














 geography
geographySimilar presentations:










Проект VAP Science.Fabric по цифровизации фабрики ЗСУ УВП
1.
Резюме - Волков Алексей Павлович, 23.10.1989 г.р.Основное образование: высшее, Екатеринбург, Уральский Геологический Горный Университет, факультет геологии и
геофизики, кафедра минералогии, петрографии и геохимии. Специальность: Горный инженер.
Год выпуска 2013.
Владение языками: Русский родной, Английский на уровне чтения и понимания технической документации
Основные технологии/инструкции/методологии:
Python 3.7, PyCharm, Anaconda, Jupiter Notebook
SQL, MySQL, CUDA, CuDF, CuPy, CuML,
OpenCV, NumPy, Pandas, SciPy,
Seaborn, Matplotlib, SKLearn,
PyTorch, TensorFlow,
основы HTML5, CSS, Flask
Опыт в разработке:
Работа с сырыми данными – первичными материалами, результатами геологоразведки и
данными, полученными с датчиков.
Работа с выделением и отбором признаков
Протипирование и тестирование гипотез
Разработка алгоритмов машинного обучения
Ориентирование в чужом коде, порядок в собственном коде согласно с PEP 8
Знание Linux на уровне среднего пользователя
Контроль версий с git
Опыт выступлений на конференциях.
Разработка с чистого листа и сопровождение следующих проектов:
- Проект VAP Science.Fabric по цифровизации фабрики ЗСУ УВП
- Проект VAP Science.Geo по цифровизации в геологии (в двух вариациях)
- Проект по поиску слепых рудных тел
- Проект VAP Astro по прогнозированию динамики роста/падения цен на рынке
Информация о дополнительном прохождении специализированных курсов и
собственных проектах представлена в следующих слайдах.
2.
Проект VAP Science.Fabric по цифровизации фабрики ЗСУ УВПЦель проекта: Разработать прогнозирующую систему, которая позволит увеличить
производительность фабрики, без потерь в технологическом извлечении и с
минимизацией предаварийных ситуаций.
Что уже сделано:
- Выполнено сведение всей совокупной информации в единый датасет и
в репрезентативный вид
- Разработан алгоритм сжатия данных, с сохранением дисперсии в данных
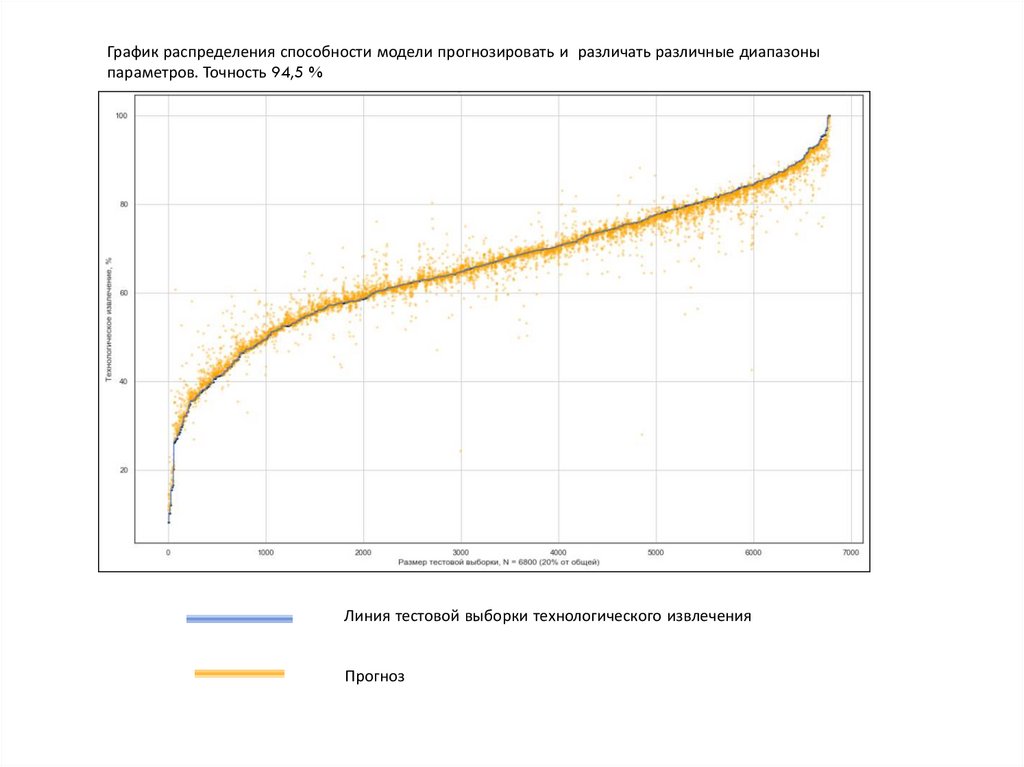
- Произведен поиск оптимальной модели прогноза технологического извлечения
золота из руды, поступающей на фабрику УВП с учетом
данных показаний датчиков. Точность прогноза модели 94%
- Отправлены материалы для согласования проекта, как разрешенного ПО
в компании для опытно-промышленных испытаний
- Осуществлен алгоритм смещения вероятности по времени, каждого
из компонентов в модели, для более детального разбиения производства
на кластеры – измельчение руды->классификация->выщелачивание->сорбция, чтобы на каждой
стадии имелись входные параметры и параметры прогноза.
