














































, имеющие")
 в коллекции. Их можно считать отдалённым аналогом таблиц реляционных СУБД, но")









 из-за того,")















 — В любой реализации распределенных вычислений возможно обеспечить не более двух из трёх следующих")




















































 + 1, где")

;")




 — есть возможность использовать запросы с строгой согласованностью взамен доступности;")

 informatics
informaticsSimilar presentations:

")




")



Современные проблемы информатики и вычислительной техники. Лекция 1
1.
СовременныеПроблемы
Информатики и
Вычислительной
Техники
1
2.
Главные ИТ-тренды в 2021 и последующие годыГенеративный искусственный интеллект
На рынок выходит новая модель ИИ - генеративный
искусственный интеллект, который представляет собой использование методов машинного обучения,
ориентированных на изучение контента или объектов и использование полученных данных для создания новых, полностью оригинальных, реалистичных
артефактов. Генеративный ИИ можно использовать
по-разному, в том числе для создания программного
кода, идентификации новых продуктов, содействия
разработке лекарств и целевого маркетинга.
2
3.
Data Fabric (ткань данных)Архитектура управления информацией Data
Fabric используется для максимально эффективного
доступа к корпоративным данным. Data Fabric
гарантирует гибкую, устойчивую интеграцию
данных между платформами и бизнес-пользователями, решение появились для упрощения инфраструктуры интеграции данных в организации и создания
масштабируемой архитектуры.
3
4.
Территориально-распределенные предприятияС распространением удаленных и гибридных моделей работы традиционные офисно-ориентированные организации превращаются в распределенные
предприятия, состоящие из географически разбросанных сотрудников. Gartner прогнозирует, что к
2023 году 75% организаций, использующих такую
модель работы, получат рост доходов на 25%
быстрее, чем конкуренты.
4
5.
Облачные платформыGartner прогнозирует, что облачные платформы будут
служить основой для более чем 95% новых цифровых
инициатив к 2025 году - по сравнению с менее чем
40% в 2021 году.
Автономные системы
По словам Грумбриджа, автономные системы , которые могут динамически изменять свои собственные
алгоритмы без обновления внешнего программного
обеспечения, станут обычным явлением
в роботах, дронах, производственных машинах и
интеллектуальных пространствах.
5
6.
Decision intelligenceDecision intelligence (интеллект при принятии
решений) - эта дисциплина объединяет лучшее из
прикладного направления data science, социальных
наук и науки управления для эффективного принятия решений. Gartner прогнозирует, что в следующие два года одна треть крупных организаций будет
использовать специальные ИИ-разработки для
принятия решений с целью повышения конкурентного преимущества.
6
7.
Составные приложенияСпрос на адаптивность бизнеса растет и для этого
требуется технологическая архитектура, которая
поддерживает быстрое, безопасное и эффективное
изменение приложений. Архитектура составных
приложений расширяет возможности этой адаптируемости, и те, кто будет использовать составные
приложения, смогут опередить конкурентов на 80%
по скорости реализации новых функций.
Гиперавтоматизация
Системы, обеспечивающие гиперавтоматизацию,
обеспечивают ускоренный рост и устойчивость
бизнеса за счет быстрой идентификации, проверки и
автоматизации огромного числа процессов.
7
8.
Вычисления, повышающие конфиденциальностьК 2025 году 60% крупных организаций будут использовать один или несколько методов вычислений, повышающих конфиденциальность. Такие решения защищают личную и конфиденциальную информацию
на уровне данных, программного или аппаратного
обеспечения.
Ячеистая сеть кибербезопасности
Смысл ячеистой сети кибербезопасности
(Cybersecurity Mesh) заключается в том, чтобы обеспечить безопасный доступ человека к любому цифровому ресурсу независимо от местонахождения как
ресурса, так и человека. Это решение формирует периметр защиты вокруг отдельной персоны, а не вокруг всей организации.
8
9.
ИИ-инженерияГруппы разработчиков, работающих над ИИ, смогут
создать действительно эффективные инструменты
для своих организаций, если будут повышать ценность за счет быстрых изменений ИИ. Разработчики
сосредоточатся на составных приложениях, ориентированных на модульные компоненты - это повысит
эффективность групп разработчиков.
Общий опыт
При подходе общего опыта все руководители дисциплин должны нести равную ответственность за удовлетворение совокупных потребностей сотрудников и
клиентов. «Традиционные подходы к управлению не
будут масштабироваться».
9
10.
Аналитики TrendForce назвали 10 ИТ-трендов на2022 год
1. Разработка дисплеев micro-LED и mini-LED будет
сосредоточена на решениях с активной
матрицей.
2. Передовая технология AMOLED и камеры под
дисплеем откроют новый этап
революции смартфонов
3. В полупроводниковом производстве
определяющим будет освоение норм 3 нм
4. Старт массового производства памяти DDR5
10
11.
5. Операторы мобильных сетей запустят большепробных проектов для сегментирования сетей 5G
SA и приложений с малой задержкой
6. Спутниковая связь
7. Цифровое производство
8. Расширенная виртуальная реальность
9. Автоматизированная парковка автомобилей
10. Новые полупроводниковые технологии
11
12.
5 главных ИТ-трендов, которые существенноповлияют на бизнес, общество и каждого человека в
ближайшие 5-10 лет.
1. Композитная бизнес-архитектура
Такая модель позволяет организациям перейти от жесткого традиционного планирования к гибкому реагированию на быстро меняющиеся потребности бизнеса.
В целом она создает возможности для внедрения инновационных подходов, снижает затраты и улучшает партнерские отношения. Другие технологии, на которые
следует обратить внимание в рамках новой бизнес-модели, включают "пакетные" бизнес-услуги, фабрики
данных, частные 5G-сети и встроенный ИИ.
12
13.
2. Алгоритмическое довериеОрганизации больше не могут доверять полностью
органам управления, и их место занимают алгоритмы. Алгоритмические модели доверия обеспечивают
конфиденциальность и безопасность данных, отслеживают их происхождение, а также подтверждают
идентичность людей и вещей. Gartner считает, что
повышенный интерес к блокчейну приведет к расширению возможностей цифровой аутентификации и
проверки. Среди технологий, связанных с алгоритмическим доверием, аналитики отмечают безопасный доступ к услугам (SASE, Secure Access Service
Edge), а также ответственный и объяснимый ИИ, то
есть алгоритм с прослеживаемыми этапами.
13
14.
3. Технологии без кремнияЗакон Мура говорит, что количество транзисторов в
плотной интегральной схеме будет удваиваться каждые два года, но технология быстро приближается к
физическим пределам кремния. В результате стали
появляться новые материалы с расширенными возможностями, которые позволяют делать технологии
компактнее и быстрее. Например, ДНК-вычисления
используют ДНК и биохимические реакции вместо
кремния или квантовых архитектур для выполнения
вычислений или хранения данных. Другие технологии в этой области включают биоразлагаемые датчики и транзисторы на основе углерода.
14
15.
4. Формирующий ИИФормирующий ИИ - это тип ИИ, способный динамически меняться, чтобы реагировать на ситуацию.
Существует множество его подтипов: от ИИ, который
может динамически адаптироваться с течением времени, до технологий, которые могут создавать новые
модели для решения конкретных проблем.
Например, генеративный ИИ - это тип ИИ, который
может создавать новый контент (изображения, видео
и т. д.) или изменять уже существующий контент.
Другие технологии включают композитный ИИ,
дифференциальную конфиденциальность, "малые
данные" и обучение с самоконтролем.
15
16.
5. Цифровизация личностиТехнологии все больше интегрируются с людьми, а
значит, появляется все больше возможностей для создания цифровых версий человека. Эти цифровые двойники людей могут существовать как в физическом, так
и в виртуальном пространстве. Например, двухсторонний нейрокомпьютерный интерфейс - это система, созданная для обмена информацией между мозгом и электронным устройством, которая может быть носимым
устройством или имплантом для регистрации электроэнцефалограммы (ЭЭГ). Их можно использовать для
идентификации, получения доступа, оплаты и иммерсивной аналитики. Среди других технологий можно
отметить «паспорт здоровья» и цифровые двойники
гражданина.
16
17. Лекция 1_1. Разновидности систем управления базами данных. Современные тенденции использования NoSQL-хранилищ,
ЛЕКЦИЯ 1_1. РАЗНОВИДНОСТИ СИСТЕМУПРАВЛЕНИЯ БАЗАМИ ДАННЫХ.
СОВРЕМЕННЫЕ ТЕНДЕНЦИИ
ИСПОЛЬЗОВАНИЯ NOSQL-ХРАНИЛИЩ,
ДОКУМЕНТООРИЕНТИРОВАННЫЕ БАЗЫ
ДАННЫХ
Ба́за да́нных — совокупность данных,
хранимых в соответствии со схемой
данных, манипулирование которыми
выполняют в соответствии с правилами
средств моделирования данных.
17
18. Определения из нормативных документов, в том числе стандартов: База данных — представленная в объективной форме совокупность
Определения из нормативных документов, в томчисле стандартов:
База данных — представленная в объективной
форме совокупность самостоятельных материалов
(статей, расчетов, нормативных актов, судебных решений и
иных подобных материалов), систематизированных таким
образом, чтобы эти материалы могли быть найдены и
обработаны с помощью электронной вычислительной
машины (ЭВМ).
База данных — совокупность данных, организованных в
соответствии с концептуальной структурой, описывающей
характеристики этих данных и взаимоотношения между
ними, которая поддерживает одну или более областей
применения.
18
19.
Систе́ма управле́ния ба́зами да́нных, сокр. СУБД(Database Management System, сокр. DBMS) —
совокупность программных и лингвистических средств
общего или специального назначения, обеспечивающих
управление созданием и использованием баз данных.
СУБД — комплекс программ, позволяющих создать базу
данных (БД) и манипулировать данными (вставлять,
обновлять, удалять и выбирать).
Система обеспечивает безопасность, надёжность
хранения и целостность данных, а также предоставляет
средства для администрирования БД.
19
20.
Основные функции СУБД•управление данными во внешней
памяти (на дисках);
•управление данными в оперативной
памяти с использованием дискового кэша;
•журнализация изменений, резервное
копирование и восстановление базы
данных после сбоев;
•поддержка языков БД (язык определения
данных, язык манипулирования данными).
20
21.
Состав СУБДОбычно современная СУБД содержит следующие
компоненты:
•ядро, которое отвечает за управление данными во
внешней и оперативной памяти и журнализацию;
•процессор языка базы данных,
обеспечивающий оптимизацию запросов на извлечение и
изменение данных и создание, как правило, машиннонезависимого исполняемого внутреннего кода;
•подсистему поддержки времени исполнения, которая
интерпретирует программы манипуляции данными,
создающие пользовательский интерфейс с СУБД;
•сервисные программы (внешние утилиты),
обеспечивающие ряд дополнительных возможностей по
обслуживанию информационной системы.
21
22.
Классификации СУБДПо модели данных
Примеры:
•Иерархические
•Сетевые
•Реляционные
•Объектно-ориентированные
•Объектно-реляционные
22
23.
