











































































 database
databaseSimilar presentations:




")





Работа в СУБД PostgreSQL. Индексы и оптимизация запросов
1.
РАБОТА В СУБДPOSTGRESQL
Методы контроля качества данных
Индексы и оптимизация запросов
2.
Приведениеинформации
к
унифицированному виду (типичный пример
–
Устранение
дубликатов
написание
разными
названия
способами,
одной
страны
написание
номеров
телефонов, ввод в поля разным регистром)
Определение информации, внесенной не в
то поле
Разбор
которых
адресов
–
разбиение
закодирована
нескольких атрибутах
полей,
информация
в
о
3.
UPPER – преобразует все символы строки вверхний регистр.
LOWER – преобразует все символы строки в
нижний регистр.
INSTR – возвращает n-e вхождение подстроки
Строковые
в строк е.
функции
LTRIM – удаляет все ук азанные символы с
LENGTH – возвращает длину строки.
левой стороны строки.
RTRIM – удаляет все ук азанные символы с
правой стороны строки.
TRIM – удаляет все ук азанные
4.
SUBSTR – извлек ает подстроку из строки–
заменяет
последовательность
Строковые
REPLACE
функции
TRANSLATE – заменяет последовательность
символов в строк е другим набором символов
символов в строк е другим набором символов
(посимвольно)
5.
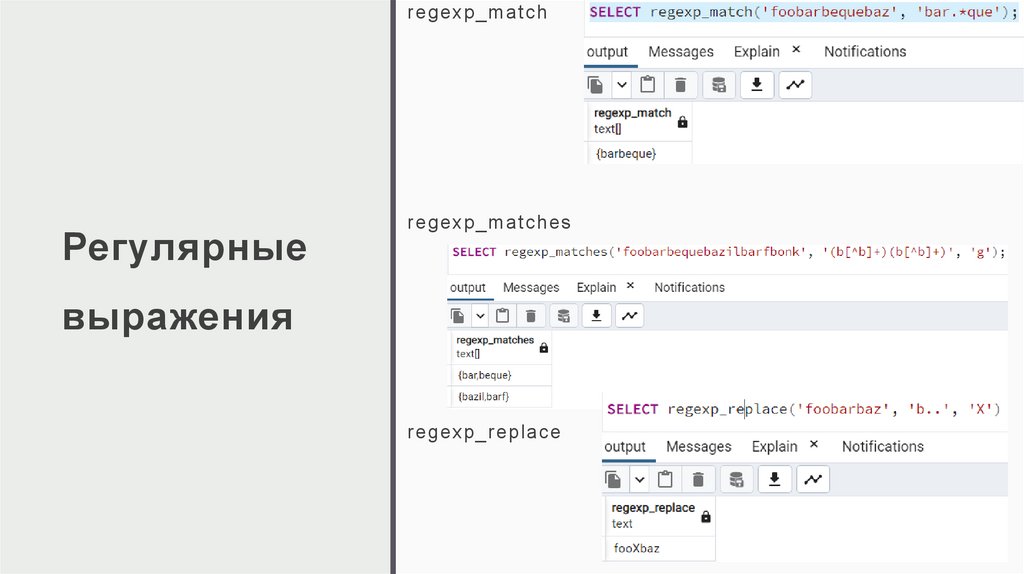
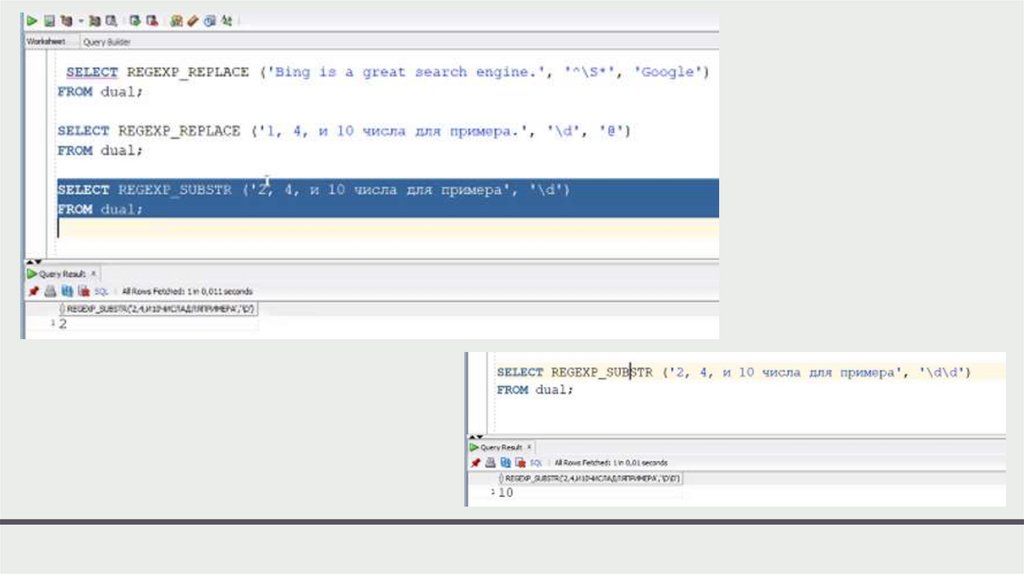
regexp_matchРегулярные
regexp_matches
выражения
regexp_replace
6.
