










































 electronics
electronicsSimilar presentations:









. Параллельная работа СГ с сетью бесконечно большой мощности")
Современные суперкомпьютерные технологии решения больших задач
1.
Научный семинар “Глобальные изменения климата”Современные суперкомпьютерные технологии
решения больших задач
Вл.В.Воеводин
НИВЦ МГУ имени М.В.Ломоносова
ИВМ РАН - 4 марта 2009 г.
2.
3.
Характеристики суперкомпьютеровIBM RoadRunner, 6562 AMD Opteron DC + 12240 IBM Cell,
1105 Tflop/s, ОП = 98 TB
SGI
Altix Ice 8200, 51200 CPUs, Intel Xeon 2.66 GHz QC,
487 Tflop/s, ОП = 51 TB, диски = 900 TB
IBM
Blue Gene, 212992 CPUs, PowerPC 440,
478 Tflop/s, ОП = 74 TB
Cray
XT4,
38642 CPUs, AMD Opteron 2.3 GHz QC,
266 Tflop/s, ОП = 77 TB, диски = 340 ТB
G = 109, T = 1012, P = 1015
4.
Суперкомпьютер СКИФ МГУ - ЧебышевСоздан МГУ, ИПС РАН и компанией “Т-Платформы” при поддержке компании Интел в
рамках суперкомпьютерной программы СКИФ-ГРИД Союзного государства
5.
Суперкомпьютер СКИФ МГУ - Чебышев60 Tflop/s, 1250 процессоров Intel Xeon (*4 ядра)
6.
Суперкомпьютер СКИФ МГУ - Чебышев7.
Суперкомпьютер СКИФ МГУ - Чебышев8.
Суперкомпьютер СКИФ МГУ - Чебышев9.
Суперкомпьютер СКИФ МГУ - Чебышев10.
Суперкомпьютер СКИФ МГУ - Чебышев11.
Суперкомпьютер СКИФ МГУ - Чебышев12.
Суперкомпьютер СКИФ МГУ - Чебышев13.
Суперкомпьютер СКИФ МГУ - Чебышев14.
Суперкомпьютер СКИФ МГУ - Чебышев15.
Суперкомпьютер СКИФ МГУ - Чебышев60 Tflop/s, Linpack = 47,17 Tflop/s (750.000 750.000)
625 узлов, 1250 Intel Xeon E5472 3.0 GHz (Harpertown), 5000 ядер,
InfiniBand DDR GE ServNet+IPMI, Panasas 60 TB, 98 м2
16.
Высокопроизводительныекомпьютерные системы
(основные классы)
Процессоры
Векторные, суперскалярные, VLIW
Компьютеры с общей памятью
Компьютеры с распределенной памятью
Распределенные вычислительные среды
SMP, NUMA, ccNUMA
MPP, кластеры
17.
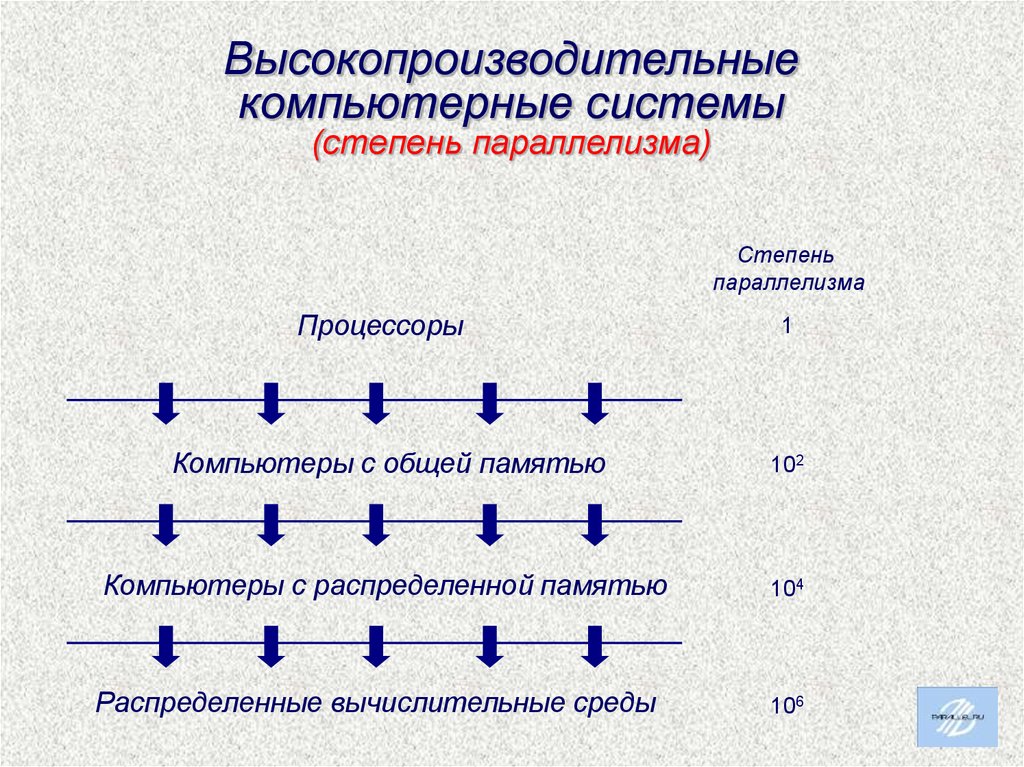
Высокопроизводительныекомпьютерные системы
(степень параллелизма)
Степень
параллелизма
Процессоры
1
Компьютеры с общей памятью
102
Компьютеры с распределенной памятью
104
Распределенные вычислительные среды
106
18.
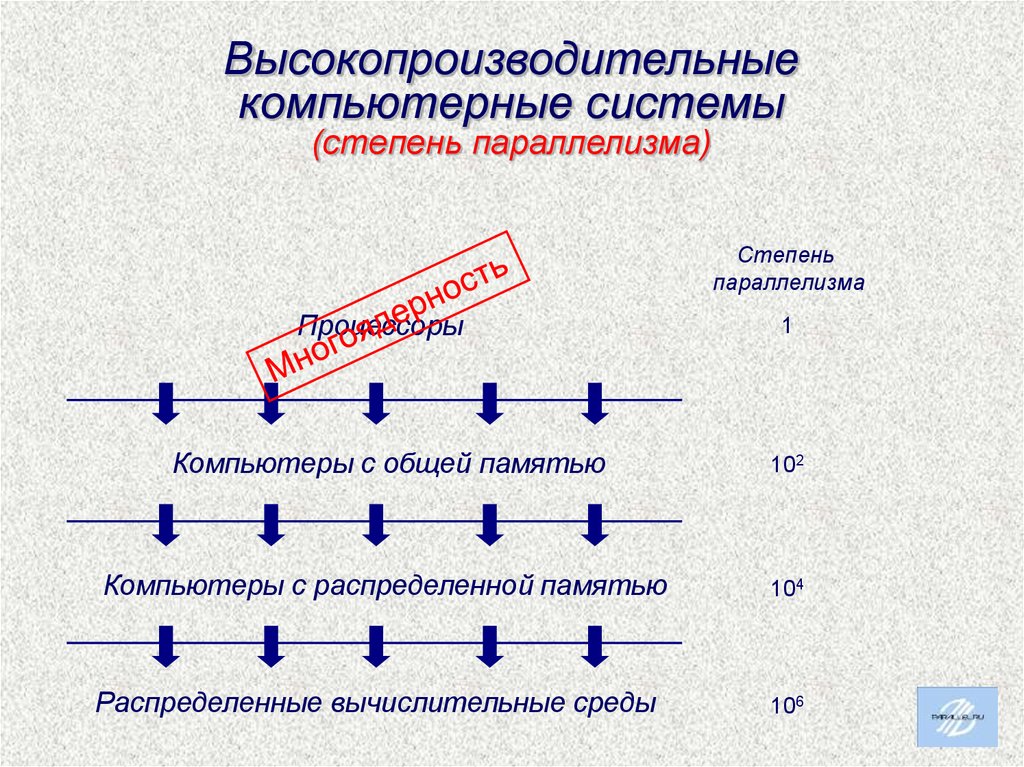
Высокопроизводительныекомпьютерные системы
(степень параллелизма)
Степень
параллелизма
Процессоры
1
Компьютеры с общей памятью
102
Компьютеры с распределенной памятью
104
Распределенные вычислительные среды
106
19.
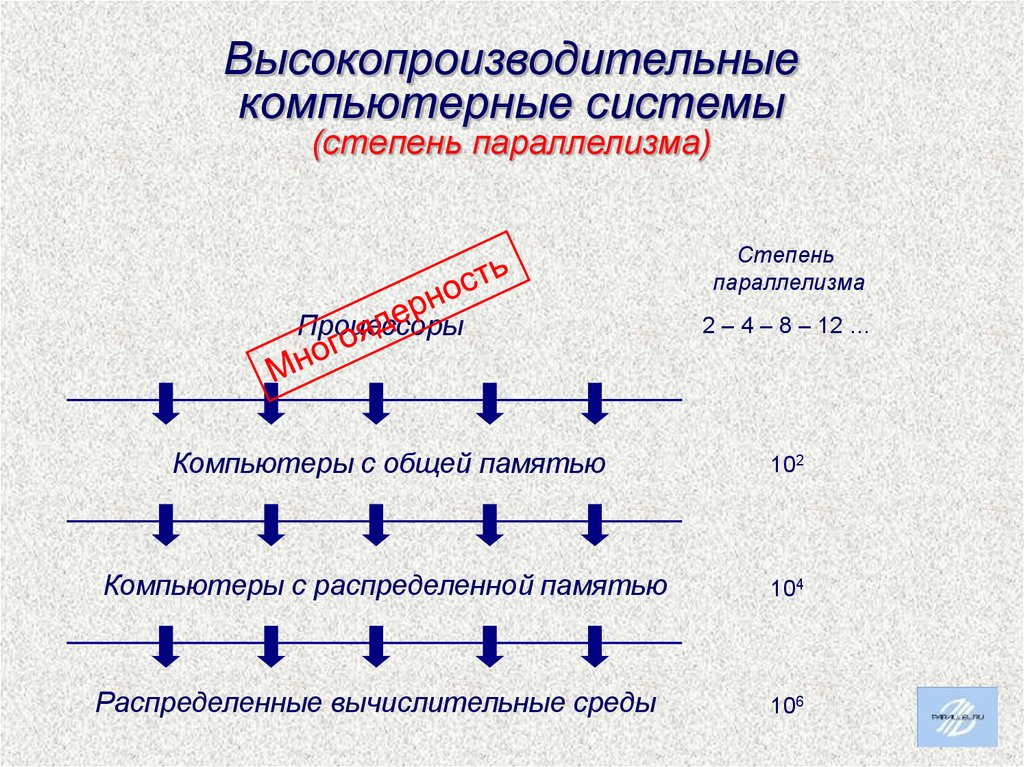
Высокопроизводительныекомпьютерные системы
(степень параллелизма)
Степень
параллелизма
Процессоры
2 – 4 – 8 – 12 …
Компьютеры с общей памятью
102
Компьютеры с распределенной памятью
104
Распределенные вычислительные среды
106
20.
