
























































































































































































































































































































































































































































 programming
programmingSimilar presentations:

")
")







Режимы конфигурации «Debug» и «Release». С++
1.
С++2.
Режимы конфигурации «Debug» и«Release»
• Конфигурация сборки (англ. "build configuration") — это набор настроек проекта,
которые определяют принцип его построения. Конфигурация сборки состоит из:
имени исполняемого файла; имени директории исполняемого файла; имен
директорий, в которых IDE будет искать другой код и файлы библиотек;
информации об отладке и параметрах оптимизации вашего проекта.
Интегрированная среда разработки имеет две конфигурации сборки: "Debug"
(Отладка) и "Release" (Релиз).
• Конфигурация "Debug" предназначена для отладки вашей программы. Эта
конфигурация отключает все настройки по оптимизации, включает информацию об
отладке, что делает ваши программы больше и медленнее, но упрощает проведение
отладки. Режим "Debug" обычно используется в качестве конфигурации по
умолчанию.
Конфигурация "Release" используется во время сборки программы для её
дальнейшего выпуска. Программа оптимизируется по размеру и
производительности и не содержит дополнительную информацию об отладке.
3.
Структура программ• Cтейтмент (англ. "statement") — это наиболее распространенный тип
инструкций в программах. Это и есть та самая инструкция, наименьшая
независимая единица в языке С++. Стейтмент в программировании — это то
же самое, что и "предложение" в русском языке. Мы пишем предложения,
чтобы выразить какую-то идею.
• В языке C++ мы пишем стейтменты, чтобы выполнить какое-то задание. Все
стейтменты в языке C++ заканчиваются точкой с запятой. Есть много разных
видов стейтментов в языке C++. Рассмотрим самые распространенные из них:
4.
Выражения• Компилятор также способен обрабатывать выражения. Выражение (англ.
"expression") — это математический объект, который создается (составляется)
для проведения вычислений и нахождения соответствующего результата.
Например, в математике выражение 2 + 3 имеет значение 5.
5.
Функции• В языке C++ стейтменты объединяются в блоки — функции. Функция — это
последовательность стейтментов. Каждая программа, написанная на языке
C++, должна содержать главную функцию main().
• Именно с первого стейтмента, находящегося в функции main(), и начинается
выполнение всей программы. Функции, как правило, выполняют конкретное
задание.
• Например, функция max() может содержать стейтменты, которые определяют
большее из заданных чисел, а функция calculateGrade() может вычислять
среднюю оценку студента по какой-либо дисциплине.
6.
Библиотека• Библиотека — это набор скомпилированного кода (например, функций),
который был "упакован" для повторного использования в других
программах.
• С помощью библиотек можно расширить возможности программ. Например,
если вы пишете игру, то вам придется подключать библиотеки звука или
графики (если вы самостоятельно не хотите их создавать).
7.
Main• Каждая программа на языке С++ должна иметь как минимум одну функцию -
функцию main(). Именно с этой функции начинается выполнение
приложения.
• Ее имя main фиксировано и для всех программ на С++ всегда
одинаково.Функция также является блоком кода, поэтому ее тело
обрамляется фигурными скобками, между которыми определяется набор
инструкций.
• В частности, при создании первой программы использовалась следующая
функция main:
8.
• Определение функии main начинается с возвращаемого типа. Функция main влюбом случае должна возвращать число. Поэтому ее определение
начинается с ключевого слова int.
• Далее идет название функции, то есть main. После названия в скобках идет
список параметров. В данном случае функция main не принимает никаких
параметров, поэтому после названия указаны пустые скобки.
• Однако есть другие варианты определения функции main, которые
подразумевыют использование параметров. В частности, нередко может
встречаться следующее определение функции main, использующей
параметры:
9.
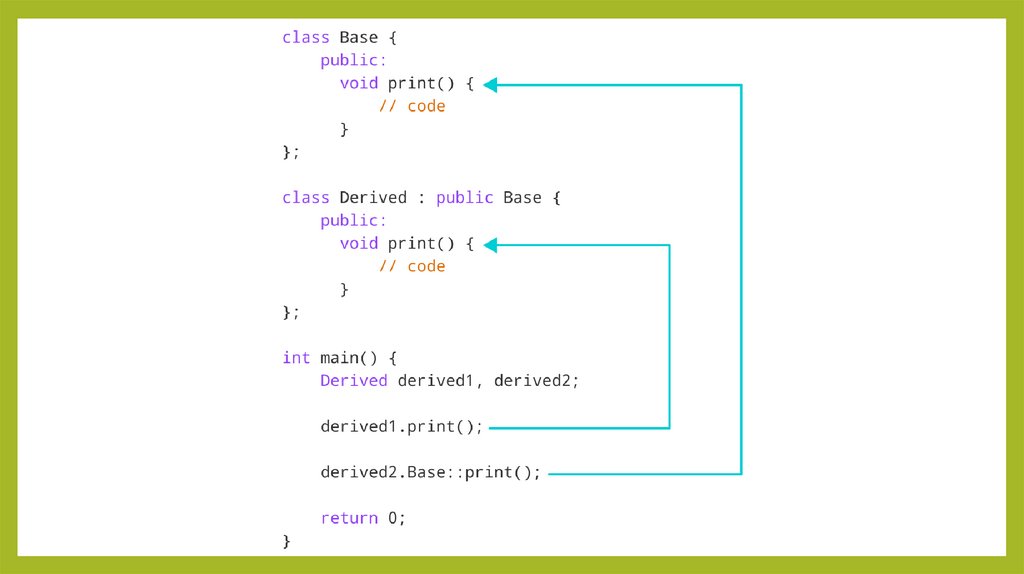
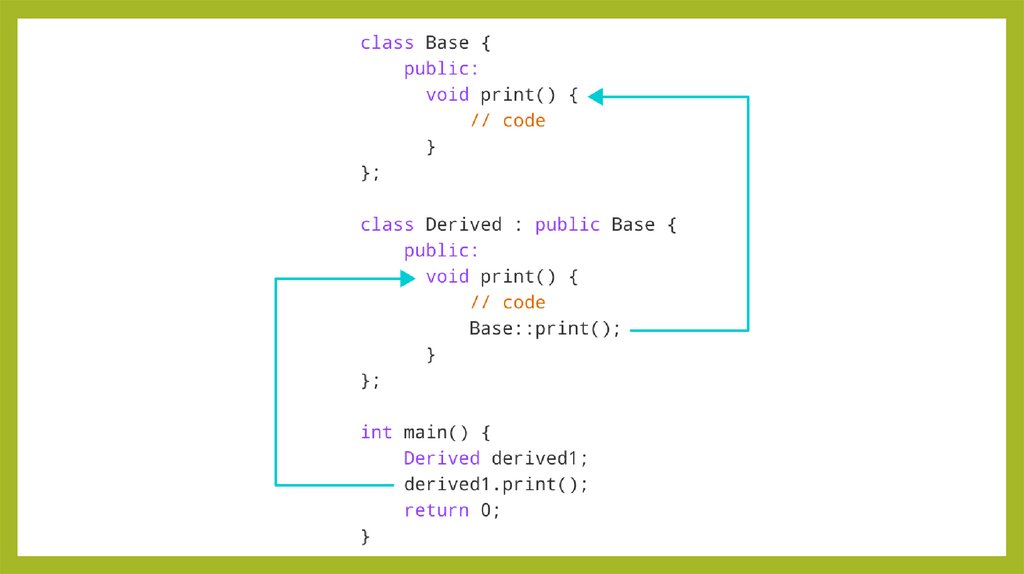
• конце функции идет инструкция return• return 0;
• Эта инструкция завершает выполнение функции, передаваяконтроль
передается операционной системе.Число 0 после оператора return указывает
операционной системе управление во вне туда, где была вызвана функция.
• В случае с функцией main, что выполнение функции завершилось успешно,
без ошибок.Также стоит отметить, что в функции main можно опустить
инструкцию return 0;:
10.
Препроцессор и Директива• Препроцессор - это программа, которая преобразует исходный код в код
понятный компилятору. В языке С/С++ препроцессор удаляет комментарии,
преобразует код в соответствии с макросами и выполняет
директивы препроцессора.
• Препроцессор имеет набор команд, называемых директивами
препроцессора. С помощью этих директив препроцессор управляет
изменениями в трансляции исходного кода в объектный.
11.
Директивы препроцессора• В примере выше на консоль выводится строка, но чтобы использовать вывод
на консоль, необходимо в начале файла с исходным кодом подключать
библиотеку iostream с помощью директивы include.
• Директива include является директивой препроцессора. Каждая директива
препроцессора размещается на одной строке. И в отличие от обычных
инструкциий языка C++, которые завершаются точкой с запятой ; , признаком
завершения препроцессорной директивы является перевод на новую строку.
• Кроме того, директива должна начинаться со знака решетки #.
Непосредственно директива "include" определяет, какие файлы и библиотеки
надо подключить в данном месте в код программы.
12.
Комментарии13.
Инициализация vs. Присваивание14.
• В отличие от других языков программирования, языки Cи и C++ неинициализируют переменные определенными значениями (например,
нулем) по умолчанию. Поэтому, при создании переменной, ей присваивается
ячейка в памяти, в которой уже может находиться какой-нибудь мусор!
Переменная без значения (со стороны программиста или пользователя)
называется неинициализированной переменной.
15.
cout, cin и endl16.
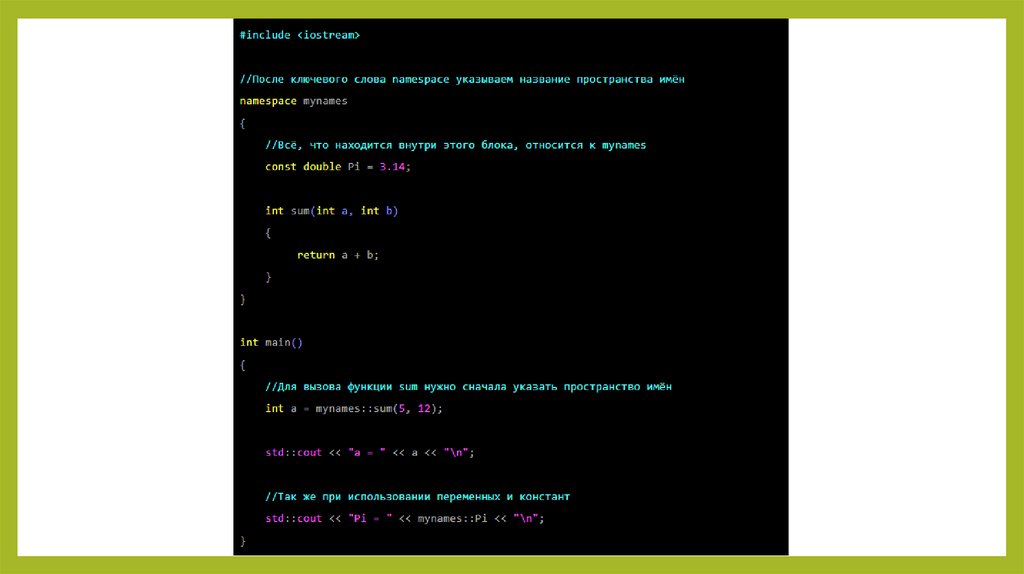
Пространства имён в C++• Пространство имён (англ. namespace) — это группа взаимосвязанных
функций, переменных, констант, классов, объектов и других компонентов
программы.
• С самого начала изучения C++ мы используем команду std: cout, чтобы
выводить данные в терминал. На самом деле команда называется
просто cout, а std — это пространство имён, в котором она находится.
• Пространства имён нужны, чтобы логически связывать части программы.
Например, математические функции, физические, бухгалтерские и так далее.
17.
18.
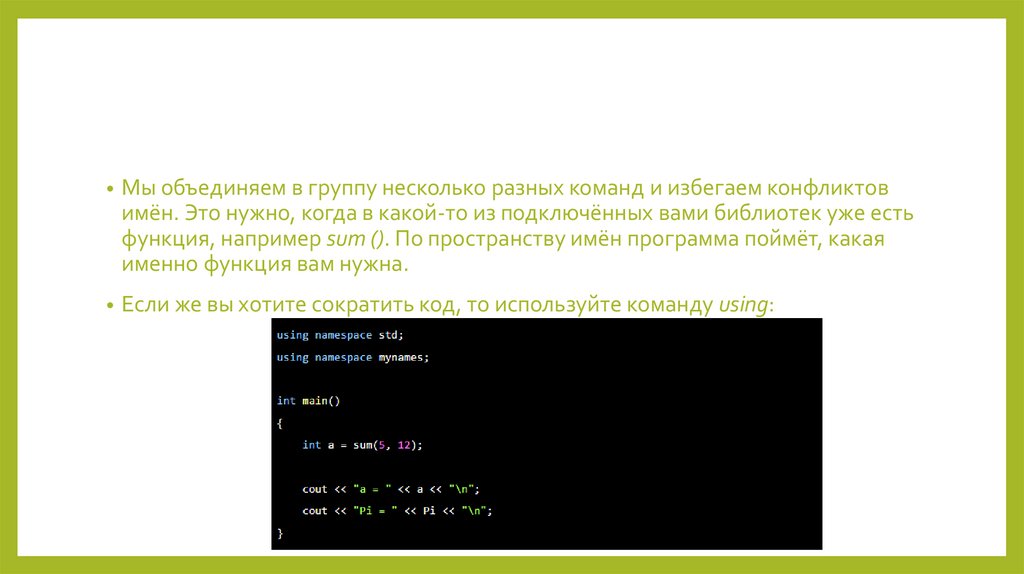
• Мы объединяем в группу несколько разных команд и избегаем конфликтовимён. Это нужно, когда в какой-то из подключённых вами библиотек уже есть
функция, например sum (). По пространству имён программа поймёт, какая
именно функция вам нужна.
• Если же вы хотите сократить код, то используйте команду using:
19.
• Также после using можно указать не целое пространство имён, а толькоотдельную функцию или переменную:
20.
Файлы заголовков в C++• Пространство имён из примера выше
можно перенести в отдельный файл,
чтобы потом подключить его к другой
программе и избавиться
от дополнительного кода в основном
файле.
• Для этого создайте файл заголовков —
сохраните код с расширением .h,
например mylib.h:
21.
• Здесь нет функции main (), потому что этот код — не самостоятельнаяпрограмма, а библиотека для других программ. Следовательно, точка входа
здесь не нужна. Также мы не подключаем iostream, потому что не собираемся
ничего выводить, но вы можете добавить в свой заголовок любые другие
файлы.
22.
23.
Идентификаторы• Во-первых, в языке C++ имена переменных начинаются с буквы в нижнем
регистре. Если имя переменной состоит из одного слова, то это слово должно
быть записано в нижнем регистре:
• Как правило, имена функций также начинаются с буквы в нижнем регистре
• Если имя переменной или функции состоит из нескольких слов, то здесь есть
два варианта: разделить подчёркиванием или использовать CamelCase —
принцип, когда несколько слов пишутся слитно, без пробелов, и каждое
новое слово пишется с заглавной буквы.
24.
КонстантыКонстантной называется именованная область памяти, в которую при
создании можно записать значение определенного типа, но далее
по ходу программы это значение можно только читать (и нельзя
изменять).
const int k1 = 13; // создали константу типа int с именем k1 и записали в
неё значение
cout << k1 = 12; // но нельзя изменить, это приведёт к ошибке
25.
ИдентификаторыПри выборе идентификатора необходимо иметь в
виду следующее:
1.
идентификатор не должен совпадать с
ключевыми словами и именами используемых
стандартных объектов языка;
2.
не рекомендуется начинать идентификаторы с
символа подчеркивания;
3.
на идентификаторы, используемые для
определения внешних переменных, налагаются
ограничения компоновщика.
4.
Для улучшения читаемости программы следует
давать объектам осмысленные имена.
26.
Простые типы данныхПростые типы делятся на целочисленные типы и типы с
плавающей точкой.
Для описания стандартных типов определены следующие
ключевые слова:
1.
int (целый);
2.
char (символьный);
3.
bool (логический);
4.
float (вещественный);
5.
double (вещественный с двойной точностью).
27.
Простые типы данныхСуществует четыре спецификатора типа, уточняющих внутреннее
представление и диапазон значений стандартных типов:
1.
short (короткий);
2.
long (длинный);
3.
signed (со знаком);
4.
unsigned (без знака).
28.
Простые типы данныхТип
Диапазон значений
Размер (байт)
bool
true и false
1
signed char
–128 .. 127
1
unsigned char
0 .. 255
1
signed short int
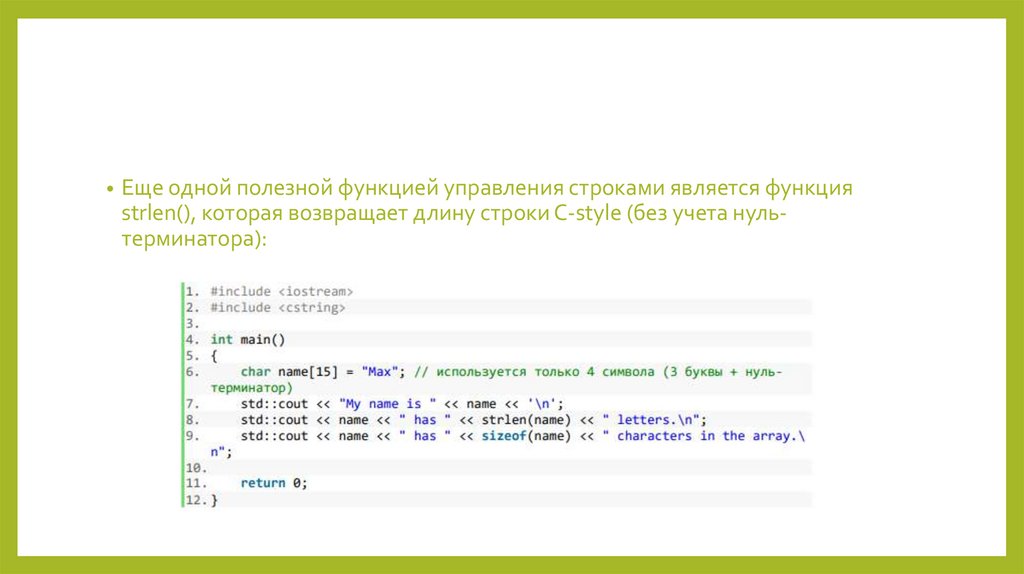
–32 768 .. 32 767
2
unsigned short int
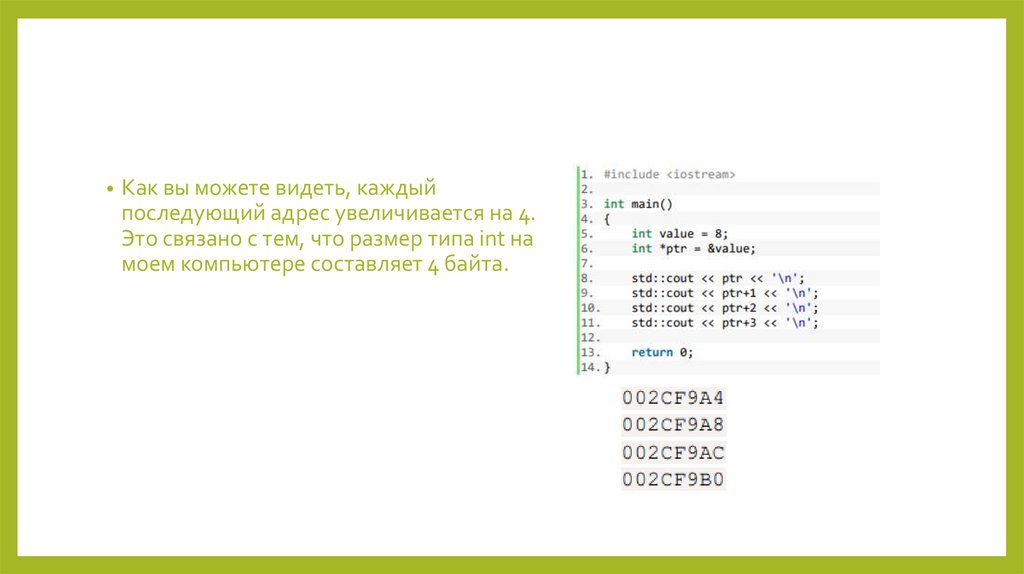
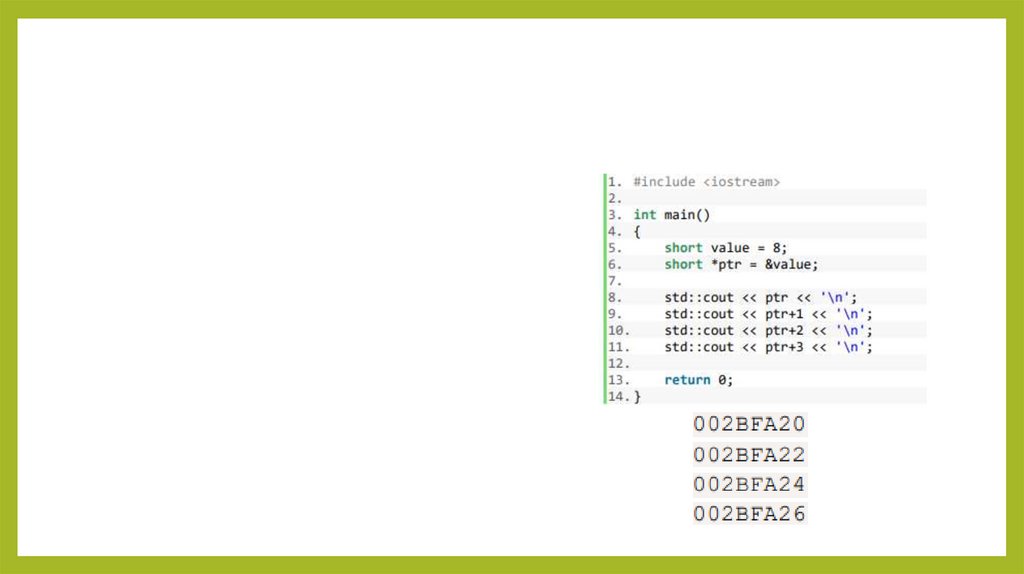
0 .. 65 535
2
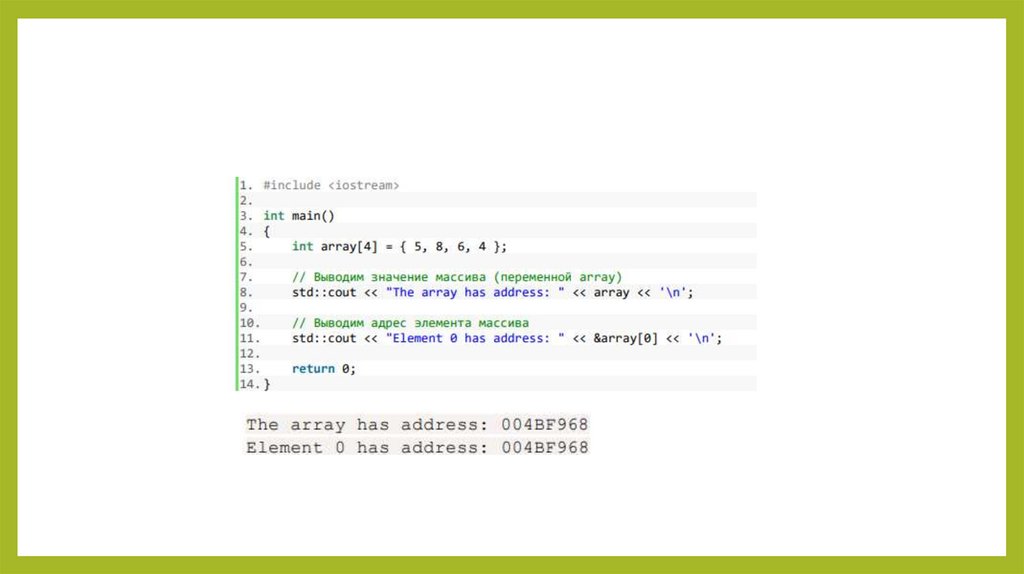
signed long int
–2 147 483 648 .. 2 147 483 647
4
unsigned long int
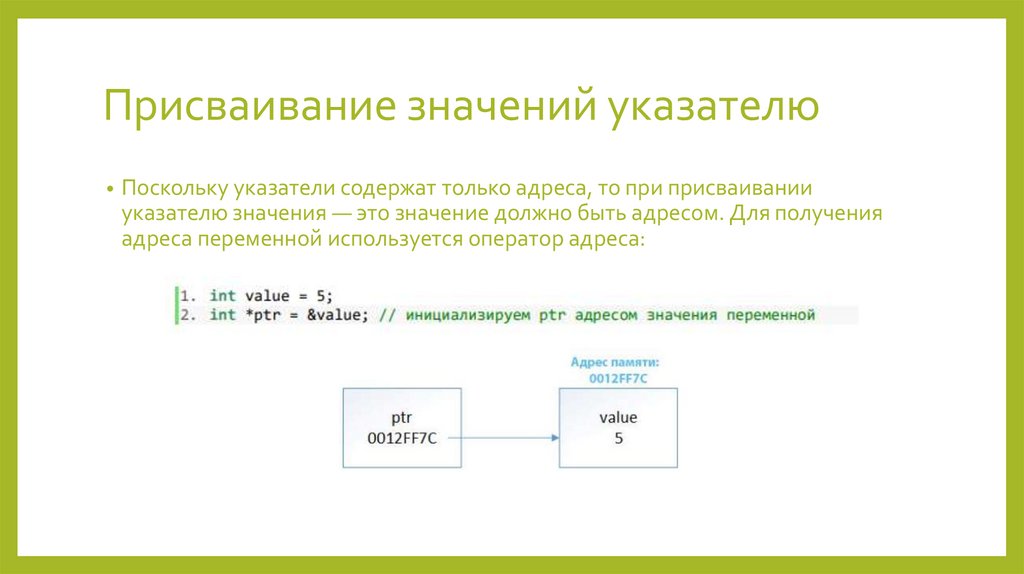
0 .. 4 294 967 295
4
float
3.4e–38 .. 3.4e+38
4
double
1.7 e–308 .. 1.7 e+308
8
long double
3.4 e–4932 .. 3.4 e+4932
10
29.