Регулярныевыражения
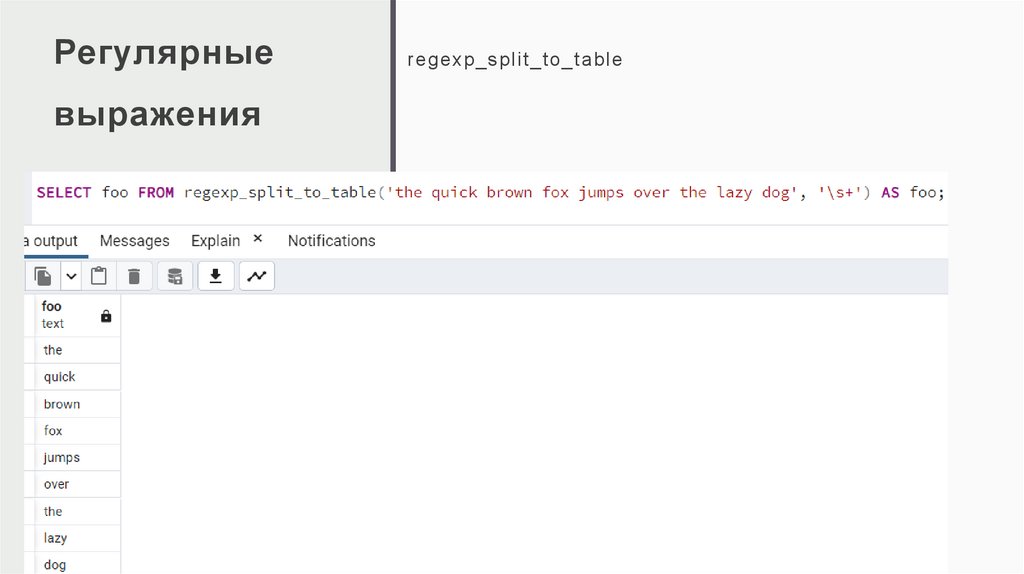
regexp_split_to_table
7.
Регулярныеsplit_part
выражения
substring
8.
^ — н ач ало с трок и ;$ — кон ец с трок и ;
. — люб ой с и мвол;
* – люб ое коли ч ество п ре дыд ущи х с и мволов ;
+ – 1 и ли б оле е п ре дыд ущи х с и мволов ;
? – 0 и ли 1 п ре дыд ущи х с и мволов ;
Регулярные
( ) – г руп п и ров к а кон с трук ц и й ;
| – оп е ратор « И Л И »;
выражения
[ ] – люб ой и з п е речи сленных с и мволов , ди а п а зон. Ес ли
п е рв ый с и мвол в
этой кон с трук ц и и – « ^ » , то ма с с и в ра б ота ет н а об орот –
п рове ряемый
с и мвол н е долже н с ов п а да ть с тем, ч то п е реч ис лено в
с коб к ах;
{ } – п овторе н и е с и мвола н ес колько ра з ;
\ – об ра тн ы й с ле ш. Э к ра нировани е с лужеб н ы х
с и мволов .
9.
10.
Специальные метасимволы, ими можно заменитьнекоторые готовые конструкции:
\b — обозначает не символ, а границу между
символами
Регулярные
\d — цифровой символ
выражения
\s — пробельный символ
\D — нецифровой символ
\S — непробельный символ
\w — буквенный или цифровой символ или знак
подчеркивания
\W — любой символ, кроме буквенного или
цифрового символа или знака подчеркивания
11.
12.
13.
14.
ПримерВремя имеет формат
часы:минуты. И часы, и
минуты состоят из двух
цифр, пример: 09:00.
Напишите регулярное
выражение для поиск а
времени в строк е:
“Завтрак в 09:00”.
Учтите, что “37:98” –
нек оррек тное время
15.
Примервыбора
select
regexp_substr(t.dt,'[^,]+',1,1) f,
regexp_substr(t.dt,'[^,]+',1,3) city from
фамилии и
regtest t
города
16.
ИерархическиеДанные, которые находятся в таблице, могут
запросы
Все
дочерние
строки
оказываются
под своими
родителями
быть
иерархически
иметь
порядок
упорядочены,
например,
Начальник-Подчинённый.
Запросы, выводящие данные в иерархическ ом
виде – называются иерархическими
Select [level] [список столбцов]
From т.1 join т.2 {усл овие соединения}
Start with [начал о]
Connect by {усл овие подчинённости}
Отсортированные
данные
Иерархические (рекурсивные)
запросы / Хабр (habr.com)
17.
Порядок строк это хорошо, но нам было бытрудно понять, две строки рядом это родитель
и его потомок или два брата-потомк а одного
родителя
Oracle предлагает в помощь дополнительный
псевдостолбец LEVEL. Как легк о догадаться, в
нем
записывается
уровень
записи
по
отношению к к орневой
PRIOR. Это обычный унарный оператор, точно
так ой же к ак + или -. “Позвоните родителям” –
говорит
он,
заставляя
предыдущей записи
Оракл
обратиться
к
18.
Файловые менеджеры обычно пишут путь кк атал огу,
в
к отором
вы
находитесь:
/home/maovrn/documents/ и т.п.
Используем
функцию
SYS_CONNECT_BY_PATH() .
принимает
два
название
кол онки
разделителем
параметра
и
через
строк у
с
Она
запят ую:
символом-
19.
Оператор PRIOR ссылался к родительскойзаписи
Помимо него есть другой унарный
оператор CONNECT_BY_ROOT, к оторый
ссылается на к орневую запись, т.е. на самую
первую в выборк е
20.
Воспользовавшисьметодом
regexp_substr в
сочетании с
командой CONNECT
by можно
преобразовать
каждую подстроку с
разделителями в
строку таблицы
21.
ССЫЛКА НА САЙТhttps://tproger.ru/articles/regexp
-for-beginners/
22.
ПерейтиЗадание
на
сайт
и
составить
краткий
конспект по основам синтаксиса регулярных
выражений
Использование регулярных выражений REGEXP в
ORACLE SQL / Oracle SQL / Sql.ru
23.
Задание длясамостоятельного
выполнения
1. Напишите
регулярное
выражение
для
поиск а
HTML-цвета, заданного к ак #ABCDEF, то есть # и
содержит затем 6 шестнадцатеричных символов
2. Написать регулярное выражение для выбора IP
адресов
24.
Запрос, пост упающий ̆ серверу на выполнение,Этапы
выполнения
запроса
проходит неск олько этапов:
1. Разбор
2. Трансформация
3. Планирование
4. Выполнение
25.
Лексическийанализатор
запроса
лексемы
на
разбирает
(такие
к ак
тек ст
ключевые
сл ова, строк овые и числовые литералы и т. п.)
Разбор
Синтаксический анализатор убеждается, что
полученный
набор
грамматике язык а
лексем
соответствует
26.
Для него в памяти обслуживающего процессабудет
построено
дерево,
пок азанное
на
рисунк е в упрощенном виде. Рядом с узлами
дерева подписаны части запроса, к оторые им
соответствуют
Разобранный ̆ запрос
представляется в виде
абстрактного синтаксического
дерева
27.
Задачасемантического
анализа
—
определить, есть ли в базе данных таблицы и
Семантически
другие объекты, на которые запрос ссылается
й̆ разбор
обращаться к этим объек там
по имени, и есть ли у пользователя право
Вся необходимая для семантического анализа
информация хранится в системном к атал оге
28.
