































 programming
programmingSimilar presentations:


")

")





Ассемблеры. Причины использования языка ассемблер (лекция № 3)
1.
АссемблерыЛекция №3
2.
Здесь ассемблер понимается как системная программа (транслятор),выполняющая перевод (транслирование) текста программы,
написанного на языке ассемблер в последовательность машинных
кодов.
Транслятор – это более общее понятие, чем ассемблер.
Транслятор выполняет перевод текста программы (исходный модуль),
написанного на некотором языке программирования в
соответствующую последовательность машинных кодов (объектный
модуль).
3.
Об ассемблере• Применение языка ассемблера позволяет разработчику
управлять ресурсами вычислительной системы (ЦП, ОП, внешние
устройства и т.д.) на уровне машинных команд.
• Каждая команда исходной программы на языке ассемблере в
результате компиляции преобразуется в 1 машинную команду.
4.
Синтаксис1.
2.
3.
4.
5.
6.
7.
8.
Синтаксис Intel. Этот синтаксис является неполным. Он определяет только синтаксис инструкций кода, а не
директив, функций, макросов и так далее. Различные диалекты синтаксиса Intel являются частью синтаксисов
большинства ассемблеров. Здесь оператор назначения находится перед оператором-источником.
Синтаксис MASM. Этот синтаксис определён макроассемблером Microsoft и также используется в ассемблерах от
Watcom и Borland. Небольшие изменения синтаксиса происходят с появлением каждой новой версии MASM (сейчас
доступна 9-я версия для win-32), но всегда остаётся обратная совместимость. Происхождение этого синтаксиса
можно проследить, вернувшись к временам появления первых персональных компьютеров в ассемблерах от IBM,
Intel и Microsoft.
Синтаксис NASM. Этот синтаксис используется ассемблерами NASM и YASM. Он подобен синтаксису MASM, но не
полностью совместим с ним. Директивы, макросы и операторы не такие как в MASM.
High Level Assembler (HLA). Включает множество конструкций языков высокого уровня. Операнд-источник
располагается перед операндом назначения. HLA используется в основном студентами для быстрого изучения
ассемблера и не очень распространён.
Другие open source ассемблеры. Это множество ассемблеров с открытым исходным кодом, имеющих свой
собственный синтаксис. NASM, наиболее популярный из них.
Встроенный (Inline) Gnu-ассемблер. Ассемблер, встроенный в Gnu-компиляторы C и C++. Для Gnuсовместимости используется специальный синтаксис при соединении ассемблерных вставок с частями программы
на C++. Это очень мощный и сложный синтаксис.
Встроенный Microsoft-ассемблер. Встроенный ассемблер в C/C++-компиляторы, совместимые с компиляторами
Microsoft. Даёт доступ к переменным, функциям и меткам C++ простой вставкой их имён в ассемблерную часть. Он
прост, но имеет ряд ограничений (нет поддержки 64-разрядных систем, нельзя определять данные и макросы,
нельзя использовать функции с несколькими точками входа, этот код не оптимизируется компилятором,
использование регистров закрывают доступ внешних переменных к ним).
Встроенные С++-функции. Это функции, которые могут быть использованы в C/C++-коде. Каждая встроенная
функция заменяет одну или несколько ассемблерных инструкций, поддерживается компиляторами Microsoft, Intel и
Gnu
5.
Наиболее популярными ассемблерами сейчас являются MASM иFASM. При этом большинство документации по разработке
драйверов и системных программ предполагает использование
именно MASM.
FASM имеет синтаксис несколько отличный от MASM, и это
несколько снижало скорость роста его популярности. Но благодаря
поддержке инструкций процессоров Intel и AMD всех поколений,
простоте и постоянному обновлению, FASM завоёвывает
популярность.
6.
Классификация ассемблеровПо количеству просмотров:
• однопросмотровые:
• с записью в ОП и выполнением;
• с записью результата на внешний диск - создается объектный файл;
• двухпросмотровые;
• многопросмотровые.
7.