Применяемые технологии: Python, Pandas, Numpy, Sklearn, Matplotlib
Достижения: работа была представлена руководству на корпоративной НПК-2019
Проект был оценен специальной номинацией. Проект находится на стадии
разработки.
3.
График распределения способности модели прогнозировать и различать различные диапазоныпараметров. Точность 94,5 %
Линия тестовой выборки технологического извлечения
Прогноз
4.
Проект VAP Science.Geo по цифровизации в геологииЦель проекта: Разработать систему, которая сможет совместить картографический
материал с результатами геохимических данных и прогнозировать перспективные
площади на поиск оруденения.
Суть проекта в том, чтобы программа могла оцифровать несколько карт, идентифицируя
карту, легенду, масштаб. Применяя тематическое моделировние, можно совместить несколько
карт разных предшественников.
Что уже сделано:
- Применена технология машинного зрения для чтения, распознавания
растровой графики, пока только распознавание самой карты
- Совмещены карта и химанализ, написан робот, который объединяет множество
файлов в один и сам приводит данные в репрезентативный вид, собирает все в один датасет
- Разработана модель, опирающаяся на несколько способов прогнозирования,
использующая несколько обучающихся алгоритмов.
За основу брались данные аэрогеофизического исследования площади. Частично
площадь покрыта площадной геохимией. Модель обучалась по известным данным,
и должна была спрогнозировать распределение металла там, где была известна
только геофизика.
- В результате получены монометалльные тепловые карты, разного масштаба.
Применяемые технологии: Python, Pandas, NumPy, Sklearn, Matplotlib, openCV
Достижения: работа была представлена руководству в геологический отдел УФ
С помощью прогнозирования модель точно обнаружила расположение уже известных
рудных полей.
Проект будет представлен руководству на НПК-2020
5.
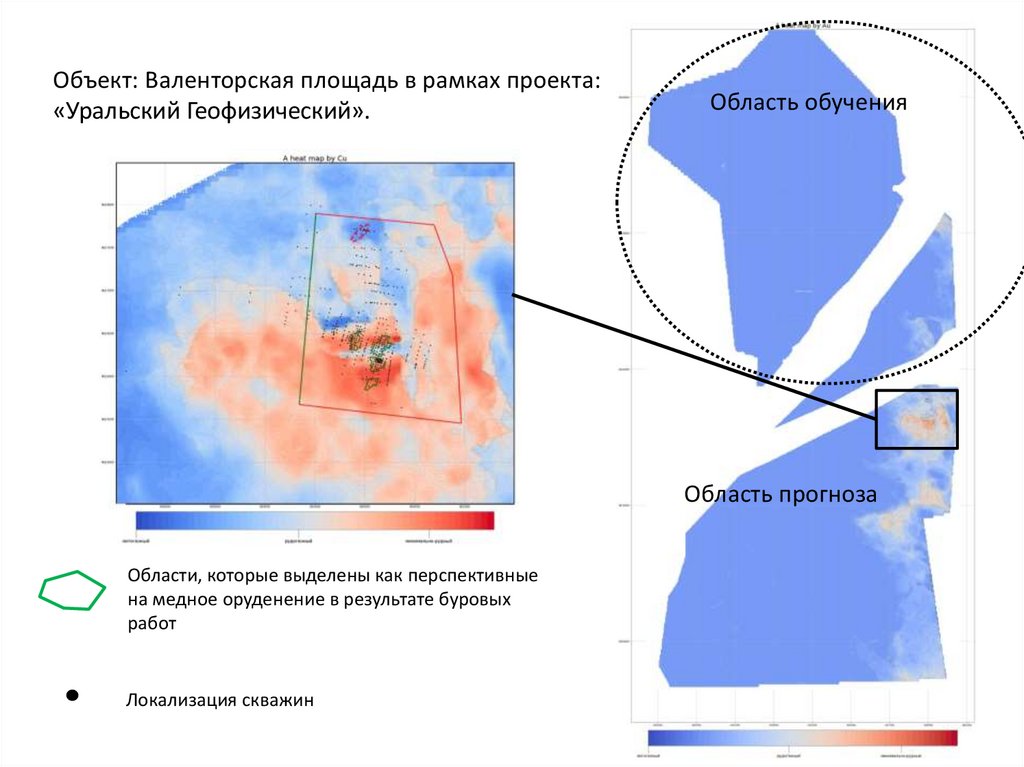
Объект: Валенторская площадь в рамках проекта:«Уральский Геофизический».
Область обучения
Область прогноза
Области, которые выделены как перспективные
на медное оруденение в результате буровых
работ
Локализация скважин
6.
Проект VAP Science.Geo прогнозирование по картам расстоянийЦель проекта: Разработать систему, которая сможет совместить картографический
материал с результатами геофизический, геохимических и иных данных и прогнозировать
перспективные площади на поиск оруденения.
Суть проекта в том, чтобы геолог самостоятельно мог создать признаковые маски для вычисление карт
расстояний от признаков. Таким образом создать возможность прогнозирования перспективных
площадей на оруденение в условиях очень слабой информативности по изученности территории
Что уже сделано:
- Использование машинного зрения для растрирования масок признаков
- Совместимость любых видов данных в один компактный датасет
- Разработка составной модели прогнозирования по принципу голосования 30 совместимых моделей
машинного обучения
За основу берутся маски признаков – магнитка, гравика, разломы, выходы магматических пород, зоны
сульфидного оруденения, геохимические ореолы разнометальные, зоны окварцевания, р ельеф и т.д.
- В результате получены монометалльные тепловые карты, разного масштаба.
Применяемые технологии: Python, Pandas, NumPy, Sklearn, Matplotlib
Достижения: данная разработка использовалась для прогнозирования новых перспективных площадей
на слабо изученных территориях и хорошо себя зарекомендовала. Результаты прогнозирования
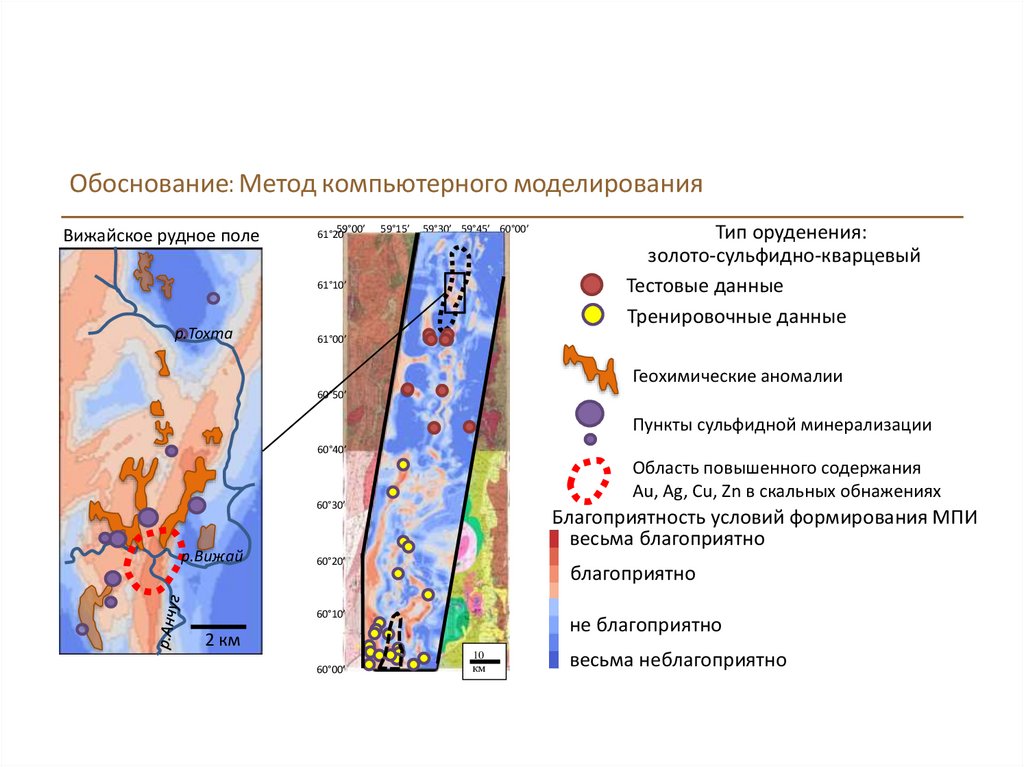
программы подтверждаются результатами общепоисковых работ. Пример, Вижайский золоторудный
узел, Тасеевский меднорудный узел.
