





")
")
")











")
")
")
")








")
")
")


















Similar presentations:



")






Antivirus Protection Chapter 16. Сучасні антивірусні системи. Машинне навчання
1. Antivirus Protection Chapter 16. Сучасні антивірусні системи. Машинне навчання. Оцінка точності методів класифікації та
виявлення аномалій. LecturerChelak Viktor
Telegram: @VictorChelak
Phone: +380 50 867 88 55
E-Mail: victor@chelak.com.ua
1
2. Сучасні антивірусні системи
На сьогоднішній період часу (2015-2021 рік) зростаєпопулярність методів машинного навчання в більшості
галузей. Антивірусні системи – не є винятком.
Сучасна
антивірусна
система
повинна
користуватися безліччю різних підходів, та для того
щоб повисити точність виявлення методів потрібно
використовувати не тривіальну систему прийняття
рішень, яка дозволить зробити комплексний висновок
в аналізі ШПЗ, загроз, файлів, трафіку тощо.
У
якості
алгоритмів
прийняття
рішень
використовують
також
алгоритми
машинного
навчання.
2
3. Приклад системи прийняття рішень
34. Map of Artificial Intelligence
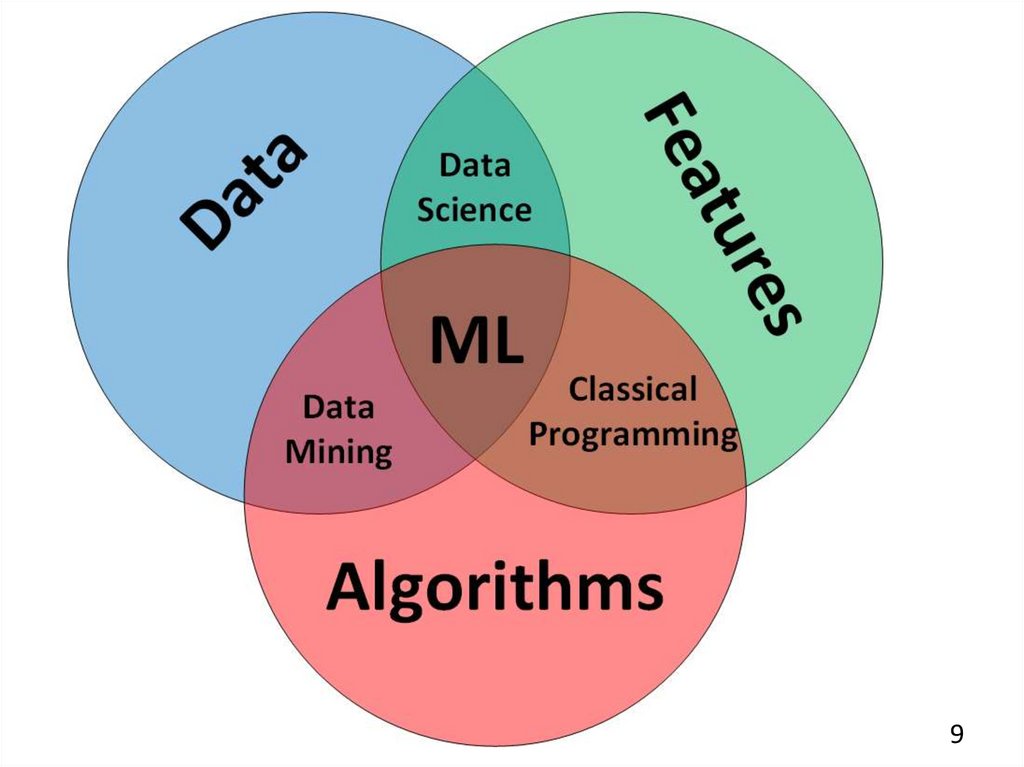
45. Розділи
Штучний інтелект – назва усього галузі знань,як біологія або хімія.
Машинне навчання – розділ штучного
інтелекту, важливий – проте не один.
Нейронні мережі – один з видів машинного
навчання. Популярний, проте є й інші, не гірші.
Глибоке навчання – архітектура нейронних
мереж, один з підходів к будування та навчанню
нейронних мереж. (Нейронні мережі з багатьма
шарами нейронів).
