





















 database
databaseSimilar presentations:








")

Индексы
1.
Индексы2.
Аналогия и указатель телефонной книги• Предположим, вам нужно найти номер телефона Джона Доу в
телефонной книге. Предполагая, что имена в телефонной книге
расположены в алфавитном порядке. Чтобы найти номер телефона
Джона Доу, вы сначала ищете страницу, где фамилия Доу, затем ищете
имя Джон и, наконец, получаете его номер телефона.Если бы имена в
телефонной книге не были расположены в алфавитном порядке, вам
пришлось бы просмотреть все страницы и проверить каждое имя, пока
не найдете номер телефона Джона Доу. Это называется
последовательным сканированием, при котором вы просматриваете
все записи, пока не найдете ту, которую ищете. Подобно телефонной
книге, данные, хранящиеся в таблице, должны быть организованы в
определенном порядке, чтобы ускорить различные поиски. Вот почему
в игру вступают индексы.
3.
• По определению, индекс — это отдельная структура данных,которая ускоряет извлечение данных из таблицы за счет
дополнительных операций записи и хранения для поддержания
индекса.
4.
Создание Индекса• Сначала укажите имя индекса после предложения CREATE INDEX. Имя
индекса должно быть осмысленным и легко запоминающимся.
• Во-вторых, укажите имя таблицы, которой принадлежит индекс.
• В-третьих, укажите метод индекса, например btree, hash, gist, spgist, gin
и brin. PostgreSQL по умолчанию использует btree.
• Наконец, перечислите один или несколько столбцов индекса. ASC и
DESC определяют порядок сортировки. Порядок сортировки по
умолчанию — ASC.
Если столбец содержит NULL, вы можете указать опцию NULLS FIRST или