Многоядерные процессоры: это навсегда80-ядерный процессор Intel
21.
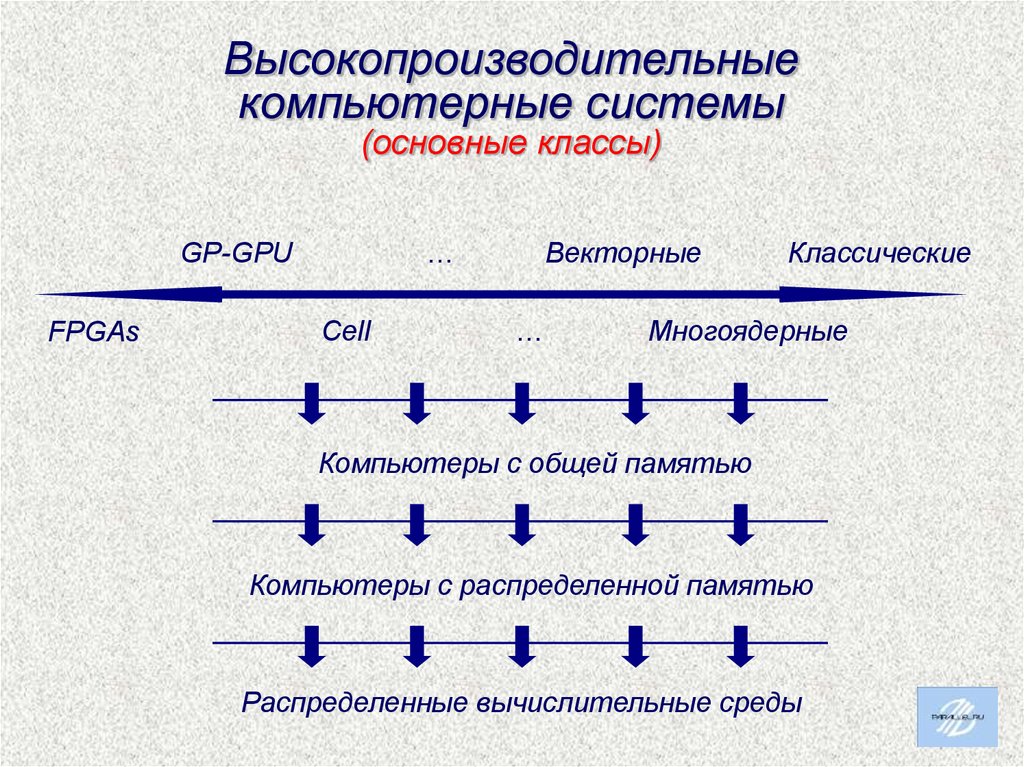
Высокопроизводительныекомпьютерные системы
(основные классы)
…
GP-GPU
FPGAs
Cell
Векторные
…
Классические
Многоядерные
Компьютеры с общей памятью
Компьютеры с распределенной памятью
Распределенные вычислительные среды
22.
Компьютеры с реконфигурируемой архитектурой(http://fpga.parallel.ru)
23.
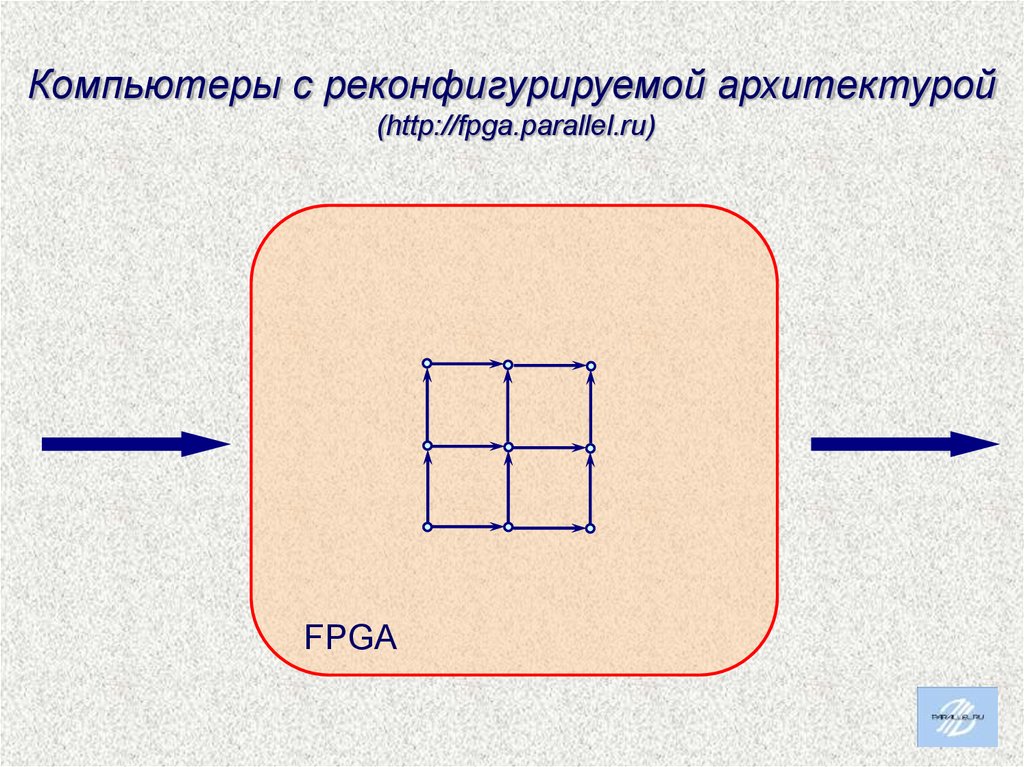
Компьютеры с реконфигурируемой архитектурой(http://fpga.parallel.ru)
FPGA
24.
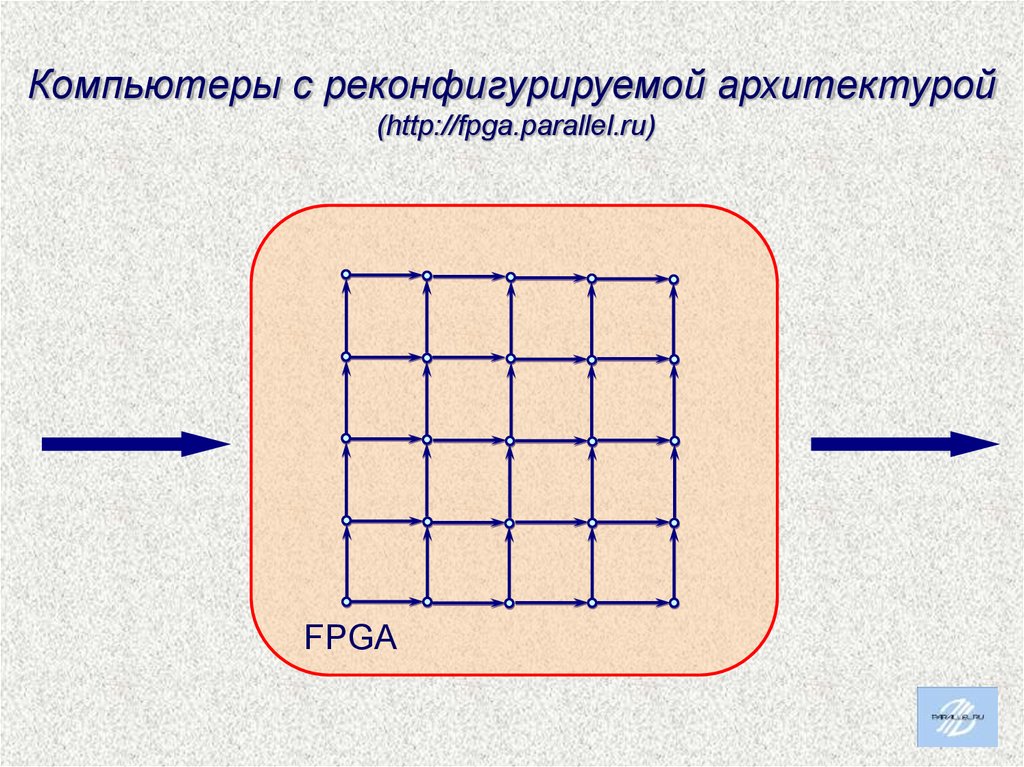
Компьютеры с реконфигурируемой архитектурой(http://fpga.parallel.ru)
FPGA
25.
Компьютеры с реконфигурируемой архитектурой(http://fpga.parallel.ru)
26.
Компьютеры с реконфигурируемой архитектурой(http://fpga.parallel.ru)
РВС-5: установка в НИВЦ МГУ в середине 2009 года
Разработчик – НИИ МВС ЮФУ, г.Таганрог
27.
Графические процессоры и HPC(http://gpu.parallel.ru)
28.
Графические процессоры и HPC(http://gpu.parallel.ru)
29.
