










































 electronics
electronicsSimilar presentations:










Основы построения и функционирования вычислительных систем
1.
ВОЕННО-КОСМИЧЕСКАЯ АКАДЕМИЯ ИМЕНИ А.Ф. МОЖАЙСКОГОКафедра информационно-вычислительных систем и сетей
РАЗДЕЛ 3. Вычислительные системы
Тема 7. Основы построения и функционирования
вычислительных систем
Доктор технических наук профессор,
БАСЫРОВ А.Г.
2.
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМЛекция №24
Параллелизм как основа
высокопроизводительных вычислений
Цель: сформировать у обучающихся знания о принципах
параллельных вычислений
Учебные вопросы:
1.Основные понятия параллельных вычислений
2.Метрики и законы параллельных вычислений
3.Способы высокопроизводительной обработки
информации
2
3.
Учебный вопрос № 1Основные понятия параллельных
вычислений
3
4.
Основные понятия параллельных вычислений4
Параллельные вычисления – совокупность вопросов,
относящихся к созданию ресурсов параллелизма в
процессе решения задач и гибкому управлению
реализацией этого параллелизма с целью достижения
наибольшей
эффективности
использования
вычислительной системы.
Параллельная
вычислительная
система
–
вычислительная система, содержащая не менее двух
вычислительных модулей, способных согласованно
одновременно (параллельно) осуществлять обработку
информации.
Параллельные процессы – процессы обработки данных,
у которых интервалы времени выполнения перекрываются
за счет использования различных ресурсов одной и той же
системы [ГОСТ 19781-90].
5.
Задачи параллельной обработки информацииПРОБЛЕМАТИКА ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ
разработка параллельных вычислительных систем
(архитектура параллельных вычислительных систем)
анализ эффективности параллельных вычислений для
оценивания получаемого ускорения вычислений
(методы анализа сложности)
создание и развитие параллельных алгоритмов для
решения прикладных задач в разных областях
(методы организации параллельных вычислений)
создание и развитие системного программного
обеспечения для параллельных вычислительных систем
(параллельное программирование - языки, среды
разработки, библиотеки).
5
6.
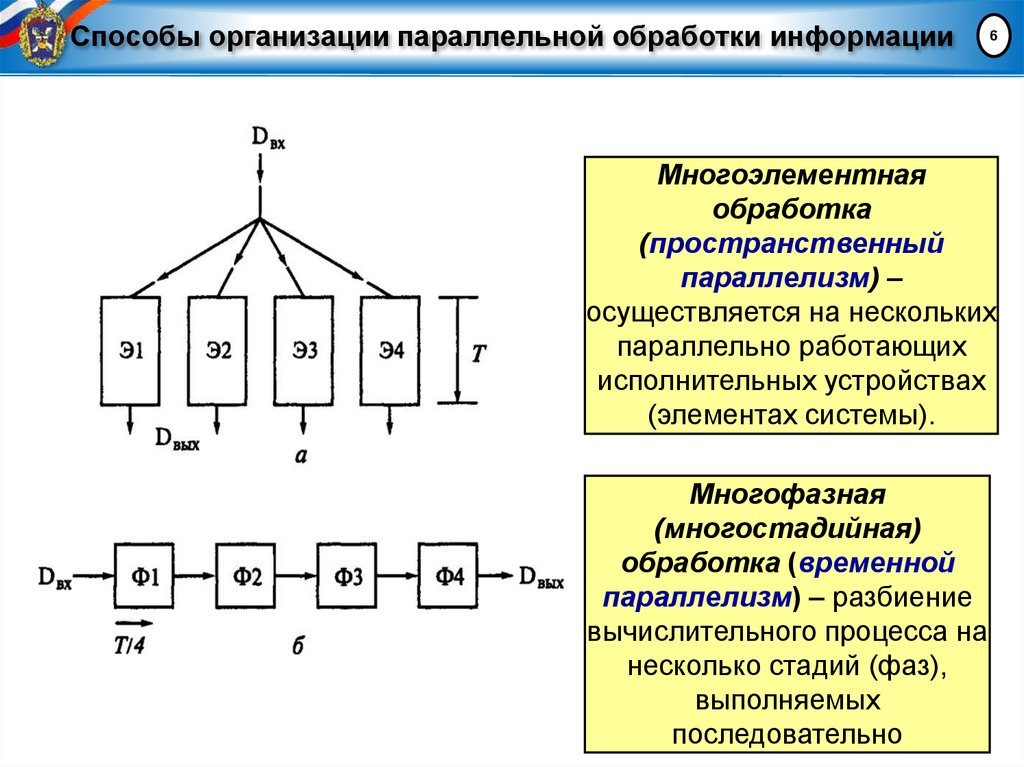
Способы организации параллельной обработки информации6
Многоэлементная
обработка
(пространственный
параллелизм) –
осуществляется на нескольких
параллельно работающих
исполнительных устройствах
(элементах системы).
Многофазная
(многостадийная)
обработка (временной
параллелизм) – разбиение
вычислительного процесса на
несколько стадий (фаз),
выполняемых
последовательно
7.
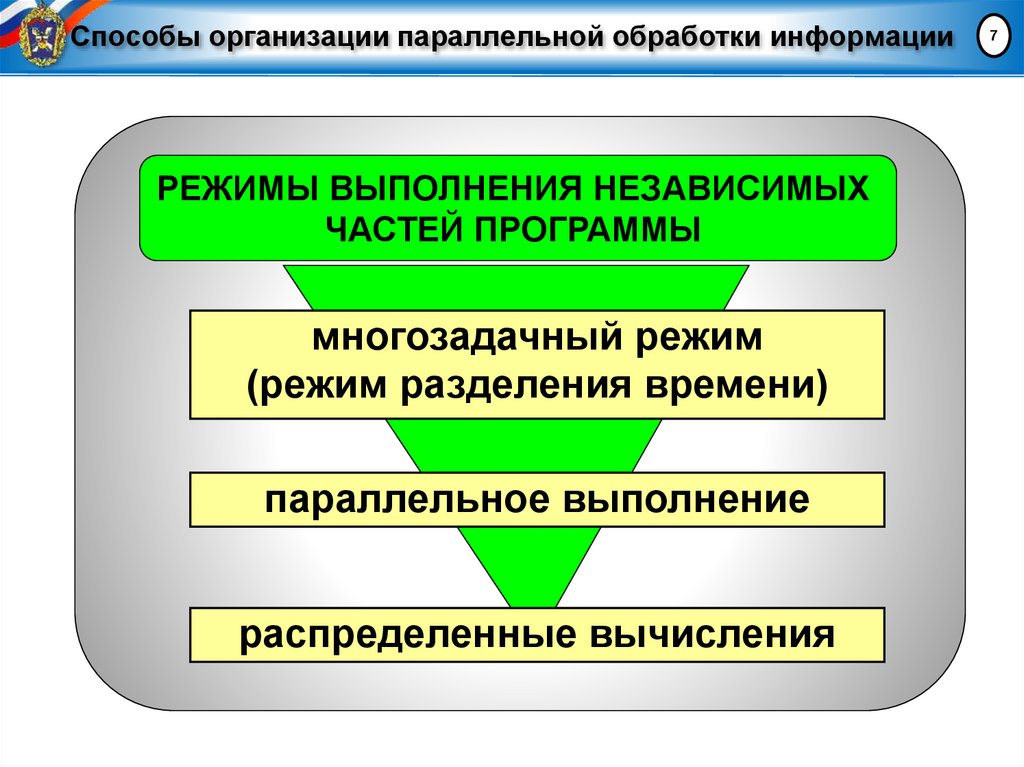
Способы организации параллельной обработки информацииРЕЖИМЫ ВЫПОЛНЕНИЯ НЕЗАВИСИМЫХ
ЧАСТЕЙ ПРОГРАММЫ
многозадачный режим
(режим разделения времени)
параллельное выполнение
распределенные вычисления
7
8.
