















 database
databaseSimilar presentations:










Документальные базы данных
1.
Дисциплина: «Базы данных»Специальность: №08080165
«Прикладная информатика (в экономике)»
Документальные
базы данных
Институт информатики, инноваций и бизнес систем
Кафедра Информационных систем и прикладной
информатики
Старший преподаватель Богданова О.Б.
2.
Основные понятияПоскольку информация не всегда представлена в виде
структурированных данных, существует необходимость
организации данных, отличных от фактографических.
Информационные системы, которые хранят документы
разных форматов носят название документальных
информационных поисковых систем (ДИПС).
3.
Основные понятияБазы данных документального типа могут быть
организованы:
•с хранением исходного документа (полнотекстовые);
(библиографические, реферативные)
•без хранения документов (БД-указатели).
4.
Основные понятияИнформационный поиск в таких системах представляет
собой поиск документов, содержащих ответ на заданный
пользователем запрос. или информации из документов
Информационный запрос пользователя представляет
собой частное значение информации, потребовавшейся в
определенный момент времени и выраженный на
естественном языке.
5.
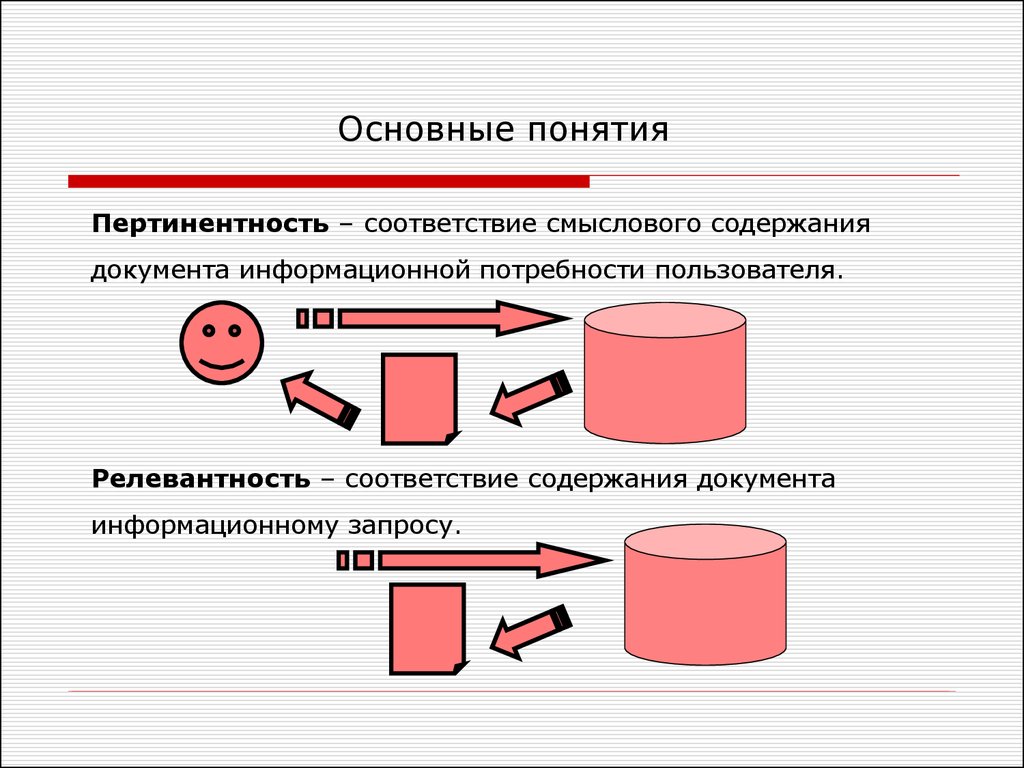
Основные понятияПертинентность – соответствие смыслового содержания
документа информационной потребности пользователя.
Релевантность – соответствие содержания документа
информационному запросу.
6.
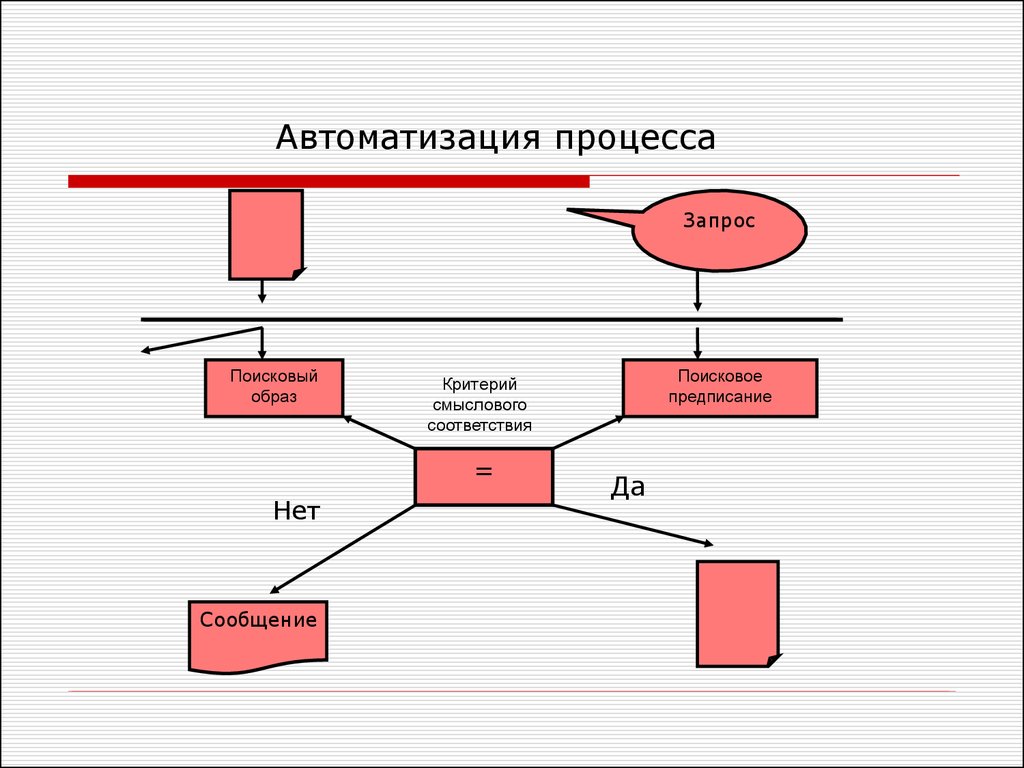
Основные понятияФормальное представление информационного
содержания запроса — поисковое предписание (ПП)
Формальное представление основного информационного
содержания документа — поисковый образ
документа (ПОД)
Набор правил, определяющий степень смысловой
близости ПОД и ПП — критерий смыслового
соответствия
7.
Автоматизация процессаЗапрос
Поисковый
образ
=
Нет
Сообщение
Поисковое
предписание
Критерий
смыслового
соответствия
Да
8.
Функциональная структураЗапрос
Подсистема
обработки
Подсистема
ввода и
регистрации
Поисковый
образ
Поисковое
предписание
Подсистема
поиска
Поисковый
образ
КСС
Словарь
Индекс
Подсистема
хранения
База
данных
9.
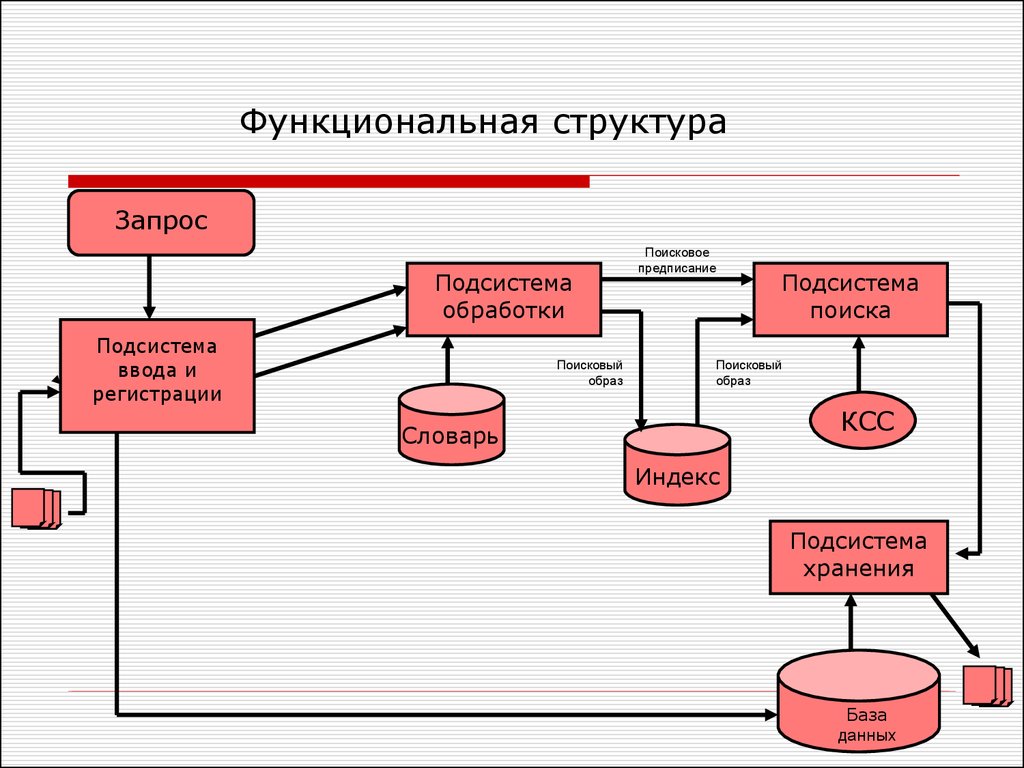
Функциональная структураПодсистема хранения никогда не хранит простую
совокупность фактов, распределенную по каталогам, так как
это может вызвать проблемы поиска информации и
неэффективное использование дискового пространства.