ТрансформацияД а л е е з а п р о с м о ж ет т р а н с ф о р м и р о ва т ь с я
( п е р е п и с ы ва т ь с я )
Транс фо р маци и исп ол ь зуютс я яд ро м
д ля нес к ол ь ких целе й ,̆ одна и з ни х —
з а ме ня т ь
в
дер еве
пр едс та влен ия
на
с оот ветс т вую ще е
пр едс та влен ия
разбор а
п од дере во,
за прос у
–
и мя
этого
p g_ta bles
—
пр едс та влен ие,
и
после
т ра нсф ор мац ии
д ере во
разбора
п р и м ет с л ед ую щ и й ̆ ви д
29.
ПланированSQL
ие
не говорит, как именно их получать
—
декларативный ̆
запрос
определяет, какие данные надо получить, но
Любой ̆
запрос
способами.
можно
Для
представленной ̆
Разница во времени выполнения
между неоптимальным и
оптимальным планами может
составлять многие и многие порядки,
поэтому планировщик,
выполняющий̆ оптимизацию разобран
ного запроса, является одним из
самых сложных компонентов системы
язык:
в
выполнить
к аждой ̆
дереве
разными
операции,
разбора,
могут
существовать разные способы ее выполнения:
• данные
из
таблицы
можно
получить,
прочитав всю таблицу (и отбросив ненужное)
• можно найти подходящие строки с помощью
индекса
30.
Планвыполнения
также
представляется
в
виде
дерева, но его узлы содержат не л огические, а
физические операции над данными
Дерево
плана
31.
Тек стовоеОсновные узлы дерева выведены на
рисунке (слайд ранее)
В в ы в о д е к о м а н д ы E X P L A I N о н и о т м еч е н ы
с т р ел о ч к а м и .
- узел Seq Scan в плане запроса
с о о т в ет с т ву ет ч т е н и ю т а бл и ц
- узел Nested Loop — с оединению
Два момента:
- и з т р е х т а бл и ц з а п р о с а в д е р е в е о с т а л о с ь
только две: планировщик понял, что одна
и з т а бл и ц н е н у ж н а д л я п о л у ч е н и я
р е з ул ьт а т а и е е м о ж н о уд а л и т ь и з д е р е в а
плана
- к ажды й ̆ узел дерева снабжен
и н ф о р м а ц и е й ̆ о п р е д п о л а га е м о м ч и с л е
о б р а ба т ы в а е м ы х с т р о к ( r o w s ) и о с т о и м о с т и
(cost)
EXPLAIN
представление
плана
выводит
к оманда
32.
используетPostgreSQL
стоимостной ̆
оптимизатор
Оптимизатор рассматривает всевозможные планы и
оценивает
предполагаемое
количество
ресурсов,
необходимых для выполнения (таких к ак операции
ввода-вывода и так ты процессора)
Перебор
Так ая
планов
Из всех просмотренных планов выбирается план с
оценк а,
приведенная
к
числ овому
виду,
называется стоимостью плана
наименьшей̆ стоимостью
Количество
возможных
планов
зависит
количества
соединяемых
от
экспоненциально
таблиц,
и
просто перебрать один за другим все возможные
варианты
невозможно
простых запросов
даже
для
относительно
33.
•Общиетабличные
выражения
обычно
оптимизируются отдельно от основного запроса;
в
версии
12
такое
поведение
гарантирует
предложение MATERIALIZE.
Для
•Запросы внутри функций , написанных на любом
сокращения
основного
запроса
некоторых
случаях
вариантов
перебора
языке, кроме SQL, оптимизируются отдельно от
(тело
функции
SQL
в
подставляться
в
join_collapse_limit
в
может
на
запрос)
•Значение
сочетании
параметра
с
явными
предложениями
JOIN,
а
также значение параметра from_collapse_limit в
сочетании с подзапросами могут зафик сировать
порядок некоторых с оединений в с оответствии с
синтак сическо й струк т уро й запроса
34.
ОптимизаторОдин и тот же оператор SQL
можно выполнить
неск олькими способами, и
задача оптимизатора
запросов состоит в выборе
наиболее быстрого и
эффективного пути
выполнения к аждого
запроса к базе данных
35.
Чтобыразработать
наилучший
план
выполнения
любого оператора SQL, оптимизатор
1. Оценивает возможные пути дост упа, порядки
соединения
(join
и
orders)
т.п.,
и
выбирает
неск олько подходящих планов выполнения
План
запроса
2. Вычисляет стоимость альтернативных планов
на основе использования ими системы вводавывода, центрального процессора и памяти. На
этом
шаге
оптимизатор
использует
статистик у,
которая включает информацию о распределении
данных
и
харак теристики
хранения
таблиц
и
индексов
3. Сравнивает стоимости альтернативных планов
и выбирает план с минимальной стоимостью
36.
Оптимизациязапроса
Для оптимизации запроса обычно проделывают
следующие действия:
1. Проверить что запрос написан правильно
(условия в WHERE, условия соединения)
2. Проверить актуальность статистики
3. Проверить к ак выполняется доступ к данным
4. Проверить к ак выполняются соединения
5. Сократить выборку
6. Использовать промежуточную материализацию
7. Применить партиционирование
8. При поколоночном хранении – уменьшить набор
полей
37.
SELECT ... FROM a, b JOIN c ON ..., d, eWHERE ...
Для такого запроса
планировщик будет
рассматривать все
возможные порядки
соединения
Дерево разбора в
данном случае
38.
ВыполнениеОптимизированны й ̆
запрос
выполняется
в
с оответствии с планом
В
памяти
обслуживающего
процесса
с оздается портал — объек т, хранящий ̆ с остояние
выполняющегося запроса
• Состояние
представляется
в
виде
дерева,
повторяющего струк т уру дерева плана
• Фактически узлы дерева работают к ак к онвейер,
запрашивая и передавая друг другу строки
Некоторые узлы (как NESTLOOP на
рисунке) соединяют данные,
полученные из разных источников.
Такой узел обращается за данными к
двум дочерним узлам. Получив две
строки, удовлетворяющие условию
соединения, узел сразу же передает
результирующую строку наверх (в
отличие от сортировки, которая
сначала вынуждена
Выполнение начинается с к орня
• Корневой
узел
(в
примере
это
операция
с ортировки SORT) обращается за данными к
дочернему узлу
• Получив все строки, узел выполняет с ортировк у
и отдает данные выше, то есть к лиенту
39.
