











































































































































 database
databaseSimilar presentations:



")




")

Выборка данных. Команда SELECT
1.
Выборка данных.Команда SELECT
2.
Для получения данных применяется команда SELECT.В упрощенном виде она имеет следующий синтаксис:
SELECT список_столбцов FROM имя_таблицы
3.
Например, пусть ранее была создана таблица Products, и в нее добавлены некоторые начальные данные:CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
INSERT INTO Products
VALUES
('iPhone 6', 'Apple', 3, 36000),
('iPhone 6S', 'Apple', 2, 41000),
('iPhone 7', 'Apple', 5, 52000),
('Galaxy S8', 'Samsung', 2, 46000),
('Galaxy S8 Plus', 'Samsung', 1, 56000),
('Mi6', 'Xiaomi', 5, 28000),
('OnePlus 5', 'OnePlus', 6, 38000)
4.
Получим все объекты из этой таблицы:SELECT * FROM Products
Символ звездочка * указывает, что нам надо получить все столбцы.
5.
6.
Получение всех столбцов с помощью символа звездочки * считается неочень хорошей практикой, так как, как правило, не все столбцы бывают
нужны. И более оптимальный подход заключается в указании всех
необходимых столбцов после слова SELECT. Исключение составляет тот
случай, когда надо получить данные по абсолютно всем столбцам таблицы.
Также использование символа * может быть предпочтительно в таких
ситуациях, когда в точности не известны названия столбцов.
Если нам надо получить данные не по всем, а по каким-то конкретным
столбцам, то тогда все эти спецификации столбцов перечисляются через
запятую после SELECT:
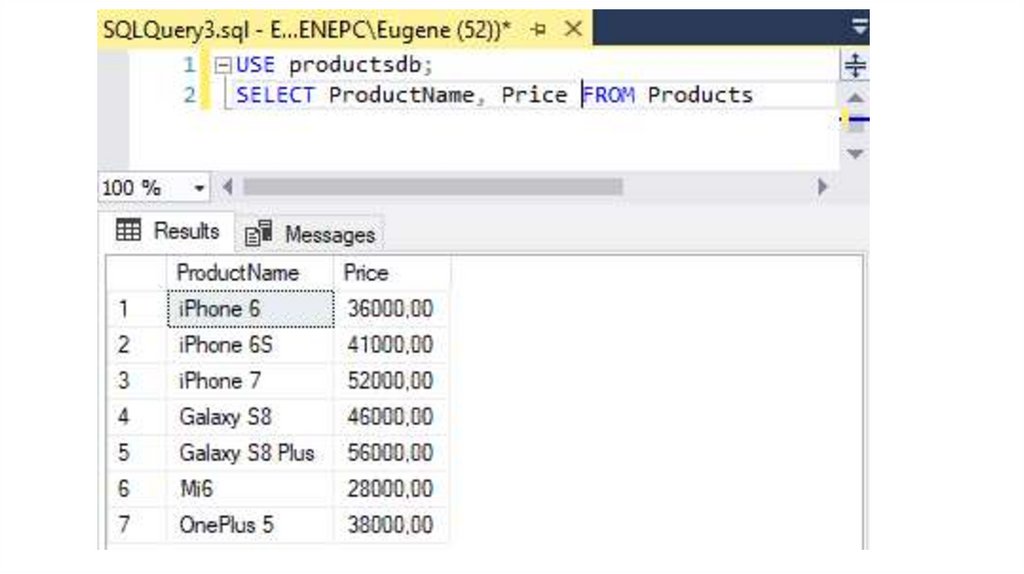
SELECT ProductName, Price FROM Products
7.
8.
Спецификация столбца необязательно должна представлять его название.Это может быть любое выражение, например, результат арифметической
операции. Так, выполним следующий запрос:
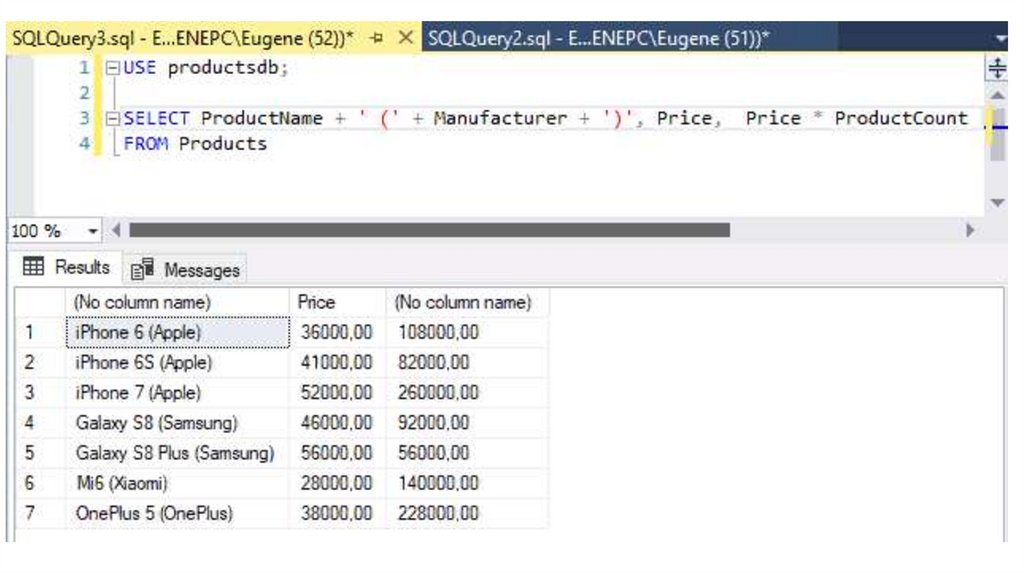
SELECT ProductName + ' (' + Manufacturer + ')', Price,
Price * ProductCount FROM Products
Здесь при выборке будут создаваться три столбца. Первый столбец
представляет результат объединения двух столбцов ProductName и
Manufacturer. Второй столбец - стандартный столбец Price. А третий
столбец представляет значение столбца Price, умноженное на значение
столбца ProductCount.
9.
10.
С помощью оператора AS можно изменить название выходного столбцаили определить его псевдоним:
SELECT
ProductName + ' (' + Manufacturer + ')' AS ModelName,
Price,
Price * ProductCount AS TotalSum
FROM Products
В данном случае результатом выборки являются данные по 3-м столбцам.
Первый столбец ModelName объединяет столбцы ProductName и
Manufacturer, второй представляет стандартный столбец Price. Третий
столбец TotalSum хранит произведение столбцов ProductCount и Price. При
этом, как в случае со столбцом Price, необязательно определять название
результирующего столбца с помощью AS.
11.
12.
DISTINCTОператор DISTINCT позволяет выбрать уникальные строки.
Например, в нашем случае в таблице может быть по несколько
товаров от одних и тех же производителей. Выберем всех
производителей:
SELECT DISTINCT Manufacturer
FROM Products
13.
В данном случаекритерием разграничения
строк является столбец
Manufacturer. Поэтому в
результирующей выборке
будут только уникальные
значения Manufacturer. И
если, к примеру, в базе
данных есть два товара с
производителем Apple, то
это название будет
встречаться в
результирующей выборке
только один раз.
14.
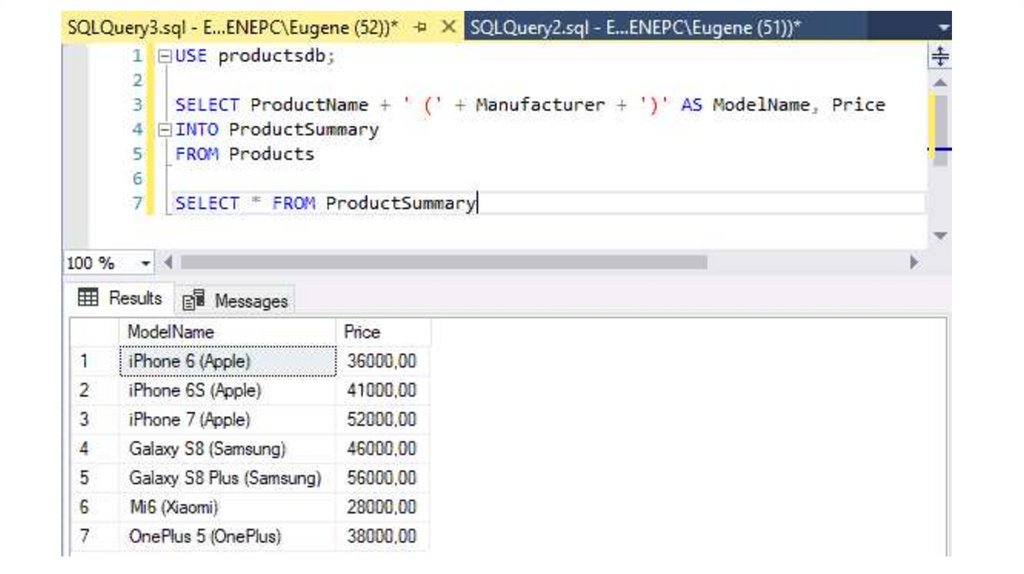
Выборка с добавлениемSELECT INTO
Выражение SELECT INTO позволяет выбрать из одной таблицы некоторые
данные в другую таблицу, при этом вторая таблица создается
автоматически. Например:
SELECT ProductName + ' (' + Manufacturer + ')' AS
ModelName, Price
INTO ProductSummary
FROM Products
SELECT * FROM ProductSummary
После выполнения этой команды в базе данных будет создана еще одна
таблица ProductSummary, которая будет иметь два столбца ModelName и
Price, а данные для этих столбцов будут взяты из таблицы Products
15.
16.
При выполнении этой команды таблица, в которую идет выборка (вданном случае ProductSummary), не должна существовать в базе данных.
Но, допустим, мы потом решили добавить все данные из таблицы Products
в уже существующую таблицу ProductSummary. В этом случае можно опять
же использовать команду INSERT:
INSERT INTO ProductSummary
SELECT ProductName + ' (' + Manufacturer + ')' AS ModelName,
Price
FROM Products
Здесь добавляемые значения фактически представляют результат выборки из таблицы
Products.
17.
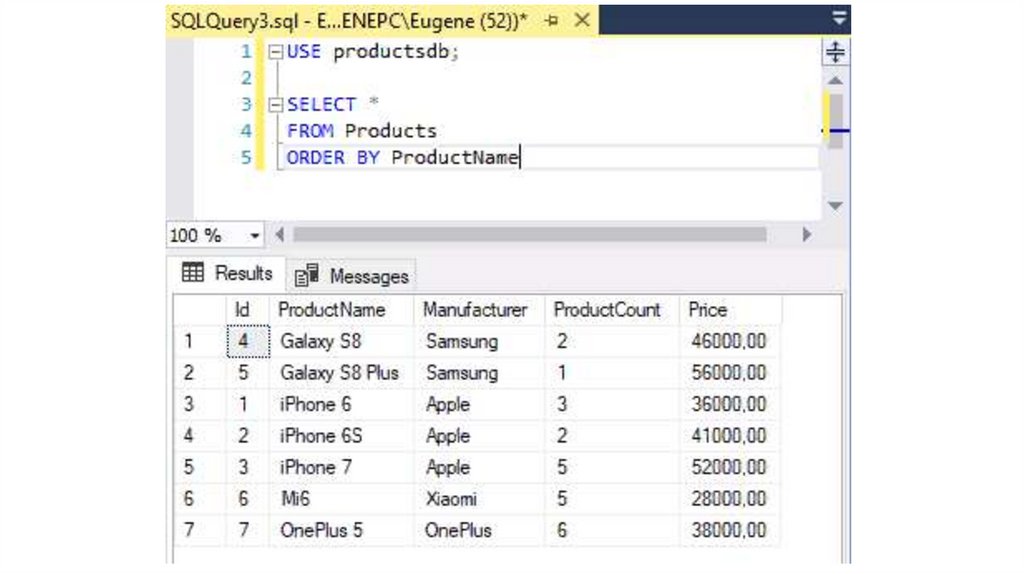
Сортировка. ORDER BYОператор ORDER BY позволяет отсортировать извлекаемые
значения по определенному столбцу:
SELECT *
FROM Products
ORDER BY ProductName
В данном случае строки сортируются по возрастанию значения
столбца ProductName
18.
19.
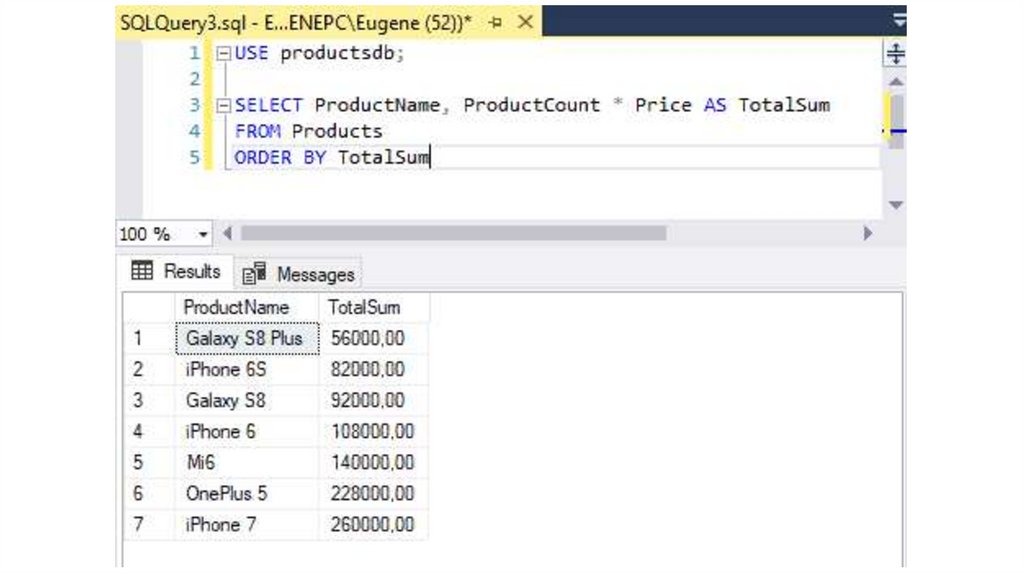
Сортировку также можно проводить по псевдониму столбца, которыйопределяется с помощью оператора AS:
SELECT ProductName, ProductCount * Price AS TotalSum
FROM Products
ORDER BY TotalSum
20.
21.
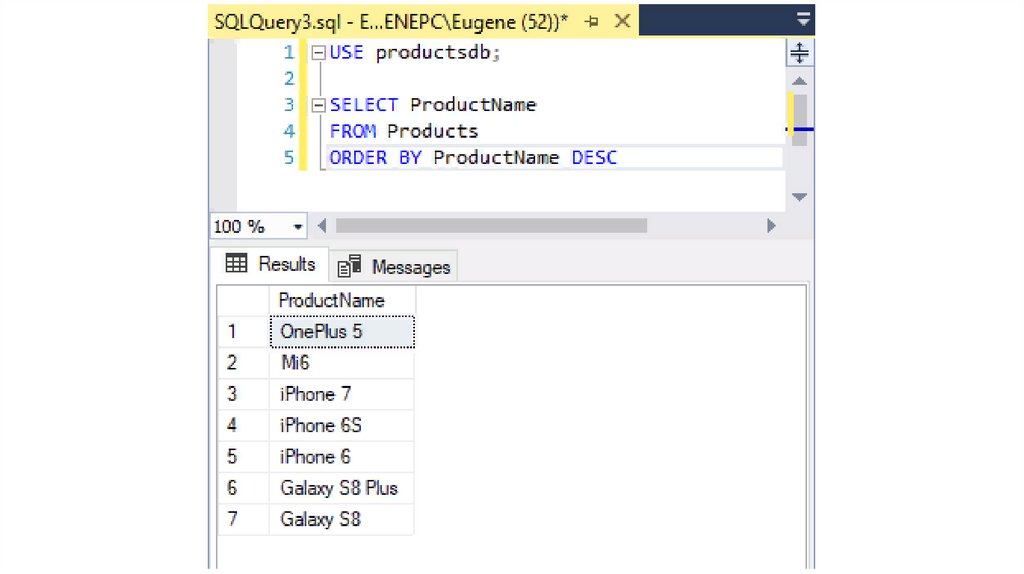
По умолчанию применяется сортировка по возрастанию. С помощьюдополнительного оператора DESC можно задать сортировку по убыванию.
SELECT ProductName
FROM Products
ORDER BY ProductName DESC
22.
23.