Способы организации параллельной обработки информациимногозадачный режим
(режим разделения времени)
Процесс 1
Процесс 2
Процесс 3
ЦП
ЦП
ЦП
ЦП
ЦП
t=6
мультипрограммирование
ЦП
8
параллельное
выполнение
ЦП1
ЦП1
ЦП2
ЦП2
ЦП3
ЦП3
t=2
мультипроцессирование
9.
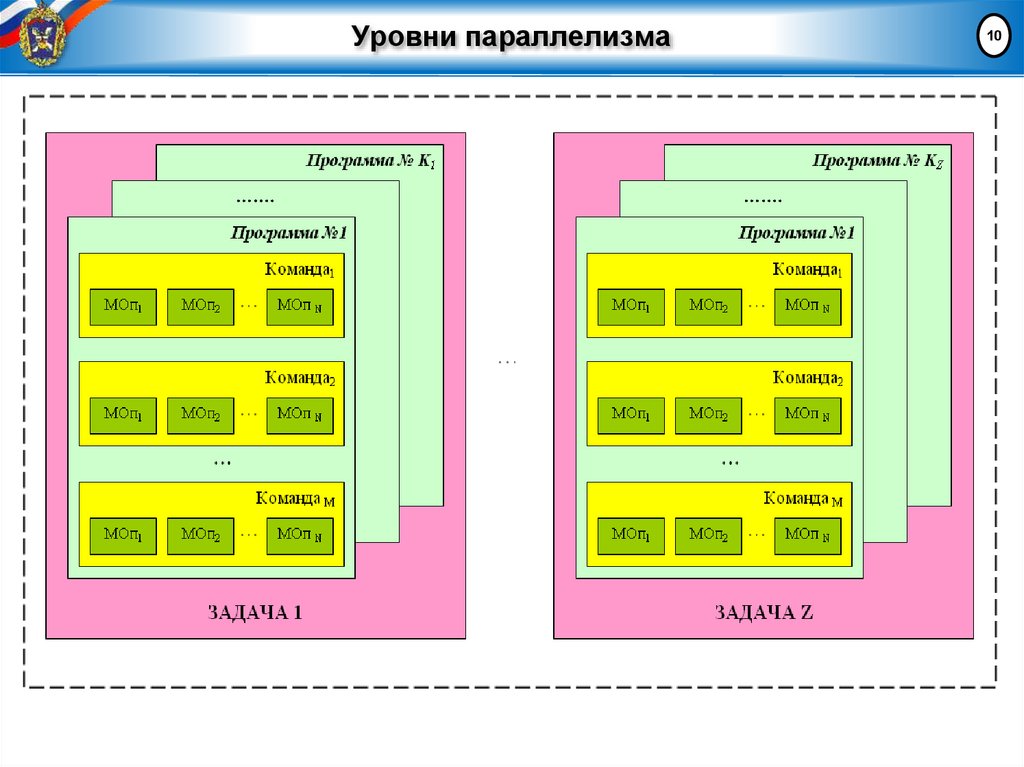
Уровни параллелизмаЧЕТЫРЕ УРОВНЯ ПАРАЛЛЕЛИЗМА
Параллелизм заданий - каждый процессор загружается
своей собственной независимой от других вычислительной
задачей
Параллелизм на уровне программы - вычислительная
программа разбивается на части, которые могут
выполняться одновременно на различных процессорах
Параллелизм команд - реализован на низком уровне
(например, конвейеры и т.д.)
Параллелизм на уровне машинных слов
и арифметических операций
9
10.
Уровни параллелизма10
11.
Виды параллелизма11
Параллелизм данных
Параллелизм задач
одна операция
выполняется сразу над
всеми элементами
массива данных
вычислительная задача
разбивается на несколько
подзадач и каждый
процессор загружается своей
собственной подзадачей
высокопроизводительный
ФОРТРАН (High Performance
FORTRAN) и параллельные
версии языка С
специализированные библиотеки
MPI (Message Passing Interface),
PVM (Parallel Virtual Machines).
12.
Учебный вопрос № 2Метрики и закономерности
параллельных вычислений
12
13.
Метрики и законы параллельной обработки информацииМетрики параллельных вычислений –
показатели качества функционирования
вычислительной системы при параллельной
обработке информации
Закон параллельных вычислений –
зависимость значения метрики от параметров
параллельной обработки информации
13
14.
Метрики параллельной обработки информацииМетрики параллельных вычислений
1) Степень параллелизма
2) Индекс параллелизма
3) Ускорение
4) Эффективность
5) Утилизация
6) Избыточность
7) Сжатие
8) Качество
9) Стоимость
Обозначения
• n – количество процессоров, используемых для
организации параллельных вычислений;
• O(n) – объем вычислений - количество
операций, выполняемых n процессорами в ходе
решения задачи;
• T(n) – общее время вычислений (решения
задачи) с использованием n процессоров.
14
15.
Метрики параллельной обработки информацииСтепень параллелизма D(t) (DOP, Degree Of
Parallelism) – число ВМ ВС, параллельно
участвующих в выполнении программы в
каждый момент времени t.
DOP позволяет определить среднее число p
операций
программы,
которые
можно
выполнять одновременно.
