






















 programming
programming informatics
informaticsSimilar presentations:
")









Введение в обработку естественного языка
1.
Введение вобработку естественного языка
2.
План лекции1. Обработка естественного языка (NLP)
2. Задачи NLP
3. Подготовка текстовых данных
4. Представление текстовых данных
5. Word2vec
6. Задача классификации текстовых данных
7. CNN для классификации текстовых данных
3.
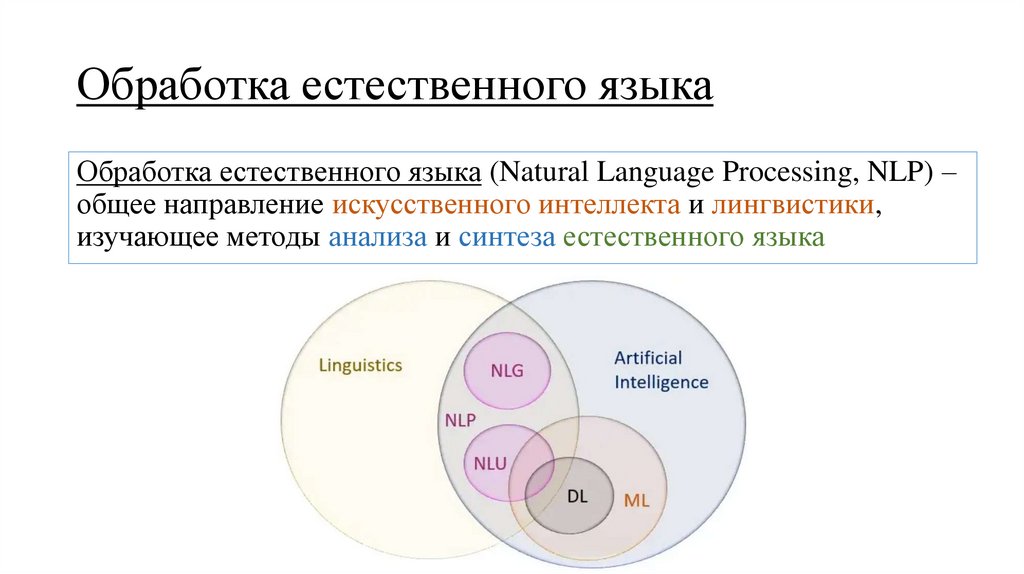
Обработка естественного языкаОбработка естественного языка (Natural Language Processing, NLP) –
общее направление искусственного интеллекта и лингвистики,
изучающее методы анализа и синтеза естественного языка
4.
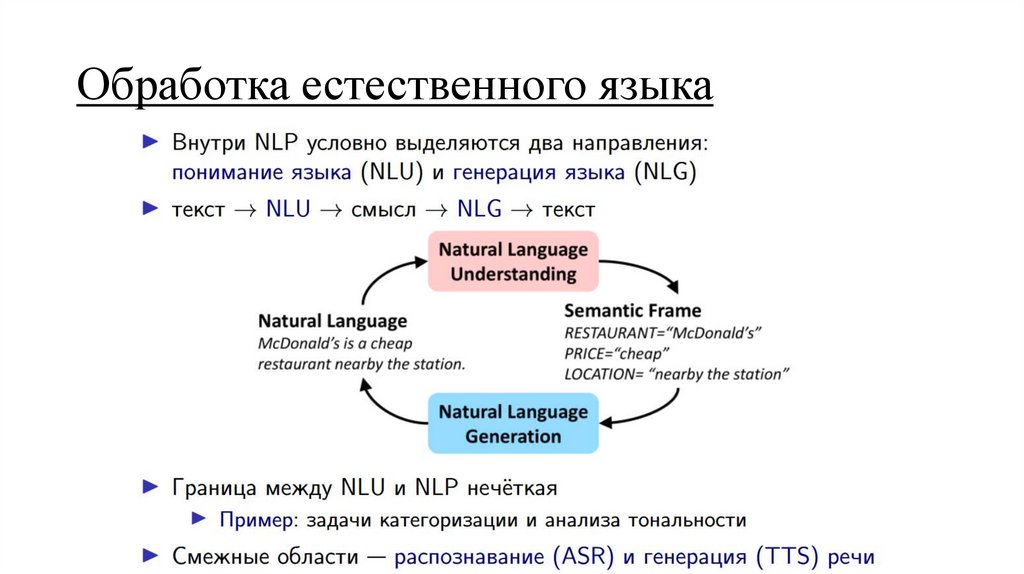
Обработка естественного языка5.
