






































 database
databaseSimilar presentations:










SQL. Оптимизация запросов. Greenplum
1.
SQLОптимизация запросов
Greenplum
Риск-аналитик
Команда разработки моделей доходности КК
Ведерников Роман
2.
Немного о GreenplumGreenplum - это распределенная СУБД,
разработанная на
основе PostgreSQL с поколоночным
хранением данных, предназначенная
для аналитическихзапросов
При плохом составленных запросах: скорость
обработки любого запроса равна скорости самого
медленного сегмента; любые операции, связанные с
перемещением таблиц между сегментами, замедляют
скорость обработки.
2
3.
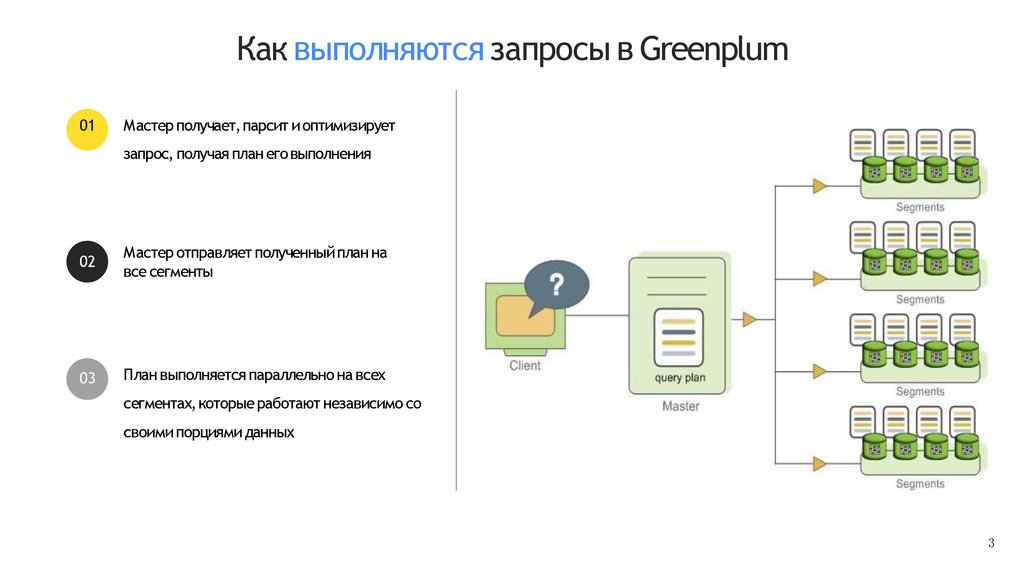
Как выполняются запросы в Greenplum01
Мастер получает,парсит и оптимизирует
запрос, получая план его выполнения
02
Мастер отправляет полученный план на
все сегменты
03
План выполняется параллельно на всех
сегментах,которые работают независимо со
своими порциями данных
3
4.
План запроса – это последовательностьопераций, которые выполняет БД для
получения требуемого в запросе результата
План запроса представляет собой дерево,
где каждый узел представляет какую-либо
операцию БД
План запроса в
Greenplum
Построением плана запроса занимается оптимизатор,
при построении плана запроса оптимизатор учитывает
такие факторы, как количество записей в таблицах,
наличие индеков,наличие партиций и др
План запроса читается и выполняется снизу
вверх (от листовых узлов к корню)
Greenplum разбивает план запроса на срезы
(slices) . Срез – это часть плана, внутри
которой операторы могут работать
независимо на всех сегментах
It’s all partof the plan
4
5.
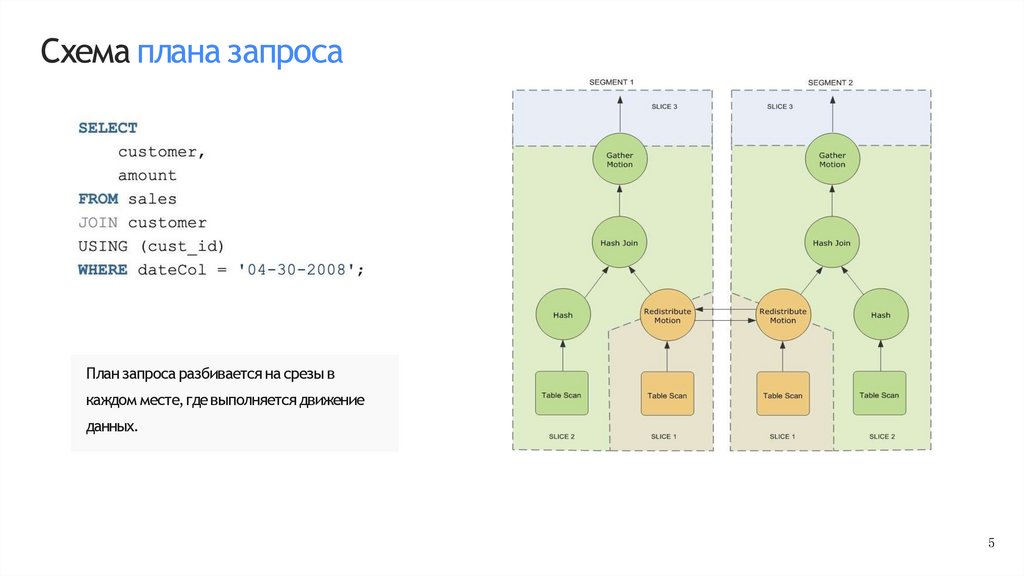
Схема плана запросаПлан запроса разбивается на срезы в
каждом месте,где выполняется движение
данных.
5
6.
