

































 programming
programmingSimilar presentations:





")
 языка Java. (Лекция 16)")
")


JPA & Hibernate
1.
JPA & Hibernateastondevs. ru
2.
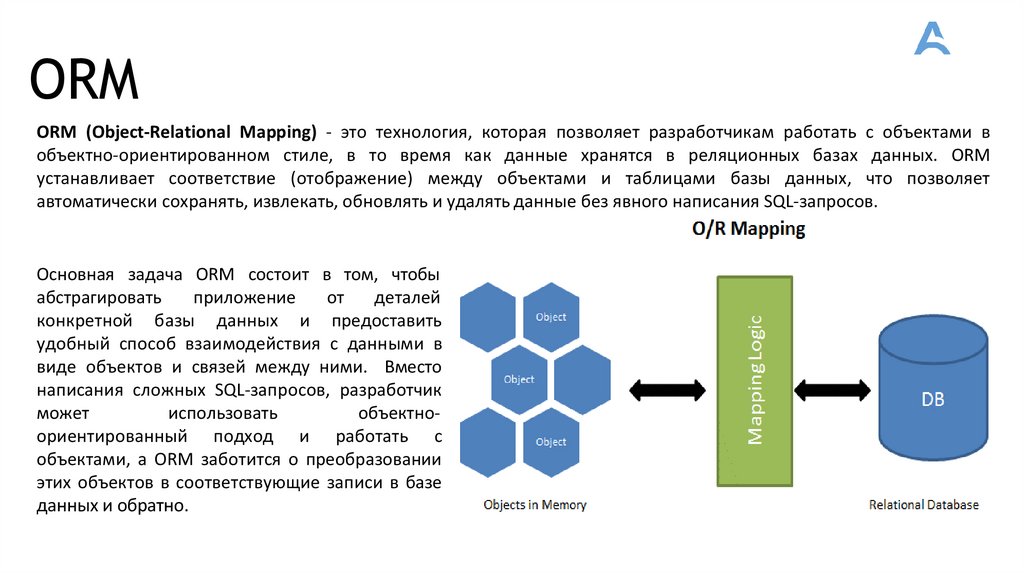
ORMORM (Object-Relational Mapping) - это технология, которая позволяет разработчикам работать с объектами в
объектно-ориентированном стиле, в то время как данные хранятся в реляционных базах данных. ORM
устанавливает соответствие (отображение) между объектами и таблицами базы данных, что позволяет
автоматически сохранять, извлекать, обновлять и удалять данные без явного написания SQL-запросов.
Основная задача ORM состоит в том, чтобы
абстрагировать
приложение
от
деталей
конкретной базы данных и предоставить
удобный способ взаимодействия с данными в
виде объектов и связей между ними. Вместо
написания сложных SQL-запросов, разработчик
может
использовать
объектноориентированный подход и работать с
объектами, а ORM заботится о преобразовании
этих объектов в соответствующие записи в базе
данных и обратно.
3.
JPAJPA (Java Persistence API) - это спецификация Java EE, которая определяет стандартный способ работы с
объектами в Java-приложениях и их сохранения в реляционных базах данных. JPA предоставляет набор
аннотаций и интерфейсов для работы с объектно-реляционным отображением (ORM).
Основная цель JPA состоит в том, чтобы абстрагировать приложение от деталей конкретной базы данных и
предоставить унифицированный интерфейс для работы с данными. Он позволяет разработчикам работать с
объектами в объектно-ориентированном стиле, в то время как JPA-провайдеры (например, Hibernate,
EclipseLink) обеспечивают преобразование этих объектов в соответствующие записи в базе данных и обратно.
JPA не является самостоятельной реализацией, а является набором спецификаций. Для использования JPA
необходимо подключить JPA-провайдер, такой как Hibernate, EclipseLink или другие, который реализует
спецификацию JPA и предоставляет конкретную реализацию ORM-функциональности.
https://docs.oracle.com/javaee/7/api/javax/persistence/package-summary.html
4.
JPA основные интерфейсы• EntityManager: является основным интерфейсом для выполнения операций по сохранению, чтению, обновлению и
удалению сущностей в базе данных. Он предоставляет методы, такие как persist(), find(), merge(), remove(), для выполнения
этих операций, а также методы для управления транзакциями.
• EntityTransaction: представляет транзакцию базы данных и предоставляет методы для управления транзакционными
операциями, такими как begin(), commit(), rollback(). Он используется для управления границами транзакций и обеспечения
согласованности изменений в базе данных.
• Query: позволяет создавать и выполнять запросы к базе данных. Он предоставляет методы для создания запросов на
основе языка запросов, таких как JPQL (Java Persistence Query Language) или Criteria API. Методы getResultList() и
getSingleResult() используются для получения результатов запроса.
• TypedQuery: является расширением интерфейса Query и предоставляет типизированные методы для работы с запросами.
Он позволяет указать ожидаемый тип результата запроса и предоставляет более типобезопасные операции.
• CriteriaQuery: представляет типобезопасный способ создания запросов с использованием Criteria API. Он позволяет
строить запросы в программном коде с помощью объектов-критериев, представляющих различные части запроса, такие как
выборка, условия и сортировка.
• CriteriaBuilder: предоставляет методы для создания объектов-критериев (CriteriaQuery, Predicate, Order и других) и
выполнения операций сравнения, логических операций и математических операций в запросах.
5.
JPA EntityJPA Entity (сущность) - это Java-класс, который отображается на соответствующую таблицу в базе данных. JPA
использует аннотации для определения сущности и ее отображения на таблицу
Может в себе содержать:
Value types:
○ базовые типы
○ вложенные типы
○ коллекции
Entity types
ORM
6.
Требования Entity1. Entity класс должен быть отмечен аннотацией Entity или описан в XML файле конфигурации JPA
2. Entity класс должен содержать public или protected конструктор без аргументов (он также может иметь
конструкторы с аргументами).
3. Entity класс должен быть классом верхнего уровня (top-level class).
4. Entity класс не может быть enum или интерфейсом.
5. Entity класс не может быть финальным классом (final class).
6. Entity класс не может содержать финальные поля или методы, если они участвуют в маппинге.
7. Если объект Entity класса будет передаваться по значению как отдельный объект, например через удаленный
интерфейс, он так же должен реализовывать Serializable интерфейс.
8. Поля Entity класс должны быть напрямую доступны только методам самого Entity класса и не должны быть
напрямую доступны другим классам, использующим этот Entity. Такие классы должны обращаться только к
методам (getter/setter методам или другим методам бизнес-логики в Entity классе).
9. Enity класс должен содержать первичный ключ, то есть атрибут или группу атрибутов которые уникально
определяют запись этого Enity класса в базе данных.
7.
Entity основные аннотации1. @Entity: Эта аннотация применяется к классу и указывает, что данный класс является сущностью. Он должен
иметь конструктор без аргументов и быть открытым для наследования или наследоваться от другого класса
2. @Table: Эта аннотация применяется к классу и используется для указания имени таблицы, к которой будет
отображаться сущность. Если имя таблицы не указано, то оно будет соответствовать имени класса
3. @Id: Эта аннотация применяется к полю или геттеру/сеттеру и указывает, что это поле является первичным
ключом сущности
4. @GeneratedValue: Эта аннотация используется в сочетании с @Id и указывает, что данное свойство будет
создаваться согласно выбранной стратегии
5. @Column: Эта аннотация применяется к полю или геттеру/сеттеру и используется для указания отображения поля
на столбец таблицы. Она также позволяет указать различные атрибуты, такие как имя столбца, тип данных,
ограничения и др.
6. @OneToOne, @OneToMany, @ManyToOne, @ManyToMany: Эти аннотации используются для определения
отношений "один-к-одному ,"один-ко-многим«, "многие-к-одному" и "многие-ко-многим" между сущностями.
7. @JoinColumn: Эта аннотация используется в сочетании с @ManyToOne или @OneToOne и указывает столбец,
который используется для связи между сущностями
8. @Transient — указывает, что свойство не нужно записывать
9. @Inheritance — наследование
8.
JPA состояния1. Transient (Переходящее): Сущность находится в состоянии transient, когда она только что создана или не
связана с текущим персистентным контекстом. В этом состоянии сущность не отслеживается JPA и не имеет
соответствующей записи в базе данных.
2. Persistent (Постоянное): Сущность находится в состоянии persistent, когда она ассоциирована с
персистентным контекстом JPA. В этом состоянии изменения, внесенные в сущность, отслеживаются JPA, и
они могут быть автоматически синхронизированы с базой данных во время фиксации транзакции.