Auto• Начиная с С++11 ключевое слово auto обретает новую жизнь. Оно говорит,
что компилятор на этапе компиляции должен определить тип переменной на
основе типа инициализируемого выражения.
30.
Преобразование типовданных
В C++ различают два вида преобразования типов данных: явное и
неявное.
Неявное
преобразование происходит автоматически. Это
выполняется во время сравнения, присваивания или вычисления
выражения различных типов.
Наивысший приоритет получает тот тип, при котором информация
теряется менее всего. Не стоит злоупотреблять неявным
преобразованием типов, так как могут возникнуть разного рода
непредвиденные ситуации.
31.
Преобразование типовданных
Явное приведение осуществляется с помощью указания целевого типа
данных (того, к которому нужно привести) в круглых скобках перед
выражением:
double s = 2.71;
int t = (int) s;
cout << t << endl; // 2
cout << (int) 3.14 << endl; // 3
cout << (int) (2.5 + t) << endl; // 4
Приведение к целым числам от вещественных осуществляется путём
отбрасывания целой части (не округлением).
32.
Библиотека math.hЧтобы воспользоваться сложными математическими
действиями, нам нужно подключить в программу библиотеку, в
которой и содержаться эти функции, а именно:
#include<math.h>
33.
Библиотека math.hРассмотрим, какие функции содержатся в этой библиотеки.
abs – это модуль, возвращает положительное число
acos (xxx)- арккосинус
asin (sss) — арксинус
atan (poiy) — арктангенс
cos (sgrgrg) — косинус
Random- вывод случайных чисел
exp — экспонента
log (56) — натуральный логарифм
log10 (45,755) — это логарифм по основанию десять.
pow(xx,yyy)- возведение в степень
sin — синус
tan — тангенс
34.
Функция system()Операционная система получает команду “выражение”:
system("выражение");
Пример
Операционная система получает команду сделать паузу:
system("pause");
35.
Арифметические операции36.
Инкремент и декремент• Также есть две унарные арифметические операции, которые производятся
над одним числом: ++ (инкремент) и -- (декремент). Каждая из операций
имеет две разновидности: префиксная и постфиксная:
• Префиксный инкремент.Увеличивает значение переменной на единицу и
полученный результат используется как значение выражения ++x
37.
• Постфиксный инкремент.• Увеличивает значение переменной на единицу, но значением выражения x++
будет то, которое было до увеличения на единицу
38.
Как использовать кириллицу впрограммах C++?
• 1. #include <Windows.h>
• 1. SetConsoleCP(1251);
• 2. SetConsoleOutputCP(1251);
39.
l-values и r-values• В языке C++ все переменные являются l-values. l-value (в переводе "л-
значение", произносится как "ел-валью") — это значение, которое имеет свой
собственный адрес в памяти. Поскольку все переменные имеют адреса, то
они все являются l-values (например, переменные a, b, c — все они являются lvalues).
• A=15
• l от слова "left", так как только значения l-values могут находиться в левой
стороне в операциях присваивания (в противном случае, мы получим
ошибку). Например, стейтмент 9 = 10; вызовет ошибку компилятора, так как 9
не является l-value. Число 9 не имеет своего адреса в памяти и, таким
образом, мы ничего не можем ему присвоить (9 = 9 и ничего здесь не
изменить).
40.
R-values• Противоположностью l-value является r-value (в переводе "р-значение",
произносится как «ер-валью»). r-value — это значение, которое не имеет
постоянного адреса в памяти. Примерами могут быть единичные числа
(например, 7, которое имеет значение 7) или выражения (например, 3 + х,
которое имеет значение х плюс 3)
41.
• b = b + 2;• Здесь переменная b используется в двух различных контекстах. Слева b
используется как l-value (переменная с адресом в памяти), а справа b
используется как r-value и имеет отдельное значение (в данном случае, 12).
42.
Функции• Функция — это последовательность стейтментов для выполнения
определенного задания. Часто ваши программы будут прерывать выполнение
одних функций ради выполнения других. Вы делаете аналогичные вещи в
реальной жизни постоянно.
• Например, вы читаете книгу и вспомнили, что должны были сделать
телефонный звонок. Вы оставляете закладку в своей книге, берете телефон и
набираете номер. После того, как вы уже поговорили, вы возвращаетесь к
чтению: к той странице, на которой остановились
43.
Когда использовать функции• Рекомендация №1: Код, который появляется более одного раза в программе,
лучше переписать в виде функции. Например, если мы получаем данные от
пользователя несколько раз одним и тем же способом, то это отличный
вариант для написания отдельной функции.
• Рекомендация №2: Код, который используется для сортировки чего-либо,
лучше записать в виде отдельной функции. Например, если у нас есть список
вещей, которые нужно отсортировать — пишем функцию сортировки, куда
передаем несортированный список и откуда получаем отсортированный.
• Рекомендация №3: Функция должна выполнять одно (и только одно) задание.
• Рекомендация №4: Когда функция становится слишком большой, сложной
или непонятной — её следует разбить на несколько подфункций. Это
называется рефакторингом кода.
44.
45.
Виды• Различают два основных вида функций:
• Функция, которая что-то возвращает;
• Функция, которая ничего не возвращает;
• Также функции можно разделить на две категории:
• Функция без параметров;
• Функция с параметрами;
• Запомните: переменная созданная в функции, умирает после завершения
функции и более не существует!
46.
Создание функции, которая возвращает• Данный тип функций является наиболее используемым, так как почти всегда
требуется что-то посчитать, произвести некое преобразование и тому
подобное, следовательно полученный результат необходимо использовать
вне функции. Всё что было создано в функции в конечном счёте умирает в
ней же, в связи с этим необходимо вернуть результат в основной код
программы.
• Сделать это помогает оператор return
47.
Создание функции, которая возвращает48.
Возврат нескольких значений из#include <iostream>
функций в C++
std::pair<std::string, int> initialize() {
return std::make_pair("A", 65);
}
Использование std::pair на C++
// Возвращаем два значения из функции
на C++
int main()
{
std::pair<std::string, int> p = initialize();
std::string s = p.first;
int i = p.second;
std::cout << "The returned string is " << s
<< " and integer is " << i;
return 0;
}
49.
#include <iostream>#include <tuple>
// Функция для возврата нескольких значений по
ссылкам
std::tuple<int, int, char, double> initialize() {
return std::make_tuple(10, 20, 'A', 1.2f);
}
Использование std::tuple
// Возвращаем несколько значений из функций в C++
int main()
{
int a, b;
char c;
double d;
std::tie(a, b, c, d) = initialize();
std::cout << "a = " << a << ", b = " << b << ", c = " << c
<< ", d = " << d;
return 0;
}
50.
Создание функции, которая ничего невозвращает
• Данный тип функции используется при работе с глобальными переменными и
если нужно что-то напечатать, вывести на экран.
• Нет, почти, никакого отличия между данным типом функции и предыдущим.
Необходимо лишь указать другой тип функции и не использовать return.
51.
Создание функции, которая ничего невозвращает
52.
Вызов функции без параметров• Чтобы работать с функциями и получать от них какой-то результат,
необходимо вызвать функцию по имени в нужном месте.
53.
Создание функции с параметрами• Бывает необходимость провести над значениями некие действия. Для этого
необходимо передать функции эти самые значения. Когда значения
передаются в функцию, то они становятся аргументами функции.
• Создадим функцию с параметрами и вызовем её в основном блоке используя
аргументы.
Возведём переменную в определённую степень и вернём значение в
переменную.
• Указываем параметры при создании функции (переменные в скобках после
имени функции). Аргументы должны быть переданы обязательно, иначе
функция не заработает, у неё элементарно не будет значения с которым она
должна взаимодействовать.
• Указываем аргументы при вызове функции (два целочисленных значения).
54.
55.
Задачи• Написать функцию, которая определяет количество разрядов введенного
целого числа.
• Функция заполнения массива случайными числами
• Функция перевода десятичного числа в двоичное
56.
public class Binary {public static void binar(int a){
int b;
String temp = "";
while(a !=0){
b = a%2;
temp = b + temp;
a = a/2;
}
System.out.print(temp); }
public static void main(String [] args) {
binar(5); } }
57.
Предварительное объявление•Что здесь произойдет?
58.
предварительное объявление.• Предварительное объявление сообщает компилятору о существовании
идентификатора ДО его фактического определения. В случае функций, мы
можем сообщить компилятору о существовании функции до её фактического
определения.
• Для этого нам следует использовать прототип этой функции. Прототип
функции (полноценный) состоит из типа возврата функции, её имени и
параметров (тип + имя параметра).
• В кратком прототипе отсутствуют имена параметров функции. Основная
часть (между фигурными скобками) опускается. А поскольку прототип
функции является стейтментом, то он также заканчивается точкой с запятой.
59.
• #include <iostream>• int add(int x, int y); // предварительное объявление функции add() (используется
её прототип
• int main() {
• std::cout << "The sum of 3 and 4 is: " << add(3, 4) << std::endl; // это работает, так как
мы предварительно (выше функции main()) объявили функцию add()
• return 0
• }
• int add(int x, int y) // хотя определение функции add() находится ниже её вызова
•{
• return x + y;
• }
60.
Многофайловые проекты в Visual Studio61.
Заголовочные файлы• По мере увеличения размера программ весь код уже не помещается в
нескольких файлах, записывать каждый раз предварительные объявления
для функций, которые мы хотим использовать, но которые находятся в
других файлах, становится всё утомительнее и утомительнее.
• Файлы .cpp не являются единственными файлами в проектах. Есть еще один
тип файлов — заголовочные файлы (или "заголовки"), которые имеют
расширение .h. Целью заголовочных файлов является удобное хранение
набора объявлений объектов для их последующего использования в других
программах.
62.
Рассмотрим следующую программу:• В этой программе мы используем cout, который нигде не определяем. Откуда
компилятор знает, что это такое? Дело в том, что cout объявлен в
заголовочном файле iostream.
• Когда мы пишем #include , мы делаем запрос, чтобы всё содержимое
заголовочного файла iostream было скопировано в наш файл. Таким образом,
всё содержимое библиотеки iostream становится доступным для
использования.
• Как правило, в заголовочных файлах записываются только объявления, без
определений. Следовательно, если cout только объявлен в заголовочном
файле iostream, то где же он определяется? Ответ: в Стандартной библиотеке
С++, которая автоматически подключается к вашему проекту на этапе
линкинга.
63.
• Если бы не было заголовочных файлов Каждый раз, при использовании cout,вам бы приходилось вручную копировать все предварительные объявления,
связанные с cout в верхнюю часть вашего файла!
64.
• Все ваши заголовочные файлы (которые вы написали самостоятельно)должны иметь расширение .h.
65.
Угловые скобки (<>) vs. Двойныекавычки ("")
• Дело в том, что, используя угловые скобки, мы сообщаем компилятору, что
подключаемый заголовочный файл написан не нами (он является
"системным", т.е. предоставляется Стандартной библиотекой С++), так что
искать этот заголовочный файл следует в системных директориях.
• Двойные кавычки сообщают компилятору, что мы подключаем наш
собственный заголовочный файл, который мы написали самостоятельно,
поэтому искать его следует в текущей директории нашего проекта. Если
файла там не окажется, то компилятор начнет проверять другие пути, в том
числе и системные директории.
66.
Почему iostream пишется безокончания .h?
• Еще один часто задаваемый вопрос: "Почему iostream (или любой другой из
стандартных заголовочных файлов) при подключении пишется без окончания
".h"?". Дело в том, что есть 2 отдельных файла: iostream.h (заголовочный
файл) и просто iostream!
• Когда C++ только создавался, все файлы библиотеки Runtime имели
окончание .h. Оригинальные версии cout и cin объявлены в iostream.h. При
стандартизации языка С++ комитетом ANSI, решили перенести все функции
из библиотеки Runtime в пространствo имен std, чтобы предотвратить
возможность возникновения конфликтов имен с пользовательскими
идентификаторами (что, между прочим, является хорошей идеей). Тем не
менее, возникла проблема: если все функции переместить в пространство
имен std, то старые программы переставали работать!
67.
• Для обеспечения обратной совместимости ввели новый набор заголовочныхфайлов с теми же именами, но без окончания ".h". Весь их функционал
находится в пространстве имен std.
• Таким образом, старые программы с #include не нужно было переписывать, а
новые программы уже могли использовать #include . Когда вы подключаете
заголовочный файл из Стандартной библиотеки C++, убедитесь, что вы
используете версию без .h (если она существует).
• В противном случае, вы будете использовать устаревшую версию
заголовочного файла, который уже больше не поддерживается.
• Кроме того, многие библиотеки, унаследованные от языка Cи, которые до сих
пор используются в C++, также были продублированы с добавлением
префикса c (например, stdlib.h стал cstdlib).
• Функционал этих библиотек также перенесли в пространство имен std, чтобы
избежать возможность возникновения конфликтов имен с
пользовательскими идентификаторами.
68.
Директивы препроцессора• Препроцессор лучше всего рассматривать как отдельную программу, которая
выполняется перед компиляцией.
• При запуске программы, препроцессор просматривает код сверху вниз, файл
за файлом, в поиске директив.
• Директивы — это специальные команды, которые начинаются с символа # и
НЕ заканчиваются точкой с запятой. Есть несколько типов директив, которые
мы рассмотрим ниже
69.
Директива #include• Вы уже видели директиву #include в действии. Когда вы подключаете файл с
помощью директивы #include, препроцессор копирует содержимое
подключаемого файла в текущий файл сразу после строки с #include. Это
очень полезно при использовании определенных данных (например,
предварительных объявлений функций) сразу в нескольких местах.
70.
Директива #define• Директиву #define можно использовать для создания макросов. Макрос —
это правило, которое определяет конвертацию идентификатора в указанные
данные. Есть два основных типа макросов: макросы-функции и макросыобъекты.
• Макросы-функции ведут себя как функции и используются в тех же
целях.(Практически не используются)
71.
Макросы-объекты можно определитьодним из следующих двух способов:
• #define идентификатор или
• #define идентификатор текст_замена
• Верхнее определение не имеет никакого текст_замена, в то время как
нижнее — имеет. Поскольку это директивы препроцессора (а не простые
стейтменты), то ни одна из форм не заканчивается точкой с запятой.
72.
Макросы-объекты с текст_замена• Когда препроцессор встречает макросы-объекты с текст_замена, то любое
дальнейшее появление идентификатор заменяется на текст_замена.
идентификатор обычно пишется заглавными буквами с символами
подчёркивания вместо пробелов
73.
Условная компиляция• Директивы препроцессора условной компиляции позволяют определить, при
каких условиях код будет компилироваться, а при каких — нет. На этом уроке
мы рассмотрим только три директивы условной компиляции:
• #ifdef
• #ifndef
• #endif
74.
• Директива #ifdef (сокр. от "if defined" = "если определено") позволяетпрепроцессору проверить, было ли значение ранее определено с помощью
директивы #define. Если да, то код между #ifdef и #endif скомпилируется.
Если нет, то код будет проигнорирован. Например:
75.
• Поскольку PRINT_JOE уже был определен, то строка std::cout << "Joe" <<std::endl; скомпилируется и выполнится. А поскольку PRINT_BOB не был
определен, то строка std::cout << "Bob" << std::endl; не скомпилируется и,
следовательно, не выполнится.
76.
• Директива #ifndef (сокр. от "if not defined" = "если не определено") — этополная противоположность к #ifdef, которая позволяет проверить, не было
ли значение ранее определено. Например:
77.
• Результатом выполнения этого фрагмента кода будет Bob, так как PRINT_BOBранее никогда не был определен.
78.
Header guards и #pragma once• Идентификатор может иметь только одно объявление. Таким образом,
программа с двумя объявлениями одной переменной получит ошибку
компиляции:
79.
• Хотя вышеприведенные ошибки легко исправить (достаточно просто удалитьдублирование), с заголовочными файлами дела обстоят несколько иначе.
• Довольно легко можно попасть в ситуацию, когда определения одних и тех
же заголовочных файлов будут подключаться больше одного раза в файл
.cpp.
• Очень часто это случается при подключении одного заголовочного файла
другим.
80.
Рассмотрим следующую программу:81.
• Эта программа, не скомпилируется! Проблема кроется в определениифункции в файле math.h.
• Сначала main.cpp подключает заголовочный файл math.h, вследствие чего
определение функции getSquareSides копируется в main.cpp.
• Затем main.cpp подключает заголовочный файл geometry.h, который, в свою
очередь, подключает math.h.
• В geometry.h находится копия функции getSquareSides() (из файла math.h),
которая уже во второй раз копируется в main.cpp.
82.
• Мы получим дублирование определений и ошибку компиляции. Еслирассматривать каждый файл по отдельности, то ошибок нет. Однако в
main.cpp, который подключает сразу два заголовочных файла с одним и тем
же определением функции, мы столкнемся с проблемами. Если для
geometry.h нужна функция getSquareSides(), а для main.cpp нужен как
geometry.h, так и math.h, то какое же решение?
83.
Header guards• На самом деле решение простое — использовать header guards (защиту
подключения в языке C++). Header guards — это директивы условной
компиляции, которые состоят из следующего
84.
• Если подключить этот заголовочный файл, то первое, что он сделает — этопроверит, был ли ранее определен идентификатор
SOME_UNIQUE_NAME_HERE. Если мы впервые подключаем этот заголовок,
то SOME_UNIQUE_NAME_HERE еще не был определен.
• Следовательно, мы определяем SOME_UNIQUE_NAME_HERE (с помощью
директивы #define) и выполняется основная часть заголовочного файла. Если
же мы раньше подключали этот заголовочный файл, то
SOME_UNIQUE_NAME_HERE уже был определен.
• В таком случае, при подключении этого заголовочного файла во второй раз,
его содержимое будет проигнорировано.
85.
• Все ваши заголовочные файлы должны иметь header guards.SOME_UNIQUE_NAME_HERE может быть любым идентификатором, но, как
правило, в качестве идентификатора используется имя заголовочного файла
с окончанием _H. Например, в файле math.h идентификатор будет MATH_H
Даже заголовочные файлы из
Стандартной библиотеки С++
используют header guards.
86.
• Теперь, при подключении в main.cppзаголовочного файла math.h, препроцессор
увидит, что MATH_H не был определен,
следовательно, выполнится директива
определения MATH_H и содержимое math.h
скопируется в main.cpp.
• Затем main.cpp подключает заголовочный файл
geometry.h, который, в свою очередь,
подключает math.h.
• Препроцессор видит, что MATH_H уже был ранее
определен и содержимое geometry.h не будет
скопировано в main.cpp.
87.
#pragma once• Большинство компиляторов поддерживают более простую, альтернативную
форму header guards — директиву #pragma:
• #pragma once используется в качестве header guards, но имеет
дополнительные преимущества — она короче и менее подвержена ошибкам.