Задачи NLPТематическое моделирование
6.
Задачи NLPТематическое моделирование
7.
Подготовка текстовых данныхЭтапы подготовки (предобработки) текстовых данных:
– приведение к одному регистру
– замена «нетекстовой» информации
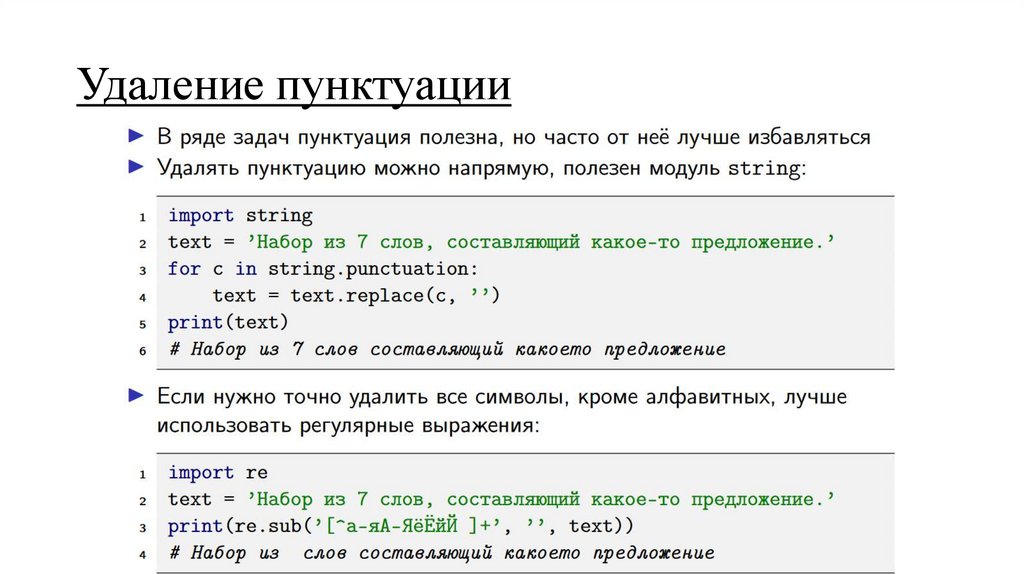
– удаление пунктуации
– токенизация
– удаление стоп-слов, редких и частых слов
– стемминг
– лемматизация
– векторизация
8.
Токенизация9.
Удаление пунктуации10.
Регистр и пунктуация11.
Лемматизация и стемминг12.
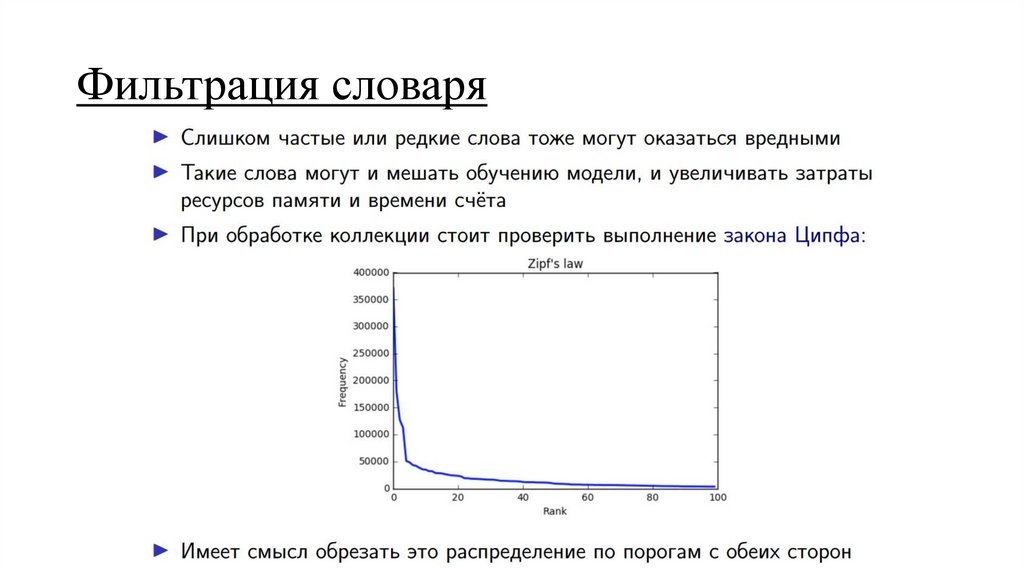
Фильтрация словаря13.
