

















 informatics
informaticsSimilar presentations:








")

Data Mining
1.
DATA MININGПревращение данных в знания
2.
Данные и ЗнанияТаблицы
Текст
Сигналы
Звук
Изображения
Видео
3.
Данные и ЗнанияДанные – совокупность зафиксированных фактов
Информация – сведения, уменьшающие
неопределённость
Знания – сведения, позволяющие действовать с
прогнозируемым результатом
Типичная проблема:
Мы располагаем данными, они хранятся в цифровом
виде, но мы не знаем, что в них.
4.
Data Mining (добыча данных,интеллектуальный анализ данных) —
совокупность методов обнаружения в данных
ранее неизвестных, нетривиальных,
практически полезных и доступных
интерпретации знаний, необходимых для
принятия решений в различных
сферах человеческой деятельности.
[Г.Пятецкий-Шапиро, 1989]
5.
Задачи интеллектуального анализа данныхЗадачи ИАД
Описательные
Ассоциативные
правила
Кластеризация
Предсказательные
Классификация
Прогнозирование
6.
Смежные и близкие областиBig Data (обработка и анализ больших данных
Data Mining ∩ Big Data ≠
Pattern Recognition (распознавание образов)
Pattern Recognition ⊂ Machine Learning
Machine learning (машинное обучение)
Data Mining ∩ Machine Learning ≠
Artificial Intelligence (искусственный интеллект)
Data Mining ⊂ Artificial Intelligence
Data Science (наука о данных)
Data Mining ⊂ Data Science
7.
Интеллектуальный анализ данных (data mining)vs машинное обучение (machine learning)
Интеллектуальный анализ данных - это процесс извлечения полезной информации из больших
массивов данных. Основное содержание курса - изучение методов, позволяющих находить в
данных закономерности
Машинное обучение - это процесс разработки и программной реализации алгоритмов, способных
обучаться на примерах данных. Основное содержание курса – практическая реализация
алгоритмов, позволяющих находить в данных закономерности
8.
Сферы приложения• Компьютерное зрение (computer vision)
• Распознавание речи (speech recognition)
• Компьютерная лингвистика и обработка естественных языков (natural
language processing)
• Медицинская диагностика
• Биоинформатика
• Техническая диагностика
• Финансовые приложения
• Рубрикация, аннотирование и упрощение текстов
• Информационный поиск
• Интеллектуальные игры
•...
9.
Используемый математический аппаратТеория вероятностей и математическая статистика
Линейная алгебра
Методы оптимизации
Численные методы
Математический анализ
Дискретная математика
и др.
10.
Классификация задач интеллектуального анализа данных11.
Обучение по прецедентам или с учителемМножество X —объекты, примеры, образцы (samples).
Множество Y —ответы, отклики, «метки», классы (responses)
Имеется некоторая зависимость g : X → Y , позволяющая по x ∈X
предсказать (или оценить вероятность появления) y ∈Y .
Зависимость известна только на объектах из обучающей выборки:
T = {(x1,y1),(x2,y2),...,(xn,yn)}
Пара (xi , yi ) ∈X × Y -прецедент.
Задача обучения по прецедентам: научиться по новым объектам x ∈X
предсказывать ответы y ∈Y .
12.
Пример обучающей выборки(классификация)
пульс
гемоглобин
диагноз
x1
70
140
здоров (y = −1)
x2
60
160
здоров (y = −1)
x3
94
120
миокардит (y = 1)
···
···
···
···
x114
86
98
миокардит (y = 1)
Обучающая выборка:
((70, 140), −1), (60, 160), −1), (94, 120), 1)...,(86, 98), 1))
Задача обучения: новый пациент x = (75, 128), y =?
13.
Графическое представление обучающей выборкиГрафическое представление обучающей выборки
14.
Признаковые описанияВход:
xj — j-й признак {свойство, атрибут, предикативная переменная, feature) объекта x.
• Если Qj конечно, то j-й признак — номинальный (категориальный или фактор).
Например, Qj = {Alfa Romeo, Audi, BMW, . . . ,Volkswagen}
Если |Qj| = 2, то признак бинарный и можно считать, например, Qj = {0, 1}.
• Если Qj конечно и упорядочено, то признак порядковый.
Например, Qj = {Beginner, Elementary, Intermediate, Advanced, Proficiency}
• Если Qj = R, то признак количественный.
Выход: y ∈ Y
• Y = R — задача восстановления регрессии (аппроксимации)
• Y = {1, 2, . . . ,K} — задача классификации. Номер класса k ∈ Y
15.
Обучение без учителя• В этом случае нет “учителя” и “обучающая выборка” состоит только из
объектов, т.е. Y отсутствует.
• Задача кластеризации: разбить объекты на группы (кластеры), так, чтобы в
одном кластере оказались близкие друг к другу объекты, а в разных кластерах
объекты были существенно различные.
• Кластер можно охарактеризовать как группу объектов, имеющих общие
свойства.
16.
Графическое представление данных длякластеризации
Графическое представление данных для кластериз
17.
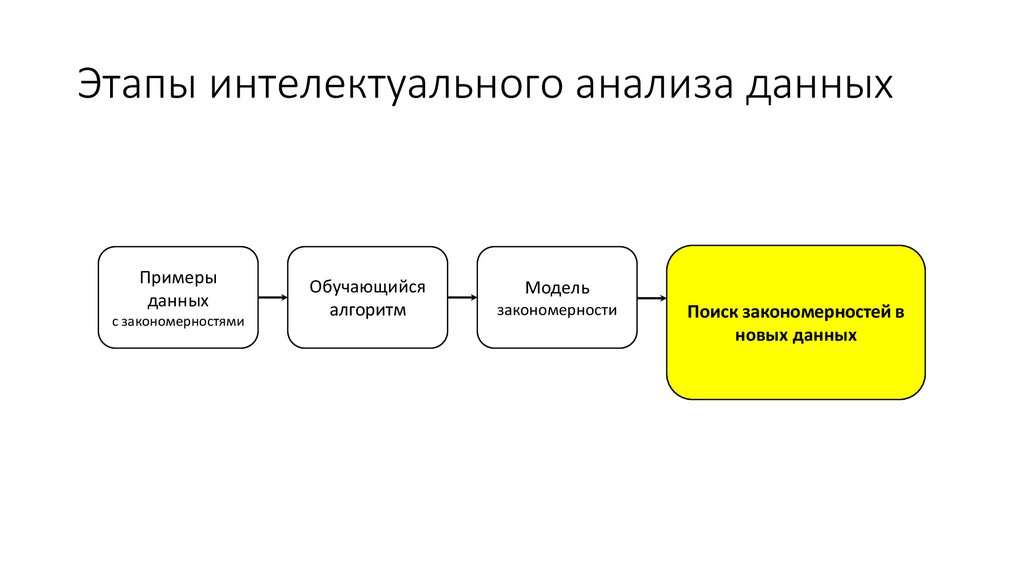
Этапы интелектуального анализа данныхПримеры
данных
с закономерностями
Обучающийся
алгоритм
Модель
закономерности
Поиск закономерностей в
новых данных
18.
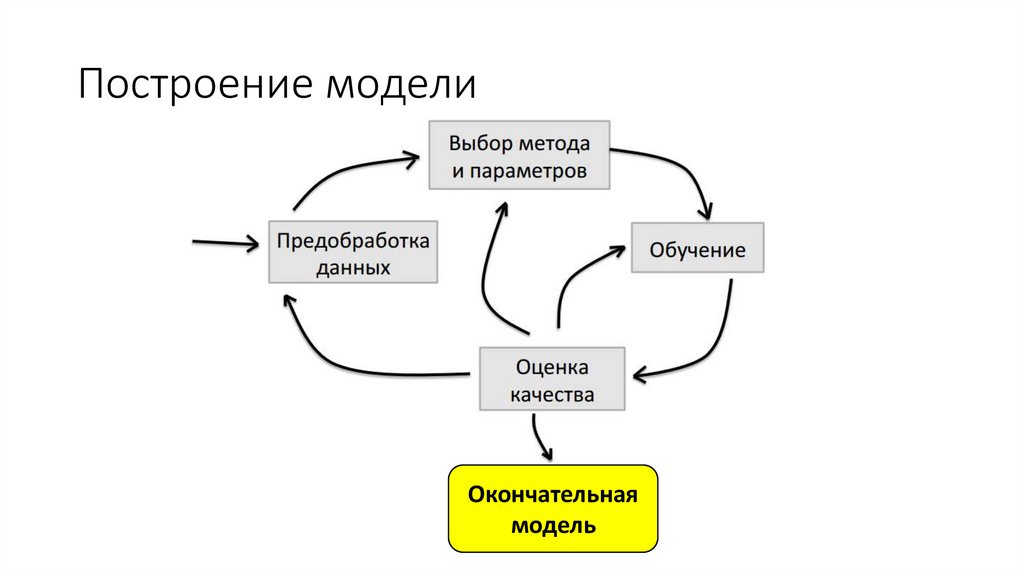
Построение моделиОкончательная
модель
19.
Пример: задача прогнозирования стоимостинедвижимости
Объект - квартира в Санкт-Петербурге.
Примеры признаков:
бинарные: наличие балкона, лифта, мусоропровода, охраны, и т. д.
номинальные: район города, тип дома
(кирпичный/панельный/блочный/монолит), и т. д.
количественные: число комнат, жилая площадь, расстояние до центра,
до метро, возраст дома, и т. д.
Особенности задачи: выборка неоднородна, стоимость меняется со
временем; разнотипные признаки.
20.
Пример: Страховая компания(кластеризация)
• Примеры признаков : Информация об автомобилях и их
владельцах: марка автомобиля; стоимость автомобиля; возраст
водителя; стаж водителя; возраст автомобиля
• Цель - разбиение автомобилей и их владельцев на клаcтеры,
каждый из которых соответствует определенной рисковойгруппе.
• Наблюдения, попавшие в одну группу, характеризуются одинаковой
вероятностью наступления страхового случая, которая впоследствии
оценивается страховщиком.