


")














")




")



")



")





 software
softwareSimilar presentations:










Как определить семантическую близость между словами
1. Как определить семантическую близость слов на основе коллекции текстов
2. Как определить семантическую близость между словами
• Проблема ресурсов (WordNet)– Трудозатратно делать
– Никогда не полны
– Могут не совсем соответстовать задаче и
предметной области
• Корпус (коллекция) текстов
– Как извлечь из текстов оценку семантической
близости слов.
3. Классический подход к созданию векторных представлений слов
• Препроцессинг– Токенизация, удаление знаков препинания
• Определение контекста
– Предложение
– Количество слов (симметрично/несимметрично)
• Подсчет матрицы совстречаемости
• Взвешивание признаков
• Вычисление близости на основе полученных
векторов
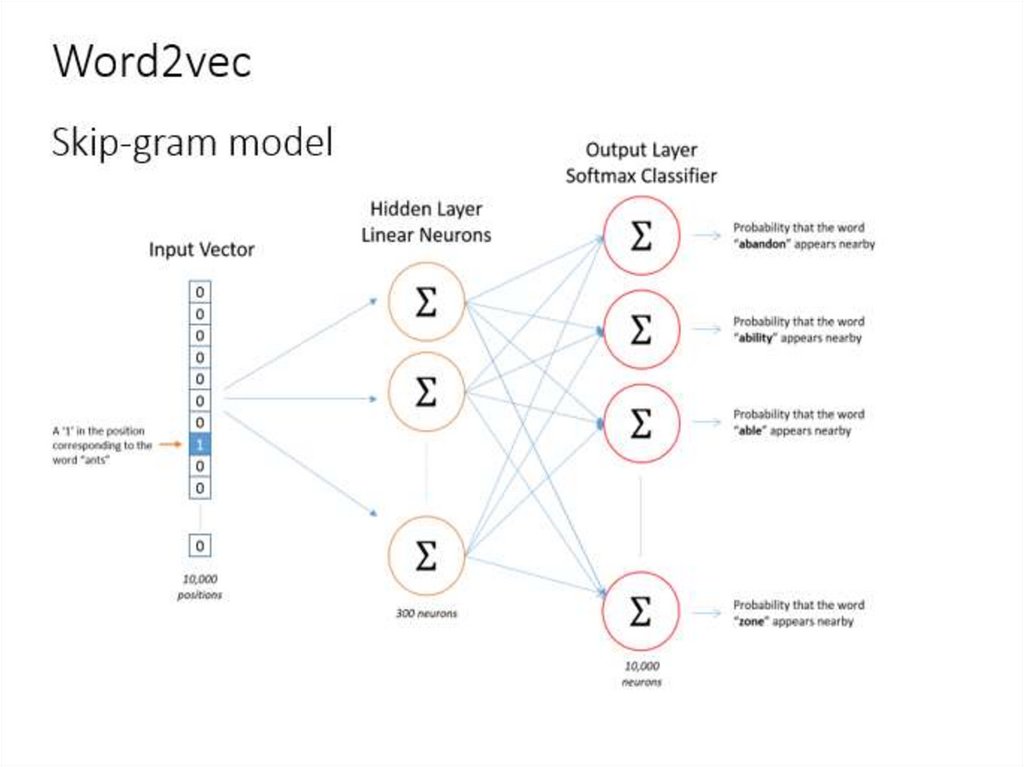
4. Представление значения слова – word2vec (Mikolov et al., 2013)
• 2 базовые архитектуры нейронных сетей:– Continuous Bag of Word (CBOW): использует окно контекста
для предсказания слова
– Skip-gram (SG): используется слово для предсказания
окружающих слов
5. Нейронная языковая модель:
• Вход – one-hot vector – вектор всех нулей и одной 1 впозиции текущего слова
• Projection – layer – выделяет из матрицы вектор, соотв.
данному слову (h)
• Выходной уровень получается линейной комбинацией:
• S=Wh
• Результат выходного уровня вероятность появления слова,
так называемый softmax
• Word2vec - это однослойный персептрон с логистической
функцией активации (обобщение для многомерного случая)
6.
7. Предсказание слова car около слова ants
8. Большие матрицы, долгая обработка
• Подходы– Subsampling frequent words
• Для the – слишком много контекстов,
• The – мало что говорит о соседних словах
• Решение
– Слова выкидываются из текста с вероятностью
пропорциональной их частоте
– Negative sampling (негативное сэмплирование)
9. Негативное сэмплирование
• Обучение по каждому примеру требует пересчетавесов для всех слов в выходном слове
• Идея: выбрать некоторое количество (например, 5)
негативных слов (т.е. тех которых нет в контексте) и
только для них перестроить веса (и также веса
пересчитываются для положительных слов)
• Негативные слова выбираются с вероятностью,
связанной с их частотой. В реализации word2vec –
это выглядит так:
10. Реализации word2vec
• Исходный код:– https://github.com/tmikolov/word2vec
