




























 database
databaseSimilar presentations:






")

")

Технологии обработки данных. Вычисления (лекция 4)
1.
Кафедра Прикладной математикиИнститута информационных технологий
РТУ МИРЭА
Дисциплина
«Большие данные»
2022-2023 у.г.
2.
Лекция 4. Технологии обработкиданных. Вычисления
2
3.
Часть 1. Операции обработкиструктурированных табличных
данных
3
4.
Трансформация данных• Трансформация данных - это выполнение различных преобразований данных с
целью их подготовки к анализу или моделированию. Среди наиболее часто
используемых операций - отбор строк или столбцов таблицы данных, вычисление
новых столбцов, подсчет итогов, группировка и ранжирование.
• Существует базовый перечень методов обработки данных, относящихся к
трансформации таблиц:
1. Выборка данных (выборка столбцов или атрибутов)
2. Сортировка данных
3. Фильтрация данных
4. Вычисления столбцов
5. Агрегация данных (группировка)
6. Обогащение данных
7. Транспонирование данных
4
5.
Задачи трансформации данных• В результате применения методов трансформации данных таблица приобретает
новую структуру, или меняет порядок и состав объектов в таблице.
• Задачи, которые решают методы трансформации данных:
1. В OLTP системах (системы оперативной обработки данных) – обеспечение
поддержки корректности форматов и типов данных, оптимизация процессов
доступа и выгрузки данных.
2. На этапе ETL-процесса трансформация производится с целью приведения данных
в соответствие с моделью, которая используется в хранилище, а также обеспечения
процесса консолидации данных и их загрузки в хранилище.
3. В аналитическом приложении производится непосредственная подготовка
данных к анализу, объединение и выделение наиболее ценной информации,
обеспечение корректной работы аналитических алгоритмов, методов и моделей.
5
6.
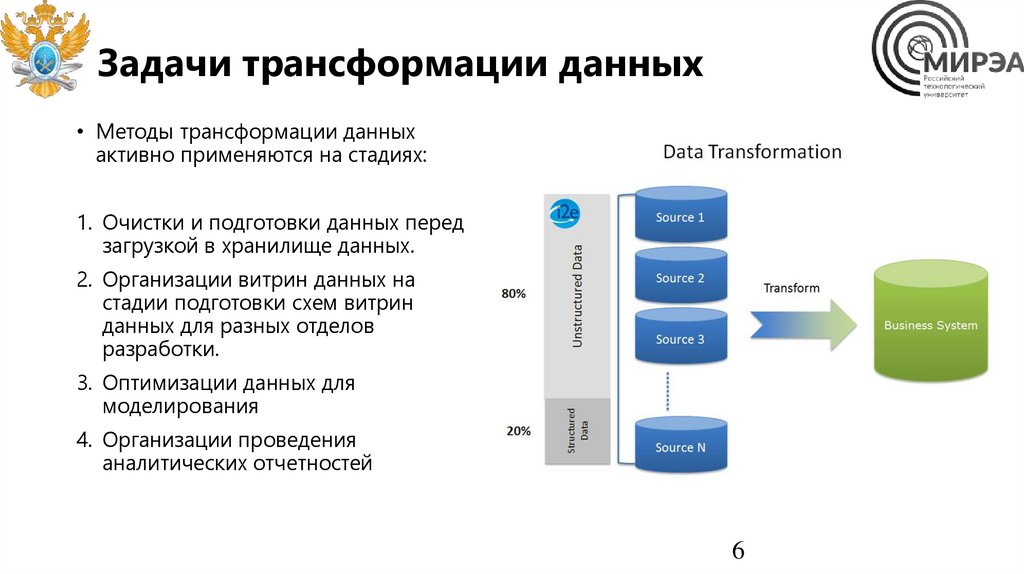
Задачи трансформации данных• Методы трансформации данных
активно применяются на стадиях:
1. Очистки и подготовки данных перед
загрузкой в хранилище данных.
2. Организации витрин данных на
стадии подготовки схем витрин
данных для разных отделов
разработки.
3. Оптимизации данных для
моделирования
4. Организации проведения
аналитических отчетностей
6
7.
Часть 2. Фильтрация и сортировкаданных
7
8.
Материалы1. Сортировка.
2. Сортировка строк
3. Иерархическая сортировка
4. Фильтрация.
5. Простая фильтрация.
6. Множественный фильтр
7. Фильтр списка
8. Регулярные выражения для сравнения со
строками
8
9.
Сортировка• Сортировка табличных данных – преобразование, упорядочивающее набор
объектов (строк) или наблюдений в связи с правилом упорядочивания по
выбранным атрибутам.
• Сортировка таблицы производит упорядочивание строк по соответствующим
значениям в сортируемом столбце. Для одинаковых значений упорядочивание
локально не происходит и порядок внутри данных с одинаковыми значениями в
сортируемом столбце остается исходным.
• Для числовых данных и данных даты и времени упорядочивание данных происходит
в естественном порядке по возрастанию или убыванию (на выбор).
• Для порядковых данных упорядочивание логически происходит по порядку
определенного уровня фактора (первый, второй, третий, ...).
9
10.
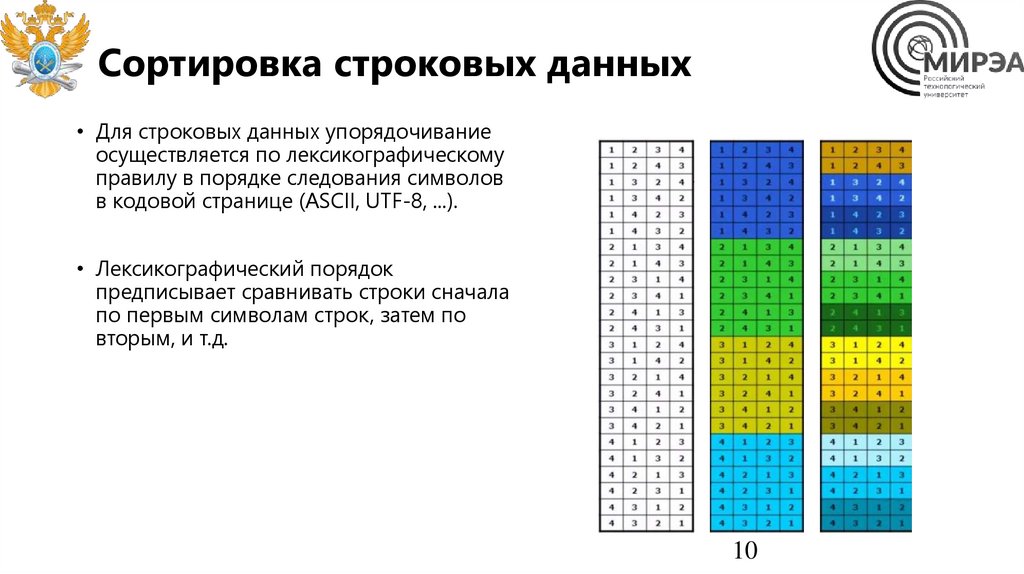
Сортировка строковых данных• Для строковых данных упорядочивание
осуществляется по лексикографическому
правилу в порядке следования символов
в кодовой странице (ASCII, UTF-8, ...).
• Лексикографический порядок
предписывает сравнивать строки сначала
по первым символам строк, затем по
вторым, и т.д.
10
11.
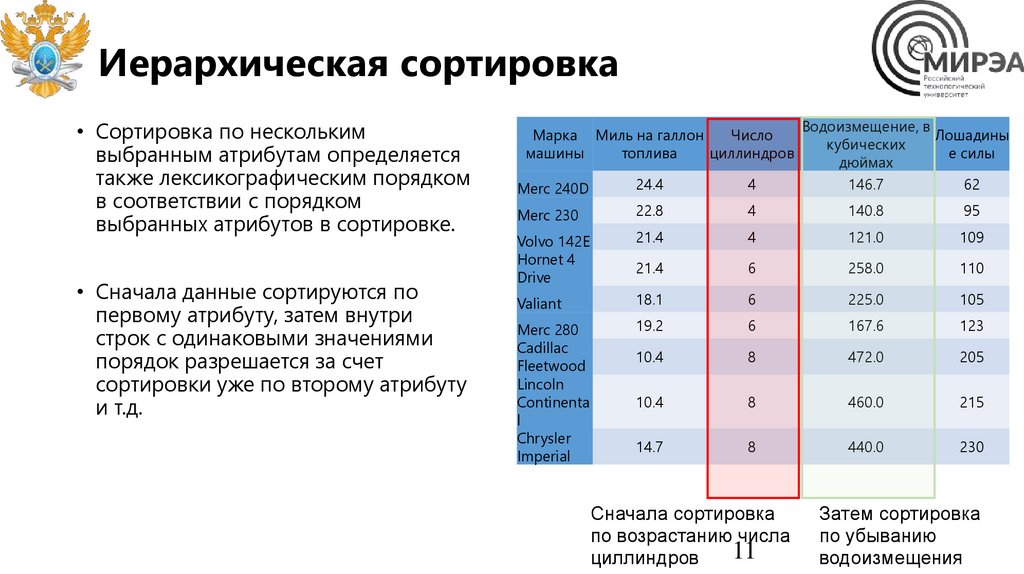
Иерархическая сортировка• Сортировка по нескольким
выбранным атрибутам определяется
также лексикографическим порядком
в соответствии с порядком
выбранных атрибутов в сортировке.
• Сначала данные сортируются по
первому атрибуту, затем внутри
строк с одинаковыми значениями
порядок разрешается за счет
сортировки уже по второму атрибуту
и т.д.
Марка Миль на галлон
Число
машины
топлива
циллиндров
Водоизмещение, в
Лошадины
кубических
е силы
дюймах
146.7
62
Merc 240D
24.4
4
Merc 230
22.8
4
140.8
95
Volvo 142E
Hornet 4
Drive
21.4
4
121.0
109
21.4
6
258.0
110
Valiant
18.1
6
225.0
105
Merc 280
Cadillac
Fleetwood
Lincoln
Continenta
l
Chrysler
Imperial
19.2
6
167.6
123
10.4
8
472.0
205
10.4
8
460.0
215
14.7
8
440.0
230
Сначала сортировка
по возрастанию числа
11
циллиндров
Затем сортировка
по убыванию
водоизмещения
12.