3. Detached (Отсоединенное): Сущность находится в состоянии detached, когда она была отсоединена от
персистентного контекста JPA. Это может произойти, например, когда транзакция, в рамках которой была
получена сущность, завершилась, или явно вызван метод отсоединения. В этом состоянии изменения в
сущности не отслеживаются JPA, и они не автоматически синхронизируются с базой данных.
4. Removed (Удаленное): Сущность находится в состоянии removed, когда она была помечена для удаления. В
этом состоянии JPA удалит соответствующую запись из базы данных при фиксации транзакции.
9.
JPA состояния entity10.
HibernateHibernate - это одна из самых популярных ORM (Object-Relational Mapping) библиотек для языка
программирования Java. Он предоставляет удобные и мощные инструменты для работы с базами данных,
позволяя разработчикам взаимодействовать с данными в объектно-ориентированном стиле, не вдаваясь в
детали работы с SQL
11.
Архитектура Hibernate12.
Архитектура Hibernate• Transaction - объект представляет собой рабочую единицу работы с БД. В Hibernate транзакции
обрабатываются менеджером транзакций
• SessionFactory - Самый важный и самый тяжёлый объект (обычно создаётся в единственном экземпляре, при
запуске приложения). Нам необходима как минимум одна SessionFactory для каждой БД, каждый из
которых конфигурируется отдельным конфигурационным файлом
• Session - используется для получения физического соединения с БД. Обычно, сессия создаётся при
необходимости, а после этого закрывается. Это связано с тем, что эти объекты крайне легковесны. Чтобы
понять, что это такое, можно сказать, что создание, чтение, изменение и удаление объектов происходит
через объект Session
• Query - использует HQL или SQL для чтения/записи данных из/в БД. Экземпляр запроса используется для
связывания параметров запроса, ограничения количества результатов, которые будут возвращены и для
выполнения запроса
• Configuration - используется для создания объекта SessionFactory и конфигурирует сам Hibernate с помощью
конфигурационного XML-файла, который объясняет, как обрабатывать объект Session
• Criteria - Используется для создания и выполнения объекто-ориентированного запроса для получения
объектов
13.
HQL (Hibernate Query Language)Query
Это объектно-ориентированный язык запросов, подобный SQL, но работающий с объектами сущностей.
HQL позволяет выполнять запросы, которые оперируют объектами и их свойствами, а не непосредственно
таблицами базы данных.
14.
Criteria QueryCriteria API позволяет создавать запросы с использованием критериев и условий, а не явно писать SQL
или HQL запросы. Он предоставляет типобезопасные и более гибкие возможности для создания запросов
15.
Native SQL QueryHibernate также позволяет выполнять нативные SQL запросы, которые напрямую работают с таблицами
базы данных.
16.
Named QueryВы можете определить именованные запросы в вашем классе сущности или в файле XML конфигурации
Hibernate. Затем вы можете вызывать эти именованные запросы, используя их уникальное имя
17.
Типы связей• OneToOne - один к одному
• OneToMany - один ко многим
• Односторонние
• ManyToOne - многие к одному
• Двунаправленные
• ManyToMany - многие ко многим
18.
One-to-OneОдносторонняя
Двунаправленная
19.
One-to-ManyОдносторонняя
Двунаправленная
20.
Many-to-Many21.
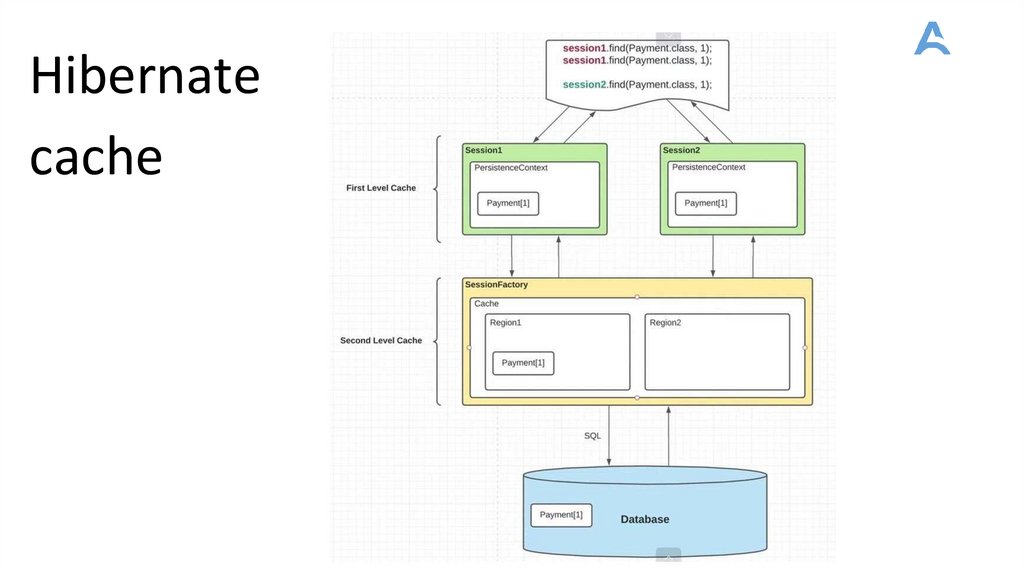
Hibernate cache1. Кэш первого уровня (First-level Cache): Кэш первого уровня в Hibernate является встроенным кэшем,
который автоматически активируется и управляется Hibernate для каждой текущей сессии (Session). Он
хранит объекты сущностей, полученные в рамках текущей сессии, и предотвращает повторные запросы к
базе данных при обращении к одному и тому же объекту в течение сессии.