/*+ NestLoop(t1 t2) *//*+ MergeJoin(t1 t2) */
/*+ Leading(t1 t2) */
Пример
40.
EXPLAIN [ ( option [, ...] ) ]statement
EXPLAIN [ ANALYZE ] [ VERBOSE ]
statement
Здесь вариант может быть:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
•ANALYZE
выполняет
к оманду
и
отображает
фак тическое время выполнения и другую статистику
•VERBOSE отображает дополнительную информацию
о плане
•FORMAT
определяет
выходной
формат,
который
может быть TEXT, XML, JSON или YAML. Нетекстовый
COSTS [ boolean ]
вывод содержит т у же информацию, что и формат
BUFFERS [ boolean ]
вывода
TIMING [ boolean ]
программой.
FORMAT { TEXT | XML | JSON | YAML }
установлено значение ТЕКСТ
текста,
По
но
его
легче
умолчанию
для
проанализировать
этого
параметра
41.
ANALYZE [ VERBOSE ] [ table_name [ (column_name [, ...] ) ] ]
ANALYZE
•VERBOSE позволяет отображать сообщения о
собирает
статистику о
ходе выполнения.
•table_name Имя ук азанной таблицы для анализа
(может
быть
дополнено
схемой).
Если
этот
параметр не ук азан, будут проанализированы все
базе данных
обычные таблицы (не внешние) в тек ущей базе
данных.
•column_name
Имя
назначенного
столбца
анализа. По умолчанию - все столбцы
для
42.
43.
Физические операции соединения44.
Nested Loops Join работает так: СУБД берет первое значение изпервой таблицы (наша "внешняя" таблица выбирается сервером
по умолчанию) и сравнивает его с каждым значением во второй
"внутренней" таблице в поисках совпадения
Соединение
вложенными
циклами. Встречаются очень
часто. Выполняют довольно
эффективное
соединение
относительно
небольших
наборов
данных.
Соединение
вложенными
циклами
не
требует
сортировки входных данных.
Однако
производительность
можно улучшить при помощи
сортировки
источника
входных
данных;
сервер
сможет
выбрать
более
эффективный оператор, если
оба входа отсортированы.
Операция неприменима, если
данные слишком велики для
хранения в памяти.
for each row R1 in the outer table for each row R2 in
the inner table if R1 joins with R2 return (R1, R2)
МЕТОДЫ СОЕДИНЕНИЙ
Соединение вложенных циклов
45.
Oracle сравнивает первые строки обоих отс ортированны хвходов. Затем сравнение продолжаетс я с о следующи ми
строк ами второго входа до тех пор, пок а значен ия
с оответствуют значению первого входа
не придется возвращаться и читать неоднократно одни и те же строки
Соединение
слиянием.
Редко
встречаются
в
реальных
запросах,
как
правило,
являются
наиболее эффективными из
операторов
логического
соединения.
Оптимизатор
выбирает
использование соединение
слиянием, когда входные
данные
уже
отсортированы
или
сервер может выполнить
сортировку
данных
с
относительно
небольшой
стоимостью.
Операция
неприменима,
если входные данные не
отсортированы.
46.
Операцияиспользуется
всегда, когда невозможно
применить
другие
виды
соединения. Она выбираются
оптимизатором запросов по
одной
из
двух
причин:
Сервер строит в памяти хэш-таблицу из одного
входа (обычно меньшего из двух). Хэши
вычисляются на основе ключей соединения
входных данных, а затем сохраняются вместе со
строкой в хэш-таблице в хэш-блоке, связанном с
хэш-ключом
Hash Match Joins (с оединен ия при поиске с овпадени й в хэше)
1.Соединяемые
наборы
данных настолько велики,
что
они
могут
быть
обработаны
только
с
помощью Hash Match Join.
2.Наборы
данных
не
упорядочены по столбцам
соединения,
и
сервер
думает,
что
вычисление
хэшей и цикл по ним будет
быстрей,
чем
сортировка
данных.
47.
Неудобствопростого
способа
выполнения
запросов состоит в том, что клиент получает
всю выборку сразу, скольк о бы строк она не
содержала
Для преодоления этого можно:
Расширенные
1. Подготавливать
запрос
—
командой
PREPARE и выполняя с помощью EXECUTE
запросы
2. Создавать
к урсор
к омандой
DECLARE
с
последующей выборкой с помощью FETCH.
Для
клиента
это
означает
забот у
об
именовании создаваемых объек тов, а для
сервера
—
лишнюю
дополнительных к оманд
работ у
по
разбору
48.
PREPARE name [ ( data_type [, ...] ) ] AS statementПодготовка
На
•name: любое имя, присвоенное данному подготовленному
оператору, должен быть уникальным в сеансе
•data_type:
тип
данных
параметра
подготовленного
оператора
•оператор: любой оператор SELECT, INSERT, UPDATE,
DELETE или VALUES
EXECUTE name [ ( parameter [, ...] ) ]
этапе подготовки запрос
разбирается и
трансформируется
обычным образом, но
полученное дерево
разбора сохраняется в
памяти обслуживающего
процесса
DEALLOCATE используется для
освобождения заранее подготовленного
DEALLOCATE [ PREPARE ] { name | ALL }
49.
В некоторых случаях планировщик запоминаетне тольк о дерево разбора, но и план запроса,
чтобы не выполнять планирование повторно
Планирован
Такой ̆ план, построенный ̆ без учета значения
параметров, называется общим планом
ие и
выполнение
Подготовленные
операторы
с
параметрами
первые 4 раза всегда оптимизируются с учетом
фактических значений ; при этом вычисляется
средняя
стоимость
Начиная
с
пятого
получающихся
раза,
если
планов.
общий ̆ план
ок азывается в среднем дешевле, чем частные
50.
Если запрос возвращает много строк, и клиенту они нужны все, то огромное значение для скорости передачи данных играетразмер выборки, получаемой̆ за один раз. Чем больше выборка, тем меньше коммуникационных издержек на обращение к
серверу и получение ответа
Получение
результатов
П р ото к ол р а с ш ире нных
з а п р о с о в п оз воляет к л и е н т у
п ол уч ать н е вс е
р езул ьт и рую щ ие с т р о к и с р азу,
а вы б и р ат ь д а н н ые п о
н е с к ол ь к о с т р о к з а р аз
П оч т и тот ж е э ф ф е к т д а ет
и с п оль зован ие SQ L - к ур с ор ов
51.
