































 lingvistics
lingvisticsSimilar presentations:







")


Математическая лингвистика
1. Математическая лингвистика
2.
Математическаялингвистика
Математическая лингвистика – дисциплина, предметом которой
является разработка формального аппарата для описания строения
естественных и некоторых искусственных языков.
Математическое описание языка основано на восходящем к Ф. де
Соссюру представлении о языке как механизме, функционирование
которого проявляется в речевой деятельности его носителей; её
результатом являются «правильные тексты» — последовательности
речевых единиц, подчиняющиеся определённым закономерностям,
многие из которых допускают математическое описание.
История
Разделы
3. История
с. 1 из 2Математическая лингвистика – молодое направление,
сформировавшееся в середине 20 века. Активное развитие
математической лингвистики в мировой науке было
обусловлено необходимостью решения проблемы
автоматической обработки, хранения, поиска и передачи
информации на естественном языке.
В 1950–1960-е годы в крупнейших исследовательских
центрах СССР были созданы лаборатории, в стенах которых
филологи и математики объединили свои усилия в работе
над системами компьютерного анализа текстов на разных
языковых уровнях, машинного перевода, порождения
и распознавания звучащей речи. Тогда же при Академии наук
СССР был сформирован Комитет по прикладной
лингвистике, призванный поддерживать новое направление,
в том числе и в сфере образования.
4. История
с. 2 из 2В 1958 году на филологическом факультете Ленинградского
государственного университета открылось первое стране
отделение по подготовке кадров в области математической
лингвистики, а в 1962 году начала действовать одноимённая
кафедра. В 1960 году отделение математической
лингвистики было открыто на филологическом факультете
Московского государственного университета, позднее
появились отделения и в некоторых других отечественных
вузах.
За рубежом обучение в области математической лингвистики
ведётся не в филологическом ракурсе, а скорее в рамках
таких дисциплин, как вычислительная техника
и информационные технологии.
5. Разделы
Математическая лингвистикаРаспознавание и синтез речи
Синтаксический анализ и генерация текста
Машинный перевод
6. Распознавание и синтез речи
Распознавание речи – набор технологий, позволяющих управлять компьютером,используя человеческий голос. Коммерческие программы по распознаванию
речи появились в начале девяностых годов. Такие программы переводят голос
пользователя в текст, таким образом, разгружая его руки. Надёжность перевода
у таких программ не очень высока, но с годами она постепенно улучшается.
Синтез речи – формирование речевого сигнала по печатному тексту. Синтез речи
может быть использован в технике связи, в информационно-справочных
системах, для помощи слепым и немым, при управлении человеком со стороны
автомата, для выдачи информации о технологических процессах, в военной и
космической технике, в робототехнике, в акустическом диалоге человека с
компьютером. Вообще синтез речи может потребоваться во всех случаях, когда
получателем информации является человек.
См. дополнительно: Типы синтеза речи
7. Типы синтеза речи
Параметрический синтез. Речевой сигнал представляется набором небольшого числанепрерывно изменяющихся параметров. Достоинством такого способа является
возможность записать речь для любого языка и любого диктора. Однако
параметрический синтез не может применяться для произвольных, заранее не заданных
сообщений.
Компиляционный синтез. Составление сообщения из предварительно записанного
словаря исходных элементов синтеза. Компилятивный синтез имеет широкое
практическое применение. Например, в справочных службах операторов сотовой связи
при получении информации о состоянии счета абонента. Основная проблема — объёмы
памяти для хранения словаря.
Полный синтез речи по правилам. Обеспечивает управление всеми параметрами
речевого сигнала и, таким образом, может генерировать речь по заранее неизвестному
тексту. Синтез реализуется путем моделирования речевого тракта, применения
аналоговой или цифровой техники. В системах, основанных на этом способе синтеза,
выделяется два подхода. Первый подход - артикуляторный синтез. Второй подход —
формантный синтез по правилам.
8. Синтаксический анализ
Синтаксиический анализ (парсинг) – это процесс сопоставления линейнойпоследовательности лексем языка с его формальной грамматикой. Результатом
обычно является дерево разбора. При парсинге исходный текст преобразуется в
структуру данных, которая отражает синтаксическую структуру входной
последовательности и хорошо подходит для дальнейшей обработки.
Области применения:
Языки программирования. Например, разбор исходного кода языков
программирования, в процессе компиляции или интерпретации.
Структурированные данные. Например, XML, HTML, CSS и т. п.
SQL-запросы
Математические выражения
Регулярные выражения
Формальные грамматики
Человеческие языки. Например, машинный перевод и генераторы текстов.
9. Дерево разбора
10. Генерация текста
Генератор текста — компьютерная программа, способная генерироватьпоследовательности символов, внешне похожие на текст, но при этом, как
правило, лишённые смысла. При этом тексты, созданные с помощью
генераторов, являются правильными с точки зрения большинства языковых
норм.
Современные программы для генерации текста используют в своей
основе цепи Маркова на уровне слов. уровня слов. При составлении
алгоритма генерации исследуются пары слов, стоящих рядом. То есть
изучается вероятность появление того или иного слова после данного.
Написание слов будет в итоге правильным добавляется и также
правильным будет синтаксис синтаксис. Таким образом получается
практически читаемый текст.
11. Машинный перевод
Машинный перевод — процесс перевода текстов с одного естественного языкана другой с помощью специальной компьютерной программы. Так же
называется направление научных исследований, связанных с построением
подобных систем.
Типы систем машинного перевода:
С постредактированием: исходный текст перерабатывается машиной, а
человек-редактор исправляет результат.
С предредактированием: человек приспосабливает текст к обработке
машиной (устраняет возможные неоднозначные прочтения, упрощает и
размечает текст), после чего начинается программная обработка.
С интерредактированием: человек вмешивается в работу системы перевода,
разрешая трудные случаи.
Смешанные системы.
12. Ссылки
Лингвистический энциклопедический словарь – 2-е изд.,доп. – М.: Большая Российская энциклопедия, 2002. –
709 с.: ил.
Значение слова «Математическая лингвистика» в
Большой Советской Энциклопедии http://bse.scilib.com/article074311.html
http://ru.wikipedia.org/wiki/Математическая_лингвистика
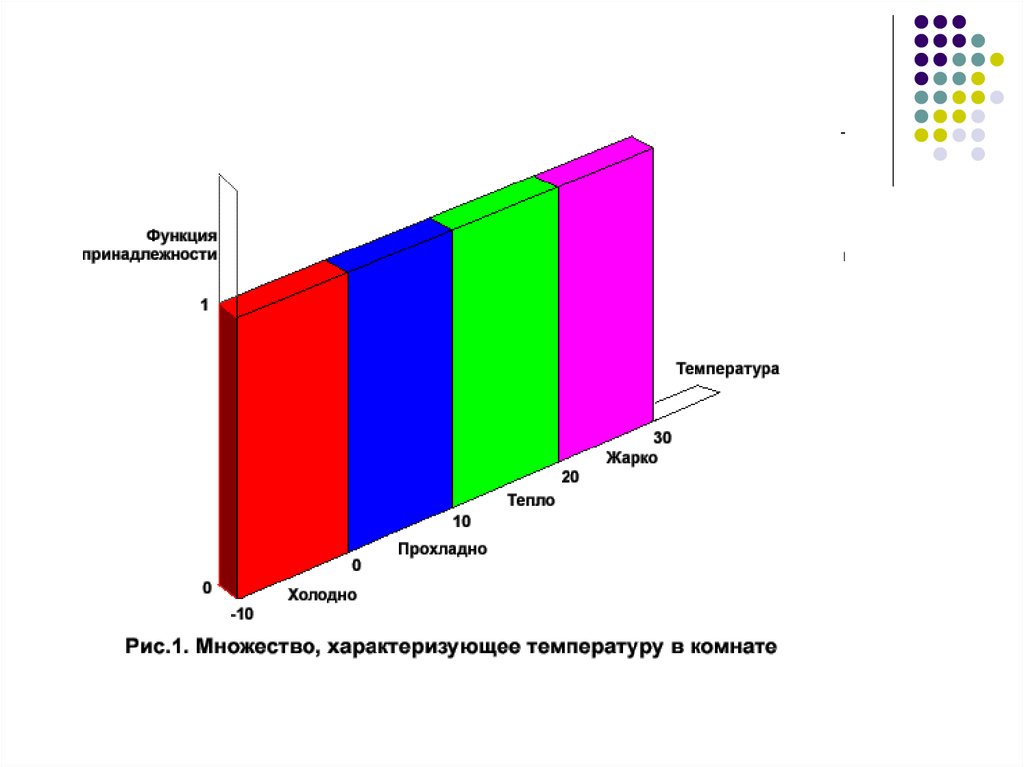
13. Нечеткие множества в лингвистике
14. Определение
Теория нечетких множеств — разделприкладной математики, посвященный
методам анализа неопределенных данных, в
которых описание неопределенностей
реальных явлений и процессов проводится с
помощью понятия о множествах, не имеющих
четких границ.