NULLS LAST. NULLS FIRST используется по умолчанию, если указан DESC, а
NULLS LAST используется по умолчанию, если DESC не указан.
5.
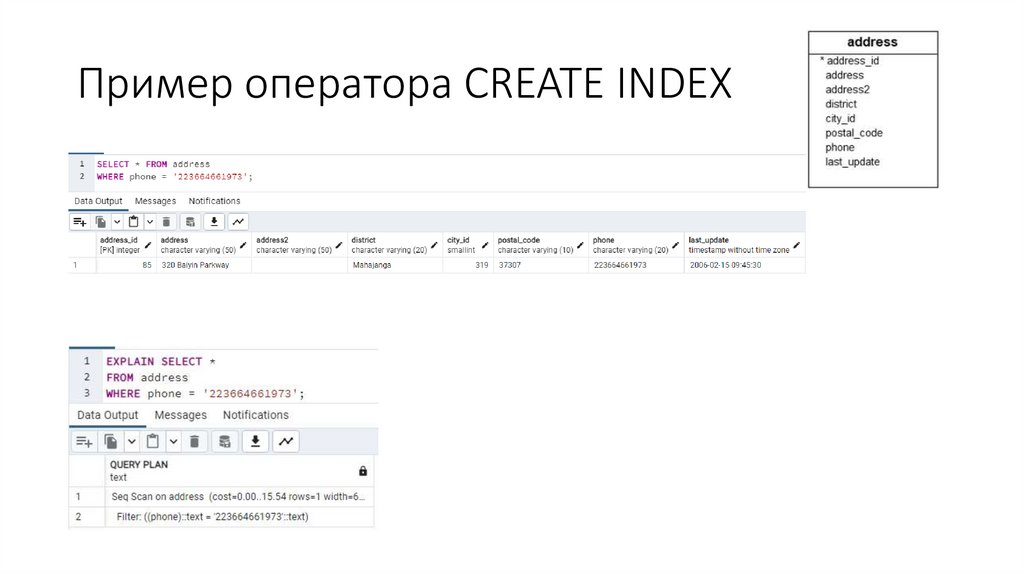
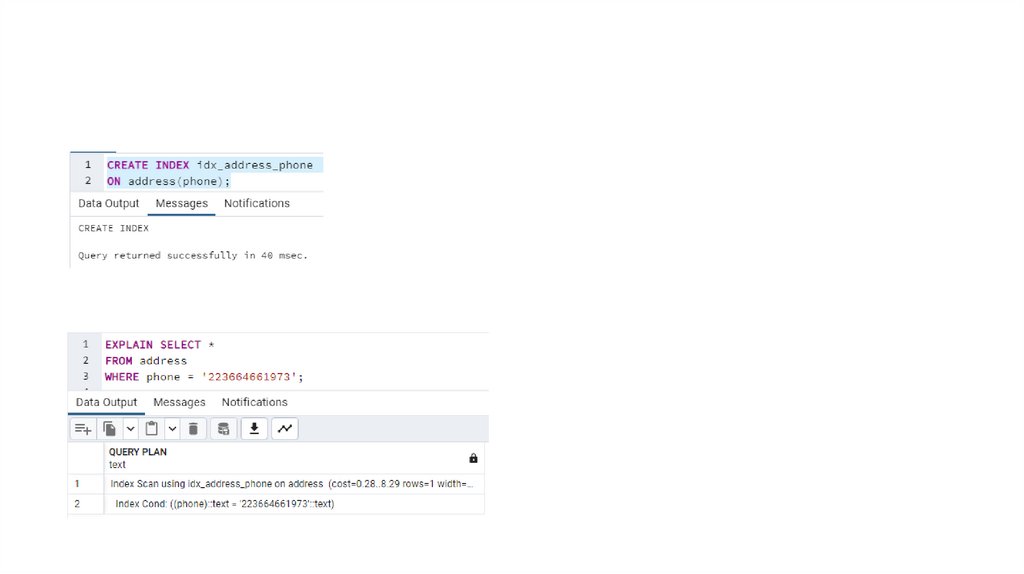
Пример оператора CREATE INDEX6.
7.
Оператор удаления DROP INDEX• index_name
После предложения DROP INDEX вы указываете имя индекса, который хотите удалить.
• IF EXISTS
Попытка удалить несуществующий индекс приведет к ошибке. Чтобы избежать этого, вы можете
использовать опцию IF EXISTS. Если вы удалите несуществующий индекс с помощью IF EXISTS, PostgreSQL
вместо этого выдаст уведомление.
• CASCADE
Если в индексе есть зависимые объекты, вы используете опцию CASCADE для автоматического удаления
этих объектов и всех объектов, которые зависят от этих объектов.
• RESTRICT (ОГРАНИЧИВАТЬ)
Опция RESTRICT указывает PostgreSQL отказаться от удаления индекса, если от него зависят какие-либо
объекты. DROP INDEX по умолчанию использует RESTRICT.
Обратите внимание, что вы можете удалить несколько индексов одновременно, разделив их запятыми
(,):
8.
Оператор удаления DROP INDEX• CONCURRENTLY (ОДНОВРЕМЕННО)
Когда вы выполняете оператор DROP INDEX, PostgreSQL получает
монопольную блокировку таблицы и блокирует другие доступы до
завершения удаления индекса.
Чтобы заставить команду ждать завершения конфликтной транзакции
перед удалением индекса, вы можете использовать опцию
CONCURRENTLY.
DROP INDEX CONCURRENTLY имеет некоторые ограничения:
• Во-первых, опция CASCADE не поддерживается.
• Во-вторых, выполнение в блоке транзакций также не поддерживается.
9.
