализа данных
для рекомендательной системы.
Основной задачей является извлечение знаний из
данных полученных от приложения,
структурирование, сохранение и обеспечение
доступа к ним.
Основными участниками автоматизации
являются администратор (функции настройки и
поддержки системы) и аналитик (работа с
основными функциями системы).
5
6.
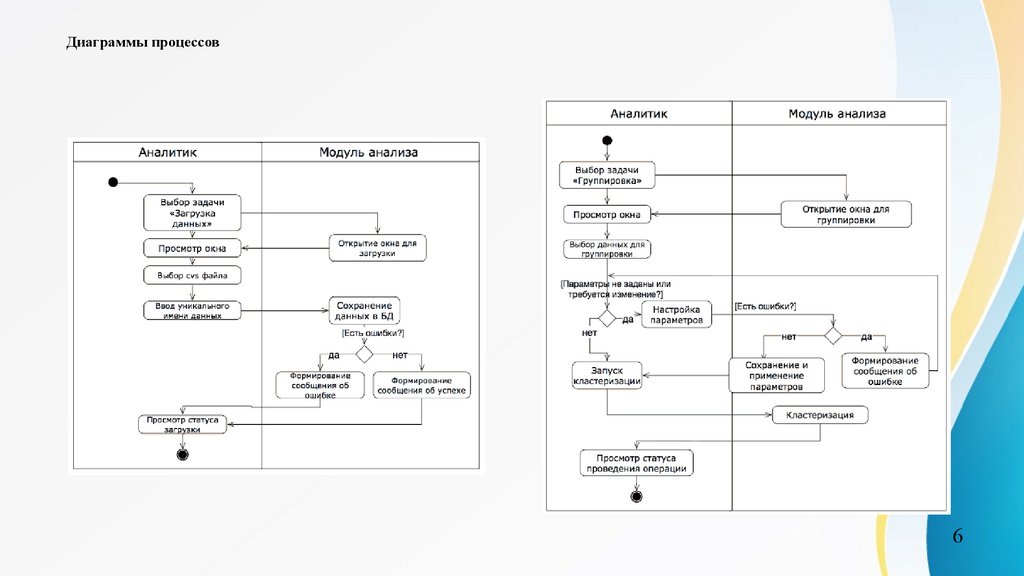
Диаграммы процессов6
7.
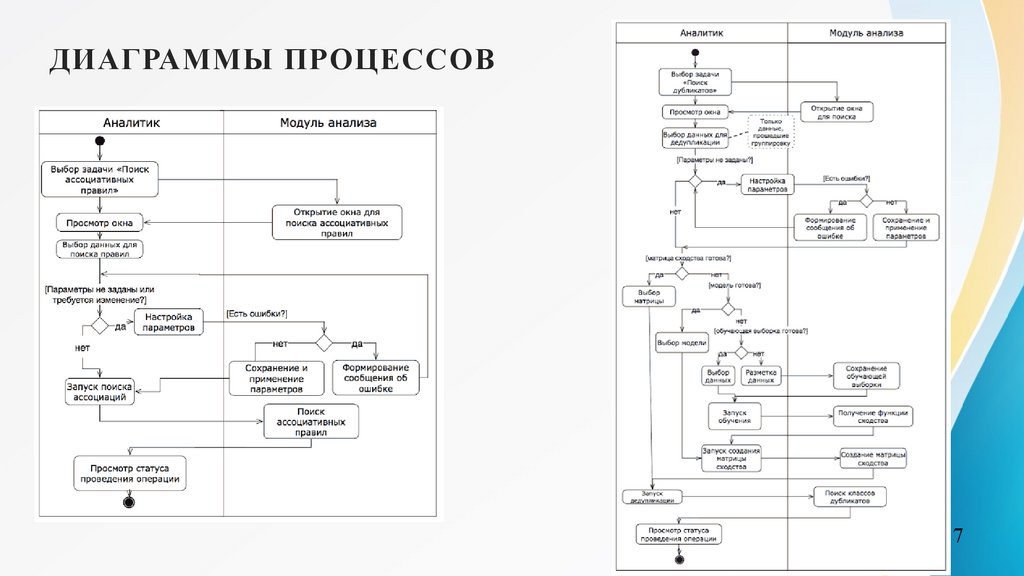
ДИАГРАММЫ ПРОЦЕССОВ7
8.