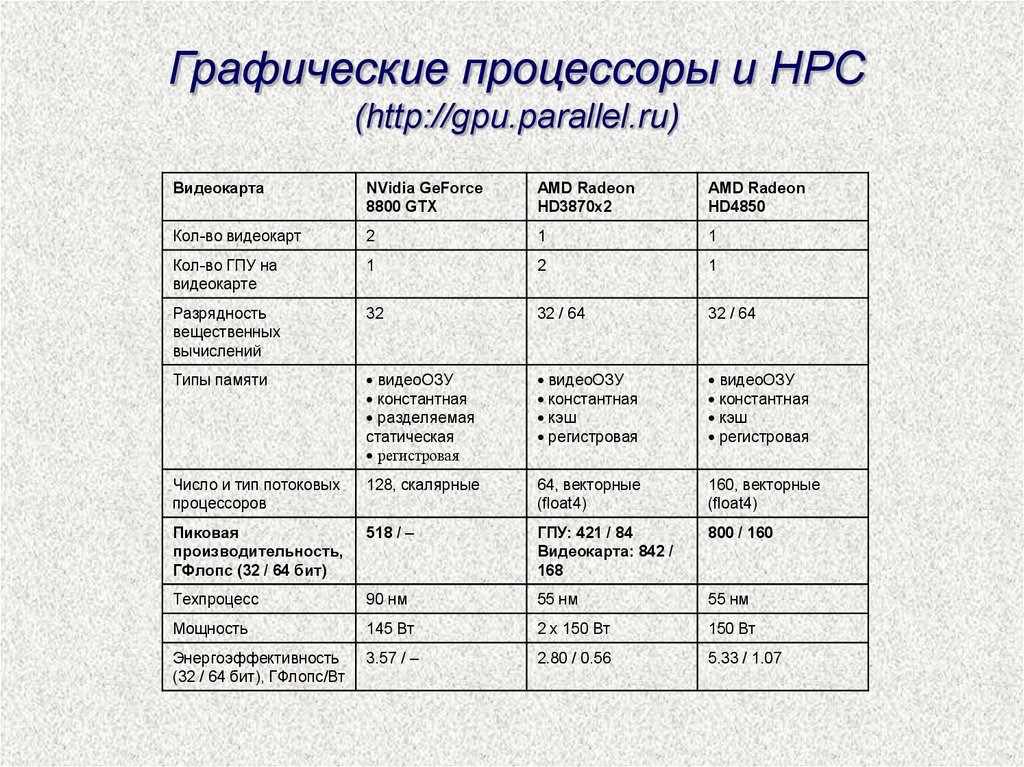
Графические процессоры и HPC(http://gpu.parallel.ru)
Видеокарта
NVidia GeForce
8800 GTX
AMD Radeon
HD3870x2
AMD Radeon
HD4850
Кол-во видеокарт
2
1
1
Кол-во ГПУ на
видеокарте
1
2
1
Разрядность
вещественных
вычислений
32
32 / 64
32 / 64
Типы памяти
видеоОЗУ
константная
разделяемая
статическая
регистровая
видеоОЗУ
константная
кэш
регистровая
видеоОЗУ
константная
кэш
регистровая
Число и тип потоковых
процессоров
128, скалярные
64, векторные
(float4)
160, векторные
(float4)
Пиковая
производительность,
ГФлопс (32 / 64 бит)
518 / –
ГПУ: 421 / 84
Видеокарта: 842 /
168
800 / 160
Техпроцесс
90 нм
55 нм
55 нм
Мощность
145 Вт
2 х 150 Вт
150 Вт
Энергоэффективность
(32 / 64 бит), ГФлопс/Вт
3.57 / –
2.80 / 0.56
5.33 / 1.07
30.
Свойства распределенных вычислительных сред• Масштабность.
• Распределенность.
• Динамичность.
• Неоднородность.
• Различная административная принадлежность.
31.
Использование вычислительных средСВОЙСТВА ВЫЧИСЛИТЕЛЬНЫХ СРЕД
Класс и
свойства
задач
Структура
процесса
вычислений
Программирование
вычислительных
сред
Выполнение
распределенных
программ
32.
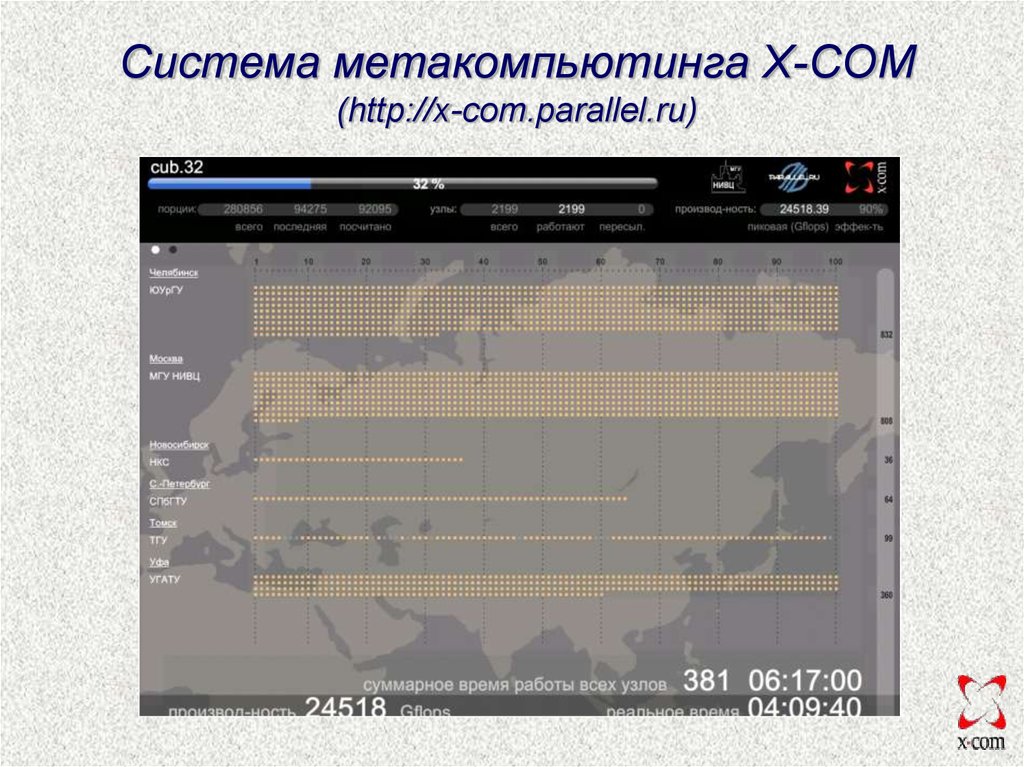
Система метакомпьютинга X-COM(http://x-com.parallel.ru)
33.
Решение больших задач в распределенныхвычислительных средах
Центр “Биоинженерия” РАН. Определение скрытой периодичности в
генетических последовательностях.
Решена за 63 часа,
2 года на 1 CPU.
8 городов,10 организаций, 14 кластеров, 407 CPUs,
Linux/Win.
Режим работы узлов среды: монопольно.
ПензГУ. Дифракция электромагнитного поля на тонких проводящих экранах.
300 CPUs, решена за 4 дня ,
3.2 года на 1 CPU.
4 кластера СКЦ НИВЦ МГУ.
Linux.
Режим работы: монопольно + по незанятости.
ИБМХ РАМН, Гематологический центр РАМН. Поиск молекул-ингибиторов
для заданных белков-мишеней (тромбин).
270 CPUs, решена за 11 дней,
4.5 года на 1 CPU.
2 города, 3 кластера, учебный класс.
Linux/Win.
Режим работы: монопольно + по незанятости + системы очередей.
34.
Система метакомпьютинга X-COM(http://x-com.parallel.ru)
35.
Куда мы планируем двигатьсядальше?
Следующий компьютер
Московского университета будет
установлен к концу 2009 года,
производительность: 0.5 Pflops
36.
Скорости растут, КПД падает…37.
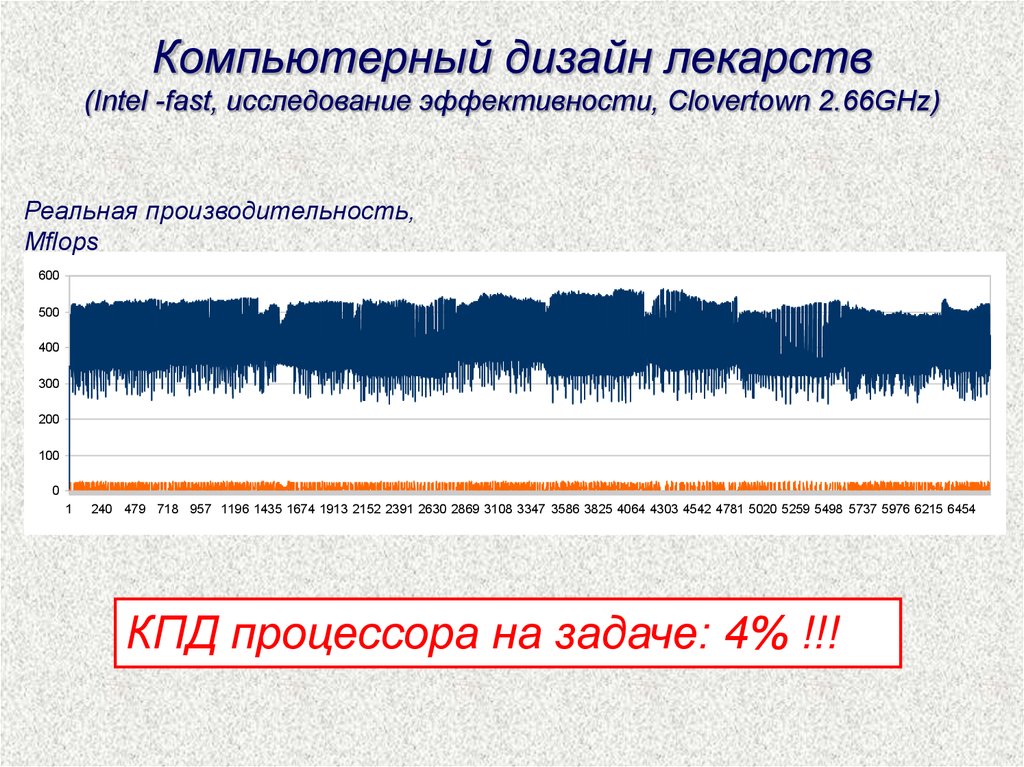
Компьютерный дизайн лекарств(Intel -fast, исследование эффективности, Clovertown 2.66GHz)
Реальная производительность,
Mflops
600
500
400
300
200
100
0
1
240 479 718 957 1196 1435 1674 1913 2152 2391 2630 2869 3108 3347 3586 3825 4064 4303 4542 4781 5020 5259 5498 5737 5976 6215 6454
КПД процессора на задаче: 4% !!!
38.
