








































 programming
programmingSimilar presentations:

")


")





Ассоциативные и неупорядоченно ассоциативные контейнеры
1.
ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙИМЕНИ МУХАММАДА АЛ-ХОРАЗМИЙ
ПРОГРАММИРОВАНИЕ 2
SWD1318
ТЕМА
03
Ассоциативные и
неупорядоченно ассоциативные
контейнеры.
АБДУЛЛАЕВА ЗАМИРА
ШАМШАДДИНОВНА
Доцент кафедры Основы
информатики
1
2.
Введение в ассоциативные контейнерыДля реализации последовательных контейнеров
(массивов, векторов, двусторонних очередей и списков)
используются массивы и списки. Кроме этого
применяются сбалансированные деревья,
предназначенные для их эффективного хранения и
извлечения.
Сбалансированные деревья составляют основу для
другой группы контейнеров, определенной в STL, так
называемых (сортированных) ассоциативных
контейнеров.
П РО Г РА М М И РО ВА Н И Е 2
2
3.
Cбалансированные деревьяБинарное дерево называется сбалансированным или
АВЛ-деревом, если для любой вершины дерева, высоты
левого и правого поддеревьев отличаются не более чем на
единицу. Показатель сбалансированности бинарного
дерева, равный +1, 0, -1, означает соответственно: правое
поддерево выше, они равной высоты, левое поддерево
выше.
М. Адельсон-Вельский и Е.М. Ландис доказали, что
при таком определении можно написать программы
добавления/удаления, имеющие логарифмическую
сложность и сохраняющие дерево сбалансированным.
П РО Г РА М М И РО ВА Н И Е 2
3
4.
Типы ассоциативных контейнеровВсего существует 5 типов этих контейнеров:
множества (sets),
множества с дубликатами (multisets),
словари (maps),
словари с дубликатами (multimaps),
битовые множества (bitset).
П РО Г РА М М И РО ВА Н И Е 2
4
5.
Множества и словариМножества – sets
Каждый элемент множества является собственным
ключом, и эти ключи уникальны. Поэтому два различных
элемента множества не могут совпадать. Например,
множество может состоять из следующих элементов:
123 124 800 950
Множества с дубликатами – multisets
Множество с дубликатами отличается от просто
множества только тем, что способно содержать несколько
совпадающих элементов.
123 123 800 950
П РО Г РА М М И РО ВА Н И Е 2
5
6.
Множества и словариСловари – maps
Каждый элемент словаря имеет несколько членов,
один из которых является ключом. В словаре не может
быть двух одинаковых ключей.
123
John
124
Mary
800
Alexander
950
Jim
П РО Г РА М М И РО ВА Н И Е 2
6
7.
Множества и словариСловари с дубликатами – multimaps
Словарь с дубликатами отличается от просто словаря тем,
что в нем разрешены повторяющиеся ключи.
123
John
123
Mary
800
Alexander
950
Jim
В отличие от последовательных контейнеров
ассоциативные контейнеры хранят свои элементы
отсортированными, вне зависимости от того, каким
образом они были добавлены.
П РО Г РА М М И РО ВА Н И Е 2
7
8.
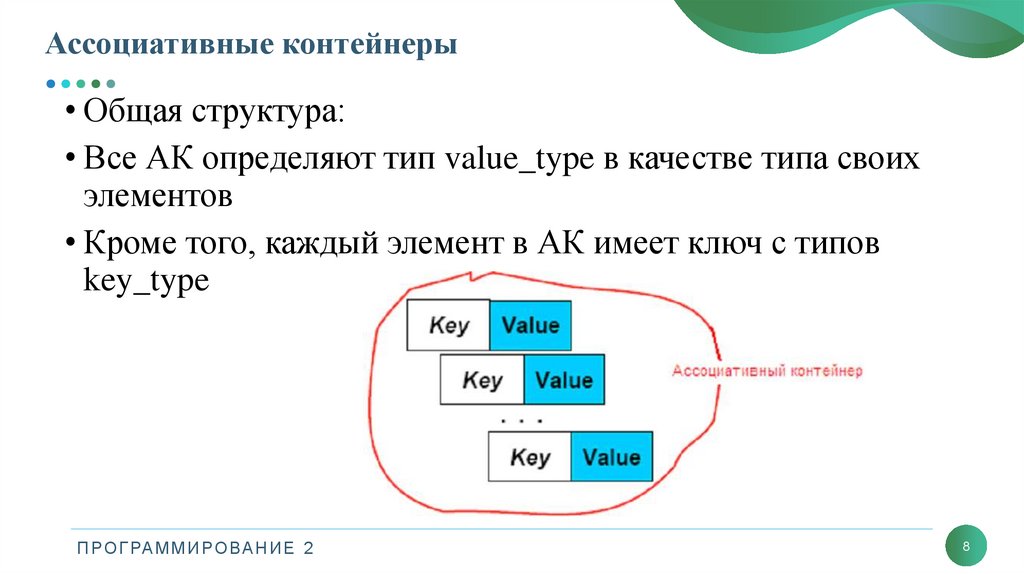
Ассоциативные контейнеры• Общая структура:
• Все АК определяют тип value_type в качестве типа своих
элементов
• Кроме того, каждый элемент в АК имеет ключ с типов
key_type
П РО Г РА М М И РО ВА Н И Е 2
8
9.
