















 programming
programmingSimilar presentations:



")
")
. Лекция 10 по основам программирования")

")


Технология программирования. Парсинг
1.
Технологияпрограммирования
Парсинг
2.
ГрамматикаГрамматика:
expr ::= term ( ( “+” | “-”) expr )?
term ::= factor ( “*” factor ) *
factor ::= number | “(“ expr “)”
number – лексема «число».
expr – начальный символ
Парсер – это функция преобразования входных лексем в дерево разбора. В
Скале – это функциональный объект, который кроме преобразования (метод
apply) имеет еще методы, необходимые для комбинирования парсеров.
Библиотека scala.util.parsing
Трейт Parsers содержит следующие операции:
-сопоставление с лексемами
-выбор между двумя операциями (|)
-последовательное выполнение двух операций (~)
-повторение операций (rep)
-выполнение необязательной операции (opt)
Трейт RegexParsers. Добавляет неявные преобразования из строк в регулярные
выражения, из регулярных выражений в парсеры. С помощью регулярных
выражений определяются лексемы во входной строке.
Трейт StdTokenParsers - для парсеров, на вход которых подается
последовательности лексем.
3.
Комбинирование операций парсераimport scala.util.parsing.combinator._
class ExprParser extends RegexParsers {
// регулярное выражение получается неявным преобразованием из строки из-за .r
val number = "[0-9]+".r
def expr : Parser[Any] = term ~ opt( ("+" | "-") ~ expr)
// эквивалент: def expr : Parser[Any] = term.~(opt( "+".|( "-").~(expr)))
def term : Parser[Any] = factor ~ rep("*" ~ factor)
def factor : Parser[Any] = number | "(" ~ expr ~ ")"
}
val parser = new ExprParser;
// parser.expr - начальный символ
val result = parser.parseAll(parser.expr, "3-5 * 4")
println(result.get)
литералы строк и рег.
выражения имеют тип String,
есть неявные преобразования в
Parser
p~q возвращает экземпляр caseкласса ~.
opt(p) возвращает Some или None
rep(p) возвращает List
parser: ExprParser = ExprParser@11424d4
result: parser.ParseResult[Any] = [1.8] parsed:
((3~List())~Some((-~((5~List((*~4)))~None))))
((3~List())~Some((-~((5~List((*~4)))~None))))
res0: Unit = ()
4.
Комбинирование операций парсераВ трейте Parsers содержится объявление абстрактного класса Parser[T] –
парсера. Парсер – это функциональный объект, который на входе принимает один
аргумент Reader[Elem] в методе apply, а возвращает результат класса
ParseResult[T]
def apply(in : Reader[Elem]) : ParseResult[T]
Тип Elem – абстрактный тип для класса парсера. Он может быть либо символом,
либо лексемой.
RegexParsers (см. пример) определеяет Elem как символ (type Elem = scala.Char),
поэтому парсер получает символьную строку для разбора.
Другой вариант – StdTokenParsers определяет Elem как лексему.
При вызове чтения для Parser[T] , парсер возвращает результат (подкласс
ParseResult[T]):
Success[T] – успешный разбор
Failure – ошибка разбора (нет подходящей альтернативы для |)
Error – ошибка выполнения (не распознается последовательность, записанная
через ~).
5.
Комбинирование операций парсераОпределение метода для правила грамматики в примере содержит функции
(комбинаторы) и неявные преобразования. Пример:
def expr : Parser[Any] = term ~ opt( ("+" | "-") ~ expr)
эквивалентно следующей записи:
def expr : Parser[Any] =
this.term.~(
this.opt((
literal("+").|(literal("-"))).~(this.expr)
)
)
где
term – другой метод данного класса, возвращает парсер для терма
term.~(парсер) – метод парсера (комбинатор) для следования символов
грамматики
this.opt(парсер) – метод парсера для необязательных символов грамматики
literal("+") – функция неявного приведения типа строки к парсеру
|(парсер) – метод парсера (комбинатор) для альтернативы символов грамматики
parser.parseAll(parser.expr, "3-5 * 4") возвращает результат класса ParseResult[T]
6.
Вычисление выраженияВ классе парсера содержится метод:
def ^^[U](f : scala.Function1[T, U]) : Parsers.this.Parser[U]
который принимает функцию для вычисления значения, а возвращает тот же
самый парсер. Поэтому ^^ не нарушает запись грамматики.
7.
Вычисление выраженияimport scala.util.parsing.combinator._
class ExprParser extends RegexParsers {
val number = "[0-9]+".r // регулярное выражение
def expr : Parser[Int] = term ~ opt( ("+" | "-") ~ expr) ^^
{
case t ~ None => t
case t ~ Some( "+" ~ e) => t + e
case t ~ Some( "-" ~ e) => t - e
}
def term : Parser[Int] = factor ~ rep("*" ~ factor) ^^
{
// здесь r - список пар ~(_1, _2), в скобках анонимная функция
// с параметром для элемента (пары) от которого берется поле _2
case f ~ r => f * r.map(_._2).product
}
def factor : Parser[Int] = number ^^ {_.toInt} |
"(" ~ expr ~ ")" ^^ {case _ ~ e ~ _ => e}
}
val parser = new ExprParser;
// parser.expr - начальный символ
val result = parser.parseAll(parser.expr, "3-5 * 4")
println(result.get)
8.
Отбрасывание лексемВ классе парсера есть комбинаторы, которые позволяют отбросить не нужные
для реализации лексемы ~> убирает лексему слева, <~ убирает ненужную
лексему справа. В результате – упрощение:
def term : Parser[Int] = factor ~ rep("*" ~> factor) ^^
{
case f ~ r => f * r.product
}
def factor : Parser[Int] = number ^^ {_.toInt} |
"(" ~> expr <~ ")" ^^ {case e => e}
9.
Замена правила в примере грамматикиРанее рассмотренная грамматика не совсем корректная
expr ::= term ( ( “+” | “-”) expr )?
term ::= factor ( “*” factor ) *
factor ::= number | “(“ expr “)”
number – лексема «число».
expr – начальный символ
Выражение 5-4-3 в этой грамматике воспринимается считается как
term {factor{number{5}}}- expr{term{factor{number{4}}}expr{factor{number{3}}}} т.е. 5-(4-3) = 4 это ошибка
Новая грамматика:
expr ::= term ( ( “+” | “-”) term )*
term ::= factor ( “*” factor ) *
factor ::= number | “(“ expr “)”
number – лексема «число».
expr – начальный символ
10.
Деревья разбораЭлементы дерева разбора – обычно case-классы. Дерево (AST – абстрактное
синтаксическое дерево) используется либо для генерации выходного кода,
либо для исполнения некоторых действий, определенных в узлах дерева.
import scala.util.parsing.combinator._
abstract class Expr {
def calc : Int;
}
case class Number(value: Int) extends Expr {
def calc: Int = value
}
case class Op(op: String, left: Expr, right: Expr) extends Expr {
def calc: Int = op match {
case "-" => left.calc - right.calc
case "+" => left.calc + right.calc
case "*" => left.calc * right.calc
}
}
11.
Деревья разбора// класс парсера для выражений
class ExprParser extends RegexParsers {
self =>
val number = "[0-9]+".r // регулярное выражение
// Правило изменили на правильное
def expr : Parser[Expr] = term ~ rep( ("+"| "-") ~ term)^^ {
case t ~ Nil => t
case t ~ r => {
var result : Expr = t
for(x <- r)
{
result = Op(x._1, result, x._2)
}
// Предыдущий вариант был неправильный,
result
// например 5-4-3 считает как 5-(4-3)
}
// def expr : Parser[Expr] = term ~ opt( ("+" | "-") ~ expr) ^^ {
}
//
case t ~ None => t
//
//
//
case t ~ Some( "+" ~ e) => Op("+", t, e)
case t ~ Some( "-" ~ e) => Op("-", t, e)
}
12.
Деревья разбораdef term : Parser[Expr] = factor ~ opt("*" ~> factor) ^^ {
case f ~ None => f
case f ~ Some(r) => Op("*", f , r)
}
def factor : Parser[Expr] = number ^^ (n => Number(n.toInt)) |
"(" ~> expr <~ ")"
}
val parser = new ExprParser;
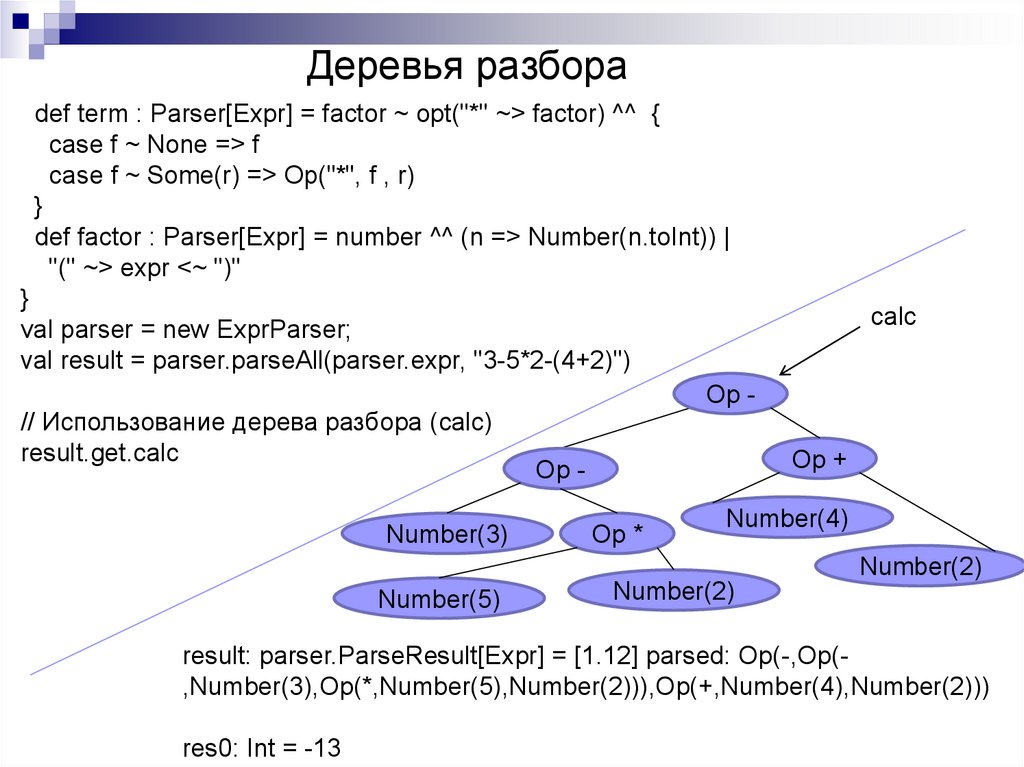
val result = parser.parseAll(parser.expr, "3-5*2-(4+2)")
// Использование дерева разбора (calc)
result.get.calc
Number(3)
calc
Op Op +
Op Op *
Number(4)
Number(2)
Number(5)
Number(2)
result: parser.ParseResult[Expr] = [1.12] parsed: Op(-,Op(,Number(3),Op(*,Number(5),Number(2))),Op(+,Number(4),Number(2)))
res0: Int = -13
13.