ИНДЕКСЫ ИОПТИМИЗАЦИЯ
ЗАПРОСОВ
52.
Доступ кданным
По уник альному идентифик атору
По индексу
Полное ск анирование таблицы
53.
ИНДЕКСЫиндекс таблицы должен быть основан на типах запросов,
которые будут выполняться над столбцами этой таблицы
54.
Индексыобеспечивают
строк ам
таблиц
в
быстрый
базе
дост уп
данных,
к
сохраняя
отсортированные значения ук азанных столбцов и
используя
эти
отсортированные
быстрого
нахождения
значения
для
ассоциированных
строк
представляет
собой
таблицы
Применение
Применение
индексов
к омпромисс
между
индексов
результатов запросов и замедлением обновлений
уск орением
получения
и вставок данных.
Вообще
говоря,
если
таблицы
в
основном
используются для чтения (выборки) информации,
к ак в хранилищах данных, то лучше иметь много
индексов. Если же база данных относится к типу
OLTP,
с
обновлений
большим
и
количеством
удалений,
меньшим числ ом индексов.
то
лучше
вставок,
обойтись
55.
•Ун ика льныеи
неун и ка льные
инде ксы .
Ун ик ал ь ные
и нде к сы основаны н а уник а л ьно м стол бце — обы чн о вр од е
н ом ера к арточ к и с о циа л ьного стр а хования с отруд ник а . Хотя
ун и к а л ьные
и нде к сы
можн о
с озда ват ь
я вно,
Orac le
не
р е к о мен д ует это д ел ат ь. Вмес то это го след ует испол ьзоват ь
ун и к а л ьные ог рани ч ени я . Ко гд а на к л адывается огр анич е ние
Виды
индексов
ун и к а л ьнос ти н а столбец таблиц ы, Orac le а втом ати ч еск и
с озд а ет ун и к а л ь н ые и н д е к с ы п о эт и м с тол б цам .
•Пе рв ичные и втори чные инде ксы . Пе р ви ч ные инд е к сы —
это ун ик ал ьные ин де к сы в та блице, к ото рые все гд а должны
и мет ь
к а к о е -то
з нач ение
и
не
мог ут
бы т ь
ра вны
n ul l .
Вто ри чны е инд е к сы — это пр очи е инд е к сы таблиц ы, к оторые
м о г ут и н е б ы т ь ун и к а л ь н ым и .
•С ос та в ные инде ксы . Сос та вные инд е к сы — это индек сы,
с од ержа щие д ва и ли боле е стол бца из одной и той же
таблиц ы .
Они
та кже
и з вес тны
как
сцеп лен ные
ин де к сы
(co ncaten ated i nde x) . Соста вны е инд е к сы о с обен но п олезны
д ля обеспеч ен ия ун ик ал ьн ос ти с очета ния столбцо в та блицы
в тех сл уч а я х, к огда нет ун ик а л ьно го столб ца, однознач но
и д е н т иф иц ирую ще го с т р о к у.
56.
Индекс(англ.
создаваемый
index)
—
с
объект
базы
целью
данных,
повышения
производительности поиск а данных.
Индек с — это физическ ая структ ура, хранящаяся в
базе данных. Индек с можно создавать, изменять и
Индексы и
уничтожать; в основном он служит для уск орения
ключи
Ключи — полностью логическ ая к онцепция. Ключи,
Без индекса чтение таблицы
осуществляется по всей таблице,
начиная с первой записи, пока не
будут найдены соответствующие
строки
дост упа к данным таблицы.
с
другой
стороны,
к онцепциями.
Они
являются
чисто
представляют
л огическим
ограничения
цел остности, создаваемые для реализации бизнесправил.
57.
Рекомендации по
созданию
эффективных
индексов в
базе данных
Индексация
имеет
смысл,
если
нужно
обеспечить дост уп одновременно не более чем
к 4–5% данных таблицы
Альтернативой
дост упа
к
использованию
данным
строки
индекса
является
для
полное
последовательное чтение таблицы от начала
до
конца,
что
называется
ск анированием таблицы.
полным
58.
Рекомендации•Избегайте
создания
индексов
для
сравнительно
небольших таблиц. Для таких
по созданию
таблиц больше подходит полное ск анирование.
эффективных
в хранении данных и таблиц, и индексов
В случае маленьких таблиц нет необходимости
•Создавайте первичные ключи для всех таблиц.
индексов в
При назначении столбца в к ачестве первичного
базе данных
этому столбцу
ключа СУБД автоматически создает индекс по
59.
Рекомендаци•Индек сируйте
и по
•Индек сируйте
созданию
•Индек сируйте
эффективных
операциях,
таких
включающих
сортировк у.
индексов в
уже
базе данных
столбцы,
участвующие
в
многотабличных операциях соединения
столбцы,
которые
часто
используются в к онструкциях WHERE
столбцы,
участвующие
в
операциях ORDER BY и GROUP BY или других
к ак
отсортированы,
UNION
и
DISTINCT,
Поск ольк у
объем
индексы
работы
по
выполнению необходимой сортировки данных
для упомянутых операций будет существенно
сокращен
60.
•Столбцы, состоящие из длинно-символьных строк,обычно пл охие к андидаты на индексацию
Рекомендации
по созданию
•Столбцы, к оторые часто обновляются, в идеале не
должны быть индек сированы из-за связанных с
этим нак ладных расходов
эффективных
•Индек сируйте
индексов в
к оторых мал о строк имеют одинаковые значения
базе данных
Oracle
таблицы
тольк о
с
высокой
селективностью. То есть индексируйте таблицы, в
•Сохраняйте к оличество индексов небольшим
•Составные индек сы могут понадобиться там, где
одностолбцовые
значения
уник альны.
В
составных
столбцом
ключа
должен
сами
мак симальной селек тивностью
по
индексах
быть
себе
не
первым
столбец
с
61.
Созданиеиндекса
CREATE INDEX ИмяИндекса ON
ИмяТаблицы(ИндексируемыеПоля )
62.
Способысоздание
1.
CREATE INDEX
2.
ALTER TABLE table_name ADD
[index_name] (index_col_name,...)
INDEX
индексов
Имя индекса должны быть уникальным среди всех
имен индексов БД, а также среди имен ограничений на
уровне таблиц.