По умолчанию вместо DESC используется оператор ASC:SELECT ProductName
FROM Products
ORDER BY ProductName ASC
Если необходимо отсортировать сразу по нескольким столбцам, то все они
перечисляются после оператора ORDER BY:
SELECT ProductName, Price, Manufacturer
FROM Products
ORDER BY Manufacturer, ProductName
В этом случае сначала строки сортируются по столбцу Manufacturer по
возрастанию. Затем если есть две строки, в которых столбец Manufacturer имеет
одинаковое значение, то они сортируются по столбцу ProductName также по
возрастанию. Но опять же с помощью ASC и DESC можно отдельно для разных
столбцов определить сортировку по возрастанию и убыванию:
SELECT ProductName, Price, Manufacturer
FROM Products
ORDER BY Manufacturer ASC, ProductName DESC
24.
25.
В качестве критерия сортировки также можно использовать сложновыражение на основе столбцов:
SELECT ProductName, Price, ProductCount
FROM Products
ORDER BY ProductCount * Price
26.
27.
Извлечение диапазона строкОператор TOP
Оператор TOP позволяет выбрать определенное количество строк
из таблицы:
SELECT TOP 4 ProductName
FROM Products
28.
29.
Дополнительный оператор PERCENT позволяет выбрать процентноеколичество строк из таблицы. Например, выберем 75% строк:
SELECT TOP 75 PERCENT ProductName
FROM Products
30.
OFFSET и FETCHОператор TOP позволяет извлечь определенное количество строк, начиная с начала таблицы.
Для извлечения набора строк из любого места, применяются операторы OFFSET и FETCH. Важно,
что эти операторы применяются только в отсортированном наборе данных после выражения
ORDER BY.
ORDER BY выражение
OFFSET смещение_относительно_начала {ROW|ROWS}
FETCH {FIRST|NEXT} количество_извлекаемых_строк {ROW|ROWS} ONLY]
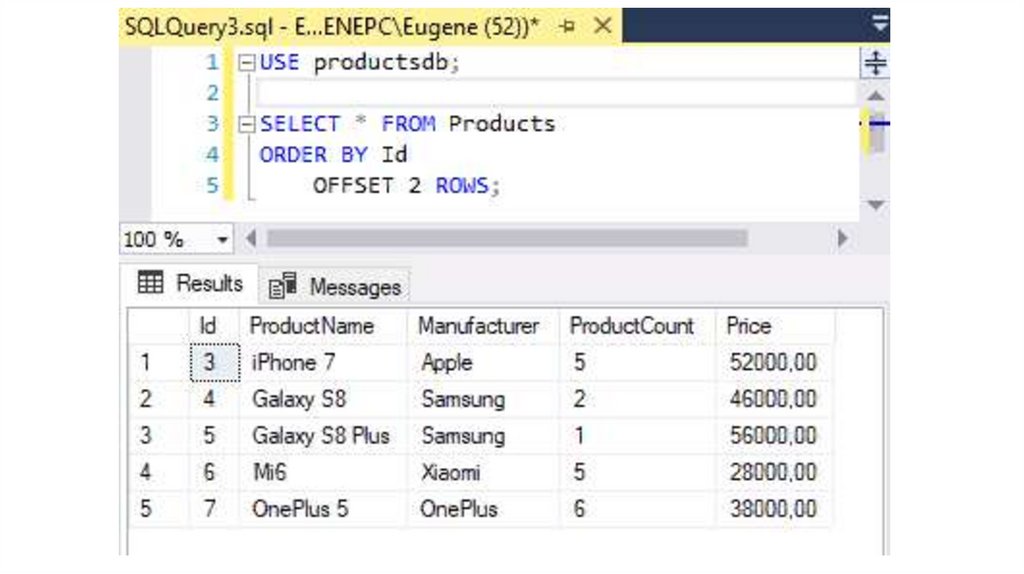
Например, выберем все строки, начиная с третьей:
SELECT * FROM Products
ORDER BY Id
OFFSET 2 ROWS;
Число после ключевого слова OFFSET указывает, сколько строк необходимо пропустить.
31.
32.
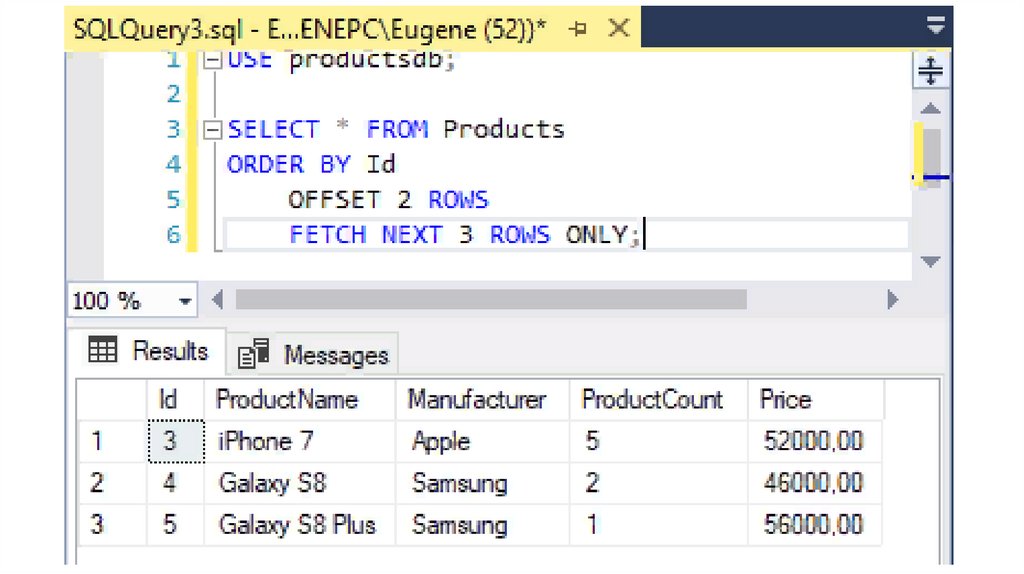
Теперь выберем только три строки, начиная с третьей:SELECT * FROM Products
ORDER BY Id
OFFSET 2 ROWS
FETCH NEXT 3 ROWS ONLY;
После оператора FETCH указывается ключевое слово FIRST или NEXT (какое
именно в данном случае не имеет значения) и затем указывается
количество строк, которое надо получить.
Данная комбинация операторов, как правило, используется для
постраничной навигации, когда необходимо получить определенную
страницу с данными.
33.
34.
Фильтрация. WHEREДля фильтрации в команде SELECT применяется оператор WHERE. После этого оператора
ставится условие, которому должна соответствовать строка:
WHERE условие
Если условие истинно, то строка попадает в результирующую выборку. Можно использовать
операции сравнения. Эти операции сравнивают два выражения. В T-SQL можно применять
следующие операции сравнения:
=
сравнение на равенство (в отличие от си-подобных языков в T-SQL для сравнения на
равенство используется один знак равно)
<>
сравнение на неравенство
<
меньше чем
>
больше чем
!<
не меньше чем
!>
не больше чем
<=
меньше чем или равно
>=
больше чем или равно
35.
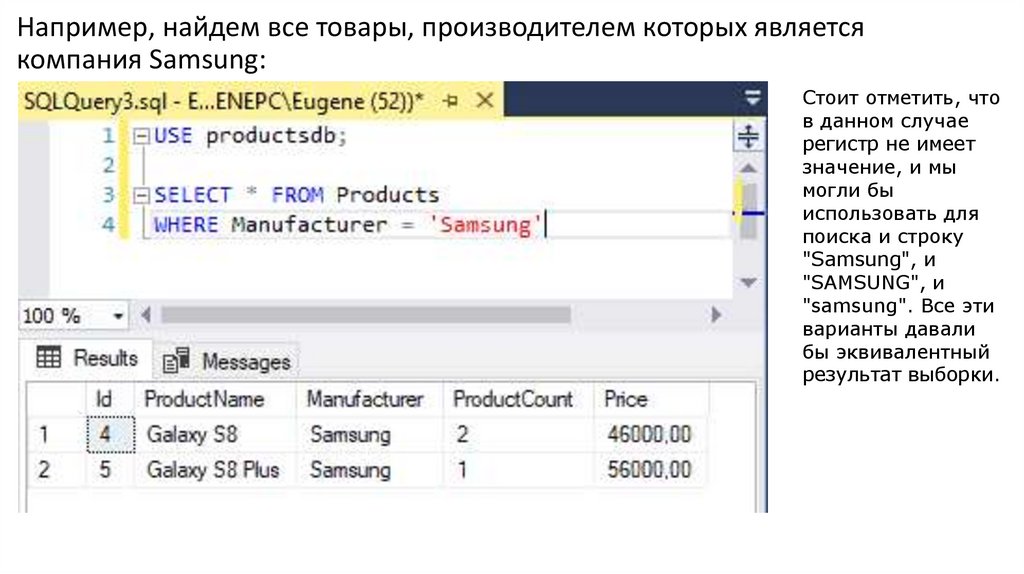
Например, найдем все товары, производителем которых являетсякомпания Samsung:
Стоит отметить, что
в данном случае
регистр не имеет
значение, и мы
могли бы
использовать для
поиска и строку
"Samsung", и
"SAMSUNG", и
"samsung". Все эти
варианты давали
бы эквивалентный
результат выборки.
36.
Другой пример - найдем все товары, у которых цена больше 45000:SELECT * FROM Products
WHERE Price > 45000
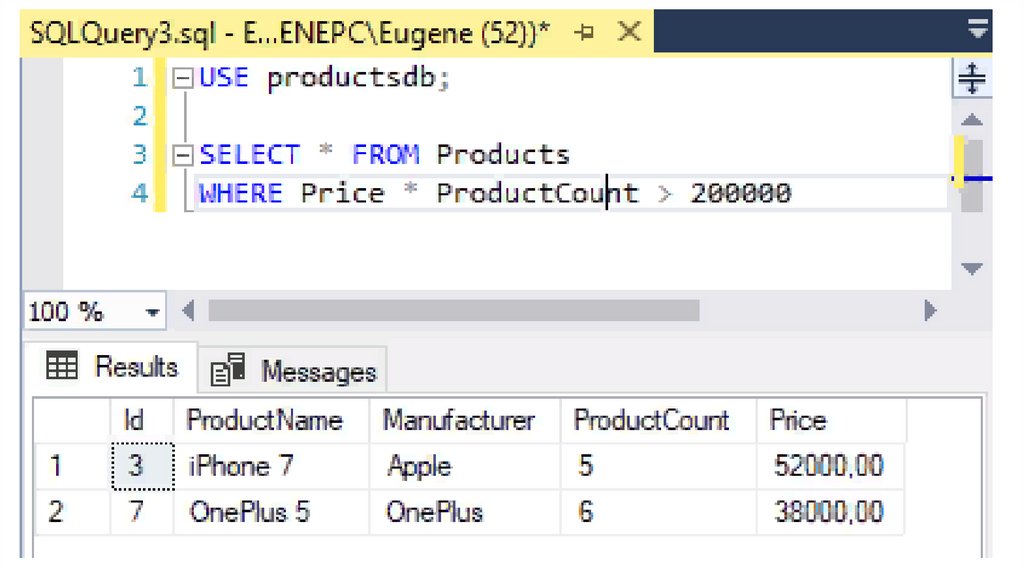
В качестве условия могут использоваться и более сложные выражения.
Например, найдем все товары, у которых совокупная стоимость больше
200 000:
SELECT * FROM Products
WHERE Price * ProductCount > 200000
37.
38.
Логические операторыДля объединения нескольких условий в одно могут использоваться
логические операторы. В T-SQL имеются следующие логические
операторы:
AND: операция логического И. Она объединяет два выражения:
выражение1 AND выражение2
Только если оба этих выражения одновременно истинны, то и общее
условие оператора AND также будет истинно. То есть если и первое
условие истинно, и второе.
39.
OR: операция логического ИЛИ. Она также объединяет два выражения:выражение1 OR выражение2
Если хотя бы одно из этих выражений истинно, то общее условие
оператора OR также будет истинно. То есть если или первое условие
истинно, или второе.
NOT: операция логического отрицания. Если выражение в этой
операции ложно, то общее условие истинно.
NOT выражение
Если эти операторы встречаются в одном выражении, то сначала
выполняется NOT, потом AND и в конце OR.
40.
Например, выберем все товары, у которых производитель Samsung иодновременно цена больше 50000:
41.
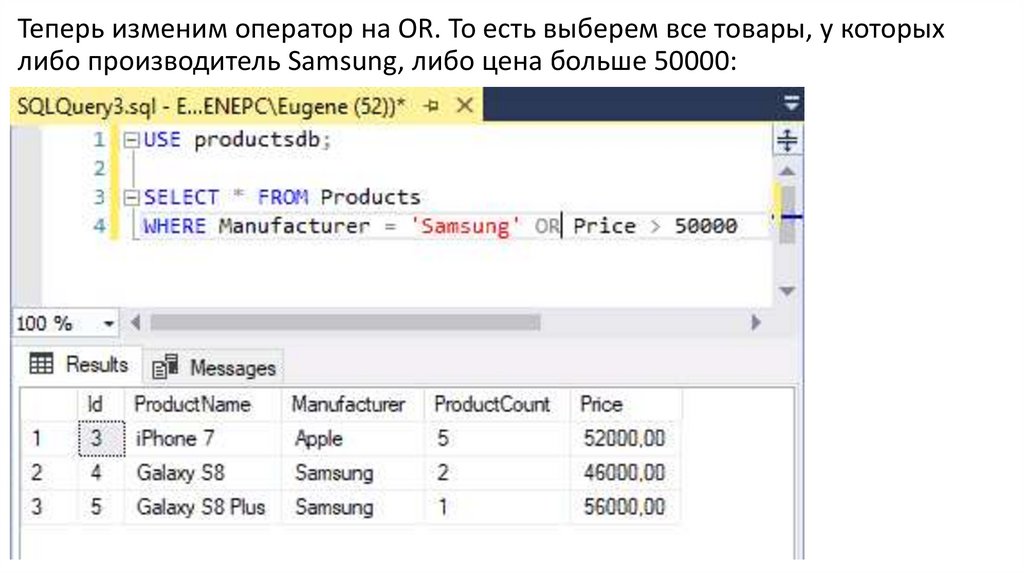
Теперь изменим оператор на OR. То есть выберем все товары, у которыхлибо производитель Samsung, либо цена больше 50000:
42.
Применение оператора NOT - выберем все товары, у которыхпроизводитель не Samsung:
43.
Но в большинстве случае вполне можно обойтись без оператора NOT.Так, в предыдущий пример мы можем переписать следующим
образом:
SELECT * FROM Products
WHERE Manufacturer <> 'Samsung‘
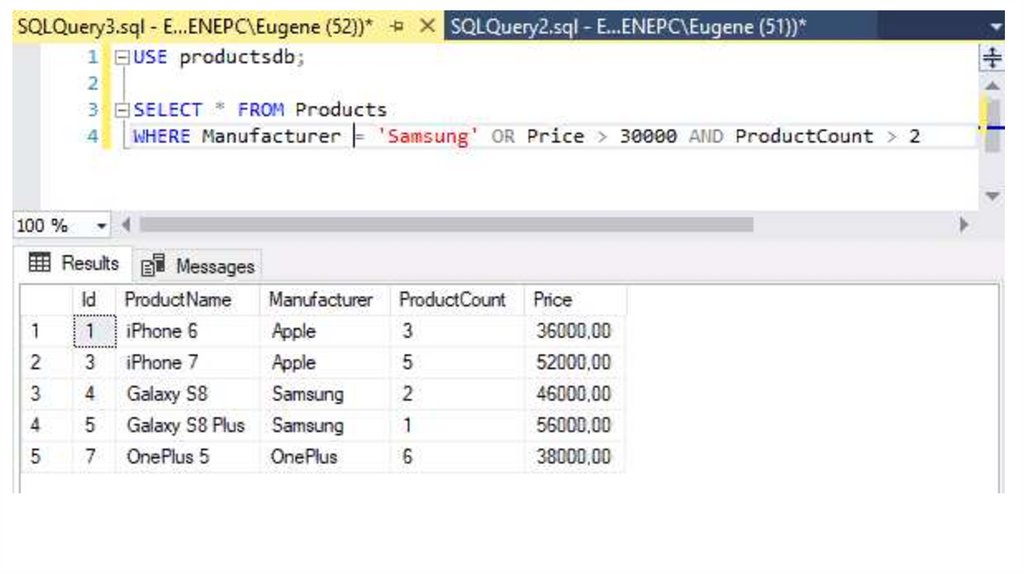
Также в одной команде SELECT можно использовать сразу несколько
операторов:
SELECT * FROM Products
WHERE Manufacturer = 'Samsung' OR Price > 30000 AND
ProductCount > 2
Так как оператор AND имеет более высокий приоритет, то сначала будет
выполняться подвыражение Price > 30000 AND ProductCount > 2, и
только потом оператор OR. То есть здесь выбираются товары, которых
на складе больше 2 и у которых одновременно цена больше 30000,
либо те товары, производителем которых является Samsung.
44.
45.