• Однако, #pragma once не является официальной частью языка C++, и не все
компиляторы её поддерживают (хотя большинство современных
компиляторов поддерживают).
• Рекомендуется использовать header guards, чтобы сохранить максимальную
совместимость вашего кода.
88.
Конфликт имен и std namespace• Допустим, что вам нужно съездить к дальним родственникам в другой город.
У вас есть только их адрес: г. Ржев, ул. Вербовая, 13. Попав в город Ржев, вы
открываете Google Карты/Яндекс.Карты и видите, что есть две улицы с
названием Вербовая
• Аналогично и в языке C++ все идентификаторы (имена
переменных/функций/классов и т.д.) должны быть уникальными. Если в
вашей программе находятся два одинаковых идентификатора, то будьте
уверены, что ваша программа не скомпилируется: вы получите ошибку
конфликта имен.
89.
90.
• По отдельности файлы a.cpp, b.cpp и main.cpp скомпилируются. Однако, еслиa.cpp и b.cpp разместить в одном проекте — произойдет конфликт имен, так
как определение функции doSomething() находится сразу в обоих файлах.
Большинство конфликтов имен происходят в двух случаях:
• Файлы, добавленные в один проект, имеют функцию (или глобальную
переменную) с одинаковыми именами (ошибка на этапе линкинга).
• Файл .cpp подключает заголовочный файл, в котором идентификатор
конфликтует с идентификатором из файла .cpp (ошибка на этапе
компиляции). Как только программы становятся больше, то и
идентификаторов используется больше.
91.
Пространство имен• В первых версиях языка C++ все идентификаторы из Стандартной библиотеки
C++ (такие как cin/cout и т.д.) можно было использовать напрямую. Тем не
менее, это означало, что любой идентификатор из Стандартной библиотеки
С++ потенциально мог конфликтовать с именем, которое вы выбрали для
ваших собственных идентификаторов.
• Чтобы устранить данную проблему, весь функционал Стандартной
библиотеки С++ перенесли в специальную область — пространство имен
(англ. "namespace")
92.
• Таким образом, std::cout состоит из двух частей: идентификатор cout ипространство имен std. Весь функционал Стандартной библиотеки C++
определен внутри пространства имен std (сокр. от «standard»).
93.
Отладчик• Отладчик (или "дебаггер", от англ. "debugger") — это компьютерная
программа, которая позволяет программисту контролировать выполнение
кода. Например, программист может использовать отладчик для выполнения
программы пошагово, последовательно изучая значения переменных в
программе.
94.
Степпинг• Степпинг (англ. "stepping") — это возможность отладчика выполнять код
пошагово (строка за строкой). Есть три команды степпинга:
• Команда "Шаг с заходом"
• Команда "Шаг с обходом"
• Команда "Шаг с выходом”
95.
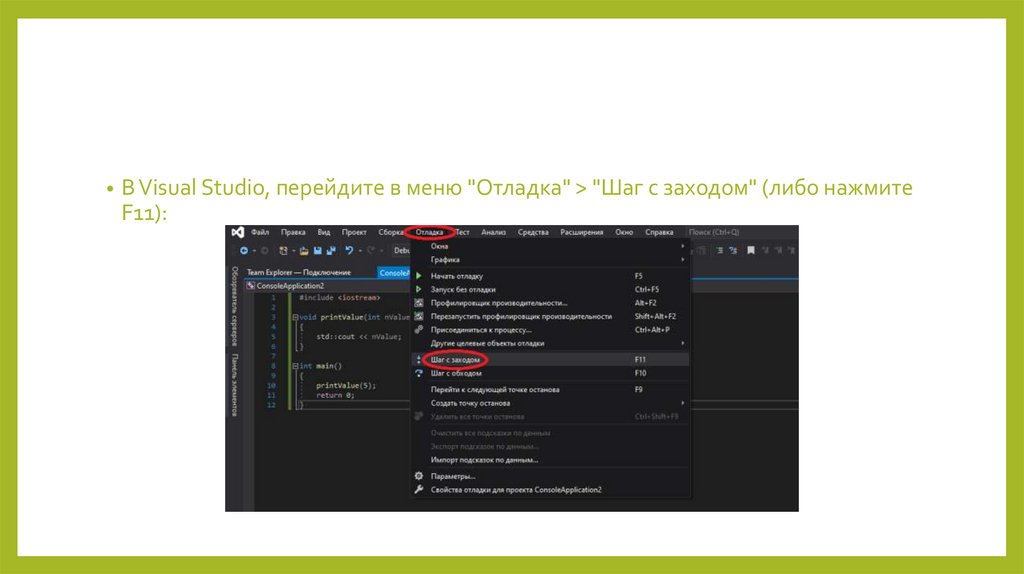
Команда "Шаг с заходом"• Команда "Шаг с заходом" (англ. "Step into") выполняет следующую строку
кода. Если этой строкой является вызов функции, то "Шаг с заходом"
открывает функцию и выполнение переносится в начало этой функции.
96.
• В Visual Studio, перейдите в меню "Отладка" > "Шаг с заходом" (либо нажмитеF11):
97.
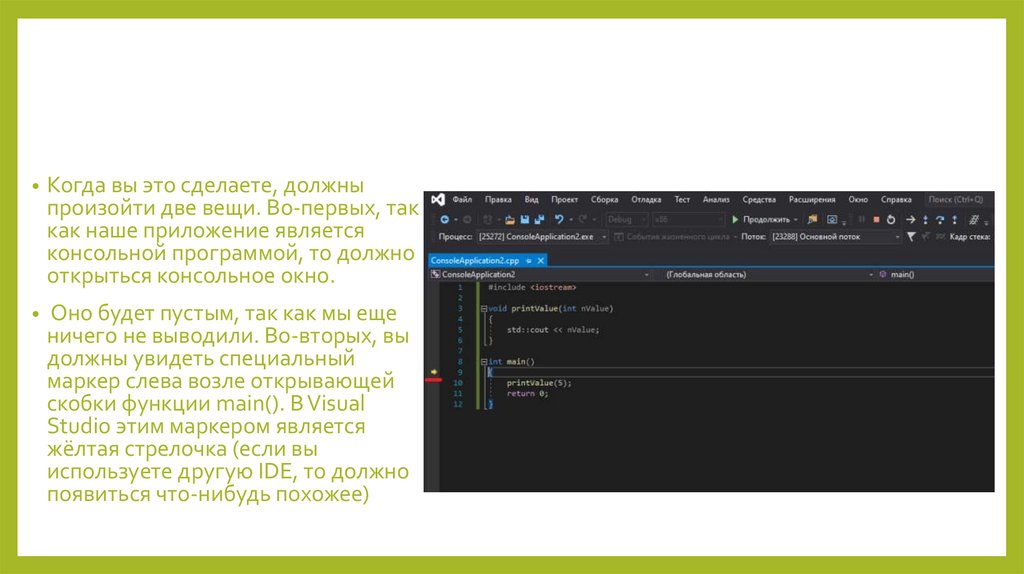
• Когда вы это сделаете, должныпроизойти две вещи. Во-первых, так
как наше приложение является
консольной программой, то должно
открыться консольное окно.
• Оно будет пустым, так как мы еще
ничего не выводили. Во-вторых, вы
должны увидеть специальный
маркер слева возле открывающей
скобки функции main(). В Visual
Studio этим маркером является
жёлтая стрелочка (если вы
используете другую IDE, то должно
появиться что-нибудь похожее)
98.
Команда "Шаг с обходом• Как и команда "Шаг с заходом", команда "Шаг с обходом" (англ. "Step over")
позволяет выполнить следующую строку кода. Только если этой строкой
является вызов функции, то "Шаг с обходом" выполнит весь код функции в
одно нажатие и возвратит нам контроль после того, как функция будет
выполнена.
• Команда "Шаг с обходом" позволяет быстро пропустить код функций, когда
мы уверены, что они работают корректно и их не нужно отлаживать.
99.
Команда "Шаг с выходом"• В отличие от двух предыдущих команд, команда "Шаг с выходом" (англ. "Step
out") не просто выполняет следующую строку кода. Она выполняет весь
оставшийся код функции, в которой вы сейчас находитесь, и возвращает
контроль только после того, когда функция завершит свое выполнение.
Проще говоря, «Шаг с выходом» позволяет выйти из функции.
• Обратите внимание, команда "Шаг с выходом" появится в меню "Отладка"
только после начала сеанса отладки (что делается путем использования
одной из двух вышеприведенных команд).
100.
Команда "Выполнить до текущейпозиции"
• В то время как степпинг полезен для изучения каждой строки кода по
отдельности, в большой программе перемещаться по коду с помощью этих
команд будет не очень удобно.
• Но и здесь современные отладчики предлагают еще несколько инструментов
для эффективной отладки программ.
Команда "Выполнить до текущей позиции" позволяет в одно нажатие
выполнить весь код до строки, обозначенной курсором. Затем контроль
обратно возвращается к вам, и вы можете проводить отладку с указанной
точки уже более детально. Давайте попробуем, используя уже знакомую нам
программу:
101.
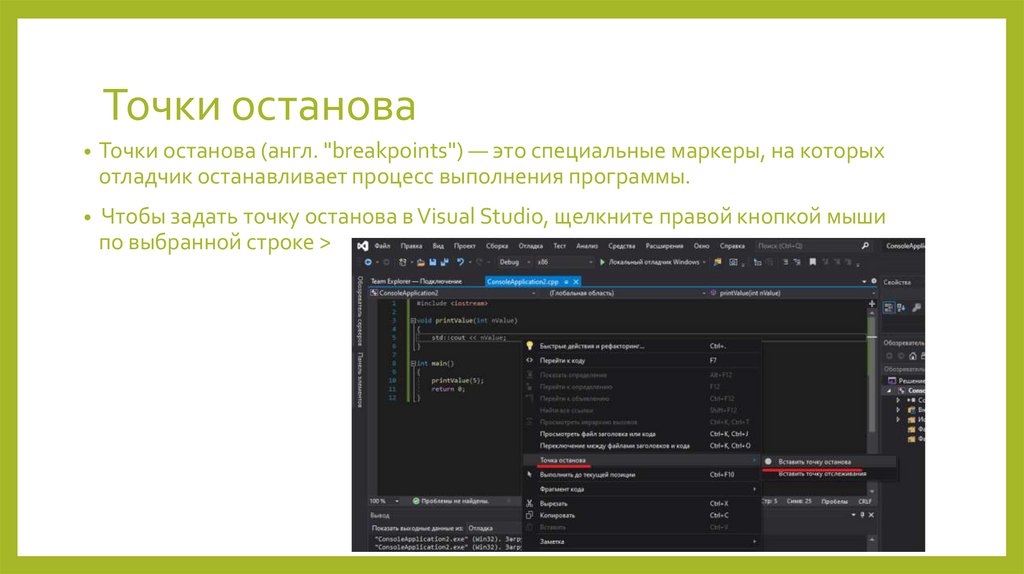
Точки останова• Точки останова (англ. "breakpoints") — это специальные маркеры, на которых
отладчик останавливает процесс выполнения программы.
• Чтобы задать точку останова в Visual Studio, щелкните правой кнопкой мыши
по выбранной строке >
102.
Отслеживание переменных• Отслеживание переменных — это процесс проверки значений переменных во
время отладки. Например:
103.
• Используя команду "Выполнить до текущей позиции" переместитесь к строкеstd::cout << x << " ";
• К этому моменту переменная х уже создана и инициализирована, поэтому,
при проверке этой переменной, вы должны увидеть число 1. Самый простой
способ отслеживания простых переменных (как х) — это наведение курсора
мыши на элемент.
• Большинство современных отладчиков поддерживают эту возможность:
104.
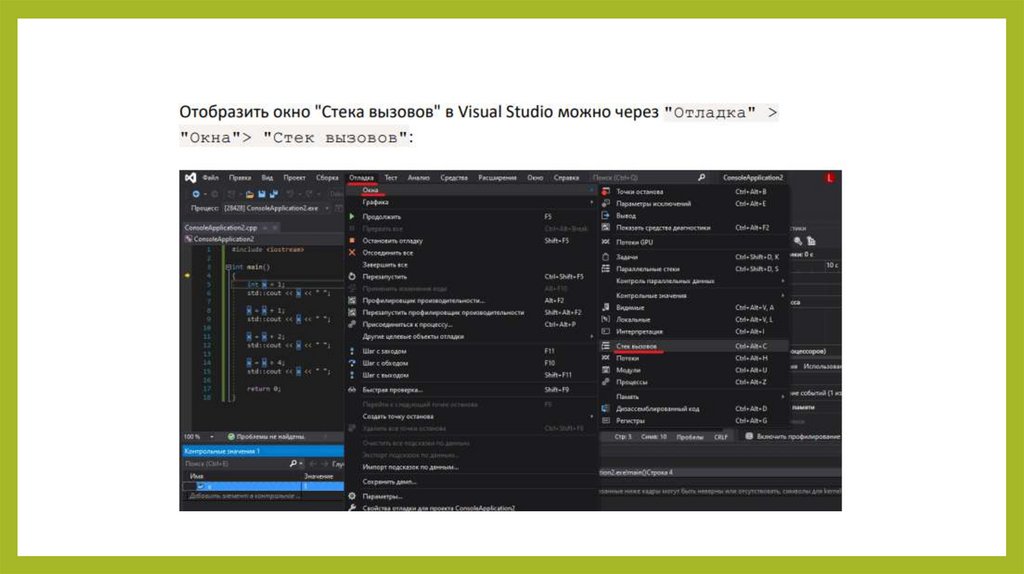
Стек вызовов• при вызове функции программа оставляет закладку в текущем
местоположении, выполняет функцию, а затем возвращается в место
закладки. Программа отслеживает все вызовы функций в стеке вызовов. Стек
вызовов — это список всех активных функций, которые вызывались до
текущего местоположения.
• В стек вызовов записывается вызываемая функция и выполняемая строка.
Всякий раз, когда происходит вызов новой функции, эта новая функция
добавляется в верх стека.
• Когда выполнение текущей функции прекращается, она удаляется из
верхней части стека и управление переходит к функции ниже (второй по
счету).
105.
106.
107.
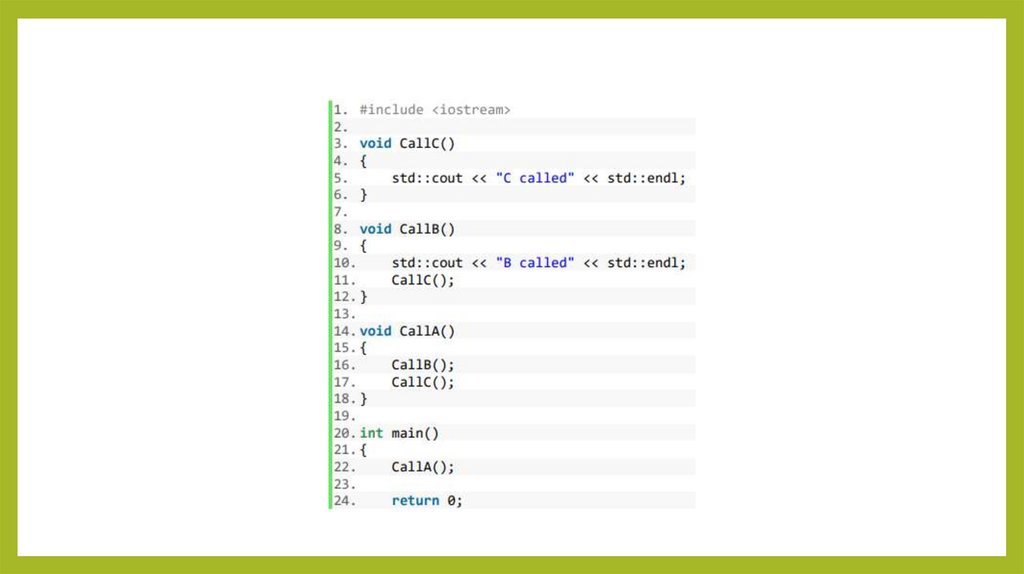
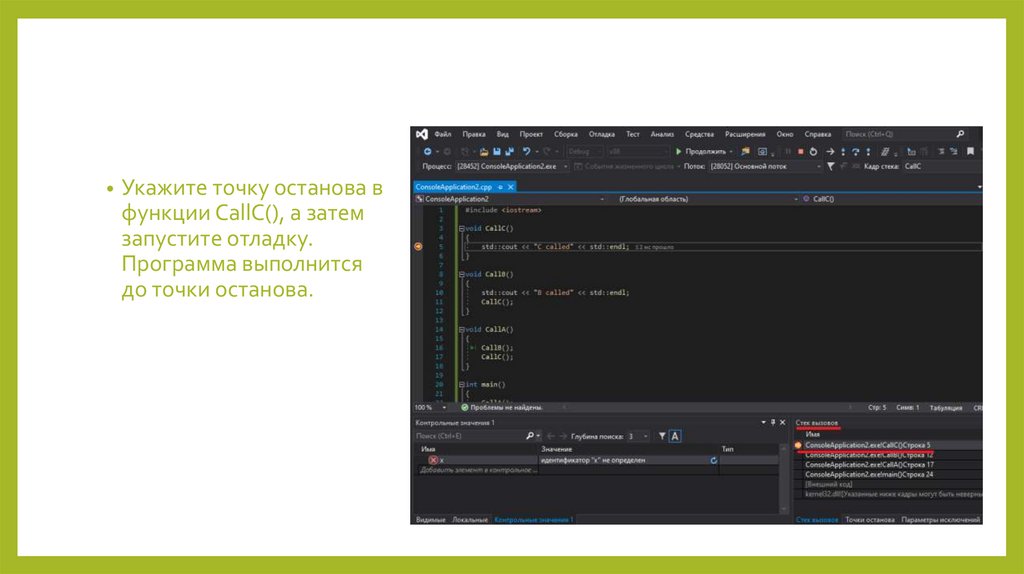
• Укажите точку останова вфункции CallC(), а затем
запустите отладку.
Программа выполнится
до точки останова.
108.
Локальные переменные, областьвидимости и продолжительность жизни
• Область видимости определяет, где можно использовать переменную.
Продолжительность жизни (или "время жизни") определяет, где переменная
создается и где уничтожается. Эти две концепции связаны между собой.
Переменные, определенные внутри блока, называются локальными
переменными.
• Локальные переменные имеют автоматическую продолжительность жизни:
они создаются (и инициализируются, если необходимо) в точке определения
и уничтожаются при выходе из блока. Локальные переменные имеют
локальную область видимости (или "блочную"), т.е. они входят в область
видимости с точки объявления и выходят в самом конце блока, в котором
определены.
109.
• Такие переменные можно использовать только внутри блоков, в которых ониопределены. Поскольку каждая функция имеет свой собственный блок, то
переменные из одной функции никак не соприкасаются и не влияют на
переменные из другой функции
110.
• В разных функциях могут находиться переменные или параметры содинаковыми именами.
111.
• Вложенные блоки считаются частью внешнего блока, в котором ониопределены. Следовательно, переменные, определенные во внешнем блоке,
могут быть видны и внутри вложенного блока:
112.
Сокрытие имен• Переменная внутри
вложенного блока может
иметь то же имя, что и
переменная внутри внешнего
блока.
• Когда подобное случается, то
переменная во вложенном
(внутреннем) блоке
«скрывает» внешнюю
переменную. Это называется
сокрытием имен
113.
Область видимости переменных• Переменные должны определяться в максимально ограниченной области
видимости. Например, если переменная используется только внутри
вложенного блока, то она и должна быть определена в нем
• Ограничивая область видимости, мы уменьшаем сложность программы,
поскольку число активных переменных уменьшается. Таким образом, легче
увидеть, где какие переменные используются. Переменная, определенная
внутри блока, может использоваться только внутри этого же блока (или
вложенных в него подблоков). Этим мы упрощаем понимание и логику
программы.
114.
Глобальные переменные• Глобальными называются переменные, которые объявлены вне блока. Они
имеют статическую продолжительность жизни, т.е. создаются при запуске
программы и уничтожаются при её завершении.
• Глобальные переменные имеют глобальную область видимости (или
"файловую область видимости"), т.е. их можно использовать в любом месте
файла, после их объявления.
115.
Определение глобальных переменных• Обычно глобальные переменные объявляют в верхней части кода, ниже
директив #include, но выше любого другого кода. Например:
116.
• с помощью оператораразрешения области
видимости (::), компилятору
можно сообщить, какую
версию переменной вы хотите
использовать: глобальную или
локальную.
#include <iostream>
2.
3. int value=4; // глобальная переменная
4.
5. int main()
6. {
7. int value = 8; // эта переменная
(локальная) скрывает значение глобальной
переменной
8. value++; // увеличивается локальная
переменная value
9. ::value--; // уменьшается глобальная
переменная value
10.
11. std::cout << "Global value: " <<
::value << "\n";
12. std::cout << "Local value: " << value
<< "\n";
13. return 0;
14. } // локальная переменная уничтожается
117.
• Использовать одинаковые имена для локальных и глобальных переменных —это прямой путь к проблемам и ошибкам, поэтому подобное делать не
рекомендуется.
• Многие разработчики добавляют к глобальным переменным префикс g_ ("g"
от англ. "global"). Таким образом, можно убить сразу двух зайцев: определить
глобальные переменные и избежать конфликтов имен с локальными
переменными.
118.
Ключевые слова static и extern• В дополнение к области видимости и продолжительности жизни,
переменные имеют еще одно свойство — связь. Связь переменной
определяет, относятся ли несколько упоминаний одного идентификатора к
одной и той же переменной или нет.
• Переменная без связей — это переменная с локальной областью видимости,
которая относится только к блоку, в котором она определена. Это обычные
локальные переменные. Две переменные с одинаковыми именами, но
определенные в разных функциях, не имеют никакой связи — каждая из них
считается независимой единицей
119.
• Переменная, имеющая внутренние связи, называется внутреннейпеременной (или "статической переменной"). Она может использоваться в
любом месте файла, в котором определена, но не относится к чему-либо вне
этого файла
• Переменная, имеющая внешние связи, называется внешней переменной.
Она может использоваться как в файле, в котором определена, так и в других
файлах.
120.