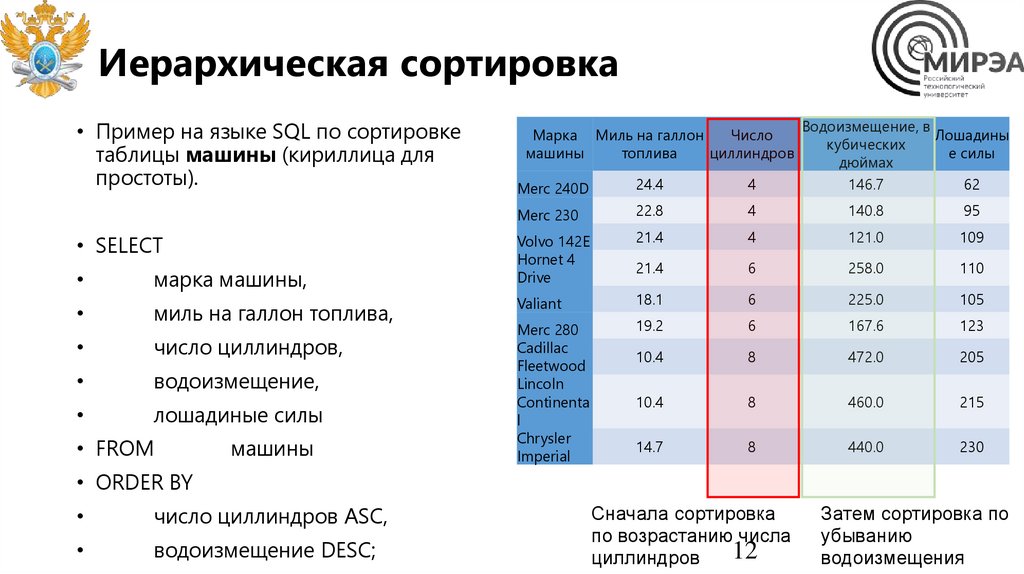
Иерархическая сортировка• Пример на языке SQL по сортировке
таблицы машины (кириллица для
простоты).
• SELECT
марка машины,
миль на галлон топлива,
число циллиндров,
водоизмещение,
лошадиные силы
• FROM
машины
Марка Миль на галлон
Число
машины
топлива
циллиндров
Водоизмещение, в
Лошадины
кубических
е силы
дюймах
146.7
62
Merc 240D
24.4
4
Merc 230
22.8
4
140.8
95
Volvo 142E
Hornet 4
Drive
21.4
4
121.0
109
21.4
6
258.0
110
Valiant
18.1
6
225.0
105
Merc 280
Cadillac
Fleetwood
Lincoln
Continenta
l
Chrysler
Imperial
19.2
6
167.6
123
10.4
8
472.0
205
10.4
8
460.0
215
14.7
8
440.0
230
• ORDER BY
число циллиндров ASC,
водоизмещение DESC;
Сначала сортировка
по возрастанию числа
12
циллиндров
Затем сортировка по
убыванию
водоизмещения
13.
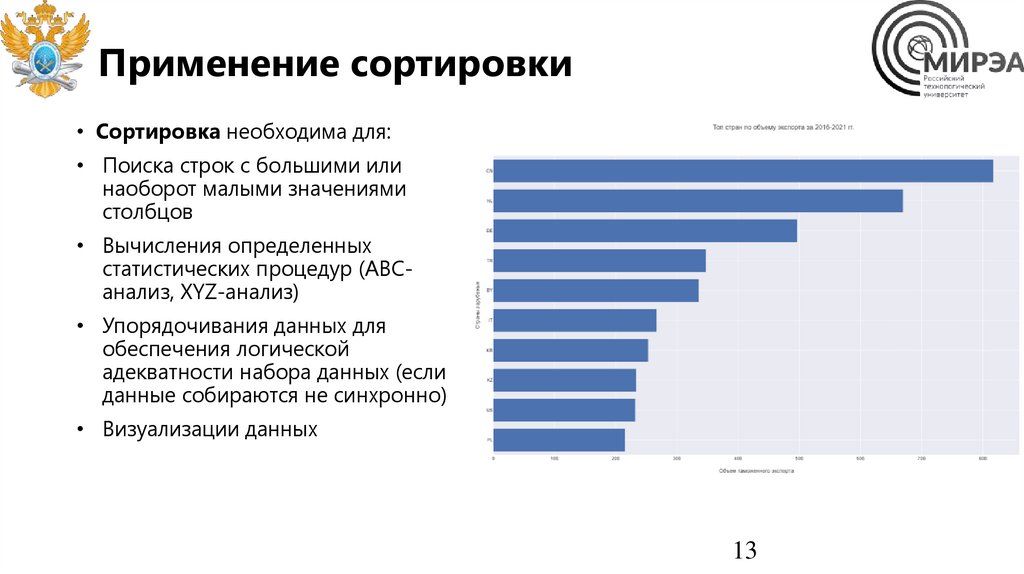
Применение сортировки• Сортировка необходима для:
• Поиска строк с большими или
наоборот малыми значениями
столбцов
• Вычисления определенных
статистических процедур (ABCанализ, XYZ-анализ)
• Упорядочивания данных для
обеспечения логической
адекватности набора данных (если
данные собираются не синхронно)
• Визуализации данных
13
14.
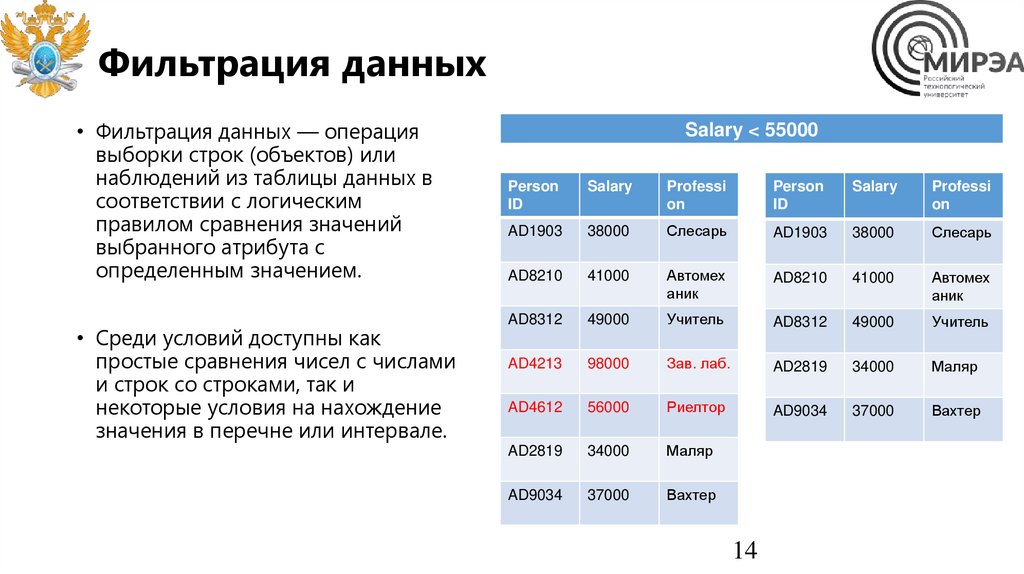
Фильтрация данных• Фильтрация данных — операция
выборки строк (объектов) или
наблюдений из таблицы данных в
соответствии с логическим
правилом сравнения значений
выбранного атрибута с
определенным значением.
• Среди условий доступны как
простые сравнения чисел с числами
и строк со строками, так и
некоторые условия на нахождение
значения в перечне или интервале.
Salary < 55000
Person
ID
Salary
Professi
on
Person
ID
Salary
Professi
on
AD1903
38000
Слесарь
AD1903
38000
Слесарь
AD8210
41000
Автомех
аник
AD8210
41000
Автомех
аник
AD8312
49000
Учитель
AD8312
49000
Учитель
AD4213
98000
Зав. лаб.
AD2819
34000
Маляр
AD4612
56000
Риелтор
AD9034
37000
Вахтер
AD2819
34000
Маляр
AD9034
37000
Вахтер
14
15.
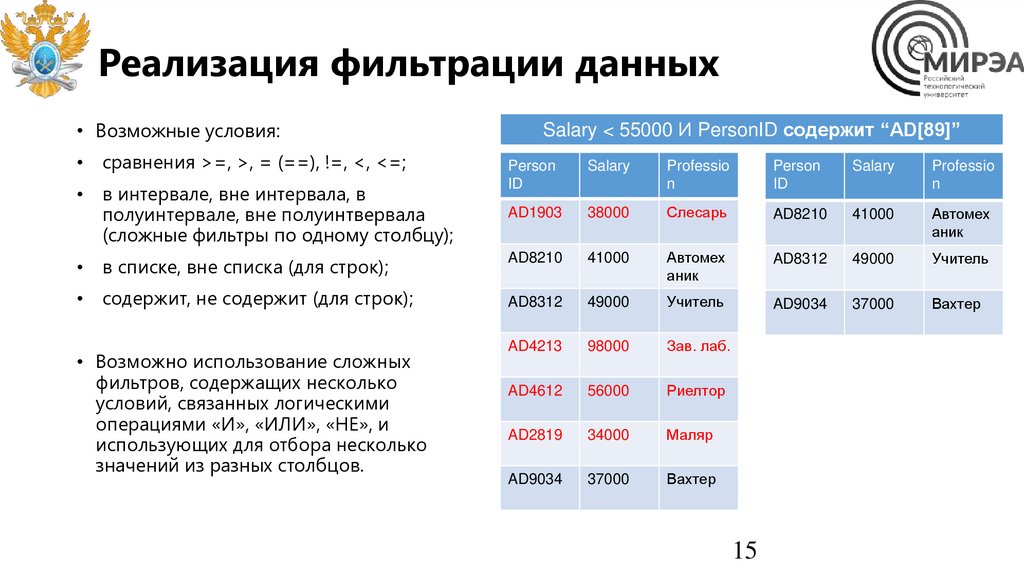
Реализация фильтрации данных• Возможные условия:
• cравнения >=, >, = (==), !=, <, <=;
Salary < 55000 И PersonID содержит “AD[89]”
Person
ID
Salary
Professio
n
Person
ID
Salary
Professio
n
AD1903
38000
Слесарь
AD8210
41000
Автомех
аник
• в списке, вне списка (для строк);
AD8210
41000
Автомех
аник
AD8312
49000
Учитель
• содержит, не содержит (для строк);
AD8312
49000
Учитель
AD9034
37000
Вахтер
AD4213
98000
Зав. лаб.