Несколько полезных комбинаторовrep(p) – ноль или более совпадений с p
rep1(p) – одно или более совпадений с p;
Пример: rep1(“[“ ~>expr <~”]”) вернет список выражений в квадратных скобках
(возможно границы многомерного массива), например [10][2*5]
repsep(p, s) – ноль или более совпадений p, разделенных совпадениями с
разделителями (separator) s. Результат List(p), а совпадения с разделителями s
опускаются.
Пример: repset(expr, “,”) вернет список выражений, разделенных запятыми.
Например, в списке фактических параметров вызова функции
Есть еще дополнительные комбинаторы, см. документацию.
14.
Обработка ошибокНеудачный результат разбора возвращается в экземпляре вложенного типа
Parsers.Failure. Он содержит поля с сообщением об ошибке (msg), номер
строки и позицию в строке (next.pos.line, next.pos.column). Фиксируется только
последняя ошибка.
При разборе нескольких константных альтернатив можно добавить внятное
сообщение об ошибке отсутствия альтернативы. Это делается с помощью
комбинатора failure.
15.
Обработка ошибокclass ExprParser extends RegexParsers {
//...
def factor : Parser[Expr] = number ^^ (n => Number(n.toInt)) |
"(" ~> expr <~ (")" | failure("ожидается \")\""))
//
}
val parser = new ExprParser;
val result = parser.parseAll(parser.expr, "3 + ( 5")
var v = result match {
case
r : parser.Failure => println(r)
// println(r.msg + " [" + r.next.pos.line + "," + r.next.pos.column + "]")
case
e : parser.Error => println(e.msg);
case _ => println("Нет ошибок");
}
[1.8] failure: ожидается ")"
3+(5
^
16.
JavaTokenParsersJavaTokenParsers – это потомок RegexParsers, т.к. он также является парсером на
основе регулярных выражений. Но в нем предопределены регулярные
выражения для некоторых лексем:
17.
Парсеры на основе лексемВместо Reader[Char] (поток символов) используется Reader[Token] (поток лексем)
Предусмотрены следующие типы лексем:
-Идентификатор - последовательность символов и цифр, начиная с символа,
Анализируется функцией ident.
-Ключевое слово (задаются в соответствующем наборе).
-Числовой литерал. Анализируется функцией numericLit.
-Символьный литерал. Анализируется функцией stringLit.
-Разделитель (задаются соответствующим набором)
Строки в “” и в ‘’
C-подобные комментарии: /* */ и //
18.
Парсеры на основе лексемimport scala.util.parsing.combinator.syntactical.StandardTokenParsers
class MyParser extends StandardTokenParsers{
// Если не включить, то эти символы будут вызывать ошибки,
// т.к. они будут относиться ни к идентификаторам,
// ни к ключевым словам
lexical.delimiters += ("+", "-", "*", "(", ")", "=")
lexical.reserved += ("auto", "int")
// Строковые константы неявно преобразуются в ключевые слова
// см. implicit def keyword(chars : scala.Predef.String)...
def assignment : Parser[Any] = ("auto" | "int") ~ ident ~ "=" ~ expr
def expr : Parser[Any] = term ~ rep(("+" | "-") ~ term)
def term : Parser[Any] = factor ~ opt("*" ~> factor)
// Здесь числовая лексема. Строковая лексема: stringLit
def factor : Parser[Any] = numericLit | "(" ~> expr <~ ")"
// Эту функцию надо определять, т.к. в библиотеке аналога нет.
def parseAll(in : String) : ParseResult[Any] =
phrase(assignment)(new lexical.Scanner(in))
}
var p = new MyParser
p.parseAll("int a = 1+5")
res0: MyParser#ParseResult[Any] = [1.12] parsed:
(((int~a)~=)~((1~None)~List((+~(5~None)))))