По степени распределённости•Локальные СУБД (все части локальной
СУБД размещаются на одном компьютере)
•Распределённые СУБД (части СУБД
могут размещаться не только на одном, но
на двух и более компьютерах).
23
24.
По способу доступа к БДФайл-серверные
В файл-серверных СУБД файлы данных
располагаются централизованно на файлсервере. СУБД располагается на каждом
клиентском компьютере (рабочей станции).
Доступ СУБД к данным осуществляется
через локальную сеть.
Примеры: Microsoft
Access, Paradox, dBase, FoxPro, Visual
FoxPro.
24
25.
•Клиент-серверныеКлиент-серверная СУБД располагается
на сервере вместе с БД и осуществляет
доступ к БД непосредственно, в
монопольном режиме.
Примеры: Oracle
Database, Firebird, Interbase, IBM
DB2, Informix, MS SQL Server, Sybase
Adaptive Server
Enterprise, PostgreSQL, MySQL, Caché, Л
ИНТЕР.
25
26.
ВстраиваемыеВстраиваемая СУБД — СУБД, которая
может поставляться как составная часть
некоторого программного продукта, не
требуя процедуры
самостоятельной установки.
Примеры: OpenEdge, SQLite, BerkeleyDB
, Firebird Embedded, Microsoft SQL Server
Compact, ЛИНТЕР.
26
27.
Стратегии работы с внешней памятью•СУБД с непосредственной записью
Все изменённые блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции.
•СУБД с отложенной записью
Изменения аккумулируются в буферах внешней памяти до наступления
соответствующего события.
27
28.
11 типов современных баз данных:Типы баз данных, называемых также
моделями БД или семействами БД,
представляют собой шаблоны и
структуры, используемые для
организации данных в системе
управления базами данных (СУБД).
28
29.
1. Простые структуры данныхПервый и простейший способ хранения
данных – текстовые файлы. Метод
применяется и сегодня для работы с
небольшими объёмами информации. Для
разделения полей используется
специальный символ: запятая или точка с
запятой в csv-файлах дата сетов,
двоеточие или пробел в *nix-подобных
системах:
29
30.
/etc/passwd в *nix системеroot:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
syslog:x:102:106::/home/syslog:/usr/sbin/nologin
bob:x:1000:1000:Bob Smith,,,:/home/bob:/bin/bash
30
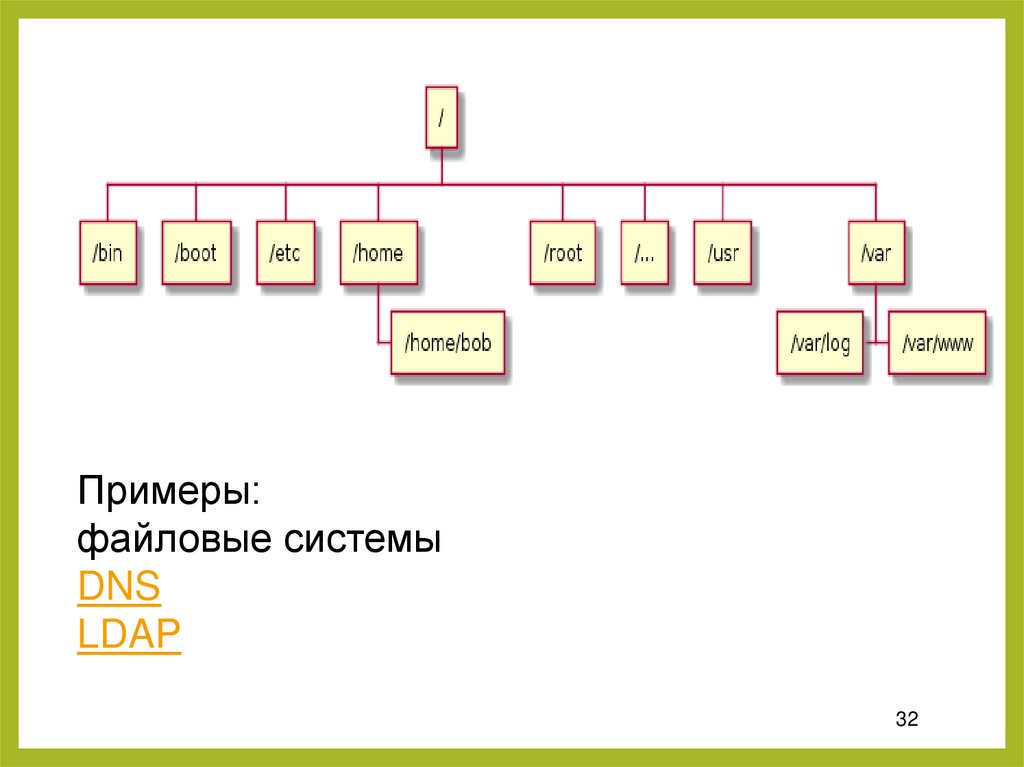
31.
2. Иерархические базы данныхВ отличие от текстовых таблиц, в
следующем типе БД появляются связи
между объектами. В иерархических базах
данных каждая запись имеет одного
«родителя». Это создаёт древовидную
структуру, в которой записи
классифицируются по их отношениям с
цепочкой родительских записей.
31
32.
Примеры:файловые системы
DNS
LDAP
32
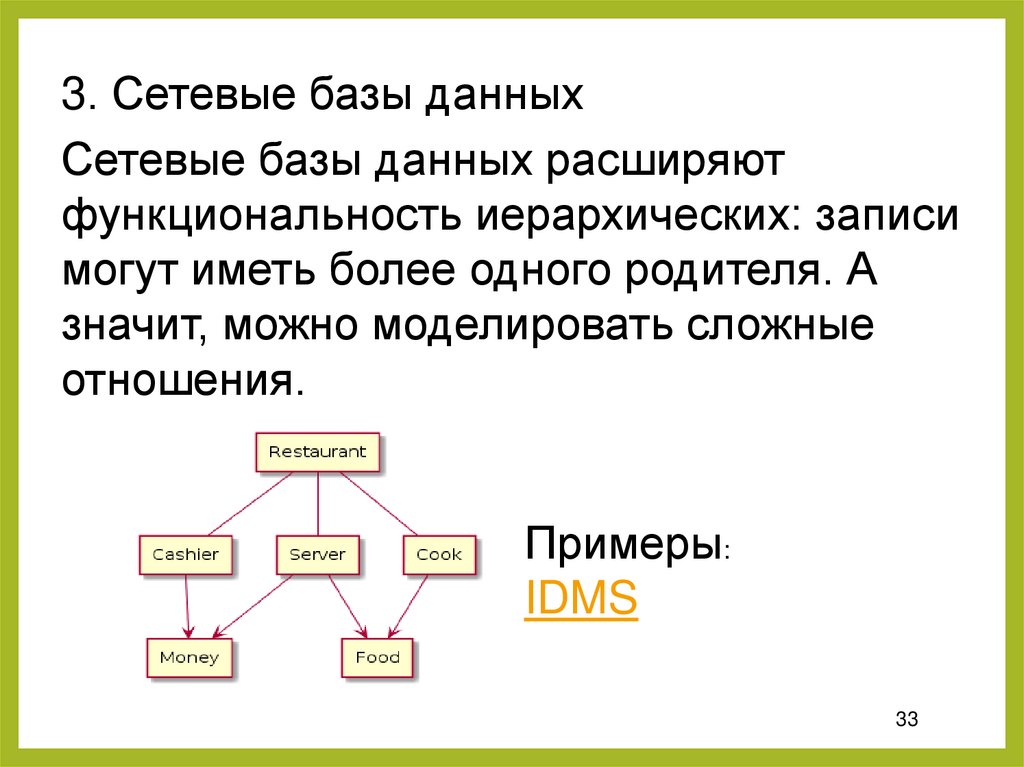
33.
3. Сетевые базы данныхСетевые базы данных расширяют
функциональность иерархических: записи
могут иметь более одного родителя. А
значит, можно моделировать сложные
отношения.
Примеры:
IDMS
33
34.
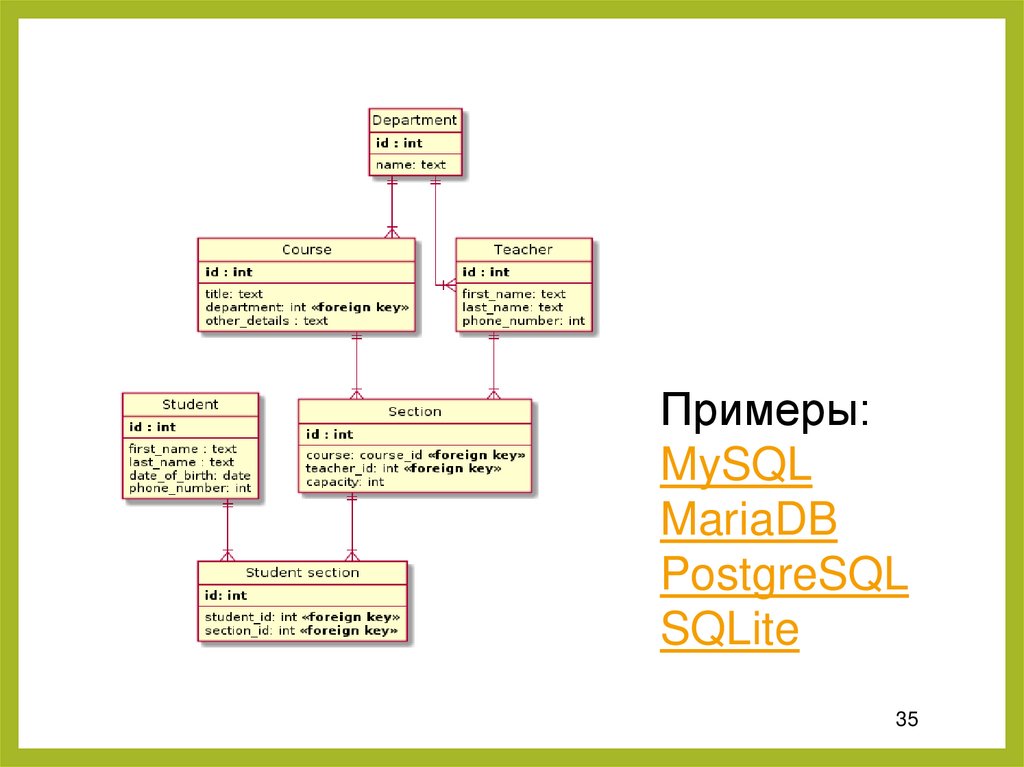
II. Реляционные БД4. SQL базы данных
Реляционные базы данных – старейший
тип до сих пор широко используемых БД
общего назначения. Данные и связи
между данными организованы с помощью
таблиц. Каждый столбец в таблице имеет
имя и тип. Каждая строка представляет
отдельную запись или элемент данных в
таблице, который содержит значения для
каждого из столбцов.
34
35.
Примеры:MySQL
MariaDB
PostgreSQL
SQLite
35
36.
III. NoSQL базы данныхNoSQL – группа типов БД, предлагающих
подходы, отличные от стандартного
реляционного шаблона. Говоря NoSQL,
подразумевают либо «не-SQL», либо «не
только SQL», чтобы уточнить, что иногда
допускается SQL-подобный запрос.
36
37.