AD4612
56000
Риелтор
AD2819
34000
Маляр
AD9034
37000
Вахтер
• в интервале, вне интервала, в
полуинтервале, вне полуинтвервала
(сложные фильтры по одному столбцу);
• Возможно использование сложных
фильтров, содержащих несколько
условий, связанных логическими
операциями «И», «ИЛИ», «НЕ», и
использующих для отбора несколько
значений из разных столбцов.
15
16.
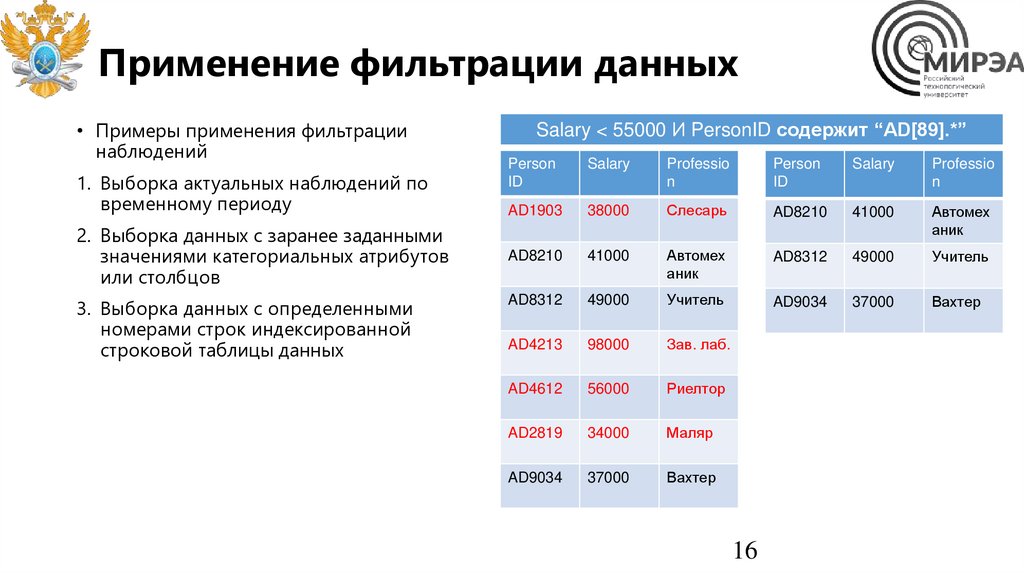
Применение фильтрации данных• Примеры применения фильтрации
наблюдений
1. Выборка актуальных наблюдений по
временному периоду
2. Выборка данных с заранее заданными
значениями категориальных атрибутов
или столбцов
3. Выборка данных с определенными
номерами строк индексированной
строковой таблицы данных
Salary < 55000 И PersonID содержит “AD[89].*”
Person
ID
Salary
Professio
n
Person
ID
Salary
Professio
n
AD1903
38000
Слесарь
AD8210
41000
Автомех
аник
AD8210
41000
Автомех
аник
AD8312
49000
Учитель
AD8312
49000
Учитель
AD9034
37000
Вахтер
AD4213
98000
Зав. лаб.
AD4612
56000
Риелтор
AD2819
34000
Маляр
AD9034
37000
Вахтер
16
17.
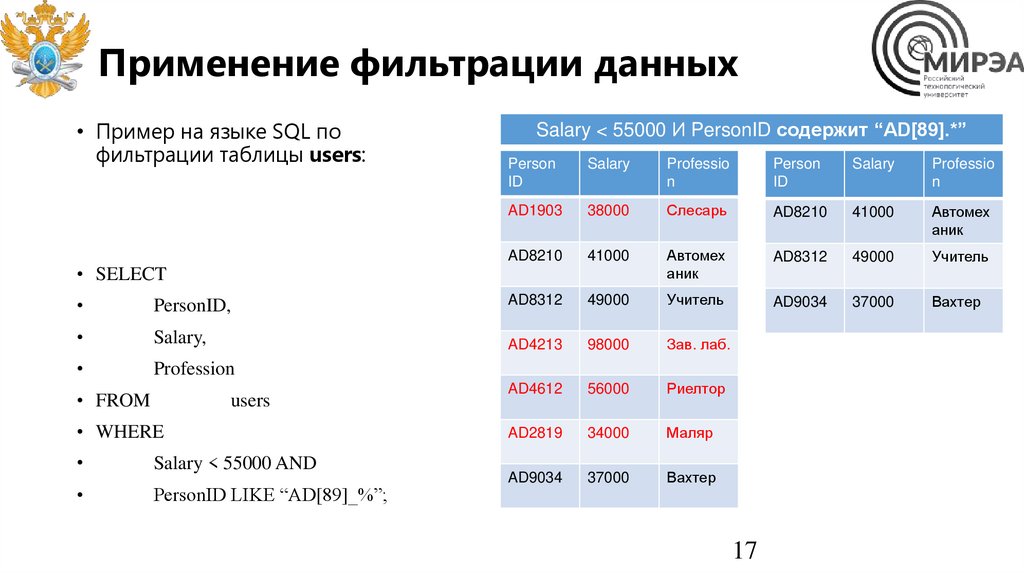
Применение фильтрации данных• Пример на языке SQL по
фильтрации таблицы users:
• SELECT
Salary < 55000 И PersonID содержит “AD[89].*”
Person
ID
Salary
Professio
n
Person
ID
Salary
Professio
n
AD1903
38000
Слесарь
AD8210
41000
Автомех
аник
AD8210
41000
Автомех
аник
AD8312
49000
Учитель
AD9034
37000
Вахтер
PersonID,
AD8312
49000
Учитель
Salary,
AD4213
98000
Зав. лаб.
Profession
AD4612
56000
Риелтор
AD2819
34000
Маляр
AD9034
37000
Вахтер
• FROM
users
• WHERE
Salary < 55000 AND
PersonID LIKE “AD[89]_%”;
17
18.
Регулярные выражения• Регулярные выражения — язык построения шаблонов для поиска подстрок в
строковых данных.
• Регулярные выражения строятся по принципу написания шаблона, который будет
находить желаемую подстроку внутри строки.
• При нахождении шаблона внутри значения конкретной строки может быть выбран
один из способов обработки строк:
• сравнение строки с шаблоном,
• поиск места подстроки в шаблоне,
• извлечение подстроки из строки по совпадающему шаблону,
• разделение строки на подстроки по шаблону.
18
19.
Шаблон регулярного выражения• Для создания регулярного выражения
необходимо использовать
определенный синтаксис: специальные
символы и конструкцию.
• Основные классы символов:
– Указатели ^, $
– Метасимволы ., |, \
– Классы символов [.], [^.], [:alpha:], ...
– Классы условных символов
\w, \s, \d, \W, \S, \D
– Группа (...)
– Квантификаторы {n}, {n, m}, ?
19
20.
Шаблон регулярного выражения• Указатели (^, $)
• ^ — начало текстовой строки
• $ — окончание текстовой строки
• Метасимволы
• . — любой отдельный символ, кроме
новой строки
• | — оператор «или»
• \ — указатель на то, что следующий
символ является литералом
• Классы символов
• [...] — любой символ из набора символов
...
[:alnum:] — буквенно-цифровые символы
(a–я, A–Я или 0–9.)
[:alpha:] — буквенные символы (a–я или A–
Я.)
[:digit:] — цифры (0-9)
[:punct:] — знаки пунктуации (! " # $ % & ' ( )
* + , \ -. / : ; < = > ? @ [ ] ^ _ ` { | })
[:print:] — отображаемые символы и
пробелы
[:space:] — пробелы, табуляция и разрывы
строк
[:word:] — буквы, цифры и знаки
подчеркивания (а–я, А–Я, 0–9 или _)
• [^...] — любой символ, не входящий в
набор символов ...
20
21.
Шаблон регулярного выражения• Классы условных символов
\w — эквивалент [[:word:]]
• \s — эквивалент [[:space:]]
• \d — эквивалент [[:digit:]]
• \W — эквивалент [^[:word:]]
• \S — эквивалент [^[:space:]]
• \D — эквивалент [^[:digit:]]
• Группа
• (...) — объединяет элементы выражения
{n, m} — Поиск не менее n и не более m
вхождений предыдущего выражения
? — Указывает на то, что предыдущий
символ или выражение могут входить в
строку 0 или 1 раз.
* — Указывает на то, что предыдущий
символ или выражение могут входить в
строку 0 или более раз.
+ — Указывает на то, что предыдущий
символ или выражение могут входить в
строку 1 или более раз.
• Квантификаторы
• {n} — поиск n вхождений предыдущего
выражения
21
22.
Применение регулярных выражений• Помимо работы с данными в разрезе трансформации применяются в:
• Валидация данных (например, правильно ли заполнена строка time)
• Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый
набор слов в определённом порядке)
• Обработка данных (преобразование сырых данных в нужный формат)
• Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
• Замена строк (даже во время написания кода в IDE, можно, например
преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”,
изменить размер букв, избегать объявление типа и т.д.)
• Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие
задачи, где нужно работать со строками (где данные не должны быть текстовыми).
22
23.
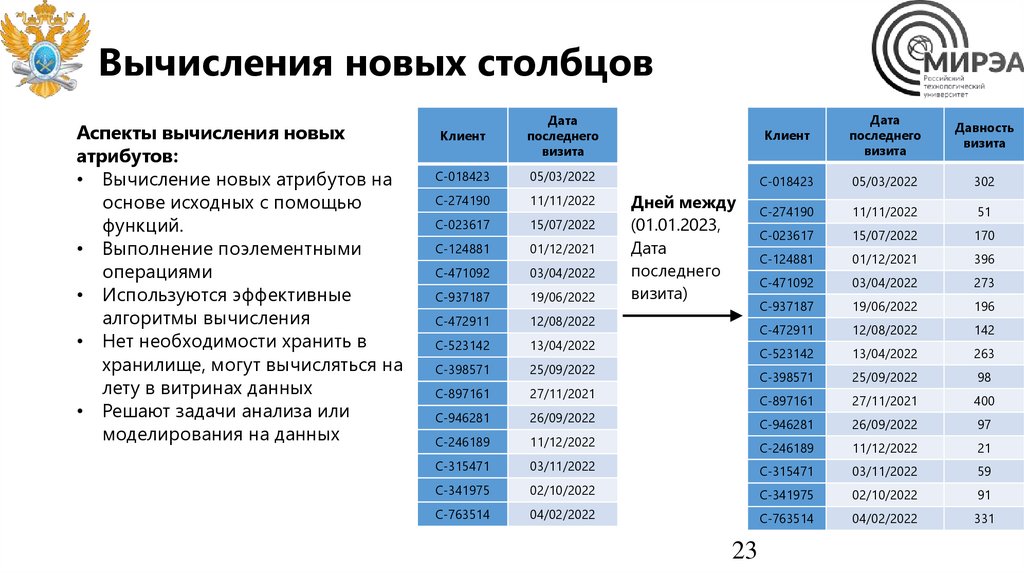
Вычисления новых столбцовАспекты вычисления новых
атрибутов:
• Вычисление новых атрибутов на
основе исходных с помощью
функций.
