
























 mathematics
mathematicsSimilar presentations:
")









Основные понятия математической статистики
1. Основные понятия математической статистики
Тишков Артем Валерьевич, к.ф.-м.н., доцентМикрюкова Надежда Николаевна
2. Основные понятия математической статистики.
Математическая статистика – это раздел математики о методахрегистрации, систематизации и анализа статистических
экспериментальных данных, полученных в результате наблюдения
массовых случайных явлений.
Статистическая совокупность – это множество объектов,
обладающих общими признаками, которые являются наиболее
важными (типичными) для характеристики этих объектов.
Серия измерений какого либо признака совокупности – это
совокупность значений случайной величины.
Объём совокупности N –это число членов совокупности.
2
3.
Генеральная совокупность – это совокупность всех объектов,которые имеют типичную характеристику или признак. Это все
возможные значения случайной величины.
Выборочная совокупность (выборка) – это отобранная тем или
иным способом часть генеральной совокупности.
Из одной генеральной совокупности можно отбирать сколь угодно
много выборок, главное, чтобы выборка была репрезентативной
(представительной), а для этого элементы выборки должны
отбираться случайным образом.
Варианта – это числовое значение изучаемого признака(
отдельные значения случайной величины).
3
4. Основные задачи, которые стоят перед математической статистикой:
1. Определение закона распределения случайнойвеличины по имеющимся статистическим данным ( по
выборке – закон распределения для всей генеральной
совокупности).
2. Определение неизвестных параметров
распределения ( по выборке оценить параметры
генеральной совокупности).
3. Задача проверки правдоподобия выдвигаемых
статистических гипотез.
4
5. Схема предварительной обработки экспериментальных данных.
1) Сбор экспериментальных данных.Чтобы определить закон распределения случайной величины,
нужно провести серию измерений или подсчётов для интересующей
нас случайной величины (признака).
В результате получаем статистический ряд – это совокупность
числовых данных или выборка объёмом n:
Затем производят упорядочивание членов выборки – эта операция
называется ранжирование.
Ранжирование -- это расположение всех имеющихся вариант по
возрастанию. Получаем ранжированный статистический ряд.
5
6. Пример:
При измерении частоты пульса у 10 пациентовполучены следующие результаты:
90, 110, 65, 80, 90, 60, 70, 80, 70, 80
Ранжированный ряд имеет вид: 60, 65, 70, 70,
80, 80, 80, 90, 90, 110.
Колебания изучаемого признака называются
варьирование. В нашем примере варьирование это изменение частоты пульса.
6
7. Схема предварительной обработки экспериментальных данных.
2) Составление вариационного ряда.вариационный ряд (статистическое распределение)
-- набор пар значение – частота, с которой это
значение встретилось в выборке.
Если случайная величина изменяется дискретно, то
составляем дискретный вариационный ряд.
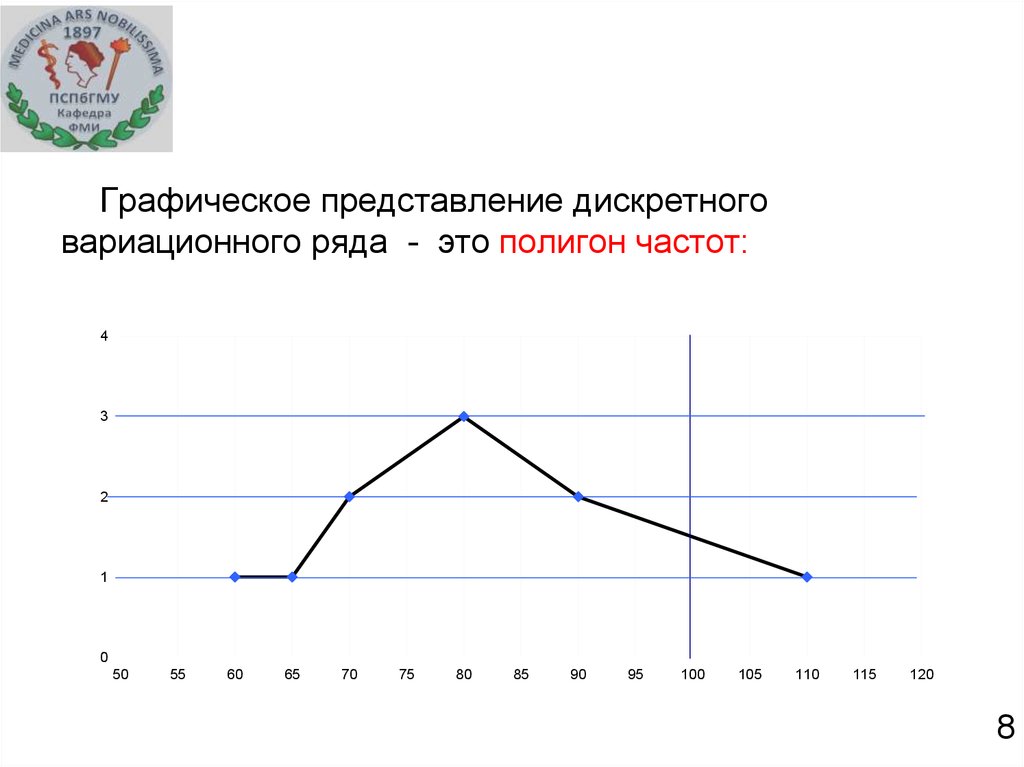
xi
60
65
70
80
90
110
mi
1
1
2
3
2
1
k
m n
i 1
i
7
8.