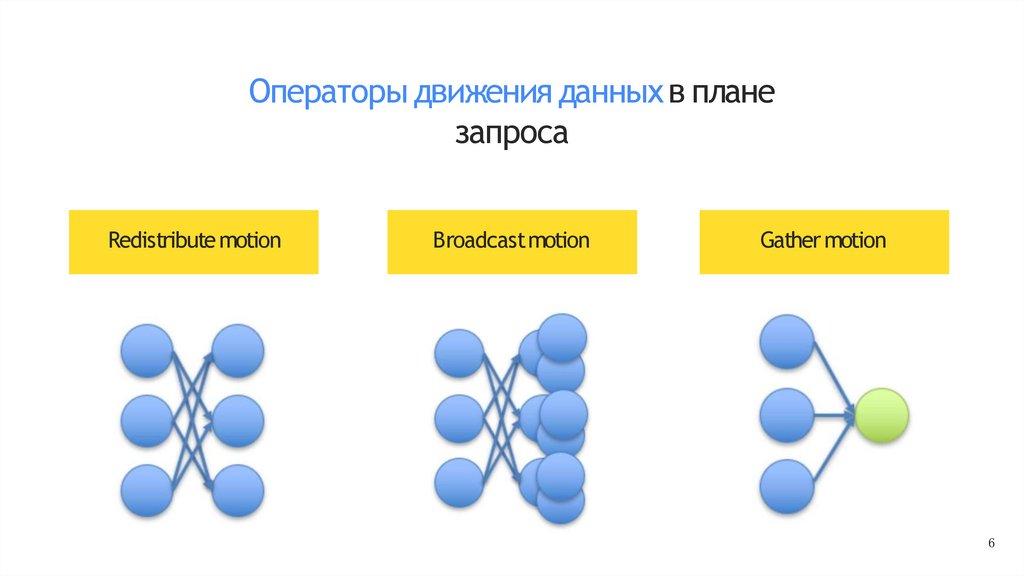
Операторы движения данных в планезапроса
Redistribute motion
Broadcastmotion
Gather motion
6
7.
Операторысоединения в
плане запроса
Hash join
Чтение меньшей
таблицы
Хэш-таблица
7
Чтение большей
таблицы
HASH
Для каждой строки
В случае leftjoin хэш-таблица строится на правую таблицу!
7
8.
Операторысоединения в
плане запроса
Nested Loop
8
Большая таблица
Меньшая таблица
Для выполнения требуется копирование меньшей таблицы на все сегменты!
8
9.
Операторысоединения в
плане запроса
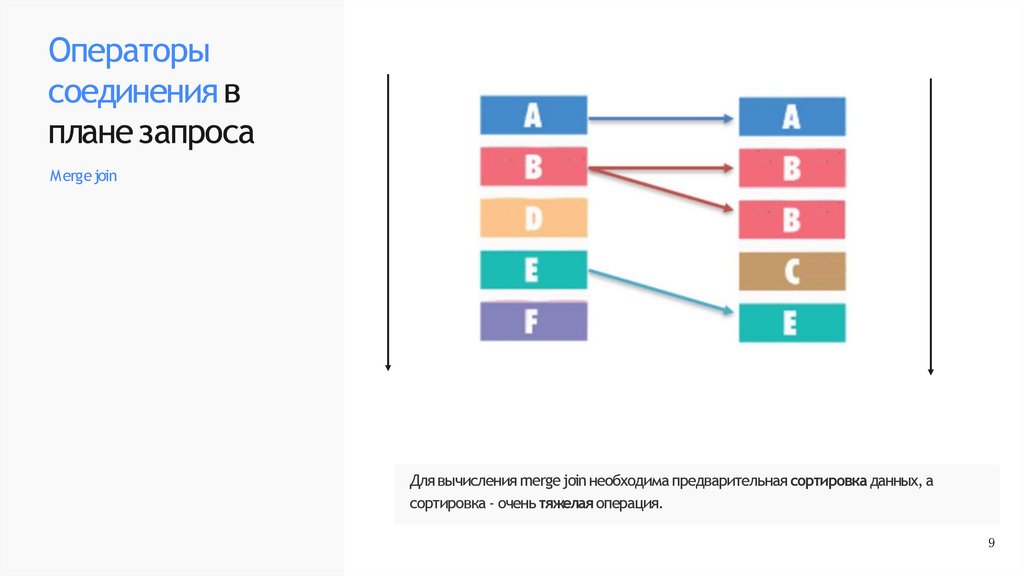
Merge join
Для вычисления merge join необходима предварительная сортировка данных, а
сортировка - очень тяжелая операция.
9
10.
Операторы чтения в плане запроса• Seq Scan on heap tables — чтение всех записей в таблице.
• Append-only Scan — чтение записей в построчной append-only таблице.
• Append-only Columnar Scan — чтение записей в поколоночной append-only таблице.
• Dynamic Table Scan — чтение партиционированной таблицы.
Прочие операторы в плане запроса
•Materialize – материализация подзапроса для повторного
использования в родительскихузлах плана
запроса.
•Sort – сортирует таблицу,подготавливая ее к операциям,требующим
сортированные данные,например,при
группировке или merge join.
• Group By – группирует строки по полю или набору полей.
• Group/HashAggregate – группирует строки используя хэш.
• Append – конкатенирует данные,например,после чтения партиций из партиционированной таблицы.
• Filter – выбирает строки, удовлетворяющие условию.
• Limit – ограничивает количество возвращаемых записей.
10
11.
Как посмотреть план запроса в GrenplumEXPLAIN
EXPLAIN ANALYZE
ВвыводекомандыEXPLAIN каждаястрокасоответствует
узлудеревапланазапроса. Встрокепомимо типа
выполняемойоперации содержатся следующиеметрики:
Отличие от explain в том, что прежде чем вывести
план запроса, GP выполняет сам запрос, что
позволяет вывести дополнительные метрики запроса:
01
cost —стоимость
выполнения операции
01
Total runtime - время (в миллисекундах),
которое работал запрос
02
rows —количество строк
02
Avg/Max rows —среднее/максимальное
количество строк насегментах
03
width —ширинав байтах
03
Количество сегментов которые были
задействованы при выполнении операции.
Учитываются только сегменты, которые вернули
строки.
11
12.
Пример плана запроса EXPLAINexplain create table prod_wrk.test as
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id)
distributed by (activity_id);
12
13.
Пример плана запроса EXPLAIN ANALYZEexplain create table prod_wrk.test as
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id)
distributed by (activity_id);
13
13
14.
Причинынеоптимальности запросов
Переко
с
данных
Большие
движения данных
Замножени
е данных
14
15.
Перекос данных:Пример 1create table prod_wrk.test as
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id)
distributed by (activity_id);
prod_wrk.main_activity – 1млрд, distributed by (activity_id)
prod_wrk.h_account – 70млн, distributed by (account_rk)
Время работы > 20 мин
15
16.
Перекос данных:Пример 116
17.
Перекос данных:Пример 117
18.
Перекос данных:Пример 1select count(*) from prod_wrk.main_activity
where asset_id is null; --818 429 538
Проблема: большой перекос при перераспределении таблицы
prod_wrk.main_activity из-за наллов.
18
19.
Перекос данных:Пример 1Решение:
explain create table prod_wrk.test as
with pre_join as
(
select
t1.activity_id,
t2.account_rk
from prod_wrk.main_activity t1
inner join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id)
where t1.asset_id is not null
)
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join pre_join t2
using (activity_id)
distributed by (activity_id);
19
20.
Перекос данных:Пример 1Вариант 1:
explain create table prod_wrk.test as
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id)
where asset_id is not null
distributed by (activity_id);
20
21.
Перекос данных:Пример 1Вариант 2:
explain create table prod_wrk.test as
select
t1.activity_id,
t1.x_ptp_id,
t1.owner_per_id,
t1.bus_proc,
t1.call_result,
t2.account_rk
from prod_wrk.main_activity t1
left join prod_wrk.h_account t2
on (t1.asset_id = t2.siebel_account_id
and asset_id is not null)
distributed by (activity_id);
21
22.
Перекос данных:Пример 2explain create table prod_wrk.test_2 as
select
t1.account_rk,
count(t2.activity_id) as cnt_act
from prod_wrk.h_account t1
left join prod_wrk.main_activity t2
on (t2.asset_id = t1.siebel_account_id)
group by account_rk
distributed by (account_rk);
Время работы ~3 мин
22
23.
Перекос данных:Пример 223
24.
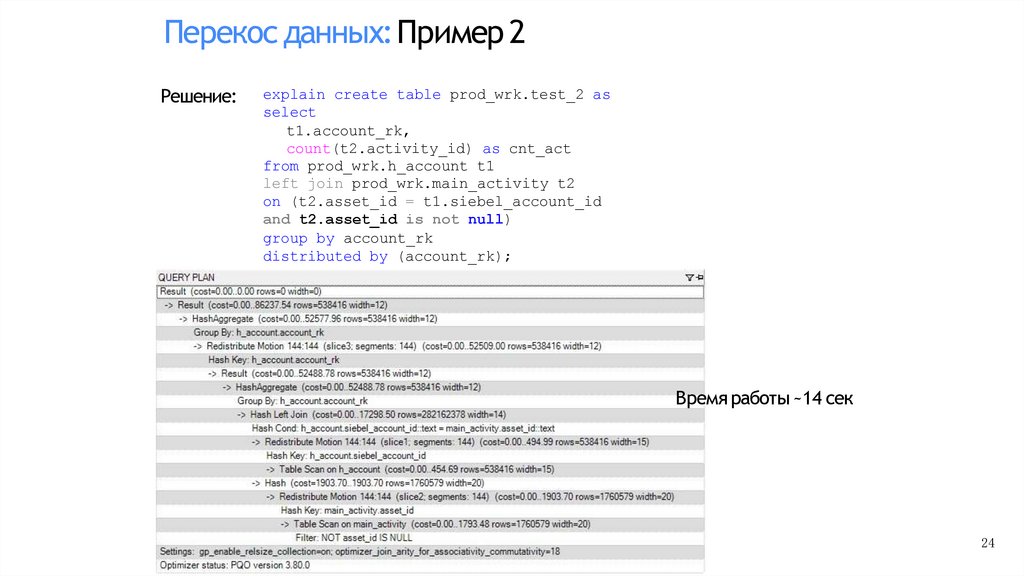
Перекос данных:Пример 2Решение:
explain create table prod_wrk.test_2 as
select
t1.account_rk,
count(t2.activity_id) as cnt_act
from prod_wrk.h_account t1
left join prod_wrk.main_activity t2
on (t2.asset_id = t1.siebel_account_id
and t2.asset_id is not null)
group by account_rk
distributed by (account_rk);
Время работы ~14 сек
24
25.
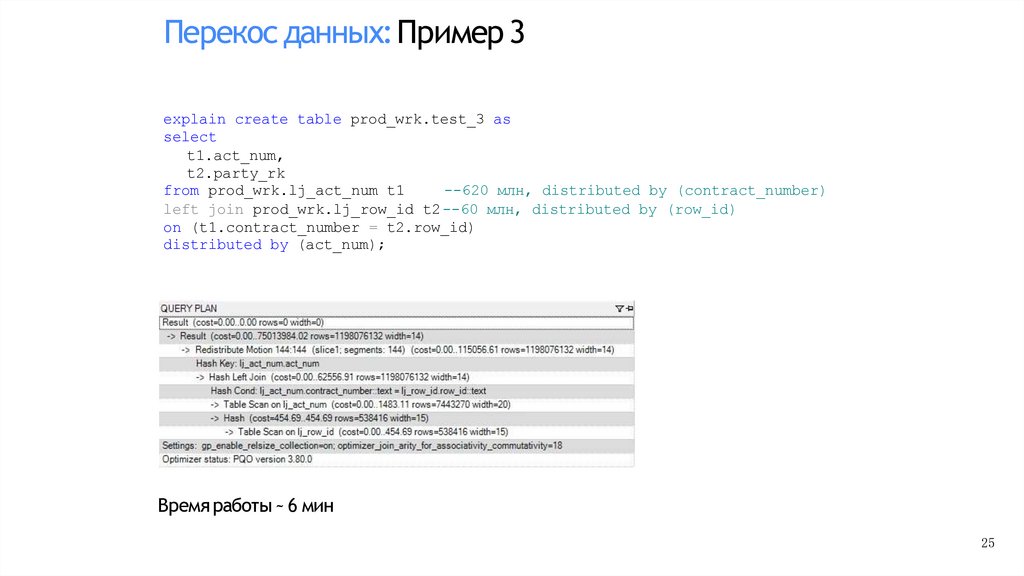
Перекос данных:Пример 3explain create table prod_wrk.test_3 as
select
t1.act_num,
t2.party_rk
from prod_wrk.lj_act_num t1
--620 млн, distributed by (contract_number)
left join prod_wrk.lj_row_id t2 --60 млн, distributed by (row_id)
on (t1.contract_number = t2.row_id)
distributed by (act_num);
Время работы ~ 6 мин
25
26.
