




























 informatics
informatics database
databaseSimilar presentations:








")

Data Mining
1.
Data MiningПроцесс извлечения знаний из различных
источников данных, таких как базы данных,
текст, картинки, видео и т.д. Полученные
знания должны быть достоверными,
полезными и интерпретируемыми.
2.
Data Mining, интеллектуальный анализ данных(ИАД) — это процесс обнаружения в сырых данных
ранее неизвестных, нетривиальных, практически
полезных, доступных интерпретации знаний,
необходимых для принятия решений в различных
сферах человеческой деятельности.
Григорий Пятецкий-Шапиро, 1992
3.
ИАД:Процесс, цель которого – обнаружить новые
значимые корреляции, образцы и тенденции в
результате просеивания большого объема
хранимых данных с использованием методик
машинного обучения, распознавания данных и
методов математической статистики, с целью
получения бизнеспреимущества
4.
Data MiningПроцесс построения модели, хорошо
описывающей закономерности, которые
порождают данные. Подходы к
построению моделей
• вычислительный
• на основании машинного обучения
• статистический
5.
6.
7.
Предмет интереса для анализа:• Нетривиальные знания
• Неявные зависимости
• Ранее неизвестные знания
• Практически полезные знания
• Доступные для интерпретации
8.
1.Анализ позволяетнайти новые
стратегические
возможности для
бизнеса
2.Увеличивается
эффективность
принятие решений
9.
Маркетинг• Выделить сегменты потребителей со сходными характеристиками
• Выявить паттерны покупок покупателей
Управление рисками и финансами
• Прогнозы
• Задачи планирования ресурсов
Конкурентный анализ
• мониторинг действий конкурентов
• анализ поведения рынка
Профилирование и анализ требований потребителей
• Какие типы потребителей покупают определенные группы товаров
• Выявление наилучших продуктов для разных потребителей
• Прогнозирование наилучшей стратегии маркетинга
10.
Ключевые шаги• Изучение предметной области Изучение априорной информации
и целей приложения, зачем решается эта задача?
Первоначальной понимание данных, селекция
• Создание модельных данных Очистка данных и предобработка:
(до 60% времени!) Уменьшение размерности данных и
трансформации Выявление полезных характеристик,
инвариантов, методов понижения размерности в модели
• Выбор алгоритмов Data Mining - поиск паттернов Суммирование,
классификация, регрессия, ассоциации
• Оценка результатов Оценка паттернов и представление знаний
Визуализация, валидация, удаление избыточных паттернов и т.д.
11.
Отличия от традиционного анализа• Огромные объемы данных Требуются масштабированные
алгоритмы для террабайтных БД
• Данные высокой размерности До десятков тысяч измерений
• Высокая сложность данных Данные временных рядов,
временные данные, данные последовательностей событий
Структурные данные, графики, социальные отношения, данные
со множественными ссылками Гетерогенные источники данных,
БД Пространственные, пространственно-временные,
мультимедиа, текстовые и Web-данные
12.
