
















































 programming
programmingSimilar presentations:










Введение в нагрузочное тестирование ПО
1.
Введение в нагрузочное тестирование ПО2.
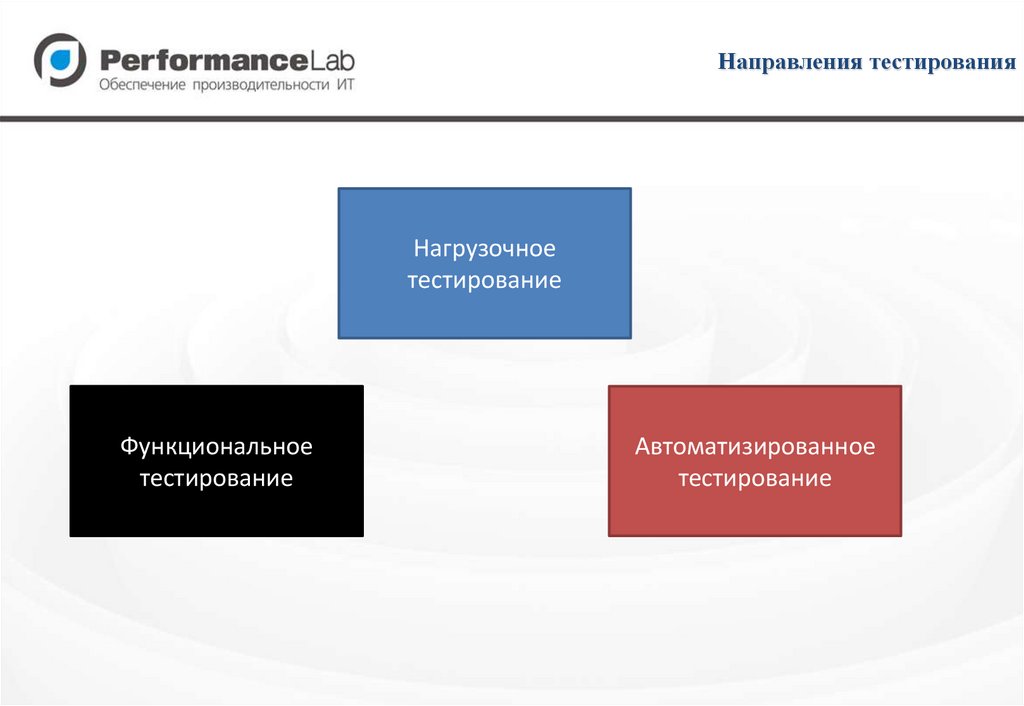
Направления тестированияНагрузочное
тестирование
Функциональное
тестирование
Автоматизированное
тестирование
3.
4.
Заказчики5.
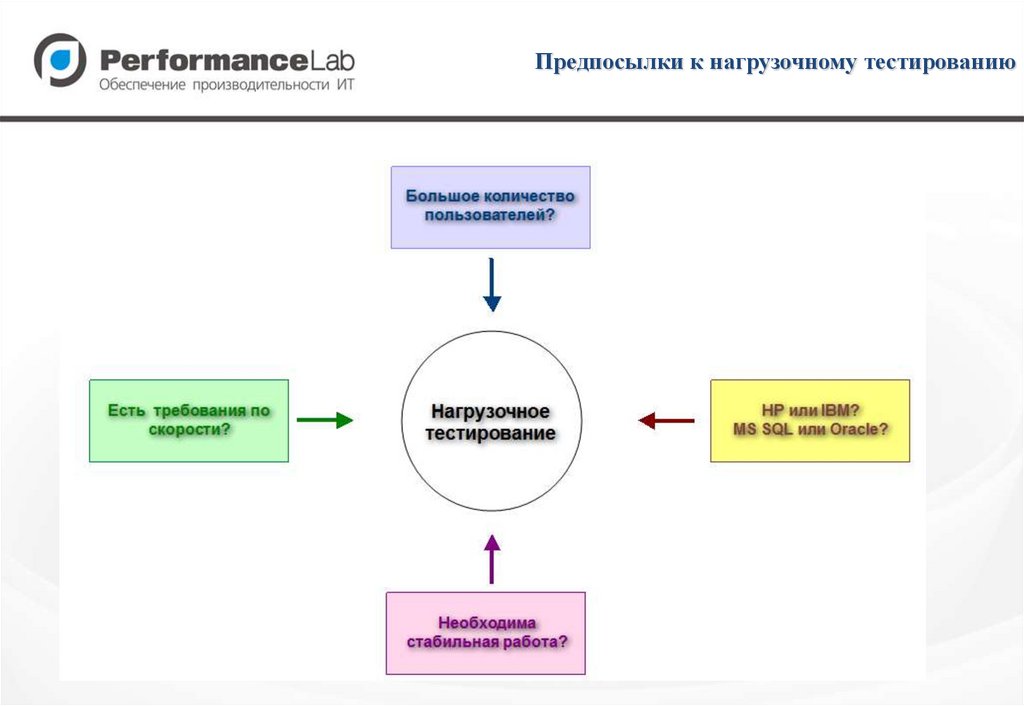
Предпосылки к нагрузочному тестированию6.
Типы нагрузочного тестирования7.
Типы нагрузочного тестированияДостаточно ли быстро работает приложение?
(Performance Testing)
Как заставить приложение работать быстрее?
(Configuration Testing)
Какое количество пользователей может работать?
(Capacity Testing)
Что произойдет при незапланированной нагрузке?
(Stress Testing)
Достаточно ли надежно работает приложение?
(Stability Testing)
Какое оборудование и ПО выбрать?
(Compare Testing)
8.
Правило №1• Нагрузочное тестирование всегда проводится после
функционального
9.
Performance / Configuration TestingСкорость работы системы определяется ее производительностью (числом
операций в секунду) и временем отклика.
Какая скорость нужна?
–
–
–
–
Бизнес требования
Опыт пользователей
Удобство работы с системой
Финансовые затраты
Чем определяется скорость работы приложения?
– Скоростью ПО
– Скоростью оборудования
– Скоростью сети
10.
Capacity / Stress TestingКак будет работать приложение с заданным числом пользователей? (Что будет
завтра? Что будет через год?)
Сколько пользователей может работать «быстро»?
Максимальное количество пользователей?
Как быстро растет объем данных, с которыми работает приложение?
11.
Stability Testing / Failover TestingСможет ли система работать долго и безошибочно?
Как повлияет на стабильность системы повышенная нагрузка?
Сможет ли система восстановить скорость и работоспособность после пиковых
нагрузок?
Что произойдет при большом числе одинаковых операций? (Что случится в
конце месяца? Что случится, если все пользователи нажмут одну и ту же
кнопку?)
Как повлияет временно отключение одного или нескольких компонентов
системы? (Что произойдет, если «упадет» Web сервер? Можно ли выполнять
профилактику каждую пятницу?)
12.
Compare TestingКакую СУБД выбрать?
Какое оборудование выбрать? (Платформа, производитель, цена)
Как повлияют на работу приложения обновления и патчи?
13.
Вопросы1)Назовите основные типы систем для НТ?
Приведите примеры каждого типа.
2)Приведите примеры проблем, с которыми
сталкиваются Заказчики перед обращением в
Performance Lab за услугой НТ?
3)Перечислите виды нагрузочного
тестирования?