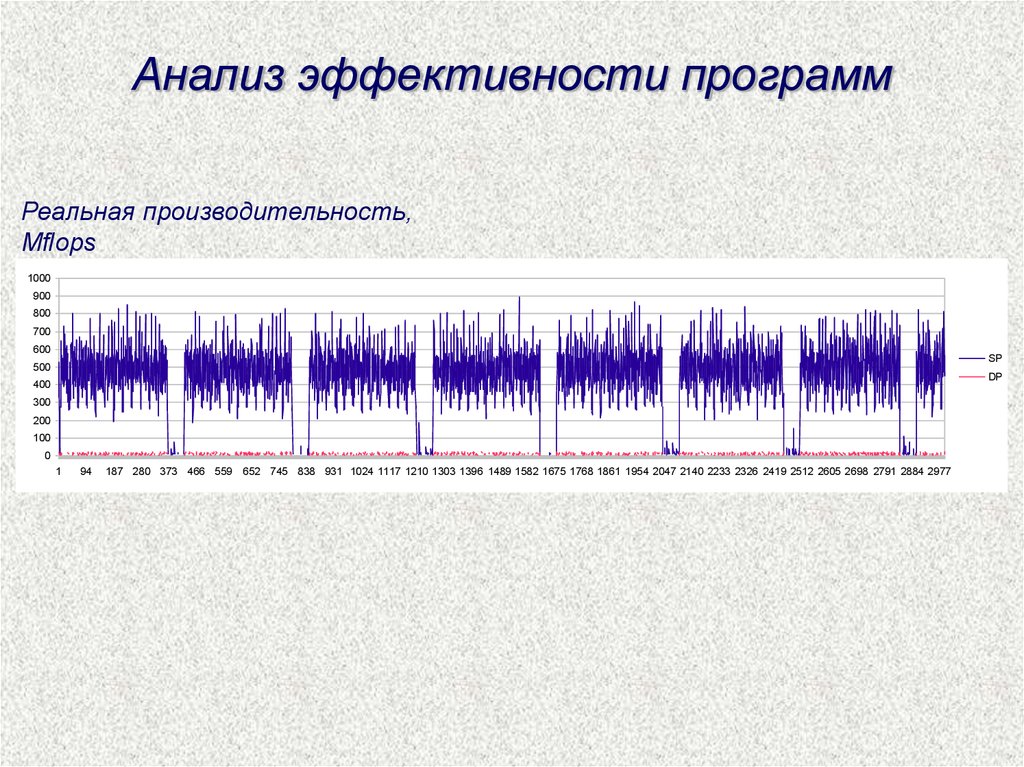
Анализ эффективности программАНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ ПО
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМНОГО ПО
АНАЛИЗ КОНФИГУРАЦИИ КОМПЬЮТЕРА
39.
Анализ эффективности программРеальная производительность,
Mflops
1000
900
800
700
600
SP
500
DP
400
300
200
100
0
1
94
187 280 373 466 559 652 745 838 931 1024 1117 1210 1303 1396 1489 1582 1675 1768 1861 1954 2047 2140 2233 2326 2419 2512 2605 2698 2791 2884 2977
40.
Анализ эффективности программАНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ ПО
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМНОГО ПО
АНАЛИЗ КОНФИГУРАЦИИ КОМПЬЮТЕРА
41. Что снижает производительность современных кластеров?
Закон АмдалаЛатентность передачи по сети
Пропускная способность каналов передачи данных
Особенности использования SMP-узлов
Балансировка вычислительной нагрузки
Возможность асинхронного счета и передачи
данных
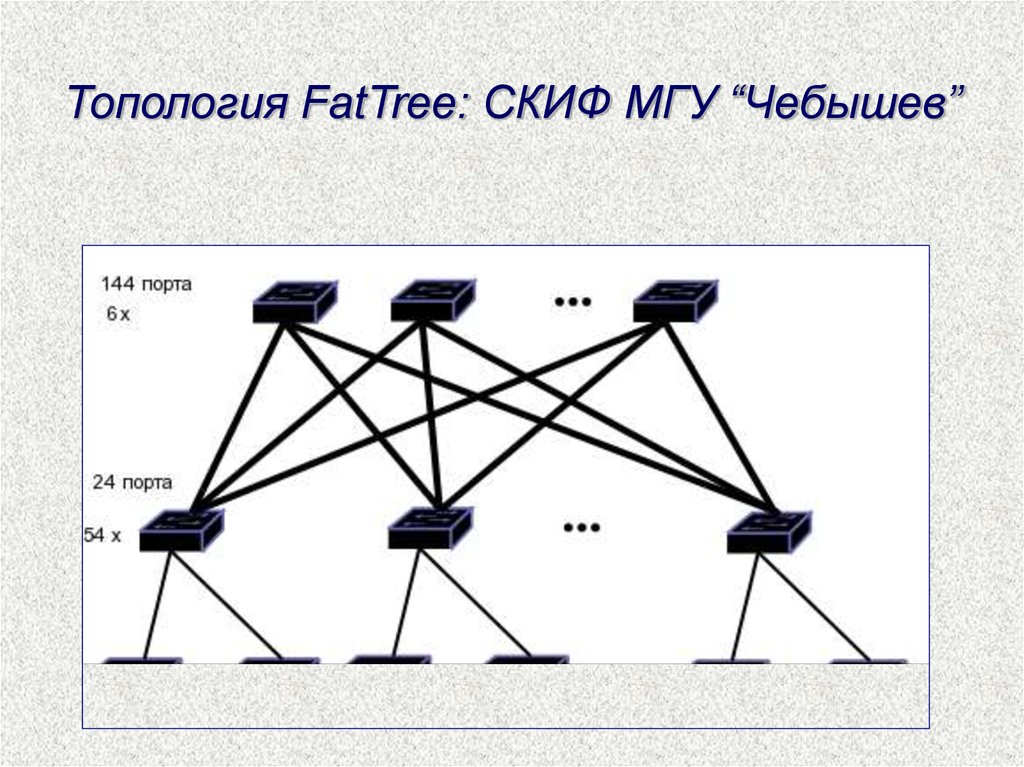
7. Особенности топологии коммуникационной сети
1.
2.
3.
4.
5.
6.
8.
42.
Топология FatTree: СКИФ МГУ “Чебышев”43. Что снижает производительность современных кластеров?
Закон АмдалаЛатентность передачи по сети
Пропускная способность каналов передачи данных
Особенности использования SMP-узлов
Балансировка вычислительной нагрузки
Возможность асинхронного счета и передачи
данных
7. Особенности топологии коммуникационной сети
8. Производительность отдельных процессоров
9. ...
1.
2.
3.
4.
5.
6.
44. Что влияет на производительность узлов кластеров?
использование суперскалярности,
неполная загрузка конвейерных функциональных устройств,
пропускная способность кэшей, основной памяти, каналов передачи данных,
объем кэш-памяти различных уровней и основной памяти,
степень ассоциативности кэш-памяти различных уровней,
несовпадение размера строк кэш-памяти различных уровней,
несовпадение степени ассоциативности кэш-памяти различных уровней,
стратегия замещения строк кэш-памяти различных уровней,
стратегия записи данных, принятая при работе с подсистемами памяти,
расслоение оперативной памяти (структура банков),
частота работы оперативной памяти,
частота FSB,
ширина FSB,
несоответствие базовых частот: процессора, FSB и оперативной памяти,
влияние “NUMA” в серверах с архитектурой ccNUMA,
влияние “cc” в серверах с архитектурой ccNUMA,
влияние ОС (менеджер виртуальной памяти, накладные расходы на сборку
мусора и выделение памяти).
45.
J,I:
A(
I,J I,J)
:A =
(I, (A
(I
J)
= ,J )+
(A
B
(I, (I,
A( J )+ J ))*
B( C
I)
(
=
I
(A ,J )) I,J )
A( (I) *C
+B (I,
I)
=
J
A (I)) )
(
*
I
A( )+ C(
I)
B( I)
=
I)
A( A (I * C(
)
I)
I)
= + B(
A
I)
A( (I)+ * C
I)
A(
=
I)*
B
C
A(
+
A(
A(
I)
I)
=
I
=
B )*C
+
A B
A( (I) +A A(I)
(I
*
I)
=
=
3. )*3 B
.
3.
1
14 41 14 1
5
5
1
A( 5+A +A (
I
I)
= (I )* )*C
A( A (I 3 .1
)
I)
4
= + A( 15
A
I
A( (I) )* A
+
I)
(
= B(I I)
A
(I) )+ C
A( *B ( (I)
I
I)
= )*C
(
A
A(
(I) I)
I)
+B
=
A (I)
(I
A
A( (I) )*B
(I
I)
= =A )
A
(I) (I)*B
A( *3.
I)
14
=
A 15
A( (I)/
A(
B(
I
I) ) =
I
=
A )
(
A
(I) I)+
A( + 3 B
.1
I)
4
=
I* 15
3.
14
15
Производительность, Mflops
Производительность на базовых операциях
Clowertown 1,6 GHz
1800
1600
1400
1200
1000
800
600
400
200
0
46.
J,I:
A(
I,J I,J)
:A =
(I, (A
(I
J)
= ,J )+
(A
B
(I, (I,
A( J )+ J ))*
B( C
I)
(
=
I
(A ,J )) I,J )
A( (I) *C
+B (I,
I)
=
J
A (I)) )
(
*
I
A( )+ C(
I)
B( I)
=
I)
A( A (I * C(
)
I)
I)
= + B(
A
I)
A( (I)+ * C
I)
A(
=
I)*
B
C
A(
+
A(
A(
I)
I)
=
I
=
B )*C
+
A B
A( (I) +A A(I)
(I
*
I)
=
=
3. )*3 B
.
3.
1
14 41 14 1
5
5
1
A( 5+A +A (
I
I)
= (I )* )*C
A( A (I 3 .1
)
I)
4
= + A( 15
A
I
A( (I) )* A
+
I)
(
= B(I I)
A
(I) )+ C
A( *B ( (I)
I
I)
= )*C
(
A
A(
(I) I)
I)
+B
=
A (I)
(I
A
A( (I) )*B
(I
I)
= =A )
A
(I) (I)*B
A( *3.
I)
14
=
A 15
A( (I)/
A(
B(
I
I) ) =
I
=
A )
(
A
(I) I)+
A( + 3 B
.1
I)
4
=
I* 15
3.
14
15
Производительность, Mflops
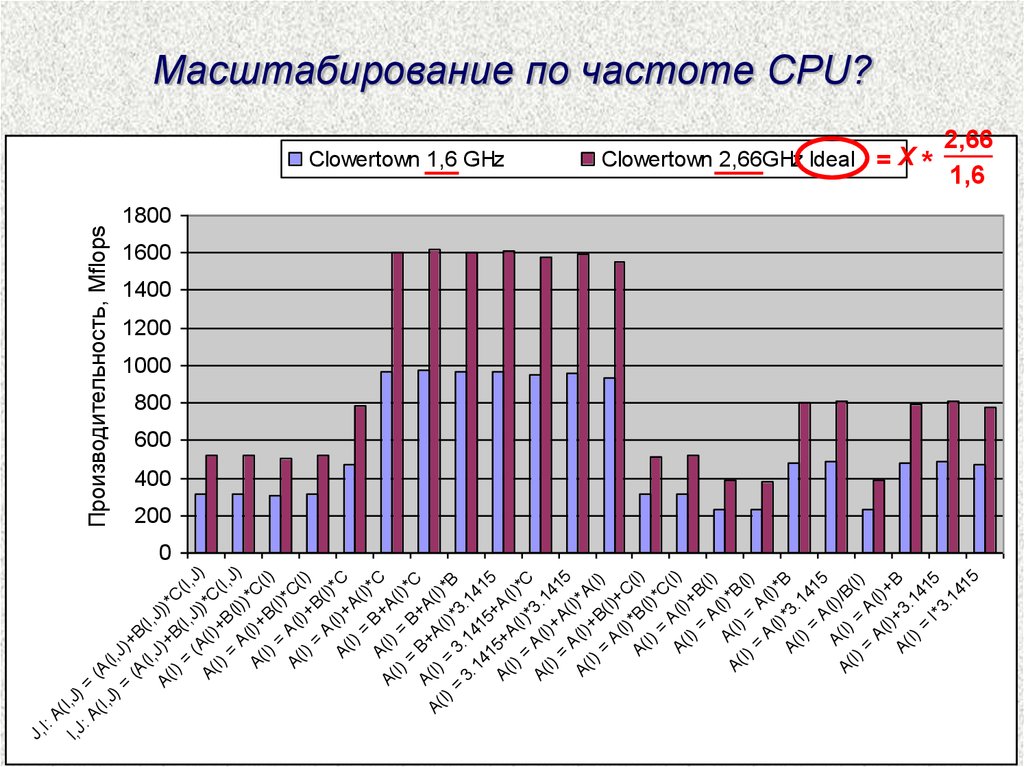
Масштабирование по частоте CPU?
Clowertown 1,6 GHz
Clowertown 2,66GHz Ideal = X
*
2,66
1,6
1800
1600
1400
1200
1000
800
600
400
200
0
47.
J,I:
A(
I,J I,J)
:A =
(I, (A
(I
J)
= ,J )+
(A
B
(I, (I,
J
A(
)+ J ))*
B( C
I)
(
=
I
(A ,J )) I,J )
A( (I) *C
+B (I,
I)
=
J
A (I)) )
A( (I)+ *C(
I)
B( I)
=
I)*
A
C
A(
(
I
)+ (I)
I)
B(
=
A
I)
(
A( I)+ * C
I)
A(
=
I)*
B
C
A(
+
A(
A(
I)
I)
=
I
=
B )*C
+
B
A
A( (I) +A A(I)
(I
*
I)
=
=
3. )*3 B
.
3.
1
14 41 14 1
5+
5
1
A( 5+A A (I
I)
(I ) )*C
=
*
A( A (I 3 .1
4
)
I)
= + A( 15
A
A( (I) I)* A
+
I)
(
= B(I I)
A
(I) )+ C
A( *B ( (I)
I
I)
= )*C
A( A (I) (I)
I)
+B
=
A (I)
(I
A
A( (I) )*B
(I
I)
= =A )
A
(I (I)*
A( )*3. B
I)
14
=
A 15
(I
A
A( (I) )/B
(I
I)
=
=
A )
(
A
(I) I)+
B
+
A(
3.
I)
14
=
I* 15
3.
14
15
Производительность, Mflops
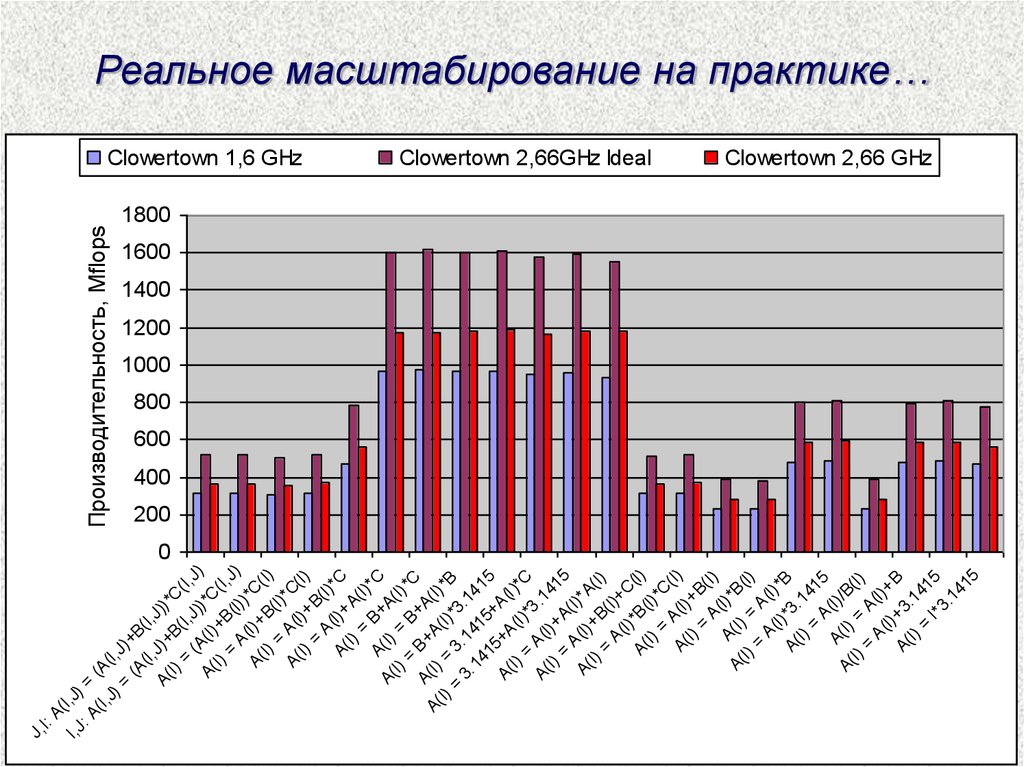
Реальное масштабирование на практике…
Clowertown 1,6 GHz
Clowertown 2,66GHz Ideal
Clowertown 2,66 GHz
1800
1600
1400
1200
1000
800
600
400
200
0
48.
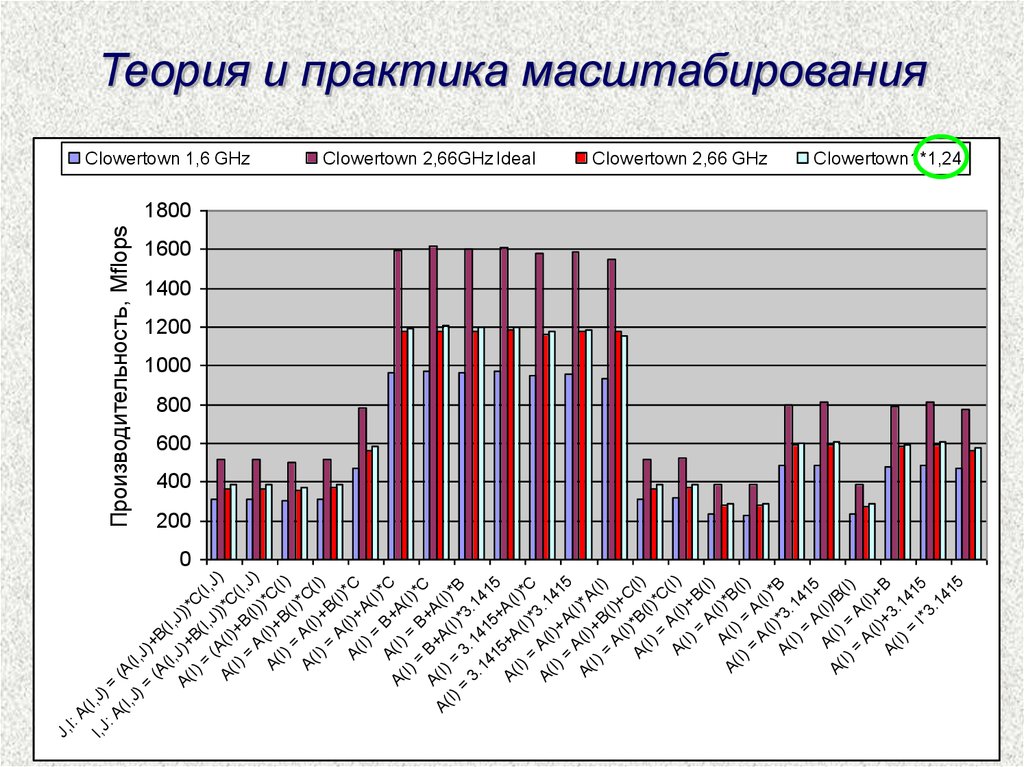
Реальное масштабирование на практике…Clowertown
Clowertown
–
–
CPU
1,6 GHz
2,66 GHz
FSB
1,066 GHz
1,333 GHz
CPU / FSB – это число тактов процессора на каждый
такт работы системной шины:
для Clowertown 1,6 GHz – это 1,5
для Clowertown 2,66 GHz – это 2
1,5 / 2 = 0,75 – замедление работы с памятью
(2,66 / 1,6 ) * 0,75 = 1,24 – реальное ускорение
49.
J,I:
A(
I,J I,J)
:A =
(I, (A
(I
J)
= ,J )+
(A
B
(I, (I,
J
A(
) J ))
I) +B( *C
(
=
I
(A ,J )) I,J )
A( (I) *C
+B (I
I)
,J
=
A (I)) )
(
A( I)+ *C(
I)
B( I)
=
I)*
A
C
A(
(
I
)+ (I)
I)
=
B(
A
I)
(
I
A(
)+ * C
I)
A(
=
I)*
B
C
A(
+
A(
A(
I)
I)
=
I
=
B )*C
+
B
A
A( (I) +A A(I)
(I
I)
*
=
=
3. )*3 B
.
3.
1
14 41 14 1
5
5
1
+
A( 5+A A (I
I)
(I ) )*C
=
*
A( A (I 3 .1
4
)
I)
= + A( 15
A
A( (I) I)* A
+
I)
(
= B(I I)
A
(I) )+ C
A( *B ( (I)
I
I)
= )*C
(
A
A(
(I) I)
I)
+B
=
A (I)
(I
A( A(I) )*B
(I
I)
= =A )
A
(I (I)*
A( )*3. B
I)
14
=
A 15
(I
A
A( (I) )/B
(I
I)
=
=
A )
(
A
(I) I)+
B
+
A(
3.
I)
14
=
I* 15
3.
14
15
Производительность, Mflops
Теория и практика масштабирования
Clowertown 1,6 GHz
Clowertown 2,66GHz Ideal
Clowertown 2,66 GHz
Clowertown1*1,24
1800
1600
1400
1200
1000
800
600
400
200
0
50.
J,I:
A
I, J (I ,J
:A )=
(I , (A
J)
(
= I,J)
(A +B
(
(
A( I,J)+ I, J)
)*
I)
= B(I, C(I
(
J
,
A( A(I ))* J)
I) )+ C(
= B( I, J
I)
A
)
A( (I)+ )*C
I)
B( (I)
=
A( A( I )*C
I)
I)
(
= +B I)
A( (I )
A( I)+ *C
I)
A(
=
I )*
A
B
A(
C
(
+
I
) = A(
I)
=
B I)
A( A(I B+ +A *C
I) ) = A(
I)* (I)*B
=
3
3. .1 3.
14 41 14
15 5
1
A( +A +A( 5
I)
(I) I)*
A( = A *3. C
1
(
I)
= I)+A 415
A( A(I (I
)*
)
I)
= +B( A(I
A( I ) )
I) +C
A( *B( (I )
I)
I)
= *C
A( A( (I)
I) I)+
=
A( B(I )
I)*
A
A(
I) (I) = B(I
)
=
A( A(I
)
I
A( )*3 *B
I) .14
=
A( 15
A
A(
I
I) (I) = )/ B(
=
I
A( A( )
I
A( I)+3 )+B
I)
= .14
I*3 15
.1
41
5
Эффективность, %
КПД работы процессоров …
Clowertown 1,6 GHz
Clowertown 2,66 GHz
16
14
12
10
8
6
4
2
0
51.
==
A
+B
(I)
+
(A
(I)
(I)
)
A(
I)
*C
(
B( I)
I
)*
=
C(
A
(I)
I
A(
+B )
I)
=
(I)
A
*C
(I)
+A
A(
I)
(I)
=
*C
B
+A
A(
I)
(I)
A(
=
*C
I)
B
=
+
A(
B
+A
A(
I)
I
(
)=
A(
I)* *B
I)
3
3.
=
14 .14
3.
15
15
14
+A
15
(I
+A
A(
(I ) )*C
I)
*3
=
.1
A
41
(
A(
I)+
5
I)
A
=
(
I
)*
A
A( (I)+ A(I)
I)
B(
=
I)+
A
C
(I)
(I)
*B
A(
(I)
I)
*C
=
(I
A
(I) )
A(
+B
I)
(I)
=
A
(I)
*B
A
(I)
A( (I)
=
I)
A
=
(I
A
(I) )*B
*3
A(
.1
I)
41
=
5
A
(I)
A
/B
(I)
A( (I) =
I)
A
=
(I)
A
+
(I)
+3 B
.1
41
5
A(
I)
A(
I)
КПД работы процессора, %
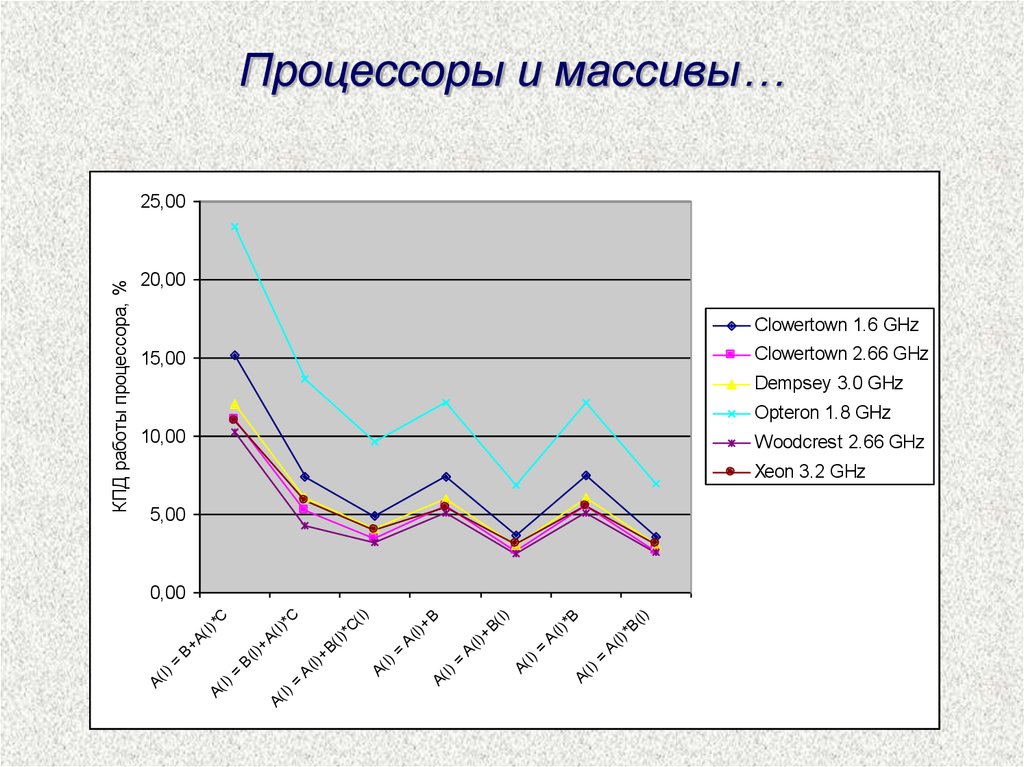
КПД работы процессоров …
Clowertown 1.6 GHz
Clowertown 2.66 GHz
Dempsey 3.0 GHz
Opteron 1.8 GHz
Woodcrest 2.66 GHz
Xeon 3.2 GHz
25,00
20,00
15,00
10,00
5,00
0,00
52.
Процессоры и массивы…20,00
Clowertown 1.6 GHz
Clowertown 2.66 GHz
15,00
Dempsey 3.0 GHz
Opteron 1.8 GHz
10,00
Woodcrest 2.66 GHz
Xeon 3.2 GHz
5,00
(I)
(I)
*B
A(
I)
=
A
A
=
A(
I)
(I)
+
A
=
A(
I)
(I)
*B
B(
I)
B
(I)
+
A
=
A(
I)
B(
I)*
C(
I)
(I)
+
A(
I)
=
A
B
=
A(
I)
=
B
(I)
+
+A
(I)
*C
A(
I)*
C
0,00
A(
I)
КПД работы процессора, %
25,00
53.
Простой пример. Исходный текстfor ( i = 1; i < N; i++) {
for ( j = 1; j < N; j++) {
for ( k = 1; k < N; k++) {
DSUM[i][k] = DSUM[i][k] + S[k] * A[k][j][i] + P[i][j] * A[k][j][i–1] +
P[i][k] * A[k][j–1][i] + P[j][k] * A[k–1][j][i];
}
}
}
54.
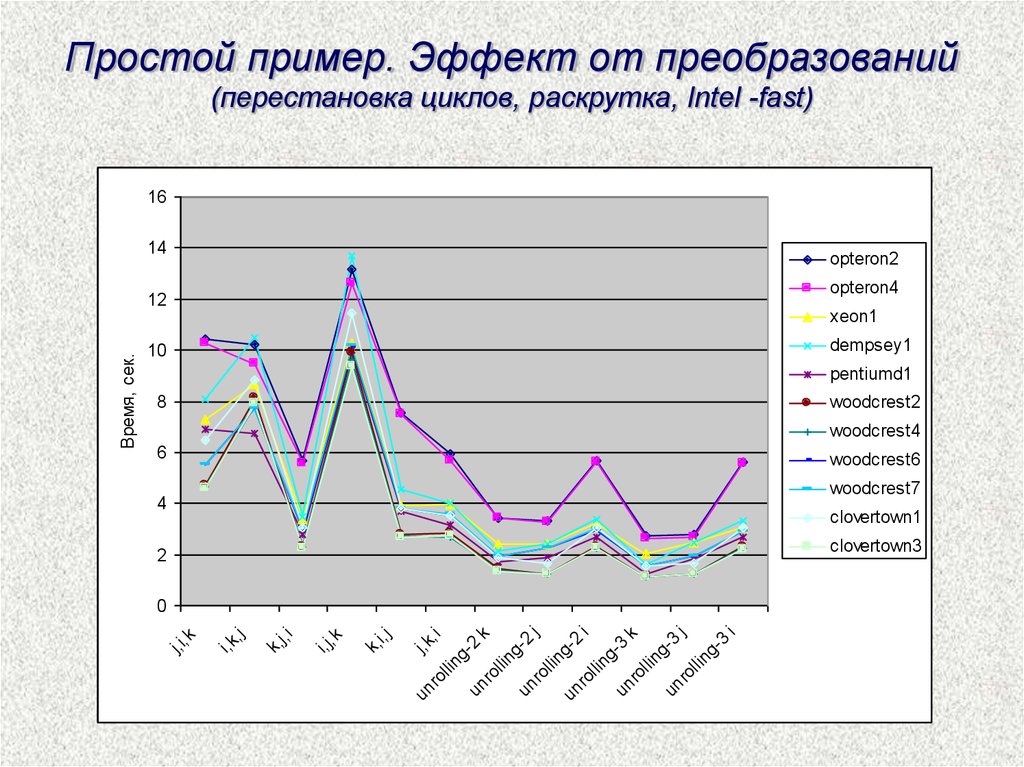
Простой пример. Эффект от преобразований(перестановка циклов, раскрутка, Intel -fast)
16
14
opteron2
opteron4
xeon1
dempsey1
10
pentiumd1
8
woodcrest2
woodcrest4
6
woodcrest6
woodcrest7
4
clovertown1
clovertown3
2
un
j, k
,
ro
llin i
g2
un
k
ro
llin
gun
2
j
ro
llin
gun
2
ro
llin i
gun
3
k
ro
llin
gun
3
j
ro
llin
g3
i
k,
i, j
k
i,j,
k,
j, i
i, k
,j
k
0
j,i,
Время, сек.
12
55.
