

























 database
databaseSimilar presentations:

")


")





Ранние подходы к организации баз данных. Лекция 3
1.
1Ранние подходы к организации баз
данных
Курс «Базы данных», лекция 3
Лекции
2.
Базы данныхЗачем изучать ранние подходы к организации баз данных?
1) Для понимания причин отказа от ранних концепций организации баз данных.
2) Внутренняя организация современных баз данных основана на методах, использованных
в ранних системах.
3) Для оценки направления развития современных баз данных.
4) Ранние системы использовались намного дольше, чем используются современные.
Накоплен очень большой объём баз данных. Необходимо использовать эти базы данных.
Лекции
2
3.
Базы данныхОбщие характеристики ранних систем
1) Ранние системы не основывались на абстрактных моделях.
2) Пользователи осуществляли явную навигацию, получая доступ к записям с
использованием алгоритмических языков, расширенных функциями СУБД.
3) Пользователь самостоятельно занимался оптимизацией и обеспечением целостности
базы данных.
Лекции
3
4.
Базы данныхТипы ранних баз данных
1) Базы данных, основанные на инвертированных списках.
2) Иерархические модели.
3) Сетевые модели .
Лекции
4
5.
Базы данныхЧто такое модель данных
Модель данных СУБД
1) Определены типы и характеристики логических структур данных (полей, записей,
файлов).
2) Заданы правила составления структур более общего типа из структур более простых
типов (например, записей из полей, файлов из записей и т.д.).
3) Определен способ представления связей (отношений) между файлами и записями:
- основные элементарные операции над данными;
- обобщенные операции (хранимые процедуры);
- средства контроля условий корректности изменения данных.
4) Основные элементарные операции:
- поиск записи с заданным значением ключа,
- чтение нужной записи,
- добавление, чтение, корректировка, удаление записи (CRUD – Create, Read,
Update, Delete).
Лекции
5
6.
Базы данных6
Эволюция моделей данных
Связь наряду с метаданными отличает базу данных от простого файла или набора файлов.
Лекции
Годы
Используемые модели
1960-е
Сетевая и иерархическая
(навигационный подход, императивное
программирование )
1970-е
1. Сетевая и иерархическая
2. Реляционная (математическая база,
декларативное программирование)
1980-е
1. Реляционная
2. Сетевая и иерархическая
1990-е
Реляционная
2000-е
1. Реляционная
2. NoSQL
7.
Базы данных7
Первые СУБД
Начало 1960-х годов
Чарльз Бахман (работал в General Electrics)
СУБД Integrated Data Store (затем IDMS,
работавшая на мейнфреймах IBM).
Получил за нее премию Тьюринга в 1973 году
Впервые доступ к данным осуществлялся не
непосредственно, как в файловой системе, а
через описание данных в виде иерархической
системы указателей.
Лекции
8.
Базы данных8
Базы данных, основанные на инвертированных списках
Линейный список:
последовательность записей базы данных с заданным отношением строгого порядка. С
каждой записью линейного списка при хранении связан физический адрес на внешнем
носителе.
Простой первичный ключ
№
Заказ
Клиент
Товар
Количество
1
22009
Иванов
Н4567
2
2
22010
Белов
Н3452
4
3
22011
Петров
Н4567
3
4
22012
Иванов
Н5500
1
Порядок задан номером заказа
Лекции
9.
Базы данных9
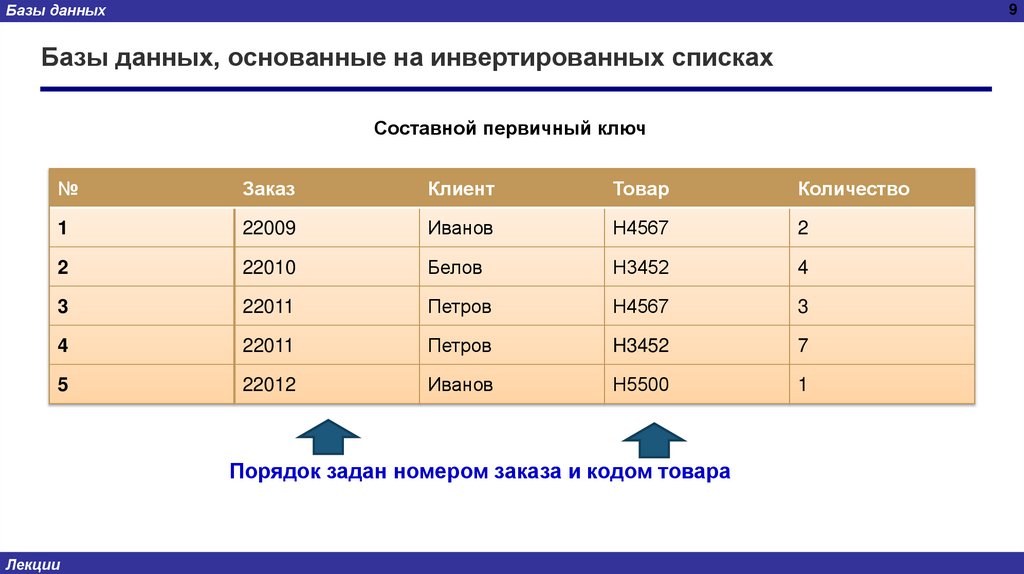
Базы данных, основанные на инвертированных списках
Составной первичный ключ
№
Заказ
Клиент
Товар
Количество
1
22009
Иванов
Н4567
2
2
22010
Белов
Н3452
4
3
22011
Петров
Н4567
3
4
22011
Петров
H3452
7
5
22012
Иванов
Н5500
1
Порядок задан номером заказа и кодом товара
Лекции
10.
Базы данныхБазы данных, основанные на инвертированных списках
ПЕРВИЧНЫЙ КЛЮЧ
поле, которое определяет только один элемент в списке.
Простой первичный ключ:
В примере первичным ключом является Заказ, в предположении, что в каждом заказе
может быть указан только один товар.
Составной первичный ключ:
Если в заказе могут быть указаны несколько товаров, то первичным ключом будет пара:
(Заказ, Товар).
Лекции
10
11.
Базы данныхБазы данных, основанные на инвертированных списках
Вторичный ключ:
ключевое поле, определяющее несколько элементов в списке.
(В роли вторичного ключа в примере выступают поля Клиент, Товар)
Поиск в линейном списке:
< название поля > < сравнение > < значение поля >.
Для обеспечения быстрого поиска по вторичным ключам в большинстве случаев
используются инвертированные списки.
Дополнительно строятся индексные структуры по полям, для которых необходимо
организовать быстрый поиск.
Лекции
11
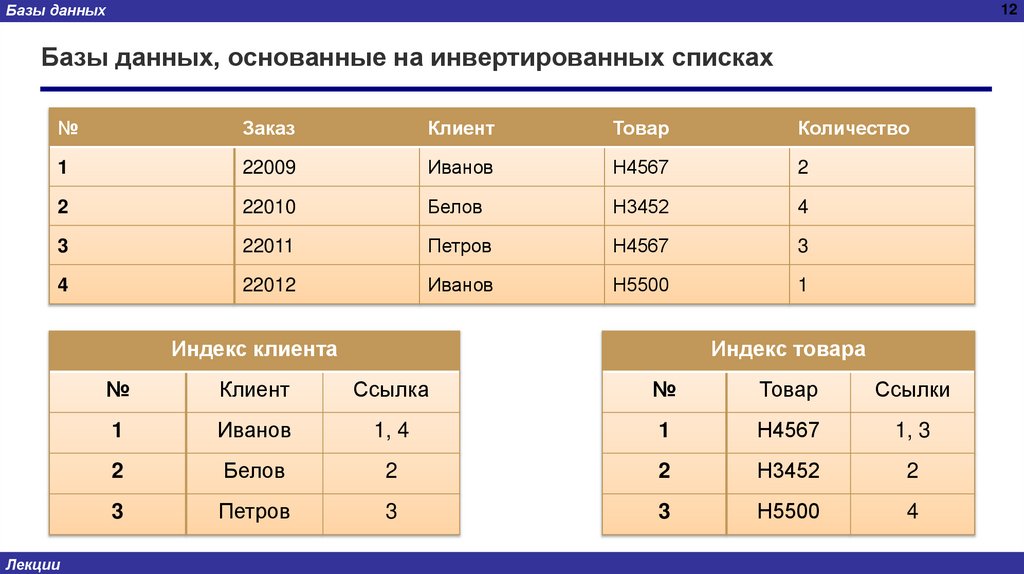
12.
Базы данных12
Базы данных, основанные на инвертированных списках
№
Заказ
Клиент
Товар
Количество
1
22009
Иванов
Н4567
2
2
22010
Белов
Н3452
4
3
22011
Петров
Н4567
3
4
22012
Иванов
Н5500
1
Индекс клиента
Лекции
Индекс товара
№
Клиент
Ссылка
№
Товар
Ссылки
1
Иванов
1, 4
1
Н4567
1, 3
2
Белов
2
2
Н3452
2
3
Петров
3
3
Н5500
4
13.
Базы данныхБазы данных, основанные на инвертированных списках
Для просмотра всех заказов от клиента Иванова необходимо:
1) По индексу «Клиент» для ключа Клиент найти соответствующий элемент ( элемент 1).
2) Выбрать ссылки для найденного элемента (множество 1; 4).
3) В основном списке выбираются последовательно элементы с номерами 1 и 4 и
выводится содержимое поля Заказ. Результатом работы алгоритма является список
(22009, 22012).
Лекции
13
14.
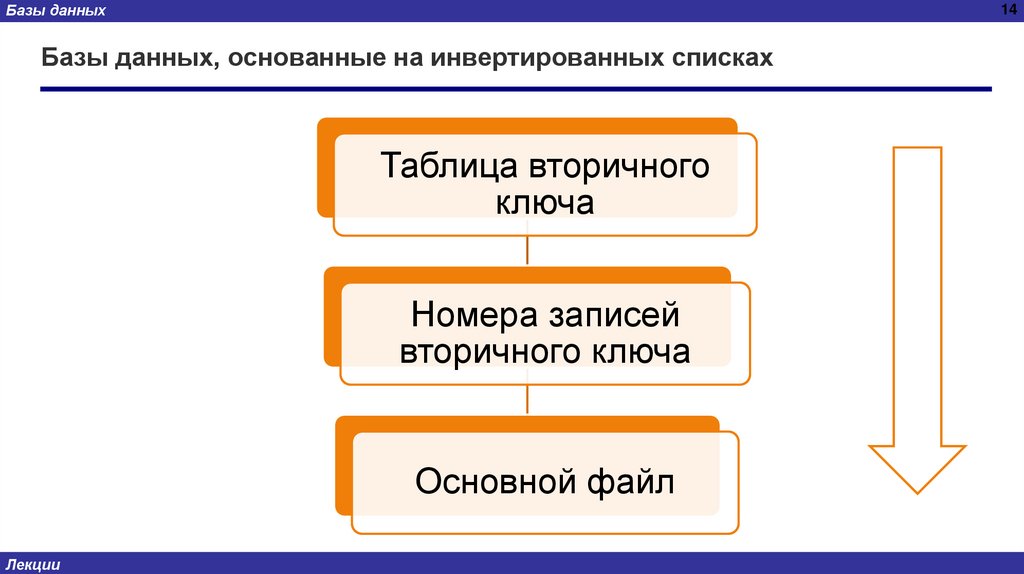
Базы данных14
Базы данных, основанные на инвертированных списках
Таблица вторичного
ключа
Номера записей
вторичного ключа
Основной файл
Лекции
15.
Базы данных15
Базы данных, основанные на инвертированных списках
СТРУКТУРА ДАННЫХ
1) Строки таблиц упорядочены системой в физической последовательности.
2) Для каждой таблицы можно определить произвольное число вторичных ключей
поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются
системой, но явно видны пользователям.
Лекции
16.
Базы данных16
Базы данных, основанные на инвертированных списках
Манипулирование данными
1) LOCATE FIRST - найти первую запись таблицы в физическом порядке; возвращает адрес
записи;
2) LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы с заданным
значением ключа поиска; возвращает адрес записи;
3) LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в
заданном пути доступа; возвращает адрес записи;
4) LOCATE NEXT WITH SEARCH KEY EQUAL - найти следующую запись таблицы в порядке
пути поиска с заданным значением; возвращает адрес записи;
5) LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы в порядке
ключа поиска со значением ключевого поля, большим заданного значения; возвращает
адрес записи;
6) RETRIVE - выбрать запись с указанным адресом;
7) UPDATE - обновить запись с указанным адресом;
8) DELETE - удалить запись с указанным адресом;
9) STORE - включить запись в указанную таблицу; операция генерирует адрес записи.
Лекции
17.
Базы данныхБазы данных, основанные на инвертированных списках
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах
поддерживаются ограничения уникальности значений некоторых полей, но в основном, все
возлагается на прикладную программу.
Организация доступа к данным на основе инвертированных списков используется
практически во всех современных СУБД, однако в этих системах пользователи не имеют
непосредственного доступа к инвертированным спискам (индексам).
Лекции
17
18.
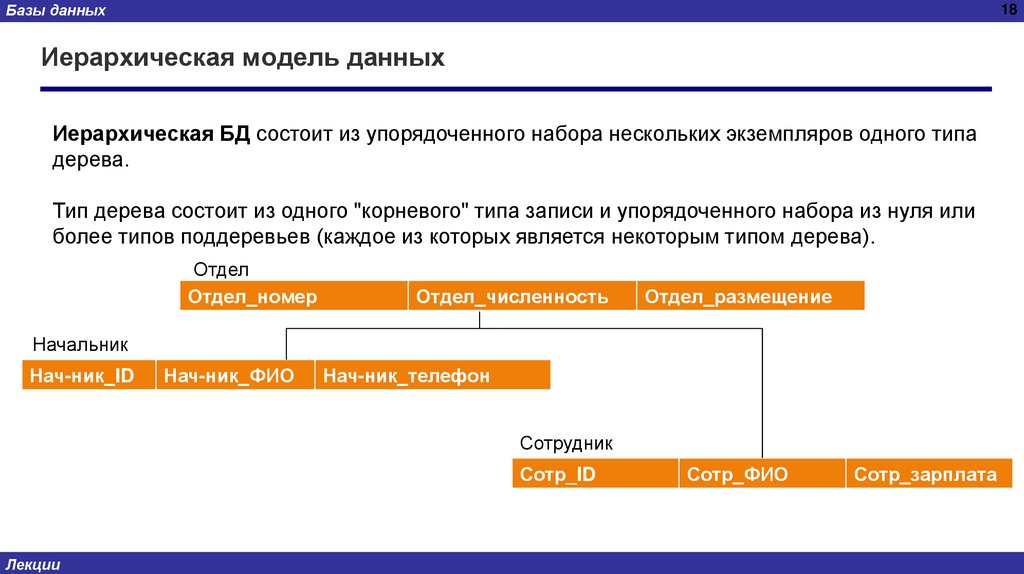
Базы данных18
Иерархическая модель данных
Иерархическая БД состоит из упорядоченного набора нескольких экземпляров одного типа
дерева.
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или
более типов поддеревьев (каждое из которых является некоторым типом дерева).
Отдел
Отдел_номер
Отдел_численность
Отдел_размещение
Начальник
Нач-ник_ID
Нач-ник_ФИО
Нач-ник_телефон
Сотрудник
Сотр_ID
Лекции
Сотр_ФИО
Сотр_зарплата
19.
Базы данных19
Иерархическая модель данных
Каждый потомок имеет одного предка.
Предок может иметь более одного потомка.
5413
К-125
25
Сотрудник
250
Сидоров
5-247
Сотрудник
251
252
Понкратов
Рыжиков
65000
67000
Все экземпляры данного типа потомка с общим экземпляром типа предка называются
близнецами.
Лекции
20.
Базы данных20
Иерархические системы
Для дерева определен фиксированный порядок обхода: сверху-вниз, слева-направо.
БАЗА ДАННЫХ
Лекции
Отдел 26
Отдел 27
Отдел 28
• Дерево
отдела
26
• Дерево
отдела
27
• Дерево
отдела
28
21.
Базы данныхИерархическая модель данных
Иерархическая база данных – это совокупность деревьев, корнями которых являются
экземпляры корневого типа сегмента.
Каждое такое дерево называется набором и образует физическую запись иерархической
базы данных.
От записи к записи (логической) можно перемещаться, только если они объединены
набором.
Лекции
21
22.
Базы данных22
Иерархическая модель данных
МАНИПУЛИРОВАНИЕ ДАННЫМИ
• Найти указанное дерево БД ;
• Перейти от одного дерева к другому;
• Перейти от одной записи к другой внутри дерева;
• Перейти от одной записи к другой в порядке обхода иерархии;
• Вставить новую запись в указанную позицию;
• Удалить текущую запись.
Лекции
23.
Базы данных23
Иерархическая модель данных
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное
правило: никакой потомок не может существовать без своего родителя.
Поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не
поддерживается.
Лекции
24.
Базы данныхИерархическая модель данных
• Данные в иерархической БД упорядочены: всегда есть первая запись и список следующих
и предыдущих.
• В БД хранятся не только данные, но и связи между ними (наборы).
• Создание прикладных систем предполагает процедурный стиль программирования –
разработчик сам определяет алгоритм получения интересующих его данных в рамках
существующих в БД связей.
Лекции
24
25.
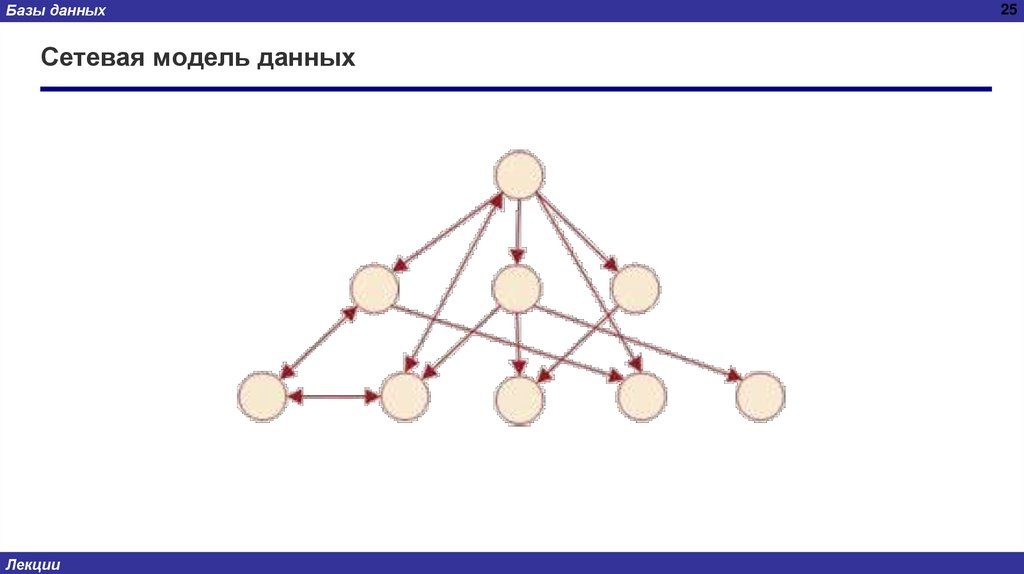
Базы данныхСетевая модель данных
Лекции
25
26.
Базы данных26
Сетевая модель данных
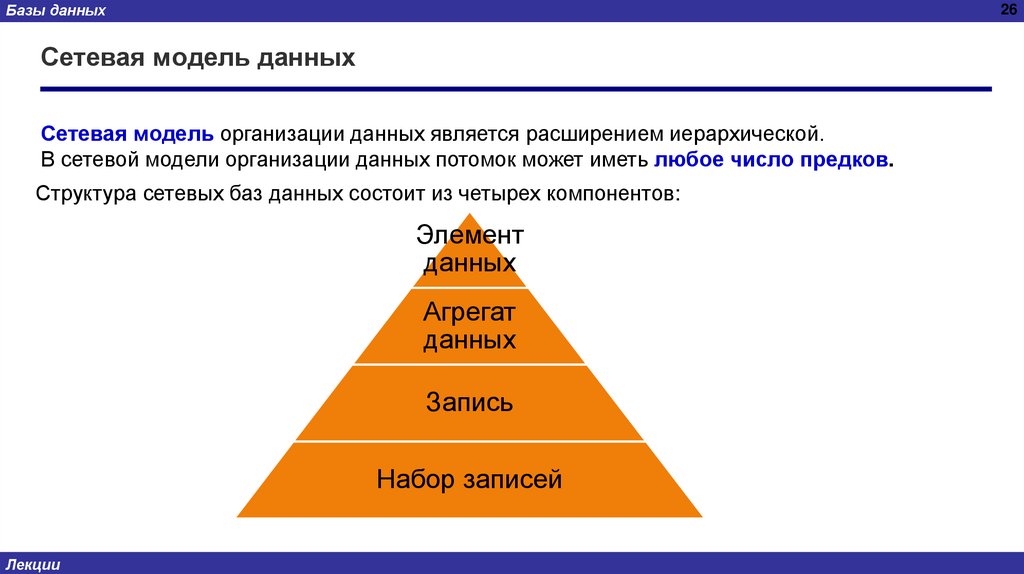
Сетевая модель организации данных является расширением иерархической.
В сетевой модели организации данных потомок может иметь любое число предков.
Структура сетевых баз данных состоит из четырех компонентов:
Элемент
данных
Агрегат
данных
Запись
Набор записей
Лекции
27.
Базы данных27
Сетевая модель данных
Элементы данных:
• ДЕНЬ
• МЕСЯЦ
• ГОД
Агрегат ДАТА типа вектор
ДАТА
ДЕНЬ
Лекции
МЕСЯЦ
ГОД
28.
Базы данных28
Сетевая модель данных
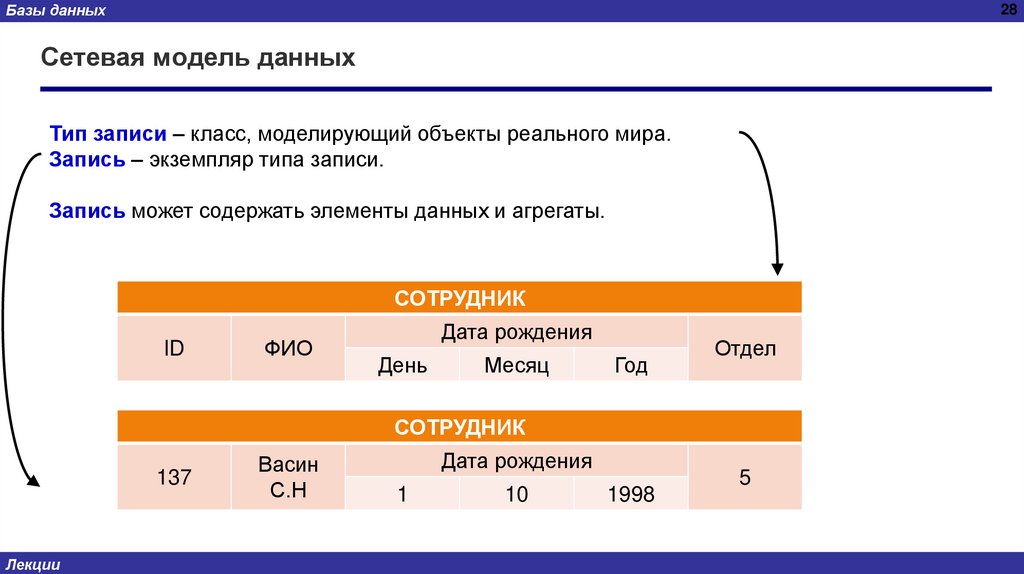
Тип записи – класс, моделирующий объекты реального мира.
Запись – экземпляр типа записи.
Запись может содержать элементы данных и агрегаты.
СОТРУДНИК
ID
ФИО
Дата рождения
День
Месяц
Год
Отдел
СОТРУДНИК
137
Лекции
Васин
С.Н
Дата рождения
1
10
1998
5
29.
Базы данных29
Сетевая модель данных
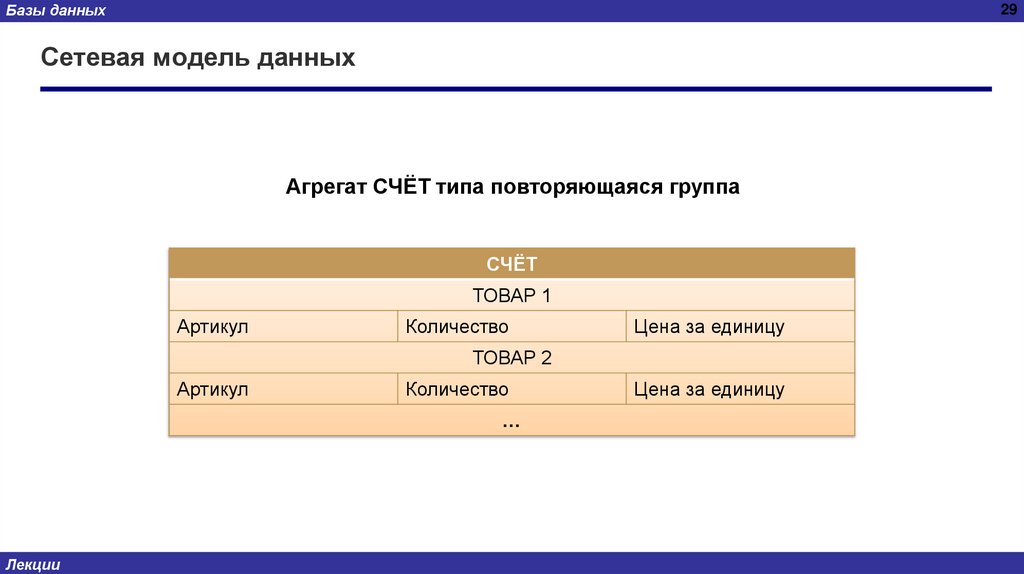
Агрегат СЧЁТ типа повторяющаяся группа
СЧЁТ
ТОВАР 1
Артикул
Количество
Цена за единицу
ТОВАР 2
Артикул
Количество
…
Лекции
Цена за единицу
30.
Базы данныхСетевая модель данных
Набор записей содержит:
управляющую запись;
управляемую запись;
связь.
Связь:
имеет идентификатор;
имеет тип: один ко многим или один к одному
Лекции
30
31.
Базы данных31
Сетевая модель данных
ПАПКА СО СЧЕТАМИ
1
Содержит
n
СЧЁТ
Лекции
32.
Базы данныхСетевая модель данных
Типы связей:
Фиксированная. Управляемая запись жестко связана с управляющей. Связь разорвать нельзя. Можно
удалить управляемую запись. При удалении управляющей записи, все управляемые записи удаляются
автоматически.
Обязательная. Управляемую запись можно переключить на другую управляющую. Удалить
управляющую запись можно только если у нее нет обязательных связей.
Необязательная. Управляемую запись можно отключить от управляющей и она сохранится в базе
данных.
Лекции
32
33.
Базы данныхСетевая модель данных
Манипулирование данными
Лекции
Найти запись в наборе записей;
Перейти от управляющей записи к управляемой по связи с указанным именем;
Перейти к следующему агрегату в повторяющейся группе;
Перейти от управляемой записи к управляющей по связи с указанным именем;
Создать новую запись;
Уничтожить запись;
Модифицировать запись;
Создать связь;
Исключить из связи;
Переставить в другую связь.
33
34.
Базы данныхДостоинства и недостатки ранних подходов к организации баз данных
Сильные стороны:
• Развитые средства управления данными во внешней памяти на низком уровне;
• Возможность построения вручную эффективных прикладных систем;
• Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Слабые стороны:
Лекции
Слишком сложно пользоваться;
Необходимы знания о физической организации хранилища данных;
Прикладные системы зависят от организации хранилища данных;
Логика прикладных систем перегружена деталями организации доступа к данным.
34