14.
Жизненный цикл тестирования15.
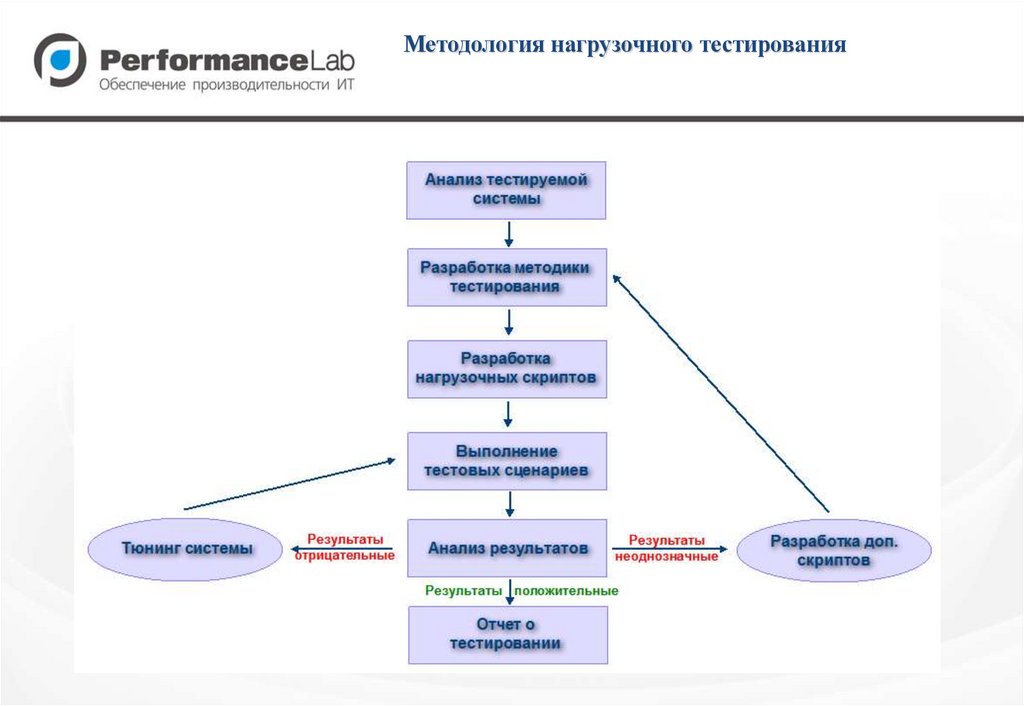
Методология нагрузочного тестирования16.
Анализ тестируемой системыЧто требуется определить:
– Требования к производительности и временам отклика
операций
– Значения текущей, прогнозируемой и пиковой
пользовательской нагрузки
– Характер и величину фоновой нагрузки
– Архитектуру продуктивной и тестовой сред
17.
Разработка методики тестированияЧто требуется подготовить:
–
–
–
–
Список тестируемых операций
Правила генерации тестовых данных
План тестирования (время / ресурсы)
Стратегию минимизации рисков
18.
Разработка нагрузочных скриптовВиртуальный пользователь (Vuser) – эмулирует действия пользователя,
выполняя бизнес-процессы в приложении. Виртуальный пользователь
представляет реального пользователя системы.
Скрипт (Vuser script) – зафиксированная последовательность действий
виртуального пользователя по выполнению бизнес-функции. Скрипт
может представлять одну или несколько бизнес-функций, или же часть ее.
Сценарий (Scenario) – один или нескольких скриптов,
выполняемых виртуальным пользователем или группой пользователей.
Сценарий представляет нагрузку.
Для разработки скриптов и работы со сценариями используются средства
автоматизированного тестирования (Apache JMeter, HP LoadRunner, etc.)
19.
Выполнение тестовых сценариевПорядок выполнения сценариев:
– Базовый сценарий (baseline) – выполняется один скрипт
одним пользователем.
– Бенчмарк (benchmark) – выполняется с нагрузкой 15-25%
от запланированной.
– Сценарий стандартной нагрузки – для проверки
соответствия системы заданным требованиям.
– Сценарий масштабируемости – выполняется с нагрузкой
120% от запланированной.
20.
Анализ результатов• Анализ результатов – самая важная и самая сложная часть в процессе
тестирования.
Для анализа используются:
– Логи тестовых сценариев
– Результаты мониторинга аппаратных и программных ресурсов
Задачи, стоящие на этом этапе:
– Проверка соответствия системы требованиям
– Поиск узких мест («bottlenecks»)
– Принятие решения по устранению узких мест и увеличению скорости
21.
Тюнинг системы• Тюнинг – итеративный процесс, выполняемый совместно с
разработчиками и/или администраторами тестируемой
системы.
• Тюнинг выполняется на всех доступных уровнях системы
(приложение, оборудование, сервера БД, сервера
приложений и т.п.)
• Все изменения, внесенные в систему на этапе тюнинга,
документируются и дополнительно тестируются.
22.
Разработка дополнительных скриптов• В зависимости от результатов тестирования и/или
найденных узких мест может потребоваться изменение
методики тестирования и разработка дополнительных
нагрузочных скриптов и сценариев.
• Дополнительные скрипты и сценарии не обязательно
должны эмулировать реальное поведение системы
(пользовательскую нагрузку), например они могут создавать
нагрузку только на узкое место, для удобства тюнинга.
23.
Отчет о тестированииОтчет о тестировании представляет собой документ установленного формата,
содержащий:
– Анализ поведения системы под нагрузкой.
– Результаты выполнения тестовых сценариев.
– Результаты тюнинга системы (конфигурационные файлы,
значения настроек и т.п.)
– Список найденных, но не устраненных узких мест.
– Рекомендации по увеличению производительности
системы.
24.
Вопросы1)Перечислите основные этапы проекта по НТ
2)Зачем нужна методика НТ?
3)Что самое главное в отчёте по НТ?
25.
Конец введения. Вопросы. Перерыв.26.
Аспекты нагрузочного тестирования1. Нормативные документы.
2. Нефункциональные требования к системе.
3. Тестовый стенд. Мониторинг системных ресурсов. Узкие места.
4. Моделирование нагрузки. Виртуальные пользователи.
5. Пользовательские активности. Нагрузочные скрипты.
6. Группы пользователей. Расписание работы.
7. Тестовые данные.
8. Измерение быстродействия системы.
9. Виды тестов.
10. Представление результатов тестирования. Кривая деградации.
27.
1.1 Методика нагрузочного тестированияЗадачи Методики нагрузочного тестирования:
– В целом описать тестируемую систему
– Представить модель нагрузки
– Перечислить тестируемые функциональности системы
– Определить роли пользователей
– Определить критерии, по которым будет определяться производительность
(времена отклика, интенсивности операций, проч.)
– Определить требования к критериям производительности, по которым будет
приниматься решение о запуске системы в промышленную эксплуатацию
– Представить список скриптов (с указанием, какие времена отклика
замеряются в скрипте)
– Представить список тестовых сценариев
– Дать подробное описание тестового стенда и его отличий от продуктивного
– Определить план нагрузочного тестирования
– Определить стратегию минимизации рисков
28.
1.2 Отчет о результатах нагрузочноготестирования
Задачи Отчета о результатах нагрузочного тестирования:
–
–
–
–
–
–
Дать краткое резюме по результатам тестирования
Представить результаты проведенных тестов
Привести обобщенные результаты тестирования
Представить результаты тюнинга системы
Сделать общие выводы по проведенному тестированию
Дать рекомендации по увеличению быстродействия
системы
29.
