






 software
softwareSimilar presentations:

")








Оценка и тестирование диалоговых моделей
1.
ТестыОценка и тестирование диалоговых моделей
2.
Метрики качестваС момента появления генеративных
диалоговых моделей, исследователи
разработали ряд подходов к их оценке, а
также конкретных метрик и методик
По мере развития больших моделей наборы
задач, положенные в основу метрик,
расширялись и усложнялись. Появление
систем для инструктивной генерации,
подобных ChatGPT, также требует
совершенствования способов оценки
возможностей моделей
При создании системы метрик в проекте
GigaChat мы руководствовались имеющимися
научными и индустриальными практиками, а
также собственным опытом создания метрик
для диалоговых моделей
3.
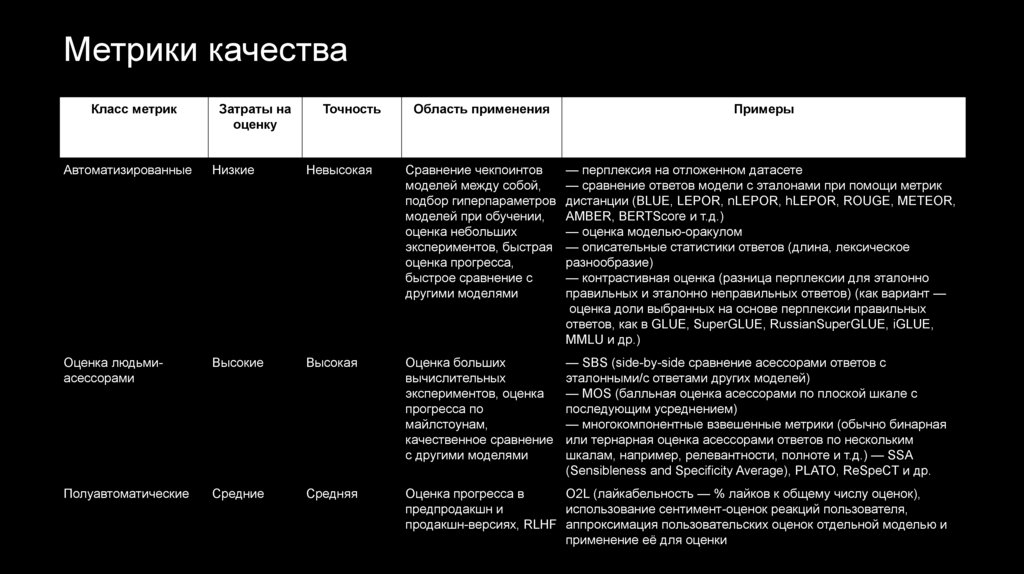
Метрики качестваКласс метрик
Затраты на
оценку
Точность
Область применения
Примеры
Автоматизированные
Низкие
Невысокая
Сравнение чекпоинтов
моделей между собой,
подбор гиперпараметров
моделей при обучении,
оценка небольших
экспериментов, быстрая
оценка прогресса,
быстрое сравнение с
другими моделями
— перплексия на отложенном датасете
— сравнение ответов модели с эталонами при помощи метрик
дистанции (BLUE, LEPOR, nLEPOR, hLEPOR, ROUGE, METEOR,
AMBER, BERTScore и т.д.)
— оценка моделью-оракулом
— описательные статистики ответов (длина, лексическое
разнообразие)
— контрастивная оценка (разница перплексии для эталонно
правильных и эталонно неправильных ответов) (как вариант —
оценка доли выбранных на основе перплексии правильных
ответов, как в GLUE, SuperGLUE, RussianSuperGLUE, iGLUE,
MMLU и др.)
Оценка людьмиасессорами
Высокие
Высокая
Оценка больших
вычислительных
экспериментов, оценка
прогресса по
майлстоунам,
качественное сравнение
с другими моделями
— SBS (side-by-side сравнение асессорами ответов с
эталонными/с ответами других моделей)
— MOS (балльная оценка асессорами по плоской шкале с
последующим усреднением)
— многокомпонентные взвешенные метрики (обычно бинарная
или тернарная оценка асессорами ответов по нескольким
шкалам, например, релевантности, полноте и т.д.) — SSA
(Sensibleness and Specificity Average), PLATO, ReSpeCT и др.
Полуавтоматические
Средние
Средняя
Оценка прогресса в
O2L (лайкабельность — % лайков к общему числу оценок),
предпродакшн и
использование сентимент-оценок реакций пользователя,
продакшн-версиях, RLHF аппроксимация пользовательских оценок отдельной моделью и
применение её для оценки
4.