Ассоциативные контейнеры• Реализация
• АК обычно реализуются в виде сбалансированного
бинарного дерева
• Пара (Key, Value) сохраняется в дереве в соответствии
с порядком сортировки Key
• Следствие
• После добавления элемента в контейнер его ключ
изменить нельзя!
• АК не имеют изменяемых итераторов, выражение *I =
v не поддерживается
П РО Г РА М М И РО ВА Н И Е 2
9
10.
Ассоциативные контейнеры• Классификация:
• Простые АК – set, multiset
• Составные АК – map, multimap
• Другая классификация:
• Уникальные АК – set, map
• Множественные АК – multiset, multimap
П РО Г РА М М И РО ВА Н И Е 2
10
11.
Пример (set)#include <iostream>
#include <set>
using namespace std;
int main()
{ set<int, less<int> > S, T;
S.insert(10); S.insert(20); S.insert(30); S.insert (10);
T.insert (20); T.insert (30); T.insert (10);
if (S == T) cout << "Equal sets, containing:\n";
for (set<int, less<int> >::iterator i = T.begin();
i != T.end(); i++)
cout << *i << " ";
// Результат:
cout << endl;
Equal sets, containing:
return 0;}
10 20 30
П РО Г РА М М И РО ВА Н И Е 2
11
12.
ЗамечанияПорядок чисел 20, 30, 10, в котором были добавлены элементы
Т, несущественен; равным образом множество S не изменяет
добавление элемента 10 во второй раз. Ключи уникальны во
множествах, но могут повторяться во множествах с
дубликатами.
Определение S и Т:
set<int, less<int> > S, Т; // > > разделены пробелом
Предикат less<int> требуется для определения упорядочения
значения выражения k1 < k2 , где k1 и k2 являются ключами.
Хотя множества и не являются последовательностями, мы
можем применять к ним итераторы и функции begin() и end().
Данные итераторы являются двунаправленными.
П РО Г РА М М И РО ВА Н И Е 2
12
13.
Таблица операций, применимых к итераторам• х - переменная того же типа, что и элементы
рассматриваемого контейнера, а n – int.
П РО Г РА М М И РО ВА Н И Е 2
13
14.
Пример (multiset)#include <iostream>
#include <set>
using namespace std;
int main()
{ multiset<int, less<int> > S, T;
S.insert(10); S.insert(20); S.insert(30); S.insert(10);
T.insert(20); T.insert(30); T.insert(10);
if (S == T) cout << "Equal multisets: \n";
else cout << "Unequal multisets:\n";
cout << "S: "; copy (S.begin() , S.end(), ostream_iterator<int>(cout, " "));
cout << endl; cout << "T: ";
// Вывод:
copy (T.begin() , T.end(),
Unequal multisets:
ostream_iterator<int>(cout, " "));
S: 10 10 20 30
cout << endl; return 0; }
Т: 10 20 30
П РО Г РА М М И РО ВА Н И Е 2
14
15.
Примеры работы со словарямиПроисхождение термина «ассоциативный контейнер»
становится ясным, когда начинаем рассматривать словари.
Например, телефонный справочник связывает (ассоциирует)
имена с номерами. Имея заданное имя или ключ, нужно узнать
соответствующий номер. Т.е., телефонная книга является
отображением имен на числа.
Если имя Johnson, J. соответствует номеру 12345, STL
позволяет определить словарь D, ->
D["Johnson, J."] = 12345;
Это означает:
"Johnson, J." -> 12345
П РО Г РА М М И РО ВА Н И Е 2
15
16.
Пример (map)#include <iostream>
#include <string>
#include <map>
using namespace std; // Создадим функциональный объект:
class compare2
{
public:
bool operator()(const char *s, const char *t) const
{ return strcmp (s, t) < 0;}
};
П РО Г РА М М И РО ВА Н И Е 2
16
17.
Пример (map)int main()
{ map<char*, long, compare2> D;
D["Johnson, J."] = 12345; D["Smith, P."] = 54321;
D["Shaw, A."] = 99999; D["Atherton, K."] = 11111;
char GivenName [30] ;
cout << "Enter a name: ";
cin.get(GivenName, 30);
if (D.find (GivenName) != D.end())
cout << "The number is " << D[GivenName];
else cout << "Not found.";
cout << endl; return 0;}
П РО Г РА М М И РО ВА Н И Е 2
17
18.
ЗамечанияПрограмма выше указанного примера содержит
определенный нами функциональный объект compare2.
Определение map<char*, long, compare2> D;
справочника D содержит следующие параметры шаблона:
тип ключа char*;
тип сопутствующих данных long;
класс функционального объекта compare2.
Функция-член operator() класса compare2 определяет
отношение меньше для ключей.
П РО Г РА М М И РО ВА Н И Е 2
18
19.
Примеры: словари с дубликатами#include <iostream>
#include <string>
#include <map>
using namespace std;
class compare3
{
public:
bool operator() (const char *s, const char *t) const
{ return strcmp(s, t) < 0; } };
П РО Г РА М М И РО ВА Н И Е 2
19
20.
Пример (multimap)typedef multimap<char*, long, compare3> mmtype;
int main()
{ mmtype D;
D.insert(mmtype::value_type("Johnson, J.", 12345));
D.insert(mmtype::value_type("Smith, P.", 54321));
D.insert(mmtype::value_type("Johnson, J.", 10000));
cout << "There are " << D.size() << " elements. \n";
return 0;
}
Программа выведет: There are 3 elements.
П РО Г РА М М И РО ВА Н И Е 2
20
21.
ЗамечанияОператор доступа по индексу [ ] не определен для множеств с
дубликатами, поэтому нельзя добавить элемент, написав, к примеру:
D["Johnson, J."] = 12345;
Вместо этого напишем:
D.insert (mmtype::value_type ("Johnson, J.", 12345));
где mmtype на самом деле означает:
multimap<char*, long, compare3>
Так как идентификатор value_type определен внутри шаблонного
класса multimap, перед value_type здесь требуется написать префикс
mmtype::. Определение идентификатора value_type основано на
шаблоне pair.
П РО Г РА М М И РО ВА Н И Е 2
21
22.
Алгоритмы работы с ассоциативными контейнерамиincludes – выполняет проверку включения одной
последовательности в другую. Результат равен true в том
случае, когда каждый элемент первой последовательности
содержится во второй последовательности.
set_intersection – создаёт отсортированное пересечение
множеств, то есть множество, содержащее только те
элементы, которые одновременно входят и в первое, и во
второе множество.
set_difference – создание отсортированной
последовательности элементов, входящих только в
первую из двух последовательностей.
П РО Г РА М М И РО ВА Н И Е 2
22
23.
Алгоритмы работы с ассоциативными контейнерамиset_union – создает отсортированное объединение множеств, то
есть множество, содержащее элементы первого и второго
множества без повторяющихся элементов.
Методы
begin() – указывает на первый элемент,
end() – указывает на последний элемент,
insert() – для вставки элементов,
erase() – для удаления элементов,
size() – возвращает число элементов,
empty() – возвращает true, если контейнер пуст и др.
П РО Г РА М М И РО ВА Н И Е 2
23
24.
Пример (set_intersection)int main()
{const int N = 5;
string s1[]= {"Bill", "Jessica", "Ben", "Mary", Monica"};
string s2[N] = {"Sju","Monica","John","Bill","Sju"};
typedef set<string> SetS;
SetS A(s1, s1 + N);
SetS B(s2, s2 + N);
print(A); print(B);
SetS prod, sum; // множества для результата
set_intersection (A.begin(), A.end(), B.begin(), B.end(),
inserter(prod, prod.begin()));
print(prod);
П РО Г РА М М И РО ВА Н И Е 2
24
25.