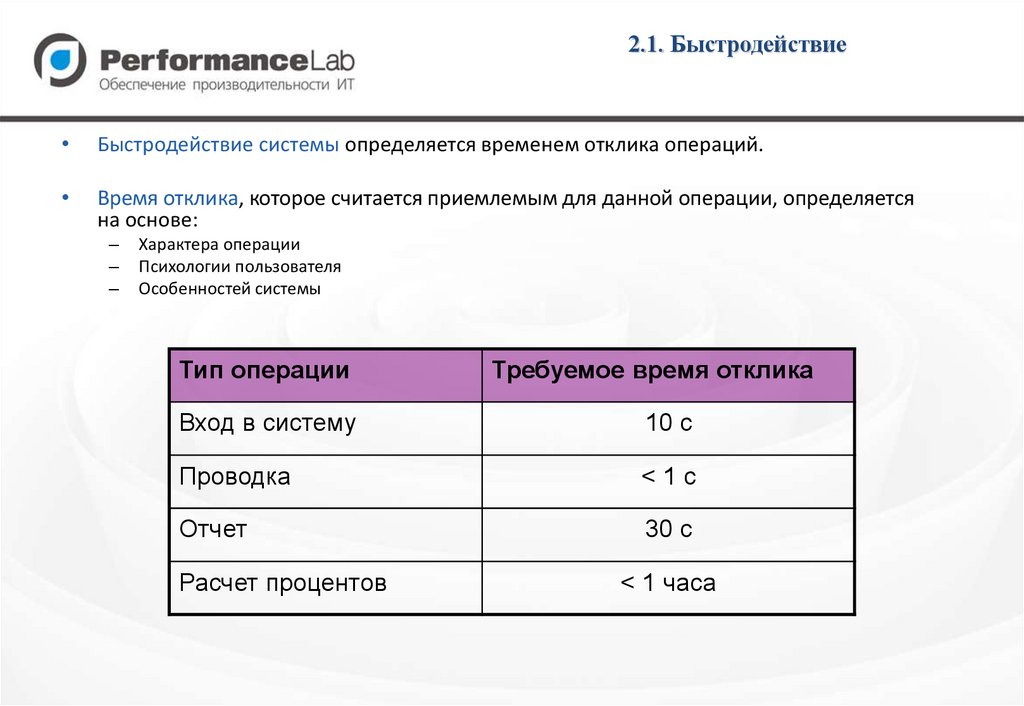
2.1. БыстродействиеБыстродействие системы определяется временем отклика операций.
Время отклика, которое считается приемлемым для данной операции, определяется
на основе:
–
–
–
Характера операции
Психологии пользователя
Особенностей системы
Тип операции
Требуемое время отклика
Вход в систему
10 с
Проводка
<1c
Отчет
30 c
Расчет процентов
< 1 часа
30.
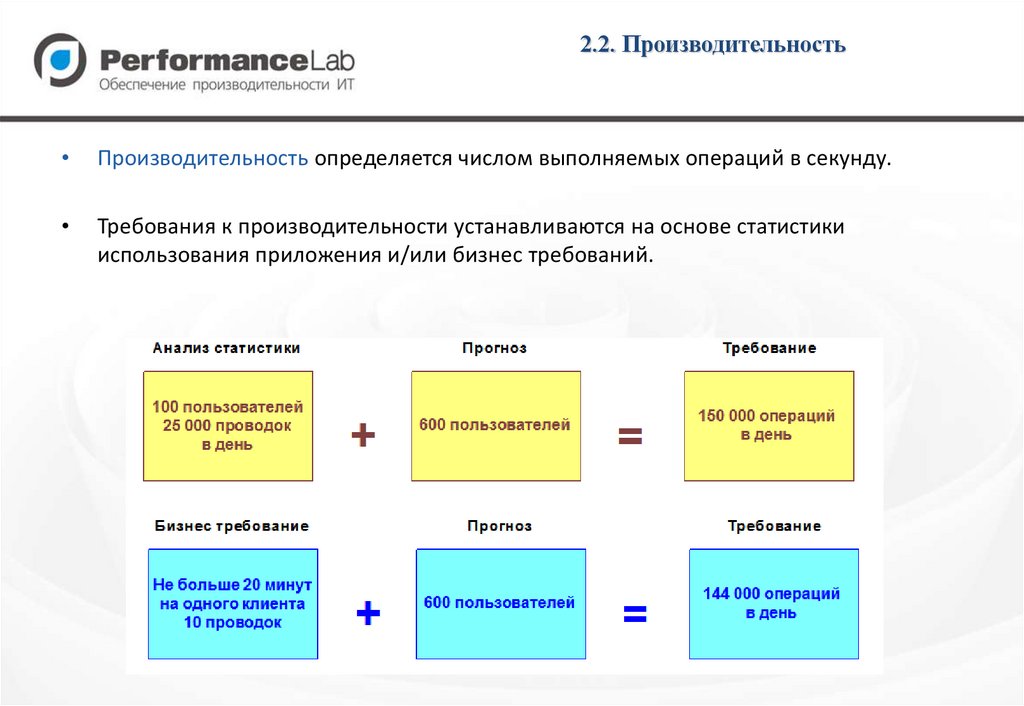
2.2. ПроизводительностьПроизводительность определяется числом выполняемых операций в секунду.
Требования к производительности устанавливаются на основе статистики
использования приложения и/или бизнес требований.
31.
2.3. Масштабируеость• Масштабируемость – в электронике и информатике означает
способность системы, сети или процесса справляться с увеличением
рабочей нагрузки (увеличивать свою производительность) при
добавлении ресурсов.
Примеры:
32.
2.4. СтабильностьСтабильность приложения определяется его возможностью безошибочно
функционировать в течение длительного времени и способностью возвращаться
в нормальное состояние после стрессовых ситуаций и сбоев.
Примеры:
– Система должна отработать 24 часа при штатной нагрузке без
увеличения объема используемой оперативной памяти.
– При возврате от пиковой нагрузки к нормальной система должна
восстанавливать прежние значения производительности и времен
отклика в течение 10 минут.
– После перезагрузки сервера приложений система должна
восстанавливать работоспособность и прежние значения
производительности и времен отклика в течение 15 минут.
33.
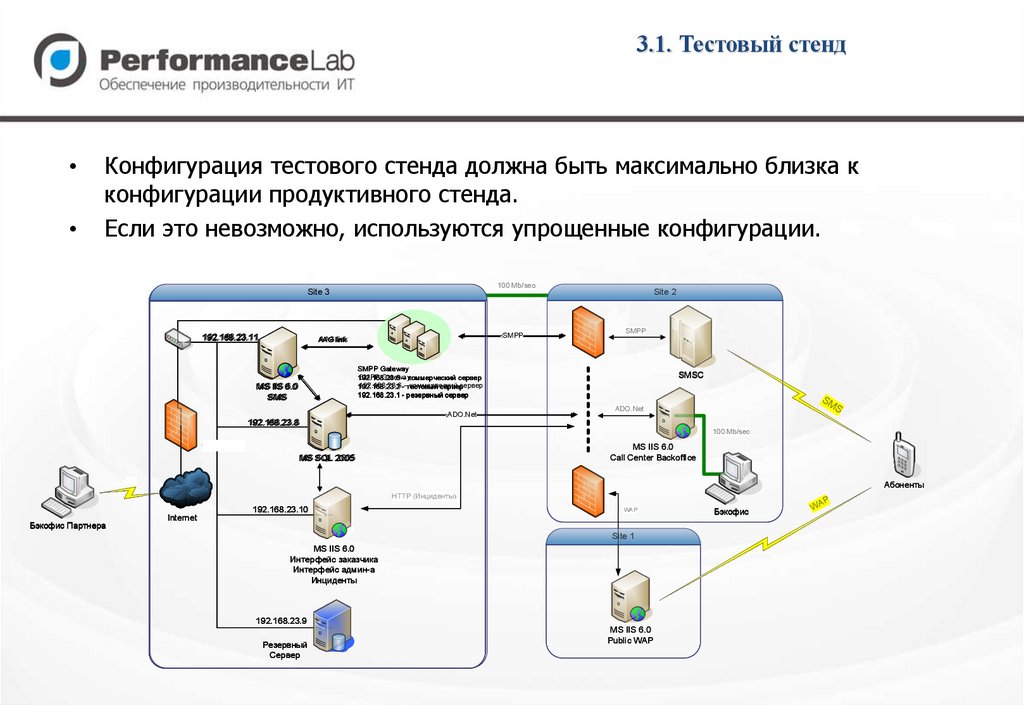
3.1. Тестовый стендКонфигурация тестового стенда должна быть максимально близка к
конфигурации продуктивного стенда.
Если это невозможно, используются упрощенные конфигурации.
100 Mb/sec
Site 33
Site
192.168.23.11
192.168.23.11
SMPP
SMPP
AAG link
link
AAG
Site 2
SMPP
SMPP Gateway
SMPP Gateway
– коммерческий сервер
192.168.23.6
192.168.23.6 -–тестовый
коммерческий
сервер
сервер
192.168.23.2
192.168.23.1 - резервный сервер
MS IIS
IIS 6.0
6.0
MS
SMS
SMS
192.168.23.8
192.168.23.8
ADO.Net
ADO.Net
SMSC
SM
S
ADO.Net
100 Mb/sec
Cisco 2610
2610
Cisco
MS IIS 6.0
Call Center Backoffice
MS SQL
SQL 2005
2005
MS
VPN
VPN
Абоненты
Абоненты
HTTP (Инциденты)
Бэкофис Партнера
Internet
Internet
192.168.23.10
192.168.23.10
WAP
Site 1
MS IIS 6.0
Интерфейс заказчика
Интерфейс админ-а
Инциденты
192.168.23.9
192.168.23.9
Резервный
Резервный
Сервер
Сервер
MS IIS 6.0
Public WAP
Бэкофис
P
WA
34.
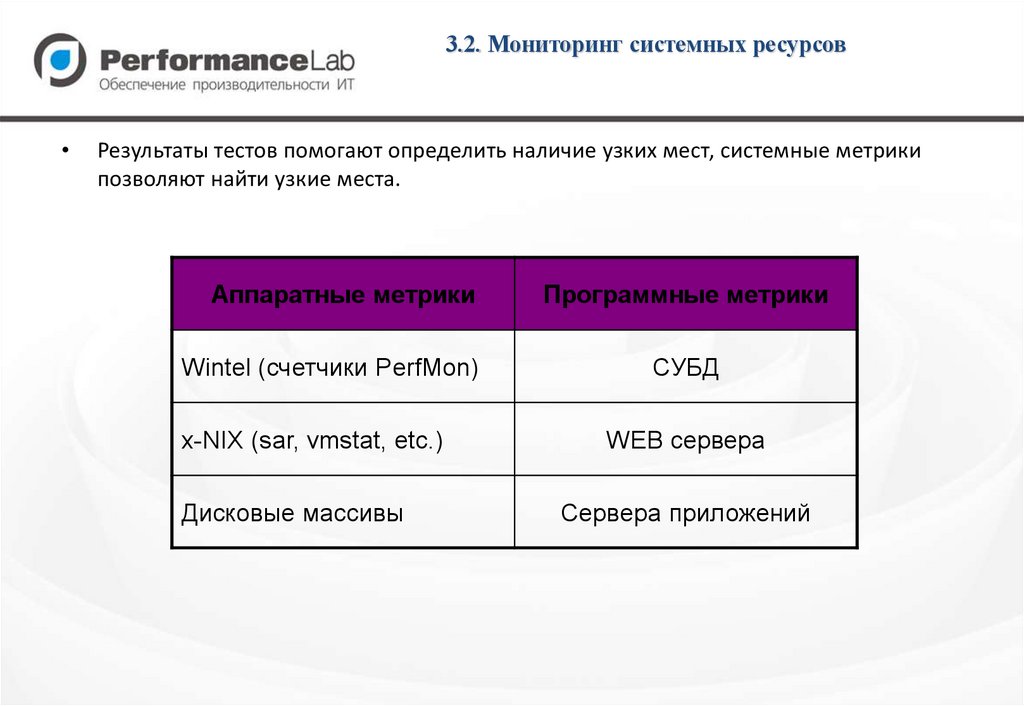
3.2. Мониторинг системных ресурсовРезультаты тестов помогают определить наличие узких мест, системные метрики
позволяют найти узкие места.
Аппаратные метрики
Wintel (счетчики PerfMon)
x-NIX (sar, vmstat, etc.)
Дисковые массивы
Программные метрики
СУБД
WEB сервера
Сервера приложений
35.
3.3. Узкие местаВ каждый момент времени существует «самая медленная» часть системы.
До тех пор, пока узкое место не будет устранено, увеличение скорости системы
невозможно.
Перед устранением узкого места, его необходимо однозначно идентифицировать.
Для тюнинга системы удобно использовать специальные скрипты, не
эмулирующие деятельность пользователей, но целенаправленно
нагружающие узкие места.
36.
4.1. Кто такие пользователи?Пользователи (users) – это все, кто взаимодействует с системой.
Human users:
–
–
–
–
–
Покупатели
Администраторы
Менеджеры
Операционисты
Контролеры
Системные пользователи (system users):
– Фоновые процессы обработки данных
– Процессы резервного копирования
– Другие системы, взаимодействующие с тестируемым приложением
37.
4.2. Цели моделированияОсновная цель моделирования пользователей – воссоздать нагрузку, создаваемую
на систему.
Из трех составляющих тестовой модели – стенд, данные, нагрузка – последняя
должна быть смоделирована максимально точно.
Чем точнее тестовая модель, тем более точные экстраполяции поведения системы
она допускает.
38.
4.3. Определение источников нагрузкиПравило 80/20: 20% от общего числа операций выполняется в течение 80%
времени.
Чтобы процесс моделирования нагрузки не сравнялся по сложности с процессом
разработки приложения, необходимо моделировать только значимые операции.
Критерии значимости:
– Выполняется часто и/или большим числом пользователей.
– Оказывает существенное влияние на другие операции и на логику работы
приложения
– Создает большую нагрузку на систему
39.
4.4. Принципы созданиявиртуальных пользователей
Виртуальный пользователь (Vuser) – представляет реального пользователя
системы.
Виртуальные пользователи должны отличаться друг от друга:
–
–
–
–
–
По разному взаимодействовать с системой
Работать с разными данными
Использовать разные интерфейсы
По разному выполнять одни и те же задачи
Использовать подключения разной скорости
Чтобы сделать одинаковых пользователей разными, используется механизм
моделирования задержек (Think Times).
40.
4.5. Think TimesРазные пользователи взаимодействуют с системой с разной скоростью.
Типичные think times:
– Время на ввод данных (печать).