С помощью скобок мы также можем переопределить порядок операций:SELECT * FROM Products
WHERE (Manufacturer = 'Samsung' OR Price > 30000) AND
ProductCount > 2
46.
IS NULLРяд столбцов может допускать значение NULL. Это значение не
эквивалентно пустой строке ''. NULL представляет полное отсутствие
какого-либо значения. И для проверки на наличие подобного значения
применяется оператор IS NULL.
Например, выберем все товары, у которых не установлено поле
ProductCount:
SELECT * FROM Products
WHERE ProductCount IS NULL
Если, наоборот, необходимо получить строки, у которых поле ProductCount
не равно NULL, то можно использовать оператор NOT:
SELECT * FROM Products
WHERE ProductCount IS NOT NULL
47.
Оператор INОператор IN позволяет определить набор значений, которые должны
иметь столбцы:
WHERE выражение [NOT] IN (выражение)
Выражение в скобках после IN определяет набор значений. Этот набор
может вычисляться динамически на основании, например, еще одного
запроса, либо это могут быть константные значения.
Например, выберем товары, у которых производитель либо Samsung, либо
Xiaomi, либо Huawei:
SELECT * FROM Products
WHERE Manufacturer IN ('Samsung', 'Xiaomi', 'Huawei')
48.
49.
Мы могли бы все эти значения проверить и через оператор OR:SELECT * FROM Products
WHERE Manufacturer = 'Samsung' OR Manufacturer =
'Xiaomi' OR Manufacturer = 'Huawei‘
Но использование оператора IN гораздо удобнее, особенно если подобных
значений очень много.
С помощью оператора NOT можно найти все строки, которые, наоборот, не
соответствуют набору значений:
SELECT * FROM Products
WHERE Manufacturer NOT IN ('Samsung', 'Xiaomi',
'Huawei')
50.
Оператор BETWEENОператор BETWEEN определяет диапазон значений с помощью начального
и конечного значения, которому должно соответствовать выражение:
WHERE выражение [NOT] BETWEEN начальное_значение AND
конечное_значение
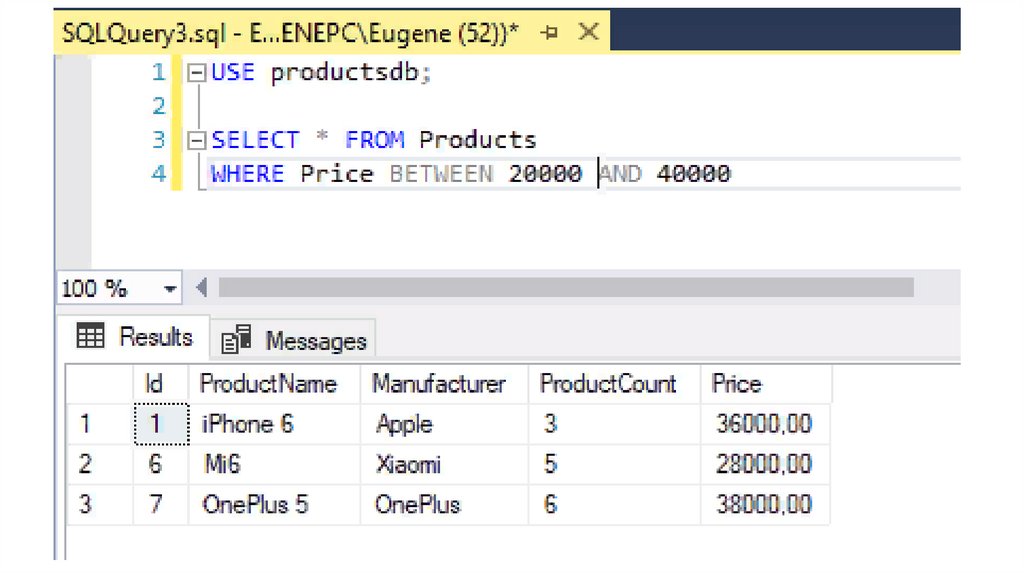
Например, получим все товары, у которых цена от 20 000 до 40 000
(начальное и конечное значения также включаются в диапазон):
SELECT * FROM Products
WHERE Price BETWEEN 20000 AND 40000
51.
52.
Если надо, наоборот, выбрать те строки, которые не попадают в данныйдиапазон, то применяется оператор NOT:
SELECT * FROM Products
WHERE Price NOT BETWEEN 20000 AND 40000
Также можно использовать более сложные выражения. Например,
получим товары, запасы которых на определенную сумму (цена *
количество):
SELECT * FROM Products
WHERE Price * ProductCount BETWEEN 100000 AND 200000
53.
Оператор LIKEОператор LIKE принимает шаблон строки, которому должно
соответствовать выражение.
WHERE выражение [NOT] LIKE шаблон_строки
Для определения шаблона могут применяться ряд специальных символов
подстановки:
%
соответствует любой подстроке, которая может иметь любое
количество символов, при этом подстрока может и не содержать ни
одного символа
_
соответствует любому одиночному символу
[]
соответствует одному символу, который указан в квадратных скобках
[ - ] соответствует одному символу из определенного диапазона
[ ^ ] соответствует одному символу, который не указан после символа ^
54.
Некоторые примеры использования подстановок:WHERE ProductName LIKE 'Galaxy%'
Соответствует таким значениям как "Galaxy Ace 2" или "Galaxy S7"
WHERE ProductName LIKE 'Galaxy S_'
Соответствует таким значениям как "Galaxy S7" или "Galaxy S8"
WHERE ProductName LIKE 'iPhone [78]'
Соответствует таким значениям как "iPhone 7" или "iPhone8"
WHERE ProductName LIKE 'iPhone [6-8]'
Соответствует таким значениям как "iPhone 6", "iPhone 7" или "iPhone8"
WHERE ProductName LIKE 'iPhone [^7]%'
Соответствует таким значениям как "iPhone 6", "iPhone 6S" или "iPhone8". Но не
соответствует значениям "iPhone 7" и "iPhone 7S"
WHERE ProductName LIKE 'iPhone [^1-6]%'
Соответствует таким значениям как "iPhone 7", "iPhone 7S" и "iPhone 8". Но не
соответствует значениям "iPhone 5", "iPhone 6" и "iPhone 6S"
55.
56.
Обновление данных. Команда UPDATEДля изменения уже имеющихся строк в таблице применяется
команда UPDATE. Она имеет следующий формальный синтаксис:
UPDATE имя_таблицы
SET столбец1 = значение1, ... столбецN = значениеN
[FROM выборка AS псевдоним_выборки]
[WHERE условие_обновления]
Например, увеличим у всех товаров цену на 5000:
UPDATE Products
SET Price = Price + 5000
57.
58.
Используем критерий, и изменим название производителя с "Samsung" на"Samsung Inc.":
UPDATE Products
SET Manufacturer = 'Samsung Inc.'
WHERE Manufacturer = 'Samsung‘
59.
Более сложный запрос - заменим у поля Manufacturer значение "Apple" на "Apple Inc." впервых 2 строках:
UPDATE Products
SET Manufacturer = 'Apple Inc.'
FROM
(SELECT TOP 2 * FROM Products WHERE Manufacturer='Apple') AS
Selected
WHERE Products.Id = Selected.Id
С помощью подзапроса после ключевого слова FROM производится выборка первых двух
строк, в которых Manufacturer='Apple'. Для этой выборки будет определен псевдоним
Selected. Псевдоним указывается после оператора AS.
Далее идет условие обновления Products.Id = Selected.Id. То есть фактически мы имеем
дело с двумя таблицами - Products и Selected (которая является производной от Products).
В Selected находится две первых строки, в которых Manufacturer='Apple'. В Products вообще все строки. И обновление производится только для тех строк, которые есть в
выборке Selected. То есть если в таблице Products десятки товаров с производителем
Apple, то обновление коснется только двух первых из них.
60.
Удаление данных. Команда DELETEДля удаления применяется команда DELETE:
DELETE [FROM] имя_таблицы
WHERE условие_удаления
Например, удалим строки, у которых id равен 9:
DELETE Products
WHERE Id=9
Или удалим все товары, производителем которых является Xiaomi и которые
имеют цену меньше 15000:
DELETE Products
WHERE Manufacturer='Xiaomi' AND Price < 15000
61.
Более сложный пример - удалим первые два товара, у которыхпроизводитель - Apple:
DELETE Products FROM
(SELECT TOP 2 * FROM Products
WHERE Manufacturer='Apple]') AS Selected
WHERE Products.Id = Selected.Id
После первого оператора FROM идет выборка двух строк из таблицы
Products. Этой выборке назначается псевдоним Selected с помощью
оператора AS. Далее устанавливаем условие, что если Id в таблице Products
имеет то же значение, что и Id в выборке Selected, то строка удаляется.
62.
63.
Если необходимо вовсе удалить все строки вне зависимости от условия,то условие можно не указывать:
DELETE Products
64.
ГруппировкаАгрегатные функции
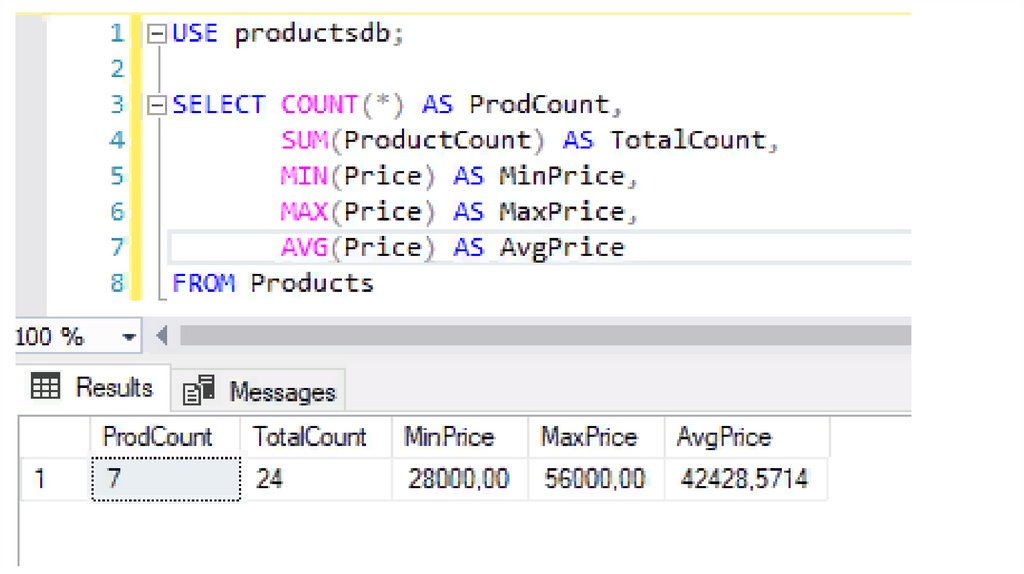
Агрегатные функции выполняют вычисления над значениями в наборе строк. В TSQL имеются следующие агрегатные функции:
AVG: находит среднее значение
SUM: находит сумму значений
MIN: находит наименьшее значение
MAX: находит наибольшее значение
COUNT: находит количество строк в запросе
В качестве аргумента все агрегатные функции принимают выражение, которое
представляет критерий для определения значений. Зачастую, в качестве
выражения выступает название столбца, над значениями которого надо
проводить вычисления.
Выражения в функциях AVG и SUM должно представлять числовое значение.
Выражение в функциях MIN, MAX и COUNT может представлять числовое или
строковое значение или дату.
Все агрегатные функции за исключением COUNT(*) игнорируют значения NULL.
65.
AvgФункция Avg возвращает среднее значение на диапазоне значений столбца
таблицы.
Найдем среднюю цену товаров из базы данных.
Для поиска среднего значения в качестве выражения в функцию передается
столбец Price. Для получаемого значения устанавливается псевдоним
Average_Price, хотя можно его и не устанавливать.
66.
Также мы можем применить фильтрацию. Например, найти среднююцену для товаров какого-то определенного производителя:
SELECT AVG(Price) FROM Products
WHERE Manufacturer='Apple‘
И, кроме того, мы можем находить среднее значение для более
сложных выражений. Например, найдем среднюю сумму всех товаров,
учитывая их количество:
SELECT AVG(Price * ProductCount) FROM Products
67.
CountФункция Count вычисляет количество строк в выборке. Есть две формы
этой функции. Первая форма COUNT(*) подсчитывает число строк в
выборке
Вторая форма функции вычисляет количество строк по
определенному столбцу, при этом строки со значениями NULL
игнорируются:
SELECT COUNT(Manufacturer) FROM Products
68.
Min и MaxФункции Min и Max возвращают соответственно минимальное и
максимальное значение по столбцу. Например, найдем минимальную цену
среди товаров:
SELECT MIN(Price) FROM Products
Поиск максимальной цены:
SELECT MAX(Price) FROM Products
Данные функции также игнорируют значения NULL и не учитывают их при
подсчете.
69.
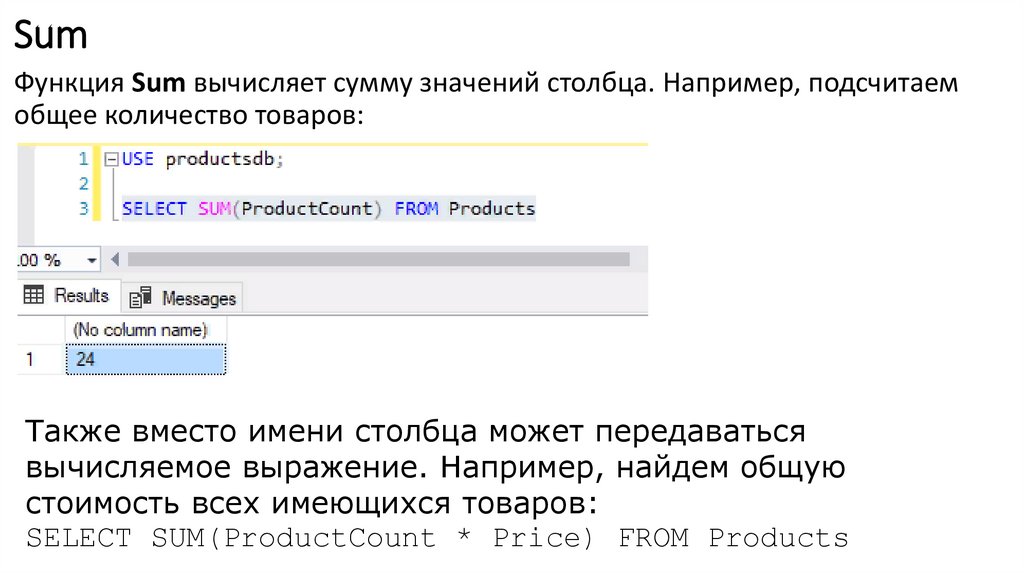
SumФункция Sum вычисляет сумму значений столбца. Например, подсчитаем
общее количество товаров:
Также вместо имени столбца может передаваться
вычисляемое выражение. Например, найдем общую
стоимость всех имеющихся товаров:
SELECT SUM(ProductCount * Price) FROM Products
70.
All и DistinctПо умолчанию все вышеперечисленных пять функций учитывают все строки
выборки для вычисления результата. Но выборка может содержать
повторяющие значения. Если необходимо выполнить вычисления только
над уникальными значениями, исключив из набора значений
повторяющиеся данные, то для этого применяется оператор DISTINCT.
SELECT AVG(DISTINCT ProductCount) AS Average_Price
FROM Products
По умолчанию вместо DISTINCT применяется оператор ALL, который
выбирает все строки:
SELECT AVG(ALL ProductCount) AS Average_Price FROM
Products
Так как этот оператор неявно подразумевается при отсутствии DISTINCT, то
его можно не указывать.
71.
72.
Операторы GROUP BY и HAVINGДля группировки данных в T-SQL применяются операторы GROUP
BY и HAVING, для использования которых применяется следующий
формальный синтаксис:
SELECT столбцы
FROM таблица
[WHERE условие_фильтрации_строк]
[GROUP BY столбцы_для_группировки]
[HAVING условие_фильтрации_групп]
[ORDER BY столбцы_для_сортировки]
73.
GROUP BYОператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
Первый столбец в выражении SELECT - Manufacturer представляет название
группы, а второй столбец - ModelsCount представляет результат функции
Count, которая вычисляет количество строк в группе.
74.
Стоит учитывать, что любой столбец, который используется ввыражении SELECT (не считая столбцов, которые хранят результат
агрегатных функций), должны быть указаны после оператора GROUP BY.
Так, например, в случае выше столбец Manufacturer указан и в
выражении SELECT, и в выражении GROUP BY.
И если в выражении SELECT производится выборка по одному или
нескольким столбцам и также используются агрегатные функции, то
необходимо использовать выражение GROUP BY. Так, следующий
пример работать не будет, так как он не содержит выражение
группировки:
SELECT Manufacturer, COUNT(*) AS ModelsCount
FROM Products
75.
Другой пример, добавим группировку по количеству товаров:SELECT Manufacturer, ProductCount, COUNT(*) AS
ModelsCount
FROM Products
GROUP BY Manufacturer, ProductCount
Оператор GROUP BY может выполнять группировку по множеству столбцов.
