





 software
softwareSimilar presentations:





")




Исследование моделей нейронных сетей в решении задач анализа тональности
1.
Московский авиационный институт(национальный исследовательский университет)
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
на тему:
«ИССЛЕДОВАНИЕ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ В РЕШЕНИИ ЗАДАЧ
АНАЛИЗА ТОНАЛЬНОСТИ»
ВЫПОЛНИЛ:
НАУЧНЫЙ РУКОВОДИТЕЛЬ:
Москва, 2023 г.
2.
Цель, объект, предмет и задачи3
ОБЪЕКТОМ исследования являются искусственные нейронные сети различных моделей, применяемые для классификации текстов на
естественном языке.
ПРЕДМЕТОМ исследования являются алгоритмы семантического анализа текста, используемые для построения классификации по
признаку тональности.
Область применения: социология, коммерция и другие области, где требуется извлечение, обработка, классификация и кластеризация
текстовой информации.
ЦЕЛЬ работы состоит в разработке рекомендаций по использованию ИНС для анализа тональности русскоязычных текстов с наибольшей
эффективностью с точки зрения скорости обучения ИНС, а также скорости выдачи и точности результата.
Чтобы выбрать метод с наибольшей скоростью работы и наименьшим количеством ошибочных результатов, необходимо решить следующие
ЧАСТНЫЕ ЗАДАЧИ:
изучение технологий и методов анализа тональности и классификации текстов.
исследование области машинной обработки русскоязычных текстов.
изучение различных моделей ИНС, пригодных для решения задачи классификации текстов.
изучение методов оценки качества ИНС.
разработка двух вариантов классификатора на основе двух различных моделей ИНС (MLP и CNN).
сравнение на практике скорости обучения различных ИНС анализу тональности текстов, а также точности данных ИНС при
тестировании, выявление оптимальной модели по сумме показателей.
составление рекомендаций по использованию ИНС для анализа тональности текстов в различных сферах деятельности предприятий.
3.
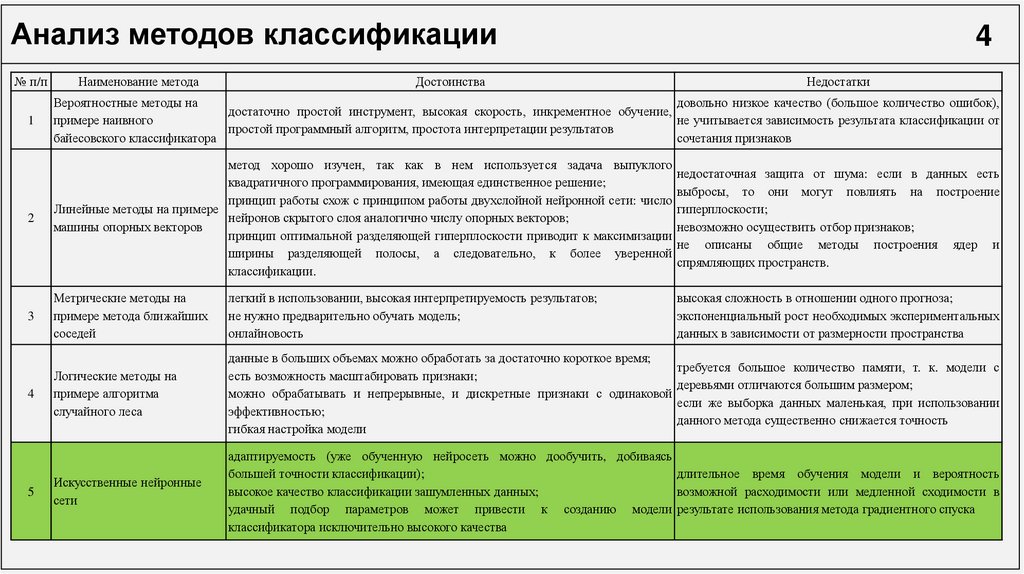
Анализ методов классификации№ п/п
Наименование метода
Достоинства
4
Недостатки
1
Вероятностные методы на
довольно низкое качество (большое количество ошибок),
достаточно простой инструмент, высокая скорость, инкрементное обучение,
примере наивного
не учитывается зависимость результата классификации от
простой программный алгоритм, простота интерпретации результатов
байесовского классификатора
сочетания признаков
2
метод хорошо изучен, так как в нем используется задача выпуклого
недостаточная защита от шума: если в данных есть
квадратичного программирования, имеющая единственное решение;
выбросы, то они могут повлиять на построение
принцип работы схож с принципом работы двухслойной нейронной сети: число
Линейные методы на примере
гиперплоскости;
нейронов скрытого слоя аналогично числу опорных векторов;
машины опорных векторов
невозможно осуществить отбор признаков;
принцип оптимальной разделяющей гиперплоскости приводит к максимизации
не описаны общие методы построения ядер и
ширины разделяющей полосы, а следовательно, к более уверенной
спрямляющих пространств.
