


































 programming
programmingSimilar presentations:








")
")
Абстрактные типы данных
1.
2.
это тип данных, которыйпредоставляет для работы с
элементами этого типа
определенный набор операций
(функций ), а также возможность
создавать элементы этого типа
при помощи специальных функций
(операций).
3.
4.
Вся внутренняя структура спрятана отразработчика программного
обеспечения.
Абстрактный тип данных определяет
набор функций, независимых от
конкретной реализации типа, для
оперирования его значениями.
5.
6.
7.
Такой подход соответствует принципу инкапсуляциив объектно-ориентированном программировании.
Пока структура данных поддерживает интерфейс,
все программы, работающие с заданной структурой
АТД, будут продолжать работать.
Разработчики структур данных стараются, не меняя
внешнего интерфейса и семантики функций,
постепенно дорабатывать реализации, улучшая
алгоритмы по скорости, надежности и используемой
Памяти.
8.
АТД позволяют достичьмодульности программных
продуктов и иметь несколько
альтернативных
взаимозаменяемых
реализаций отдельного
модуля.
9.
10.
это абстрактный тип данных, представляющий собойупорядоченный набор значений, в котором некоторое
значение может встречаться более одного раза.
Экземпляры значений, находящихся в списке,
называются элементами списка; если значение
встречается несколько раз, каждое вхождение
считается отдельным элементом.
Термином список также называется несколько
конкретных структур данных, применяющихся при
реализации абстрактных списков, особенно связных
списков
11.
являются фундаментальной структуройБольшинство функциональных языков имеет
встроенные средства для работы со списками:
получение длины списка, головы (первый
элемент списка), хвоста (часть списка, идущая за
первым элементом), применения функции к
каждому элементу списка (Map), свертки списка и
пр.
12.
структура данных, представляющая собой списокэлементов, организованных по принципу LIFO(англ.
last in — first out,
«последним пришел — первым вышел»).
В 1946 Алан Тьюринг ввел понятие стека.
А в 1957 году немцы Клаус Самельсон и Фридрих Л.
Бауэр запатентовали идею.
Алан Тьюринг
Фридрих Л. Бауэр
13.
поместить элемент в стек push(…)извлечь элемент из стека pop(…)
посмотреть не элемент на стеке без
извлечения top(…) или peek(…)
проверить стек на пустоту empty (…)
проверить стек на переполнение full (…)
подготовить стек к работе init (…)
14.
const int SIZE=50;struct stack {
arr [SIZE];
* top;
};
void push(stack &s,
x) {
if (s.top == (s.arr+SIZE)) { throw("Stack Overflow"); }
*s.top = x;
s.top++;
}
peek(stack &s) {
if (s.top == s.arr) { throw ("Stack Underflow"); }
s.top--;
return *s.top;
}
15.
top(stack s) {if (s.top == s.arr) { throw ("Stack Underflow"); }
return *(s.top-1);
}
bool empty(stack s) {
return (s.top == s.arr);
}
bool full (stack s){
return (s.top == (s.arr+SIZE)) ;
}
void init(stack &s) {
s.top=s.arr;
}
16.
Обход деревав качестве
используем t_ptr
struct stack {
t_ptr arr [SIZE];
t_ptr * top;
};
stack st;
t_ptr tree, p;
bool flag;
17.
init (st);p= tree;
flag = 1;
while ( flag ) {
if (p) {
push ( st, p);
p = p->lt;
} else
if empty(st) flag = 0;
else {
p = pop(st);
cout << p->inf<< " ";
p = p->rt;}
}
18.
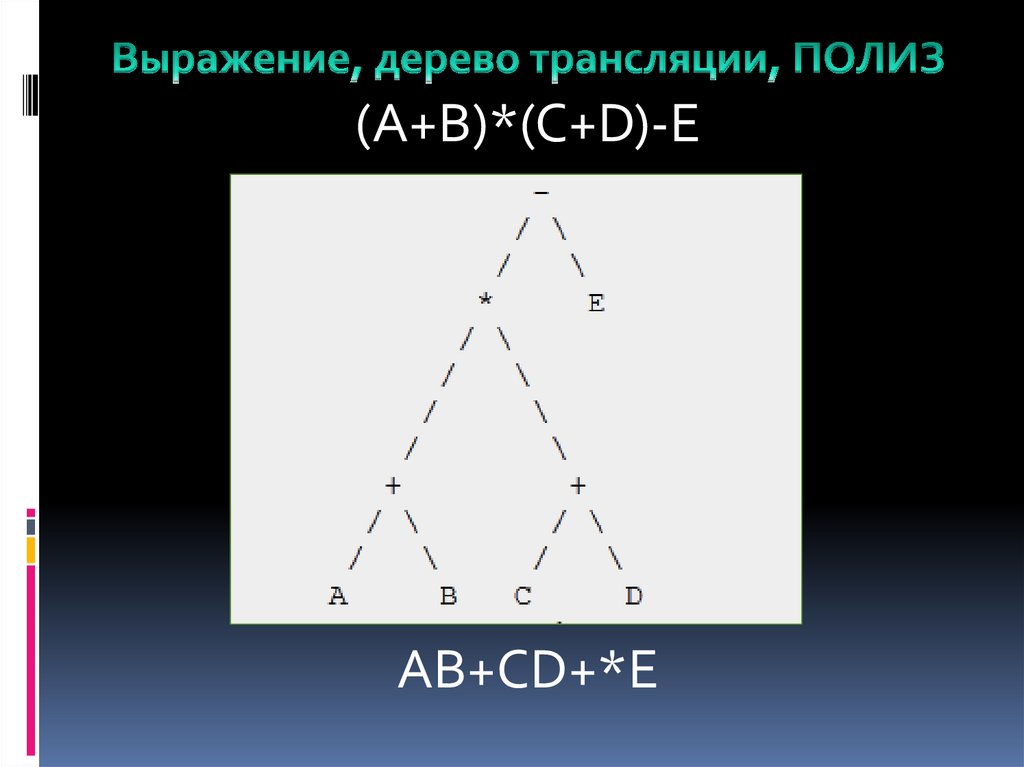
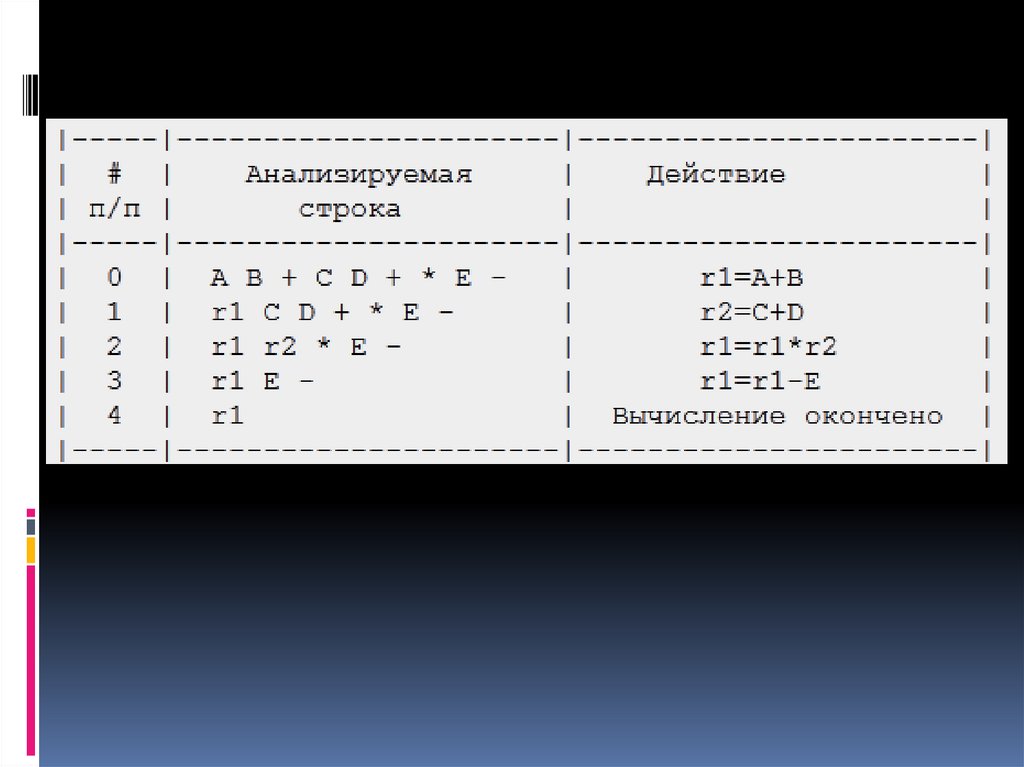
(A+B)*(C+D)-EAB+CD+*E
19.
- форма записи математическихвыражений, в которой операнды
расположены перед знаками операций.
Вычисление выражения, записанного в
, может поводиться путем
однократного пpосмотpа, что является
весьма удобным при генерации
объектного кода программы.
20.
21.
AB+CD+*E22.
Получениеиз исходного выражения
может выполняться с использованием стека на
основе простого алгоритма, предложенного
Дейкстpой.
Введем понятие стекового пpиоpитета операций
23.
Пpосматpивается исходная строка символовслева направо, операнды переписываются в
выходную строку, а знаки операций заносятся
в стек на основе приоритета:
а) если стек пуст, то операция из входной
строки
переписывается в стек;
б) операция выталкивает из стека все
операции с большим или равным
пpиоpитетом в выходную строку, потом
записывается в стек;
24.
в) если очередной символ из исходной строкиесть открывающая скобка, то он проталкивается
в стек;
г) закрывающая круглая скобка выталкивает все
операции из стека до ближайшей открывающей
скобки, сами скобки в выходную строку не
переписываются, а уничтожают друг друга.
25.
(A+B)*(C+D)-E26.
struct stack {char arr [SIZE];
char * top;
};
stack st;
char v[ ] =― (a+b)*(c+d)-e‖;
char poliz[20];
char *str = v, *srt1=poliz;
init (st);
27.
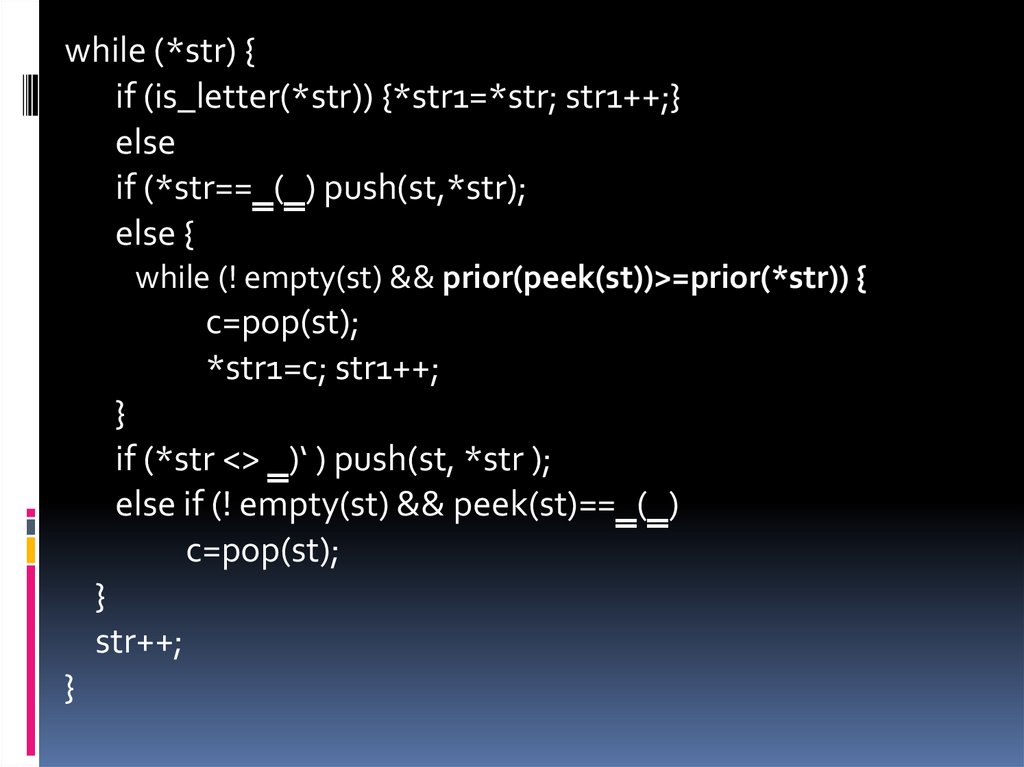
while (*str) {if (is_letter(*str)) {*str1=*str; str1++;}
else
if (*str==‗(‗) push(st,*str);
else {
while (! empty(st) && prior(peek(st))>=prior(*str)) {
c=pop(st);
*str1=c; str1++;
}
if (*str <> ‗)‘ ) push(st, *str );
else if (! empty(st) && peek(st)==‗(‗)
c=pop(st);
}
str++;
}
28.
while (!empty(st)) {c=pop(st);
*str1=c;
str1++;
}
29.
структура данных с дисциплиной доступа кэлементам «первый пришел — первый вышел»
(FIFO, First In — First Out).
Добавление элемента возможно лишь в конец
очереди (принято обозначать словом
),
выборка — только из начала очереди (что
принято называть словом
), при этом
выбранный элемент из очереди удаляется.
30.
(от англ.— double ended queue;
двухсторонняя очередь, двусвязный
список, очередь с двумя концами) —
структура данных, в которой элементы
можно добавлять и удалять как в
начало, так и в конец, то есть
дисциплинами обслуживания
являются одновременно
и
31.
добавить в очередь элемент снaзначенным приоритетом.
извлечь из очереди и вернуть элемент
с наивысшим приоритетом.
(необязательная операция):
просмотреть элемент с наивысшим приоритетом
без извлечения.
32.
const int N= . . .; //размер очередиstruct Queue {
int data[N]; //массив данных
int first; //указатель на начало
int last; //указатель на конец
};
Проблема – образуется пустота в начале массива
33.
const int N=. . .; //размер очередиstruct Queue {
int data[N]; //массив данных
int first; //указатель на начало
int last; //указатель на конец
};
void create(Queue &Q) {
Q.first=Q.last=0;
}
bool isEmpty(const Queue &Q) {
if (Q.last==Q.first) return true;
else return false;
}
int getSize(const Queue &Q) {
if (Q.first >Q.last) return (N-1)-(Q.first - Q.last);
else return Q.last – Q.first;
}
34.
void push ( Queue &Q, int value) {if ((Q.last%(N-1))+1==Q.first)
throw("Overflow");
else {
Q.data[ Q.last ] = value;
Q.last = (Q.last%(N-1))+1;
}
}
int peek(const Queue &Q) {
returnQ.data[Q.first];
}
void pop(Queue &Q) {
Q.first=(Q.first%(N-1))+1;
}
35.
тип данных, хранящийинформацию о присутствии в
множестве объектов любого
счетного типа.
Наиболее эффективная
реализация для множеств
ограниченного размера
(мощности) – битовая шкала.
36.
АТД, позволяющий хранить пары вида«(ключ, значение)» и поддерживающий
операции добавления пары, а также
поиска и удаления пары по ключу:
• INSERT(ключ, значение)
• FIND(ключ)
• REMOVE(ключ)
37.
Ассоциативный массив не может хранитьдве пары с одинаковыми ключами.
Ассоциативный массив с точки зрения
интерфейса удобно рассматривать как
обычный массив, в котором в качестве
индексов можно использовать не только
целые числа, но и значения других типов
— например, строки.