2. Кэш второго уровня (Second-level Cache): Кэш второго уровня в Hibernate является распределенным кэшем,
который доступен для всех сессий и сохраняется между ними. Он может быть настроен для хранения
повторно используемых данных сущностей или запросов, чтобы избежать повторных обращений к базе
данных. Для работы с кэшем второго уровня необходимо использовать сторонние поставщики кэша, такие
как Ehcache, Infinispan, Hazelcast и другие
3. Кэш запросов (Query Cache): Кэш запросов в Hibernate позволяет кэшировать результаты запросов. Это
особенно полезно для запросов, которые выполняются часто и возвращают стабильные результаты. Кэш
запросов может быть включен и настроен для конкретных запросов с использованием соответствующей
настройки
22.
Hibernatecache
23.
Hibernate. НаследованиеЕдиная таблица для всей иерархии классов (SINGLE_TABLE)
Одна таблица для каждого класса с использованием соединений (JOINED)
Одна таблица для каждого класса через Union (TABLE_PER_CLASS)
Одна таблица для каждого класса (@MappedSuperClass)
24.
Одна таблица (Single Tаble)• Все классы в иерархии наследуются от одной
таблицы базы данных
• В таблице есть дополнительный столбец,
который указывает тип сущности
@Entity
@Inheritаnce(strаtegy = InheritаnceType.SINGLE_TABLE)
public class Customer {
@Id
private long id;
private String nаme;
}
@Entity
@DiscriminаtorVаlue("ExternаlCustomer")
public class ExternаlCustomer extends Customer {
private long sum;
}
@Entity
@DiscriminаtorVаlue("EmployeeCustomer")
public class EmployeeCustomer extends Customer {
private int monthsInCompаny;
}
25.
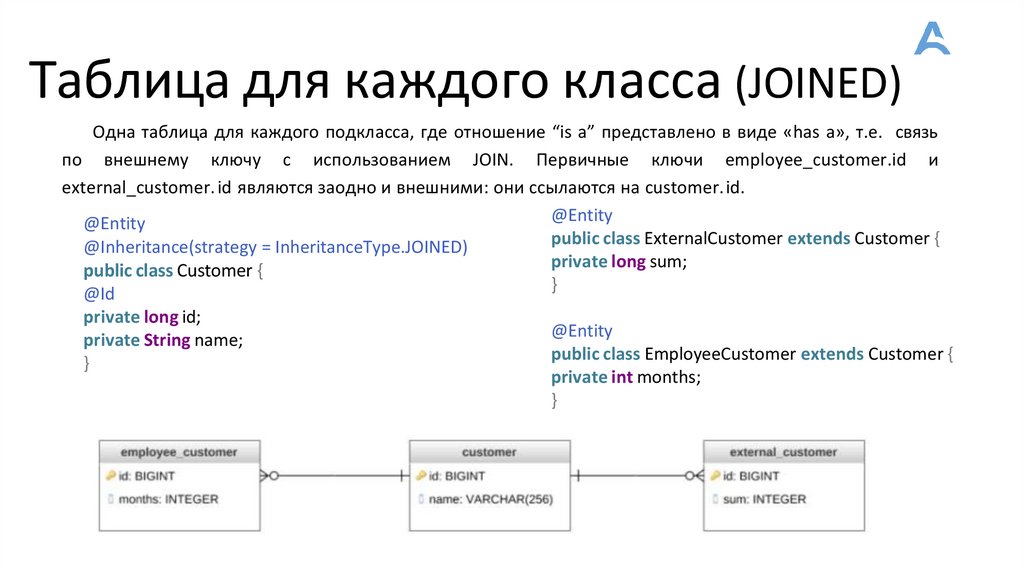
Таблица для каждого класса (JOINED)Одна таблица для каждого подкласса, где отношение “is a” представлено в виде «has a», т.е. связь
по внешнему ключу с использованием JOIN. Первичные ключи employee_customer.id и
external_customer. id являются заодно и внешними: они ссылаются на customer. id.