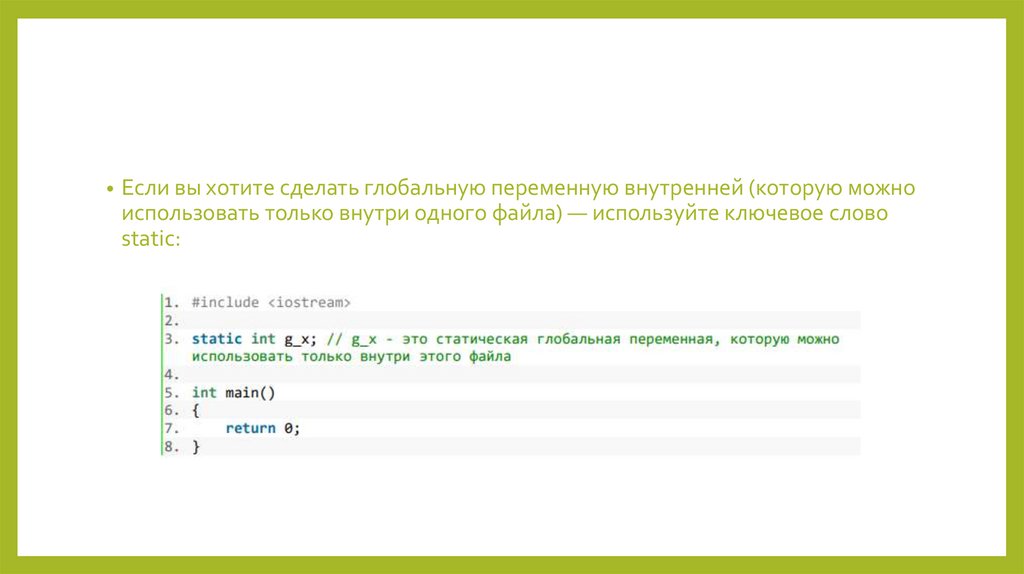
• Если вы хотите сделать глобальную переменную внутренней (которую можноиспользовать только внутри одного файла) — используйте ключевое слово
static:
121.
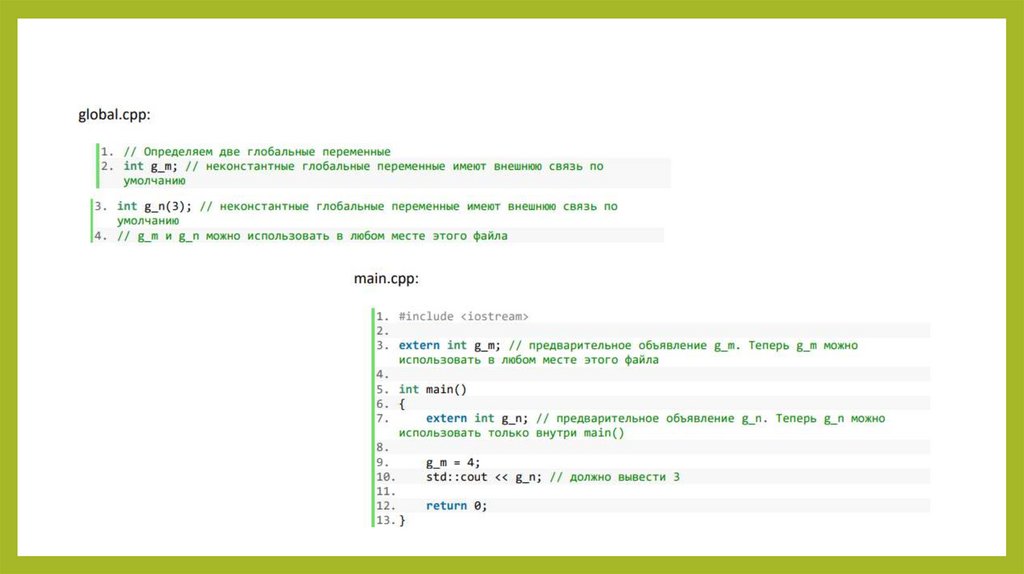
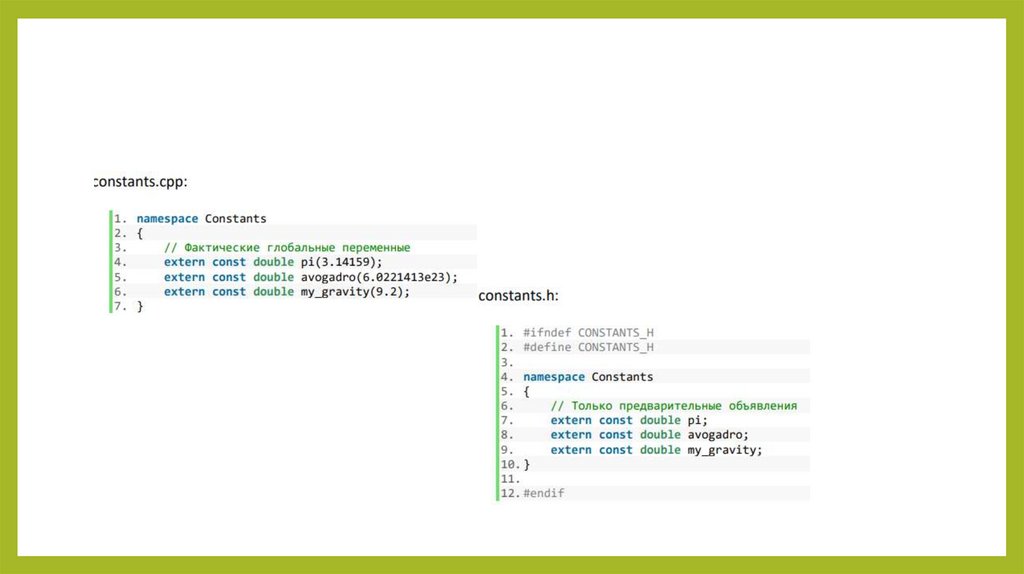
Предварительные объявленияпеременных с использованием extern
• Как мы уже знаем из предыдущих уроков, для использования функций,
которые определены в другом файле, нужно применять предварительные
объявления.
• Аналогично, чтобы использовать внешнюю глобальную переменную, которая
была объявлена в другом файле, нужно записать предварительное
объявление переменной с использованием ключевого слова extern (без
инициализируемого значения). Например
122.
123.
124.
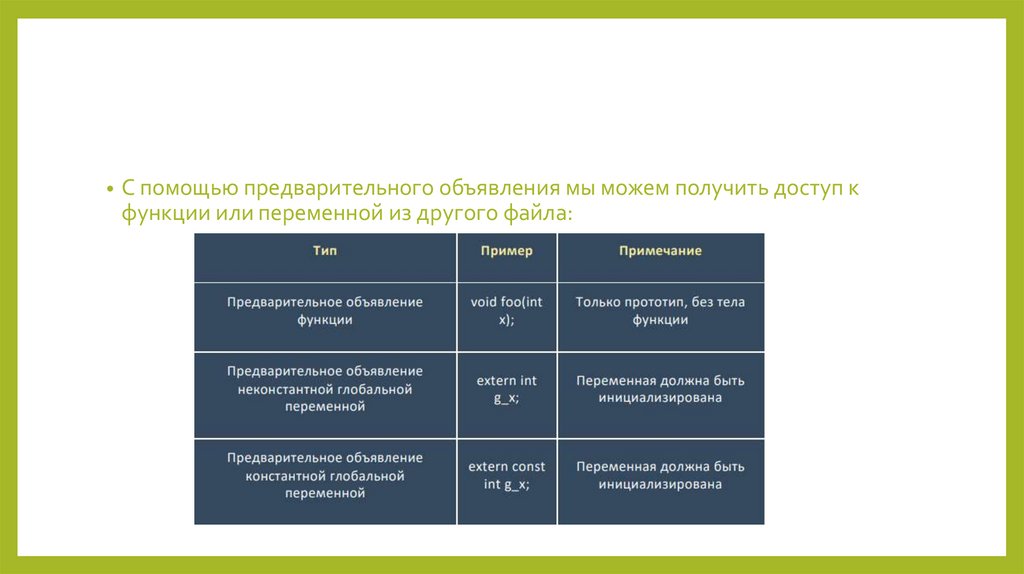
• С помощью предварительного объявления мы можем получить доступ кфункции или переменной из другого файла:
125.
Связи функций• Функции имеют такие же свойства связи, что и переменные. По умолчанию
они имеют внешнюю связь, которую можно сменить на внутреннюю с
помощью ключевого слова static:
126.
Оператор static_cast• В языке C++ есть еще один оператор явного преобразования типов данных —
оператор static_cast.
127.
Введение в std::string• Тип данных string
• Чтобы иметь возможность использовать строки в C++, сначала нужно
подключить заголовочный файл string. Как только это будет сделано, мы
сможем определять переменные типа string:
128.
Ввод/вывод строк• Строки можно выводить с помощью std::cout:
129.
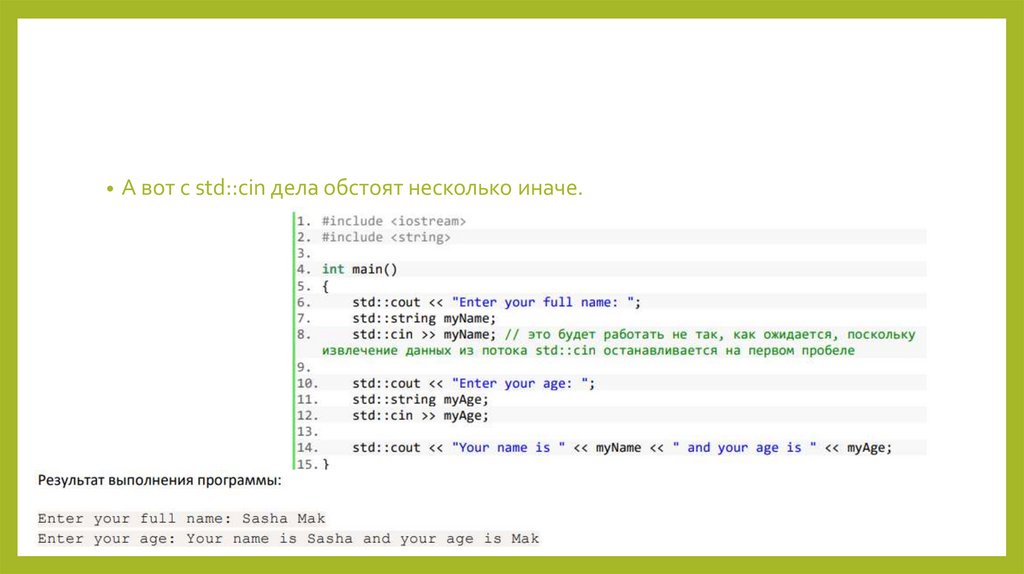
• А вот с std::cin дела обстоят несколько иначе.130.
• оператор извлечения (>>) возвращает символы из входного потока данныхтолько до первого пробела. Все остальные символы остаются внутри cin,
ожидая следующего извлечения.
• Поэтому, когда мы использовали оператор >> для извлечения данных в
переменную myName, только Sasha был извлечен, Mak остался внутри
std::cin, ожидая следующего извлечения. Когда мы использовали оператор >>
снова, чтобы извлечь данные в переменную myAge, мы получили Mak вместо
25. Если бы мы сделали третье извлечение, то получили бы 25
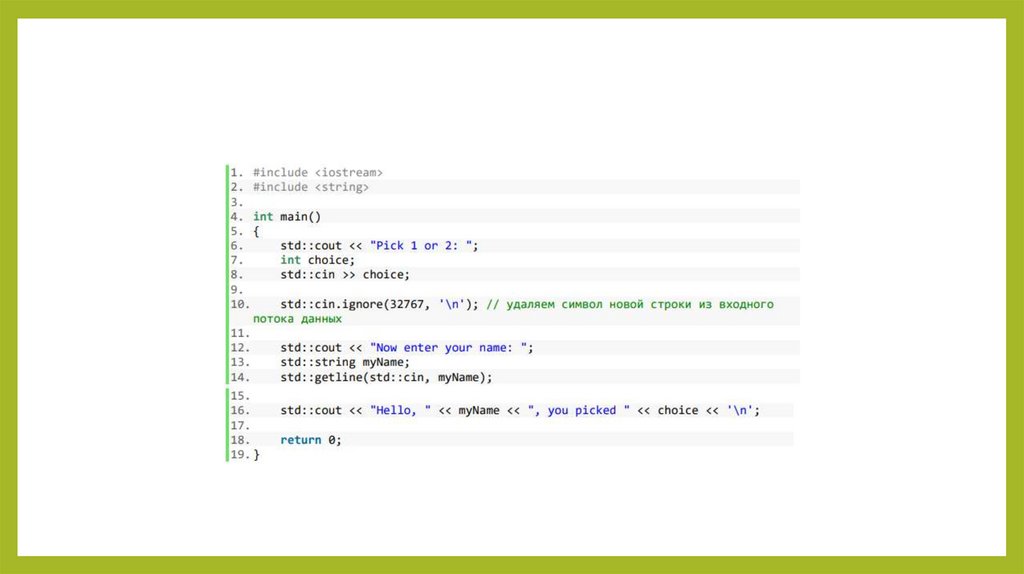
131.
Использование std::getline()• Чтобы извлечь полную строку из входного потока данных (вместе с
пробелами), используйте функцию std::getline(). Она принимает два
параметра: первый — std::cin, второй — переменная типа string
132.
Использование std::getline() c std::cin• Извлечение данных из std::cin с помощью std::getline() иногда может
приводить к неожиданным результатам.
133.
• когда вы запустите эту программу, и она попросит вас ввести ваше имя, онане будет ожидать вашего ввода, а сразу выведет результат (просто пробел
вместо вашего имени)!
• когда вы вводите числовое значение, поток cin захватывает вместе с вашим
числом и символ новой строки. Поэтому, когда мы ввели 2, cin фактически
получил 2\n. Затем он извлек значение 2 в переменную, оставляя \n (символ
новой строки) во входном потоке. Затем, когда std::getline() извлекает данные
для myName, он видит в потоке \n и думает, что мы, должно быть, ввели
просто пустую строку!
134.
• Хорошей практикой является удалять из входного потока данных символновой строки.
135.
136.
Добавление строк• Вы можете использовать оператор + для объединения двух строк или
оператор += для добавления одной строки к другой.
137.
Длина строк138.
Выделение части строки– метод substrs = "0123456789";
s1 = s.substr ( 3, 5 );
cout << s1 << endl;
Фрагмент копирует в строку s1 пять символов строки s (с 3-го по 7-й).
Этот метод принимает два параметра: номер начального символа и
количество символов.
Если второй параметр при вызове substr не указан, метод возвращает все
символы до конца строки. Например,
s = "0123456789";
s1 = s.substr ( 3 );
вернёт «3456789».
139.
Удаление части строки- метод erases = "0123456789";
s.erase ( 3, 6 );
В строке s остаётся значение «0129» (удаляются 6 символов, начиная с 3-го).
Обратите внимание, что процедура erase изменяет строку.
140.
Вставка символов в строку– метод inserts = "0123456789";
s.insert ( 3, "ABC" );
Переменная s получит значение
«012ABC3456789».
141.
Поиск в строке- метод findЭта функция возвращает номер найденного символа (номер первого
символа подстроки) или –1, если найти нужный фрагмент не удалось.
фрагмент не удалось. Пример:
string s = "Здесь был Вася.";
int n;
n = s.find ( 'с' );
if ( n >= 0 )
cout << "Номер первого символа 'c': " << n << endl;
else cout << "Символ не найден " << endl;
142.
Преобразование строки в число143.
Массивы символов• Строки в С++ представляются как массивы элементов
типа char,
• Символьные строки состоят из набора символьных констант
заключённых в двойные кавычки.
• char string[10];
• char string[10] =
{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'f’};
• При объявлении строки не обязательно указывать её размер,
но при этом обязательно нужно её инициализировать
начальным значением.
• char string[]
= "abcdefghf";
144.
• Строка может содержать символы, цифры и специальные знаки. В С++ строкизаключаются в двойные кавычки.
145.
Функционал std::string• Размер и ёмкость:
capacity() — возвращает количество символов, которое строка
может хранить без дополнительного перевыделения памяти;
empty() — возвращает логическое значение, указывающее,
является ли строка пустой;
length(), size() — возвращают количество символов в строке;
max_size() — возвращает максимальный размер строки, который
может быть выделен;
reserve() — расширяет или уменьшает ёмкость строки.
• Доступ к элементам:
146.
Изменение• =, assign() — присваивают новое значение строке;
+=, +, append(), push_back() — добавляют символы к концу строки;
insert() — вставляет символы в произвольный индекс строки;
clear() — удаляет все символы строки;
erase() — удаляет символы по произвольному индексу строки;
replace() — заменяет символы произвольных индексов строки
другими символами;
resize() — расширяет или уменьшает строку (удаляет или добавляет
символы в конце строки);
swap() — меняет местами значения двух строк.
147.
Сравнение строк• ==, != — сравнивают, являются ли две строки равными/неравными
(возвращают значение типа bool);
<, <=, >, >= — сравнивают, являются ли две строки меньше или
больше друг друга (возвращают значение типа bool);
compare() — сравнивает, являются ли две строки
равными/неравными (возвращает -1, 0 или 1).
148.
Поиск:• find — ищет индекс первого символа/подстроки;
find_first_of — ищет индекс первого символа из набора символов;
find_first_not_of — ищет индекс первого символа НЕ из набора символов;
find_last_of — ищет индекс последнего символа из набора символов;
find_last_not_of — ищет индекс последнего символа НЕ из набора
символов;
rfind — ищет индекс последнего символа/подстроки.
149.
• begin(), end() — возвращают «прямой» итератор, указывающий на первый ипоследний (элемент, который идет за последним) элементы строки;
150.
• 1. Напишите программу, которая считывает строку с клавиатуры и выводит ее длину.• 2. Напишите программу, которая определяет, является ли строка палиндромом.
• 3. Напишите программу, которая заменяет все вхождения подстроки в строке на
другую подстроку.
• 4. Напишите программу, которая находит вхождение подстроки "ha" в строку "hello".
• 5. Напишите программу, которая подсчитывает количество раз, когда строка "ha"
встречается в строке "helloha".
• 6. Напишите программу, которая объединяет две строки в одну, используя символ
пробела в качестве разделителя.
• 7. Напишите программу, которая удаляет все пробелы в строке, оставляя только один
пробел между словами.
• 8. Напишите программу, которая разбивает строку на подстроки, разделенные
символом пробела.
• 9. Напишите программу, которая проверяет, является ли заданная строка
палиндромом в алфавите.
• 10. Напишите программу, которая переставляет символы строки в обратном порядке.
151.
Перечисления• Перечисляемые типы
• Перечисление (или
"перечисляемый тип") — это тип
данных, где любое значение
(или "перечислитель")
определяется как символьная
константа. Объявить
перечисление можно с помощью
ключевого слова enum.
152.
• Объявление перечислений не требует выделения памяти. Только когдапеременная перечисляемого типа определена (например, как переменная
paint в примере, приведенном выше), только тогда выделяется память для
этой переменной.
153.
Имена перечислений• Идентификаторы перечислений часто начинаются с заглавной буквы, а имена
перечислителей вообще состоят только из заглавных букв. Поскольку
перечислители вместе с перечислением находятся в едином пространстве
имен, то имена перечислителей не могут повторяться в разных
перечислениях:
154.
Значения перечислителей• Каждому перечислителю
автоматически присваивается
целочисленное значение в
зависимости от его позиции в списке
перечисления.
• По умолчанию, первому
перечислителю присваивается целое
число 0, а каждому следующему — на
единицу больше, чем предыдущему:
155.
Обработка перечислений• Поскольку значениями перечислителей являются целые числа, то их можно
присваивать целочисленным переменным, а также выводить в консоль (как
переменные типа int)
156.
Вывод перечислителей• Попытка вывести перечисляемое
значение с помощью std::cout
приведет к выводу целочисленного
значения самого перечислителя (т.е.
его порядкового номера). Но как
вывести значение перечислителя в
виде текста? Один из способов —
написать функцию с использованием
стейтментов if:
157.
Выделение памяти для перечислений• Перечисляемые типы считаются частью семейства целочисленных типов, и
компилятор сам определяет, сколько памяти выделять для переменных типа
enum. По стандарту C++ размер перечисления должен быть достаточно
большим, чтобы иметь возможность вместить все перечислители. Но чаще
всего размеры переменных enum будут такими же, как и размеры обычных
переменных типа int.
• Поскольку компилятору нужно знать, сколько памяти выделять для
перечисления, то использовать предварительное объявление с ним вы не
сможете. Однако существует простой обходной путь. Поскольку определение
перечисления само по себе не требует выделения памяти и, если
перечисление необходимо использовать в нескольких файлах, его можно
определить в заголовочном файле и подключать этот файл везде, где
необходимо использовать перечисление.
158.
Польза• Перечисляемые типы
лучше всего
использовать при
определении набора
связанных
идентификаторов.
159.
160.
Классы enum• Хотя перечисления и
считаются отдельными
типами данных в языке
C++, они не столь
безопасны и в
некоторых случаях
позволят вам делать
вещи, которые не
имеют смысла.
161.
• Когда C++ будет сравнивать переменные fruit и color, он неявно преобразуетих в целочисленные значения и сравнит эти целые числа. Так как значениями
этих двух переменных являются перечислители, которым присвоено
значение 0, то это означает, что в примере, приведенном выше, fruit = color. А
это не совсем то, что должно быть, так как fruit и color из разных
перечислений и их вообще нельзя сравнивать (фрукт и цвет!). С обычными
перечислителями нет способа предотвратить подобные сравнения
• . Для решения этой проблемы в C++11 добавили классы enum (или
"перечисления с областью видимости"), которые добавляют перечислениям,
как вы уже могли понять, локальную область видимости со всеми её
правилами. Для создания такого класса нужно просто добавить ключевое
слово class сразу после enum.
162.
163.
• Стандартные перечислители находятся в той же области видимости, что исамо перечисление (в глобальной области видимости), поэтому вы можете
напрямую получить к ним доступ (например, PINK). Однако с добавлением
класса, который ограничивает область видимости каждого перечислителя
областью видимости его перечисления, для доступа к нему потребуется
оператор разрешения области видимости (например, Colors::PINK). Это
значительно снижает риск возникновения конфликтов имен.
164.
• вы можете ввести целое число, а затем использовать оператор static_cast,чтобы поместить целочисленное значение в перечисляемый тип:
165.
• С классами enum компиляторбольше не сможет неявно
конвертировать значения
перечислителей в целые числа. Это
хорошо!
• Но иногда могут быть ситуации,
когда нужно будет вернуть эту
особенность. В таких случаях вы
можете явно преобразовать
перечислитель класса enum в тип int,
используя оператор static_cast:
166.
1.Цвета светофора: Определите перечисление TrafficLight с элементами,представляющими цвета светофора: Red, Yellow и Green. Напишите
программу, которая просит пользователя ввести цвет светофора и
выводит сообщение о том, нужно ли остановиться или можно
продолжать движение.
167.
2.Размеры одежды: Определите перечисление ClothingSize сэлементами, представляющими размеры одежды: Small,
Medium, Large и т.д. Напишите программу, которая просит
пользователя выбрать размер одежды и выводит сообщение о
том, какой тип фигуры подходит для данного размера.
168.
• Планеты Солнечной системы: Определите перечисление Planets сэлементами, представляющими планеты Солнечной системы.
Напишите программу, которая принимает от пользователя название
планеты и выводит ее порядковый номер относительно расстояния от
Солнца.
169.
typedef и type alias• Ключевое слово typedef позволяет программисту создать псевдоним для
любого типа данных и использовать его вместо фактического имени типа.
Чтобы объявить typedef (использовать псевдоним типа) — используйте
ключевое слово typedef вместе с типом данных, для которого создается
псевдоним, а затем, собственно, сам псевдоним
170.