Эта подсистема всегда применяет средства сжатия и
представляет собой совокупность СУБД,
средств архивации и т.д.
10.
Функциональная структураПодсистема обработки создает для каждого документа его
поисковый образ, который сохраняется с индексе.
Логически индекс представляет собой таблицу, где строки
соответствуют документам, а столбцы информационным
признакам.
11.
Функциональная структураПодсистема поиска предназначена для отыскания в индексе
поискового образа документа, удовлетворяющего поисковому
предписанию с точки зрения критерия смыслового
соответствия.
Идентификаторы найденных релевантных документов с
выхода подсистемы поиска передаются на вход
подсистемы хранения, которая обеспечивает выдачу самих
документов пользователю.
12.
Информационно-поисковые языки13.
Информационно-поисковые языкиИнформационно-поисковым языком называется
специализированный язык, предназначенный для описания
смыслового содержания поступивших в систему сообщений с
целью обеспечения возможности их последовательного поиска.
Два основных типа:
Классификационные языки;
Дескрипторные языки
•с граматикой и без граматики
•с контролируемой и свободной лексикой
14.
Обработка входящей текстовойинформации
Процесс перевода документа с естественного языка на
информационно-поисковый язык носит название
рубрицирования или индексирования.
Автоматическое индексирование
Автоматическое
индексирование
документов
может
основываться на простых, однословных или многословных
составных
терминах
(фразах).
Термины-фразы
более
осмысленны, обладают большей дискриминирующей мощью.
15.
Обработка входящей текстовойинформации
Процесс перевода документа с естественного языка на
информационно-поисковый язык носит название
рубрицирования или индексирования.
В рубрицировании документа выделяют 2 основных
подхода:
1. Рубрицирование, основанное на знаниях;
2. Рубрицирование, основанное на обучении на
примерах.
16.
Обработка входящей текстовойинформации
Две основные модели представления знаний:
1. Семантическая сеть (СС)
Тезаурус – иерархическая сеть понятий и отношений между
ними.
2. Продукционная модель (ПМ)
Выделяют 2 группы:
Статическое рубрицирование
Нейросетевые методы
17.
Обработка входящей текстовойинформации
Статистическое рубрицирование — определение степени
соответствия терминологического портрета документа и
терминологического портрета рубрики на основе
статистических характеристик субъектов сравнения
Нейросетевые методы рубрицирования используют
нейронную сеть в качестве обучающего классификатора.
Существует подборка текстов, каждый из которых помечен как
релевантный или нерелевантный для рубрики.
18.
Поиск текстовой информацииЛюбая модель поиска информации
характеризуется следующими параметрами:
1. Представление документов и запросов
2. Критерий смыслового соответствия
3. Методы ранжирования редакторов поиска
4. Механизм образования связи
19.
Основные модели поиска• Булева модель представляет документы с помощью набора
терминов, присутствующих в индексе, каждый из которых
рассматривается как булева переменная
• Модель нечетных множеств допускает частичную
принадлежность элемента множеству
• Пространственно-векторная рассматривает совокупность
документов как набор векторов в пространстве, определяемом из
n нормализованных векторов терминов
• Вероятностная модель определяет вероятность вхожения
термина в документ