продолжениеset_union (A.begin(), A.end(), B.begin(),B.end(),
inserter (sum, sum.begin()));
print(sum);
if(includes (A.begin(), A.end(), prod.begin(), prod.end()))
cout << "Yes" << endl;
else cout <<"No" << endl; return 0; }
// Результат:
Ben Bill Jessica Mary Monica // Множество А
Bill John Monica Sju
// Множество B
// Пересечение set_intersection -> prod
Bill Monica
// Объединение set_union -> sum
Ben Bill Jessica John Mary Monica Sju
// Включение
includes можества prod в множество А Yes
П РО Г РА М М И РО ВА Н И Е 2
25
26.
Программа «Формирование частотного словаря»Программа формирует частотный словарь появления отдельных слов в
некотором тексте. Исходный текст читается из файла prose.txt, результат –
частотный словарь – записывается в файл freq_map.txt.
#include <iostream>
#include <fstream>
#include <iomanip>
#include <map>
#include <set>
#include <string> …
int main()
{char punct[6] = {'.', ',', '?', '!', ':', ';'};
set <char> punctuation(punct, punct + 6);
ifstream in("prose.txt"); if (!in) { cerr << "File not found\n"; exit(1);}
П РО Г РА М М И РО ВА Н И Е 2
26
27.
Программа «Формирование частотного словаря»map<string, int> wordCount;
string s;
while (in >> s) { int n = s.size();
if (punctuation.count(s[n - 1]))
s.erase(n - 1, n); ++wordCount[s]; }
ofstream out("freq_map.txt");
map<string, int>::const_iterator it = wordCount.begin();
for (it; it != wordCount.end(); ++it)
out<<setw(20)<<left<<it->first<<setw(4)<<right
<<it->second << endl;
cout <<"Rezalt in file freq_map.txt" << endl;
return 0;}
П РО Г РА М М И РО ВА Н И Е 2
27
28.
РезультатФайл prose.txt:
«Рассмотрим, как работает эта программа.
Программа подсчитывает сколько раз
встречается каждое слово.
Эта важная программа для изучения
повторяемости различных слов.
Хорошая программа! Хорошая погода!»
П РО Г РА М М И РО ВА Н И Е 2
Файл freq_map.txt:
Программа
1
Рассмотрим
1
Хорошая
2
Эта
1
важная
1
встречается
1
для
1
изучения
1
каждое
1
как
1
повторяемости 1
погода
1
подсчитывает 1
программа
3
работает
1
раз
1
различных
1
сколько
1
слов
1
слово
1
эта
1
28
29.
Неупорядоченные ассоциативные контейнерыНеупорядоченные контейнеры <unordered_set>,
<unordered_map> построены на хэш-таблице
(обычно это хэш-таблица списков эквивалентных
элементов — блоков или “бакетов” bucket) и опираются
на некоторую хэш-функцию (по умолчанию std::hash<T> из <functional>,
определённую для ряда стандартных типов) и операцию “равно” (по
умолчанию используется оператор ==).
Два элемента считаются эквивалентными, если их хэши равны и
операция “равно” возвращает истину. Неупорядоченные контейнеры
предоставляют доступ к элементам через однонаправленные итераторы.
П РО Г РА М М И РО ВА Н И Е 2
29
30.
Неупорядоченные ассоциативные контейнеры• В некоторых задачах автоматическая сортировка может
рассматриваться как существенный недостаток, если
накладные расходы по упорядочиванию элементов будут
высоки. В этом случае заменой классов упорядоченных
множеств и словарей могут стать классы неупорядоченных
ассоциативных контейнеров (далее - неупорядоченные
контейнеры) unordered_set, unordered_multiset, unordered_ma
p и unordered_multimap. Операции поиска, вставки и
удаления в неупорядоченных контейнерах имеют среднюю
постоянную временную сложность (О(1)). Данные
контейнеры вошли в стандарт начиная с C++11.
П РО Г РА М М И РО ВА Н И Е 2
30
31.
Неупорядоченные ассоциативные контейнеры• Неупорядоченные контейнеры реализованы в виде хештаблиц. Выполнение операции в хеш-таблице начинается с
вычисления хеш-функции (хеширования) от ключа.
Получающееся хеш-значение (также «хеш», «хеш-код»)
играет роль индекса в массиве. Хеш-таблица похожа на
обычный словарь в котором литера может считаться хэшзначением. Хеш-таблицы неупорядоченных контейнеров
представляют собой массив ячеек, которые могут содержать
неограниченное количество элементов. Такую ячейку мы
будем называть сегментом. Фактически сегмент (с которым
связан хеш) является связным списком.
П РО Г РА М М И РО ВА Н И Е 2
31
32.
Неупорядоченные ассоциативные контейнеры• Число хранимых элементов, делённое на размер массива
(число возможных значений хеш-функции),
называется коэффициентом заполнения хеш-таблицы (load
factor) и является важным параметром, от которого зависит
среднее время выполнения операций.
Для начала работы с
классами unordered_set и unordered_multiset необходимо
подключить заголовок unordered_set (общий для обоих
классов) следующей директивой:
• #include <unordered_set>
П РО Г РА М М И РО ВА Н И Е 2
32
33.
Неупорядоченные ассоциативные контейнеры• Аналогично, для классов unordered_map и unordered_multimap
подключается заголовок: #include <unordered_map>
• Типы неупорядоченных контейнеров включают в себя следующие шаблонные
параметры:
1. const Key – тип ключа (unordered_set, unordered_multiset, unordered_map,
unordered_multimap)
2. T – тип значения (unordered_map, unordered_multimap)
3. alloc – функция аллокатора (необязательно)
4. size_type bucket_count – минимальное количество сегментов для
использования при инициализации (если не указан, определяется
реализацией значением по умолчанию)
5. hash – хэш-функция (не обязательно)
6. equal – Функция сравнения, используемая для сравнения ключей
(необязательно)
П РО Г РА М М И РО ВА Н И Е 2
33
34.
Пустой массив• Объекты классов unordered_set и unordered_map можно получить с
помощью следующих конструкторов:
• unordered_set<Key> ar;
• unordered_set<Key, hash, equal> ar;
• unordered_map<Key, T> ar;
• unordered_map<Key, T, hash, equal> ar;
• Примечание. Если хеш-функция hash опущена, то предполагается, что
используется хеш-функция по умолчанию hash<key_type>. Если
опущена функция сравнения equal, то предполагается, что
используется equal_to<> (operator==). Для
простоты Allocator() и bucket_count опущены.
П РО Г РА М М И РО ВА Н И Е 2
34
35.
Конструктор копирования/перемещения• Конструктор копирования/перемещения
• unordered_set<Key> ar(other);
• unordered_map<Key, T> ar(other);
• С помощью итераторов (вставки)
• unordered_set<Key> ar(first, last);
• unordered_set<Key, hash, equal> ar(first, last);
• unordered_map<Key, T> ar(first, last);
• unordered_map<Key, T, hash, equal> ar(first, last);
П РО Г РА М М И РО ВА Н И Е 2
35
36.
Конструктор копирования/перемещения• С помощью списка инициализации
• unordered_set<Key> ar {init};
• unordered_set<Key> ar(init);
• unordered_set<Key, hash, equal> ar(init);
• unordered_map<Key, T> ar {init};
• unordered_map<Key, T> ar(init);
• unordered_map<Key, T, hash, equal> ar(init);
• Деструктор (уничтожает объекты
классов unordered_set и unordered_map)
• ar.~unordered_set(); ar.~unordered_map();
П РО Г РА М М И РО ВА Н И Е 2
36
37.
Методы, которые не поддерживаютсяНеупорядоченные контейнеры и их упорядоченные аналоги
имеют общие методы за исключением следующих, которые не
поддерживаются:
Операции сравнения >, <, >=, <= (поддерживаются
только == и !=)
lower_bound и upper_bound
Реверсивные итераторы: rbegin, crbegin, rend, crend
П РО Г РА М М И РО ВА Н И Е 2
37
38.
Методы неупорядоченных контейнеровДанные методы позволяют управлять
производительностью
неупорядоченных контейнеров.
•load_factor() – возвращает
коэффициент заполнения (см. выше)
•max_load_factor() – если используется
без аргумента, то возвращает
тип float коэффициент максимального
заполнения, если использует в качестве
аргумента тип float, то устанавливает
коэффициент максимального
заполнения. Контейнер может
автоматически увеличить количество
сегментов, если коэффициент
заполнения превышает этот порог.
П РО Г РА М М И РО ВА Н И Е 2
•rehash(size_type count) – производит
рехешинг контейнера так, чтобы количество
сегментов (backet_count) было backet_count
>= count и backet_count >
size/max_load_factor
•reserve(size_type count) – устанавливает
количество сегментов к такому числу,
которое необходимо для размещения по
крайней мере count элементов без
превышения коэффициента максимального
заполнения и проведения рехешинга
контейнера.