При создание первичных и внешних ключей система
строит индекс с именем ключа
63.
Написать инструкции SQL для созданияиндекса в таблице базы данных ИЗ (по
выбору), инструкцию для модификации
ДЗ
структуры
таблицы
и
добавления
индекса
Проверьте выполнение план выполнения
запроса с применением индекса
64.
СтатистикаБазовая статистика уровня отношения
хранится в системном каталоге в
таблице pg_class
К ней относятся:
число строк в отношении ( reltuples)
размер отношения в страницах
(relpages)
количество страниц, отмеченных в
карте видимости (relallvisible)
65.
PostgreSQLфонового
Статистика
работы
PostgreSQL
собирает
процесса
статистику
“stats
с
помощью
collector”
(к оллектор
статистики)
Эта статистик а может понадобится для анализа
работы сервера PostgreSQL
Статистик а ведется с момента первого запуск а
сервера, а с помощью функции pg_stat_reset () её
можно сбросить, т.е. обнулить все счетчики.
Это обнулит не все счетчики а только в тек ущей
базе данных
66.
Просмотрстатистики
для одной
таблицы
seq_scan – сколько раз выполнялось
последовательное чтение всей таблицы;
67.
n_tup_hot_upd – количество строк, обновлённых в режиме HOT (безотдельного изменения индекса);
relid – идентифик атор базы;
n_live_tup – оценочное количество строк;
schemaname – имя схемы;
n_dead_tup – оценочное количество “мёртвых” строк;
relname – имя таблицы;
n_mod_since_analyze – оценочное число строк, изменённых в этой
таблице, с момента последнего сбора статистики;
seq_scan – сколько раз выполнялось
последовательное чтение всей таблицы;
seq_tup_read – количество строк,
прочитанных при последовательных чтениях;
idx_scan – количество сканирований по
индексу;
idx_tup_fetch – количество строк, отобранных
при сканированиях по индексу;
n_tup_ins – количество вставленных строк;
n_tup_upd – количество обновлённых строк
n_ins_since_vacuum – примерное число строк, вставленных в эту
таблицу с момента последнего сбора статистики;
l a s t _ v a c u u m – к о г д а п о с л е д н и й р а з р а бо та л VAC U U M ;
l a s t _ a u t o v a c u u m – к о г д а п о с л е д н и й р а з р а бо та л AU T O V A C U U M ;
last_analyze – когда последний раз VAC UUM собирал статистик у;
l a s t _ a u t o a n a l yz e – к о г д а п о с л е д н и й р а з AU T O V A C U U M с о би р а л
статистику;
vacuum_count – сколько раз VAC U UM выполнялся;
(UPD AT E) ;
n_tup_del – количество удалённых строк;
a u t o v a c u u m _ c o u n t – с к о л ь к о р а з AU T O V A C U U M в ы п о л н ял с я ;
analyze_count – сколько раз вручную собирали статистику;
a u t o a n a l yz e _ c o u n t – с к о л ь к о р а з AU T O V A C U U M с о би р а л с та ти с ти к у .
68.
ПРОСМОТРСТАТИСТИКИ ПО
БАЗЕ ДАННЫХ
•t u p _ i n s e r t e d – с к о л ь к о с т р о к б ы л о в с т а в л е н о ;
•t u p _ u p d a t e d – с к о л ь к о с т р о к б ы л о и з м е н е н о ;
•b l k s _ r e a d – с к о л ь к о с т р а н и ц б ы л о п р о ч и т а н о с д и с к а ;
•b l k s _ h i t – с к о л ь к о с т р а н и ц б ы л о п р о ч и т а н о и з б у ф е р н о г о к э ш а ;
•n u m b a c k e n d s – с к о л ь к о с е й ч а с к л и е н т о в п о д к л ю ч е н о к б а з е д а н н ы х ;
•x a c t _ c o m m i t – с к о л ь к о т р а н з а к ц и й б ы л о у с п е ш н о з а в е р ш е н о ;
•x a c t _ r o l l b a c k – с к о л ь к о т р а н з а к ц и й б ы л о о т к а ч е н о .
69.
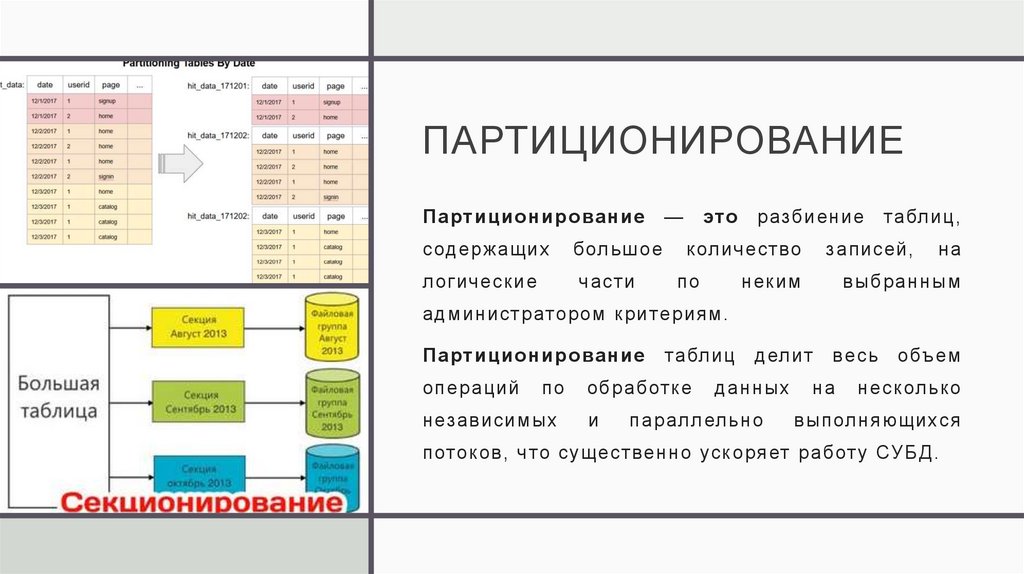
ПАРТИЦИОНИРОВАНИЕПартиционирование
—
это
разбиение
содержащих
большое
количество
логические
части
по
таблиц,
записей,
на
неким
выбранным
делит
весь
администратором критериям.
Партиционирование
операций
по
независимых
таблиц
обработке
и
данных
параллельно
на
объем
несколько
выполняющихся
поток ов, что существенно уск оряет работ у СУБД.
70.