Если столбец, по которому производится группировка, содержит значение
NULL, то строки со значением NULL составят отдельную группу.
76.
Следует учитывать, что выражение GROUP BY должно идти послевыражения WHERE, но до выражения ORDER BY:
77.
Фильтрация групп. HAVINGОператор HAVING определяет, какие группы будут включены в выходной
результат, то есть выполняет фильтрацию групп.
Применение HAVING во многом аналогично применению WHERE. Только
есть WHERE применяется к фильтрации строк, то HAVING используется для
фильтрации групп.
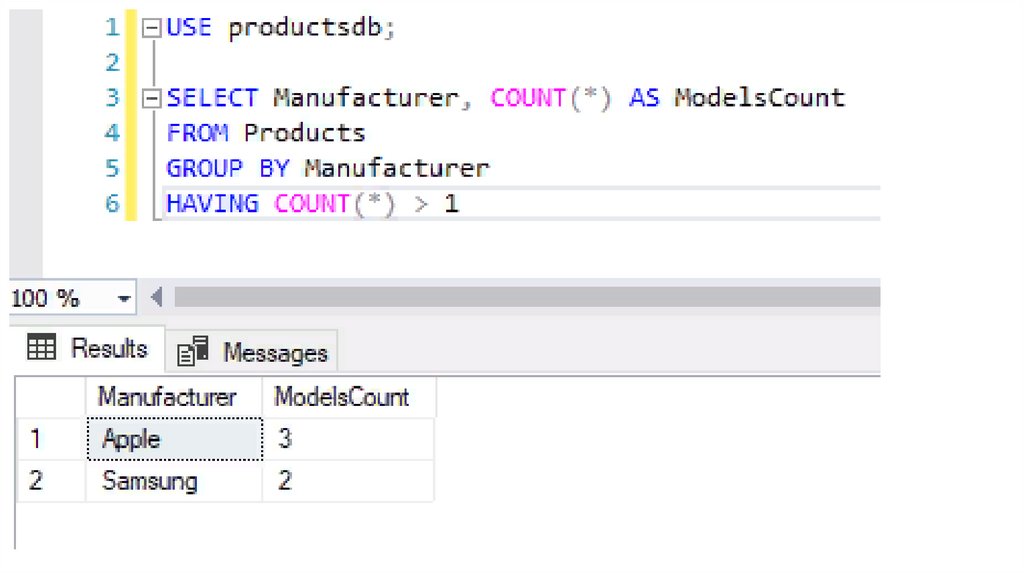
Например, найдем все группы товаров по производителям, для которых
определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount
FROM Products
GROUP BY Manufacturer
HAVING COUNT(*) > 1
78.
79.
При этом в одной команде мы можем использовать выражения WHERE иHAVING:
SELECT Manufacturer, COUNT(*) AS ModelsCount
FROM Products
WHERE Price * ProductCount > 80000
GROUP BY Manufacturer
HAVING COUNT(*) > 1
То есть в данном случае сначала фильтруются строки: выбираются те
товары, общая стоимость которых больше 80000. Затем выбранные товары
группируются по производителям. И далее фильтруются сами группы выбираются те группы, которые содержат больше 1 модели.
80.
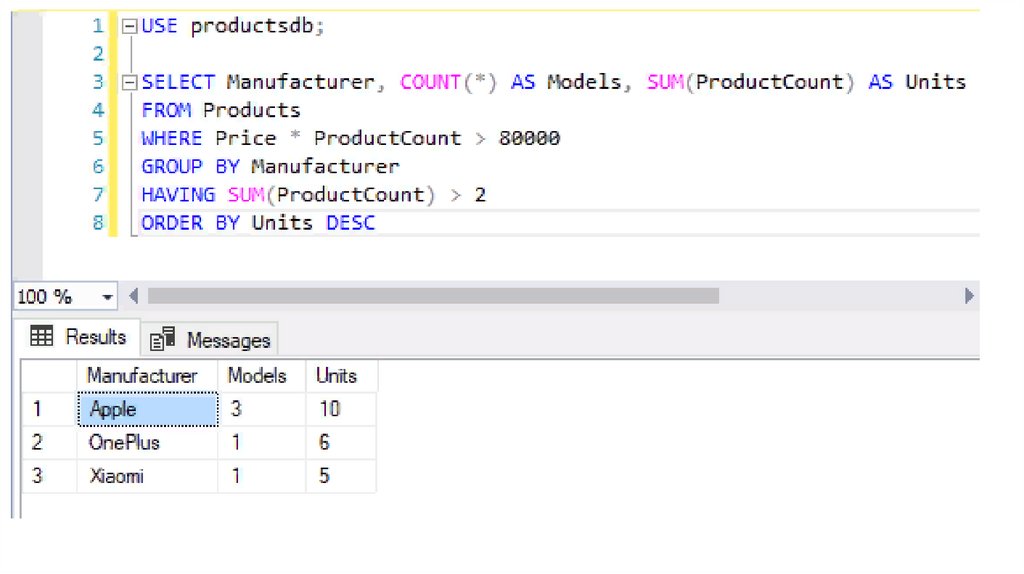
Если при этом необходимо провести сортировку, то выражение ORDER BYидет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models,
SUM(ProductCount) AS Units
FROM Products
WHERE Price * ProductCount > 80000
GROUP BY Manufacturer
HAVING SUM(ProductCount) > 2
ORDER BY Units DESC
В данном случае группировка идет по производителям, и также выбирается
количество моделей для каждого производителя (Models) и общее
количество всех товаров по всем этим моделям (Units). В конце группы
сортируются по количеству товаров по убыванию.
81.
82.
ПодзапросыCREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(30) NOT NULL
);
CREATE TABLE Orders
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE,
CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE,
CreatedAt DATE NOT NULL,
ProductCount INT DEFAULT 1,
Price MONEY NOT NULL
);
83.
INSERT INTO Customers VALUES ('Tom'), ('Bob'),('Sam')INSERT INTO Orders
VALUES
(
(SELECT Id FROM Products WHERE ProductName='Galaxy S8'),
(SELECT Id FROM Customers WHERE FirstName='Tom'),
'2017-07-11',
2,
(SELECT Price FROM Products WHERE ProductName='Galaxy S8')),
(
(SELECT Id FROM Products WHERE ProductName='iPhone 6S'),
(SELECT Id FROM Customers WHERE FirstName='Tom'),
'2017-07-13',
1,
(SELECT Price FROM Products WHERE ProductName='iPhone 6S')),
(
(SELECT Id FROM Products WHERE ProductName='iPhone 6S'),
(SELECT Id FROM Customers WHERE FirstName='Bob'),
'2017-07-11',
1,
(SELECT Price FROM Products WHERE ProductName='iPhone 6S'))
84.
Найдем товары из таблицы Products, которые имеют минимальнуюцену:
SELECT * FROM Products
WHERE Price = (SELECT MIN(Price) FROM Products)
Или найдем товары, цена которых выше средней:
SELECT * FROM Products
WHERE Price > (SELECT AVG(Price) FROM Products)
85.
Коррелирующие подзапросыПодзапросы бывают коррелирующими и некоррелирующими. В примерах
выше команды SELECT выполняли фактически один подзапрос для всей
команды, например, подзапрос возвращает минимальную или среднюю
цену, которая не изменится, сколько бы мы строк не выбирали в основном
запросе. То есть результат подзапроса не зависел от строк, которые
выбираются в основном запросе. И такой подзапрос выполняется один раз
для всего внешнего запроса.
Но также существуют коррелирующие подзапросы (correlated subquery),
результаты которых зависят от строк, которые выбираются в основном
запросе.
86.
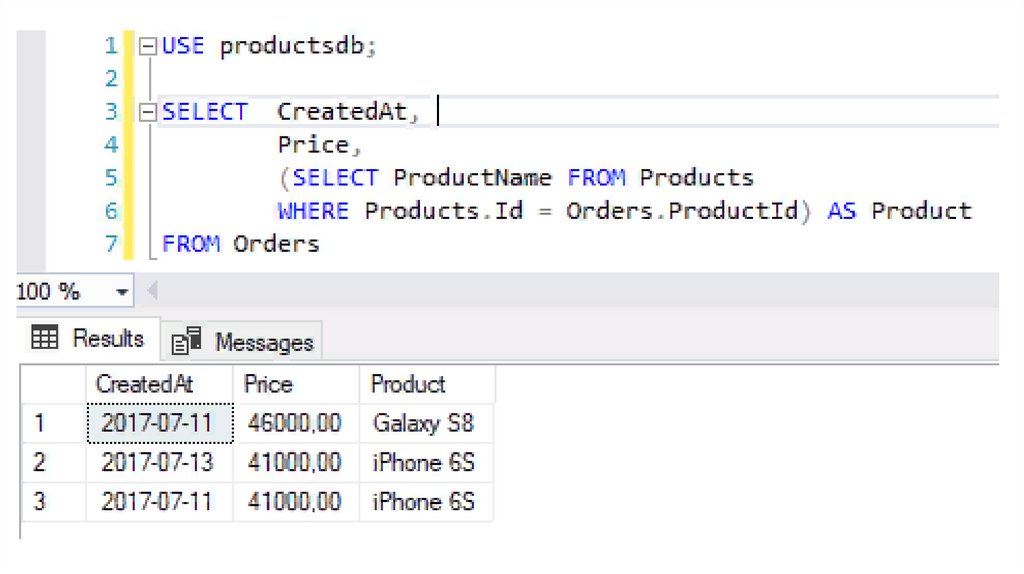
Например, выберем все заказы из таблицы Orders, добавив к ниминформацию о товаре:
SELECT
CreatedAt,
Price,
(SELECT ProductName FROM Products
WHERE Products.Id = Orders.ProductId) AS
Product
FROM Orders
Здесь для каждой строки из таблицы Orders будет выполняться подзапрос,
результат которого зависит от столбца ProductId. И каждый подзапрос
может возвращать различные данные.
87.
88.
Коррелирующий подзапрос может выполняться и для той же таблицы, к которойвыполняется основной запрос. Например, выберем из таблицы Products те
товары, стоимость которых выше средней цены товаров для данного
производителя:
89.
В данном случае определено два коррелирующих подзапроса. Первыйподзапрос определяет спецификацию столбца AvgPrice. Он будет
выполняться для каждой строки, извлекаемой из таблицы Products. В
подзапрос передается производитель товара и на его основе выбирается
средняя цена для товаров именно этого производителя. И так как
производитель у товаров может отличаться, то и результат подзапроса в
каждом случае также может отличаться.
Второй подзапрос аналогичен, только он используется для фильтрации
извлекаемых из таблицы Products. И также он будет выполняться для
каждой строки.
Чтобы избежать двойственности при фильтрации в подзапросе при
сравнении производителей (SubProds.Manufacturer=Prods.Manufacturer)
для внешней выборки установлен псевдоним Prods, а для выборки из
подзапросов определен псевдоним SubProds.
Следует учитывать, что коррелирующие подзапросы выполняются для
каждой отдельной строки выборки, то выполнение таких подзапросов
может замедлять выполнение всего запроса в целом.
90.
Встроенные функциидля работы со строками
LEN: возвращает количество символов в строке. В качестве
параметра в функцию передается строка, для которой надо найти
длину:
SELECT LEN('Apple') -- 5
LTRIM: удаляет начальные пробелы из строки. В качестве
параметра принимает строку:
SELECT LTRIM(' Apple')
RTRIM: удаляет конечные пробелы из строки. В качестве параметра
принимает строку:
SELECT RTRIM(' Apple
')
91.
CHARINDEX: возвращает индекс, по которому находится первое вхождениеподстроки в строке. В качестве первого параметра передается подстрока, а
в качестве второго - строка, в которой надо вести поиск:
SELECT CHARINDEX('pl', 'Apple') – 3
PATINDEX: возвращает индекс, по которому находится первое вхождение
определенного шаблона в строке:
SELECT PATINDEX('%p_e%', 'Apple')
-- 3
LEFT: вырезает с начала строки определенное количество символов.
Первый параметр функции - строка, а второй - количество символов,
которые надо вырезать сначала строки:
SELECT LEFT('Apple', 3) – App
RIGHT: вырезает с конца строки определенное количество символов.
Первый параметр функции - строка, а второй - количество символов,
которые надо вырезать с конца строки:
SELECT RIGHT('Apple', 3)
-- ple
92.
SUBSTRING: вырезает из строки подстроку определенной длиной, начинаяс определенного индекса. Певый параметр функции - строка, второй начальный индекс для вырезки, и третий параметр - количество
вырезаемых символов:
SELECT SUBSTRING('Galaxy S8 Plus', 8, 2)
-- S8
REPLACE: заменяет одну подстроку другой в рамках строки. Первый
параметр функции - строка, второй - подстрока, которую надо заменить, а
третий - подстрока, на которую надо заменить:
SELECT REPLACE('Galaxy S8 Plus', 'S8 Plus', 'Note 8')
-- Galaxy Note 8
REVERSE: переворачивает строку наоборот:
SELECT REVERSE('123456789') -- 987654321
93.
CONCAT: объединяет две строки в одну. В качестве параметра принимает от2-х и более строк, которые надо соединить:
SELECT CONCAT('Tom', ' ', 'Smith') -- Tom Smith
LOWER: переводит строку в нижний регистр:
SELECT LOWER('Apple') -- apple
UPPER: переводит строку в верхний регистр
SELECT UPPER('Apple') -- APPLE
94.
95.
96.
Функции для работы с числамиROUND: округляет число. В качестве первого параметра передается
число. Второй параметр указывает на длину. Если длина
представляет положительное число, то оно указывает, до какой
цифры после запятой идет округление. Если длина представляет
отрицательное число, то оно указывает, до какой цифры с конца
числа до запятой идет округление:
SELECT ROUND(1342.345, 2)
SELECT ROUND(1342.345, -2)
-- 1342.350
-- 1300.000
97.
ISNUMERIC: определяет, является ли значение числом. В качествепараметра функция принимает выражение. Если выражение является
числом, то функция возвращает 1. Если не является, то возвращается 0.
SELECT ISNUMERIC(1342.345)
-- 1
SELECT ISNUMERIC('1342.345')
-- 1
SELECT ISNUMERIC('SQL')
-- 0
SELECT ISNUMERIC('13-04-2017') -- 0
ABS: возвращает абсолютное значение числа.
SELECT ABS(-123)
-- 123
CEILING: возвращает наименьшее целое число, которое больше или равно
текущему значению.
SELECT CEILING(-123.45)
-- -123
SELECT CEILING(123.45)
-- 124
98.
FLOOR: возвращает наибольшее целое число, которое меньше или равнотекущему значению.
SELECT FLOOR(-123.45)
SELECT FLOOR(123.45)
-- -124
-- 123
SQUARE: возводит число в квадрат.
SELECT SQUARE(5)
-- 25
SQRT: получает квадратный корень числа.
SELECT SQRT(225)
-- 15
99.
RAND: генерирует случайное число с плавающей точкой в диапазоне от 0 до1.
SELECT RAND()
-- 0.707365088352935
SELECT RAND()
-- 0.173808327956812
COS: возвращает косинус угла, выраженного в радианах
SELECT COS(1.0472) -- 0.5 - 60 градусов
SIN: возвращает синус угла, выраженного в радианах
SELECT SIN(1.5708) -- 1 - 90 градусов
TAN: возвращает тангенс угла, выраженного в радианах
SELECT TAN(0.7854) -- 1 - 45 градусов
100.
Функции по работе с датами и временемGETDATE: возвращает текущую локальную дату и время на основе системных
часов в виде объекта datetime
SELECT GETDATE()
-- 2017-07-28 21:34:55.830
GETUTCDATE: возвращает текущую локальную дату и время по гринвичу
(UTC/GMT) в виде объекта datetime
SELECT GETUTCDATE()
-- 2017-07-28 18:34:55.830
SYSDATETIME: возвращает текущую локальную дату и время на основе системных
часов, но отличие от GETDATE состоит в том, что дата и время возвращаются в
виде объекта datetime2
SELECT SYSDATETIME() -- 2017-07-28 21:02:22.7446744
SYSUTCDATETIME: возвращает текущую локальную дату и время по гринвичу
(UTC/GMT) в виде объекта datetime2
SELECT SYSUTCDATETIME() -- 2017-07-28 18:20:27.5202777
101.
SYSDATETIMEOFFSET: возвращает объект datetimeoffset(7), которыйсодержит дату и время относительно GMT
SELECT SYSDATETIMEOFFSET()
--2017-07-28 21:02:22.7446744 +03:00
DAY: возвращает день даты, который передается в качестве параметра
SELECT DAY(GETDATE())
-- 28
MONTH: возвращает месяц даты
SELECT MONTH(GETDATE())
-- 7
YEAR: возвращает год из даты
SELECT YEAR(GETDATE())
-- 2017
102.