Графическое представление дискретноговариационного ряда - это полигон частот:
m
4
3
2
1
х
0
50
55
60
65
70
75
80
85
90
95
100
105
110
115
120
8
9.
Если признак изменяется непрерывно, тосоставляется интервальный вариационный ряд: набор
пар вид интервал – частота.
Для построения интервального вариационного ряда
выборку разбивают на интервалы. Есть несколько
рекомендаций по вычислению числа интервалов:
k=log2n+1 (формула Стерджесса), k=√n и др ,
подробнее см.
http://ami.nstu.ru/~headrd/seminar/publik_html/Z_lab_8.htm
Длина интервала ΔX рассчитывается по формуле:
xmax xmin
x
k
9
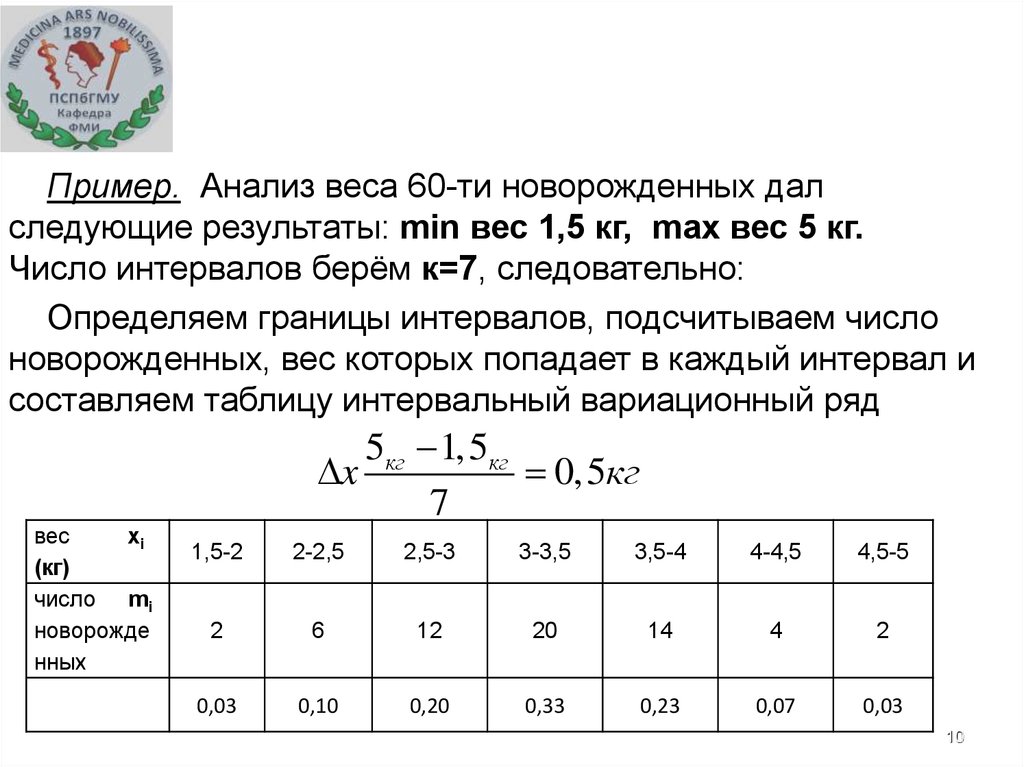
10.
Пример. Анализ веса 60-ти новорожденных далследующие результаты: min вес 1,5 кг, max вес 5 кг.