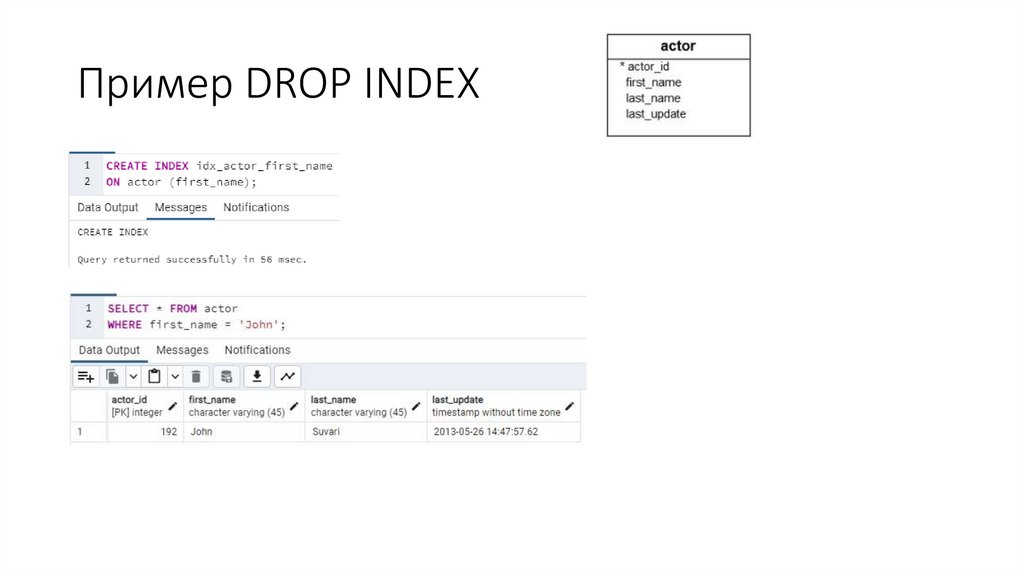
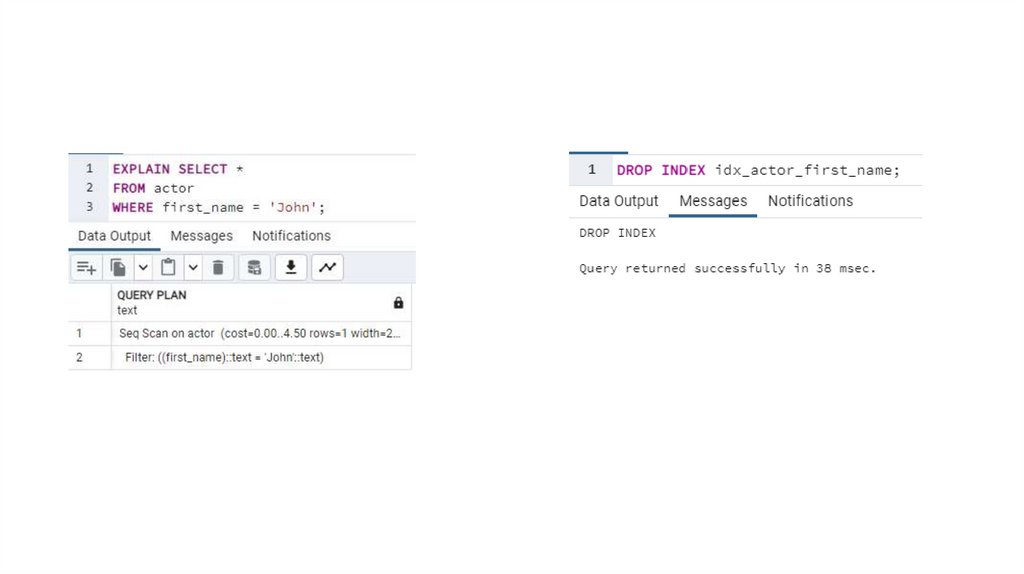
Пример DROP INDEX10.
11.