классификации.
3
Метрические методы на
примере метода ближайших
соседей
легкий в использовании, высокая интерпретируемость результатов;
не нужно предварительно обучать модель;
онлайновость
Логические методы на
примере алгоритма
случайного леса
данные в больших объемах можно обработать за достаточно короткое время;
требуется большое количество памяти, т. к. модели с
есть возможность масштабировать признаки;
деревьями отличаются большим размером;
можно обрабатывать и непрерывные, и дискретные признаки с одинаковой
если же выборка данных маленькая, при использовании
эффективностью;
данного метода существенно снижается точность
гибкая настройка модели
Искусственные нейронные
сети
адаптируемость (уже обученную нейросеть можно дообучить, добиваясь
большей точности классификации);
длительное время обучения модели и вероятность
высокое качество классификации зашумленных данных;
возможной расходимости или медленной сходимости в
удачный подбор параметров может привести к созданию модели результате использования метода градиентного спуска
классификатора исключительно высокого качества
4
5
высокая сложность в отношении одного прогноза;
экспоненциальный рост необходимых экспериментальных
данных в зависимости от размерности пространства
4.
Постановка задачи на исследование5
ВХОДНЫЕ ДАННЫЕ:
наборы отзывов с сервиса «Кинопоиск» (в период с 2018 по 2023 гг.)
ПОРЯДОК ПРОВЕДЕНИЯ ИССЛЕДОВАНИЯ:
1. Самостоятельная подготовка датасета на основе отзывов с популярных агрегаторов (например, с
сервиса «Кинопоиск» (в период с 2018 по 2023 гг.), загрузку возможно осуществлять с помощью
Kinopoisk API);
2. Разработка архитектуры вариантов классификатора на основе двух различных моделей ИНС (MLP
и CNN);
3. Обучение вариантов классификатора на основе двух различных моделей ИНС (MLP и CNN);
4. Экспериментальное сравнение на практике скорости обучения различных ИНС анализу
тональности текстов, а также точности данных ИНС при тестировании;
5. Выявление оптимальной модели классификатора по сумме показателей;
6. Составление рекомендаций по использованию ИНС для анализа тональности текстов в различных
сферах деятельности предприятий
ПРОГРАММНЫЕ
СРЕДСТВА
ВЫХОДНЫЕ ДАННЫЕ:
1. Результаты оценки эффективности модели MLP (по показателям точности и потерь)
2. Результаты оценки эффективности модели CNN (по показателям точности и потерь)
3. Результаты сравнения эффективности моделей MLP и CNN (должны быть представлены в табличной форме)
5.
Подготовка датасета6
1. Преобразование текста в нижний регистр
2. Удаление пунктуации
3. Удаление пробельных символов
4. Удаление стоп-слов
5. Лемматизация
Фрагмент исходных данных (наборы отзывов с сервиса «Кинопоиск»
(в период с 2018 по 2023 гг.)
Исходное распределение
тональности отзывов
Распределение собранных
отзывов по годам
Этапы предварительной подготовки данных
График распределения частотности использования словарных слов
6.
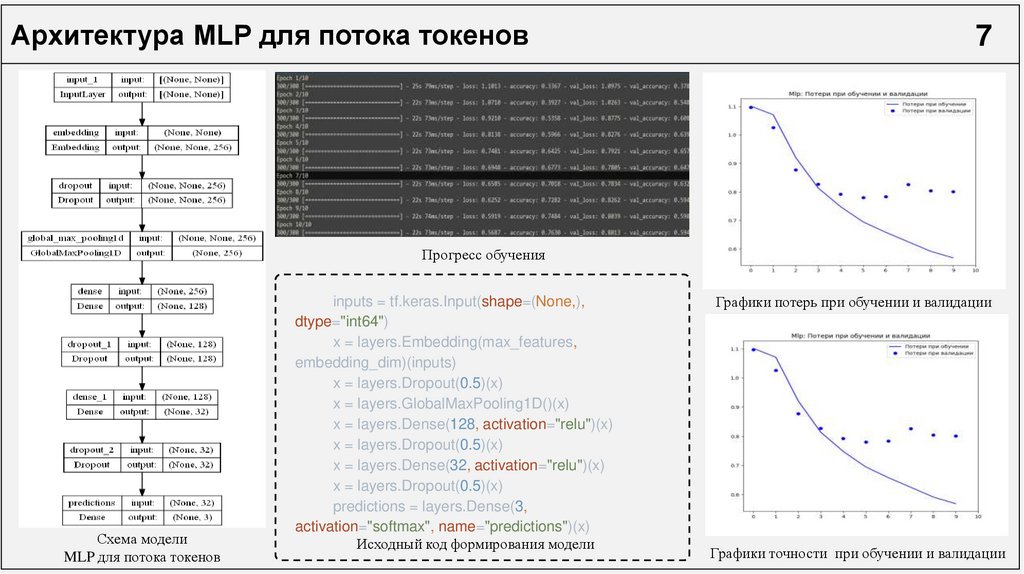
Архитектура MLP для потока токенов7
Прогресс обучения
Схема модели
MLP для потока токенов
inputs = tf.keras.Input(shape=(None,),
dtype="int64")
x = layers.Embedding(max_features,
embedding_dim)(inputs)
x = layers.Dropout(0.5)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation="relu")(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(32, activation="relu")(x)
x = layers.Dropout(0.5)(x)
predictions = layers.Dense(3,
activation="softmax", name="predictions")(x)
Исходный код формирования модели
Графики потерь при обучении и валидации
Графики точности при обучении и валидации
7.