Число интервалов берём к=7, следовательно:
Определяем границы интервалов, подсчитываем число
новорожденных, вес которых попадает в каждый интервал и
составляем таблицу интервальный вариационный ряд
5кг 1,5кг
x
0,5кг
7
вес
xi
(кг)
число mi
новорожде
нных
1,5-2
2-2,5
2,5-3
3-3,5
3,5-4
4-4,5
4,5-5
2
6
12
20
14
4
2
0,03
0,10
0,20
0,33
0,23
0,07
0,03
10
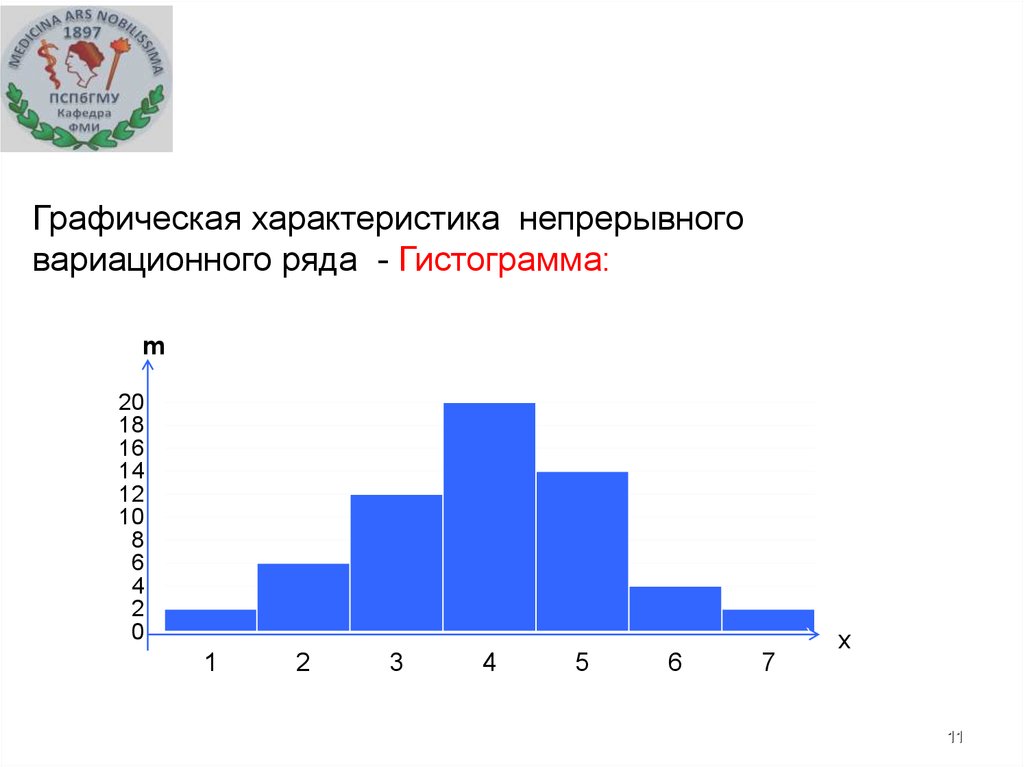
11.
Графическая характеристика непрерывноговариационного ряда - Гистограмма:
m
20
18
16
14
12
10
8
6
4
2
0
1
2
3
4
5
6
7
x
11
12.
Закономерности распределения генеральнойсовокупности оцениваются по выборочной совокупности.
При увеличении объёма выборки (n→∞), относительные
частоты стремятся к вероятностям соответствующих
значений с.в., то есть к закону распределения.
mi
P (x i )
n
12
13.
Статистические характеристикисовокупности
Характеристики генеральной совокупности
Математическое ожидание M[X]
дисперсия D[X]
среднее квадратическое отклонение σ[X]
Характеристики выборки (статистики)
x- среднее арифметическое
S n2 - дисперсия
S n -стандартное отклонение (среднее квадратическое)
13
14.
Генеральная совокупность (n→∞)Выборка (n- конечно)
ν=n-1 число степеней свободы
n
n
k
x
i 1
n
M X xi P xi
i 1
i
D X xi M X P xi
i 1
x
i 1
i
M X
i 1
2
i
n
n
2
k
n
x
x
S n2
x
i 1
i
n 1
n
X D X
x
2
2
n
S n S n2
x
i 1
i
x
n 1
Sn-стандартное отклонение
14
15.
Ошибка среднего арифметическогоИзвлечём из генеральной совокупности N выборок, тогда
их средние арифметические сами будут являться
значениями случайной величины X x . x , ...x
1
2
N
Все эти значения имеют отклонения (рассеивание) от
истинного значения М[X].