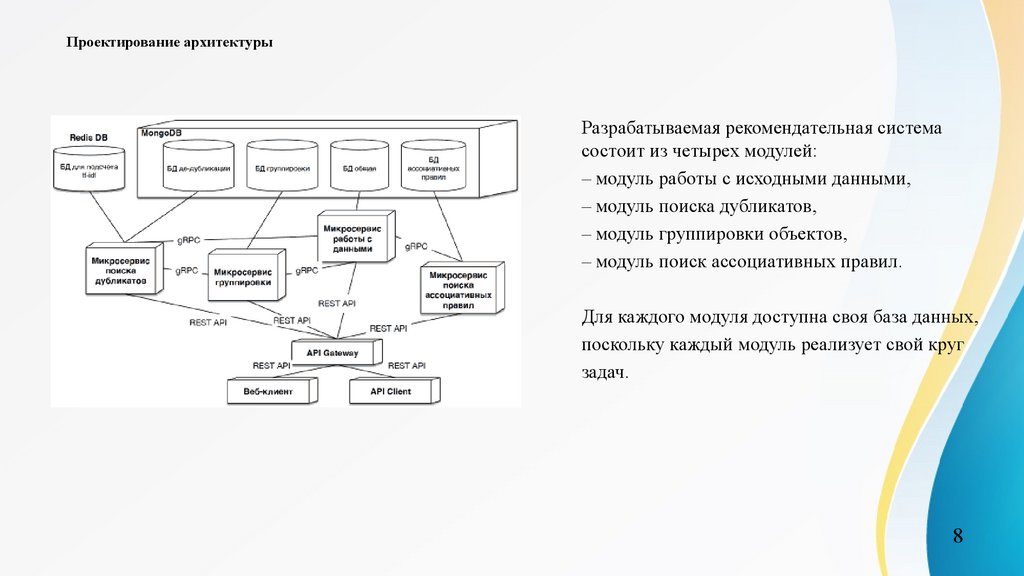
Проектирование архитектурыРазрабатываемая рекомендательная система
состоит из четырех модулей:
– модуль работы с исходными данными,
– модуль поиска дубликатов,
– модуль группировки объектов,
– модуль поиск ассоциативных правил.
Для каждого модуля доступна своя база данных,
поскольку каждый модуль реализует свой круг
задач.
8
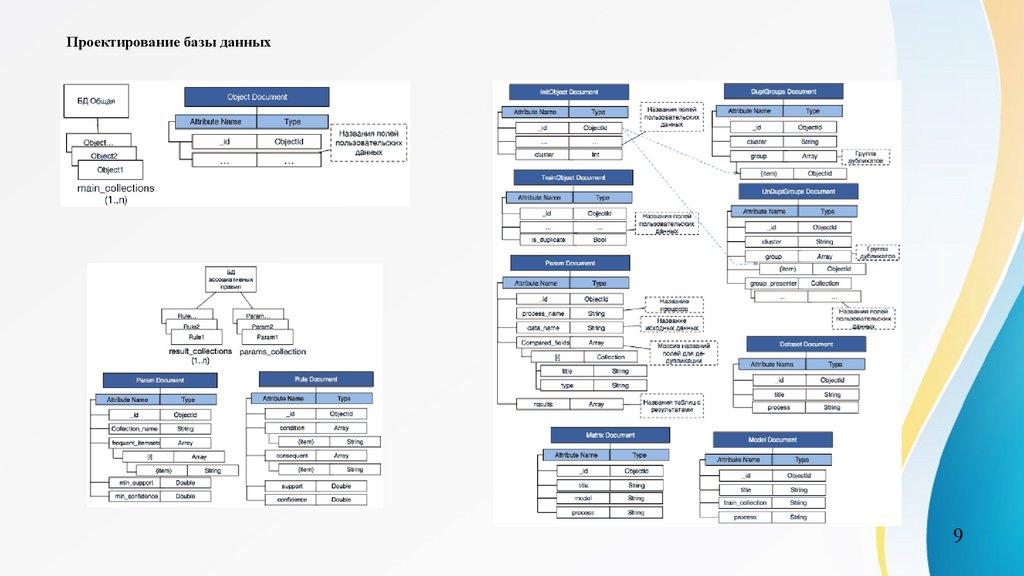
9.
Проектирование базы данных9
10.
РеализацияРеализация модуля поиска дубликатов:
Процесс поиска дубликатов состоит из нескольких подпроцессов:
– определение разницы объектов,
Поиск tf-idf меры подразумевает разбивку на слова, среди которых выделяется основа. Все строковые
данные подвергаются расчету мер и сохраняются под ключом в базе данных redis .
– определение функции схождения,
Функция сходства представляет собой обученную модель gradient boosted decision trees. Для
построения такого вида решающих деревьев использован фреймворк XGBoost.
Модуль для работы с функцией сходства должен включать в себя функции для обучения и
предсказания.
– формирование матрицы схождения и поиск групп дубликатов,
Формирование матрицы сходства происходит для всех групп, сформированных модулем группировки.
Для решения задачи группировки был выбран алгоритм k-means, как наиболее популярный и простой.
– корректировка и обобщение групп дубликатов.
9
11.
ЗаключениеВ рамках данной работы выполнено проектирование модуля анализа для
рекомендательной системы, а также разработаны модули для группировки, поиска
дубликатов и ассоциативных правил.
Работоспособность системы проверена на примере работы с товарами из сферы
продуктов питания. Группировка объектов выполнена с помощью алгоритма
кластеризации k-means, который на тестовых примерах показал достаточно точные
результаты. Поиск дубликатов выполнен с помощью комбинации таких методов
машинного обучения и анализа данных, как tf-idf, cosine similarity, gradient boosted
decision trees и иерархической кластеризации. Поиск дубликатов предложено искать в
несколько стадий: разметка данных, поиск функции сходства, формирование матрицы
сходства, группировка матрицы сходства. Данный алгоритм на примерах показал
точность более 80%.
10