Автоматизированные метрикиНазвание метрики
Назначение
Pro et contra
Перплексия на отложенном
датасете
Оценка генеративных языковых
моделей
Простая в вычислении метрика, требующая наличие отложенного датасета с
вопросами и эталонными ответами. Отражает оценку степени неожиданности для
модели соответствующей последовательности (ответа на вопрос). Минусы: не
отличает важные и не важные с точки зрения смысла участки последовательности,
исследования Meta показывают, что перплексия недостаточно коррелирует с
качеством ответов диалоговых моделей, наши собственные исследования это также
подтверждают.
Сравнение ответов модели с
Оценка моделей машинного
эталонами при помощи метрик перевода, вопросно-ответных
дистанции
систем
Для каждого вопроса заготавливаются наборы эталонных ответов. Измеряется
дистанция ответа модели от эталонных ответов (метрики дистанции могут быть
разными). Метрика простая в вычислении, но требует обычно наличия нескольких
эталонов, и не годится для генеративных задач, когда множество «хороших» ответов
может быть очень велико.
Оценка моделью-оракулом
Оценка генеративных языковых
моделей
При наличии заведомо более ёмких моделей, такие модели могут быть
использована в качестве «арбитра»; скажем, может оцениваться перплексия ответа
оцениваемой модели с точки зрения модели-оракула. Минус: необходимость
наличия ёмкой модели-оракула.
Описательные статистики
Оценка генеративных языковых
моделей
Оценка формальных статистик ответов модели (длина, лексическое разнообразие и
т. п.). Простые и интерпретируемые метрики, позволяющие оценить полноту
генеративных ответов, но в них отсутствует способ оценки релевантности ответов.
Контрастивная оценка
Оценка генеративных языковых
моделей
Разница перплексии для эталонно правильных и эталонно неправильных ответов.
Как вариант — оценка доли выбранных на основе перплексии правильных ответов.
Минус: необходимость наличия нескольких эталонов правильных и неправильных
ответов.
5.
Асессорские метрикиНазвание метрики Создатели
Назначение
Компоненты
SSA
Оценка моделей семейства
Meena
Sensibleness (релевантность), Specificity (специфичность). Оценка по бинарной
шкале (1 = да / 0 = нет) отдельных реплик диалога с последующим усреднением
по асессорам.
Acute-Eval
Meta
Оценка моделей семейства
BlenderBot
Engagingness, Interestingness, Humanness, Knowledgeable — сравнение
диалогов разных моделей между собой по принципу “С какая из моделей, на
ваш взгляд, более интересно вести диалог?”
PLATO-XL
Baidu
Оценка модели PLATO-XL
(Chinese, English)
Coherence, Inconsistency, Informativeness, Hallucination, Engagingness —
развитие идей SSA, разметка отдельных реплик.
ReSpeCT
SberDevices
Оценка диалоговых
моделей Собеседника
(retrieval, generative)
Relevance, Specificity, Coherence, Trueness — Адаптация лучших академических
практик оценки моделей под индустриальные продуктовые реалии, разметка
отдельных реплик с последующей агрегацией по асессорам.
ODMEN (Offline
Dialogue Model
Evaluation Norms)
SberDevices
Оценка диалоговых
моделей Собеседника
(retrieval, generative)
Безопасность (бинарная), Достоверность (бинарная), Ошибки (бинарная),
Интересность (тернарная), Общая оценка (пятибалльная) — разметка на
уровне диалога в целом без дробления на реплики. Учтён весь накопленный
опыт работы с диалоговыми метриками, упрощены инструкции для асессоров,
существенно ускорена процедура разметки.
ODMEN+
SberAI +
SberDevices
Оценка инструктивных
диалоговых моделей
Безопасность (бинарная), Достоверность (бинарная), Ошибки (бинарная),
Полнота/подробность/интересность (тернарная), Общая оценка (пятибалльная)
— разметка на уровне диалога в целом без дробления на реплики. Учтён весь
накопленный опыт работы с диалоговыми метриками, упрощены инструкции
для асессоров, существенно ускорена процедура разметки.
6.
ODMEN+❏
❏
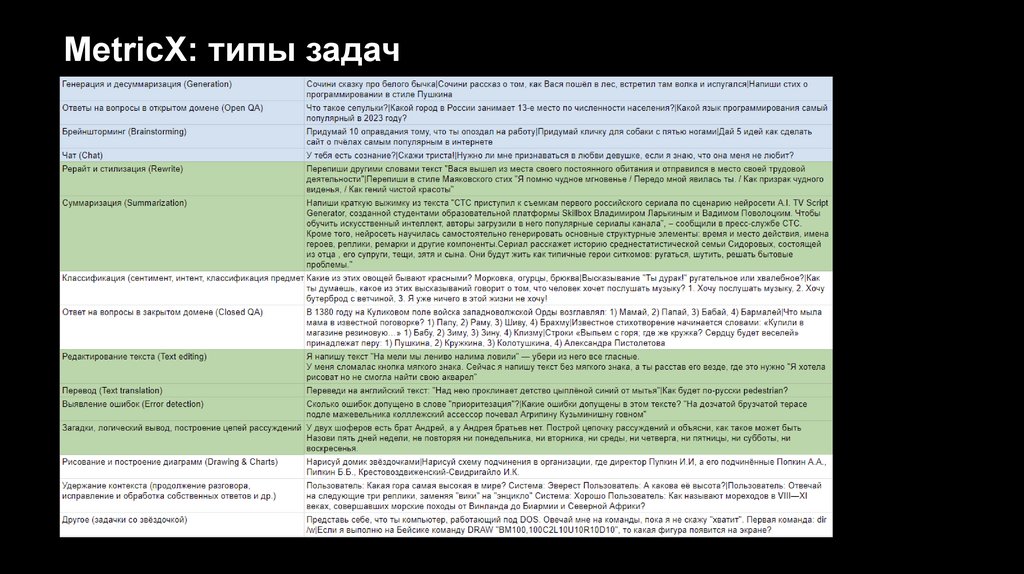
Сформированы справочники с типами задач и
тематиками запросов — использована
комбинация экспертного подхода и аналитики
запросов ChatGPT.
Для сравнения моделей между собой важно
иметь сбалансированную корзину как по типам
задач, так и по тематикам — равномерно
наполняем все классы запросами, далее
можем взвешивать по важности с учётом
бизнес-кейсов.
7.
MetricX: типы задач8.
MetricX: тематикиДомен
Досуг, искусство и развлечения
Пояснения
Включает спорт, музыку, кино, сериалы, соцсети
Образование и карьера
Медицина и здоровье
Школа, вуз, работа, учёба, бизнес, стартапы
В том числе профилактика заболеваний, здоровый образ жизни и т. д.
Повседневная жизнь
Жильё, ремонт, бытовые проблемы, растения, животные, кулинария, еда, гаджеты
Человеческие отношения
Семья, отношения полов, соседи, друзья, знакомства, события из жизни, эмоции и чувства, родственные связи
Общество, политика
Популярная психология, религия,
эзотерика
Товары и услуги
Социальные темы, политика, глобальные проблемы человечества
Включая суеверия, приметы и т. д.
Путешествия и туризм
Этика
Путешествия, транспорт, туризм и т. д.
Вопросы, которые относятся к области этики (чтобы уметь оценивать «этичность» и ценности моделей)
STEM
Наука, технологии, инженерное дело, математика (включая программирование)
Гуманитарные науки
Код
Философия, социология, история и т. д.
Отдельный домен для задач по коду (выделяем отдельно, чтобы оценить способности модели решать задачи в
области программирования)
Производство, покупка, продажа, подарки, маркетинг, финансы и банковское дело
При составлении корзины тестов, её содержимое балансируется таким образом, чтобы корзина содержала
одинаковое количество запросов для каждой пары «тематика (домен) — тип задачи». Это позволяет
использовать корзину для более тонкой диагностики — при необходимости получить оценки по отдельным
доменам и типам задач.
9.
Карта метрикКласс метрик
Метрики ChatWintermute
Автоматизированные
Перплексия на отложенной выборке:
• на основе корзины MetricX с эталонными ответами
• на основе корзины MetricX с ответами chatGPT
Сравнение ответов модели с эталонами при помощи метрик дистанции
• дистанция по BERTScore для ответов ChatWintermute с эталонными ответами
• дистанция по BERTScore для ответов ChatWintermute с ответами ChatGPT
Оценка при помощи модели-оракула:
• на базе ёмких языковых моделей
Описательные статистики:
• средняя длина ответа
• лексическое разнообразие
Контрастивная оценка:
• на основе корзины MetricX с эталонными плохими и хорошими ответами
Общепринятые наборы тестов:
• RussianSuperGLUE
• BigBench
Оценка людьмиасессорами
SBS
• Side-by-side-сравнение с ChatGPT на основе корзины MetricX
Многокомпонентные взвешенные метрики:
• MetricX
Полуавтоматические
O2L (на основе данных стенда: сумма слайков плюс полусумма ok, делённые на число оценок)