• Выполнение поэлементными
операциями
• Используются эффективные
алгоритмы вычисления
• Нет необходимости хранить в
хранилище, могут вычисляться на
лету в витринах данных
• Решают задачи анализа или
моделирования на данных
Клиент
Дата
последнего
визита
Давность
визита
C-018423
05/03/2022
302
C-274190
11/11/2022
51
C-023617
15/07/2022
170
C-124881
01/12/2021
396
C-471092
03/04/2022
273
C-937187
19/06/2022
196
C-472911
12/08/2022
142
C-523142
13/04/2022
263
C-398571
25/09/2022
98
C-897161
27/11/2021
400
C-946281
26/09/2022
97
11/12/2022
C-246189
11/12/2022
21
C-315471
03/11/2022
C-315471
03/11/2022
59
C-341975
02/10/2022
C-341975
02/10/2022
91
C-763514
04/02/2022
C-763514
04/02/2022
331
Клиент
Дата
последнего
визита
C-018423
05/03/2022
C-274190
11/11/2022
C-023617
15/07/2022
C-124881
01/12/2021
C-471092
03/04/2022
C-937187
19/06/2022
C-472911
12/08/2022
C-523142
13/04/2022
C-398571
25/09/2022
C-897161
27/11/2021
C-946281
26/09/2022
C-246189
Дней между
(01.01.2023,
Дата
последнего
визита)
23
24.
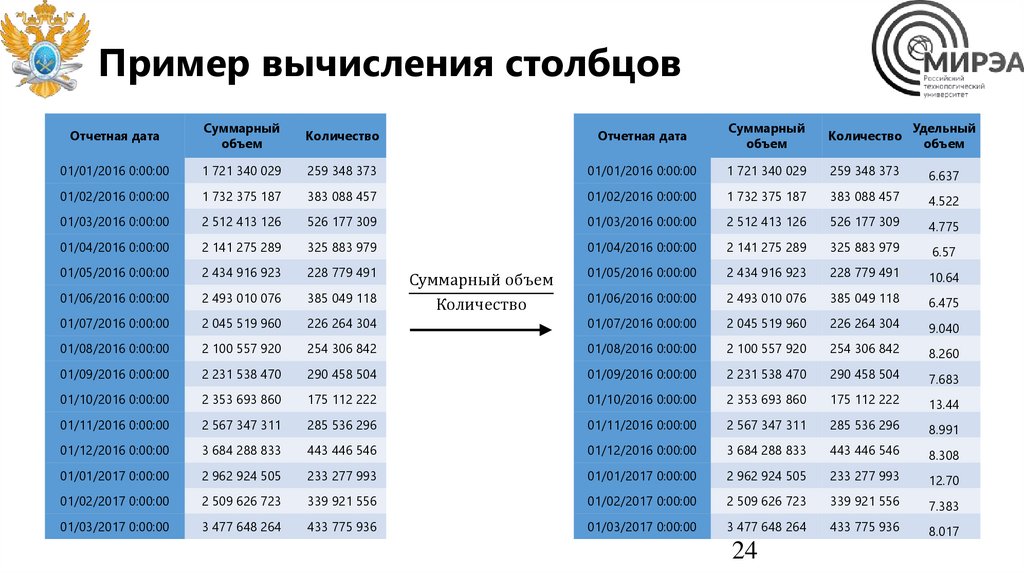
Пример вычисления столбцовОтчетная дата
Суммарный
объем
Количество
Отчетная дата
Суммарный
объем
Количество
Удельный
объем
01/01/2016 0:00:00
1 721 340 029
259 348 373
01/01/2016 0:00:00
1 721 340 029
259 348 373
6.637
01/02/2016 0:00:00
1 732 375 187
383 088 457
01/02/2016 0:00:00
1 732 375 187
383 088 457
4.522
01/03/2016 0:00:00
2 512 413 126
526 177 309
01/03/2016 0:00:00
2 512 413 126
526 177 309
4.775
01/04/2016 0:00:00
2 141 275 289
325 883 979
01/04/2016 0:00:00
2 141 275 289
325 883 979
6.57
01/05/2016 0:00:00
2 434 916 923
228 779 491
01/05/2016 0:00:00
2 434 916 923
228 779 491
10.64
01/06/2016 0:00:00
2 493 010 076
385 049 118
01/06/2016 0:00:00
2 493 010 076
385 049 118
6.475
01/07/2016 0:00:00
2 045 519 960
226 264 304
01/07/2016 0:00:00
2 045 519 960
226 264 304
9.040
01/08/2016 0:00:00
2 100 557 920
254 306 842
01/08/2016 0:00:00
2 100 557 920
254 306 842
8.260
01/09/2016 0:00:00
2 231 538 470
290 458 504
01/09/2016 0:00:00
2 231 538 470
290 458 504
7.683
01/10/2016 0:00:00
2 353 693 860
175 112 222
01/10/2016 0:00:00
2 353 693 860
175 112 222
13.44
01/11/2016 0:00:00
2 567 347 311
285 536 296
01/11/2016 0:00:00
2 567 347 311
285 536 296
8.991
01/12/2016 0:00:00
3 684 288 833
443 446 546
01/12/2016 0:00:00
3 684 288 833
443 446 546
8.308
01/01/2017 0:00:00
2 962 924 505
233 277 993
01/01/2017 0:00:00
2 962 924 505
233 277 993
12.70
01/02/2017 0:00:00
2 509 626 723
339 921 556
01/02/2017 0:00:00
2 509 626 723
339 921 556
7.383
01/03/2017 0:00:00
3 477 648 264
433 775 936
01/03/2017 0:00:00
3 477 648 264
433 775 936
8.017
Суммарный объем
Количество
24
25.
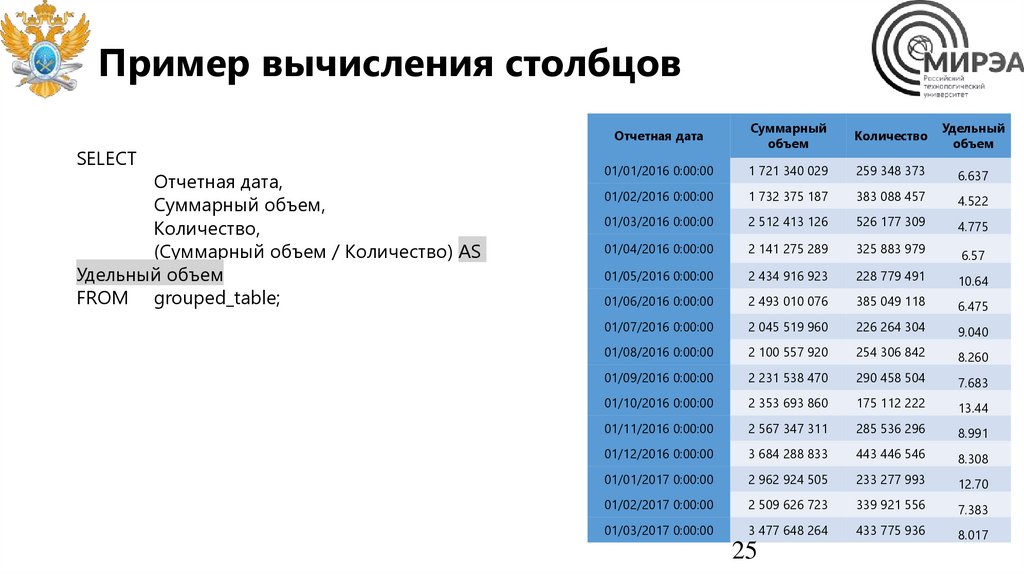
Пример вычисления столбцовSELECT
Отчетная дата,
Суммарный объем,
Количество,
(Суммарный объем / Количество) AS
Удельный объем
FROM grouped_table;
Отчетная дата
Суммарный
объем
Количество
Удельный
объем
01/01/2016 0:00:00
1 721 340 029
259 348 373
6.637
01/02/2016 0:00:00
1 732 375 187
383 088 457
4.522
01/03/2016 0:00:00
2 512 413 126
526 177 309
4.775
01/04/2016 0:00:00
2 141 275 289
325 883 979
01/05/2016 0:00:00
2 434 916 923
228 779 491
10.64
01/06/2016 0:00:00
2 493 010 076
385 049 118
6.475
01/07/2016 0:00:00
2 045 519 960
226 264 304
9.040
01/08/2016 0:00:00
2 100 557 920
254 306 842
8.260
01/09/2016 0:00:00
2 231 538 470
290 458 504
7.683
01/10/2016 0:00:00
2 353 693 860
175 112 222
13.44
01/11/2016 0:00:00
2 567 347 311
285 536 296
8.991
01/12/2016 0:00:00
3 684 288 833
443 446 546
8.308
01/01/2017 0:00:00
2 962 924 505
233 277 993
12.70
01/02/2017 0:00:00
2 509 626 723
339 921 556
7.383
01/03/2017 0:00:00
3 477 648 264
433 775 936
8.017
25
6.57
26.
Часть 3. Агрегация данных26
27.
Материалы1. Способы агрегации данных (Скалярная агрегация
данных, Многозначная агрегация данных).
2. Ограничения на агрегацию данных. Измерения и
показатели.
3. Статистические функции для агрегации данных.
4. Кросс-таблица (сводная таблица).
5. Сечение данных по категориям.
27
28.
Задачи агрегации данных• Агрегирование данных — это сбор
информации из баз данных с целью
подготовки комбинированных наборов
данных для обработки данных.
• Агрегация данных более общий термин для
понятия группировки данных.