5. Базы данных «ключ-значение»В базах данных «ключ-значение» для
хранения информации вы предоставляте
ключ и объект данных, который нужно
сохранить. Например, JSON-объект,
изображение или текст. Чтобы запросить
данные, отправляете ключ и
получаете blob-объект.
Примеры:
Redis
memcached
etcd
37
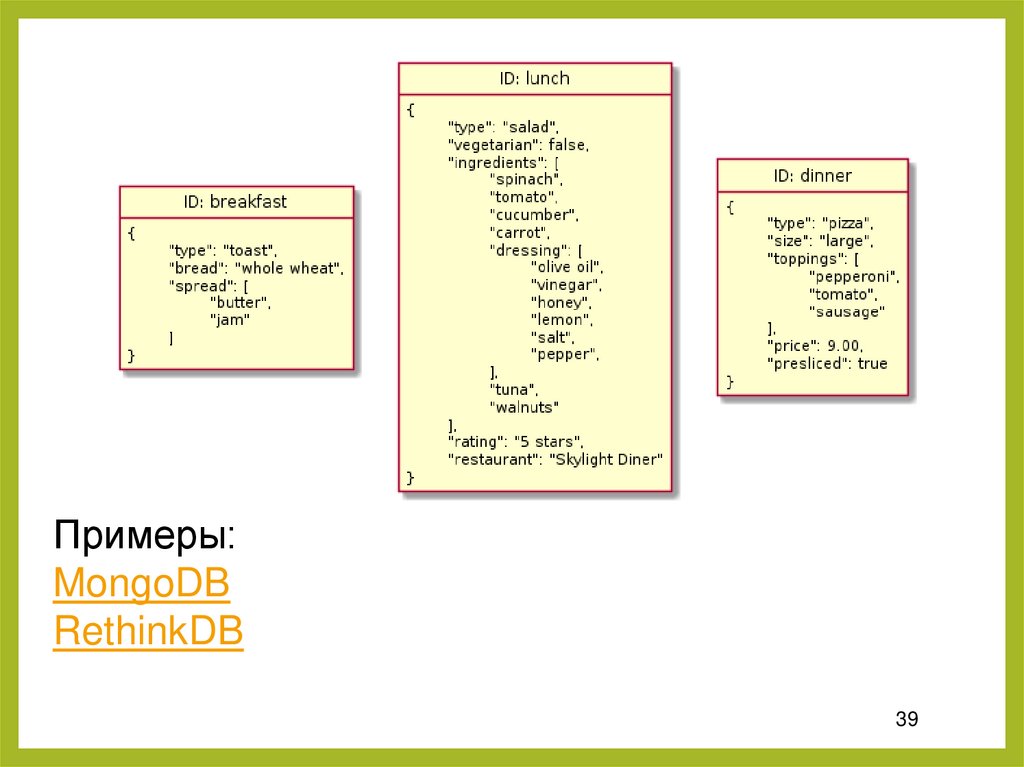
38.
6. Документная база данныхДокументные базы данных (также документоориентированные БД или хранилища
документов), совместно используют базовую семантику доступа и поиска хранилищ
ключей и значений. Используют ключ для
уникальной идентификации данных.
Разница между БД «ключ-значение» и документными БД в том, что вместо хранения
blob-объектов, документоориентированные
базы хранят данные в форматах – JSON,
BSON или XML.
38
39.
Примеры:MongoDB
RethinkDB
39
40.
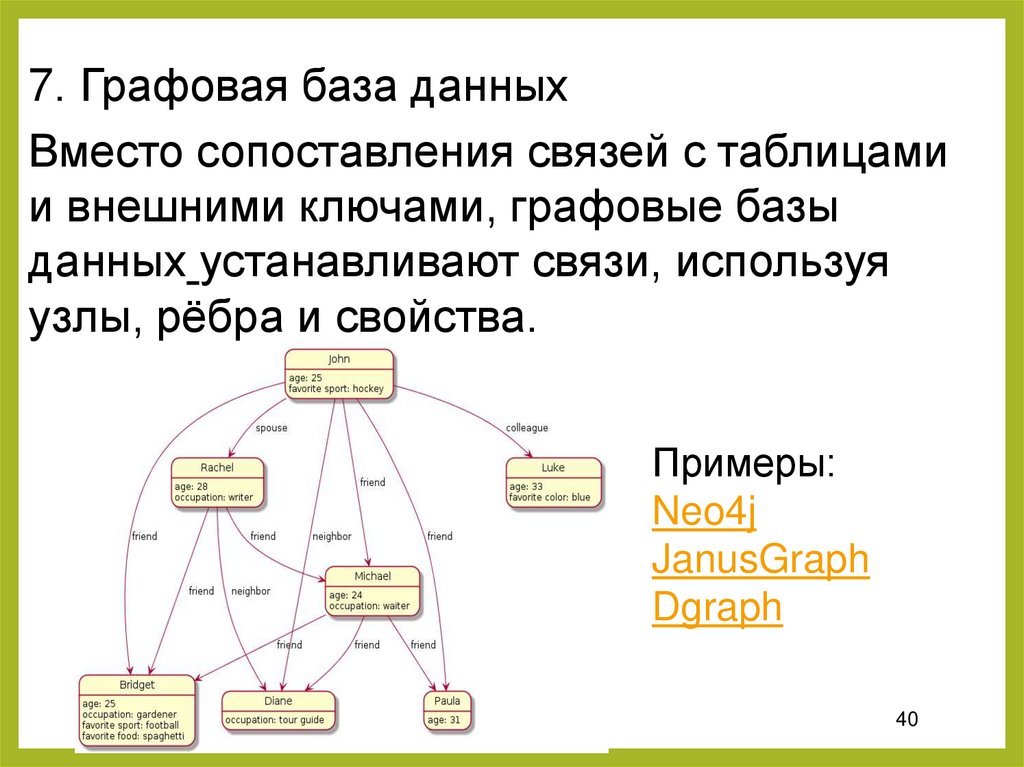
7. Графовая база данныхВместо сопоставления связей с таблицами
и внешними ключами, графовые базы
данных устанавливают связи, используя
узлы, рёбра и свойства.
Примеры:
Neo4j
JanusGraph
Dgraph
40
41.
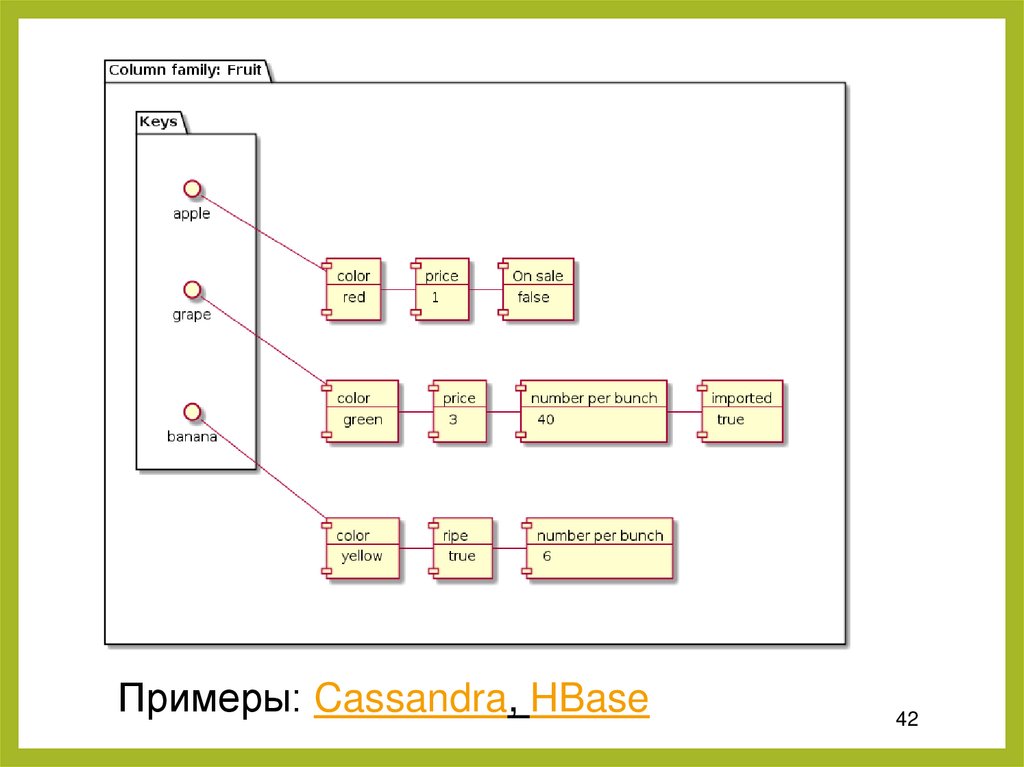
8. Колоночные базы данныхКолоночные базы данных (также
нереляционные колоночные хранилища или
базы данных с широкими столбцами)
принадлежат к семейству NoSQL БД, но
внешне похож на реляционные БД. Как и
реляционные, колоночные БД хранят
данные, используя строки и столбцы, но с
иной связью между элементами
41
42.
Примеры: Cassandra, HBase42
43.
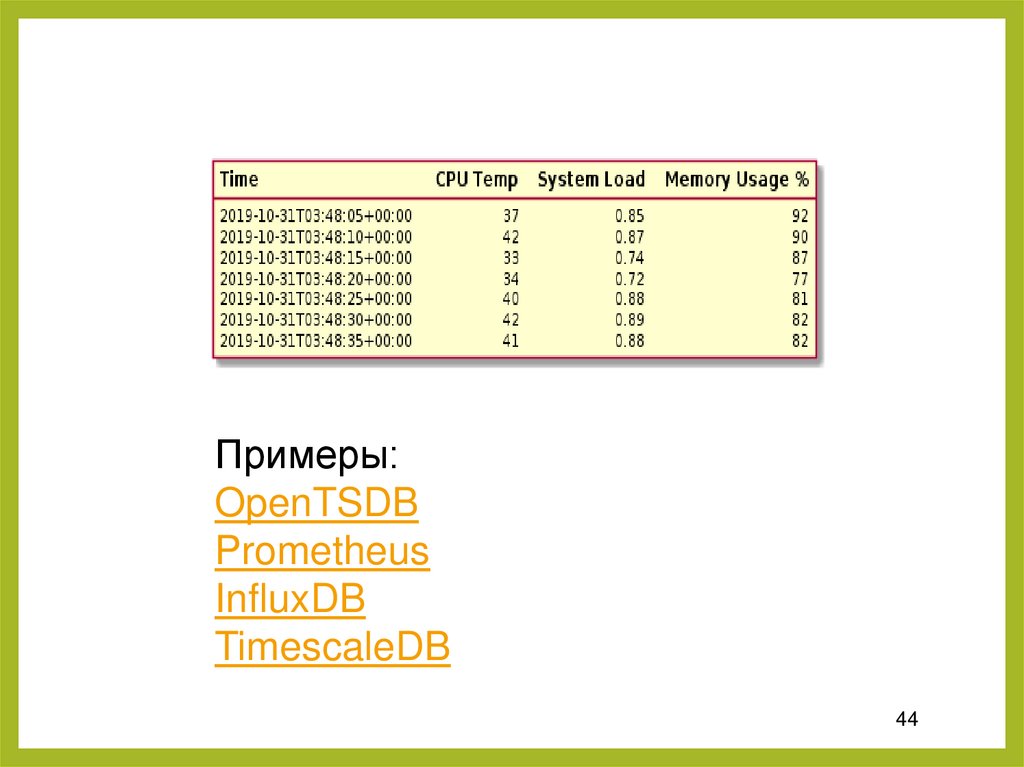
9. Базы данных временных рядовБазы данных временны́х рядов созданы
для сбора и управления элементами,
меняющимися с течением времени.
