


 programming
programmingSimilar presentations:





. (Лекция 18)")
")



Spring Eureka – Netflix Server Discovery
1.
Spring Eureka – Netflix Server DiscoveryДля подключения
Server:
1. Добавить зависимость
2. @EnableEurekaServer Application
3. eureka.client.register-with-eureka=false (каждый еврика сервер одновременно и клиент)
4. eureka.client.fetch-registry=false
Spring Config Server:
@EnableConfigServer Application
spring.cloud.config.server.git.uri= GitHub repo with properties
Get properties – ip/<filename>/<profile>
Client:
Добавить зависимость
@EnableEurekaClient Application (не обязательно)
(spring.application.name)
Dynamic Config:
Добавить Spring Actuator
В класс где нужно обновлять @Value добавить
@RefreshScope
Для обновления вызвать ip/actuator/refresh
Spring Config Client:
Spring.cloud.config.uri= Config server ip
На RestTemplate или WebClient поставить @LoadBalanced
------------------------------------------------------------------------------------------------------------------------------------------------Hystrix – Netflix Microservices Fault Tolerance (Circuit Breaker)
Подключение:
Добавить зависимость
@EnableCircuitBreaker Application
@HystrixCommand на запросе, fallbackMethod = название метода
Bulkhead (Переборка) – создание разных тредпулов
@ConfigurationProperties(“db”)
Actuator Dependency – Получить всю конфигурацию
(ip/actuator/configprops)
Application profile – properties-<profilename>.yml
@DisplayName
@RepeatedTest
@ParametrizedTest
@ValueSource
@MethodSource
@Nested
2.
Характеристика REST:1. Модель клиент-сервер
2. Отсутствие состояния (запрос содержит все данные
для получения ответа)
3. Кэширование
4. Единообразный интерфейс
5. Слои (клиент не знает с кем он общается)
1. YAGNI – не оставлять ненужный код
2. KISS – не усложнять
3. DRY – не повторять код
4. Big Design Up Front – перед написанием кода все продумать
5. Avoid Premature Optimization – не оптимизировать пока не надо
6. SOLID
S – Single-responsibility principle
O – Open–closed principle (расширяем без модификации)
L – Liskov substitution principle (метод принимает и наследников)
I – Interface segregation principle
D – Dependency inversion principle (все зависит от абстракций)
Характеристика SOAP:
Протокол обмена структурированными сообщениями в распределённой
вычислительной среде
Модель:
Envelope - корневой, определяет пространство имен
Header - атрибуты сообщения
Body - ответ
Fault - ошибки (необязательный)
A – Атомарность (транзакция либо есть либо нет)
C – Согласованность (транзакция не нарушает согласованность
I – Изолированность (транзакция не видит изменения других транзакций
D – Долговечность (завершенная транзакция не отменится из за сбоя)
3.
Так, ну начну немного издалека, программированием я занимаюсь уже лет 7, сначала делал всякие игры напитоне, потом перешел на c# с юнити, но это как то не очень понравилось, дальше был фриланс уже на java,
чатботы для вк и дискорда на заказ, а потом знакомый пригласил поработать к себе на проект. Компания у них
вообще в тюмени, но я работал удаленно с питера
Приложение над которым я работал это в принципе дефолтная CRMка для внутренних нужд компании и
взаимодействия с клиентами, деятельность компании была связана с нефтяной отраслью, ну и вот через эту
CRM систему организовывалось отслеживание закупок, поставок, документов, которые со всем этим связаны,
там связь клиента с менеджером, техподдержка и так далее
Стек на проекте у меня был: 11 Java, Spring Boot, Spring Data на Хибере, Spring Cloud по типу Eureka, Hystrix и
OpenFeign, Kafka, Swagger
Для бд юзали Postgre с Flyway
Вообще изначально когда я пришел на проект там был монолит с фронтом на Vaadin (это такой фреймворк
который позволяет писать фронт полностью на java), у меня даже были таски по типу приделать какую-нибудь
кнопку чтобы открылось определенное окошечко, все это было очень запутанно вперемешку с фронтом, еще и
производительность проседала потому что монолита не хватало, но к счастью через несколько месяцев
донабрали фронтов и стали постепенно переходить на микросервисы. Микросервисы мы изначально строили
на ресте, но там опять возникли проблемы с производительностью (ну потому что рест синхронный), и поэтому
целиком перешли на кафку, а рест остался только для фронта
В итоге сделали 7 микросервисов, это без учета config server/discovery server/gateway
Я в основном работал с сервисами для документов и уведомлений. Вот к примеру, некоторые типы
оборудования имеют сертификат поверки (это документ который гарантирует что прибор работает верно), и эти
сертификаты нужно периодически обновлять и уведомлять владельцев оборудования о том что нужно
обновить сертификат. Реализовывал через спринговский шедулер, ежедневно проверял бд с сертификами, и за
30 дней и за неделю до истечения срока высылалось уведомление на почту или смс клиенту, в зависимости от
того как у него выбрано в лк. Для рассылки почты юзали спринговский емейл, а для смс была своя апишка на
edna. К слову, для реализации уведомлений использовался паттерн декоратор
Писал юнит тесты, покрытие кода было в районе 70%
Логировали через ElasticSearch в связке с logStash и kibana
Для CI/CD использовали GitLab, суммарно у нас было 3 стенда – для разработчиков, тестировщиков и
следовательно прод
По команде было суммарно 10 человек, включая меня, это:
3 бэка + лид
2 фронта на реакте со своим лидом
2 тестировщика
1 аналитик
1 девопс
Работали по обычному скраму, спринт 2 недели, ретро когда как, иногда после каждого спринта был иногда раз
в 2 спринта, ну в общем в зависимости от того сколько работы за спринт сделали
Таски раздавал тимлид на основании скрампокера в начале спринта, делали перекрестный код ревью, ну и
перед слиянием в dev ветку тимлид еще дополнительно сам ревьюил коммит
Микросервисы:
1. EmployeeService - Личные кабинеты, разделение сотрудников по
отделам
2. CustomerService - Работа с клиентами, интеграция с daData
3. SecurityService
4. DocumentService
5. IntegrationService - 1C, EDNA
6. NotificationService
7. FactoryLifeService – цикл от закупки до техподдержки
Было много тасок связанных с интеграциями с даДатой (это
сервис для проверки данных о юр лицах), в целом писал
апишку для взаимодействия с дадатой, или например,
формирование отчета по сделанному заказу, отчет в эксель
отправлялся на почту, для экселя юзали Apache POI
4.
5.
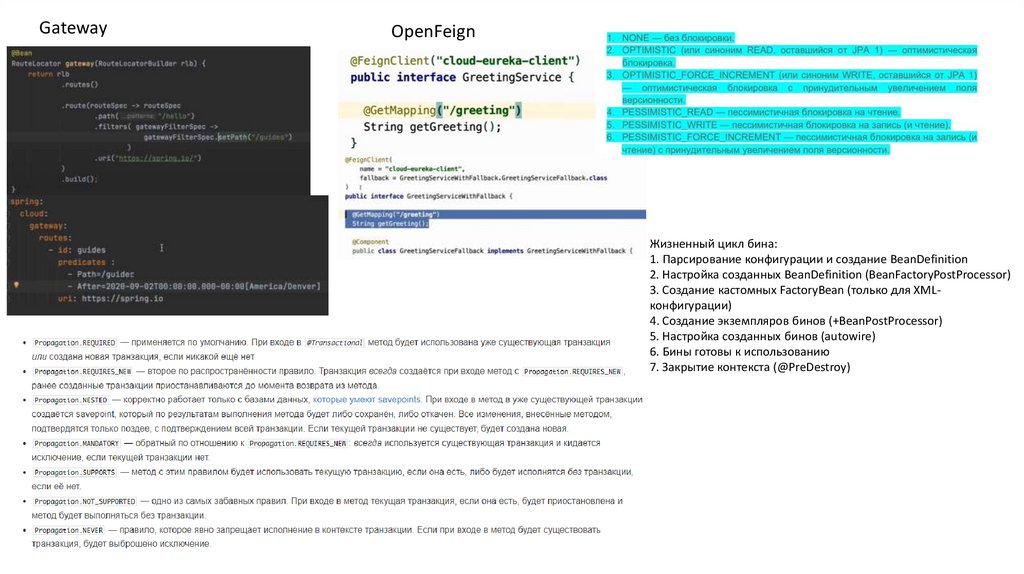
GatewayOpenFeign
Жизненный цикл бина:
1. Парсирование конфигурации и создание BeanDefinition
2. Настройка созданных BeanDefinition (BeanFactoryPostProcessor)
3. Создание кастомных FactoryBean (только для XMLконфигурации)
4. Создание экземпляров бинов (+BeanPostProcessor)
5. Настройка созданных бинов (autowire)
6. Бины готовы к использованию
7. Закрытие контекста (@PreDestroy)