• Gensim
– https://radimrehurek.com/gensim/models/word2
vec.html
• Есть реализации в пакетах нейронных
сетей (Torch, TensorFlow, Theano)
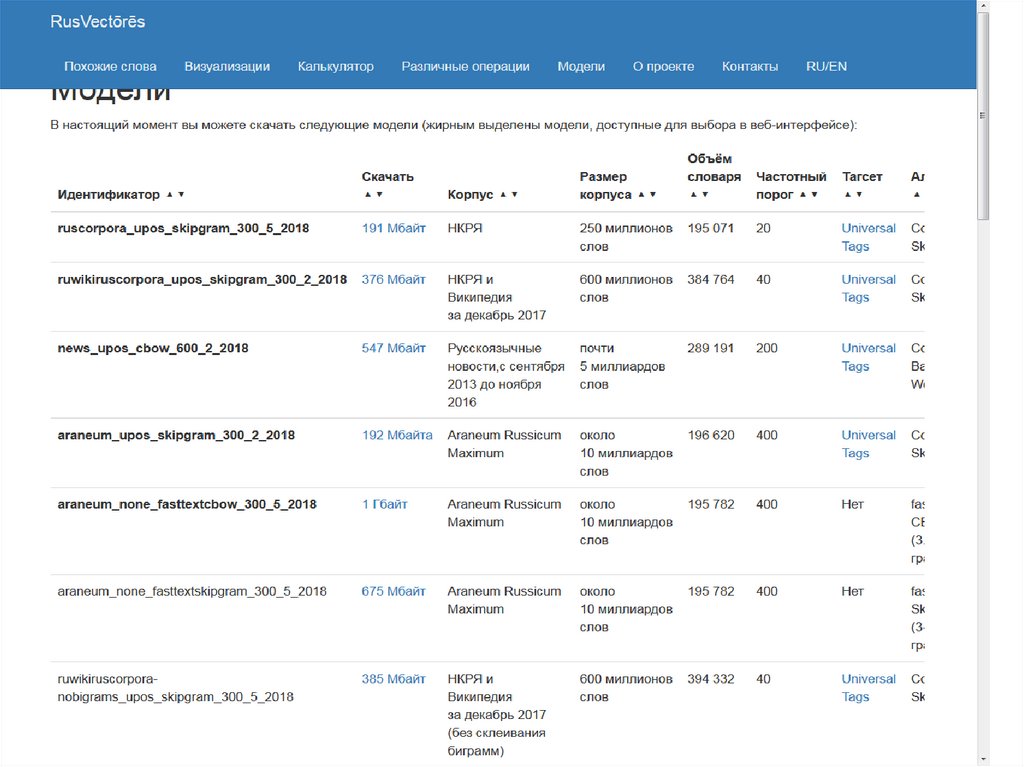
• Есть уже насчитанные модели
– Для русского языка (rusvectores.org )
11.
12. Сайт rusvectores.ru: сходство векторов слов
13. Подход FastText
• В качестве векторного представления для словаберется среднее из представлений входящих в него
n-грамм
– то есть слово «ребенок» - это некоторая
усредненная сумма векторов «ре», «еб», «бе»,
«ен» и т.д. (пример для биграмм)
• Плюсы подхода:
– Символьные n-граммы встречаются чаще, чем
слова целиком.
– Учтем похожесть контекстов слов с одинаковыми
аффиксами.
• n-граммы из аффиксов «выловят» семантику и
синтаксис,
• n-граммы из корней – лексику.
14. FastText для 157 языков
• https://fasttext.cc/docs/en/crawlvectors.html• Обучение
– Интернет-корпус Common-crawl+Wikipedia
• ~104 миллиардах токенов в случае русского
языка (103 Common Crawl и 1 это вики)
– Cbow, размерность 3
– Нграммы длиной 5
– Negative sampling 10
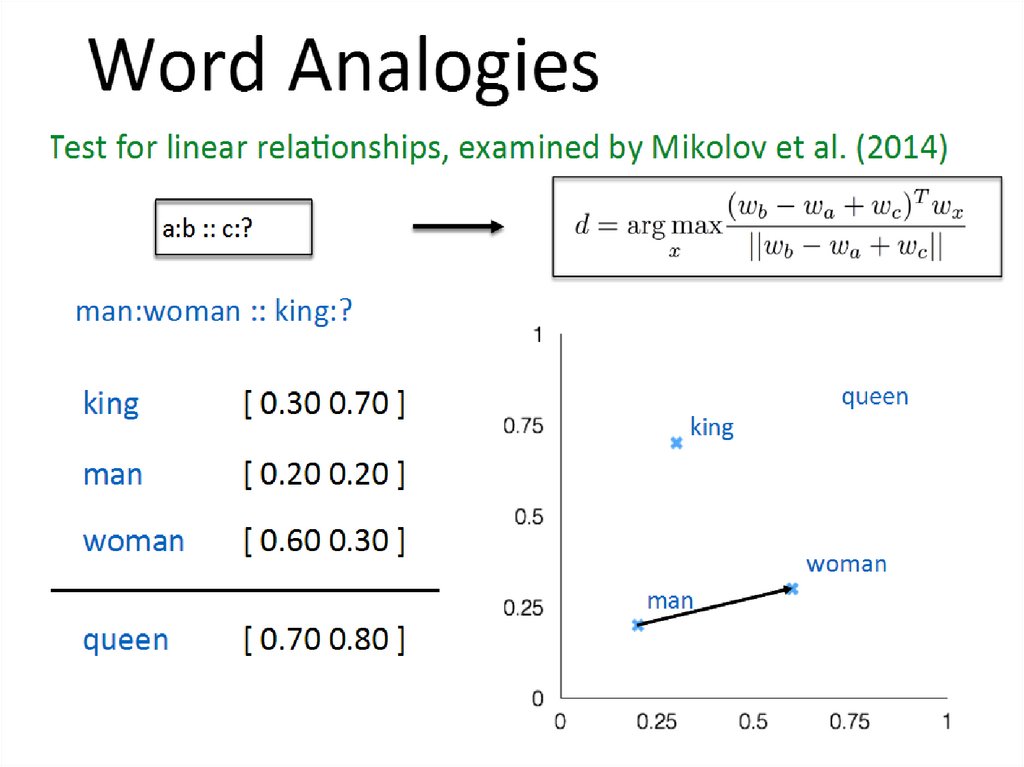
15. Тестирование моделей
• Датасеты пар слов с человеческимиоценками близости
• Вставка синонимов
• Пропорции-аналогии
16.
17.
18. Сексизм нейронных языковых моделей
19. Датасеты для тестирования по аналогиии
• Аналогии “a is to a ∗ as b is to b∗– MSR’s analogy dataset
• 8000 морфосинтаксических аналогий
• good is to best as smart is to smartest
– Google’s analogy dataset
• 19544 морфосинтаксических и семантических
аналогий
• Paris is to France as Tokyo is to Japan
20. “Neural Word Embeddings as Implicit Matrix Factorization” Levy & Goldberg, NIPS 2014
“Neural Word Embeddings as Implicit MatrixFactorization”
Levy & Goldberg, NIPS 2014
21.
22. Skip-Grams with Negative Sampling (SGNS)
“word2vecExplained…”
22
23. What is SGNS learning?
2324. What is SGNS learning?
2425. What is SGNS learning?
“Neural Word Embeddings as25
Implicit Matrix Factorization”
26. Точнее: What is SGNS learning?
“Neural Word Embeddings as26
Implicit Matrix Factorization”
27. Conclusions: Distributional Similarity (Levy et al., 2014)
The Contributions of Word Embeddings:•Novel Algorithms
•New Hyperparameters
What’s really improving performance?
•Hyperparameters (mostly)
•The algorithms are an improvement as well
•SGNS is robust (том смысле, что на различных наборах данных
занимал 1 или 2 место среди других методов)