– Время на восприятие данных (просмотр отчета).
– Время на принятие решения (выбор следующего действия на основании результатов
предыдущего).
Методы определения значений think times:
–
–
–
–
Анализ логов приложения.
Использование стандартных значений.
Экспериментальный метод.
Интуитивный метод.
41.
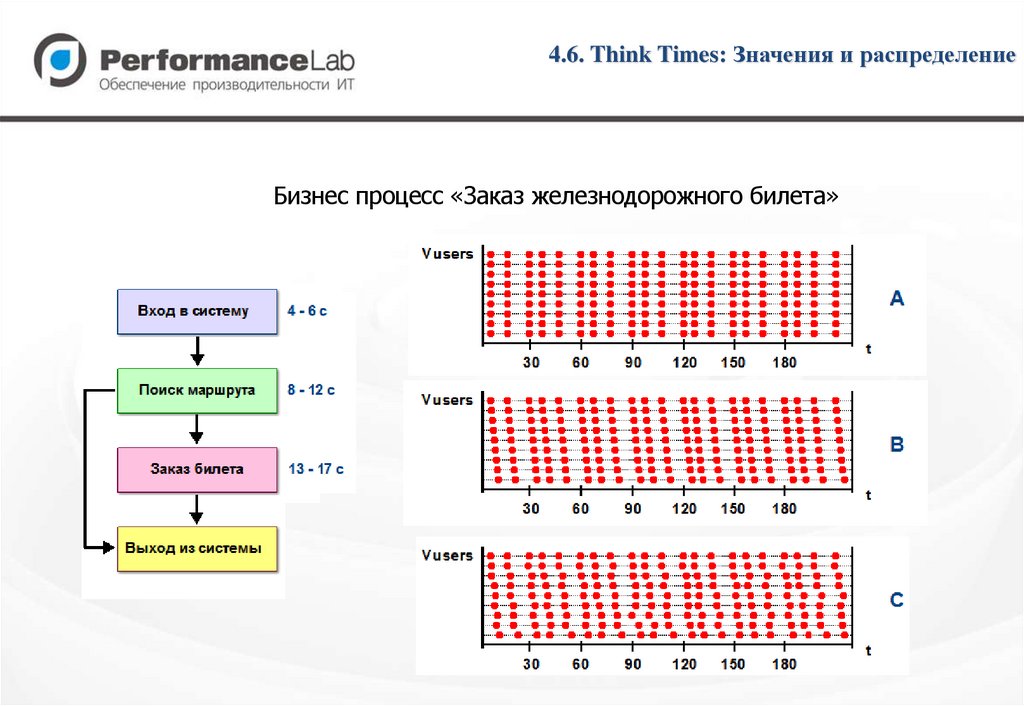
4.6. Think Times: Значения и распределениеБизнес процесс «Заказ железнодорожного билета»
42.
Вопросы1)Перечислите основные типы
нефункциональных требований к системе.
Приведите примеры.
2)Приведите примеры метрик
производительности.
3)Каковы критерии выбора операций для НТ?
43.
Вопросы. Перерыв.44.
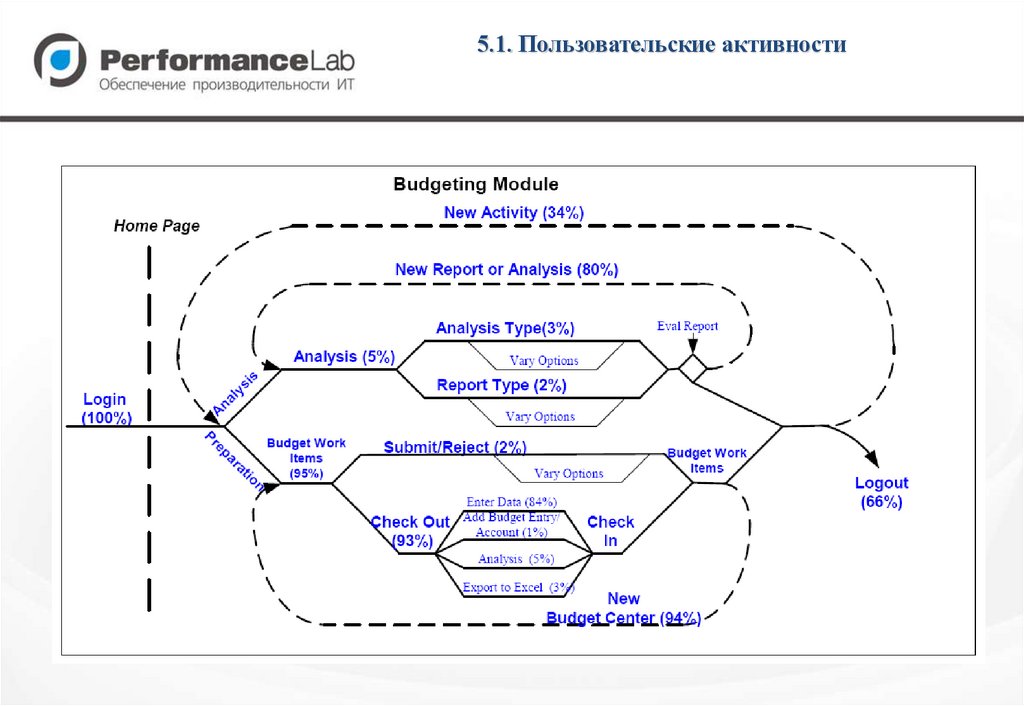
5.1. Пользовательские активности45.
5.2. Нагрузочные скриптыДля работы с нагрузочными скриптами
используются программы
автоматизированного тестирования
(Apache JMeter, HP LoadRunner).
Принципы работы:
– Бизнес-операция выполняется вручную
один или несколько раз.
– Производится запись трафика на уровне
протоколов (WEB, MS SQL, Oracle, Webservices, etc).
– Скрипт формализуется на языке программы
автоматизированного тестирования.
– При выполнении скрипта не вызывается
само клиентское приложение.
– С точки зрения системы скрипт действует
точно так же, как обычный пользователь.
46.
5.3. Редактирование скриптовПоследовательность редактирования скриптов:
–
–
–
–
–
–
–
Объявление транзакций.
Пробный запуск на выполнение.
Добавление вариативности входных данных.
Установление зависимости между данными.
Расстановка think times.
Добавление вариативности логики выполнения.
Обработка ошибочных ситуаций.
47.
5.4. Тестовое приложение «Web сайт книжногомагазина»
Пользователь всегда начинает с заглавной страницы.
Выбор книги осуществляется одним из способов:
– Поиск по названию и/или автору (30%).
– Из списка бестселлеров (50%).
– Из списка «фантастическая литература» (20%).
После выбора книги пользователь оформляет покупку.
48.
5.5. Варианты моделированияпользовательских активностей
Метод полного пути – каждому возможному варианту соответствует свой
скрипт.
Метод сегментов – каждому горизонтальному сегменту диаграммы
соответствует свой скрипт. Скрипты объединяются в наборы (suites).
Метод обобщений – один скрипт соответствует всем возможным вариантам
активности.
49.
5.6. Метод полного путиКоличество скриптов равно количеству вариантов активности.
Достоинства:
– Скрипты просто записывать и они не требуют большого объема редактирования.
Недостатки:
– Для сложных систем число скриптов очень велико, скрипты сложно поддерживать,
большой объем повторяющегося кода.
50.
5.7. Метод сегментовКоличество скриптов равно количеству шагов, включая альтернативные.
Достоинства:
– Требуется меньше времени для записи, просто поддерживать, мало повторяющегося
кода.
Недостатки:
– Большое количество скриптов, необходимость передавать данные между скриптами.
51.
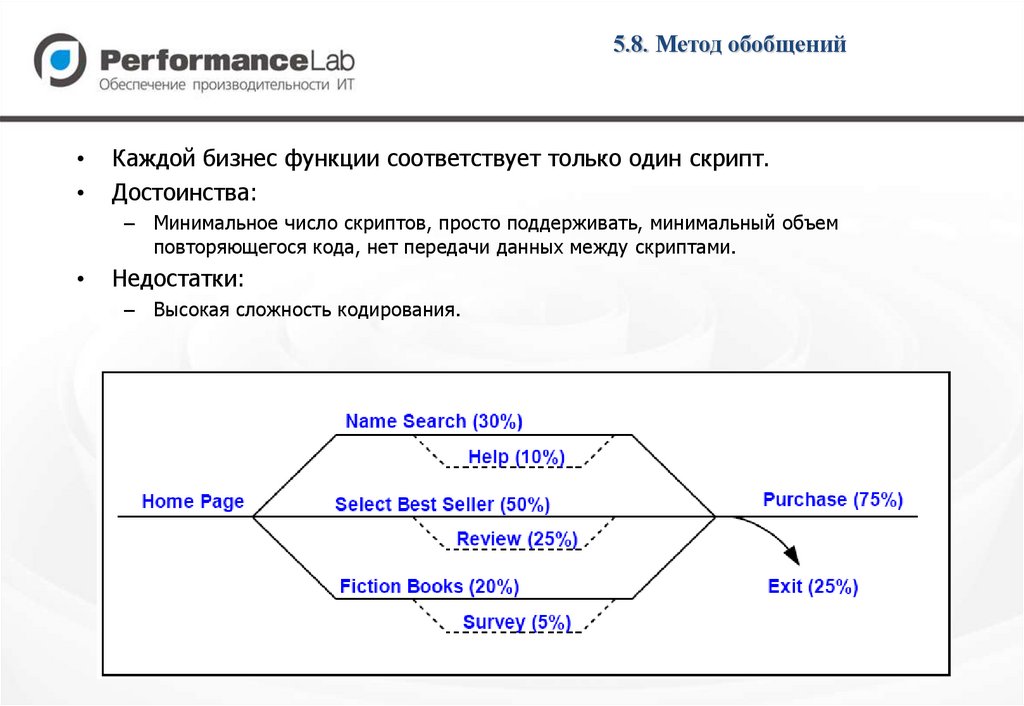
5.8. Метод обобщенийКаждой бизнес функции соответствует только один скрипт.
Достоинства:
– Минимальное число скриптов, просто поддерживать, минимальный объем
повторяющегося кода, нет передачи данных между скриптами.
Недостатки:
– Высокая сложность кодирования.
52.
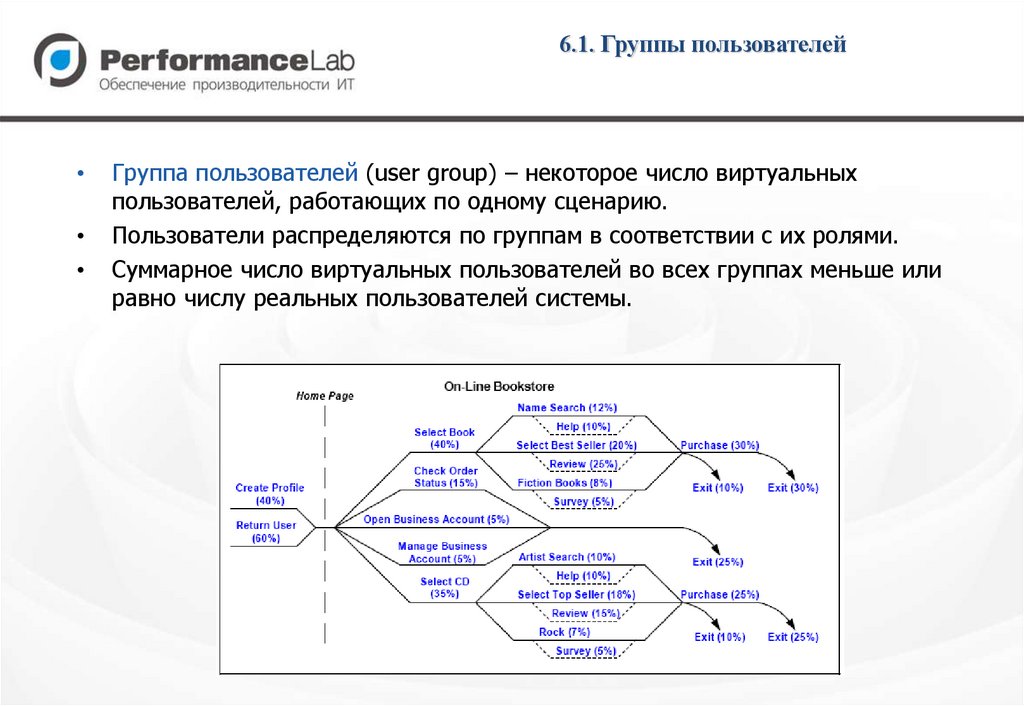
6.1. Группы пользователейГруппа пользователей (user group) – некоторое число виртуальных
пользователей, работающих по одному сценарию.
Пользователи распределяются по группам в соответствии с их ролями.
Суммарное число виртуальных пользователей во всех группах меньше или
равно числу реальных пользователей системы.
53.
6.2. Пользовательскаяактивность с двух точек
зрения
С точки зрения пользователей:
– 23 пользователя начинают и
заканчивают работу в разное
время.
С точки зрения сервера:
– 10 пользователей работают
постоянно.
54.
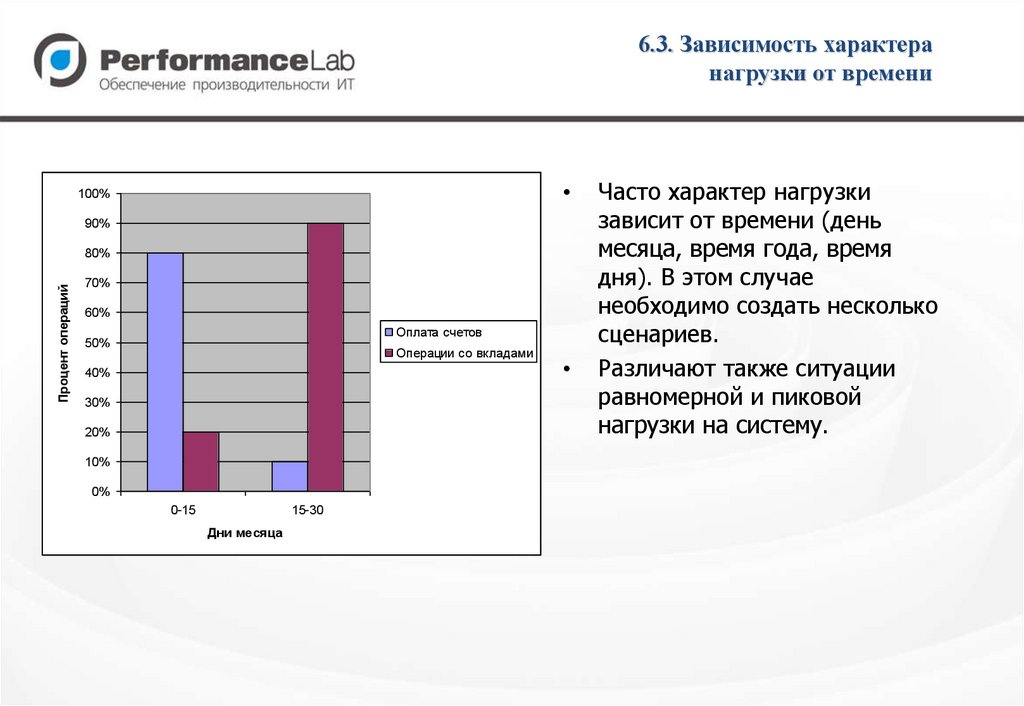
6.3. Зависимость характеранагрузки от времени
100%
90%
Процент операций
80%
70%
60%
Оплата счетов
50%
Операции со вкладами
40%
30%
20%
10%
0%
0-15
15-30
Дни месяца
Часто характер нагрузки
зависит от времени (день
месяца, время года, время
дня). В этом случае
необходимо создать несколько
сценариев.