Это отклонение называется ошибка среднего
арифметического, она в n раз меньше отклонения каждого xi
от x для данной выборки объёмом n
n
Sn
Sx
n
x x
i 1
2
i
n n 1
15
16.
S x показывает насколько выборочное среднееарифметическое близко к матожиданию М[X]
генеральной совокупности.
Чем больше объём выборки n, тем ближе среднее
арифметическое к М[X] генеральной совокупности (
т.е., ошибка меньше, чем больше n). Этот вывод
получил название Закон больших чисел.
16
17.
Доверительный интервал идоверительная вероятность
Истинные значения М[X] и D[X] можно найти по
генеральной совокупности, что практически невозможно. По
выборке из этой совокупности мы находим лишь их точечные
оценки и
, но насколько их значения близки истинным
2
М[X] и D[X]?
как велика разность
x SНапример,
n
Поэтому наряду с точечными оценками, применяют
x x M X ?
интервальные оценки параметров генеральной
совокупности по выборке.
То есть мы хотим найти интервал ΔX, такой что:
x x M X x x
или M X x x M X x
17
18.
Если известна функция распределения, то этот интервалможно
найти из соотношения:
M X x
f x dx F M X x F M X x P M X x x M X x
зная границы интервала, можно найти вероятность
случайной величины X x1. x2 , ...x N принимать значения из
данного интервала.
Но нам требуется решить обратную задачу: определить
границы интервала, следовательно, для этого надо заранее
задать вероятность, с которой мы этот интервал будем
определять. Эту вероятность называют доверительной
вероятностью РД, а определённый с её помощью интервал - доверительным интервалом ΔXд.
M X x
18
19.
Доверительным интервалом какого либо параметра,называют такой интервал, о котором можно сказать, что с
вероятностью РД он содержит в себе этот параметр.
Доверительную вероятность обычно берут равной РД=0,95,
но в особо ответственных случаях принимают РД=0,99 или
даже РД=0,999.
С доверительной вероятностью связан уровень значимости
α=1-РД.
Уровень значимости α --это вероятность того, что
значение исследуемого параметра не попадёт в
доверительный интервал.
19
20.
Основная масса случайных величин в биологии имедицине распределена по нормальному закону
распределения, следовательно, задав доверительную
вероятность можно определить доверительный интервал:
M X X D M X
M X X D M X
X D
X D
PD
x
x
x
x
X D
X D
X D
X D PD 1
1
2
1
x
x
x
x
2
Например, при РД=0,95
X D 0,95 1
0,975
2
x
X D
1,96 X D 1,96 x
x
20
21.
Где x стандартное отклонение для случайнойвеличины X x1. x2 , ...xN
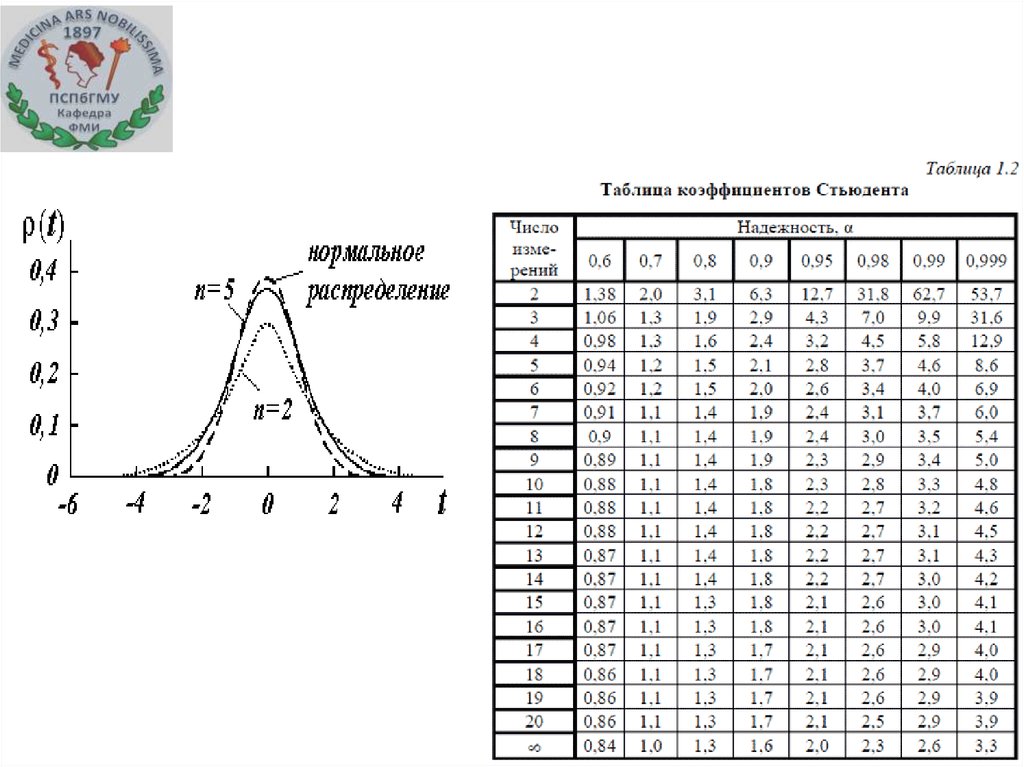
Но для малых выборок (n<30) распределение может
значительно отличаться от нормального.
В 1908 г английский математик и химик Уильям Госсет
под псевдонимом Стьюдент предложил распределение
случайной величины для малых выборок.
21
22.
Распределение СтьюдентаНормированная случайная величина вычисляется
по формуле:
x M X
t
Sx
Плотность вероятности случайной величины:
t St
S t St , n Bn 1
n
1
2
n
2
Где Вn -- параметр , зависит от n.
По мере увеличения объёма выборок n,
распределение Стьюдента довольно быстро
приближается к нормальному распределению Гаусса
и при n˃30 практически не отличается от него.
22
23.
Практическим следствием этого открытия явиласьвозможность определять границы доверительного
интервала для М[X] с заданной доверительной
2
вероятностью РД:
n
X D t St PD , n S x t St PD , n
x x
i 1
n n 1
t St PD , n t St коэффициент Стьюдента, находим в таблице
для заданной РД и известного n.
Таким образом, определив доверительный интервал,
можно записать:
M X x X D
23
24.
2425.
Пример:При определении концентрации белка в растворе
были получены следующие результаты (в мг/л):110,
112, 115, 113, 114. Найти среднее значение,
стандартное отклонение и доверительный интервал
для Рд=0.95.
x
110 112 115 113 114
112,8
5
Sn
n
i 1
(x i x)
2
n 1
(110 112,8) 2 (112 112,8) 2 (115 112,8) 2 (113 112,8) 2 (114 112,8)2
5 1
2,82 0,82 2, 22 0, 22 1, 22
7,84 0, 64 4,84 0, 04 1, 44
14,8
1,92
4
4
4
25
26.
SxSx
Sn 1,92 1,92
0,86
2,
24
n
5
n
2
(x
x
)
i
i 1
n(n 1)
(110 112,8)2 (112 112,8)2 (115 112,8)2 (113 112,8)2 (114 112,8)2
5(5 1)
2,82 0,82 2, 22 0, 22 1, 22
7,84 0, 64 4,84 0, 04 1, 44
5 4
5 4
14,8
0, 74 0,86
20
xD tst S x 2,8 0,86 2, 4
M X 112,8 2, 4( мг / л)
Для
PD =0,95
26
27.
Алгоритм обработкирезультатов прямых измерений
1.Провести серию измерений, не менее трех x1 , x2 ,... x N , N 3.
x1 x2 x3 ... x N
x
.
2.Найти среднее арифметическое
N
3.Вычислить доверительный интервал (случайную ошибку).
для заданной доверительной вероятности, например, PD 0,95.
N
xсл t St
x
i 1
i
x
2
N N 1
4.Найти систематическую ошибку.
а). если указан класс точности прибора:
Кл. т.
xсист
100%
хшкалы
xсист
Кл. т. хшкалы
100%
27
28.
где Х шкалы – это предел шкалы (максимальное значение нашкале)
б). если класс точности не указан ( например линейка
цена _ деления
или термометр) xсист
2
2
2
x
x
х
сл
.
общ
сист.
5. Вычислить общую ошибку:
Эту ошибку называют еще абсолютной ошибкой.
6. Записать окончательный результат:
x x xобщ , для PD 0,95
7. Кроме абсолютной ошибки желательно также найти
коэффициент вариации (или относительную ошибку,
выраженную в процентах): % x 100 %.
x
28
29. Контрольные вопросы.
1.Равномерный закон распределениянепрерывной случайной величины.
2.Нормальный закон распределения
непрерывной случайной величины.
3.Основные понятия математической статистики.
4.Схема предварительной обработки
экспериментальных данных.
5.Статистические характеристики совокупности.
6.Ошибка среднего арифметического.
7.Доверительный интервал и доверительная
вероятность.
8.Распределение Стьюдента.