5
6. Основні терміни
Тренувальна вибірка (Training set) – вхіднідані, що подаємо на методи, з метою
налаштування/навчання оперувати над цими
даними.
Тестова вибірка (Validation set) – вибірка,
яку
використовують
для
тестування
налаштованого/побудованого
методу
з
метою перевірки методу на даних, які він не
бачив при навчанні.
6
7. Основні терміни (Помилки)
Помилка bias – скільки зразків тренувальноївибірки було опрацьовано неправильно.
(Наприклад з 100 прикладів нейронна мережа
здатна розпізнати лише 94 зразка правильно,
тоді помилка bias = 6/100= 0.06 = 6%)
Помилка variance – модуль різниці помилки
bias та помилки на тестової вибірки. Показує
наскільки ситуація на тренувальній вибірки
різниться з тестовою. (Приклад 6% - помилка
тренувальної та 46% – помилка на тестовій, тоді
variance = |6%-46%| = 40% (перенавчання)).
7
8. Основні терміни (головні терміни)
• Дані. Хочемо визначати спам - потрібні приклади спамлистів, передбачати курс акцій - потрібна історія цін,дізнатися інтереси користувача - потрібні його лайки або
пости. Даних потрібно якомога більше. Десятки тисяч
прикладів - це самий злий мінімум для відчайдушних.
• Ознаки (features) - властивості, характеристики, ознаки ними можуть бути пробіг автомобіля, стать користувача,
ціна акцій, навіть лічильник частоти появи слова в тексті
може бути ознакою.
• Алгоритм. Одну задачу можна вирішити різними
методами приблизно завжди. Від вибору методу
залежить точність, швидкість роботи і розмір готової
моделі. Але, якщо дані погані, навіть найкращий
алгоритм не допоможе.
8
9.
910. Основні терміни (Помилки)
Перенавчання (overfitting) – коли помилкаvariance – висока.
10
11. Карта машинного навчання
1112. Основні види машинного навчання
• Класичне навчання (Прості дані, простипризнаки)
• Навчання з підкріпленням (Даних нема, проте
є середовище, з якою можна взаємодіяти)
• Ансамблі (коли якість – насправді проблема)
• Нейронні мережі та глибоке навчання
(Складні дані, незрозуміло де признаки, є віра
в диво)
12
13. Класичне навчання
• З вчителем (Supervised Learning) (дані маютькатегорії або значення (мітки))
– Класифікація (прогнозувати категорію)
– Регресія (прогнозувати значення)
• Без вчителя (Unsupervised Learning)(дані не
міток)
– Кластерізація (Поділити за схожістю на категорії)
– Зменшення розмірності (узагальнення, пошук
залежності)
– Асоціація (Виявити послідовності)
13
14. Класифікація
Спам-фільтр
Визначення мови
Пошук схожих документів
Аналіз тональності
Розпізнавання рукописних букв та цифр
Визначення підозрілих транзакцій.
14
15. Класифікація
1516. Класифікація
1617. Регресія
Прогнозування вартості цінних паперів.
Аналіз попиту, обсягу продажів
Медичні діагнози
Будь-які залежності числа від часу
17
18. Регресія
1819. Кластерізація
Сегментація ринку
Об’єднання близьких точок на карті
Стиснення зображень
Аналіз та розмітка нових даних
Детектори аномальної поведінки
19
20. Кластерізація
2021. Кластерізація
2122. Зменшення розмірності (узагальнення)
Рекомендаційні системи
Красиві візуалізації
Визначення тематики та пошуку документів
Аналіз фейкових зображень
Ризик-менеджмент
22
23. Зменшення розмірності (узагальнення)
2324. Зменшення розмірності (узагальнення)
2425. Пошук правил (асоціація)
Прогноз акцій і розпродажі
Аналіз товарів, що купуються разом
Розстановка товарів на полицях
Аналіз шаблонів поведінки на веб-сайтах
25
26. Навчання з підкріпленням
Самокеровані автомобілі
Смарт-порохотяг
Ігри
Автоматична торгівля
Управління ресурсами підприємств
26
27. Ансамблі
• Всього, де підходять класичні алгоритми(але працюють точніше)
• Пошукові системи.
• Комп'ютерний зір.