Графическое представление степени
параллелизма называют профилем
параллельной программы
15
16.
Профиль параллельной программы16
Средний параллелизм
ti – интервал времени
загрузки i процессоров ВС
Общий объем вычислений O(n) за заданный
период пропорционален площади под кривой
профиля параллелизма:
Δ - производительность одиночного процессора ВС - количество
операций в единицу (квант) времени, не учитывая издержек, связанных
с обращением к памяти и пересылкой данных
17.
Метрики параллельной обработки информацииИндекс параллелизма - средняя
скорость параллельных вычислений
Ускорением параллельных вычислений, получаемым
при использовании параллельного алгоритма для n
процессоров, по сравнению с последовательным
вариантом выполнения вычислений называется величина:
где Т(1) – время исполнения алгоритма на одном
процессоре,
T(n) – время исполнения параллельного алгоритма на
n процессорах.
17
18.
Метрики параллельной обработки информацииЭффективностью n-процессорной ПВС
называется величина:
E(n) = S(n) / n,
т.е. ускорение, приходящееся на один процессор
Величина эффективности определяет среднюю долю
времени выполнения параллельного алгоритма, в
течение которого процессоры реально используются
для решения задачи
18
19.
Метрики параллельной обработки информацииУтилизация учитывает вклад каждого
процессора при параллельном вычислении
в виде количества операций, выполненных
процессором в единицу времени.
Избыточность – отношение объема
параллельных вычислений к объему
эквивалентных
последовательных
вычислений:
Сжатие
–
избыточности:
величина,
обратная
19
20.
Метрики параллельной обработки информации20
Избыточность и сжатие характеризуют
эффективность параллельных вычислений путем
сравнения объема вычислений, выполненного при
параллельном и последовательном решении задачи.
Утилизация может быть выражена через метрики
избыточности и эффективности
здесь учитывается соотношение T(1) = O(1).
21.
Метрики параллельной обработки информацииКачество – метрика, связывающая метрики
ускорения, эффективности и сжатия.
Качество является более объективным показателем
улучшения производительности за счет параллельных
вычислений.
21
22.
Метрики параллельной обработки информации22
Стоимость вычислений – произведение
количества процессоров на время параллельной
обработки.
Стоимостно-оптимальный параллельный метод
обработки информации – метод, стоимость которого
является
пропорциональной
времени
выполнения
наилучшего последовательного алгоритма.
23.
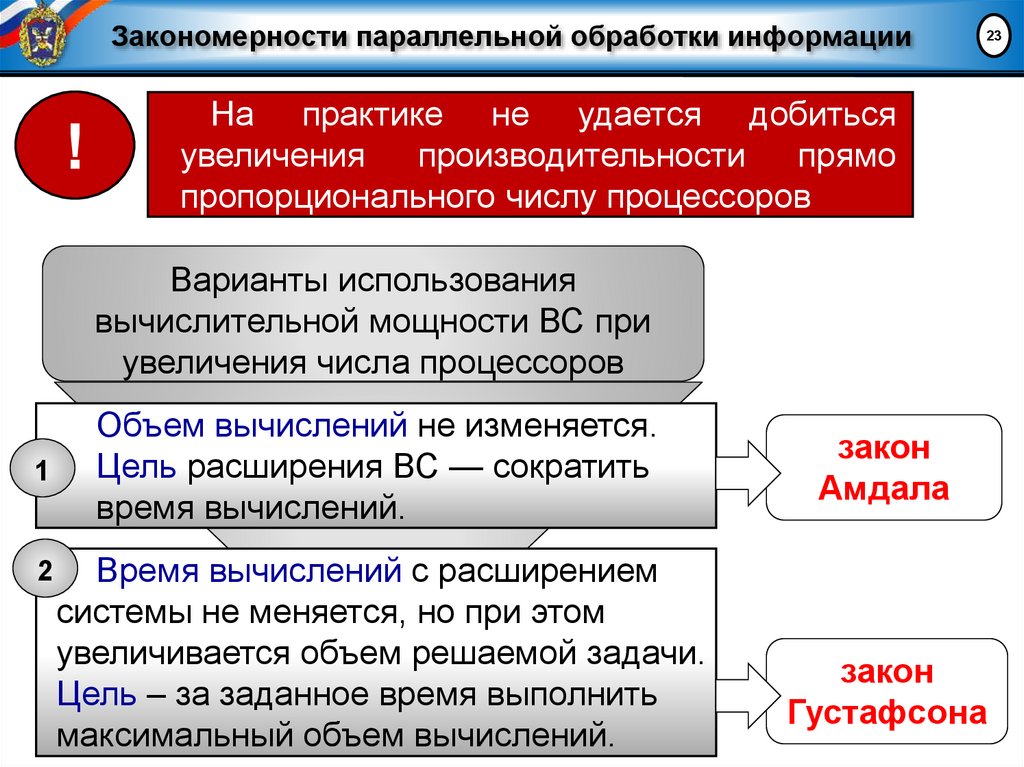
Закономерности параллельной обработки информации!
23
На практике не удается добиться
увеличения
производительности
прямо
пропорционального числу процессоров
Варианты использования
вычислительной мощности ВС при
увеличения числа процессоров
1
2
Объем вычислений не изменяется.
Цель расширения ВС — сократить
время вычислений.
Время вычислений с расширением
системы не меняется, но при этом
увеличивается объем решаемой задачи.
Цель – за заданное время выполнить
максимальный объем вычислений.
закон
Амдала
закон
Густафсона
24.
Закономерности параллельной обработки информацииЗаконы параллельных вычислений определяют
зависимость ускорения от количества процессоров и
свойств алгоритма задачи.
свойства алгоритма
f - доля операций, которые должны выполняться
последовательно (одним из процессоров)
0≤f≤1
f = 0 - полностью распараллеливаемая программа
f = 1 - полностью последовательная программа
последовательная часть ts
распараллеливаемая часть tp
программа
24
25.