Результаты использования разработки представлена руководству в рамках двух конкурсов
геологоразведочных проектов «Золотая Лихорадка» в 2020 и 2021 годах.
7.
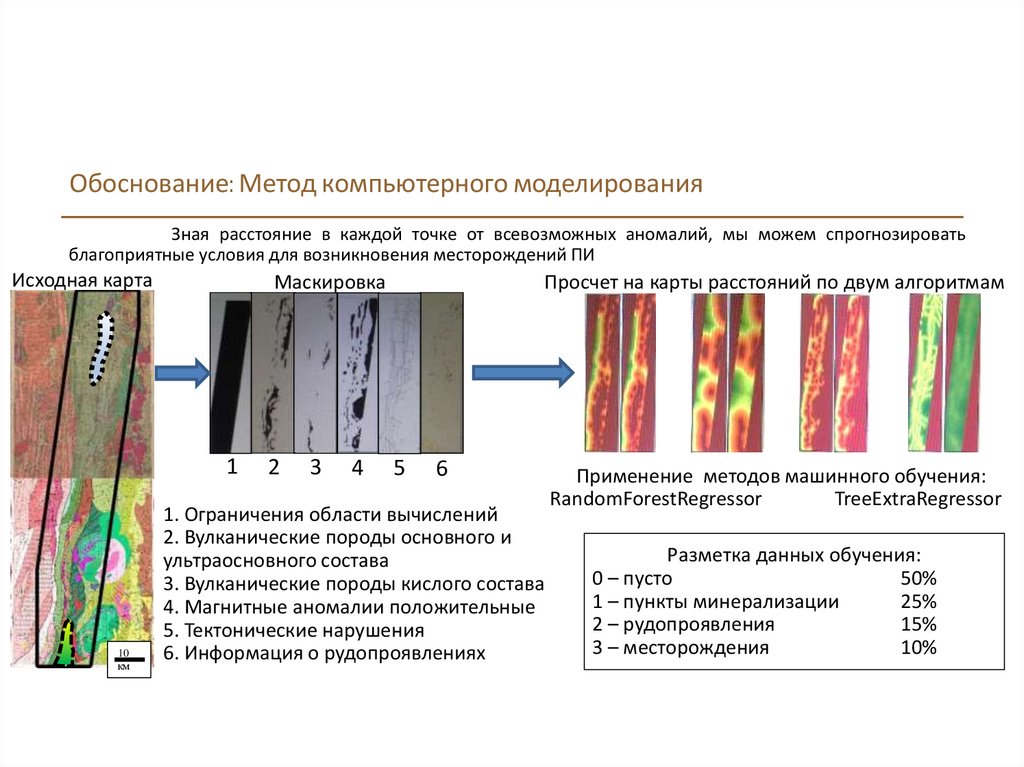
Обоснование: Метод компьютерного моделированияЗная расстояние в каждой точке от всевозможных аномалий, мы можем спрогнозировать
благоприятные условия для возникновения месторождений ПИ
Исходная карта
Маскировка
1
10
км
2
3
4
Просчет на карты расстояний по двум алгоритмам
5
6
1. Ограничения области вычислений
2. Вулканические породы основного и
ультраосновного состава
3. Вулканические породы кислого состава
4. Магнитные аномалии положительные
5. Тектонические нарушения
6. Информация о рудопроявлениях
Применение методов машинного обучения:
RandomForestRegressor
TreeExtraRegressor
Разметка данных обучения:
0 – пусто
50%
1 – пункты минерализации
25%
2 – рудопроявления
15%
3 – месторождения
10%
8.