• Обычно к псевдонимам typedef добавляют окончание _t, указывая, такимобразом, что идентификатором является тип, а не переменная. typedef не
определяет новый тип данных.
• Это просто псевдоним (другое имя) для уже существующего типа. Его можно
использовать везде, где используется обычный тип
171.
typedef и читабельность кода• typedef используется в улучшении документации и разборчивости кода.
Имена таких типов, как char, int, long, double и bool хороши для описания
того, какой тип возвращает функция, но чаще всего мы хотим знать, с какой
целью возвращается значение
172.
typedef и упрощениеПисать std::vector<std::pair> всякий раз, когда нужно
использовать этот тип — не очень эффективно
173.
174.
type alias• синтаксис typedef становится уже менее привлекательным в связке со
сложными типами данных
• Для решения этих проблем, в C++11 ввели новый улучшенный синтаксис для
typedef, который имитирует способ объявления переменных. Этот синтаксис
называется type alias. С помощью type alias мы пишем имя, которое затем
используется как синоним конкретного типа данных (т.е. принцип тот же, но
синтаксис более удобен)
175.
176.
• Обратите внимание, что хоть мы и используем ключевое слово using, оно неимеет ничего общего с using-стейтментами. Это ключевое слово имеет
различный функционал в зависимости от контекста.
• Новый синтаксис создания псевдонимов создает меньше проблем при
использовании в сложных ситуациях, и его рекомендуется применять вместо
обычного typedef, если ваш компилятор поддерживает C++11.
177.
• Задание №1 Используя следующий прототип функции:• 1. int editData();
• Преобразуйте тип возвращаемого значения int в status_t,
используя ключевое слово typedef. В ответе к этому заданию
укажите стейтмент typedef и обновленный прототип
функции.
178.
• Задание №2 Используя прототип функции из задания №1,преобразуйте тип возвращаемого значения int в status_t,
используя ключевое слово using (C++11). В ответе к этому
заданию укажите стейтмент создания псевдонима типа и
обновленный прототип функци
179.
Массивы180.
Понятие массиваМассив – конечная последовательность однотипных величин, имеющая общее имя.
Аналог понятия массива – вектор.
Формат описания массива:
тип имя_переменной[размер];
тип – тип элементов, хранящихся в массиве;
имя_переменной – название массива;
размер – константное положительное целочисленное выражение, определяющее количество элементов
массива.
Элементы массива размещаются в памяти последовательно.
181.
Примеры описания массивовconst int MAX_SIZE = 20;
const int MAX_LENGTH = 50;
int values[100];
double mas[MAX_SIZE];
short int a[2 * MAX_SIZE];
char s[MAX_LENGTH + 1];
182.
Нумерация элементов массиваВсе элементы массива нумеруются с 0 до размера массива минус 1
Пример
int mas[5];
mas[0] mas[1] mas[2] mas[3] mas[4]
Элементы массива располагаются в памяти последовательно – один за
другим.
Доступ к элементу массива осуществляется по его номеру (индексу).
183.
Доступ к элементам массива поиндексу (присвоение значения)
Присвоение значения элементу массива осуществляется аналогично тому,
как это делается с обычной (скалярной) переменной, только добавляются
квадратные скобки [] c индексом
Формат записи:
имя_переменной[индекс] = выражение;
Пример
int a[5];
a[0] = 20;
for (int i = 0; i < 5; i++)
a[i] = i + 1;
a[0]
a[1]
a[2]
a[3]
a[4]
a[0]
a[1]
a[2]
a[3]
a[4]
1
2
3
4
5
a[0]
a[1]
a[2]
a[3]
a[4]
20
184.
Доступ к элементам массива поиндексу (чтение значения)
Чтение значения элемента массива осуществляется аналогично чтению
значения обычной переменной.
Пример:
int fib[20];
fib[0] = fib[1] = 1;
for (int i = 2; i < 20; i++)
fib[i] = fib[i – 1] + fib[i – 2];
185.
Инициализация массиваС указанием размера массива
//mas[0] = 2, mas[1] = 4, mas[2] = 8, mas[3] = 16
//mas[4] = … = mas[9] = 0
int mas[10] = {2, 4, 8, 16};
//d[0] = 12.4, d[1] = 3.45, d[2] = 1.0, d[3] = 3.2
double d[4] = {12.4, 3.45, 1.0, 3.2};
Без указания размера массива
long a[] = {-2, -1, 0, 1, 2};
186.
Основные операции над массивами• Ввод элементов массива с консоли
• Задание элементам массива случайных значений
• Определение размера массива
• Печать элементов на экран
• Поиск минимального (максимального) элемента
• Сортировка элементов массива
187.
Ввод элементов массива с консолиПример
const int MAX_SIZE = 20;
int mas[MAX_SIZE];
int n;
cin >> n;
for (int i = 0; i < n; i++)
cin >> mas[i];
188.
Задание элементам массива случайныхзначений
Справка по функциям:
Пример
#include <stdlib.h>
#include <time.h>
- задает начальное значение для
последовательности псевдослучайных
чисел.
int rand();
- возвращает следующее
…
srand(time(NULL));
for (int i = 0; i < n; i++)
псевдослучайное число из диапазона 0
до RAND_MAX (32767).
time_t time(time_t *timer);
- возвращает количество секунд,
прошедших с 0:00:00 1 января 1970 г.
{
mas[i] = rand() % 100;
}
void srand(unsigned int seed);
189.
Определение размера массиваПример
int values[] = {5, 33, 22, 4, 5, 6, 7};
int valuesCount = sizeof(values) / sizeof(int);
cout << valuesCount << endl;
190.
Печать элементов на экранПример
int mas[100];
int n; //Количество элементов в массиве
………
cout << “mas : “ << endl;
for (int i = 0; i < n; i++)
cout << mas[i] << “ “;
cout << endl;
191.
Поиск минимального (максимального)элемента
Пример
int min = mas[0];
for (int i = 1; i < n; i++)
{
if (mas[i] < min)
{
min = mas[i];
}
}
cout << "min = " << min << endl;
Нахождение максимального элемента в массиве осуществляется аналогично.
192.
Сортировка элементов массива (методвыбора)
for (int i = 0; i < n - 1; i++)
{
//Поиск минимального элемента среди mas[i],...,mas[n-1]
int minIndex = i;
for (int j = i + 1; j < n; j++)
{
if (mas[j] < mas[minIndex])
minIndex = j;
}
//Обмен местами элементов mas[i] и mas[minIndex]
int tmpValue = mas[i];
mas[i] = mas[minIndex];
mas[minIndex] = tmpValue;
}
193.
Массивы и перечисления• Одна из основных проблем при использовании массивов состоит в том, что
целочисленные индексы не предоставляют никакой информации
программисту об их значении. Рассмотрим класс из 5 учеников:
194.
• Это можно решить, используя перечисление, в котором перечислителисопоставляются каждому из возможных индексов массива:
195.
Массивы и классы enum• Классы enum не имеют неявного преобразования в целочисленный тип,
поэтому, если вы попробуете сделать следующее:
То получите ошибку от компилятора.
196.
• Это можно решить, используя оператор static_cast для конвертацииперечислителя в целое число:
197.
Многомерные массивыМногомерные массивы – это массивы, элементы которых могут быть в свою
очередь массивами.
Формат описания:
тип имя_переменной[размер1][размер2]…[размерN];
Пример:
double matrix[5][6];
int cube[7][7][7];
198.
Доступ к элементам многомерногомассива
Обращение к элементу с индексами (i1, i2, .., iN) в многомерном массиве осуществляется с помощью следующего
выражения:
имя_переменной[i1][i2]…[iN]
Индекс каждого измерения меняется от 0 до размера - 1.
Пример:
int a[3][3];
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++)
a[i][j] = i * 3 + j;
0
1
2
a[0][0] a[0][1] a[0][2]
3
4
5
a[1][0] a[1][1] a[1][2]
6
7
8
a[2][0] a[2][1] a[2][2]
199.
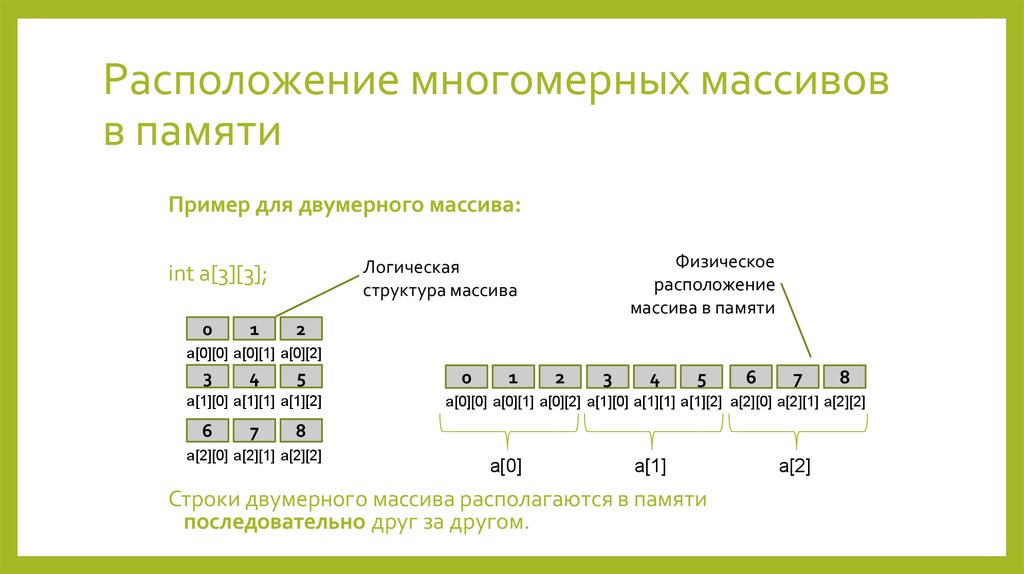
Расположение многомерных массивовв памяти
Пример для двумерного массива:
0
1
Физическое
расположение
массива в памяти
Логическая
структура массива
int a[3][3];
2
a[0][0] a[0][1] a[0][2]
3
4
5
a[1][0] a[1][1] a[1][2]
6
7
0
1
2
3
4
5
6
7
a[0][0] a[0][1] a[0][2] a[1][0] a[1][1] a[1][2] a[2][0] a[2][1] a[2][2]
8
a[2][0] a[2][1] a[2][2]
8
a[0]
a[1]
Строки двумерного массива располагаются в памяти
последовательно друг за другом.
a[2]
200.
Инициализация многомерныхмассивов
Инициализация с группировкой значений по измерениям
int mas[3][2] = { { 0, -2}, {1, 1}, {-5, 45} };
Инициализация без группировки значений по измерениям
int mas1[3][2] = { 0, -2, 1, 1, -5, 45 };
201.
• Создать 2 двумерных массива заполнить рандомными числами найти суммунаибольшее и наименьшее значение из этих массивов
202.
int main()
{
int a[3][3];
for (int i = 0; i < 3; i++){
for (int j = 0; j < 3; j++) {
a[i][j] = i * 3 + j;
}
}
for (int i = 0; i < 3; i++) {
cout << endl;
for (int j = 0; j < 3; j++) {
cout << "[" << a[i][j] << "] ";
}
}
int j = 0;
string d = "";
for (int i = 0; i < 3; i++) {
cout << endl;
cout << d << "[" << a[i][j] << "] ";
j++;
d = d + " ";
}
/*string q[3] = { "
j = 2;
"," ","" };
203.
Пример (вычисления суммы двухматриц) – шаг 1
Объявляем константы максимальных размеров матриц и двумерные массивы для
матриц A, B и С:
……
const int MAX_ROW_COUNT = 10;
const int MAX_COL_COUNT = 10;
int main()
{
int n, m;
int masA[MAX_ROW_COUNT][MAX_COL_COUNT],
masB[MAX_ROW_COUNT][MAX_COL_COUNT], masC[MAX_ROW_COUNT][MAX_COL_COUNT];
204.
Пример (вычисления суммы двухматриц) – шаг 2
Вводим размеры и элементы матриц A и B:
cout << "n = ";
cin >> n;
cout << "m = ";
cin >> m;
cout << "Enter matrix A :" << endl;
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
cin >> masA[i][j];
cout << "Enter matrix B :" << endl;
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
cin >> masB[i][j];
205.
Пример (вычисления суммы двухматриц) – шаг 3
Вычисление суммы двух матриц и вывод результатов:
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
masC[i][j] = masA[i][j] + masB[i][j];
cout << "matrix C = A + B :" << endl;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
cout << masC[i][j] << " ";
cout << endl;
}
return 0;
} //Main
206.
Динамические массивыДинамические массивы – это массивы, размеры которых могут задаваться в процессе исполнения
программы, описываются как указатели и создаются с помощью операции new.
Создание динамического массива
тип* переменная_указатель = new тип [размер];
Память под динамические массивы выделяется в куче.
Освобождение памяти динамического массива
delete[] переменная_указатель;
207.
Пример использования динамическихмассивов
int n;
cin >> n;
int* mas = new int [n];
for (int i = 0; i < n; i++)
mas[i] = i*i;
for (int i = 0; i < n; i++)
cout << mas[i] << “ ”;
cout << endl;
delete[] mas;
208.
Строки C-style• Современный C++ поддерживает два разных типа строк:
• std::string (как часть Стандартной библиотеки С++);
• строки C-style (изначально унаследованные от языка Cи)
209.
Строки C-style• Строка C-style — это простой массив символов, который использует
нультерминатор. Нуль-терминатор — это специальный символ (ASCII-код
которого равен 0), используемый для обозначения конца строки. Строка Cstyle еще называется "нуль-терминированной строкой“
• Для её определения нужно просто объявить массив типа char и
инициализировать его литералом (например, string):
210.
• Хотя string имеет только 6 букв, C++ автоматически добавляет нуль-терминатор в конец строки (нам не нужно добавлять его вручную).
Следовательно, длина массива mystring на самом деле равна 7!
211.
• Важно отметить, что строки C-style следуют всем тем же правилам, что имассивы. Это означает, что вы можете инициализировать строку при
создании, но после этого не сможете присваивать ей значения с помощью
оператора присваивания:
212.
• Поскольку строки C-style являются массивами, то вы можете использоватьоператор [] для изменения отдельных символов в строке:
213.
Строки C-style и std::cin• Есть много случаев, когда мы не знаем заранее, насколько длинной будет
наша строка. Например, рассмотрим проблему написания программы, где мы
просим пользователя ввести свое имя. Насколько длинным оно будет? Это
неизвестно до тех пор, пока пользователь его не введет!
214.
• В программе, приведенной выше, мы объявили массив из 255 символов,предполагая, что пользователь не введет имя длиннее 255 символов. Хоть
это и распространенная практика, но она не очень эффективна, так как
пользователю ничего не мешает ввести имя, содержащее более 255 символов
(случайно или намеренно).
215.
• Вызов cin.getline() будет принимать до 254 символов в массив name (оставляяместо для нуль-терминатора!). Любые лишние символы будут
проигнорированы. Таким образом, мы можем гарантировать, что массив не
будет переполнен
216.
Управление строками C-style• Язык C++ предоставляет множество функций для управления строками C-
style, которые подключаются с помощью заголовочного файла cstring.
• Функция strcpy_s() позволяет копировать содержимое одной строки в
другую. Чаще всего это используется для присваивания значений строке:
217.
• Еще одной полезной функцией управления строками является функцияstrlen(), которая возвращает длину строки C-style (без учета нультерминатора):
218.
• функция strcat() — добавляет одну строку к другой (опасно);• функция strncat() — добавляет одну строку к другой (с проверкой размера
места назначения);
• функция strcmp() — сравнивает две строки (возвращает 0, если они равны);
• функция strncmp() — сравнивает две строки до определенного количества
символов (возвращает 0, если до указанного символа не было различий)
219.
Стоит ли использовать строки C-style?• Знать о строках C-style стоит, так как они используются не так уж и редко, но
использовать их не рекомендуется. Вместо строк C-style используйте
std::string (подключая заголовочный файл string), так как он проще,
безопаснее и гибче.
220.
Указатели• При выполнении инициализации переменной, ей автоматически
присваивается свободный адрес памяти, и, любое значение, которое мы
присваиваем переменной, сохраняется по этому адресу в памяти. Например:
• 1. int b = 8
• При выполнении этого стейтмента процессором, выделяется часть
оперативной памяти. В качестве примера предположим, что переменной b
присваивается ячейка памяти под номером 150. Всякий раз, когда программа
встречает переменную b в выражении или в стейтменте, она понимает, что
для того, чтобы получить значение — ей нужно заглянуть в ячейку памяти
под номером 150.;
221.
• Хорошая новость — нам не нужно беспокоиться о том, какие конкретноадреса памяти выделены для определенных переменных. Мы просто
ссылаемся на переменную через присвоенный ей идентификатор, а
компилятор конвертирует это имя в соответствующий адрес памяти. Однако
этот подход имеет некоторые ограничения, которые мы обсудим на этом и
следующих уроках.
222.
Оператор адреса &• Оператор адреса & позволяет узнать, какой адрес памяти присвоен
определенной переменной.
223.
Оператор разыменования *• Оператор разыменования * позволяет получить значение по указанному
адресу:
224.
Указатели• Указатель — это переменная, значением которой является адрес ячейки
памяти. Указатели объявляются точно так же, как и обычные переменные,
только со звёздочкой между типом данных и идентификатором:
225.
• Синтаксически язык C++ принимает объявление указателя, когда звёздочканаходится рядом с типом данных, с идентификатором или даже посередине.
Обратите внимание, эта звёздочка не является оператором разыменования.
Это всего лишь часть синтаксиса объявления указателя
• Однако, при объявлении нескольких указателей, звёздочка должна
находиться возле каждого идентификатора. Это легко забыть, если вы
привыкли указывать звёздочку возле типа данных, а не возле имени
переменной.
226.
Присваивание значений указателю• Поскольку указатели содержат только адреса, то при присваивании
указателю значения — это значение должно быть адресом. Для получения
адреса переменной используется оператор адреса:
227.
• Вот почему указатели имеют такое имя: ptr содержит адрес значенияпеременной value, и, можно сказать, ptr указывает на это значение.
228.
• Тип указателя должен соответствовать типу переменной, на которую онуказывает:
229.
• не является допустимым:• Это связано с тем, что указатели могут содержать только адреса, а
целочисленный литерал 7 не имеет адреса памяти. Если вы все же сделаете
это, то компилятор сообщит вам, что он не может преобразовать
целочисленное значение в целочисленный указатель.
230.
Разыменование указателей• Как только у нас есть указатель,
указывающий на что-либо, мы
можем его разыменовать, чтобы
получить значение, на которое
он указывает.
• Разыменованный указатель —
это содержимое ячейки памяти,
на которую он указывает:
231.
• Без типа указатель не знал бы, как интерпретировать содержимое, накоторое он указывает (при разыменовании). Также, поэтому и должны
совпадать тип указателя с типом переменной. Если они не совпадают, то
указатель при разыменовании может неправильно интерпретировать биты
(например, вместо типа double использовать тип int).
232.
• Когда адрес значения переменной присвоен указателю, то выполняетсяследующее:
• ptr — это то же самое, что и &value;
• *ptr обрабатывается так же, как и value. Поскольку *ptr обрабатывается так
же, как и value, то мы можем присваивать ему значения так, как если бы это
была обычная переменная. Например:
233.
В чём польза указателей?• Случай №1: Массивы реализованы с помощью указателей. Указатели могут
использоваться для итерации по массиву.
• Случай №2: Они являются единственным способом динамического выделения
памяти в C++. Это, безусловно, самый распространенный вариант использования
указателей.
• Случай №3: Они могут использоваться для передачи большого количества данных в
функцию без копирования этих данных.
• Случай №4: Они могут использоваться для передачи одной функции в качестве
параметра другой функции.
• Случай №5: Они используются для достижения полиморфизма при работе с
наследованием.
• Случай №6: Они могут использоваться для представления одной структуры/класса в
другой структуре/классе, формируя, таким образом, целые цепочки.
234.
Нулевое значение и нулевые указатели• Помимо адресов памяти, есть еще одно значение, которое указатель может
хранить: значение null. Нулевое значение (или "значение null") — это
специальное значение, которое означает, что указатель ни на что не
указывает. Указатель, содержащий значение null, называется нулевым
указателем.
235.
Ключевое слово nullptr в C++11• Обратите внимание, значение 0 не является типом указателя, и присваивание
указателю значения 0 для обозначения того, что он является нулевым —
немного противоречиво.В редких случаях, использование 0 в качестве
аргумента-литерала может привести к проблемам, так как компилятор не
сможет определить, используется ли нулевой указатель или целое число 0:
236.
• Для решения этой проблемы в C++11 ввели новое ключевое слово nullptr,которое также является константой r-value.
• Начиная с C++11, при работе с нулевыми указателями, использование nullptr
является более предпочтительным вариантом, нежели использование 0:
237.
• Язык C++ неявно преобразует nullptr в соответствующий тип указателя. Такимобразом, в вышеприведенном примере, nullptr неявно преобразуется в
указатель типа int, а затем значение nullptr присваивается ptr.
• nullptr также может использоваться для вызова функции (в качестве
аргумента литерала):
238.
Указатели и массивыСходства между указателями и массивами
• Для нас это массив из 4 целых чисел, но для компилятора array является
переменной типа int[4].
• Мы знаем что array[0] = 5, array[1] = 8, array[2] = 6 и array[3] = 4.
• Но какое значение имеет сам array? Переменная array содержит адрес
первого элемента массива, как если бы это был указатель!
239.
240.
• Обратите внимание, адрес, хранящийся в переменной array, являетсяадресом первого элемента массива. Распространенная ошибка думать, что
переменная array и указатель на array являются одним и тем же объектом.
Это не так. Хотя оба указывают на первый элемент массива, информация о
типе данных у них разная. В вышеприведенном примере типом переменной
array является int[4], тогда как типом указателя на массив является int *.
• Путаница вызвана тем, что во многих случаях, при вычислении,
фиксированный массив распадается (неявно преобразовывается) в указатель
на первый элемент массива. Доступ к элементам по-прежнему
осуществляется через указатель, но информация, полученная из типа
массива (например, его размер), не может быть доступна из типа указателя.
241.
• Однако и это не является столь весомым аргументом, чтобы рассматриватьфиксированные массивы и указатели как разные значения. Например, мы
можем разыменовать массив, чтобы получить значение первого элемента:
• Обратите внимание, мы не разыменовываем фактический массив. Массив
(типа int[4]) неявно конвертируется в указатель (типа int *), и мы
разыменовываем указатель, который указывает на значение первого
элемента массива.
242.
Также мы можем создать указатель иприсвоить ему array:
• Это работает из-за того, что переменная array распадается в указатель типа
int *, а тип нашего указателя такой же (т.е. int *).
243.
Различия между указателями имассивами
• Однако есть случаи, когда разница между фиксированными массивами и
указателями имеет значение. Основное различие возникает при
использовании оператора sizeof.
• При использовании в фиксированном массиве, оператор sizeof возвращает
размер всего массива (длина массива * размер элемента). При
использовании с указателем, оператор sizeof возвращает размер адреса
памяти (в байтах).
244.
245.
• Фиксированный массив знает свою длину, а указатель на массив — нет.Второе различие возникает при использовании оператора адреса &.
Используя адрес указателя, мы получаем адрес памяти переменной
указателя.
• Используя адрес массива, возвращается указатель на целый массив. Этот
указатель также указывает на первый элемент массива, но информация о
типе отличается. Вряд ли вам когда-нибудь понадобится это использовать.
246.
Передача массивов в функции• При передаче массива в качестве аргумента в функцию, массив распадается в
указатель на массив и этот указатель передается в функцию:
247.
Обратите внимание, результат будет такимже, даже если параметром будет
фиксированный массив:
248.
• В примере, приведенном выше, C++ неявно конвертирует параметр изсинтаксиса массива ([]) в синтаксис указателя (*). Это означает, что
следующие два объявления функции идентичны:
• 1. void printSize(int array[]);
• 2. void printSize(int *array);
• Некоторые программисты предпочитают использовать синтаксис [], так как
он позволяет понять, что функция ожидает массив, а не указатель на
значение.
• Однако, в большинстве случаев, поскольку указатель не знает, насколько
велик массив, вам придется передавать размер массива в качестве
отдельного параметра (строки являются исключением, так как они нультерминированные).
249.
• Рекомендуется использовать синтаксис указателя, поскольку он позволяетпонять, что параметр будет обработан как указатель, а не как фиксированный
массив, и определенные операции, такие как в случае с оператором sizeof,
будут выполняться с параметром-указателем (а не с параметром-массивом).
250.
Передача по адресу• Тот факт, что массивы распадаются на указатели при передаче в функции,
объясняет основную причину, по которой изменение массива в функции
приведет к изменению фактического массива. Рассмотрим следующий
пример:
251.
• При вызове функции changeArray(), массив распадается на указатель, азначение этого указателя (адрес памяти первого элемента массива)
копируется в параметр ptr функции changeArray().
• Хотя значение ptr в функции является копией адреса массива, ptr все равно
указывает на фактический массив (а не на копию!). Следовательно, при
разыменовании ptr, разыменовывается и фактический массив!
252.
Массивы в структурах и классах• Стоит упомянуть, что массивы, которые являются частью структур или
классов, не распадаются, когда вся структура или класс передается в
функцию.
253.
Адресная арифметика• Язык C++ позволяет выполнять целочисленные операции
сложения/вычитания с указателями. Если ptr указывает на целое число, то ptr
+ 1 является адресом следующего целочисленного значения в памяти после
ptr. ptr - 1 — это адрес предыдущего целочисленного значения (перед ptr).
254.
• Обратите внимание, ptr + 1 не возвращает следующий любой адрес памяти,который находится сразу после ptr, но он возвращает адрес памяти
следующего объекта, тип которого совпадает с типом значения, на которое
указывает ptr.
• Если ptr указывает на адрес памяти целочисленного значения (размер
которого 4 байта), то ptr + 3 будет возвращать адрес памяти третьего
целочисленного значения после ptr. Если ptr указывает на адрес памяти
значения типа char, то ptr + 3 будет возвращать адрес памяти третьего
значения типа char после ptr.
• При вычислении результата выражения адресной арифметики (или
"арифметики с указателями") компилятор всегда умножает целочисленный
операнд на размер объекта, на который указывает указатель.
255.
• Как вы можете видеть, каждыйпоследующий адрес увеличивается на 4.
Это связано с тем, что размер типа int на
моем компьютере составляет 4 байта.
256.
257.
Расположение элементов массива впамяти
• Используя оператор адреса &, мы можем легко определить, что элементы
массива расположены в памяти последовательно. То есть, элементы 0, 1, 2 и
т.д. размещены рядом (друг за другом):
258.
Индексация массивов• Мы уже знаем, что элементы массива расположены в памяти
последовательно и то, что фиксированный массив может распадаться на
указатель, который указывает на первый элемент (элемент под индексом 0)
массива.
• Также мы уже знаем, что добавление единицы к указателю возвращает адрес
памяти следующего объекта этого же типа данных.
• Следовательно, можно предположить, что добавление единицы к
идентификатору массива приведет к возврату адреса памяти второго
элемента (элемента под индексом 1) массива.
259.
• При разыменовании результата выражения адресной арифметики скобкинеобходимы для соблюдения приоритета операций, поскольку оператор *
имеет более высокий приоритет, чем оператор +
260.
• когда компилятор видит оператор индекса [], он, на самом деле,конвертирует его в указатель с операцией сложения и разыменования! То
есть, array[n] — это то же самое, что и *(array + n), где n является
целочисленным значением. Оператор индекса [] используется в целях
удобства, чтобы не нужно было всегда помнить о скобках.
261.
Использование указателя дляитерации по массиву
• Мы можем использовать
указатели и адресную
арифметику для выполнения
итераций по массиву.
• Хотя обычно это не делается
(использование оператора
индекса, как правило,
читабельнее и менее
подвержено ошибкам),
следующий пример показывает,
что это возможно:
262.
• Программа использует указатель для прогона каждого элемента массивапоочередно. Помните, что массив распадается в указатель на первый элемент
массива? Поэтому, присвоив name для ptr, сам ptr стал указывать на первый
элемент массива.
• Каждый элемент разыменовывается с помощью выражения switch, и, если
текущий элемент массива является гласной буквой, то numVowels
увеличивается. Для перемещения указателя на следующий символ (элемент)
массива в цикле for используется оператор ++. Работа цикла завершится,
когда все символы будут проверены.
263.
• Напишите функцию, которая принимает два числа по ссылке и меняет их местами.• Создайте функцию, которая принимает массив по указателю и находит сумму всех его
элементов.
• Реализуйте функцию, которая принимает указатель на строку и возвращает ее длину.
• Напишите программу, которая принимает массив чисел и находит наибольший и
наименьший элементы, используя указатели.
• Создайте функцию, которая принимает указатель на массив чисел и сортирует его в
порядке возрастания.
• Напишите программу, которая принимает указатель на массив строк и выводит их в
обратном порядке.
• Реализуйте функцию, которая принимает указатель на структуру и изменяет ее поля.
• Создайте программу, которая принимает указатель на функцию и вызывает ее.
• Напишите функцию, которая принимает указатель на функцию сравнения и сортирует
массив объектов с использованием этой функции.
• Реализуйте программу, которая принимает указатель на класс и вызывает его методы.
264.
Ссылки• До этого момента мы успели рассмотреть 2 основных типа переменных:
• обычные переменные, которые хранят значения напрямую;
• указатели, которые хранят адрес другого значения (или null), для доступа к
которым выполняется операция разыменования указателя.
• Ссылки — это третий базовый тип переменных в языке C++.
265.
• Ссылка — это тип переменной в языке C++, который работает как псевдонимдругого объекта или значения. Язык C++ поддерживает 3 типа ссылок:
• Ссылки на неконстантные значения (обычно их называют просто «ссылки»
или «неконстантные ссылки»), которые мы обсудим на этом уроке.
• Ссылки на константные значения (обычно их называют «константные
ссылки»), которые мы обсудим на следующем уроке.
• В C++11 добавлены ссылки r-value.
• Ссылка (на неконстантное значение) объявляется с использованием
амперсанда (&) между типом данных и именем ссылки:
266.
• Ссылки обычно ведут себя идентично значениям, на которые они ссылаются.В этом смысле ссылка работает как псевдоним объекта, на который она
ссылается, например:
267.
Инициализация ссылок• Ссылки должны быть инициализированы при создании:
• В отличие от указателей, которые могут содержать нулевое значение, ссылки
нулевыми быть не могут. Ссылки на неконстантные значения могут быть
инициализированы только неконстантными l-values. Они не могут быть
инициализированы константными l-values или r-values:
268.
Ссылки в качестве параметров вфункциях
• Ссылки чаще всего используются в качестве параметров в функциях. В этом
контексте ссылка-параметр работает как псевдоним аргумента, а сам
аргумент не копируется при передаче в параметр. Это в свою очередь
улучшает производительность, если аргумент слишком большой или
затратный для копирования.
269.
• Когда аргумент x передается в функцию, то параметр функции ref становитсяссылкой на аргумент x. Это позволяет функции изменять значение x
непосредственно через ref! Обратите внимание, переменная x не
обязательно должна быть ссылкой.
• Совет: Передавайте аргументы в функцию через неконстантные ссылки-
параметры, если они должны быть изменены функцией в дальнейше
270.
Ссылки vs. Указатели• Ссылка — это тот же указатель, который неявно разыменовывается при
доступе к значению, на которое он указывает ("под капотом" ссылки
реализованы с помощью указателей). Таким образом, в следующем коде:
271.
• Поскольку ссылки должны быть инициализированы корректными объектами(они не могут быть нулевыми) и не могут быть изменены позже, то они, как
правило, безопаснее указателей (так как риск разыменования нулевого
указателя отпадает). Однако они немного ограничены в функциональности
по сравнению с указателями.
• Если определенное задание может быть решено с помощью как ссылок, так и
указателей, то лучше использовать ссылки. Указатели следует использовать
только в тех ситуациях, когда ссылки являются недостаточно эффективными
(например, при динамическом выделении памяти).
272.
Динамическое выделение памяти• Язык С++ поддерживает три основных типа выделения (или "распределения")
памяти, с двумя из которых, мы уже знакомы:
• Статическое выделение памяти выполняется для статических и глобальных
переменных. Память выделяется один раз (при запуске программы) и
сохраняется на протяжении работы всей программы.
• Автоматическое выделение памяти выполняется для параметров функции и
локальных переменных. Память выделяется при входе в блок, в котором
находятся эти переменные, и удаляется при выходе из него.
• Динамическое выделение памяти
273.
Динамическое выделение переменных• Как статическое, так и автоматическое распределение памяти имеют два
общих свойства:
• Размер переменной/массива должен быть известен во время компиляции.
• Выделение и освобождение памяти происходит автоматически (когда
переменная создается/уничтожается).
274.
• Например, при использовании строки для хранения имени пользователя, мыне знаем наперед насколько длинным оно будет, пока пользователь его не
введет.
• Или нам нужно создать игру с непостоянным количеством монстров (во
время игры одни монстры умирают, другие появляются, пытаясь, таким
образом, убить игрока).
• Если нам нужно объявить размер всех переменных во время компиляции, то
самое лучшее, что мы можем сделать — это попытаться угадать их
максимальный размер, надеясь, что этого будет достаточно:
275.
276.
Это плохое решение, по крайней мере,по трем причинам:
• Во-первых, теряется память, если переменные фактически не используются
или используются, но не все. Например, если мы выделим 30 символов для
каждого имени, но имена в среднем будут занимать по 15 символов, то
потребление памяти получится в два раза больше, чем нам нужно на самом
деле. Или рассмотрим массив rendering: если он использует только 20 000
полигонов, то память для других 20 000 полигонов фактически тратится
впустую (т.е. не используется)!
• Во-вторых, память для большинства обычных переменных (включая
фиксированные массивы) выделяется из специального резервуара памяти —
стека. Объем памяти стека в программе, как правило, невелик: в Visual Studio
он по умолчанию равен 1МБ. Если вы превысите это значение, то произойдет
переполнение стека, и операционная система автоматически завершит
выполнение вашей программы.
277.
• Лимит в 1МБ памяти может быть проблематичным для многих программ,особенно где используется графика.
• В-третьих, и самое главное, это может привести к искусственным
ограничениям и/или переполнению массива. Что произойдет, если
пользователь попытается прочесть 500 записей с диска, но мы выделили
память максимум для 400? Либо мы выведем пользователю ошибку, что
максимальное количество записей — 400, либо (в худшем случае) выполнится
переполнение массива и затем что-то очень нехорошее.
278.
• Динамическое выделение памяти — это способ запроса памяти изоперационной системы запущенными программами по мере необходимости.
Эта память не выделяется из ограниченной памяти стека программы, а
выделяется из гораздо большего хранилища, управляемого операционной
системой — кучи.
• На современных компьютерах размер кучи может составлять гигабайты
памяти. Для динамического выделения памяти одной переменной
используется оператор new:
279.
• В примере, приведенном выше, мы запрашиваем выделение памяти дляцелочисленной переменной из операционной системы. Оператор new
возвращает указатель, содержащий адрес выделенной памяти
• Для доступа к выделенной памяти создается указатель:
• Затем мы можем разыменовать указатель для получения значения:
280.
std::array• Ранее мы подробно говорили о фиксированных и динамических массивах.
Хотя они очень полезны и активно используются в языке C++, у них также
есть свои недостатки: фиксированные массивы распадаются в указатели,
теряя информацию о своей длине; в динамических массивах проблемы могут
возникнуть с освобождением памяти и с попытками изменить их длину после
выделения.
• Поэтому в Стандартную библиотеку C++ добавили функционал, который
упрощает процесс управления массивами: std::array и std::vector.
281.
• Представленный в C++11, std::array — это фиксированный массив, который нераспадается в указатель при передаче в функцию. std::array определяется в
заголовочном файле array, внутри пространства имен std. Объявление
переменной std::array следующее:
282.
• Доступ к значениям массива через оператор индекса осуществляется какобычно:
• std::array поддерживает вторую форму доступа к элементам массива —
функция at(), которая осуществляет проверку диапазона:
283.
С помощью функции size() можноузнать длину массива
284.
• Вы можете отсортировать std::array, используя функцию std::sort(), котораянаходится в заголовочном файле algorithm:
285.
ВЕКТОР В С++286.
Vector• В отличие от std::array, который недалеко отходит от базового функционала
обычных фиксированных массивов, std::vector идет в комплекте с
дополнительными возможностями, которые делают его одним из самых
полезных и универсальных инструментов в языке C++.
• Представленный в C++, vector (или просто «вектор») — это тот же
динамический массив, но который может сам управлять выделенной себе
памятью. Это означает, что вы можете создавать массивы, длина которых
задается во время выполнения, без использования операторов new и
delete (явного указания выделения и освобождения памяти). vector
находится в заголовочном файле vector.
287.
Создание288.
Обратите внимание, что в неинициализированном, что в инициализированном случаях вам не нужноявно указывать длину массивов. Это связано с тем, что std::vector динамически выделяет память для
своего содержимого по запросу.
Подобно std::array, доступ к элементам массива может выполняться как через оператор (который не
выполняет проверку диапазона), так и через функцию at() (которая выполняет проверку диапазона):
[]
289.
AT• Разница между c[i] и c.at(i) заключается в том, что at() вызывает
исключение std::out_of_range , если i выходит за пределы диапазона вектора, в
то время как operator[] просто вызывает неопределенное поведение, что
означает, что может произойти все, что угодно.
290.
Длина векторов• В отличие от стандартных динамических массивов, которые не знают свою
длину, std::vector свою длину запоминает. Чтобы её узнать, нужно
использовать функцию size():
291.
• Изменить длину стандартного динамически выделенного массива довольнопроблематично и сложно. Изменить длину std::vector так же просто, как
вызвать функцию resize():
292.
МетодыДля добавления нового элемента в конец вектора используется
метод push_back(). Количество элементов определяется методом size(). Для
доступа к элементам вектора можно использовать квадратные скобки [],
также, как и для обычных массивов.
•pop_back() — удалить последний элемент
•clear() — удалить все элементы вектора
•empty() — проверить вектор на пустоту
293.
294.
295.
296.
297.
• Напишите программу, которая принимает целочисленные значения отпользователя и сохраняет их в векторе. Затем выведите содержимое вектора.
• Реализуйте функцию, которая принимает вектор чисел и возвращает сумму
всех элементов.
• Напишите программу, которая находит наименьший и наибольший элементы
в векторе.
• Напишите программу, которая сортирует вектор чисел в порядке
возрастания.
298.
• Параметр функции (или "формальный параметр") — это переменная,создаваемая в объявлении функции:
• Аргумент (или "фактический параметр") — это значение, которое передает в
функцию вызывающий объект (caller)
• Существует 3 основных способа передачи аргументов в функцию:
• передача по значению;
• передача по ссылке;
• передача по адресу.
299.
. Передача по значению• По умолчанию, аргументы в C++ передаются по значению. Когда аргумент
передается по значению, то его значение копируется в параметр функции.
Например:
300.
• В первом вызове функции boo()аргументом является литерал 7. При
вызове boo() создается переменная y, в
которую копируется значение 7. Затем,
когда boo() завершает свое выполнение,
переменная y уничтожается.
• Поскольку в функцию передается копия
аргумента, то исходное значение не может
быть изменено функцией.
301.
Плюсы и минусы передачи по значению• Плюсы передачи по значению:
• Аргументы, переданные по значению, могут быть переменными (например,
x), литералами (например, 8), выражениями (например, x + 2), структурами,
классами или перечислителями (т.е. почти всем, чем угодно).
• Аргументы никогда не изменяются функцией, в которую передаются, что
предотвращает возникновение побочных эффектов
302.
• Минусы передачи по значению:• Копирование структур и классов может привести к значительному снижению
производительности (особенно, когда функция вызывается много раз).
• Когда использовать передачу по значению:
• При передаче фундаментальных типов данных и перечислителей, когда
предполагается, что функция не должна изменять аргумент.
• Когда не использовать передачу по значению:
• При передаче массивов, структур и классов.
303.
Передача по ссылке• Хотя передача по значению является хорошим вариантом во многих случаях,
она имеет несколько ограничений.
• Во-первых, при передаче по значению большой структуры или класса в
функцию, создается копия аргумента и уже эта копия передается в параметр
функции. В большинстве своем это бесполезная трата ресурсов, которая
снижает производительность.
• Во-вторых, при передаче аргументов по значению, единственный способ
вернуть значение обратно в вызывающий объект — это использовать
возвращаемое значение функции. Но иногда случаются ситуации, когда
нужно, чтобы функция изменила значение переданного аргумента. Передача
по ссылке решает все эти проблемы
304.
Передача по ссылке• При передаче переменной по ссылке нужно просто объявить параметры
функции как ссылки, а не как обычные переменные:
305.
• При вызове функции переменная x станет ссылкой на аргумент. Посколькуссылка на переменную обрабатывается точно так же, как и сама переменная,
то любые изменения, внесенные в ссылку, приведут к изменениям исходного
значения аргумента! В следующем примере это хорошо проиллюстрировано:
306.
Передача по константной ссылке307.
Плюсы и минусы передачи по ссылке• Плюсы передачи по ссылке:
• Ссылки позволяют функции изменять значение аргумента, что иногда
полезно. В противном случае, для гарантии того, что функция не изменит
значение аргумента, нужно использовать константные ссылки.
• Поскольку при передаче по ссылке копирования аргументов не происходит,
то этот способ гораздо эффективнее и быстрее передачи по значению,
особенно при работе с большими структурами или классами.
• Ссылки могут использоваться для возврата сразу нескольких значений из
функции (через параметры вывода).
308.
• Минусы передачи по ссылке:• Трудно определить, является ли параметр, переданный по неконстантной
ссылке, параметром ввода, вывода или того и другого одновременно.
Разумное использование const и суффикса Out для внешних переменных
решает эту проблему.
• По вызову функции невозможно определить, будет аргумент изменен
функцией или нет. Аргумент, переданный по значению или по ссылке,
выглядит одинаково. Мы можем определить способ передачи аргумента
только просмотрев объявление функции. Это может привести к ситуации,
когда программист не сразу поймет, что функция изменяет значение
аргумента.
309.
• Когда использовать передачу по ссылке:• при передаче структур или классов (используйте const, если нужно только
для чтения);
• когда нужно, чтобы функция изменяла значение аргумента.
• Когда не использовать передачу по ссылке:
• при передаче фундаментальных типов данных (используйте передачу по
значению);
• при передаче обычных массивов (используйте передачу по адресу)
310.
Перегрузка функций• Перегрузка функций — это возможность определять несколько функций с
одним и тем же именем, но с разными параметрами. Например:
• Здесь мы выполняем операцию вычитания с целыми числами. Однако, что,
если нам нужно использовать числа типа с плавающей запятой? Эта функция
совсем не подходит, так как любые параметры типа double будут
конвертироваться в тип int, в результате чего будет теряться дробная часть
значений.
• Одним из способов решения этой проблемы является определение двух
функций с разными именами и параметрами
311.
• Но есть и лучшее решение — перегрузка функции. Мы можем простообъявить еще одну функцию subtract(), которая принимает параметры типа
double:
312.
313.
• Может показаться, что произойдет конфликт имен, но это не так. Компиляторможет определить сам, какую версию subtract() следует вызывать на основе
аргументов, используемых в вызове функции. Если параметрами будут
переменные типа int, то C++ понимает, что мы хотим вызвать subtract(int, int).
• Если же мы предоставим два значения типа с плавающей запятой, то C++
поймет, что мы хотим вызвать subtract(double, double). Фактически, мы можем
определить столько перегруженных функций subtract(), сколько хотим, до тех
пор, пока каждая из них будет иметь свои (уникальные) параметры.
314.
Параметры по умолчанию• Параметр по умолчанию (или «необязательный параметр») — это параметр
функции, который имеет определенное (по умолчанию) значение. Если
пользователь не передает в функцию значение для параметра, то
используется значение по умолчанию. Если же пользователь передает
значение, то это значение используется вместо значения по умолчанию.
Например
315.
Несколько параметров по умолчанию316.
Стек и Куча• Память, которую используют программы, состоит из нескольких частей —
сегментов:
• Сегмент кода (или «текстовый сегмент»), где находится скомпилированная
программа. Обычно доступен только для чтения.
• Сегмент bss (или «неинициализированный сегмент данных»), где хранятся
глобальные и статические переменные, инициализированные нулем.
• Сегмент данных (или «сегмент инициализированных данных»), где хранятся
инициализированные глобальные и статические переменные.
• Куча, откуда выделяются динамические переменные.
Стек вызовов, где
хранятся параметры функции, локальные переменные и другая информация,
связанная с функциями.
317.
Куча• Сегмент кучи (или просто «куча») отслеживает память, используемую для
динамического выделения. Мы уже немного поговорили о куче на уроке о
динамическом выделении памяти. В языке C++ при использовании оператора
new динамическая память выделяется из сегмента кучи самой программы:
• Адрес выделяемой памяти передается обратно оператором new и затем он
может быть сохранен в указателе. О механизме хранения и выделения
свободной памяти нам сейчас беспокоиться незачем. Однако стоит знать, что
последовательные запросы памяти не всегда приводят к выделению
последовательных адресов памяти
318.
• При удалении динамически выделенной переменной, память возвращаетсяобратно в кучу и затем может быть переназначена (исходя из последующих
запросов). Помните, что удаление указателя не удаляет переменную, а
просто приводит к возврату памяти по этому адресу обратно в операционную
систему
319.
Куча имеет свои преимущества инедостатки
• Выделение памяти в куче сравнительно медленное.
• Выделенная память остается выделенной до тех пор, пока не будет
освобождена (остерегайтесь утечек памяти) или пока программа не завершит
свое выполнение.
• Доступ к динамически выделенной памяти осуществляется только через
указатель. Разыменование указателя происходит медленнее, чем доступ к
переменной напрямую.