• Группировка данных – процесс получения
обобщенных статистик для некоторой
большой выборки табличных данных с
целью получить важную информацию по
уникальным группам категорий объектов.
28
29.
Сущности группировки данныхГруппа – столбец, значения которого
выбираются за уникальные сущности в
пределах которого считается
агрегированный показатель. Синоним:
измерение, категория
В качестве группы могут быть выбраны
любые столбцы любого вида и шкалы
данных.
Показатель – столбец, значения которого
берутся за основу подсчитанной
агрегированной меры на основе
статистических функций агрегации.
Возраст/Год
2010
2020
2021
0-4
951
944
944
5-9
953
947
946
10-15
953
953
951
15-19
961
956
959
20-24
972
964
966
25-29
994
952
950
30-34
1021
987
981
35-39
1046
1017
1016
40-44
1065
1068
1061
45-49
1118
1092
1100
50-54
1188
1144
1136
55-59
1303
1235
1233
60-64
1414
1388
1370
65-69
1683
1597
1603
70 и более
2370
2302
2278
29
30.
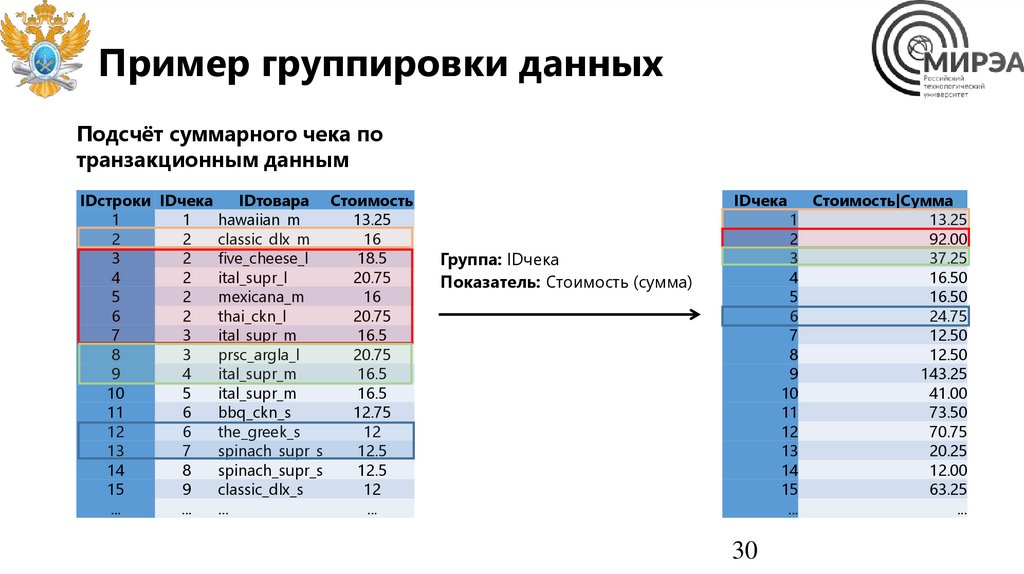
Пример группировки данныхПодсчёт суммарного чека по
транзакционным данным
IDстроки IDчека
IDтовара Стоимость
1
1
hawaiian_m
13.25
2
2
classic_dlx_m
16
3
2
five_cheese_l
18.5
4
2
ital_supr_l
20.75
5
2
mexicana_m
16
6
2
thai_ckn_l
20.75
7
3
ital_supr_m
16.5
8
3
prsc_argla_l
20.75
9
4
ital_supr_m
16.5
10
5
ital_supr_m
16.5
11
6
bbq_ckn_s
12.75
12
6
the_greek_s
12
13
7
spinach_supr_s
12.5
14
8
spinach_supr_s
12.5
15
9
classic_dlx_s
12
...
...
...
...
IDчека
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
...
Группа: IDчека
Показатель: Стоимость (сумма)
30
Стоимость|Сумма
13.25
92.00
37.25
16.50
16.50
24.75
12.50
12.50
143.25
41.00
73.50
70.75
20.25
12.00
63.25
...
31.
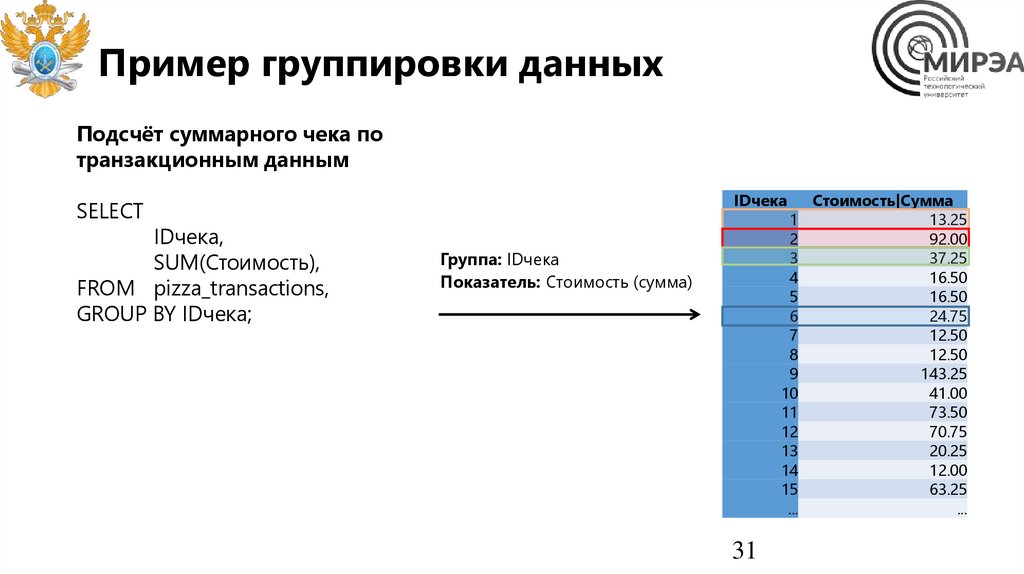
Пример группировки данныхПодсчёт суммарного чека по
транзакционным данным
IDчека
SELECT
IDчека,
SUM(Стоимость),
FROM pizza_transactions,
GROUP BY IDчека;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
...
Группа: IDчека
Показатель: Стоимость (сумма)
31
Стоимость|Сумма
13.25
92.00
37.25
16.50
16.50
24.75
12.50
12.50
143.25
41.00
73.50
70.75
20.25
12.00
63.25
...
32.
Ограничения на группировку данныхС точки зрения обработки данных,
группировка данных имеет смысл по
дискретным данным или квантованным
данным, как на примере ранее.
С точки зрения аналитики данных,
группировка данных имеет смысл также по:
данным с фиксированным перечнем
значений и заранее подготовленным
атрибутам
IDчека
Стоимость|Сумма
1
13.25
2
92.00
3
37.25
4
16.50
5
16.50
6
24.75
7
12.50
8
12.50
9
143.25
10
41.00
11
73.50
12
70.75
13
20.25
14
12.00
15
63.25
...
32
...
33.
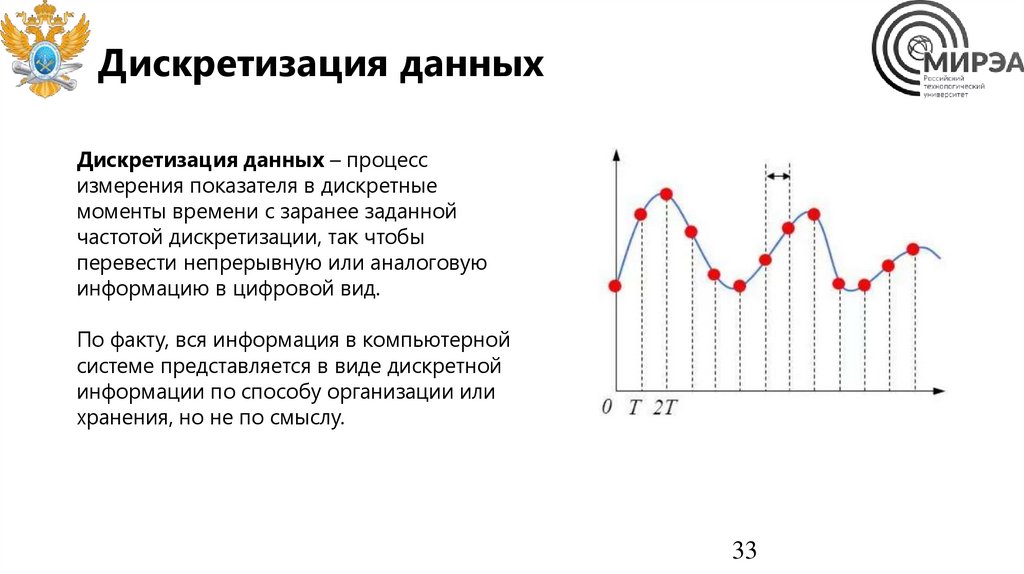
Дискретизация данныхДискретизация данных – процесс
измерения показателя в дискретные
моменты времени с заранее заданной
частотой дискретизации, так чтобы
перевести непрерывную или аналоговую
информацию в цифровой вид.
По факту, вся информация в компьютерной
системе представляется в виде дискретной
информации по способу организации или
хранения, но не по смыслу.
33
34.
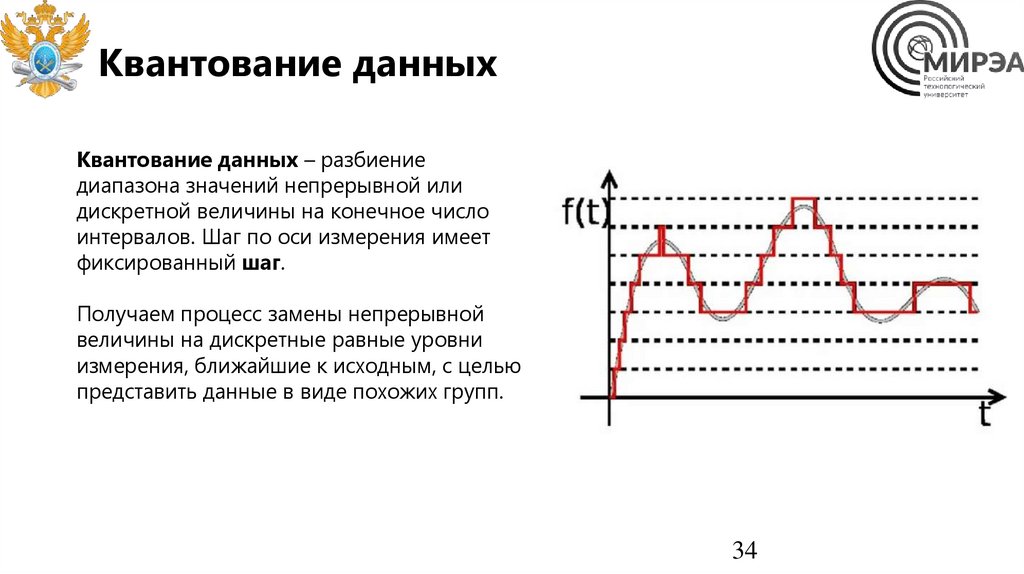
Квантование данныхКвантование данных – разбиение
диапазона значений непрерывной или
дискретной величины на конечное число
интервалов. Шаг по оси измерения имеет
фиксированный шаг.