DATENAME: возвращает часть даты в виде строки. Параметр выбора части даты передается вкачестве первого параметра, а сама дата передается в качестве второго параметра:
SELECT DATENAME(month, GETDATE())
-- July
Для определения части даты можно использовать следующие параметры (в скобках указаны их
сокращенные версии):
year (yy, yyyy): год
quarter (qq, q): квартал
month (mm, m): месяц
dayofyear (dy, y): день года
day (dd, d): день месяца
week (wk, ww): неделя
weekday (dw): день недели
hour (hh): час
minute (mi, n): минута
second (ss, s): секунда
millisecond (ms): миллисекунда
microsecond (mcs): микросекунда
nanosecond (ns): наносекунда
tzoffset (tz): смешение в минутах относительно гринвича (для объекта datetimeoffset)
103.
DATEPART: возвращает часть даты в виде числа. Параметр выбора части датыпередается в качестве первого параметра (используются те же параметры, что и
для DATENAME), а сама дата передается в качестве второго параметра:
SELECT DATEPART(month, GETDATE())
-- 7
DATEADD: возвращает дату, которая является результатом сложения числа к
определенному компоненту даты. Первый параметр представляет компонент
даты, описанный выше для функции DATENAME. Второй параметр - добавляемое
количество. Третий параметр - сама дата, к которой надо сделать прибавление:
SELECT DATEADD(month, 2, '2017-7-28')
-- 2017-09-28 00:00:00.000
SELECT DATEADD(day, 5, '2017-7-28')
-- 2017-08-02 00:00:00.000
SELECT DATEADD(day, -5, '2017-7-28')
-- 2017-07-23 00:00:00.000
Если добавляемое количество представляет отрицательное число, то фактически
происходит уменьшение даты.
104.
DATEDIFF: возвращает разницу между двумя датами. Первый параметр компонент даты, который указывает, в каких единицах стоит измерятьразницу. Второй и третий параметры - сравниваемые даты:
SELECT DATEDIFF(year, '2017-7-28', '2018-9-28')
-- разница 1 год
SELECT DATEDIFF(month, '2017-7-28', '2018-9-28')
-- разница 14 месяцев
SELECT DATEDIFF(day, '2017-7-28', '2018-9-28')
-- разница 427 дней
DATEFROMPARTS: по году, месяцу и дню создает дату
SELECT DATEFROMPARTS(2017, 7, 28)
-- 2017-07-28
105.
EOMONTH: возвращает дату последнего дня для месяца, которыйиспользуется в переданной в качестве параметра дате.
SELECT EOMONTH('2017-02-05')
-- 2017-02-28
SELECT EOMONTH('2017-02-05', 3) -- 2017-05-31
В качестве необязательного второго параметра можно передавать
количество месяцев, которые необходимо прибавить к дате. Тогда
последний день месяца будет вычисляться для новой даты.
ISDATE: проверяет, является ли выражение датой. Если является, то
возвращает 1, иначе возвращает 0.
SELECT ISDATE('2017-07-28')
-- 1
SELECT ISDATE('2017-28-07')
-- 0
SELECT ISDATE('28-07-2017')
-- 0
SELECT ISDATE('SQL')
-- 0
106.
В качестве примера использования функций можно привести создание таблицызаказов, которая содержит дату заказа:
CREATE TABLE Orders
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL,
CustomerId INT NOT NULL,
CreatedAt DATE NOT NULL DEFAULT GETDATE(),
ProductCount INT DEFAULT 1,
Price MONEY NOT NULL
);
Выражение DEFAULT GETDATE() указывает, что если при добавлении данных не
передается дата, то она автоматически вычисляется с помощью функции
GETDATE().
107.
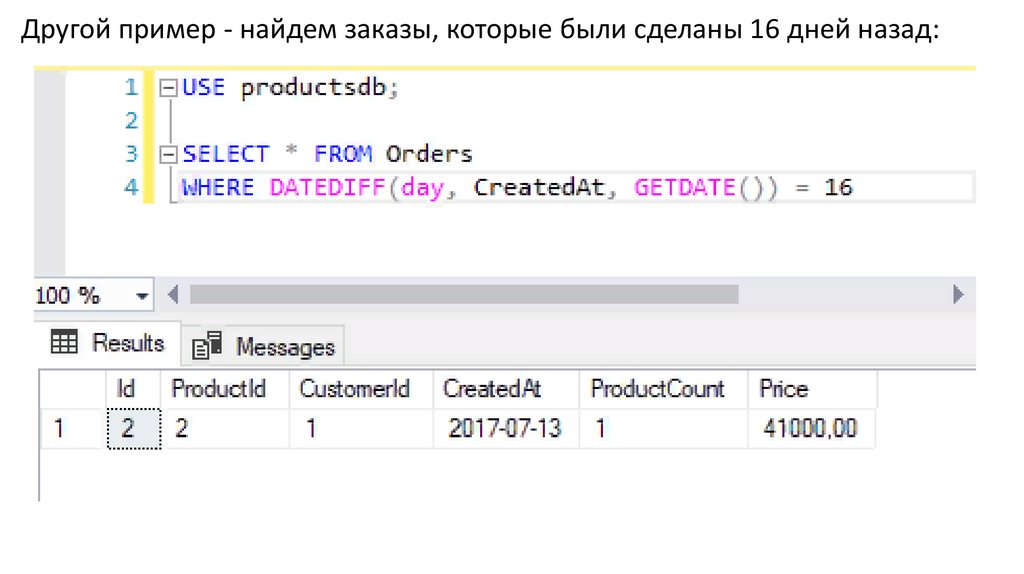
Другой пример - найдем заказы, которые были сделаны 16 дней назад:108.
Преобразование данныхКогда мы присваиваем значение одного одного типа столбцу, который
хранит данные другого типа, либо выполняем операции, которые
вовлекают данные разных типов, SQL Server пытается выполнить
преобразование и привести используемое значение к нужному типу.
Но не все преобразования SQL Server может выполнить автоматически.
SQL Server может выполнять неявные преобразования от типа с
меньшим приоритетом к типу с большим приоритетом. Таблица
приоритетов:
datetime > smalldatetime > float > real > decimal >
money > smallmoney > int > smallint > tinyint > bit
> nvarchar > nchar > varchar > char
То есть SQL Server автоматически может преобразовать число 100.0
(float) в дату и время (datetime).
109.
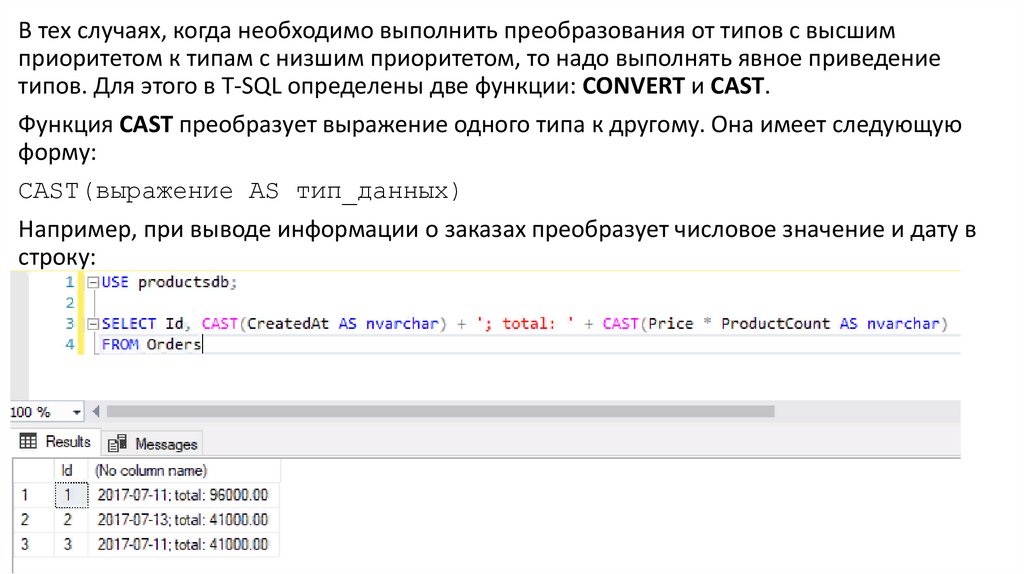
В тех случаях, когда необходимо выполнить преобразования от типов с высшимприоритетом к типам с низшим приоритетом, то надо выполнять явное приведение
типов. Для этого в T-SQL определены две функции: CONVERT и CAST.
Функция CAST преобразует выражение одного типа к другому. Она имеет следующую
форму:
CAST(выражение AS тип_данных)
Например, при выводе информации о заказах преобразует числовое значение и дату в
строку:
110.
ConvertБольшую часть преобразований охватывает функция CAST. Если же необходимо какое-то дополнительное
форматирование, то можно использовать функцию CONVERT. Она имеет следующую форму:
CONVERT(тип_данных, выражение [, стиль])
Третий необязательный параметр задает стиль форматирования данных. Этот параметр представляет
числовое значение, которое для разных типов данных имеет разную интерпретацию. Например, некоторые
значения для форматирования дат и времени:
0 или 100 - формат даты "Mon dd yyyy hh:miAM/PM" (значение по умолчанию)
1 или 101 - формат даты "mm/dd/yyyy"
3 или 103 - формат даты "dd/mm/yyyy"
7 или 107 - формат даты "Mon dd, yyyy hh:miAM/PM"
8 или 108 - формат даты "hh:mi:ss"
10 или 110 - формат даты "mm-dd-yyyy"
14 или 114 - формат даты "hh:mi:ss:mmmm" (24-часовой формат времени)
Некоторые значения для форматирования данных типа money в строку:
0 - в дробной части числа остаются только две цифры (по умолчанию)
1 - в дробной части числа остаются только две цифры, а для разделения разрядов применяется запятая
2 - в дробной части числа остаются только четыре цифры
111.
112.
TRY_CONVERTПри использовании функций CAST и CONVERT SQL Server выбрасывает
исключение, если данные нельзя привести к определенному типу. Например:
SELECT CONVERT(int, 'sql')
Чтобы избежать генерации исключения можно использовать
функцию TRY_CONVERT. Ее использование аналогично функции CONVERT за
тем исключением, что если выражение не удается преобразовать к нужному
типу, то функция возвращает NULL:
SELECT TRY_CONVERT(int, 'sql')
-- NULL
SELECT TRY_CONVERT(int, '22')
-- 22
113.
Дополнительные функцииКроме CAST, CONVERT, TRY_CONVERT есть еще ряд функций, которые могут
использоваться для преобразования в ряд типов:
STR(float [, length [,decimal]]): преобразует число в строку. Второй параметр
указывает на длину строки, а третий - сколько знаков в дробной части числа надо
оставлять
CHAR(int): преобразует числовой код ASCII в символ. Нередко используется для тех
ситуаций, когда необходим символ, который нельзя ввести с клавиатуры
ASCII(char): преобразует символ в числовой код ASCII
NCHAR(int): преобразует числовой код UNICODE в символ
UNICODE(char): преобразует символ в числовой код UNICODE
SELECT STR(123.4567, 6,2)
-- 123.46
SELECT CHAR(219)
-- Ы
SELECT ASCII('Ы')
-- 219
SELECT NCHAR(1067)
-- Ы
SELECT UNICODE('Ы')
-- 1067
114.
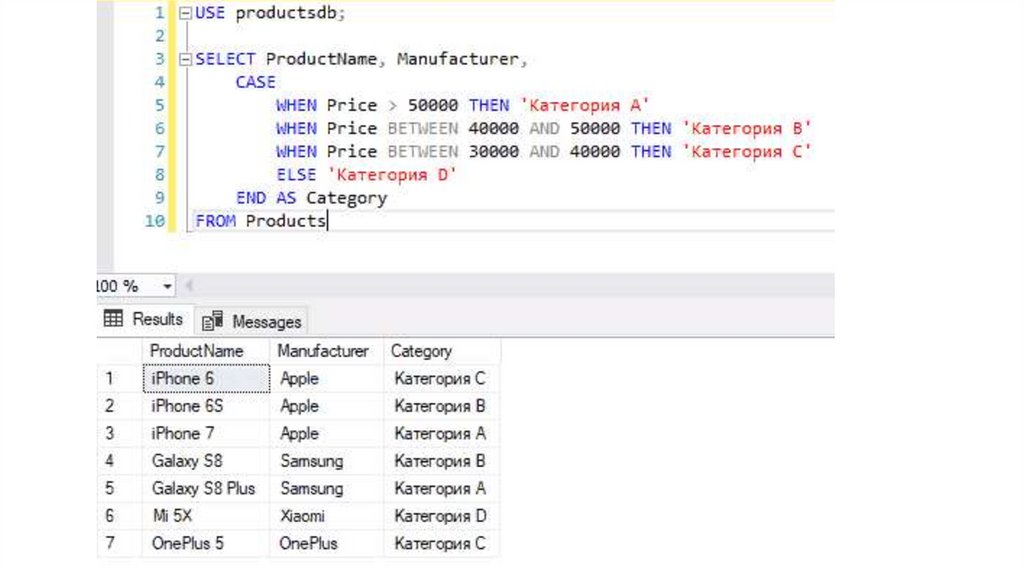
Функции CASE и IIFCASE
Функция CASE проверяет значение некоторого выражение, и в зависимости
от результата проверки может возвращать тот или иной результат.
CASE выражение
WHEN значение_1 THEN результат_1
WHEN значение_2 THEN результат_2
.................................
WHEN значение_N THEN результат_N
[ELSE альтернативный_результат]
END
115.
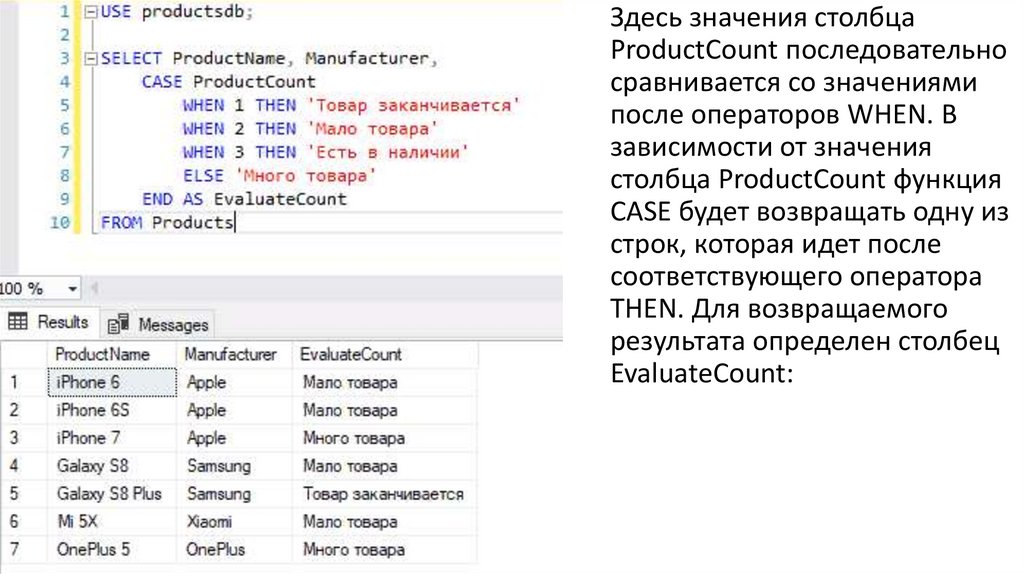
Здесь значения столбцаProductCount последовательно
сравнивается со значениями
после операторов WHEN. В
зависимости от значения
столбца ProductCount функция
CASE будет возвращать одну из
строк, которая идет после
соответствующего оператора
THEN. Для возвращаемого
результата определен столбец
EvaluateCount:
116.
Также функция CASE может принимать еще одну форму:CASE
WHEN выражение_1 THEN результат_1
WHEN выражение_2 THEN результат_2
.................................
WHEN выражение_N THEN результат_N
[ELSE альтернативный_результат]
END
117.
118.
IIFФункция IIF в зависимости от результата условного выражения возвращает
одно из двух значений. Общая форма функции выглядит следующим образом:
IIF(условие, значение_1, значение_2)
119.
Функции NEWID, ISNULL и COALESCENEWID
Для генерации объекта UNIQUEIDENTIFIER, то есть некоторого уникального
значения, используется функция NEWID(). Например, мы можем определить
для столбца первичного ключа тип UNIQUEIDENTIFIER и по умолчанию
присваивать ему значение функции NEWID:
CREATE TABLE Clients
(
Id UNIQUEIDENTIFIER PRIMARY KEY DEFAULT NEWID(),
FirstName NVARCHAR(20) NOT NULL,
LastName NVARCHAR(20) NOT NULL,
Phone NVARCHAR(20) NULL,
Email NVARCHAR(20) NULL
)
120.