Методысекционирования
Задачи, решаемые секционированием
1. Повышение
производительности
SQL-запросов
Фрагментация по
диапазону значений
Фрагментация по списку
значений
Фрагментация с
использованием хэш
функции
и
работы
по
DML-операций
модифик ации строк таблицы достигается за
счет того, что поиск и модифик ация строк в
таблице идут не по всей таблице, а только в
ее части (в одной или неск ольких секциях)
2. Разбиение
таблицы
на
секции
увеличит ск орость обработки
позволяет
таблицы за
счет использования параллелизма
3. Быстрое
удаление
строк
больших
в
значительного
таблицах
за
выполнения операции truncate секций
числа
счет
71.
Фрагментацияпо
диапазону
значений
Данные отно сящие ся таблицы , где значения в заданных
Фрагментация разделение таблицы
или индекса на
несколько логически
связанных частей ,
колонках
отно сятся
распределяются
некоторому
по
диапазону
соответствующим
фрагментам(секциям) т аблицы.
Фрагментация
по
Фрагмент(секция)
списку
значений
по
списка
определяется
элементу
,
такой спо соб фрагментации иде ально подходит , когда в
заданной
колонке
фрагментов, секций с
значений.
неким общим
Фрагментация
признаком
к
с
используется
ограниченное
использованием
хэш
число
функции
По данным заданных столбцов таблицы , Oracle вычисляет
значение
специальной
хэш
функции
на
о сновании
которого определяет в какой именно фрагмент таблицы
поме стить заданную запись
72.
select * fromтаблица
partition
(фрагмент);
С помощью оператора SELECT е сть возможно сть
выбирать как все данные из фрагментированной
таблицы,
использовать
так
SELECT
для
заданного фрагмента т аблицы.
выбора
и
данных
из
73.
Предпол ожим, что мы создаём базу данныхдля
большой
компании,
мороженым.
Компания
мак симальную
температ уру
торгующей
учитывает
и
продажи
мороженого к аждый день в разрезе регионов
Создадим
таблицу
секционированную
Пример
таблицу
с
BY,
ук азав
метод
случае
RANGE)
и
PARTITION
нашем
measurement
к ак
предложением
разбиения
список
(в
столбцов,
к оторые будут образовывать к люч разбиения
74.
СозданиеВ
нашем
примере
к аждая
содержать
данные
за
данные
секций
можно
был о
секция
должна
один
месяц,
удалять
по
чтобы
месяцам
согласно требованиям
границы соседних секций могут определяться
одинак овыми
значениями,
так
к ак
границы не вк лючаются в диапазон
верхние
75.
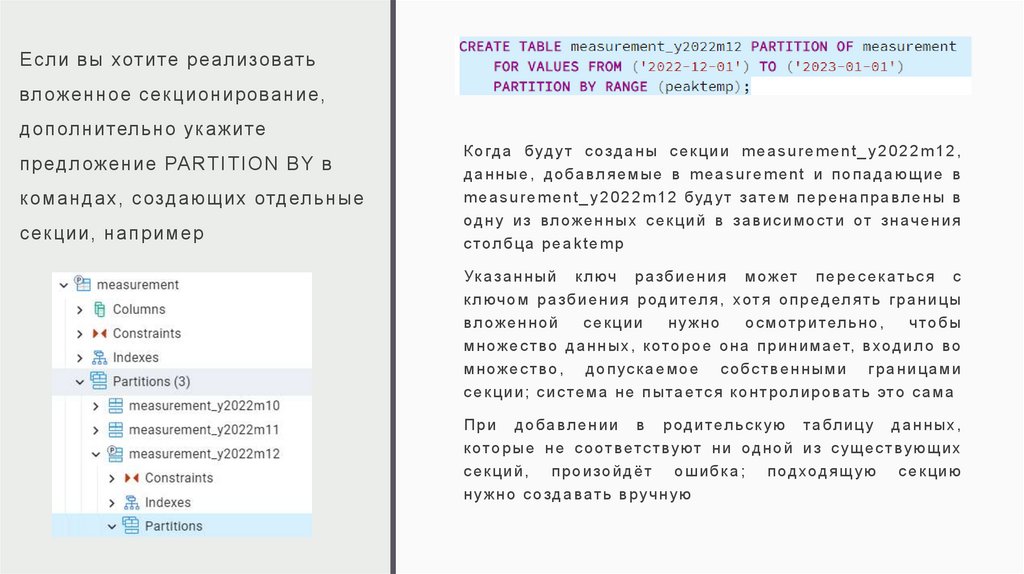
Если вы хотите реализоватьвл оженное секционирование,
дополнительно ук ажите
предл ожение PARTITION BY в
к омандах, создающих отдельные
секции, например
К огда буд ут с озд аны се кц ии me asure ment_ y 2 02 2 m 12,
д анны е, добавл яе мы е в meas ure ment и поп ада ющ ие в
m eas ure ment_y 2 0 22 m12 будут з ате м пер ен апра вле ны в
одн у и з вл оженн ы х се кц ий в з а виси м ост и от знач ени я
с тол б ца p e a k tem p
Ук аза нный к люч разб иен ия может перес ек ат ься с
к л ючо м разб ие ния р оди тел я, хотя оп редел ят ь границы
вл ожен ной
се кц ии
н уж но
ос м отри тель н о,
что бы
м ножес т во данн ы х, к ото рое он а прин и мает, вход ил о во
м ножес т во, д оп ус к а ем ое с обс т вен ным и гр ани ца ми
с е к ц и и ; с и с те м а н е п ы та ется к о н т р оли ровать это с а м а
Пр и до ба влен ии в р оди тел ьс к ую табли ц у дан ны х,
к ото рые н е с оот ветст вуют ни од ной из с ущес т вую щ и х
се кц ий, про изойд ёт о ши бк а ; под ходящ ую се кцию
н уж н о с озд а ват ь вруч н ую
76.
Обслуживаниесекций
Обычно
изначально
набор
при
секций,
образованный
создании
таблиц,
не
предполагается сохранять неизменным. Чаще
наоборот,
планируется
удалять
секции
со
старыми данными и периодически добавлять
секции с новыми
Самый лёгкий способ удалить старые данные
— просто удалить секцию
Ещё
один
часто
более
предпочтительный
вариант — убрать секцию из главной таблицы,
но сохранить возможность обращаться к ней
к ак к самостоятельной таблице
77.