@Entity
@Entity
public class ExternalCustomer extends Customer {
@Inheritance(strategy = InheritanceType.JOINED)
private long sum;
public class Customer {
}
@Id
private long id;
private String name;
}
@Entity
public class EmployeeCustomer extends Customer {
private int months;
}
26.
Конкретные таблицы (TABLE_PER_CLASS)• Каждый класс в иерархии имеет отдельную таблицу базы данных без общих полей (внешних ключей
нет, только первичные)
• Каждая таблица содержит только поля, определенные в соответствующем классе
• Для полиморфного поведения во время выполнения будут использоваться UNION-запросы
@Entity
@Entity
public class ExternalCustomer extends Customer {
@Inheritance(strategy = InheritanceType. TABLE_PER_CLASS)
private long sum;
public class Customer {
}
@Id
private long id;
@Entity
private String name;
public class EmployeeCustomer extends Customer {
}
private int monthsInCompany;
}
27.
@MappedSuperclassАннотация @MappedSuperclass позволяет вынести общие поля в родительский класс, но при этом не
создавать для него отдельную таблицу. При такой стратегии классы-наследники преобразуются в независимые
таблицы. @MappedSuperclass никак не влияет на структуру в базе — это просто способ вынести общие поля.
@MappedSuperclass
public class Customer {
@Id
private long id;
private String name;
}
@Entity
public class ExternalCustomer extends Customer {
private long sum;
}
@Entity
public class EmployeeCustomer extends Customer {
private int monthsInCompany;
}
28.
Стратегии генерация IDСтандарт JPA определяет четыре стратегии генерации ID (@GeneratedValue):
• AUTO - JPA провайдер решает, как генерировать уникальные ID для нашей сущности
• IDENTITY - используется встроенный в БД тип данных столбца -identity - для генерации значения первичного
ключа
• SEQUENCE - используется последовательность – специальный объект БД для генерации уникальных
значений
• TABLE - для генерации уникального значения используется отдельная таблица, которая эмулирует
последовательность. Когда требуется новое значение, JPA провайдер блокирует строку таблицы, обновляет
хранящееся там значение и возвращает его обратно в приложение. Эта стратегия – наихудшая по
производительности и ее желательно избегать. Больше про этот подход можно узнать из документации,
здесь мы его рассматривать не будем
29.
Стратегия генерации AUTOВ соответствии с руководством разработчика, если мы выставляем тип ID, отличный от UUID (Long,
Integer и т. д.) и используем стратегию генерации AUTO, то Hibernate (начиная с версии 5.0) сделает
следующее:
• Попробует использовать стратегию SEQUENCE
• Если БД не поддерживает последовательности (например, MySQL), то будет использоваться
стратегия TABLE (или IDENTITY, в версии до 5.0)
Если для генерации ID оставить значения по
умолчанию, то, скорее всего, это негативно
повлияет на производительность приложения. Для
«боевого» применения будет лучше более тонко
настроить стратегии генерации
30.
Стратегия генерации SEQUENCEСтратегия SEQUENCE использует специализированный объект БД – последовательность (sequence) для
генерации уникального значения ID сущности и это значение присваивается до сохранения сущности в БД.
Такой алгоритм обеспечивает возможность пакетного (batch) сохранения данных. Это происходит за счет того,
что приложению не надо перезапрашивать из базы значение ID после сохранения каждой записи, как это
происходит в случае использования identity столбцов. В большинстве БД максимальное количество значений
последовательности 263 − 1, исчерпать такое количество значений, конечно, сложновато. Но все возможно,
если ваше приложение генерирует огромное количество данных, то нужно менять параметры генерации ID
31.
Стратегия генерации SEQUENCEТакже если не используются настройки последовательность по умолчанию, Hibernate «кэширует» значения
ID при выборке из последовательности. Идея в том, чтобы при одном запросе «захватить» какой-то диапазон
значений и потом назначать значения ID из этого диапазона. По умолчанию, Hibernate захватывает 50
значений. Для настройки параметров генерации ID, например, для уменьшения шага последовательности,
используется аннотация @SequenceGenerator
32.
Стратегия генерации IDENTITYIDENTITY - специальный тип данных столбца таблицы, которые автоматом назначает уникальные значения
вставляемым строкам. Когда мы определяем стратегию IDENTITY для генерации значений ID, мы получаем
надежный способ обеспечения уникальности первичного ключа. Для каждого оператора INSERT, база данных
автоматически генерирует уникальное значение ID поля. Хотя в некоторых СУБД, если мы указываем значение
ID явно, то оно не будет перезаписано, так что, в теории, несколько клиентов могут получить нарушение
уникальности, если они назначают значения ID явно
33.
Стратегия генерации IDENTITYПоведение стратегии IDENTITY схоже с SEQUENCE, если мы определим шаг последовательности равным 1.
Но есть одно значительное различие. Нужно помнить, что для назначения ID данные должны быть физически
вставлены в таблицу. И только после того, как оператор INSERT выполнился, мы сможем узнать значение ID.
Следовательно, JPA провайдер должен каким-то образом вернуть это значение обратно в приложение после
сохранения объекта в БД.
Если JDBC драйвер БД поддерживает JDBC v.3 (а современные БД поддерживают), это делается
автоматически. JPA провайдер неявно вызывает метод Statement.getGeneratedValues(), который и
возвращает сгенерированное значение, иначе пытается получить значение ID на основании сохраненных
данных.
Использование IDENTITY не позволяет использовать пакетную вставку данных, поскольку ORM должен
получать ID после каждой вставки, а БД не гарантирует порядок вставки для пакетных операций, так что ID
могут быть не в том порядке, в котором был наш список объектов
34.
Стратегии генерации IDSEQUENCE
IDENTITY
Хорошей практикой считается задание Если
СУБД
не
поддерживает
отдельной последовательности для последовательности, то IDENTITY будет
каждой сущности. Нужно избегать хорошим выбором
использования
значений
по
умолчанию в настройках.
Используйте @SequenceGenerator для Создается небольшой объем данных
тонкой настройки генерации значений
ID и параметров генерируемой
последовательности.
Шаг последовательности задавайте в В базу данных могут писать другие
соответствии с нагрузкой приложения
приложения
По возможности старайтесь не использовать стратегии TABLE и AUTO, с ними
будет наихудшая производительность
35.
Проблема N+1Проблема N+1 является распространенной проблемой в Hibernate (и других ORM-фреймворках),
которая возникает при загрузке связанных данных из базы данных. Эта проблема может привести к
неэффективной работе и снижению производительности приложения.
Проблема N+1 возникает в следующих случаях:
Загрузка связанных коллекций: Когда вы загружаете сущность, которая имеет связанную коллекцию
(например, One-to-Many или Many-to-Many отношение), и для каждого элемента в коллекции
выполняется отдельный запрос к базе данных. Это может привести к большому количеству запросов, что
замедляет работу приложения.
Ленивая загрузка: Если вы используете ленивую загрузку (lazy loading) для связанных данных, то при
обращении к этим данным Hibernate выполняет дополнительные запросы для загрузки связанных
объектов, что может привести к N+1 проблеме.
36.
Проблема N+1 решенияJoin fetch
Entity graph
@FetchMode (SUBSELECT, JOIN)
@BatchSize
Примеры:
Batch https://www.youtube.com/watch?v=nuTI3O06kUc&ab_channel=MissXing
Entity Graph https://www.youtube.com/watch?v=qPE98hZwBXA&t=1s&ab_channel=MissXing
Join Fetch https://www.youtube.com/watch?v=J2BC9zEA4U4&t=8s&ab_channel=MissXing
FetchMode https://www.youtube.com/watch?v=V0tjqtqLIBw&ab_channel=MissXing
37.
Литература• https://sysout. ru/kak-rabotaet-flush-v-hibernate/
• https://habr.com/ru/articles/337488/
• https://sysout. ru/nasledovanie-sushhnostej-s-pomoshhyu-single-table-primer-nahibernate-i-spring-boot/
• https://sysout. ru/nasledovanie-sushhnostej-s-pomoshhyu-joined-table-primer-nahibernate-i-spring-boot/
• https://sysout. ru/nasledovanie-inheritancetype-table_per_class/
• https://sysout. ru/nasledovanie-s-mappedsuperclass/
• https://habr. com/ru/companies/otus/articles/529692/
• https://habr.com/ru/companies/haulmont/articles/653843/