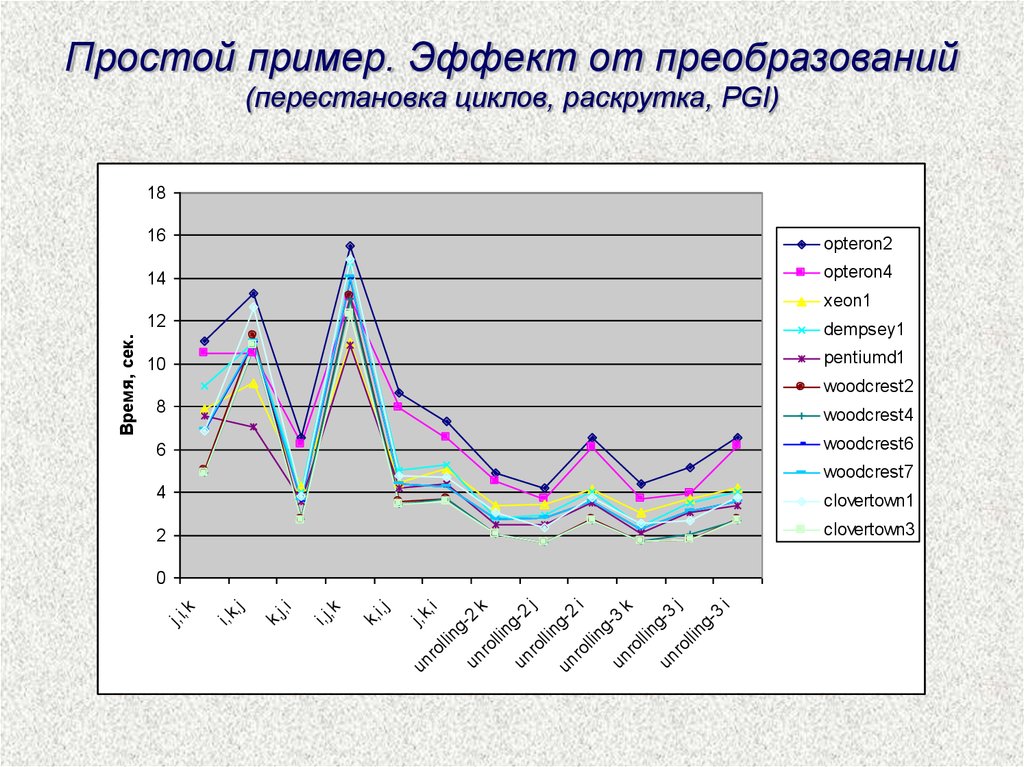
Простой пример. Эффект от преобразований(перестановка циклов, раскрутка, PGI)
18
16
opteron2
14
opteron4
dempsey1
10
pentiumd1
woodcrest2
8
woodcrest4
6
woodcrest6
woodcrest7
4
clovertown1
2
clovertown3
j, k
un
,i
ro
llin
g2
un
k
ro
llin
gun
2
j
ro
llin
gun
2
ro
llin i
g3
un
k
ro
llin
gun
3
j
ro
llin
g3
i
k,
i, j
k
i,j,
k,
j, i
i, k
,j
k
0
j,i,
Время, сек.
xeon1
12
56.
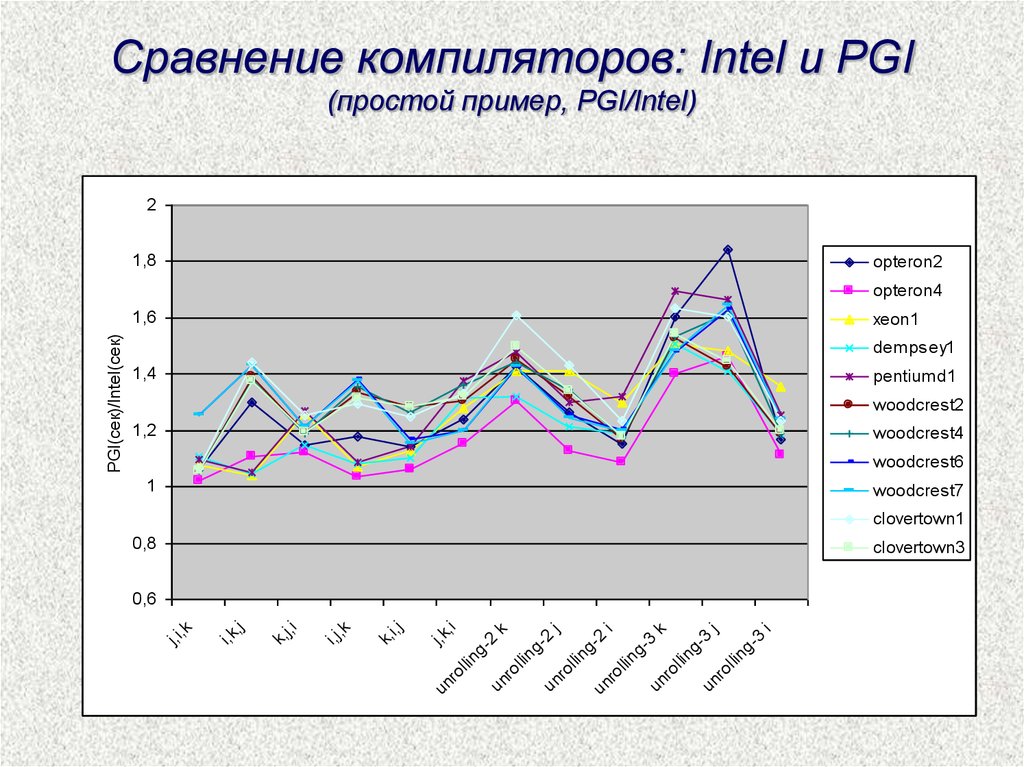
Сравнение компиляторов: Intel и PGI(простой пример, PGI/Intel)
2
1,8
opteron2
opteron4
PGI(сек)/Intel(сек)
1,6
xeon1
dempsey1
1,4
pentiumd1
woodcrest2
1,2
woodcrest4
woodcrest6
1
woodcrest7
clovertown1
0,8
clovertown3
0,6
j,i
,k
,j
i,k
j,i
k,
i,j
,k
i,j
k,
,i
j,k
ro
un
llin
2
g-
k
ro
un
2
lli
ng
j
ro
un
lli
-2
g
n
i
l
ro
n
u
lin
3
g-
k
l
ro
n
u
li
-3
g
n
j
l
ro
n
u
3
li
ng
i
57. Характеристики работы программно-аппаратной среды
Количество задач в состоянии счёта на узле
Число переключений контекста
Процент использования CPU программами пользователя
Процент использования CPU системой
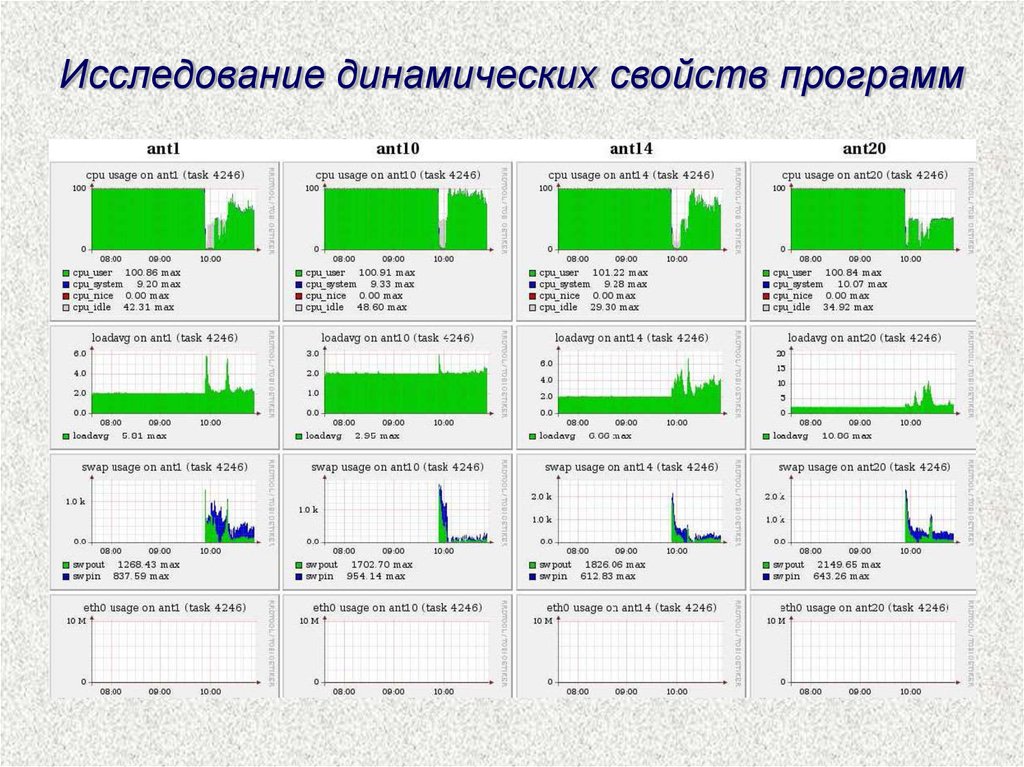
Процент использования CPU программами с приоритетом nice
Процент простоя CPU
Длина очереди процессов на счёт
Объём памяти, занятой под системные кэши
Объём памяти, свободной
Объём памяти, используемой
Общий объём памяти
Количество принятых пакетов по сети Ethernet; Количество отправленных пакетов по сети Ethernet;
Количество принятых байт по сети Ethernet; Количество отправленных байт по сети Ethernet;
Количество ошибок типа carrier (отсутствие сигнала) в Ethernet; Количество ошибок типа collision
(коллизия при передаче) в Ethernet; Количество ошибок типа drop (потеря пакета) в Ethernet;
Количество ошибок типа err (прочие ошибки) в Ethernet; Количество ошибок типа fifo (переполнение
буфера) в Ethernet; Количество ошибок типа frame (приём неверно сконструированного пакета) в
Ethernet;
Количество принятых блоков по NFS; Количество отправленных блоков по NFS; Число авторизаций на
NFS сервере; Число операций на NFS сервере; Число перепосылок при общении с NFS сервере;
Количество блоков, считанных из файла подкачки (paging); Количество блоков, записанных в файл
подкачки (paging); Количество блоков, считанных из файла подкачки (swaping); Количество блоков,
записанных в файл подкачки (swaping)
Чтение с локального жёсткого диска; Запись на локальный жёсткий диск;
Свободное место в /tmp
58.
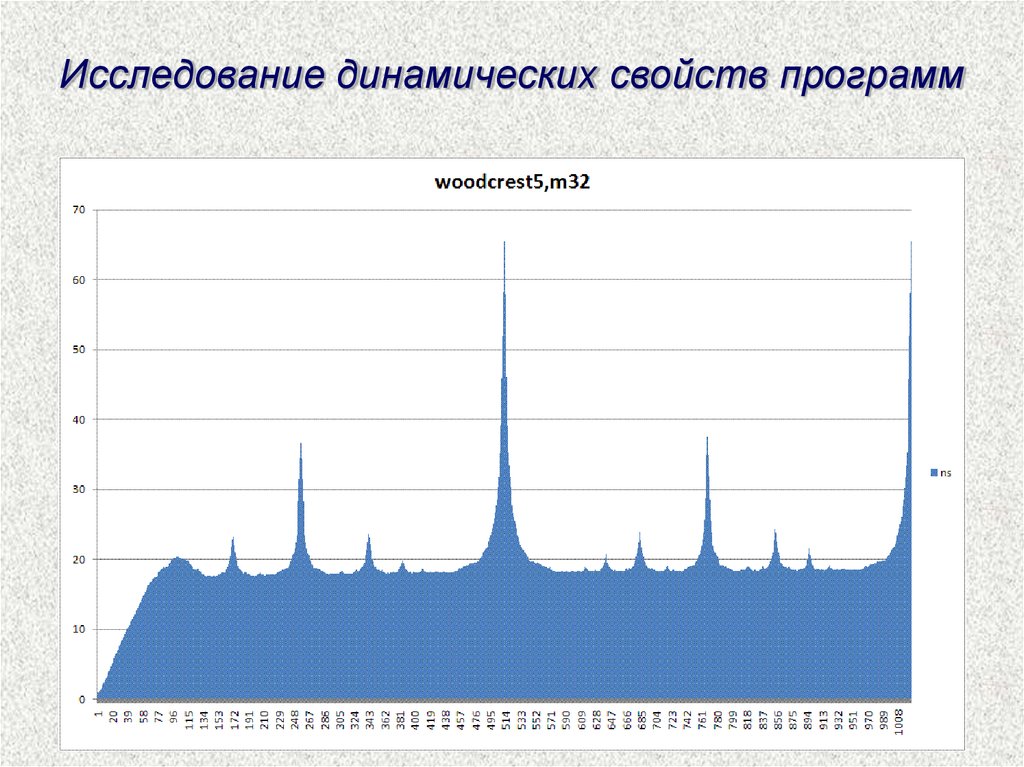
Исследование динамических свойств программ59.
Исследование динамических свойств программ60.
Исследование динамических свойств программ61.
Исследование динамических свойств программ62.
Сертификация эффективностипараллельных программ
• Эффективность последовательная
• Эффективность параллельная
Объекты исследования:
Задача – Алгоритм – Программа – Системное ПО – Компьютер
Необходимы методика, технологии и программные
инструменты сертификации эффективности и для
пользователей, и для администраторов больших машин
Необходима развитая инфраструктура ПО для решения задачи
отображения программ и алгоритмов на архитектуру
современных вычислительных систем
63.
Параллелизм – новый этап развитиякомпьютерного мира
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
64.
Учебный процесс и образование65.
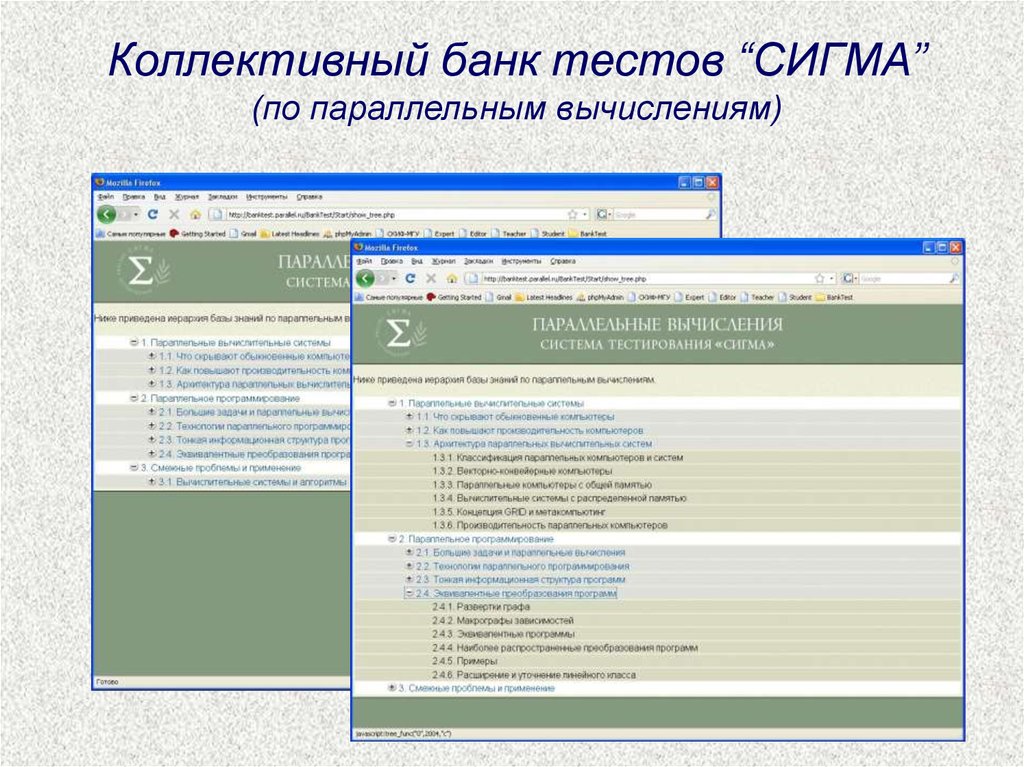
Коллективный банк тестов “СИГМА”(по параллельным вычислениям)
66.
Коллективный банк тестов “СИГМА”(по параллельным вычислениям)
67.
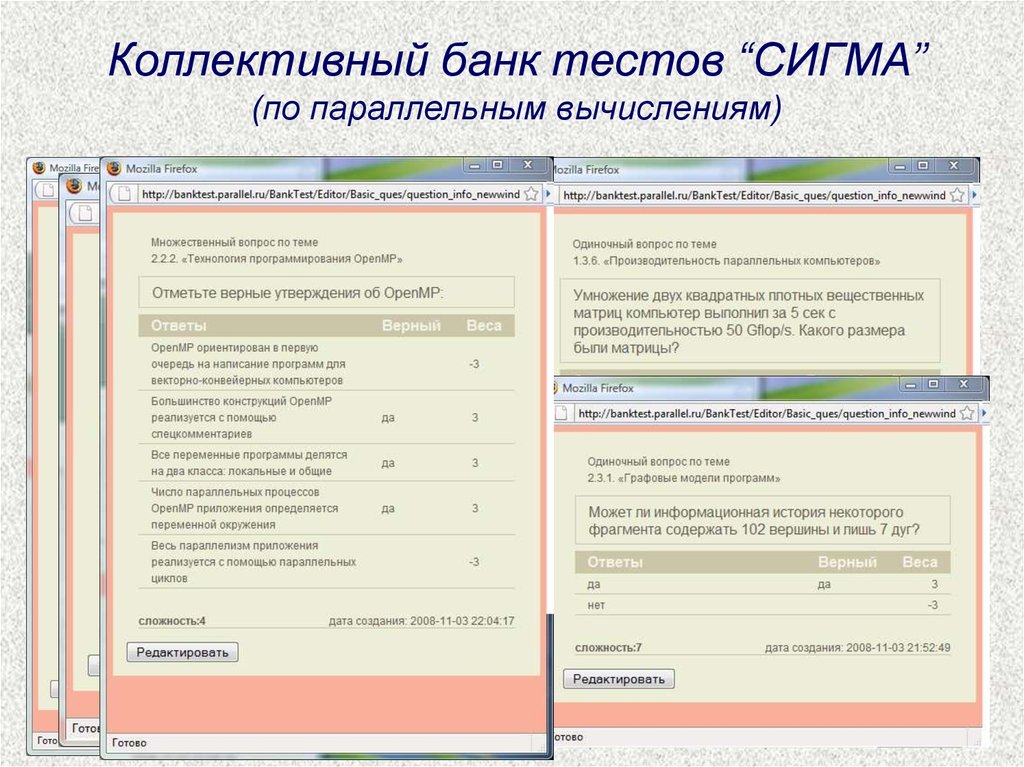
Коллективный банк тестов “СИГМА”(по параллельным вычислениям)
68.
Коллективный банк тестов “СИГМА”(по параллельным вычислениям)
69.
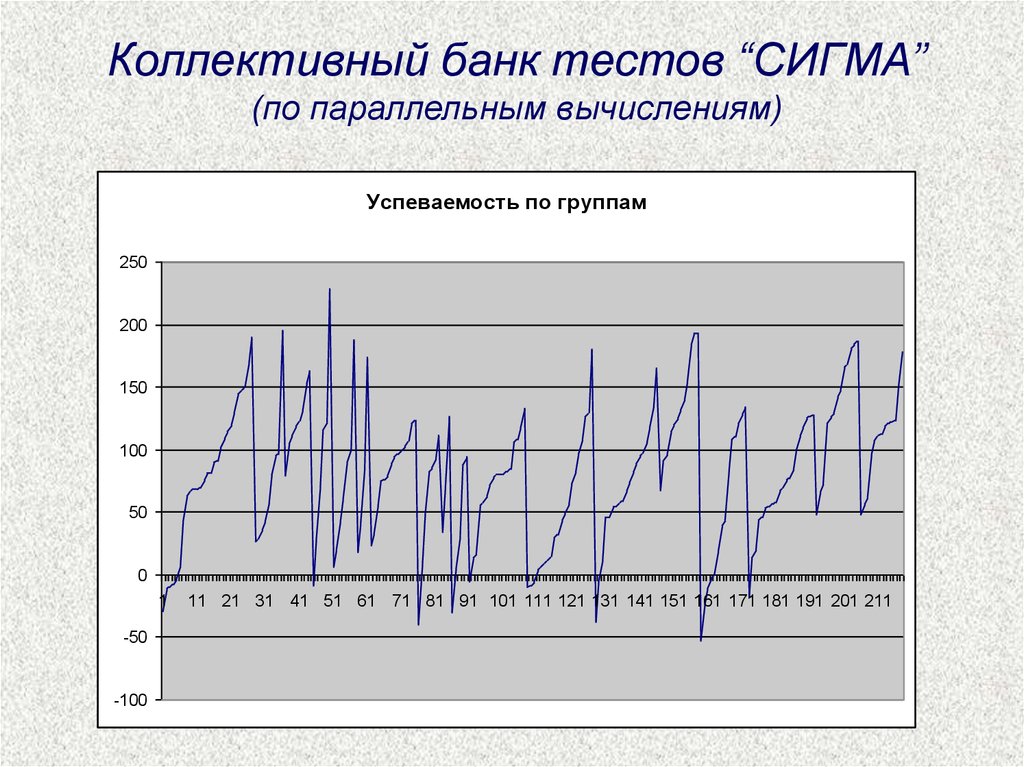
Коллективный банк тестов “СИГМА”(по параллельным вычислениям)
Успеваемость по группам
250
200
150
100
50
0
1
-50
-100
11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211