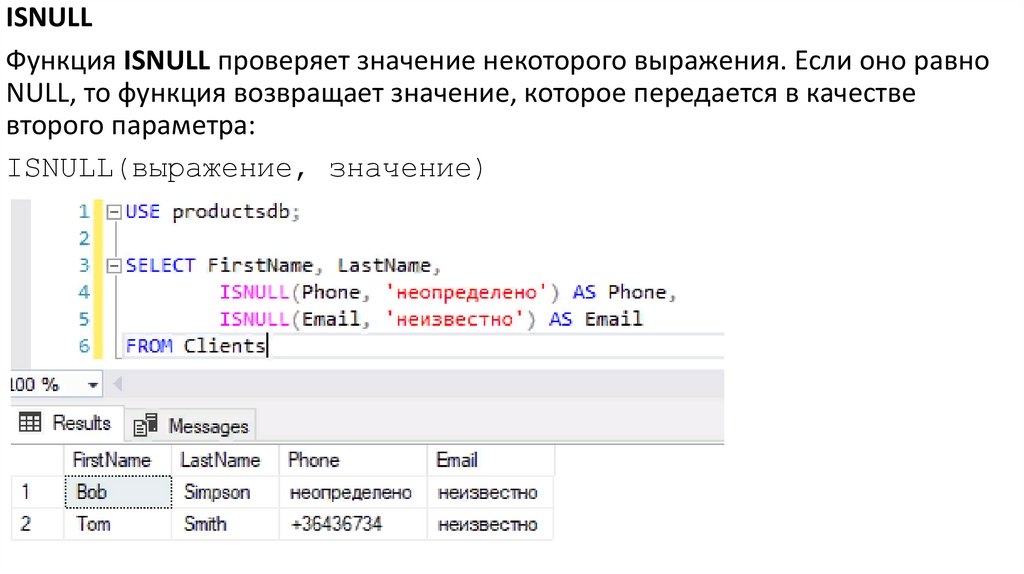
ISNULLФункция ISNULL проверяет значение некоторого выражения. Если оно равно
NULL, то функция возвращает значение, которое передается в качестве
второго параметра:
ISNULL(выражение, значение)
121.
COALESCEФункция COALESCE принимает список значений и возвращает первое из них,
которое не равно NULL:
COALESCE(выражение_1, выражение_2, выражение_N)
Например, выберем из таблицы Clients пользователей и в контактах у них
определим либо телефон, либо электронный адрес, если они не равны NULL:
SELECT FirstName, LastName,
COALESCE(Phone, Email, 'не определено') AS
Contacts
FROM Clients
То есть в данном случае возвращается телефон, если он определен. Если он не
определен, то возвращается электронный адрес. Если и электронный адрес не
определен, то возвращается строка "не определено".
122.
Переменные и управляющие конструкцииПеременные в T-SQL
Переменная представляет именованный объект, который хранит некоторое
значение. Для определения переменных применяется
выражение DECLARE, после которого указывается название и тип
переменной. При этом название локальной переменной должно
начинаться с символа @:
DECLARE @название_переменной тип_данных
Например, определим переменную name, которая будет иметь тип
NVARCHAR:
DECLARE @name NVARCHAR(20)
Также можно определить через запятую сразу несколько переменных:
DECLARE @name NVARCHAR(20), @age INT
123.
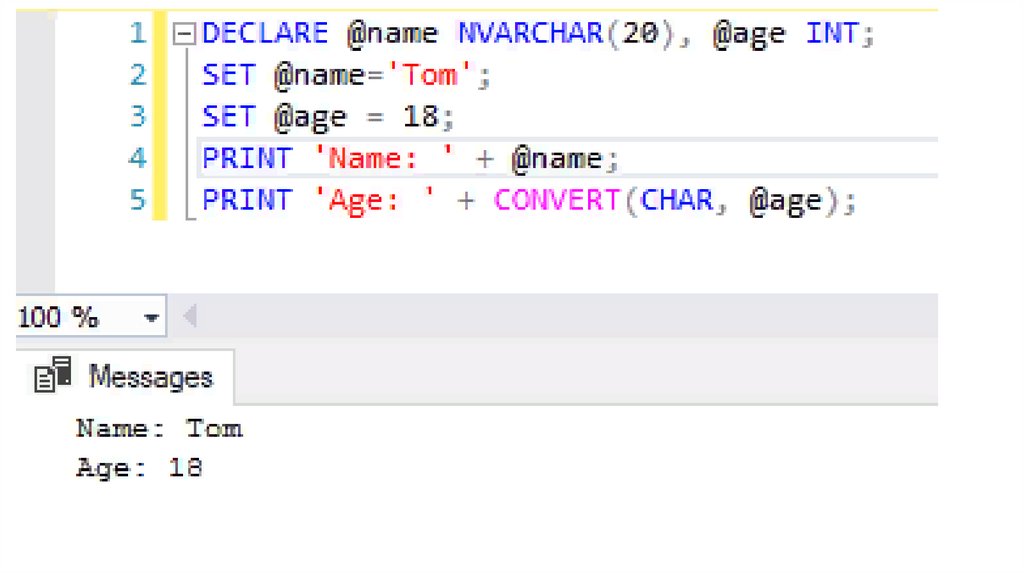
С помощью выражения SET можно присвоить переменной некотороезначение:
DECLARE @name NVARCHAR(20), @age INT;
SET @name='Tom';
SET @age = 18;
Так как @name предоставляет тип NVARCHAR, то есть строку, то этой
переменной соответственно и присваивается строка. А переменной @age
присваивается число, так как она представляет тип INT.
Выражение PRINT возвращает сообщение клиенту. Например:
PRINT 'Hello World‘
124.
125.
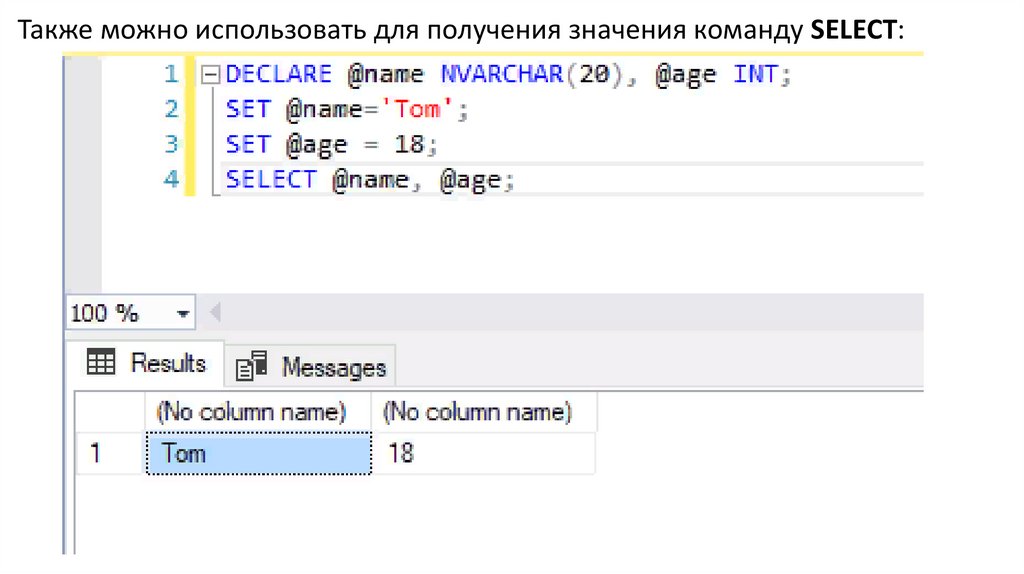
Также можно использовать для получения значения команду SELECT:126.
Переменные в запросахЧерез переменные мы можем передавать данные в запросы. И также мы
можем получать данные, которые являются результатом запросов, в
переменные. Например, при выборке из таблиц с помощью
команды SELECT мы можем извлекать данные в переменную с помощью
следующего синтаксиса:
SELECT @переменная_1 = спецификация_столбца_1,
@переменная_2 = спецификация_столбца_2,
......................................
@переменная_N = спецификация_столбца_N
Кроме того, в выражении SET значение, присваиваемое переменной, также
может быть результатом команды SELECT.
127.
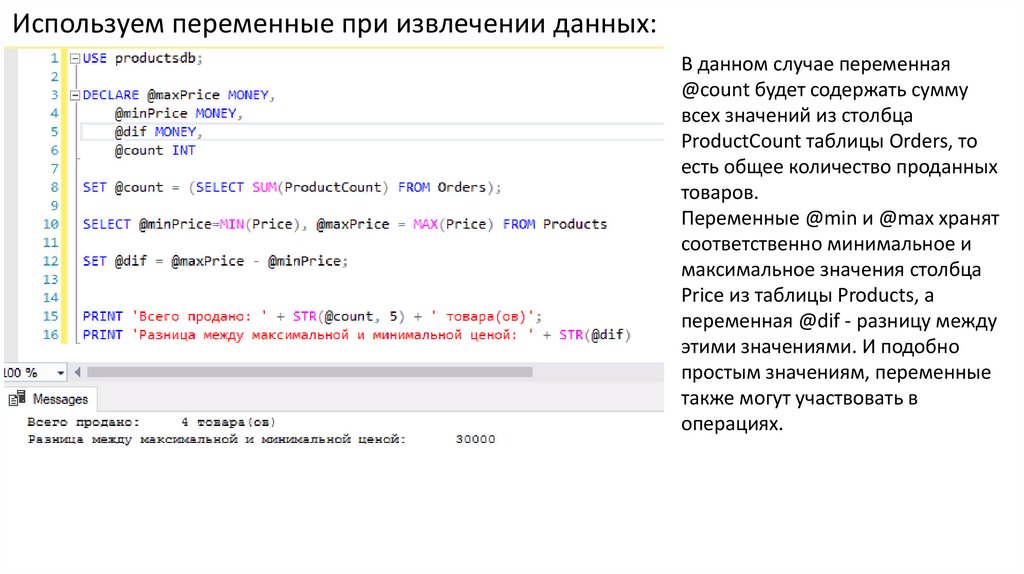
Используем переменные при извлечении данных:В данном случае переменная
@count будет содержать сумму
всех значений из столбца
ProductCount таблицы Orders, то
есть общее количество проданных
товаров.
Переменные @min и @max хранят
соответственно минимальное и
максимальное значения столбца
Price из таблицы Products, а
переменная @dif - разницу между
этими значениями. И подобно
простым значениям, переменные
также могут участвовать в
операциях.
128.
Другой пример:Здесь извлекаемые данные из двух
таблиц Products и Orders
группируются по столбцам Id и
ProductName из таблицы Products.
Затем данные фильтруются по
столбцу Id из Products. А
извлеченные данные попадают в
переменные @sum, @name,
@prodid.
129.
Условные выраженияДля выполнения действий по условию используется выражение
IF ... ELSE. SQL Server вычисляет выражение после ключевого слово IF. И если
оно истинно, то выполняются инструкции после ключевого слова IF. Если
условие ложно, то выполняются инструкции после ключевого слова ELSE.
Если после IF или ELSE располагает блок инструкций, то этот блок заключается
между ключевыми словами BEGIN и END:
IF условие
{инструкция|BEGIN...END}
[ELSE
{инструкция|BEGIN...END}]
Выражение ELSE является необязательным, и его можно опускать.
130.
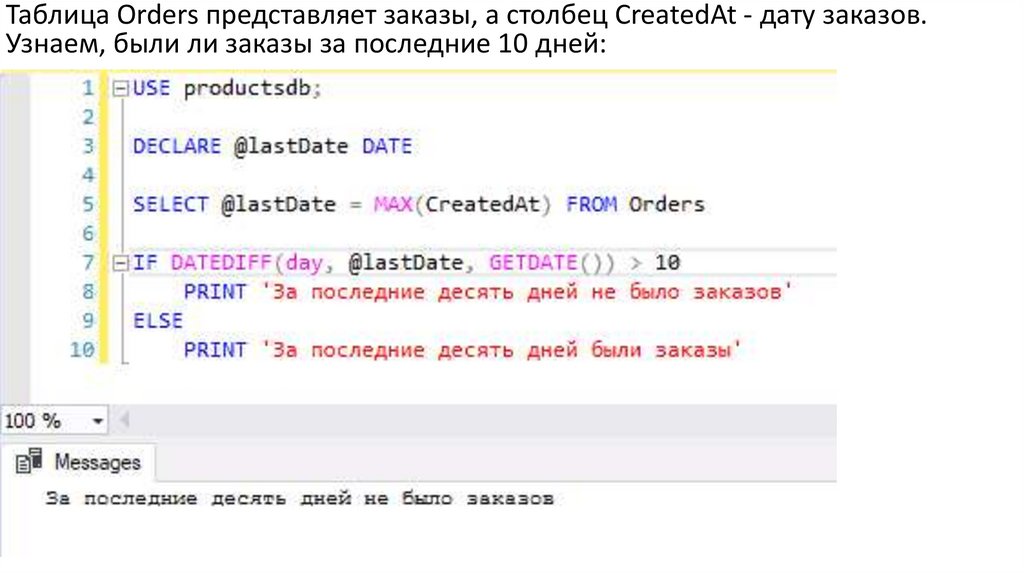
Таблица Orders представляет заказы, а столбец CreatedAt - дату заказов.Узнаем, были ли заказы за последние 10 дней:
131.
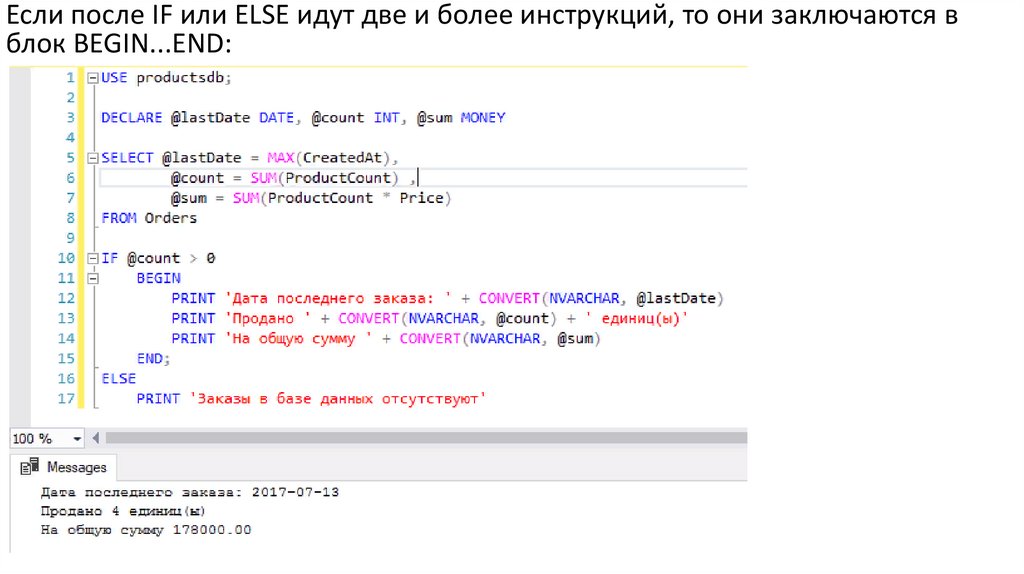
Если после IF или ELSE идут две и более инструкций, то они заключаются вблок BEGIN...END:
132.
ЦиклыДля выполнения повторяющихся операций в T-SQL применяются циклы. В
частности, в T-SQL есть цикл WHILE. Этот цикл выполняет определенные
действия, пока некоторое условие истинно.
WHILE условие
{инструкция|BEGIN...END}
Если в блоке WHILE необходимо разместить несколько инструкций, то все они
помещаются в блок BEGIN...END.
133.
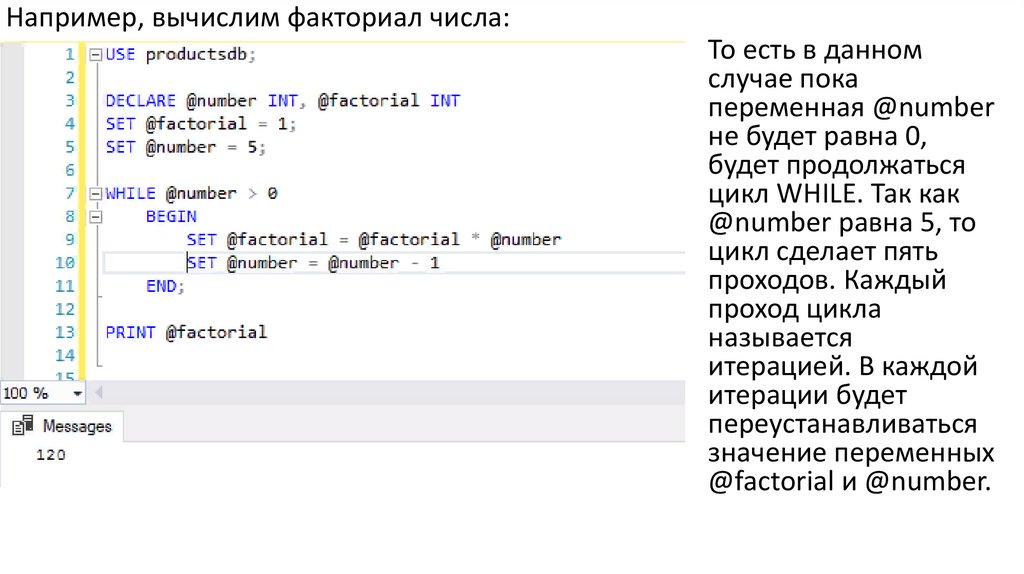
Например, вычислим факториал числа:То есть в данном
случае пока
переменная @number
не будет равна 0,
будет продолжаться
цикл WHILE. Так как
@number равна 5, то
цикл сделает пять
проходов. Каждый
проход цикла
называется
итерацией. В каждой
итерации будет
переустанавливаться
значение переменных
@factorial и @number.