Функции ассемблера1. Распознавание машинных команд и перевод (1-й просмотр).
2. Распознавание директив ассемблера:
• директивы управления ассемблированием (1-й просмотр);
• директивы описания данных (2-й просмотр).
3. Распределение памяти (минимально возможный объём
машинной команды) (1-й просмотр).
4. Контроль синтаксиса (1-й просмотр).
5. Контроль семантики (1-й просмотр).
8.
Причины использования языка ассемблер1. Образовательная причина. Очень важно знать, как микропроцессоры и компиляторы
работают на уровне машинных инструкций.
2. Отладка и проверка. Для просмотра ассемблерного кода, сгенерированного
компилятором, или просмотра листинга, выданного дизассемблером, с целью поиска ошибок
и проверки качества оптимизации критических участков программы.
3. Создание компиляторов. Понимание технологии ассемблирования непосредственно для
создания компиляторов, отладчиков и других средств разработки.
4. Разработка компиляторов для языков высокого уровня. При появлении новой
архитектуры или операционной системы нужно также разработать компиляторы для
множества различных языков программирования. Сначала пишут и отлаживают ассемблеры
для этой системы.
А потом пишут трансляторы с другим языком программирования в
язык ассемблера. Так разрабатываются Gnu-компиляторы
9.
5. Драйверы и системный код. Обращение к аппаратному обеспечению, регистрам ит.д. достаточно сложно организовать на языке высокого уровня.
6.Вызов инструкций, которые недоступны в языках высокого уровня.
7.Оптимизация кода по размеру. В настоящее время требования к размеру
программы, налагаемые вследствие ограниченности размера памяти, не
существенны. Однако, для работы с некоторыми ограниченными ресурсами
(например, кэш-память сетевой платы) лучше использовать небольшой код.
8.Оптимизация кода по скорости. Современные C++ компиляторы оптимизируют
код очень хорошо в большинстве случаев. Но бывает, что и эти компиляторы не могут
сделать программу такой быстрой, какой её можно сделать на ассемблере,
правильно расположив команды.
9.Создание функциональных библиотек, совместимых с множеством компиляторов
и операционных систем. Это возможно при создании библиотек с множеством
входов для различных компиляторов и операционных систем. Это используется в
ассемблерном программировании.
10.
Причины неиспользования языка ассемблерСуществует множество проблем, возникающих при программировании на ассемблере, которых можно
избежать, используя другие языки при решении некоторых задач. Основные причины для отказа от
использования ассемблера при программировании таковы:
1. Время разработки. Написание кода на ассемблере требует гораздо больше времени, чем при
использовании языков высокого уровня.
2. Безопасность и надёжность. Очень просто допустить ошибку в ассемблерном коде. Ассемблер не
будет контролировать сохранность регистров и переменных, если вызываемая вами функция будет
их менять. Никто не скажет вам, что количество положенных в стек данных с помощью функции
PUSH, не соответствует количеству выбранных данных из стека функцией POP, или, что их
размерности не совпадают. А также существует возможность появления скрытых ошибок, которые
невозможно выявить без систематического тестирования и отладки.
3. Отладка и проверка. Ассемблерный код достаточно сложно отлаживать и проверять, потому что
он менее чувствителен к ошибкам, чем языки высокого уровня.
4. Удобство сопровождения. Ассемблерный код сложно модифицировать и сопровождать
5. Переносимость. Ассемблерный код машиннозависимый. Переносить его на различные
платформы очень сложно.
6. Системный код можно реализовать на встроенном ассемблере. Лучшие С++-компиляторы имеют
возможность доступа к прерываниям, регистрам, и другим системным ресурсам, через
использование встроенного ассемблера. Ассемблерный код не так часто нужен при написании
драйверов и системных вызовов, и может быть заменён встроенным ассемблером по мере
необходимости.
11.
Этапы выполненияM1.asm
M1.obj
загр.
модуль
ассемблер
компоновщик
др.
модули
...
загрузчик
загрузка
программы в
ОП,
Выполенение
12.
Структуры (базы) данных Ассемблера13.