Фильтрация словаря14.
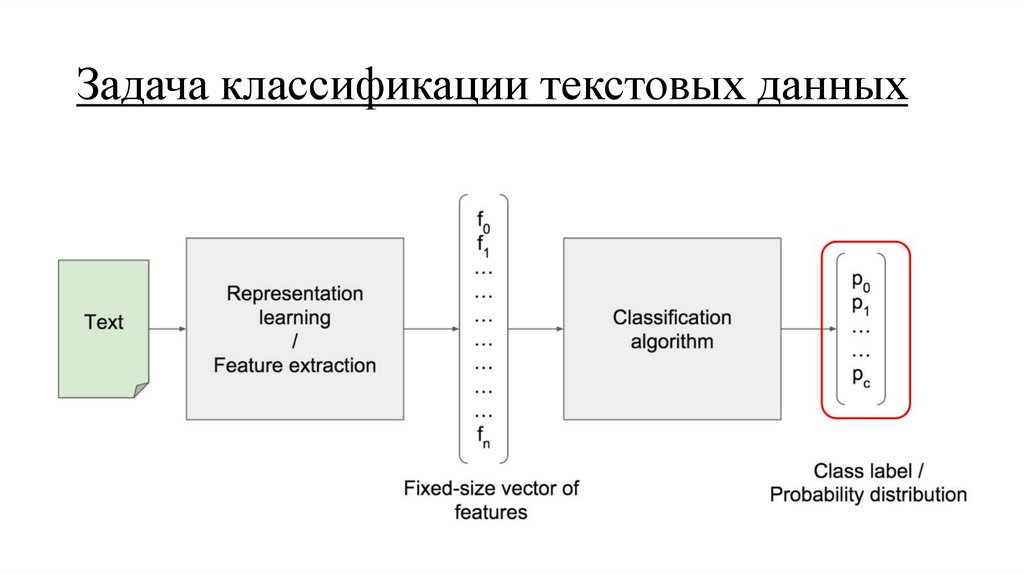
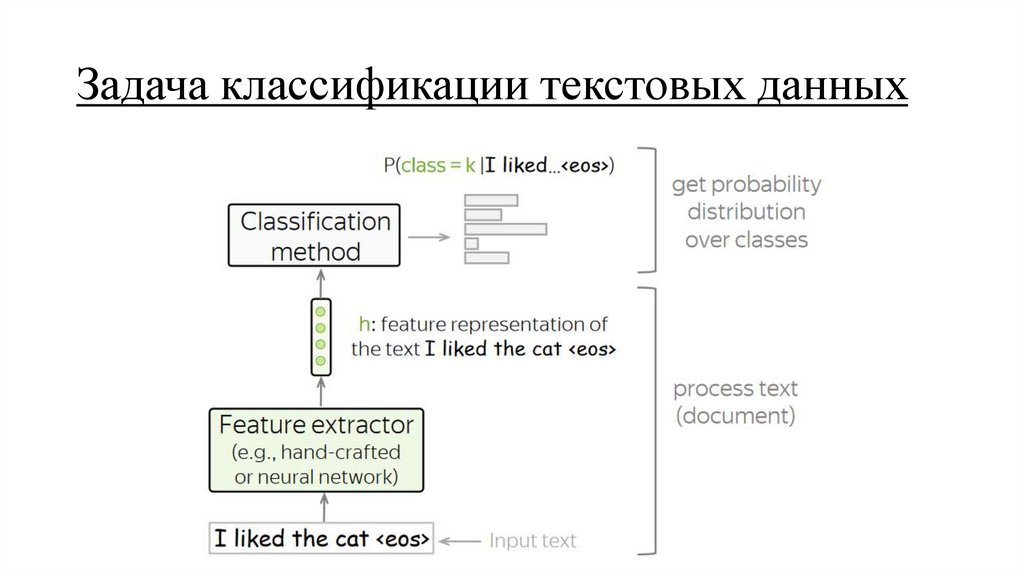
Задача классификации текстовых данных15.