• Розпізнавання об'єктів
27
28. Ансамблі
2829. Ансамблі
2930. Ансамблі
3031. Нейронні мережі та глибоке навчання
• Замістьвсіх
перерахованих
вище
алгоритмів взагалі
• Визначення об'єктів на фото і відео
• Розпізнавання і синтез мови
• Обробка зображень, перенесення стилю
• Машинний переклад
31
32. Нейронні мережі та глибоке навчання
3233. Нейронні мережі та глибоке навчання
3334. Згорткові нейронні мережі (CNN)
Бібліотека Detectron34
35. Згорткові нейронні мережі (CNN)
3536. Рекурентні нейронні мережі (RNN)
3637. LSTM
3738. Генеративні змагальні мережі GAN
3839. Капсульна нейронна мережа
3940. Капсульна нейронна мережа
4041. AutoEncoders
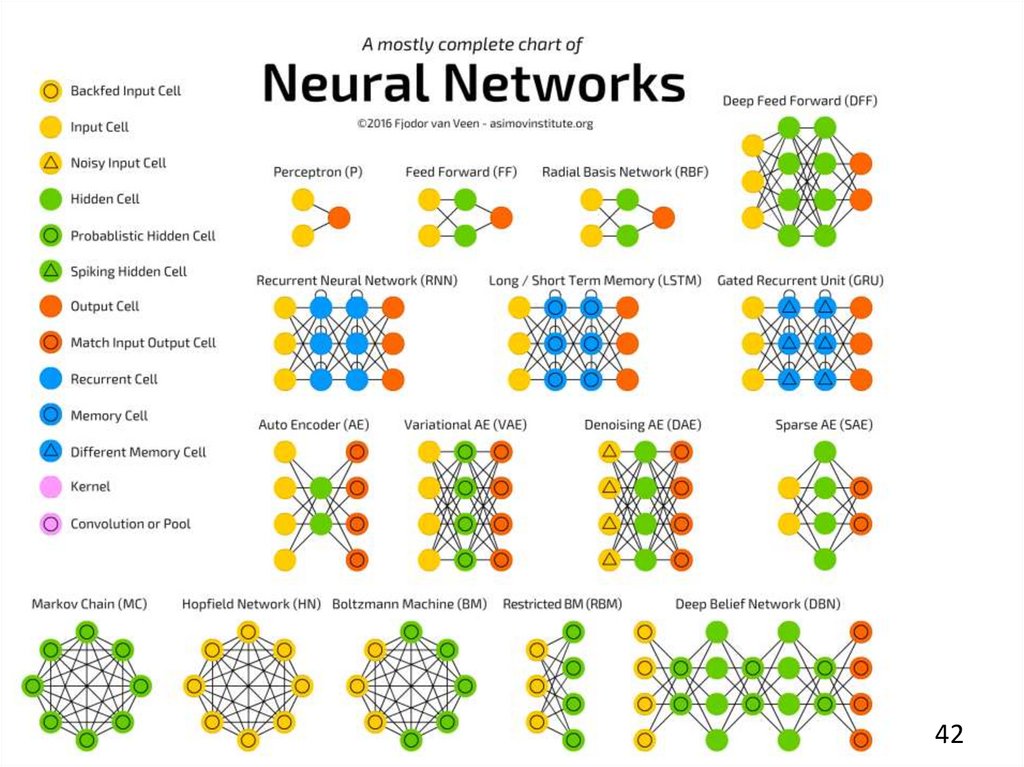
4142.