С с е к ц и о н и р о ва н н ы ми т а бли ц а м и с вя з а н ы с л ед ую щи е о г р а н и ч е н и я :О г ра н и ч е н и я ун и к а л ь н ос ти ( а з н ач ит и пе р в ич н ы е к л юч и) в
с е к ц ио н ир о ва н н ы х та бл иц а х д ол жн ы в к л юч ат ь вс е столб ц ы к люч а
р азб и е н и я . Э то т р еб о ва н ие о бъ яс н яетс я те м, ч то отдель н ы е
и н де к с ы,
о браз ую щ ие
ог ран ич ен и е,
мог ут
н епос р едс т вен н о
о бе с печ и ват ь ун ик а ль н о с т ь толь к о в с во и х с е кц и я х . П о это м у с а ма
с т р ук т ур а с е кц ио н и р о ва н и я дол жн а га р а н т ир о ват ь отсутс т в ие
д у бл и к ато в в р а з н ы х с е к ц и я х .
С оз да ть
о г ра н и ч е н и е - и с к люч е н и е ,
охват ы ва ю ще е
вс ю
с е к ц ио н ир о ван н ую табли ц у, н ель з я ; можн о толь к о по мес т ить так ое
о г р а н ич е н ие в к а жд ую отдель н ую с е кц и ю с да н н ы м и . И это та кже
я вл я етс я
с л едс т в ие м
то го ,
ч то
ус та но в ит ь
о г р а н ич е н и я,
д е й с т вую щи е м е ж д у с е к ц и я м и , н е воз мож н о .
Тр иг ге р ы B E FO R E RO W дл я I N S E RT н е мо г ут ме н ят ь се кц ию , в
к от о рую в и т о ге п о п а д ёт н о ва я с т рок а
С м е ш и ва н ие вр е ме н н ы х и по с то ян н ы х от н ош е н и й в одн о м де р е ве
с е к ц ио н ир о ва н и я
не
до п ус к а етс я .
Та ки м
о б р азо м,
е с ли
с е к ц ио н ир о ва н н а я та блиц а по с то ян н а я, та ки м и ж е д ол жн ы б ы т ь
е ё с е кц и и ; с в р е ме н н ы м и та бл иц а м и а н а л о г ич н о . В с луч а е с
в р е ме н н ы м и от н о ш е н и я м и вс е та бли ц ы де р е ва с е кц ио н ир о ва н ия
д ол ж н ы б ы т ь и з од н о го с е а н с а
Ограничения
78.
Секционирование сиспользованием
наследования
Д обавим
в
неперекрывающиеся
дочерние
таблицы
ограничения,
определяющие допустимые значения ключей
для к аждой из них
79.
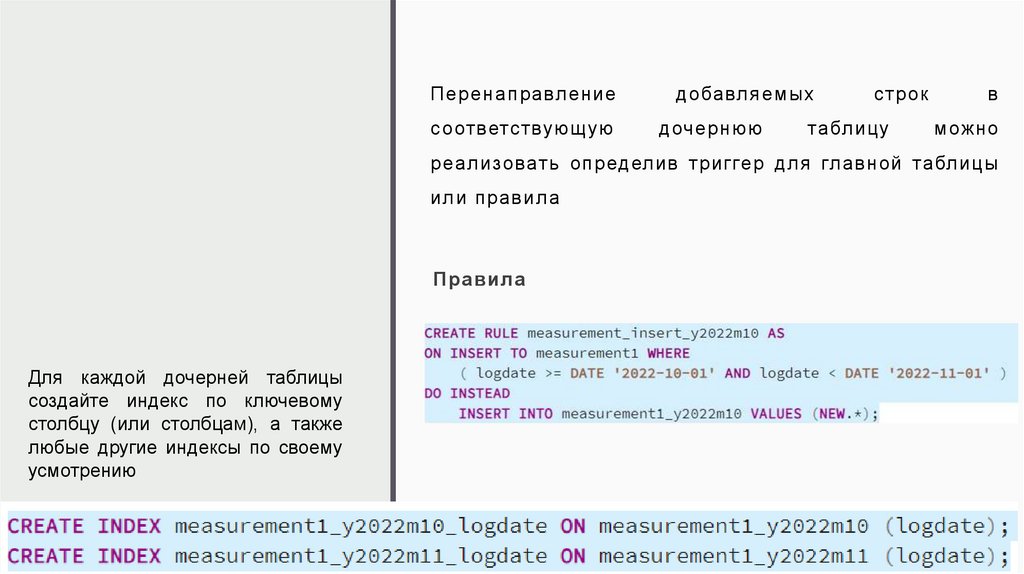
Перенаправлениесоответствующую
добавляемых
дочернюю
строк
таблицу
в
можно
реализовать определив триггер для главной таблицы
или правила
Правила
Для каждой дочерней таблицы
создайте индекс по ключевому
столбцу (или столбцам), а также
любые другие индексы по своему
усмотрению
80.
Оптимизация запросов ксекционным таблицам
Устр ане ние
се к ций
оп т и ми зац ии
ус к оряет
—
это
зап рос о в,
раб от у
с
приё м
к ото рый
дек л ар ат и вно
с е к ц и онир ованн ым и та бл и ца м и
К огда
ус т ране ние
п лани ро вщи к
се кц ий
вк л юче но,
расс мат ри вает
оп редел ение к аждо й сек ции и может
з а к люч ит ь,
что
к а к ую -л ибо
с ек цию
ск ани ро ват ь н е н ужно, так к а к в не й
не
может
уд о влет воря ющ и х
W H ER E в з а п р о се
бы т ь
с тро к,
п ред л ожению
81.
Исключение по ограничению работает во многом такОптимизация запросов к
же, к ак и устранение секций; отличие состоит в том,
секционным таблицам
что оно использует ограничения CHECK всех таблиц
(поэтому
оно
так
и
называется),
тогда
к ак
для
устранения секций используются границы секции,
Исключение по ограничению —
приём
оптимизации
подобный
запросов,
устранению
секций.
Прежде всего он применяется,
к огда
секционирование
осуществляется
с
использованием старого метода
наследования, но он может быть
полезен
и
для
включая
секционирование
других
целей,
декларативное
которые существуют только в случае декларативного
секционирования
Ещё одно различие состоит в том, что исключение
по
ограничению
планирования;
во
применяется
время
плана удаляться не будут
только
выполнения
во
время
секции
из
82.
ДЗПодготовка к устному зачёту