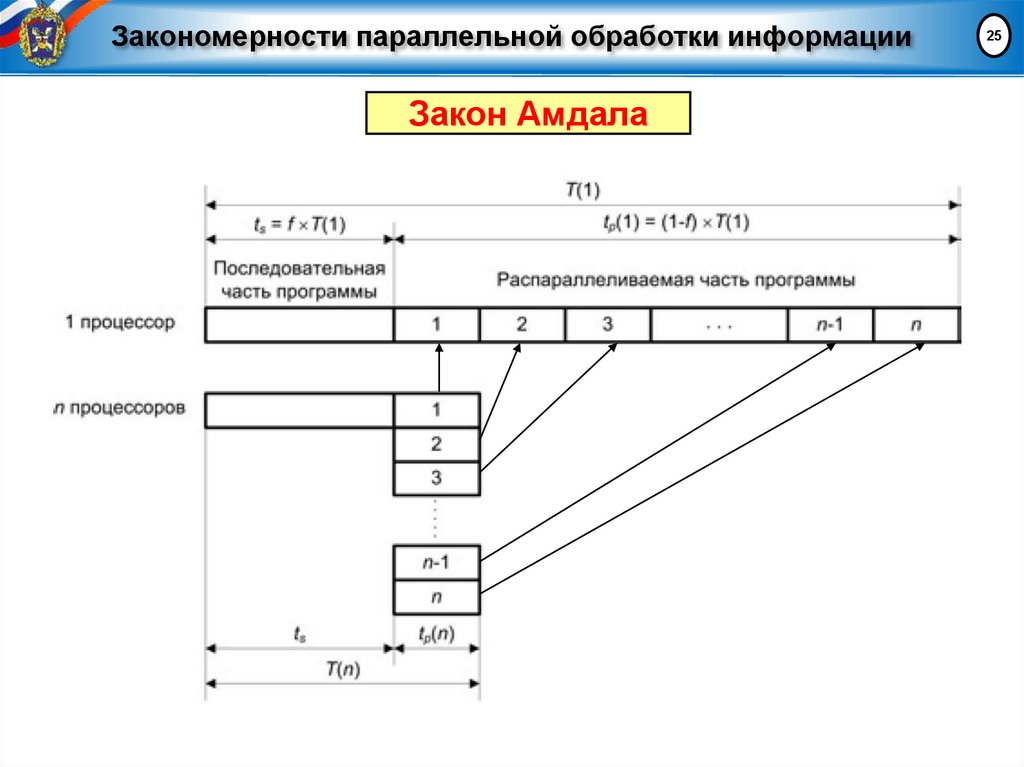
Закономерности параллельной обработки информацииЗакон Амдала
25
26.
Закономерности параллельной обработки информации26
Закон Амдала
Ускорение для n-процессорной вычислительной системы:
S = T(1) / T(n),
Время параллельного выполнения задачи:
(1 f ) T (1)
T (n) f T (1)
n
T (1)
n
S ( n)
T (n) 1 (n 1) f
закон Амдала
Пример. Если в программе 10% последовательных операций (f=0,1),
то сколько бы процессоров не использовалось, принципиально
невозможно получить ускорение более, чем в 10 раз.
27.
Закономерности параллельной обработки информацииЗакон Амдала
Зависимость коэффициента
ускорения от числа процессоров
Зависимость коэффициента
ускорения от доли
последовательных операций
программы
27
28.
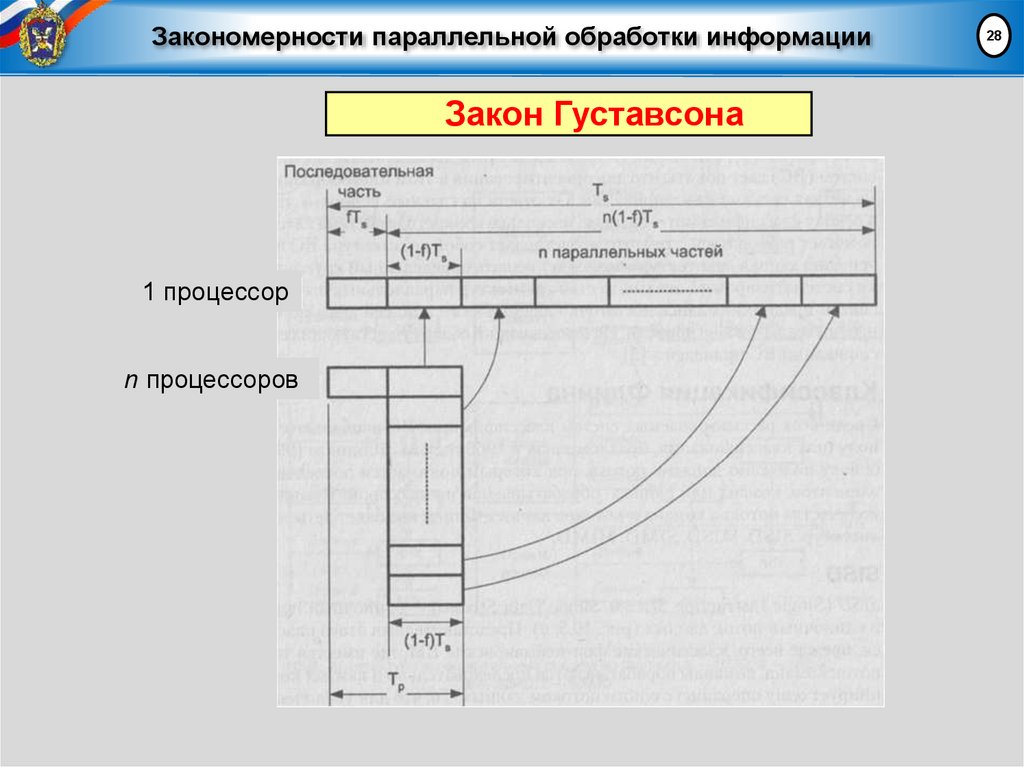
Закономерности параллельной обработки информацииЗакон Густавсона
1 процессор
n процессоров
28
29.
Закономерности параллельной обработки информацииЗакон Густавсона
Для оценивания возможности ускорения вычислений,
когда их объем увеличивается с ростом количества
процессоров в системе (при постоянстве общего времени
вычислений), используется закон ГУСТАВСОНА:
Выражение известно как закон масштабируемого
ускорения или закон Густавсона
(иногда называют закон Густавсона-Барсиса)
29
30.
Учебный вопрос № 3Способы высокопроизводительной
обработки информации
30
31.
Конвейерная обработка информацииИдея конвейеризации вычислений состоит разбиении
сложной операции на множество более простых, которые
могут выполняться одновременно
При движении объектов по конвейеру на разных его участках
выполняются разные операции, а при достижении каждым объектом
конца конвейера он окажется полностью обработанным
структура конвейера
31
32.
Конвейерная обработка информации32
Принципы конвейерной обработки
Выполнение каждой команды складывается из
ряда последовательных этапов (шагов, стадий,
ступеней), суть которых от команды к команде не
меняется
В каждый момент времени процессор работает над
различными стадиями выполнения нескольких
команд, причем на выполнение каждой стадии
выделяются отдельные аппаратные ресурсы
команда 1
ступень 1
ступень 2
ступень 3
…
ступень 2
ступень 3
ступень N
команда 2
ступень 1
…
ступень N
33.
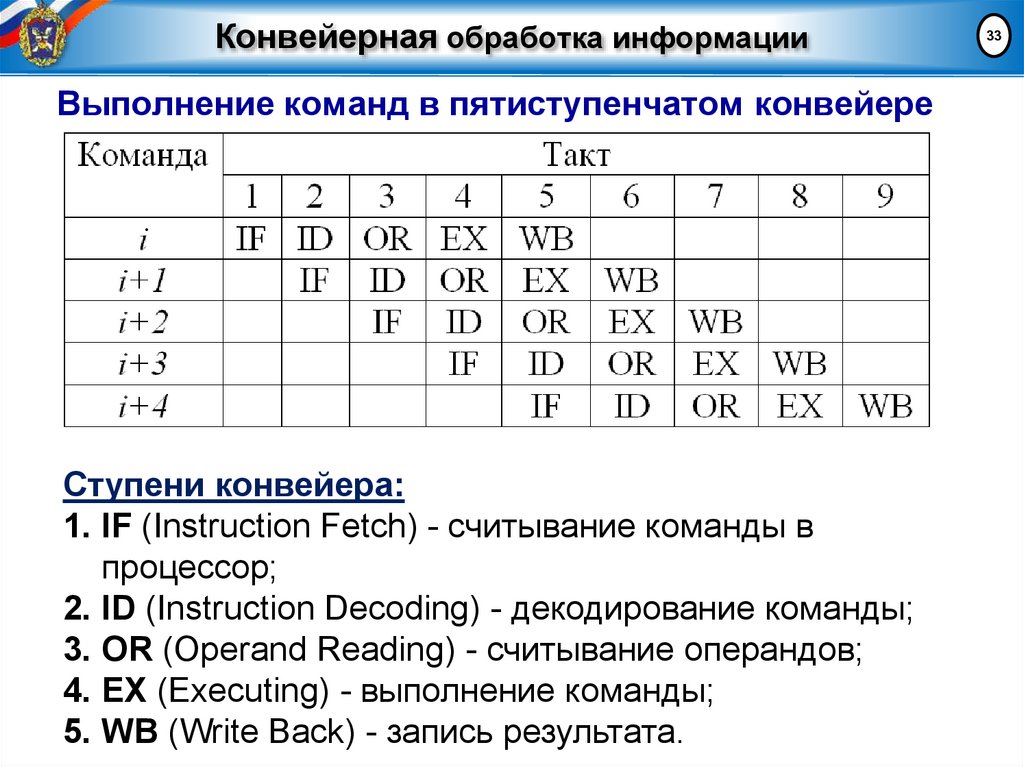
Конвейерная обработка информацииВыполнение команд в пятиступенчатом конвейере
Ступени конвейера:
1. IF (Instruction Fetch) - считывание команды в
процессор;
2. ID (Instruction Decoding) - декодирование команды;
3. OR (Operand Reading) - считывание операндов;
4. EX (Executing) - выполнение команды;
5. WB (Write Back) - запись результата.
33
34.
Конвейерная обработка информации34
Пример расчета времени работы конвейера
Пусть для выполнения отдельных стадий обработки
требуются следующие затраты времени (в усл. ед.):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени
составляют dt = 5 единиц, получим время такта:
T = max {TIF, TID, TOR, TEX, TWB} + dt = 30.
При последовательной обработке время выполнения N
команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
При конвейерной обработке после получения результата
выполнения первой команды, результат очередной команды
появляется в следующем такте работы процессора.
Следовательно, Tконв = 5T + (N-1) · T = T· (N+4).
35.
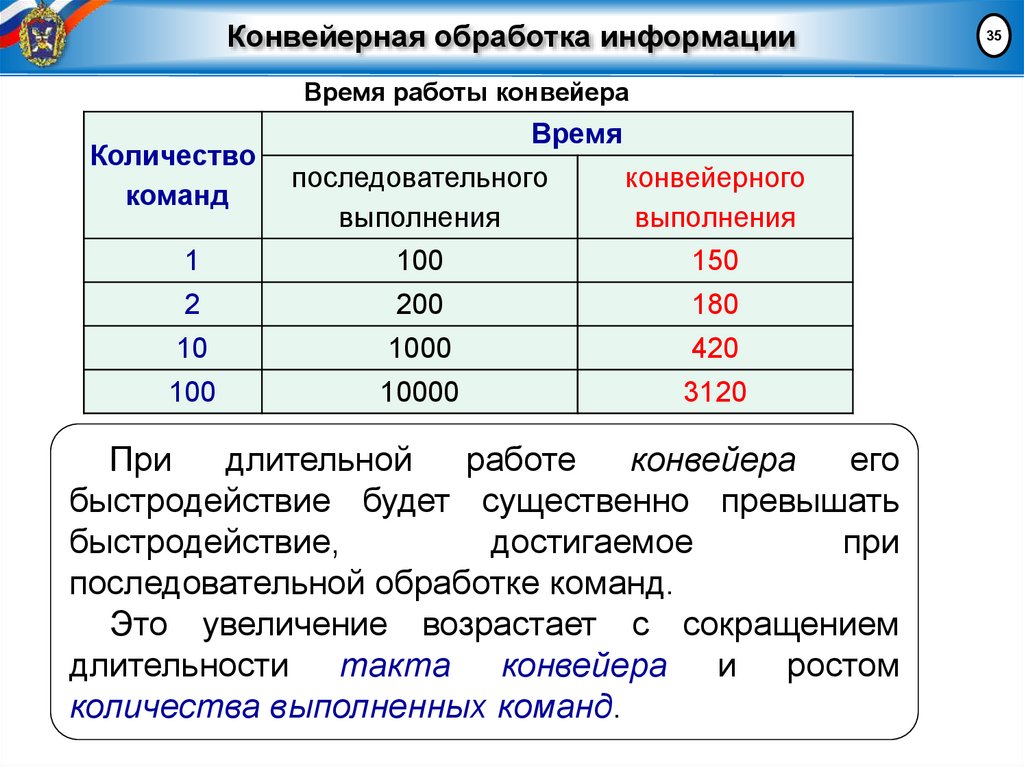
Конвейерная обработка информацииВремя работы конвейера
Количество
команд
Время
последовательного
выполнения
конвейерного
выполнения
1
100
150
2
200
180
10
1000
420
100
10000
3120
При
длительной
работе
конвейера
его
быстродействие будет существенно превышать
быстродействие,
достигаемое
при
последовательной обработке команд.
Это увеличение возрастает с сокращением
длительности такта конвейера и ростом
количества выполненных команд.
35
36.
Метрики конвейерной обработки информации36
1.Ускорение – отношение времени обработки
без конвейера ко времени при наличии конвейера.
Теоретически наилучшее время обработки входного потока из N
значений на конвейере с K ступенями и тактовым периодом Тк
определяется выражением:
T NK ( K N 1) T к
Ускорение S вычислений за счет их конвейеризации
NK T K
NK
S
( K N 1) T K K N 1
!
При N→∞ ускорение стремится к величине, равной
количеству ступеней в конвейере.
37.
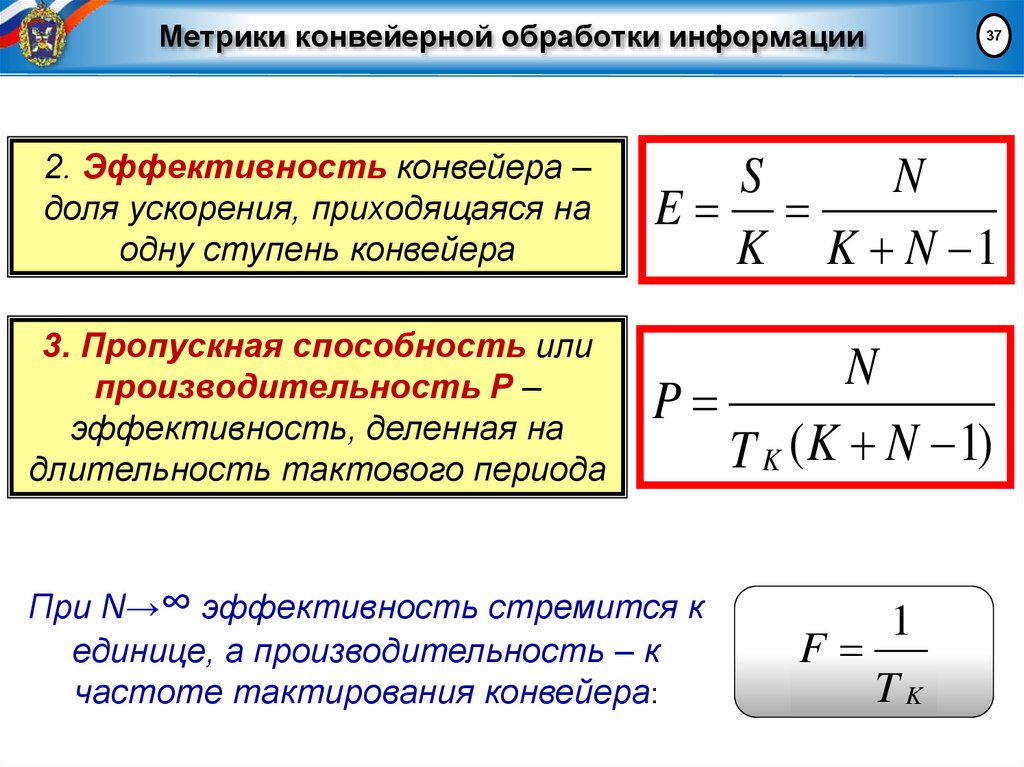
Метрики конвейерной обработки информации37
2. Эффективность конвейера –
доля ускорения, приходящаяся на
одну ступень конвейера
S
N
E
K K N 1
3. Пропускная способность или
производительность Р –
эффективность, деленная на
длительность тактового периода
N
P
T K ( K N 1)
При N→∞ эффективность стремится к
единице, а производительность – к
частоте тактирования конвейера:
F
1
TK
38.
Конвейерная обработка информации38
Количество подопераций (ступеней) называют
глубиной конвейера
Данные, подаваемые в конвейер, должны быть
независимыми.
Если очередной операнд зависит от результата
предыдущей операции, возникают периоды простоя в
работе конвейера ("пузыри")
Команда 1
результат
ЯП
операнд
Команда 2
команда 1
IF
ID
OR
EX
WR
OR
EX
команда 2
IF
ID
WR
39.
Конвейерная обработка информации39
КОНФЛИКТЫ - ситуации в конвейерной обработке,
которые препятствуют выполнению очередной команды в
предназначенном для нее такте
Конфликты делятся на три группы:
1) структурные, 2) по управлению, 3) по данным
Структурные конфликты возникают в том случае, когда
аппаратные средства процессора не могут поддерживать все
возможные комбинации команд в режиме одновременного
выполнения с совмещением
Конфликты по управлению возникают при конвейеризации команд
переходов и других команд, изменяющих значение счетчика команд
Конфликты по данным возникают в случаях, когда выполнение
одной команды зависит от результата выполнения предыдущей
команды
40.
Конвейерная обработка информацииСуперконвейерность – архитектура
процессора, использующая
многоступенчатую технологию
обработки машинных команд и совмещение
во времени выполнения различных этапов
двух и более команд
Суперконвейеризация
сводится
к
увеличению количества ступеней конвейера
как за счет добавления новых ступеней, так
и
путем
дробления
имеющихся
на
несколько простых подступеней
40
41.
Конвейерная обработка информацииДлина конвейера команд в популярных
микропроцессорах
Тип микропроцессора
Количество ступеней в
конвейере команд
MIPS R4400
UltraSPARC I
Pentium III
Itanium
UltraSPARC III
Pentium IV Willamette
Pentium IV Prescott
Intel Core
8
9
10
10
14
22
31
14
(K>6)
41
42.
Суперскалярная обработка информации42
Суперскалярность — архитектура вычислительного ядра,
использующая несколько декодеров команд, которые могут
нагружать работой множество исполнительных блоков
В суперскалярном процессоре параллельно обрабатывается
несколько машинных команд.
Планирование
исполнения
потока
команд
является
динамическим и осуществляется самим вычислительным ядром
Принцип функционирования суперскалярного процессора
43.