134.
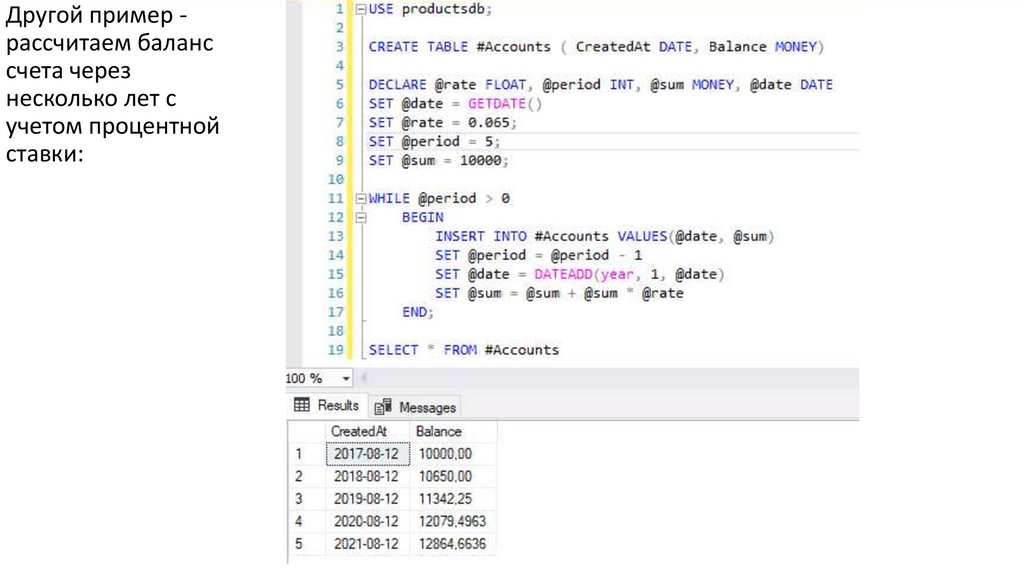
Другой пример рассчитаем баланссчета через
несколько лет с
учетом процентной
ставки:
135.
Операторы BREAK и CONTINUEОператор BREAK позволяет
завершить цикл, а оператор
CONTINUE - перейти к новой
итерации.
Когда переменная @number
станет равна 4, то с помощью
оператора CONTINUE произойдет
переход к новой итерации,
поэтому последующая строка
PRINT 'Конец итерации' не будет
выполняться, хотя цикл
продолжится.
Когда переменная @number
станет равна 7, то оператор BREAK
произведет выход из цикла, и он
завершится.
136.
Обработка ошибокДля обработки ошибок в T-SQL применяется конструкция TRY...CATCH. Она
имеет следующий формальный синтаксис:
BEGIN TRY
инструкции
END TRY
BEGIN CATCH
инструкции
END CATCH
Между выражениями BEGIN TRY и END TRY помещаются инструкции, которые
потенциально могут вызвать ошибку, например, какой-нибудь запрос. И если
в этом блоке TRY возникнет ошибка, то управление передается в блок CATCH,
где можно обработать ошибку.
137.
В блоке CATCH для обработки ошибки мы можем использовать ряд функций:ERROR_NUMBER(): возвращает номер ошибки
ERROR_MESSAGE(): возвращает сообщение об ошибке
ERROR_SEVERITY(): возвращает степень серьезности ошибки. Степень
серьезности представляет числовое значение. И если оно равно 10 и меньше,
то такая ошибка рассматривается как предупреждение и не обрабатывается
конструкцией TRY...CATCH. Если же это значение равно 20 и выше, то такая
ошибка приводит к закрытию подключения к базе данных, если она не
обрабатывается конструкцией TRY...CATCH.
ERROR_STATE(): возвращает состояние ошибки
138.
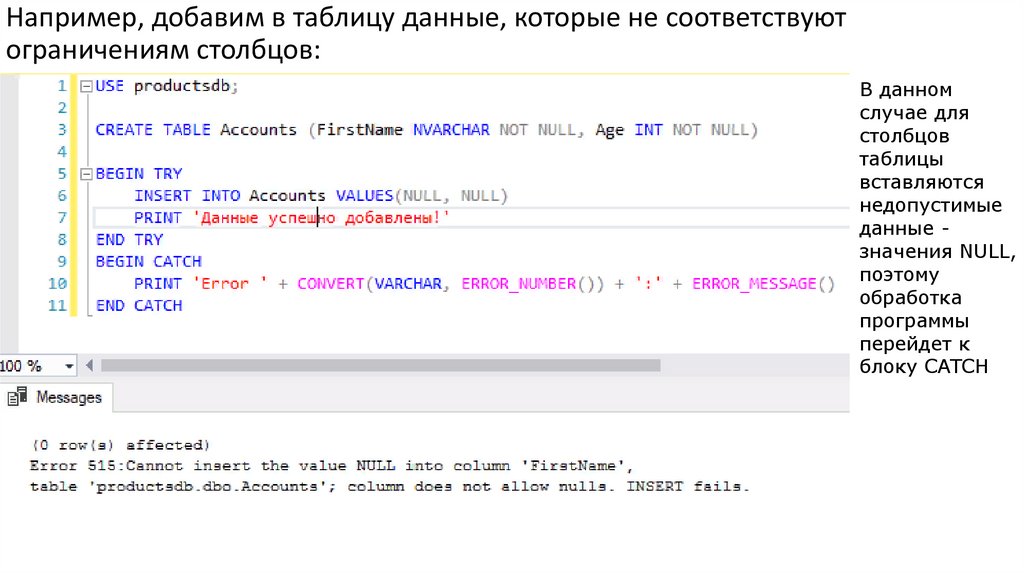
Например, добавим в таблицу данные, которые не соответствуютограничениям столбцов:
В данном
случае для
столбцов
таблицы
вставляются
недопустимые
данные значения NULL,
поэтому
обработка
программы
перейдет к
блоку CATCH
139.
ТриггерыОпределение триггеров
Триггеры представляют специальный тип хранимой процедуры, которая
вызывается автоматически при выполнении определенного действия над
таблицей или представлением, в частности, при добавлении, изменении или
удалении данных, то есть при выполнении команд INSERT, UPDATE, DELETE.
Формальное определение триггера:
CREATE TRIGGER имя_триггера
ON {имя_таблицы | имя_представления}
{AFTER | INSTEAD OF} [INSERT | UPDATE | DELETE]
AS выражения_sql
140.
Для создания триггера применяется выражение CREATE TRIGGER, после которогоидет имя триггера. Как правило, имя триггера отражает тип операций и имя
таблицы, над которой производится операция.
Каждый триггер ассоциируется с определенной таблицей или представлением, имя
которых указывается после слова ON.
Затем устанавливается тип триггера. Мы можем использовать один из двух типов:
AFTER: выполняется после выполнения действия. Определяется только для таблиц.
INSTEAD OF: выполняется вместо действия (то есть по сути действие - добавление,
изменение или удаление - вообще не выполняется). Определяется для таблиц и
представлений
После типа триггера идет указание операции, для которой определяется
триггер: INSERT, UPDATE или DELETE.
Для триггера AFTER можно применять сразу для нескольких действий, например,
UPDATE и INSERT. В этом случае операции указываются через запятую. Для триггера
INSTEAD OF можно определить только одно действие.
И затем после слова AS идет набор выражений SQL, которые собственно и
составляют тело триггера.
141.
Определим триггер, который будет срабатывать при добавлении иобновлении данных:
USE productdb;
GO
CREATE TRIGGER Products_INSERT_UPDATE
ON Products
AFTER INSERT, UPDATE
AS
UPDATE Products
SET Price = Price + Price * 0.38
WHERE Id = (SELECT Id FROM inserted)
142.
Допустим, в таблице Products хранятся данные о товарах. Но цена товаранередко содержит различные надбавки типа налога на добавленную
стоимость, налога на добавленную коррупцию и так далее. Человек,
добавляющий данные, может не знать все эти тонкости с налоговой базой, и
он определяет чистую цену. С помощью триггера мы можем поправить цену
товара на некоторую величину.
Таким образом, триггер будет срабатывать при любой операции INSERT или
UPDATE над таблицей Products. Сам триггер будет изменять цену товара, а
для получения того товара, который был добавлен или изменен, находим
этот товар по Id. Но какое значение должен иметь Id такой товар? Дело в том,
что при добавлении или изменении данные сохраняются в промежуточную
таблицу inserted. Она создается автоматически. И из нее мы можем получить
данные о добавленных/измененных товарах.
И после добавления товара в таблицу Products в реальности товар будет
иметь несколько большую цену, чем та, которая была определена при
добавлении
143.
144.
Удаление триггераДля удаления триггера необходимо применить команду DROP TRIGGER:
DROP TRIGGER Products_INSERT_UPDATE
Отключение триггера
Бывает, что мы хотим приостановить действие триггера, но удалять его
полностью не хотим. В этом случае его можно временно отключить с
помощью команды DISABLE TRIGGER:
DISABLE TRIGGER Products_INSERT_UPDATE ON Products
А когда триггер понадобится, его можно включить с помощью
команды ENABLE TRIGGER:
ENABLE TRIGGER Products_INSERT_UPDATE ON Products
145.
Триггеры для операций INSERT, UPDATE, DELETEДля рассмотрения операций с триггерами определим следующую базу данных productsdb:
CREATE DATABASE productsdb;
GO
USE productsdb;
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
CREATE TABLE History
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL,
Operation NVARCHAR(200) NOT NULL,
CreateAt DATETIME NOT NULL DEFAULT GETDATE(),
);
Здесь определены две таблиц: Products - для хранения товаров и History - для хранения истории операций с товарами.
146.
ДобавлениеПри добавлении данных (при выполнении команды INSERT) в триггере мы можем
получить добавленные данные из виртуальной таблицы INSERTED.
Определим триггер, который будет срабатывать после добавления:
USE productsdb
GO
CREATE TRIGGER Products_INSERT
ON Products
AFTER INSERT
AS
INSERT INTO History (ProductId, Operation)
SELECT Id, 'Добавлен товар ' + ProductName + '
фирма ' +
Manufacturer
FROM INSERTED
Этот триггер будет добавлять в таблицу History данные о добавлении товара,
которые берутся из виртуальной таблицы INSERTED.
147.
Выполним добавление данных в Products и получим данные из таблицыHistory:
148.
Удаление данныхПри удалении все удаленные данные помещаются в виртуальную
таблицу DELETED:
USE productsdb
GO
CREATE TRIGGER Products_DELETE
ON Products
AFTER DELETE
AS
INSERT INTO History (ProductId, Operation)
SELECT Id, 'Удален товар ' + ProductName + '
фирма ' +
Manufacturer
FROM DELETED
Здесь, как и в случае с предыдущим триггером, помещаем информацию об
удаленных товарах в таблицу History.
149.
Выполним команду на удаление:150.
Изменение данныхТриггер обновления данных срабатывает при выполнении операции UPDATE. И в
таком триггере мы можем использовать две виртуальных таблицы. Таблица
INSERTED хранит значения строк после обновления, а таблица DELETED хранит те
же строки, но до обновления.
Создадим триггер обновления:
USE productsdb
GO
CREATE TRIGGER Products_UPDATE
ON Products
AFTER UPDATE
AS
INSERT INTO History (ProductId, Operation)
SELECT Id, 'Обновлен товар ' + ProductName + '
фирма ' +
Manufacturer
FROM INSERTED
151.
152.
Триггер INSTEAD OFТриггер INSTEAD OF срабатывает вместо операции с данными. Он определяется в принципе также, как
триггер AFTER, за тем исключением, что он может определяться только для одной операции - INSERT, DELETE
или UPDATE. И также он может применяться как для таблиц, так и для представлений (триггер AFTER
применяется только для таблиц).
Например, создадим следующие базу данных и таблицу:
CREATE DATABASE prods;
GO
USE prods;
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
Price MONEY NOT NULL,
IsDeleted BIT NULL
);
Здесь таблица содержит столбец IsDeleted, который указывает, удалена ли запись. То есть вместо жесткого
удаления полностью из базы данных мы хотим выполнить мягкое удаление, при котором запись остается в
базе данных.
153.
Определим триггер для удаления записи:USE prods
GO
CREATE TRIGGER products_delete
ON Products
INSTEAD OF DELETE
AS
UPDATE Products
SET IsDeleted = 1
WHERE ID =(SELECT Id FROM deleted)
154.
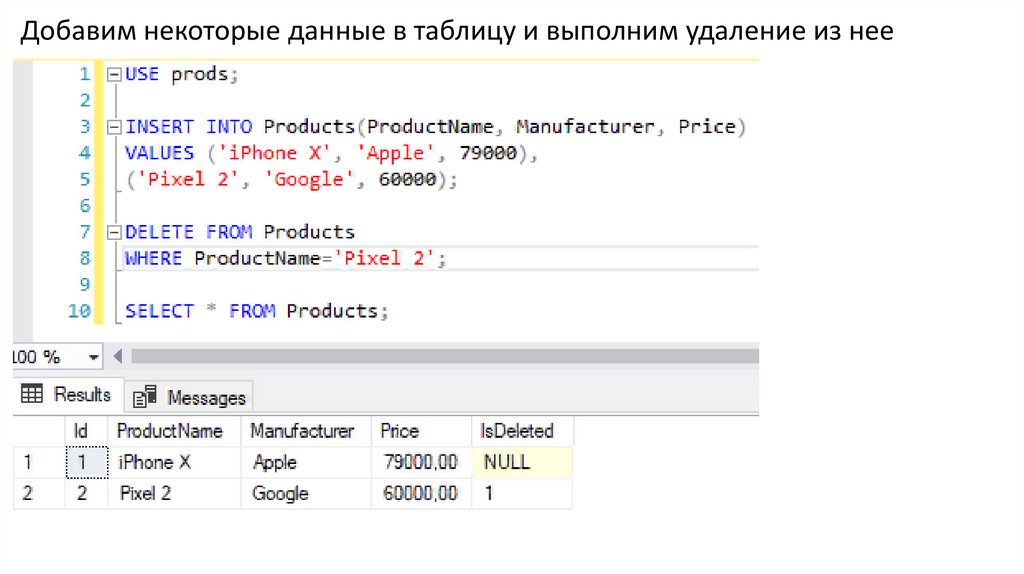
Добавим некоторые данные в таблицу и выполним удаление из нее155.
ПредставленияПредставления или Views представляют виртуальные таблицы. Но в отличии
от обычных стандартных таблиц в базе данных представления содержат
запросы, которые динамически извлекают используемые данные.
Представления дают нам ряд преимуществ. Они упрощают комплексные
SQL-операции. Они защищают данные, так как представления могут дать
доступ к части таблицы, а не ко всей таблице. Представления также
позволяют возвращать отформатированные значения из таблиц в нужной и
удобной форме.
Для создания представления используется команда CREATE VIEW, которая
имеет следующую форму:
CREATE VIEW название_представления [(столбец_1,
столбец_2, ....)] AS выражение_SELECT
156.
Например, пусть у нас есть три связанных таблицы:CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
CREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(30) NOT NULL
);
CREATE TABLE Orders
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE,
CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE,
CreatedAt DATE NOT NULL,
ProductCount INT DEFAULT 1,
Price MONEY NOT NULL
);
157.
Теперь добавим в базу данных, в которой содержатся данные таблицы,следующее представление:
CREATE VIEW OrdersProductsCustomers AS
SELECT Orders.CreatedAt AS OrderDate,
Customers.FirstName AS Customer,
Products.ProductName As Product
FROM Orders INNER JOIN Products ON Orders.ProductId =
Products.Id
INNER JOIN Customers ON Orders.CustomerId =
Customers.Id
158.
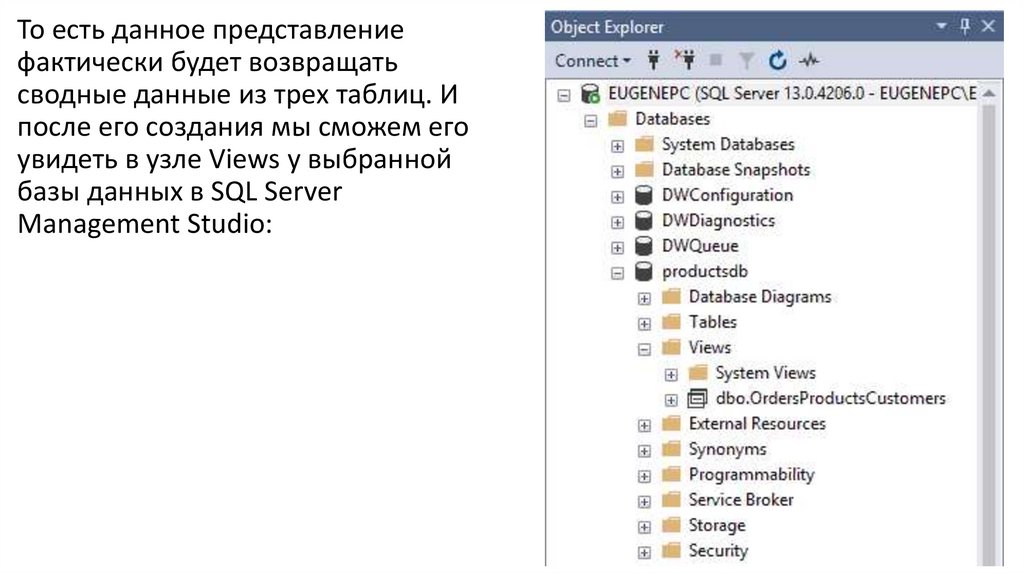
То есть данное представлениефактически будет возвращать
сводные данные из трех таблиц. И
после его создания мы сможем его
увидеть в узле Views у выбранной
базы данных в SQL Server
Management Studio:
159.
Теперь используем созданное выше представление для получения данных:160.
При создании представлений следует учитывать, что представления, как и таблицы, должныиметь уникальные имена в рамках той же базы данных.
Представления могут иметь не более 1024 столбцов и могут обращать не более чем к 256
таблицам.
Также можно создавать представления на основе других представлений. Такие представления
еще называют вложенными (nested views). Однако уровень вложенности не может быть больще
32-х.
Команда SELECT, используемая в представлении, не может включать выражения INTO или ORDER
BY (за исключением тех случаев, когда также применяется выражение TOP или OFFSET). Если же
необходима сортировка данных в представлении, то выражение ORDER BY применяется в
команде SELECT, которая извлекает данные из представления.
Также при создании представления можно определить набор его столбцов:
CREATE VIEW OrdersProductsCustomers2 (OrderDate, Customer,Product)
AS SELECT Orders.CreatedAt,
Customers.FirstName,
Products.ProductName
FROM Orders INNER JOIN Products ON Orders.ProductId = Products.Id
INNER JOIN Customers ON Orders.CustomerId = Customers.Id
161.
Изменение представленияДля изменения представления используется команда ALTER VIEW. Эта команда
имеет практически тот же самый синтаксис, то и CREATE VIEW:
ALTER VIEW название_представления [(столбец_1, столбец_2,
....)]
AS выражение_SELECT
Например, изменим выше созданное представление OrdersProductsCustomers:
ALTER VIEW OrdersProductsCustomers
AS SELECT Orders.CreatedAt AS OrderDate,
Customers.FirstName AS Customer,
Products.ProductName AS Product,
Products.Manufacturer AS Manufacturer
FROM Orders INNER JOIN Products ON Orders.ProductId =
Products.Id
INNER JOIN Customers ON Orders.CustomerId = Customers.Id
162.
Удаление представленияДля удаления представления вызывается команда DROP VIEW:
DROP VIEW OrdersProductsCustomers
Также стоит отметить, что при удалении таблиц также следует удалить и
представления, которые используют эти таблицы.
163.
Хранимые процедурыСоздание и выполнение процедур
Нередко операция с данными представляет набор инструкций, которые необходимо
выполнить в определенной последовательности. Например, при добавлении покупке
товара необходимо внести данные в таблицу заказов. Однако перед этим надо
проверить, а есть ли покупаемый товар в наличии. Возможно, при этом понадобится
проверить еще ряд дополнительных условий. То есть фактически процесс покупки товара
охватывает несколько действий, которые должны выполняться в определенной
последовательности. И в этом случае более оптимально будет инкапсулировать все эти
действия в один объект - хранимую процедуру (stored procedure).
То есть по сути хранимые процедуры представляет набор инструкций, которые
выполняются как единое целое. Тем самым хранимые процедуры позволяют упростить
комплексные операции и вынести их в единый объект. Изменится процесс покупки
товара, соответственно достаточно будет изменить код процедуры. То есть процедура
также упрощает управление кодом.
Также хранимые процедуры позволяют ограничить доступ к данным в таблицах и тем
самым уменьшить вероятность преднамеренных или неосознанных нежелательных
действий в отношении этих данных.
И еще один важный аспект - производительность. Хранимые процедуры обычно
выполняются быстрее, чем обычные SQL-инструкции. Все потому что код процедур
компилируется один раз при первом ее запуске, а затем сохраняется в
скомпилированной форме.
164.
Для создания хранимой процедуры применяется команда CREATEPROCEDURE или CREATE PROC.
Таким образом, хранимая процедура имеет три ключевых особенности:
упрощение кода, безопасность и производительность.
Например, пусть в базе данных есть таблица, которая хранит данные о
товарах:
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
165.
Создадим хранимую процедуру для извлечения данных из этой таблицы:USE productsdb;
GO
CREATE PROCEDURE ProductSummary AS
SELECT ProductName AS Product, Manufacturer, Price
FROM Products
Поскольку команда CREATE PROCEDURE должна вызываться в отдельном пакете, то после
команды USE, которая устанавливает текущую базу данных, используется команда GO для
определения нового пакета.
После имени процедуры должно идти ключевое слово AS.
Для отделения тела процедуры от остальной части скрипта код процедуры нередко помещается в
блок BEGIN...END:
USE productsdb;
GO
CREATE PROCEDURE ProductSummary AS
BEGIN
SELECT ProductName AS Product, Manufacturer, Price
FROM Products
END;
166.
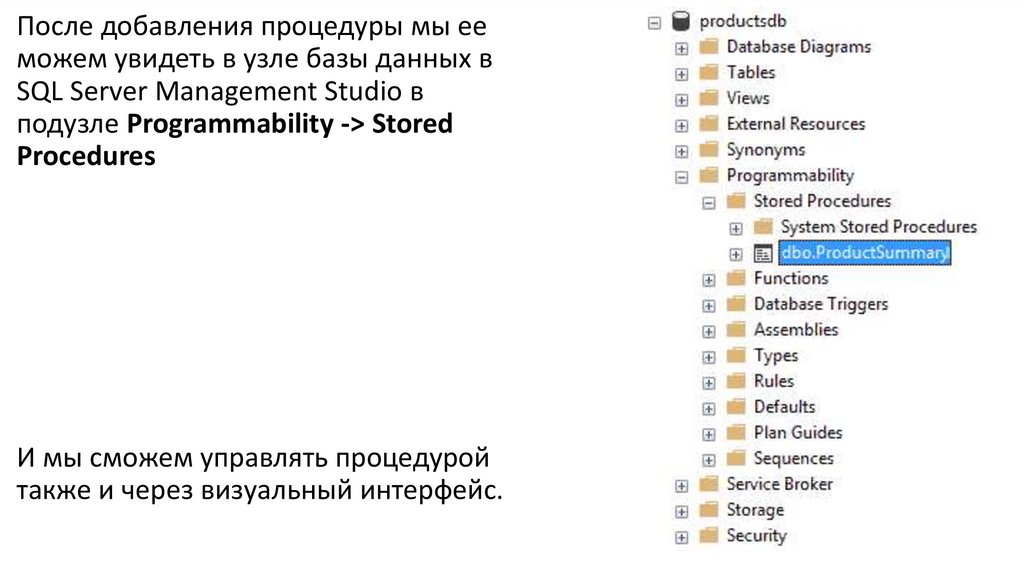
После добавления процедуры мы ееможем увидеть в узле базы данных в
SQL Server Management Studio в
подузле Programmability -> Stored
Procedures
И мы сможем управлять процедурой
также и через визуальный интерфейс.
167.
Для выполненияхранимой процедуры
вызывается команда
EXEC или EXECUTE
Для удаления
процедуры применяется
команда DROP
PROCEDURE:
DROP PROCEDURE
ProductSummary
168.
Параметры в процедурахПроцедуры могут принимать параметры. Параметры бывают входными - с их
помощью в процедуру можно передать некоторые значения. И также параметры
бывают выходными - они позволяют возвратить из процедуры некоторое
значение.
Например, пусть в базе данных будет следующая таблица Products:
USE productsdb;
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
169.
Определим процедуру, которая будет добавлять данные в эту таблицу:USE productsdb;
GO
CREATE PROCEDURE AddProduct
@name NVARCHAR(20),
@manufacturer NVARCHAR(20),
@count INT,
@price MONEY
AS
INSERT INTO Products(ProductName, Manufacturer, ProductCount,
Price)
VALUES(@name, @manufacturer, @count, @price)
После названия процедуры идет список входных параметров, которые определяются
также как и переменные - название начинается с символа @, а после названия идет тип
переменной. И с помощью команды INSERT значения этих параметров будут
передаваться в таблицу Products.
170.
Используем процедуру.Здесь передаваемые в
процедуру значения
определяются через
переменные. При вызове
процедуры ей через
запятую передаются
значения. При этом
значения передаются
параметрам
процедуры по позиции.
Так как первым определен
параметр @name, то ему
будет передаваться
первое значение значение переменной
@prodName. Второму
параметру @manufacturer
передается второе
значение - значение
переменной @company и
так далее. Главное, чтобы
между передаваемыми
значениями и
параметрами процедуры
было соответствие по типу
данных.
171.
Также можно было бы передать непосредственно значения:EXEC AddProduct 'Galaxy C7', 'Samsung', 5, 22000
Также значения параметрам процедуры можно передавать по имени:
USE productsdb;
DECLARE @prodName NVARCHAR(20), @company NVARCHAR(20);
SET @prodName = 'Honor 9'
SET @company = 'Huawei'
EXEC AddProduct @name = @prodName,
@manufacturer=@company,
@count = 3,
@price = 18000
При передаче параметров по имени параметру процедуры присваивается некоторое
значение.
172.
Параметры можно отмечать как необязательные, присваивая им некотороезначение по умолчанию. Например, в случае выше мы можем автоматически
устанавливать для количества товара значение 1, если соответствующее значение
не передано в процедуру:
USE productsdb;
GO
CREATE PROCEDURE AddProductWithOptionalCount
@name NVARCHAR(20),
@manufacturer NVARCHAR(20),
@price MONEY,
@count INT = 1
AS
INSERT INTO Products(ProductName, Manufacturer,
ProductCount, Price)
VALUES(@name, @manufacturer, @count, @price)
173.
При этом необязательные параметры лучше помещать в конце списка параметровпроцедуры.
DECLARE @prodName NVARCHAR(20), @company NVARCHAR(20),
@price MONEY
SET @prodName = 'Redmi Note 5A'
SET @company = 'Xiaomi'
SET @price = 22000
EXEC AddProductWithOptionalCount @prodName, @company,
@price
SELECT * FROM Products
И в этом случае для параметра @count в процедуру можно не передавать
значение.
174.
Выходные параметры и возвращение результатаВыходные параметры позволяют возвратить из процедуры некоторый
результат. Выходные параметры определяются с помощью ключевого
слова OUTPUT. Например, определим еще одну процедуру:
USE productsdb;
GO
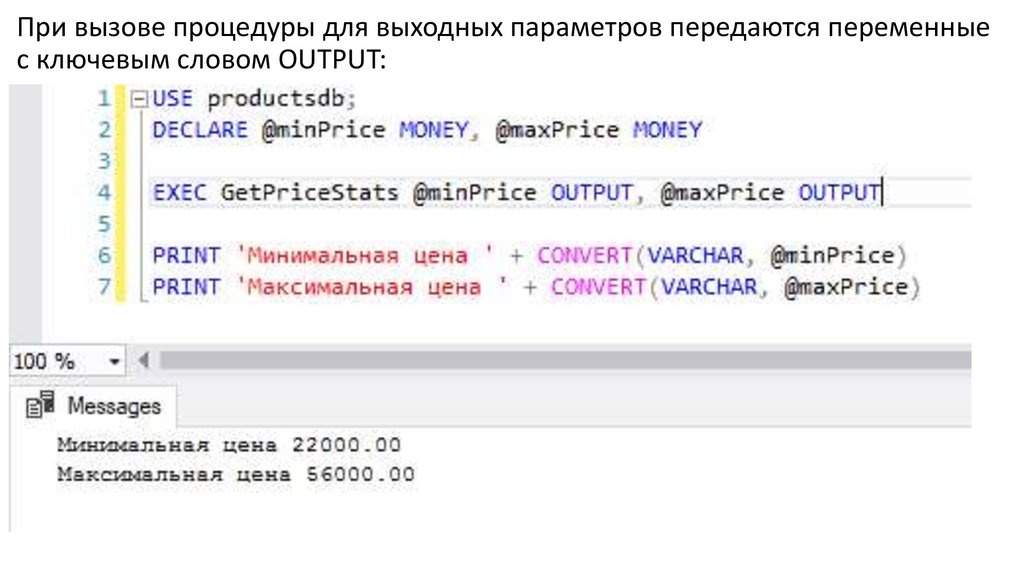
CREATE PROCEDURE GetPriceStats
@minPrice MONEY OUTPUT,
@maxPrice MONEY OUTPUT
AS
SELECT @minPrice = MIN(Price), @maxPrice = MAX(Price)
FROM Products
175.
При вызове процедуры для выходных параметров передаются переменныес ключевым словом OUTPUT:
176.
Также можно сочетать входные и выходные параметры. Например, определимпроцедуру, которая добавляет новую строку в таблицу и возвращает ее id:
USE productsdb;
GO
CREATE PROCEDURE CreateProduct
@name NVARCHAR(20),
@manufacturer NVARCHAR(20),
@count INT,
@price MONEY,
@id INT OUTPUT
AS
INSERT INTO Products(ProductName, Manufacturer,
ProductCount, Price)
VALUES(@name, @manufacturer, @count, @price)
SET @id = @@IDENTITY
177.
С помощью глобальной переменной @@IDENTITY можно получитьидентификатор добавленной записи.
При вызове этой процедуры ей также по позиции передаются все входные и
выходные параметры:
USE productsdb;
DECLARE @id INT
EXEC CreateProduct 'LG V30', 'LG', 3, 28000, @id OUTPUT
PRINT @id
178.
Возвращение значенияКроме передачи результата выполнения через выходные параметры хранимая процедура
также может возвращать какое-либо значение с помощью оператора RETURN. Хотя данная
возможность во многом нивелирована использованием выходных параметров, через которые
можно возвращать результат, тем не менее, если надо возвратить из процедуры одно
значение, то вполне можно использовать оператор RETURN.
Например, возвратим среднюю цену на товары:
USE productsdb;
GO
CREATE PROCEDURE GetAvgPrice AS
DECLARE @avgPrice MONEY
SELECT @avgPrice = AVG(Price)
FROM Products
RETURN @avgPrice;
После оператора RETURN указывается возвращаемое значение. В данном случае это значение
переменной @avgPrice.
179.
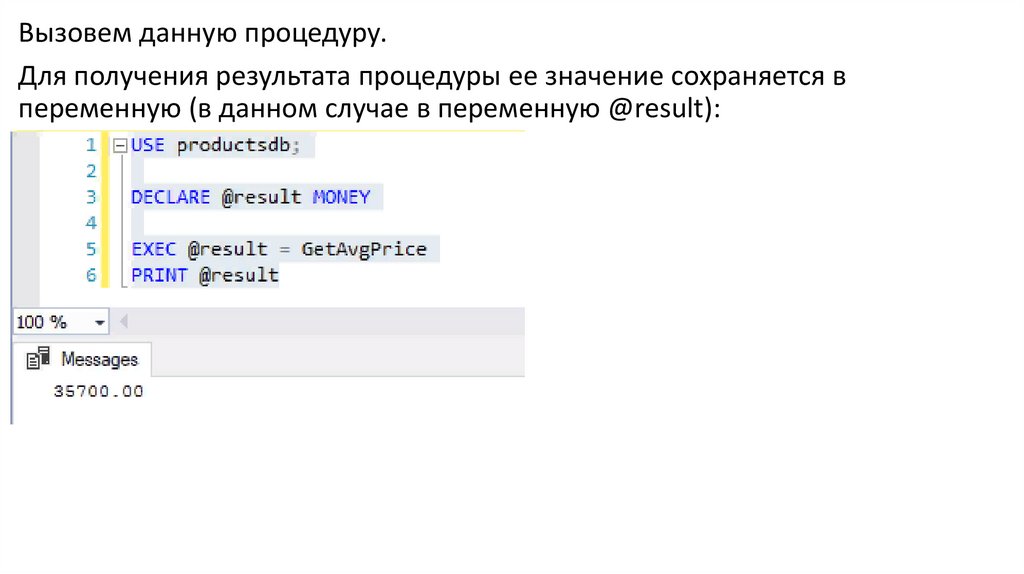
Вызовем данную процедуру.Для получения результата процедуры ее значение сохраняется в
переменную (в данном случае в переменную @result):