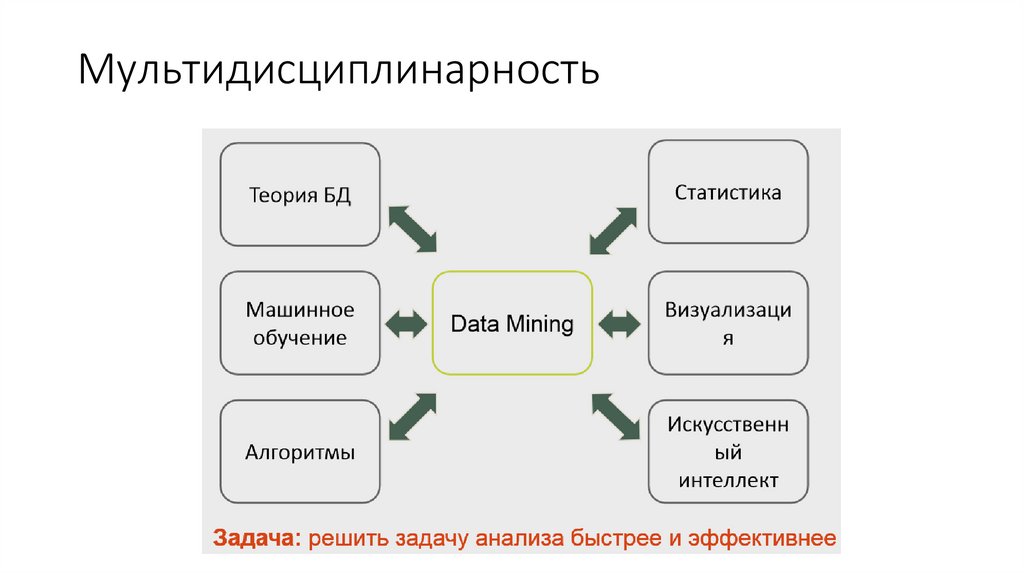
Мультидисциплинарность13.
Задачи Data MiningОписательные (descriptive) - наглядное описание имеющихся скрытых
закономерностей:
• поиск ассоциативных правил или паттернов (образцов)
• группировка объектов, кластерный анализ
• построение регрессионной модели
Предсказательные (predictive) - предсказание для тех случаев, для
которых данных ещѐ нет:
• классификация объектов (для заранее заданных классов)
• регрессионный анализ, анализ временных рядов
14.
Классификация задач ИАД1. Выявление ассоциативных связей
Определение закономерностей в событиях или процессах
Ассоциативная связь различных фактов одного события
Результат:
Лучшее понимание природы процессов
Прогнозирование новых событий
15.
2. Кластеризация объектовРазделение исследуемого множества
объектов на группы («кластеры») по
принципу сходства.
В процессе кластеризации методами
ИАД определяются схожие
характеристики объектов, на их основе
объекты объединяются.
16.
3. КлассификацияОтнесение объектов к одному из известных классов на основе их
характеристик
17.
4. Задачи регрессииЗадача определения значения одного из параметров
анализируемого объекта на основе других характеристик
Все характеристики - количественные
Все задачи взаимосвязаны, из одной вытекает другая
18.
Типы Data MiningСфера применения Data Mining ничем не ограничена - Data
Mining нужен везде, где имеются какие-либо данные.
• Анализ рыночных корзин
• Управление взаимоотношениями с клиентами
• Анализ текстовой информации (Text Mining)
• Анализ информации, порождаемой в сети Интернет (Web Mining)
• Анализ социальных медиа (Social Mining)
19.
Анализ рыночной корзины (market basket analysis) — это поиск наиболеетипичных, шаблонных покупок в супермаркетах (поиск ассоциативных
правил).
Анализ рыночной корзины производится путем анализа баз данных, с
целью определения комбинаций товаров, которые связанны между собой.
В каждой такой паре один товар будет ключевым, а товар покупаемый
вместе с ним — сопутствующим.
Подобный анализ позволит выявить частоту покупки парных товаров, а
также вероятность с которой сопутствующий товар покупается вместе с
ключевым.
Типичная описательная задача,
класс - выявление ассоциативных связей
20.
Business IntelligenceОптимизация ассортимента товаров и запасов
Размещение товаров в торговых залах
Планирование промоакций (предоставление скидок на пары
товаров)
Увеличение объѐмов продаж за счет продвижения сопутствующих
товаров
21.
Взаимоотношения с клиентамиМЕТОДОЛОГИЯ
Customer Relationship Management (CRM) - процесс в
компании, изучение и понимание потребностей
существующих и потенциальных клиентов и определяющая
правила взаимодействия с клиентами.
Благодаря современным возможностям Data Mining,
поведенческой аналитики, сегментации и Business
Intelligence, использование клиентского менеджмента
становится максимально эффективным.
22.