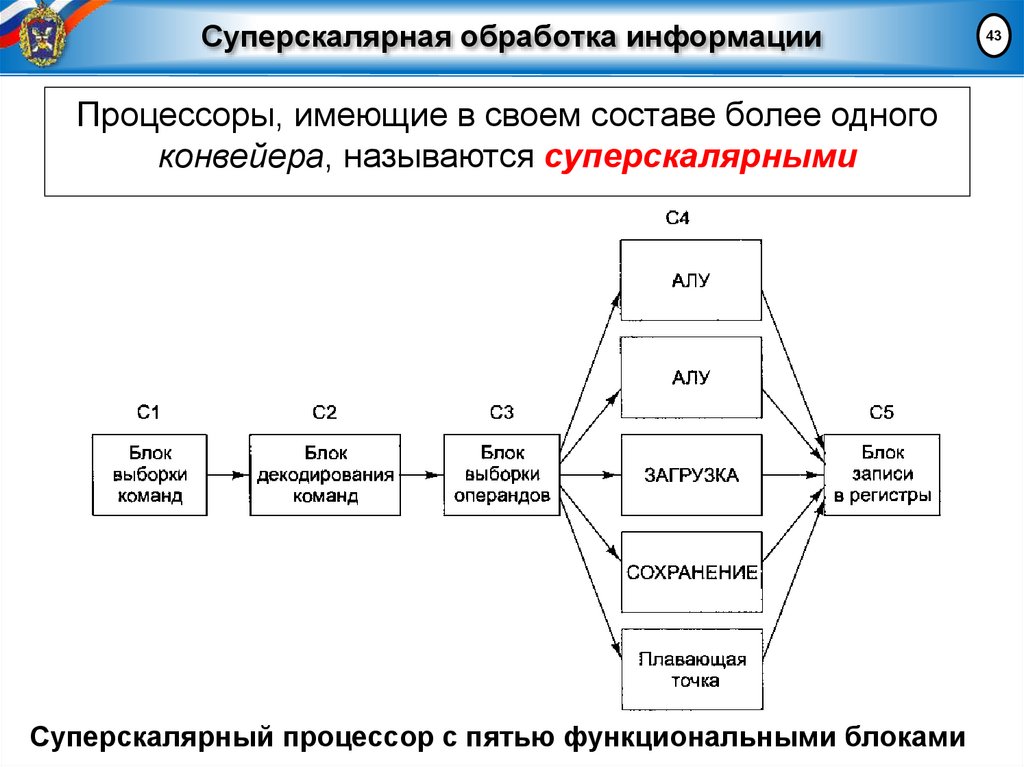
Суперскалярная обработка информацииПроцессоры, имеющие в своем составе более одного
конвейера, называются суперскалярными
Суперскалярный процессор с пятью функциональными блоками
43
44.
Суперскалярная обработка информации44
Суперскалярная
обработка
обработка
с
многопотоковым конвейером команд, при которой
процессор может выполнять больше одной команды за такт
В суперскалярном процессоре последовательный поток команд
исходной программы преобразуется в
несколько параллельных
потоков, проходящих через несколько исполнительных устройств
К1
К3
Конвейер 1
ФБ 1
К1
К2
К2 … Кm
последовательный
поток команд
Конвейер 2
…
…
К4
Кm
программа
параллельные
потоки команд
ФБ 2
Конвейер N
ФБ k
Память (регистры)
К1
К2
К3
К4
…
Кm
исполнительные
устройства
45.
Суперскалярная обработка информации45
В суперскалярных процессорах одновременная работа нескольких
конвейеров создает проблему последовательности поступления команд
на исполнение и проблему последовательности завершения команд
проблемы
1
2
неупорядоченная выдача команд - очередность выдачи
декодированных команд на исполнительные блоки отличается
от последовательности, предписанной программой
конфликт по функциональному блоку (структурный
конфликт) - на один ФБ претендуют несколько команд,
поступивших из разных конвейеров
Недостаток суперскалярных микропроцессоров:
необходимость синхронного продвижения команд в
каждом из конвейеров
46.
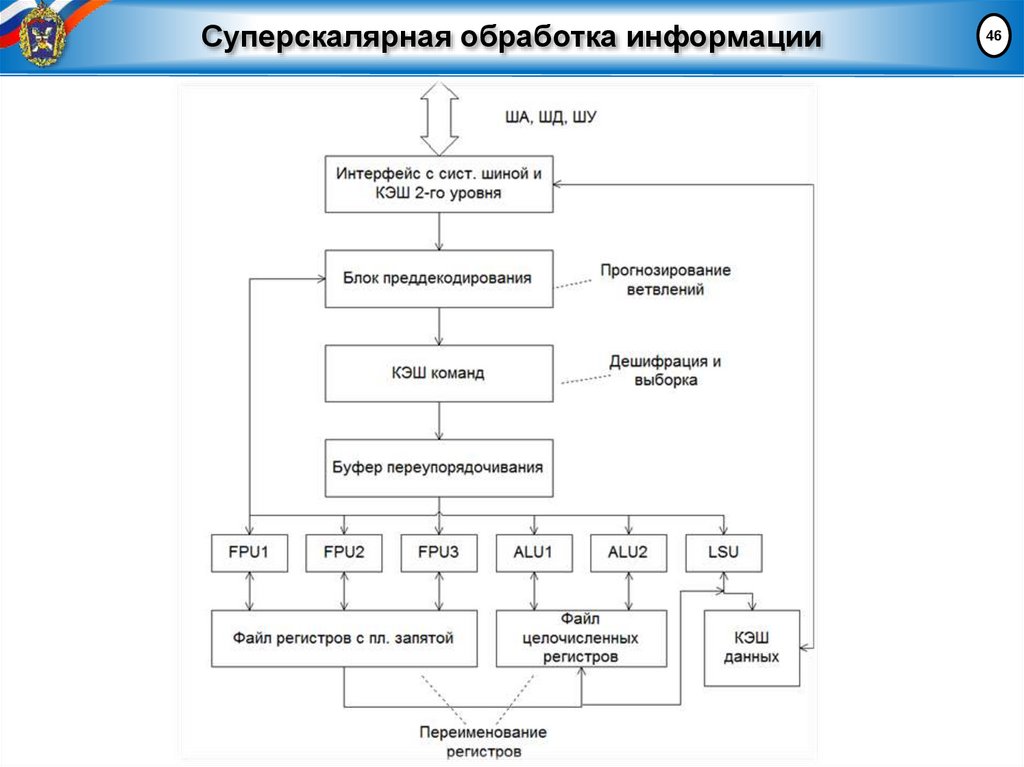
Суперскалярная обработка информации46
47.