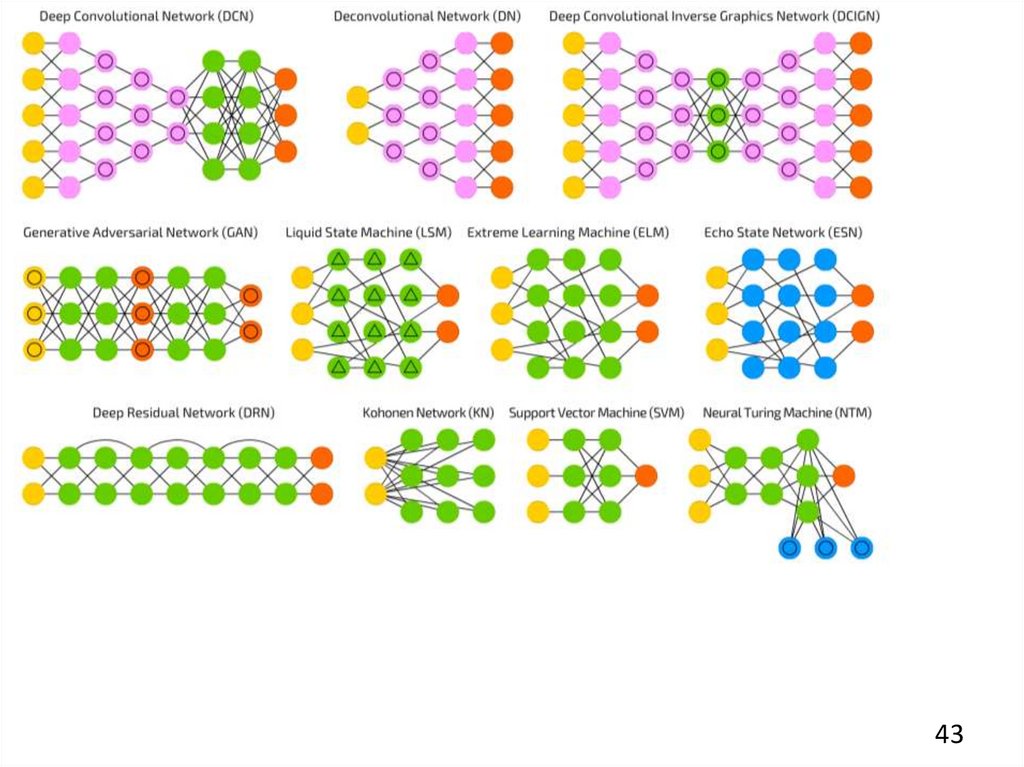
4243.
4344. Оцінка точності методів класифікації та виявлення аномалій.
• Оцінка точності в більшості випадкахвиконується
за
допомогою
матриці
невідповідностей (confusion matrix).
44
45. Оцінка точності методів класифікації та виявлення аномалій.
4546. Оцінка точності методів класифікації та виявлення аномалій.
4647. Оцінка точності методів класифікації та виявлення аномалій.
• True Positive (TP) – очікувалось виявленняаномалії – отримали виявлення аномалії
• False Positive (FP) (A.K.A. Type I error) –
очікували нормальний стан – отримали
виявлення аномалії (хибне спрацьовування)
• False Negative (FN) (A.K.A. Type II error) –
очікували аномальний стан – отримали
нормальний стан (пропуск).
• True Negative (TN) – очікувалось нормальний
стан – отримали нормальний стан
47
48. Оцінка точності методів класифікації та виявлення аномалій.
4849. Оцінка точності методів класифікації та виявлення аномалій.
• True Positive Rate (TPR) (A.K.A. Recall,Sensitivity, Probability of detection, Power) –
TP/(TP+FN)
• False Positive Rate (FPR) (A.K.A. Fall-out,
probability of false alarm) – FP/(FP+TN)
• False Negative Rate (FNR) (A.K.A. Miss rate) –
FN/(TP+FN)
• True Negative Rate (TNR) (A.K.A Specificity,
Selectivity) – TN/(FP+TN)
49
50. Оцінка точності методів класифікації та виявлення аномалій.
5051. Оцінка точності методів класифікації та виявлення аномалій.
• Positive Predictive Value (PPV, Precision) =TP/(TP+FP)
• False Discovery Rate (FDR) = FP/(TP+FP)
• False Omission Rate (FOR) = FN/(FN+TN)
• Negative Predictive Value (NPV) =
TN/(FN+TN)
51
52. Оцінка точності методів класифікації та виявлення аномалій.
• Prevalence – поширеність «хвороби» =(TP+FN)/(TP+FN+FP+TN)
• Accuracy (ACC) = (TP+TN)/(TP+FN+FP+TN)
• Positive likelihood ratio (LR+) = TPR/FPR
• Negative likelihood ratio (LR-) = FNR/TNR
• Diagnostic odds ratio (DOR) = LR+/LR• F1-score = TP/(TP+0.5*(FP+FN))
52
53. ROC-крива
• Receiver Operating Characteristic - графік, щодозволяє оцінити якість бінарної класифікації,
відображає співвідношення між часткою
об'єктів від TPR і FPR при варіюванні порога
вирішального правила.
• Кількісну інтерпретацію ROC дає показник
AUC (Area under ROC curve) - площа,
обмежена ROC-кривої і віссю частки
помилкових позитивних класифікацій.
53