15.
16.
17.
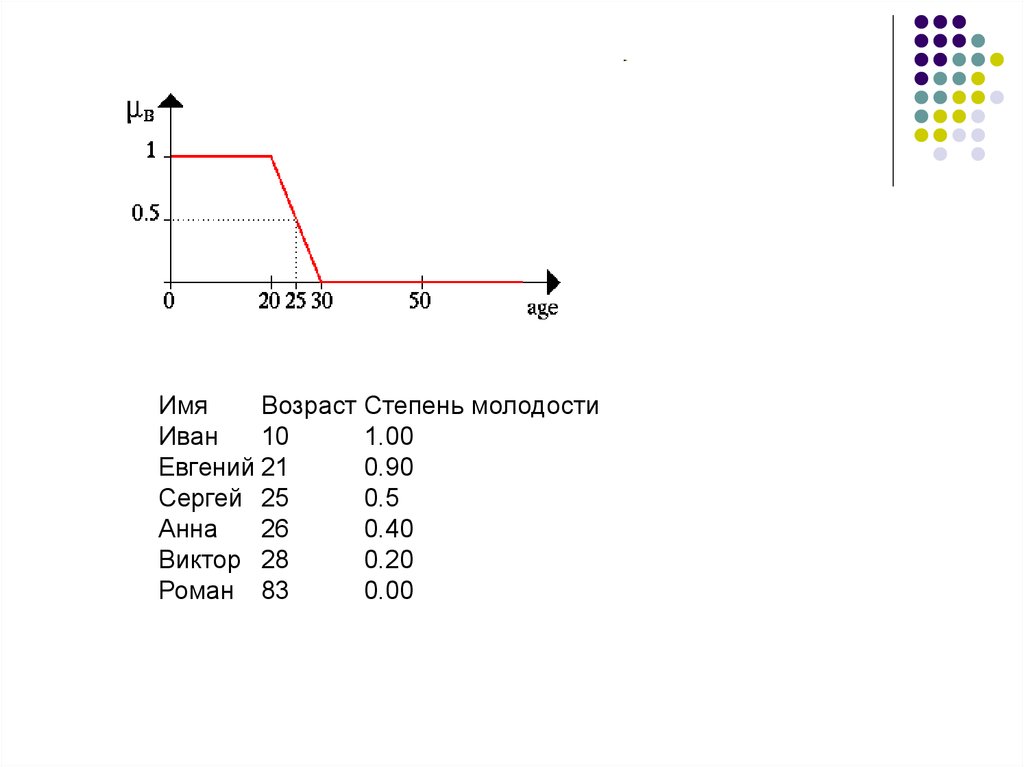
ИмяВозраст Степень молодости
Иван
10
1.00
Евгений 21
0.90
Сергей 25
0.5
Анна
26
0.40
Виктор 28
0.20
Роман 83
0.00
18.
19.
<0/1>,<0.4/3>,<1/7>Это множество говорит о том, что 7 - это на 0% единица, на 40%
тройка и на 100% семерка.
<"Семь",{1,3,7},{<0/1>,<0.4/3>,<1/7>}>
Этой записью мы определили соответствия между словом и
некоторыми цифрами. Причем, как в названии переменной, так
и в значениях x можно было использовать любые записи,
несущие какую-либо информацию.
20.
A U B = {<Maub(x)/x>}Maub(x) = max {Ma(x), Mb(x)}
ПЕРЕСЕЧЕНИЕ: создается новое множество из одинаковых
элементов исходных множеств, принадлежность которых
берется минимальной.
A П B = {<Maпb(x)/x>}
Maпb(x) = min {Ma(x), Mb(x)}
ДОПОЛНЕНИЕ: инвертируется принадлежность каждого
элемента.
C = ~A = {<Mc(x)/x>}
Mc(x) = 1-Ma(x)
СТЕПЕНЬ: принадлежность каждого элемента возводится в
степень.
CON - концентрация, степень=2 (уменьшает степень
нечеткости)
DIN - растяжение, степень=1/2 (увеличивает степень
нечеткости)
РАЗНОСТЬ: новое множество состоит из одинаковых
элементов исходных множеств.
21.
A - B = {<Ma-b(x)/x>}Ma-b(x) = Ma(x)-Mb(a), если Ma(x)>Mb(x)
иначе 0
НОСИТЕЛЬ: состоит из элементов исходного множества,
принадлежности которых больше нуля.
Supp(A) = {x|x?X /\ Ma(x)>0}
УМНОЖЕНИЕ НА ЧИСЛО: принадлежности элементов
домножаются на число.
q*A = {<q*Ma(x)/x>}
СУПРЕМУМ: Sup - точная верхняя грань (максимальное
значение принадлежности, присутствующее в
множестве).
22. Ссылки
http://www.aup.ru/books/m162/3_6.htmhttp://www.intuit.ru/department/ds/fuzzysets/
http://www.plink.ru/tnm/gl12.htm
http://www.codenet.ru/progr/alg/Smart/Fuzzy-Sets.php
http://www.msclub.ce.cctpu.edu.ru/fuzzy/FUZZ_WKR/report3.
htm
http://sapr.mgsu.ru/biblio/ex-syst/Glava9/Index8.htm
23. Математические модели в лингвистике
24.
Модель в лингвистике - искусственносоздаваемое лингвистом реальное или
мысленное устройство, воспроизводящее,
имитирующее своим поведением (обычно
в упрощенном виде) поведение оригинала
в лингвистических целях.
25. Типы моделей в лингвистике:
по охвату структуры языка:общие (глобальные) стремятся охватить весь язык:
частные: фонетическая модель русского языка, модель системы
гласных
1.
по типологическому статусу:
универсальные стремятся охватить все языки мира:
специфические характерны для определенного языка или группы
языков:
2.
3.
по гносеологическому статусу:
модели языка
модели лингвистических знаний различные фонетические школы
модели деятельности лингвиста
26.
4.по конечной цели исследования
теоретические
описательные
прикладные
5.
по используемым методам
математические модели
психологические модели
социологические модели
6.
по функциональному статусу
абстрактно обобщающие модели
действующие
7.
по используемым материальным средствам
графические
символьные
компьютерные
27.
Математическая лингвистика используетдля изучения языков:
Аналитические
Порождающие
Исследовательские
Синтетические
28. Синтаксические аналитические модели
ВходТекст
Выход
Синтаксическая
структура
29. Семантические аналитические модели
ВходТекст
Выход
Смысловую запись
каждого предложения
на специальном
семантическом языке
30. Синтаксические синтетические модели
ВходВыход
Синтаксическая
структура
предложений
Правильные
предложения
данного языка
31. Семантические синтетические модели
ВходСмысловая запись
некоторого
предложения на
семантическом языке
Выход
Множество
предложений
естественного
языка
32. Порождающие модели
ВходВыход
Смысловая запись
некоторого
предложения на
семантическом языке
Множество
предложений
естественного
языка
33. Исследовательские модели
ВходТекст и все сведения о
системе
Текст и множество
правильных фраз
данного языка
Текст множество
правильных фраз и
множество
семантических
инвариантов
Выход
Словарь, какая-либо
грамматика, ее правила,
или же описание какоголибо лингвистического
явления.