38
39.
Интерфейс сегментовДля непосредственной работы с элементами сегмента (как связного списка)
используются следующие методы:
•begin(), end(), cbegin(), cend() – итераторы. Обращаю внимание, что это именно
итераторы по сегменту, а не по массиву в целом! Для контейнера также
определены аналогичные итераторы.
•size_type bucket_count() – возвращает количество сегментов в массиве
•size_type max_bucket_count() – максимально возможное количество сегментов
(связанное с ограничениями в реализации или системы)
•size_type bucket_size(size_type n) – количество элементов в сегменте с
индексом n
•size_type bucket(Key) – возвращает индекс сегмента по ключу
С помощью этих методов мы можем создать наглядное представление хешмассива.
П РО Г РА М М И РО ВА Н И Е 2
39
40.
Пример#include <bits/stdc++.h>
using namespace std;
int main()
{ // объявляем набор для хранения строкового типа данных
unordered_set <string> stringSet ;
// вставляем различную строку, эта же строка будет сохранена
stringSet.insert("code") ;
stringSet.insert("in") ;
stringSet.insert("c++") ;
stringSet.insert("is") ;
stringSet.insert("fast") ;
string key = "slow" ; // find возвращает end итератор, если ключ не найде
иначе он возвращает итератор к этому ключу
П РО Г РА М М И РО ВА Н И Е 2
40
41.
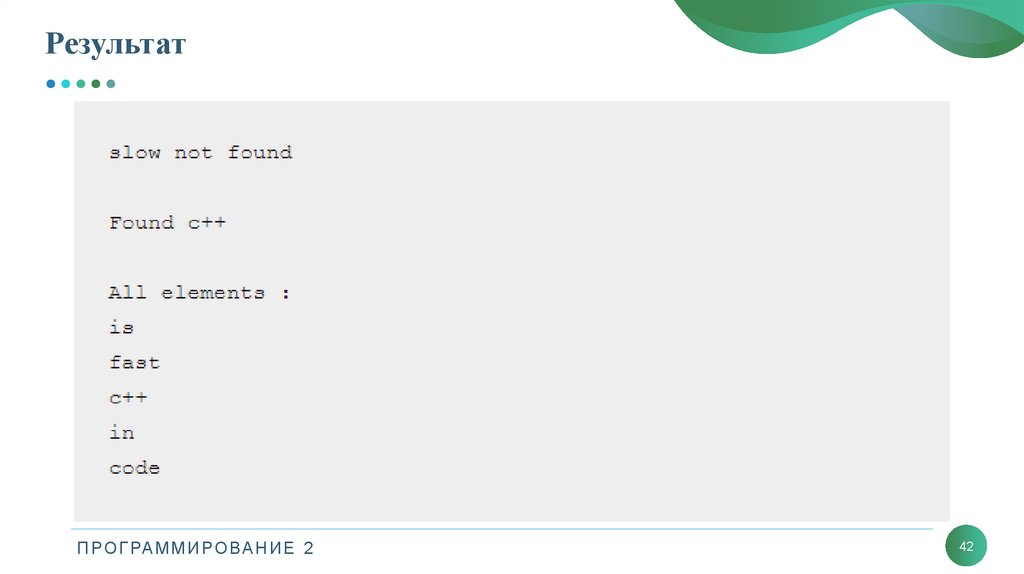
Примерif (stringSet.find(key) == stringSet.end())
cout << key << " not found" << endl << endl ;
else
cout << "Found " << key << endl << endl ;
key = "c++";
if (stringSet.find(key) == stringSet.end())
cout << key << " not found\n" ;
else
cout << "Found " << key << endl ;
cout << "\nAll elements : ";
unordered_set<string> :: iterator itr;
for (itr = stringSet.begin(); itr != stringSet.end(); itr++)
cout << (*itr) << endl;
}
П РО Г РА М М И РО ВА Н И Е 2
41
42.
РезультатП РО Г РА М М И РО ВА Н И Е 2
42
43.
ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙИМЕНИ МУХАММАДА АЛ-ХОРАЗМИЙ
СПАСИБО ЗА ВНИМАНИЕ!
АБДУЛЛАЕВА ЗАМИРА
ШАМШАДДИНОВНА
Доцент кафедры Основы
информатики
43