Различают также ситуации
равномерной и пиковой
нагрузки на систему.
55.
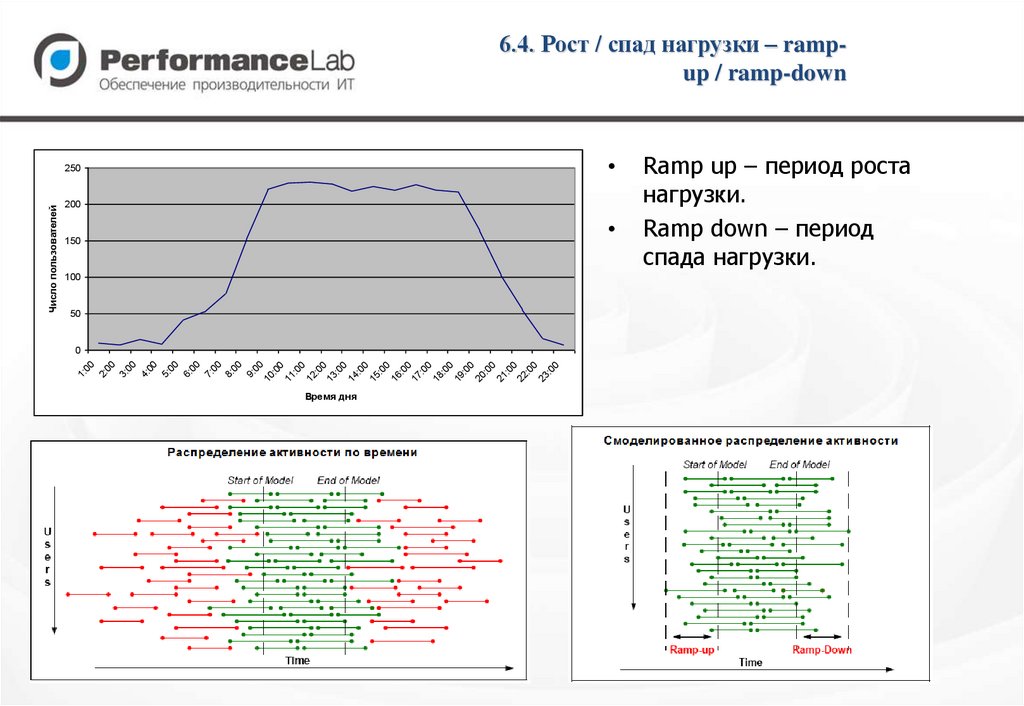
6.4. Рост / спад нагрузки – rampup / ramp-down200
150
100
50
0
1:
00
2:
00
3:
00
4:
00
5:
00
6:
00
7:
00
8:
00
9:
00
10
:0
0
11
:0
0
12
:0
0
13
:0
0
14
:0
0
15
:0
0
16
:0
0
17
:0
0
18
:0
0
19
:0
0
20
:0
0
21
:0
0
22
:0
0
23
:0
0
Число пользователей
250
Время дня
Ramp up – период роста
нагрузки.
Ramp down – период
спада нагрузки.
56.
6.5. Вариативность входных данныхДанные, которые должны быть уникальными для каждого пользователя:
– Идентифицирующая информация.
– Информация сильно меняющаяся по размеру.
– Входные данные существенно влияющие на ответ сервера.
Данные, которые могут быть одинаковыми для всех пользователей:
– Информация для вставки в БД (не ключевые поля).
57.
7.1. Тестовые данныеВиртуальные пользователи должны работать с реальными данными.
Если скрипты меняют данные в БД, перед каждым запуском сценария
необходимо восстанавливать БД.
С помощью нагрузочных скриптом можно увеличивать объемы баз данных с
тем, чтобы проверить, как влияют размеры БД на поведение приложения
под нагрузкой.
58.
8.1. Измерение быстродействия системыСуществует два методологических подхода к измерению быстродействия
системы: «сверху вниз» (top-down) и «снизу вверх» (bottom-up).
Подход «сверху вниз» - от измерения к узким местам.
Подход «снизу вверх» - от узкого места к пониманию того, как оно влияет
на быстродействие.
59.
8.2. Таймеры (транзакции)Таймер (транзакция) ограничивает часть скрипта, для которой измеряется
время выполнения.
Минимальное число таймеров равно числу бизнес функций, для которых
заданы требуемые времена отклика.
Таймеры могут быть вложенными, но не должны быть пересекающимися.
Вложенные таймеры позволяют точнее идентифицировать узкие места.
Внутри таймера должна быть клиент-серверная активность.
Необходимо учитывать think times, попадающие в область действия
таймера.
60.
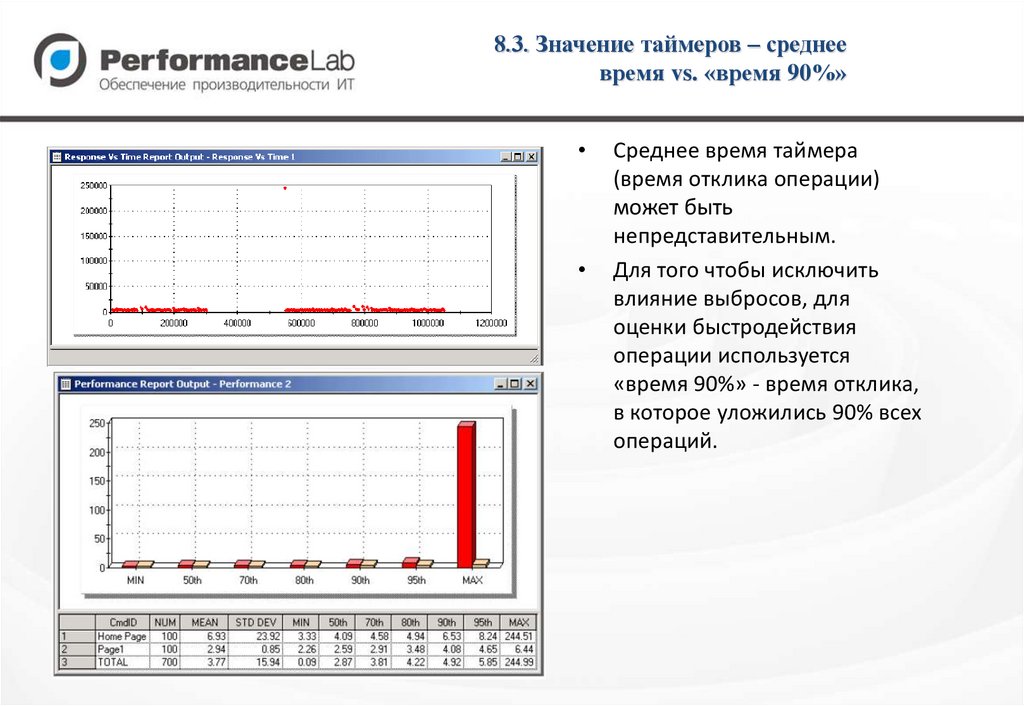
8.3. Значение таймеров – среднеевремя vs. «время 90%»
Среднее время таймера
(время отклика операции)
может быть
непредставительным.
Для того чтобы исключить
влияние выбросов, для
оценки быстродействия
операции используется
«время 90%» - время отклика,
в которое уложились 90% всех
операций.
61.
9.1. Виды тестовТесты с пониженной нагрузкой (меньше чем 15-25%):
– Baseline.
– Benchmark.
– Тесты отдельных компонент системы.
Тесты с нормальной нагрузкой (100-125%):
– Performance.
– Scalability.
– Тесты отдельных компонент системы.
Тесты с повышенной нагрузкой (> 300%):
– Stability.
– Recovery.
– Capacity planning.
Специальные тесты.
62.
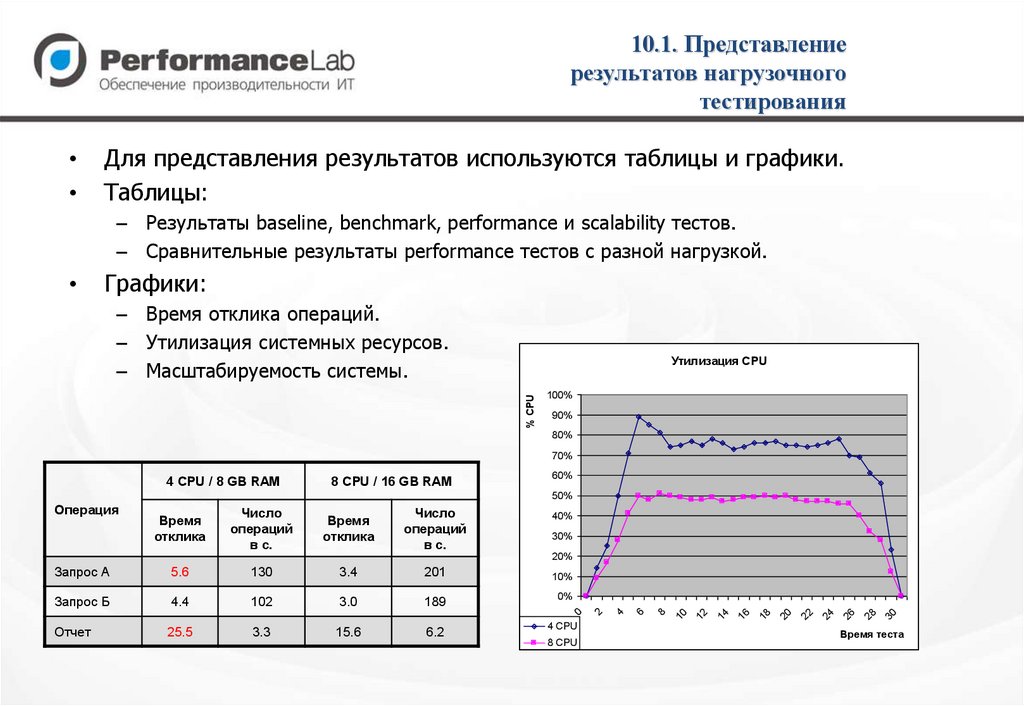
10.1. Представлениерезультатов нагрузочного
тестирования
Для представления результатов используются таблицы и графики.
Таблицы:
– Результаты baseline, benchmark, performance и scalability тестов.
– Сравнительные результаты performance тестов с разной нагрузкой.
Графики:
– Время отклика операций.
– Утилизация системных ресурсов.
– Масштабируемость системы.
% CPU
Утилизация CPU
100%
90%
80%
70%
4 CPU / 8 GB RAM
8 CPU / 16 GB RAM
60%
50%
Время
отклика
Число
операций
в с.
40%
130
3.4
201
10%
4.4
102
3.0
189
25.5
3.3
15.6
6.2
8 CPU
30
28
26
24
22
20
18
16
14
12
4 CPU
10
Отчет
0%
8
Запрос Б
20%
6
5.6
4
Запрос А
30%
0
Время
отклика
Число
операций
в с.
2
Операция
Время теста
63.
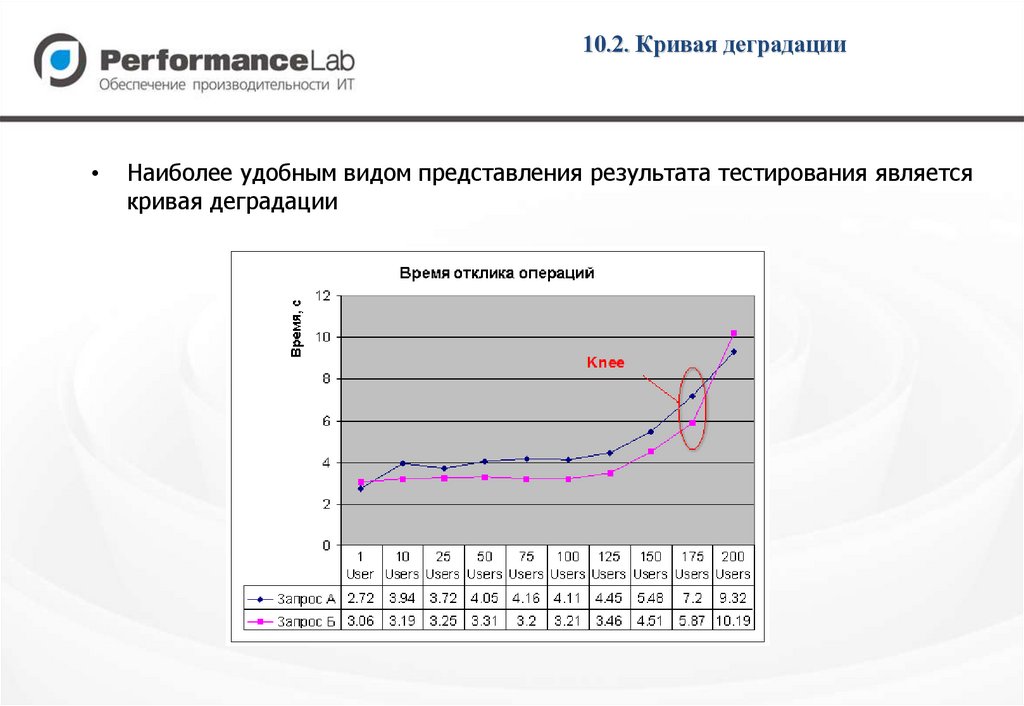
10.2. Кривая деградацииНаиболее удобным видом представления результата тестирования является
кривая деградации
64.
Вопросы1)Перечислите основные шаги при разработке
скриптов
2)Какие способы улучшения модели нагрузки
вы знаете?
3)Для чего нужна вариативность входных
данных?
4)Зачем нужны ramp up и ramp down?