Большинство таких БД организованы в
структуры, которые записывают значения
для одного элемента. Например, можно
создать таблицу для отслеживания
температуры процессора. Внутри каждое
значение будет состоять из временной
метки и показателя температуры. В
таблице может быть несколько метрик.
43
44.
Примеры:OpenTSDB
Prometheus
InfluxDB
TimescaleDB
44
45.
IV. Комбинированные типыNewSQL и многомодельные БД являются
разными типами баз данных, но решают
одну группу проблем, вызванных
полярными подходами SQL или NoSQLстратегии. Почему бы не объединить
преимущества обеих групп?
45
46.
10. NewSQL базы данныхNewSQL базы данных наследуют реляционную структуру и семантику, но построены с
использованием более современных, масштабируемых конструкций. Цель – обеспечить большую масштабируемость, нежели
реляционные БД, и более высокие гарантии
согласованности, чем в NoSQL. Компромисс
между согласованностью и доступностью
является фундаментальной проблемой
распределённых баз данных, описываемой
теоремой CAP.
46
47.
Примеры:– MemSQL
– VoltDB
– Spanner
– Calvin
– CockroachDB
– FaunaDB
– yugabyteDB
47
48.
11. Многомодельные базы данныхМногомодельные базы данных – базы,
объединяющие функциональные
возможности нескольких видов БД.
Преимущества такого подхода очевидны –
одна и та же система может использовать
различные представления для разных
типов данных.
Примеры:
–ArangoDB
–OrientDB
48
–Couchbase
49.
NoSQL (от англ. not only SQL — не толькоSQL) — обозначение широкого класса
разнородных систем управления базами
данных, появившихся в конце 2000-х — начале 2010-х годов и существенно отличающихся от традиционных реляционных СУБД
с доступом к данным средствами языка SQL.
Применяется к системам, в которых делается
попытка решить проблемы масштабируемости и доступности за счёт полного или
частичного отказа от требований атомарности и согласованности данных.
49
50.
Основные чертыТрадиционные СУБД ориентируются на
требования ACID к транзакционной
системе: атомарность (англ. atomicity),
согласованность (англ. consistency),
изолированность (англ. isolation),
долговечность(англ. durability), тогда как в
NoSQL вместо ACID может
рассматриваться набор свойств BASЕ:
50
51.
•базовая доступность (англ. basicavailability) — каждый запрос гарантированно завершается (успешно или безуспешно).
•гибкое состояние (англ. soft state) —
состояние системы может изменяться со
временем, даже без ввода новых данных,
для достижения согласования данных.
•согласованность в конечном счёте
(англ. eventual consistency) — данные могут
быть некоторое время рассогласованы, но
приходят к согласованию через некоторое
время.
51
52.
Решения NoSQL отличаются не толькопроектированием с учётом
масштабирования:
•Применение различных типов хранилищ.
•Возможность разработки базы данных без
задания схемы.
•Линейная масштабируемость (добавление
процессоров увеличивает
производительность).
•Инновационность: «не только SQL»
открывает много возможностей для
хранения и обработки данных.
52
53.
Типы системВ зависимости от модели данных и
подходов
к распределённости и репликации в
NoSQL-движении выделяются четыре
основных типа систем: «ключ — значение»
(англ. key-value store), «семейство
столбцов» (column-family store),
документоориентированные (document
store), графовые.
53
54.
Документоориентированная СУБДДокументоориентированные СУБД служат
для хранения иерархических структур
данных. Находят своё применение
в системах управления содержимым,
издательском деле, документальном
поиске.
Примеры СУБД данного типа —
CouchDB, Couchbase, MongoDB, eXist,
Berkeley DB XML.
54
55. В основе документоориентированных СУБД лежат документные хранилища (англ. document store), имеющие
В основе документоориентированныхСУБД лежат документные хранилища
(англ. document store), имеющие
структуру дерева (иногда леса).
Структура дерева начинается с
корневого узла и может содержать
несколько внутренних и листовых узлов
55
56. Документы могут быть организованы (сгруппированы) в коллекции. Их можно считать отдалённым аналогом таблиц реляционных СУБД, но
Документы могут быть организованы(сгруппированы) в коллекции. Их можно
считать отдалённым аналогом таблиц
реляционных СУБД, но коллекции могут
содержать другие коллекции.
Хотя документы коллекции могут быть
произвольными, для более эффективного
индексирования лучше объединять в
коллекцию документы с похожей
структурой.
56
57. Согласно статье 1260 Гражданского кодекса РФ, базой данных является представленная в объективной форме совокупность
самостоятельныхматериалов (статей, расчетов,
нормативных актов, судебных решений
и т.д.), систематизированных таким
образом, чтобы эти материалы могли
быть найдены и обработаны с помощью
электронной вычислительной машины
(ЭВМ).
57
58. Тенденции использования ДОБД Документоориентированные базы данных обычно используются для: аналитической обработки большого
объема данных и насайтах с очень высокой нагрузкой, поскольку
легко масштабируются горизонтально.
Часто ДОБД используются совместно с
традиционными решениями на реляционных
базах данных.
ДОБД не является заменой реляционных баз
данных, это скорее альтернатива. Это инструмент, который может делать то же, что могут
делать множество прочих. Кое-что - лучше,
58
кое-что - нет.
59. Преимущества ДОБД 1. В сравнении с реляционными базами данных лучшая производительность при индексировании больших объёмов
данных и большим количествезапросов на чтение.
2. Легче масштабируются в сравнении с SQL
решениями.
3. Децентрализированы.
4. Легко менять "схему" данных: не нужно выполнять
никаких операций обновления для добавления новых
полей.
5. Нет проблем с хранением неструктурированных
данных.
6. Единое место хранения всей информации об
объекте: меньше операций вида "join".
7. Простой интерфейс общения с БД (ключ →
значение, нет SQL).
59
60. Недостатки ДОБД Отсутствие транзакционной логики и контроля целостности в большинстве реализаций: необходимо реализовывать её в
логике приложения. С другойстороны, специализированная логика может
оказаться эффективнее общих алгоритмов
реляционных ДБ.
Для обработки данных необходимо использование
дополнительного языка программирования. Для
программистов, которые этот язык знают, минус
превращается в плюс. Кроме того иногда для этих
целей можно использовать разные языки.
60
61. ЧЕМ ХОРОШИ И ПЛОХИ НЕРЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ? ГЛАВНЫЕ ДОСТОИНСТВА И недостатки
ЧЕМ ХОРОШИ И ПЛОХИНЕРЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ?
ГЛАВНЫЕ ДОСТОИНСТВА И НЕДОСТАТКИ
61
62. По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами: линейная масштабируемость –
По сравнению с классическими SQL-базами,нереляционные СУБД обладают
следующими преимуществами:
линейная масштабируемость – добавление
новых узлов в кластер увеличивает общую
производительность системы;
гибкость, позволяющая оперировать
полуструктирированные данные, реализуя,
в. т.ч. полнотекстовый поиск по базе;
возможность работать с разными
представлениями информации, в т.ч. без
задания схемы данных;
62
63. высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического
высокая доступность за счет репликацииданных и других механизмов
отказоустойчивости, в частности, шаринга –
автоматического разделения данных по
разным узлам сети, когда каждый сервер
кластера отвечает только за определенный
набор информации, обрабатывая запросы на
его чтение и запись. Это увеличивает
скорость обработки данных и пропускную
способность приложения.
63
64. производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или
производительность за счет оптимизациидля конкретных видов моделей данных
(документной, графовой, колоночной или
«ключ-значение») и шаблонов доступа;
широкие функциональные возможности –
собственные SQL-подобные языки запросов,
RESTful-интерфейсы, API и сложные типы
данных, например, map, list и struct,
позволяющие обрабатывать сразу множество
значений.
64
65. Обратной стороной вышеуказанных достоинств являются следующие недостатки: ограниченная емкость встроенного языка запросов.
Например, HBase предоставляетвсего 4 функции работы с данными (Put, Get,
Scan, Delete), в Cassandra отсутствуют
операции Insert и Join, несмотря на наличие
SQL-подобного языка запросов. Для решения
этой проблемы используются сторонние
средства трансляции классических SQLвыражений в исполнительный код для
конкретной нереляционной базы.
Например, Apache Phoenix для HBase
или универсальный Drill.
65
66. сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того,
сложности в поддержке всех ACIDтребований к транзакциям (атомарность,консистентность, изоляция, долговечность)
из-за того, что NoSQL-СУБД вместо CAPмодели (согласованность, доступность,
устойчивость к разделению) скорее
соответствуют модели BASE (базовая
доступность, гибкое состояние и итоговая
согласованность).
66
67. сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных,
сильная привязка приложения кконкретной СУБД из-за специфики
внутреннего языка запросов и гибкой
модели данных, ориентированной на
конкретный случай;
недостаток специалистов по NoSQLбазам по сравнению с реляционными
аналогами.
67
68. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например,
локальнаяERP-система или облачная CRM.
Однако, в случае обработки большого
объема полуструктурированных и
неструктурированных данных, т.е. Big Data,
в распределенной системе следует
выбирать из множества NoSQL-хранилищ,
учитывая специфику самой задачи.
68
69. Нереляционные СУБД находят больше областей приложений, чем традиционные SQL-решения
6970. Литература: 1. Фаулер Мартин, Садаладж Прамодкумар Дж. NoSQL: новая методология разработки нереляционных баз данных. : Пер. с
англ. - М.: ООО "И.Д. Вильяме", 2013. 192 с.: ил. - Парал. тит. англ.2. Основы технологий баз данных:
учебное пособие/Б.А. Новиков, Е.А.
Горшкова, под ред.
Е.В. Рогова.- М.:ДМК Пресс,2019.-240с.
70
71. Лекция 1_2. Транзакции, ACID, варианты реализации в различных СУБД, распределенные базы данных, базы данных redis, cassandra.
ЛЕКЦИЯ 1_2. ТРАНЗАКЦИИ, ACID,ВАРИАНТЫ РЕАЛИЗАЦИИ В
РАЗЛИЧНЫХ СУБД, РАСПРЕДЕЛЕННЫЕ
БАЗЫ ДАННЫХ, БАЗЫ ДАННЫХ REDIS,
CASSANDRA.
Транза́кция (англ. transaction) — группа
последовательных операций с базой данных,
которая представляет собой логическую
единицу работы с данными.
71
72.
Транзакция может быть выполнена либоцеликом и успешно, соблюдая целостность
данных и независимо от параллельно идущих
других транзакций, либо не выполнена вообще,
и тогда она не должна произвести никакого
эффекта. Транзакции обрабатываются
транзакционными системами, в процессе
работы которых создаётся история транзакций.
72
73.
Различают последовательные (обычные),параллельные и распределённые транзакции.
Распределённые транзакции подразумевают
использование более чем одной
транзакционной системы и требуют намного
более сложной логики (например, two-phase
commit — двухфазный протокол фиксации
транзакции). Также в некоторых системах
реализованы автономные транзакции, или подтранзакции, которые являются автономной
частью родительской транзакции.