•В любом случае появились удобные инструменты для
построения распределенных представлений слов 27
28. Применение векторных представлений слов
• 1) Исследование семантических близостейслов
– Группирование слов,
– Предсказание отношений между словами
• 2) Вход всех нейронных сетей для
автоматической обработки текстов – это
векторные представления слов (+ доп.
признаки()
– Эффективно брать предобученные векторные
представления
29. RUSSE: The First Workshop on Russian Semantic Similarity
Panchenko A., Loukachevitch N. V., Ustalov D.,Paperno D., Meyer C. M., Konstantinova N.
30. Human judgements: Crowdsourcing
31. Example of human judgements about semantic similarity (HJ)
32. Top 5 best models according to the HJ benchmark
33. Graph Embeddings
34. Graph Embeddings
Случайное блуждание по графу можно представитькак последовательность слов, где слово – это вершина.
И тогда можно применять любые модели для
получения векторных представлений
35. Node2vec (2016)
• Рассматривается граф со взвешеннымиребрами
• Случайные блуждания по графу можно
рассматривать как предложения в корпусе.
• Каждый узел в графе рассматривается как
отдельное слово, а случайное блуждание
рассматривается как предложение.
• By feeding these "sentences" into a skip-gram,
or by using the continuous bag of words model
paths found by random walks can be treated as
sentences,
36. Случайное блуждание
• Случайный переход пределяется на основедвух шагов – 2 nd order random walk
• Параметры p и q, которые направляют
переходы:
– Поиск в ширину (Breadth-first Sampling)
– Поиск в глубину Depth-first Sampling (DFS)
– Return parameter, p – контролирует вероятность
немедленного захода в исходную вершину
– In-out parameter q – контролирует движение к
внешним вершинам, дальше от предыдуще
37. Node2vec
38. Случайные переходы управляются параметрами p и q
39. Результат случайных блужданий
• Текстовая запись прохода по вершинам, покоторой можно обучать эмбеддинги разных
типов
40. Задание
• Библиотека Fasttext https://fasttext.cc/– Используйте вектора, насчитанные на Википедии:
https://dl.fbaipublicfiles.com/fasttext/vectorsenglish/wiki-news-300d-1M.vec.zip
• Посчитать близости для пар слов из списков wordsim
similarity, wordsim-relatedness.
• Вычислить корреляцию Спирмена (пакет)
результатов с ручными оценками
• Сравнить с результатами вычисления близости на
основе WordNet