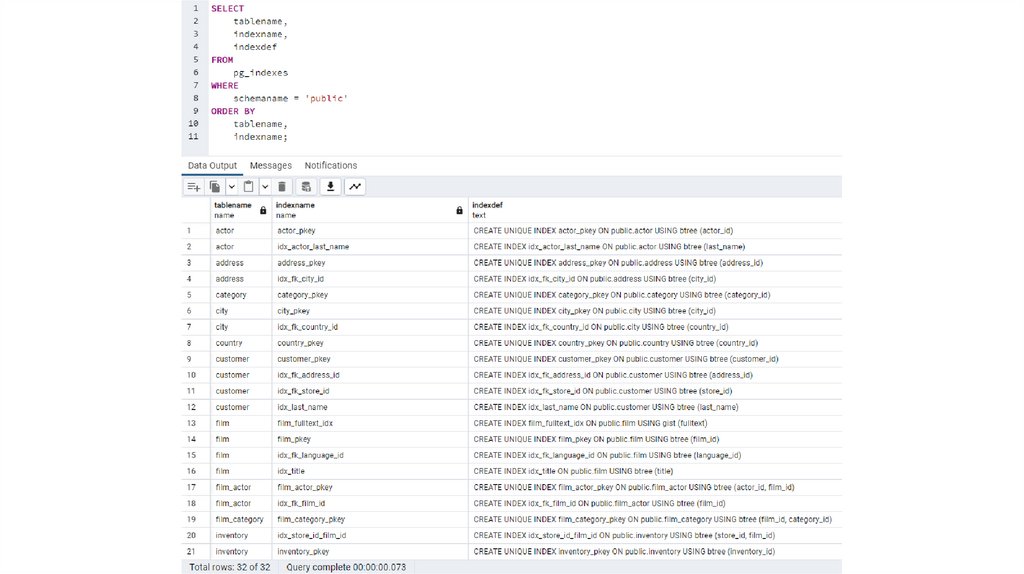
Получение списка индексов• PostgreSQL не предоставляет такую команду, как SHOW INDEXES,
для вывода информации об индексе таблицы или базы данных.
• Однако он предоставляет вам доступ к представлению
pg_indexes, чтобы вы могли запрашивать информацию об
индексе.
• Если вы используете программу psql для взаимодействия с базой
данных PostgreSQL, вы можете использовать команду \d для
просмотра информации об индексе таблицы.
12.
Получение списка индексов с помощьюпредставления pg_indexes
• Представление pg_indexes позволяет получить доступ к полезной
информации по каждому индексу в базе данных PostgreSQL.
Представление pg_indexes состоит из пяти столбцов:
• schemaname : хранит имя схемы, содержащей таблицы и индексы.
• tablename: хранит имя таблицы, которой принадлежит индекс.
• indexname: сохраняет имя индекса.
• tablespace : хранит имя табличного пространства, содержащего
индексы.
• indexdef: сохраняет команду определения индекса в форме оператора
CREATE INDEX.
13.
14.
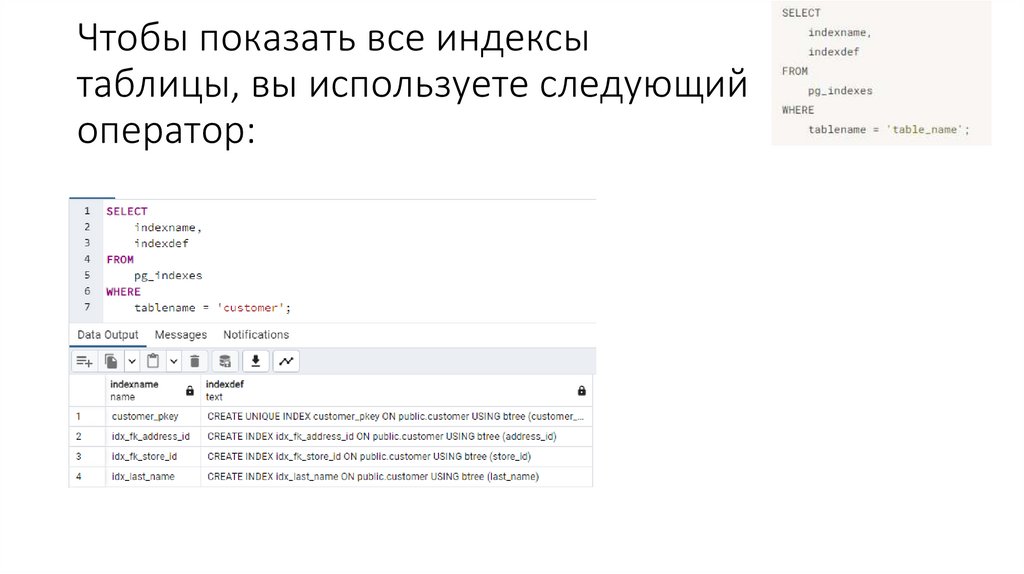
Чтобы показать все индексытаблицы, вы используете следующий
оператор:
15.