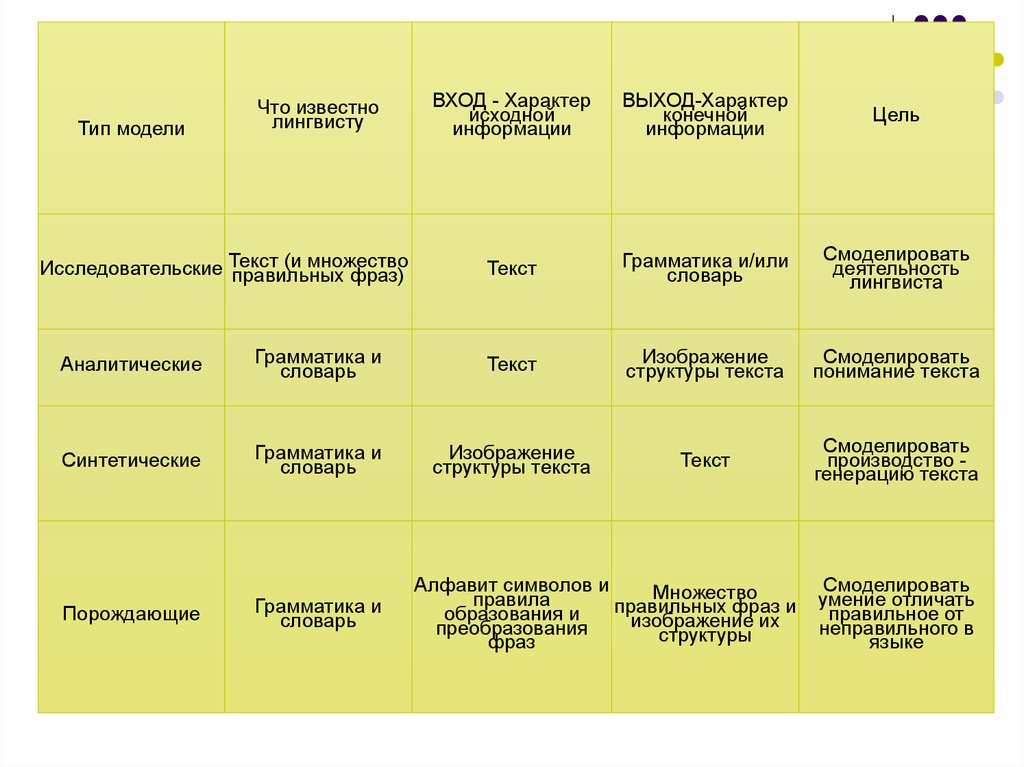
34.
Тип моделиЧто известно
лингвисту
(и множество
Исследовательские Текст
правильных фраз)
ВХОД - Характер
исходной
информации
ВЫХОД-Характер
конечной
информации
Цель
Текст
Грамматика и/или
словарь
Смоделировать
деятельность
лингвиста
Аналитические
Грамматика и
словарь
Текст
Изображение
структуры текста
Смоделировать
понимание текста
Синтетические
Грамматика и
словарь
Изображение
структуры текста
Текст
Смоделировать
производство генерацию текста
Порождающие
Грамматика и
словарь
Алфавит символов и
Множество
правила
правильных фраз и
образования и
изображение их
преобразования
структуры
фраз
Смоделировать
умение отличать
правильное от
неправильного в
языке
35. Ссылки
http://slovari.yandex.ru/dict/bse/article/00046/12500.htmhttp://elementy.ru/lib/164549
http://www.umk.utmn.ru/?section=discipline&d_id=5892&dh_i
d=8808
http://yazykoznanie.ru/content/view/75/279/
http://shop.ecnmx.ru/books/a-63067.html