73
74.
Уровни изолированности транзакций0 —Чтение незафиксированных данных (Read
Uncommitted) — чтение незафиксированных
изменений как своей транзакции, так и
параллельных транзакций. Нет гарантии, что
данные, изменённые другими транзакциями,
не будут в любой момент изменены в
результате их отката, поэтому такое чтение
является потенциальным источником ошибок.
Невозможны потерянные изменения (lost
changes), возможны грязное чтение (dirty read),
неповторяемое чтение и фантомы.
74
75.
1 — Чтение зафиксированных данных (ReadCommitted) — чтение всех изменений своей
транзакции и зафиксированных изменений
параллельных транзакций. Потерянные
изменения и грязное чтение не допускается,
возможны неповторяемое чтение и фантомы.
75
76.
2 — Повторяемое чтение (Repeatable Read,Snapshot) — чтение всех изменений своей
транзакции, любые изменения, внесённые
параллельными транзакциями после начала
своей, недоступны. Потерянные изменения,
грязное и неповторяемое чтение
невозможны, возможны фантомы.
76
77.
3 — Сериализуемый (Serializable) —сериализуемые транзакции. Результат
параллельного выполнения сериализуемой
транзакции с другими транзакциями должен
быть логически эквивалентен результату их
какого-либо последовательного выполнения.
Проблемы синхронизации не возникают.
77
78.
Уровни описаны в порядке увеличенияизолированности транзакций и,
соответственно, надёжности работы с
данными.
Чем выше уровень изоляции, тем больше
требуется ресурсов, чтобы его обеспечить.
Соответственно, повышение
изолированности может приводить к
снижению скорости выполнения
параллельных транзакций, что является
«платой» за повышение надёжности.
78
79.
Обеспечиваемые транзакциями гарантиифункциональной безопасности часто
описываются известной аббревиатурой
ACID (atomicity, consistency, isolation,
durability) — атомарность, согласованность,
изоляция и сохраняемость).
Системы, не соответствующие критериям
ACID, иногда называются BASE: «как
правило, доступна» (Basically Available),
«гибкое состояние» (Soft state) и «конечная
согласованность» (Eventual consistency).
79
80.
Атомарность.В общем атомарность определяется как
«невозможность разбиения на меньшие
части».
Согласованность.
-Согласованность реплик и вопрос конечной
согласованности, возникающий в
асинхронно реплицируемых системах.
-Согласованное хеширование — метод
секционирования, используемый в
некоторых системах для перебалансировки.
80
81.
-В теореме CAP слово «согласованность»используется для обозначения
линеаризуемости (linearizability).
-В контексте ACID под согласованностью
понимается то, что база данных находится, с
точки зрения приложения, в «хорошем
состоянии».
81
82. Теорема CAP (теорема Брюера) — В любой реализации распределенных вычислений возможно обеспечить не более двух из трёх следующих
Теорема CAP (теорема Брюера) — В любойреализации распределенных вычислений
возможно обеспечить не более двух из трёх
следующих свойств:
согласованность данных (англ. consistency) —
во всех вычислительных узлах в один момент
времени данные не противоречат друг другу;
доступность (англ. availability) — любой запрос
к распределённой системе завершается
корректным откликом;
устойчивость к разделению (англ. partition
tolerance) — расщепление распределённой
системы на изолированные секции не приводит
к некорректности отклика от каждой из секций.
82
83.
Атомарность, изоляция и сохраняемость —свойства базы данных, в то время как
согласованность (в смысле ACID) — свойство
приложения. Оно может полагаться на
свойства атомарности и изоляции базы
данных, чтобы обеспечить согласованность,
но не на одну только базу.
83
84.
Изоляция в смысле ACID означает, чтоконкурентно выполняемые транзакции
изолированы друг от друга — они не могут
помешать друг другу. Классические
учебники по базам данных понимают под
изоляцией сериализуемость (serializability).
То есть каждая транзакция выполняется так,
будто она единственная во всей базе. БД
гарантирует, что результат фиксации
транзакций такой же, как если бы они
выполнялись последовательно, хотя в
реальности они могут выполняться
конкурентно.
84
85. Изоляция
Рис. 1 - Состояние гонки между двумя клиентамиконкурентно увеличивающими значение
счетчика
85
86.
СохраняемостьСохраняемость (durability) —
обязательство базы не терять
записанных (успешно зафиксированных)
транзакций данных, даже в случае сбоя
аппаратного обеспечения
или фатального сбоя самой БД.
86
87.
Обработка ошибок и прерывание транзакцийОтличительная особенность транзакций —
возможность их прерывания и безопасного
повторного выполнения в случае
возникновения ошибки. На этом принципе
построены базы данных ACID: при
возникновении риска нарушения гарантий
атомарности, изоляции или сохраняемости БД
скорее полностью отменит транзакцию, чем
оставит ее незавершенной.
87
88. Чтение зафиксированных данных
Рис. 2 - Никаких «грязных» операций чтения:пользователь 2 видит новое значение x
только после фиксации результатов
транзакции, выполняемой пользователем 1
88
89. Рис. 3 - В случае «грязных» операций записи конфликтующие операции записи различных транзакций могут оказаться перепутаны
8990.
Рис. 4 - Асимметрия чтения: Алиса видитбазу данных в несогласованном состоянии
90
91.
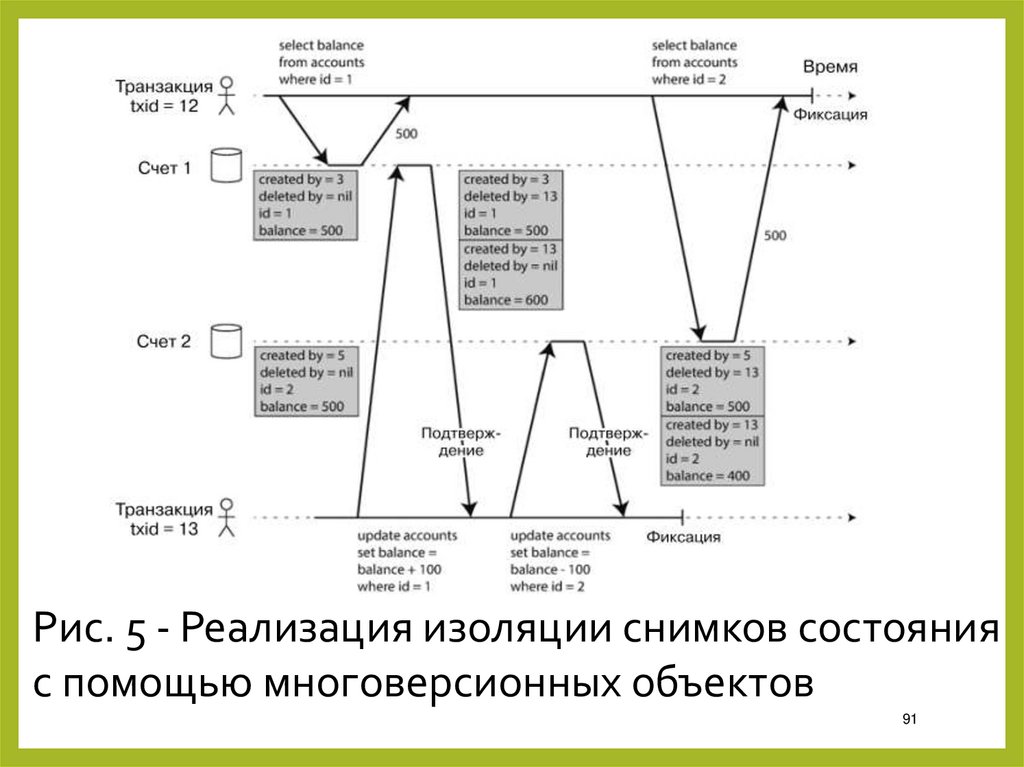
Рис. 5 - Реализация изоляции снимков состоянияс помощью многоверсионных объектов
91
92.
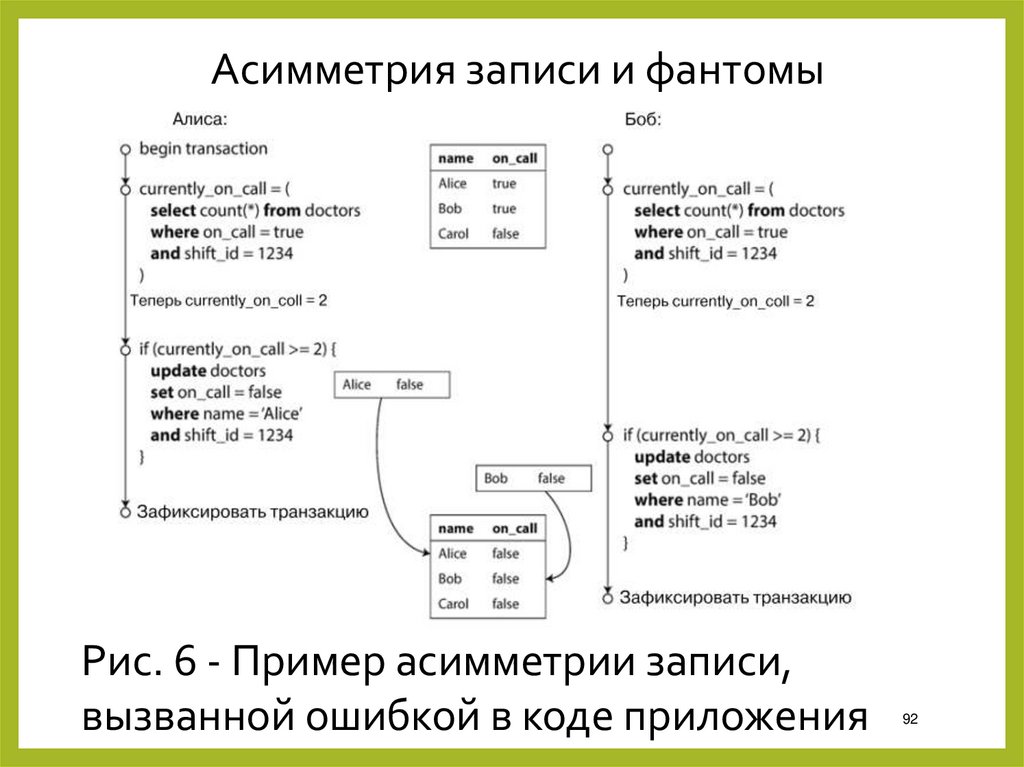
Асимметрия записи и фантомыРис. 6 - Пример асимметрии записи,
вызванной ошибкой в коде приложения
92
93.
Если использовать уровень сериализуемостиневозможно, то вторым лучшим решением
будет, вероятно, явная блокировка строк,
необходимых для транзакции:
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE;
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;
93
94.
СериализуемостьСериализуемость (serializability) обычно
считается самым сильным уровнем изоляции.
Она гарантирует, что даже при конкурентном
выполнении транзакций результат останется
таким же, как и в случае их последовательного
выполнения, без всякой конкурентности.
Следовательно, база предотвращает
все возможные состояния гонки.
94
95.
Большинство современных БД,обеспечивающих сериализуемость,
применяют один из трех методов:
- действительно последовательное
выполнение транзакций;
- двухфазную блокировку;
- методы оптимистического управления
конкурентным доступом,
например, сериализуемую изоляцию
снимков состояния (SSI).
95
96.
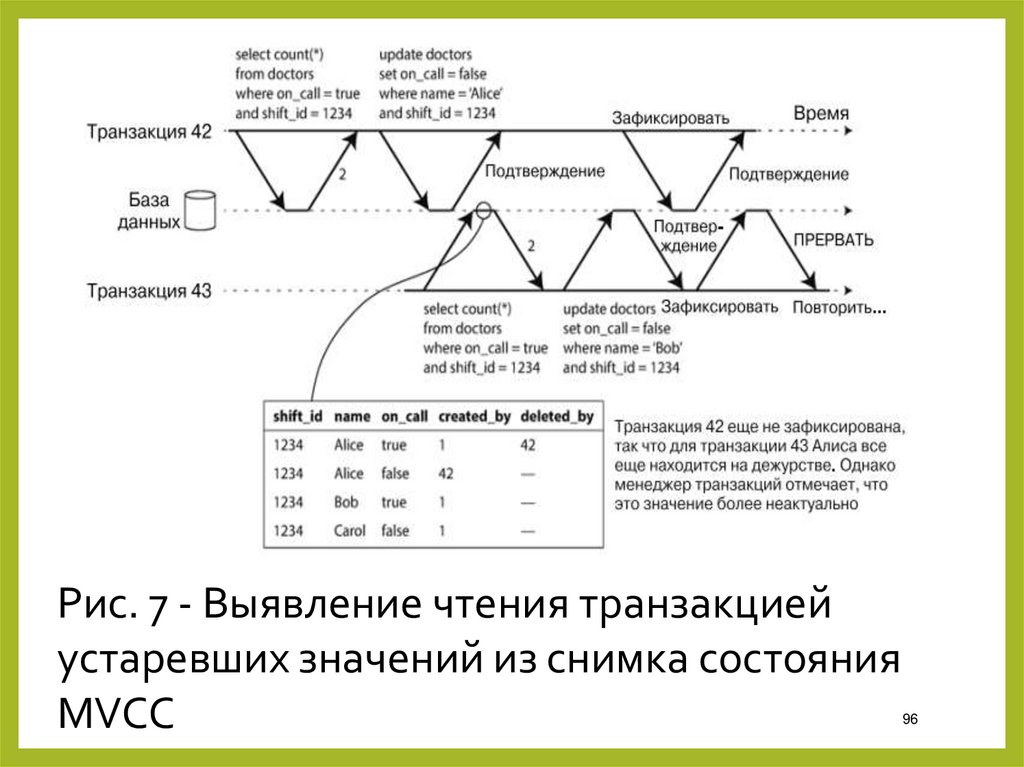
Рис. 7 - Выявление чтения транзакциейустаревших значений из снимка состояния
MVCC
96
97.
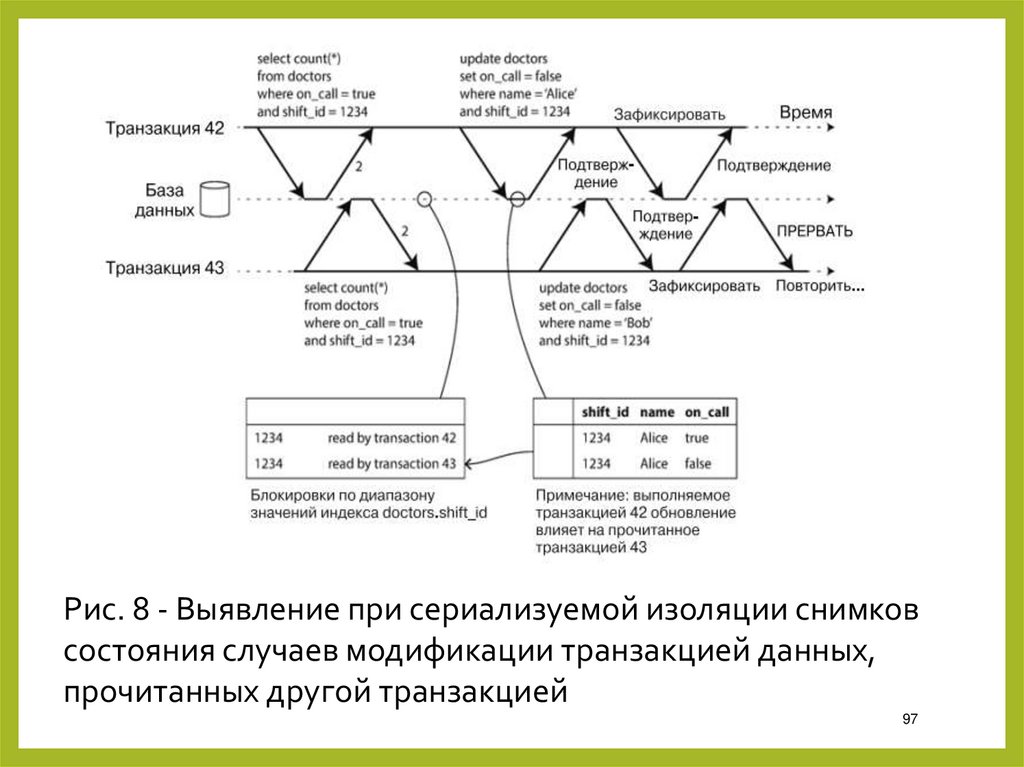
Рис. 8 - Выявление при сериализуемой изоляции снимковсостояния случаев модификации транзакцией данных,
прочитанных другой транзакцией
97
98.
ВыводТранзакции представляют собой слой
абстракции, благодаря которому приложение
может не обращать внимания на отдельные
проблемы конкурентного доступа и некоторые
виды сбоев аппаратного и программного
обеспечения. Широкий класс ошибок сводится
к простому прерыванию транзакции, а
приложению достаточно просто повторить
выполнение транзакции.
98
99.
Redis (от англ. remote dictionary server) —резидентная система управления базами
данных класса NoSQL с открытым исходным
кодом, работающая со структурами данных
типа «ключ — значение». Используется как
для баз данных, так и для реализации
кэшей, брокеров сообщений.
Ориентирована на достижение максимальной
производительности на атомарных операциях
(заявляется о приблизительно 100 тыс. SETи GET-запросов в секунду на Linux-сервере
начального уровня).
99
100.
Хранит базу данных в оперативной памяти,снабжена механизмами снимков и журналирования для обеспечения постоянного хранения (на дисках, твердотельных накопителях).
Все данные Redis хранит в виде словаря, в котором ключи связаны со своими значениями.
Одно из ключевых отличий Redis от других
хранилищ данных заключается в том, что
значения этих ключей не ограничиваются
строками. Поддерживаются следующие
абстрактные типы данных:
строки, списки, множества, хеш-таблицы,
упорядоченные множества.
100
101.
Языковая поддержка RedisRedis поддерживает большинство
ведущих языков программирования и
протоколов, включая перечисленные ниже.
Python, Java, PHP, Perl, Go, Ruby, C/C#/C++,
JavaScript, Node.js
101
102.
Модели данныхВсе данные Redis хранит в виде словаря, в котором
ключи связаны со своими значениями. Одно из ключевых отличий Redis от других хранилищ данных заключается в том, что значения этих ключей не ограничиваются строками. Поддерживаются следующие
абстрактные типы данных:
строки, списки, множества, хеш-таблицы, упорядоченные множества.
Тип данных значения определяет, какие операции
(команды) доступны для него; поддерживаются такие
высокоуровневые операции, как объединение и
разность наборов, сортировка наборов.
102
103.
Восстановление данных и репликацияВосстановление данных проводится двумя разными
способами. Первый — это механизм снимков, в котором данные асинхронно переносятся из оперативной
памяти в файл формата RDB (расширение дампов
Redis). Второй способ (с версии 1.1) — журнал упреждающей записи, доступный только для дозаписи, в
котором хранятся все операции, изменявшие данные
в памяти.
103
104.
Система поддерживает репликацию с ведущих узловна ведомые. Данные с любого сервера Redis могут
реплицироваться произвольное количество раз. Все
данные, которые попадают на один узел Redis
(master), будут попадать также на другие узлы
( slave). Для конфигурирования ведомых узлов можно
изменить опцию slaveof или аналогичную по написанию команду (узлы, запущенные без подобных опций, являются ведущими узлами).
104
105.
Репликация помогает защитить данные, копируя ихна другие сервера. Репликация также может быть использована для увеличения производительности, так
как запросы на чтение могут обслуживаться ведомыми узлами (горизонтальное масштабирование по чтению, но не по записи). Узлы-реплики могут ответить
слегка устаревшими данными, но для многих приложений это приемлемо.
Система репликации Redis сама по себе не поддерживает автоматическую отказоустойчивость: если ведущий узел выходит из строя, необходимо вручную выбрать нового ведущего среди ведомых узлов; но имеется система Redis Sentinel, обеспечивающая мониторинг и автоматическое переключение.
105
106.
Redis Sentinel — специализированная система управления узлами Redis, выполняющая задачи:-мониторинг: постоянно проверяется, что ведущий и
ведомые узлы работают так, как ожидается;
-уведомление: сообщает, что с отслеживаемыми узлами что-то не так;
-автоматическое переключение: если ведущий узел
не работает так, как ожидается, Sentinel может начать
процесс восстановления работоспособности, в котором один из ведомых узлов объявляется как ведущий,
другие ведомые узлы меняют конфигурацию на использование нового ведущего;
-поставщик конфигурации: сообщение клиентам и
другим Redis-узлам адреса текущего ведущего узла, в
случае отказа Sentinel сообщает новый адрес.
106
107.
Преимущества RedisХранилище данных в памяти
Все данные Redis находятся в основной памяти сервера, в отличие от таких баз данных, как PostgreSQL,
Cassandra, MongoDB и других, которые большую
часть данных хранят на магнитных дисках или
SSD-накопителях. Хранилища данных в памяти, такие
как Redis, свободны от этого ограничения. Благодаря
этому многократно увеличивается количество выполняемых операций и сокращается время отклика. В результате обеспечивается чрезвычайно высокая производительность. Операции чтения или записи в среднем занимают менее миллисекунды, скорость работы
достигает миллионов операций в секунду.
107
108.
Гибкие структуры данныхТипы данных Redis включают:
-строки – текстовые или двоичные данные размером
до 512 МБ;
-списки – коллекции строк, упорядоченные в порядке
добавления;
-множества – неупорядоченные коллекции строк с
возможностью пересечения, объединения и
сравнения с другими типами множеств;
-сортированные множества – множества, упорядоченные по значению;
-хэш-таблицы – структуры данных для хранения списков полей и значений;
108
109.
-битовые массивы – тип данных, который даетвозможность выполнять операции на уровне битов;
-структуры HyperLogLog – вероятностные структуры
данных, служащие для оценки количества
уникальных элементов в наборе данных.
Простота и удобство
Redis упрощает код, позволяя писать меньше строк
для хранения, использования данных и организации
доступа к данным в приложениях. К примеру, если
приложение содержит данные, хранящиеся в
хэш-таблице, и требуется сохранить эти данные в
хранилище, можно просто использовать структуру
данных хэш-таблицы Redis.
109
110.
Решение подобной задачи с использованием хранилища данных, не поддерживающего структурыхэш-таблиц, потребует написания серьезного объема
кода для преобразования данных из одного формата
в другой. Redis уже оснащен встроенными структурами данных и предоставляет множество возможностей их комбинирования и взаимодействия с данными
клиента. Разработчикам под Redis доступны более
ста клиентов с открытым исходным кодом.
Поддерживаемые языки программирования
включают Java, Python, PHP, C, C++, C#, JavaScript,
Node.js, Ruby, R, Go и многие другие.
110
111.
Репликация и постоянное хранениеВ Redis применяется архитектура узлов
«ведущий-подчиненный» и поддерживается асинхронная репликация, при которой данные могут
копироваться на несколько подчиненных серверов.
Это обеспечивает как улучшенные характеристики
чтения (так как запросы могут быть распределены
между серверами), так и ускоренное восстановление
в случае сбоя основного сервера. Для обеспечения
постоянного хранения Redis поддерживает снимки
состояния на момент времени (копирование наборов
данных Redis на диск).
111
112.
Высокая доступность и масштабируемостьRedis предлагает архитектуру «ведущий-подчиненный» с одним ведущим узлом или с кластерной топологией. Это позволяет создавать высокодоступные
решения, обеспечивающие стабильную производительность и надежность. Если требуется настроить
размер кластера, доступны различные варианты
вертикального и горизонтального масштабирования.
В результате можно наращивать кластер в соответствии с потребностями.
112
113.
Возможность расширенияRedis – проект с открытым исходным кодом, поддерживаемый активным сообществом. Поскольку Redis
базируется на открытых стандартах, поддерживает
открытые форматы данных и имеет множество
клиентов, отсутствует вероятность блокировки
поставщиком или технологического тупика.
113
114.
Распространенные примеры использования RedisКэширование
Redis прекрасно подходит для организации высокодоступного кэша в памяти, который уменьшает задержку доступа и снижает нагрузку на реляционную
базу данных или базу данных NoSQL и на приложение. Redis может обеспечить доступ к часто запрашиваемым данным с задержкой в доли миллисекунды и
позволяет с легкостью выполнять масштабирование,
справляясь с повышением нагрузок без дорогостоящего наращивания мощности БД на уровне сервера.
Примеры использования Redis – это кэширование результатов запросов к базе данных, долговременных
сессий, веб-страниц или часто используемых объектов, таких как изображения, файлы и метаданные.
114
115.
Чат, обмен сообщениями и очередиRedis поддерживает системы «издатель – подписчик»
с заданными шаблонами и различные структуры данных, такие как списки, сортированные множества и
хэш-таблицы. Это позволяет использовать Redis для
создания высокопроизводительных комнат чата, лент
комментариев, работающих в режиме реального времени, лент новостей в социальных сетях и систем взаимодействия серверов. Списки Redis List обеспечивают выполнение элементарных операций, а также возможности блокировки, поэтому подходят для различных приложений, в которых требуется надежный
брокер сообщений или циклический список.
115
116.
Игровые таблицы лидеровРазработчики игр нередко применяют Redis для создания таблиц лидеров в режиме реального времени.
Достаточно просто использовать структуру данных
Redis Sorted Set, которая обеспечивает уникальность
элементов и сортировку списка по результатам
пользователей. Создание ранжированного списка в
режиме реального времени в итоге требует лишь обновления результата пользователя при его изменении. Можно также применять структуры Sorted Set
для обработки временных данных с использованием в
качестве результата временных меток.
116
117.
Хранилище сессийRedis как хранилище данных в памяти с высокой доступностью и долговременным хранением широко
применяется для хранения данных сессий в приложениях, работающих в масштабе всего Интернета, а
также для управления такими данными. Redis обеспечивает задержку на уровне долей миллисекунды,
масштабируемость и отказоустойчивость, необходимые для управления такими данными сессий, как
профили пользователей, учетные данные, состояние
сессий и индивидуальные пользовательские
настройки.
117
118.
Потоковая передача мультимедиаRedis предлагает быстрое хранилище данных в памяти для примеров использования с потоковой передачей в режиме реального времени. Redis можно использовать для хранения метаданных профилей
пользователей и историй просмотров, данных и токенов аутентификации миллионов пользователей, а
также файлов манифеста. Это позволяет сетям CDN
одновременно выполнять потоковую передачу видео миллионам пользователей мобильных и настольных компьютеров.
118
119.
Работа с геопространственными даннымиRedis предлагает специально разработанные операторы и структуры данных в памяти для управления
поступающими в режиме реального времени геопространственными данными в нужном масштабе и с
высокой скоростью.
Machine Learning
Чтобы быстро обрабатывать огромные объемы разнообразных данных, передаваемых на большой скорости, и автоматизировать принятие решений, современным приложениям, управляемым данными, требуется машинное обучение. Redis предоставляет скоростное хранилище данных в памяти, обеспечивающее быстрое создание, обучение и развертывание
моделей машинного обучения.
119
120.
Аналитика в режиме реального времениRedis может использоваться с решениями потоковой
передачи, такими как Apache Kafka и Amazon Kinesis,
в качестве хранилища данных в памяти для сбора,
обработки и анализа данных в режиме реального
времени с задержкой на уровне долей миллисекунды. Redis – идеальный выбор для аналитики в режиме реального времени в таких примерах использования, как аналитика в социальных сетях, рекламный
таргетинг, персонализация контента и IoT.
120
121.
Apache Cassandra – это нереляционнаяотказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных масси=вов данных, представленных в виде хэша.
Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду
Apache Software Foundation в 2009. Эта СУБД
относится к гибридным NoSQL-решениям,
поскольку она сочетает модель хранения данных на базе семейства столбцов (ColumnFamily)
с концепцией key-value (ключ-значение).
121
122.
Модель данных Cassandra включает в себя:-столбец или колонка (column) – ячейка с
данными, включающая 3 части – имя (column
name) в виде массива байтов, метку времени
(timestamp) и само значение (value) также в
виде байтового массива.
-строка или запись (row) – именованная
коллекция столбцов;
-семейство столбцов (column family) –
именованная коллекция строк;
-пространство ключей (keyspace) – группа из
нескольких семейств столбцов, собранных
вместе.
122
123.
в рассматриваемой СУБД доступны следующиетипы данных:
•BytesType: любые байтовые строки (без валидации);
•AsciiType: ASCII строка;
•UTF8Type: UTF-8 строка;
•IntegerType: число с произвольным размером;
•Int32Type: 4-байтовое число;
•LongType: 8-байтовое число;
•UUIDType: UUID 1-ого или 4-ого типа;
•TimeUUIDType: UUID 1-ого типа;
•DateType: 8-байтовое значение метки времени;
•BooleanType: два значения: true = 1 или false = 0;
•FloatType: 4-байтовое число с плавающей запятой;
•DoubleType: 8-байтовое число с плавающей запятой;
•DecimalType: число с произвольным размером и плавающей запятой;
•CounterColumnType: 8-байтовый счётчик.
123
124.
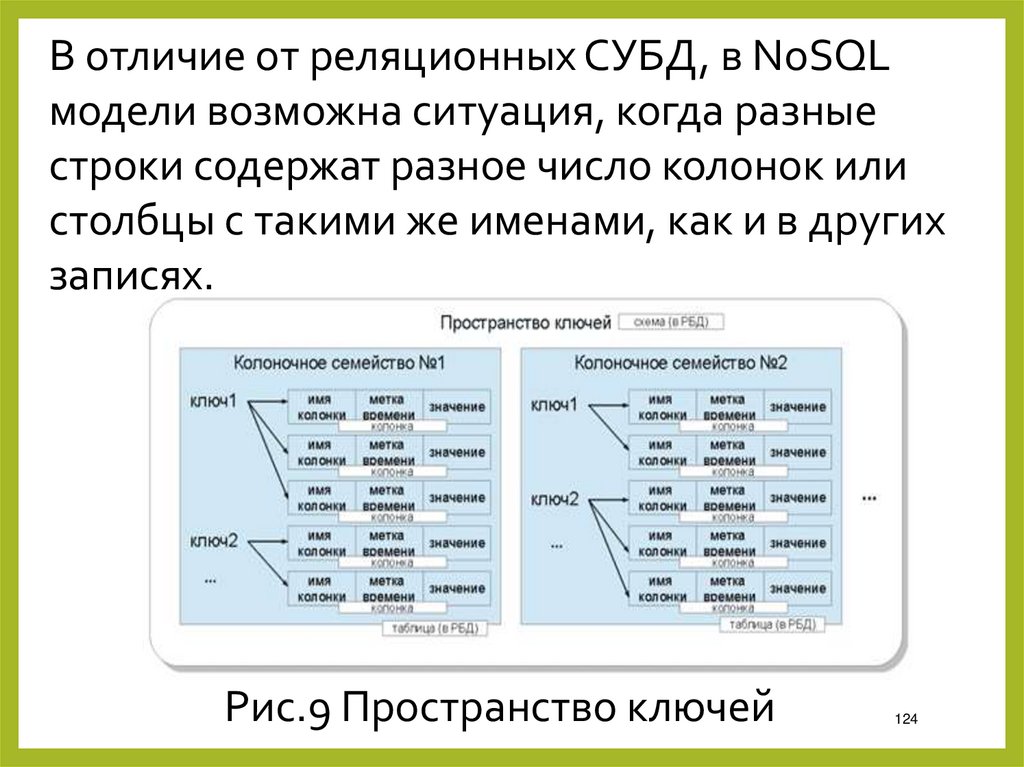
В отличие от реляционных СУБД, в NoSQLмодели возможна ситуация, когда разные
строки содержат разное число колонок или
столбцы с такими же именами, как и в других
записях.
Рис.9 Пространство ключей
124
125.
Конкретное значение, хранимое в ApacheCassandra, идентифицируется следующими
привязками:
-к приложению или предметной области в пространстве ключей, что позволяет на одном кластере размещать данные разных приложений;
-к запросу в рамках семейства столбцов;
-к узлу кластера с помощью ключа, который
определяет, на какие узлы попадут сохранённые
колонки;
-к атрибуту в записи с помощью имени
колонки, что позволяет в одной записи хранить
несколько значений.
125
126.
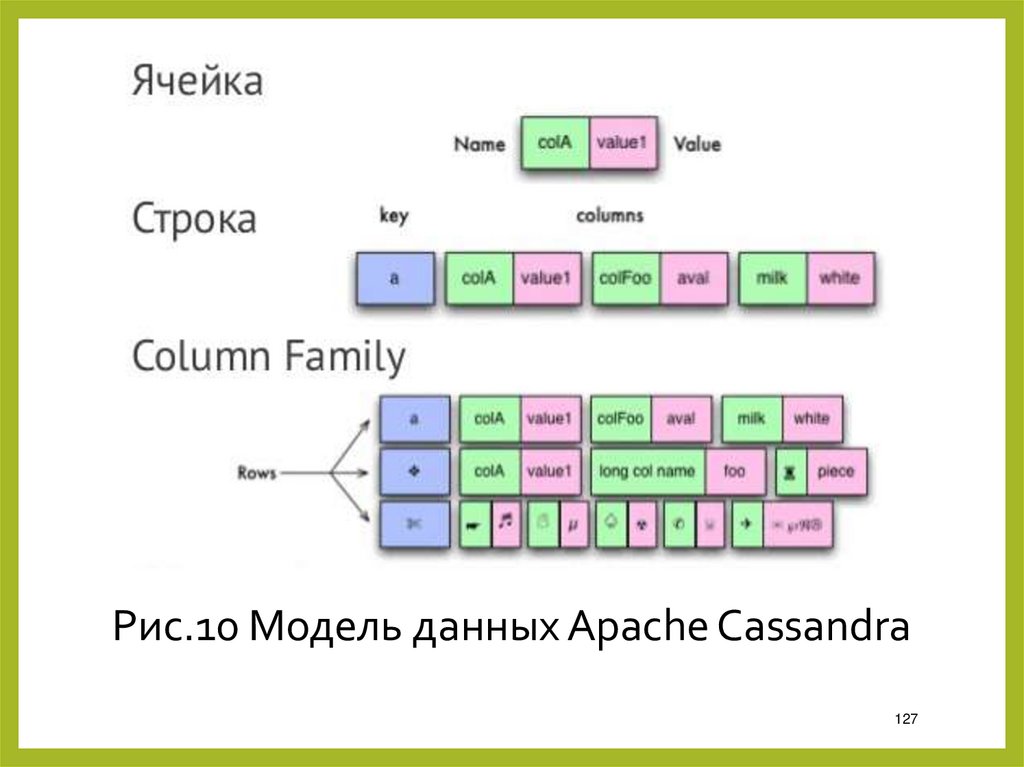
Структура данных при этом выглядит так:Keyspace
ColumnFamily
Row
Key
Column
Name
Value
Column
…
…
126
127.
Рис.10 Модель данных Apache Cassandra127
128.
АРХИТЕКТУРАApache Cassandra – это децентрализованная
распределенная система, состоящая из нескольких узлов, по которым она распределяет
данные. В отличие от многих других Big Data
решений экосистемы Apache Hadoop (Hbase,
HDFS), эта СУБД не поддерживает концепцию
master/slave (ведущий/ведомый), когда один
из серверов является управляющим для
других компонентов кластера.
128
129.
Благодаря такой распределенной архитектуре, Cassandra предоставляет следующиевозможности:
-распределение данных между узлами
кластера прозрачно для пользователей –
каждый сервер может принимать любой
запрос (на чтение, запись или удаление
данных), пересылая его на другой узел, если
запрашиваемая информацию хранится не
здесь;
129
130.
-пользователи могут сами определить необходимое количество реплик, создание и управление которыми обеспечит Cassandra;-настраиваемый пользователями уровень
согласованности данных по каждой
операции хранения и считывания;
высокая скорость записи (около 80-360
МБ/с на узел) – данные записываются быстрее, чем считываются за счет того, что их
большая часть хранится в оперативной памяти ответственного узла, и любые обновления сперва выполняются в памяти, а только
потом – в файловой системе.
130
131. - гибкая масштабируемость – можно постро-ить кластер даже на сотню узлов, способный обрабатывать петабайты данных. Таким
- гибкая масштабируемость – можно построить кластер даже на сотню узлов, способныйобрабатывать петабайты данных.
Таким образом, отсутствие центрального
узла лишает Кассандру главного недостатка,
свойственного системам master/slave, в
которых отказывает весь кластер при сбое
главного сервера (Master Node). В кластере
Cassandra все узлы равноценны между собой
и, если один из них отказал, его функции
возьмет на себя какой-то из оставшихся.
131
132. Благодаря такой децентрализации Apache Cassandra отлично подходит для географически распределенных систем с высокой
доступностью, расположенных в разных датацентрах. Однако, привсех преимуществах такой гибко
масштабируемой архитектуры, она
обусловливает особенности операций
чтения и записи, а также накладывает
ряд существенных ограничений на
использование этой СУБД в реальных
Big Data проектах.
132
133. Рис.10 Кластерная архитектура Apache Cassandra
133134. Рис.11 Выбор узлов кластера по уровню репликации
134135. Рис.12 Иллюстрация, отображающая при по-мощи встроенной утилиты nodetool , кольцо кластера из 6 узлов с равномерно
Рис.12 Иллюстрация, отображающая при помощи встроенной утилиты nodetool , кольцокластера из 6 узлов с равномерно распределенными метками.
135
136. Согласованность данных Узлы кластера кассандры равноценны, и клиенты могут соединятся с любым из них, как для записи, так и для
чтения. Запросы проходят стадию координации. Будем называтьузел, который выполняет координацию —
координатором (coordinator), а узлы, которые
выбраны для сохранения записи с данным
ключом — узлами-реплик (replica nodes).
Физически координатором может быть один
из узлов-реплик — это зависит только от
ключа, разметчика и меток.
136
137. Для записи существуют такие уровни согласованности: ONE — координатор шлёт запросы всем уз-лам-реплик, но, дождавшись
Для записи существуют такие уровнисогласованности:
ONE — координатор шлёт запросы всем узлам-реплик, но, дождавшись подтверждения
от первого же узла, возвращает управление
пользователю;
TWO — то же самое, но координатор дожидается подтверждения от двух первых узлов;
THREE — аналогично, но координатор ждет
подтверждения от трех первых узлов;
QUORUM — собирается кворум: координатор
дожидается подтверждения записи от более
чем половины узлов-реплик, а именно
round(N / 2) + 1, где N — уровень репликации;
137
138. LOCAL_QUORUM — координатор дожидается подтверждения от более чем половины узлов-реплик в том же ЦОДе, где и координатор;
LOCAL_QUORUM — координатор дожидаетсяподтверждения от более чем половины узловреплик в том же ЦОДе, где и координатор;
EACH_QUORUM — координатор дожидается
подтверждения от более чем половины узловреплик в каждом центре обработки данных;
ALL — координатор дожидается подтверждения от всех узлов-реплик;
ANY — даёт возможность записать данные,
даже если все узлы-реплики не отвечают.
Координатор дожидается или первого ответа
от одного из узлов-реплик, или когда данные
сохранятся при помощи направленной
отправки (hinted handoff) на координаторе.
138
139. Рис.13 Схема записи с заданным уровнем согласованности
139140. Для чтения существуют такие уровни согласованности: ONE — координатор шлёт запросы к ближайшему узлу-реплике. Остальные реплики
также читаются в целях чтенияс исправлением (read repair) с заданной в
конфигурации кассандры вероятностью;
TWO — то же самое, но координатор
шлёт запросы к двум ближайшим узлам.
Выбирается то значение, которое имеет
большую метку времени;
THREE — аналогично предыдущему
варианту, но с тремя узлами;
140
141. QUORUM — собирается кворум, то есть координатор шлёт запросы к более чем половине узлов-реплик, а именно round(N / 2) + 1, где
N — уровень репликации;LOCAL_QUORUM — собирается кворум в том
ЦОДе, в котором происходит координация, и
возвращаются данные с последней меткой
времени;
EACH_QUORUM — координатор возвращает
данные после собрания кворума в каждом из
ЦОДов;
ALL — координатор возвращает данные
после прочтения со всех узлов-реплик.
141
142. Рис.14 Схема чтения с заданным уровнем согласованности
142143. Восстановление данных Кассандра поддерживает три механизма восстановления данных: -чтение с восстановлением (read repair);
Восстановление данныхКассандра поддерживает три
механизма восстановления данных:
-чтение с восстановлением (read repair);
-направленной отправки (hinted
handoff);
-анти-энтропийное восстановление
узла (anti-entropy node repair).
143
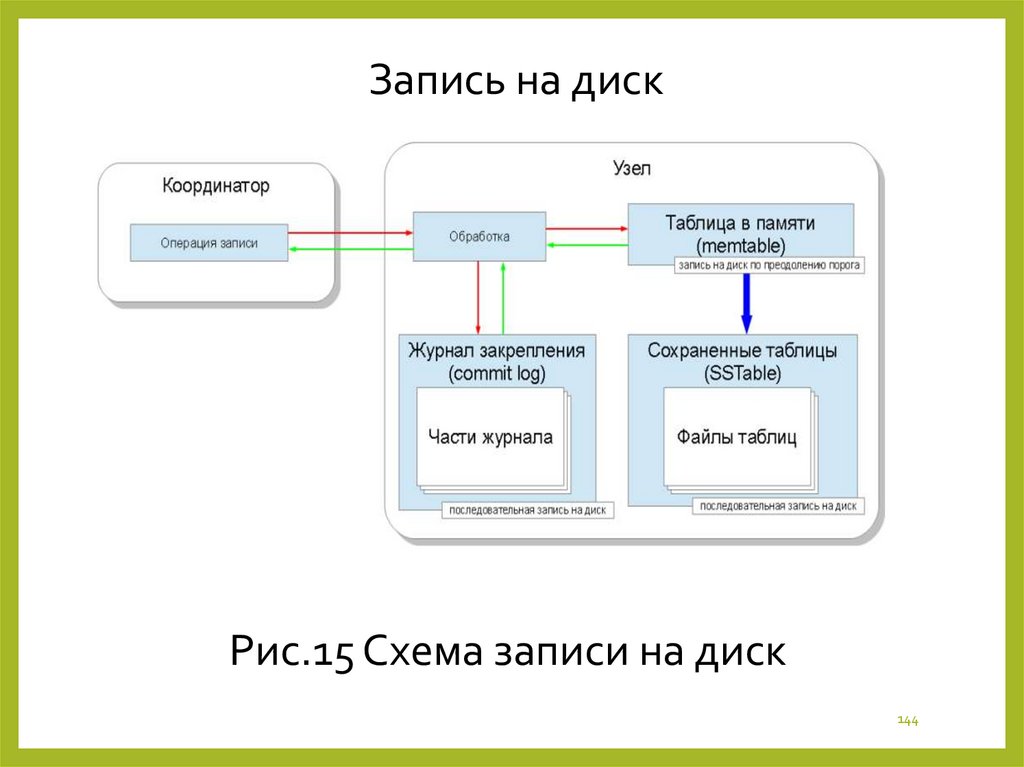
144.
Запись на дискРис.15 Схема записи на диск
144
145. Рис.16 Схема записи с использованием блум-фильтрацией
Рис.16 Схема записи с использованием блумфильтрацией145
146. Уплотнение
Рис.17 Схема уплотнения таблиц146
147. Операции удаления С точки зрения внутреннего устройства, операции удаление колонок — это операции записи специального значения
—затирающего значения (tombstone). Когда
такое значение получается в результате
чтения, то оно пропускается. В результате же
уплотнения, такие значения постепенно
вытесняют устаревшие реальные значения и,
возможно, исчезают вовсе. Если же появятся
колонки с реальными данными с еще более
новыми метками времени, то они перетрут, в
конце концов, и эти затирающие значения.
147
148. Транзакционность Кассандра поддерживает транзакционность на уровне одной записи, то есть для набора колонок с одним ключом. Вот
как выполняютсячетыре требования ACID:
-атомарность (atomicity) — все
колонки в одной записи за одну
операцию будут или записаны, или нет;
148
149. согласованность (consistency) — есть возможность использовать запросы с строгой согласованностью взамен доступности;
согласованность (consistency) — естьвозможность использовать запросы с строгой
согласованностью взамен доступности;
изолированность (isolation) —когда во время
записи колонок одной записи другой пользователь, который читает эту же запись, увидит
или полностью старую версию записи или,
уже после окончания операции, новую версию, а не часть колонок из одной и часть из
второй;
долговечность (durability) обеспечивается наличием журнала закрепления, который будет
воспроизведён и восстановит узел до нужного
состояния в случае какого-либо отказа.
149