16.
Типы индексов• Далее вы узнаете о различных типах индексов PostgreSQL и о том,
как их правильно использовать.
• PostgreSQL имеет несколько типов индексов: B-дерево, Hash, GiST,
SP-GiST, GIN и BRIN. Каждый тип индекса использует другую
структуру хранения и алгоритм для обработки разных типов
запросов.
• Когда вы используете оператор CREATE INDEX без указания типа
индекса, PostgreSQL по умолчанию использует тип индекса Bдерева, поскольку он лучше всего подходит для наиболее
распространенных запросов.
17.
Индекс B-tree (b-дерево)• B-дерево — это самобалансирующееся дерево,
которое поддерживает отсортированные данные и
позволяет выполнять поиск, вставку, удаление и
последовательный доступ за логарифмическое
время.
• Планировщик запросов PostgreSQL будет
рассматривать возможность использования индекса
B-дерева всякий раз, когда столбцы индекса
участвуют в сравнении, в котором используется один
из следующих операторов:
18.
• Кроме того, планировщик запросов может использовать индекс Bдерева для запросов, в которых используются операторысопоставления с образцом LIKE и ~, если шаблон является константой и
привязан к началу шаблона, например:
• Кроме того, планировщик запросов рассмотрит возможность
использования индексов B-дерева для ILIKE и ~*, если шаблон
начинается с неалфавитного символа, то есть символов, на которые не
влияет преобразование верхнего/нижнего регистра.
• Если вы начали использовать индекс для оптимизации базы данных
PostgreSQL, вероятно, вам нужно B-дерево.
19.
Индекс Hash (Хэш-индекс)• Хэш-индексы могут обрабатывать только простое сравнение на
равенство (=). Это означает, что всякий раз, когда
индексированный столбец участвует в сравнении с
использованием оператора равенства (=), планировщик запросов
будет рассматривать возможность использования хеш-индекса.
• Чтобы создать хеш-индекс, вы используете оператор CREATE
INDEX с типом индекса HASH в предложении USING следующим
образом:
20.
GIN индекс• GIN означает обобщенные инвертированные индексы. Его
обычно называют ГИН.
• Индексы GIN наиболее полезны, когда в одном столбце хранится
несколько значений, например hstore, array, jsonb и типы
диапазонов.
21.
BRIN индекс• BRIN означает индексы диапазона блоков. BRIN намного меньше
и менее затратен в обслуживании по сравнению с индексом Bдерева.
• BRIN позволяет использовать индекс для очень большой таблицы,
что ранее было непрактично при использовании B-дерева.
• BRIN часто используется для столбца с линейным порядком
сортировки, например для столбца даты создания таблицы
заказов на продажу.
22.
Индексы GiST• GiST означает «обобщенное
дерево поиска». Индексы GiST
позволяют создавать общие
древовидные структуры.
• Индексы GiST полезны при
индексировании геометрических
типов данных и полнотекстовом
поиске.
• SP-GiST означает разделенный на
пространство GiST. SP-GiST
поддерживает
секционированные деревья
поиска, которые облегчают
разработку широкого спектра
различных несбалансированных
структур данных.
• Индексы SP-GiST наиболее
полезны для данных, которые
имеют естественный элемент
кластеризации и не являются
одинаково сбалансированным
деревом, например ГИС,
мультимедиа, телефонная
маршрутизация и IPмаршрутизация.
23.
UNIQUE индекс• Индекс PostgreSQL UNIQUE обеспечивает уникальность значений
в одном или нескольких столбцах. Чтобы создать УНИКАЛЬНЫЙ
индекс, вы можете использовать следующий синтаксис:
24.
• Обратите внимание, что только индексы B-дерева могут бытьобъявлены как уникальные индексы.
• Когда вы определяете УНИКАЛЬНЫЙ индекс для столбца, столбец не
может хранить несколько строк с одинаковыми значениями.