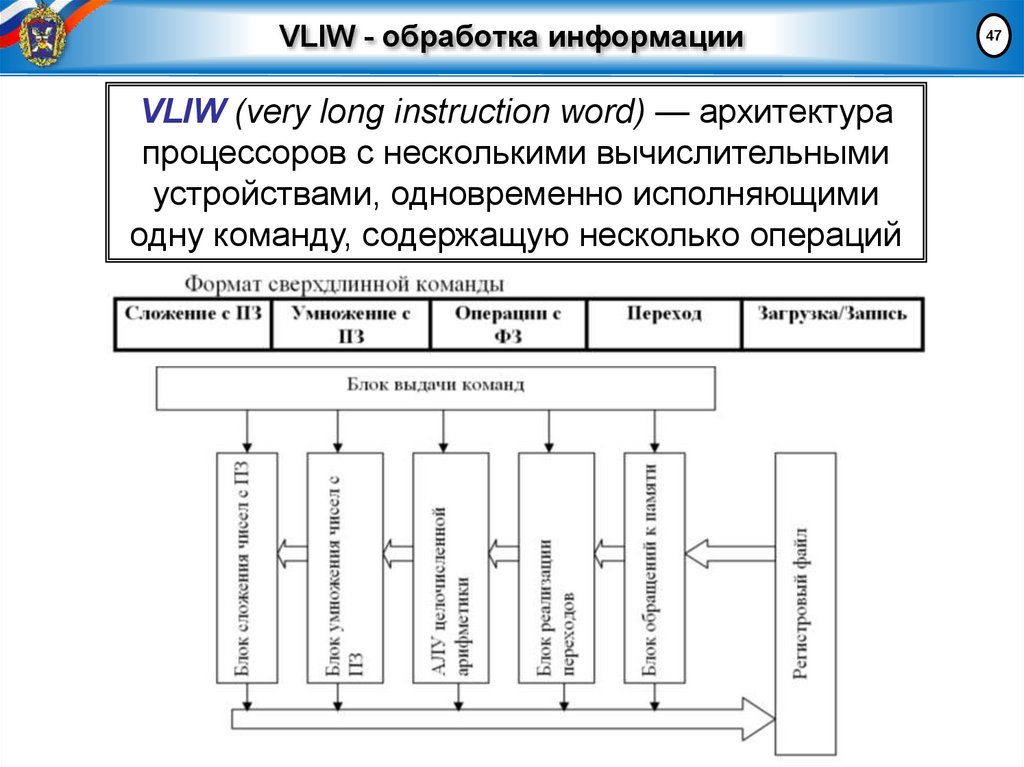
VLIW - обработка информацииVLIW (very long instruction word) — архитектура
процессоров с несколькими вычислительными
устройствами, одновременно исполняющими
одну команду, содержащую несколько операций
47
48.
VLIW - обработка информации48
Идея VLIW базируется на том, что задача эффективного
планирования параллельного выполнения нескольких
команд возлагается на «разумный» компилятор.
1
компилятор исследует исходную программу с целью
обнаружить все команды, которые могут быть выполнены
одновременно, причем так, чтобы это не приводило к
возникновению конфликтов
2
компилятор пытается объединить такие команды в пакеты,
каждый из которых рассматривается так одна сверхдлинная
команда
3
каждое поле сверхдлинной команды отображается на свой
функциональный блок, который исполняет простую команду
VLIW-архитектура - статическая суперскалярная архитектура,
в которой распараллеливание кода производится на этапе
компиляции, а не динамически во время исполнения
49.
491) Устранение компилятором зависимости между командами
до их выполнения.
2) Отсутствие зависимостей между командами ведет к
упрощению
аппаратных
средств
процессора
и
к
существенному подъему его быстродействия.
3) Наличие
множества
функциональных
блоков
дает
возможность выполнять несколько команд параллельно.
1) Требуются
компиляторы,
способные
анализировать
программу, искать в ней независимые команды, связывать такие
команды в строки длиной 256 - 1024 бит, обеспечить их
параллельное выполнение.
2) Компилятор должен учитывать конкретные детали аппаратных
средств.
3) При определенных ситуациях программа оказывается
недостаточно гибкой.
НЕДОСТАТКИ
ПРЕИМУЩЕСТВА
Особенности VLIW - систем
50.
Примеры процессоров с VLIW - архитектуройсигнальные процессоры TMS320C6x
(Texas Instruments)
процессор Crusoe (Transmeta)
процессоры с архитектурой IA-64
(Intel Itanium)
процессоры Эльбрус-2000 (Е2к, Россия)
50
51.
ВC с явным параллелизмом команд (EPIC)51
EPIC ( Explicitly Parallel Instruction Computing) - архитектура
IA-64 - усовершенствованный вариант технологии VLIW
Команда 2
Команда 1
Команда 0
Шаблон
27 26
21 20
14 13
7 8
39
Код
операции
Предикат
РОН
операнда 1
РОН
операнда 2
0
РОН
результата
АРХИТЕКТУРА IA-64
128 64-разрядных регистров общего назначения (РОН)
128 80-разрядных регистров с плавающей запятой
64 однобитовых регистров предикатов
Варианты составления связки команд
К1 || К2 || К3
К1 & К2 || К3
К1 || К2 & К3
К1 & К 2 & К3
52.
ВC с явным параллелизмом команд (EPIC)52
Предикация ‒ способ обработки условных ветвлений.
при которой компилятор указывает, что обе ветви
выполняются на процессоре параллельно
1
Если в программе встречается условное ветвление, то команды
из разных ветвей помечаются разными регистрами предиката
(РП), далее они выполняются совместно, но их результаты не
записываются, пока значения РП не определены.
2
3
Когда вычисляется условие ветвления, РП,
соответствующий
«правильной»
ветви,
устанавливается в 1, а другой ‒ в 0.
Перед записью результатов процессор проверяет поле предиката
и записывает результаты только тех команд, поле предиката
которых указывает на РП с единичным значением
53.
ОСОБЕННОСТИ АРХИТЕКТУРЫ EPIC53
1) большое количество регистров;
2) масштабируемость архитектуры до большого
количества функциональных блоков;
3) явный параллелизм в машинном коде — поиск
зависимостей между командами осуществляет
не процессор, а компилятор;
4) предикация — команды из разных ветвей
условного предложения снабжаются полями
предикатов и запускаются параллельно
5) предварительная
загрузка:
данные
из
медленной основной памяти загружаются
заранее
54.
ЗАКЛЮЧЕНИЕ54
Два основных типа архитектур
современных процессоров
Суперскалярные
С широким
командным словом
динамическая
статическая
Кто планирует
выполнение
команд
аппаратура во время
выполнения программы
компилятор до
выполнения программы
Недостаток
сложность аппаратуры
слабая мобильность ПО,
сложный компилятор
Достоинство
высокая мобильность и
простота ПО
высокая
производительность
Примеры
архитектур
SPARC
Эльбрус
Тип
компиляции
программ
55.
Задание на самостоятельную работуЗадание:
1. Повторить материал лекции по конспекту
2. Изучить рекомендованную литературу [3, с.23-36],
[4, с.450-462];
Ответить на следующие вопросы:
в
каком
случае
параллельная
обработка
информации не дает ускорения?;
в каких диапазонах изменяются значения метрик
«ускорение» и «эффективность»?;
какое количество команд необходимо подать на
вход пятиступенчатого конвейера для достижения им
ускорения 4,5?
55