Архитектура MLP для TF-IDF7
Прогресс обучения
inputs =
tf.keras.Input(shape=(vectorize_layer.vocabulary_size(),),
dtype="float64")
x = layers.Dense(128, activation="relu")(inputs)
x = layers.Dense(64, activation="relu")(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(16, activation="relu")(x)
x = layers.Dropout(0.5)(x)
predictions = layers.Dense(3, activation="softmax",
name="predictions")(x)
model = tf.keras.Model(inputs, predictions)
Схема модели
MLP для потока токенов
Исходный код формирования модели
Графики потерь при обучении и валидации
Графики точности при обучении и валидации
8.
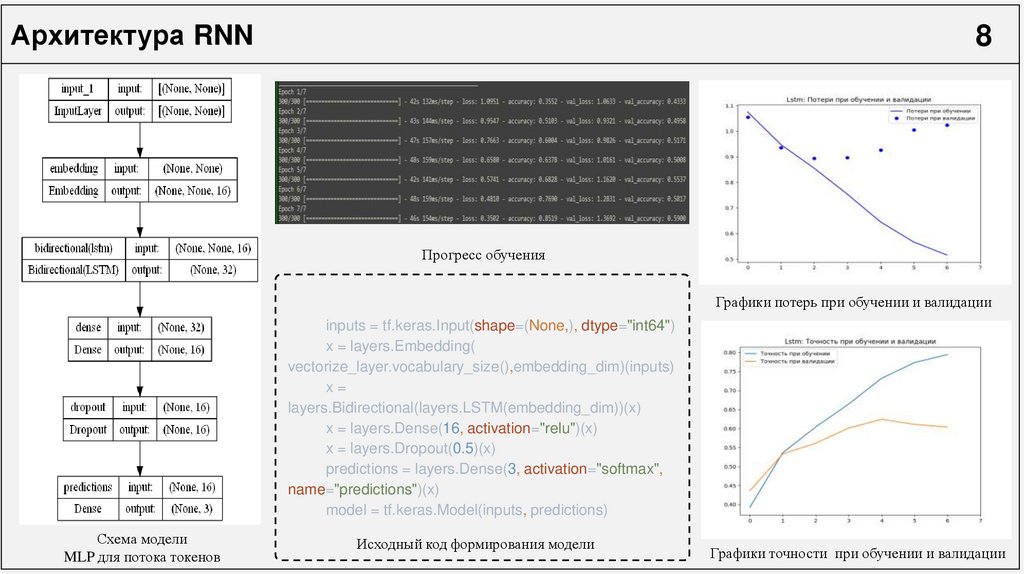
Архитектура RNN8
Прогресс обучения
Графики потерь при обучении и валидации
inputs = tf.keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(
vectorize_layer.vocabulary_size(),embedding_dim)(inputs)
x=
layers.Bidirectional(layers.LSTM(embedding_dim))(x)
x = layers.Dense(16, activation="relu")(x)
x = layers.Dropout(0.5)(x)
predictions = layers.Dense(3, activation="softmax",
name="predictions")(x)
model = tf.keras.Model(inputs, predictions)
Схема модели
MLP для потока токенов
Исходный код формирования модели
Графики точности при обучении и валидации
9.