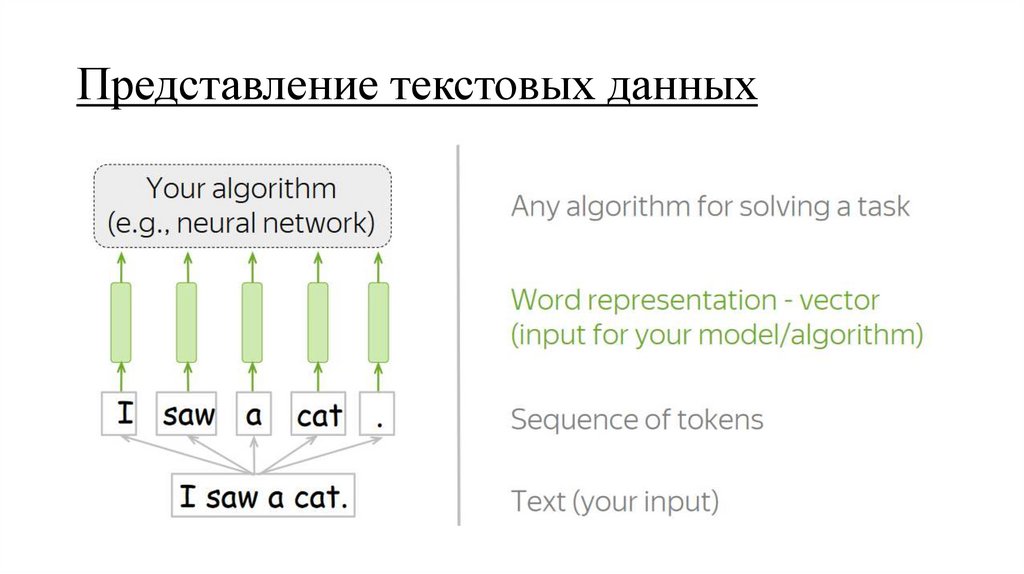
Представление текстовых данных16.
One-Hot Vector и мешок слов (BOW)17.
One-Hot Vector и мешок слов (BOW)18.
Гипотеза дистрибутивной семантики19.
Count-based подходыЗадача:
• вложение (embedding, вектор) слова должно содержать информацию о контексте
Count-based решение:
• рассчитать вложение на основе глобальных статистик документа
20.
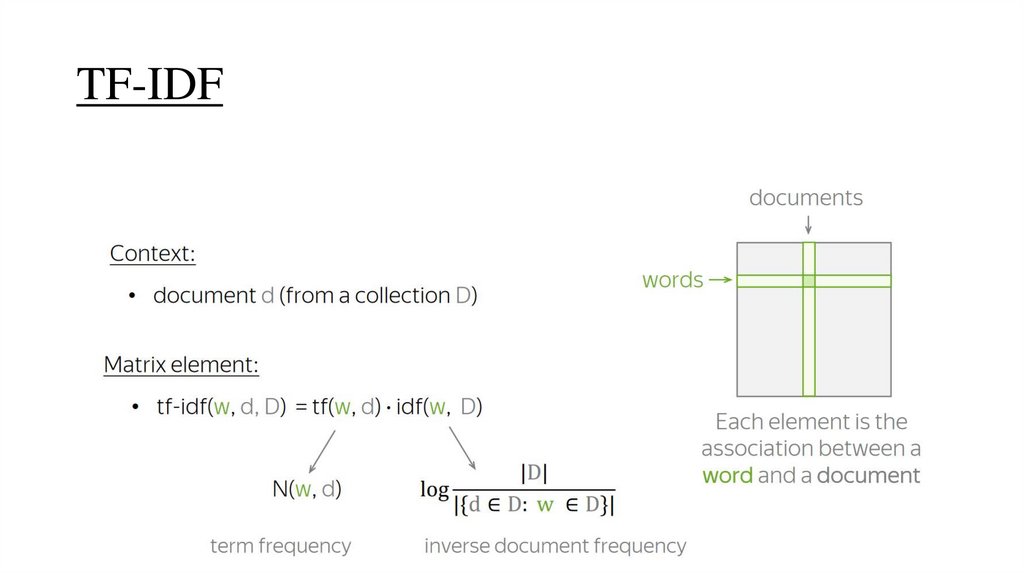
TF-IDF21.
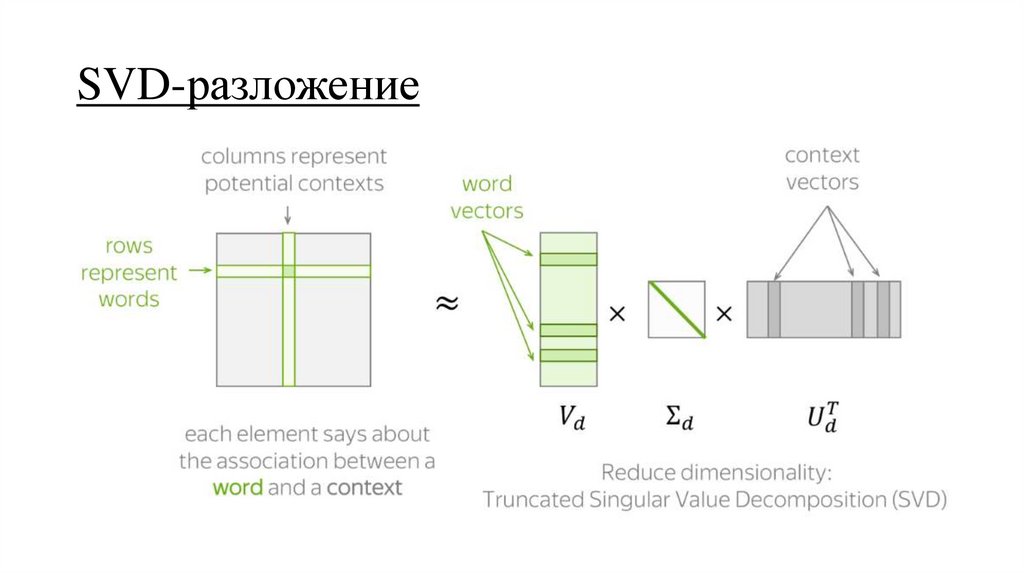
SVD-разложение22.
SVD-разложение: обоснование23.
SVD-разложение: обоснование24.
SVD-разложение: обоснование25.
Поточечная взаимная информацияПоточечная взаимная информация (Pointwise Mutual Information, PMI)
26.
Prediction-based подходыЗадача:
• вложение (embedding, вектор) слова должно содержать информацию о контексте
Prediction-based решение:
• обновлять параметры вложений во время обучения модели
Модели векторных представлений на основе prediction-based подходов:
– word2vec
– GloVe
– fasttext
–…
27.
Word2vec: Skip-Gram and CBOW28.
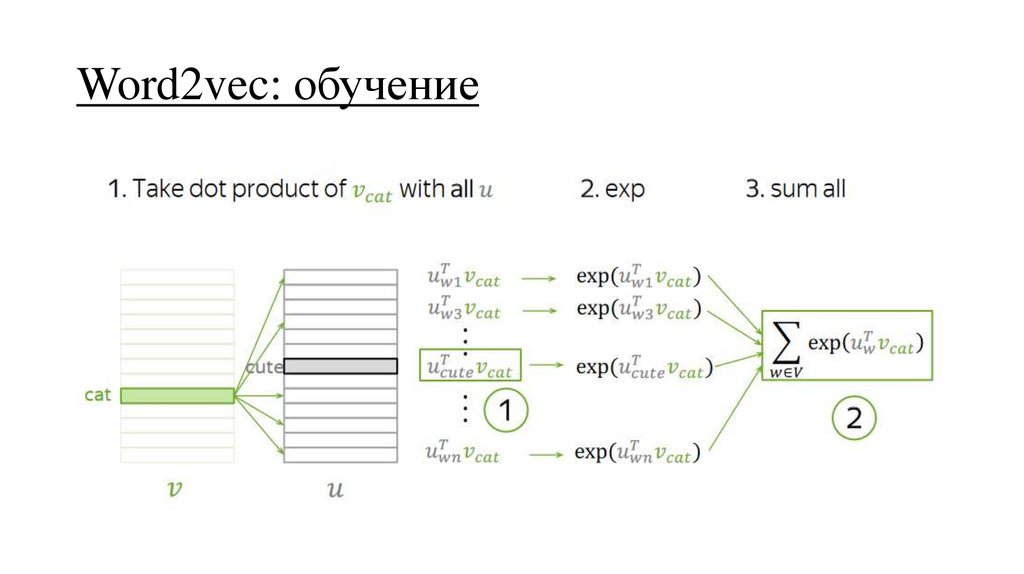
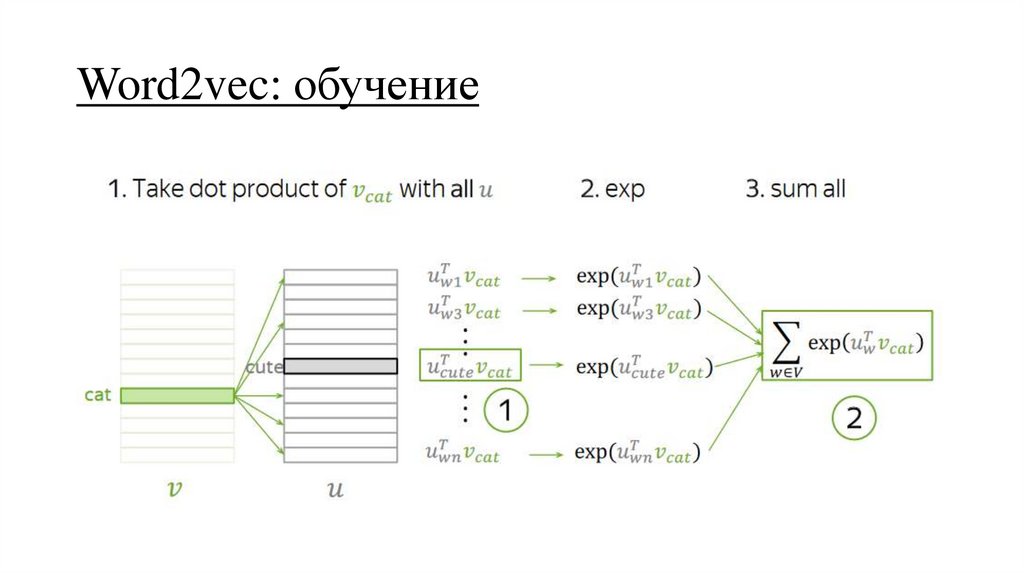
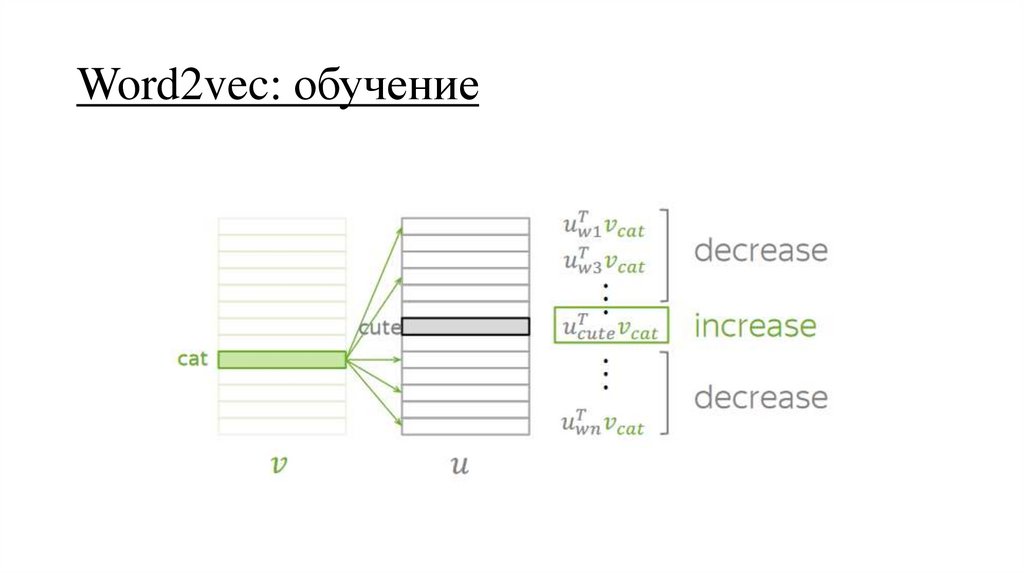
Word2vec: обучение29.
Word2vec: обучение30.
Word2vec: обучение31.
Word2vec: обучение32.
Word2vec*Всяческие картинки про сумму векторов: король – мужчина = королева*
33.
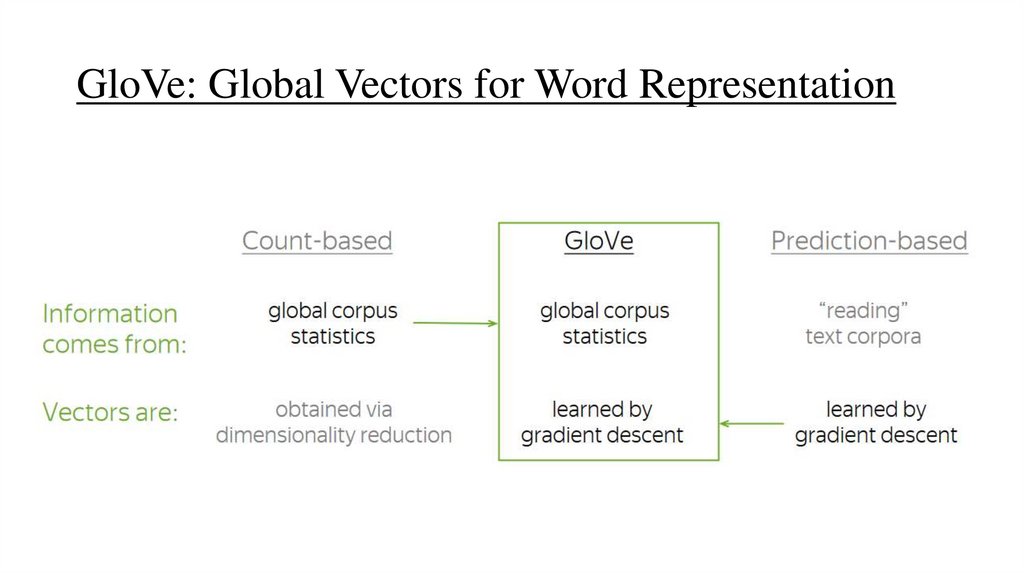
GloVe: Global Vectors for Word Representation34.
FastText35.
Задача классификации текстовых данных36.
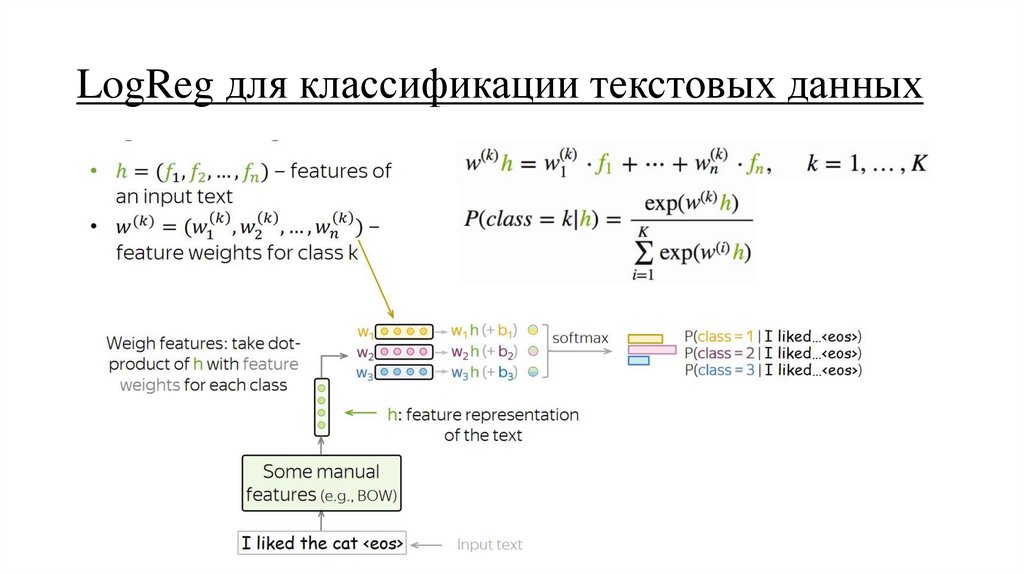
LogReg для классификации текстовых данных37.