Получаем процесс замены непрерывной
величины на дискретные равные уровни
измерения, ближайшие к исходным, с целью
представить данные в виде похожих групп.
34
35.
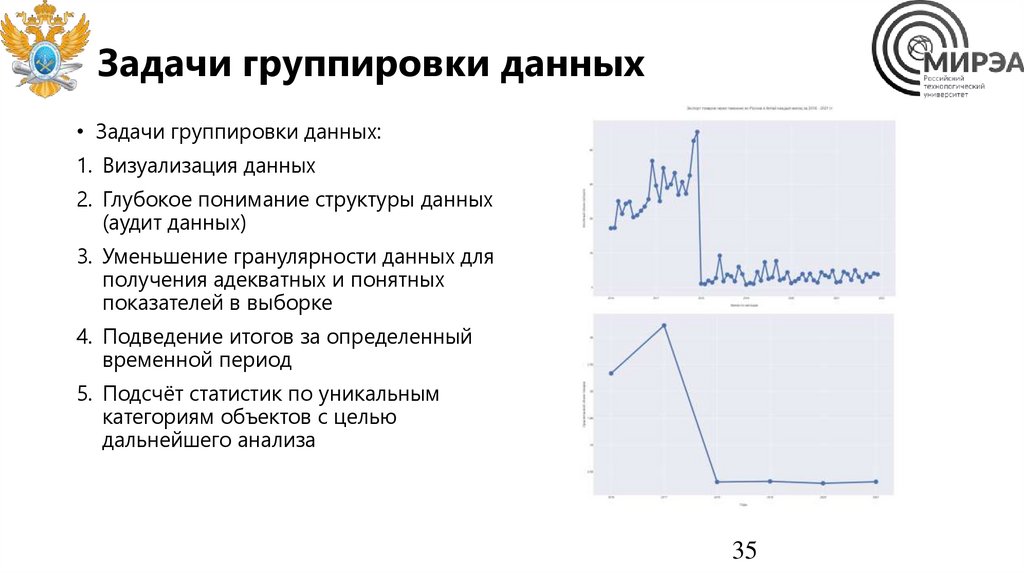
Задачи группировки данных• Задачи группировки данных:
1. Визуализация данных
2. Глубокое понимание структуры данных
(аудит данных)
3. Уменьшение гранулярности данных для
получения адекватных и понятных
показателей в выборке
4. Подведение итогов за определенный
временной период
5. Подсчёт статистик по уникальным
категориям объектов с целью
дальнейшего анализа
35
36.
Статистические функции группировки• Функции агрегации табличных данных
ставят в соответствие ряду данных одно
характеризующее их значение:
• Сумма
• Среднее
• Средний квадрат отклонения
• Медиана
• Минимум
• Максимум
• Количество
• Количество уникальных
• Количество пропусков
• Первое
• Последнее
36
37.
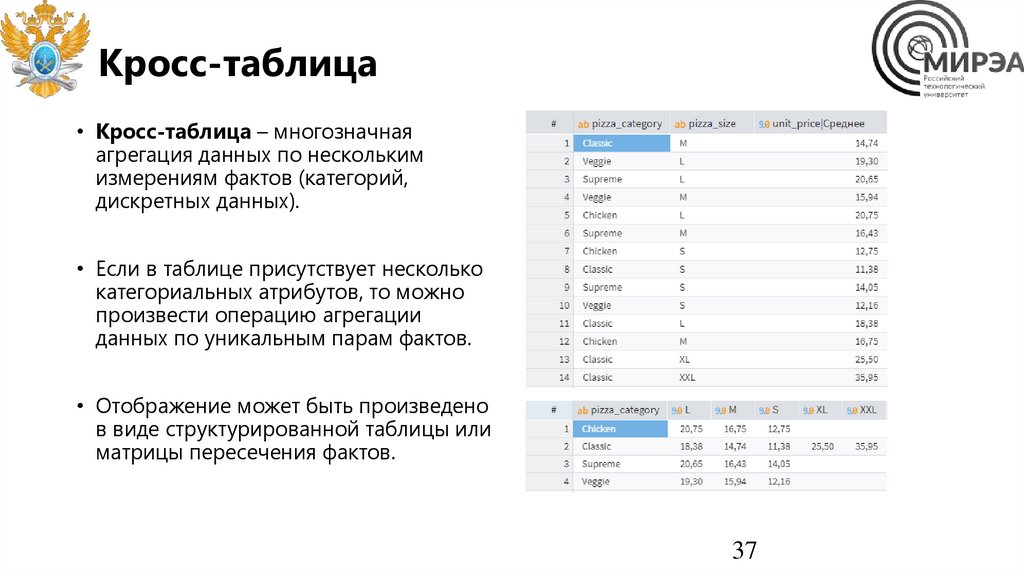
Кросс-таблица• Кросс-таблица – многозначная
агрегация данных по нескольким
измерениям фактов (категорий,
дискретных данных).
• Если в таблице присутствует несколько
категориальных атрибутов, то можно
произвести операцию агрегации
данных по уникальным парам фактов.
• Отображение может быть произведено
в виде структурированной таблицы или
матрицы пересечения фактов.
37
38.
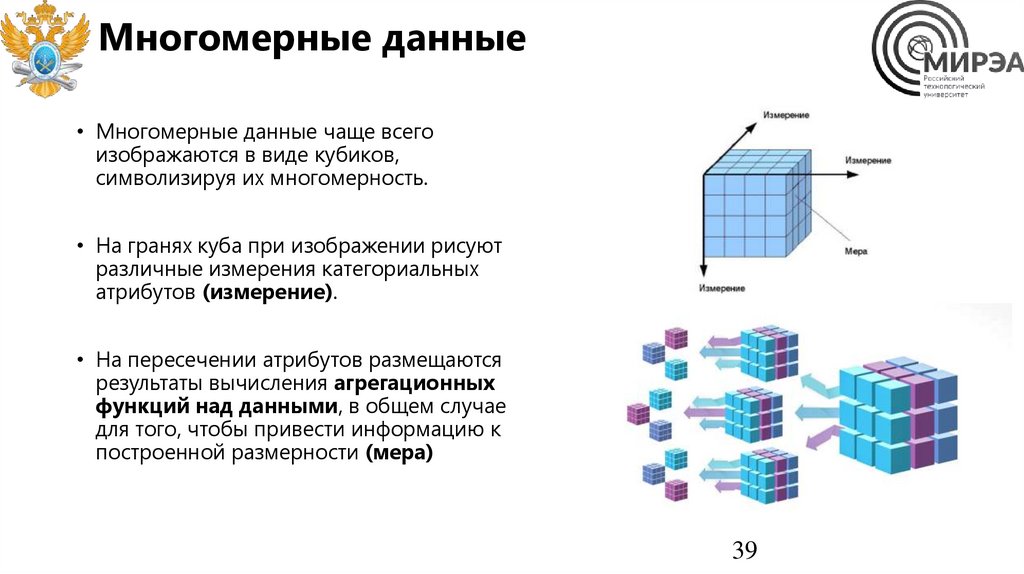
Многомерные данные• Многомерные данные – дополнительное
определение для табличных данных с
большим количеством категориальных
атрибутов (столбцов).
• Данные называются многомерными из-за
большого числа факторов, по которым
можно производить агрегацию данных.
• Многомерные данные хранятся в OLAP
системах аналитических баз данных вместо
множества таблиц в хранилище данных,
согласно правилам нормализации.
38
39.
Многомерные данные• Многомерные данные чаще всего
изображаются в виде кубиков,
символизируя их многомерность.
• На гранях куба при изображении рисуют
различные измерения категориальных
атрибутов (измерение).
• На пересечении атрибутов размещаются
результаты вычисления агрегационных
функций над данными, в общем случае
для того, чтобы привести информацию к
построенной размерности (мера)
39
40.
Многомерные данныеКод страны
Направление
торговли
Месяц и год
Сумма(Суммарный
объем)
40
41.
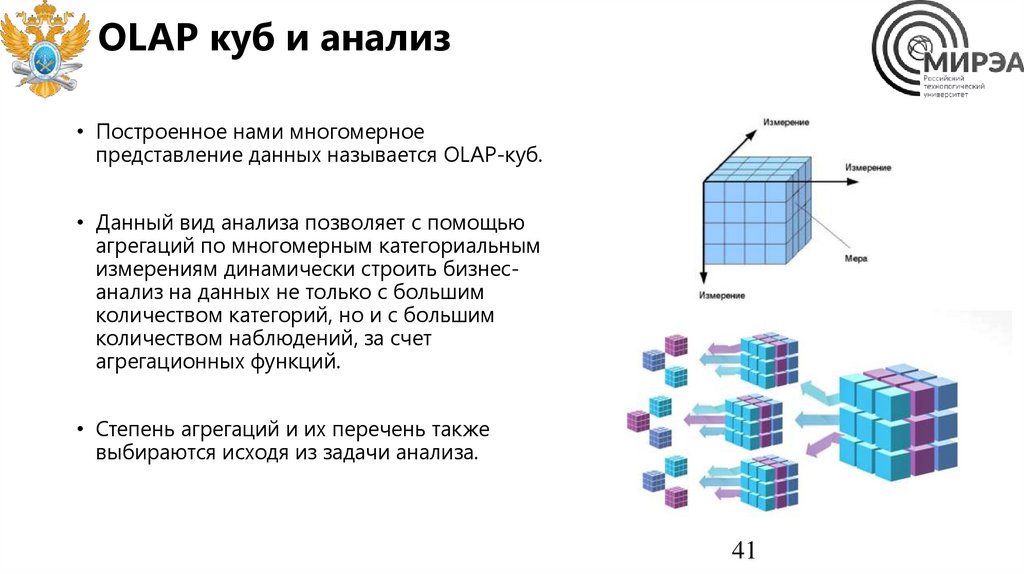
OLAP куб и анализ• Построенное нами многомерное
представление данных называется OLAP-куб.
• Данный вид анализа позволяет с помощью
агрегаций по многомерным категориальным
измерениям динамически строить бизнесанализ на данных не только с большим
количеством категорий, но и с большим
количеством наблюдений, за счет
агрегационных функций.
• Степень агрегаций и их перечень также
выбираются исходя из задачи анализа.
41
42.
Часть 4. Обогащение данных42
43.
Материалы1. Задачи обогащения данных. Внешнее и
внутреннее обогащение данных.
2. Операция объединения данных (UNION).
3. Операция соединения данных (CONCATENATE).
4. Операция дополнения данных (LEFT JOIN).
5. Операция слияния данных (JOIN) (левое, правое,
внутреннее, полное).
43
44.
Задача обогащения данных• Задача обогащения данных напрямую связана
с темой их обработки и анализа. Обогащение
нужно для того, чтобы конечные потребители
данных получали качественную и полную
информацию.
• Обогащение данных — это процесс
дополнения сырых данных той информацией,
которая в исходном виде в них отсутствует, но
необходима для качественного анализа.
• Конечными потребителями такой информации
чаще всего являются аналитики.
44
45.
Задача обогащения данныхЛокальное обогащение данных получение отсутствующей информации
путём обработки уже имеющихся данных
• Структурное обогащение
(корректировка записей с заданной
точностью)
• Статистическое (обработка на основе
статистических показателей
предыдущего временного ряда)
Внешнее обогащение данных получение отсутствующей
информации из иных
информационных систем
Возможные источники:
• Похожие системы
• Специализированные базы / графы
знаний
• Семантическое (регулярные
выражения, кодирование
категориальных, …)
• Прагматическое (выборка/совмещение
признаков)
45
46.
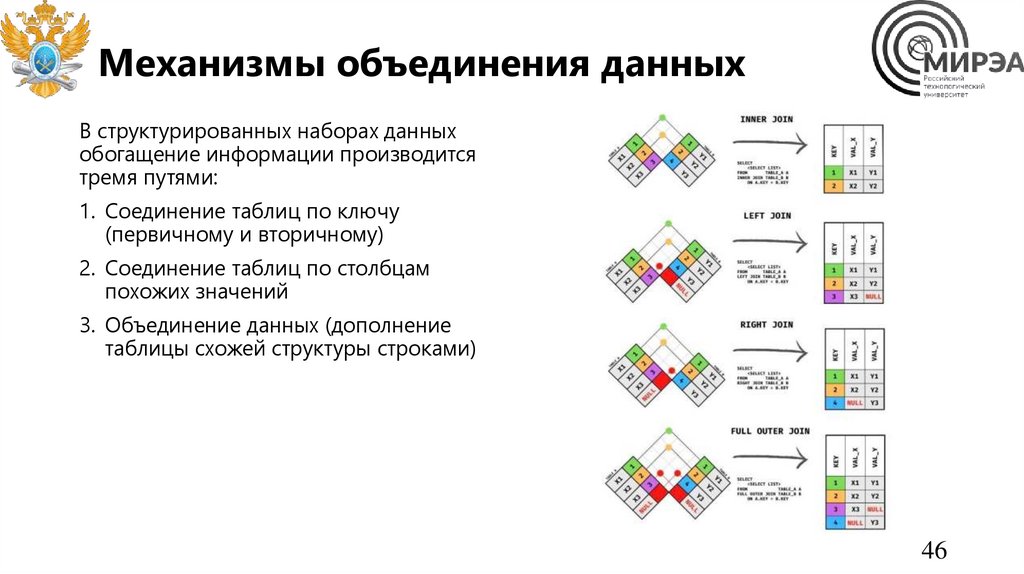
Механизмы объединения данныхВ структурированных наборах данных
обогащение информации производится
тремя путями:
1. Соединение таблиц по ключу
(первичному и вторичному)
2. Соединение таблиц по столбцам
похожих значений
3. Объединение данных (дополнение
таблицы схожей структуры строками)
46
47.
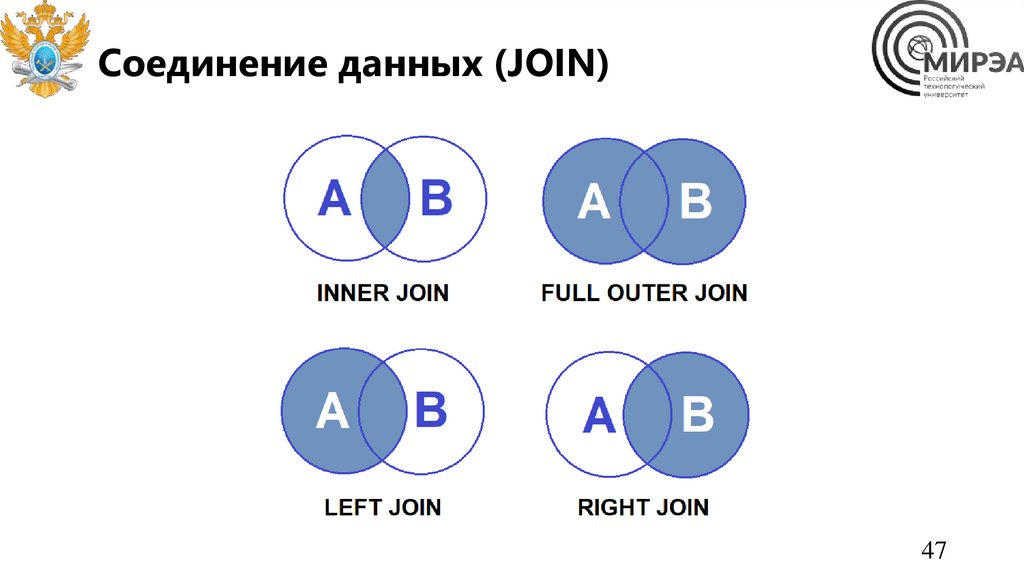
Соединение данных (JOIN)47
48.
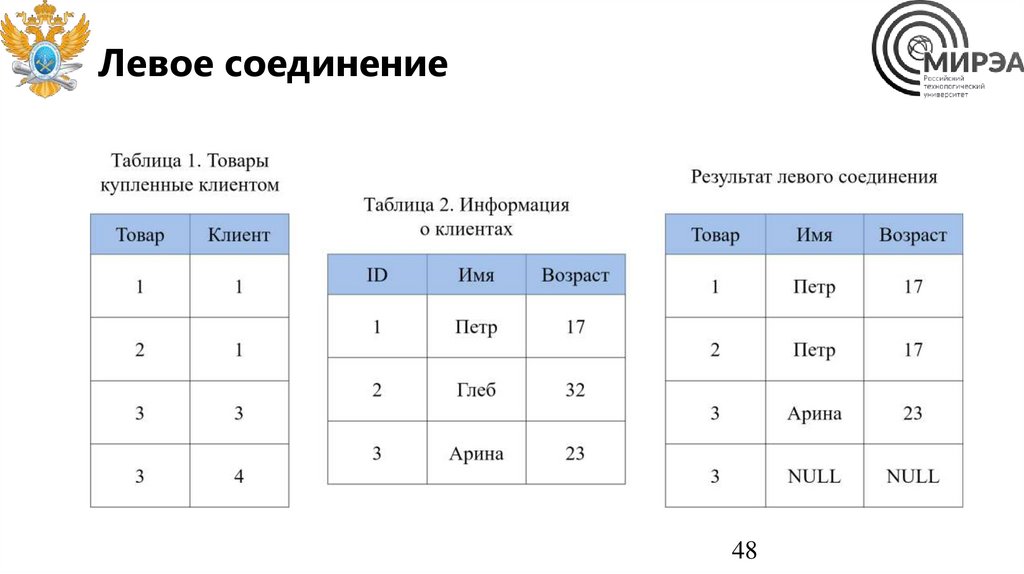
Левое соединение48
49.
Левое соединениеSELECT
table1.товар,
table2.имя,
table2.возраст
FROM table1
LEFT JOIN table2 ON table1.клиент = table2.id
49
50.
Внутреннее соединение50
51.
Внутреннее соединениеSELECT
table1.товар,
table2.имя,
table2.возраст
FROM table1
INNER JOIN table2 ON table1.клиент = table2.id
51
52.
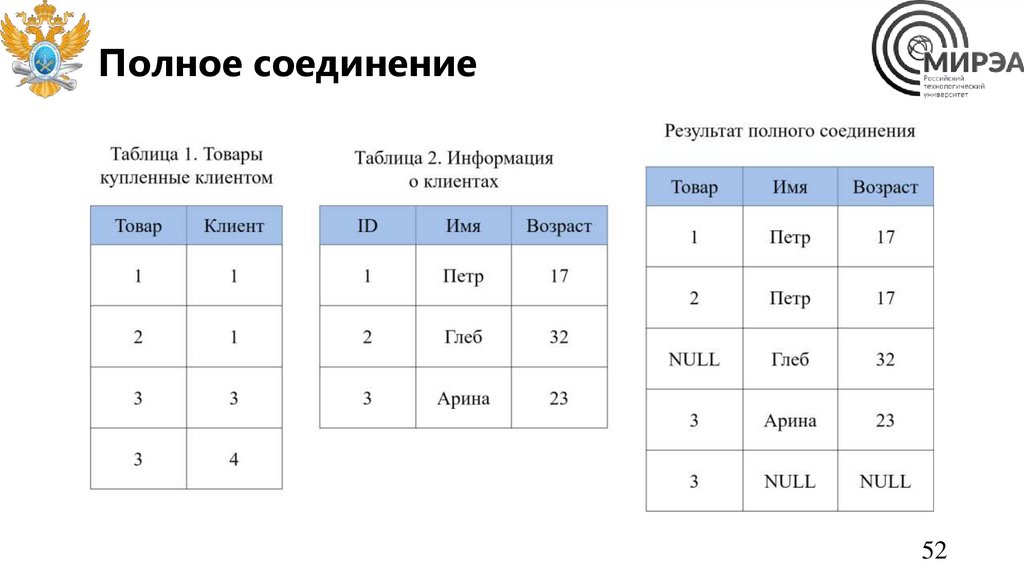
Полное соединение52
53.