• Если вы определяете индекс UNIQUE для двух или более столбцов,
объединенные значения в этих столбцах не могут дублироваться в
нескольких строках.
• PostgreSQL рассматривает NULL как отдельные значения, поэтому в
столбце с индексом UNIQUE может быть несколько значений NULL.
• Когда вы определяете первичный ключ или ограничение уникальности
для таблицы, PostgreSQL автоматически создает соответствующий
индекс UNIQUE.
25.
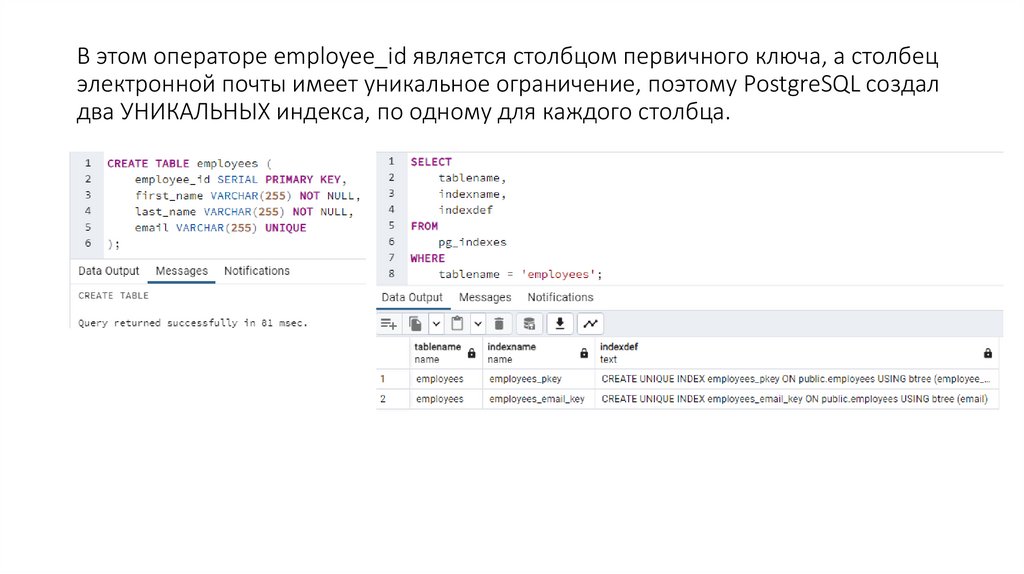
В этом операторе employee_id является столбцом первичного ключа, а столбецэлектронной почты имеет уникальное ограничение, поэтому PostgreSQL создал
два УНИКАЛЬНЫХ индекса, по одному для каждого столбца.
26.
UNIQUE индекс – пример одного столбца• Следующий оператор добавляет столбец mobile_phone в таблицу
сотрудников:
• Чтобы номера мобильных телефонов были разными для всех
сотрудников, вы определяете UNIQUE индекс для столбца
mobile_phone следующим образом:
27.
• Сначала вставьте новую строку в таблицу сотрудников:• Во-вторых, попытайтесь вставить еще одну строку с тем же
номером телефона:
28.
УНИКАЛЬНЫЙ индекс – пример несколькихстолбцов
• Следующий оператор добавляет в таблицу сотрудников два
новых столбца с именами work_phone и Extension:
• Несколько сотрудников могут использовать один и тот же
рабочий номер телефона. Однако они не могут иметь
одинаковый добавочный номер. Чтобы обеспечить соблюдение
этого правила, вы можете определить УНИКАЛЬНЫЙ индекс для
столбцов work_phone и Extension:
29.
• Чтобы протестировать этот индекс, сначала вставьте строку втаблицу сотрудников:
• Во-вторых, вставьте другого сотрудника с тем же номером
рабочего телефона, но с другим добавочным номером:
30.
• Этот оператор работает, поскольку комбинация значений встолбцах work_phone и Extension уникальна.
• В-третьих, попытайтесь вставить строку с одинаковыми
значениями в столбцы work_phone и Extension, которые уже
существуют в таблице сотрудников: