

























































 database
databaseSimilar presentations:

")
")


")
")


. Определение базы данных")
Database Theory Introduction
1.
Александр Загоруйко © 2022Database Theory Introduction
2.
Программа курса по БДТеория и практика баз данных
СУБД: SQL Server, MySQL, SQLite
DML: SELECT, INSERT, UPDATE, DELETE
Многотабличные БД и запросы
Нормализация, проектирование
Функции агрегирования, подзапросы
DDL: CREATE, ALTER, DROP
Индексы, пользователи и права
ГК QA: 20 пар (БД + Python)
3.
Примеры условий запросов4.
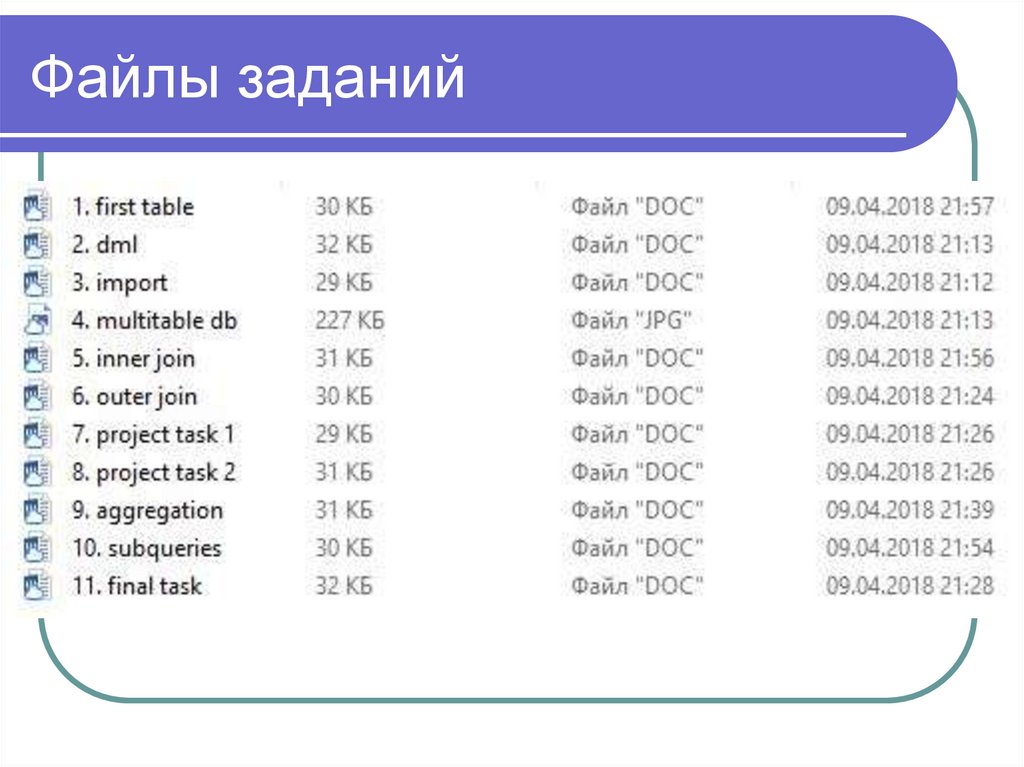
Файлы заданий5.
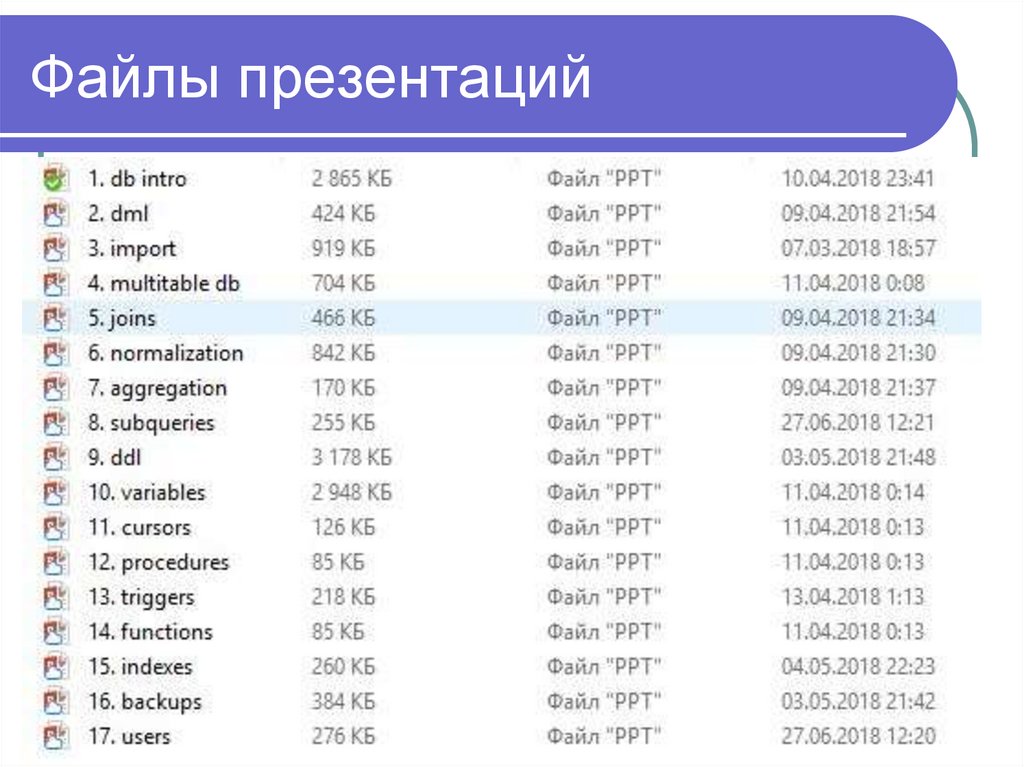
Файлы презентаций6.
Литература по базам данныхhttps://proglib.io/p/sql-digest/
Линн Бейли (Headfirst)
Кристофер Дейт
7.
Полезные сайтыhttps://www.hackerrank.com/domains/sql
https://www.codecademy.com/learn/learn-sql
http://www.quizful.net/test
https://www.youtube.com/playlist?list=PLWCo
o5SF-qANaHABEiNOJ-yBcmYqOEve1
https://techrocks.ru/2018/07/05/ms-sqlpractice/
8.
Статьи и курсыhttp://habrahabr.ru/company/mailru/blog/266811/
http://habrahabr.ru/post/255361/
http://habrahabr.ru/post/255523/
https://class.stanford.edu/courses/Home/Databases/Engineeri
ng/about
https://www.codecademy.com/learn/learn-sql
http://www.intuit.ru/studies/courses/74/74/info
http://www.w3schools.com/sql/
http://www.sql-ex.ru/learn_exercises.php
http://www.sqlmanager.net/en/products/mssql/manager
http://citforum.ru/database/
9.
Виды (модели) баз данныхМодель базы данных - это способ описания
логической структуры БД, который определяет, каким
образом данные могут храниться, организовываться и
обрабатываться. Самым популярным примером модели
базы данных является реляционная модель, которая
использует табличный формат. Основные модели:
Иерархическая
Сетевая
Объектная
NoSQL (not only SQL)
Реляционная (RDBMS)
10.
Сам себе режиссёр ;)Как вариант, всегда можно создать
программно либо вручную текстовый /
двоичный файл, и записывать в него
необходимую информацию. Такой способ
хранения данных по сути будет
представлять собой простейшую файловую
базу данных, где внутренний формат, а
также протокол записи / чтения будет
придуман лично нами самими.
11.
Хранение информацииДля программиста работа с
файлами имеет очень большое
значение. Длительное хранение
информации только в оперативной
памяти невозможно. Файл же хранит
информацию на диске / карте, что
позволяет обратиться к ней в любой
момент.
12.
Определение понятия файлФайл - это конечная именованная совокупность байтов,
размещённая на некотором носителе информации (в
том числе в памяти).
Файл не может располагаться на диске / карте непрерывно,
однако пользователю файл предоставляется цельным
блоком последовательной байтовой информации
Большинство файлов обладает расширением - сочетанием
символов, с помощью которых операционная система
определяет тип файла (появятся ли слова песни, если
поменять mp3 на txt? )
У каждого файла есть так называемые атрибуты (например
- скрытый, системный, архивный, является папкой, только
для чтения и тд.)
13.
Виды файловБинарный файл - это самый обычный файл,
просто совокупность байтов. Условно можно
рассматривать такой файл как массив.
Текстовый файл - это файл, который при
интерпретации значений его байтов, как кодов
его символов и представлении его на экране в
виде совокупности этих символов - образует
осмысленный текст. По сути, это совокупность
строк (единицей измерения файла является
строка). Разделителем строк является символ
перевода строки.
14.
Задачи при работе с даннымиЗадачи, которые приходится решать при
работе с файлом – это, в первую очередь,
добавление, изменение и удаление
данных, а также их поиск. Эти задачи
являются рутинными и типичными, но
далеко не самыми простыми, и поэтому
программисты уже давно задались целью их
формализировать. Теория БД как раз и
появилась как способ решения этих задач.
15.
Иерархическая БДКонцепции теории БД менялись в
течении длительного периода времени.
Одним из первых видов БД были
иерархические БД. Как следует из их
названия, предназначались одни для
хранения данных, связанных друг с
другом иерархическими связями. Однако
иерархическая модель оказалась
эффективной только для таких данных.
16.
Проблемы иерархических БДДалеко не все данные можно представить
при помощи иерархической модели, а если
и можно, то эффективность работы с такими
данными часто оставляет желать лучшего.
Иерархические БД используются до сих пор,
но только в достаточно специфических
случаях и для хранения данных, связи
между которыми имеют древовидную
структуру (пример - реестр Windows).
https://ru.wikipedia.org/wiki/%D0%98%D0%B5%D1%80%D0%B0%D1%80%D1%85%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0
%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
17.
Сетевая модель БДТакже существует сетевая модель БД, она является
более универсальной, однако также имеет
множество недостатков. Данные в сетевой БД
хранятся в виде связанных т.н. «наборов» –
именованных двухуровневых деревьев. Наборы
связаны между собой специальными отдельно
хранящимися связями. Центральное понятие узел. Каждый элемент может быть связан с
любым другим элементом. На схеме узлы
иерархического дерева представляются вершинами
графа. Главный недостаток - ненадёжность.
Пример: dbVista.
18.
Проблемы сетевых БДТакая структура по определению
приводила к ухудшению
производительности, осложняя как
модификацию БД, так и поиск по ней.
Попытки улучшить производительность
сетевых БД привели к их значительному
усложнению, а значит нестабильности и
неустойчивости.
https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%B0%D1%8F_%D0%BC%D0%
BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
19.
NoSQLSQL (Structured Query Language) —
универсальный язык запросов, который
используется всеми реляционными системами.
Преимущества NoSQL - скорость обработки данных,
масштабируемость, распределённость систем.
Сильные стороны NoSQL - возможность хранения
больших объёмов неструктурированной информации.
В NoSQL нет ограничений на типы хранимых данных,
а при необходимости можно добавлять новые типы
данных.
Примеры NoSQL баз: MongoDB, Firebase
20.
NoSQLNoSQL-базы лучше поддаются масштабированию. Хотя
масштабирование поддерживается и в SQL-базах, это требует
гораздо больших затрат человеческих и аппаратных ресурсов.
Вычислительные мощности железа ограничены. А цена
нескольких простых серверов меньше, чем одного
высокопроизводительного. Горизонтальное
масштабирование (несколько независимых машин
соединяются вместе и каждая из них обрабатывает свою
часть запросов) позволяет увеличить мощность кластера
добавлением нового сервера.
Рассчитанные на работу в распределённых системах NoSQL
хранилища проектируются так, что все процедуры
распределения данных и обеспечения отказоустойчивости
выполняются NoSQL базой. Было бы что масштабировать ;)
21.
Реляционная модель БДРеляционная модель на сегодняшний день
является наиболее распространённой, и
именно её мы будем разбирать на
протяжении всего курса по БД.
В основе реляционной модели лежит
понятие отношения (relation, отношение
строк к столбцам таблицы, отсюда и
название), или собственно таблицы.
https://en.wikipedia.org/wiki/Relation_(database)
22.
Требования к РБД (ACID)Атомарность (atomicity) - перевод БД из одного целостного
состояния в другое. Гарантирует, что никакая транзакция не
будет зафиксирована частично (если деньги списались с одного
счёта, но на другой не зачислились - это как-то не круто)
Согласованность (consistency) - завершённая транзакция
сохраняет согласованность БД. Каждая успешная транзакция по
определению фиксирует только допустимые результаты.
(пример - возраст не может быть отрицательным)
Изолированность (isolation) - во время выполнения
транзакции параллельные транзакции не должны оказывать
влияние на её результат. Это весьма «дорогое» требование
Надёжность (durability) - если получено подтверждение, что
транзакция выполнена, можно быть уверенным, что сделанные
изменения не будут отменены из-за какого-либо аппаратного
сбоя
23.
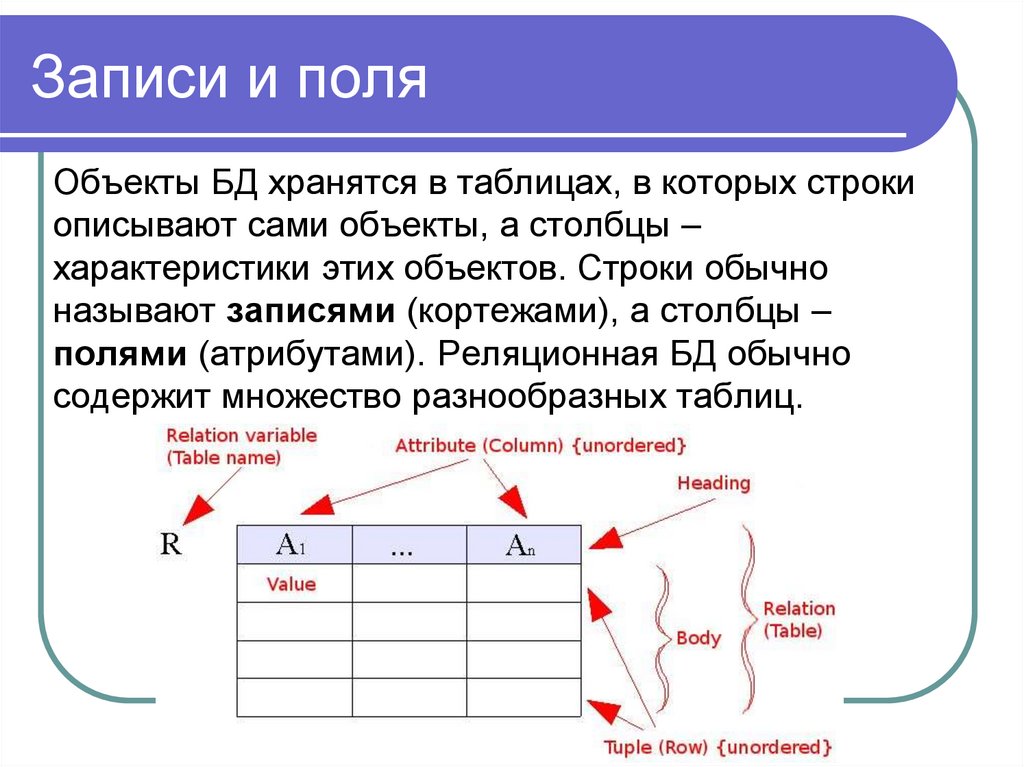
Записи и поляОбъекты БД хранятся в таблицах, в которых строки
описывают сами объекты, а столбцы –
характеристики этих объектов. Строки обычно
называют записями (кортежами), а столбцы –
полями (атрибутами). Реляционная БД обычно
содержит множество разнообразных таблиц.
24.
Определение реляционной БДРеляционная БД – это совокупность
отношений, которые связаны между
собой. Каждое отношение (таблица) это набор полей и записей. Записи это фактически объекты
определённого типа. Каждая запись
описывает один конкретный объект,
одну конкретную сущность.
25.
Понятие первичного ключаВ теории РБД существует исключительно
важное понятие - первичный ключ – это
одно или несколько полей, однозначно
идентифицирующих запись в таблице.
Значение, или комбинация значений не
должны повторяться в рамках
первичного ключа конкретной таблицы.
Используется первичный ключ в первую
очередь для того, чтобы отличать записи
друг от друга.
26.
Значения идентификаторовВ большинстве ситуаций в качестве первичного
ключа используется уникальный
идентификатор (обычно, целое число),
собственное значение которого не важно,
главное – чтобы не было двух записей с одним
и тем же идентификатором. То есть,
идентификаторы необязательно начинаются с
1, и необязательно идут по порядку.
Настоятельно рекомендуется создавать в
каждой таблице первичный ключ, однако, это
не обязательно.
27.
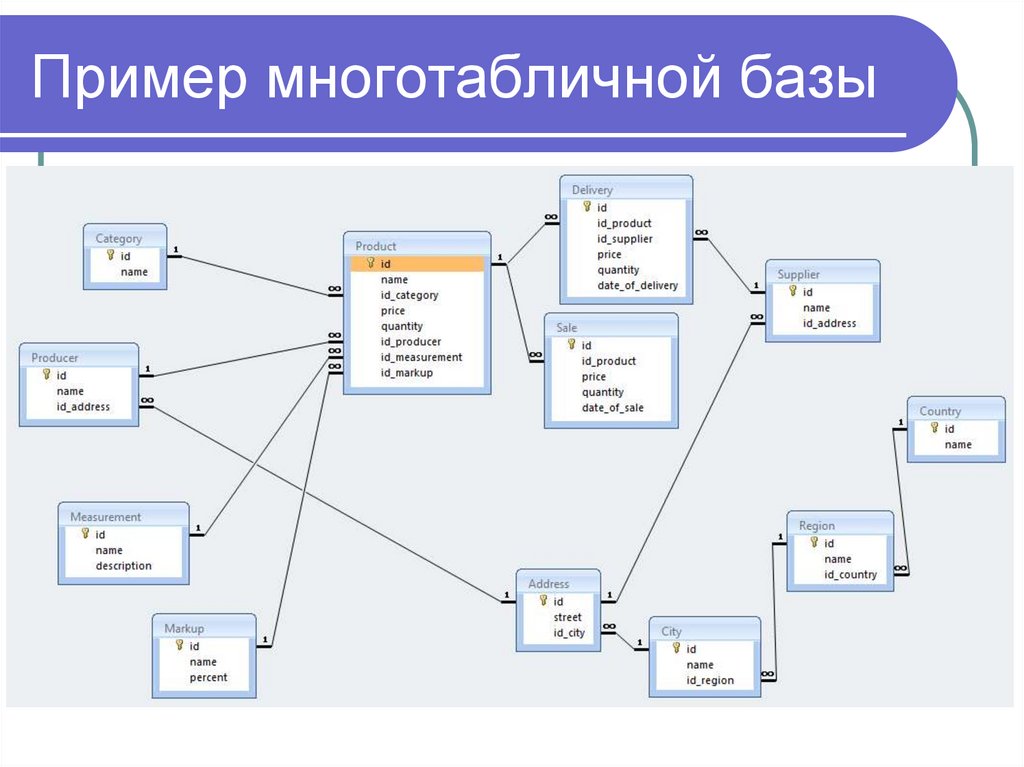
Пример многотабличной базы28.
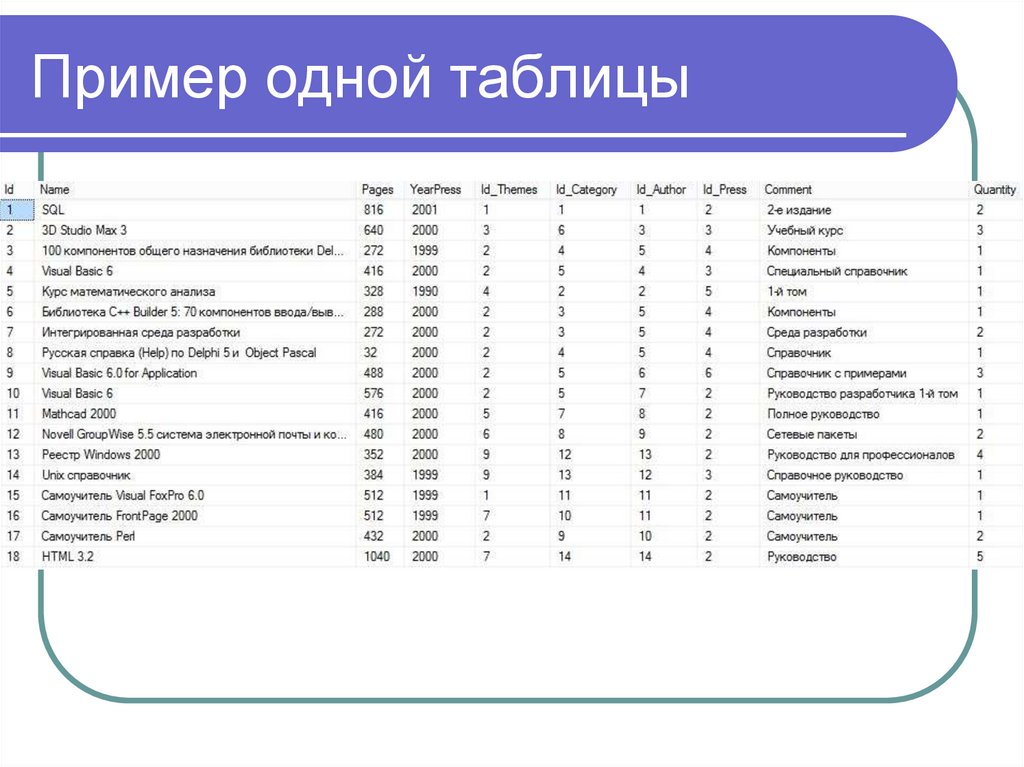
Пример одной таблицы29.
Определение базы данныхСама по себе БД – это совокупность
файлов на диске, в которых
определённым незашифрованным
образом хранится логически связанная
информация. Кроме самой базы
необходима ещё и прикладная программа,
позволяющая управлять этой БД.
Системы, предназначенные для
управления и работы с БД, называются
СУБД.
https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%
B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
30.
Основные функции СУБДуправление данными во внешней
памяти (на дисках)
управление данными в оперативной
памяти
журнализация изменений, резервное
копирование и восстановление базы
данных после сбоев
поддержка языков БД (DDL, DML, DCL)
31.
Распределённость БДПо степени распределённости БД
делят на:
Локальные БД (все части локальной
БД размещаются на одном
компьютере)
Распределённые БД (части БД могут
размещаться на двух и более
компьютерах)
32.
Способы доступа СУБД к БДФайл-серверные (Microsoft Access,
FoxPro)
Клиент-серверные (Oracle, Microsoft
SQL Server, Firebird, DB2, PostgreSQL,
MySQL)
Встраиваемые (СУБД SQLite,
используется в Android, iOS, встроена
в браузеры!)
33.
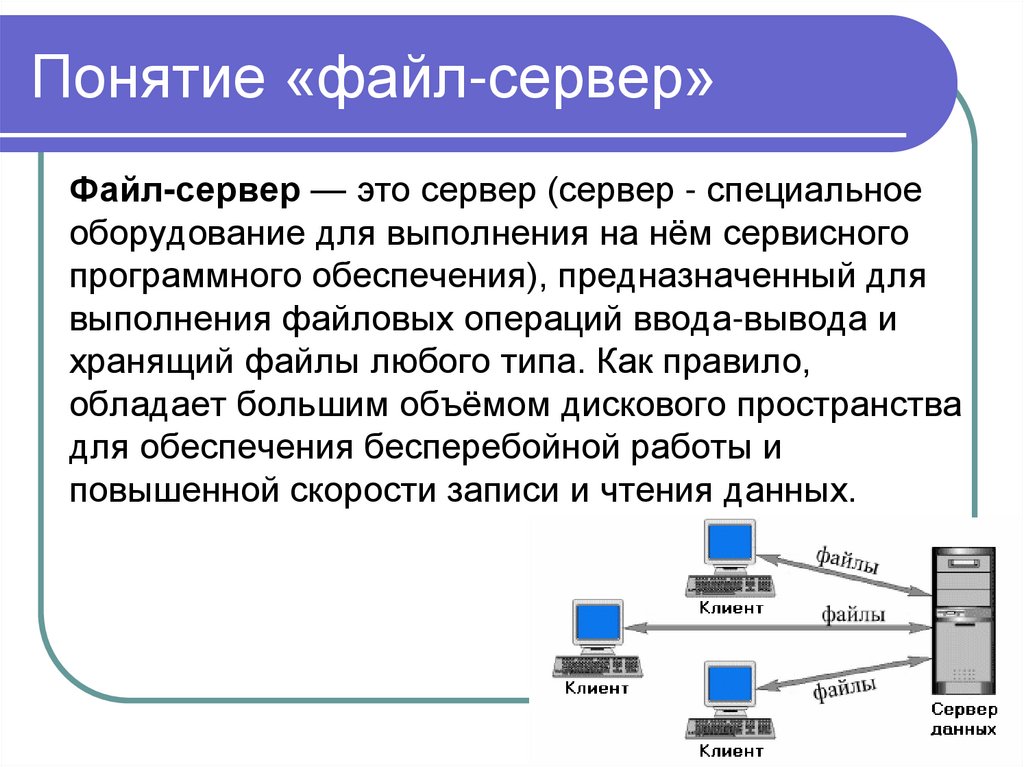
Понятие «файл-сервер»Файл-сервер — это сервер (сервер - специальное
оборудование для выполнения на нём сервисного
программного обеспечения), предназначенный для
выполнения файловых операций ввода-вывода и
хранящий файлы любого типа. Как правило,
обладает большим объёмом дискового пространства
для обеспечения бесперебойной работы и
повышенной скорости записи и чтения данных.
34.
Особенности архитектурыФункции сервера обычно ограничиваются
хранением данных (возможно также
хранение исполняемых файлов), обработка
данных происходит исключительно на
стороне клиента. Количество клиентов
ограничено десятками ввиду невозможности
одновременного доступа на запись к одному
файлу. Однако клиентов может быть больше,
если они обращаются к файлам
исключительно в режиме чтения.
35.
Плюсы и минусыДостоинства:
низкая стоимость разработки
высокая скорость разработки
невысокая стоимость обновления и изменения ПО
Недостатки:
рост числа клиентов резко увеличивает объём
трафика и нагрузку на сети передачи данных
высокие затраты на модернизацию и
сопровождение сервисов бизнес-логики на каждой
клиентской рабочей станции
36.
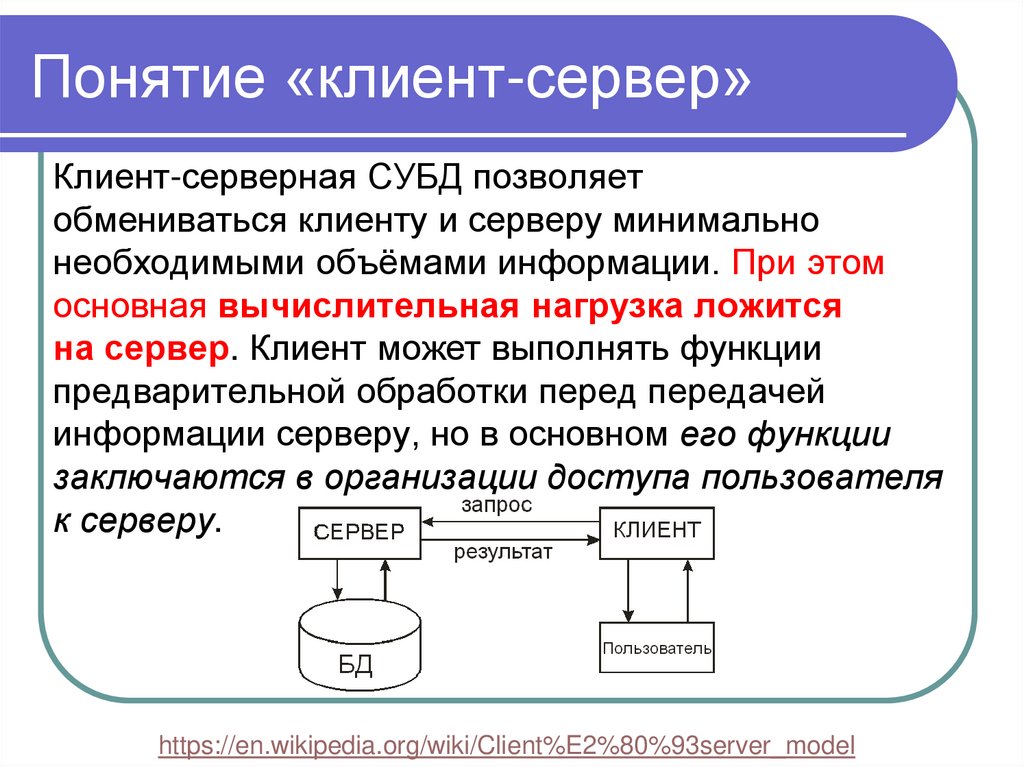
Понятие «клиент-сервер»Клиент-серверная СУБД позволяет
обмениваться клиенту и серверу минимально
необходимыми объёмами информации. При этом
основная вычислительная нагрузка ложится
на сервер. Клиент может выполнять функции
предварительной обработки перед передачей
информации серверу, но в основном его функции
заключаются в организации доступа пользователя
к серверу.
https://en.wikipedia.org/wiki/Client%E2%80%93server_model
37.
ПреимуществаОтсутствие дублирования кода программы-
сервера программами-клиентами
Так как все вычисления выполняются на
сервере, то требования к компьютерам, на
которых установлен клиент, снижаются
Все данные хранятся на сервере, который, как
правило, защищён гораздо лучше большинства
клиентов. На сервере проще организовать
контроль полномочий, чтобы разрешать доступ к
данным только клиентам с соответствующими
правами доступа
38.
НедостаткиНеработоспособность сервера может сделать
неработоспособной всю вычислительную сеть.
Неработоспособным сервером следует считать
сервер, производительности которого не
хватает на обслуживание всех клиентов, а
также сервер, находящийся на ремонте,
профилактике и тп.
Поддержка работы данной системы требует
отдельного специалиста — системного
администратора
Высокая стоимость оборудования
39.
Встраиваемые системыВстраиваемая система управления
базами данных — архитектура систем
управления базами данных, когда СУБД
тесно связана с программой, и работает на
том же устройстве, не требуя
профессионального администрирования.
Встраиваемые СУБД применяются во
многих программах, которые хранят
большие объёмы данных, но при этом не
требуется доступ с многих компьютеров.
40.
Примеры использованияПрограммы, в которых может быть
использована встраиваемая
СУБД: почтовые клиенты и месенджеры
(базы переписки), медиапроигрыватели
(плей-листы и обложки), просмотрщики
изображений (метаданные и уменьшенные
эскизы), различные локальные БД
наподобие телефонных справочников
и геоинформационных систем.
https://en.wikipedia.org/wiki/Embedded_database
41.
Правила КоддаРеляционная модель была введена
сотрудником корпорации IBM Эдгаром
Коддом, который опубликовал статью,
описывающую общие концепции этой
модели. Среди прочего в этой статье
Кодд описал 12 правил, которым должна
соответствовать реляционная БД. Эти
правила в дальнейшем получили
название правил Кодда.
42.
1. Правило информацииВся информация в БД должна быть
представлена исключительно на логическом
уровне и только одним способом – в виде
значений, содержащихся в таблицах. По
сути, это правило является неформальным
определением реляционной базы данных.
Обратите внимание на то, что реляционные
БД позволяют сконцентрироваться на самих
данных, избегая при этом вопросов их
физического хранения.
43.
2. Гарантированный доступЛюбое значение в БД должно быть
гарантированно доступным через комбинацию
имени таблицы, первичного ключа и имени
столбца. Это правило оговаривает важнейшую
роль первичного ключа при организации поиска
информации в БД. Имя таблицы даёт
возможность найти нужную таблицу, первичный
ключ даёт возможность найти искомую строку, а
имя столбца даёт возможность найти в этой
строке требуемый столбец, содержащий
необходимую информацию.
44.
3. Поддержка NULLСУБД должна уметь работать с пустыми значениями.
Пустое значение – это неизвестное, неприменимое
значение, в отличие от значений по умолчанию и
обычных значений. Это правило говорит о том, что в
РБД должна быть реализована поддержка
недействительных значений, которые отличаются от
пустых строк или нулевых значений и используются
для представления отсутствующих данных
независимо от типа этих данных. Таким образом,
отсутствующие данные можно представить с
помощью недействительных значений, обычно
обозначаемых NULL.
45.
4. Описание содержимого БДОписание БД должно быть определено на логическом
уровне через таблицы, к которым можно применять
запросы, используя язык манипулирования данными
(DML). Т.е. описание БД на логическом уровне должно
быть представлено в том же виде, что и основные
данные, чтобы пользователи могли работать с ним с
помощью того же реляционного языка, который они
применяют для работы с основными данными. Это
правило говорит о том, что реляционная БД должна
описывать сама себя. Это значит, что в ней должны
содержаться специальные системные таблицы,
описывающие структуру самой базы данных.
46.
5. Исчерпывающий язык БДПоддерживаемый БД язык должен иметь
чётко определенный синтаксис и быть
самодостаточным. Им должно
поддерживаться определение данных и
манипулирование ими, правила целостности,
авторизация и транзакции. Это правило
требует, чтобы СУБД использовала язык,
который поддерживает все основные функции
СУБД – создание базы данных, чтение и
выборка данных, защита базы данных и тп.
47.
6. Обновление представленийВсе представления (views), которые
теоретически можно обновить, должны
быть доступны для обновления.
Это правило касается представлений,
позволяющих показывать различным
пользователям различные фрагменты
структуры базы данных. Представления
в дальнейшем будут рассмотрены
более подробно.
48.
7. Редактирование данныхСУБД поддерживает не только
запросы на выборку данных, но и их
вставку, обновление и удаление. Это
правило говорит о том, что БД по сути
своей являются множествами. Оно
требует, чтобы операции добавления,
удаления и обновления можно было
выполнять над множествами строк.
49.
8. Физическая независимостьЛогика программ-приложений остаётся
прежней при изменении физических
методов доступа к данным и структур
хранения. Это правило говорит о том, что
приложения и утилиты для работы с БД
должны на логическом уровне оставаться
неизменными при любых изменениях
физических способов хранения данных
или методов доступа к ним.
50.
9. Логическая независимостьПриложения и утилиты для работы с
данными должны на логическом уровне
оставаться неизменными при внесении в
базовые таблицы любых изменений,
которые теоретически позволяют
сохранить неизменными содержащиеся в
этих таблицах данные. 8 и 9 правило
требуют отделения конечного
пользователя и приложений от
низкоуровневой реализации БД.
51.
10. Поддержка целостностиЯзык БД должен быть способен
определять ограничения целостности, и
не должно быть способа их обойти.
Правило 10 гласит, что язык базы
данных должен поддерживать
ограничительные условия, налагаемые
на вводимые данные и действия,
которые могут быть выполнены над
данными.
52.
11. Независимость распространенияРеляционная БД не должна зависеть от
потребностей конкретного клиента.
Это правило говорит о том, что язык БД
должен предоставлять возможность
работы с распределёнными данными,
расположенными на других
компьютерах.
53.
12. Правило единственностиЕсли в БД есть низкоуровневой язык
(обрабатывающий одну запись за один
раз), то должна отсутствовать
возможность использования его для
того, чтобы обойти правила и условия
целостности, выраженные на
реляционном языке высокого уровня
(обрабатывающем несколько записей за
один раз).
54.
Обзор СУБДДля работы с базой данных, нам
необходимо её где-то разместить. В
качестве СУБД будем использовать:
Microsoft SQL Server
MySQL
SQLite
55.
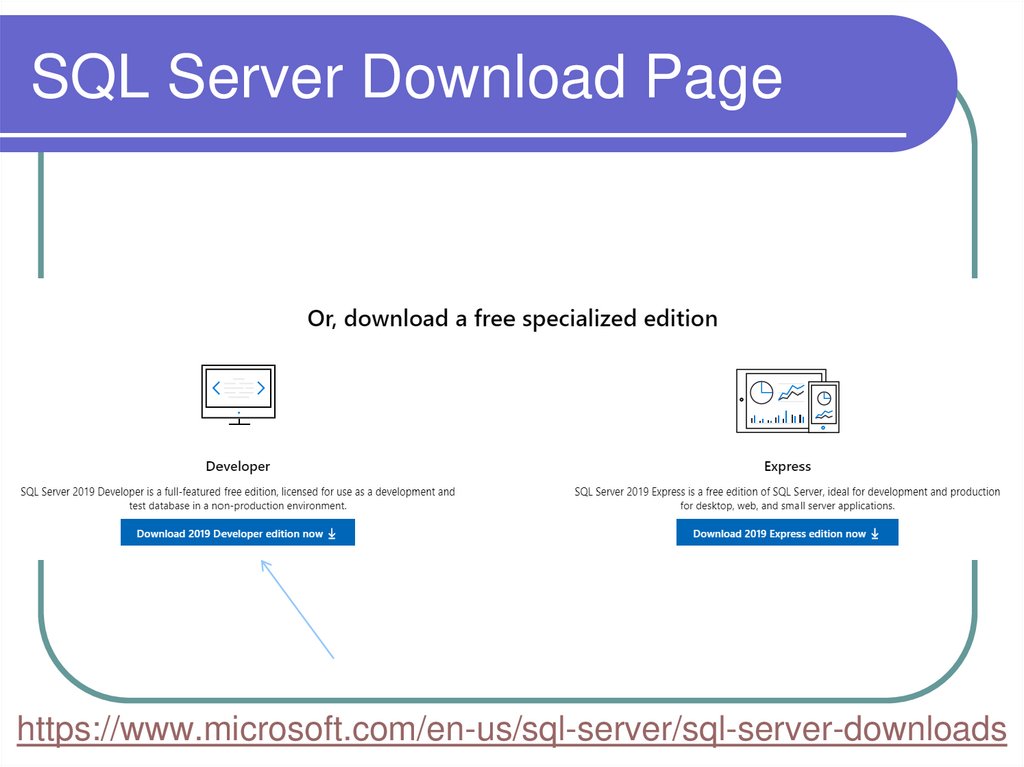
SQL Server Download Pagehttps://www.microsoft.com/en-us/sql-server/sql-server-downloads
56.
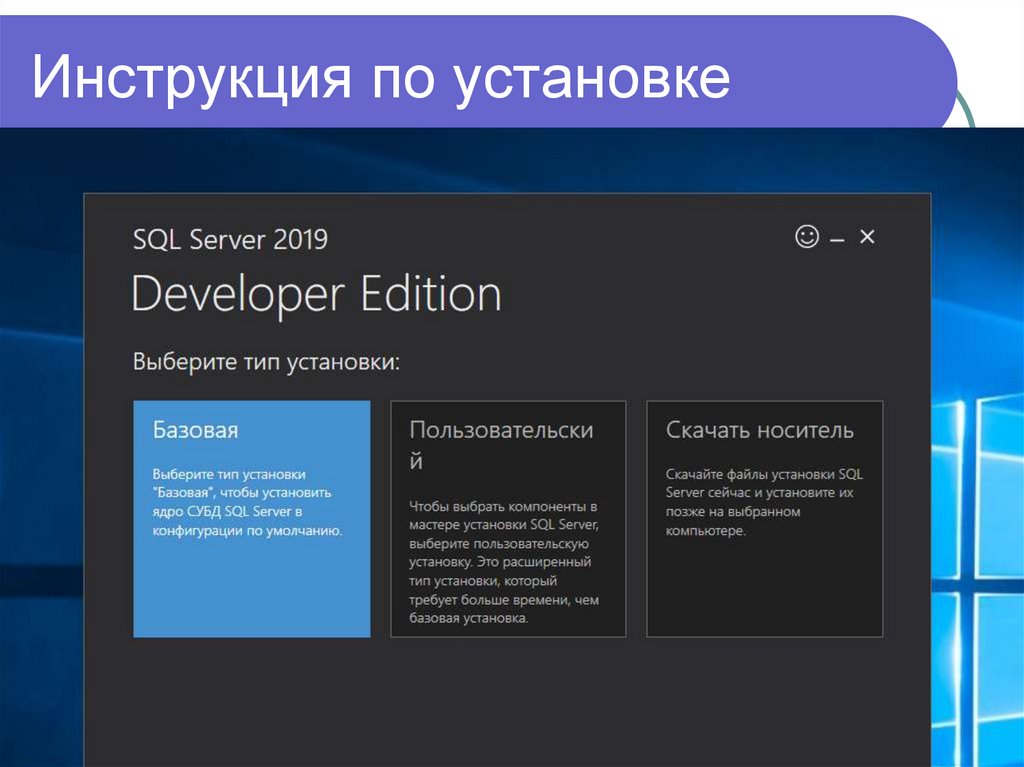
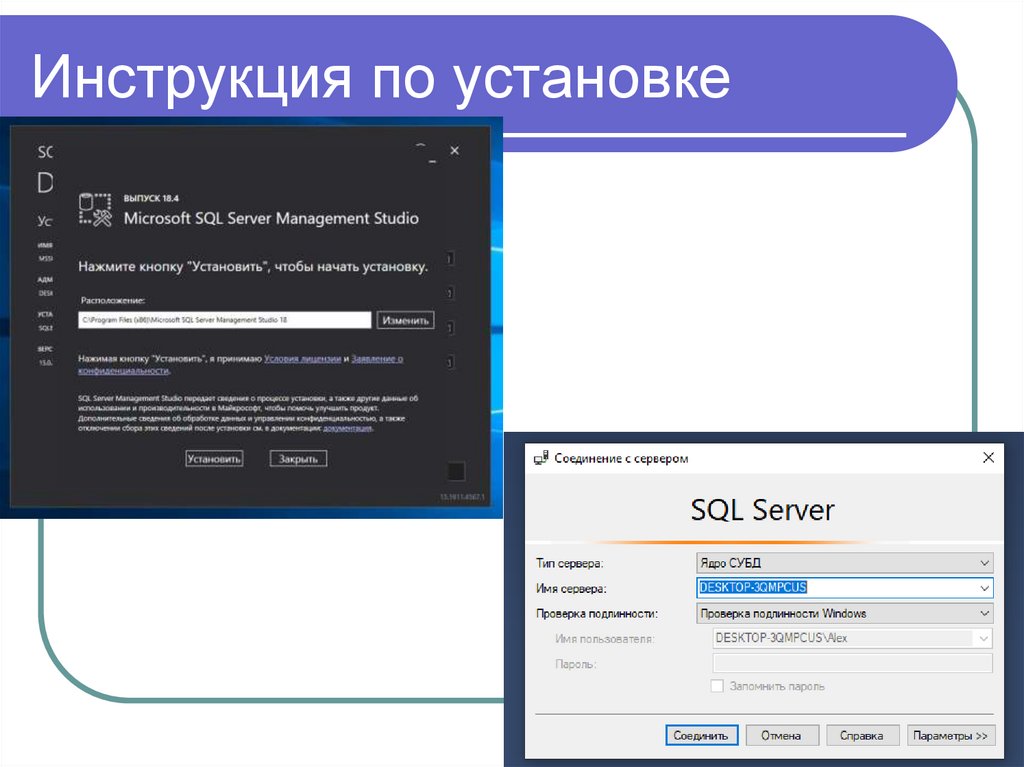
Инструкция по установке57.
Инструкция по установке58.
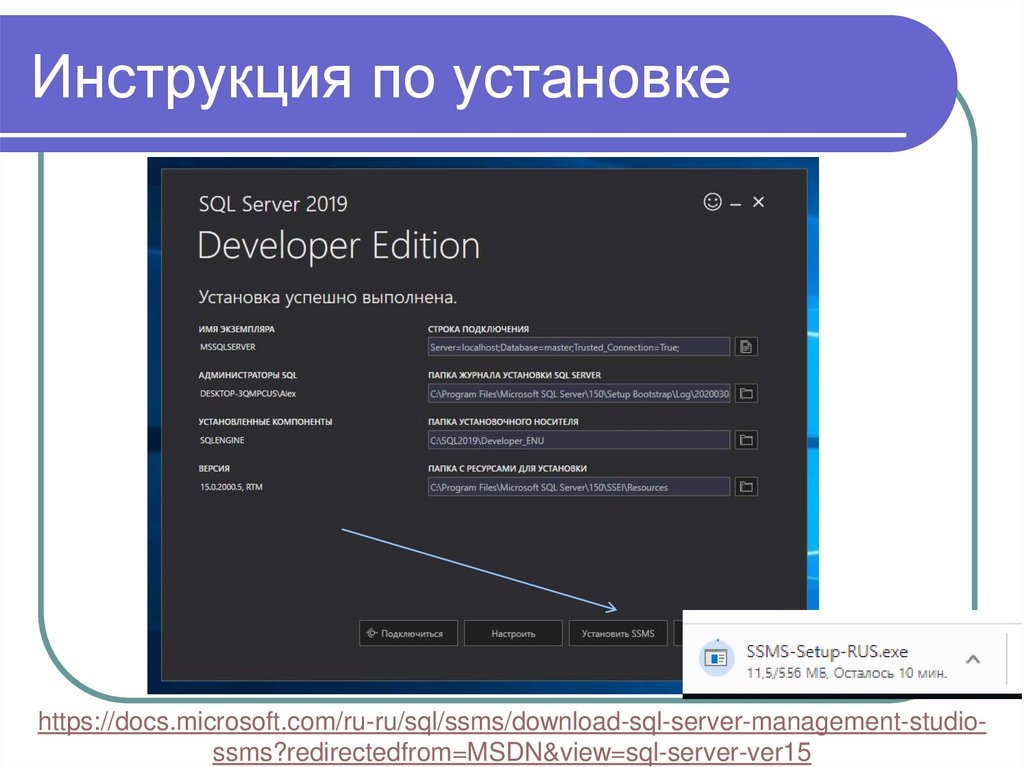
Инструкция по установкеhttps://docs.microsoft.com/ru-ru/sql/ssms/download-sql-server-management-studiossms?redirectedfrom=MSDN&view=sql-server-ver15
59.
Инструкция по установке60.
Установка на диск D:\https://stackoverflow.com/questions/43490699/change
-the-default-installation-path-of-sql-servermanagement-studio?rq=1
https://stackoverflow.com/questions/15705983/how-tochange-default-language-for-sql-server
https://dba.stackexchange.com/questions/28459/howdo-i-modify-the-user-interface-language-in-ssms
61.
ПрактикаСоздание базы данных Animals
Создание таблицы Cats
Создание полей (nick, birthdate, etc)
Редактирование таблицы Cats
Заполнение таблицы (5-10 записей)
Поля в реляционных БД типизированы. Для первичного
ключа обычно выбирают тип int, и назначают свойство
identity specification (чтобы сделать счётчик). Также
для поля можно выставить значение по умолчанию, или
сделать его обязательным.
https://docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studiossms
62.
Identity specificationБез identity, при добавлении новой записи к таблице
программисту пришлось бы определять и где-то запоминать
последнее используемое значение идентификатора,
прибавлять к нему единицу и полученное значение
использовать в качестве идентификатора новой записи. Это
очень трудоёмко, особенно если иметь в виду, что операции
добавления записей в таблицу могут происходить регулярно.
Поэтому многие СУБД избавляют программиста от
необходимости совершать всю эту рутинную работу. Вместо
этого они реализуются специальный тип поля, который часто
называют автоинкрементным. В SQL Server это делается с
помощью identity specification. Суть в том, что при
добавлении новой записи в таблицу, SQL Server
автоматически подставляет в это поле очередное
уникальное значение идентификатора.
63.
Именование полейВ именах полей настоятельно рекомендуется
использовать только буквы латинского алфавита, цифры и
символ подчеркивания. Хотя конечно можно использовать
ещё и пробелы, и буквы кириллицы, но следует избегать
использования и того, и другого, и третьего. Причины в
том, что для обращения к полям с пробелами в именах
придется использовать какие-нибудь ограничители –
например, в SQL Server ими являются квадратные скобки.
Но в то же время, при показе таблицы хочется показывать
пользователю русскоязычные названия полей для лучшего
понимания предоставляемой информации. В таком случае
можно будет использовать псевдонимы (AS).
http://citforum.ck.ua/database/articles/naming_rule/
64.
SQLПятое правило Кодда говорит о том, что
должен существовать некий язык БД, при
помощи которого можно было бы
взаимодействовать с ней. Несмотря на то,
что формально таких языков может быть
сколько угодно, реально существует всего
один распространённый и
стандартизованный язык - SQL (Structured
Query Language, т.е. язык
структурированных запросов).
65.
Идея языка SQLИдея, заложенная в язык SQL, отражает суть
подхода к работе с БД: вместо того, чтобы
программист концентрировался на вопросах
физического хранения данных (как было при
работе с файлами без сериализаторов),
программист может сконцентрироваться на
самих данных. Таким образом, ему не нужно
больше копаться в файлах БД – вместо него это
будет делать СУБД. Всё, что нужно – это просто
сформулировать запрос к реляционной СУБД на
некотором реляционном языке (в нашем случае –
на языке SQL).
http://telegra.ph/SQL-za-20-minut-04-09
66.
Декларативный языкSQL является не алгоритмическим
языком (т.е. не языком
программирования), а декларативным
языком! Он состоит из команд-запросов,
обрабатываемых реляционной СУБД и
предоставляет все необходимые
средства для управления БД.
Функционально язык SQL делят на
четыре части:
67.
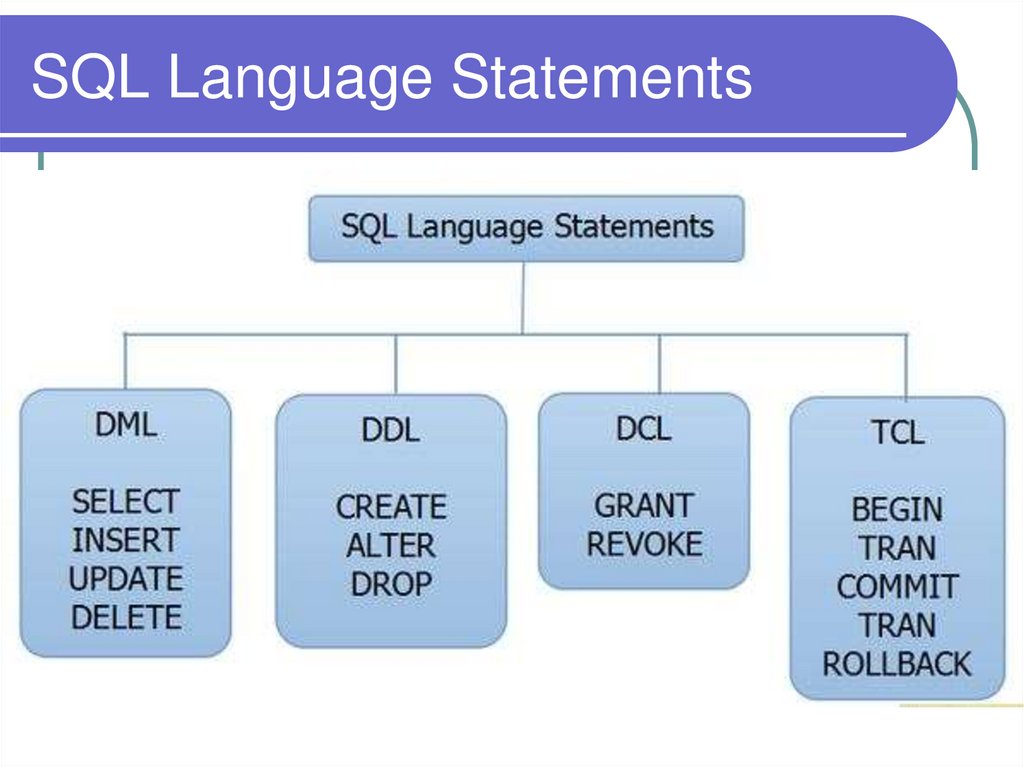
SQL Language Statements68.
DDLDDL (Data Definition Language, язык
определения данных). Содержит
команды создания, модификации и
удаления самой базы данных, таблиц,
представлений, индексов, триггеров,
процедур и прочих структурных
элементов реляционной БД. При
помощи этой части SQL создается и
меняется структура БД.
69.
DML – тема следующего занятияDML (Data Manipulation Language,
язык манипулирования данными).
Содержит команды, позволяющие
манипулировать собственно данными,
хранящимися в БД, т.е. добавлять,
модифицировать, удалять, а также
получать сами данные из таблиц и
представлений.
70.
DCL и TCLDCL (Data Control Language, язык
управления данными). Содержит
команды, дающие возможность
разграничить права доступа
пользователей БД к самой БД.
TCL (Transact Control Language, язык
обработки транзакций).
71.
Домашнее задание72.
Комментарии по ДЗДомашнее задание нужно выслать на
mystat в виде скриншота таблицы
Products (SELECT TOP 1000 rows)