РезультатыВ CRM-системах широко используются такие практики Data Mining,
как:
• Сегментация клиентов - алгоритмы кластеризации
•Прогнозирование реакций - ассоциативный поиск и классификация
При объединении технологий CRM и Data Mining и грамотном их
внедрении в бизнес компания получает значительные преимущества
перед конкурентами.
Поставщики аналитических решений для CRM:
•Oracle
•Microsoft Dynamics CRM
23.
Практическая работаИскусственные нейросеть (ИНС) — это программная реализация
нейронных структур нашего мозга.
Нейроны могут изменять тип передаваемых сигналов в зависимости
от электрических или химических сигналов, которые в них
передаются.
Нейросеть в человеческом мозге — огромная взаимосвязанная
система нейронов, где сигнал, передаваемый одним нейроном,
может передаваться в тысячи других нейронов. Обучение
происходит через повторную активацию некоторых нейронных
соединений. Из-за этого увеличивается вероятность вывода нужного
результата при соответствующей входной информации (сигналах).
Такой вид обучения использует обратную связь — при правильном
результате нейронные связи, которые выводят его, становятся более
плотными.
24.
Искусственные нейронные сети имитируютповедение мозга в простом виде. Они могут быть
обучены контролируемым и неконтролируемым
путями. В контролируемой ИНС, сеть обучается путем
передачи соответствующей входной информации и
примеров исходной информации.
Например, спам-фильтр в электронном почтовом
ящике: входной информацией может быть список
слов, которые обычно содержатся в спамсообщениях, а исходной информацией —
классификация для уведомления (спам, не спам).
Такой вид обучения добавляет веса связям ИНС.
Неконтролируемое обучение в ИНС пытается
«заставить» ИНС «понять» структуру передаваемой
входной информации «самостоятельно».
25.
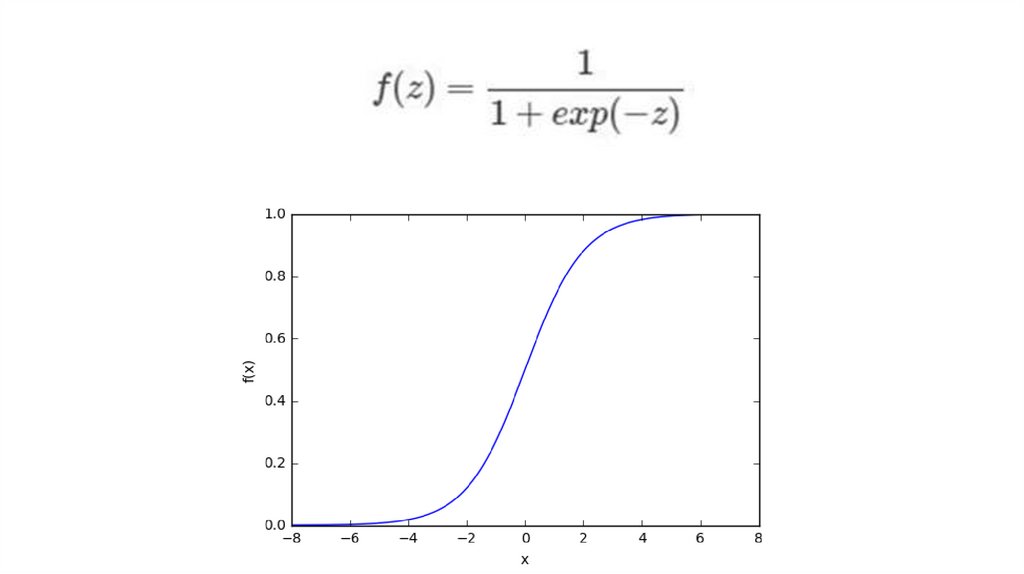
Структура ИНСБиологический нейрон имитируется в ИНС через
активационную функцию. В задачах классификации
(например определение спам-сообщений)
активационная функция должна иметь
характеристику «включателя».
Иными словами, если вход больше, чем некоторое
значение, то выход должен изменять состояние,
например с 0 на 1 или -1 на 1 Это имитирует
«включение» биологического нейрона. В качестве
активационной функции обычно используют
сигмоидальную функцию:
26.