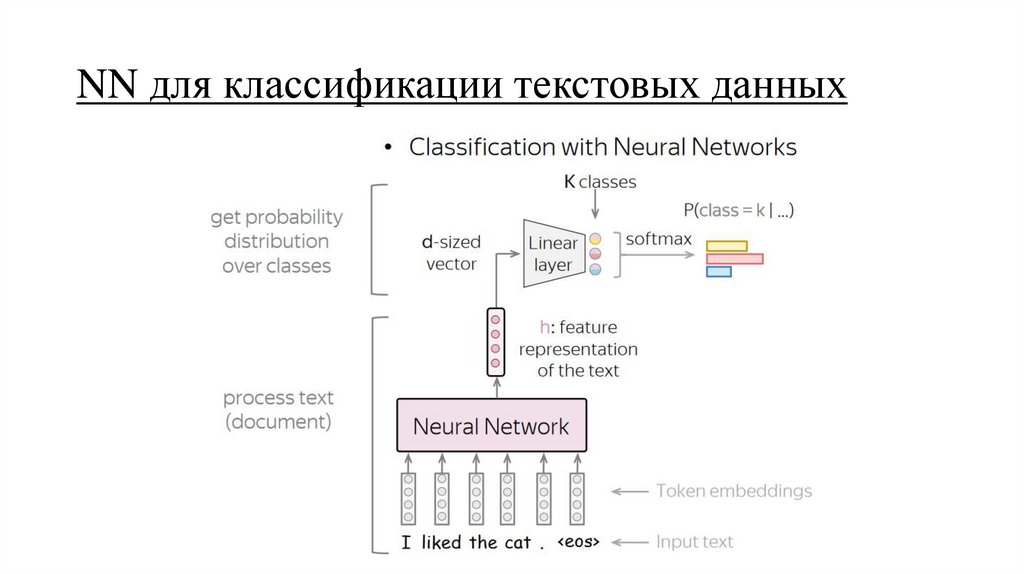
NN для классификации текстовых данных38.
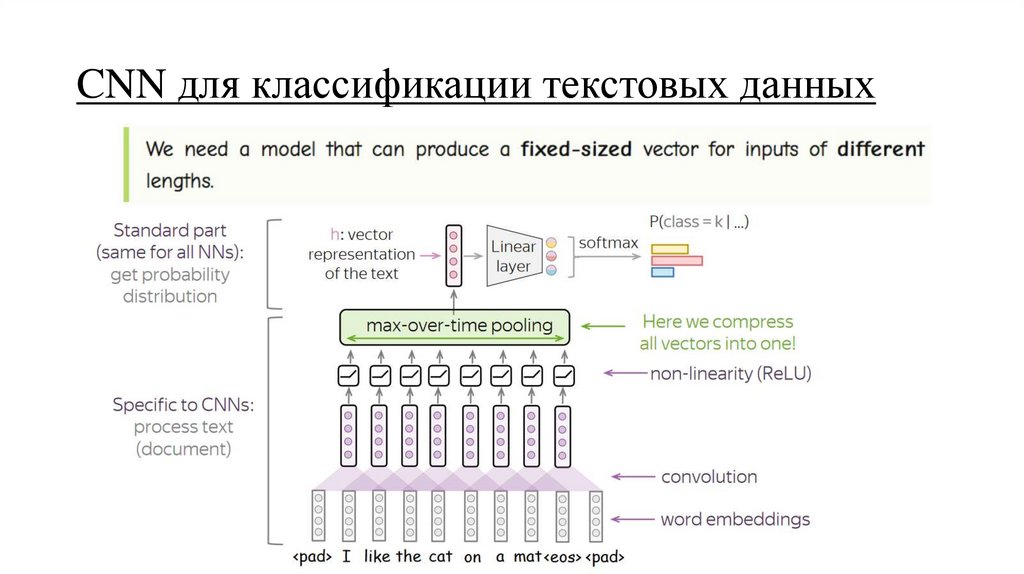
CNN для классификации текстовых данных39.
Инструменты для NLPСпецифичные:
– NLTK (предобработка, …)
– Gensim (векторизация,
тематическое моделирование, …)
– SpaCy (основные задачи NLP)
– Natasha (для русского языка:
предобработка, векторизация, NER)
– DeepPavlov (для русского языка:
векторизация, NER и остальные
основные задачи)
Знакомые:
– Sklearn (предобработка,
векторизация, тематическое
моделирование, …)
– Hugging Face (предобученные
модели, наборы данных)
– PyTorch
– re