Таблицы АссемблераВстроенные в ассемблер
а) Таблица мнемокодов
мнемо
код
ADD
ADD
ADD
MOV
…
ор1
ор2
КОП
размер
AX
r16
m16
AX
…
i
i
i
i
…
05
83
8306
B8
…
3
4
6
3
…
б )Таблица директив
имя директивы
assume
DB
…
процедура обработки
адрес проц. assume
адрес проц. DB
…
Мнемокод, операнды ⇒ КОП, длина команды.
Обнаруживаемые ошибки: несуществующий мнемокод, недопустимое
сочетание операндов или недопустимый операнд.
14.
Строятся во время трансляции программы:В) Таблица имён (ТИ)
имя
…
тип
…
значение сегмент
…
…
длина
…
г) Таблица сегментов (ТС)
имя
…
адрес нач.
…
размер
…
параметр
…
д) Таблица распределения сегментных регистров (ТРСР)
сегм. рег.
…
сегмент
…
Строится заново на каждом проходе.
Заполняется и изменяется по директивам assume. Используется для трансляции имён (проверка
доступности переменной через объявленный сегм. регистр и префиксы замены сегментов,
проверка расположения метки в кодовом сегменте)
15.
Первый проход ассемблера.• Цель - собрать информацию об именах и заполнить таблицу имён.
• Данные: программа на ассемблере, таблица директив и таблица
мнемокодов.
• Результат: таблица имён, таблица сегментов.
Программа читается строка за строкой, каждая строка-предложение
обрабатывается:
• заполняются таблицы, вычисляется значение счётчика размещения СР
(адрес размещаемого байта в сегменте).
• При обработке команд для определения длины команды используется
информация из таблицы мнемокодов и уже собранная информация об
описании переменной и о соответствии сегментных регистров
программным сегментам.
16.
Проблема ссылок вперед• Основная трудность, возникающая при попытке ассемблировать программу за один
просмотр, связана со ссылками вперед.
• Часто в качестве операндов команд используются имена, которые еще не были
определены в исходной программе. Поэтому ассемблер не знает, какие адреса занести в
транслируемую программу.
• Довольно легко исключить ссылки вперед на данные; достаточно потребовать, чтобы все
области данных определялись в исходной программе раньше, чем появляются команды,
которые на них ссылаются. Это не слишком жесткое ограничение. Программист просто
размещает все области данных в начало программы, а не в конец.
• Ссылки вперед на метки команд – решить сложнее. Логика программы часто требует
передачи управления вперед. (Например, выход из цикла после проверки некоторого
условия.) Требование исключить все такие передачи управления оказалось бы гораздо
более жестким и неудобным.
• Поэтому ассемблер должен предпринимать специальные меры для обработки ссылок
вперед. Однако для того, чтобы облегчить задачу, многие однопросмотровые ассемблеры
действительно запрещают (или, по крайней мере, не рекомендуют) ссылки вперед на
данные.
17.
Решение проблемы ссылок вперед• Проблема обработки операторов имеющих ссылку на впереди
определенные метки и переменные решаются с помощью 2х
просмотров.
18.
Задачей 1го просмотра является:1. Распределение памяти, т.е определение длины команды и
длины данных, заданных операторами.
2. Определение значений, меток, и переменных, т.е. адресов.
19.
Задачей 2го просмотра является:1. Формирование кодов команд и данных.
2. Формирование объектного кода.
3. Формирование протокола трансляции.
20.
Алгоритмы работы Ассемблеров• Ассемблер просматривает исходный программный модуль один
или несколько раз.
• Наиболее распространенными являются двухпроходные
Ассемблеры, выполняющие два просмотра исходного модуля.
• На первом проходе Ассемблер формирует таблицу символов
модуля, а на втором - генерирует код программы
21.
Алгоритм 1-го прохода1.
Начало 1-го прохода ассемблирования.
2.
Начальные установки:
установка в 0 счетчика адреса СчА;
создание пустой таблицы символов;
создание пустой таблицы литералов;
открытие файла исходного модуля;
3.
Считывание следующей строки исходного модуля.
4.