27.
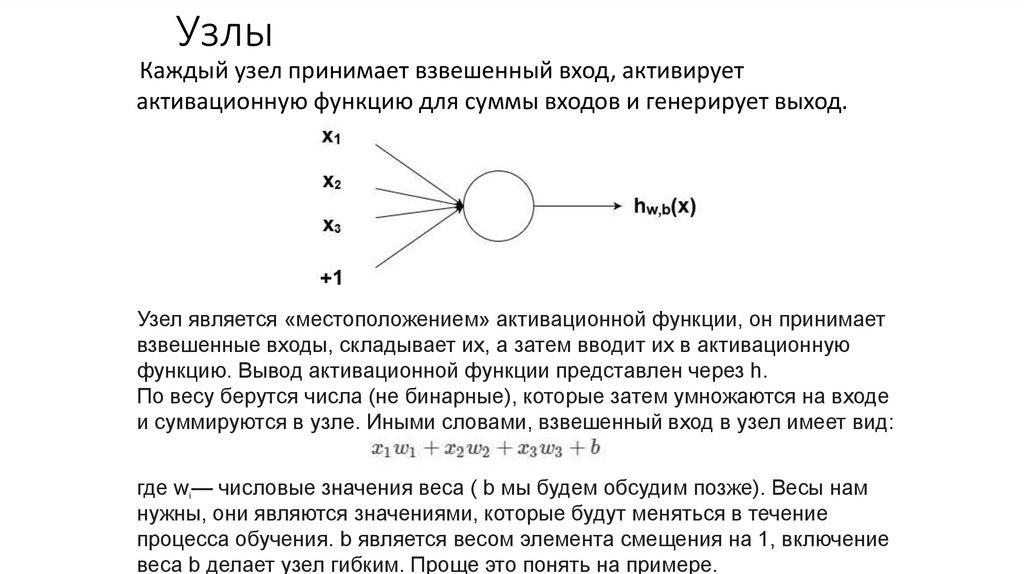
УзлыКаждый узел принимает взвешенный вход, активирует
активационную функцию для суммы входов и генерирует выход.
Узел является «местоположением» активационной функции, он принимает
взвешенные входы, складывает их, а затем вводит их в активационную
функцию. Вывод активационной функции представлен через h.
По весу берутся числа (не бинарные), которые затем умножаются на входе
и суммируются в узле. Иными словами, взвешенный вход в узел имеет вид:
где wi— числовые значения веса ( b мы будем обсудим позже). Весы нам
нужны, они являются значениями, которые будут меняться в течение
процесса обучения. b является весом элемента смещения на 1, включение
веса b делает узел гибким. Проще это понять на примере.
28.
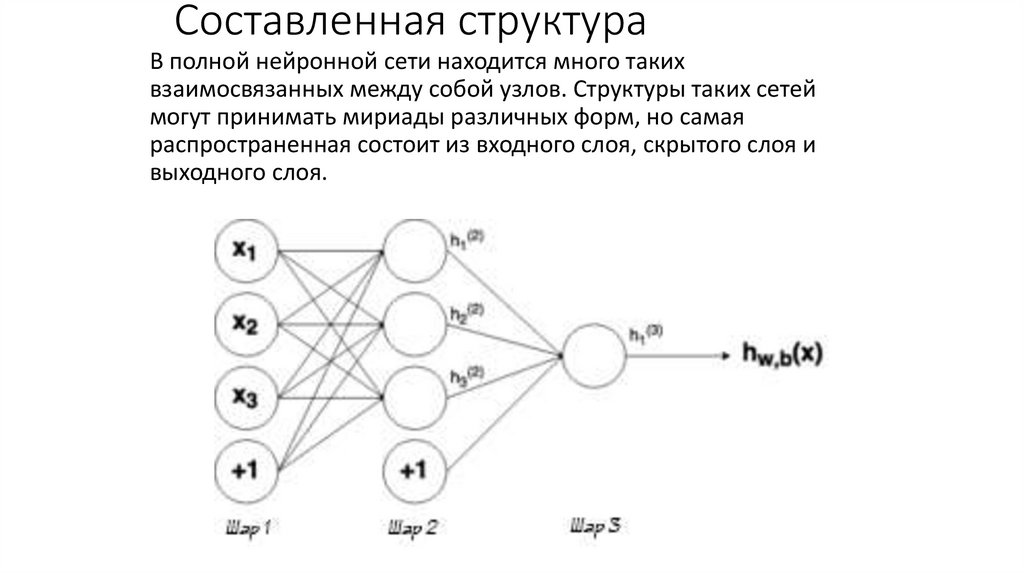
Составленная структураВ полной нейронной сети находится много таких
взаимосвязанных между собой узлов. Структуры таких сетей
могут принимать мириады различных форм, но самая
распространенная состоит из входного слоя, скрытого слоя и
выходного слоя.