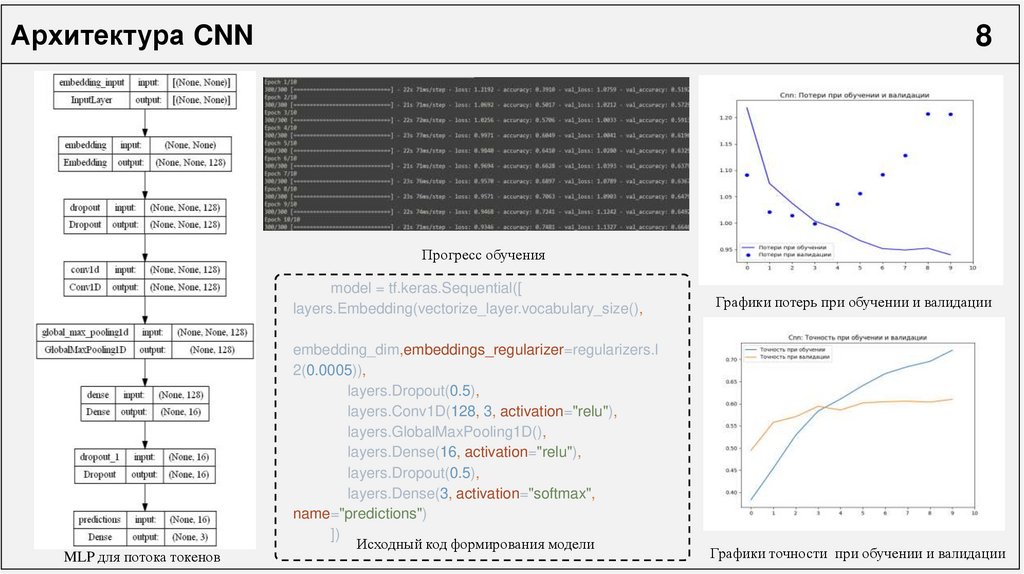
Архитектура CNN8
Прогресс обучения
model = tf.keras.Sequential([
layers.Embedding(vectorize_layer.vocabulary_size(),
Схема модели
MLP для потока токенов
embedding_dim,embeddings_regularizer=regularizers.l
2(0.0005)),
layers.Dropout(0.5),
layers.Conv1D(128, 3, activation="relu"),
layers.GlobalMaxPooling1D(),
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(3, activation="softmax",
name="predictions")
])
Исходный код формирования модели
Графики потерь при обучении и валидации
Графики точности при обучении и валидации
10.
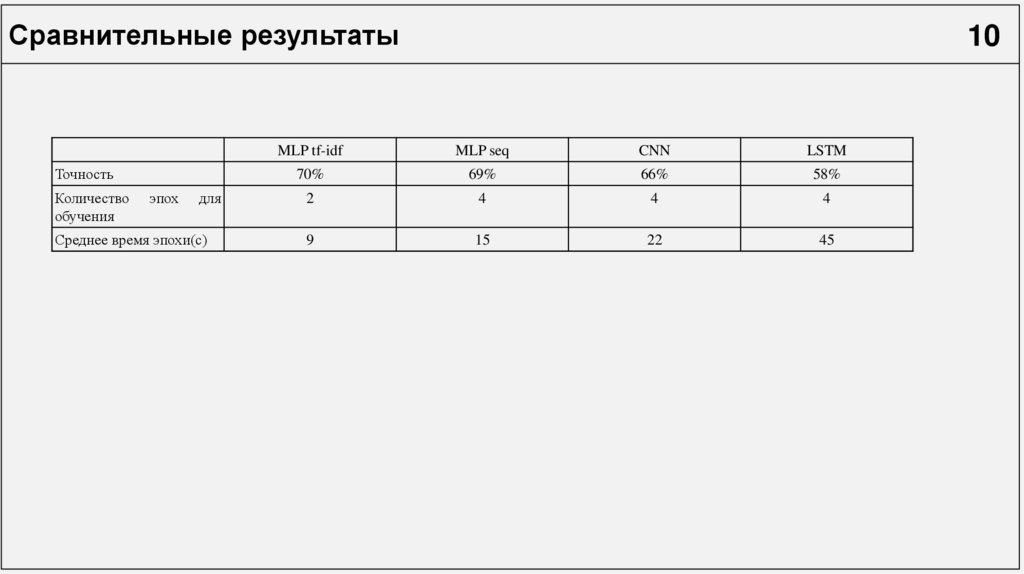
Сравнительные результатыТочность
Количество
обучения
эпох
для
Среднее время эпохи(с)
10
MLP tf-idf
MLP seq
CNN
LSTM
70%
69%
66%
58%
2
4
4
4
9
15
22
45
11.
Спасибо завнимание
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА на тему:
«ИССЛЕДОВАНИЕ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ В РЕШЕНИИ
ЗАДАЧ АНАЛИЗА ТОНАЛЬНОСТИ»
ВЫПОЛНИЛ:
НАУЧНЫЙ РУКОВОДИТЕЛЬ: