



































































 database
databaseSimilar presentations:


")




. Часть 1. Лекция 7")


Обзор современных BI систем (часть 2)
1.
DATA SCIENTISTМОДУЛЬ 5. ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА ДЛЯ
АНАЛИТИКИ ДАННЫХ И ВИЗУАЛИЗАЦИИ
Тема 1. Обзор современных BI систем (часть 2)
Мишин Александр Юрьевич
к.э.н., доцент департамента бизнесинформатики
1
2.
Тема 1. Обзор современных BI системТеоретические основы анализа данных
2
3.
Базовая терминологияданные - это факты, текст, графики, картинки, звуки, аналоговые или цифровые видеосегменты, представленные в форме, пригодной для хранения, передачи и обработки
сущность (entity) – это предмет, который может быть идентифицирован некоторым
способом, отличающим его от других предметов
набор однородных сущностей – множество сущностей
атрибут – свойство сущности (как, правило, атомарное)
связь (relationship) – это ассоциация, устанавливаемая между сущностями
степень связи – количество связанных сущностей
в ориентированных на строки СУБД обычно по вертикали отображаются объекты, по
горизонтали – атрибуты
объект – это сущность, хранящая в таблице
3
4.
ШкалыШкала - правило, в соответствии с которым объектам присваиваются значения.
Существует 5 основных видов шкал:
номинальная шкала (nominal scale)
порядковая шкала (ordinal scale)
интервальная шкала (interval scale)
относительная шкала (ratio scale)
дихотомическая шкала (dichotomous scale)
4
5.
ШкалыНоминальная шкала (nominal scale):
• содержит только категории
• данные в этом виде шкал не могут упорядочиваться
• с данными шкалы не могут производиться арифметические действия
• может состоять из: названий, категорий, имен для классификации и сортировки объектов
или наблюдений по некоторому признаку
Пример номинальной шкалы – проектная роль:
• 1 – Менеджер проекта
• 2 – Бизнес-аналитик
• 3 – Дата-аналитик
• 4 – Системный аналитик
Допустимые операции для номинальной шкалы:
• равно / не равно
Не всегда обязательно присваивать численные значения категориальным признакам.
Это зависит от программного обеспечения.
5
6.
ШкалыПорядковая шкала (ordinal scale):
состоит из численных значений
значения шкалы обозначают относительную позицию объектов в некотором
упорядоченном списке
дает возможность ранжировать значения переменных
по значениям порядковой шкалы объектов в порядковой шкале нельзя оценить,
насколько одна величина больше другой
Пример порядковой шкалы – уровень грейда:
1 - Джуниор
2 - Миддл
3 - Сеньор
Допустимые операции для порядковой шкалы:
• равно / не равно
• больше / меньше
6
7.
ШкалыИнтервальная шкала (interval scale):
• устанавливает отношения порядка между интервалами, расстояниями одних значений
признака от других
• порядок определяется конкретным значением, а не рангом
• позволяет вычислить интервал между двумя значениями шкалы
• обладает свойствами номинальной и порядковой шкал
Допустимые операции для интервальной шкалы:
• равно / не равно
• больше / меньше
• сложение / вычитание
7
8.
ШкалыОтносительная шкала (ratio scale):
количественная шкала
есть определенная точка отсчета
возможно вычисление отношений между значениями шкалы
Допустимые операции для интервальной шкалы:
равно / не равно
больше / меньше
сложение / вычитание
умножение / деление
8
9.
Форматы файлов с даннымиФормат CSV:
высокая совместимость с электронными таблицами
удобочитаемость данных
только для двумерных таблиц
невозможна обработка вложенных данных
проблемы с разделителем могут привести к проблемам с качеством данных.
подходит для исследовательского анализа (EDA), проверки концепта (Proof of concept)
9
или небольших наборов данных
10.
Форматы файлов с даннымиФормат JSON:
активно используется в API
оптимизирован для вложения
содержимого
широко распространён
человекочитаемый, легко визуально
отлаживать
лучше
всего
подходит
для
небольших наборов данных и
передачи данных через API
плохо
подходит
для
больших
объемов данных
10
11.
Форматы файлов с даннымиФормат Avro:
идеально подходит хранения строковых данных
хранит в себе схему данных и поддерживает её эволюцию
эффективная сочетается с Kafka и озерами данных, активно применяемый в экосистеме
Apache Hadoop
поддерживает разделение файлов
данные медленно читаются из него, но записываются очень быстро
для блоков данных может использовать компактную бинарную кодировку или
человекочитаемый формат JSON
не является строго типизированным форматом: информация о типе каждого поля
хранится в разделе метаданных вместе со схемой, поэтому для чтения сериализованной
информации не требуется предварительное знание схемы
отлично подходит для ETL-хранилищ и витрин данных, где требуется чтение всех полей
записи
меньшая производительность при выполнении избирательных запросов и больший
11
расход дискового пространства для хранения данных
12.
Форматы файлов с даннымиСтруктура заголовка файла AVRO:
• 4 байта, ASCII ‘O’, ‘b’, ‘j’, далее номер версии AVRO (1)
• метаданные файла, содержащие схему – структуру представления данных
• 16-байтное случайное число — маркер файла
https://www.bigdataschool.ru/wiki/avro
12
13.
Форматы файлов с даннымиAvro обеспечивает богатую структуру данных, поддерживая следующие типы:
• примитивные (null, Boolean, int, long, float, double, string, bytes, fixed)
• сложные составные (union, recod, enum, array, map)
• логические (decimal, date, time-millis, time-micros, timestamp-millis, timestamp-micros, uuid)
https://www.bigdataschool.ru/wiki/avro
13
14.
НормализацияНормализация БД - это процесс организации данных в базе данных, включающий создание
таблиц и установление отношений между ними в соответствии с правилами, которые
обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и
несогласованные зависимости.
14
15.
Нормализация БД. Нормальные формы1NF:
• сохраняемые данные на пересечении строк и столбцов представляют скалярное значение
• таблицы не должны содержать повторяющихся строк
2NF:
• Каждый неключевой столбец зависит от первичного ключа
3NF:
• каждый неключевой столбец зависит только от первичного ключа
4NF:
• нет многозначных зависимостей (ситуаций, когда столбец с первичным ключом имеет
связь один-ко-многим с неключевым столбцом)
5NF:
• разделяет таблицы на более малые таблицы для устранения избыточности данных до тех
пор, пока нельзя будет воссоздать оригинальную таблицу путем объединения малых
таблиц
6NF (domain key normal form):
• каждое ограничение в связях между таблицами зависит только от ограничений ключа и
домена (набора допустимых значений для столбца)
• данная форма, как правило, не применима на уровне СУБД
15
16.
Правила КоддаАвтор идеи OLAP - Эдгар Кодд. Он который сформулировал 12 правил, определивших эту
технологию:
1. Многомерный концептуальный взгляд на данные (Multidimensional conceptual view).
2. Прозрачность для пользователя (Transparency)
3. Доступность разнородных источников данных (Accessibility)
4. Постоянство характеристик производительности при увеличении числа измерений
(Consistent reporting performance)
5. Клиент-серверная архитектура (Client server architecture)
6. Общность измерений по структуре и возможностям обработки (Generic Dimensionality)
7. Обработка разреженных матриц (Dynamic sparse matrix handling)
8. Наличие многопользовательской среды (Multi-user support)
9. Операции с любым числом измерениями (Unrestricted cross-dimensional operations)
10. Интуитивное манипулирование данными (Intuitive data manipulation)
11. Гибкое формирование отчётности (Flexible reporting)
12. Неограниченное число измерений и уровней агрегирования данных (Unlimited
Dimensions and aggregation levels)
16
17.
FASMIв настоящее время список из 12 правил Кодда расширен до 18 главных правил (всего их
около 300).
есть альтернатива правилам Кодда для определения OLAP
это тест FASMI (Fast Analysis of Shared Multidimensional Information – быстрый анализ
разделяемой многомерной информации), включающий пять критериев, которым должно
удовлетворять приложение, чтобы относится к категории OLAP:
1.
2.
3.
4.
5.
высокая скорость выполнения аналитических запросов
мощная подсистемы анализа
организация разделенного доступа к данным
многомерное представление данных
доступность информации
17
18.
Тема 1. Обзор современных BI системПравила и методы проектирования моделей данных, внедрения
аналитических отчетов, дашбордов, информационных панелей
мониторинга в компоненты ИТ инфраструктуры организации для
проведения мониторинга и контроллинга стратегии предприятий
18
19.
Виды моделей БДРазработка баз данных и информационных систем начинается с высокого уровня
абстракции и с каждым шагом становится все точнее и конкретнее:
Три вида моделей:
концептуальная
логическая
физическая
https://learn.microsoft.com/ru-ru/azure/data-explorer/kusto/concepts/fact-and-dimension19
tables
20.
Виды моделей данных. Концептуальнаямодель данных
она же - модель предметной области
обычно создается в процессе сбора
исходных требований к проекту
• отвечает на вопросы:
o что будет содержать система
o как она будет организована
o какие
бизнес-правила
будут
задействованы
• включает:
o классы сущностей
o характеристики
и
ограничения
сущностей
o отношения между сущностями
o требования
к
безопасности
и
целостности данных
20
21.
Виды моделей данных. Этапы разработкиконцептуальной модели данных
1.
2.
3.
4.
5.
6.
7.
Определение сущностей и их документирование
Определение связей между сущностями и их документирование
Создание ER-модели предметной области
Определение атрибутов и их документирование
Определение значений атрибутов и их документирование
Определение первичных ключей для сущностей и их документирование
Обсуждение концептуальной модели данных с конечными пользователями
21
22.
Виды моделейдиаграммы
данных.
Нотации
ER-
наименования диаграммы:
o сущность/отношения
o объект/связь
o ER-диаграмма
o EDR (entity-relationship diagram)
правила написания и условные обозначения ER-диаграммы называют нотацией
o классическая нотация П. Чена
o нотация IDEFIX (Integration Definition for Information Modeling)
o нотация Ч. Бахмана
o нотация Дж. Мартина («вороньи лапки»)
o нотация Ж.-Р. Абриаля (мин-макс)
o диаграммы классов UML
22
23.
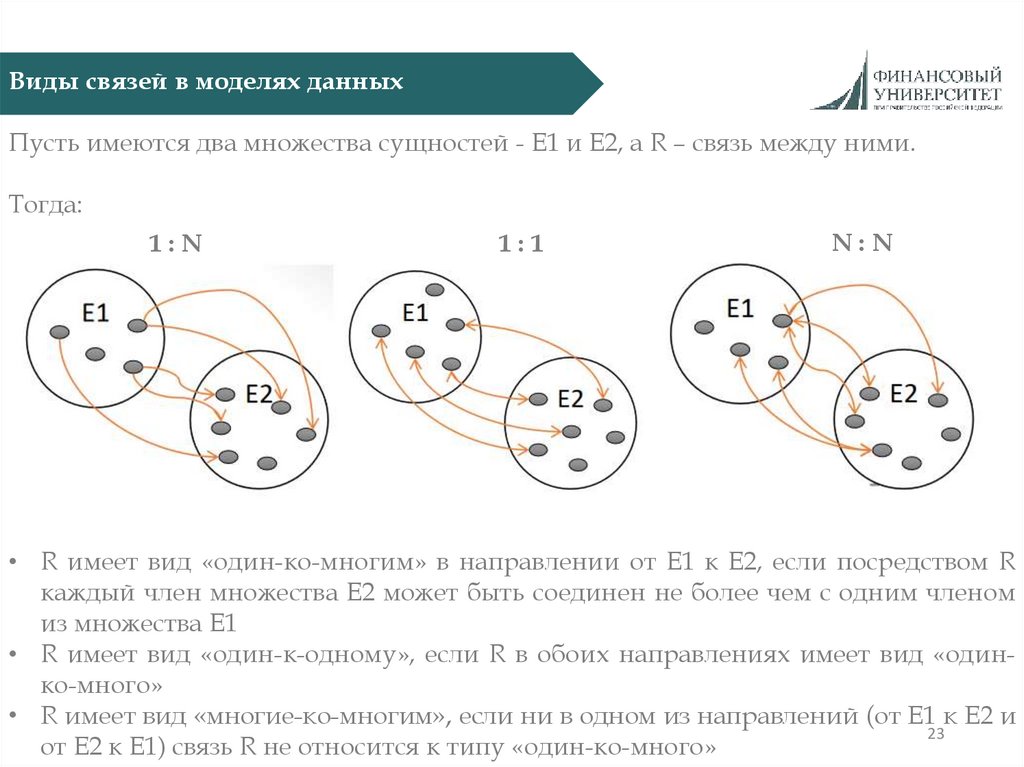
Виды связей в моделях данныхПусть имеются два множества сущностей - E1 и E2, а R – связь между ними.
Тогда:
1:N
1:1
N:N
• R имеет вид «один-ко-многим» в направлении от E1 к E2, если посредством R
каждый член множества E2 может быть соединен не более чем с одним членом
из множества E1
• R имеет вид «один-к-одному», если R в обоих направлениях имеет вид «одинко-много»
• R имеет вид «многие-ко-многим», если ни в одном из направлений (от E1 к E2 и
23
от E2 к E1) связь R не относится к типу «один-ко-много»
24.
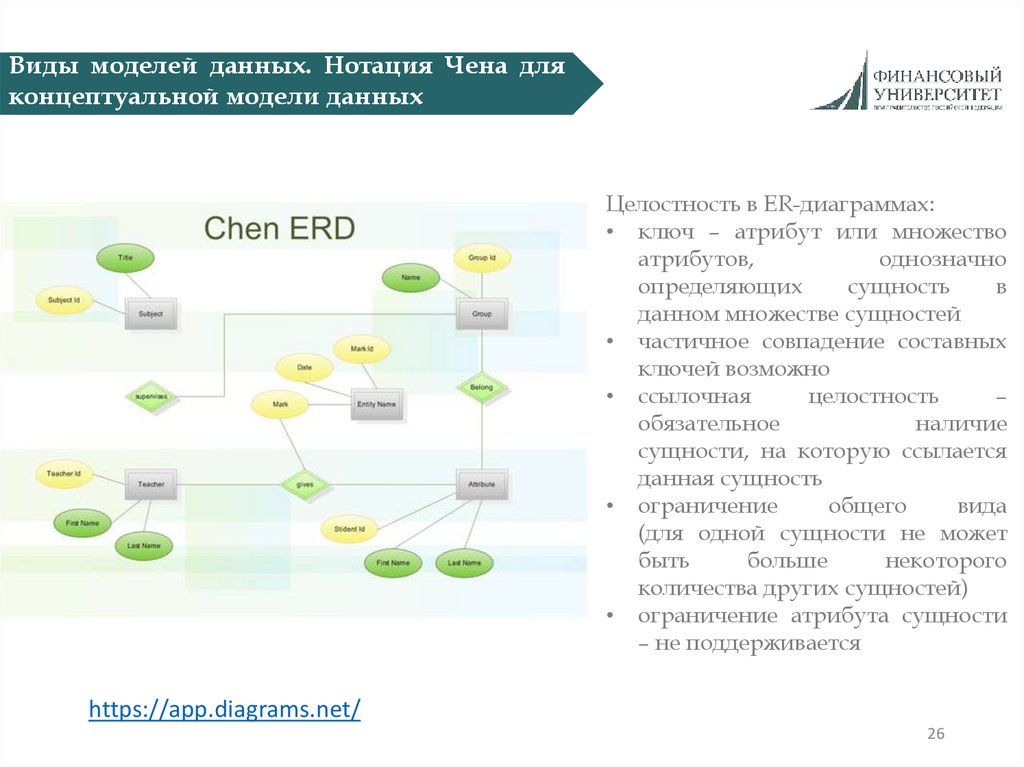
Виды моделей данных. Нотация Чена дляконцептуальной модели данных
Была предложена профессором Peter Pin-Shen Chen (Питер Чен) в 1976 году
прямоугольник - сущность или объект
ромб - отношения
овал - атрибуты объектов
линия со стрелкой - связь сущности с
отношением
пунктирная линия - необязательная
связь
двойная линия - мощная связь
каждый атрибут может быть связан с
одним объектом (сущностью)
24
25.
Виды моделей данных. Нотация Чена дляконцептуальной модели данных
cвязь может являться сущностью и
может иметь атрибуты
атрибут связи может быть заменен на
связь
с
новой
сущностью,
обладающей
соответствующим
атрибутом
25
26.
Виды моделей данных. Нотация Чена дляконцептуальной модели данных
Целостность в ER-диаграммах:
• ключ – атрибут или множество
атрибутов,
однозначно
определяющих
сущность
в
данном множестве сущностей
• частичное совпадение составных
ключей возможно
• ссылочная
целостность
–
обязательное
наличие
сущности, на которую ссылается
данная сущность
• ограничение
общего
вида
(для одной сущности не может
быть
больше
некоторого
количества других сущностей)
• ограничение атрибута сущности
– не поддерживается
https://app.diagrams.net/
26
27.
Хранилище данныхХранилище данных:
• разновидность систем хранения, ориентированная на поддержку процесса анализа
данных, обеспечивающая целостность, непротиворечивость и хронологию данных, а
также высокую скорость выполнения аналитических запросов
• система, в которой собраны данные из различных источников внутри компании и эти
данные используются для поддержки принятия управленческих решений
Метаданные:
• высокоуровневые средства отражения информационной модели и описания структуры
данных, используемой в ХД
• должны содержать описание структуры данных хранилища и структуры данных
импортируемых источников
• хранятся отдельно от данных в так называемом репозитарии метаданных
27
28.
Проектирование ХДХранилище данных — разновидность систем хранения, ориентированная на поддержку
процесса анализа данных, обеспечивающая целостность, непротиворечивость и хронологию
данных, а также высокую скорость выполнения аналитических запросов.
Укрупненные универсальные шаги по проектированию архитектуры хранилища данных:
1.
2.
3.
4.
Определение области бизнес-процессов, поддерживаемых хранилищем;
Определение атомарного уровня данных
Определение признаков, применяемых к каждой записи таблицы фактов
Определение единиц измерения для каждого значения в таблице фактов
28
29.
Два подхода к проектированию ХДПодход «снизу вверх» Ральфа Кимбалла:
• витрины данных (ХД, принадлежащие конкретным направлениям бизнеса) важны
• ХД - сочетание различных витрин данных для эффективной отчетности и анализа
Нисходящий подход Билла Инмона:
• ХД - централизованное для всех корпоративных данных
• организация сначала создает нормализованную модель ХД, а затем уже витрины
размерных данных на основе модели хранилища
29
30.
Архитектура ХДОбщая архитектура хранилища
данных:
клиентский (верхний) уровень
o инструменты аналитики
o анализ данных
o отчеты
• средний уровень
o сервер OLAP
• нижний уровень
o сервер базы данных
уровень других источников данных
30
31.
Сравнение OLTP и OLAPOLTP
Оперирует последними
транзакционными данными
Относительно небольшой размер БД
Выполняет операции «день в день»
Быстрая скорость транзакций
Эффективно выполняет только простые
запросы
OLAP
Управляет всеми историческими
данными
Огромный размер базы данных
Поддерживает принятие решений
Медленные транзакции
Эффективно выполняет сложные
запросы
Требует операций чтения / записи
Обновление части данных
Данные в двумерных таблицах
Требует только операций чтения
Может обновить все данные
Данные в многомерных кубах
31
32.
Хранение данных в реляционной модели(OLTP)
32
33.
Принцип работы OLAP33
34.
Виды серверов OLAPOLAP-сервера бывают трех видов:
многомерный OLAP (MOLAP) — индексирует непосредственно многомерную базу
данных
• реляционный OLAP (ROLAP) — выполняет динамический многомерный анализ данных,
хранящихся в реляционной базе данных
• гибридный OLAP (HOLAP):
o комбинация ROLAP и MOLAP
o сочетает большую емкость данных ROLAP с быстрой обработкой MOLAP
34
35.
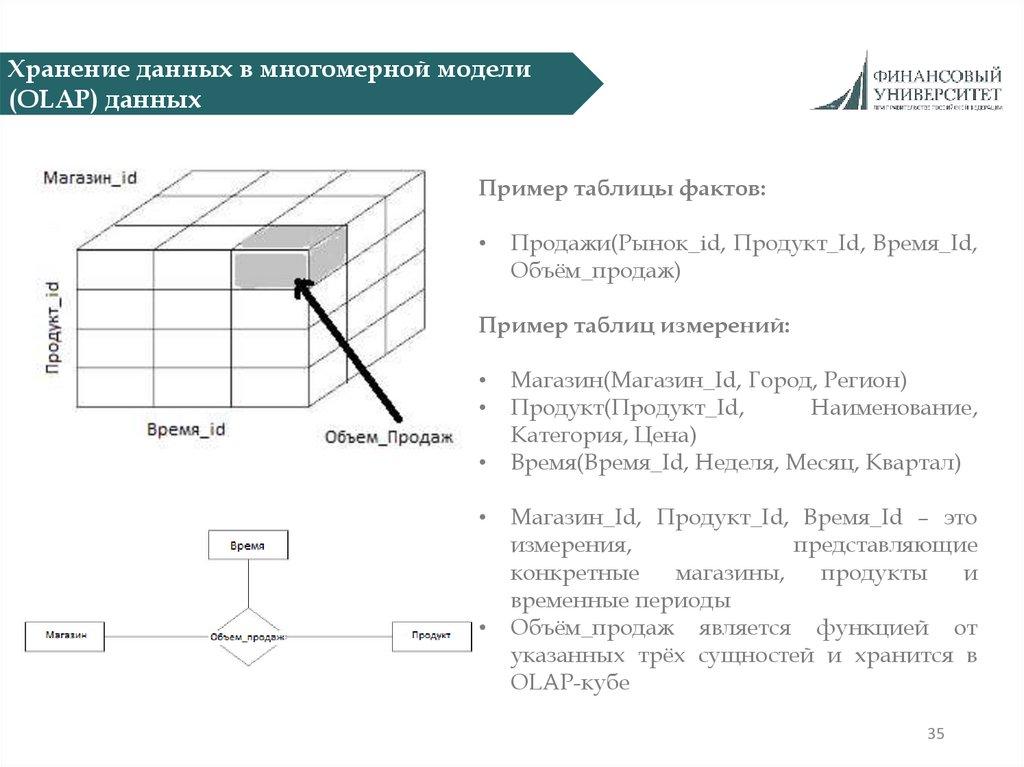
Хранение данных в многомерной модели(OLAP) данных
Пример таблицы фактов:
Продажи(Рынок_id, Продукт_Id, Время_Id,
Объём_продаж)
Пример таблиц измерений:
Магазин(Магазин_Id, Город, Регион)
Продукт(Продукт_Id,
Наименование,
Категория, Цена)
Время(Время_Id, Неделя, Месяц, Квартал)
Магазин_Id, Продукт_Id, Время_Id – это
измерения,
представляющие
конкретные
магазины,
продукты
и
временные периоды
Объём_продаж является функцией от
указанных трёх сущностей и хранится в
OLAP-кубе
35
36.
Моделирование хранилища данных. Схема«Звезда»
в центре звезды расположена таблица фактов
таблица фактов содержит агрегированные
данные, используемые для составления отчетов
звезда разбивает таблицу фактов на ряд
денормализованных таблиц измерений
таблицы измерений описывают хранимые
данные
таблица фактов использует только одну ссылку
для
присоединения
к
каждой
таблице
измерений
денормализованные структуры просты для
обработки, т.к. данные сгруппированы
в ХД звездоообразной схемы значительно проще
писать сложные запросы
36
37.
Моделирование хранилища данных. «Звезда»Пример схемы «звезда»
37
38.
Моделирование хранилища данных. Схема«Снежинка»
«снежинка»
использует
нормализованные
данные, т.е. каждая таблица не содержит
избыточных данных
отдельные таблицы измерений разветвляются на
отдельные таблицы измерений
используется меньше дискового пространства
лучше обеспечивается целостность данных
недостаток - сложные запросы (каждый запрос
должен пройти несколько соединений таблиц
для получения данных)
38
39.
Моделирование хранилища данных.«Снежинка»
Пример схемы данных «снежинка»
39
40.
Ориентированная на столбцы БДОриентированная на столбцы БД
• OLAP остается негибкой технологией, т.к.
требует моделирования БД для кубов
• со
временем
может
понадобится
отдельное ХД для нужд OLAP
• ориентированная
на
столбцы
БД
предоставляет возможности, аналогичные
возможностям базы данных OLAP
• каждая таблица здесь представляет
измерение,
которое
можно
быстро
просмотреть и проанализировать
40
41.
Варианты архитектур ХД. Базовый вариантпозволяет
конечным
пользователям
хранилища напрямую получать доступ к
сводным
данным,
полученным
из
исходных систем, создавать отчеты и
анализировать эти данные
для случаев, когда источники данных
происходят из одних и тех же типов СУБД
41
42.
Варианты архитектур ХД.промежуточной областью
Вариант
с
подходит
для
организации
с
разнородными источниками данных с
множеством различных типов и форматов
данных
промежуточная
область
преобразует
данные
в
обобщенный
структурированный формат, который
проще запрашивать с помощью BIинструментов
42
43.
Варианты архитектурвитринами
ХД.
Вариант
с
в витринах данных хранятся сводные
данные
по
конкретному
бизнеснаправлению
их легче анализировать, т.к. данные
лучше адаптированы для конечного
пользователя
43
44.
Варианты архитектурхранилища
ХД.
Облачные
Примеры продуктов: Azure, Panoply, Redshift
Особенности и проблемы облачных СХД:
проблемы с доступностью сервисов ХД
шаг вперед по сравнению с традиционной архитектурой
загрузка данных в облачные ХД сложна
требуются дополнительные инструменты поддержка процесса ETL для крупных
конвееров
обновления, вставки и удаления могут быть сложными и должны выполняться
осторожно, чтобы не допустить снижения производительности запросов
затруднена обработка полуструктурированных данных
вложенные структуры обычно не поддерживаются
необходимо преобразовать вложенные таблицы в форматы, понятные ХД
постоянное переконфигурирование облачных кластеров из-за изменений нагрузок,
наборов данных или даже типов запросов
нужны дополнительные инструменты оптимизации запросов
сложные процессы резервного копирования и восстановления
44
45.
BI-функционал в ERP-системеНа примере прогнозирование продаж и запасов в MS Dynamics NAV 2018
Используемые модели:
ARIMA
ETS
STL
ETS+ARIMA (returns average as result)
ETS+STL (returns average as result)
ALL
TBATS
45
46.
BI-функционал в ERP-системеНа примере прогнозирование продаж и запасов в MS Dynamics NAV 2018
46
47.
Интеграция BI-функционала вприложения. Power BI Embedded
мобильные
47
48.
48Power BI Embedded
Power BI Embedded - сервис для независимых
вендоров
программного
обеспечения,
позволяющий
внедрять
визуальные
элементы
в
свои
приложения
без
необходимости создавать свои собственные
решения для аналитики
49.
49Power BI Embedded
Power BI Embedded. Варианты внедрения
Внедрение для клиентов:
• позволяет внедрять панели мониторинга и отчеты для пользователей, у
которых нет учетной записи Power BI
• такое внедрение и называется Power BI Embedded
50.
50Power BI Embedded
Power BI Embedded. Варианты внедрения
Можно внедрять Power BI Embedded
• совместно с Power BI
• развертывать через Azure
Возможности службы Power BI (SaaS) и Power BI Embedded в Azure (PaaS)
предоставляют единый API для внедрения информационных панелей и
отчетов
51.
51Power BI Embedded
Power BI Embedded. Концепция
52.
52Power BI Mobile
Power BI Mobile. Ключевой функционал
приложений
• доступ к локальным данным, хранящимся в SQL Server, или к
данным в облаке
• Microsoft Intune для защиты и управления мобильными
устройствами и приложениями
• Поддерживаемые ОС: Windows, iOS и Android
• Mobile friendly-интерфейс
• Голосовое управление для переключения панелей и поиска данных
• Фунционал командной работы
• Заметки в отчетах на сенсорном экране
• Пересылка отчетов
• Поддержка push-уведомлений, технологии 3D Touch
• Обновление данных в реальном времени на телефонах, планшетах
и часах Apple Watch
53.
53Power BI Mobile
Power BI Mobile
Для создания мобильного приложения Power
BI нужно:
• Скачать
универсальное
мобильное
приложение
• Подключиться в нем к Power BI-сервисам
(Salesforce, Microsoft Dynamics, Google
Analytics и т.д.), либо подключиться к
службе Power BI с помощью Ваших
учетных данных
• Далее Power BI создает рабочую область с
панелью мониторинга и набором отчетов
• Выбираем нужные представления
54.
54Power BI Mobile
Внешний вид панелей мониторинга у
iPhone и Android-смартфонов
55.
Тема 1. Обзор современных BI системАлгоритмические и программные методы проведения OLAP и
интеллектуального анализа данных для принятия взвешенных
решений
55
56.
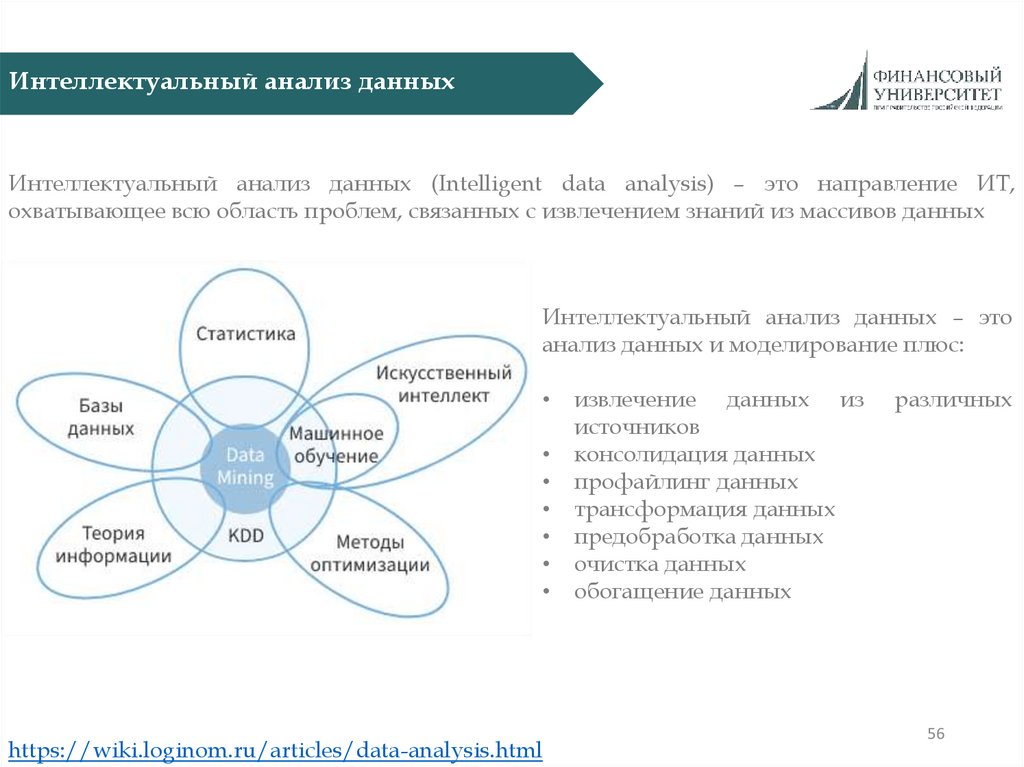
Интеллектуальный анализ данныхИнтеллектуальный анализ данных (Intelligent data analysis) – это направление ИТ,
охватывающее всю область проблем, связанных с извлечением знаний из массивов данных
Интеллектуальный анализ данных – это
анализ данных и моделирование плюс:
https://wiki.loginom.ru/articles/data-analysis.html
извлечение данных из
источников
консолидация данных
профайлинг данных
трансформация данных
предобработка данных
очистка данных
обогащение данных
различных
56
57.
Консолидация данныхКонсолидация
данных
– это
процесс, включающий в рамках
ETL-процесса:
извлечение
данных
из
различных источников
обеспечение
необходимого
уровня их информативности и
качества
преобразование
к
единому
формату
Альтернатива ETL-процессу – виртуализация данных:
интегрирует данные из разнородных источников данных без их репликации или
перемещения
консолидированное виртуальное представление информации.
данные могут быть извлечены через виртуальный интерфейс
57
58.
Профилирование (профайлинг) данныхПрофайлинг данных:
процесс извлечения метаданных из
данных
процесс автоматического обнаружения и
исправления данных в соответствии с
заданным сценарием
проверяются поля источника данных на
соответствие заданным ограничениям
(тип поля, длина, диапазон значений,
соответствие шаблону)
может выявить причину проблем с
качеством данных
58
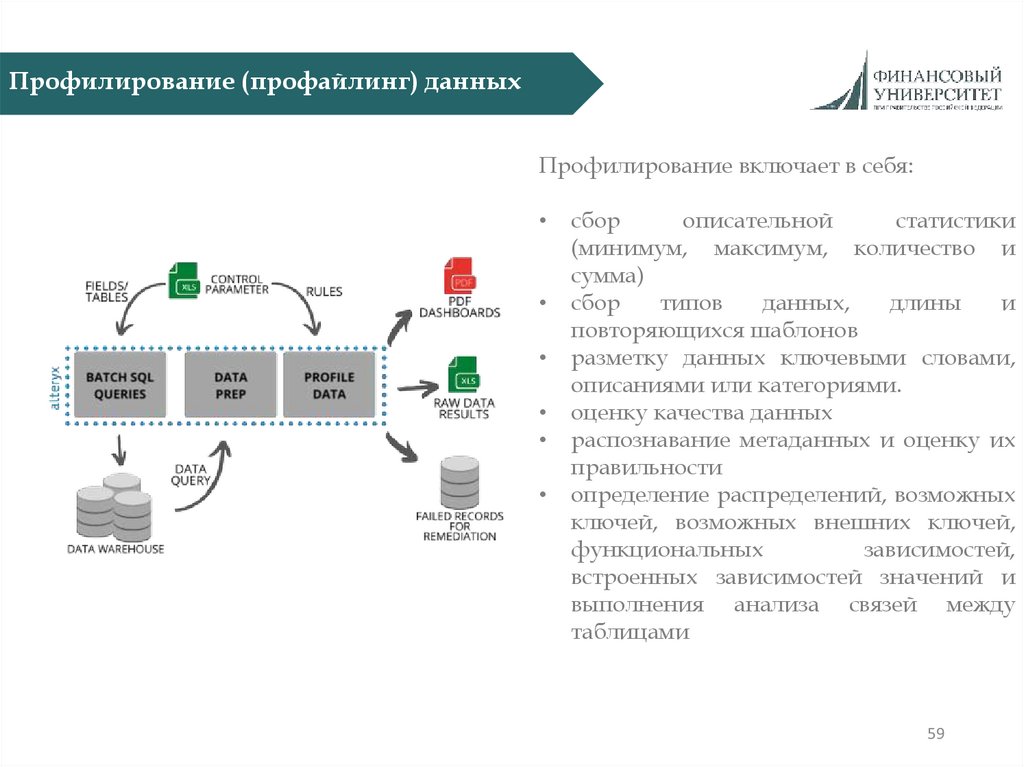
59.
Профилирование (профайлинг) данныхПрофилирование включает в себя:
сбор
описательной
статистики
(минимум, максимум, количество и
сумма)
сбор
типов
данных,
длины
и
повторяющихся шаблонов
разметку данных ключевыми словами,
описаниями или категориями.
оценку качества данных
распознавание метаданных и оценку их
правильности
определение распределений, возможных
ключей, возможных внешних ключей,
функциональных
зависимостей,
встроенных зависимостей значений и
выполнения анализа связей между
таблицами
59
60.
Терминология процессинга данныхТрансформация данных:
https://restapp.io/blog/data-transformation/
извлечение
данных
из
различных источников
обеспечение
необходимого
уровня их информативности и
качества
преобразование
к
единому
формату
заключается в оптимизации
представлений
данных
и
форматов с точки зрения
решаемых
задач
и
целей
анализа
не ставит целью изменить
содержание данных
представляет данные в наиболее
эффективном для обработки
виде
60
61.
Преобразование (трансформация) данныхОперации трансформации данных:
https://restapp.io/blog/data-transformation/
фильтрация и разбиение на
подмножества
преобразование
символьных
кодировок
стандартизация
агрегирование
61
62.
Финальный этап предобработки данныхФинальный этап предобработки данных:
подготовка к анализу
самый важный этап Data Mining
принцип GIGO — garbage in, garbage out
основные подпроцессы:
o очистка
o снижение размерности
o отбор признаков
o выявление и исключение незначащих признаков
o нормализация
62
63.
Терминология процессинга данныхПредобработка данных:
https://appilux.io/data-preparation/
подготовка к анализу
самый важный этап Data Mining
принцип GIGO — garbage in,
garbage out
включает два подпроцесса:
o очистка
o оптимизация
снижение
размерности,
выявление
и
исключение
незначащих
признаков
63
64.
Алгоритмы Data MiningОбогащение данных:
процесс
насыщения
данных
новой информацией
бывает внешнее и внутреннее
приводит к появлению новых
полей или таблиц в ХД
для него могут использоваться и
результаты
анализа
уже
имеющихся данных
https://www.oktopost.com/blog/complete-guide-data-enrichment/
64
65.
Разведочный анализ данных (EDA)Разведочный анализ данных (EDA, Eploratory data analysis):
быстрое прототипирование с помощью визуализации
создание большого количества различных визуальных представлений одних и тех же
данных
нахождение скрытых взаимосвязей, зависимостей, закономерностей
выявление аномалий
проверка гипотез и предположений
первичная оценка набора данных для последующего применения более сложных
инструментов анализа
черновая визуализация
определение методов и моделей для последующих этапов анализа данных
65
66.
Инструменты EDAКонкретные статистические методы и инструменты EDA:
методы кластеризации и уменьшения размерности, которые помогают создавать
графические отображения многомерных данных, содержащих множество переменных
одномерная визуализация каждого поля в необработанном наборе данных со сводной
статистикой
двумерные визуализации и сводная статистика, которые позволяют оценить связь между
каждой переменной в наборе данных и целевой переменной
многомерные визуализации для отображения и понимания связей между различными
полями в данных
кластеризация K-средних
некоторые прогнозные модели
66
67.
Способы EDAСуществует четыре основных способа EDA:
1. Одномерный неграфический
2. Одномерный графический
• диаграммы вида «стебель-листья», которые показывают все значения данных и форму
распределения
• гистограммы, столбчатые диаграммы
• коробчатые диаграммы, которые графически изображают пятизначную сводку
минимума, первого квартиля, медианы, третьего квартиля и максимума
3. Многомерный неграфический: многомерные данные возникают из более чем одной
переменной. Многомерные неграфические методы EDA обычно показывают взаимосвязь
между двумя или более переменными данных посредством перекрестных таблиц или
статистики
4. Многомерная графика для отображения взаимосвязей между двумя или более наборами
данных. Наиболее часто используемая графика представляет собой сгруппированную
гистограмму или гистограмму, где каждая группа представляет один уровень одной из
переменных, а каждая полоса в группе представляет уровни другой переменной.
67
68.
Способы EDAДругие распространенные типы многомерной графики:
двумерная точечная диаграмма – показывает, насколько одна переменная зависит от
другой
многомерная диаграмма, графическое представление отношений между факторами и
откликом
динамическая диаграмма - линейный график на оси времени
пузырьковая диаграмма — двумерная визуализация данных
тепловая карта, представляющая собой цветовое графическое представление данных
68
69.
Способы EDAПример тепловой карты веб-сайта
https://www.umi-cms.ru/support/poleznye-stati/teplovye_karty/
69
70.
Методы Data Mining. АссоциацияМетод ассоциации используется для поиска
зависимости между двумя или более
элементами путем выявления скрытого
паттерна в датасете
Сферы применения:
• анализ клиентского поведения
• медицинские исследования
• web-mining
• text-mining
Пример математической постановки задачи для решения с помощью метода
ассоциации:
70
71.
Методы Data Mining. КлассификацияМетод классификации используется
для разделения элементов в наборах
данных на классы или группы, что
помогает
точнее
предсказать
поведение сущностей в группе:
это базовая задача анализа данных
классификаторы - аналитические
модели,
решающие
задачу
классификации
классифицирующие правила могут
быть
сформулированы
на
естественном языке
Наиболее распространенные методы решения задач классификации:
нейронные сети
логистическая и пробит-регрессия
деревья решений
метод ближайшего соседа
машины опорных векторов
дискриминантный анализ
71
72.
Методы Data Mining. Кластерный анализКластеризация – это объединение
объектов
или
наблюдений
в
непересекающиеся группы на основе
близости значений их признаков
Наиболее распространенные методы решения задач кластеризации:
иерархическая кластеризация
сеточные методы
методы разбиения
кластеризация по плотности элементов
72
73.
Методы Data Mining. Кластерный анализСравнение некоторых алгоритмов кластерного анализа и их вычислительная
сложность
Алгоритм
кластеризации
Иерархический
k-средних
c-средних
Выделение связных
компонент
Минимальное
покрывающее дерево
Послойная
кластеризация
Форма кластеров
Произвольная
Входные данные
Результаты
Число кластеров или
порог расстояния для
усечения иерархии
Бинарное дерево
кластеров
Алгоритм
кластеризации
Вычислительная
сложность
Иерархический
O(n2)
k-средних
c-средних
O(nkl), где k – число
кластеров, l – число
итераций
Гиперсфера
Число кластеров
Центры кластеров
Гиперсфера
Число кластеров,
степень нечеткости
Центры кластеров,
матрица
принадлежности
Произвольная
Порог расстояния R
Древовидная
структура кластеров
Выделение связных
компонент
зависит от
алгоритма
Произвольная
Число кластеров или
порог расстояния для
удаления ребер
Древовидная
структура кластеров
Минимальное
покрывающее
дерево
O(n2 log n)
Послойная
кластеризация
O(max(n, m)), где m
< n(n-1)/2
Произвольная
Последовательность
порогов расстояния
https://habr.com/ru/post/101338/
Древовидная
структура кластеров с
разными уровнями
иерархии
73
74.
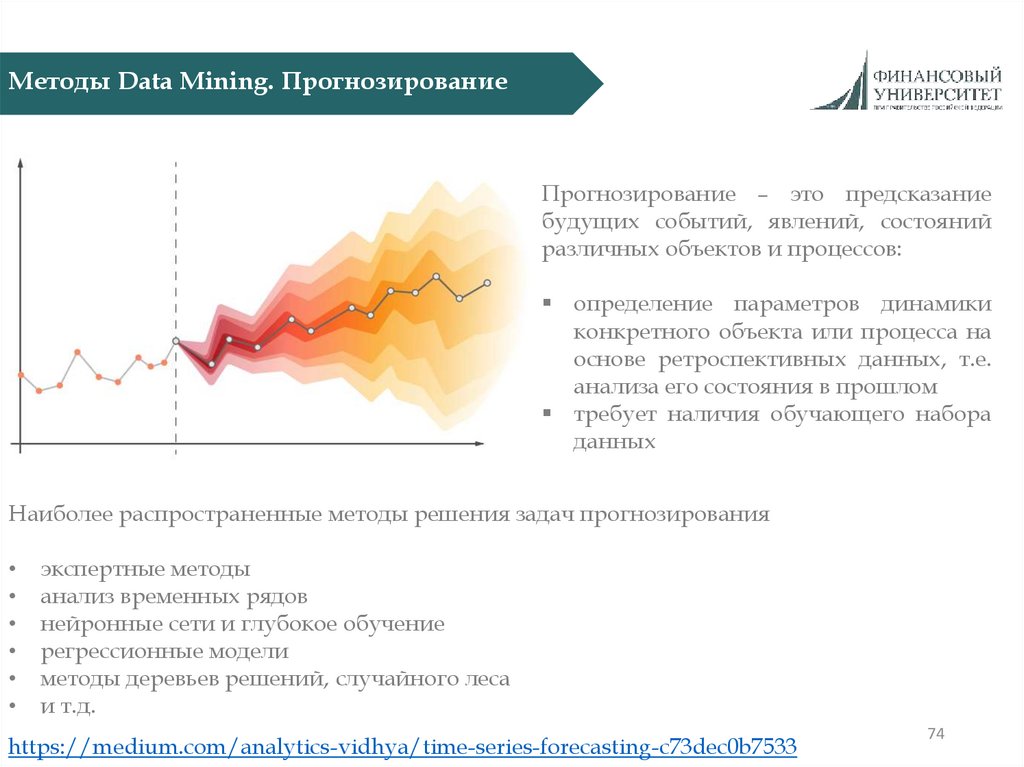
Методы Data Mining. ПрогнозированиеПрогнозирование – это предсказание
будущих событий, явлений, состояний
различных объектов и процессов:
определение параметров динамики
конкретного объекта или процесса на
основе ретроспективных данных, т.е.
анализа его состояния в прошлом
требует наличия обучающего набора
данных
Наиболее распространенные методы решения задач прогнозирования
экспертные методы
анализ временных рядов
нейронные сети и глубокое обучение
регрессионные модели
методы деревьев решений, случайного леса
и т.д.
https://medium.com/analytics-vidhya/time-series-forecasting-c73dec0b7533
74