29.
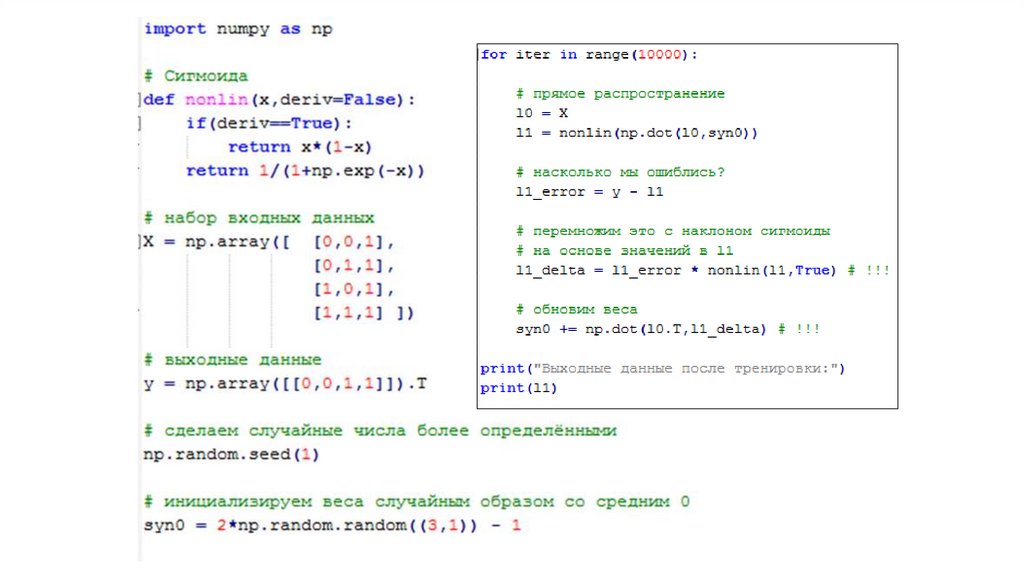
Нейросеть в 11 строчек на PythonНейросеть, тренируемая через обратное распространение
(backpropagation), пытается использовать входные данные для
предсказания выходных.
30.
31.
Выходные данные после тренировки:[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]
32.
Переменные и их описаниеX — матрица входного набор данных; строки –
тренировочные примеры
y – матрица выходного набора данных; строки –
тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
"*" — поэлементное умножение – два вектора одного
размера умножают соответствующие значения, и на
выходе получается вектор такого же размера
"-" – поэлементное вычитание векторов
x.dot(y) – если x и y – это вектора, то на выходе получится
скалярное произведение. Если это матрицы, то получится
перемножение матриц. Если матрица только одна из них –
это перемножение вектора и матрицы.
33.
34.
• сравните l1 после первой итерации и послепоследней
• посмотрите на функцию nonlin.
• посмотрите, как меняется l1_error
• разберите строку 36 – (отмечена !!!)
• разберите строку 39 – (отмечена !!!)
• предсказать выходные данные на основе трёх
входных столбцов данных: