









 programming
programmingSimilar presentations:


")







Дослідження принципів паралелізму на рівні даних для оптимізації виконання програмного коду
1.
Група К22-2МПрисяжнюк Роман
Олександрович
2024
Керівник к.ф.
-м.н., доц.
Фірсов О.Д.
Дослідження принципів
паралелізму на рівні даних
для оптимізації виконання
програмного коду
2.
Об’єктом дослідження є процес оптимізаціївиконання
програмного
коду
через
застосування принципів паралелізму на рівні
даних.
Предметом дослідження є оптимізація
виконання
програмного
коду
з
використанням принципів паралелізму на
рівні даних.
3.
Мета магістерської роботи полягає в дослідженні тарозробці методів оптимізації виконання програмного коду
через застосування принципів паралелізму на рівні даних
Таким чином, предмет дослідження сконцентровано
на конкретних методах і засобах, спрямованих на
поліпшення виконання програм через ефективне
використання паралелізму на рівні даних.
4.
Поняття паралелізмуПаралелізм – це концепція, що використовується в
різних галузях науки і техніки, яка має на увазі
виконання декількох завдань або операцій
одночасно. У комп’ютерних науках паралелізм
широко
застосовується
для
збільшення
продуктивності та ефективності обробки даних
5.
Цей підхід ґрунтується на ідеї розподілу обчислювальних завдань міжкількома обробниками або ядрами, що працюють паралельно. Одним із
важливих аспектів паралелізму є його застосування в багатозадачних
системах, де кілька завдань виконуються одночасно, забезпечуючи більш
ефективне використання ресурсів.
6.
06МЕТОДИКА
1) Постановка задачі
2) Опис функцій
3) Фіксація результатів та робота з ресурсами
4) Опис використаних програмних засобів
5) Проведення експериментів
6) Висновки та подальші дії
7.
Фіксація результатів та робота з ресурсамиСтворюються масиви a, b і c розміром SIZE, заповнені випадковими
значеннями. Виконується почерговий виклик кожної з функцій з подальшим
вимірюванням часу виконання. Результати виводяться на екран, включаючи час
виконання кожної функції.
Для очищення ресурсів. Виконується звільнення виділеної динамічної
пам’яті для масивів a, b і c.
SIMD (Single Instruction, Multiple Data) використовується для оптимізації
продуктивності, здійснюючи одну інструкцію на кілька даних за один такт
процесора.
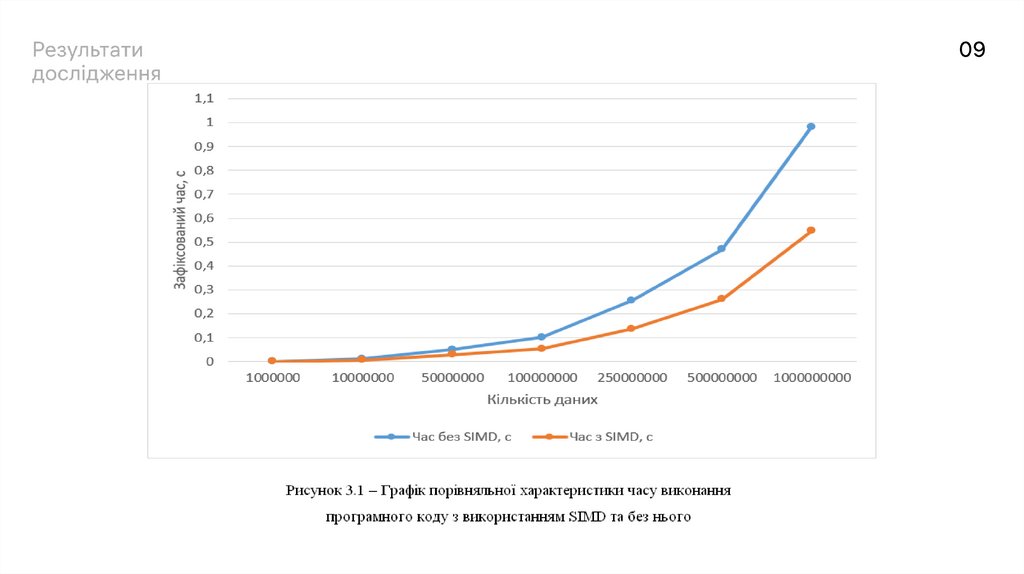
В таблиці 3.1 відображені результати проведених експериментів по сумуванню елементів двох різних
масивів для різної кількості даних
8.
№Кількість даних
Час без SIMD, с
Час з SIMD, с
1
1000000
0,0009264
0,0005633
2
10000000
0,0108431
0,0058366
3
50000000
0,0492741
0,0283793
4
100000000
0,101383
0,0530152
5
250000000
0,255758
0,136178
6
500000000
0,469409
0,261017
7
1000000000
0,98162
0,545597
9.
10.
Була чітко сформульована задача оцінки продуктивності операцій додавання, обчисленнясереднього значення та суми елементів масивів з використанням SIMD-інструкцій.
Розглянуто функції для звичайного та оптимізованого додавання масивів, обчислення
середнього значення та суми елементів. Експерименти та вимірювання часу
підтверджують переваги використання SIMD-інструкцій у певних сценаріях, особливо при
роботі з великими обсягами даних. Також вказано, що ефективність SIMD може залежати
від архітектури процесора та оптимізацій компілятора. Результати експериментів
допомагають зрозуміти переваги оптимізації з використанням SIMD у конкретних
сценаріях.
В цілому, робота охоплює широкий спектр аспектів паралелізму на рівні
даних, від теоретичних концепцій до практичної реалізації та
експериментів. Введення в технології розподілених обчислень, моделі
програмування та застосування SIMD у мові C++ доповнюють огляд
досліджень у цій галузі.