Полное соединениеSELECT
table1.товар,
table2.имя,
table2.возраст
FROM table1
FULL OUTER JOIN table2 ON table1.клиент = table2.id
53
54.
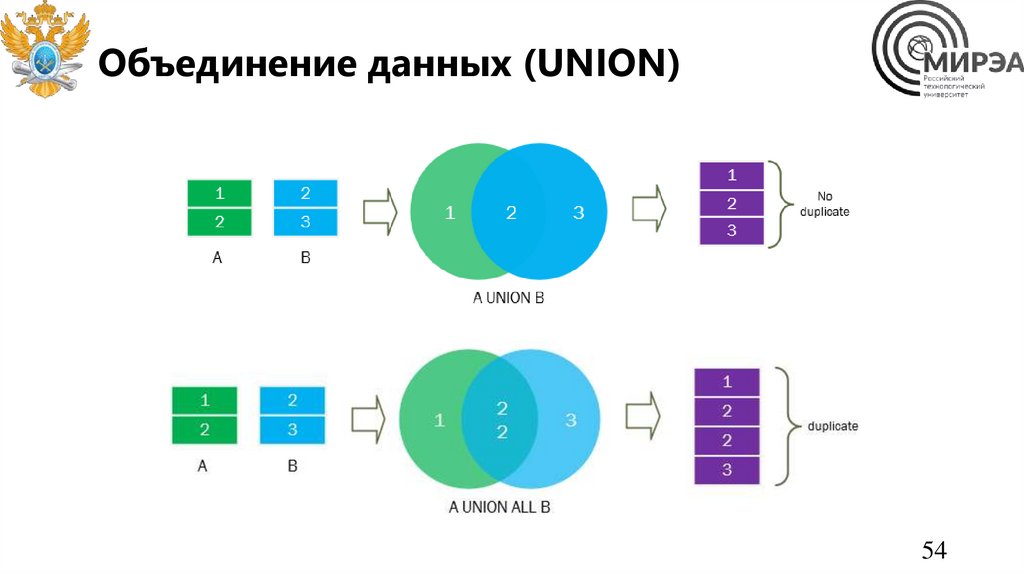
Объединение данных (UNION)54
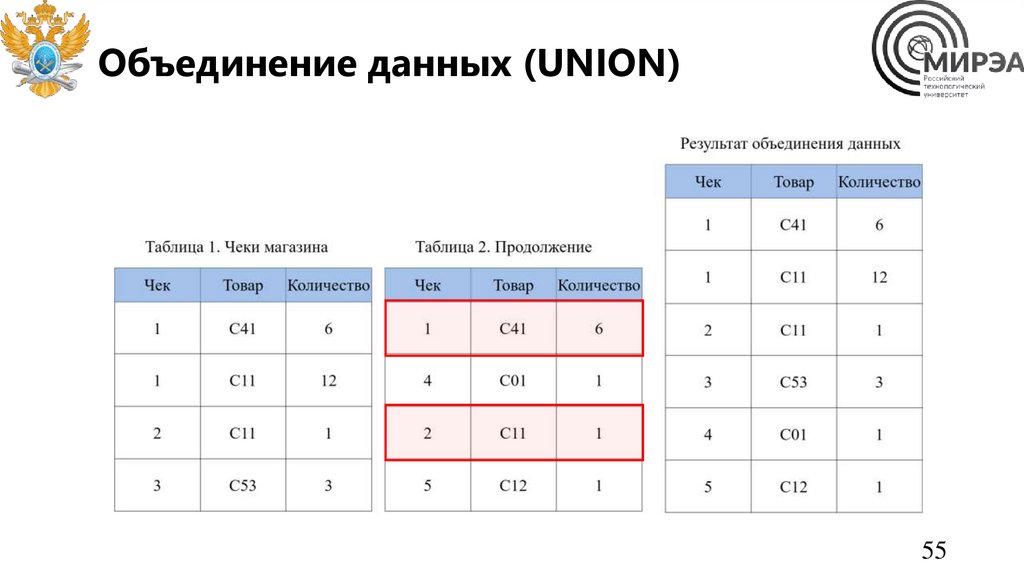
55.
Объединение данных (UNION)55
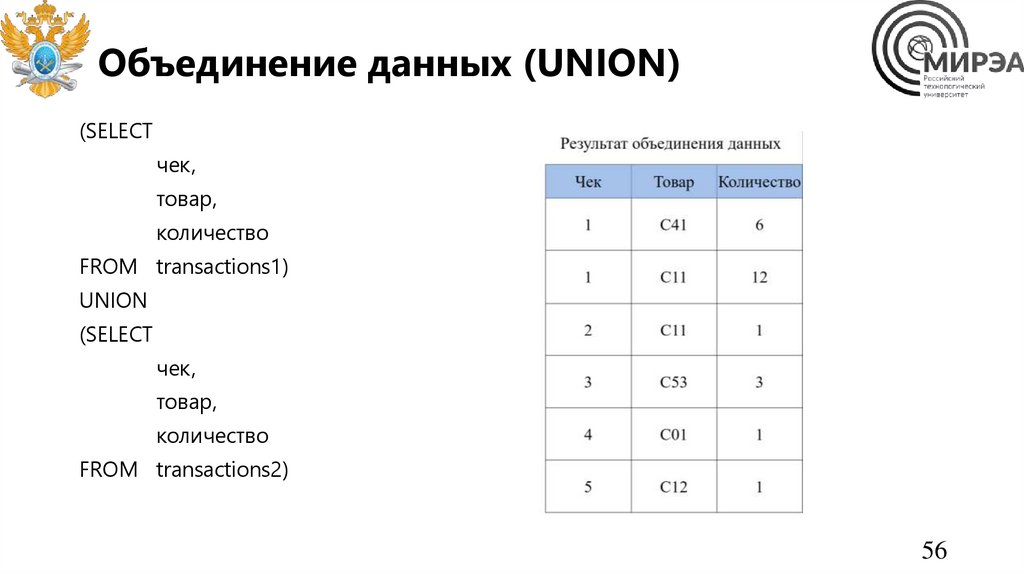
56.
Объединение данных (UNION)(SELECT
чек,
товар,
количество
FROM transactions1)
UNION
(SELECT
чек,
товар,
количество
FROM transactions2)
56
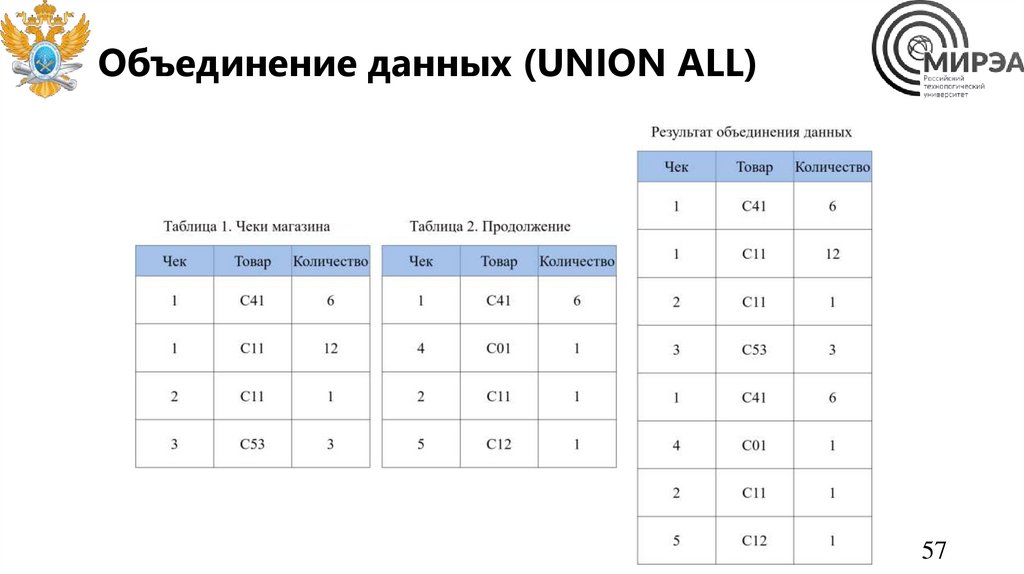
57.
Объединение данных (UNION ALL)57
58.
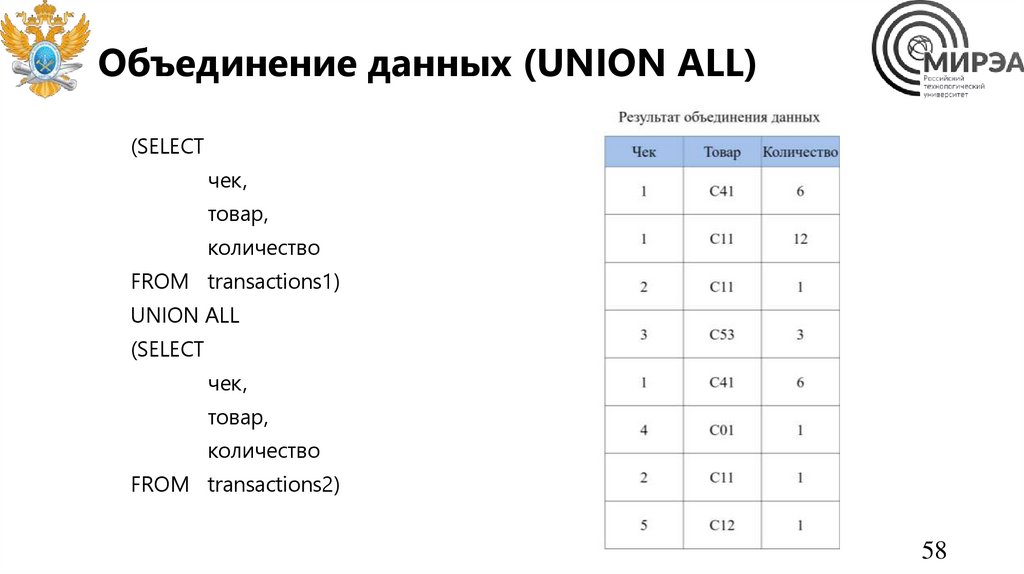
Объединение данных (UNION ALL)(SELECT
чек,
товар,
количество
FROM transactions1)
UNION ALL
(SELECT
чек,
товар,
количество
FROM transactions2)
58