• Поскольку куча представляет собой большой резервуар памяти, то именно
она используется для выделения больших массивов, структур или классов.
320.
Стек вызовов• Стек вызовов (или просто «стек») отслеживает все активные функции (те,
которые были вызваны, но еще не завершены) от начала программы и до
текущей точки выполнения, и обрабатывает выделение всех параметров
функции и локальных переменных.
• Стек вызовов реализуется как структура данных «Стек». Поэтому, прежде чем
мы поговорим о том, как работает стек вызовов, нам нужно понять, что такое
стек как структура данных
321.
Пример• Например, рассмотрим несколько почтовых ящиков, которые расположены
друг на друге. Каждый почтовый ящик может содержать только один
элемент, и все почтовые ящики изначально пустые. Кроме того, каждый
почтовый ящик прибивается гвоздем к почтовому ящику снизу, поэтому
количество почтовых ящиков не может быть изменено. Если мы не можем
изменить количество почтовых ящиков, то как мы получим поведение,
подобное стеку?
322.
Пример• Во-первых, мы используем наклейку для обозначения того, где находится
самый нижний пустой почтовый ящик. Вначале это будет первый почтовый
ящик, который находится на полу. Когда мы добавим элемент в наш стек
почтовых ящиков, то мы поместим этот элемент в почтовый ящик, на котором
будет наклейка (т.е. в самый первый пустой почтовый ящик на полу), а затем
переместим наклейку на один почтовый ящик выше.
• Когда мы вытаскиваем элемент из стека, то мы перемещаем наклейку на один
почтовый ящик ниже и удаляем элемент из почтового ящика. Всё, что
находится ниже наклейки - находится в стеке. Всё, что находится в ящике с
наклейкой и выше — находится вне стека.
323.
• В компьютерном программировании стек представляет собой контейнер (какструктуру данных), который содержит несколько переменных (подобно
массиву). Однако, в то время как массив позволяет получить доступ и
изменять элементы в любом порядке (так называемый «произвольный
доступ»), стек более ограничен.
• В стеке вы можете:
• Посмотреть на верхний элемент стека (используя функцию top() или peek()).
• Вытянуть верхний элемент стека (используя функцию pop()).
• Добавить новый элемент поверх стека (используя функцию push()).
• Стек — это структура данных типа LIFO (англ. "Last In, First Out" = "Последним
пришел, первым ушел"). Последний элемент, который находится на вершине
стека, первым и уйдет из него. Если положить новую тарелку поверх других
тарелок, то именно эту тарелку вы первой и возьмете. По мере того, как
элементы помещаются в стек — стек растет, по мере того, как элементы
удаляются из стека — стек уменьшается.
324.
Сегмент стека вызовов• Сегмент стека вызовов содержит память, используемую для стека вызовов.
При запуске программы, функция main() помещается в стек вызовов
операционной системой. Затем программа начинает свое выполнение. Когда
программа встречает вызов функции, то эта функция помещается в стек
вызовов. При завершении выполнения функции, она удаляется из стека
вызовов. Таким образом, просматривая функции, добавленные в стек, мы
можем видеть все функции, которые были вызваны до текущей точки
выполнения.
325.
• Во-первых, мы используем наклейку для обозначения того, где находитсясамый нижний пустой почтовый ящик. Вначале это будет первый почтовый
ящик, который находится на полу. Когда мы добавим элемент в наш стек
почтовых ящиков, то мы поместим этот элемент в почтовый ящик, на котором
будет наклейка (т.е. в самый первый пустой почтовый ящик на полу), а затем
переместим наклейку на один почтовый ящик выше.
• Когда мы вытаскиваем элемент из стека, то мы перемещаем наклейку на
один почтовый ящик ниже и удаляем элемент из почтового ящика. Всё, что
находится ниже наклейки - находится в стеке. Всё, что находится в ящике с
наклейкой и выше — находится вне стека.
326.
Рекурсия и Числа Фибоначчи• Рекурсивная функция (или просто "рекурсия") в языке C++ — это функция,
которая вызывает сама себя. Например
327.
• При вызове функции countOut(4) на экран выведется push 4, а затемвызывается countOut(3). countOut(3) выведет push 3 и вызывает countOut(2).
Последовательность вызова countOut(n) других функций countOut(n-1)
повторяется бесконечное количество раз (аналог бесконечного цикла).
Попробуйте запустить у себя.
• При Изучении стека и кучи мы узнали, что при каждом вызове функции,
определенные данные помещаются в стек вызовов. Поскольку функция
countOut() никогда ничего не возвращает (она просто снова вызывает
countOut()), то данные этой функции никогда не вытягиваются из стека!
Следовательно, в какой-то момент, память стека закончится и произойдет
переполнение стека.
328.
Условие завершения рекурсии• Рекурсивные вызовы функций работают точно так же, как и обычные вызовы
функций. Однако, программа, приведенная выше, иллюстрирует наиболее
важное отличие простых функций от рекурсивных: вы должны указать
условие завершения рекурсии, в противном случае — функция будет
выполняться «бесконечно» (фактически до тех пор, пока не закончится
память в стеке вызовов).
• Условие завершения рекурсии — это условие, которое, при его выполнении,
остановит вызов рекурсивной функции самой себя. В этом условии обычно
используется оператор if
329.
330.
• Теперь, когда мы обсудили основной механизм вызова рекурсивных функций,давайте взглянем на несколько другой тип рекурсии, который более
распространен
331.
• Рассмотреть рекурсию с первого взгляда на код не так уж и легко. Лучшимвариантом будет посмотреть, что произойдет при вызове рекурсивной
функции с определенным значением. Например, посмотрим, что произойдет
при вызове вышеприведенной функции с value = 4:
332.
Числа Фибоначчи• Одним из наиболее известных математических рекурсивных алгоритмов
является последовательность Фибоначчи. Последовательность Фибоначчи
можно увидеть даже в природе: ветвление деревьев, спираль ракушек, плоды
ананаса, разворачивающийся папоротник и т.д
333.
Спираль Фибоначчи выглядитследующим образом:
334.
• Каждое из чисел Фибоначчи — это длина горизонтальной стороны квадрата,в которой находится данное число. Математически числа Фибоначчи
определяются следующим образом:
335.
336.
• Факториал целого числа N определяется как умножение всех чисел между 1 иN (0! = 1). Напишите рекурсивную функцию factorial(), которая возвращает
факториал ввода. Протестируйте её с помощью первых 8 чисел.
337.
Эллипсис• Эллипсис (англ. "ellipsis"), который представлен в виде многоточия … в языке
C++, всегда должен быть последним параметром в функции. О нем можно
думать, как о массиве, который содержит любые другие параметры, кроме
тех, которые указаны в список_аргументов.
338.
339.
Структуры• В программировании есть много случаев, когда может понадобиться больше
одной переменной для представления определенного объекта. Например,
для представления самого себя, вы, скорее всего, захотите указать свое имя,
день рождения, рост, вес или любую другую информацию
340.
• Но теперь у вас есть 6 отдельных независимых переменных. Если вы захотитепередать информацию о себе в функцию, то вам придется передавать
каждую переменную по отдельности. Кроме того, если вы захотите хранить
информацию о ком-то еще, то вам придется дополнительно объявить еще 6
переменных на каждого человека! Невооруженным глазом видно, что такая
реализация не очень эффективна.
• К счастью, язык C++ позволяет программистам создавать свои собственные
пользовательские типы данных — типы, которые группируют несколько
отдельных переменных вместе. Одним из простейших пользовательских
типов данных является структура. Структура позволяет сгруппировать
переменные разных типов в единое целое.
341.
Объявление и определение структур• Поскольку структуры определяются программистом, то вначале мы должны
сообщить компилятору, как она вообще будет выглядеть. Для этого
используется ключевое слово struct
342.
• Мы определили структуру с именем Employee. Она содержит 3 переменные• id типа short;
• age типа int;
• salary типа double.
• Эти переменные, которые являются частью структуры, называются членами
структуры (или "полями структуры"). Employee — это простое объявление
структуры. Хотя мы и указали компилятору, что она имеет переменныечлены, память под нее сейчас не выделяется. Имена структур принято писать
с заглавной буквы, чтобы отличать их от имен переменных.
343.
• Чтобы использовать структуру Employee, нам нужно просто объявитьпеременную типа Employee:
• Здесь мы определили переменную типа Employee с именем john. Как и в
случае с обычными переменными, определение переменной, типом которой
является структура, приведет к выделению памяти для этой переменной.
344.
Доступ к членам структур• Когда мы объявляем переменную структуры, например, Employee john, то
john ссылается на всю структуру. Для того, чтобы получить доступ к
отдельным её членам, используется оператор выбора члена (.). Например, в
коде, приведенном ниже, мы используем оператор выбора членов для
инициализации каждого члена структуры:
345.
Инициализация структур• Инициализация структур путем присваивания значений каждому члену по
порядку — занятие довольно громоздкое (особенно, если этих членов много),
поэтому в языке C++ есть более быстрый способ инициализации структур — с
помощью списка инициализаторов. Он позволяет инициализировать
некоторые или все члены структуры во время объявления переменной типа
struct:
346.
• Если в списке инициализаторов не будет одного или нескольких элементов,то им присвоятся значения по умолчанию (обычно, 0). В примере,
приведенном выше, члену james.salary присваивается значение по
умолчанию 0.0, так как мы сами не предоставили никакого значения во время
инициализации.
347.
В C++11 добавили возможностьприсваивать членам структуры значения по
умолчанию
348.
Структуры и функции• Большим преимуществом
использования структур,
нежели отдельных
переменных, является
возможность передать всю
структуру в функцию,
которая должна работать с
её членами:
349.
Функция также может возвращатьструктуру
350.
Вложенные структуры• В этом случае, если бы мы хотели
узнать, какая зарплата у CEO
(исполнительного директора), то
нам бы пришлось использовать
оператор выбора членов дважды:
351.
Размер структур• Как правило, размер структуры — это сумма размеров всех её членов, но не
всегда! Например, рассмотрим структуру Employee. На большинстве
платформ тип short занимает 2 байта, тип int — 4 байта, а тип double — 8 байт.
Следовательно, ожидается, что Employee будет занимать 2 + 4 + 8 = 14 байт.
Чтобы узнать точный размер Employee, мы можем воспользоваться
оператором sizeof:
352.
Доступ к структурам из несколькихфайлов
• Поскольку объявление структуры не провоцирует выделение памяти, то
использовать предварительное объявление для нее вы не сможете. Но есть
обходной путь: если вы хотите использовать объявление структуры в
нескольких файлах (чтобы иметь возможность создавать переменные этой
структуры в нескольких файлах), поместите объявление структуры в
заголовочный файл и подключайте этот файл везде, где необходимо
использовать структуру.
• Переменные типа struct подчиняются тем же правилам, что и обычные
переменные. Следовательно, если вы хотите сделать переменную структуры
доступной в нескольких файлах, то вы можете использовать ключевое слово
extern.
353.
1.Создайте структуру Person, которая содержит поля для имени, возраста и адреса. Напишитепрограмму, которая принимает данные о нескольких людях и выводит их на экран.
2.Реализуйте структуру Point, представляющую точку в трехмерном пространстве с полями x, y и
z. Напишите функцию, которая вычисляет расстояние между двумя точками.
3.Создайте структуру Rectangle, которая содержит поля для ширины и высоты прямоугольника.
Напишите функцию, которая вычисляет площадь и периметр прямоугольника.
4.Реализуйте структуру Student, содержащую поля для имени, возраста и средней оценки.
Напишите программу, которая принимает данные о нескольких студентах и выводит
информацию о самом старшем студенте.
5.Создайте структуру Date, представляющую дату с полями для дня, месяца и года. Напишите
функцию, которая определяет, является ли заданная дата високосной.
354.
6.Реализуйте структуру Circle, содержащую поле для радиуса окружности. Напишите функцию, которая вычисляетдлину окружности и площадь круга.
7.Создайте структуру Book, содержащую поля для названия, автора и года выпуска книги. Напишите программу,
которая принимает данные о нескольких книгах и выводит информацию о самой старой книге.
8.Реализуйте структуру Employee, содержащую поля для имени, должности и заработной платы сотрудника.
Напишите программу, которая принимает данные о нескольких сотрудниках и выводит информацию о сотруднике с
наивысшей заработной платой.
9.Создайте структуру Car, содержащую поля для марки, модели и года выпуска автомобиля. Напишите программу,
которая принимает данные о нескольких автомобилях и выводит информацию о самом старом автомобиле.
10.Реализуйте структуру Fraction, представляющую дробь с числителем и знаменателем. Напишите функции для
сложения, вычитания, умножения и деления дробей.
355.
. Введение в ООП• Так что же тогда является объектно-ориентированным программированием?
Для лучшего понимания воспользуемся аналогией. Оглянитесь вокруг, везде
находятся объекты: книги, здания, еда и даже вы сами.
• Объекты имеют два основных компонента:
• свойства (например, вес, цвет, размер, прочность, форма и т.д.);
• поведение, которое они могут проявлять (например, открывать что-либо,
делать что-то и т.д.). Свойства и поведение неотделимы друг от друга
356.
• Объектно-ориентированное программирование (сокр. "ООП") предоставляетвозможность создавать объекты, которые объединяют свойства и поведение
в самостоятельный союз, который затем можно многоразово использовать.
• Объектно-ориентированное программирование также предоставляет
несколько других полезных концепций, таких как наследование,
инкапсуляция, абстракция и полиморфизм. Мы рассмотрим каждую из этих
концепций на соответствующих уроках. Будет много нового материала, но
как только вы разберетесь с ООП, вам уже не захочется возвращаться к
традиционному программированию.
357.
Классы, Объекты и Методы• Хотя язык C++ предоставляет ряд фундаментальных типов данных
(например, char, int, long, float, double и т.д.), которых бывает достаточно для
решения относительно простых проблем, для решения сложных проблем
функционала этих простых типов может не хватать.
358.
Классы• Одной из наиболее полезных особенностей языка C++ является возможность
определять собственные типы данных, которые будут лучше соответствовать
в решении конкретных проблем. Вы уже видели, как перечисления и
структуры могут использоваться для создания собственных
пользовательских типов данных. Например, структура для хранения даты:
359.
• Перечисления и структуры — это традиционный (не объектно-ориентированный) мир программирования, в котором мы можем только
хранить данные. В C++11 мы можем создать и инициализировать структуру
следующим образом:
360.
• Для вывода даты на экран (что может понадобиться выполнить и не раз, и недва) хорошей идеей будет написать отдельную функцию, например:
361.
• В объектно-ориентированном программировании типы данных могутсодержать не только данные, но и функции, которые будут работать с этими
данными. Для определения такого типа данных в языке C++ используется
ключевое слово class. Использование ключевого слова class определяет
новый пользовательский тип данных — класс.
• В языке C++ классы очень похожи на структуры, за исключением того, что
они обеспечивают гораздо большую мощность и гибкость. Фактически,
следующая структура и класс идентичны по функционалу:
362.
• Единственным существенным отличием здесьявляется public — ключевое слово в классе (о нем
мы поговорим детально на соответствующем
уроке). Так же, как и объявление структуры,
объявление класса не приводит к выделению
какой-либо памяти. Для использования класса
нужно объявить переменную этого типа класса
363.
• В языке C++ переменная класса называется экземпляром (или "объектом")класса. Точно так же, как определение переменной фундаментального типа
данных (например, int x) приводит к выделению памяти для этой
переменной, так же создание объекта класса (например, DateClass today)
приводит к выделению памяти для этого объекта.
364.
Методы классов• Помимо хранения данных, классы могут содержать и функции! Функции,
определенные внутри класса, называются методами. Методы могут быть
определены, как внутри, так и вне класса.
365.
Точно так же, как к членам структуры, так ик членам (переменным и функциям) класса
доступ осуществляется через оператор
выбора членов (.):
366.
• Обратите внимание, как эта программа похожа на вышеприведеннуюпрограмму, где используется структура. Однако есть несколько отличий. В
версии DateStruct нам нужно было передать переменную структуры
непосредственно в функцию print() в качестве параметра. Если бы мы этого
не сделали, то функция print() не знала бы, какую переменную структуры
DateStruct выводить. Нам тогда бы пришлось явно ссылаться на члены
структуры внутри функции.
• Методы класса работают несколько иначе: все вызовы методов должны быть
связаны с объектом класса. Когда мы вызываем today.print(), то мы сообщаем
компилятору вызвать метод print() объекта today.
367.
• На что фактически ссылаются m_day, m_month и m_year? Они ссылаются насвязанный объект today (который определен caller-ом). Поэтому, при вызове
today.print(), компилятор интерпретирует:
• m_day, как today.m_day;
• m_month, как today.m_month;
• m_year, как today.m_year.
• Если бы мы вызвали tomorrow.print(), то m_day ссылался бы на
tomorrow.m_day.
368.
пример программы с использованиемкласса
369.
• когда вы создаете объект любого из этих типов, вы создаете объект класса. Акогда вы вызываете функцию с использованием этих объектов, вы вызываете
метод:
370.
• Используйте ключевое слово struct для структур, используемых только дляхранения данных. Используйте ключевое слово class для объектов,
объединяющих как данные, так и функции.
371.
Модификаторыы доступа public иprivate
• Здесь мы объявляем структуру DateStruct, а
затем напрямую обращаемся к её членам для
их инициализации. Это работает, так как все
члены структуры являются открытыми по
умолчанию. Открытые члены (или "publicчлены") — это члены структуры или класса, к
которым можно получить доступ извне этой же
структуры или класса. В программе,
приведенной выше, функция main() находится
вне структуры, но она может напрямую
обращаться к членам day, month и year, так как
они являются открытыми.
372.
373.
• Вам бы не удалось скомпилировать эту программу, так как все члены классаявляются закрытыми по умолчанию. Закрытые члены (или "private-члены") —
это члены класса, доступ к которым имеют только другие члены этого же
класса.
• Поскольку функция main() не является членом DateClass, то она и не имеет
доступа к закрытым членам объекта date.
374.
• Хотя члены класса являются закрытыми по умолчанию, мы можем сделать ихоткрытыми, используя ключевое слово public:
375.
• Ключевое слово public вместе с двоеточием называется спецификаторомдоступа. Спецификатор доступа определяет, кто имеет доступ к членам этого
спецификатора. Каждый из членов «приобретает» уровень доступа в
соответствии со спецификатором доступа (или, если он не указан, в
соответствии со спецификатором доступа по умолчанию).
• В языке C++ есть 3 уровня доступа:
• спецификатор public делает члены открытыми;
• спецификатор private делает члены закрытыми;
• спецификатор protected открывает доступ к членам только для
дружественных и дочерних классов (детально об этом на соответствующем
уроке).
376.
377.
Структуры vs. Классы• Теперь, когда мы узнали о спецификаторах доступа, мы можем поговорить о
фактических различиях между классом и структурой в языке C++. Класс по
умолчанию устанавливает всем своим членам спецификатор доступа private.
Структура же по умолчанию устанавливает всем своим членам спецификатор
доступа public.
• Есть еще одно незначительное отличие: структуры наследуют от других
конструкций языка С++ открыто, в то время как классы наследуют закрыто
378.
Зачем делать переменные-членыкласса закрытыми?
• В качестве ответа, воспользуемся аналогией. В современной жизни мы имеем
доступ ко многим электронным устройствам. К телевизору есть пульт
дистанционного управления, с помощью которого можно
включать/выключать телевизор. Управление автомобилем позволяет в разы
быстрее передвигаться между двумя точками. С помощью фотоаппарата
можно делать снимки.
• Все эти 3 вещи используют общий шаблон: они предоставляют вам простой
интерфейс (кнопка, руль и т.д.) для выполнения определенного действия.
Однако, то, как эти устройства фактически работают, скрыто от вас (как от
пользователей). Для нажатия кнопки на пульте дистанционного управления
вам не нужно знать, что выполняется «под капотом» пульта для
взаимодействия с телевизором. Когда вы нажимаете на педаль газа в своем
автомобиле, вам не нужно знать о том, как двигатель внутреннего сгорания
приводит в движение колеса.
379.
• Когда вы делаете снимок, вам не нужно знать, как датчики собирают свет впиксельное изображение. Такое разделение интерфейса и реализации
чрезвычайно полезно, поскольку оно позволяет использовать объекты, без
необходимости понимания их реализации. Это значительно снижает
сложность использования этих устройств и значительно увеличивает их
количество (устройства с которыми можно взаимодействовать). По
аналогичным причинам разделение реализации и интерфейса полезно и в
программировании.
380.
Инкапсуляция• В объектно-ориентированном программировании инкапсуляция (или
"сокрытие информации") — это процесс скрытого хранения деталей
реализации объекта. Пользователи обращаются к объекту через открытый
интерфейс.
• В языке C++ инкапсуляция реализована через спецификаторы доступа. Как
правило, все переменные-члены класса являются закрытыми (скрывая детали
реализации), а большинство методов являются открытыми (с открытым
интерфейсом для пользователя).
• Хотя требование к пользователям использовать интерфейс может показаться
более обременительным, нежели просто открыть доступ к переменнымчленам, но на самом деле это предоставляет большое количество полезных
преимуществ, которые улучшают возможность повторного использования
кода и его поддержку.
381.
Конструкторы• Когда все члены класса (или структуры) являются открытыми, то мы можем
инициализировать класс (или структуру) напрямую, используя список
инициализаторов или uniform-инициализацию (в C++11):
382.
• Однако, как только мы сделаем какие-либо переменные-члены классазакрытыми, то больше не сможем инициализировать их напрямую. Здесь есть
смысл: если вы не можете напрямую обращаться к переменной (потому что
она закрыта), то вы и не должны иметь возможность напрямую её
инициализировать.
• Как тогда инициализировать класс с закрытыми переменными-членами?
Использовать конструкторы
383.
• Конструктор — это особый тип метода класса, который автоматическивызывается при создании объекта этого же класса. Конструкторы обычно
используются для инициализации переменных-членов класса значениями,
которые предоставлены по умолчанию/пользователем, или для выполнения
любых шагов настройки, необходимых для используемого класса (например,
открыть определенный файл или базу данных).
• В отличие от обычных методов, конструкторы имеют определенные правила
их именования:
• конструкторы всегда должны иметь то же имя, что и класс (учитываются
верхний и нижний регистры);
• конструкторы не имеют типа возврата (даже void).
384.
• Обратите внимание, конструкторы предназначены только для выполненияинициализации. Не следует пытаться вызывать конструктор для повторной
инициализации существующего объекта. Хотя это может скомпилироваться
без ошибок, результаты могут получиться неожиданные (компилятор создаст
временный объект, а затем удалит его).
385.
Конструкторы по умолчанию• Конструктор, который не
имеет параметров (или
содержит параметры,
которые все имеют значения
по умолчанию), называется
конструктором по
умолчанию. Он вызывается,
если пользователем не
указаны значения для
инициализации. Например:
386.
• Этот класс содержит дробь в виде отдельных значений типа int. Конструкторпо умолчанию называется Fraction (как и класс). Поскольку мы создали
объект класса Fraction без аргументов, то конструктор по умолчанию
сработал сразу же после выделения памяти для объекта, и инициализировал
наш объект
• Результат выполнения программы: 0/1
387.