Перекос данных:Пример 326
27.
Перекос данных:Пример 3select count(*) from prod_wrk.lj_act_num
where contract_number is null; --487389685
Проблема: большой перекос исходной таблицы
Решение:
alter table prod_wrk.lj_act_num set distributed by (act_num);
27
28.
Перекос данных:Пример 3explain create table prod_wrk.test_3 as
select
t1.act_num,
t2.party_rk
from prod_wrk.lj_act_num t1
left join prod_wrk.lj_row_id t2
on (t1.contract_number = t2.row_id)
where t1.contract_number is not null
union all
select
act_num,
null as party_rk
from prod_wrk.lj_act_num
where contract_number is null
distributed by (act_num);
28
29.
Перекос данных:Пример 3Время работы ~ 30 сек
29
30.
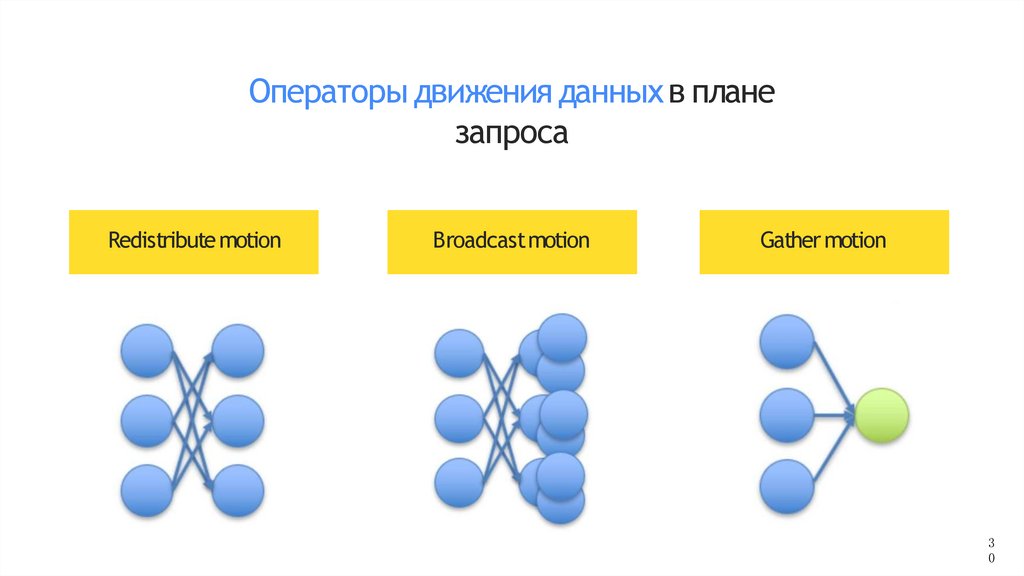
Операторы движения данных в планезапроса
Redistribute motion
Broadcastmotion
Gather motion
3
0
31.
Большие движения данных:Пример 1explain create table prod_wrk.test_1 as
select
t1.transaction_rk,
t1.transaction_type_cd,
t1.transaction_amt,
t2.account_rk,
t2.account_status_cd,
t2.contract_number
from prod_wrk.transactions t1
inner join prod_wrk.accounts t2
using (account_rk)
distributed by (account_rk);
prod_wrk.transactions – 600млн, distributed by (transaction_rk)
prod_wrk.accounts – 400млн, distributed by (account_id)
Время работы > 20 мин
31
32.
Большие движения данных:Пример 1Проблема: бродкаст большой таблицы.
32
33.
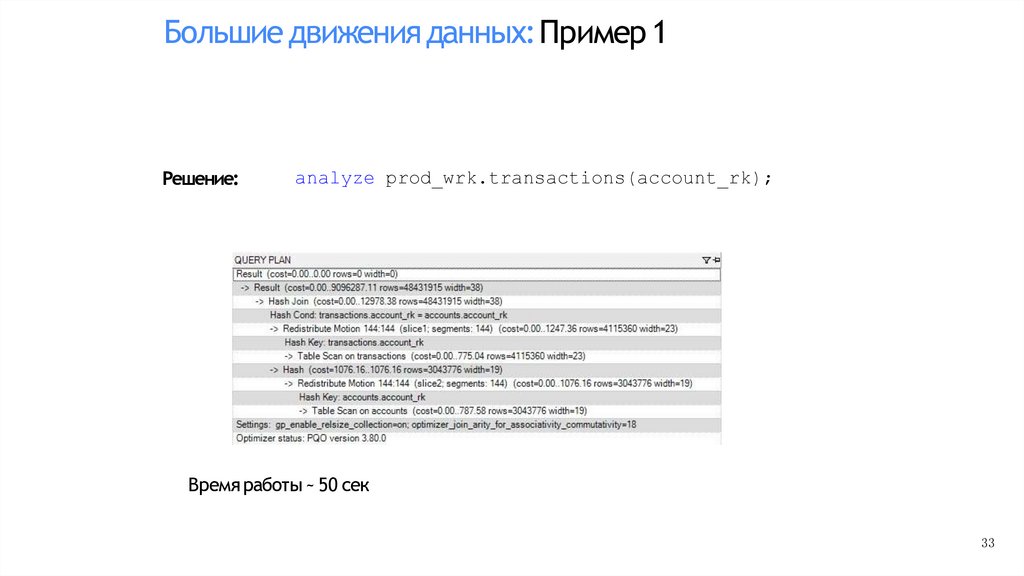
Большие движения данных:Пример 1Решение:
analyze prod_wrk.transactions(account_rk);
Время работы ~ 50 сек
33
34.
Большие движения данных:Пример 2explain create table prod_wrk.test_2 as
select
t1.serno,
t1.institution_id,
t1.caccserno,
t1.product,
t2.ops_id,
t2.pg_id,
t2.target_id
from prod_wrk.ij_serno t1
inner join prod_wrk.cl_fields t2
using(serno)
distributed by (serno);
prod_wrk.ij_serno – 8млрд, distributed by (serno)
prod_wrk.cl_fields – 7млрд, distributed by (serno)
Время работы ~ 8 мин
34
35.
Большие движения данных:Пример 2prod_wrk.ij_serno – тип поля serno - bigint
prod_wrk.cl_field – тип поля serno - numeric
Проблема: лишнее перераспределение из-за джойна по разным
типам.
35
36.
Большие движения данных:Пример 2Решение: создавать временные таблицы с одинаковыми типами в
ключах джойна.
Не нужно создавать копию таблицы с правильным типом.
Время работы ~ 2 мин
36
37.
Большие движения данных:Пример 3explain create table prod_wrk.test_3 as
select
t1.payment_id,
t1.cpayee_account,
t2.dtrntran,
t2.ctrnaccc
from prod_wrk.lj_by_id_1 as t1
left join prod_ods_xxi.TRN as t2
on (t1.ntc_num = t2.itrnnum)
distributed by (payment_id);
prod_wrk.lj_by_id_1 – 700к, distributed by (ntc_num)
prod_ods_xxi.TRN – 13.5млрд, distributed by (itrnnum, itrnanum)
Время работы ~ 5 мин
37
38.
Большие движения данных:Пример 3Проблема: перераспределение большой таблицы.
38
39.
Большие движения данных:Пример 3Решение:
explain create table prod_wrk.test_3 as
with pre_join as
(
select
t1.ntc_num,
t2.dtrntran,
t2.ctrnaccc
from prod_wrk.lj_by_id_1 as t1
inner join prod_ods_xxi.TRN as t2
on (t1.ntc_num = t2.itrnnum)
)
select
t1.payment_id,
t1.cpayee_account,
t2.dtrntran,
t2.ctrnaccc
from prod_wrk.lj_by_id_1 t1
left join pre_join t2
using (ntc_num)
distributed by (payment_id);
39
40.
Большие движения данных:Пример 3Время работы ~ 1 мин
40
41.
Замножение данных:Примерexplain create table prod_wrk.test_1 as
select distinct on (entity_id)
entity_id,
app_rk
from prod_wrk.ij_entity_id--800млн, distributed by (entity_id)
order by entity_id, app_rk desc
distributed by (entity_id);
Время работы ~ 90 сек
41
42.
Замножение данных:ПримерПроблема:сортировка большого объема данных
42
43.
Замножение данных:ПримерРешение:
explain create table prod_wrk.test_1 as
select
entity_id,
max(app_rk) as app_rk
from prod_wrk.ij_entity_id
group by entity_id
distributed by (entity_id);
Время работы ~ 15 сек
43
44.
Общие рекомендации по написанию запросов01
02
03
В идеальном случае join следует делать по
Необходимо максимально уменьшать количество
полям дистрибуции хотя бы одной из
данных передjoin' ом.(Для каждой
таблиц.
рассматриваемой сущности настраиваем фильтры,
Order by. Операция сортировки - одна из
самых тяжелыхопераций и не стоит ее
использовать без крайней необходимости.
Выполняйте сам запрос без сортировки,а
результирующие данные сортируйте уже в
приемнике
чтобы выбрать только необходимую для анализа
часть данных на стороне GP)
04
05
06
Distinct. Не рекомендуется использовать
Использовать партиции. Одним из главных
Не используем OR, IN, LIKE в условиях
оператор Distinct.Он часто требует
механизмов оптимизации запросов к большим
соединения по полям
перераспределения таблицы по всем
таблицам в GP является партиционирование.
указанным в запросе полям. По этой же
причине не рекомендуется использовать
Union,лучше применять UnionAll
44
45.
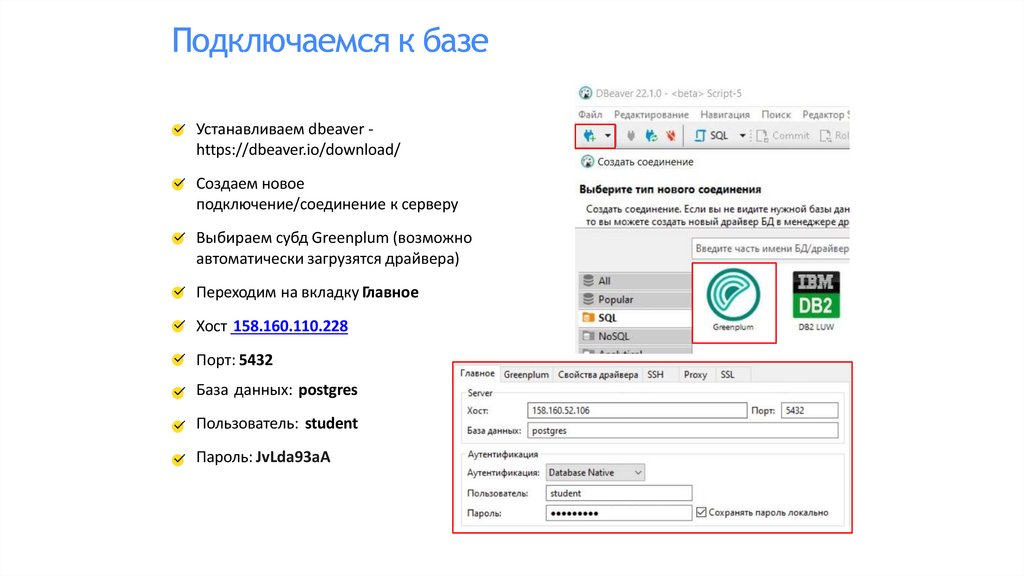
Подключаемся к базеУстанавливаем dbeaver https://dbeaver.io/download/
Создаем новое
подключение/соединение к серверу
Выбираем субд Greenplum (возможно
автоматически загрузятся драйвера)
Переходим на вкладку Главное
Хост 158.160.110.228
Порт: 5432
База данных: postgres
Пользователь: student
Пароль: JvLda93aA
46.