Обоснование: Метод компьютерного моделированияВижайское рудное поле
59°00’
61°20’
59°15’
59°30’ 59°45’ 60°00’
61°10’
р.Тохта
Тип оруденения:
золото-сульфидно-кварцевый
Тестовые данные
Тренировочные данные
61°00’
Геохимические аномалии
60°50’
Пункты сульфидной минерализации
60°40’
Область повышенного содержания
Au, Ag, Cu, Zn в скальных обнажениях
60°30’
р.Вижай
Благоприятность условий формирования МПИ
весьма благоприятно
60°20’
благоприятно
60°10’
не благоприятно
2 км
60°00’
10
км
весьма неблагоприятно
9.
Проект по поиску слепых рудных телПроблема: При бурении глубоких скважин, есть вероятность, что в тело могли не попасть при ряде
причин. Сейчас на ЗСУ ведутся поиски так называемой «второй Воронцовки», километровыми скважинами.
Цель проекта: Разработать программу, которая будет обучена на исторических данных по
опробованию скважин на химический анализ и данных по геологической документациии керна,
которая сможет прогнозировать расстояние до слепого тела в каждой точке в скважине.
Суть проекта в том, чтобы исключить недобур или перебур скважин на основании минерального состава
пород и результатов спектрального анализа.
Что уже сделано:
- Программа считывает данные АГР (пока что переведенные в csv файлы), с последующим
масштабированием, совмещает их с данными спектрального и пробирного анализа
- Обучается на известных данных и может с точностью до 70% дать оценку расстоянию до рудного тела.
Применяемые технологии: Python, Pandas, NumPy, Sklearn, Matplotlib
В данный момент проект в стадии доработки и обсуждения с руководством
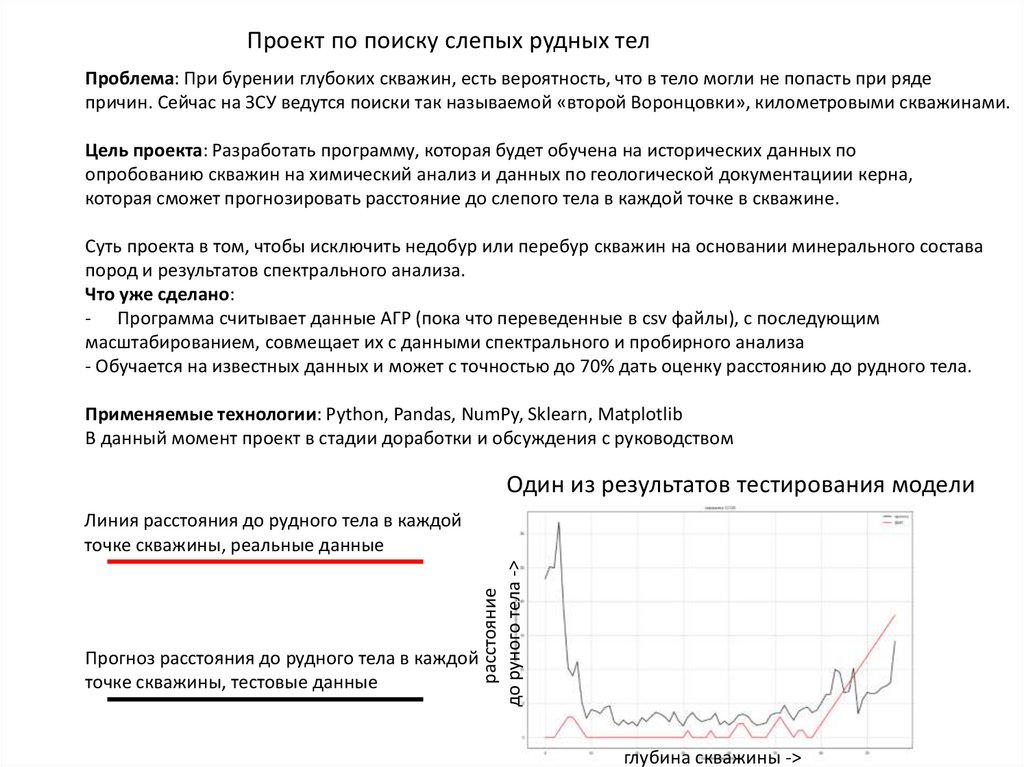
Один из результатов тестирования модели
Прогноз расстояния до рудного тела в каждой
точке скважины, тестовые данные
расстояние
до руного тела ->
Линия расстояния до рудного тела в каждой
точке скважины, реальные данные
глубина скважины ->
10.
Проект VAP Astro по прогнозированию динамики роста/падения цен на рынкеЦель проекта: Разработать систему, которая используя исторические данные о кризисах,
используя данные по расположению и перемещению планет сможет прогнозировать волатильность
на рынке.