• Обратите внимание, наш числитель (m_numerator) и знаменатель(m_denominator) были инициализированы значениями, которые мы задали в
конструкторе по умолчанию! Это настолько полезная особенность, что почти
каждый класс имеет свой конструктор по умолчанию. Без него значениями
нашего числителя и знаменателя был бы мусор до тех пор, пока мы явно не
присвоили бы им нормальные значения.
388.
Конструкторы с параметрами• Хотя конструктор по умолчанию
отлично подходит для обеспечения
инициализации наших классов
значениями по умолчанию, часто
может быть нужно, чтобы экземпляры
нашего класса имели определенные
значения, которые мы предоставим
позже. К счастью, конструкторы также
могут быть объявлены с параметрами.
Вот пример конструктора, который
имеет два целочисленных параметра,
которые используются для
инициализации числителя и
знаменателя:
389.
• Обратите внимание, теперь у нас есть два конструктора: конструктор поумолчанию, который будет вызываться, если мы не предоставим значения, и
конструктор с параметрами, который будет вызываться, если мы предоставим
значения. Эти два конструктора могут мирно сосуществовать в одном классе
благодаря перегрузке функций. Фактически, вы можете определить любое
количество конструкторов до тех пор, пока у них будут уникальные
параметры (учитывается их количество и тип).
390.
391.
• Значения по умолчанию для конструкторов работают точно так же, как и длялюбой другой функции, поэтому в вышеприведенном примере, когда мы
вызываем seven(7), вызывается Fraction(int, int), второй параметр которого
равен 1 (значение по умолчанию).
• Правило: Используйте прямую инициализацию или uniform-инициализацию
с объектами ваших классов.
392.
393.
• Рекомендуется всегда создавать по крайней мере один конструктор в классе.Это позволит вам контролировать процесс создания объектов вашего класса,
и предотвратит возникновение потенциальных проблем после добавления
других конструкторов.
394.
Классы, содержащие другие классы• Одни классы могут содержать
другие классы в качестве
переменных-членов. По
умолчанию, при создании
внешнего класса, для
переменных-членов будут
вызываться конструкторы по
умолчанию. Это произойдет до
того, как тело конструктора
выполнится. Это можно
продемонстрировать следующим
образом:
395.
• Результат выполнения программы: A B• При создании переменной b вызывается конструктор B(). Прежде чем тело
конструктора выполнится, m_a инициализируется, вызывая конструктор по
умолчанию класса A. Таким образом выведется A. Затем управление
возвратится обратно к конструктору B, и тело конструктора B начнет свое
выполнение. Здесь есть смысл, так как конструктор B() может захотеть
использовать переменную m_a, поэтому сначала нужно инициализировать
m_a!
396.
Деструкторы• Деструктор — это специальный тип метода класса, который выполняется при
удалении объекта класса. В то время как конструкторы предназначены для
инициализации класса, деструкторы предназначены для очистки памяти после него.
• Когда объект автоматически выходит из области видимости или динамически
выделенный объект явно удаляется с помощью ключевого слова delete, вызывается
деструктор класса (если он существует) для выполнения необходимой очистки до
того, как объект будет удален из памяти. Для простых классов (тех, которые только
инициализируют значения обычных переменных-членов) деструктор не нужен, так
как C++ автоматически выполнит очистку самостоятельно.
• Однако, если объект класса содержит любые ресурсы (например, динамически
выделенную память или файл/базу данных), или, если вам необходимо выполнить
какие-либо действия до того, как объект будет уничтожен, деструктор является
идеальным решением, поскольку он производит последние действия с объектом
перед его окончательным уничтожением.
397.
Имена деструкторов• Так же, как и конструкторы, деструкторы имеют свои правила, которые
касаются их имен:
• деструктор должен иметь то же имя, что и класс, со знаком тильда (~) в
самом начале;
• деструктор не может принимать аргументы;
• деструктор не имеет типа возврата.
• Из второго правила вытекает еще одно правило: для каждого класса может
существовать только один деструктор, так как нет возможности перегрузить
деструкторы, как функции, и отличаться друг от друга аргументами они не
могут.
398.
399.
Выполнение конструкторов идеструкторов
• Как мы уже знаем, конструктор
вызывается при создании
объекта, а деструктор — при
его уничтожении. В следующем
примере мы будем
использовать стейтменты с cout
внутри конструктора и
деструктора для отображения
их времени выполнения
400.
Результат выполнения программы:• Constructing Another 1
• 1
• Constructing Another 2
•2
• Destructing Another 2
• Destructing Another 1
• Обратите внимание, Another 1 уничтожается после Another 2, так как мы
удалили pObject до завершения выполнения функции main(), тогда как
объект object не был удален до конца main()
401.
Скрытый указатель *this• как C++ отслеживает то, какой объект его вызвал?». Ответ заключается в том,
что C++ для этих целей использует скрытый указатель *this!
402.
403.
• Результат выполнения программы: 4• При вызове another.setNumber(4); C++ понимает, что функция setNumber()
работает с объектом another, а m_number — это фактически
another.m_number. Рассмотрим детально, как это всё работает.
• Возьмем, к примеру, следующую строку: 1. another.setNumber(4);
404.
• Хотя на первый взгляд кажется, что у нас здесь только один аргумент, но насамом деле у нас их два! Во время компиляции строка another.setNumber(4);
конвертируется компилятором в следующее:
• 1. setNumber(&another, 4); // объект another конвертировался из объекта,
который находился перед точкой, в аргумент функции!
405.
• Теперь это всего лишь стандартный вызов функции, а объект another(который ранее был отдельным объектом и находился перед точкой) теперь
передается по адресу в качестве аргумента функции.
• Но это только половина дела. Поскольку в вызове функции теперь есть два
аргумента, то и метод нужно изменить соответствующим образом (чтобы он
принимал два аргумента). Следовательно, следующий метод:
406.
• При компиляции обычного метода, компилятор неявно добавляет к немупараметр *this. Указатель *this — это скрытый константный указатель,
содержащий адрес объекта, который вызывает метод класса.
• Есть еще одна деталь. Внутри метода также необходимо обновить все члены
класса (функции и переменные), чтобы они ссылались на объект, который
вызывает этот метод. Это легко сделать, добавив префикс this-> к каждому из
них. Таким образом, в теле функции setNumber(), m_number (переменнаячлен класса) будет конвертирована в this->m_number. И когда *this указывает
на адрес another, то this->m_number будет указывать на another.m_number.
407.
• Соединяем всё вместе:• При вызове another.setNumber(4) компилятор фактически вызывает
setNumber(&another, 4).
• Внутри setNumber() указатель *this содержит адрес объекта another.
• К любым переменным-членам внутри setNumber() добавляется префикс this-
>. Поэтому, когда мы говорим m_number = number, компилятор фактически
выполняет this -> m_number = number, который, в этом случае, обновляет
another.m_number на number.
408.
• Хорошей новостью является то, что это всё происходит скрыто от нас(программистов), и не имеет значения, помните ли вы, как это работает или
нет. Всё, что вам нужно запомнить — все обычные методы класса имеют
указатель *this, который указывает на объект, связанный с вызовом метода
класса.
409.
Указатель *this всегда указывает натекущий объект
• Начинающие программисты иногда путают, сколько указателей *this
существует. Каждый метод имеет в качестве параметра указатель *this,
который указывает на адрес объекта, с которым в данный момент
выполняется операция, например:
• Обратите внимание, указатель *this поочерёдно содержит адрес объектов X
или Y в зависимости от того, какой метод вызван и сейчас выполняется.
410.
Явное указание указателя *this• В большинстве случаев вам не нужно явно указывать указатель *this. Тем не
менее, иногда это может быть полезным. Например, если у вас есть
конструктор (или метод), который имеет параметр с тем же именем, что и
переменная-член, то устранить неоднозначность можно с помощью
указателя *this:
411.
• Здесь конструктор принимает параметр с тем же именем, что и переменная-член. В этом случае data относится к параметру, а this->data относится к
переменной-члену. Хотя это приемлемая практика, но рекомендуется
использовать префикс m_ для всех имен переменных-членов вашего класса,
так как это помогает предотвратить дублирование имен в целом!
412.
Статические переменные-члены класса• мы уже знаем, что статические переменные сохраняют свои значения и не
уничтожаются даже после выхода из блока, в котором они объявлены,
например:
• Результат выполнения программы: 1 2 3
413.
• Обратите внимание, s_id сохраняет свое значение после каждого вызовафункции generateID(). Ключевое слово static имеет другое значение, когда
речь идет о глобальных переменных — оно предоставляет им внутреннюю
связь (что ограничивает их видимость/использование за пределами файла, в
котором они определены).
• Поскольку использование глобальных переменных – это зло, то ключевое
слово static в этом контексте используется не очень часто.
• В языке C++ ключевое слово static можно использовать в классах:
статические переменные-члены и статические методы. Мы поговорим о
статических переменных-членах на этом уроке, а о статических методах на
следующем.
414.
• Прежде чем мы перейдем к ключевому слову static с переменными-членамикласса, давайте сначала рассмотрим следующий класс:
415.
• При создании объекта класса, каждый объект получает свою собственнуюкопию всех переменных-членов класса. В этом случае, поскольку мы
объявили два объекта класса Anything, у нас будет две копии m_value:
first.m_value и second.m_value.
• Это разные значения, следовательно, результат выполнения программы: 4 3
416.
• Переменные-члены класса можно сделать статическими, используя ключевоеслово static. В отличие от обычных переменных-членов, статические
переменные-члены являются общими для всех объектов класса. Рассмотрим
следующую программу:
417.
• Поскольку s_value является статической переменной-членом, то она являетсяобщей для всех объектов класса Anything. Следовательно, first.s_value — это
та же переменная, что и second.s_value. Вышеприведенная программа
показывает, что к значению, которое мы установили через первый объект,
можно получить доступ и через второй объект.
418.
Дружественные функции и классы• мы говорили о том, что данные вашего класса должны быть private. Однако
может возникнуть ситуация, когда у вас есть класс и функция, которая
работает с этим классом, но которая не находится в его теле. Например, есть
класс, в котором хранятся данные, и функция (или другой класс), которая
выводит эти данные на экран. Хотя код класса и код функции вывода
разделены (для упрощения поддержки кода), код функции вывода тесно
связан с данными класса. Следовательно, сделав члены класса private, мы
желаемого эффекта не добьемся.
419.
В таких ситуациях есть два варианта:• Сделать открытыми методы класса и через них функция будет
взаимодействовать с классом. Однако здесь есть несколько нюансов. Вопервых, эти открытые методы нужно будет определить, на что потребуется
время, и они будут загромождать интерфейс класса. Во-вторых, в классе
нужно будет открыть методы, которые не всегда должны быть открытыми и
предоставляющими доступ извне.
• Использовать дружественные классы и дружественные функции, с помощью
которых можно будет предоставить функции вывода доступ к закрытым
данным класса. Это позволит функции вывода напрямую обращаться ко всем
закрытым переменным-членам и методам класса, сохраняя при этом
закрытый доступ к данным класса для всех остальных функций вне тела
класса! На этом уроке мы рассмотрим, как это делается.
420.
Дружественные функции• Дружественная функция — это функция, которая имеет доступ к закрытым
членам класса, как если бы она сама была членом этого класса. Во всех
других отношениях дружественная функция является обычной функцией. Ею
может быть, как обычная функция, так и метод другого класса. Для
объявления дружественной функции используется ключевое слово friend
перед прототипом функции, которую вы хотите сделать дружественной
классу. Неважно, объявляете ли вы её в public- или в privateзоне класса.
Например:
421.
422.
• Здесь мы объявили функцию reset(), которая принимает объект классаAnything и устанавливает m_value значение 0. Поскольку reset() не является
членом класса Anything, то в обычной ситуации функция reset() не имела бы
доступа к закрытым членам Anything. Однако, поскольку эта функция
является дружественной классу Anything, она имеет доступ к закрытым
членам Anything.
• Обратите внимание, мы должны передавать объект Anything в функцию
reset() в качестве параметра. Это связано с тем, что функция reset() не
является методом класса. Она не имеет указателя *this и, кроме как передачи
объекта, она не сможет взаимодействовать с классом.
423.
424.
• Здесь мы объявили функцию isEqual() дружественной классу Something.Функция isEqual() принимает в качестве параметров два объекта класса
Something. Поскольку isEqual() является другом класса Something, то
функция имеет доступ ко всем
• Здесь мы объявили функцию isEqual() дружественной классу Something.
Функция isEqual() принимает в качестве параметров два объекта класса
Something. Поскольку isEqual() является другом класса Something, то
функция имеет доступ ко всем
425.
Дружественныеклассы
• Один класс может быть
дружественным другому
классу. Это откроет всем
членам первого класса
доступ к закрытым
членам второго класса,
например:
426.
• Поскольку класс Display является другом класса Values, то любой из членовDisplay имеет доступ к private-членам Values. Результат выполнения
программы: 8.4 7
427.
Примечания о дружественных классах:• Во-первых, даже несмотря на то, что Display является другом Values, Display
не имеет прямой доступ к указателю *this объектов Values.
• Во-вторых, даже если Display является другом Values, это не означает, что
Values также является другом Display. Если вы хотите сделать оба класса
дружественными, то каждый из них должен указать в качестве друга
противоположный класс. Наконец, если класс A является другом B, а B
является другом C, то это не означает, что A является другом C
428.
Наследование• Наследование (inheritance) представляет один из ключевых аспектов
объектно-ориентированного программирования, который позволяет
наследовать функциональность одного класса (базового класса) в другом производном классе (derived class).
• Зачем нужно наследование? Рассмотрим небольшую ситуацию, допустим, у
нас есть классы, которые представляют человека и сотрудника компании:
429.
430.
• В данном случае класс Employee фактически содержит функционал классаPerson: свойства name и age и функцию print. В целях демонстрации все
переменные здесь определены как рубличные. И здесь, с одной стороны, мы
сталкиваемся с повторением функционала в двух классах. С другой строны,
мы также сталкиваемся с отношением is ("является"). То есть мы можем
сказать, что сотрудник компании ЯВЛЯЕТСЯ человеком. Так как сотрудник
компании имеет в принципе все те же признаки, что и человек (имя, возраст),
а также добавляет какие-то свои (компанию). Поэтому в этом случае лучше
использовать механизм наследования. Унаследуем класс Employee от класса
Person:
431.
432.
• Для установки отношения наследования после названия класса ставитсядвоеточие, затем идет спецификатор доступа и название класса, от которого
мы хотим унаследовать функциональность. В этом отношении класс Person
еще будет называться базовым классом (также называют суперклассом,
родительским классом), а Employee - производным классом (также называют
подклассом, классом-наследником).
• Спецификатор доступа позволяет указать, к каким членам класса
производный класс будет иметь доступ. В данном случае используется
спецификатор public, который позволяет использовать в производном классе
все публичные члены базового класса. Если мы не используем модификатор
доступа, то класс Employee ничего не будет знать о переменных name и age и
функции print.
433.
После установкинаследования мы
можем убрать из
класса Employee те
переменные,
которые уже
определены в классе
Person. Используем
оба класса:
434.
Конструкторы• Но теперь сделаем все
переменные приватными, а для
их инициализации добавим
конструкторы. И тут стоит
учитывать, что конструкторы
при наследовании не
наследуются. И если базовый
класс содержит только
конструкторы с параметрами, то
производный класс должен
вызывать в своем конструкторе
один из конструкторов базового
класса:
435.
• После списка параметров конструктора производного класса черездвоеточие идет вызов конструктора базового класса, в который передаются
значения параметров n и a.
436.
Подключение конструктора базовогокласса
• В примерах выше конструктор
Employee отличается от
конструктора Person одним
параметром - company. Все
остальные параметры из Employee
передаются в Person. Однако, если
бы у нас было бы полное
соответствие по параметрам между
двумя классами, то мы могли бы и не
определять отдельный конструктор
для Employee, а подключить
конструктор базового класса:
437.
• Здесь в классе Employee подключаем конструктор базового класса спомощью ключевого слова using:
• Таким образом, класс Employee фактически будет иметь тот же конструктор,
что и Person с теми же двумя параметрами. И этот конструктор мы также
можем вызвать для создания объекта Employee:
438.
Запрет наследования• Иногда наследование от класса может быть нежелательно. И с помощью
спецификатора final мы можем запретить наследование:
• После этого мы не сможем унаследовать другие классы от класса User. И,
например, если мы попробуем написать, как в случае ниже, то мы столкнемся
с ошибкой:
439.
полиморфизм• Слово полиморфизм означает наличие многих форм. Как правило,
полиморфизм возникает, когда существует иерархия классов, и они связаны
наследованием.
• Полиморфизм C ++ означает, что вызов функции-члена вызовет выполнение
другой функции в зависимости от типа объекта, который вызывает эту
функцию.
440.
ПЕРЕГРУЗКА ИПЕРЕОПРЕДЕЛЕНИЕ
441.
• Перегрузка (англ. overloading) означает, что у вас в одной области видимостиопределено несколько функций с одинаковым именем.
• Переопределение(англ. overriding) Функция в дочернем классе
переопределяет функцию в родительском классе.
442.
переопределение функции443.
444.
Функция переопределения доступа в C++• Чтобы получить доступ к
переопределенной
функции базового класса,
мы используем оператор
разрешения области
видимости ::.
445.
446.
вызов из производного класса447.
448.
с использованием указателя449.
450.
Перегрузка• class A {
void print();
void print(int i);
void print(int I, double b);
• };
451.
452.
ШАБЛОНЫ ФУНКЦИЙ453.
• Хотя функции и классы являются мощными и гибкими инструментами дляэффективного программирования, в некоторых случаях они ограничены изза требования C++ указывать типы всех используемых параметров.
Например, предположим, что нам нужно написать функцию для вычисления
наибольшего среди двух чисел:
454.
• Всё отлично до тех пор, пока мы работаем с целочисленными значениями. Ачто, если нам придется работать и со значениями типа double? Вы, вероятно,
решите перегрузить функцию max() для работы с типом double:
455.
• Однако, поскольку C++ требует, чтобы мы указывали типы нашихпеременных, нам приходится записывать несколько версий одной и той же
функции, где единственное, что меняется — это тип параметров.
• И, что самое важное, это нарушает одну из концепций эффективного
программирования — сократить до минимума дублирование кода. Правда,
было бы неплохо написать одну версию функции max(), которая работала бы
с параметрами ЛЮБОГО типа?
456.
• В языке C++ шаблоны функций — это функции, которые служат образцом длясоздания других подобных функций.
• Главная идея — создание функций без указания точного типа(ов) некоторых
или всех переменных. Для этого мы определяем функцию, указывая тип
параметра шаблона, который используется вместо любого типа данных.
После того, как мы создали функцию с типом параметра шаблона, мы
фактически создали «трафарет функции».
457.
Создание шаблонов функций• Мы можем назвать этот тип как угодно, главное, чтобы это не было
зарезервированным/ключевым словом. В языке C++ принято называть типы
параметров шаблонов большой буквой T (сокр. от «Type»).
458.
• Чтобы всё заработало, нам нужно сообщить компилятору две вещи:• Определение шаблона функции.
• Указание того, что Т является типом параметра шаблона функции. Мы можем
сделать это в одной строке кода, выполнив объявление шаблона (а точнее —
объявление параметров шаблона):
459.
460.
• Сначала пишем ключевое слово template, которое сообщает компилятору,что дальше мы будем объявлять параметры шаблона.
• Параметры шаблона функции указываются в угловых скобках (<>).
• Для создания типов параметров шаблона используются ключевые слова
typename .
• Затем называем тип параметра шаблона (обычно T).
461.
• Если требуется несколько типов параметров шаблона, то они разделяютсязапятыми:
462.
Примечание• : Поскольку тип аргумента функции,
передаваемый в тип T, может быть
классом, а классы, как правило, не
рекомендуется передавать по
значению, то лучше сделать
параметры и возвращаемое значение
нашего шаблона функции
константными ссылками, например:
463.
ИСКЛЮЧЕНИЯ464.
465.
• Примеры действий в программе, которые могут привести к возникновениюисключительных ситуаций:
• деление на нуль;
• нехватка оперативной памяти при использовании оператора new для ее
выделения (или другой функции);
• доступ к элементу массива за его пределами (ошибочный индекс);
• переполнение значения для некоторого типа;
• взятие корня из отрицательного числа;
466.
• Для перехвата и обработки исключительных ситуаций в языке C++введена конструкция try…catch, которая имеет следующую общую
форму:
• type1, type2, …, typeN – соответственно тип
аргументов argument1, argument2, …, argumentN.
467.
Оператор throw.• Чтобы в блоке try сгенерировать исключительную ситуацию, нужно
использовать оператор throw. Оператор throw может быть вызван внутри
блока try или внутри функции, которая вызывается из блока try.
468.
• В языке C++ оператор throw используется для сигнализирования овозникновении исключения или ошибки (аналогия тому, когда свистит
арбитр). Сигнализирование о том, что произошло исключение, называется
генерацией исключения (или "выбрасыванием исключения").6
469.
Исключения обрабатываютсянемедленно
470.
471.
• добавим несколько компонентов, которые помогут среагировать на даннуюситуацию без прерывания работы программы. А именно:
• блок try или try-блок (попытка, проба);
• генератор исключения – блок throw (обработать, запустить);
• обработчик исключения, который его перехватывает -
команда catch (поймать, ловить)
472.
473.
• Обработка исключений, на самом деле, довольно-таки проста, и всё, что вамнужно запомнить, размещено в следующих двух абзацах:
При выбрасывании исключения (оператор throw), точка выполнения
программы немедленно переходит к ближайшему блоку try. Если какой-либо
из обработчиков catch, прикрепленных к блоку try, обрабатывает этот тип
исключения, то точка выполнения переходит в этот обработчик и, после
выполнения кода блока catch, исключение считается обработанным.
Если подходящих обработчиков catch не существует, то выполнение
программы переходит в следующий блок try. Если до конца программы не
найдены соответствующие обработчики catch, то программа завершает свое
выполнение с ошибкой исключения.
474.
Есть три распространенные вещи, которыевыполняют блоки catch, когда они поймали
исключение:
Во-первых, блок catch может вывести сообщение об ошибке (либо в
консоль, либо в лог-файл).
Во-вторых, блок catch может возвратить значение или код ошибки обратно
в caller.
В-третьих, блок catch может сгенерировать другое исключения. Поскольку
блок catch не находится внутри блока try, то новое сгенерированное
исключение будет обрабатываться следующим блоком try.
475.
// обработка выражения sqrt(a)/sqrt(b)476.
#include <iostream> using namespace std; void main() { // обработка выражения sqrt(a)/sqrt(b) double a, b; cout << "a = "; cin >> a; cout << "b = "; cin >> b;477.
void exception() {
int a;
std::cout << "VVEDITE A";
std::cin >> a;
if (a == 1) {
throw 123;
}
else if (a == 4) {
throw 124;
}
else if (a == 2) {
throw 1.2;
}
else if (a == 3) {
throw "Error #3";
}
}
int main()
{