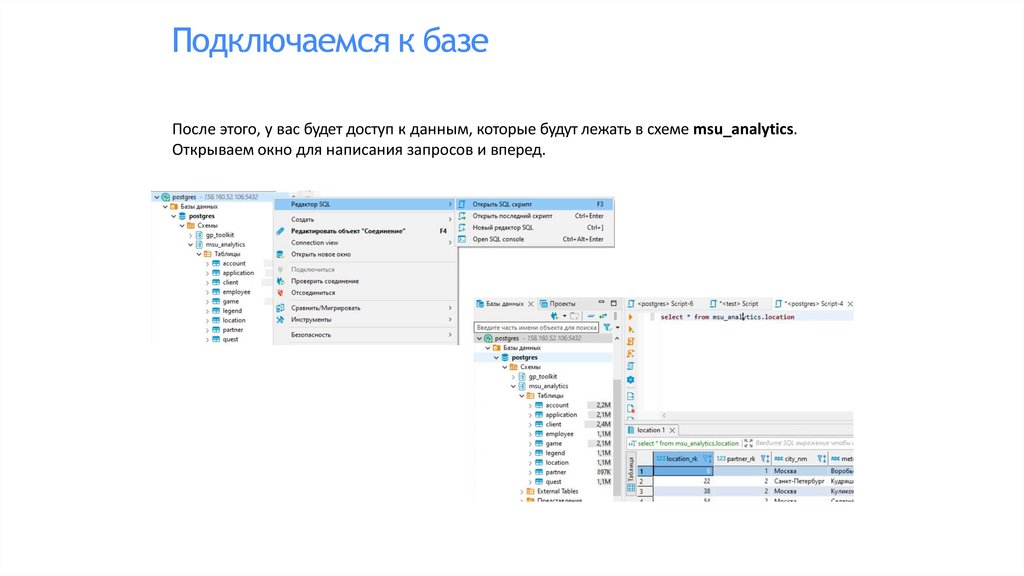
Подключаемся к базеПосле этого, у вас будет доступ к данным, которые будут лежать в схеме msu_analytics.
Открываем окно для написания запросов и вперед.
47.
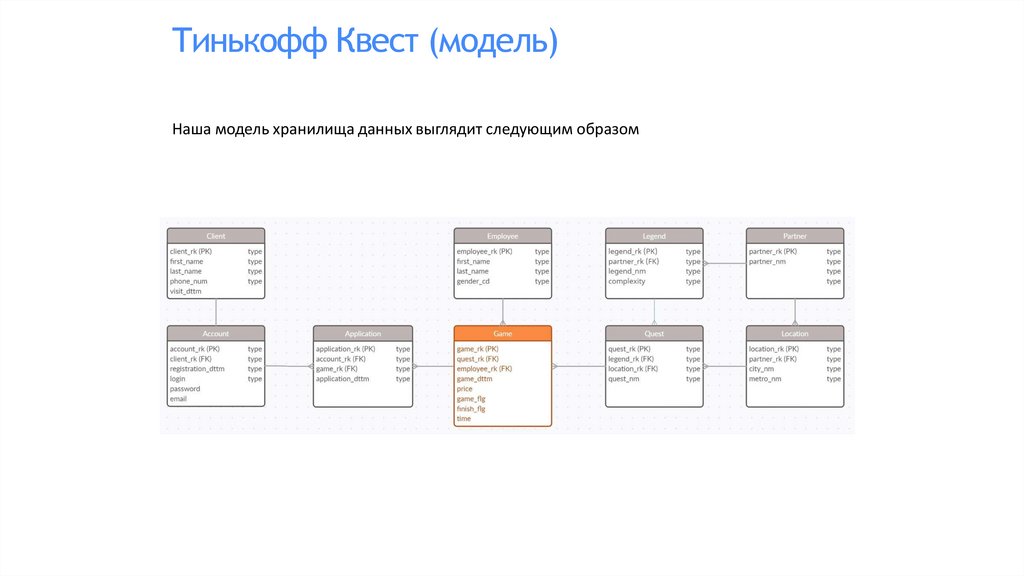
Тинькофф Квест (модель)Наша модель хранилища данных выглядит следующим образом
48.
PartnerВитрина содержит информацию о наших бизнес партнерах
Название поля
Описание
Partner_rk
Ключ партнера в хранилище
данных
Partner_nm
Название партнера
49.
LocationВитрина содержит информацию о тех локациях, на которых проходят квесты нашей
франшизы
Название поля
Описание
Location_rk
Ключ локации в хранилище
данных
Partner_rk
Ключ партнера, которому
принадлежит эта локация
City_nm
Название города, в котором
расположена локация
Metro_nm
Название ближайшей
станции метро к локации
38
50.
LegendВитрина содержит информацию о легендах (сценариях/сюжетах) конкретных квестов.
Название поля
Описание
Legend_rk
Ключ легенды в хранилище
данных
Partner_rk
Ключ партнера, которому
принадлежит авторское
право на эту легенду
Legend_nm
Запатентованное название
сюжета
Complexity
Сложность квеста, идущего
по данному сюжету
51.
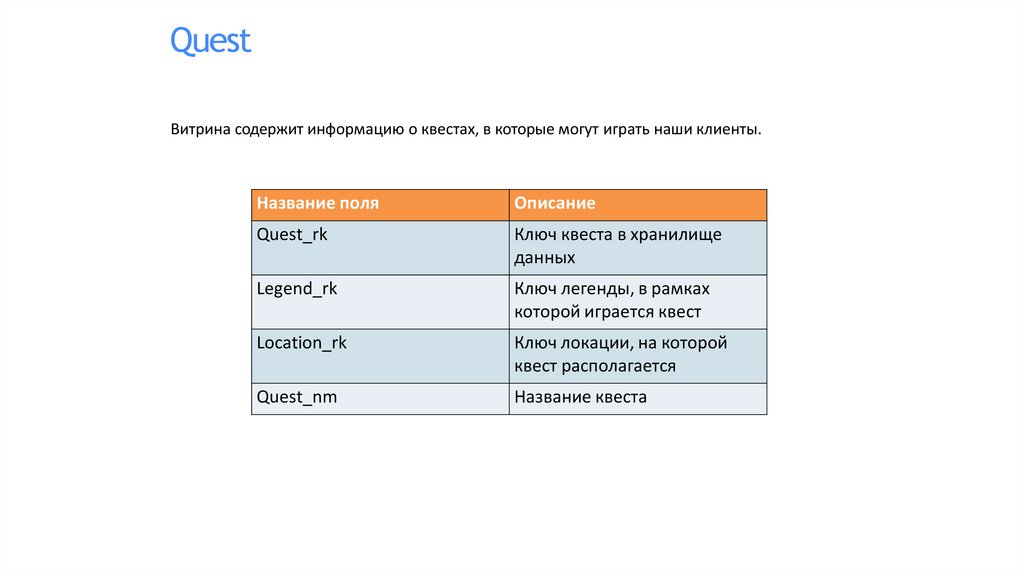
QuestВитрина содержит информацию о квестах, в которые могут играть наши клиенты.
Название поля
Описание
Quest_rk
Ключ квеста в хранилище
данных
Legend_rk
Ключ легенды, в рамках
которой играется квест
Location_rk
Ключ локации, на которой
квест располагается
Quest_nm
Название квеста
52.
EmployeeВитрина содержит информацию о сотрудниках, которые проводят игры и помогают
командам.
Название поля
Описание
Employee_rk
Ключ сотрудника в
хранилище данных
First_name
Имя сотрудника
Last_name
Фамилия сотрудника
Gender_cd
Пол сотрудника
53.
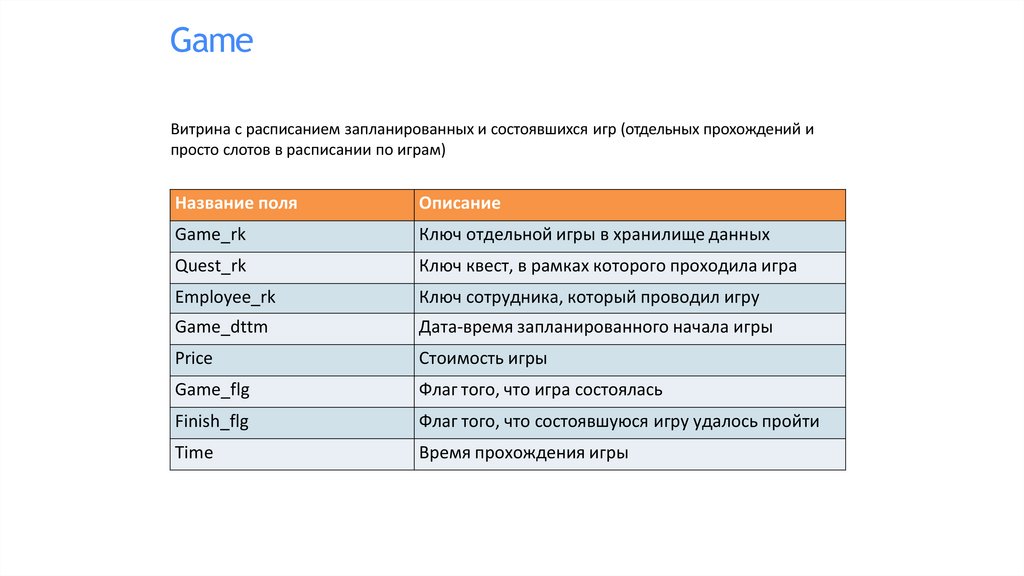
GameВитрина с расписанием запланированных и состоявшихся игр (отдельных прохождений и
просто слотов в расписании по играм)
Название поля
Описание
Game_rk
Ключ отдельной игры в хранилище данных
Quest_rk
Ключ квест, в рамках которого проходила игра
Employee_rk
Ключ сотрудника, который проводил игру
Game_dttm
Дата-время запланированного начала игры
Price
Стоимость игры
Game_flg
Флаг того, что игра состоялась
Finish_flg
Флаг того, что состоявшуюся игру удалось пройти
Time
Время прохождения игры
54.
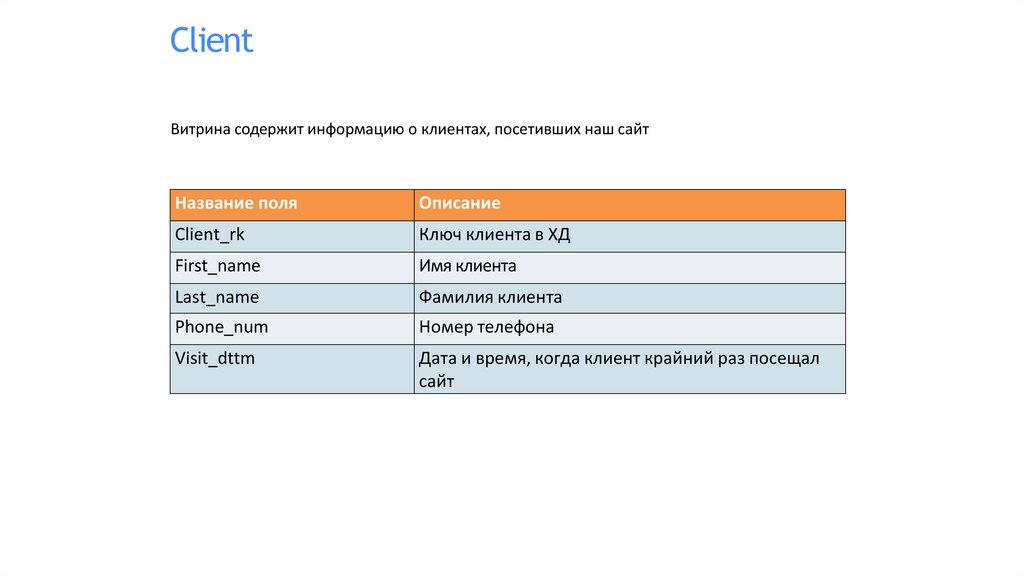
ClientВитрина содержит информацию о клиентах, посетивших наш сайт
Название поля
Описание
Client_rk
Ключ клиента в ХД
First_name
Имя клиента
Last_name
Фамилия клиента
Phone_num
Номер телефона
Visit_dttm
Дата и время, когда клиент крайний раз посещал
сайт
55.
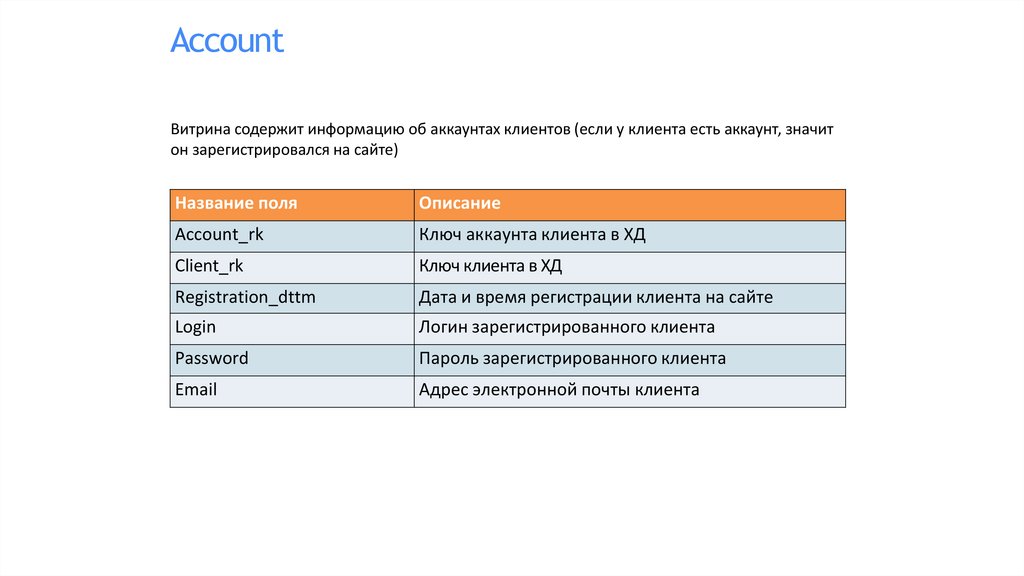
AccountВитрина содержит информацию об аккаунтах клиентов (если у клиента есть аккаунт, значит
он зарегистрировался на сайте)
Название поля
Описание
Account_rk
Ключ аккаунта клиента в ХД
Client_rk
Ключ клиента в ХД
Registration_dttm
Дата и время регистрации клиента на сайте
Login
Логин зарегистрированного клиента
Password
Пароль зарегистрированного клиента
Адрес электронной почты клиента
56.
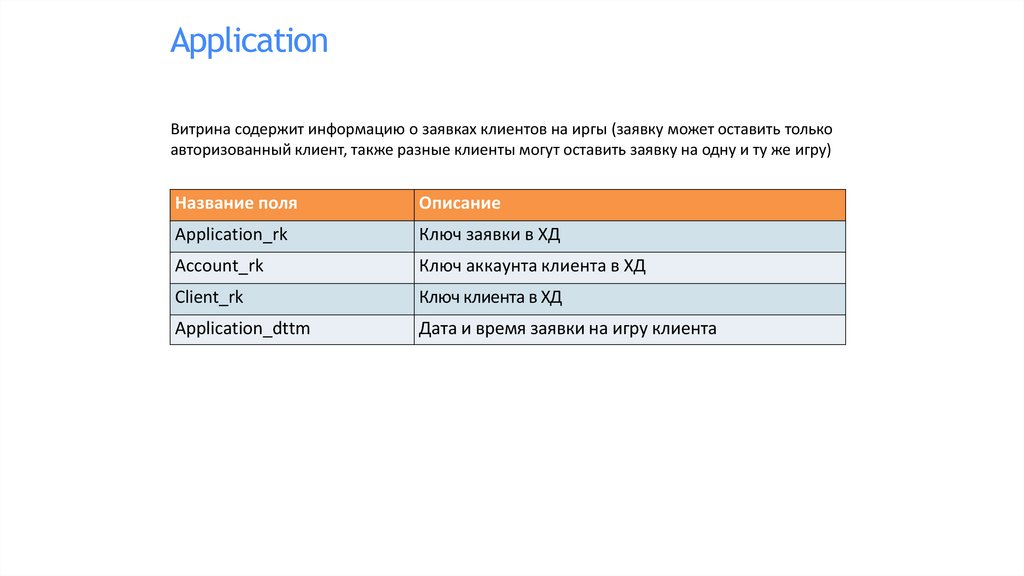
ApplicationВитрина содержит информацию о заявках клиентов на иргы (заявку может оставить только
авторизованный клиент, также разные клиенты могут оставить заявку на одну и ту же игру)
Название поля
Описание
Application_rk
Ключ заявки в ХД
Account_rk
Ключ аккаунта клиента в ХД
Client_rk
Ключ клиента в ХД
Application_dttm
Дата и время заявки на игру клиента