Суть проекта в том, чтобы заранее планировать экономическую обстановку в мире,
или в отдельной стране. Так как можно рассчитать положение планет в любое время, то можно также
спрогнозировать волатильность в экономике.
Применяемые технологии: Python, CUDF, CuPy, CuDF, CuML, Matplotlib
Достижения: осуществлен прогноз, по росту акций POLY в конце 2019 г., также рост курса доллара,
прогнозы подтвердились временем.
Также, при неудачной сделке ОПЕК в марте, были сделаны прогнозы по датам следующих встреч ОПЕК –
в середине апреля и в середине июня. Один из прогнозов подтвердился. Второй в ожидании.
Проект неформально существует, делового значения не имеет. Однако может пригодится при
планировании бюджета компании и т.п. Также проект разрабатывался проверить собственные возможности
и силы в машинном обучении.
11.
Ссылка на сертификат: https://stepik.org/cert/19891312.
Название курса: Программирование на PythonАвтор: Институт биоинформатики
Чему научился на практике в этом курсе:
1.
2.
3.
4.
5.
6.
7.
8.
9.
Синтаксис Python3, основы ООП
Логические, вещественные, целочисленные переменные, операции над ними
Операции сравнения
Операторы ввода/вывода, условия
Циклы, строки, списки, множества
Функции, словари, модули, файлы
Отладка приложений try-except-else
Основы функционального программирования
Сортировка списков, работа с многомерными массивами
13.
Ссылка на сертификат: https://stepik.org/cert/19570314.
Название курса: Основы статистикиАвтор: Институт биоинформатики
Чему научился на практике в этом курсе:
1.
2.
3.
4.
5.
6.
7.
Использование свойств нормального распределения
Выборочная дисперсия
Среднеквадратичное отклонение
Построение доверительных интервалов
Вычисление границ интервалов с помощью квантилей
Корреляционный анализ
Применение линейной регрессии
15.
Ссылка на сертификат: coursera.org/verify/KKN8PFW5CRZV16.
Название курса: Математика и Python для анализа данныхАвтор: Московский физико-технический институт & Яндекс
Чему научился на практике в этом курсе:
1.
2.
3.
4.
5.
6.
7.
8.
9.
Ручная и программная аппроксимация функций
Применение косинусного и евклидового расстояний при анализе текстов
Минимизация гладкой и не гладкой функций
Анализ распределений по выборочным дисперсиям
Операции с матрицами применяя библиотеку numpy
Визуализация данных с matplotlib
Работа с данными в Pandas
Применение библиотеки Seaborn
Использование библиотеки Scipy
17.
Ссылка на сертификат: coursera.org/verify/EV7WEEMMKAHF18.
Название курса: Обучение на размеченных данныхАвтор: Московский физико-технический институт & Яндекс
Чему научился на практике в этом курсе:
1. Стратегии выполнения кросс-валидации алгоритмов
2. Минимизация квадратичной ошибки при обучении модели
3. Применение линейной регрессии и логистической регрессии
4. Идентификация переобученности и необученности модели
5. Регуляризация данных. Отсев неинформативных признаков.
6. Решение задачи бинарной классификации
7. Способы обработки пропусков в данных
8. Использование Бэггинг-классификацию и случайный лес
9. Классификация по методам ближайших соседей
10. Классификация по Баесовским методам, их отличия
11. Использование метрик качества для оценки точности алгоритмов обучения
12. Интерпретация кривой AUC-ROC, F1-score, Log-loss
13. Применение градиентного бустинга
14. Градиентный спуск и стохастический градиентный спуск
15. Использование функционала библиотеки SKlearn
19.
Ссылка на сертификат: coursera.org/verify/MWNA5LHWZHKE20.
Название курса: Поиск структуры в данныхАвтор: Московский физико-технический институт & Яндекс
Чему научился на практике в этом курсе:
1. Визуализация данных. Поиск аномалий в данных
2. Применение метода главных компонент
3. Понижение размерности данных методами – логарифм правдоподобия,
MDS, tSNE, анализа дисперсии главных компонент
4. Применение методов KNN для анализа координат перемещений объектов
5. Использование алгоритмов кластеризации: DBSCAN,
аггломеративная кластеризация, KMeans, MeanShift. Их отличия.
6. Кластеризация данных
7. Анализ методом главных компонент PCA
8. Тематическое моделирование
9. Основные методы библиотеки gensim