Лексический разбор оператора программы. При этом:
выделяется метка/имя, если она есть;
выделяется мнемоника операции;
выделяется поле операндов;
удаляются комментарии в операторе;
распознается строка, содержащая только комментарий.
5.
Поиск Мнемоники операции в таблице директив.
6.
Если мнемоника была найдена в таблице директив, происходит ветвление, в зависимости от того, какая директива
была опознана.
7.
Добавка к счетчику адреса устанавливается равной суммарному размеру объектов данных, определяемых директивой.
8.
Если мнемоника операции не найдена в таблице директив, она ищется в таблице команд.
22.
9. Если мнемоника не была найдена в таблице команд, - ошибка (неправильнаямнемоника).
10. Если мнемоника найдена в таблице команд - определение длины команды, она
же будет добавкой к счетчику адреса.
11. Есть ли в операторе литерал?
12. Занесение литерала в таблицу литералов (если его еще нет в таблице).
13. Была ли в операторе метка?
14. Поиск имени в таблице символов.
15. Имя в таблице символов найдено?
16. Если имя найдено в таблице символов - ошибка (повторяющееся имя).Если имя
не найдено в таблице символов - занесение имени в таблицу символов.
17. Формирование и печать строки листинга.
18. Модификация счетчика адреса вычисленной добавкой к счетчику
19. Печать строки листинга и переход к чтению следующего оператора.
20. При окончании обработки - закрытие файла исходного модуля.
23.
Функции 2-го прохода• Обычно 2-й проход Ассемблера читает исходный модуль с самого
начала и отчасти повторяет действия 1-го прохода (лексический
разбор, распознавание команд и директив, подсчет адресов).
• Генерация объектного кода
24.
Формат объектного файла• ОФ состоит из записей переменной длины и разного типа
• В начале каждой записи указывается её тип и длина, а затем
содержание
• Длина может указываться в зависимости от типа записи в
различных единицах (в байтах, словах, количестве элементов)
25.
Форматы записей объектного файла• Запись-заголовок содержит имя программы, ее начальный адрес
и длину.
Длина записи
Имя программы
Доп. информация
I
• Запись –команда содержит машинные команды и данные
программы с указанием адресов их загрузки.
Длина записи
ОК
С
• Запись стартового адреса отмечает конец объектной
программы и определяет адрес, с которого следует начать
Стартовый адрес
исполнение программы (точку входа). S
• Запись-модификатор
М
Длина или количество эл.
Адрес ячейки
..........
26.
Форматы команд4 байта
КОП
1
Load
St
Add
Sub
cmp
3 байта
R
адрес
КОП
2
1
100
101
Halt
2
Jmp
Je
53
Jne
102
1
1
54
40
Адрес или
значение
КОП
2
1
1 байт
255
27.
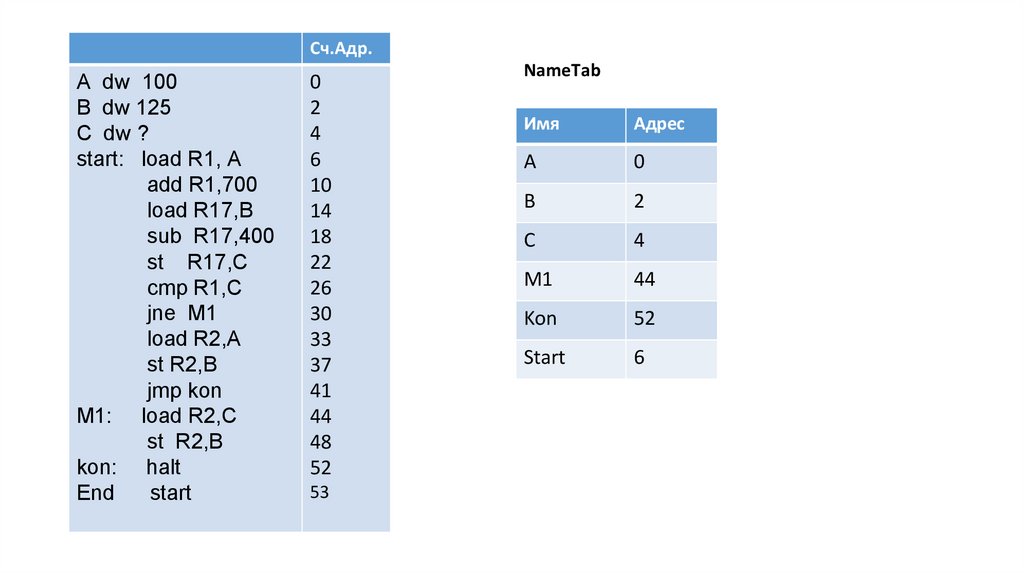
Сч.Адр.A dw 100
B dw 125
C dw ?
start: load R1, A
add R1,700
load R17,B
sub R17,400
st R17,С
cmp R1,С
jne M1
load R2,A
st R2,B
jmp kon
M1: load R2,C
st R2,B
kon: halt
End
start
0
2
4
6
10
14
18
22
26
30
33
37
41
44
48
52
53
NameTab
Имя
Адрес
А
0
B
2
С
4
M1
44
Kon
52
Start
6
28.
Сч.Адр.A dw 100
B dw 125
C dw ?
start: load R1, A
add R1,700
load R17,B
sub R17,400
st R17, C
cmp R1, C
jne M1
load R2, A
st R2, B
jmp kon
M1: load R2, C
st R2, B
kon: halt
End
start
0
2
4
6
10
14
18
22
26
30
33
37
41
44
48
52
М
10
8 16 24 28 31 35 39 42 46 50
29.
Счетчик адреса• Для определения значений имен ассемблер организует
счетчик адреса (счетчик размещений)- CntA
• В процессе трансляции ассемблер отсчитывает адреса от начала
программы или сегмента и текущее значение постоянно находится в
этой переменной
• Начальное значение =0
• При обработке команды увеличивается на длину команды
• При обработке директивы выделения памяти увеличивается на
размер выделяемой памяти
• Длина команды- количество байт занимаемое в оттранслированном
виде вместе с операндами
• Когда встречается метка, её значение определяется текущим
значениемCntA
30.
Модификаторы• Одним из способов решения проблемы модификации –
модификаторы.
• На каждый операнд-адрес вводится модификатор, который
показывает, что к данному адресу при загрузке нужно
прибавить адрес загрузки программы
• Формат записи модификаторов млжет быть различным, так
как на разных типах машин разные способы представления
ОК
• В случае одинакового формата команд применяют маски модификаторы
31.
Перемещаемая программа• Фактический начальный адрес программы не известен до момента
загрузки.
• Так как Ассемблеру не известен фактический адрес начала загрузки,
он не может выполнить необходимую настройку адресов,
используемых программой.
• Однако Ассемблер может указать загрузчику те части объектной
программы, которые нуждаются в настройке при загрузке.
• Объектная программа, содержащая информацию, необходимую для
выполнения подобной модификации, называется перемещаемой
программой.
• Программа, которую загружают с определенного адреса называют
абсолютной программой
32.
• Независимо от того, куда загружается программа, разница междуопределенным адресом и началом программы постоянная
• Значит решить проблему перемещения программы можно
следующим образом:
1. Когда ассемблер генерирует объектный код команды он заносит адрес метки
относительно начала программы. (Вот почему мы установили вначале счетчик
адреса равным 0.).
2. Ассемблер, кроме того, вырабатывает команду для загрузчика, которая
предписывает ему прибавить к содержимому адресного поля команды
начальный адрес программы.
• Естественно, что команда загрузчика должна быть составной частью
объектной программы. Это можно сделать с помощью типа записи
объектного формата - записи-модификатора.
• Для каждого адресного поля, требующего настройки при
перемещении программы, имеется своя запись-модификатор
33.
Сч.Адр.Z dw ?
X dw 500
start: load R1, X
add R1, Z
load R2,
sub R2,100
st R2,150
cmp R1,200
jne L1
load R2,X
st R2,B
jmp L2
L1: load R2,Z
st R2,B
L2: halt
End start
Упражнение №1
Построить объектный код для
заданного исходного кода.